
你所了解的Java线程池
在jvm中,线程是一个宝贵的资源,创建与销毁都会抢占宝贵的内存资源,为了有效的重用线程,我们用线程池来管理线程,让创建的线程进行复用。
JDK提供了一套Executor框架,帮助我们管理线程,核心成员如下:
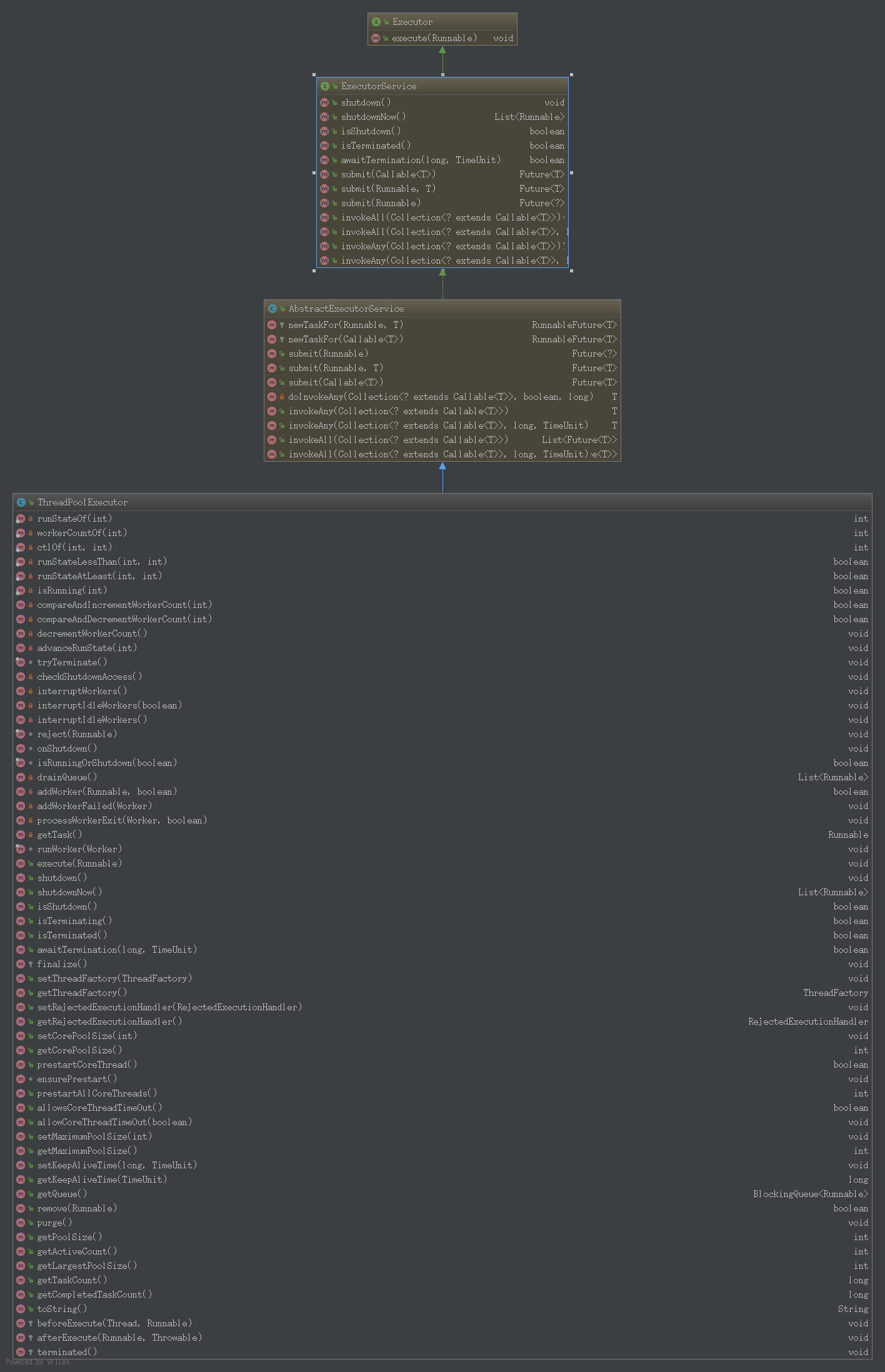
它们都在java.util.concurrent包中,是JDK并发包的核心类,其中,Executor是一个interface,只有一个execute方法;Executors扮演着线程工厂的角色;ThreadPoolExecutor表示一个线程池,用来管理我们的线程。
ThreadPoolExecutor通用的构造函数如下:
1 public ThreadPoolExecutor( 2 int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit timeUnit, 3 BlockingQueue<Runnable> workQueue) { 4 super(corePoolSize, maximumPoolSize, keepAliveTime, timeUnit, workQueue); 5 }
corePoolSize:线程池基本大小;maximumPoolSize:线程池最大大小;keepAliveTime:线程的存活时间;timeUnit:线程活动保持的时间单位;workQueue:工作队列;
说明:BlockingQueue,可以称之为共享队列,后续有专门的文章来介绍。
线程池工作原理:
1.线程池判断核心线程池中线程是否都在工作,如果不是,则创建一个新的工作线程来执行任务,如果核心线程池中的线程都在执行任务,则进入下一步;
2.线程池会判断工作线程是否已经满了,如果工作队列没有满,则将新提交的任务存储在工作队列中等待执行,如果队列满了,则进入下一步;
3.线程池判断线程池(这里判断的是否到达maximumPoolSize)是否都处于执行状态,如果没有的话,则创建一个新的线程来执行,如果满了,则交给饱和策略来处理这个任务,默 认是抛出异常(AbortPolicy),也可以自定义饱和策略。
现在来看一下exwcute方法:
public void execute(Runnable var1) { if(var1 == null) {
//如果没有任务,直接抛出异常 throw new NullPointerException(); } else {
//ct1表示一个AtomicInteger,是一个原子类,非阻塞的,相比与synchronzied与锁,性能更好,后续文章会详细介绍,这里的含义表示在当前的线程数 int var2 = this.ctl.get();
// 创建一个新的线程,并把当前任务 command 作为这个线程的第一个任务(firstTask)
if(workerCountOf(var2) < this.corePoolSize) {
//执行的结果会包装为一个FutureTask返回,后续有文章介绍异步(Future) if(this.addWorker(var1, true)) {
//return直接返回,保证线程池的高可用,其他的任务交给addWorker()去执行,线程池去处理下一个任务。 return; } var2 = this.ctl.get(); }
//执行到这里,要么是因为,达到核心线程数,要么是因为,doWorker()执行失败,没有走return
//首先会判断线程池的运行状态,然后把该任务放入到工作队列中 if(isRunning(var2) && this.workQueue.offer(var1)) { int var3 = this.ctl.get();
//如果线程池不在运行状态,移除该任务,并且执行拒绝策略 if(!isRunning(var3) && this.remove(var1)) { this.reject(var1); } else if(workerCountOf(var3) == 0) {
//否则执行该任务 this.addWorker((Runnable)null, false); }
//进入这里表示上面的1,2都失败了,在maximumPoolSize来创建线程执行任务,如果失败,则执行决绝策略。 } else if(!this.addWorker(var1, false)) { this.reject(var1); } } }
然后我们来看一下,上面多次调用的doWorker()方法:
//两个参数,分别表示任务与判断是否进入的分支(true为corePoolSize,false为maximumPoolSize)
private boolean addWorker(Runnable var1, boolean var2) { while(true) {
//上面讲述过 int var3 = this.ctl.get(); int var4 = runStateOf(var3);
// 如果线程池已关闭,并满足以下条件之一,那么不创建新的 worker:
//var4>0表示,线程池已经关闭
//若果任务不存在或者工作队列为空或者线程池正在关闭等,表示不执行该任务 if(var4 >= 0 && (var4 != 0 || var1 != null || this.workQueue.isEmpty())) { return false; } while(true) { int var5 = workerCountOf(var3); if(var5 >= 536870911 || var5 >= (var2?this.corePoolSize:this.maximumPoolSize)) {
//var2通过true或者false来判断当前线程池的状况,大于corePoolSize或者maximumPoolSize,则决绝执行。 return false; }
//成功则创建线程执行任务
//compareIncreamentWorkerCount()该方法表示原子操作,底层调用的是AtomicInteger.compareAndSet(int var1,int var2),表示当前值为var1,则设置为var2,后续会详细介绍
//如果失败,说明不止有一个线程同时操作此方法,创建线程。 if(this.compareAndIncrementWorkerCount(var3)) {
// worker 是否已经启动 boolean var18 = false;
/ 是否已将这个 worker 添加到 workers 这个 HashSet 中 boolean var19 = false; ThreadPoolExecutor.Worker var20 = null; try {
//创建线程执行任务 var20 = new ThreadPoolExecutor.Worker(var1);
//Worker的构造方法会调用 ThreadFactory 来创建一个新的线程 Thread var6 = var20.thread; if(var6 != null) {
//重入锁,锁住下列操作,保证原子性,保证在操作过程中,线程池不会被关闭 ReentrantLock var7 = this.mainLock; var7.lock(); try { int var8 = runStateOf(this.ctl.get()); if(var8 < 0 || var8 == 0 && var1 == null) { if(var6.isAlive()) { throw new IllegalThreadStateException(); }
//增加到Set集合中。用于执行 this.workers.add(var20); int var9 = this.workers.size();
//因为 workers 是不断增加减少的,通过这个值可以知道线程池的大小曾经达到的最大值 if(var9 > this.largestPoolSize) { this.largestPoolSize = var9; } var19 = true; } } finally { var7.unlock(); } if(var19) {
//启动线程执行 var6.start(); var18 = true; } } } finally { if(!var18) { this.addWorkerFailed(var20); } } //返回线程的状态 return var18; } var3 = this.ctl.get(); if(runStateOf(var3) != var4) { break; } } } }
以上就是整个线程池的工作原理。
接下来:会把一个线程封装为一个Worker(工作线程),也是一个线程,实现了序列化与队列的功能
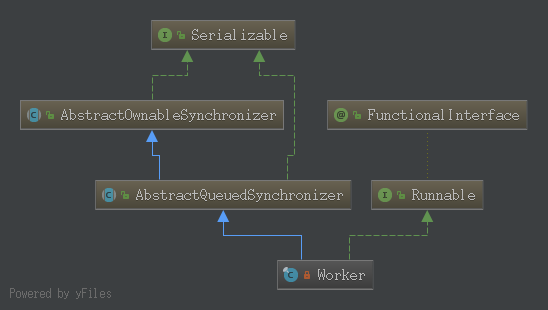
Worker在执行完任务后,会循环执获取工作队列中的任务来执行。如下:
final void runWorker(ThreadPoolExecutor.Worker var1) { Thread var2 = Thread.currentThread(); Runnable var3 = var1.firstTask; var1.firstTask = null; var1.unlock(); boolean var4 = true; try {
//循环从队列中去任务执行 while(var3 != null || (var3 = this.getTask()) != null) { var1.lock();
//判断线程池的状态 if((runStateAtLeast(this.ctl.get(), 536870912) || Thread.interrupted() && runStateAtLeast(this.ctl.get(), 536870912)) && !var2.isInterrupted()) { var2.interrupt(); } try {
//钩子方法,后续介绍 this.beforeExecute(var2, var3); Object var5 = null; try {
//^_^终于可以执行任务了。 var3.run(); } catch (RuntimeException var28) { var5 = var28; throw var28; } catch (Error var29) { var5 = var29; throw var29; } catch (Throwable var30) { var5 = var30; throw new Error(var30); } finally { this.afterExecute(var3, (Throwable)var5); } } finally { var3 = null; ++var1.completedTasks; var1.unlock(); } } var4 = false; } finally { this.processWorkerExit(var1, var4); } }
然后来看看getTask()方法
1 private Runnable getTask() { 2 boolean var1 = false; 3 4 while(true) { 5 int var2 = this.ctl.get(); 6 int var3 = runStateOf(var2);
// 1. rs == SHUTDOWN && workQueue.isEmpty()
// 2. rs >= STOP 7 if(var3 >= 0 && (var3 >= 536870912 || this.workQueue.isEmpty())) {
//CAS操作,较少线程数 8 this.decrementWorkerCount(); 9 return null; 10 } 11 12 int var4 = workerCountOf(var2);
/核心线程的回收,如果发生超时,则关闭 13 boolean var5 = this.allowCoreThreadTimeOut || var4 > this.corePoolSize; 14 if(var4 <= this.maximumPoolSize && (!var5 || !var1) || var4 <= 1 && !this.workQueue.isEmpty()) { 15 try { 16 Runnable var6 = var5?(Runnable)this.workQueue.poll(this.keepAliveTime, TimeUnit.NANOSECONDS):(Runnable)this.workQueue.take(); 17 if(var6 != null) { 18 return var6; 19 } 20 21 var1 = true; 22 } catch (InterruptedException var7) { 23 var1 = false; 24 } 25 } else if(this.compareAndDecrementWorkerCount(var2)) { 26 return null; 27 } 28 } 29 }
线程池的主要运行流程基本如下,还有很多要学习的,望大家指点。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号