
结对第二次—文献摘要热词统计及进阶需求
格式描述
- 课程名称:软件工程1916|W(福州大学)
- 作业要求:结对第二次—文献摘要热词统计及进阶需求
- 结对学号:221600123林信康 | 221600128王华峰
- 作业目标:学会热词统计编程,爬虫挖掘数据。
- Github项目地址:GitHub地址
- Github的代码签入记录:
作业正文
一、分工描述
221600123:需求分析,编写热词统计代码,博客撰写
221600128:需求分析,编写爬虫挖掘数据,代码测试
二、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| •Estimate | • 估计这个任务需要多少时间 | 670 | 890 |
| Development | 开发 | ||
| • Analysis | • 需求分析 (包括学习新技术) | 60 | 120 |
| • Design Spec | • 生成设计文档 | 30 | 40 |
| • Design Review | • 设计复审 | 30 | 40 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 30 | 20 |
| • Design | • 具体设计 | 60 | 80 |
| • Coding | • 具体编码 | 240 | 300 |
| • Code Review | • 代码复审 | 60 | 120 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 60 | 60 |
| Reporting | 报告 | ||
| • Test Report | • 测试报告 | 60 | 60 |
| • Size Measurement | • 计算工作量 | 10 | 10 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 30 | 40 |
| 合计 | 670 | 890 |
三、解题思路
首先,大致浏览要求文档,知道本次作业是热词统计,并且分成基础与进阶两个部分。
其次,讨论构思代码整体框架和需要使用的函数、结构,并将任务分工。
接着,各自编写代码,遇到生疏的知识点百度查询。
然后,跟据具体要求一一改进代码,以功能块为单位进行代码测试。
最后,进行完整的代码测试后,完成任务。
四、改进思路
关于单词存储一开始不知道怎么用比较快,本来想用链表,但是查询和排序会很慢。之后听同学建议用map,hash表果然快很多。一开始将所有代码写在main函数里,显得很凌乱。之后整理了一次,拆分核心代码块,就很清晰明了。
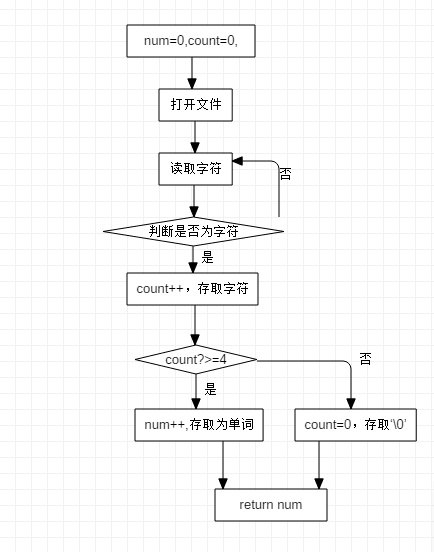
五、函数流程图
计算单词个数流程图
六、性能分析
七、核心代码
//计算单词数量
int count_word()
{
int num=0,flag=0,count=0;
char ch,word[100];
//ch每次读取一个字符,word存放缓存单词
ifstream in("input.txt");
if(!in.is_open())
{
cout<<"Error opening file";
exit (1);
}
while(!in.eof())
{
in.get(ch);
//读取一个字符依次判断
if(count<4&&((ch>='A'&&ch<='Z')||(ch>='a'&&ch<='z')))
{
if(ch>='A'&&ch<='Z')ch+=32;
word[count++]=ch;
}
else if(count>=4&&((ch>='A'&&ch<='Z')||(ch>='a'&&ch<='z')||(ch>='0'&&ch<='9')))
{
if(ch>='A'&&ch<='Z')ch+=32;
word[count++]=ch;
}
else
{
if(count>=4)
//计算单词长度,如果单词长度大等4,计数加一,并且存入map
{
num++;
++word_count[word];
}
//结束一次单词判断后重置长度计数和缓存单词
count=0;
for(int i=0;i<30;i++)
word[i]='\0';
}
}
if(count>=4)
{
word[count-1]='\0';
num++;
++word_count[word];
}
in.close();
return num;
}
//比较函数用于vec排序
bool cmp(pair<int, string> a, pair<int, string> b)
{
return (a.first != b.first) ? a.first > b.first:a.second < b.second;
}
//将map存入vec进行排序
void MapSortOfValue(vector<pair<int, string> >& vec, map<string, int>& m)
{
for(map<string, int>::iterator it = m.begin(); it != m.end(); it++)
vec.push_back(make_pair(it->second, it->first));
sort(vec.begin(),vec.end(),cmp);
}
//python爬虫代码
import requests
from bs4 import BeautifulSoup
from urllib.request import urlopen
sUrl = 'http://openaccess.thecvf.com/CVPR2018.py'
fb = open(r'd:\result.txt', 'w', encoding='utf-8')
def getPager(Url):
req = requests.get(Url)
req.encoding = 'utf-8'
soup = BeautifulSoup(req.text, 'html.parser')
fb.write('Title: %s\n' % soup.select('#papertitle')[0].text.strip())
fb.write('Abstract: %s\n\n\n' % soup.select('#abstract')[0].text.strip())
return
num = 0
res = requests.get(sUrl)
res.encoding = 'utf-8'
# noinspection SpellCheckingInspection
soup1 = BeautifulSoup(res.text, 'html.parser')
# noinspection SpellCheckingInspection
for ptitles in soup1.select('.ptitle'):
each_url = ptitles.select('a')[0]['href']
temp = 'http://openaccess.thecvf.com/' + each_url
print(num, file=fb)
getPager(temp)
num = num + 1
八、心得总结
221600123林信康
- 自我评价
在编写热词搜索的程序中,bug出现的频率还是挺高的,特别是刚刚解决了一个bug,又产生了一个新的问题。解决方案就是打开调试,一步一步运行监视变量,找到问题关键,对症下药。 - 队友评价
关于我的队友我觉得他是一个十分稳健的队友,爬虫代码他一个人自学完成,交付任务。我的代码遇到难题,与他探讨也是能得到启发,合作过程也十分愉快。
221600128王华峰
- 自我评价
写爬虫程序最大的难题就是这是一个全新的挑战。以前都没学习过这个东西,突然从认识到入手还是费了一点时间。然后自学了python语言,有点生疏,写代码也是犹犹豫豫不够自信。最后爬取数据等了10分钟,一度以为自己的代码有问题,与同学交流后才明白是常态,才完成任务。 - 队友评价
我的队友在c++编程上会略强于我,思路清晰,所以分工是他写热词搜索代码。虽然写的比较简单,但是还是基本完成了要求。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号