

Scrapy实战篇(八)之爬取教育部高校名单抓取和分析
本节我们以网址https://daxue.eol.cn/mingdan.shtml为初始链接,爬取教育部公布的正规高校名单。
思路:
1、首先以上面的地址开始链接,抓取到下面省份对应的链接。
2、在解析具体的省份源代码,获取数据。虽然山东和河南的网页结构和其他不同,我们也不做特殊处理,直接不做抓取即可;将抓取到的数据存储到mongodb数据库
3、对高校数据做数据分析及数据可视化。

抓取数据
1、定义数据结构
class daxueItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() province = Field() # 省份 name = Field() # 学校名称 bianhao = Field() # 学校编号 zhishujigou = Field() # 直属机构 diqu = Field() # 所属城市名称 jibei = Field() # 学校级别
2、编写爬虫
class DaxueSpider(scrapy.Spider): name = 'daxue' #allowed_domains = ['daxue.eol.cn'] start_urls = ['https://daxue.eol.cn/mingdan.shtml'] def parse(self, response): #初始网页的解析函数 soup = BeautifulSoup(response.text, 'lxml') gx_url_list = soup.find_all(name='div', class_='province') for gx_url in gx_url_list: url = gx_url.a['href'] yield Request(url = url,callback = self.parse_daxue_list) #回调函数 def parse_daxue_list(self,response): #response.encoding = 'utf-8' # 解决中文乱码 soup = BeautifulSoup(response.text, 'lxml') prov = soup.find_all(name='div', class_='title')[0].text.replace('正规高校名单', '') #获取省份名称 dx_list = soup.find_all(name='table', class_='table-x') for dx_details in dx_list: for dx_detail in dx_details.find_all(name='tr'): if (dx_detail == dx_details.find_all(name='tr')[0] or dx_detail == dx_details.find_all(name='tr')[1]): continue else: daxue = daxueItem() daxue['province'] = prov daxue['name'] = dx_detail.find_all(name='td')[1].text daxue['bianhao'] = dx_detail.find_all(name='td')[2].text daxue['zhishujigou'] = dx_detail.find_all(name='td')[3].text daxue['diqu'] = dx_detail.find_all(name='td')[4].text daxue['jibei'] = dx_detail.find_all(name='td')[5].text yield daxue
3、将数据存入mongodb数据库,编写pipeline
class MongoPipeline(object): def __init__(self,mongo_url,mongo_db,collection): self.mongo_url = mongo_url self.mongo_db = mongo_db self.collection = collection @classmethod def from_crawler(cls,crawler): return cls( mongo_url=crawler.settings.get('MONGO_URL'), mongo_db = crawler.settings.get('MONGO_DB'), collection = crawler.settings.get('COLLECTION') ) def open_spider(self,spider): self.client = pymongo.MongoClient(self.mongo_url) self.db = self.client[self.mongo_db] def process_item(self,item, spider): name = self.collection self.db[name].insert(dict(item)) return item def close_spider(self,spider): self.client.close()
4、配置setting文件,需要配置的项:mongodb的连接信息,放开pipeline即可,没有其他复杂的配置。
5、运行项目即可获取数据;刨除山东和河南,我们共抓取数据2361条,全部高校数据均被抓取下来。

代码链接:https://gitee.com/liangxinbin/Scrpay/tree/master/scrapydaxue
分析数据
1、以饼图展示全国高校中,本科和专科的数据占比,代码
def daxue(): client = pymongo.MongoClient(host='localhost', port=27017) db = client['test'] # 指定数据库 collection = db['daxue'] # 指定集合 daxue = collection.find() dx_data = DataFrame(list(daxue)) # 将读取到的mongo数据转换为DataFrame数据集合 dx_data = dx_data.drop(['_id'],axis=1) df_jibei = dx_data['jibei'] # 从数据集中取出学校级别一列 df = df_jibei.value_counts() # 统计专科很本科的数据量 labels = df.index # 显示在图形上的标签 sizes = df.values # 要在图中显示的数据 # 解决中文乱码问题 plt.rcParams['font.sans-serif'] = ['SimHei'] plt.rcParams['axes.unicode_minus'] = False fig1, ax1 = plt.subplots() ax1.pie(sizes, labels=labels, autopct='%1.1f%%', shadow=True, startangle=90) # 使用pie()方法绘制饼图。 ax1.axis('equal') ax1.set(title="全国高校本科专科占比") # 设置饼图标题 plt.show()
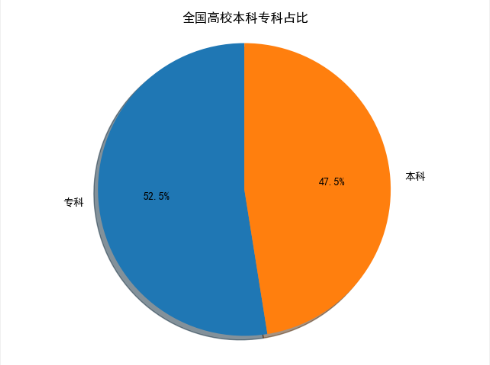
抓取的数据中,本科1121,专科1240,由此可见,占比差异不大。
2、以条形图展示各个身份的高校数量
def daxue_shuliang(): client = pymongo.MongoClient(host='localhost', port=27017) db = client['test'] # 指定数据库 collection = db['daxue'] # 指定集合 daxue = collection.find() dx_data = DataFrame(list(daxue)) dx_data = dx_data.drop(['_id'], axis=1) df = dx_data['province'] df1 = df.value_counts() ind = np.arange(len(df1.values)) width = 0.8 fig, ax = plt.subplots() rects1 = ax.bar(ind,df1.values, width, color='SkyBlue') # # Add some text for labels, title and custom x-axis tick labels, etc. ax.set_ylabel('数量') ax.set_title('全国高校分布情况') ax.set_xlabel('省份') ax.set_xticklabels((df1.index)) ax.legend() x = np.arange(len(df1.index)) # 解决中文乱码问题 plt.rcParams['font.sans-serif'] = ['SimHei'] plt.rcParams['axes.unicode_minus'] = False plt.yticks(np.arange(0, 180, 10)) # 设置y轴的刻度范围 plt.xticks(x, df1.index, rotation=45, fontsize=9) # 设置x轴上显示的省份个数 # 在图形上面添加数值,并设置数值的位置 # for x, y in enumerate(df1.values): # plt.text(x, y + 100, '%s' % round(y,2), ha='left') plt.show()

可以看到,江苏省和广东省的高校数量遥遥领先,刚好,这两个省份也是全国经济最发达的两个省份(个人见解);由此可见,教育对省份经济的促进作用。
上面我们从省份的维度查看了高校的分布,现在我们从城市的角度出发,在看一下高校在各个城市的分布情况。
def daxue_shuliang_city(): client = pymongo.MongoClient(host='localhost', port=27017) db = client['test'] # 指定数据库 collection = db['daxue'] # 指定集合 daxue = collection.find() dx_data = DataFrame(list(daxue)) dx_data = dx_data.drop(['_id'], axis=1) df = dx_data['diqu'] df1 = df.value_counts() df1 = df1[df1.values >= 15] #因城市太多,我们只取了城市大学数量超过15的城市 print(df1) ind = np.arange(len(df1.values)) width = 0.5 fig, ax = plt.subplots() rects1 = ax.bar(ind,df1.values, width, color='SkyBlue') # # Add some text for labels, title and custom x-axis tick labels, etc. ax.set_title('全国高校分布情况') ax.set_xlabel('城市') ax.set_ylabel('数量') ax.set_xticklabels((df1.index)) ax.legend() x = np.arange(len(df1.index)) # 解决中文乱码问题 plt.rcParams['font.sans-serif'] = ['SimHei'] plt.rcParams['axes.unicode_minus'] = False plt.yticks(np.arange(0, 100, 10)) # 设置y轴的刻度范围 plt.xticks(x, df1.index, rotation=45, fontsize=9) # 设置x轴上显示的省份个数 # 在图形上面添加数值,并设置数值的位置 # for x, y in enumerate(df1.values): # plt.text(x, y + 100, '%s' % round(y,2), ha='left') plt.show()
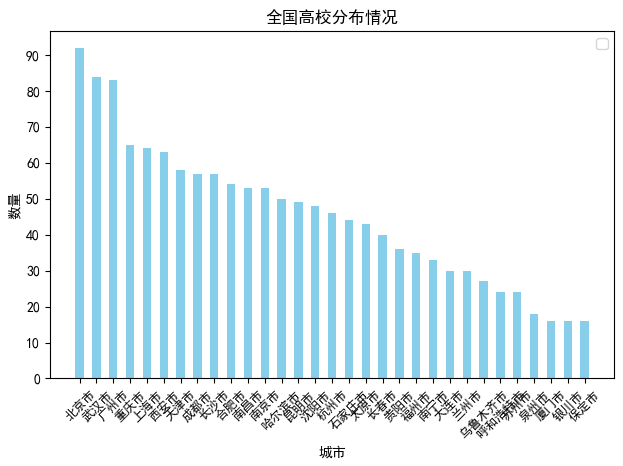
从图中可以考到,首都北京的高校数量时最多的,排名前五的城市依次是北京,武汉,广州,重庆,和上海,这五个城市在全国都是经济非常发达的城市。因此我们大致可以得出,城市大学数量和城市经济呈正相关。
可能会有人郁闷了,上面我们以省份为维度时,高校数量最多的省份是江苏省,但是以城市为维度时,大学数量超过15的城市,属于江苏省的只有南京和苏州,且排名都不怎么靠前,那好,接下来我们以江苏省为基准,查看江苏省内高校数量的分布情况。
def daxue_shuliang_prov_jiangsu(): client = pymongo.MongoClient(host='localhost', port=27017) db = client['test'] # 指定数据库 collection = db['daxue'] # 指定集合 daxue = collection.find() dx_data = DataFrame(list(daxue)) dx_data = dx_data.drop(['_id'], axis=1) dx_data = dx_data[dx_data['province'] == '江苏省'] dx_data = dx_data.sort_values('diqu') df1 = dx_data['diqu'] df1 = df1.value_counts() ind = np.arange(len(df1.values)) width = 0.5 fig, ax = plt.subplots() rects1 = ax.bar(ind,df1.values, width, color='SkyBlue') # # # Add some text for labels, title and custom x-axis tick labels, etc. # ax.set_title('江苏省高校分布情况') ax.set_xlabel('城市') ax.set_ylabel('数量') ax.set_xticklabels((df1.index)) ax.legend() # x = np.arange(len(df1.index)) # 解决中文乱码问题 plt.rcParams['font.sans-serif'] = ['SimHei'] plt.rcParams['axes.unicode_minus'] = False plt.yticks(np.arange(0, 60, 10)) # 设置y轴的刻度范围 plt.xticks(x, df1.index, rotation=45, fontsize=9) # 设置x轴上显示的省份个数 # 在图形上面添加数值,并设置数值的位置 # for x, y in enumerate(df1.values): # plt.text(x, y + 100, '%s' % round(y,2), ha='left') plt.show()
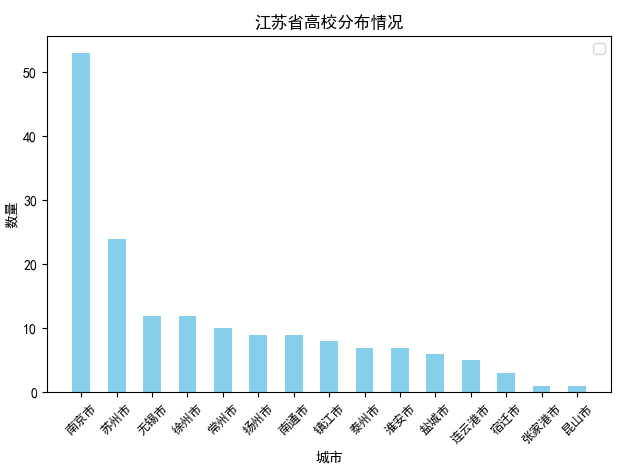
从图中可以看到,江苏省除了南京市和苏州市之外,其他城市大学数量分布较为均匀,基本都在10个左右;如果加上南京和苏州,计算江苏省内城市平均大学数量,应该会超过10个,城市大学数量平均10个,这在其他省份应该不太多,这也从另一方面说明了为什么江苏省内地区发展均为均衡的原因吧。
我们接着查看全国各省份有大学城市的城市大学平均个数
def daxue_shuliang_prov_mean(): client = pymongo.MongoClient(host='localhost', port=27017) db = client['test'] # 指定数据库 collection = db['daxue'] # 指定集合 daxue = collection.find() dx_data = DataFrame(list(daxue)) dx_data = dx_data.drop(['_id'], axis=1) dx_prov = dx_data.groupby('province') #按照省份对数据进行分组 dx_avg_list = [] for name, group in dx_prov: #遍历分组之后的数据,计算平均个数,形成省份和平均数量的字典,添加到列表中 dx_avg_dic = {} dx_avg_dic['prov'] = name dx_avg_dic['avg'] = (group['province'].count()/len(group.groupby('diqu')['name'].count())).round(decimals=2) dx_avg_list.append(dx_avg_dic) dx_df = DataFrame(list(dx_avg_list)) #以字典的列表构造df数据集 df1 = dx_df.sort_values('avg',ascending=False) ind = np.arange(len(df1['avg'])) width = 0.5 fig, ax = plt.subplots() rects1 = ax.bar(ind, df1['avg'], width, color='SkyBlue') # # # Add some text for labels, title and custom x-axis tick labels, etc. # ax.set_title('全国省份平均高校数量') ax.set_xlabel('省份') ax.set_ylabel('数量') ax.set_xticklabels(df1['prov']) ax.legend() x = np.arange(len(df1['avg'])) # 解决中文乱码问题 plt.rcParams['font.sans-serif'] = ['SimHei'] plt.rcParams['axes.unicode_minus'] = False plt.yticks(np.arange(0, 100, 10)) # 设置y轴的刻度范围 plt.xticks(x, df1.prov, rotation=45, fontsize=9) # 设置x轴上显示的省份个数 plt.show()
包含北京,上海,天津,重庆四大直辖市
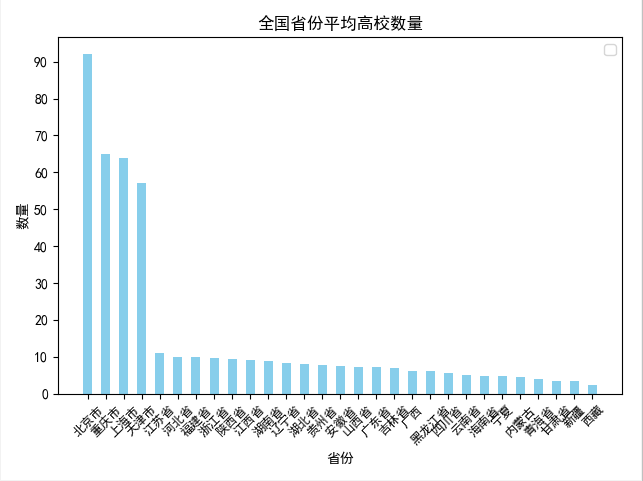
刨除北京,上海,天津,重庆四大直辖市
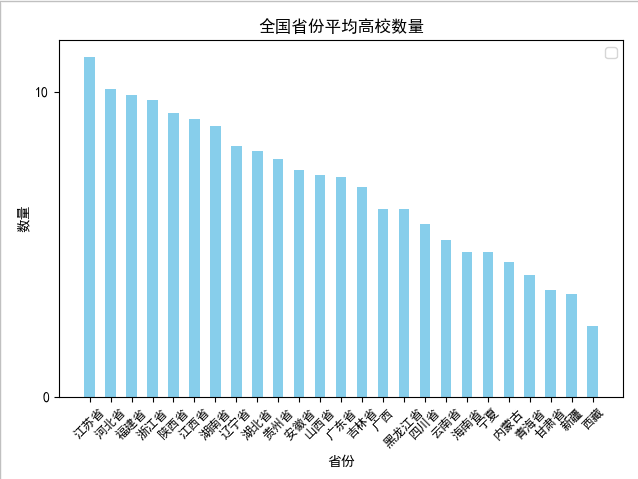
从上面两张图可以看出,在刨除北京,上海,天津,重庆四个直辖市之后,城市平均大学数量排名第一的是 江苏省,达到了11.13个,也印证了我们上面的分析。
有趣的是,排名第二的河北省,经济却比较落后,可能是距离北京太近了吧,O(∩_∩)O哈哈~
至此,我们完成了对全国高校数据的抓取和分析,仅仅是小试牛刀,完整代码请参见: https://gitee.com/liangxinbin/Scrpay/blob/master/Vsualization.py
作者: liangxb
出处:https://www.cnblogs.com/lxbmaomao/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号