Spark-寒假-实验3
1.安装 Hadoop 和 Spark
进入 Linux 系统,参照本教程官网“实验指南”栏目的“Hadoop 的安装和使用”,完成 Hadoop 伪分布式模式的安装。完成 Hadoop 的安装以后,再安装 Spark(Local 模式)。

2.HDFS 常用操作
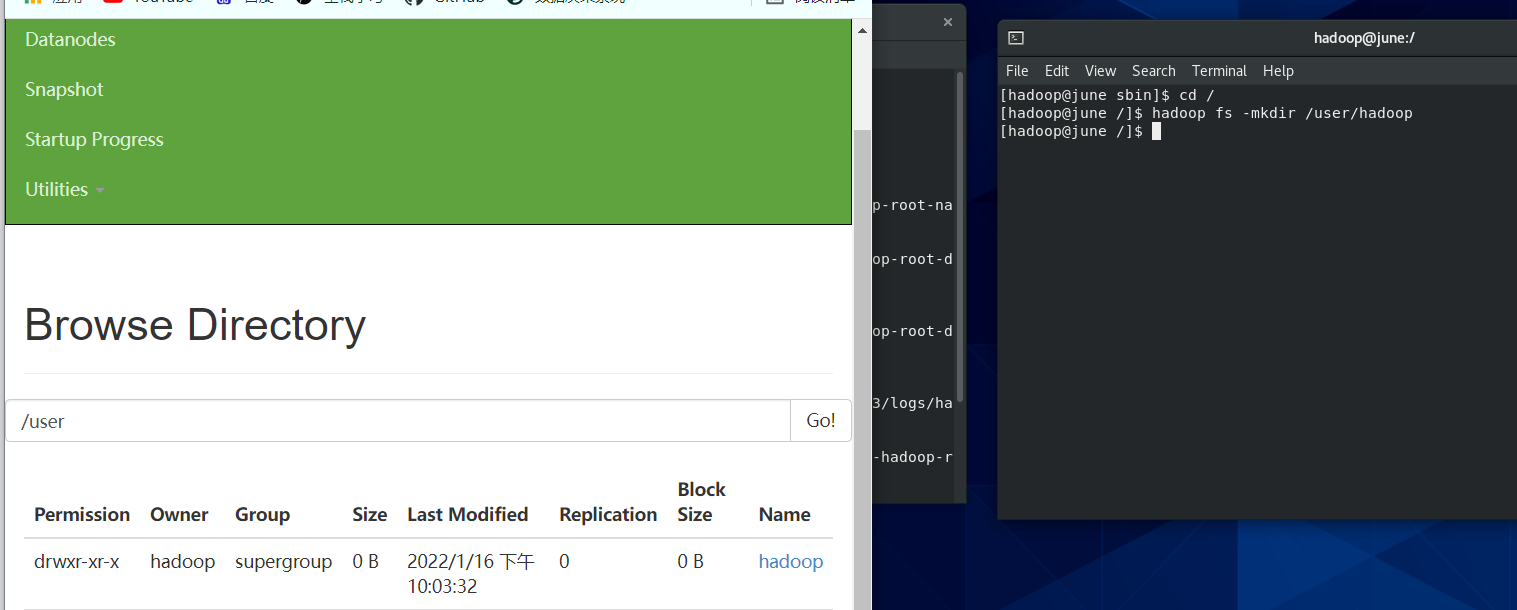
(1) 启动 Hadoop,在 HDFS 中创建用户目录“/user/hadoop”;
(2) 在 Linux 系统的本地文件系统的“/home/hadoop”目录下新建一个文本文件 test.txt,并在该文件中随便输入一些内容,然后上传到 HDFS 的“/user/hadoop” 目录下;

(3) 把 HDFS 中“/user/hadoop”目录下的 test.txt 文件,下载到 Linux 系统的本地文 件系统中的“/home/hadoop/下载”目录下;

(4) 将HDFS中“/user/hadoop”目录下的test.txt文件的内容输出到终端中进行显示;

(5) 在 HDFS 中的“/user/hadoop”目录下,创建子目录 input,把 HDFS 中 “/user/hadoop”目录下的 test.txt 文件,复制到“/user/hadoop/input”目录下;

(6) 删除HDFS中“/user/hadoop”目录下的test.txt文件,删除HDFS中“/user/hadoop” 目录下的 input 子目录及其子目录下的所有内容。

3. Spark 读取文件系统的数据
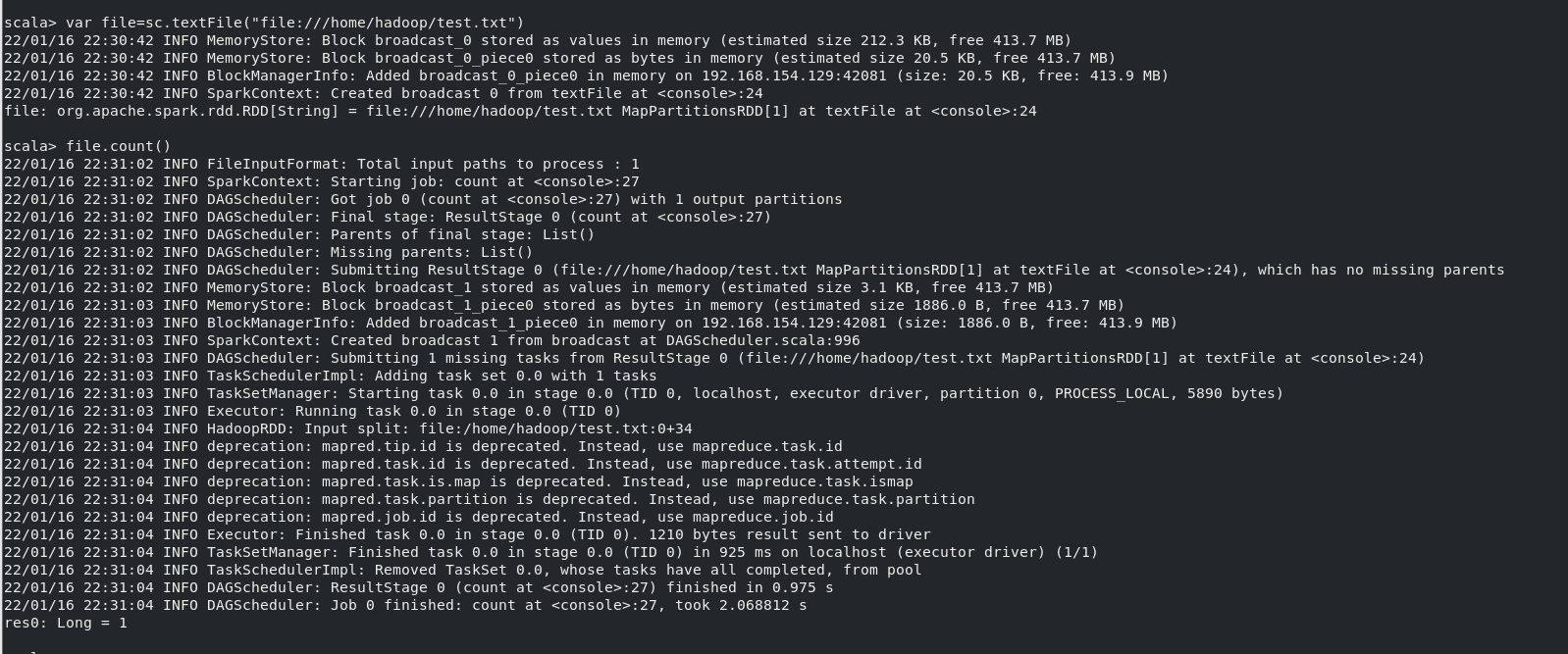
(1)在 spark-shell 中读取 Linux 系统本地文件“/home/hadoop/test.txt”,然后统计出文 件的行数;
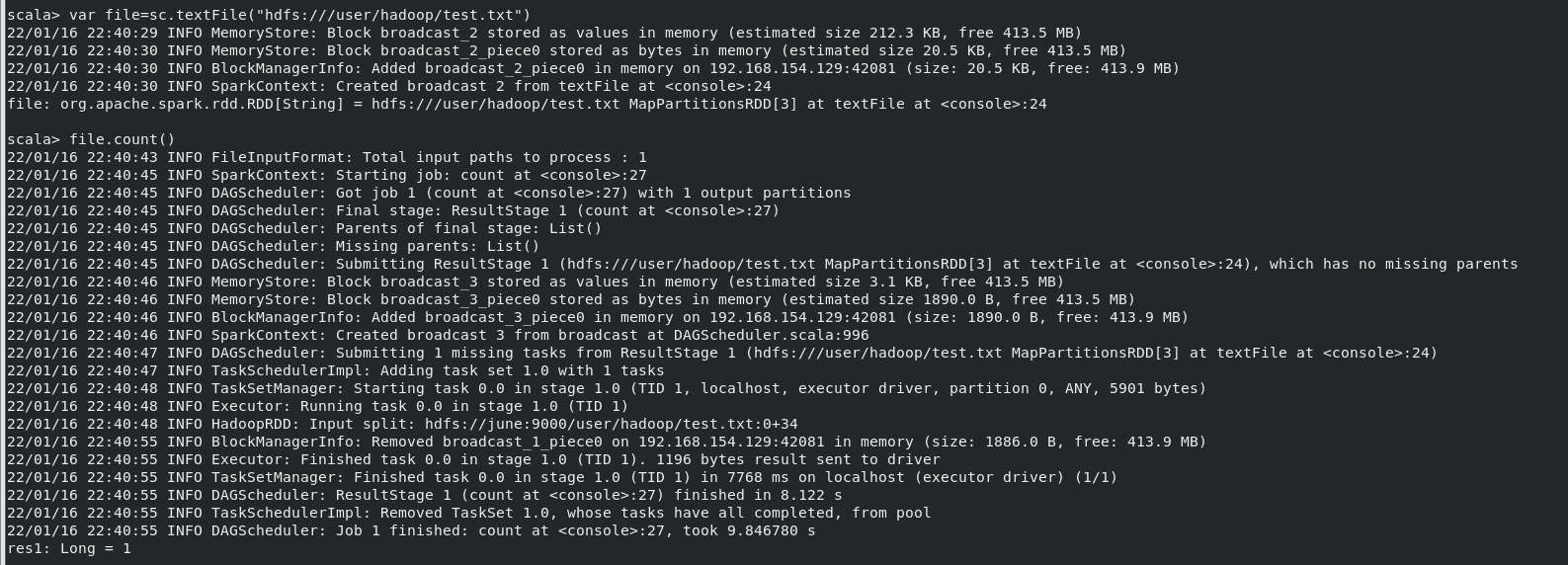
(2)在 spark-shell 中读取 HDFS 系统文件“/user/hadoop/test.txt”(如果该文件不存在, 请先创建),然后,统计出文件的行数
(3)编写独立应用程序,读取 HDFS 系统文件“/user/hadoop/test.txt”(如果该文件不存在, 请先创建),然后,统计出文件的行数;通过 sbt 工具将整个应用程序编译打包成 JAR 包, 并将生成的 JAR 包通过 spark-submit 提交到 Spark 中运行命令。
1)centos下安装sbt
下载压缩包
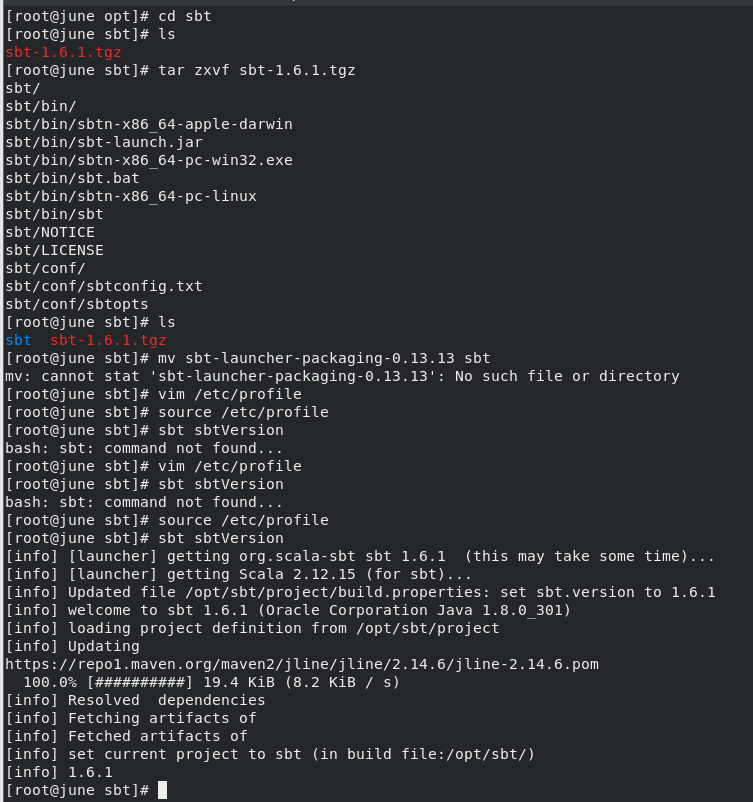
配置环境变量(根据需要复制路径,修改自己所下压缩包的版本号):
export JAVA_HOME=/opt/java/jdk1.8.0_301
export HADOOP_HOME=/opt/Hadoop/hadoop-2.7.3
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_HOME}/lib/native
export SPARK_HOME=/opt/spark/spark-2.1.0-bin-hadoop2.6
export SCALA_HOME=/opt/scala/scala-2.11.8
export CLASSPATH=$:CLASSPATH:$JAVA_HOME/lib/
export SBT_HOME=/opt/sbt/sbt
export PATH=.:${JAVA_HOME}/bin:${HIVE_HOME}/bin:${HADOOP_HOME}/bin:/opt/mongodb/bin:${SPARK_HOME}/bin:${SCALA_HOME}/bin:${SBT_HOME}/bin:$PATH
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native
export HIVE_HOME=/opt/hive/apache-hive-2.3.9-bin
export HIVE_CONF_DIR=${HIVE_HOME}/conf
2)创建项目(在自己的目录下创建wordcount文件夹,下图为进入wordcount文件夹后的有关操作)

test.scala(localhost记得改为自己虚拟机的静态ip,hdfs相关路径以及文件名亦需要修改为自己的)
import org.apache.spark.SparkContext import org.apache.spark.SparkContext._ import org.apache.spark.SparkConf object WordCount { def main(args: Array[String]) { val logFile = "hdfs://localhost:9000/user/hadoop/Data01.txt" val conf = new SparkConf().setAppName("WordCount") val sc = new SparkContext(conf) val logData = sc.textFile(logFile, 2) val num = logData.count() printf("The num of this file is %d", num) } }
simple.sbt(scala的版本号即scalaVersion,请根据自己的scala版本进行修改)
name := "WordCount Project" version := "1.0" scalaVersion := "2.11.8" libraryDependencies += "org.apache.spark" %% "spark-core" % "1.6.2"
3)打包项目(命令自己打,几个字母)

4)运行jar包(jar包一般在/wordcount/target/scala-2.11/下)

运行: 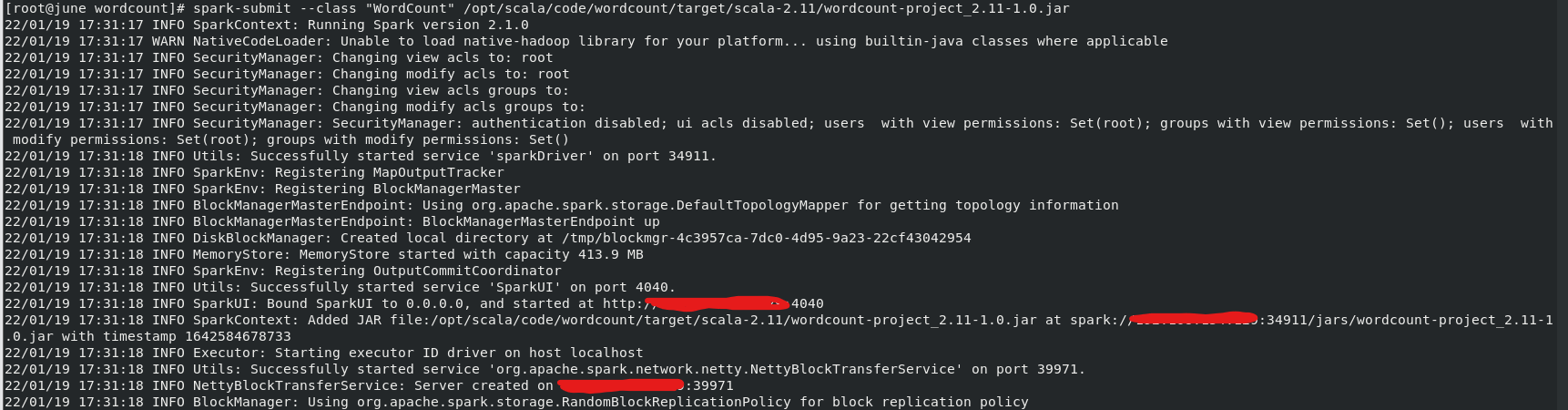
运行结果(在运行日志的打印信息中):


 浙公网安备 33010602011771号
浙公网安备 33010602011771号