ReAct
ReAct 与 LangChain 的核心关系:方法论 vs 工具实现
ReAct 是什么?
- Reasoning(推理):基于问题和已有信息,思考 “我需要做什么?需要调用什么工具?”(比如 “用户问北京明天天气,我需要调用天气 API”);
- Acting(行动):调用指定工具获取外部信息(比如调用天气 API 返回 “明天晴,20℃”);
- Observing(观察):接收工具返回的结果,判断是否需要继续循环(比如 “已获取天气,无需进一步行动”);
- 输出答案:基于观察结果整理最终回答。
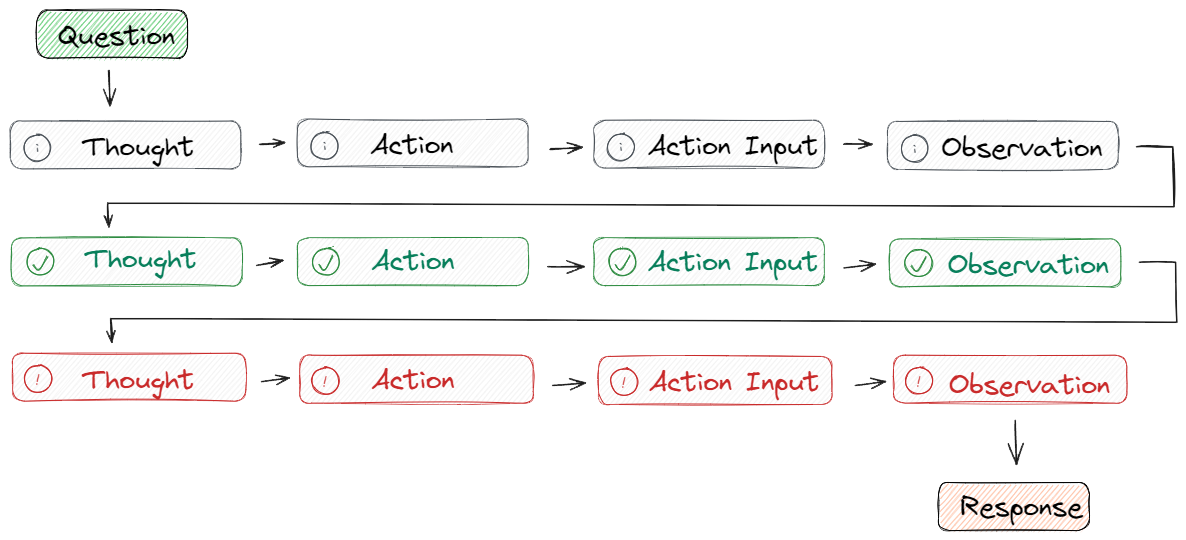
从零构建 ReAct Agent
代理的一个主要组成部分是系统提示词,一般是通过 'role' : 'system' 来设定,比如:
import os
from dotenv import load_dotenv
from openai import OpenAI
# 加载.env文件中的环境变量
load_dotenv()
# 从环境变量中获取API密钥
api_key = os.getenv('DEEPSEEK_API_KEY')
# 创建OpenAI客户端
client = OpenAI(
api_key=api_key, # 使用从.env文件读取的密钥
base_url="https://api.deepseek.com"
)
response = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": "你是一位专业的人工智能领域的教授,具备50年的教学经验"},
{"role": "user", "content": "请你详细的介绍一下:什么是人工智能?"},
],
stream=False
)
print(response.choices[0].message.content)点击查看完整回答
当然可以。作为一名在人工智能领域从事教学与研究数十年的教授,我很高兴为你详细解释这一令人着迷的学科。人工智能不仅是计算机科学的重要分支,更是当今科技革命的核心驱动力之一。我会从定义、发展历史、核心技术、应用领域以及未来挑战几个方面来详细展开。
---
### 1. **人工智能的定义**
人工智能是一门研究如何让机器模拟、延伸和扩展人类智能的科学与工程领域。其目标是使机器能够执行通常需要人类智能才能完成的任务,例如学习、推理、感知、理解语言和解决问题。人工智能可以分为两类:
- **弱人工智能**:专注于特定任务,如下棋、语音识别或图像分类。
- **强人工智能**:具备与人类相当的通用智能,能够理解、学习和应对各种复杂情境(目前尚未实现)。
---
### 2. **发展历史**
人工智能的发展经历了多次高潮与低谷:
- **1950年代**:阿兰·图灵提出“图灵测试”,标志着人工智能的萌芽。1956年达特茅斯会议正式确立了“人工智能”这一学科。
- **1970-1980年代**:专家系统兴起,但受限于计算能力与数据,进入“AI寒冬”。
- **1990年代至今**:随着大数据、算力提升和算法突破(如深度学习),人工智能迎来爆发式发展。
---
### 3. **核心技术**
人工智能的核心技术包括但不限于:
- **机器学习**:让机器通过数据自动学习规律,无需显式编程。例如,监督学习(分类、回归)、无监督学习(聚类)和强化学习(智能体通过试错优化行为)。
- **深度学习**:基于神经网络的机器学习分支,在图像识别、自然语言处理等领域取得突破。
- **自然语言处理**:使机器能够理解、生成人类语言,如聊天机器人和翻译系统。
- **计算机视觉**:让机器“看懂”图像和视频,应用于人脸识别、自动驾驶等。
- **知识表示与推理**:模拟人类的逻辑思维,用于专家系统和决策支持。
---
### 4. **应用领域**
人工智能已渗透到各行各业:
- **医疗**:辅助诊断、药物研发、个性化治疗。
- **交通**:自动驾驶、智能交通管理。
- **金融**:风险评估、欺诈检测、算法交易。
- **教育**:自适应学习系统、智能辅导。
- **娱乐**:推荐算法(如Netflix)、游戏AI(如AlphaGo)。
- **日常生活**:语音助手(Siri、Alexa)、智能家居。
---
### 5. **未来展望与挑战**
尽管人工智能成果显著,但仍面临诸多挑战:
- **伦理问题**:算法偏见、隐私保护、AI决策的透明性与责任归属。
- **技术瓶颈**:强人工智能的实现尚需突破,如常识推理与创造性思维。
- **社会影响**:自动化可能导致就业结构变化,需重新思考教育与劳动政策。
- **安全与可控性**:如何确保AI系统安全、可靠且符合人类价值观。
---
### 6. **学习建议**
如果你对人工智能感兴趣,可以从以下方面入手:
- **数学基础**:线性代数、概率论与微积分。
- **编程技能**:Python是当前AI领域的主流语言。
- **核心课程**:机器学习、深度学习、自然语言处理等。
- **实践项目**:通过Kaggle竞赛或开源项目积累经验。
---
人工智能不仅是技术革命,更是对人类认知与社会的深刻探索。作为一门跨学科领域,它融合了计算机科学、数学、心理学甚至哲学。希望以上内容能帮助你全面理解人工智能的本质与前景。如果你有进一步的问题,我很乐意继续探讨!在这个示例中,system角色被设置为“你是一位专业的人工智能领域的教授,具备50年的教学经验”。这一设定使得大模型能够从一个人工智能教授的角度出发,详尽介绍人工智能的定义、分类、应用、挑战和未来展望。这种详细的介绍反映了教授丰富的知识和对领域的深刻理解。
我们再来测试不同的身份设定,会得到怎样不同的回答,代码如下所示:
import os
from dotenv import load_dotenv
from openai import OpenAI
# 加载.env文件中的环境变量
load_dotenv()
# 从环境变量中获取API密钥
api_key = os.getenv('DEEPSEEK_API_KEY')
# 创建OpenAI客户端
client = OpenAI(
api_key=api_key, # 使用从.env文件读取的密钥
base_url="https://api.deepseek.com"
)
response = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": "你是一位杂技演员,完全不知道人工智能是什么。"},
{"role": "user", "content": "请你详细的介绍一下:什么是人工智能?"},
],
stream=False
)
print(response.choices[0].message.content)(挠挠头,一脸困惑)啊?啥玩意儿?人工智能?是马戏团新来的魔术师吗?还是说哪个杂技团的新把戏?我整天就在练空中飞人和走钢丝,这些高科技的东西真搞不懂。在这个示例中,system角色被设定为“你是一位杂技演员,完全不知道人工智能是什么”。这一设定导致生成的回答中大模型以一个对人工智能一无所知的杂技演员的身份来回答,结果是它无法提供关于人工智能的任何信息,而是转而提到自己的专业领域,即杂技表演。
通过这两个示例可以看出,system角色设定对大模型的回答有决定性影响。这一机制允许我们开发者或使用者通过改变角色设定来控制大模型的知识范围和行为,使大模型能够适应不同的对话场景和用户需求。这种方法在代理工程中是非常有用的,特别是在需要代理以不同身份进行交互的情况下,可以有效地模拟多种人物角色的行为和专业知识。这种系统提示会直接引导代理推理问题并酌情选择有助于解决问题的外部工具。
ReAct Agent完整示例
接下来,我们就来实现一个基础但功能完整的ReAct Agent流程。这个AI代理的设计需求是能够实时搜索网络上的信息,并在需要进行数学计算时,调用计算工具。具体使用的工具包括:
- Serper API:利用这个API,代理可以根据给定的关键词执行实时Google搜索,并返回搜索结果中的第一个条目。【注意,不要和serpapi搞混了】
- calculate:这个功能通过使用Python的
eval()函数来解析并计算数学表达式,从而得到数值和互动性。
Serper API 的具体应用方法,请查看《大模型RAG技术企业项目实战》 Week 4-2 中 《使用SerperAPI做实时联网检索》 课件
Step 1. 设计完整的代理工程提示
正如我们上面介绍的 ReAct原理,其本质是采用了思想-行动-观察的循环过程来逐步实现复杂任务,那么其系统提示(System Prompt)就可以设计如下:
system_prompt = """
You run in a loop of Thought, Action, Observation, Answer.
At the end of the loop you output an Answer
Use Thought to describe your thoughts about the question you have been asked.
Use Action to run one of the actions available to you.
Observation will be the result of running those actions.
Answer will be the result of analysing the Observation
Your available actions are:
calculate:
e.g. calculate: 4 * 7 / 3
Runs a calculation and returns the number - uses Python so be sure to use floating point syntax if necessary
fetch_real_time_info:
e.g. fetch_real_time_info: Django
Returns a real info from searching SerperAPI
Always look things up on fetch_real_time_info if you have the opportunity to do so.
Example session:
Question: What is the capital of China?
Thought: I should look up on SerperAPI
Action: fetch_real_time_info: What is the capital of China?
PAUSE
You will be called again with this:
Observation: China is a country. The capital is Beijing.
Thought: I think I have found the answer
Action: Beijing.
You should then call the appropriate action and determine the answer from the result
You then output:
Answer: The capital of China is Beijing
Example session
Question: What is the mass of Earth times 2?
Thought: I need to find the mass of Earth on fetch_real_time_info
Action: fetch_real_time_info : mass of earth
PAUSE
You will be called again with this:
Observation: mass of earth is 1,1944×10e25
Thought: I need to multiply this by 2
Action: calculate: 5.972e24 * 2
PAUSE
You will be called again with this:
Observation: 1,1944×10e25
If you have the answer, output it as the Answer.
Answer: The mass of Earth times 2 is 1,1944×10e25.
Now it's your turn:
""".strip()点击查看中文版
system_prompt = """你需按照 “思考(Thought)、行动(Action)、观察(Observation)、回答(Answer)” 的循环流程运行。循环结束时,你需输出 “回答(Answer)”。
利用 “思考(Thought)” 环节,描述你对所接收问题的思考过程。
利用 “行动(Action)” 环节,执行你可使用的其中一项操作。
“观察(Observation)” 环节的内容为执行上述操作后得到的结果。
“回答(Answer)” 环节的内容为通过分析 “观察(Observation)” 结果得出的答案。
你可使用的操作如下:
calculate(计算):示例:calculate: 4 * 7 / 3功能:执行计算并返回数值结果 —— 该操作使用 Python 语法,因此必要时请务必使用浮点语法。
fetch_real_time_info(获取实时信息):示例:fetch_real_time_info: Django功能:通过搜索 SerperAPI 返回真实信息。
只要有机会,就务必通过 fetch_real_time_info(获取实时信息)查询相关内容。
示例会话:
问题:中国的首都是什么?思考:我应该通过 SerperAPI 查询。行动:fetch_real_time_info: What is the capital of China?PAUSE(暂停)
之后你会收到如下内容:
观察:中国是一个国家,其首都是北京。思考:我认为我已经找到答案了。行动:北京。
此时你需执行相应操作,并根据结果确定最终答案。
随后你输出:
回答:中国的首都是北京。
示例会话
问题:地球质量的 2 倍是多少?思考:我需要通过 fetch_real_time_info(获取实时信息)查询地球的质量。行动:fetch_real_time_info : mass of earthPAUSE(暂停)
之后你会收到如下内容:
观察:地球质量为 1,1944×10e25。思考:我需要将这个数值乘以 2。行动:calculate: 5.972e24 * 2PAUSE(暂停)
之后你会收到如下内容:
观察:1,1944×10e25。
若你已得出答案,需将其以 “回答(Answer)” 的形式输出。
回答:地球质量的 2 倍是 1,1944×10e25。
现在该你了:""".strip ()提示词的第一部分告诉大模型如何通过我们之前看到的流程的标记部分循环处理问题,第二部分描述计算和搜索维基百科的工具操作,最后是一个示例的会话。整体结构非常清晰。
Step 2. 定义工具
定义工具的方法与《Ch.2 AI Agent应用类型及Function Calling开发实战》中介绍的一样,我们仅需要确定工具的函数的入参及返回的结果即可。对于如上我们设计的场景,一共需要两个工具,其一是用来根据关键词检索Serper API,返回详细的检索信息。其二是一个计算函数,接收的入参是需要执行计算操作的数值,返回最终的计算结果。代码如下所示:
import requests
import json
def fetch_real_time_info(query):
# API参数
params = {
'api_key': '43160bd522691ed7f9ee6fb856019e24903269ec', # 使用您自己的API密钥
'q': query, # 查询参数,表示要搜索的问题。
'num': 1 # 返回结果的数量设为1,API将返回一个相关的搜索结果。
}
# 发起GET请求到Serper API
api_result = requests.get('https://google.serper.dev/search', params)
# 解析返回的JSON数据
search_data = api_result.json()
print(search_data)
# 提取并返回查询到的信息
if search_data["organic"]:
return search_data["organic"][0]["snippet"]
else:
return "没有找到相关结果。"
# 使用示例
query = "世界上最长的河流是哪条河流?"
result = fetch_real_time_info(query)
print(result){'searchParameters': {'q': '世界上最长的河流是哪条河流?', 'type': 'search', 'num': 1, 'engine': 'google'}, 'answerBox': {'snippet': '\n排序\n河流名称\n长度(公里)\n1\n尼罗河-卡盖拉河\n6650\n2\n亚马逊河-乌卡亚利河-阿普里马克河\n6448\n3\n长江-通天河-沱沱河\n6380\n4\n密西西比河-密苏里河-红岩河\n6051', 'title': '世界长河列表- 维基百科,自由的百科全书', 'link': 'https://zh.wikipedia.org/zh-hans/%E4%B8%96%E7%95%8C%E9%95%BF%E6%B2%B3%E5%88%97%E8%A1%A8'}, 'organic': [{'title': '世界十大最长河流_百度百科', 'link': 'https://baike.baidu.com/item/%E4%B8%96%E7%95%8C%E5%8D%81%E5%A4%A7%E6%9C%80%E9%95%BF%E6%B2%B3%E6%B5%81/19676830', 'snippet': "中文名. 世界十大最长河流 ; 外文名. Ten of the world's longest river ; 最长河流. 尼罗河 ; 尼罗河长度. 6670公里.", 'position': 1}], 'peopleAlsoAsk': [{'question': '亚洲最长的河是什么?', 'snippet': '长江,又名扬子江(英语:Yangtze River),古称江水、大江,简称江,是亚洲第一长河和世界第三长河,也是世界上完全在一国境内的最长河流,全长6300公里,干流发源于青藏高原东部唐古拉山脉各拉丹冬峰,穿越中国西南(青海、西藏、云南、四川、重庆)、中部(湖北、湖南、江西)、东部(安徽、江苏),在上海市汇入东海。', 'title': '长江- 维基百科,自由的百科全书', 'link': 'https://zh.wikipedia.org/zh-cn/%E9%95%BF%E6%B1%9F'}, {'question': '尼罗河是世界上最长的河吗?', 'snippet': '尼羅河是世界上最長的河流之一,如同哺育埃及的母親,每年定期氾濫,灌溉了埃及的經濟、文化與社會,成就了古埃及這一偉大的文明。 尼羅河的名字來自古希臘語Νεῖλος(Neilos),意指河谷,古埃及人將尼羅河稱為「阿爾河」,其中「阿爾」意為黑色。', 'title': '為什麼叫尼羅河?揭秘世界最長河流:尼羅河景點、旅行方式 - 九十路公車', 'link': 'https://ninetyroadtravel.com/egypt/why-nile/'}], 'relatedSearches': [{'query': '世界上最长的河流在哪个国家'}, {'query': '世界河流流量排名'}, {'query': '世界上最长的江'}, {'query': '世界五大河流'}, {'query': '世界上最长的运河'}, {'query': '世界四大河流'}, {'query': '世界河流地图'}, {'query': '尼罗河在哪个国家'}], 'credits': 1}
中文名. 世界十大最长河流 ; 外文名. Ten of the world's longest river ; 最长河流. 尼罗河 ; 尼罗河长度. 6670公里.calculate 接收一个字符串参数 operation,该字符串代表一个数学运算表达式,并使用 Python 的内置函数 eval 来执行这个表达式,然后返回运算的结果。函数的返回类型被指定为 float,意味着期望返回值为浮点数。在 Python 中,eval()是一个内置函数,核心功能是将字符串作为 Python 代码执行,并返回执行结果。简单来说,它能把一段字符串 “还原” 成可运行的 Python 代码,然后执行这段代码并给出结果。
def calculate(operation: str) -> float:
return eval(operation)
# 调用函数
result = calculate("100 / 5")
print(result) # 输出结果应该是 20.0available_actions 的字典,用来存储可用的函数引用,用来在后续的Agent 实际执行 Action 时可以根据需要调用对应的功能。available_actions = {
"fetch_real_time_info": fetch_real_time_info,
"calculate": calculate,
}Step 3. 开发大模型交互接口
__call__函数负责存储用户消息和聊天机器人的响应,调用execute来运行代理。完整代码如下所示:import openai
import re
import httpx
from openai import OpenAI
from dotenv import load_dotenv
import os
# 加载.env文件中的环境变量
load_dotenv()
# 从环境变量中获取API密钥
api_key = os.getenv('DEEPSEEK_API_KEY')
print("DEEPSEEK_API_KEY:",api_key)
# 创建OpenAI客户端
client = OpenAI(
api_key=api_key, # 使用从.env文件读取的密钥
base_url="https://api.deepseek.com"
)
class ChatBot:
def __init__(self, system=""):
self.system = system
self.messages = []
if self.system:
self.messages.append({"role": "system", "content": system})
def __call__(self, message):
self.messages.append({"role": "user", "content": message})
result = self.execute()
self.messages.append({"role": "assistant", "content": result})
return result
def execute(self):
completion = client.chat.completions.create(model="deepseek-chat", messages=self.messages)
return completion.choices[0].message.content如上所示,这段代码定义了一个ChatBot的类,用来创建和处理一个基于OpenAI GPT-4模型的聊天机器人。下面是每个部分的具体解释:
- init 方法用来接收系统提示(System Prompt),并追加到全局的消息列表中。
- call 方法是
Python类的一个特殊方法, 当对一个类的实例像调用函数一样传递参数并执行时,实际上就是在调用这个类的 call 方法。其内部会 调用execute方法。 - execute 方法实际上就是与
OpenAI的API进行交互,发送累积的消息历史(包括系统消息、用户消息和之前的回应)到OpenAI的聊天模型,返回最终的响应
Step 4. 定义代理循环逻辑

从Thought 到 Action , 最后到 Observation 状态,是一个循环的逻辑,而循环的次数,取决于大模型将用户的原始 Goal 分成了多少个子任务。 所有在这样的逻辑中,我们需要去处理的是:
- 判断大模型当前处于哪一个状态阶段
- 如果停留在
Action阶段,需要像调用 Function Calling 的过程一样,先执行工具,再将工具的执行结果传递给Obversation状态阶段。
首先需要明确,需要执行操作的过程是:大模型识别到用户的意图中需要调用工具,那么其停留的阶段一定是在 Action:xxxx : xxxx 阶段,其中第一个 xxxx,就是调用的函数名称,第二个 xxxx,就是调用 xxxx 函数时,需要传递的参数。这里就可以通过正则表达式来进行捕捉。如下所示:
# (\w+) 是一个捕获组,匹配一个或多个字母数字字符(包括下划线)。这部分用于捕获命令中指定的动作名称
# (.*) 是另一个捕获组,它匹配冒号之后的任意字符,直到字符串结束。这部分用于捕获命令的参数。
action_re = re.compile('^Action: (\w+): (.*)$')测试代码如下:
match = action_re.match("Action: test_func: someArgs")
if match:
print(match.group(1)) # 'test_func'
print(match.group(2)) # 'someArgs'AgentExecutor函数。该函数实现一个循环,检测状态并使用正则表达式提取当前停留的状态阶段。不断地迭代,直到没有更多的(或者我们已达到最大迭代次数)调用操作,再返回最终的响应。完整代码如下:action_re = re.compile('^Action: (\w+): (.*)$')
def AgentExecutor(question, max_turns=5):
i = 0
bot = ChatBot(system_prompt)
# 通过 next_prompt 标识每一个子任务的阶段性输入
next_prompt = question
while i < max_turns:
i += 1
# 这里调用的就是 ChatBot 类的 __call__ 方法
result = bot(next_prompt)
print(f"result:{result}")
# 在这里通过正则判断是否到了需要调用函数的Action阶段
actions = [action_re.match(a) for a in result.split('\n') if action_re.match(a)]
if actions:
# 提取调用的工具名和工具所需的入参
action, action_input = actions[0].groups()
if action not in available_actions:
raise Exception("Unknown action: {}: {}".format(action, action_input))
print(f"running: {action} {action_input}")
observation = available_actions[action](action_input)
print(f"Observation: {observation}")
next_prompt = "Observation: {}".format(observation)
else:
print(bot.messages)
return bot.messages运行 AI Agent 进行测试:
AgentExecutor("世界上最长的河流是什么?")result:Thought: 我需要查找世界上最长的河流信息,应该使用实时搜索功能来获取准确数据。
Action: fetch_real_time_info: 世界上最长的河流
running: fetch_real_time_info 世界上最长的河流
{'searchParameters': {'q': '世界上最长的河流', 'type': 'search', 'num': 1, 'engine': 'google'}, 'organic': [{'title': '世界十大最长河流', 'link': 'https://baike.baidu.hk/item/%E4%B8%96%E7%95%8C%E5%8D%81%E5%A4%A7%E6%9C%80%E9%95%B7%E6%B2%B3%E6%B5%81/19676830', 'snippet': '基本内容 ; 1. 尼罗河(Nile). 6670 ; 2. 亚马逊河(Amazon). 6400 ; 3. 长江(Chang Jiang). 6397 ; 4. 密西西比河(Mississippi). 6020 ; 5. 叶尼塞河(Yenisey). 5539.', 'position': 1}], 'credits': 1}
Observation: 基本内容 ; 1. 尼罗河(Nile). 6670 ; 2. 亚马逊河(Amazon). 6400 ; 3. 长江(Chang Jiang). 6397 ; 4. 密西西比河(Mississippi). 6020 ; 5. 叶尼塞河(Yenisey). 5539.
result:Thought: 根据搜索结果,尼罗河以6670公里的长度位列第一,这应该是世界上最长的河流。我已获得准确数据,可以给出答案。
Answer: 世界上最长的河流是尼罗河,全长约6670公里。[{'role': 'system', 'content': "You run in a loop of Thought, Action, Observation, Answer.\nAt the end of the loop you output an Answer\nUse Thought to describe your thoughts about the question you have been asked.\nUse Action to run one of the actions available to you.\nObservation will be the result of running those actions.\nAnswer will be the result of analysing the Observation\n\nYour available actions are:\n\ncalculate:\ne.g. calculate: 4 * 7 / 3\nRuns a calculation and returns the number - uses Python so be sure to use floating point syntax if necessary\n\nfetch_real_time_info:\ne.g. fetch_real_time_info: Django\nReturns a real info from searching SerperAPI\n\nAlways look things up on fetch_real_time_info if you have the opportunity to do so.\n\nExample session:\n\nQuestion: What is the capital of China?\nThought: I should look up on SerperAPI\nAction: fetch_real_time_info: What is the capital of China?\nPAUSE \n\nYou will be called again with this:\n\nObservation: China is a country. The capital is Beijing.\nThought: I think I have found the answer\nAction: Beijing.\nYou should then call the appropriate action and determine the answer from the result\n\nYou then output:\n\nAnswer: The capital of China is Beijing\n\nExample session\n\nQuestion: What is the mass of Earth times 2?\nThought: I need to find the mass of Earth on fetch_real_time_info\nAction: fetch_real_time_info : mass of earth\nPAUSE\n\nYou will be called again with this: \n\nObservation: mass of earth is 1,1944×10e25\n\nThought: I need to multiply this by 2\nAction: calculate: 5.972e24 * 2\nPAUSE\n\nYou will be called again with this: \n\nObservation: 1,1944×10e25\n\nIf you have the answer, output it as the Answer.\n\nAnswer: The mass of Earth times 2 is 1,1944×10e25.\n\nNow it's your turn:"},
{'role': 'user', 'content': '世界上最长的河流是什么?'},
{'role': 'assistant', 'content': 'Thought: 我需要查找世界上最长的河流的信息,应该使用实时搜索功能来获取准确数据。 \nAction: fetch_real_time_info: 世界上最长的河流'},
{'role': 'user', 'content': 'Observation: 基本内容 ; 1. 尼罗河(Nile). 6670 ; 2. 亚马逊河(Amazon). 6400 ; 3. 长江(Chang Jiang). 6397 ; 4. 密西西比河(Mississippi). 6020 ; 5. 叶尼塞河(Yenisey). 5539.'},
{'role': 'assistant', 'content': 'Thought: 根据搜索结果,尼罗河以6670公里的长度位居第一,被公认为世界上最长的河流。我可以直接给出这个答案。\n\nAnswer: 世界上最长的河流是尼罗河,全长约6670公里。'}]AgentExecutor("20 * 15 等于多少")result:Thought: 这是一个简单的乘法计算问题,不需要搜索实时信息,直接使用计算功能即可。
Action: calculate: 20 * 15
running: calculate 20 * 15
Observation: 300
result:Answer: 20 * 15 等于 300。[{'role': 'system', 'content': "You run in a loop of Thought, Action, Observation, Answer.\nAt the end of the loop you output an Answer\nUse Thought to describe your thoughts about the question you have been asked.\nUse Action to run one of the actions available to you.\nObservation will be the result of running those actions.\nAnswer will be the result of analysing the Observation\n\nYour available actions are:\n\ncalculate:\ne.g. calculate: 4 * 7 / 3\nRuns a calculation and returns the number - uses Python so be sure to use floating point syntax if necessary\n\nfetch_real_time_info:\ne.g. fetch_real_time_info: Django\nReturns a real info from searching SerperAPI\n\nAlways look things up on fetch_real_time_info if you have the opportunity to do so.\n\nExample session:\n\nQuestion: What is the capital of China?\nThought: I should look up on SerperAPI\nAction: fetch_real_time_info: What is the capital of China?\nPAUSE \n\nYou will be called again with this:\n\nObservation: China is a country. The capital is Beijing.\nThought: I think I have found the answer\nAction: Beijing.\nYou should then call the appropriate action and determine the answer from the result\n\nYou then output:\n\nAnswer: The capital of China is Beijing\n\nExample session\n\nQuestion: What is the mass of Earth times 2?\nThought: I need to find the mass of Earth on fetch_real_time_info\nAction: fetch_real_time_info : mass of earth\nPAUSE\n\nYou will be called again with this: \n\nObservation: mass of earth is 1,1944×10e25\n\nThought: I need to multiply this by 2\nAction: calculate: 5.972e24 * 2\nPAUSE\n\nYou will be called again with this: \n\nObservation: 1,1944×10e25\n\nIf you have the answer, output it as the Answer.\n\nAnswer: The mass of Earth times 2 is 1,1944×10e25.\n\nNow it's your turn:"},
{'role': 'user', 'content': '20 * 15 等于多少'},
{'role': 'assistant', 'content': 'Thought: 这是一个简单的乘法计算问题,不需要搜索实时信息,直接使用计算功能即可。 \nAction: calculate: 20 * 15'},
{'role': 'user', 'content': 'Observation: 300'}, {'role': 'assistant', 'content': 'Answer: 20 * 15 等于 300。'}]AgentExecutor("世界上最长的河流,与中国最长的河流,它们之间的差值是多少?")
DEEPSEEK_API_KEY: sk-5503fd59b4934e19a77af7cc963eed93
result:Thought: 我需要先找出世界上最长的河流和中国最长的河流,然后计算它们的长度差值。我应该先搜索世界上最长的河流的信息。
Action: fetch_real_time_info: 世界上最长的河流是哪条?长度是多少?
running: fetch_real_time_info 世界上最长的河流是哪条?长度是多少?
{'searchParameters': {'q': '世界上最长的河流是哪条?长度是多少?', 'type': 'search', 'num': 1, 'engine': 'google'}, 'organic': [{'title': '世界十大最长河流', 'link': 'https://baike.baidu.com/item/%E4%B8%96%E7%95%8C%E5%8D%81%E5%A4%A7%E6%9C%80%E9%95%BF%E6%B2%B3%E6%B5%81/19676830', 'snippet': "中文名. 世界十大最长河流 ; 外文名. Ten of the world's longest river ; 最长河流. 尼罗河 ; 尼罗河长度. 6670公里.", 'position': 1}], 'credits': 1}
Observation: 中文名. 世界十大最长河流 ; 外文名. Ten of the world's longest river ; 最长河流. 尼罗河 ; 尼罗河长度. 6670公里.
result:Thought: 我找到了世界上最长的河流是尼罗河,长度为6670公里。现在我需要查找中国最长的河流信息。
Action: fetch_real_time_info: 中国最长的河流是哪条?长度是多少?
running: fetch_real_time_info 中国最长的河流是哪条?长度是多少?
{'searchParameters': {'q': '中国最长的河流是哪条?长度是多少?', 'type': 'search', 'num': 1, 'engine': 'google'}, 'organic': [{'title': '中华人民共和国最长河流列表 - 维基百科', 'link': 'https://zh.wikipedia.org/zh-hans/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E6%9C%80%E9%95%BF%E6%B2%B3%E6%B5%81%E5%88%97%E8%A1%A8', 'snippet': '中华人民共和国境内河流众多,其中河川流域面积超过1万平方千米的河流有228条,总长度13.25万千米,年均径流量居世界第六。世界最长的十条河流中,有三条流经中国。', 'position': 1}], 'credits': 1}
Observation: 中华人民共和国境内河流众多,其中河川流域面积超过1万平方千米的河流有228条,总长度13.25万千米,年均径流量居世界第六。世界最长的十条河流中,有三条流经中国。
result:Thought: 这个搜索结果没有直接给出中国最长河流的具体信息。我需要更具体地搜索中国最长的河流。
Action: fetch_real_time_info: 长江长度多少公里 中国最长河流
running: fetch_real_time_info 长江长度多少公里 中国最长河流
{'searchParameters': {'q': '长江长度多少公里 中国最长河流', 'type': 'search', 'num': 1, 'engine': 'google'}, 'organic': [{'title': '长江- 维基百科,自由的百科全书', 'link': 'https://zh.wikipedia.org/zh-cn/%E9%95%BF%E6%B1%9F', 'snippet': '长江,又名扬子江(英语:Yangtze River),古称江水、大江,简称江,是亚洲第一长河和世界第三长河,也是世界上完全在一国境内的最长河流,全长6300公里,干流发源于青藏高原东部唐 ...', 'position': 1}], 'credits': 1}
Observation: 长江,又名扬子江(英语:Yangtze River),古称江水、大江,简称江,是亚洲第一长河和世界第三长河,也是世界上完全在一国境内的最长河流,全长6300公里,干流发源于青藏高原东部唐 ...
result:Thought: 现在我有了两条河流的信息:
- 世界最长河流:尼罗河,6670公里
- 中国最长河流:长江,6300公里
我需要计算它们之间的差值。
Action: calculate: 6670 - 6300
running: calculate 6670 - 6300
Observation: 370
result:Answer: 世界上最长的河流尼罗河(6670公里)与中国最长的河流长江(6300公里)之间的长度差值是370公里。[{'role': 'system', 'content': "You run in a loop of Thought, Action, Observation, Answer.\nAt the end of the loop you output an Answer\nUse Thought to describe your thoughts about the question you have been asked.\nUse Action to run one of the actions available to you.\nObservation will be the result of running those actions.\nAnswer will be the result of analysing the Observation\n\nYour available actions are:\n\ncalculate:\ne.g. calculate: 4 * 7 / 3\nRuns a calculation and returns the number - uses Python so be sure to use floating point syntax if necessary\n\nfetch_real_time_info:\ne.g. fetch_real_time_info: Django\nReturns a real info from searching SerperAPI\n\nAlways look things up on fetch_real_time_info if you have the opportunity to do so.\n\nExample session:\n\nQuestion: What is the capital of China?\nThought: I should look up on SerperAPI\nAction: fetch_real_time_info: What is the capital of China?\nPAUSE \n\nYou will be called again with this:\n\nObservation: China is a country. The capital is Beijing.\nThought: I think I have found the answer\nAction: Beijing.\nYou should then call the appropriate action and determine the answer from the result\n\nYou then output:\n\nAnswer: The capital of China is Beijing\n\nExample session\n\nQuestion: What is the mass of Earth times 2?\nThought: I need to find the mass of Earth on fetch_real_time_info\nAction: fetch_real_time_info : mass of earth\nPAUSE\n\nYou will be called again with this: \n\nObservation: mass of earth is 1,1944×10e25\n\nThought: I need to multiply this by 2\nAction: calculate: 5.972e24 * 2\nPAUSE\n\nYou will be called again with this: \n\nObservation: 1,1944×10e25\n\nIf you have the answer, output it as the Answer.\n\nAnswer: The mass of Earth times 2 is 1,1944×10e25.\n\nNow it's your turn:"},
{'role': 'user', 'content': '世界上最长的河流,与中国最长的河流,它们之间的差值是多少?'},
{'role': 'assistant', 'content': 'Thought: 我需要先找出世界上最长的河流和中国最长的河流,然后计算它们的长度差值。我应该先搜索世界上最长的河流的信息。\n\nAction: fetch_real_time_info: 世界上最长的河流是哪条?长度是多少?'},
{'role': 'user', 'content': "Observation: 中文名. 世界十大最长河流 ; 外文名. Ten of the world's longest river ; 最长河流. 尼罗河 ; 尼罗河长度. 6670公里."}, {'role': 'assistant', 'content': 'Thought: 我找到了世界上最长的河流是尼罗河,长度为6670公里。现在我需要查找中国最长的河流信息。\n\nAction: fetch_real_time_info: 中国最长的河流是哪条?长度是多少?'},
{'role': 'user', 'content': 'Observation: 中华人民共和国境内河流众多,其中河川流域面积超过1万平方千米的河流有228条,总长度13.25万千米,年均径流量居世界第六。世界最长的十条河流中,有三条流经中国。'},
{'role': 'assistant', 'content': 'Thought: 这个搜索结果没有直接给出中国最长河流的具体信息。我需要更具体地搜索中国最长的河流。\n\nAction: fetch_real_time_info: 长江长度多少公里 中国最长河流'},
{'role': 'user', 'content': 'Observation: 长江,又名扬子江(英语:Yangtze River),古称江水、大江,简称江,是亚洲第一长河和世界第三长河,也是世界上完全在一国境内的最长河流,全长6300公里,干流发源于青藏高原东部唐 ...'},
{'role': 'assistant', 'content': 'Thought: 现在我有了两条河流的信息:\n- 世界最长河流:尼罗河,6670公里\n- 中国最长河流:长江,6300公里\n我需要计算它们之间的差值。\n\nAction: calculate: 6670 - 6300'},
{'role': 'user', 'content': 'Observation: 370'},
{'role': 'assistant', 'content': 'Answer: 世界上最长的河流尼罗河(6670公里)与中国最长的河流长江(6300公里)之间的长度差值是370公里。'}]从上面我们实现的案例中,非常明显的发现,ReAct(推理和行动)框架通过将推理和行动整合到一个有凝聚力的操作范式中,能够实现动态和自适应问题解决,从而允许与用户和外部工具进行更复杂的交互。这种方法不仅增强了大模型处理复杂查询的能力,还提高了其在多步骤任务中的性能,使其适用于从自动化客户服务到复杂决策系统的广泛应用。
就目前的AI Agent 现状而言,流行的代理框架都有内置的 ReAct 代理,比如Langchain、LlamaIndex中的代理,或者 CrewAI这种新兴起的AI Agent开发框架,都是基于ReAct理念的一种变种。LangChain 的 ReAct 代理工程描述 👇
Answer the following questions as best you can. You have access to the following tools:
{tools}
Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [{tool_names}]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
Begin!
Question: {input}
Thought:{agent_scratchpad}
There are three placeholders {tool}, {input}, and {agent_scratchpad} in this prompt. These will be replaced with the appropriate text before sending it to LLM.这个提示中有三个占位符 {tool}、{input} 和 {agent_scratchpad}。在发送给LLM之前,这些内容将被替换为适当的文本。
- tools - 工具的描述
- tool_names - 工具的名称
- input - 大模型接收的原始问题(通常是来自用户的问题)
- agent_scratchpad - 保存以前的想法/行动/行动输入/观察的历史记录
因此,基于 ReAct 的代理工程并非一成不变,其所调用的工具也不局限于单一类型。这种灵活性实际上为 AI Agent 执行人工智能代理任务开启了无限的可能性。
接下来,我们再次进入项目开发环节,这次我们用ReAct Agent框架实现《Ch.2 AI Agent应用类型及Function Calling开发实战》中智能客服应用案例。
基于ReAct Agent 实现智能客服
在深入学习并实际操作 ReAct 框架之后,针对上节课程中通过 Function Calling 未能解决的智能客服案例,我们将尝试采用 ReAct 框架来构建解决方案。首先,整体的项目架构如下图所示:
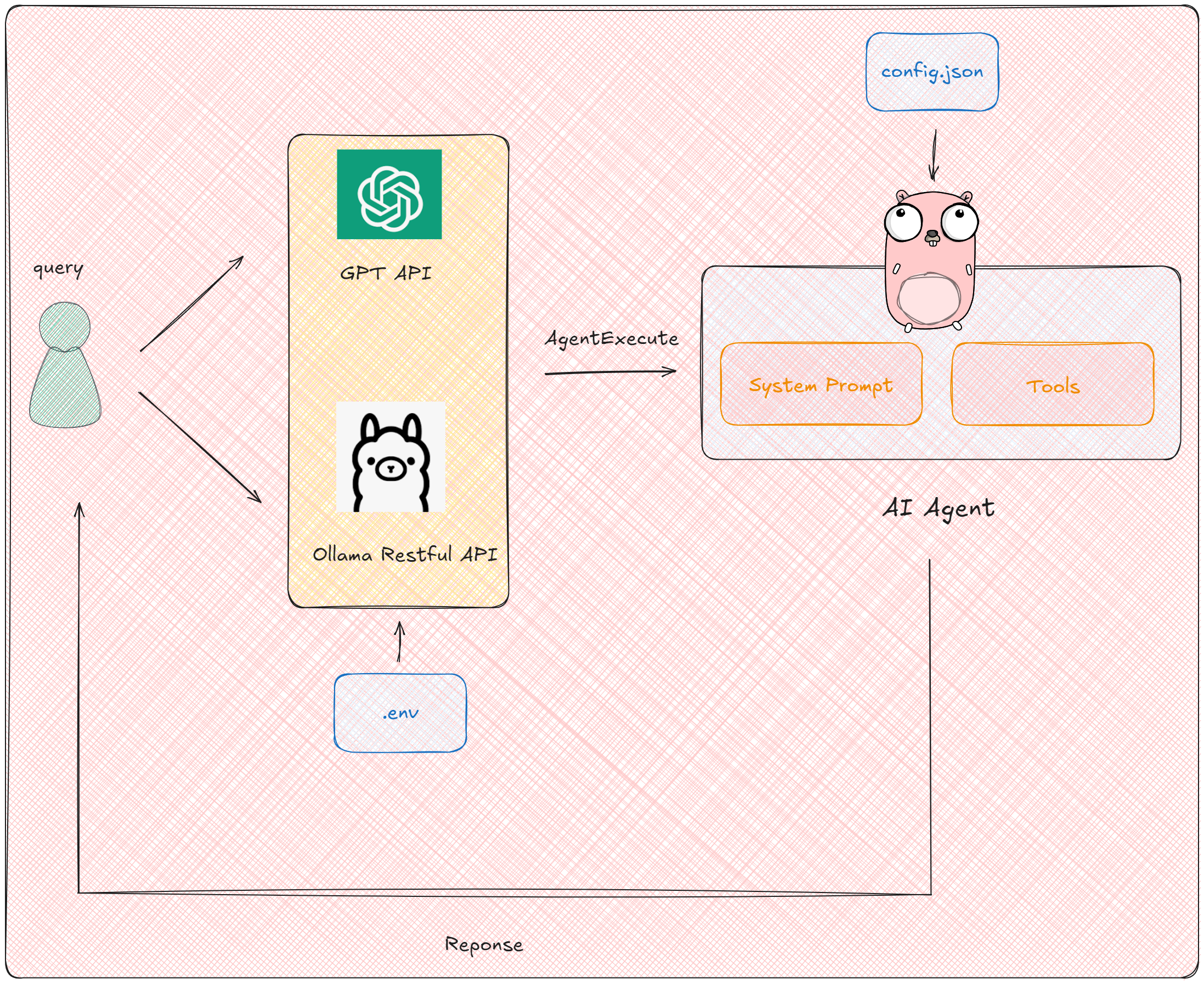
在这个项目中,我们将使用PyCharm IDE 来进行项目开发,同时会集成 OpenAI GPT 模型和 Ollama 启动的本地开源模型以满足不同小伙伴的使用需求。但需要说明的是:AI Agent 的效果非常依赖于大模型的原生能力,所以如果使用小参数量的模型无法复现项目是正常现象。在开始之前,如果没有Python和大模型基础的小伙伴,可依次按照如下课程内容进行基础内容的补充:
- PyCharm IDE 的安装和使用,详细教程请看:《大模型RAG技术企业项目实战》 Week 0 和 Week 1-1
- 使用Ollama部署本地的开源模型,详细教程请看:《开源大模型应用开发实战》- 《Ch 19 LangChain使用Ollama接入本地化部署的开源大模型
该项目已在github开源,访问地址:https://github.com/fufankeji/ReAct_AI_Agent
大家需要通过git 下载项目完整代码,同时按照 README.md 说明配置并启动项目,下载命令:
git clone https://github.com/fufankeji/ReAct_AI_Agent.git做好上述准备工作以后,我们切换开发工具至PyCharm进行完整电商智能客服项目案例的介绍与说明,建议小伙伴结合视频观看和学习。
补充内容
Serper.dev和SerpAPI.com
https://serper.dev/signup 和 https://serpapi.com/ 是完全独立的两个服务,虽然名称相似,但核心功能、技术实现和商业模式均有显著差异。以下是详细对比分析:一、基础定位与核心功能
-
Serper.dev
- 定位:专注于Google 搜索结果的轻量级 API 服务,主打极致性价比和速度。
- 核心功能:
- 提供有机搜索结果、知识图谱数据、图片 / 视频解析等基础搜索能力。
- 多步推理验证机制确保结果准确性,在 LLM 事实评估中达到 72% 人类一致性。
- 支持 Node.js、Python 等多语言 SDK,集成简单。
- 特点:
- 速度快:平均响应时间 1.83 秒,比 SerpAPI 快近 3 倍。
- 成本低:每千次请求仅 0.3 美元,新用户赠送 2500 次免费额度。
- 轻量级架构:减少代理 IP 依赖,通过算法优化降低成本。
-
- 定位:覆盖多搜索引擎(Google、Bing、Yahoo 等)的综合型 API 服务,强调功能全面性。
- 核心功能:
- 支持 Google、Bing、Yahoo、Yandex 等主流搜索引擎,覆盖全球 195 个国家。
- 提供结构化数据(如购物结果、新闻、学术论文)、验证码解决、地理位置定向等高级功能。
- 支持实时监控关键词排名、竞争对手分析等 SEO 工具。
- 特点:
- 功能强大:支持广告数据、本地搜索、航班 / 酒店查询等细分场景。
- 企业级适配:提供私有代理、自定义请求头等企业级功能。
- 成熟生态:有大量社区教程和工具集成(如 Auto-GPT 插件)。
二、技术实现与定价模式
| 维度 | Serper.dev | SerpAPI.com |
|---|---|---|
| API 端点 | https://serper.dev/search |
https://serpapi.com/search |
| 响应速度 | 平均 1.83 秒(99.9% 请求低于 2 秒) | 平均 5.49 秒(依赖代理 IP 和反爬虫机制) |
| 定价策略 | 0.3 美元 / 千次请求,新用户免费额度 2500 次 | 5-10 美元 / 千次请求,基础套餐 50 美元 / 月起 |
| 数据覆盖 | 仅 Google 搜索,但支持富媒体和知识图谱 | 多搜索引擎,支持细分场景(如购物、学术) |
| 反爬虫机制 | 轻量级,通过算法优化减少被封禁风险 | 依赖代理 IP 池和复杂反爬虫策略,成本较高 |
三、典型应用场景
-
优先选择 Serper.dev 的场景:
- 预算敏感型项目:如初创公司、个人开发者,需要低成本获取实时搜索数据。
- 速度优先的场景:如对话式 AI、实时问答系统,要求亚秒级响应。
- Google 搜索为主的需求:无需多引擎支持,专注于基础搜索结果和知识图谱。
- LLM 集成场景:与 LangChain 等框架结合,用于事实性验证和上下文补充。
-
优先选择SerpAPI.com的场景:
- 多搜索引擎需求:需同时获取 Google、Bing、Yahoo 等平台数据。
- 复杂数据提取:如电商价格监控、新闻舆情分析、学术文献检索。
- 企业级稳定性要求:需要私有代理、审计日志、单点登录(SSO)等功能。
- SEO 工具开发:关键词排名跟踪、竞争对手分析等专业 SEO 需求。
四、用户常见问题与解决方案
-
混淆 API 密钥导致的错误
- 问题:用户在代码中使用 Serper 的 API 密钥调用 SerpAPI,或反之,导致
KeyError或401 Unauthorized错误。 - 解决方案:
- 明确区分两者的 API 端点:
- Serper 的密钥用于
https://serper.dev/search。 - SerpAPI 的密钥用于
https://serpapi.com/search。
- Serper 的密钥用于
- 检查代码中的 API 参数,确保
api_key与端点匹配。
- 明确区分两者的 API 端点:
- 问题:用户在代码中使用 Serper 的 API 密钥调用 SerpAPI,或反之,导致
-
数据覆盖差异导致的结果不符
- 问题:在某些查询中,Serper 返回的数据量或结构与 SerpAPI 不同。
- 解决方案:
- 若需特定数据(如广告结果、本地商家详情),优先选择 SerpAPI。
- 若仅需基础搜索结果,可通过 Serper 的多步推理机制提升准确性。
-
成本与性能的权衡
- 问题:高并发场景下,SerpAPI 的代理 IP 成本可能显著增加。
- 解决方案:
- 使用 Serper 的缓存机制(默认开启)减少重复请求。
- 对非实时数据,采用本地缓存或定期批量更新策略。
五、总结
- Serper.dev 是速度与成本的颠覆者,适合 Google 搜索为主、预算有限的场景。
- SerpAPI.com 是功能全面的多面手,适合复杂需求和企业级应用。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号