


一、概述
随机森林:最为新兴起的、高度灵活的一种机器学习算法,随机森林(Random Forset,简称RF)拥有广泛的应用前景,从市场销售到医疗保健保险,既可以用来做市场销售模拟的建模,统计客户来源,保留和流失,也可用预测疾病的风险和病患者的易感性。
随机森林算法是一种重要的基于bagging的集成学习方法;将若干弱分类器(决策树)的分类结果进行投票选择,从而组成一个强分类器,这就是随机森林bagging的思想。
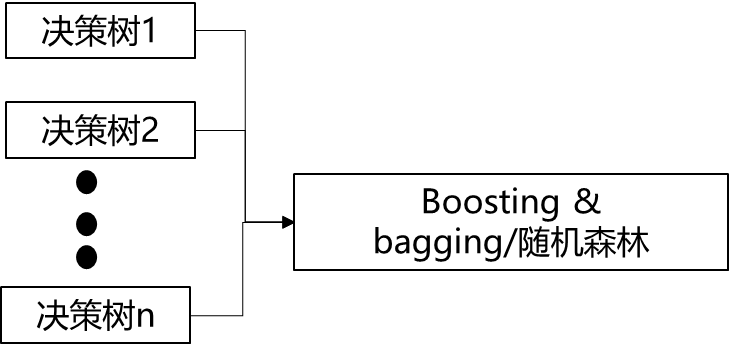
特点:
- 具有几号的准确率,不容易过拟合(样本随机,特征随机);
- 能够有效地运行在大数据集上;
- 能够处理具有高维特征的输入样本,而且不需要降维,能够评估各个特征在分类问题上的重要性;
- 在生成过程中,能够获得取到内部生成误差的一种无偏估计;
- 对于缺省值问题也能够获得很好的结果。
随机森林的生成过程:
- 从样本集(m)中通过自助采样(随机且有放回地)的方式产生m个样本;
- 假设样本特征数目为n(属性),对m个样本随机选择n个钟的n‘个特征,用建立决策树的方式获得最佳分割点;
- 重复t次,产生t颗决策树;
- 多数投票机制来进行预测。
1. 自助采样法(Bootstap sampling),即对于m个样本的原始训练集,每次选随机采集一个样本放入采样集,接着把该样本放回,也就是说下次采样时该样本仍有可能被采集到;
2. 两个随机性:样本的随机性(有放回),特征的随机性(无放回)。两个随机性的引入对随机森林的分类性能至关重要。由于它们的引入,是的随机森林不容易陷入过拟合,并且具有很好的抗噪声能力(比如:对缺省值不敏感)。
RF = 决策树 + Bagging + 随机属性选择
随机森林分类效果(错误率)与两个因素有关:
1. 森林中任意两棵树的相关性:相关性越大,错误率越大;
2. 树的生长参数:树越深,单颗树的分类能力越强,树的相关性也变强;
3. 选择的特征个数n‘: n‘越大,单颗树的分类能力越强,树的相关性也变强。
根据袋外误差选择最优的n‘:
对于每棵树都有一部分样本er没有被抽取到,这样的样本就被称为袋外样本,随机森林对袋外样本的预测错误率被称为袋外误差(Out-of-bag Error, OOB Error)
计算流程:对于每个样本,计算它作为OOB样本的树对它的分类情况;一投片的方式确定该样本的分类结果;将误分类样本个数占总数的比率作为随机森林的袋外误差。
随机森林的python实现(参数设置):
n_features:推荐值为特征数量的平方根;
n_trees:森林中的树按说越多越好,但是当数量多到一定程度时,精度的提升已经不明显,但是极端消耗却很大。
随机森林的缺点:
- 随机森林在解决回归问题时并没有像它的分类中表现的那么好,这是因为它并不能给出一个连续型的输出。当进行回归时,随机森林不能够做出超越训练集数据范围的预测,这可能导致在对某些还有特定噪声的数据进行建模时出现过度拟合;
- 对于许多统计建模者来说,随机森林给人的感觉像是一个黑盒子--你几乎无法控制模型内部的运行,只能在不同的参数和随机种子之间进行尝试。
二、案例
数据库导入
数据集导入

仅标红处存在4个缺失值。

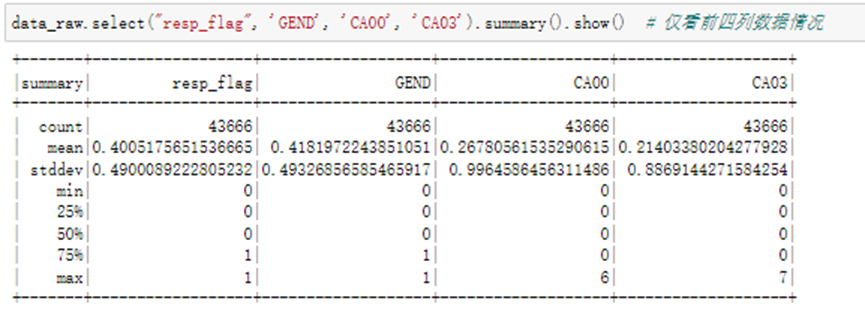
仅看前四列数据情况
样本平衡情况确认

首先确认缺失列age的平均值情况

然后将平均值直接填充至缺失值处,同时也可以再次确认数据信息,age确实不存在缺失值了。

生成特征列(Spark专属数据类型)

随机森林建模

模型预测以及评估
模型对test数据集进行预测,评估准确率约为0.6898。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号