
关于真正量化和假冒量化的原理分析
关于真正量化和假冒量化的原理分析
背景:

目前大量的 GPT-base 模型的量化仅仅对权重(weights)进行量化,而没有对特征图(feature maps)进行量化。这样的量化模型实际上并不是真正的量化模型。 在深度学习中,模型参数(weights)和输入数据(feature maps)都可以进行量化,从而在计算和存储上大大降低了模型的计算和存储开销。但是,如果只对权重进行量化而不对特征图进行量化,那么在模型推理时,仍然需要使用高精度浮点数进行计算,因为特征图没有被量化。这就导致了量化后的模型仍然需要较大的计算和存储开销,而且没有达到真正的量化的效果。 因此,对于 GPT-base 模型的量化,如果只对权重进行量化而不对特征图进行量化,那么虽然可以降低模型的大小,但是无法真正实现模型的加速和优化,而真正的量化模型需要将权重和特征图都进行量化。
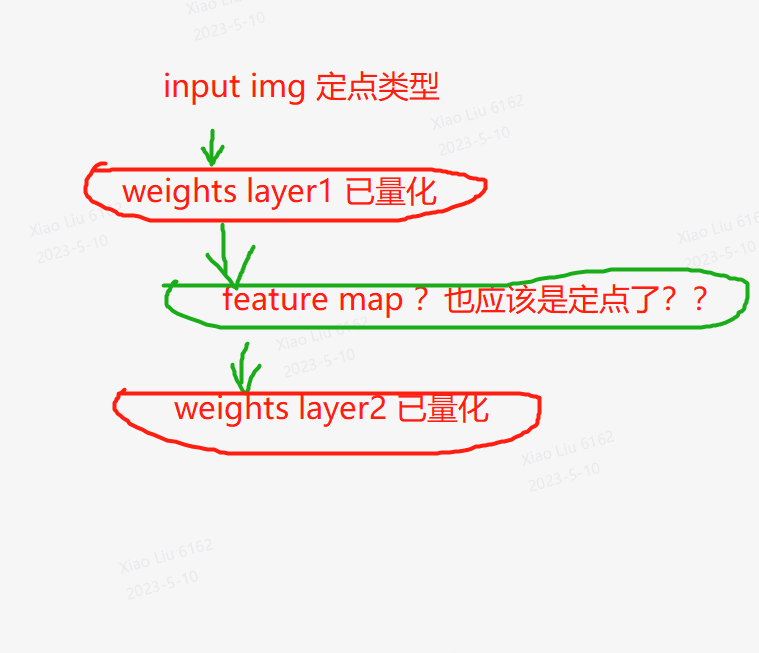
问:绿色部分是计算值 所以我理解一定也是 定点了 为什么还要单独对featurmap量化
答:只是对weight进行了量化,实际forward算的时候,可以理解为还是把weight又反量化成了浮点数,然后和浮点数的featuremap做运算
说明:当然也可能是反过来,运算时在线把某一层的输入featuremap量化后送给算子算,算完了后把输出featuremap又反量化成浮点。
这种情况的概率很小,毕竟gpt类模型这么算的话,精度可能不能保证。
关于前处理
问:但是我的输入图片/序列, 都是经过前处理,变为 定点整形了呀,难道还要再把定点图片数据再转为 浮点型 ?
答:图片或者nlp中的字符index的话本身就可以是定点的,估计在某几层后的featuremap就是float型了
理解
问:某几层后的float的featuremap -> weights 反量化为浮点 ->计算得到结果 是这样吧
答:是的。主要是省模型存储空间和内存占用,运算上省不了多少。
问:目前量化 weights的意义在于, load 模型的大小变小了,如原来float32 ->int16了 所以只是模型加载到内存占用小了。 实际的计算可能开销还更大了?
答:运算不至于更大,只能说是减少的有限。
这个过程“某几层后的float的featuremap -> weights 反量化为浮点 ->计算得到结果 ”可以做的不怎么额外费时。
对featuremap量化难点
问:那么我们为什么不做featuremap量化? 难点在哪里?
答:它这种情况肯定是为了减少量化损失,featuremap量化后的损失在他这种情况肯定是过大不可接受了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号