


Python学习之基础语法
一、print(打印)
🐹 1. print()函数概述
print() 方法用于打印输出,是python中最常见的一个函数。
该函数的语法如下:
print(*objects, sep=' ', end='\n', file=sys.stdout)
参数的具体含义如下:
-
objects --表示输出的对象。输出多个对象时,需要用 , (逗号)分隔。
#【单个对象】 # 输出数字 print(1) #数值类型可以直接输出 # 输出字符串 print("Hello World") #字符串类型可以直接输出 # 输出变量 a = 1 print(a)
#【多个对象】 # 输出多个数字 print(1,2,3) # 输出多个字符串 print("Hello world","Python","HaHa") #注意⚠️:如果直接输出字符串,而不是用对象表示的话,可以不使用逗号 print("Hello world""Python""HaHa") # 输出多个变量 a = 1 b = 2 c = 3 print(a,b,c)
-
sep -- 用来间隔多个对象。
#【多个对象】 # 输出多个数字 print(1,2,3,sep='@') # 1@2@3 # 输出多个字符串 print("Hello world","Python","HaHa",sep='&') # Hello world&Python&HaHa #注意:如果直接输出字符串,而不是用对象表示的话,可以不使用逗号 print("Hello world""Python""HaHa",sep='*') # Hello worldPythonHaHa # 输出多个变量 a = 1 b = 2 c = 3 print(a,b,c,sep='%') # 1%2%3
-
end -- 用来设定以什么结尾。默认值是换行符 \n,我们可以换成其他字符。
#【多个对象】 # 输出多个数字 print(1,2,3,sep='@',end='😊') # 1@2@3😊 # 输出多个字符串 print("Hello world","Python","HaHa",sep='&',end='😢') # Hello world&Python&HaHa😢 #注意:如果直接输出字符串,而不是用对象表示的话,可以不使用逗号 print("Hello world""Python""HaHa",sep='*',end='😅') # Hello worldPythonHaHa😅 # 输出多个变量 a = 1 b = 2 c = 3 print(a,b,c,sep='%',end='🌞') # 1%2%3🌞
-
file -- 要写入的文件对象。
file 参数必须是一个具有write(string)方法的对象;如果参数不存在或为None,则将使用sys.stdout。 由于要打印的参数会被转换为文本字符串,因此print()不能用于二进制模式的文件对象。 对于这些对象,可以使用file.write(...)。
🐹 2. 数据的格式化输出
在C语言中,我们可以使用printf("%-.4f", a)之类的形式,实现数据的的格式化输出。在python中,我们同样可以实现数据的格式化输出。我们可以先看一个简单的例子:s = "Duan Yixuan" x = len(s) print('The Length of %s is %d' %(s,x)) # 输出结果:The Length of Duan Yixuan is 11
分析:
'The length of %s is %d' 这部分叫做:格式控制符
(s,x) 这部分叫做:转换说明符
% 字符,表示标记转换说明符的开始,类似于C语言中的用的逗号
接下来我们仔细探讨一下格式化输出
🐡 最小字段宽度和精度
最小字段宽度:转换后的字符串至少应该具有该值指定的宽度。如果是*(星号),则宽度会从值元组中读出。
点(.)后跟精度值:如果需要输出实数,精度值表示出现在小数点后的位数。如果需要输出字符串,那么该数字就表示最大字段宽度。如果是*,那么精度将从元组中读出。
#【示例一】 PI = 3.141592653 print('%10.3f'%PI)#字段宽10,精度3 #输出结果:3.142
#【示例二】 PI=3.1415926 #注意:精度为3,所以只显示142,指定宽度为10,所以在左边需要补充5个空格,以达到10位的宽度 #注意:用*从后面的元组中读取字段宽度或精度,可以读取出来精度是3位 print("PI=%.*f"%(3,PI)) #输出结果: PI=3.142
#【示例三】 PI=3.1415926 #没有指定宽度,所以不需要缩进 print("%*.3f"%(10,PI)) #精度为3,总长为10. #输出结果: 3.142
* 所处的位置不同,读取的内容也不同🐡 转换标志
转换标志:
- :表示左对齐; + :表示在数值前要加上正负号; " " :(空白字符)表示正数之前保留空格(); 0 :表示转换值若位数不够则用0填充。
具体的我们可以看一下例子:
#【示例一】 PI=3.1415926 print('%-10.3f' %PI) #注意:左对齐,还是10个字符,但空格显示在右边。 #3.142
#【示例二】 PI = 3.1415926 print('%+f' % PI) #显示正负号 #+3.141593 # 类型f的默认精度为6位小数。
#【示例三】 # 类型f的默认精度为6位小数。 PI = 3.1415926 print('%010.3f'%PI) #字段宽度为10,精度为3,不足处用0填充空白 #000003.142 0表示转换值若位数不够则用0填充
🐡 格式字符归纳
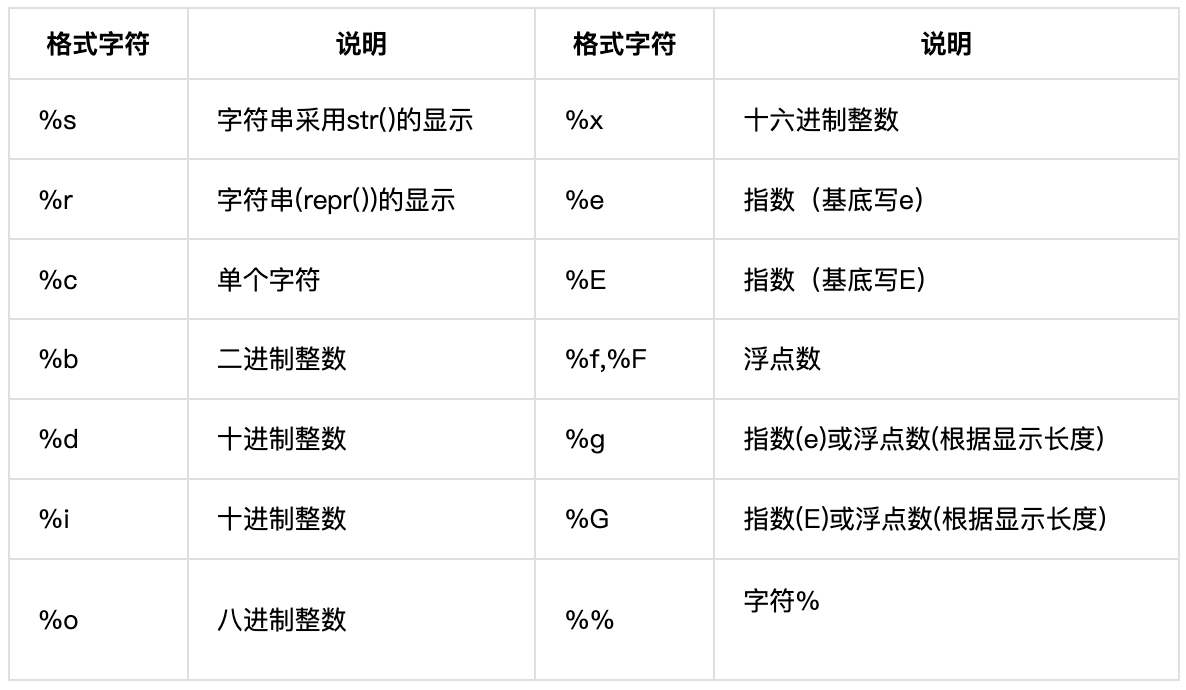
🐡 换行与防止换行
for x in range(0,5): print(x) #输出结果: 0 1 2 3 4
for x in range(0,5): print(x,end=' ') #输出结果: # 0 1 2 3 4
二、字符串与字符串连接符
🐹 1. 字符串连接
字符串之间用“+”号作为连接符。
#字符串连接1 str = 'Python' + ':' + "在所有的编程语言中我最厉害!" print(str) #Python:在所有的编程语言中我最厉害! #字符串连接2 print('川普'+':'+'没人比我更懂得这个世界!') #川普:没人比我更懂得这个世界!
🐹 2. 单双引号转义
#单双引号转义 print("He said "good!"") #报错
此行程序会出错,默认为前面两个引号为一组,后面两个引号为一组,第二个到第三个引号之间的内容会出错。
需要改为以下指令:
#双引号包裹单引号 print('He said "good"') #单引号包裹双音号 print("He said 'good'")
如果一句话内有单引号和双引号,例如:
#报错 "He said "Let's go!""
需要在引号前加反斜杠\,表示后面的引号为引号符号,是内容的一部分,不是结束符。
#正确 print("He said \"Let\'s go!\"" ) #输出结果:He said "Let's go!"
🐹 3. 换行
\n 表示换行
#正确 print("Hello!\nHi") #输出结果 #Hello! #Hi
🐹 4. 三引号跨行字符串
三个连在一起单引号 或 双引号。
- 双引号(""" """):

- 单引号(''' '''):

三、变量
变量名称规则:字母、数字、下划线组成;
🐝 不能有除了下划线以外的符号;
#🙅错误 user&name = 'Python' # ❌ user@name = 'Python' # ❌ user#name = 'Python' # ❌ user~name = 'Python' # ❌
🐝 不能有空格;
#🙅错误 user name = 'Python' # ❌
🐝 不能以数字开头;
1username = 'Python' # ❌
🐝 不能用双引号包括;
#🙅错误 user"12"name = 'Python' # ❌ user""name = 'Python' # ❌ user"name" = 'Python' # ❌
🐝 变量区分大小写;
#对大小写敏感,为不同的变量 username = 'Python' Username = 'Python'
🐝 不能使用专用关键字。
#🙅错误 def = 'Python' # ❌ if = 'Python' # ❌ while = 'Python' # ❌
变量命名建议:不要使用拼英,使用英文单词组命名,Python3.0版本后支持中文变量,但是不建议使用中文变量,可能存在乱码。
Python变量命名约定俗成使用下划线命名法。
1、字母全部小写。
2、不同单词用下划线分隔。
#👍 建议用下划线命名法, 不建议用驼峰命名法 user_age = '下划线命名法' user_gender = '下划线命名法'
四、数学运算
🐹 1. 基础运算符
🐡 算数运算
+:加; -:减; *:乘; **:乘方; /:除; //:整除(小数转化成整数) %:取余;
#加法:有浮点型数据则结果返回浮点型 print('加法 +') print(1+1) #2 print(1+1.0) #2.0 print(2.5+2.5) #2.0 #减法:有浮点型数据则结果返回浮点型 print('减法 -') print(1-1) #0 print(1-1.0) #0.0 print(2.5-2.5) #0.0 #乘法:有浮点型数据则结果返回浮点型 print('乘法 *') print(0*1) #0 print(1*1) #1 print(1*1.0) #1.0 print(2.5*2.5) #6.25 print(2*2.5) #5.0 #乘方:幂运算符用于计算一个数的指数次幂,其形式为“a ** b”,表示将a的b次幂。有浮点型数据则结果返回浮点型;负数直接使用,无需括号 print('乘方 **') print(3**2) #9 print(4**3) #64 print(5**7) #78125 print(2.1**3) #9.261000000000001 print(2**3.5) #11.313708498984761 print(2**-3) #0.125 #除法:无论数据是否整形,结果都会是浮点型 print('除法 /') # print(1/0) #直接报错提示,终止进程 print(1/1) #1.0 整型相除也会是浮点 print(6/4) #1.5 print(2.5/1) #2.5 print(2.5/2.5) #1.0 #整除:有浮点型数据则结果返回浮点型;向下取整数(int是只保留整数部分) print('整除 //') print(16//3) #2 print(16//-3) #-3 print(16//3.5) #4.0 print(16//-3.5) #-5.0 #取余:有浮点型数据则结果返回浮点型 print('取余 %') print(5%2) #1 print(5.1%2) #1.0999999999999996 print(5%2.5) #0.0 print(2%5) #2 print(2%5.1) #2.0
🐡 比较运算
==:等于; !=:不等于; <:小于; >:大于; <=:小于等于; >=:大于等于;
#运算结果为布尔值(True or False) print(10==10.0) #只比较值是否相等,不识别类型:True print(3.14!=3.1415) #True print(255>170) #True print(255<170) #False print(255>=255) #True print(255<=255) #True
tips: 0<x<100 两个符号同时运行,不分先后(5<x and x<20)
🐡 逻辑运算
and :与; or :或 ; not :非;
格式:
A and B , A or B , not A
意义:A 和 B 都是表达式,
🐝:在 逻辑与 情况下,先行判断A的布尔判断是否为真(True), 若为真则继续执行B的布尔判断,以此作为结果;若A为假,则直接结束此语句,结果为假。
#【老师列子: and】 # 示例一 # 定义fn函数,def相当于其它语言中的function关键词 def fn(): print("执行了fn") # 打印 return 10 # 定义fm函数 def fm(): print("执行了fm") # 打印 return 20 # 与操作 fn()为真, 接着执行fm() re = fn() and fm() print(re) #⚠️注意:由于fn() 和 fm() 都为真,所以以fm的返回值作为结果输出,为20 # 运行结果: # 执行了fn # 执行了fm # 20
# 示例二 # 定义fn函数,def相当于其它语言中的function关键词 def fn(): print("执行了fn") # 打印 return 0 # 定义fm函数 def fm(): print("执行了fm") # 打印 return 20 # 与操作 fn()为假,直接输出 re = fn() and fm() print(re) #⚠️注意:由于fn() 为假,直接跳出逻辑判断,以fn的返回值作为结果输出, 为0
# 运行结果: # 执行了fn # 0
🐝:在 逻辑或 情况下,先行判断A的布尔判断是否为真(True), 若为真则直接结束此语句,结果为真;若A为假,继续执行B的布尔判断,以此作为结果。
#【老师列子: or】 # 定义fn函数,def相当于其它语言中的function关键词 def fn(): print("执行了fn") # 打印 return 10 # 定义fm函数 def fm(): print("执行了fm") # 打印 return 20 # 或操作 re = fn() or fm() print(re) #⚠️注意:由于逻辑条件为只要有一个为真就行,当fn()为真时,就没必要执行fm()的, 所以最终以fn的返回结果作为输出结果, 为10 #运行结果: #执行了fn #10
# 定义fn函数,def相当于其它语言中的function关键词 def fn(): print("执行了fn") # 打印 return 0 # 定义fm函数 def fm(): print("执行了fm") # 打印 return 20 # 或操作 re = fn() or fm() print(re) #⚠️注意:由于逻辑条件为只要有一个为真就行,当fn()为假时,就需要执行fm()判断, 所以最终以fm的返回结果作为输出结果, 为20 # 运行结果: # 执行了fn # 执行了fm # 20
🐝:在 逻辑非 情况下,取A的结果的反面进行布尔判断是否为真(True)。
#【老师列子: not】 # 定义fn函数,def相当于其它语言中的function关键词 def fn(): print("执行了fn") # 打印 return 0 re = not fn() print(re) #True #输出结果: #执行了fn #True
# 定义fn函数,def相当于其它语言中的function关键词 def fn(): print("执行了fn") # 打印 return 10 # 否操作 re = not fn() print(re) #False #输出结果: #执行了fn #False
🐡 位运算
& : 与; |: 或; ^: 异或; ~: 取反; <<: 左移位; >>: 右移位
运算结果为布尔值(True or False)
#通过bin() 内置函数,用于将整数转换为二进制形式的字符串。因为位运算是建立在二进制的运算 a=79 b=80 b1=-80 print(bin(a)) #0b1001111 print(bin(b)) #0b1010000 print(bin(b1)) #-0b1010000 # & 位与 两个二进制数对应位都为1时,结果的该位才为1 print('& 位与') c=a&b print(bin(c)) #0b1000000 都是1 则取1否则为0 # | 位或 两个二进制数对应位有一个为1,结果的该位就为1。 print('| 位或') c=a|b print(bin(c)) #0b1011111 都是0 则取0否则为1 # ^ 位异或 两个二进制数对应位不同,结果的该位为1。 print('^ 位异或') c=a^b print(bin(c)) #0b0011111 不同取1,相同则取0 # ~ 取反 将二进制数的每一位取反(0变1,1变0) print('~ 取反') c=~b c1=~b1 print(bin(c)) # 0b1010000 变成 -0b1010001 print(bin(c1)) #-0b11010000 变成 0b01001111 print(c) #-81 print(c1) #79 # << 左移位 将二进制数的所有位向左移动指定的位数,右侧补0 print('<< 左移位') c=a<<2 print(bin(c)) #0b100111100 # >> 右移位 将二进制数的所有位向右移动指定的位数,左侧补0(对于无符号数)或补符号位(对于有符号数)。 print('>> 右移位') c=a>>2 print(bin(c)) #0b10011 print(c) #19
🔊 tips:
1. 位运算使用二进制运算,使用十进制数据时,系统换算为二进制,若使用八进制数据则提示字符串不能用于位运算
2. 左移位直接在右边添加零;右移位直接右边删掉移位位数
3. 取反操作可使用 ~n = -(n+1) 快速计算;
🐡 赋值运算
= :赋值; += :加法赋值; -= : 减法赋值; *= :乘法赋值; /= : 除法赋值; %= : 取模赋值; **= :幂运算赋值; //= :整除赋值;
#赋值 a = 12 # 加法赋值 a = a + 12 #等价于 a += 12 # 减法赋值 a = a - 12 #等价于 a -= 12 # 乘法赋值 a = a * 12 #等价于 a *= 12 # 除法赋值 a = a / 12 #等价于 a /= 12 # 取模赋值 a = a % 12 #等价于 a %= 12 # 幂运算赋值 a = a ** 12 #等价于 a **= 12 # 整除赋值 a = a // 12 #等价于 a //= 12
🔊 tips:没有 a++、 a-- 这种自增自减运算符;
🐡 成员运算符
in :属于; not in :不属于;
# 定义列表 my_list = [1, 2, 3, 4, 5] # 3 属于 my_list 元素 print(3 in my_list) # 输出:True # 6 不属于 my_list print(6 not in my_list) # 输出:True
🔊tips: 成员运算符用于检查某个元素是否属于某个集合
🐡 身份运算符
is :属于; is not :不属于;
# 定义变量 x = 10 y = 10 z = 5 # x 是 y print(x is y) # 输出:True # x 不是 z print(x is not z) # 输出:True
🔊tips:身份运算符用于检查两个对象是否是同一对象
🐹 2. 数据转化
# 定义数字变量 x = 10 y = 1 # int() 函数 print(int(x)) # 转换为十进制整数 10 # float() 函数 print(float(x)) # 转换到一个浮点数 10.0 # bin() 函数 print(bin(x)) # 转换为二进制 0b1010 # oct() 函数 print(oct(x)) # 转换为八进制 0o12 # hex() 函数 print(hex(x)) # 转换为十六进制 0xa # complex() 函数 print(complex(x)) # 转成实部为x 虚部为0 复数 0 (10+0j) print(complex(x, y)) # 转成实部为x 虚部为y 复数 0 (10+1j) # bool() 函数 print(bool(x)) # 转化为布尔值 True print(bool(0)) # 转化为布尔值 False
五、注释
🐹 1. 注释的形式
🐡 单行注释:使用“#”符号注释,“#”符号时一次只能注释一行代码
#print("Hello World!") #使用“#”符号可以注释程序,也可以注释文字
🐡 多行注释:使用一对三个英文单引号注释,“ ''' ” 符号可以注释程序,也可以注释文字
''' print("Hello World!") print("Hello World!") print("Hello World!") '''
🐡 多行注释:使用一对三个英文双引号注释,“ """ ”符号可以注释程序,也可以注释文字
""" print("Hello World!") print("Hello World!") print("Hello World!") """
🐹 2. Python中注释的作用
🐡 注释程序:当一些程序加上注释后,Python的解释器便不再将这些程序进行解释处理了。简单来说就是加了注释的程序计算机是不会执行的。
print("这个没有加注释") #print("这个加了注释")
运行可以看到,加了“ # ”注释的语句没有运行。当程序中一些代码不想让它运行的时候,便可以加上注释。
🐡 解释说明:对程序起到解释说明的作用
#单行注释:这是一个实现两个数相加的函数 def add(a, b): return a + b
sum = add(1, 2) print(sum) ''' 多行注释: 这是一个实现两个数相加的函数 ''' def add(a, b): return a + b
sum = add(1, 2) print(sum)
六、基本数据类型
🔊:Python语言在定义变量时,不需要指定变量的数据类型,Python程序会根据变量值,自动确定变量类型。
在python中基本数据类型主要是以下5种分别是 1. Int(整型);2. Float(浮点型);3. Complex(复数型); 4. Bool(布尔型);5. Str(字符串);6. None(空值);
🐹 1. Int(整数)
✨ 与数学中的整数含义相同,无取值范围;
- 二进制:以0b或0B开头:0b1101,-0B10;
- 八进制:以0o或0O开头:0o456,-0O789;
- 十进制:123,-321,0;
- 十六进制:以0x或0X开头:0x1A,-0X2B。
0b1010 = 0o12 = 10 = 0xa
🐹 2. Float(浮点数)
✨ 与数学中的实数含义相同,带有小数及小数的数字,存在取值范围;
浮点数包括常规方法和科学计数法2种方式表示;
- 常规方法:整数后面带有小数
#常规 a = 3.145 print(a)
- 科学计数法:使用字母e或E作为幂的符号,以10位基数,
#科学计数法 a = 4.3e-3 b = 9.8E7 print(a) # 0.0043 print(b) # 98000000.0
📢 不确定尾数问题:浮点数直接运算,可能产生不确定尾数。不确定尾数问题来源于浮点数在计算机中表示不精确的实际情况,广泛存在于编程语言中。可以使用 round() 辅助浮点数运算,消除不确定尾数。
🐹 3. 复数类型
✨ 复数类型对应着数学中的复数。 复数是由一个实数和一个虚数组合构成,表示为:a+bj
Python语言中复数的虚数部分用“J”或“j”表示,不区分大小写字母,大小写效果、作用等同。
4j , 11.5+J , 1.23e-4+43j
要知道,python中一般都是“大小写字母敏感”的,大小写字母视为不同的对象。
对于一个复数a,可以用a.real和a.imag分别获得它的实数和虚数部分。如;
#复数 a = 1.23e-4 + 43j #实部 print(a.real) # 0.000123 #虚部 print(a.imag) # 43.0
🐹 4. Bool(布尔值)
✨ 布尔值表示逻辑上的真或假,只有两个取值:True 和 False。
#注释:这里的True 和 False,不同于其它的语言,都是首字母大写。 a = True a = False
Python中 布尔类型可以和整数直接相加的:
#True: 可以看着是整数1,True -1 变为 False a = True + 1 print(a) #输出: 2 a = True - 2 print(a) #输出: -1 # False: 可以看做是整数0, Flase + 1 变为 True b = False - 1 print(b) #输出: -1 b = False + 1 print(b) #输出: 1
🐹 5. Str(字符串)
✨ 字符串是由字符组成的序列,用于表示文本数据。字符串可以用单引号(' ')、双引号(" ")或三引号(''' ''' 或 """ """)来定义。三引号通常用于定义多行字符串。
字符串是一种不可变的数据类型,一旦创,就不能直接修改其中的字符,可以通过使用各种操作和方法来处理和操作字符串
🐡 字符串创建
Python中,使用单引号(')或双引号(")也可以使用三引号(''')创建多行字符串。
-
使用单引号
# 使用单引号 str1 = 'test str'
-
使用双引号
# 使用单引号 str2 = "test str"
-
使用三引号 ( 主要用于多行字符串 )
# 使用三引号 string3 = '''hello test str ya world'''
!!!注意:单引号有其他用途时,需要转义(使用反斜杠 \ 转义特殊字符)
🐡 字符串拼接
在 Python 中,我们可以使用加法操作符 + 来拼接字符串,也可以使用join()连接字符串数组,还可以通过\跨行连接字符串。
-
使用 + 拼接字符串
# 使用 + 拼接字符串 str1 = 'Hello' str2 = 'World' str3 = str1 + str2 print(str3) #输出 HelloWorld
-
使用join连接字符串组
# 字符串集合连接 a = {"aa","bb","cc"} print("是".join(a)) #输出结果:aa是bb是cc # 字符串数组连接 print("是".join(['cc','dd'])) # # 需要注意针对字典,join结合的是键 a = {"name":"test", "sex":"nan"} print("是".join(a)) #输出结果:name是sex
-
使用 \ 字符串跨行连接
a = "test1\ test2" print(a) ##输出的结果是test1 test2
🐡 字符串索引、切片
Python 中,字符串也是一种序列类型,因此支持序列操作
-
索引访问字符串中某元素
索引指的是使用单个下标访问字符串中的某个字符,其语法为 string[index],其中 index 表示要访问的字符在字符串中的位置。Python 中的索引从0开始,表示字符串中第一个字符
string = 'Hello, World' print(string[1]) #输出:e
-
切片访问字符串中的字串
切片指的是提取字符串中的一个子串,其语法为 string[start : end : step],左闭右开(不包含最后1个),默认步长为1。当省略 start 或 end 参数时,分别默认为字符串开头和结尾。
string = 'Hello,world!' print(string[0:5]) # 输出第1至第5个字符Hello print(string[6:]) # 输出第6个至结尾的字符world! print(string[::2]) # 输出从开头至结尾步长为2的字符Hlowrd print(string[0]) # 输出第1个字符H print(string[-1]) # 输出倒数第一个字符! print(string[-3:]) # 输出倒数第三个字符到结尾ld! print(string[100:105]) # 切片的时候起始位置和终止位置都超出的时候不会进行报错,超出不会打印出来 print(string[100]) # 🙅报错:索引的时候索引值超出范围的时候会报错string index out of range
!!!注意:
1、索引的时候索引值超出范围的时候会报错string index out of range;
2、切片的时候起始位置和终止位置都超出的时候不会进行报错,超出不会打印出来
🐡 使用split 拆分字符串
通过指定分隔符对字符串进行切片,并返回分割后的字符串列表。其语法为:
str.split(str=“”, num=string.count(str))[n]
str: 表示为分隔符,默认为空格,但是不能为空。若字符串中没有分隔符,则把整个字符串作为列表的一个元素。
num: 表示分割次数。如果存在参数num,则仅分隔成 num+1 个子字符串,并且每一个子字符串可以赋给新的变量 不写num,就是将出现分隔符的地方都分割 [n]: 表示选取第n个分片 分隔后取得值的类型是str, 就是通过列表的下标取值。
strvar = "you#can#you#up#no#can#no#bb" lst1 = strvar.split() lst2 = strvar.split("#") print(lst1) # 把整个字符串作为列表的一个元素输出 ['you#can#you#up#no#can#no#bb'] print(lst2) # 以#分隔输出新的列表元素 ['you', 'can', 'you', 'up', 'no', 'can', 'no', 'bb']
🐡 使用split截取字符串
可通过split截取字符串中想要的字段
str1 = "hello boy<[www.baidu.com]>byebey" c = str1.split("[")[1].split("]")[0] print(c) #输出:www.baidu.com
🐡 使用replace字符串替换
replace 把字符串的旧字符换成新字符 并不会将原有字符串修改,将替换后的结果赋值给新字符串.
语法如下:
str.replace(old, new[, max])
字符串序列.replace(“原字符串”,“新字符串”,修改的次数) 如果查到出现的次数,就从左到右替换该次数,省略不写次数,全部替换,次数超过了,也不报错,全部替换
示例如下:
test1 = 'hello world' test2 = test1.replace('o','(0)',1)
print(test2) # 只替换第1个,输入结果hell(o) world print(test1) # 原字符串不受影响hello world
🐡 使用eval函数将字符串str当成有效的表达式来求值并返回计算结果
eval函数 用来执行一个字符串表达式,并返回表达式的值。可以把字符串转化为 list, dict , tuple。
语法如下:

说明:
- expression -- 表达式。
- globals -- 变量作用域,全局命名空间,如果写,则必须是一个字典对象。
- locals -- 变量作用域,局部命名空间,如果写,可以是任何映射对象。
- return:返回表达式计算结果。
示例如下:
1、使用eval()函数,将字符串还原为数字类型,和int()函数的作用类似
# 1.使用eval()函数,将字符串还原为数字类型,和int()函数的作用类似 a = input() print(type(a)) #利用eval()将字符串类型转为整形 print(type(eval(a)),type(int(a)))
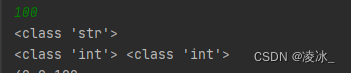 2、将输入的字符串转为对应的数据类型:如列表、元组、字典
2、将输入的字符串转为对应的数据类型:如列表、元组、字典
# 2.将输入的字符串转为对应的数据类型:如列表、元组、字典 # [1,2,4] # (1, 2, 4) # {'a':1,'b':2} a = input() n = eval(a) # 得到一个列表 print(type(n),type(a))
3、对表达式的结果进行计算,返回计算后的值
# 3.对表达式的结果进行计算,返回计算后的值 ss1 = "5*8" num=90 print(eval(ss1), eval("pow(3,2)"),eval('num+10'))
4、可以使用格式化字符串的操作更加简便
#4.可以使用格式化字符串的操作更加简便 a=10 oper='+' b=5 #加法运算 sums=eval(f'{a}{oper}{b}') print(f'{a}{oper}{b}={sums}')
🐡 字符串格式化
Python 的字符串格式化有三种常见方式:百分号(%)格式化、str.format()方法、f-string表达式
- %占位符
使用百分号(%)作为占位符。
其中 %s 表示字符串类型,%d 表示整数类型,%f 表示浮点型。%d 和 %f 后面可以加上 .n,表示保留 n 位小数。当需要在字符串中表示 % 字符时,需要用两个百分号转义
age = 18 name = 'Tom' print('My name is %s, and I am %d years old.' % (name, age)) #My name is Tom, and I am 18 years old.
- str.format()方法
此方法可以使用花括号 `{}` 作为占位符,`{}` 中可以加入数字,表示占位符的顺序
age = 18 name = 'Tom' print('{1} is {0} years old.'.format(age, name)) #Tom is 18 years old.
- f-string表达式
f-string表达式,可以解析任意类型的数据,运行的时候渲染,性能比%,.format()更好
age = 18 name = 'Tom' print(f'My name is {name}, and I am {age} years old.') #My name is Tom, and I am 18 years old.
🐡 字符串常用函数
🦋 1、字符串大小写转换 capitalize(),upper(),lower(),swapcase(),title()
- capitalize() : 将字符串中的首字母转换为大写
#定义 字符串 str = 'hello world' #输出 首字母大写 print(str.capitalize()) # Hello world
- upper() : 将字符串转换为全部大写。
#定义 字符串 str = 'hello world' #输出 全部大写 print(str.upper()) # HELLO WORLD
- lower() :将字符串转换为全部小写。
#定义 字符串 str = 'HELLO WORLD' #输出 全部小写 print(str.lower()) # hello world
- swapcase() : 将字符串中的小写字符转换为大写或大写字符转换为小写。
#定义 字符串 str = 'Hello Word' #输出 大写转小写,小写转大写 print(str.swapcase()) # hELLO wORD
- title() : 将字符串中的单词首字母转换为大写
#定义 字符串 str = 'hello world' #输出 每个单词首字母大写 print(str.title()) # Hello World
🦋 2、计算字符串的长度 len()
- len() : 计算字符串的长度
#定义 字符串 str = 'hello world' #输出 计算字符串的长度 print(len(str)) # 11
🦋 3、统计某元素的数量 count(字符,[开始值,结束值])
- count(字符,[开始值,结束值]):统计字符串中某个元素的数量 ,不存在返回0,但不报错
#定义 字符串 str = "真热真热呀" #输出 print(str.count("真")) # 2 print(str.count("热",2)) # 1 只有一个数,是开始位置 print(str.count("热",2,3)) # 只有真这个字符 没有热,所以输出0
🦋 4、字符串是否以某字符开头和结尾 startswith() ,endswith()
- startswith() :判断是否以某个字符或字符串为开头
#定义 string = "hello world" #输出 print(string.startswith("l")) #校验不是以l开头,输出False print(string.startswith("h")) #校验是以h开头,输出True
- endswith() :判断是否以某个字符或字符串为结尾
#定义 string = "hello world" #输出 print(string.endswith("l")) #校验不是以l开头,输出False print(string.endswith("d")) #校验是以h开头,输出True
🦋 5、字符串的 encode() 和 decode() 方法:

- encode('xx'):将字符串编码成字节串,通常用于写入文件或网络传输。xx表示编码方式,如utf-8
#【encode】 unicode_str=u'您好世界' # 指定字符串类型对象u print(unicode_str.encode('utf-8')) # b'\xe6\x82\xa8\xe5\xa5\xbd\xe4\xb8\x96\xe7\x95\x8c' print(unicode_str.encode('gbk')) # b'\xc4\xfa\xba\xc3\xca\xc0\xbd\xe7'
- decode('xx'):将字节串解码成字符串,是encode()的逆操作。xx表示解码方式,如utf-8
#【decode】 str1 = b'\xe6\x82\xa8\xe5\xa5\xbd\xe4\xb8\x96\xe7\x95\x8c' #utf-8 编码后结果 str2 = b'\xc4\xfa\xba\xc3\xca\xc0\xbd\xe7' #gbk编码后结果 print(str1.decode('utf-8')) #您好世界 print(str2.decode('gbk')) #您好世界
🦋 6、字符串查找元素 find(), index(), rfind(), rindex()
find(), index() 开始从正面查找, rfind(), rindex() 开始从后面查找
- find() :find()用于查找子字符串,如果找到则返回第一个匹配的索引,否则find()返回-1。语法为:find(字符,[开始值,结束值])
string = "hello world" index = string.find("world") print(index) # 输出 6
- index() :与 `find()` 功能相同,index()方法用于查找子字符串,如果找到则返回第一个匹配的索引,否则index()会抛出一个ValueError异常。
#定义 string = "hello world" result_find = string.find("world0") result_index = string.index("world0")
#输出 print(result_find) # 输出 -1 print(result_index) #🙅错误: 输出Error错误substring not found
- rfind() : 与 `find()` 方法类似,但是它从字符串的末尾开始查找子字符串,并返回最后一次出现的索引。如果没有找到子字符串,则返回 -1
#定义 string = "hello world" result = string.find("l") result1 = string.rfind("l")
#输出 print(result) # 输出2 print(result1) # 输出9
- rindex():与 `index()` 方法类似, rindex()方法从字符串的末尾开始查找。如果找到则返回最后一次匹配的索引,否则rindex()会抛出一个ValueError异常。
#定义 string = "hello world" result_find = string.rindex("o") result_index = string.rindex("world0") #输出 print(result_find) # 输出 7 print(result_index) #🙅错误: 输出Error错误substring not found
🦋 7. 字符串的 split() 和 join(), replace()方法:
- split() :根据指定的分隔符将字符串分割出来。
myStr = 'hello world and Python and java and php' list1 = myStr.split('and') print(list1) # ['hello world ', ' Python ', ' java ', ' php'] list1 = myStr.split('and', 2) # 2 表示的是分割字符出现的次数,即将来返回数据个数为3个 print(list1) # ['hello world ', ' Python ', ' java and php']
- join() :将裁剪出来的中的元素进行替换连接成一个字符串。
myList = ['aa', 'bb', 'cc'] # 需求:最终结果为: aa...bb...cc new_list = '...'.join(myList) print(new_list) # aa...bb...cc new_list = '/'.join(myList) print(new_list) # aa/bb/cc
- replace() :替换字符串中的某些字符或子字符串。
myStr = 'hello world and Python and java and php' new_str = myStr.replace('and', 'he') print(myStr) # hello world and Python and java and php print(new_str) # hello world he Python he java he php # 原字符串调用了replace函数后,原有字符串中的数据并没做任何修改,修改后的数据是replace函数电动的返回值 # 说明:replace函数有返回值,返回值是修改后的字符串 # 字符串是不可变数据类型,数据是否可以改变划分为:可变类型 和 不可变类型 new_str = myStr.replace('and', 'he', 1) print(new_str) # hello world he Python and java and php new_str = myStr.replace('and', 'he', 10) print(new_str) # hello world he Python he java he php # 替换次数如果超出了子串出现的次数,表示替换所有这个子串
🦋 8. 填充字符串center(),ljust(),rjust(),zfill()的方法:
- center() :返回一个原字符串在中间,并使用fillchar(默认为空格)填充左边和右边形成一个新字符串。str.center(width[, fillchar])
# 语法:str.center(width[, fillchar])。width:指定字符串长度;fillchar:填充字符,默认为空格。 # 定义 str1 = 'sentence' str2 = 'word' # 输出 print(str1.center(20)) # sentence print(str2.center(20)) # word
- ljust() :返回一个原字符串左对齐,并使用fillchar(默认为空格)填充至指定宽度的新字符串。
#语法:str.ljust(width[, fillchar])。 width:指定字符串长度。fillchar:填充字符,默认为空格。 #定义 str1 = 'sentence' str2 = 'word' #输出 print(str1.ljust(20)) # sentence print(str2.ljust(20)) # word
- rjust() :返回一个原字符串右对齐,并使用fillchar(默认为空格)填充至指定宽度的新字符串。
# 语法:str.rjust(width[, fillchar])。 width:指定字符串长度。fillchar:填充字符,默认为空格。 str1 = 'sentence' str2 = 'word' #输出 print(str1.rjust(20)) # sentence print(str2.rjust(20)) # word
设置填充字符:
str1 = 'sentence' str2 = 'word' print(str1.rjust(20,'-')) # ------------sentence print(str2.rjust(20,'-')) # ----------------word print(str1.ljust(20,'*')) # sentence************ print(str2.ljust(20,'*')) # word**************** print(str1.center(20,'-')) # ------sentence------ print(str2.center(20,'-')) # --------word--------
- zfill :返回字符串左端填充零直到长度为width的字符串。相当于rjust(number,'0')
str1 = 'sentence' print(str1.zfill(20)) # 000000000000sentence #相当于 print(str1.rjust(20,'0')) # 000000000000sentence
🦋 9、字符串方法:strip(), lstrip(), rstrip()方法
- strip() : 去除字符串两端的空白字符(包括空格、换行符\n、制表符\t等),也可以指定
#语法为:str.strip(”chars“) ,其中str 是字符串,chars 是指定的字符 string1 = " hello world " string2 = string1.strip() #输出 print(string1) # ' hello world' print(string2) # 'hello world'
- lstrip() : lstrip()用于去除左端的空白字符。
string1 = " hello world " string2 = string1.lstrip() #输出 print(string1) # ' hello world ' print(string2) # 'hello world '
- rstrip() : rstrip()用于去除右端的空白字符。
string1 = " hello world " string2 = string1.lstrip() #输出 print(string1) # ' hello world ' print(string2) # ' hello world'
🦋 10、IS系列函数
- isupper() :判断字符串是否都是大写字母
str1 = "THIS IS PYTHON....WOW!!!" print(str1.isupper()) #True str2 = "THIS is python....wow!!!" print(str2.isupper()) #False
- islower() : 判断字符串是否都是小写字母
str1 = "Python 大星....wow!!!" print(str1.islower()) #False str2 = "phthon 大星....wow!!!" print(str2.islower()) #True
- istitle():判断字符串中所有的单词拼写首字母是否为大写,且其他字母为小写
str1 = "Python大星!!!" #True print(str1.istitle()) str2 = "python大星!!!" #False print(str2.istitle()) str3 = "Hello Wolrd" print(str3.istitle()) #True str4 = "Hellowolrd" print(str4.istitle()) #True str5 = "Hello wolrd" print(str5.istitle()) #False
- isdecimal() : 检测字符串是否以数字组成 必须是纯数字,有小数点都不算纯数字
str1 = "python2019" print(str1.isdecimal()) #False str2 = "23443434" print(str2.isdecimal()) #True
- isinstance() : 判断一个对象是否是一个已知的类型,类似 type()。
print(isinstance('python',str)) #True print(isinstance(13,int)) #True print(isinstance(2019.08,float)) #True print(isinstance([1,2,3,4],list)) #True print(isinstance([1,2,3,4],set)) #false print(isinstance((1,2,3,4),tuple)) #True print(isinstance({'name':'Python大星'},object)) #True
- isdigit() : 判断字符串是否是数字组成
str1 = "123456" print(str1.isdigit()) #True str2 = "123456四五六" print(str2.isdigit()) #False str3 = "Python 大星....wow!!!" print(str3.isdigit()) #False
⚠️ 注意:这里必须是‘1234567890’组成的数字,中文‘四’,‘五’,‘六’... 不被认为是数字
- isnumeric() : 检测字符串是否以数字组成
str = "Python 大星" print(str.isnumeric()) #False str1 = "23443434" print(str1.isnumeric()) #True str2 = "2344四五六" print(str2.isnumeric()) #True
⚠️ 注意:中文的数字比如"四",也被认为是数字
- isalnum() : 判断字符串是否由数字,字母,汉字组成
print(' '.isalnum()) #False print('1'.isalnum()) #True print('a'.isalnum()) #True print('a1'.isalnum()) #True print('a1哈哈'.isalnum()) #True print('www.baidu.com'.isalnum()) #False
- isalpha() : 判断字符串是否由字母和文字组成
print(" ".isalpha()) #False print("1".isalpha()) #False print("12".isalpha()) #False print("a".isalpha()) #True print("ab".isalpha()) #True print("a1".isalpha()) #False print("a哈哈".isalpha()) #True print("a1哈哈".isalpha()) #False print("www.baidu.com".isalpha()) #False
- isspace() : 判断字符串是否由空白符组成。
str = " " print(str.isspace()) #True str2 = "Python....wow!!!" print(str2.isspace()) #False print(' \t\r\n'.isspace()) #True print('\0'.isspace()) #False print(' a '.isspace()) #False
- isidentifier() : 判断字符串是有效的 Python 标识符。
print('if'.isidentifier()) #True print('def'.isidentifier()) #True print('class'.isidentifier()) #True print('_a'.isidentifier()) #True print('中国123a'.isidentifier()) #True print('123'.isidentifier()) #False print('3a'.isidentifier()) #False print("".isidentifier()) #False
🐹 6. NoneType (空值类型)
None 表示空值或者不存在的值。
✨ 只有一种值:None
✨ 表示完全没有值:None 不是0,不是空字符串””,也不是False。
print(type("Hello")) #<class 'str'> 字符串类型 print(type(6)) #<class 'int'> 整数类型 print(type(6.0)) #<class 'float'> 浮点类型 print(type(True)) #<class 'bool'> 布尔类型 print(type(None)) #<class 'NoneType'> 空值类型
🐹 7. List(列表)
✨ 列表 特点:有序,可重复,可扩展,可以存储不同类型的元素。
在Python中,列表(List)是一种有序的集合,可以包含任意类型的对象,包括数字、字符串、甚至其他列表等。列表是可变的,这意味着在创建后可以修改列表的内容。列表使用方括号[]定义,并且列表中的元素通过逗号,分隔。
#【创建列表】 # 🌾有序 list = ["苹果", "玉米", "水蜜桃", "南瓜", "葡萄"] # 🌾可重复 list1 = ["苹果", "玉米", "水蜜桃","玉米","南瓜", "葡萄"] # 🌾可扩展 list2 = ["苹果", "玉米", "水蜜桃","玉米","南瓜", "葡萄"] list2.append('西瓜') print(list2) # ['苹果', '玉米', '水蜜桃', '玉米', '南瓜', '葡萄', '西瓜'] # 🌾可以存储不同元素 list3 = ["苹果", "玉米", "水蜜桃","玉米","南瓜", "葡萄",1,2,True,{'name':'python'}] print(list3) # ['苹果', '玉米', '水蜜桃', '玉米', '南瓜', '葡萄', 1, 2, True, {'name': 'python'}]
🐡 列表的遍历
🦋 使用 for 循环遍历:最常见的方法是使用 for 循环来遍历列表中的每一个元素。
- 常规遍历
#【创建列表】 list3 = ["苹果", "玉米", "水蜜桃","玉米","南瓜", "葡萄",1,2,True,{'name':'python'}] # 🌾for 循环便利
# 通过value这个变量中,每次在循环体内部都可以访问当前这一次获取到的数据 for value in list3 : print(f"列表元素:{value}") #用差值语法,注意前面的f 不要忘记 !!! for value in list3 : print("列表元素: %s"%value) #格式化输出, 注意%字符,表示标记转换说明符的开始,类似于C语言中的用的逗号。
# 下标迭代遍历 for i in range(len(list3)): print("列表元素:%s"%list3[i]) #【输出结果】 #列表元素: 苹果 #列表元素: 玉米 #列表元素: 水蜜桃 #列表元素: 玉米 #列表元素: 南瓜 #列表元素: 葡萄 #列表元素: 1 #列表元素: 2 #列表元素: True #列表元素: {'name': 'python'}
优点:不需要设计计数器,也不需要对计数器进行操作
-
enumerate
list1 = ["这", "是", "一个", "测试"] for index, item in enumerate(list1, 1): print (index, item) #输出结果: # 1 这 # 2 是 # 3 一个 # 4 测试
优点:enumerate可以 返回 索引 和 值,同时可以用第二个参数指定索引的初始值
-
zip()
# 🌾 两个数据长度一致 a = [1,2,3,4] b = [5,6,7,8] for i,j in zip(a,b): print(i,j) #【输出结果】 # 1 5 # 2 6 # 3 7 # 4 8 # 🌾 两个数据长度不一致,输出与短数据长度对齐 a = [1,2,3,4] b = ['😂','😄'] for (i,j) in zip(a,b): print(i,j) #【输出结果】 # 1 😂 # 2 😄
优点:打包两个可遍历数据,一起循环
🦋 使用 while 循环和索引:可以通过索引来遍历列表,虽然不如 for 循环直接,但有时也很有用。
my_list = ["Hello", "World", "Python"] # 循坏控制变量通过下标索引来控制,默认0 # 每一次循环将下标索引变量+1 # 循环条件:下标索引变量 < 列表的元素数量 # 定义一个变量用来标记列表的下标 index = 0 # 初始值为0 while index < len(my_list): # 通过index变量取出对应下标的元素 element = my_list[index] print(f"列表的元素:{element}") # 至关重要 将循环变量(index)每一次循环都+1 index += 1
🐡 列表的常用方法
-
创:创建list
#示例一 list = [1,2,3] print(list,type(list)) # [1, 2, 3] <class 'list'> #示例二 list1 = ['a','b','c'] print(list1,type(list1)) # ['a', 'b', 'c'] <class 'list'> #示例三 list2 = [] print(list2,type(list2)) # [] <class 'list'>
-
增:添加新的元素
list.append():在list末尾增加一个元素
list.insert(n,3):在指定位置添加元素,如果指定的下标不存在,那么就在末尾添加
list1.extend(list2):把list2的元素合并到list1中,list2中元素任然正常,list1为合并后
list = ['a', 'b', 'c'] list1 = [1, 2, 3, 4] print(list, type(list)) # ['a', 'b', 'c'] <class 'list'> # 在list最后插入元素2 list.append(2) print(list, type(list)) # ['a', 'b', 'c', 2] <class 'list'> # 在list第三位插入元素da list.insert(2, 'da') print(list, type(list)) # ['a', 'b', 'da', 'c', 2] <class 'list'> # 把list1的元素合并到list中 list.extend(list1) print(list, type(list)) # ['a', 'b', 'da', 'c', 2, 1, 2, 3, 4] <class 'list'> print(list1, type(list1)) # [1, 2, 3, 4] <class 'list'>
-
查:查看列表中的元素
print(list):打印整个列表
print(list[n]):查看下标索引为n的列表中的值,如果索引n不存在会报错
print(list.count(xx)):查看列表中值为xx的元素的个数,如果该元素不存在,那么返回0
print(list.index(xx)):找元素xx的索引值,如果有多个,返回第一个xx元素的索引值,如果元素xx不存在则会报错
list = ['a', 'b', 'c','a','ab'] list1 = [1, 2, 3, 4] #打印整个列表 print(list) #查看下标索引为n的列表中的值,如果索引n不存在会报错 print(list[1]) #查看列表中值为xx的元素的个数,如果该元素不存在,那么返回0 print(list.count('a'),list.count('d')) #找元素xx的索引值,如果有多个,返回第一个xx元素的索引值,如果元素xx不存在则会报错 print(list.index('a'))
-
删:删除list中的元素
list.pop():删除最后一个元素
list.pop(n):删除指定索引的元素,如果该索引不存在则会报错
list.remove(xx):删除list的一个元素xx,如果有多个xx,删除第一个,如果不存在则报错
print(list.pop()):有返回值 print(list.remove()):无返回值
clear: 清空list中的元素,list不能访问
list = ['a', 'b', 'c','a','ab'] list1 = [1,2,3,4,6,1,5,3] #删除最后一个元素 print('list is:',list) print('list.pop() is:',list.pop()) print('list is:',list) #删除指定索引的元素,如果该索引不存在则会报错 print('list.pop(1) is:',list.pop(1)) print('list is:',list) #删除list的一个元素xx,如果有多个xx,删除第一个,如果不存在则报错 print('list1.remove(1) is:',list1.remove(1)) print('list1 is:',list1) #清空 print('list1 clear is:',list1.clear()) print('list1 is:',list1)
-
排序和反转
list.reverse()将列表反转
list.sort()排序,默认升序
list.sort(reverse=True)降序排列!!!注意:list中有字符串,数字时不能排序,排序针对的同类型
list = ['a', 'b', 'c','a','ab'] list1 = [1,2,3,4,6,1,5,3] #list元素反转 list.reverse() print('list is:',list) #list is: ['ab', 'a', 'c', 'b', 'a'] print('list1 is:',list1) #list1 is: [1, 2, 3, 4, 6, 1, 5, 3] #list默认升序排列 list1.sort() print('list1 is:',list1) #list1 is: [1, 1, 2, 3, 3, 4, 5, 6] #list降序排列 list1.sort(reverse=True) print('list1 is:',list1) #list1 is: [6, 5, 4, 3, 3, 2, 1, 1]
-
列表操作函数
len(list):列表元素个数
max(list):返回列表元素的最大值
min(list):返回列表元素的最小值
enumerate用法,打印元素对应的下标
list = ['a', 'b', 'c','a','ab'] list1 = [1,2,3,4,6,1,5,3] tuple1 = (1,2,'a','b') #1.len(list):列表元素个数 n = len(list) print('list 元素个数为:',n) #list 元素个数为: 5 #2.max(list) 与 min(list) #max(list):返回列表元素的最大值 #min(list):返回列表元素的最小值 print('list中max值:',max(list)) #list中max值: c print('list1中min值:',min(list1)) #list1中min值: 1 #3.enumerate用法,打印元素对应的下标 for i, v in enumerate(list): print('index= %s ,value =%s'%(i,v)) #【输出结果】 #index= 0 ,value =a #index= 1 ,value =b #index= 2 ,value =c #index= 3 ,value =a #index= 4 ,value =ab
- list切片
name[n:m]切片是不包括后面那个元素的值(顾前不顾尾)
name[:m]如果切片前面值缺失,从头开始取值
name[n:]如果切换后面值缺失,取值到最后一个
name[:]如果前后值全部缺失,取全部
name[n:m:s] s:步长,s=2表示隔1个元素取一次
步长为正数,从左往右取 步长为负数,从右往左取!!!注意:切片同样适用于字符串
list = ['a', 'b', 'c','a','ab'] list1 = [1,2,3,4,6,1,5,3] #name[n:m]切片是不包括后面那个元素的值(顾前不顾尾) list2 = list[1:4] print('list2 is:',list2) #name[:m]如果切片前面值缺失,从头开始取值 list3 = list1[:3] print('list3 is:',list3) #name[n:]如果切换后面值缺失,取值到最后一个 list4 = list1[2:] print('list4 is:',list4) #name[:]如果前后值全部缺失,取全部 list5 = list[:] print('list5 is:',list5) #name[n:m:s] s:步长,s=2表示隔1个元素取一次 #步长为正数 list6 = list1[4:1:-2] print('list6 is:',list6) #步长为负数 list7 = list1[1:4:2] print('list7 is:',list7)
🐹 8. Tuple(元组)
✨ 元组 特点:有序,可重复,不可扩展
元组(Tuple)是Python中的一种内置数据类型,用于存储一系列有序的元素。与列表(List)相似,但元组是不可变的(immutable),即一旦创建,就不能修改其内部的元素。元组使用圆括号()来定义,元素之间用逗号,分隔。如果元组中只有一个元素,需要在该元素后面加上逗号,以区分于该元素本身和元组。
🐡 元组创建
#创建 colors = ('red', 'green', 'blue') #可重复 colors = ('red', 'green', 'blue','red') # 有序 print(colors[1]) # 输出: green # 不可拓展, "添加"、"删除"等操作都不能操作 print(colors.append()) #报错🙅 print(colors.remove()) #报错🙅
🐡 遍历元组
使用 for 循环遍历元组中的每个元素
# 定义元组 my_tuple = (1, 3, 5, 7, 9) # 遍历元组 for item in my_tuple: print(item)
使用 while 循环和索引变量遍历元组中的每个元素
#定义元组 my_tuple = (1, 3, 5, 7, 9) #遍历元组 index = 0 while index < len(my_tuple): print(my_tuple[index]) index += 1
使用 enumerate() 函数遍历元组中的每个元素,同时获取索引
# 定义元组 my_tuple = (1, 3, 5, 7, 9) # 遍历元组 for index, item in enumerate(my_tuple): print(f"Index: {index}, Item: {item}")
使用 range() 函数和索引访问元组中的每个元素
# 定义元组 my_tuple = (1, 3, 5, 7, 9) # 遍历元组 for index in range(len(my_tuple)): print(my_tuple[index])
🐡 查找元素
-
通过索引直接获取
元组中的每个元素都有一个索引,索引是元素在元组中位置的序号,从0开始。
tup = ('apple', 'banana', 'cherry') print(tup[0]) # 输出 'apple' print(tup[1]) # 输出 'banana' print(tup[2]) # 输出 'cherry'
- 使用for循环遍历
tup = ('apple', 'banana', 'cherry') for item in tup: print(item) # 输出 'apple' # 输出 'banana' # 输出 'cherry'
- 使用while循环和索引遍历
tup = ('apple', 'banana', 'cherry') i = 0 while i < len(tup): print(tup[i]) i += 1 # 输出 'apple' # 输出 'banana' # 输出 'cherry'
- 使用列表表达式一步获取所有值
tup = ('apple', 'banana', 'cherry') values = [value for value in tup] print(values) # 输出 ['apple', 'banana', 'cherry']
- 使用max(), min(), sum()等聚合函数
tup = (1, 2, 3, 4, 5) print(max(tup)) # 输出 5 print(min(tup)) # 输出 1 print(sum(tup)) # 输出 15
- 使用count()函数计数元素出现的次数
tup = ('apple', 'banana', 'cherry', 'apple') print(tup.count('apple')) # 输出 2
- 使用index()函数获取元素的索引
tup = ('apple', 'banana', 'cherry') print(tup.index('banana')) # 输出 1
🐡 计算长度:使用len()函数可以获取元组中元素的数量。
tuple = (123,1,4,9,10) print(len(tuple)) #5
🐡 元组的连接使用 + 操作符可以拼接两个或多个元组。
A = (1,2,3) B = (4,5,6) print(A + B) # 输出: (1,2,3,4,5,6)
🐡 元组重复:使用乘号 * 重复元组中的元素。
tuple = (123,) tuple *= 3 print(tuple) #(123, 123, 123)
🐹 9. Dict(字典)
🐡 字典的定义
字典(Dictionary)是Python中一种用于存储键值对(key-value pair)的数据结构。每个键(key)都与一个值(value)相关联,键必须是唯一的,但值可以是任意数据类型(如整数、字符串、列表、甚至其他字典)。字典的创建使用花括号 {},每个键值对使用冒号 : 分隔,键和值之间使用逗号 , 分隔。
🐡 字典的键与值键(Key):字典中的键是唯一的,并且通常是不可变的数据类型,比如整数、字符串或元组。键用于访问其相关联的值。
值(Value):字典中每个键对应一个值,值可以是任何数据类型,包括整数、字符串、列表、字典等。
🐡 字典的基本用法
1、访问字典的值
通过 key 访问value
scores_dict = {'语文':105,'数学':140, '英语':120}
print(scores_dict['语文']) # 通过键“语文”获取对应的值 105
2、添加键值对
通过 key 添加 key-value 对
scores_dict = {'语文': 105, '数学': 140, '英语': 120}
scores_dict['物理'] = 97 # 添加 ‘物理’: 97
print(scores_dict) #{'语文': 105, '数学': 140, '英语': 120, '物理': 97}
3、删除键值对
通过 key 删除 key-value 对
scores_dict = {'语文': 105, '数学': 140, '英语': 120}
del scores_dict['数学'] # 删除 ’语文‘: 105
print(scores_dict) # 输出 {'语文': 105, '英语': 120}
4、修改字典值
通过 key 修改 key-value 对
scores_dict = {'语文': 105, '数学': 140, '英语': 120}
scores_dict['数学'] = 120 # 修改将“数学”修改为120
print(scores_dict) # 输出 {'语文': 105, '数学': 120, '英语': 120}
5、判断键值对是否存在
如果要判断字典是否包含指定的 key,则可以使用 in 或 not in 运算符。需要指出的是,对于 dict 而言,in 或 not in 运算符都是基于 key 来判断的。
scores_dict = {'语文': 105, '数学': 140, '英语': 120}
# 判断scores_dict是否包含名为'语文'的key
print('语文' in scores_dict) # True
# 判断scores_dict不包含'历史'的key
print('历史' not in scores_dict) # True
🐡 字典的常用方法
1、clear()方法
clear() 用于清空字典中所有的 key-value 对,对一个字典执行 clear() 方法之后,该字典就会变成一个空字典。
scores_dict = {'语文': 105, '数学': 140, '英语': 120}
print(scores_dict) # 输出 {'语文': 105, '数学': 140, '英语': 120}
scores_dict.clear() # 删除字典所有内容
print(scores_dict) # 输出{}
2、get()方法
get() 方法其实就是根据 key 来获取 value,它相当于方括号语法的增强版,当使用方括号语法访问并不存在的 key 时,字典会引发 KeyError 错误;但如果使用 get() 方法访问不存在的 key,该方法会简单地返回 None,不会导致错误。
scores_dict = {'语文': 105, '数学': 140, '英语': 120}
print(scores_dict.get('历史')) # 输出 None
print(scores_dict['历史']) # 报错 KeyError: '历史'
3、update()方法
update() 方法可使用一个字典所包含的 key-value 对来更新己有的字典。在执行 update() 方法时,如果被更新的字典中己包含对应的 key-value 对,那么原 value 会被覆盖;如果被更新的字典中不包含对应的 key-value 对,则该 key-value 对被添加进去。
scores_dict = {'语文': 105, '数学': 140, '英语': 120}
scores_dict.update({'语文': 120, '数学': 110})
print(scores_dict) # 输出{'语文': 120, '数学': 110, '英语': 120}
4、items()方法
以列表返回可遍历的(键, 值) 元组数组
scores_dict = {'语文': 105, '数学': 140, '英语': 120}
print(scores_dict.items()) # 输出 dict_items([('语文', 105), ('数学', 140), ('英语', 120)])
5、keys()方法
以列表返回一个字典所有的键
scores_dict = {'语文': 105, '数学': 140, '英语': 120}
print(scores_dict.keys()) # 输出 dict_keys(['语文', '数学', '英语'])
6、values()方法
以列表返回字典中的所有值
scores_dict = {'语文': 105, '数学': 140, '英语': 120}
print(scores_dict.values()) # 输出 dict_values([105, 140, 120])
7、pop()方法
pop() 方法用于获取指定 key 对应的 value,并删除这个 key-value 对。
scores_dict = {'语文': 105, '数学': 140, '英语': 120}
scores_dict.pop('英语') # 删除'英语'的键和值
print(scores_dict) # 输出{'语文': 105, '数学': 140}
8、popitem()方法
popitem() 方法用于弹出字典中最后一个key-value对
scores_dict = {'语文': 105, '数学': 140, '英语': 120}
print(scores_dict.popitem()) # 输出('英语', 120)
9、setdefault()方法
setdefault() 方法也用于根据 key 来获取对应 value 的值。但该方法有一个额外的功能,即当程序要获取的 key 在字典中不存在时,该方法会先为这个不存在的 key 设置一个默认的 value,然后再返回该 key 对应的值。
scores_dict = {'语文': 105, '数学': 140, '英语': 120}
# 设置'语文'默认值为100
scores_dict.setdefault('语文', 100)
print(scores_dict) # 输出{'语文': 105, '数学': 140, '英语': 120}
# 设置'历史'默认值为140
scores_dict.setdefault('历史', 140)
print(scores_dict) # 输出{'语文': 105, '数学': 140, '英语': 120, '历史': 140}
10、fromkeys()方法
fromkeys() 方法使用给定的多个key创建字典,这些key对应的value默认都是None;也可以额外传入一个参数作为默认的value。该方法一般不会使用字典对象调用(没什么意义),通常会使用 dict 类直接调用。例如如下代码:
scores_dict = dict.fromkeys(['语文', '数学']) print(scores_dict) # 输出{'语文': None, '数学': None} scores_dict = dict.fromkeys(('语文', '数学')) print(scores_dict) # 输出{'语文': None, '数学': None} # 使用元组创建包含2个key的字典,指定默认的value scores_dict = dict.fromkeys(('语文', '数学'), 100) print(scores_dict) # 输出{'语文': 100, '数学': 100}
11、len()方法
计算字典元素个数,即键的总数。
scores_dict = {'语文': 105, '数学': 140, '英语': 120}
print(len(scores_dict)) # 输出 3
12、str()方法
输出字典可打印的字符串
scores_dict = {'语文': 105, '数学': 140, '英语': 120}
print(str(scores_dict)) # 输出{'语文': 105, '数学': 140, '英语': 120}
13、type()方法
返回输入的变量类型,如果变量是字典就返回字典类型。
scores_dict = {'语文': 105, '数学': 140, '英语': 120}
print(type(scores_dict)) # 输出<class 'dict'>
🐡 Python字典的for循环遍历
1、遍历key的值
scores_dict = {'语文': 105, '数学': 140, '英语': 120}
for key in scores_dict:
print(key)
2、遍历value的值
scores_dict = {'语文': 105, '数学': 140, '英语': 120}
for value in scores_dict.values():
print(value)
3、遍历字典键值对
scores_dict = {'语文': 105, '数学': 140, '英语': 120}
for key in scores_dict:
print(key + ":" + str(scores_dict[key]))
#【输出结果:】
#语文:105
#数学:140
#英语:120
scores_dict = {'语文': 105, '数学': 140, '英语': 120}
for i in scores_dict.items():
print(i) # 返回元组
#【输出结果:】
#('语文', 105)
#('数学', 140)
#('英语', 120)
scores_dict = {'语文': 105, '数学': 140, '英语': 120}
for key, value in scores_dict.items():
print(key + ':' + str(value))
#【输出结果:】
# 语文:105
# 数学:140
# 英语:120
🐹 10. Set(集合)
✨ 无序,不可重复,可扩展
在Python中,集合(Set)是一种无序且元素唯一的数据集合。集合通常用于去重或者检查成员是否存在,其元素可以是任何不可变的数据类型,比如整数、浮点数、字符串或元组。集合使用花括号 {} 来创建,元素之间使用逗号 , 分隔。
🐡 集合的定义
一般通过花括号或set来定义一个集合,例如
S = set() # 定义一个空的集合
使用花括号定义一个有数据的集合
S = {1}
🐡 集合的常见操作
1、添加元素
常用的两种添加元素方法:add:向集合中添加一个元素。如果集合中已经存在该元素,则不会进行任何操作。
update:向集合中添加一个或多个元素,参数可以是可迭代对象。
S = {"A", "B"}
# 🌾:添加一个元素 add
S.add(10)
print(S) #{'A', 10, 'B'}
#🌾:添加多个元素 update
S.update([1, 2, 3])
print(S) #{1, 2, 'A', 'B', 3, 10}
2、删除元素
常见有4种删除元素的方法:
remove:如果元素在集合中,则移除该元素,否则会引发 KeyError 错误。
discard:如果元素在集合中,则移除该元素,否则不做任何操作。
pop:随机移除并返回集合中的一个元素。如果集合为空,会引发 KeyError 错误。
clear:移除集合中所有的元素
S1 = {"A", "B", "C"}
#🌾:移除一个元素,若不存在则引发错误 remove
S1.remove("A")
print(S1) #{'B', 'C'}
S2 = {"A", "B", "C"}
#🌾:移除一个元素,若不存在则不做任何操作 discard
S2.discard("A")
print(S2) #{'B', 'C'}
S3 = {"A", "B", "C"}
#🌾:随机移除一个元素,若集合为空则报错 pop
S3.pop()
print(S3) #{'C', 'A'}
S4 = {"A", "B", "C"}
#🌾:清空元素 clear
S4.clear()
print(S4) #set()
3、修改元素
集合是无序且不可更改的,所以需要修改某个元素时只能先删除,后添加
S = {"A", "B", "C"}
#🌾:移除B
S.discard("B")
print(S)
#🌾:添加E
S.add("E")
print(S)
4、访问元素
由于集合是无序的,所以在需要使用索引来访问某个元素时,可以将其转换为列表后操作。但问题又来了,虽然可以使用列表访问,但顺序已经被打乱后是无法精确匹配某个元素的,这对我们来说毫无意义。
集合一般是用于存储唯一元素的无序数据结构,重点在于元素的唯一性和高效的成员关系测试。所以它的重点并不是用于访问单个元素,而是用于快速读取。
S = {1, 2, "A", "B"}
for i in S:
print(f"当前元素是: {i}")
#【输出结果】:
#当前元素是: 1
#当前元素是: 2
#当前元素是: B
#当前元素是: A
5、统计元素
统计元素的个数、以及求最大值、最小值等#🌾:统计元素个数 len S = {1, 2, "A", "B"} len(S) #🌾:求最大值(仅全数字)max S = {1.2, 5, 0.8, 6} max(S) #🌾:求最小值(仅全数字)min S = {1.2, 5, 0.8, 6} min(S) #🌾:求和(仅全数字)sum S = {1.2, 5, 0.8, 6} sum(S) #🌾:求平均值(仅全数字)sum/len S = {1.2, 5, 0.8, 6} sum(S) / len(S)
6、成员检查
集合提供了一种高效的方法来检查元素是否属于某个集合。使用集合的成员关系操作,可以快速判断一个元素是否在集合中。在集合中一般通过 in 判断某个元素是否存在。成功为True,失败为False
S = {1, 2, "A", "B"}
#【in】
if "A" in S :
print("A 属于 S 元素")
else :
print("A 不属于 S 元素")
# 【not in】
if "A" not in S :
print("A 不属于 S 元素")
else :
print("A 属于 S 元素")
🐡 集合的运算
集合可以进行并集、交集、差集、对称差集等运算,用于解决各种集合操作问题。
1、并集运算
并集是指将两个或多个集合中的所有元素合并成一个新的集合的操作。在数学符号中,通常用符号∪(并集符号)表示。在集合中使用符号 | 或者 union() 方法来实现。
当两个集合中存在相同的元素时将被合并成1个。
# | 符号实现并集 S1 = {1, 2, 3} S2 = {3, 4, 5} union_set = S1 | S2 print(union_set) #{1, 2, 3, 4, 5} # union() 实现并集 S1 = {1, 2, 3} S2 = {3, 4, 5} union_set = S1.union(S2) print(union_set) #{1, 2, 3, 4, 5}
2.、交集运算
交集是指两个集合中共同存在的元素所构成的新集合。在数学符号中,通常用符号∩(交集符号)表示。在集合中使用符号 & 或者 intersection() 方法来实现。
# & 符号实现交集 S1 = {1, 2, 3} S2 = {3, 4, 5} intersection_set = S1 & S2 print(intersection_set) # {3} # intersection() 实现交集 S1 = {1, 2, 3} S2 = {3, 4, 5} intersection_set = S1.intersection(S2) print(intersection_set) # {3}
3、差集运算
差集是指一个集合相对于另一个集合的差异部分所构成的新集合。在数学符号中,通常使用符号 (-(减号)) 或者 (-(差集符号)) 表示。在集合中使用符号 - 或者 difference() 方法来实现。# 符号 - 实现差集 S1 = {1, 2, 3, 4, 5} S2 = {3, 4, 5} difference_set = S1 - S2 print(difference_set) # {1, 2} # difference() 实现差集 S1 = {1, 2, 3, 4, 5} S2 = {3, 4, 5} difference_set = S1.difference(S2) print(difference_set) # {1, 2} # 被 - 集合存在不同的元素 S1 = {1, 2, 3, 4, 5} S2 = {3, 4, 5, 6} difference_set = S1 - S2 print(difference_set) # {1, 2}
4、对称差集
对称差集用于表示两个集合之间的差异,包含的是那些只属于其中一个集合的元素,而不属于两个集合的交集。
# 符号 ^ 实现对称差集 S1 = {1, 2, 3} S2 = {2, 3, 4} symmetric_difference = S1 ^ S2 print(symmetric_difference) #{1, 4} # symmetric_difference() 实现对称差集 S1 = {1, 2, 3} S2 = {2, 3, 4} symmetric_difference = S1.symmetric_difference(S2) print(symmetric_difference) #{1, 4}
🐹 11. 总结
在Python中,数据类型可以分为可变(mutable)和不可变(immutable)两种类型:
🐡 可变数据类型:
List(列表):列表可以通过添加、删除或更改元素来改变其内容。
Dict(字典):字典中的键和值可以被添加、删除或修改。
Set(集合):集合支持添加、删除和更新操作。
🐡 不可变数据类型:
Int(整数):整数是不可变类型,一旦创建就不能更改其值。
Float(浮点数):浮点数也是不可变的。
Bool(布尔值):布尔值 True 和 False 是不可变的。
Str(字符串):字符串一旦创建就不能被修改,可以通过切片和拼接来创建新的字符串。
Tuple(元组):元组是不可变的,一旦创建就不能更改其内容。
可变性的概念在于是否允许对象在被创建后修改其值或结构。可变对象可以在运行时改变其值或内容,而不可变对象在创建后保持不变。
七、input——用户输入指令
执行input指令时,读取用户输入的数据。
🐹 1. 语法参考
input() 函数可以提示并接收用户的输入内容,将所有的输入内容按照字符串进行处理,返回一个字符串。input()函数的基本用法如下:
input(prompt)
参数说明:“prompt” 可选参数,表示提示信息。
示例说明:
#示例一:接收用户输入的内容并保存在变量中,代码如下: name = input("please enter your name:") # 提示:请输入你的名字 print(name) # 输出名字
#示例二:输入《静夜思》中的诗句 a = input("输入第一句:") b = input("输入第二句:") c = input("输入第三句:") d = input("输入第四句:") print(list[a,b,c,d]) # 打印列表内容 #【输出内容】 #输入第一句:窗前明月光 #输入第二句:疑是地上霜 #输入第三句:举头望明月 #输入第四句:低头思故乡
提示说明:input() 函数返回的值是字符串类型的,如果要让输入的数字变为整型,可以使用int()函数将字符串类型的数字转换为正数。
🐹 2. 常规用法
🐡 1. 常用输入
name = input("") # 无提示型输入,不换行 name1 = input("name") # 简洁型输入 name2 = input("请输入您的姓名:") # 提示型输入,不换行 name3 = input("姓名:\n") # 提示型输入,换行
#将多条语句放在列表中,将实现把输入结果保存到列表的功能。 data = [input('姓名'),input('电话:'),input('学校:')] print(data)
🐡 2.去除输入的非法字符
name = input("请输入您的姓名:").strip('') # 去除输入数据两端的空格 age = input("请输入您的年龄:").lstrip('') # 去除输入数据左侧的空格 print(name) print(age)
🐡 3. 多数据输入
#🌾:一行输入两个不限定类型的值 x,y = input("请输入出发地点的横、纵坐标值,用英文逗号分隔:").split(',') print(x,y) name,age,height = input("请输入你的姓名、年龄和身高,用英文逗号分隔:\n").split(',') print(age) #🌾:一行输入两个限定类型为int的值 a,b = map(int,input("请输入两个数,用空格分隔:").split()) print(a,b)
sum = 0 for x in input("请输入多个加数,中间用空格分隔:").split(' '): sum = sum + int(x) print(sum)
🐡 4. 强制转换输入
age = int(input('age: ')) print(age) print(type(age))
有时对输入的字符是有一定要求的,如首字母大写、全部为小写等,这时可以使用字符串的lower()、upper()、capitalize() 或者 title()等方法对输入的字符串进行强制转换。代码如下:
password = input('请输入您的密码:').upper() # 将输入的字符串转换为全部大写 name= input('请输入您的姓名:').capitalize() # 将输入的字符串转换为首字母大写 school= input('请输入您的学校:').title() # 将输入的全部转换为首字母大写 print(password,name,school) # 输出以上转换后的内容
八、条件语句
条件语句是编程中的基本控制结构之一,用于根据特定条件执行不同的代码块。在Python中,条件语句主要包括if、elif和else。
if 判断条件: 执行语句…… elif:判断条件: 执行语句…… else: 执行语句……
🐹 1. 基本条件语句
🐡 if 语句if 语句用于测试一个条件是否为真。如果条件为真,则执行代码块。
age = 18 if age >= 18: #如果变量 age 的值大于或等于18,程序将输出“你是成年人” print("你是成年人")
🐡 else 语句else 语句用于在条件为假时执行另一个代码块。
age = 16 # 如果 age 小于18,程序将输出“你是未成年人”;大于18,程序将输出“你是成年人” if age >= 18: print("你是成年人") else: print("你是未成年人")
🐡 elif 语句
elif 语句用于在第一个条件为假时测试另一个条件。如果第一个条件为假且第二个条件为真,则执行第二个代码块。
score = 85 # 如果 score 大于或等于90,程序将输出“优秀”;如果 score 大于或等于80但小于90,程序将输出“良好”;否则,程序将输出“及格”。 if score >= 90: print("优秀") elif score >= 80: print("良好") else: print("及格")
🐡 嵌套条件语句
条件语句可以相互嵌套,以便在更复杂的条件下执行不同的代码块。
age = 20 is_student = True # 外部 if 语句检查 age 是否大于或等于18,然后内部 if 语句根据 is_student 的值进一步细化输出。 if age >= 18: if is_student: print("你是成年学生") else: print("你是成年人") else: print("你是未成年人")
🐹 2. 条件表达式
条件表达式(也称为三元运算符)是一种简洁的条件语句书写方式。它允许在单行中执行条件判断并返回相应的值。
age = 20 # status 的值根据 age 的值进行判断并赋值。 status = "成年人" if age >= 18 else "未成年人" print(status) # 输出: 成年人
🐹 3. 多条件判断
使用逻辑运算符(and 和 or)可以在一个条件语句中进行多条件判断。
# 使用 and 运算符将两个条件组合在一起,以便在条件都为真时执行代码块。 age = 20 is_student = True if age >= 18 and is_student: print("你是成年学生") elif age >= 18 and not is_student: print("你是成年人") else: print("你是未成年人")
🐹 4. 常见错误和最佳实践
🐡 常见错误
- 忘记缩进:在Python中,缩进表示代码块。如果忘记缩进,Python会抛出错误。
age = 18 if age >= 18: print("你是成年人") # 缩进错误
- 使用赋值运算符
=代替比较运算符==:
age = 18 if age = 18: # 错误 print("你是成年人")
🐡 最佳实践
- 保持代码简洁:避免过度嵌套条件语句。使用
elif语句而不是多个嵌套的if-else语句。
# 推荐 if condition1: # do something elif condition2: # do something else else: # do another thing # 不推荐 if condition1: # do something else: if condition2: # do something else else: # do another thing
- 使用有意义的变量名:确保变量名清晰易懂,便于代码的阅读和维护。
# 推荐 age = 20 is_student = True if age >= 18 and is_student: print("你是成年学生") # 不推荐 a = 20 b = True if a >= 18 and b: print("你是成年学生")
九、for循环
🐹 1. for 循环语法
for 循环语句包含七个要素:

① 关键字 "for" 和③关键字 "in"是固定搭配。
② 是循环变量。
④ 可迭代对象。
⑤ 英文冒号":"。
⑥ 缩进,冒号下的语句前有四个空格的缩进。缩进快捷键:ctrl+]或Tab。
⑦ 循环体,可以理解为 for 循环语句下的一个代码块,就是需要反复执行的代码。正常情况下,每循环一次,这个代码块都会被执行一次。
可迭代对象可以理解为一个"盒子",可以被程序一次一次地取出数据。
循环变量,是用来接收 for 循环语句遍历(即一次次取出)可迭代对象里的数据。
循环变量的名字我们可以自己命名,命名注意事项和变量命名一样,不能用Python中的关键字。
🐹 2. 可迭代对象
🐡 字符串
#🙆:字符串循环 for i in "Python": print(i) # 输出结果 # P # y # t # h # o # n
🐡 列表
#🙆:循环对象为列表 for i in [1, 2, 3, 4, 5, 6] : print(i) # ✅输出结果: # 1 # 2 # 3 # 4 # 5 # 6
🐡 元组
#🙆:循环对象为元组 for i in (1, 2, 3, 4): print(i) # ✅输出结果: # 1 # 2 # 3 # 4
🐡 字典
-
遍历键
!!!注意:for循环遍历字典时,输出的是字典的键。
#🙆:循环对象为字典 my_dict = {"北京":100000, "上海":200000, "广州":510000} for i in my_dict: print(i) # ✅输出结果: # 北京 # 上海 # 广州
-
遍历值
#🙆:循环对象为字典 my_dict = {"北京":100000, "上海":200000, "广州":510000} for i in my_dict: print(my_dict[i]) # ✅输出结果: # 100000 # 200000 # 510000
-
遍历键值对
#🙆:循环对象为字典 my_dict = {"北京":100000, "上海":200000, "广州":510000} for i in my_dict.items(): print(i) # ✅输出结果: # ('北京', 100000) # ('上海', 200000) # ('广州', 510000)
🐡 集合
#🙆:循环对象为集合 for i in {"北京", "上海", "广州"} : print(i) # ✅输出结果: # 北京 # 上海 # 广州
🐡 range对象
- 只有1个参数
range函数只有1个参数时,默认开始start整数为0,步长step为1。
start = 0(包含)
end = 3(不包含)
step = 1#🙆:循环对象为range对象 for i in range(3): print(i) # ✅输出结果: # 0 # 1 # 2
-
有2个参数
range函数有2个参数时,默认步长step为 1。
start = 2(包含)
end = 7(不包含)
step = 1#🙆:循环对象为range对象 for i in range(2,7): print(i) # ✅输出结果: # 2 # 3 # 4 # 5 # 6
-
有3个参数
range函数有2个参数时,默认步长为1。start = 3(包含)
end = 11(不包含)
step = 2 (形象理解为等差为2的公差数列)#🙆:循环对象为range对象 for i in range(3,11,2): print(i) # ✅输出结果: # 3 # 5 # 7 # 9
🐹 3. 不可迭代对象
🐡 整数整数是不可迭代对象。
#🙅:循环的对象不能为整数 for i in 12345: print(i) # ❌输出结果:TypeError: 'int' object is not iterable
🐡 浮点数
浮点数为不可迭代对象。
#🙅:循环的对象不能为浮点数 for i in 3.1415926: print(i) # ❌输出结果:'float' object is not iterable
🐡 布尔值
布尔类型为不可迭代对象。
#🙅:循环的对象不能为布尔类型 for i in True: print(i) # ❌输出结果:'bool' object is not iterable
🐹 4. for循环的跳出循环:break、continue、return
🐡 break
break: 跳出循环体,不再继续执行后面的代码。当程序执行到 break 语句时,程序将会直接跳出整个 for 循环。
#🌾:break 跳出循环体,不再继续执行后面的代码。 fruits = ["苹果", "香蕉", "樱桃", "草莓", "羊角蜜"] for fruit in fruits: if fruit == "樱桃": break print(fruit) # 输出结果: # 樱桃
🐡 continue
continue: 跳过当前循环,执行下一次循环。当程序执行到 continue 语句时,将会直接跳过本次循环剩下的代码,并开始下一次循环。
#🌾:continue: 跳过当前循环,执行下一次循环 fruits = ["苹果", "香蕉", "樱桃", "草莓", "羊角蜜"] for fruit in fruits: if fruit == "樱桃": continue print(fruit) # 输出结果: # 苹果 # 香蕉 # 草莓 # 羊角蜜
🐡 return
return: 结束整个函数,并返回一个指定的值。当程序执行到 return 语句时,将立即结束函数并返回指定的值(如果没有指定返回值,则返回 None)。
#🌾:结束整个函数,并返回一个指定的值。 fruits = ["苹果", "香蕉", "樱桃", "草莓", "羊角蜜"] def find_fruit(fruits): for fruit in fruits: if fruit == "草莓": return True return False # 打印输出结果 print(find_fruit(fruits)) # 输出结果: # True
🐡 pass语句
pass 在Python中是一个空语句,什么都不做,占位语句,它的主要目的是为了保持程序结构的完整性。当你在编写代码时,可能只想先搭建起程序的整体逻辑结构,而暂时不去实现某些细节。在这种情况下,你可以使用pass语句来占位,这样就可以避免因为语句块为空而导致的语法错误。pass语句不会执行任何操作,它只是一个空白的语句块。
#🌾:输出 Python 的每个字母 for letter in 'Python': if letter == 'h': pass print('这是 pass 语句') print('当前字母 :%s'%letter) print('Good bye!') # 输出结果: # 当前字母 :P # 当前字母 :y # 当前字母 :t # 这是 pass 语句 # 当前字母 :h # 当前字母 :o # 当前字母 :n # Good bye!
十一、while循环
for 循环用于针对集合中的每个元素都一个代码块,而while 循环不断地运行,直到指定的条件不满足为止。
🐹 1. while 循环语法

执行语句可以是单个语句或语句块。判断条件可以是任何表达式,任何非零、或非空(null)的值均为true。
当判断条件假 false 时,循环结束。
#🌾:示例 current_number = 1 while current_number <= 5: #成立条件 print(current_number) current_number += 1 #输出结果: # 1 # 2 # 3 # 4 # 5
🐡 配合input(prompt)使用
可使用while 循环让程序在用户愿意时不断地运行,我们在其中定义了一个退出值,只要用户输入的不是这个值,程序就接着运行。
prompt = "\nTell me something, and I will repeat it back to you:" prompt += "\nEnter 'quit' to end the program. " message = "" while message != 'quit': message = input(prompt) print(message)
🐡 使用break 退出循环
要立即退出while 循环,不再运行循环中余下的代码,也不管条件测试的结果如何,可使用break 语句。break 语句用于控制程序流程,可使用它来控制哪些代码行将执行,哪些代码行不执行,从而让程序按你的要求执行你要执行的代码。
prompt = "\nTell me something, and I will repeat it back to you:" prompt += "\nEnter 'quit' to end the program. " while True: message = input(prompt) if message == 'quit': break else: print(message)
🐡 使用continue跳出该次循环
要返回到循环开头,并根据条件测试结果决定是否继续执行循环,可使用continue 语句,它不像break 语句那样不再执行余下的代码并退出整个循环。
current_number = 0 while current_number < 10: current_number += 1 if current_number % 2 == 0: continue print(current_number) #输出结果: # 1 # 3 # 5 # 7 # 9
🐡 循环中的else语句
在 python 中,while … else 在循环条件为 false 时执行 else 语句块
count = 0 # 在循环条件(count < 5)为 false 时执行 else 语句块 while count < 5: print(count, "比5要小") count = count + 1 else: print(count,"不比5小") #输出结果: # 0 比5要小 # 1 比5要小 # 2 比5要小 # 3 比5要小 # 4 比5要小 # 5 不比5小
🐹 2. 使用while 循环来处理列表和字典
for 循环是一种遍历列表的有效方式,但在for 循环中不应修改列表,否则将导致Python难以跟踪其中的元素。要在遍历列表的同时对其进行修改,可使用while 循环。通过将while 循环同列表和字典结合起来使用,可收集、存储并组织大量输入,供以后查看和显示。
🐡 在列表之间移动元素
假设有一个列表,其中包含新注册但还未验证的网站用户;验证这些用户后,如何将他们移到另一个已验证用户列表中呢?一种办法是使用一个while 循环,在验证用户的同时将其从未验证用户列表中提取出来,再将其加入到另一个已验证用户列表中。代码可能类似于下面这样:
# 首先,创建一个待验证用户列表和一个已验证用户列表 unconfirmed_users = ['Ada','Bob','Cindy'] confirmed_users = [] # 验证每个用户,直到没有未验证用户为止,然后将每个经过验证的列表都移动到已验证用户列表中 while unconfirmed_users: current_user = unconfirmed_users.pop() print("Verifying user:" + current_user.title()) confirmed_users.append(current_user) # 显示所有已验证用户 print("\nThe following users have been confirmed:") for confirmed_user in confirmed_users: print(confirmed_user.title())
测试记录:
Verifying user:Cindy
Verifying user:Bob
Verifying user:Ada
The following users have been confirmed:
Cindy
Bob
Ada
🐡 删除包含特定值的所有列表元素
假设你有一个宠物列表,其中包含多个值为'cat' 的元素。要删除所有这些元素,可不断运行一个while 循环,直到列表中不再包含值'cat' 。
如下所示,通过值删除,每次只能删除重复的cat中的一个,有多少个需要执行多少次,因为列表中'cat'数是不固定的,此时可以通过while循环来实现。
pets = ['dog','cat','dog','goldfish','cat','rabbit','cat'] print(pets) # ['dog', 'cat', 'dog', 'goldfish', 'cat', 'rabbit', 'cat'] #********通过while遍历,并删除重复数据********** while 'cat' in pets: pets.remove('cat') #******************************************* print(pets) # ['dog', 'dog', 'goldfish', 'rabbit']
🐡 使用用户输入来填充字典
可使用while循环提示用户输入任意数量的信息。 下面我们来做一个数据库排名的字典,通过用户输入数据库及排名,然后将输入打印出来.
ranks = {} # 设置一个标志,指出调查是否继续 polling_active = True while polling_active: # 提示输入数据库的名称和排名 database = input("\nPlease input your database:") rank = input("\nPlease input your database rank:") # 将排名存储在字典中 ranks[database] = rank; # 看看是否还需要继续输入 repeat = input("Would you like to input another database? (yes/ no) ") if repeat == 'no': polling_active = False # 输入结束,显示结果 print("\n--- input Results ---") for database, rank in ranks.items(): print(database + " ranking is " + rank + ".")
十二、range整数序列
在Python中,range()是一个内置函数,用于生成一个整数序列,通常用于循环遍历。以下是range()函数的一些常见用法:
range(n): 从0数到n. 不包含nrange(m, n): 从m数到n, 不包含nrange(m, n, s): 从m数到n, 不包含n, 每次的间隔是s
🐹 1. 常见用法
🐡 默认情况
当你调用range()函数时,它会生成一个从0开始到给定数字(不包括该数字)的整数序列。
for i in range(5): print(i) # 输出: 0, 1, 2, 3, 4
🐡 指定开始和结束
range()函数可以接受三个参数,分别表示起始点、终止点和步长。起始点默认为0,终止点是生成的数字的最大值(不包括该值),步长是每次递增的间隔。
for i in range(2, 5): print(i) # 输出: 2, 3, 4
🐡 指定步长
还可以通过设置步长参数来改变生成的数字的间隔。
例如,步长为2将使序列中的每个数字之间的间隔为2。
for i in range(0, 10, 2): print(i) # 输出: 0, 2, 4, 6, 8
🐡 与列表结合使用
还可以将range()函数与list()函数结合使用来创建一个列表。
例如,下面的代码将创建一个包含1到10(包括10)的整数的列表。
my_list = list(range(10)) # ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9'] print(my_list)
十三、格式化字符串
🐹 1. 百分号(%)
最早的格式化是用%(百分号), 它这么用:
name = 'Alice' age = 25 print('My name is %s and I am %d years old.' % (name, age))
🐹 2. str.format()
format内的参数起始编号以0开始,即花括号引用的0表示第一个参数,1表示第二个参数。
name = 'Alice' age = 25 print('My name is {} and I am {} years old.'.format(name, age))
🐹 3. f-string
f字符串引用已定义的字符串变量。
name = 'Alice' age = 25 print(f'My name is {name} and I am {age} years old.')
十四、函数
函数:是指一段可以直接被另一段程序或代码引用的程序或代码。 在编写代码时,常将一些常用的功能模块编写成函数,放在函数库中供公共使用,可 减少重复编写程序段和简化代码结构。
🐹 1. 定义与调用
def 函数名(参数1,参数2,...): 函数体 return 返回值列表
- def:关键字,标志着函数的开始; 类似于其它语言中的function 或者 func 关键字
- 函数名: 函数唯一的标识,命名方式遵循变量的命名规则;
- 参数:参数列表中的参数是形式参数,是调用该函数时传递给它的值,可以是0个,也可以是一个或多个。当传递多个参数时,各参数由逗号分隔。没有参数也需要保留括号。形参只在函数体中有效。
- 函数体: 冒号:用于标记函数体的开始。函数每次被调用时执行的代码,由一行或多行代码组成。
- return:
标志函数的结束,将返回值赋给函数的调用者。
若是没有返回值,则无须保留return语句,在函数体结束位置将控制权返回给调用者。
# 定义函数 def fmax(a,b): return max(a,b) # 调用函数 result = fmax(1,2)
🐹 2. 函数传参
🐡 1、位置传参
在调用函数时,我们一般要按照函数定义时参数的位置传递如参数
def fmax(a, b): return max(a, b) fmax(1, 2) # 1赋给a,2赋给b
🐡 2、关键字传参
python中的函数可以使用key = value语法发送参数。这样,参数的顺序就不重要了。
# 定义函数 def my_function(child3,child2,child1): print("函数有三个参数,分别为{},{},{}".format(child1,child2,child3)) #⚠️注意: 通过key = value 语法,可以不用考虑,参数的顺序。 my_function(child1='大娃',child3='三娃',child2='二娃') #输出结果:函数有三个参数,分别为大娃,二娃,三娃
🐡 3、参数默认值
参数默认值: 预先给参数定义默认值,如果调用函数时没指定该值,则用默认值
#🌾:定义函数 def f(a,b=2): # b参数不传参,默认值是2 return a + b #调用函数并输出 print(f(1)) # 这里没有传b的参数,b默认传参2, 得到的结果是3 print(f(1,3)) # 给b传参为3,1+3 得到的结果为4
🐡 4、包裹传递参数
当不知道有多少个参数时可以在参数前面加*与**,表示可接收任意多个参数。
-
*args :接收任意多个参数,并放到一个元组中,
def func(*args): x = 0 for i in args: #接收任意多个参数,放在了一个元组中,通过for in 遍历 x += i return x print(func(1,2,3)) #6 -
**kwargs :接收一个键值,并存储为字典
def func1(**kwargs): for k, v in kwargs.items(): # 接收一个键值,并存储为字典 print("名称:%s\t价格:%s" % (k, v)) func1(主机=5000, 显示器=1000, 鼠标=60, 键盘=150)
🐡 5、解包裹传递
解包裹传递是让容器里面的元素与多个参数一一对应。
-
使用*解包序列(元组、列表均可),使其元素称为独立的参数位置参数:
def fmax(a,b,c,d): return max(a,b,c,d) numbers=[1,3,2,4] fmax(*numbers) # numbers列表解包分别传递给a,b,c,d
-
使用**解包字典,使其元素称为独立的关键字参数。
def func(*args): print(args) args = (1,3,4) func(*args) #(1, 3, 4) #解包,所以元组有三个元素 func(args) #((1, 3, 4),) #没有解包,所以元组只有一个元素
🐡 6、混合传递
# 1. 混合使用位置传递、默认值传递和可变位置参数 def fmax(a, b=10, *args): numbers = (a, b) + args return max(numbers) fmax(3) # a=3,b使用默认值10,没有其他参数,返回10 fmax(3, 4, 6, 8, 1) # a=3,b=4,args=(6,8,1),返回8 # 2. 混合使用位置传递、默认值传递、可变位置参数和可变关键字参数 def fmax(a, b=10, *args, **kwargs): # 接收map numbers = (a, b) + args + tuple(kwargs.values()) return max(numbers) fmax(3, 4, 2, 9, x=5, y=7) # a=3,b=4,args=(2,9),kwargs={'x':5,'y':7},返回9 fmax(3, x=11, y=6) # a=3,b使用默认值10,没有位置参数,kwargs={'x':11,'y':6},返回11
如果要让函数接受不同类型的实参,必须将接纳任意数量实参的形参放在最后。
def make_pizza(size, *toppings): """概述要制作的比萨。""" print(f"\nMaking a {size}-inch pizza with the following toppings:") for topping in toppings: print(f"- {topping}") if __name__ == '__main__': make_pizza(16, 'pepperoni') make_pizza(12, 'mushrooms', 'green peppers', 'extra cheese')
!!!注意:你经常会看到通用形参名*args,它也收集任意数量的位置实参。
🐹 3. 匿名函数
匿名函数顾名思义就是没有名字的函数,使用lambda关键字定义,可以接受任意数量的参数,但只能有一个表达式。
#🌾:语法 lambda 参数 : 表达式 #🌾:示例 # 将10添加到参数a,并返回结果: x = lambda a : a + 10 print(x(5)) #5
❓ 为什么使用Lambda函数?
Lambda的强大之处在于,当您将它们用作另一个函数中的匿名函数时,它们表现得更好。假设您有一个函数定义,该函数接受一个参数,该参数将与一个未知的数字相乘:
def myfunc(n): return lambda a : a * n
使用该函数定义创建一个函数,该函数始终将发送的数字加倍:
def myfunc(n): return lambda a : a * n
mydoubler = myfunc(2)
print(mydoubler(11))
或者,使用相同的函数定义创建一个函数,该函数始终将发送的数字乘以3:
def myfunc(n): return lambda a : a * n mytripler = myfunc(3) print(mytripler(11))
或者,在同一程序中使用相同的函数定义创建两个函数:
def myfunc(n): return lambda a : a * n mydoubler = myfunc(2) mytripler = myfunc(3) print(mydoubler(11)) print(mytripler(11))
🐹 4. pass语句
由于python用:取代了{ } , 为保持代码可读性,函数定义不能空着,所以如果由于某种原因,您的函数定义没有内容,可以加入pass语句以避免出错。
def myfunction(): #用: 取代其它语言中的{} pass
十五、引入模块
Python含有很多的函数模块,不同模块内存不同功能的函数,可以在程序里面引入使用。
注意:import可以在程序中的任意位置使用,第一次使用import关键字导入模块后,会将模块加载到内存中,后续针对同一模块的import不会重新执行模块内的语句。
🐹 1. import 模块名
需要使用模块的函数或变量的时候格式如下:
模块名.函数名
模块名.变量名
示例:
# 引入" statistics " 模块 import statistics # 使用 " statistics " 模块 print(statistics.median([19, -5, 36])) print(statistics.mean([19, -5, 36]))
🐹 2. import 模块名 as 别名
在Python中,你可以使用import 模块名 as 别名的语法来导入一个模块,并为它指定一个更简短的别名。这样,在你的代码中就可以使用这个别名来引用模块中的对象,而不必每次都使用模块的完整名称。
# 引入 “math” 模块 并称别名为 m import math as m # 使用别名来调用模块中的函数 result = m.sqrt(25) print(result) # 输出: 5.0
在这个例子中,math模块被导入,并且给它指定了别名m。随后,我们使用m来访问math模块中的sqrt函数,计算出25的平方根。
🐹 3. from 模块名 import 方法名
在Python中,你可以使用from 模块名 import 方法名语句来从特定模块中导入一个或多个方法。这样做可以直接调用导入的方法,而不必每次都使用模块名前缀。
# 引入 "math" 模块 from math import sqrt # 调用sqrt函数,不需要使用math.前缀 result = sqrt(25) print(result) # 输出: 5.0
如果你想从math模块中导入多个方法,可以用逗号分隔它们:
from math import sqrt, exp sqrt_result = sqrt(25) exp_result = exp(1) print(sqrt_result) # 输出: 5.0 print(exp_result) # 输出: 2.718281828459045
🐹 4. from 模块名 import *
在Python中,from 模块名 import *语句用于从一个模块中导入所有函数、类和其他名称。这样做可以直接使用模块中定义的所有名称,而不必每次都指定模块名。
例如,假设你有一个名为math_utils.py的模块,其中包含一些数学相关的实用函数:
# math_utils.py def add(a, b): return a + b def subtract(a, b): return a - b def multiply(a, b): return a * b def divide(a, b): return a / b
你可以使用from math_utils import *来导入这个模块中的所有函数:
# main.py from math_utils import * result = add(3, 5) print(result) # 输出 8 result = subtract(10, 4) print(result) # 输出 6 # ... 以此类推,可以使用导入的所有函数
⚠️注意:这种做法有利有弊。好处是可以简化导入过程,不必每次都写明模块名。不过,这也可能导致代码的可读性下降,并增加命名冲突的风险。
🐹 5. from 模块名 import 方法名 as 别名
在Python中,你可以使用import语句的as子句为导入的方法或类指定别名。这样做可以简化你在代码中引用这些方法或类的方式,使其更易于阅读和理解。
例如,假设你有一个名为math_functions.py的模块,其中包含一个名为add的函数,你可以这样导入并使用它:
# math_functions.py def add(a, b): return a + b
你可以使用别名来简化对add函数的引用:
# main.py from math_functions import add as add_func result = add_func(3, 5) print(result) # 输出 8
在这个例子中,add_func就是add函数的别名,在main.py中使用时更直观、简洁。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号