
Generating Perturbations with Hilbert Curves and Differential Privacy for Location Privacy
摘要-基于位置的服务(LBS)系统的位置隐私保护方法主要取决于可信任的第三方匿名服务器。 当攻击者具有足够的背景知识时,就会证明基于使用隐身区域强制进行的位置混淆,k匿名将无法充分保护位置隐私。 但是,已经证明具有差异隐私的基于扰动的机制可以有效地防御具有任何背景知识的攻击者。 本文通过强制增量式最近邻查询,利用k-匿名性和差分隐私来产生扰动,从而达到LBS隐私保护的目的。 实验表明,基于扰动的机制如何在隐私和服务准确性之间提供良好平衡的权衡。
综述- 位置混淆技术存在不足,无法抵抗有足够背景知识的攻击者,但从扰动中发送查询,不存在与单个用户关联的风险。本文将k匿名与差分隐私相结合,生成扰动,然后根据扰动进行增量最近邻查询,可以最大限度的抵御背景知识的攻击。但对用户位置均匀分布周围的移动节点的隐私保护效果较好。当采用希尔伯特隐身算法生成扰动时,可以保证最近邻查询的增量。如何将该方案应用于连续查询,是未来要解决的问题。
1 介绍
随着无线通信技术和移动定位技术的发展,越来越多的移动设备具有GPS精确定位功能,使得位置服务越来越普及。LBS是指基于移动设备的地理位置等信息,为移动用户提供的信息和娱乐服务[1]。典型应用包括基于地图的应用、POI、优惠券或折扣、GPS导航和位置感知社会网络等[1]。用户在轻松访问各种LBS时,必然会在网络中留下大量的数字痕迹和服务属性,附着在数字痕迹或服务属性上的上下文暴露了用户的个人习惯、兴趣爱好、人际关系、身体状况等个人信息。因此,将这些个人信息暴露给不值得信任的第三方(如LBS提供商),必然会引起严重的隐私问题。如果对手收集到这些信息并进行融合分析,用户的隐私将无从谈起。
差别隐私是Dwork在2006年针对统计数据库的隐私披露提出的一个新的隐私定义[2]。它描述了数据集的计算结果对某个元素的变化不敏感。因此,一个元素加入数据集所引起的隐私泄露风险被控制在可接受范围内。攻击者无法观察到计算结果,无法获得准确的个体信息。差分隐私可以解决传统隐私保护模式的两个缺点。首先,差分隐私模型假设攻击者可以获得除目标元素以外的所有元素,其总和可以理解为攻击者可以掌握背景的最大知识。其次,它具有扎实的数学基础;对隐私保护进行了严格的定义,并提供了量化的评估方法,可以比较不同参数的数据集在保护下所提供的隐私程度。因此,差分隐私理论逐渐成为隐私保护领域的热门话题。
因此,如何防止攻击者利用所有可用数据并结合现有背景知识充分推测用户的隐私,是应对新形势下LBS隐私保护的问题。许多具有k匿名性的泛化技术已经被证明不能充分保护LBS隐私[3],但一种具有差分隐私保证的扰动技术已经被证明可以有效地对抗具有任意背景知识的攻击者[4,5]。不考虑攻击者可能存在的任何背景知识,差分隐私是目前一般保护攻击者先验知识的最有效技术。所以本文通过利用用户活动来防止攻击者推断外部链接,降低查询错误率。带扰动的查询不能承担任何直接链接到单个用户的风险,避免了区域查询的高计算和通信开销。不利的是,带扰动的查询会导致结果集不准确。然而,如果扰动位置相当接近真实位置,则查询结果可能足够接近真实结果集。所涉及的结果集的准确性和扰动的选择之间一定有一个内在的权衡。本文重点讨论扰动的产生,并分析后期的权衡。
2. 相关工作
2.1系统架构。
本文提出的LBS隐私保护架构由移动终端、可信匿名服务器和LBS服务器[6]组成,其系统架构如图1所示 匿名服务器负责收集用户的精确位置信息,并响应位置更新;通过匿名算法将用户的精确位置信息转换为隐蔽区域;从LBS服务器返回候选结果集,并选择正确的查询结果给对应的移动用户。
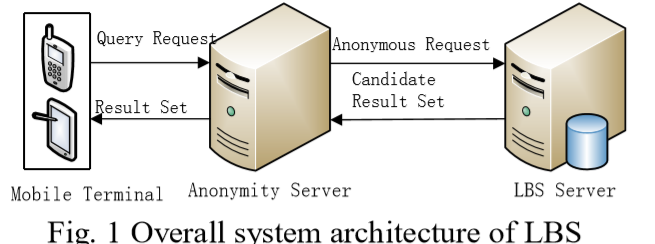
中心服务器架构具有用户信息全局化、隐私保护效果好、移动终端与匿名服务器之间通信开销较小等优点。但缺点是匿名服务器需要负责大量用户频繁的位置更新,匿名处理查询结果的细化。因此,如何处理是系统的瓶颈;匿名服务器掌握了所有移动用户和位置相关的知识,当受到攻击时会导致极其严重的隐私泄露;在可信匿名服务器上部署大量用户是非常困难的。
基于差分隐私的数据保护框架是一个交互式框架,如图2所示。数据管理器根据数据应用的需求设计了相应的差分隐私功能K。当用户向数据服务器发送查询时,结果将返回给由函数k处理的用户。数据库在匿名服务器中。

2.2相关定义。
定义1 LBS查询由一个四元组<U,t,loc,Upoi>表示,其中U是用户ID,t是当前时间,loc是用户在时间t提交查询的位置,而Upoi是服务属性。
LBS隐私包括查询隐私和位置隐私。查询隐私与Upoi的公开有关,而位置隐私与loc的公开和滥用有关。
定义2希尔伯特曲线[7]由用户的二维[8,9]转换为一维。通过B +树索引移动的用户,并通过选择具有串行希尔伯特值的k个用户来构造隐藏区域。
希尔伯特变换可确保二维附近的两个点也更接近一维。在图3中,使用8×8分区二维地绘制了希尔伯特曲线。在图4中,希尔伯特曲线是二维的,划分为4×4。如果U1发送带有匿名请求k = 3的查询,则希尔伯特斗篷算法会将10个用户划分为3个存储桶。为了使每个存储桶至少包含3个用户,构成隐藏区域的返回结果为{U1,U2,U3}。如果用户U1发送k = 4的匿名请求,则结果为{U1,U2,U3,U4}。
使用k-匿名的匿名主要分为两个步骤:(1)当用户提交查询<U,t,loc,Upoi>时,匿名服务器使用希尔伯特(Hilbert)伪装算法生成至少包含k个用户的伪装区域,以满足互惠 根据用户位置。 (2)然后对k个用户的(x,y)坐标作为数据集执行z分数归一化。 然后对归一化的数据集求平均,然后添加拉普拉斯噪声。 xp和yp加上噪声后的平均值被用作扰动,并为LBS服务器执行了增量最近邻居查询[13]。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号