

Spark1
- 安装部署
1,下载spark,上传到/export/software/spark-3.2.3-bin-hadoop3.2-scala2.13.tgz 2,解压缩tar -zxvf spark-3.2.3-bin-hadoop3.2-scala2.13.tgz -C /export/server 3,cd /export/server,修改目录名称 mv spark-3.2.3-bin-hadoop3.2-scala2.13/ spark 4,修改配置文件,cd /export/server/spark/conf, cp spark-env.sh.template spark-env.sh vim spark-env.sh 在该文件后面添加: #配置java环境变量 export JAVA_HOME=/export/server/jdk1.8.0_241 #指定master的ip export SPARK_MASTER_HOST=node1 #指定master的端口 export SPARK_MASTER_PORT=7077 5,复制 workers cp workers.template workers 编辑workers,添加从节点ip node2 node3 6,分发spark文件到其他节点 scp -r /export/server/spark node2:/export/server scp -r /export/server/spark node3:/export/server 7,启动spark集群 先启动hadoop,start-all.sh 再启动spark,sbin/start-all.sh ---------------------------------------- Spark HA集群部署(先要安装zookeeper) 1,修改spark-env.sh export JAVA_HOME=/export/server/jdk1.8.0_241 #export SPARK_MASTER_HOST=node1 export SPARK_MASTER_PORT=7077 SPARK_MASTER_WEBUI_PORT=8989 export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node1:2181,node2:2181,node3:2181 -Dspark.deploy.zookeeper.dir=/spark" 分发spark-env.sh 进入spark/conf文件夹 scp spark-env.sh node02:/export/server/spark/conf scp spark-env.sh node03:/export/server/spark/conf 2,先启动hadoop,依次启动zookeeper zkServer.sh start 3,在node1上启动spark集群 sbin/start-all.sh 4,在node2上单独启动master节点 sbin/start-master.sh 5,在node01上关闭master进程 sbin/stop-master.sh 查看: http://node1:8989,http://node2:8989
启动spark为了与Hadoop区分在sbin目录下的脚本启动 要启动需要进去spark文件夹,否则会找不到目录 localhost是本机IP地址
- 出现单点故障怎么办zookepper
![]()
选举 黑帮教父
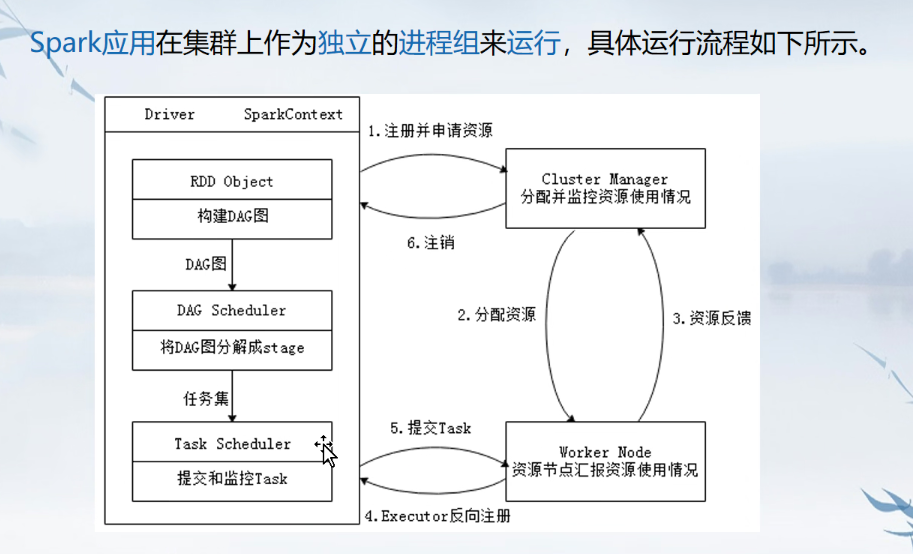
- spark运行架构和原理
![]()
![]()
实训是一个job,每天都有task,一周一个stage
- 运行基本流程
![]()
由驱动器构建上下文,将项目划分为一个一个任务交给workernode
- 简述
![]()
管理界面访问node1:8080
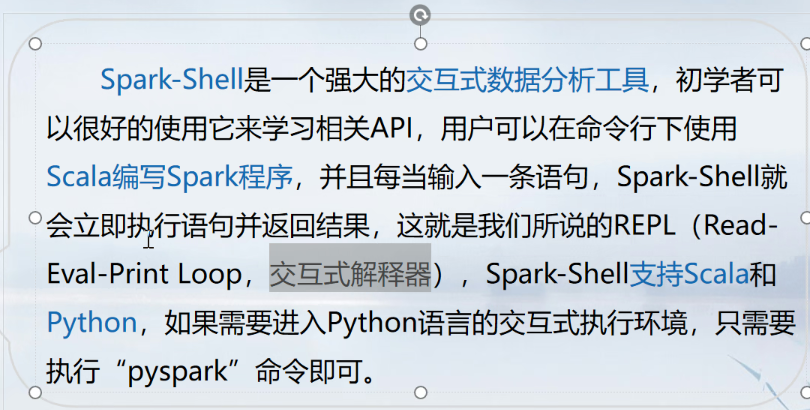
- 交互式解释器 shell命令
![]()
![]()
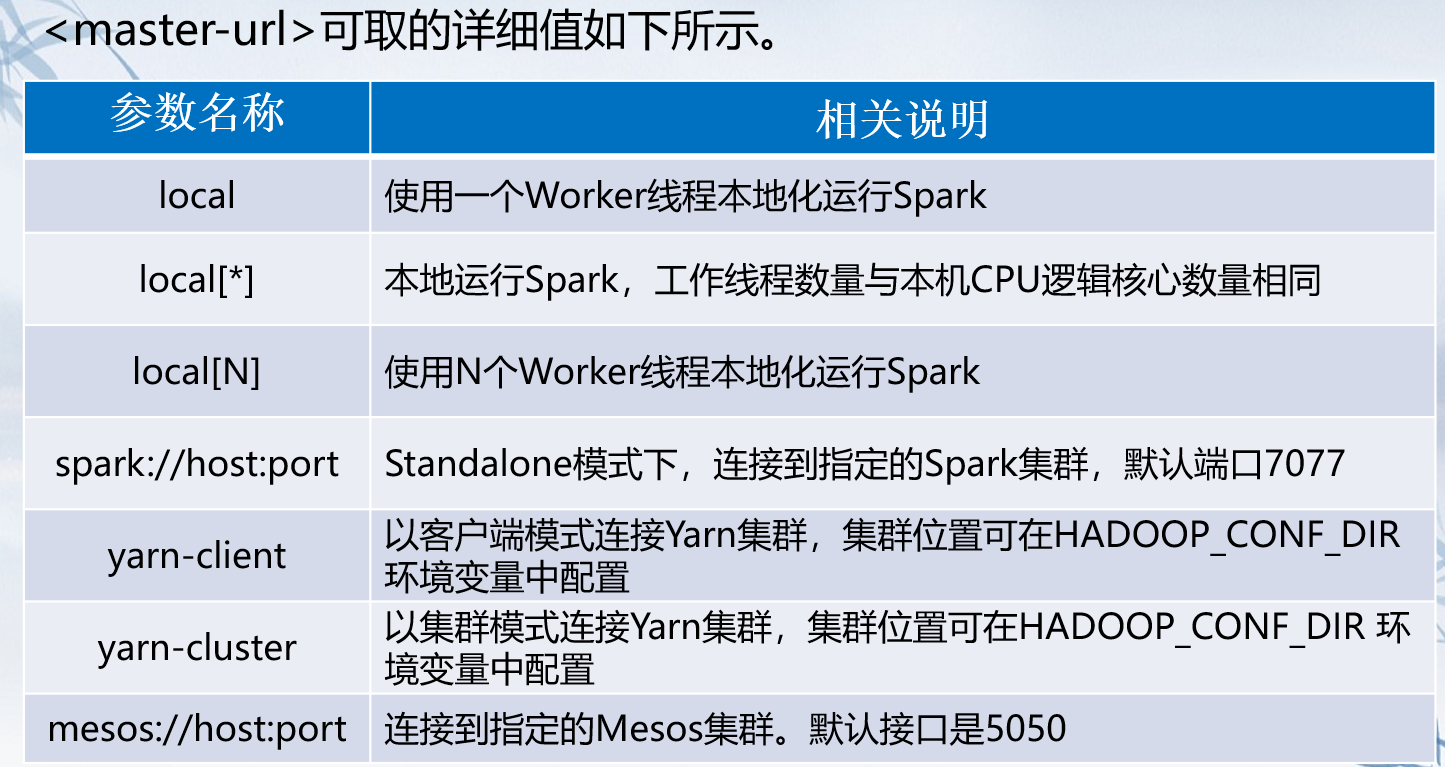
运行模式目前有两种,一种是local 后面参数是工作线程数 一种是单例模式
![]()
- Linux快速移动·光标到行首Ctrl A 移动到行莫Ctrl E 你不同于vim编辑器home end
scala> sc.textFile("file:///node1/usr/1.test").fat 不用加节点名默认是本地文件
- 记录踩大坑
![]()
![]()
jdk版本过高 改成1,。8即可 如果下载了新的jdk其实什么都没有需要按照提示重新下载
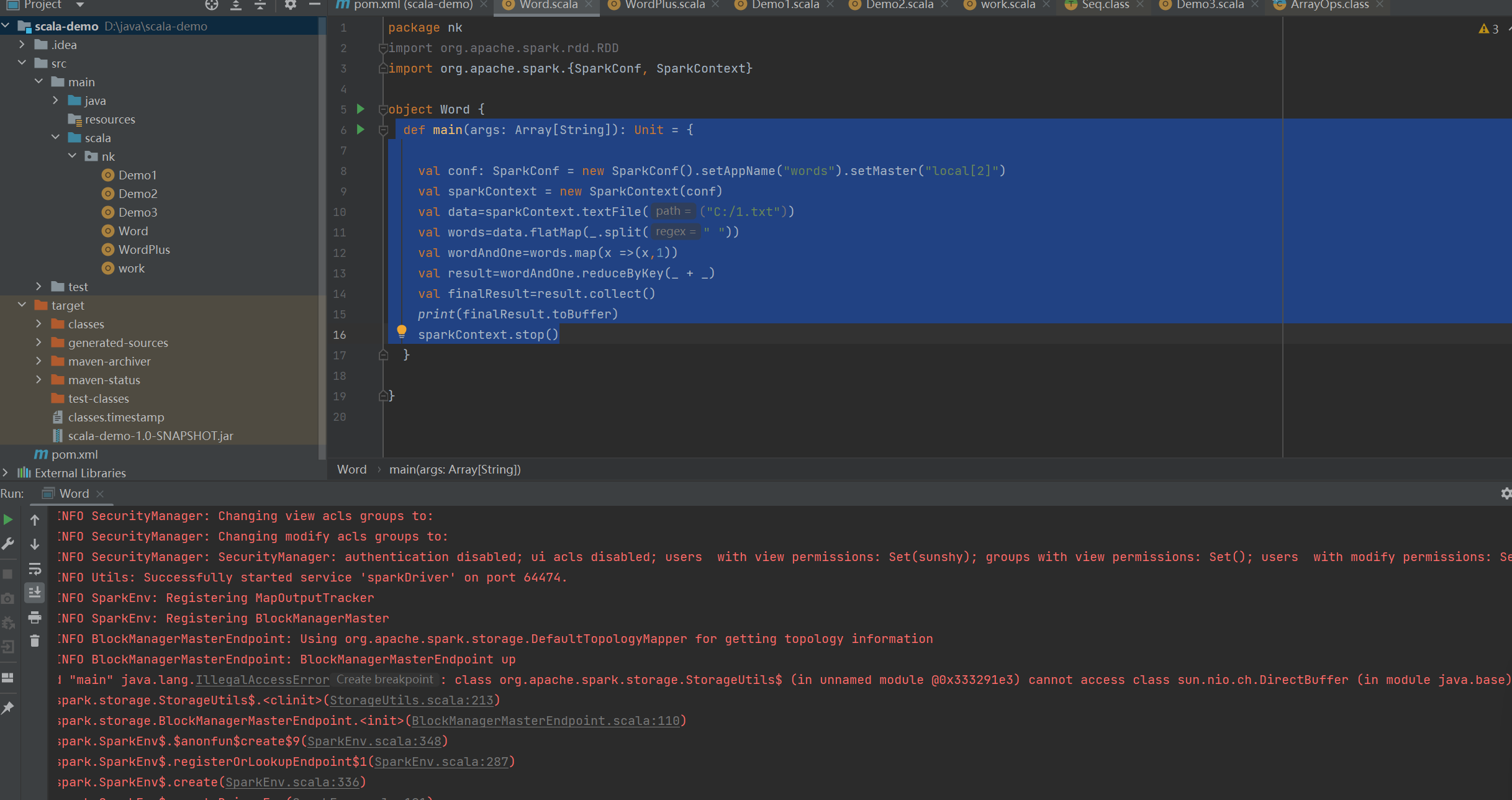
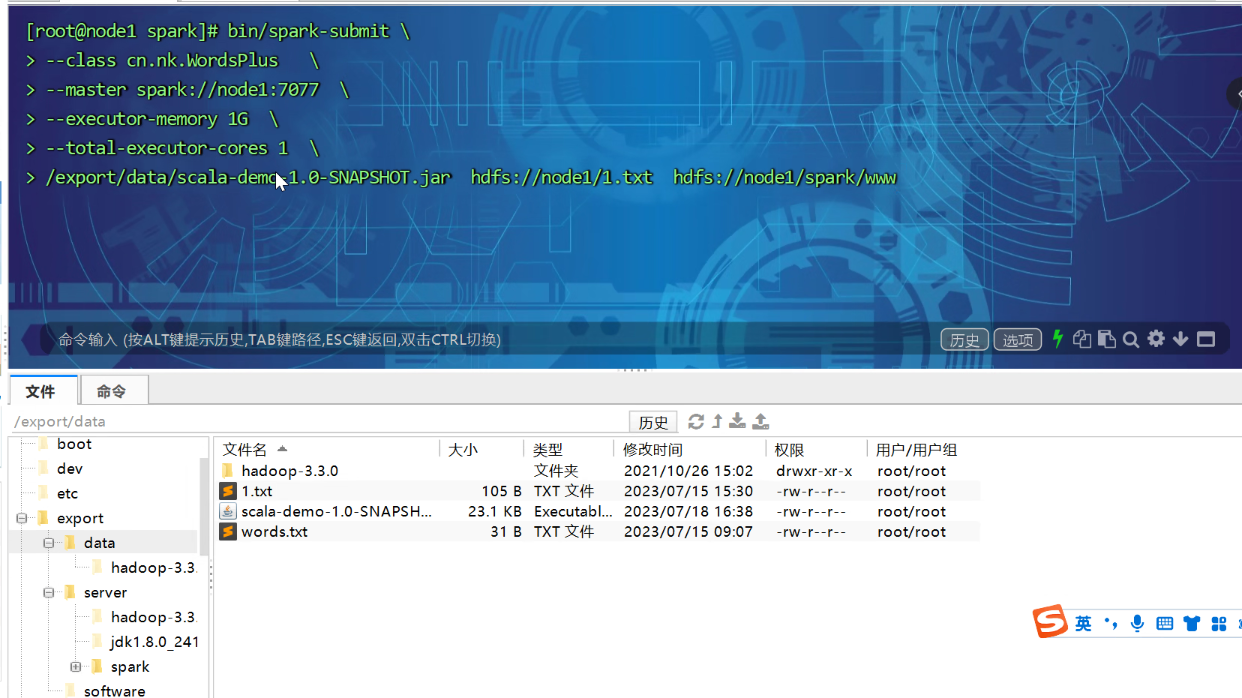
- 打包上传
![]()
后面两个参数十分关键 倒数第二个是要处理的HDFS文件,倒数第一是要输出的文件目录 该目录必须是完成时新建的 这个参数就是arg0 1
- 几个需要注意的点
bin/spark-submit \ --class nk.WordPlus \ --master spark://node1:7077 \ --executor-memory 1G \ --total-executor-cores 1 \ /export/data/words-1.0-SNAPSHOT.jar hdfs://node1/input/1.txt hdfs://node1/worlf/www
一个jar包中大多数情况下不止一个Scala伴生对象 这是用全限定类名就可以了区分 jar包要上传到Linux环境中







 浙公网安备 33010602011771号
浙公网安备 33010602011771号