

第一次编程作业
第一次个人编辑作业
| 这个作业属于哪个课程 | 软件工程 |
|---|---|
| 这个作业要求在哪里 | 作业要求 |
| 这个作业目标 | 实现论文查重算法+PSP表格+使用JProfiler性能分析 |
1、作业GitHub链接
https://github.com/lwcv587/311905465
2计算模块接口的设计与实现过程
(1)在该项目中选用了Jieba.lcut()接口,默认精确模式,直接生成一个分词列表。
(2)readline() 方法用于从文件读取整行,包括 "\n" 字符。如果指定了一个非负数的参数,则返回指定大小的字节数,包括 "\n" 字符。
循环读取文件的每一整行。
(3)re库是Python拥有全部的正则表达式功能,主要用于字符串匹配。
该项目中选用了re.sub和re.compile接口实现文本预处理清洗功能。只保留英文a-zA-z、数字0-9和中文\u4e00-\u9fa5的结果,去除标点符号。增加文章相似度的准确性。
(4)常用文本查重率计算方法有余弦相似度算法、TF-IDF算法、欧几里德距离、切比雪夫距离、曼哈顿距离、SimHash + 汉明距离等。
个人觉得最容易上手的是余弦相似度算法。
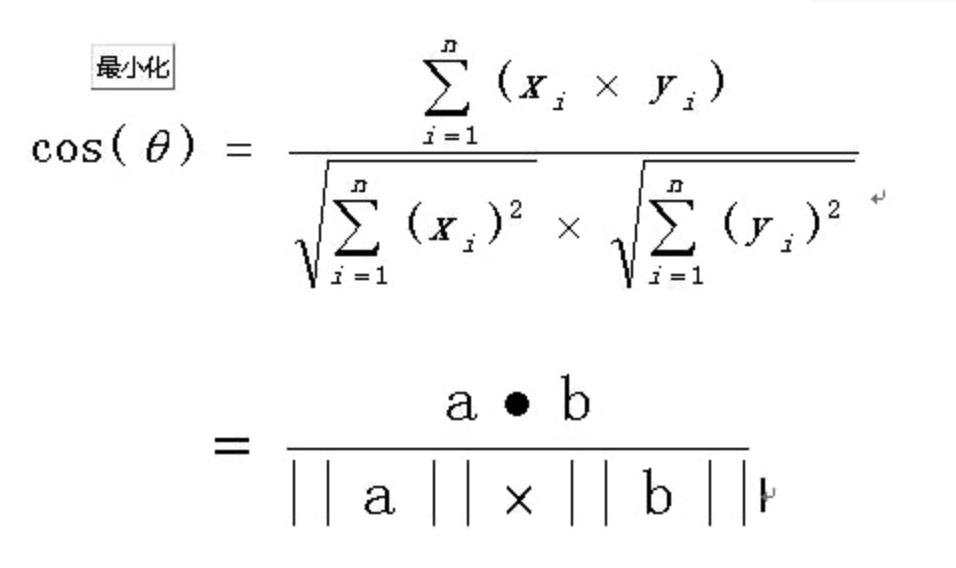
该项目选用的是余弦相似度算法计算文本相似度。
思路是先分词然后列出所有词、分词编码、套用余弦函数计量两个句子的相似度、词频向量化。
3代码
import sys
import jieba # 结巴分词
import re # 正则表达式库
import math
from line_profiler_pycharm import profile
import coverage
from setuptools.sandbox import save_path
@profile
def read_text(path):
data = ''
file = open(path, 'r', encoding='UTF-8') # 只读
line = file.readline()
while line:
data += line
line = file.readline()
file.close()
return data
@profile
# 文本清洗+分词
def text_clean(data):
newtext = []
pattern = re.compile(u"[^a-zA-Z0-9\u4e00-\u9fa5]") # 定义正则表达式匹配模式
data = pattern.sub("", data) # 只保留英文a-zA-z、数字0-9和中文\u4e00-\u9fa5的结果。 去除标点符号
newtext = [i for i in jieba.cut(data, cut_all=False) if i != ''] # 分词
return newtext
@profile
# 列出所有词,将listA和listB放在一个set中
# 余弦公式计算文本相似度
def cos(newtext1, newtext2):
word_set = set(newtext1).union(set(newtext2))
word_dict = dict()
i = 0
for word in word_set:
word_dict[word] = i
i += 1
text1_cut_index = [word_dict[word] for word in newtext1]
text2_cut_index = [word_dict[word] for word in newtext2]
text1_cut_index = [0] * len(word_dict)
text2_cut_index = [0] * len(word_dict)
for word in newtext1:
text1_cut_index[word_dict[word]] += 1
for word in newtext2:
text2_cut_index[word_dict[word]] += 1
sum = 0
sq1 = 0
sq2 = 0
cos_result = 0
for i in range(len(text1_cut_index)):
sum += text1_cut_index[i] * text2_cut_index[i]
sq1 += pow(text1_cut_index[i], 2)
sq2 += pow(text2_cut_index[i], 2)
cos_result = round(float(sum) / (math.sqrt(sq1) * math.sqrt(sq2)), 2)
return cos_result
@profile
def liweichen(path1,path2,save_path):
# path1 = 'orig.txt' # 论文原文的文件的绝对路径 作业要求
# path2 = 'orig_0.8_add.txt' # 抄袭版论文的文件的绝对路径
# save_path = 'return_1.txt' # 输出结果绝对路径
# path1 = sys.argv[1]
# path2 = sys.argv[2]
# save_path = sys.argv[3]
data1 = read_text(path1)
data2 = read_text(path2)
if len(data2) == 0:
print("文章相似度: %.4f" % 0)
# 将相似度结果写入指定文件
file = open(save_path, 'w', 1) # 只写
file.write("文章相似度: %.4f" % 0)
file.close()
else:
text1 = text_clean(data1)
text2 = text_clean(data2)
cos_result = cos(text1, text2)
print("文章相似度: %.4f" % cos_result)
# 将相似度结果写入指定文件
file = open(save_path, 'w', 1) # 只写
file.write("文章相似度: %.4f" % cos_result)
file.close()
if __name__ == '__main__':
liweichen()
单元测试
性能分析
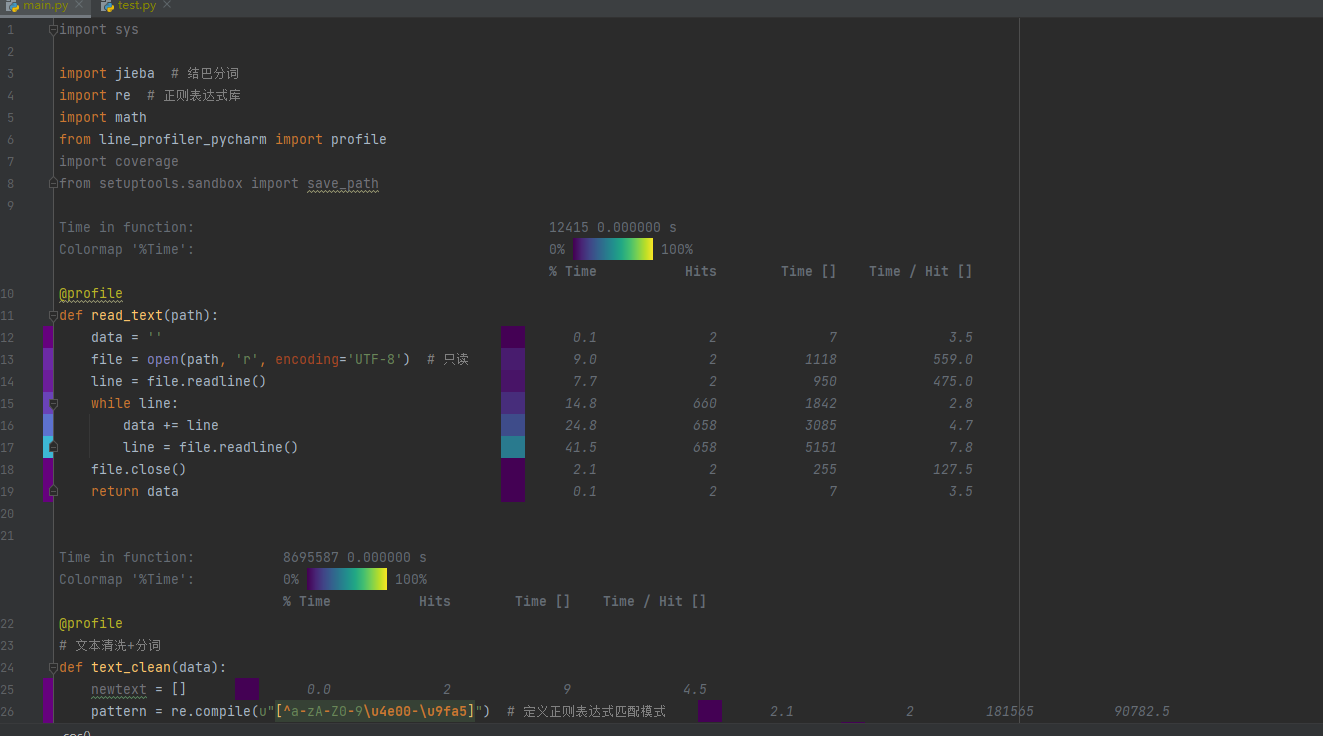

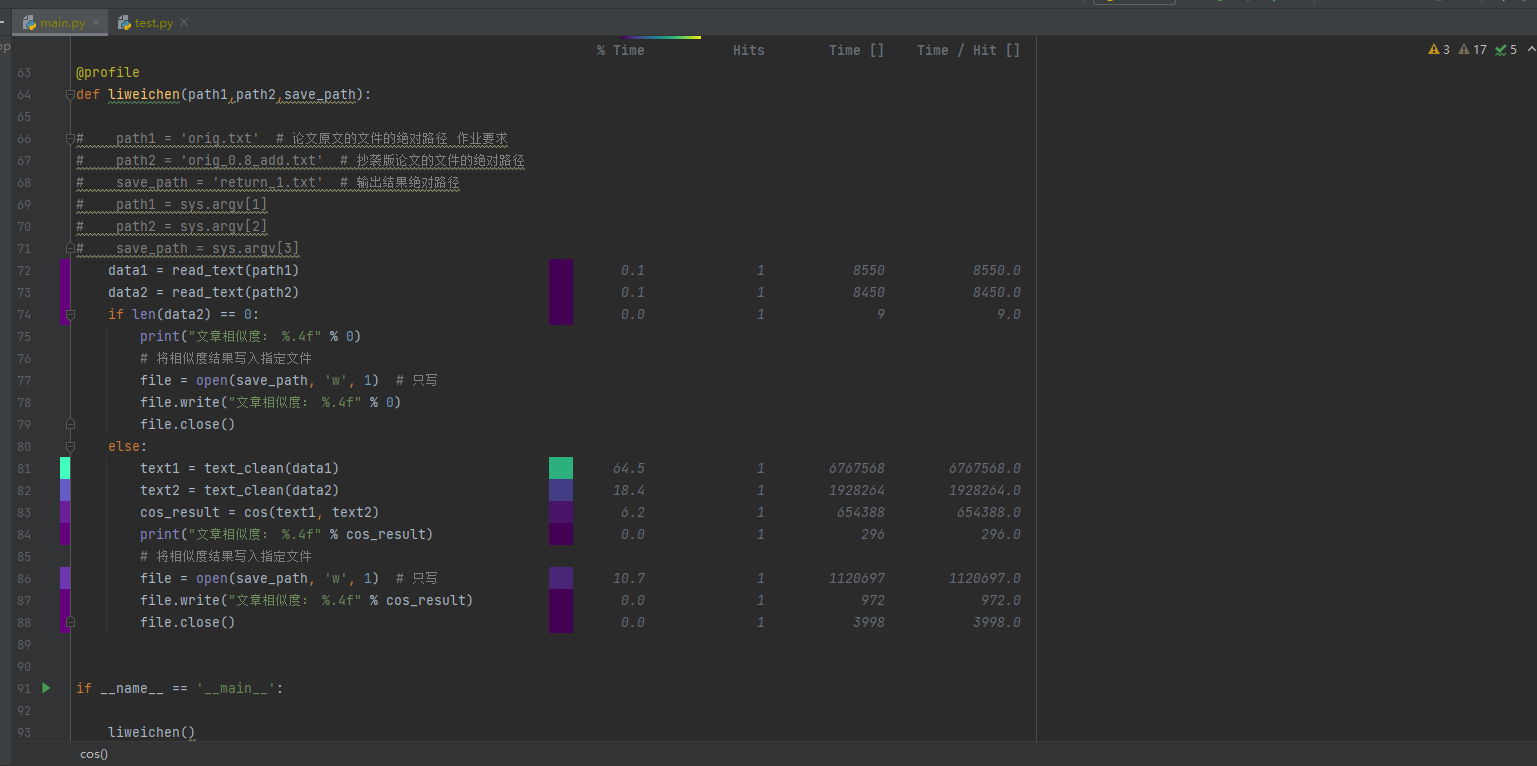
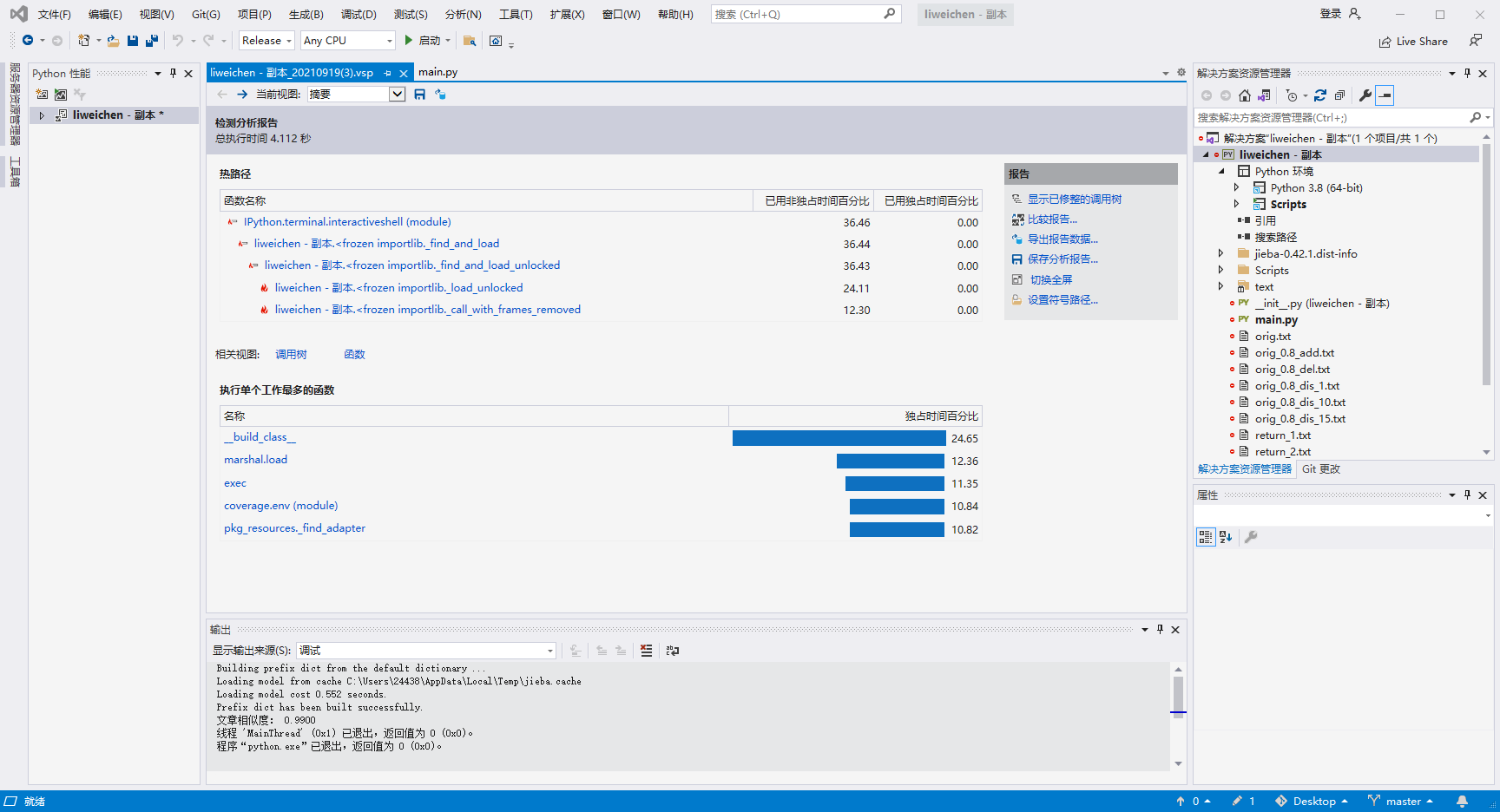
代码覆盖率
测试结果

5、计算模块部分异常处理说明
如果文件名输入错了,就会报错说没有该文件存在,把文件名确认一次就好了
PSP表格
| PSP | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 40 |
| Estimate | 估计这个任务需要多少时间 | 1100 | 1000 |
| Development | 开发 | 320 | 310 |
| Analysis | 需求分析 (包括学习新技术) | 80 | 50 |
| Design Spec | 生成设计文档 | 60 | 90 |
| Design Review | 设计复审 | 60 | 70 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 40 | 20 |
| Design | 具体设计 | 40 | 40 |
| Coding | 具体编码 | 500 | 520 |
| Code Review | 代码复审 | 100 | 110 |
| Test | 测试(自我测试,修改代码,提交修改) | 15 | 10 |
| Reporting | 报告 | 60 | 50 |
| Test Repor | 测试报告 | 10 | 20 |
| Size Measurement | 计算工作量 | 10 | 5 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 5 | 5 |
| Total | 合计 | 1355 | 1340 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号