
如何将一个h5ad文件内部添加一个csv文件作为属性obsm
问题展开
学习生物信息的时候发现,需要将一个M * N的csv文件作为anndata文件的.X部分,一个M * 2的csv文件作为anndata文件的空间位置信息标识。
首先先读M*N的文件
mydata = pd.read_csv(denoised_result_path,sep='\t')
其次读取M * 2的csv文件
spot = pd.read_csv(spot_path,sep=',')
随后将M*N的文件转换为anndata格式
adata = anndata.AnnData(mydata)
然后检查作为adata文件的属性列obs的类型
发现adata.obs和spot的index是不同的
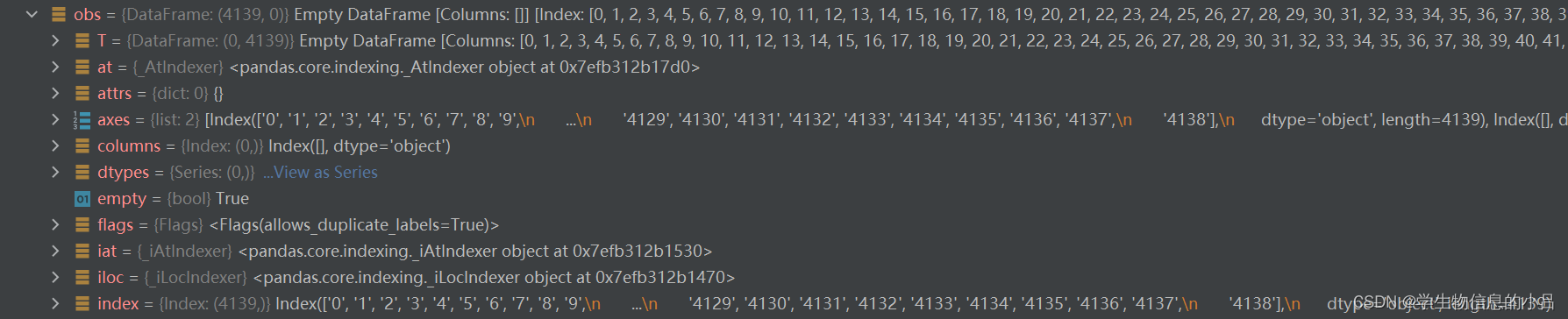
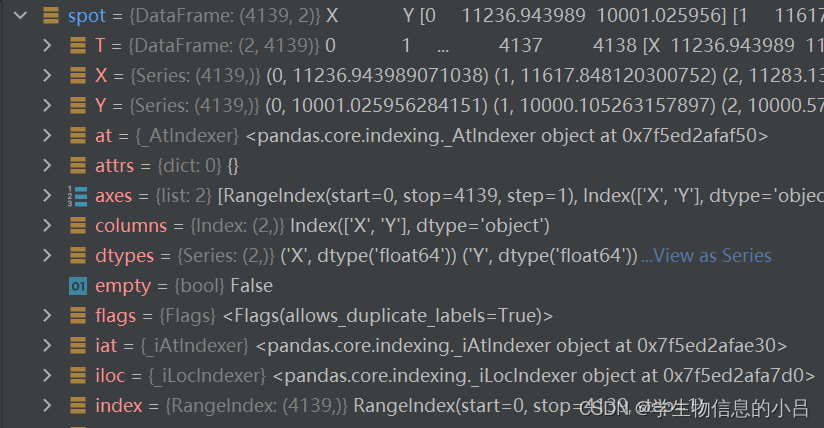
因此需要更改spot的index为adata的index类型格式
spot.index = adata.obs_names
随后便可以将spot这一dataframe添加为adata文件的一个属性列
adata.obsm['spatial'] = spot
adata.write_h5ad(denoised_sprod_path)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号