
数据采集第三次作业
目录
作业一:
运行代码及结果-1
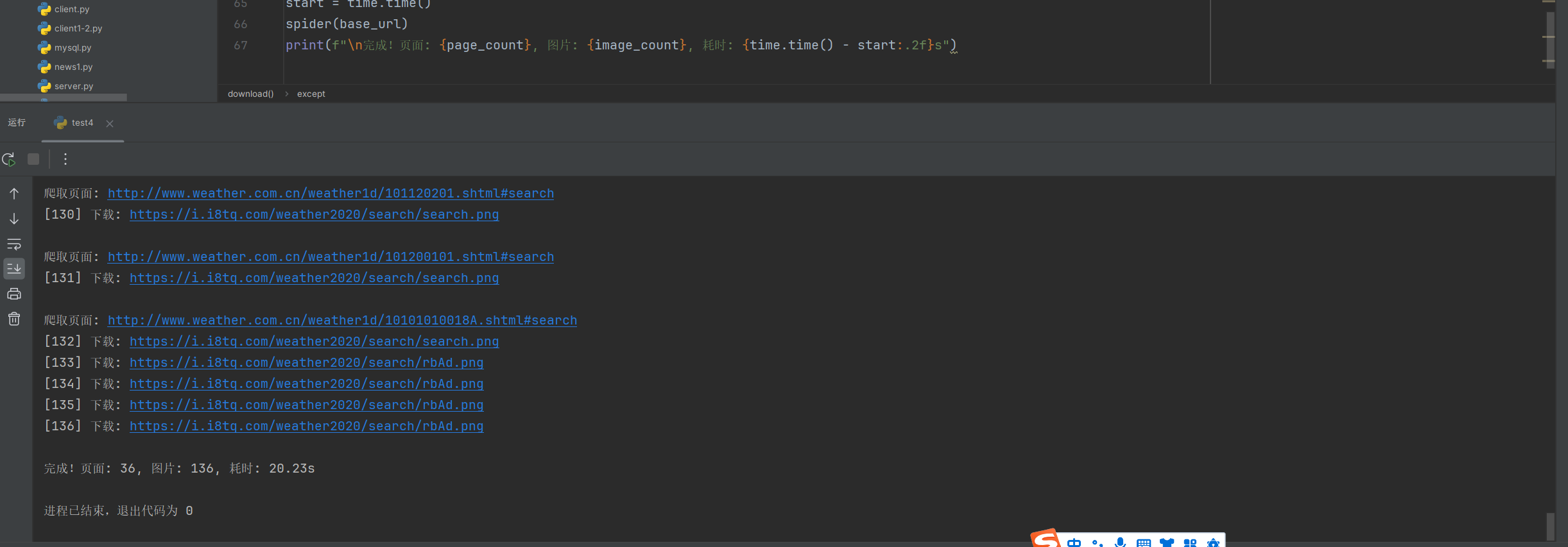
1、控制总页数36页、总图片136张
max_pages, max_images = 36, 136 page_count = image_count = 0
2、分配策略
点击查看代码
def spider(url):
global page_count, image_count
if page_count >= max_pages or url in visited: return # 限制总页数
visited.add(url)
# 请求并解析页面
data = urllib.request.urlopen(urllib.request.Request(url, headers=headers), timeout=10).read()
soup = BeautifulSoup(UnicodeDammit(data, ["utf-8", "gbk"]).unicode_markup, "lxml")
page_count += 1 # 页数计数
img_downloaded = 0
# 1-2页全下,3-35页每页1张,36页补满136张
for img in soup.select("img"):
src = img.get("src")
if not src: continue
img_url = urllib.request.urljoin(url, src)
# 按规则下载图片
if (page_count <= 2) or (3 <= page_count <= 35 and img_downloaded < 1) or (page_count == 36 and image_count < max_images):
if any(ext in img_url.lower() for ext in ['.jpg', '.png', '.gif', '.bmp']):
download(img_url)
img_downloaded += 1
# 递归爬取下一页(保证总页数≤36)
for a in soup.select("a[href]"):
href = a.get("href")
if href and base_url in urllib.request.urljoin(url, href) and page_count < max_pages:
spider(urllib.request.urljoin(url, href))
3、单线程主要框架
点击查看代码
def spider(url):
global page_count, image_count
if page_count >= max_pages or url in visited: return # 单线程终止条件
visited.add(url)
# 单线程请求页面
data = urllib.request.urlopen(urllib.request.Request(url, headers=headers), timeout=10).read()
soup = BeautifulSoup(UnicodeDammit(data, ["utf-8", "gbk"]).unicode_markup, "lxml")
page_count += 1
img_downloaded = 0
# 单线程处理图片下载
for img in soup.select("img"):
src = img.get("src")
if not src: continue
img_url = urllib.request.urljoin(url, src)
if (page_count <= 2) or (3 <= page_count <= 35 and img_downloaded < 1) or (page_count == 36 and image_count < max_images):
if any(ext in img_url.lower() for ext in ['.jpg', '.png', '.gif', '.bmp']):
download(img_url) # 单线程顺序下载
img_downloaded += 1
# 单线程递归爬取链接(同步执行)
for a in soup.select("a[href]"):
href = a.get("href")
if href and base_url in urllib.request.urljoin(url, href):
spider(urllib.request.urljoin(url, href)) # 单线程递归调用
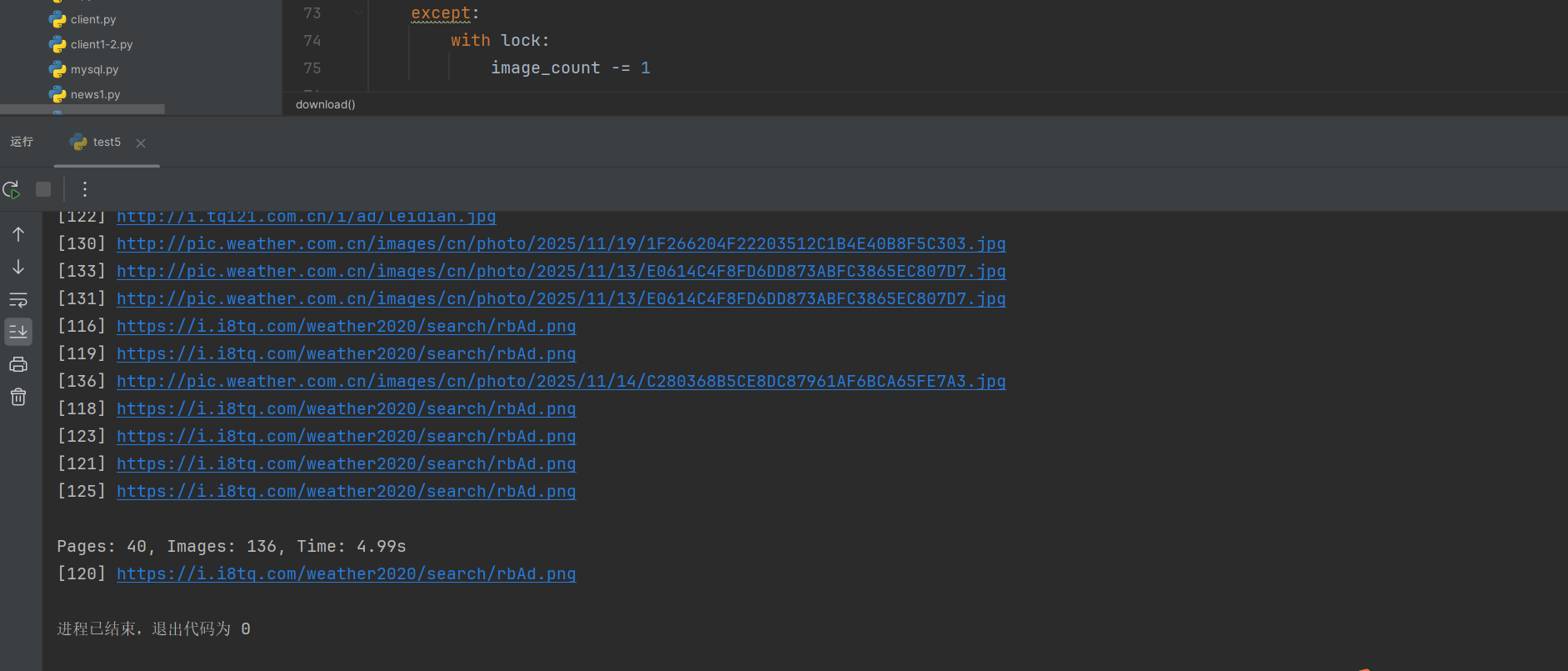
4、多线程主要框架(和单线程最大的不同就是多线程在下载过程中创建了多线程并发执行,但是由于多线程执行顺序不固定,最后打印下载结果时会交错输出)
点击查看代码
import queue
import threading
url_queue = queue.Queue() # 任务队列
lock = threading.Lock() # 资源锁
page_count, image_count = 0, 0 # 全局计数器
max_pages, max_images = 36, 136 # 限制条件
# 爬虫线程逻辑(消费者+生产者)
def spider():
while page_count < max_pages and image_count < max_images:
url = url_queue.get(timeout=3)
with lock:
if url in visited: continue
visited.add(url)
# 解析页面、提取图片链接
threading.Thread(target=download, args=(img_url,)).start() # 创建下载线程
url_queue.put(next_url)
# 下载线程逻辑
def download(url):
with lock: # 线程安全计数
if image_count >= max_images: return
image_count += 1
curr_count = image_count
#线程池管理
def main():
url_queue.put(base_url)
threads = [threading.Thread(target=spider) for _ in range(5)]
[t.start() for t in threads] # 启动线程
[t.join() for t in threads]
单线程
多线程(输出结果在images2文件夹)
心得体会-1
单线程虽简单但慢,想要提速的话可以使用多线程,不过要花功夫处理锁和共享资源
代码链接:https://gitee.com/lin-weijie123/2025_crawl_project/tree/master/作业三/1
作业二:
运行代码及结果-2
1、创建 Scrapy 项目stock_spider

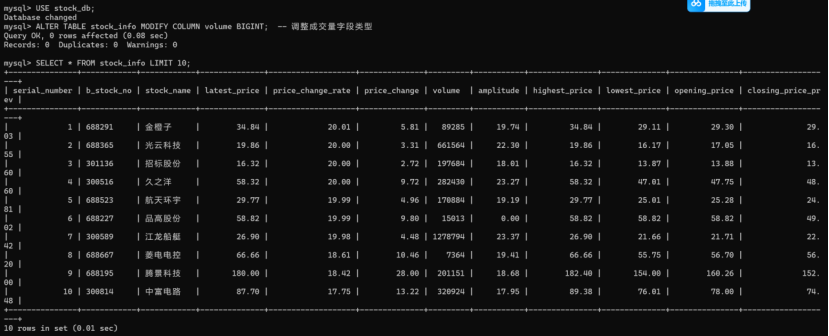
2、登录 MySQL,创建数据库和表,表名为stock_info,浏览网页观察股票都有哪些信息,写sql语句如下
点击查看代码
CREATE DATABASE IF NOT EXISTS stock_db
DEFAULT CHARACTER SET utf8mb4
DEFAULT COLLATE utf8mb4_unicode_ci;
USE stock_db;
-- 创建股票信息表
CREATE TABLE IF NOT EXISTS stock_info (
serial_number INT PRIMARY KEY AUTO_INCREMENT COMMENT '自增序号',
b_stock_no VARCHAR(20) NOT NULL COMMENT '股票代码',
stock_name VARCHAR(50) NOT NULL COMMENT '股票名称',
latest_price DECIMAL(10,2) COMMENT '最新报价',
price_change_rate DECIMAL(6,2) COMMENT '涨跌幅',
price_change DECIMAL(10,2) COMMENT '涨跌额',
volume BIGINT COMMENT '成交量(股数)',
amplitude DECIMAL(6,2) COMMENT '振幅',
highest_price DECIMAL(10,2) COMMENT '当日最高价',
lowest_price DECIMAL(10,2) COMMENT '当日最低价',
opening_price DECIMAL(10,2) COMMENT '当日开盘价',
closing_price_prev DECIMAL(10,2) COMMENT '昨日收盘价',
crawl_time DATETIME DEFAULT CURRENT_TIMESTAMP COMMENT '数据爬取时间',
-- 添加唯一索引防止重复数据
UNIQUE KEY uk_stock_no (b_stock_no)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='东方财富网A股股票信息表';
3、在items.py中定义一下需要爬取的字段,对应 MySQL 表中的字段
点击查看代码
import scrapy
class StockItem(scrapy.Item):
b_stock_no = scrapy.Field()
stock_name = scrapy.Field()
latest_price = scrapy.Field()
price_change_rate = scrapy.Field()
price_change = scrapy.Field()
volume = scrapy.Field()
amplitude = scrapy.Field()
highest_price = scrapy.Field()
lowest_price = scrapy.Field()
opening_price = scrapy.Field()
closing_price_prev = scrapy.Field()
点击查看代码
import scrapy
import json
from stock_spider.items import StockItem
class EastmoneySpider(scrapy.Spider):
name = 'eastmoney'
allowed_domains = ['eastmoney.com']
# API接口URL(pn=页码,pz=每页条数)
base_url = 'https://67.push2.eastmoney.com/api/qt/clist/get?pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152'
def start_requests(self):
# 爬取前5页数据
for page in range(1, 6):
url = self.base_url.format(page)
yield scrapy.Request(url=url, callback=self.parse_api)
def parse_api(self, response):
# 解析JSON响应
data = json.loads(response.text)
stock_list = data.get('data', {}).get('diff', [])
for stock in stock_list:
item = StockItem()
item['b_stock_no'] = stock.get('f12') # 股票代码
item['stock_name'] = stock.get('f14') # 股票名称
item['latest_price'] = stock.get('f2') # 最新报价
item['price_change_rate'] = stock.get('f3') # 涨跌幅(%)
item['price_change'] = stock.get('f4') # 涨跌额
item['volume'] = stock.get('f5') # 成交量
item['amplitude'] = stock.get('f7') # 振幅(%)
item['highest_price'] = stock.get('f15') # 最高
item['lowest_price'] = stock.get('f16') # 最低
item['opening_price'] = stock.get('f17') # 今开
item['closing_price_prev'] = stock.get('f18') # 昨收
yield item
点击查看代码
import pymysql
from itemadapter import ItemAdapter
class StockSpiderPipeline:
def __init__(self):
# 连接MySQL数据库
self.conn = pymysql.connect(
host='localhost',
user='root',
password='123456',
database='stock_db',
charset='utf8mb4'
)
self.cursor = self.conn.cursor() # 创建游标
def process_item(self, item, spider):
sql = """
INSERT INTO stock_info (b_stock_no, stock_name, latest_price, price_change_rate,
price_change, volume, amplitude, highest_price,
lowest_price, opening_price, closing_price_prev)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
"""
values = (
item.get('b_stock_no'),
item.get('stock_name'),
float(item.get('latest_price', 0)), # 转换为浮点数
float(item.get('price_change_rate', 0)),
float(item.get('price_change', 0)),
int(item.get('volume', 0)), # 转换为整数
float(item.get('amplitude', 0)),
float(item.get('highest_price', 0)),
float(item.get('lowest_price', 0)),
float(item.get('opening_price', 0)),
float(item.get('closing_price_prev', 0))
)
try:
self.cursor.execute(sql, values)
self.conn.commit()
except Exception as e:
self.conn.rollback()
spider.logger.error(f"插入失败:{e}")
return item
def close_spider(self, spider):
# 关闭数据库连接
self.cursor.close()
self.conn.close()
点击查看代码
# 启用Pipeline
ITEM_PIPELINES = {
'stock_spider.pipelines.StockSpiderPipeline': 300,
}
ROBOTSTXT_OBEY = False
# 设置请求头
DEFAULT_REQUEST_HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
}
# 设置下载延迟,避免请求过于频繁
DOWNLOAD_DELAY = 1
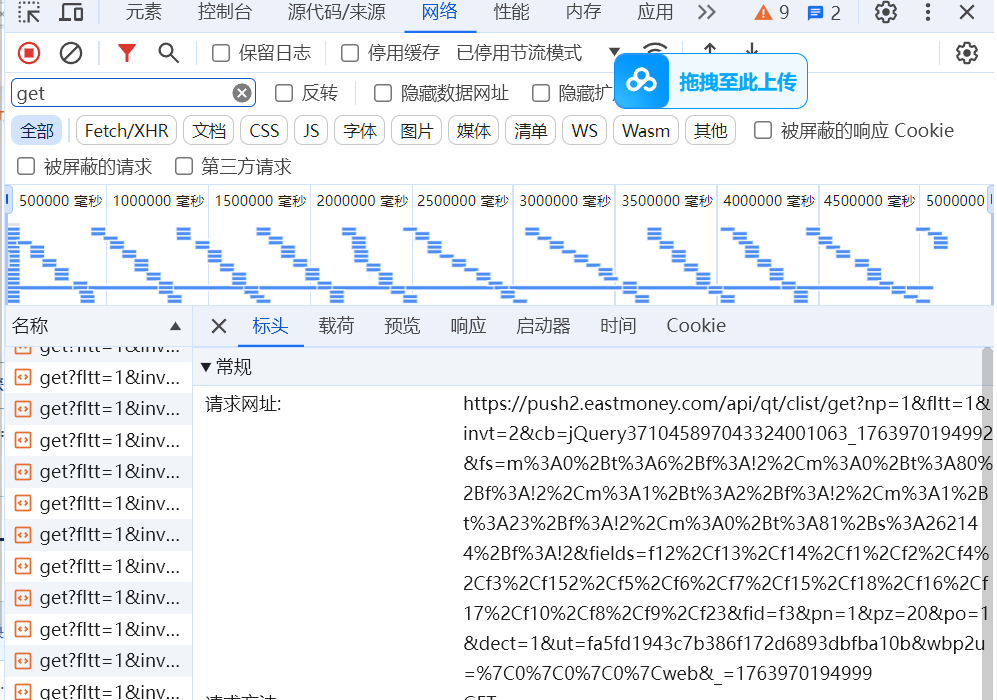
爬取20条股票数据
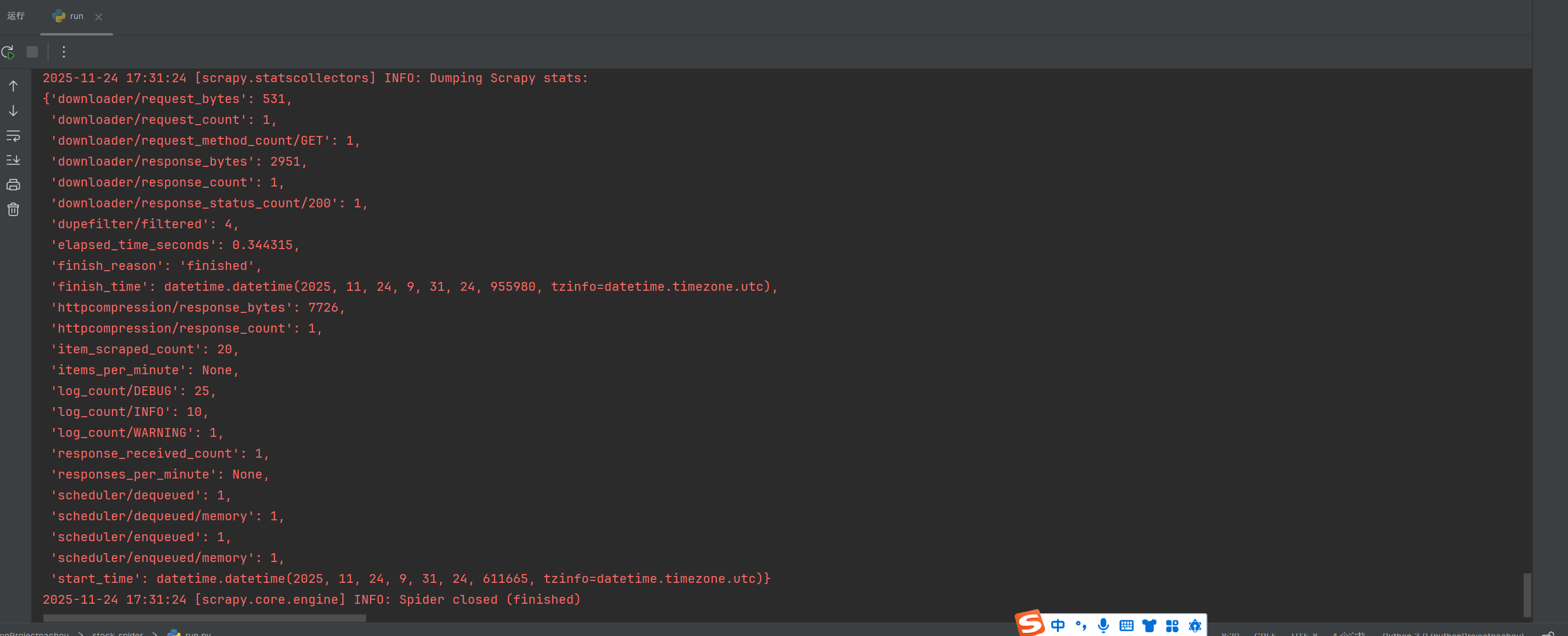
在数据库中查看结果
心得体会-2
这次实验让我学会了用爬虫技术的灵活性解决问题,最初依赖 XPath 解析 HTML 处处碰壁,解析不出页面中的完整信息。转向 API 接口获取 JSON 数据的方法还是太高效了
代码链接:https://gitee.com/lin-weijie123/2025_crawl_project/tree/master/作业三/2
作业三:
运行代码及结果-3
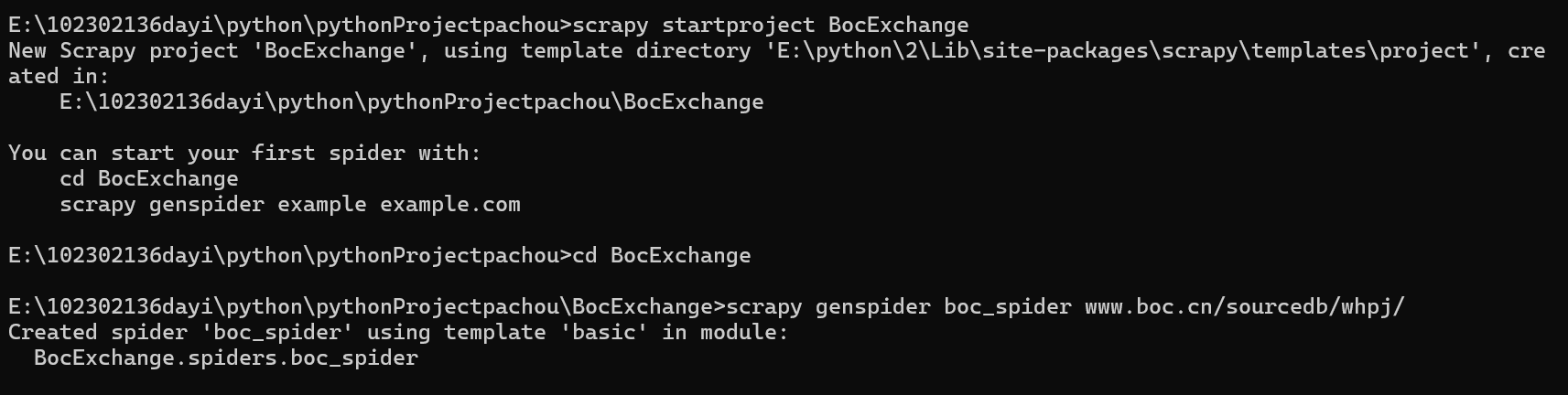
1、创建 Scrapy 项目
2、修改items.py
点击查看代码
import scrapy
class BocExchangeItem(scrapy.Item):
Currency = scrapy.Field() # 货币名称
TBP = scrapy.Field() # 现汇买入价
CBP = scrapy.Field() # 现钞买入价
TSP = scrapy.Field() # 现汇卖出价
CSP = scrapy.Field() # 现钞卖出价
Time = scrapy.Field() # 时间
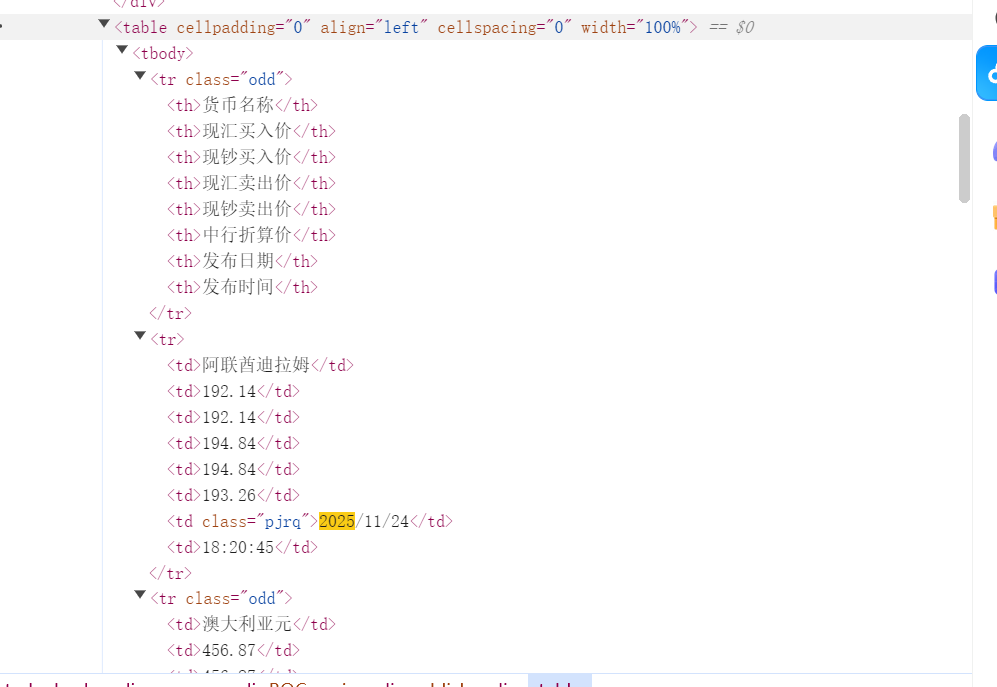
3、由于Xpath定位需根据表格结构提取对应字段,所以先去网页上查看表结构,从而正确定位表格数据,再编写boc_spider.py
点击查看代码
import scrapy
from BocExchange.items import BocExchangeItem
class BocSpider(scrapy.Spider):
name = 'boc_spider'
allowed_domains = ['boc.cn']
start_urls = ['https://www.boc.cn/sourcedb/whpj/']
def parse(self, response):
# 直接定位页面中cellpadding="0"的表格
rows = response.xpath('//table[@cellpadding="0"]//tr[position()>1]')
self.logger.info(f"找到{len(rows)}行数据")
for row in rows:
item = BocExchangeItem()
# 按你页面顺序提取(1=货币,2=现汇买入,3=现钞买入,4=现汇卖出,5=现钞卖出,8=时间)
item['Currency'] = row.xpath('./td[1]/text()').extract_first(default='').strip()
item['TBP'] = row.xpath('./td[2]/text()').extract_first(default='').strip()
item['CBP'] = row.xpath('./td[3]/text()').extract_first(default='').strip()
item['TSP'] = row.xpath('./td[4]/text()').extract_first(default='').strip()
item['CSP'] = row.xpath('./td[5]/text()').extract_first(default='').strip()
item['Time'] = row.xpath('./td[8]/text()').extract_first(default='').strip()
if item['Currency']:
yield item
self.logger.info(f"成功爬取:{item['Currency']} - {item['Time']}")
4、修改settings.py,启用 Pipeline
ITEM_PIPELINES = { 'BocExchange.pipelines.BocExchangePipeline': 300, }
5、修改pipelines.py
点击查看代码
import pymysql
class BocExchangePipeline:
def __init__(self):
self.conn = pymysql.connect(
host='localhost',
user='root',
password='123456',
database='foreign_exchange',
charset='utf8mb4',
use_unicode=True
)
self.cursor = self.conn.cursor()
self.create_table()
def create_table(self):
sql = """
CREATE TABLE IF NOT EXISTS exchange_rate (
id INT AUTO_INCREMENT PRIMARY KEY,
Currency VARCHAR(50) NOT NULL,
TBP DECIMAL(10,2) NULL, -- 允许NULL
CBP DECIMAL(10,2) NULL,
TSP DECIMAL(10,2) NULL,
CSP DECIMAL(10,2) NULL,
Time VARCHAR(20)
)
"""
self.cursor.execute(sql)
self.conn.commit()
def process_item(self, item, spider):
# 将空字符串转为None
def clean_value(val):
return val if val.strip() else None
sql = """
INSERT INTO exchange_rate (Currency, TBP, CBP, TSP, CSP, Time)
VALUES (%s, %s, %s, %s, %s, %s)
"""
self.cursor.execute(sql, (
item['Currency'],
clean_value(item['TBP']),
clean_value(item['CBP']),
clean_value(item['TSP']),
clean_value(item['CSP']),
item['Time']
))
self.conn.commit()
return item
def close_spider(self, spider):
self.cursor.close()
self.conn.close()
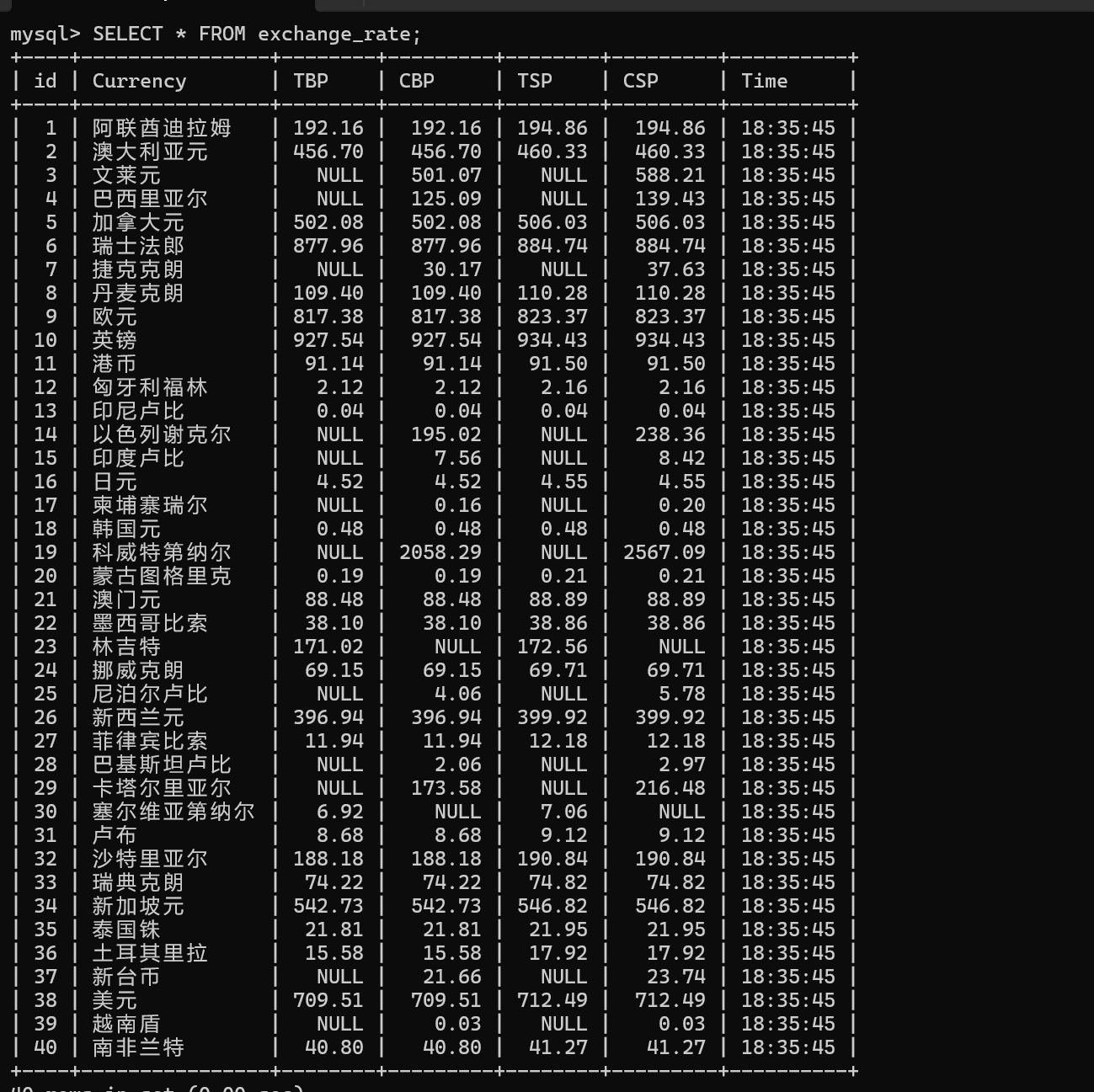
6、sql语句创建数据库和外汇存储表
点击查看代码
CREATE DATABASE IF NOT EXISTS foreign_exchange
CHARACTER SET utf8mb4
COLLATE utf8mb4_unicode_ci;
USE foreign_exchange;
CREATE TABLE IF NOT EXISTS exchange_rate (
id INT AUTO_INCREMENT PRIMARY KEY, -- 自增主键
Currency VARCHAR(50) NOT NULL, -- 货币名称
TBP DECIMAL(10,2), -- 现汇买入价
CBP DECIMAL(10,2), -- 现钞买入价
TSP DECIMAL(10,2), -- 现汇卖出价
CSP DECIMAL(10,2), -- 现钞卖出价
Time VARCHAR(20) -- 数据更新时间
);
心得体会-3
一开始 XPath 定位不准爬不到数据,进入网页中查看网页结构才成功定位,后来又因为空值插入 Decimal 字段报错耽误了一点时间。Scrapy 批量爬取静态页面的效率还是挺高的,结构化处理数据的能力也比较强
代码链接:https://gitee.com/lin-weijie123/2025_crawl_project/tree/master/作业三/3

 浙公网安备 33010602011771号
浙公网安备 33010602011771号