

Spark-1.0.0 standalone分布式安装教程
Spark目前支持多种分布式部署方式:一、Standalone Deploy Mode;二Amazon EC2、;三、Apache Mesos;四、Hadoop YARN。第一种方式是单独部署,不需要有依赖的资源管理器,其它三种都需要将spark部署到对应的资源管理器上。
除了部署的多种方式之外,较新版本的Spark支持多种hadoop平台,比如从0.8.1版本开始分别支持Hadoop 1 (HDP1, CDH3)、CDH4、Hadoop 2 (HDP2, CDH5)。目前Cloudera公司的CDH5在用CM安装时,可直接选择Spark服务进行安装。
目前Spark最新版本是1.0.0。
我们就以1.0.0版本,来看看如何实现Spark分布式集群的安装:
一、Spark 1.0.0需要JDK1.6或更高版本,我们这里采用jdk 1.6.0_31;
二、Spark 1.0.0需要Scala 2.10或更高版本,我们这里采用scala 2.10.3;
三、从https://spark.apache.org/downloads.html 下载合适的bin包来安装,我们这里选择CDH4版本的spark-1.0.0-bin-cdh4.tgz;下载到tongjihadoop165上;
四、解压bin包:tar –zxf spark-1.0.0-bin-cdh4.tgz;
五、重命名:mv spark-1.0.0-bin-cdh4 spark-1.0.0-cdh4;
六、cd spark-1.0.0-cdh4 ;
mv ./conf/spark-env.sh.template ./conf/spark-env.sh
七、vi ./conf/spark-env.sh 添加以下内容:
export SCALA_HOME=/usr/lib/scala-2.10.3
export JAVA_HOME=/usr/java/jdk1.6.0_31
export SPARK_MASTER_IP=10.32.21.165
export SPARK_WORKER_INSTANCES=3
export SPARK_MASTER_PORT=8070
export SPARK_MASTER_WEBUI_PORT=8090
export SPARK_WORKER_PORT=8092
export SPARK_WORKER_MEMORY=5000m
SPARK_MASTER_IP这个指的是master的IP地址;SPARK_MASTER_PORT这个是master端口;SPARK_MASTER_WEBUI_PORT这个是查看集群运行情况的WEB UI的端口号;SPARK_WORKER_PORT这是各个worker的端口 号;SPARK_WORKER_MEMORY这个配置每个worker的运行内存。
八、vi ./conf/ slaves 每行一个worker的主机名,内容如下:
10.32.21.165
10.32.21.166
10.32.21.167
九、(可选) 设置 SPARK_HOME 环境变量,并将 SPARK_HOME/bin 加入 PATH:
vi /etc/profile ,添加内容如下:
export SPARK_HOME=/usr/lib/spark-1.0.0-cdh4
export PATH=$SPARK_HOME/bin:$PATH
十、将tongjihadoop165上的spark复制到tongjihadoop166和tongjihadoop167上:
sudo scp -r hadoop@10.32.21.165:/usr/lib/spark-1.0.0-cdh4 /usr/lib
安装scala时也可以这样远程拷贝文件并修改环境变量文件/etc/profile,改完之后别忘了source。
十一、执行 ./sbin/start-all.sh 启动spark集群;
如果start-all方式无法正常启动相关的进程,可以在$SPARK_HOME/logs目录下查看相关的错误信息。其实,你还可以像Hadoop一样单独启动相关的进程,在master节点上运行下面的命令:
在Master上执行:./sbin/start-master.sh
在Worker上执行:./sbin/start-slave.sh 3 spark://10.32.21.165:8070 --webui-port 8090
十二、检查进程是否启动,执行jps命令,可以看到Worker进程或者Master进程。然后可以在WEB UI上查看http://tongjihadoop165:8090/可以看到所有的work 节点,以及他们的 CPU 个数和内存等信息。
十三、Local模式运行demo
比如:./bin/run-example SparkLR 2 local 或者 ./bin/run-example SparkPi 2 local
这两个例子前者是计算线性回归,迭代计算;后者是计算圆周率
十四、启动交互式模式:./bin/spark-shell --master spark://10.32.21.165:8070 , 如果在conf/spark-env.sh中配置了MASTER(加上一句export MASTER=spark://${SPARK_MASTER_IP}:${SPARK_MASTER_PORT}),就可以直接用 ./bin/spark-shell启动了。
spark-shell作为应用程序,是将提交作业给spark集群,然后spark集群分配到具体的worker来处理,worker在处理作业的时候会读取本地文件。
这个shell是修改了的scala shell,打开一个这样的shell会在WEB UI中可以看到一个正在运行的Application,如下图: 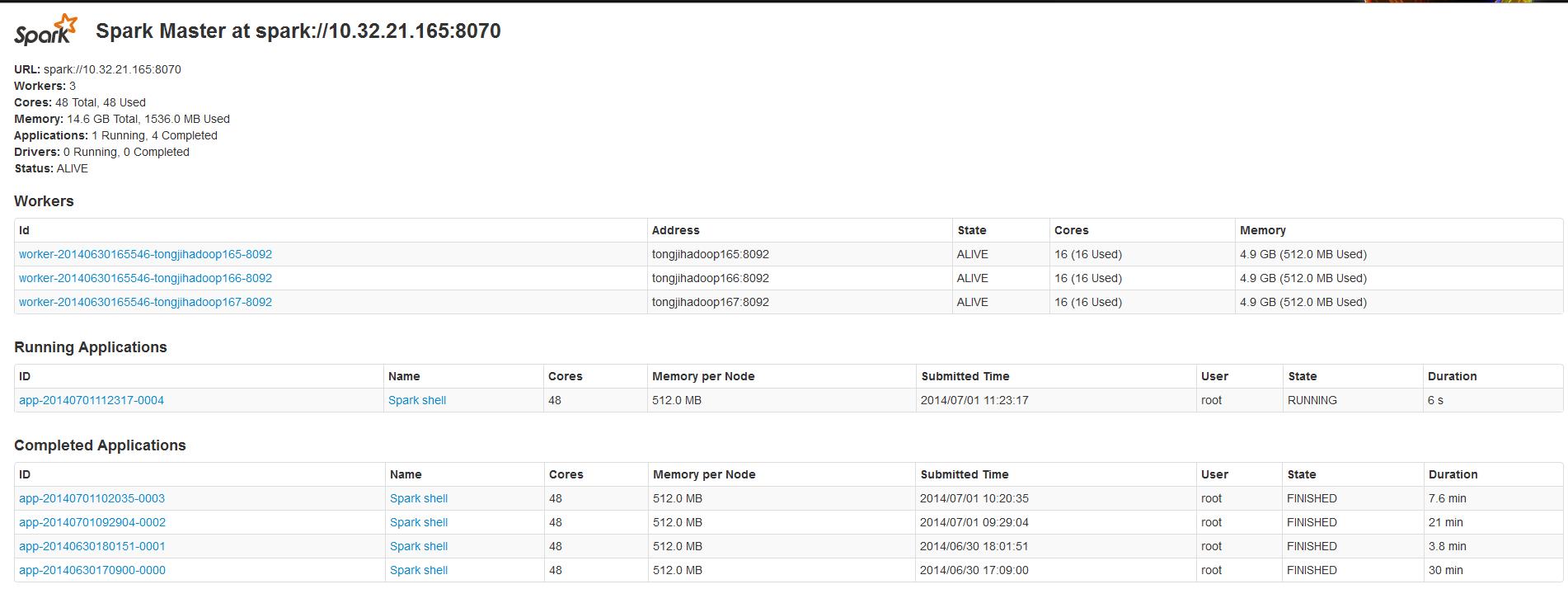
最下面的是运行完成的Applications,workers列表是集群的节点列表。
我们可以在这个打开的shell下对HDFS上的数据做一些计算,在shell中依次输入:
A、val file = sc.textFile("hdfs://10.32.21.165:8020/1639.sta") #这是加载HDFS中的文件
B、file.map(_.size).reduce(_+_) #这是计算文件中的字符个数
运行情况,如下图:
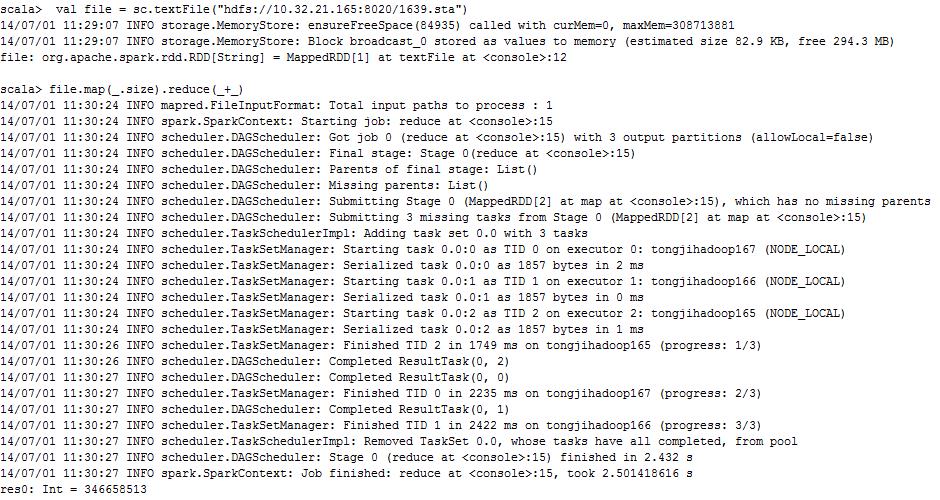
最终结果可以看出有346658513个字符。速度非常快用时不到3s。
或者B阶段执行val count = file.flatMap(line => line.split("\t")).map(word => (word, 1)).reduceByKey(_+_) 和count.saveAsTextFile("hdfs://10.32.21.165:8020/spark") 将计算结果存储到HDFS上的/spark目录下。
也可以执行./bin/spark-shell --master local[2] ,启动一个本地shell ,[2]可以指定线程数,默认是1。
执行exit可以退出shell。
十五、执行 ./sbin/stop-all.sh 停止spark集群
也可以通过单独的进程的stop脚本终止
注意:三台机器spark所在目录必须一致,因为master会登陆到worker上执行命令,master认为worker的spark路径与自己一样。
参考:
1、 http://www.linuxidc.com/Linux/2014-06/103210p2.htm
2、 http://spark.apache.org/docs/latest/
3、 http://blog.csdn.net/myrainblues/article/details/22084445

