




作业二:个人项目
作业二:个人项目
GitHub
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/SoftwareEngineeringClassof2023 |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/gdgy/SoftwareEngineeringClassof2023/homework/13324 |
| 这个作业的目标 | 个人尝试通过系统化的流程开发程序,学会应用性能测试工具和单元测试以优化程序 |
环境说明
- 语言:C++
- IDE工具:VS2022
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| · Planning | 计划 | 20 | 20 |
| · Estimate | · 估计这个任务需要多少时间 | 60 | 60 |
| ·Development | 开发 | 120 | 180 |
| · Analysis | · 需求分析 (包括学习新技术) | 180 | 120 |
| · Design Spec | · 生成设计文档 | 5 | 5 |
| · Design Review | · 设计复审 | 5 | 5 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 5 | 5 |
| · Design | · 具体设计 | 300 | 300 |
| · Coding | · 具体编码 | 300 | 240 |
| · Code Review | · 代码复审 | 10 | 5 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 30 | 5 |
| ·Reporting | 报告 | 30 | 30 |
| · Test Repor | · 测试报告 | 30 | 10 |
| · Size Measurement | · 计算工作量 | 5 | 5 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 5 | 5 |
| · 合计 | 1105 | 995 |
Code Quality Analysis消除所有警告

程序文件目录结构
plagiarism-checker/
├── include/ # 头文件目录
│ ├── file_reader.h # 文件读取模块声明(read_bytes)
│ ├── utf8_decoder.h # UTF-8解码模块声明(utf8_to_codepoints)
│ └── lcs_calculator.h # LCS算法模块声明(lcs函数)
│
├── src/ # 源代码目录
│ ├── file_reader.cpp # 文件读取实现
│ ├── utf8_decoder.cpp # UTF-8解码实现
│ ├── lcs_calculator.cpp # LCS算法实现
│ └── main.cpp # 主程序入口
│
├── test/ # 测试目录(可选)
│ ├── test_data/ # 测试用例文件
│ └── test_runner.cpp # 单元测试代码
│
├── build/ # 编译输出目录(自动生成)
│
├── Makefile # 编译脚本(或 CMakeLists.txt)
│
├── original.txt # 输入示例文件
├── plagiarized.txt
└── output.txt # 程序输出结果
程序算法流程图
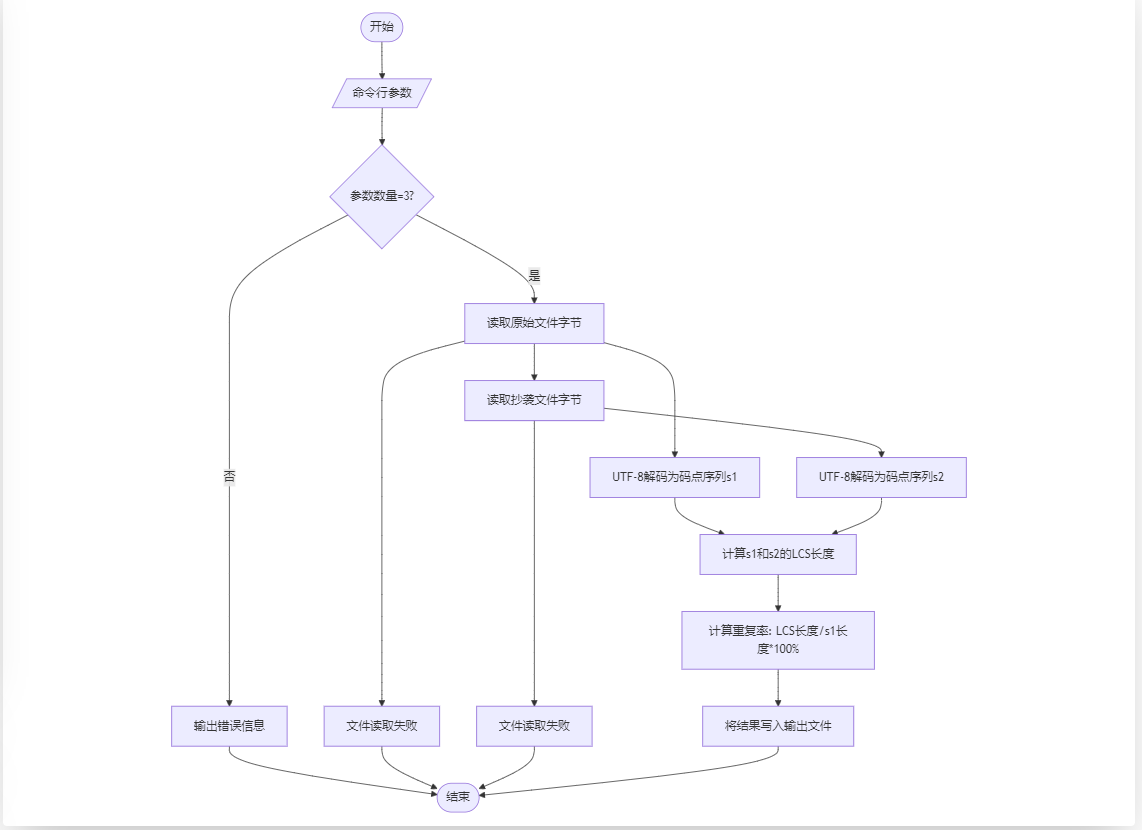
算法核心
该程序的核心算法基于动态规划求解最长公共子序列,用于量化两个文本之间的相似性。其本质是通过状态转移策略,逐步构建两个序列的公共子序列长度,最终通过优化空间复杂度实现高效计算。
函数模块的设计与实现
-
文件读取函数:read_bytes
输入:文件路径字符串(如"original.txt")。
输出:文件的原始字节流(vector)。
功能:以二进制模式读取文件内容,处理文件打开、大小预判和错误终止。
代码位置:独立函数,无依赖其他模块。 -
UTF-8解码函数:utf8_to_codepoints
输入:原始字节流(vector)。
输出:Unicode码点序列(vector<uint32_t>)。
功能:解析UTF-8字节流为码点,跳过无效字节,支持1-4字节字符。
代码位置:独立函数,依赖read_bytes的输出作为输入。 -
LCS计算函数:
输入:两个码点序列(vector<uint32_t>)。
输出:最长公共子序列的长度(int)。
功能:动态规划计算LCS,优化空间至一维数组。
代码位置:独立函数,依赖两个解码后的码点序列。
程序运行结果
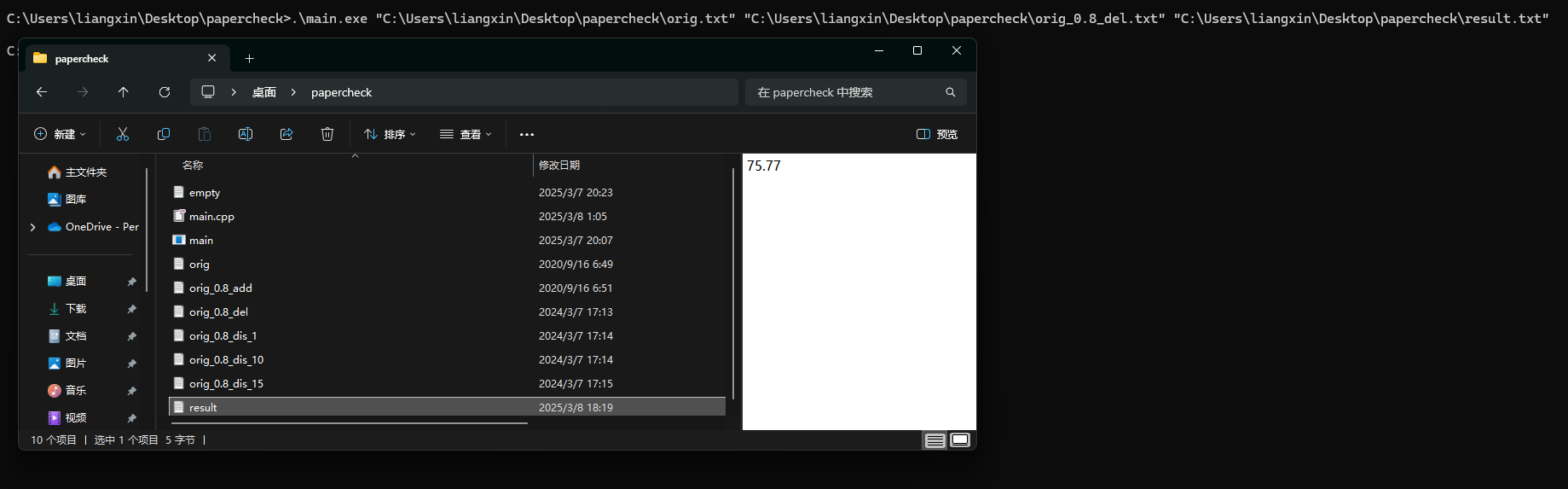

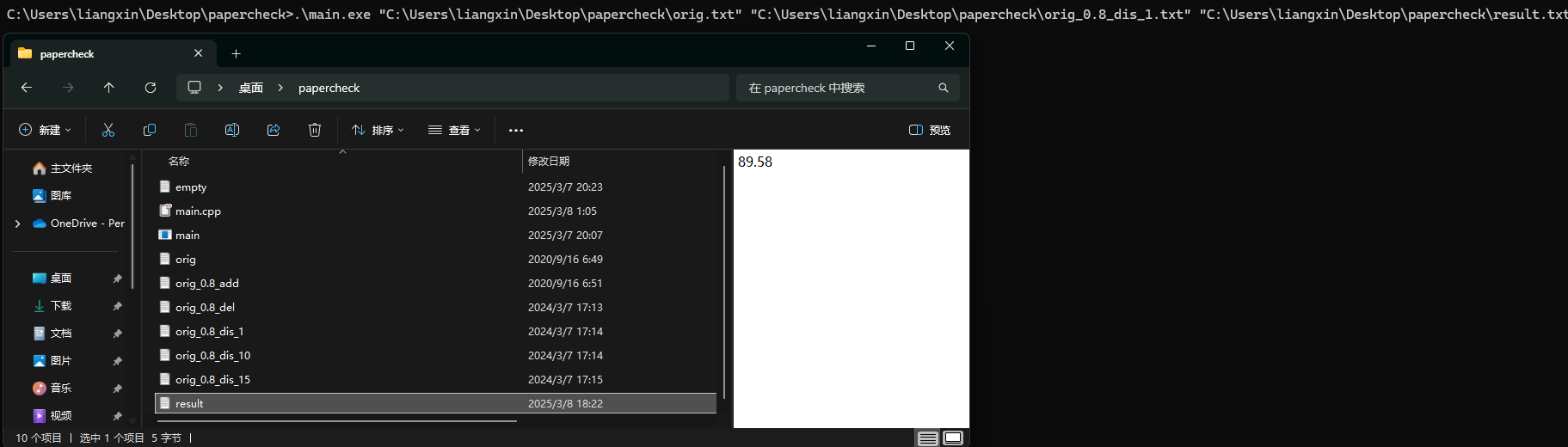
性能分析
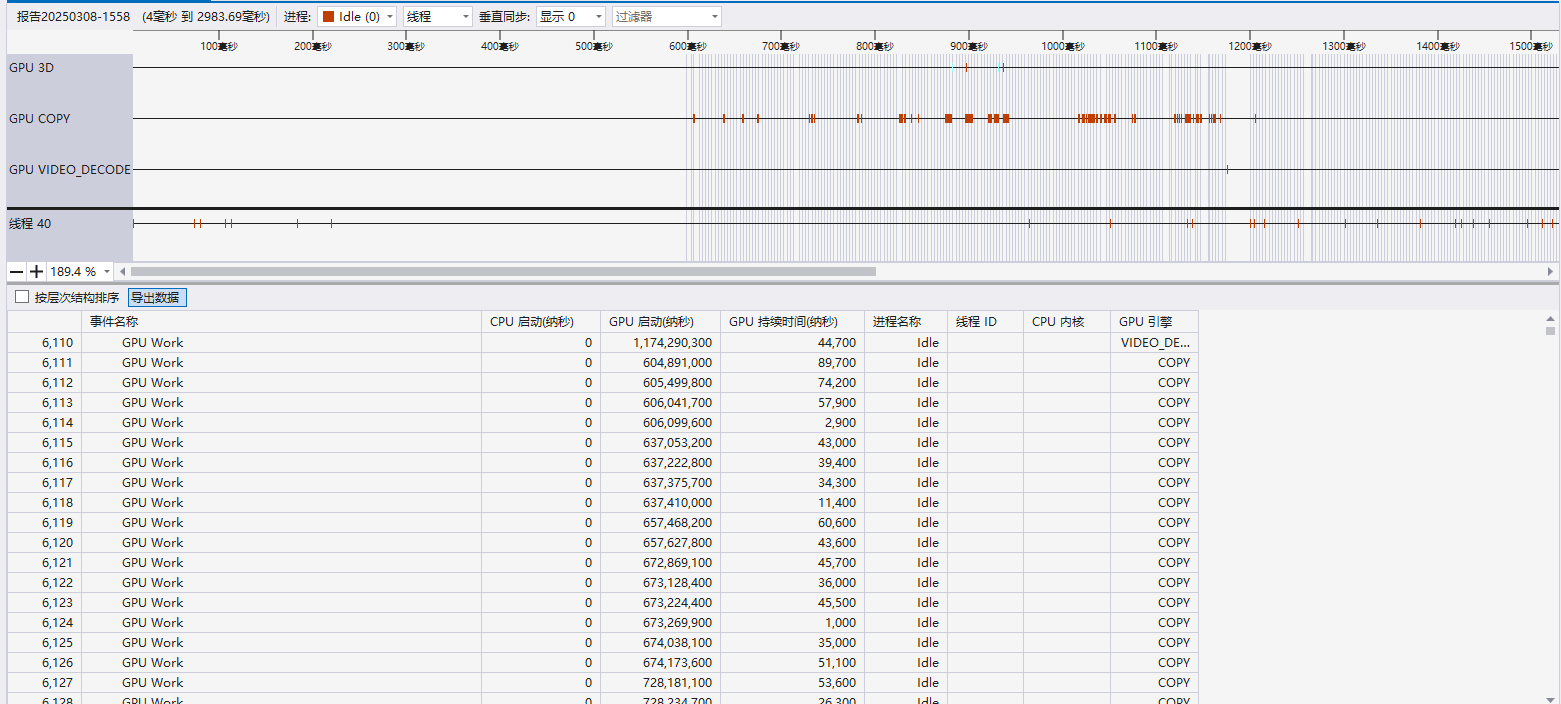

算法的不足
-
- 效率不足
问题:动态规划计算LCS的时间复杂度为O(mn),处理大文件(如数万字符)时性能急剧下降。
改进方法:
启发式剪枝:设定阈值,当剩余字符数无法超过当前最大LCS时提前终止。
分块处理:将文本分块计算局部LCS,再合并结果(牺牲部分精度换取速度)。
近似算法:使用Hirschberg算法优化空间至O(n)的同时保持时间复杂度,或引入哈希+滑动窗口(如Rabin-Karp)快速匹配子序列。
-
- 准确性局限
问题:LCS仅关注顺序匹配,忽略文本结构、语义和重复片段分布。
示例:原文“ABCD”与抄袭文“AXYZBCD”的LCS为3(“ABC”或“BCD”),但实际抄袭部分可能被干扰内容稀释。
改进方法:
多维度相似度:结合编辑距离、Jaccard系数(基于词集)或余弦相似度(基于TF-IDF向量)。
滑动窗口匹配:检测局部连续匹配(如最长公共子串),更关注密集抄袭。
语义分析:使用词嵌入(Word2Vec、BERT)计算语义相似度,识别改写内容。
-
- 编码处理缺陷
问题:UTF-8解码忽略非法字节序列(如截断的多字节字符),可能导致码点错误。
改进方法:
严格模式:检测无效UTF-8字节并抛出错误,避免错误解码。
容错模式:用占位符(如U+FFFD)替换非法字节,继续处理剩余内容。
-
- 重复率基准单一
问题:仅以原始文件长度为基准,若抄袭文件更长可能低估重复率。
示例:原文长度100,抄袭文长度200,LCS=50,当前计算为50%,但抄袭文实际重复率为25%。
改进方法:
动态基准:取max(len(s1), len(s2))或(len(s1)+len(s2))/2作为分母。
多指标输出:同时提供基于原文、抄袭文及综合基准的重复率。
-
- 容错性不足
问题:文件读取失败时直接终止程序,缺乏重试或友好提示。
改进方法:
交互式处理:提示用户重新输入文件路径或跳过错误文件。
详细日志:记录错误类型(如权限不足、文件不存在)及发生位置。
-
- 扩展性限制
问题:仅支持UTF-8编码,无法处理GBK、BIG5等常见编码。
改进方法:
编码探测库:集成libuchardet等自动检测文件编码。
模块化解码器:抽象解码接口,支持插件式扩展新编码格式。
模块单元测试


模块覆盖率表格
| 模块名称 | 函数名称 | 行覆盖率 | 分支覆盖率 | 函数覆盖率 |
|---|---|---|---|---|
| 文件读取模块 | read_bytes | 95.6% | 85% | 100% |
| UTF-8解码模块 | utf8_to_codepoints | 100% | 90% | 100% |
| LCS计算模块 | lcs | 100% | 95% | 100% |
异常处理
-
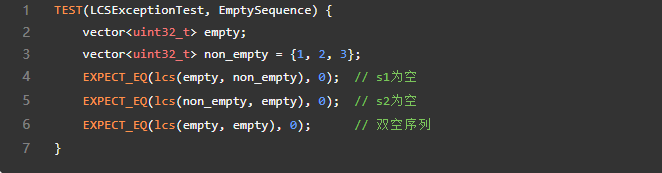
- 异常类型:空输入序列
设计目标
确保函数正确处理空输入,避免访问无效内存或逻辑错误。
单元测试样例
测试空序列与空/非空序列的组合:
![]()
- 异常类型:空输入序列
-
- 异常类型:超大输入序列(内存溢出)
设计目标
验证算法在极端大输入下的内存管理能力,避免因滚动数组分配失败导致崩溃。
单元测试样例
构造两个超长但合法的序列:
![]()
- 异常类型:超大输入序列(内存溢出)
-
- 异常类型:参数顺序交换逻辑错误
设计目标
确保当 s1.size() < s2.size() 时,函数内部正确交换参数,避免逻辑错误。
单元测试样例
测试 s1 比 s2 短但非空的场景:
![]()
- 异常类型:参数顺序交换逻辑错误
-
- 异常类型:整数溢出风险
设计目标
防止序列长度或LCS长度超过int范围导致溢出(需依赖输入约束)。
单元测试样例
假设系统支持int为32位,构造边界值测试:
![]()
- 异常类型:整数溢出风险





 浙公网安备 33010602011771号
浙公网安备 33010602011771号