


一、Kmeans原理
Kmeans算法是一种常见的聚类算法,用于将数据集划分成k个不重叠的簇。其主要思想是通过迭代的方式将样本电话分到不同的簇中,使得同一簇内的样本点相似度较高,不同簇之间的相似度较低。

Kmeans算法的详细步骤:
- 初始化:选择k个初始聚类中心,可以是随机选择或者根据某种启发式方法选择。聚类中心通常是从数据集中选择的k个样本点;
- 分配样本点:对于每个样本点,计算其与各个聚类中心的距离(如欧式距离),将样本点分配给距离最近的聚类中心所在的簇;
- 更新聚类中心:对于每个簇,计算其所有样本点的均值,将该均值作为新的聚类中心;
- 重复步骤2和3:直到聚类中心不再发生变化或者达到预定的迭代次数;
- 输出结果:最终得到k个聚类簇,每个簇包含一组样本点。
Kmeans算法的特点:
- kmeans算法是一种迭代算法,通过多次迭代优化聚类结果;
- kmeans算法基于距离度量来进行样本点的分配和聚类中心的更新;
- kmeans算法对离群点敏感,离群点可能会影响聚类结果;
- kmeans算法要求事先指定聚类的个数k。
Kmeans算法的优化方法:
- 通过增加迭代次数或设置收敛条件来控制算法的迭代次数;
- 使用更好的初始化方法,如Kmeans++算法,可以更好地选择初始聚类中心;
- 对于离群点的处理,可以使用基于距离的异常值检测方法,或者采用基于密度的聚类算法。
二、实验环境
三、Kmeans简单代码实现
1. 构造数据
import numpy as np data = np.array([[3, 2], [4, 1], [3, 6], [4, 7], [3, 9], [6, 8], [6, 6], [7, 7]])
2. 可视化展示
impotrt matplotlib.pyplot as plt plt.scatter(data[:, 0], data[:, 1], c='red', marker='o', label='samples') plt.legend() # 设置图例,图例内容为上面设置的label参数 plt.show()

3. 聚类成二分类
from sklearn.cluster import KMeans kms = KMeans(c_clusters=2) kms.fit(data) ?KMeans(algorithm='auto', copy_x=True, init='k-means++', max_iter=300, n_clusters=2, n_init=10, n_jobs=None, precompute_distances='auto', random_state=None, tol=0.0001, verbose=0)
4. 获取结果
label = kms.labels_ print(label)

5. 结果可视化
plt.scatter(data[label == 0][:, 0], data[label == 0][:, 1], c="red", marker='o', label='class0') # 以红色圆圈样式绘制散点图并加上标签 plt.scatter(data[label == 1][:, 0], data[label == 1][:, 1], c="green", marker='*', label='class1') # 以绿色星星样式绘制散点图并加上标签 plt.legend() # 设置图例 plt.show()

6. 聚类成3类
from sklearn.cluster import KMeans kms_3 = KMeans(c_clusters=3) kms_3.fit(data) label_3 = kms_3.label_ print(label_3)
![]()
7. 结果可视化
plt.scatter(data[label_3 == 0][:, 0], data[label_3 == 0][:, 1], c="red", marker='o', label='class0') # 以红色圆圈样式绘制散点图并加上标签 plt.scatter(data[label_3 == 1][:, 0], data[label_3 == 1][:, 1], c="green", marker='*', label='class1') # 以绿色星星样式绘制散点图并加上标签 plt.scatter(data[label_3 == 2][:, 0], data[label_3 == 2][:, 1], c="blue", marker='+', label='class2') # 以蓝色加号样式绘制散点图并加上标签 plt.legend() # 设置图例 plt.show()

四、Kmeans案例实战
1. 案例背景
银行通常拥有海量的客户,对于不同的客户,银行需要进行不同的营销与工作开展策略,列如对于高收入且分线承受能力强的客户,可以进行重点挖掘业务机会,例如可以给他推销一些收益率高但是周期相对较长的理财产品;而对于低收入且风险承受能力较弱的客户,则需要指定不同的营销与工作策划。因此对于银行来说,通常需要将客户进行分群处理,对于不同分群的客户进行不同的处理。
2. 读取数据
import pandas as pd data = pd.read_excel('data.xlsx') data.head(10)

3. 可视化展示
import matplotlib.pyplot as plt plt.scatter(data.iloc[:, 0], data.iloc[:, 1], c="green", marker='*') # 以绿色星星样式绘制散点图 plt.xlabel('age') # 添加x轴名称 plt.ylabel('salary') # 添加y轴名称 plt.show()

4. 数据建模
from sklearn.cluster import KMeans kms = KMeans(n_clusters=3, random_state=123) kms.fit(data) label = kms.labels_ label = kms.fit_predict(data) print(label)

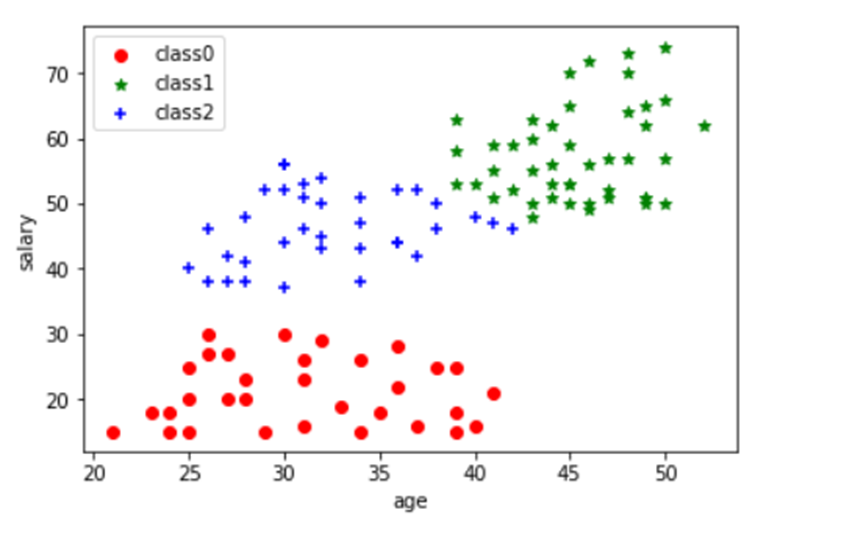
5. 建模效果可视化展示
plt.scatter(data[label == 0].iloc[:, 0], data[label == 0].iloc[:, 1], c="red", marker='o', label='class0') # 以红色圆圈样式绘制散点图并加上标签 plt.scatter(data[label == 1].iloc[:, 0], data[label == 1].iloc[:, 1], c="green", marker='*', label='class1') # 以绿色星星样式绘制散点图并加上标签 plt.scatter(data[label == 2].iloc[:, 0], data[label == 2].iloc[:, 1], c="blue", marker='+', label='class2') # 以蓝色加号样式绘制散点图并加上标签 plt.xlabel('age') # 添加x轴名称 plt.ylabel('salary') # 添加y轴名称 plt.legend() # 设置图例 plt.show()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号