
ceph_OSD的添加删除
this is my first ‘ceph’ article ,just start .....................! ! !
一,手动增加OSD
在ceph里,一个OSD一般是一个ceph-osd守护进程,它运行在硬盘之上,当集群容量达到使用上限,或接近near full 比率后,需要增加OSD或OSD主机来扩容。
在一个运行的ceph集群里添加一个osd要依次创建数据目录,把硬盘挂载到数据目录,把OSD加入集群,然后把OSD加入CRUSHMAP, ceph集群尽量使用统一
硬件,如果新增容量不一的磁盘,创建过程中还需调整它的权重。
添加OSD前,保证集群环境OK
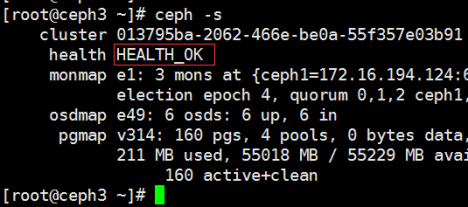
当前集群环境三台主机,6个OSD

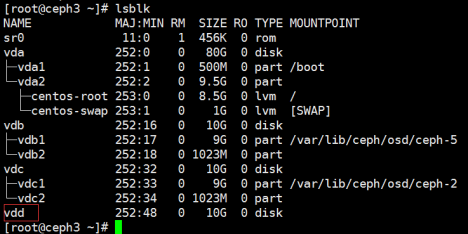
1,创建OSD,如果未指定UUID,OSD启动时会自动生成一个,下列命令会输出OSD号(VDD是新添加的磁盘)
#ceph osd create [ uuid 或 id ] (如果指定了ID 那么它将作为OSD id,一般来说不建议指定ID,让ceph按顺序自动分配)

#ceph osd tree

2,在新OSD主机上创建默认目录
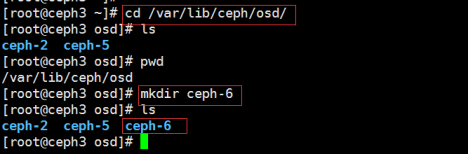
3,格式化磁盘,挂载到刚创建的目录下
# mkfs.xfs /dev/vdd

4,初始化OSD数据目录
# ceph-osd -i 6 --mkfs --mkkey
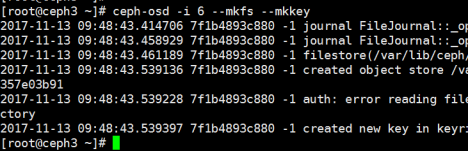
正常报错不用担心
5,注册OSD的认证秘钥,
# ceph auth add osd.6 osd 'allow *' mon 'allow rwx' -i /var/lib/ceph/osd/ceph-6/keyring

6,把OSD加入CRUSHMAP 这样新加入的OSD才能开始接受数据,(也可以通过反编译crushmap 把OSD加入列表设备)
#ceph osd crush add 6 0.00999 host=ceph3


注意:对在使用中的ceph集群,为降低对用户 I/O 性能的影响,加入 CRUSH 图时应该把 OSD 的初始权重设为 0 ,然后每次增大一点、逐步增大 CRUSH 权重。例如每次增加 0.2 :
#ceph osd crush reweight {osd-id} .2
迁移完成前,可以依次把权重重置为 0.4 、 0.6 等等,直到达到期望权重
为降低 OSD 失败的影响,你可以设置:
#mon osd down out interval = 0
它防止挂了的 OSD 自动被标记为 out ,然后逐步降低其权重:
#ceph osd reweight {osd-num} .8
等着集群完成数据迁移,然后再次调整权重,
注意/var/lib/ceph/osd/ceph-X的权限,应该属主属组都是ceph
以下为通过反编译CRUSHMAP的方式添加OSD到CRUSH
(1)利用ceph工具获取当前的crush map
#ceph osd getcrushmap -o ./mycrushmap
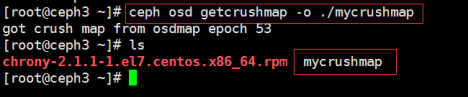
(2)反编译crush map ./mycrushmap 是一个二进制文件,需要通过crushtool反编译成文本文件才能进行编辑
#crushtool -d ./mycrushmap > ./mycrushmap.txt

(3)编辑crush map 文本文件
[root@ceph3 ~]# vi mycrushmap.txt
# begin crush map
tunable choose_local_tries 0
tunable choose_local_fallback_tries 0
tunable choose_total_tries 50
tunable chooseleaf_descend_once 1
tunable straw_calc_version 1
# devices
device 0 osd.0
device 1 osd.1
device 2 osd.2
device 3 osd.3
device 4 osd.4
device 5 osd.5
device 6 osd.6
# types
type 0 osd
type 1 host
type 2 chassis
type 3 rack
type 4 row
type 5 pdu
type 6 pod
type 7 room
type 8 datacenter
type 9 region
type 10 root
# buckets
host ceph1 {
id -2 # do not change unnecessarily
# weight 0.020
alg straw
hash 0 # rjenkins1
"mycrushmap.txt" 77L, 1279C
此处不过多介绍,具体添加方式自行了解
(4)编辑完成后,在编译crush map 文本文件为二进制文件
# crushtool -c ./mycrushmap.txt -o ./newmap

(5)把新编译的crush map 应用于集群使之生效
#ceph osd setcrushmap -i ./newmap
(6)查看CRUSH结构,确认新的CRUSH MAP 已经生效
#ceph osd tree
启动OSD
还未把OSD加入到CEPH后,OSD就在集群配置里了,但是它处于运行状态,此时处于down 且out ,要启动OSD后它才开始接受数据
#/etc/init.d/ceph start osd.6
一旦启动了OSD后,其状态变为UP且IN
观察数据迁移,把新的OSD加入集群CRUSH MAP 后,ceph会重新均衡数据,一些归置组会迁移到新的OSD里,观察集群数据迁移过程
#ceph -w
你会看到归置组状态从 active+clean 变为 active, some degraded objects (有降级的对象)、且迁移完成后回到 active+clean 状态
二,OSD的删除
当磁盘损坏,需要更换磁盘时,需要删除OSD ,通常,操作前应该检查集群容量,看是否快达到上限了,确保删除 OSD 后不会使集群达到 near full 比率。
1,把 OSD 踢出集群
删除 OSD 前,它通常是 up 且 in 的,要先把它踢出集群,以使 Ceph 启动重新均衡、把数据拷贝到其他 OSD
#ceph osd out osd.6
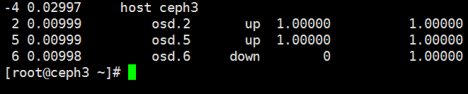
2,观察数据迁移
一旦把 OSD 踢出( out )集群, Ceph 就会开始重新均衡集群、把归置组迁出将删除的 OSD
#ceph -w
你会看到归置组状态从 active+clean 变为 active, some degraded objects 、迁移完成后最终回到 active+clean 状态
注意:
有时候,(通常是只有几台主机的“小”集群,比如小型测试集群)拿出( out )某个 OSD 可能会使 CRUSH 进入临界状态,这时某些 PG 一直卡在 active+remapped 状态。
如果遇到了这种情况,应该先把此 OSD 标记为 in
#ceph osd in {osd-num}
等回到最初的状态后,在把它的权重设置为 0 ,而不是标记为 out
#ceph osd crush reweight osd.{osd-num} 0
执行后,你可以观察数据迁移过程,应该可以正常结束。把某一 OSD 标记为 out 和权重改为 0 的区别在于,前者,包含此 OSD 的桶、其权重没变;而后一种情况下,
桶的权重变了(降低了此 OSD 的权重)。某些情况下, reweight 命令更适合“小”集群
3,停止OSD
把 OSD 踢出集群后,它可能仍在运行,就是说其状态为 up 且 out 。删除前要先停止 OSD 进程
#/etc/init.d/ceph stop osd.6 停止 OSD 后,状态变为 down
4,删除OSD
(1),把OSD移除CRUSHMAP
#ceph osd crush remove osd.6


(2)删除OSD的认证秘钥
#ceph auth del osd.6

(3)删除OSD
#ceph osd rm osd.6


OSD.6 已被完全删除
(4)卸载OSD挂载目录,通过mount 查看

# umount /var/lib/ceph/osd/ceph-6/

删除osd.6相关信息
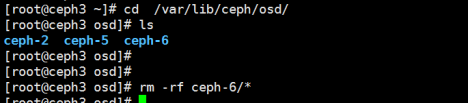
到此OSD的手动添加和删除基本完成,不同系统环境或者不同ceph版本 有些操作命令不近相同,
ceph H 版本启动命令:#/etc/init.d/ceph start osd.x
#/etc/init.d/ceph start mon
ceph J 版本启动命令:#systemctl stop ceph-mon@ceph01.service 停止mon 服务
#systemctl stop ceph-osd@12.service 停止各OSD服务
参考文档:ceph 官网, 《ceph分布式存储实战》
三,通过执行puppet 添加OSD
1,首先我在集群ceph2这台服务器上添加 一块磁盘VDD

2,修改ceph.yaml 文件
#vi /var/tmp/openstackha/tripleo/hieradata/ceph.yaml
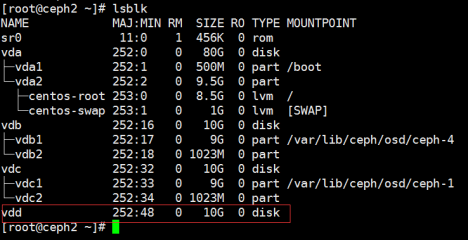
删除原有磁盘信息,从新写入需要添加的磁盘,如下: 如有多块磁盘可依次写入相应信息
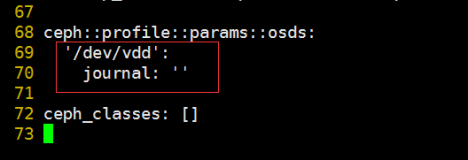
保存退出
3,执行osd.pp 文件
#puppet apply --modulepath /var/tmp/openstackha/puppet/modules/ /var/tmp/openstackha/tripleo/manifests/osd.pp -d
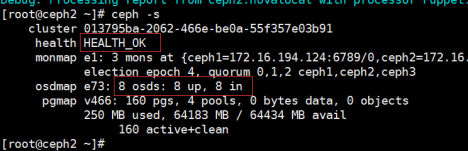
4,执行完成查看验证
#ceph -s
#ceph osd tree
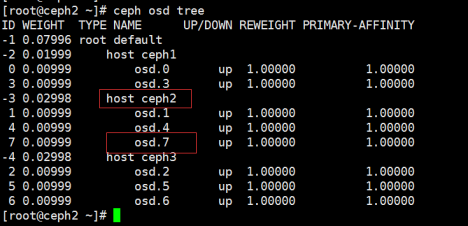
注意:添加磁盘时最好在每台主机均匀添加,使每台主机磁盘数量保存一致,这样有利于数据均匀分布

 浙公网安备 33010602011771号
浙公网安备 33010602011771号