

3/24MapReduce面试必看
- 本质上是三个进程运行,一个maptask 一个reducetask 一个MR程序
- 写程序 添加依赖后,mapper reducer driver yarn集群的配置
- 为了实现数据落盘和网络传输还要进行序列化和反序列化,本质就是将各个结构体里的基本数据类型一一传递 实现writable接口 顺序要一致
- 输入和输出基本都是keyv
- 如果还要排序那么要实现comparade接口
- mapper类 首先要定义输入还是输出?输出!的键值对类型 主要还是要实现map方法,reduce同理 driver是获取配置后将map和reduce关联起来
- driver 主要是拿到job对象,提交job
![]()
![]()
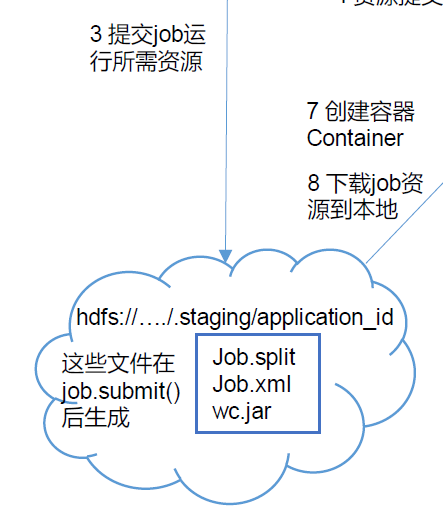
- 这个资源到底是什么?终于解惑 ,其实就是并行度切片文件,切片节点,长度,jar包,job的xml文件 yarn根据切片决定启多少maptask,这才需要访问hdfs
![]()
- 切片策略
![]()
![]()
小文件根据长度,不管多小,都会切成一块,很多切片,很多maptask!浪费,效率底下!
- 为什么combinetsxt inputformat可以减少切片?这是切片的本质决定的,切片并不是真的把文件分割了,而是逻辑上进入数据量的大小,所以当然可以逻辑上合并
![]()
![]()
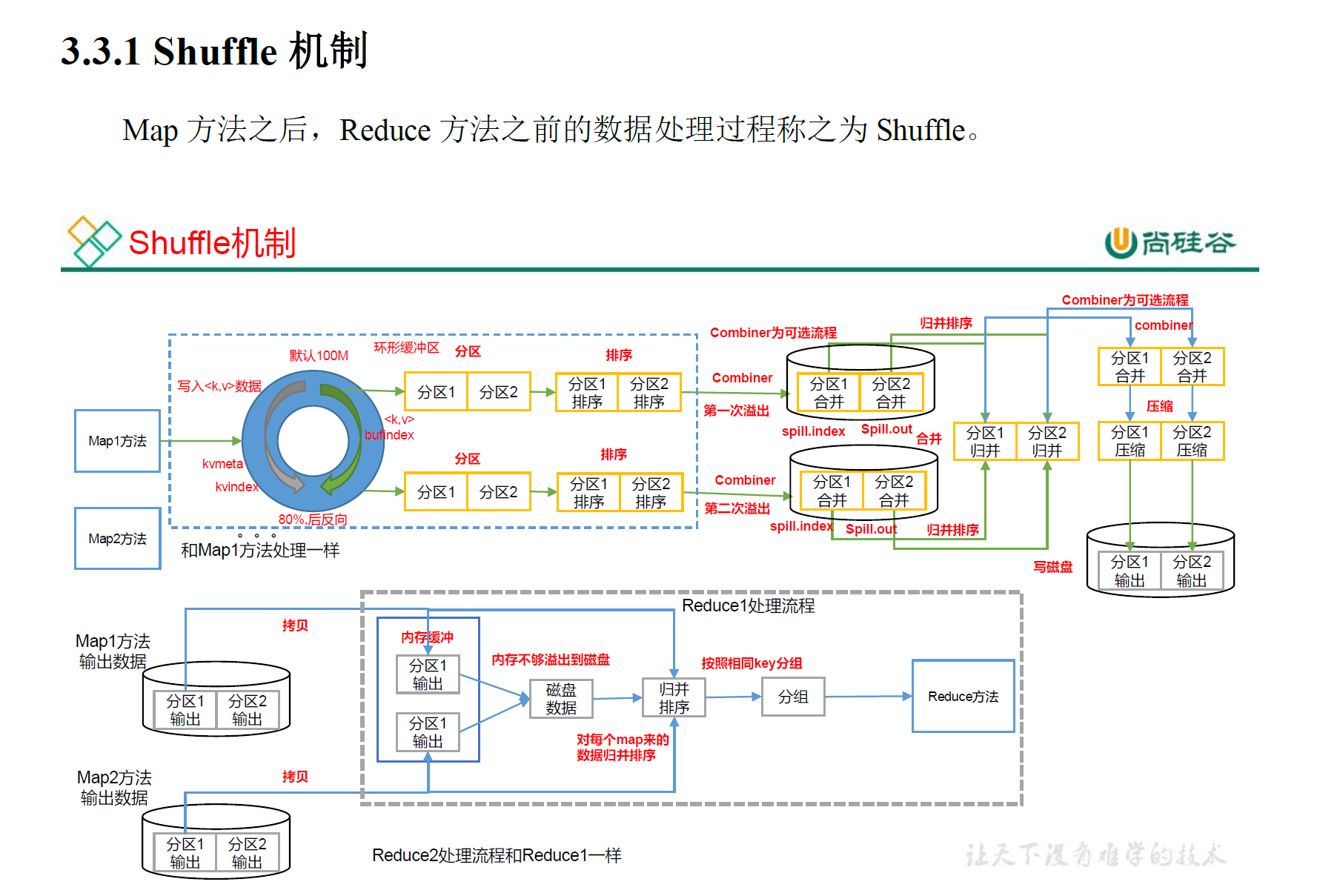
- shuffle过程
![]()
![]()
patitopn阶段为什么在shuffle,因为reduce取数据的过程在shuffle
![]()
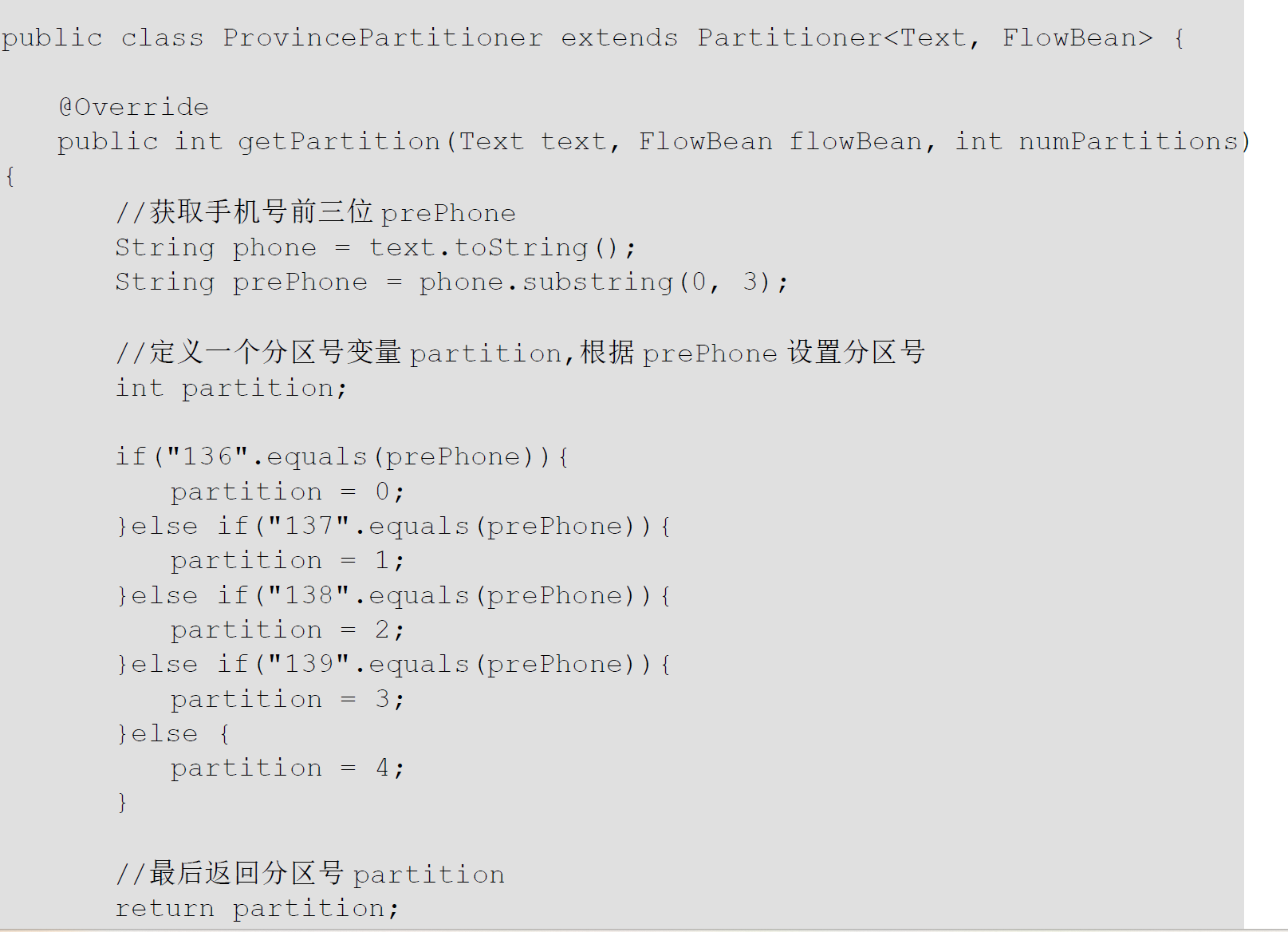
- 分区
![]()
![]()
![]()
- 排序
![]()
![]()
![]()
- maptask 各个阶段详情
- 读入 默认是textinputformat 根据切片策略读入
- map阶段,一个个key键值对
- Collection阶段 输出到缓冲区
- 溢出 分区排序
- 合并 合并成最终一个大文件
![]()
![]()
![]()
![]()
- reducetask
- 拷贝 将数据远程拷贝进不同的reduce分区里
- reduce排序
- 合并输出 由于已经在maptask部分排序过了,只需再排序一次
![]()
- 这是recude join过程
![]()
![]()
![]()





















 浙公网安备 33010602011771号
浙公网安备 33010602011771号