私有化部署大模型并使用FastApi暴露访问接口(glm4-9b-chat)
流程
glm4-9b-chat模型部署
了解模型说明
再部署任何模型之前,我们都可以去官网或者github上或者modelscope了解模型的详细信息,例如glm-4-9b-chat的详细说明:

最低硬件要求:如果希望运行官方提供的最基础代码 (transformers 后端) 您需要:
-
Python >= 3.10
-
显存不少于 32 GB
如果希望运行官方提供的本文件夹的所有代码,还需要:
-
Linux 操作系统 (Debian 系列最佳)
-
大于 8GB 显存的,支持 CUDA 或者 ROCM 并且支持
BF16推理的 GPU 设备。(FP16精度无法训练,推理有小概率出现问题)
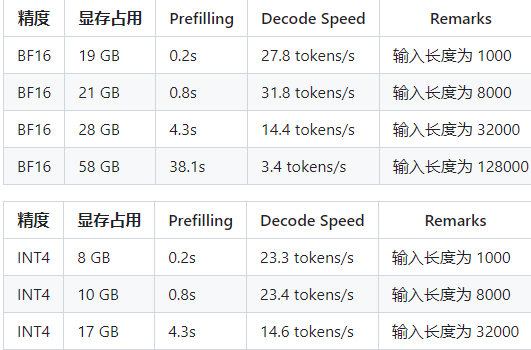
如果具备符合上述要求的本地硬件资源,可以尝试进行私有化部署glm4-9b-chat进行测试,这里,我们以一张 4 * 3090 显卡的本地服务器配置进行部署演示。
-
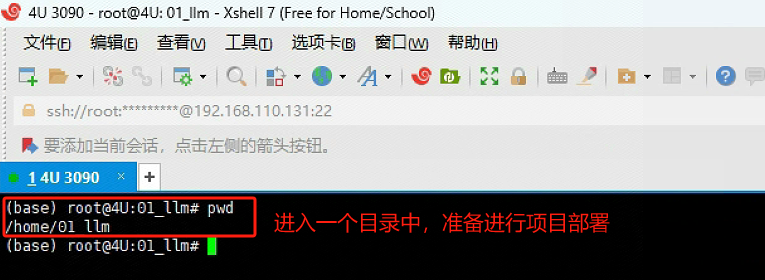
Step 1. 使用 Xshell 远程连接 服务器
-
Step 2. 下载GLM 4 的官方GitHub项目文件
首先进入GLM 4 官方GitHub地址:https://github.com/THUDM/GLM-4/tree/main , 找到远程仓库的链接:
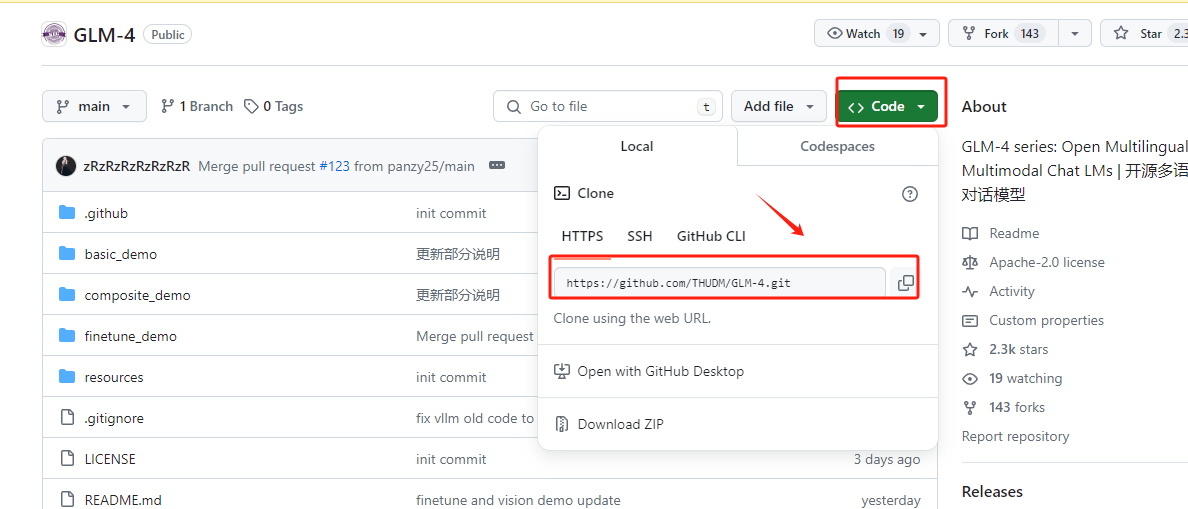
在Xshell中执行如下代码:
git clone https://github.com/THUDM/GLM-4.git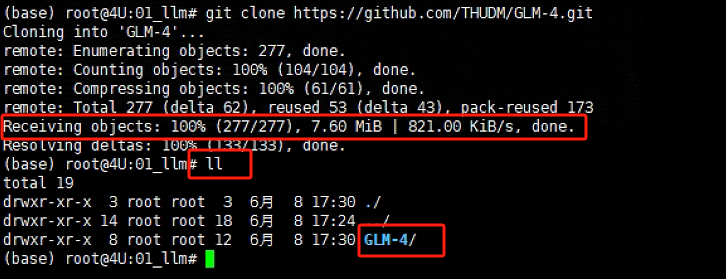
如果全部文件显示100%下载,且在当前路径下生成一个 GLM-4文件夹,说明项目文件已经下载成功。
-
Step 3. 安装独立的虚拟环境
Conda创建虚拟环境的意义在于提供了一个隔离的、独立的环境,用于Python项目和其依赖包的管理。每个虚拟环境都有自己的Python运行时和一组库。这意味着我们可以在不同的环境中安装不同版本的库而互不影响。例如,可以在一个环境中使用Python 3.8,而在另一个环境中使用Python 3.9。对于大模型来说,建议Python版本3.10以上。创建的方式也比较简单,使用以下命令创建一个新的虚拟环境:
# myenv 是你想要给环境的名称,python=3.8 指定了要安装的Python版本。你可以根据需要选择不同的名称和/或Python版本。
conda create --name glm4 python=3.11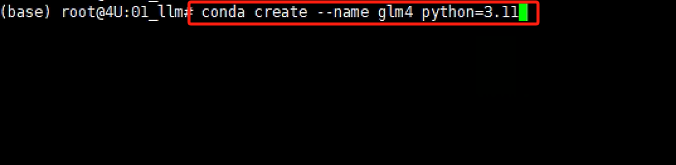
创建完独立的虚拟环境后,需要进入该虚拟环境进行后续的操作。使用以下命令进入glm 4 的Python 虚拟环境:
conda activate glm4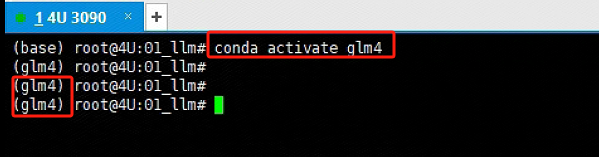
-
Step 5. 安装GLM 4 项目依赖
进入GLM 4文件夹后,执行如下命令一次性安装全部依赖。执行命令如下:
# 进入指定路径
cd GLM-4/basic_demo
# 执行如下命令安装依赖
pip install -r requirements.txt
-
Step 5. 下载glm 4-9b-chat的模型权重
国内用户建议使用ModelScope下载地址 , 国外用户建议使用 huggingface下载地址 。
在远程服务器终端,先安装 modelscope 第三方依赖包,执行代码:
pip install modelscope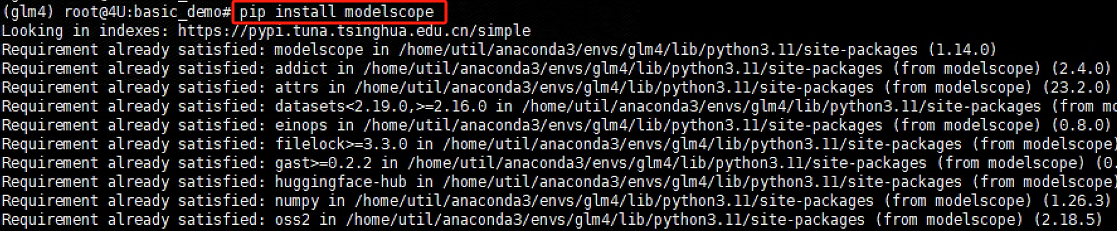

然后新建一个.py文件,执行命令如下:
vim download_models.py
写入如下代码:
# 文件中的内容如下:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# 先安装 pip install modelscope
from modelscope.hub.snapshot_download import snapshot_download
snapshot_download('ZhipuAI/glm-4-9b-chat', cache_dir='./', revision='master')写入 download_models.py 文件后,保存退出,输入如下代码执行.py文件,等待glm-4-9b-chat模型下载完成即可。
python download_models.py
待下载完成后,会在当前路径下生成一个ZhipuAI的文件夹,里面会存储着glm4-9b-chat的全部模型权重文件:
cd ZhipuAI
cd glm-4-9b-chat/ && ll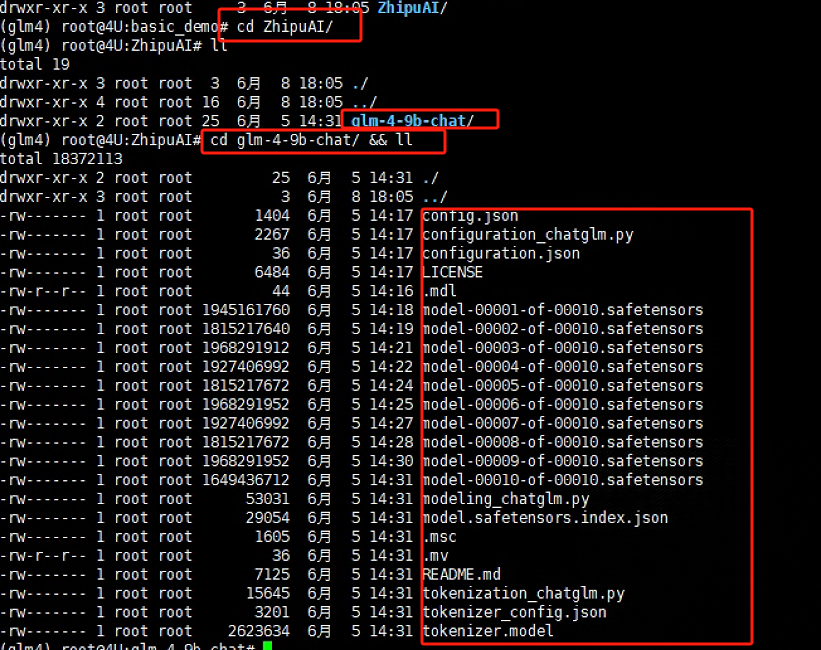
-
Step 6. 启动模型服务
大模型的官方GitHub项目一般都会提供多种与大模型的交互形式,最常用的就是 基于命令行的交互对话、基于Gradio/Streamlit构建的WebUI交互页面,以及最普遍使用的基于OpenAI API的API接口规范。
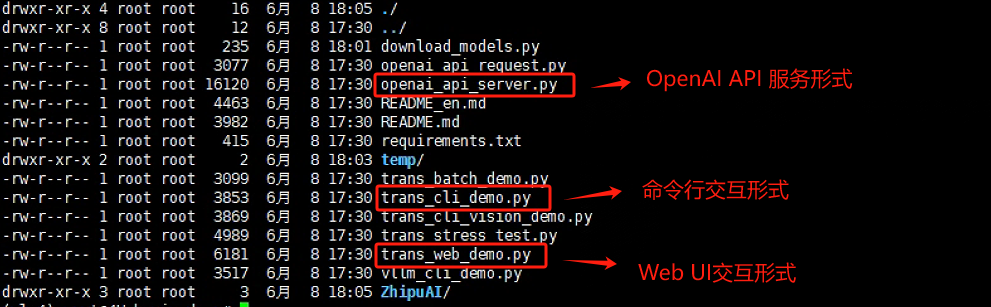
而不论哪种形式,其需要我们修改的内容并不多,主要基于以下两点对官方提供的源代码脚本进行更改:
-
大模型的加载路径
-
服务启动的默认参数
我们以OpenAI API Server 为例。首先将模型的加载路径替换为本地的实际存储路径:
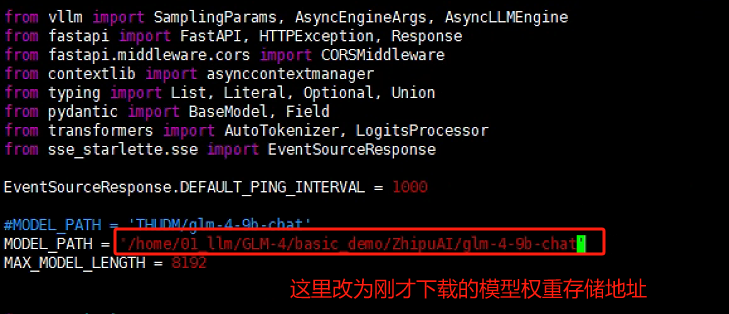
然后根据自己服务器的实际情况,灵活调整启动服务的参数:(在代码文件的最后面)
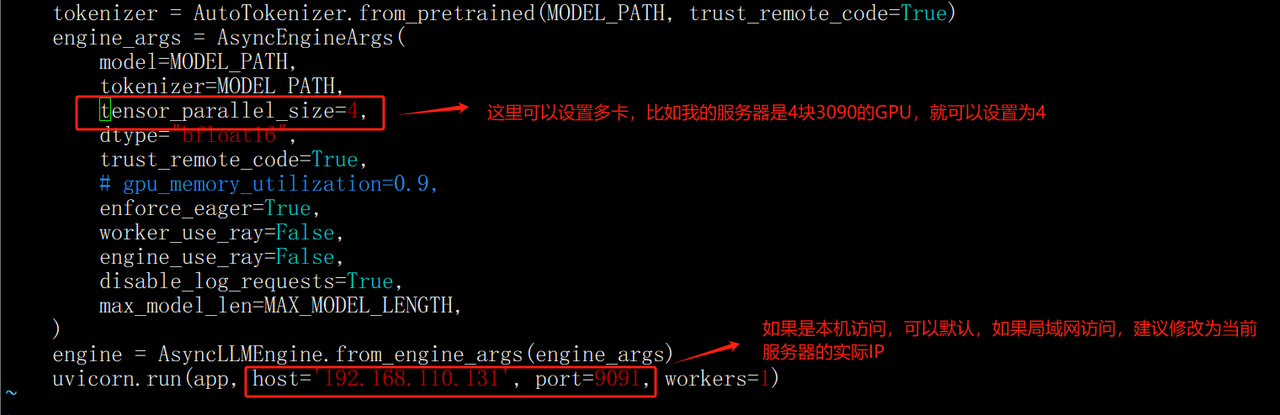
保存配置修改后,执行如下代码:
python openai_api_server.py如果启动成功,会出现如下图所示内容:
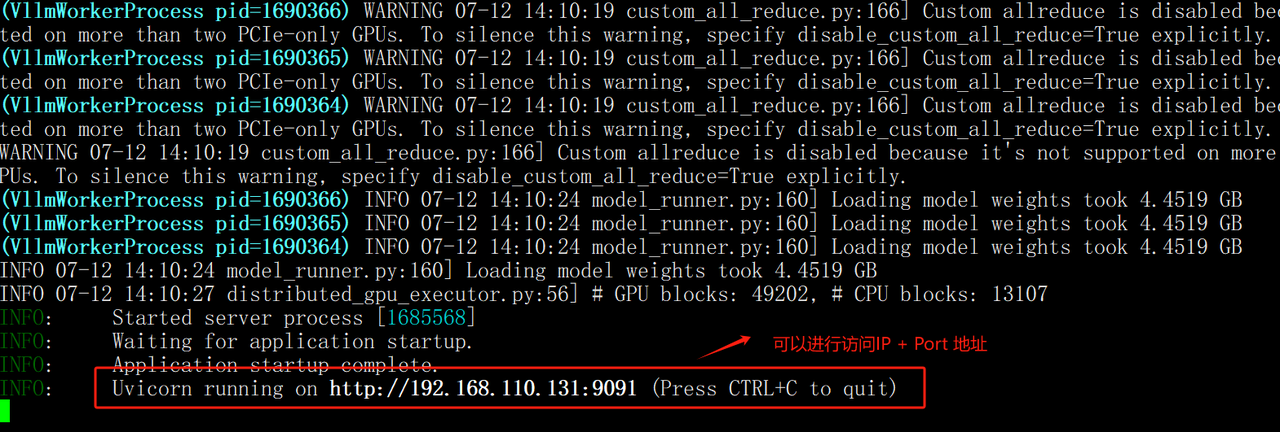
在四卡3090的服务器上显存占用情况如下:

glm4-9b-chat模型调用
当启动了glm4-9b模型服务以后,如果我们想在代码程序中调用,就要分两种情况:
1.如果Python调用环境与部署glm4-9b-chat模型的环境为同一台服务器
2.如果调用环境和部署环境不是同一台机器
无论是那种情况都需要对Jupyter进行环境注册和配置,参照:《配置大模型开发环境(Jupyter Lab)》
配置好环境之后,就可以直接进行调用测试,比如:我们可以使用Jupyter Lab 或者 Pycharm进行测试,核心代码如下:
from openai import OpenAI
base_url = "http://192.168.110.131:8000/v1/"
client = OpenAI(api_key="EMPTY", base_url=base_url)
messages = [{"role": "user", "content": "你好,请你介绍一下你自己"}]
response = client.chat.completions.create(
model="glm-4",
messages=messages,
)
print(response.choices[0].message.content)responseChatCompletion(id='', choices=[Choice(finish_reason='stop', index=0, logprobs=None, message=ChatCompletionMessage(content='你好!我是一个基于人工智能技术的智能助手。我的任务是提供信息、解答问题以及帮助用户解决问题。我可以通过分析大量的数据来理解用户的提问,并给出合适的回答或建议。无论是日常生活咨询、科技知识讲解还是其他各类问题,我都会尽力为您服务。请问有什么可以帮助您的吗?', role='assistant', function_call=None, tool_calls=None))], created=1717844915, model='glm-4', object='chat.completion', system_fingerprint=None, usage=CompletionUsage(completion_tokens=63, prompt_tokens=12, total_tokens=75))print(response.choices[0].message.content)你好!我是一个基于人工智能技术的智能助手。我的任务是提供信息、解答问题以及帮助用户解决问题。我可以通过分析大量的数据来理解用户的提问,并给出合适的回答或建议。无论是日常生活咨询、科技知识讲解还是其他各类问题,我都会尽力为您服务。请问有什么可以帮助您的吗?messages = [
{"role": "system", "content": "你是一位说话风格非常风趣幽默的人"},
{"role": "user", "content": "你好,请你介绍一下你自己"}
]response = client.chat.completions.create(
model="glm-4",
messages=messages,
)print(response.choices[0].message.content)哎呀呀,听你这话说得,我这人就像是个行走的喜剧片,自带笑点呢!我是个虚拟的人工智能助手,虽然不是真人,但我的存在就是为了给生活加点料。我懂笑话、会调侃,还能帮你解答各种问题,从宇宙的奥秘到日常琐事,无所不知,无所不谈。你说什么我都乐意接招,有时候可能还会来点即兴表演,让你忍俊不禁哦!怎么样,是不是觉得和我聊天比看喜剧还过瘾?😄🎭💬流式输出调用
def simple_chat(use_stream=False):
messages = [
{
"role": "system",
"content": "你是 GLM-4,请你热情回答用户的问题。",
},
{
"role": "user",
"content": "你好,请你用生动的话语给我讲一个小故事吧"
}
]
response = client.chat.completions.create(
model="glm-4",
messages=messages,
stream=use_stream,
max_tokens=1024,
temperature=0.8,
presence_penalty=1.1,
top_p=0.8)
if response:
if use_stream:
for chunk in response:
print(chunk.choices[0].delta.content)
else:
content = response.choices[0].message.content
print(content)
else:
print("Error:", response.status_code)
if __name__ == "__main__":
simple_chat(use_stream=True)当然可以!让我们一起踏上一次奇幻的冒险之旅。
在一个遥远的神秘森林里,有一座古老的神庙,传说中这里藏有世间最神秘的宝藏。这座神庙位于一片幽静的湖泊中心,四周环绕着参天古树和五颜六色的花朵。湖面波光粼粼,微风拂过时,泛起层层涟漪。
有一天,一个名叫小智的小男孩听说了这个传说,他一心想要找到这座神庙,揭开宝藏的秘密。于是,他决定踏上一段充满未知与惊喜的探险之旅。
为了到达目的地,小智历经千辛万苦。他跋山涉水,穿过了蜿蜒的山路,攀爬了险峻的高峰。在旅途中,他还结识了一只聪明可爱的小松鼠——多多。它成了小智的好帮手,不仅给他带来了许多欢乐,还帮助他在关键时刻化险为夷。
一天晚上,他们在一家破旧的小客栈歇脚。店主告诉他们,要想通过最后一道难关,必须解开一道谜题。这道谜题是关于一座隐藏在水下的宫殿,而要进入宫殿,需要三个关键的钥匙。这三个钥匙分别对应三种奇特的植物:千年灵芝、万年雪莲和月影花。
第二天一早,小智和多多带着地图,开始了寻找钥匙的任务。他们翻越崇山峻岭,穿越茂密丛林,终于在一片开阔地找到了那三株神奇的植物。
拿到钥匙后,他们迫不及待地来到水面,发现了一座通往水下宫殿的石桥。然而,石桥上布满了机关陷阱,稍有不慎就会落入深渊。
在这关键的时刻,多多展现出了它的智慧。它巧妙地利用自己的尾巴,吸引了敌人的注意,让小智得以顺利通过石桥。最终,他们来到了传说中的水下宫殿。
宫殿内金碧辉煌,琳琅满目的珍宝让人眼花缭乱。正当小智准备拿走宝藏时,一位美丽的女神出现了。她告诉小智,这些宝藏并非真正的财富,而是智慧和勇气的象征。只有拥有这两样东西的人,才能真正获得幸福。
听完女神的话,小智明白了人生的真谛。他将宝藏留在了宫殿,带着收获满满的感悟回到了家乡。从此,他努力学习和锻炼自己,成为了一名勇敢善良的人。
这个故事告诉我们,人生中的真正财富并不是金银财宝,而是知识和勇气。只要我们勇敢地去追求梦想,不断学习成长,就能找到属于自己的宝藏。Transformer库直接加载
import torch
from modelscope import AutoModelForCausalLM, AutoTokenizer
device = "cuda"
#这里填写本地模型路径
tokenizer = AutoTokenizer.from_pretrained("/home/01_llm/GLM-4/basic_demo/ZhipuAI/glm-4-9b-chat",trust_remote_code=True)
query = "你好"
inputs = tokenizer.apply_chat_template([{"role": "user", "content": query}],
add_generation_prompt=True,
tokenize=True,
return_tensors="pt",
return_dict=True
)
inputs = inputs.to(device)
model = AutoModelForCausalLM.from_pretrained(
"/home/01_llm/GLM-4/basic_demo/ZhipuAI/glm-4-9b-chat",
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
trust_remote_code=True
).to(device).eval()
gen_kwargs = {"max_length": 2500, "do_sample": True, "top_k": 1}
with torch.no_grad():
outputs = model.generate(**inputs, **gen_kwargs)
outputs = outputs[:, inputs['input_ids'].shape[1]:]
print(tokenizer.decode(outputs[0], skip_special_tokens=True))2024-06-08 19:18:24,797 - modelscope - INFO - PyTorch version 2.3.0 Found.
2024-06-08 19:18:24,803 - modelscope - INFO - Loading ast index from /root/.cache/modelscope/ast_indexer
2024-06-08 19:18:24,862 - modelscope - INFO - Loading done! Current index file version is 1.14.0, with md5 d5459e508855650d79101993a03a684e and a total number of 976 components indexed
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.Loading checkpoint shards: 0%| | 0/10 [00:00<?, ?it/s]你好👋!很高兴见到你,有什么可以帮助你的吗?通过FastApi封装成对外API接口
项目结构:
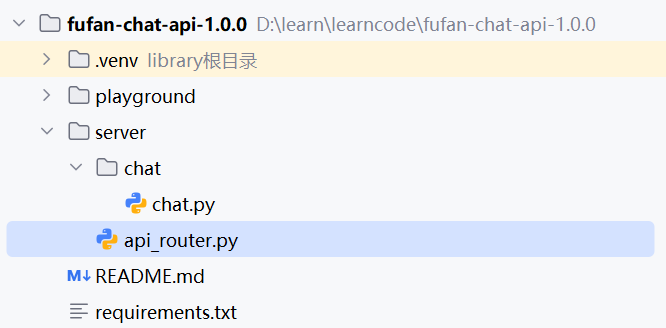
项目依赖文件
requirements.txt:
# fastapi依赖
executing==2.0.1
asttokens==2.4.1
six==1.16.0
blinker>=1.6.2
fastapi==0.111.0
# langchain依赖
langchain==0.2.7
langchain_community==0.2.7
loguru==0.7.2
zhipuai==2.1.2安装所有依赖:
pip install -r requirement.txt封装调用大模型api逻辑
chat.py:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
from fastapi import Body, HTTPException
from typing import List, Union, Optional
# 使用LangChain调用ChatGLM3-6B的依赖包
from langchain.chains.llm import LLMChain
from langchain_community.llms.chatglm3 import ChatGLM3
from langchain_core.messages import AIMessage
from langchain_core.prompts import PromptTemplate
# 日志包
from loguru import logger
def chat(query: str = Body("", description="用户的输入"),
# model_name: str = Body("chatglm3-6b", description="基座模型的名称"),
model_name: str = Body("glm4-9b-chat", description="基座模型的名称"),
temperature: float = Body(0.8, description="大模型参数:采样温度", ge=0.0, le=2.0),
max_tokens: Optional[int] = Body(None, description="大模型参数:最大输入Token限制"),
):
"""
:param query: 用户输入的问题
:param model_name: 使用哪个大模型作为后端服务
:param temperature: 采样温度
:param max_tokens: 最大输入Token限制
:return: 大模型的回复结果
"""
logger.info("Received query: {}", query)
logger.info("Model name: {}", model_name)
logger.info("Temperature: {}", temperature)
logger.info("Max tokens: {}", max_tokens)
# 使用LangChain调用glm4-9b-chat 或者 ChatGLM3-6B服务
try:
# 使用LangChain调用ChatGLM3-6B服务
template = """{query}"""
prompt = PromptTemplate.from_template(template)
endpoint_url = "http://192.168.110.131:9091/v1/chat/completions"
llm = ChatGLM3(
endpoint_url=endpoint_url,
model_name=model_name,
temperature=temperature,
max_tokens=max_tokens,
)
llm_chain = prompt | llm
response = llm_chain.invoke(query)
if response is None:
raise ValueError("Received null response from LLM")
return {"LLM Response": response}
except ValueError as ve:
# 捕获值错误并返回400响应
raise HTTPException(status_code=400, detail=str(ve))
except Exception as e:
# 捕获所有其他异常并返回500响应
raise HTTPException(status_code=500, detail="Internal Server Error: " + str(e))启动FastApi服务
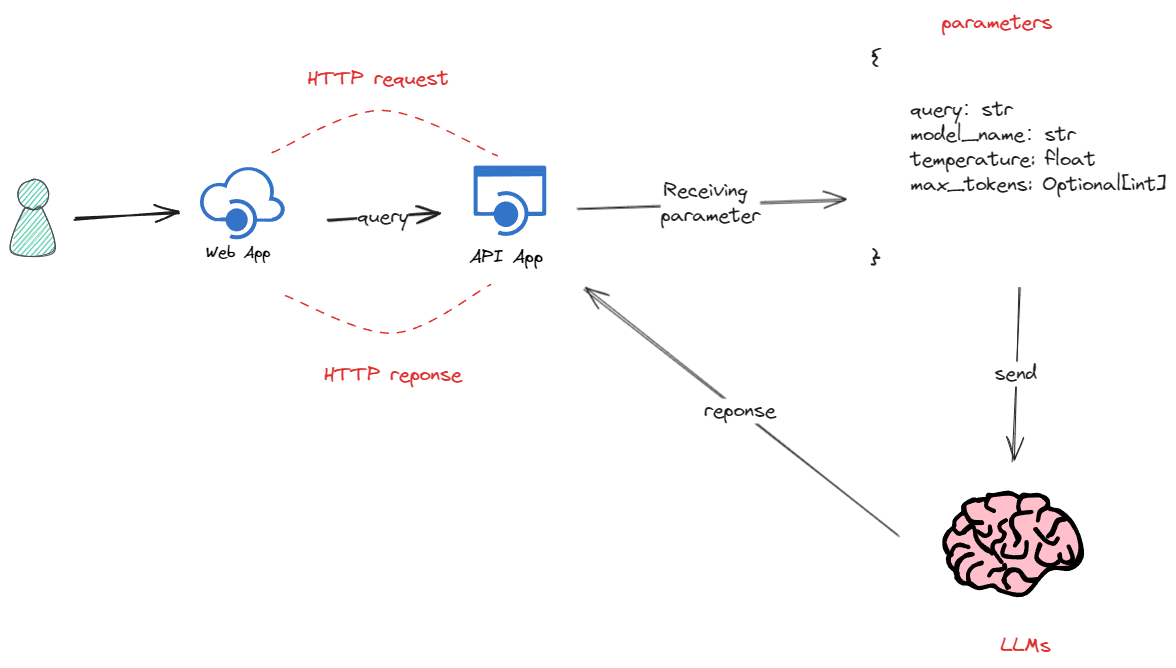
api_router.py
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# FastAPI教程地址:https://fastapi.tiangolo.com/tutorial/first-steps/
from fastapi import FastAPI
from chat.chat import chat
import uvicorn
app = FastAPI(
description="FuFan Chat Web API Server"
)
# 使用路由函数的方式定义,在动态添加路由或在运行时修改路由配置时更为灵活。
app.post("/api/chat",
tags=["Chat"],
summary="大模型对话交互接口",
)(chat)
if __name__ == '__main__':
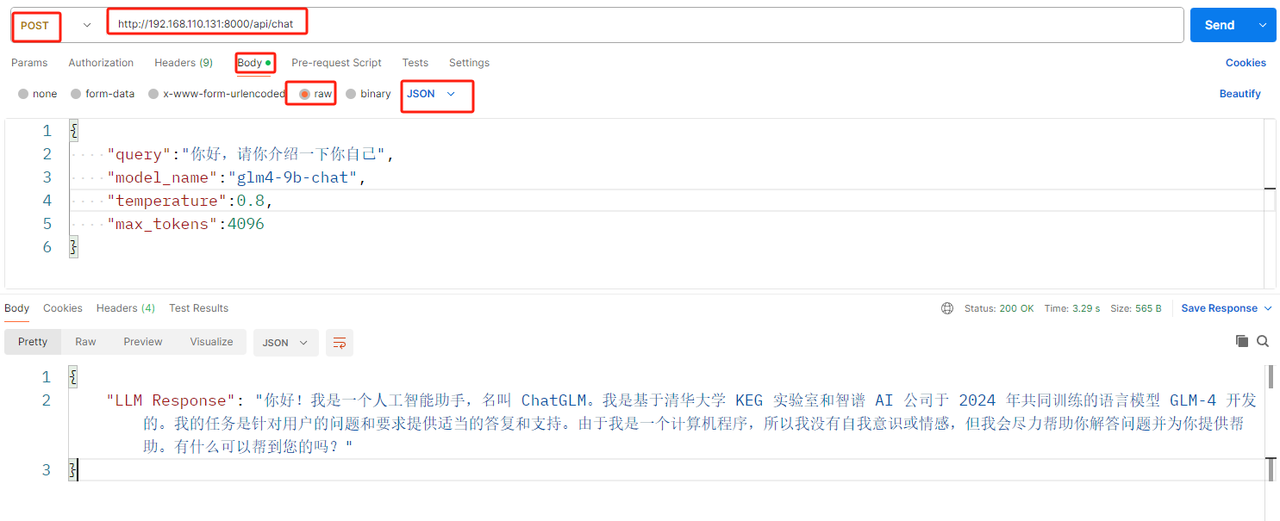
uvicorn.run(app, host='192.168.110.131', port=8000)postman调用接口测试
测试数据:
# http://192.168.110.131:8000/api/chat
{
"query":"你好,请你介绍一下你自己",
"model_name":"glm4-9b-chat", # 或者 chatglm3-6b
"temperature":0.8,
"max_tokens":4096
}
如果报错:
File "/home/util/anaconda3/envs/fufan-chat-api/lib/python3.11/site-packages/charset_normalizer/api.py", line 10, in <module>
from charset_normalizer.md import mess_ratio
AttributeError: partially initialized module 'charset_normalizer' has no attribute 'md__mypyc' (most likely due to a circular import)
## 解决办法
pip install --force-reinstall charset-normalizer==3.1.0


 浙公网安备 33010602011771号
浙公网安备 33010602011771号