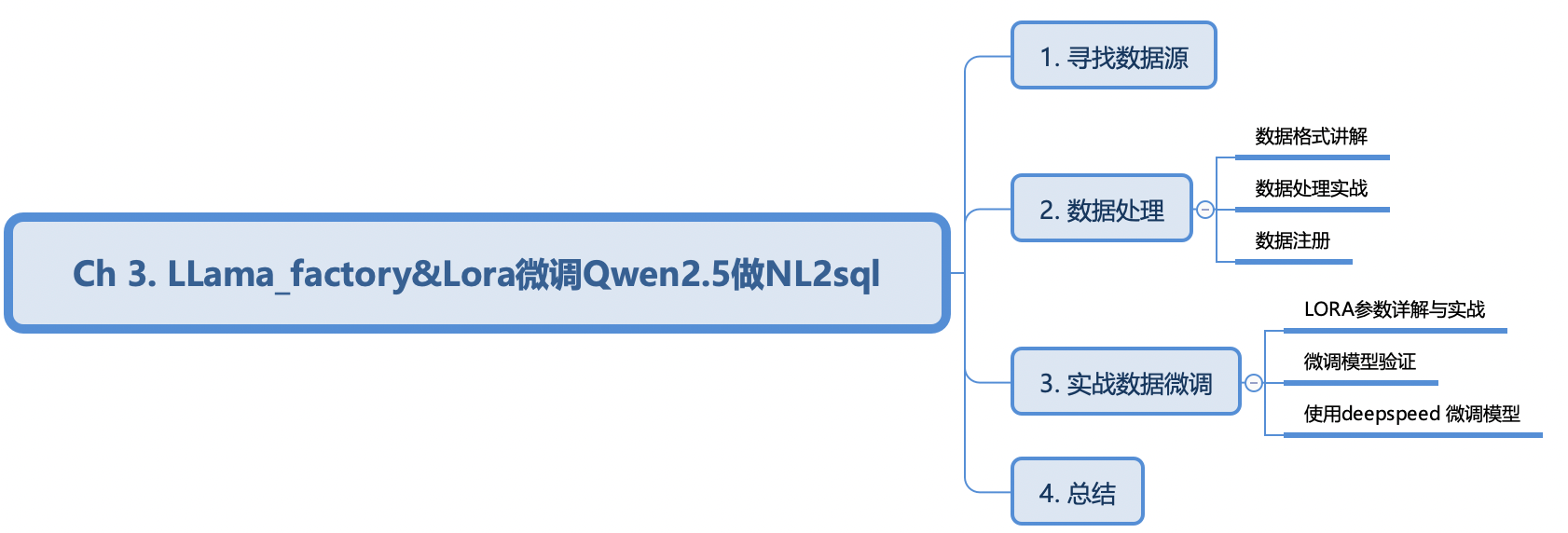
LLama_factory&Lora微调Qwen2.5做NL2sql
- 什么是nl2sql?
NL2SQL(Natural Language to SQL)也叫text2SQL, 主要的想法就是将自然语言查询转换为可执行 SQL 语句的技术。能够让用户通过自然语言交流的方式来操作数据库,而不用学sql这种复杂的语法。
这种情况经常用于数据分析、数据查询、智能客服、信息检索等功能。单纯使用RAG很难让大模型理解该怎么写一条sql是准确的。所以这种场景是需要进行大模型微调。
大模型微调必备条件:1、有大模型 2、有对应领域的数据 3、用资源或框架如何寻找数据集
1、国外hugging face
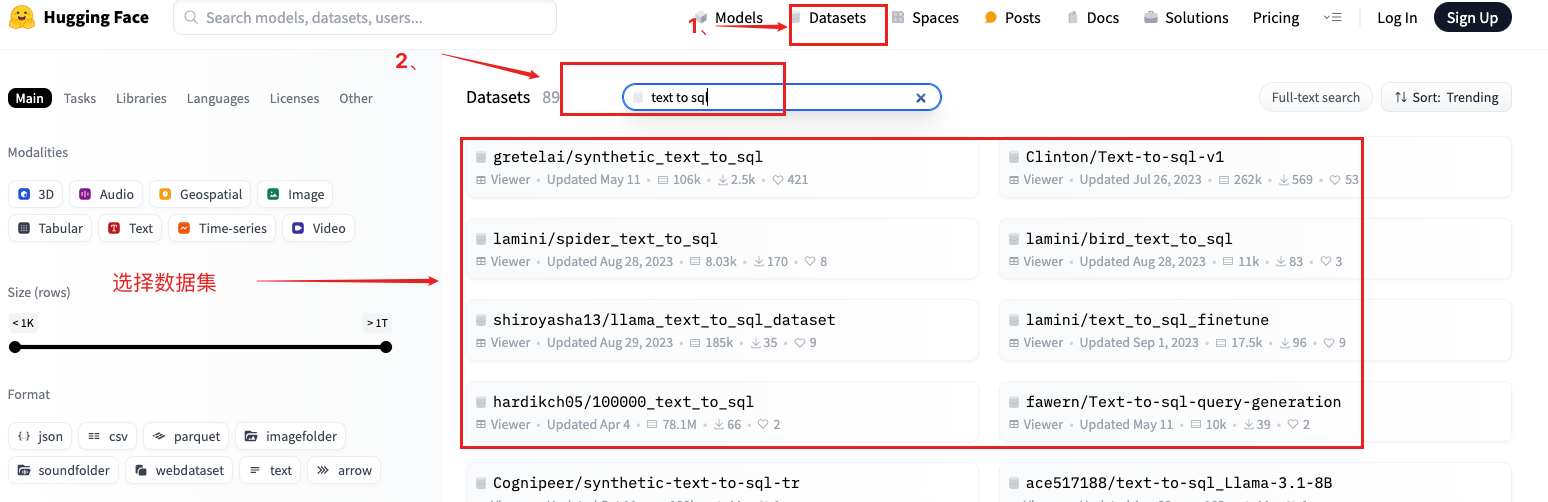
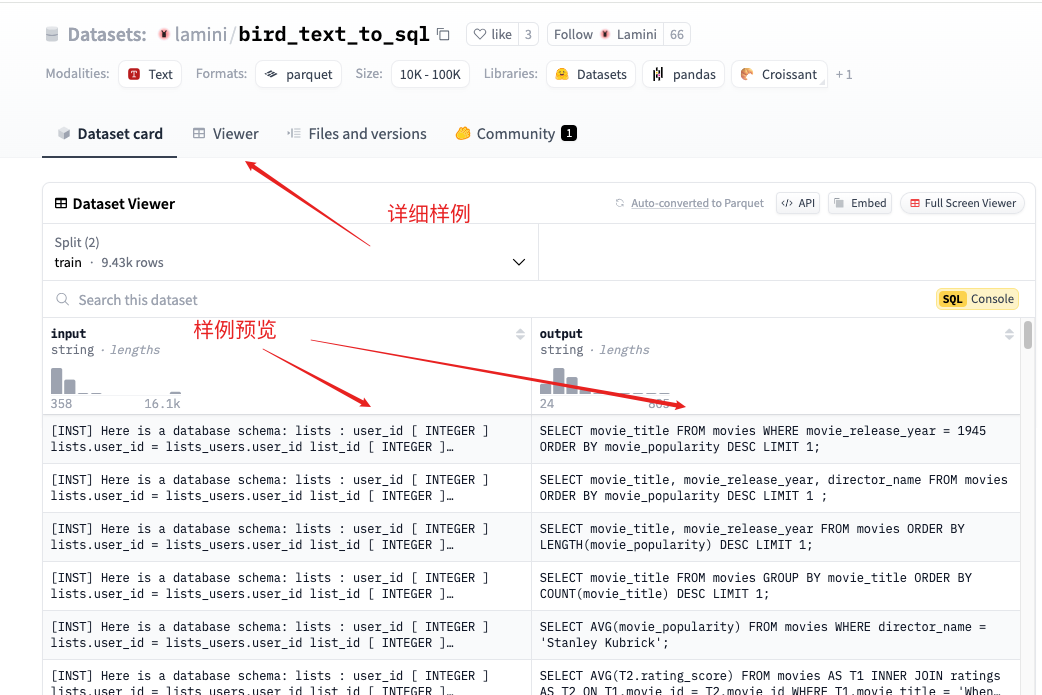
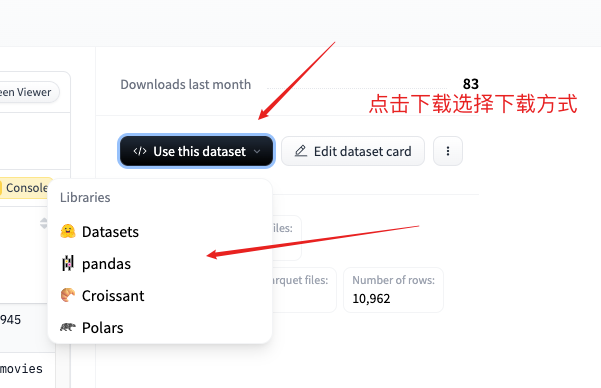
国内考虑modelscope
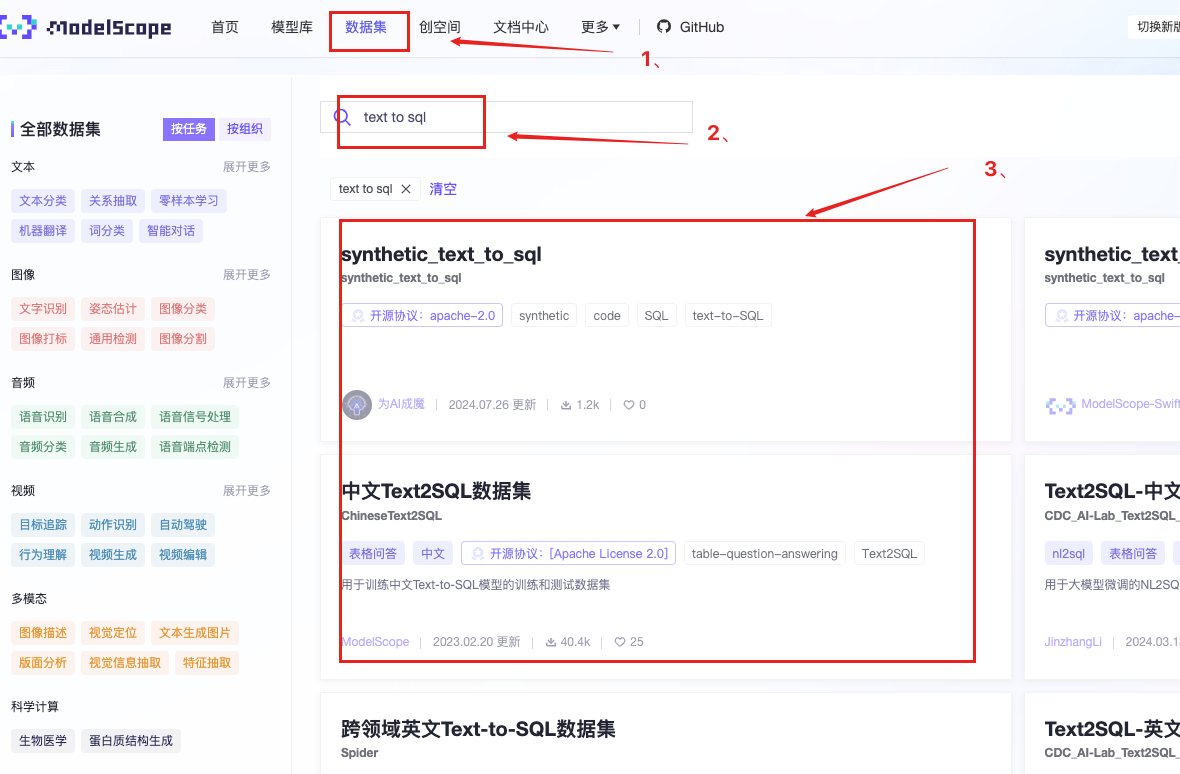
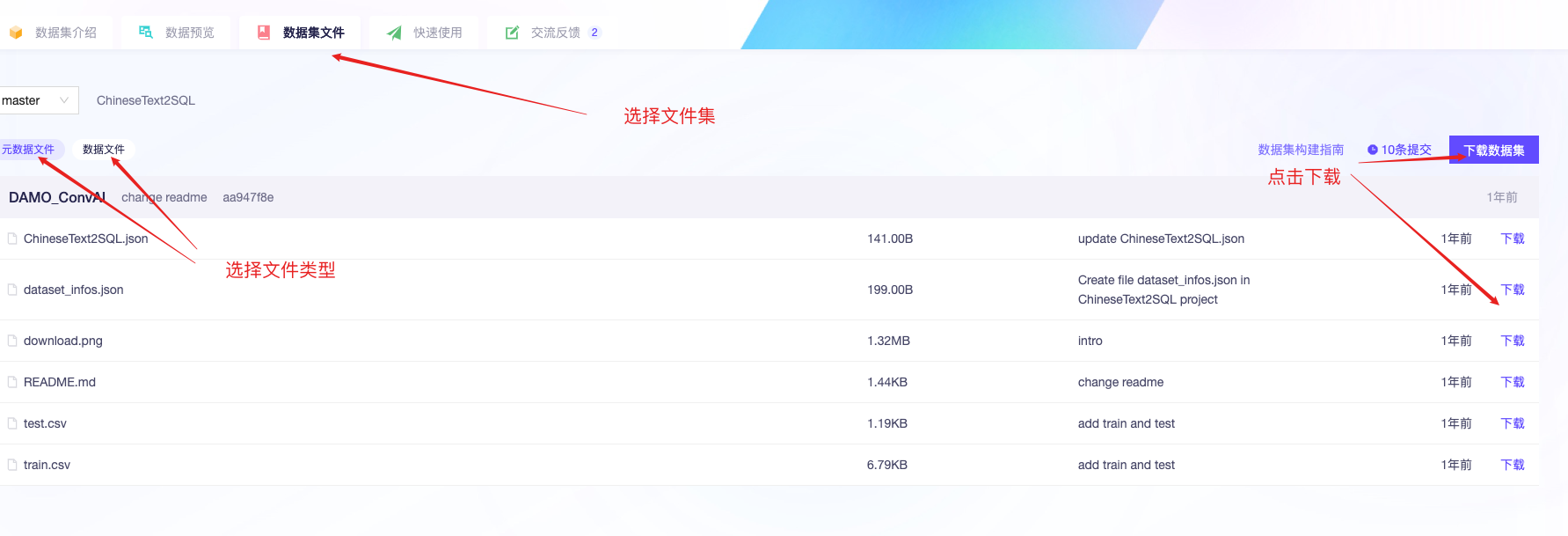

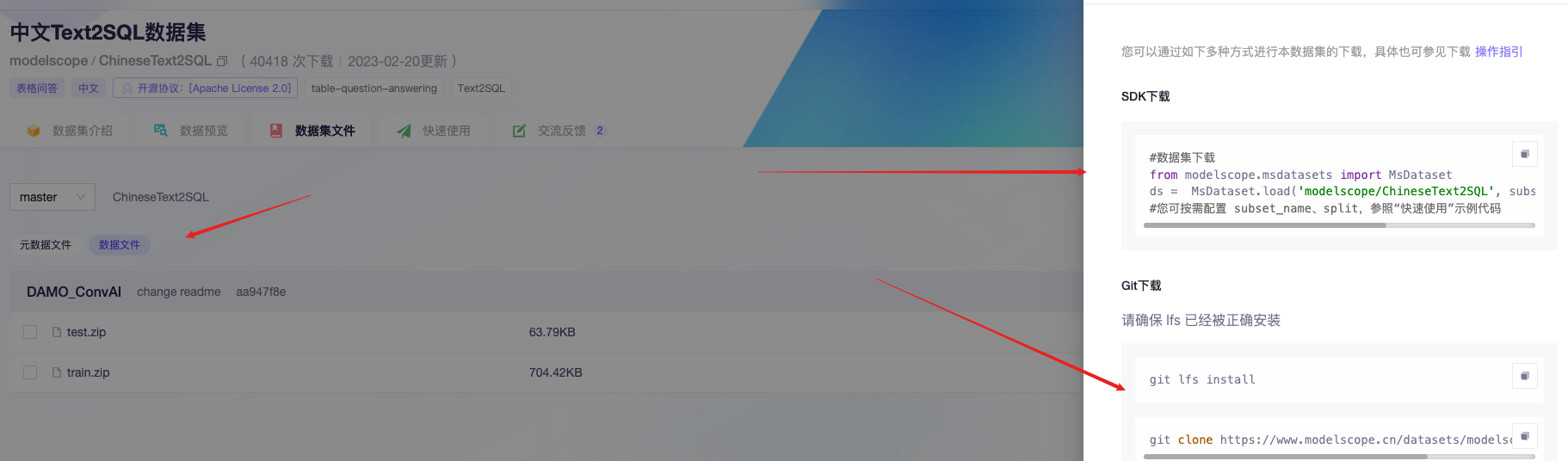
其他大学与企业合作:
英文:
wikiSQL: https://github.com/salesforce/WikiSQL
属于单领域,包含了80654个自然语言问题,77840个SQL语句,SQL语句形式比较简单,不包含排序、分组、子查询等复杂操作。
数据集解压后文件

dev.json文件
{
"phase":1,
"question"":who is the manufacturer for the order year 1998?",
"sql":{
"conds":[
[
0,
0,
"1998"
]
],
"sel":1,
"agg":0
},
"table_id"":1-10026563-1"
}
phase:数据集收集的阶段。我们分两个阶段收集 WikiSQL。
question:工人写的自然语言问题。
sql:与问题对应的 SQL 查询。它包含以下子字段:
conds:三元组列表(column_index, operator_index, condition),其中:
column_index:正在使用的条件列的数字索引。您可以从表中找到实际的列。
operator_index:正在使用的条件运算符的数字索引。您可以从中找到实际的运算Query.cond_ops符lib/query.py。
condition:条件的比较值,为string或float类型。
sel:所选列的数字索引。您可以从表中找到实际的列。
agg:正在使用的聚合运算符的数字索引。您可以从中找到实际的运算Query.agg_ops符lib/query.py。
table_id:该问题对应的表格的ID。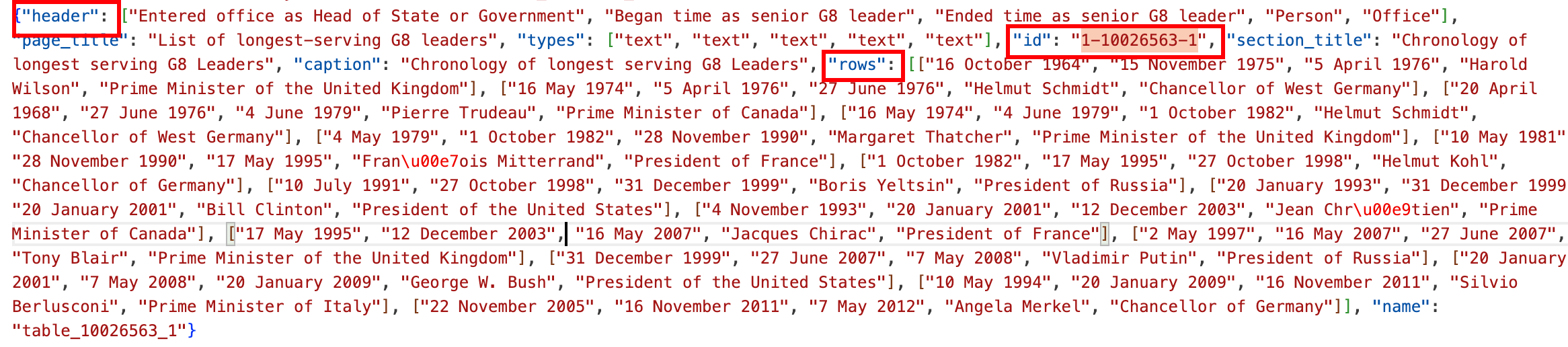
对应dev.tables.jsonl文件
id:表ID。
header:表中列名的列表。
rows:行列表。每行都是行条目的列表。
表格也包含在相应的*.db文件中。这是一个具有相同信息的 SQL 数据库。db文件就是查询后的文件,用来验证sql结果
Spider: https://yale-lily.github.io/spider
耶鲁大学提出的多数据库、多表、单轮查询的Text-to-SQL数据集,也是业界公认难度最大的大规模跨领域评测榜单,包含了10181个自然语言问题,5693个SQL语句,涉及138个不同领域的200多个数据库,难易程度分为:简单、中等、困难、特别困难。
{
"db_id": "concert_singer",
"query": "SELECT count(*) FROM singer",
"query_toks": [
"SELECT",
"count",
"(",
"*",
")",
"FROM",
"singer"
],
"query_toks_no_value": [
"select",
"count",
"(",
"*",
")",
"from",
"singer"
],
"question": "How many singers do we have?",
"question_toks": [
"How",
"many",
"singers",
"do",
"we",
"have",
"?"
],
"sql": {
"from": {
"table_units": [
[
"table_unit",
1
]
],
"conds": []
},
"select": [
false,
[
[
3,
[
0,
[
0,
0,
false
],
null
]
]
]
],
"where": [],
"groupBy": [],
"having": [],
"orderBy": [],
"limit": null,
"intersect": null,
"union": null,
"except": null
}
}
query_toks 和 question_toks 都是经过分词和编码处理后的文本表示,主要用于将自然语言输入转换为模型可以处理的格式。可以做一下大模型预训练,分词训练等。
query_toks_no_value 更适合用于模型训练和解析,帮助模型理解查询的逻辑而不被具体值干扰,减少掉数值的概念。
from:表示SQL查询的FROM子句,即从哪些表中获取数据。
table_units:一个数组,包含了一个或多个表单元(table_unit)。
["table_unit", 1]:表示从表1中获取数据。对应.sql文件中就是表singer
conds:一个数组,表示FROM子句中的条件。在这个例子中,conds数组为空,表示没有额外的条件
select:表示SQL查询的SELECT子句,即要选择哪些列或表达式。
false:表示是否选择所有列(*)。false表示不是选择所有列。
[[3, [0, [0, 0, false], null]]]:一个嵌套数组,表示选择的具体列或表达式。
3:表示选择的列或表达式的类型。具体类型需要根据上下文确定,常见的类型有:
0:列名
1:聚合函数(如COUNT, SUM等)
2:子查询
3:列的别名
[0, [0, 0, false], null]:表示具体的列或表达式。
0:表示列的类型,0通常表示列名。
[0, 0, false]:表示列的具体信息,具体含义需要根据上下文确定。
null:表示没有别名。concert_singer对应的数据库信息

SParC : https://drive.google.com/uc?export=download&id=1Uu7NMHTR1tdQw1t7bAuM7OPU4LElVKfg
SParC,用于复杂、跨域、上下文相关(多轮)语义解析和Text-to-SQL任务,该数据集由4298个连贯的问题序列组成(有12k+个自然语言问题到SQL标注的Question-SQL对,由14名耶鲁大学学生标注),通过用户与138个领域的200个复杂数据库的交互获得。
CoSQL :https://yale-lily.github.io/cosql
跨域数据库CoSQL,它由30k+轮次和10k+带注释的SQL查询组成。
KaggleDBQA:https://github.com/Chia-Hsuan-Lee/KaggleDBQA/tree/main?tab=readme-ov-file#Data-Format
华盛顿大学与微软联合创建,是一个真是数据集它包括跨 8 个数据库的 272 个示例,每个数据库平均有 2.25 个表。 该数据集以其真实世界的数据源、自然的问题创作环境以及具有丰富领域知识的数据库文档而闻名。 主要统计数据:8.7% WHERE 子句、73.5% VAL、24.6% SELECT 和 6.8% NON-SELECT。
中文:
CHASE: https://github.com/xjtu-intsoft/chase/tree/page/data
西安交通大学和微软等提出了首个跨领域、多轮Text-to-SQL中文数据集,包含了5459个多轮问题组成的列表,17940个<query, SQL>二元组。
BIRD-SQ: https://bird-bench.github.io/
香港大学和阿里巴巴提出了一个大规模跨域数据集BIRD,其中包含超过12751个独特的问题 SQL、95个大数据库,总大小为33.4GB。它还涵盖区块链、曲棍球、医疗保健和教育等超过37个专业领域。
BIRD-SQL Mini-Dev
从11个不同的数据库中编译了500个高质量的text2SQL对,并支持MySQL和PostgreSQL格式。
{
"question_id": 34,
"db_id": "california_schools",
"question": "What is the free rate for students between the ages of 5 and 17 at the school run by Kacey Gibson?",
"evidence": "Eligible free rates for students aged 5-17 = `Free Meal Count (Ages 5-17)` / `Enrollment (Ages 5-17)`",
"SQL": "SELECT CAST(T2.`Free Meal Count (Ages 5-17)` AS REAL) / T2.`Enrollment (Ages 5-17)` FROM schools AS T1 INNER JOIN frpm AS T2 ON T1.CDSCode = T2.CDSCode WHERE T1.AdmFName1 = 'Kacey' AND T1.AdmLName1 = 'Gibson'",
"difficulty": "moderate"
},
{
"question_id": 33,
"db_id": "california_schools",
"question": "If there are any, what are the websites address of the schools with a free meal count of 1,900-2,000 to students aged 5-17? Include the name of the school.",
"evidence": "",
"SQL": "SELECT T2.Website, T1.`School Name` FROM frpm AS T1 INNER JOIN schools AS T2 ON T1.CDSCode = T2.CDSCode WHERE T1.`Free Meal Count (Ages 5-17)` BETWEEN 1900 AND 2000 AND T2.Website IS NOT NULL",
"difficulty": "moderate"
}DuSQL :https://www.luge.ai/#/luge/dataDetail?id=13
百度针对跨域文本到SQL任务提出了一个大规模、实用的中文数据集DuSQL,它包含200个数据库、813个表和23797个Question-SQL对。
TableQA :https://www.luge.ai/#/luge/dataDetail?id=12
包含64891个问题和6000多个表的20311个唯一SQL查询。

dev.json
{
"db_id": "69cc8c0c334311e98692542696d6e445",
"question": "长沙2011年平均每天成交量是3.17,那么近一周的成交量是多少",
"question_id": "qid1",
"sql": {
"agg": [
0
],
"cond_conn_op": 1,
"sel": [
6
],
"conds": [
[
2,
2,
"3.17"
],
[
1,
2,
"长沙"
]
]
},
"query": "SELECT 近7日成交 WHERE 2011年日均成交 == \"3.17\" and 城市 == \"长沙\""
}db_schema.json

db_content.json

2. 数据处理
2.1 数据格式
LLaMA-Factory 在 data 文件夹中提供了多个训练数据集,可以直接使用。如果您打算使用自定义数据集,请按照以下方式准备您的数据集。
LLaMA-Factory 支持以 alpaca 或 sharegpt 格式的数据集。
alpaca 格式的数据集应遵循以下格式:
[
{
"instruction": "user instruction (required)",
"input": "user input (optional)",
"output": "model response (required)",
"system": "system prompt (optional)",
"history": [
["user instruction in the first round (optional)", "model response in the first round (optional)"],
["user instruction in the second round (optional)", "model response in the second round (optional)"]
]
}
]
[
{
"instruction": "人类指令(必填)",
"input": "人类输入(选填)",
"output": "模型回答(必填)",
"system": "系统提示词(选填)",
"history": [
["第一轮指令(选填)", "第一轮回答(选填)"],
["第二轮指令(选填)", "第二轮回答(选填)"]
]
}
]
通常会用[
{
"instruction": "人类指令(必填)",
"input": "",
"output": "模型回答(必填)",
}
]
组合起来系统识别 instruction=prompt,input=用户输入信息,output=大模型回复
为什么instruction 是必选?input是可选?
instruction 本身就是为了引导模型生成特定的响应而设计的。例如,如果用户的指令是“写一篇关于气候变化的文章”,那么这个指令就可以理解是模型的 prompt。
将 instruction 作为 prompt 值的做法有助于模型更好地理解用户的意图,从而生成更相关和高质量的输出。通过明确的指令,模型能够更准确地把握任务的核心特点:适合单轮指令微调,强调指令与响应的直接关系 用途:主要用于指令监督微调,适合需要明确指令和响应的任务,如问答、文本生成等。 场景:适合简单的任务执行,强调模型对单一指令的响应能力。
sharegpt 格式的数据集应遵循以下格式:
[
{
"conversations": [
{
"from": "human",
"value": "user instruction"
},
{
"from": "gpt",
"value": "model response"
}
],
"system": "system prompt (optional)",
"tools": "tool description (optional)"
}
]
{
"conversations": [
{
"from": "human",
"value": "人类指令"
},
{
"from": "gpt",
"value": "模型回答"
}
],
"system": "系统提示词(选填)",
"tools": "描述工具信息(选填)"
}这种就类似我们正常和大模型对话格式,function call 基本一致,标记出对话角色进行对话。
用途:适用于多轮对话微调,能够处理复杂的对话场景,支持多种角色(如 human、gpt、observation、function)。
场景:适合聊天机器人、虚拟助手等需要自然交互的应用,能够保持对话的上下文。
两种数据可以混合使用
多样性:混合使用这两种格式的数据集可以增加训练数据的多样性,帮助模型更好地理解不同类型的输入和输出,从而提高其泛化能力。
任务适应性:通过结合 Alpaca 的指令跟随能力和 ShareGPT 的对话上下文处理能力,模型可以在执行具体任务时表现得更加灵活和智能。
- 当前数据来自bird
{
"question_id": 34,
"db_id": "california_schools",
"question": "What is the free rate for students between the ages of 5 and 17 at the school run by Kacey Gibson?",
"evidence": "Eligible free rates for students aged 5-17 = `Free Meal Count (Ages 5-17)` / `Enrollment (Ages 5-17)`",
"SQL": "SELECT CAST(T2.`Free Meal Count (Ages 5-17)` AS REAL) / T2.`Enrollment (Ages 5-17)` FROM schools AS T1 INNER JOIN frpm AS T2 ON T1.CDSCode = T2.CDSCode WHERE T1.AdmFName1 = 'Kacey' AND T1.AdmLName1 = 'Gibson'",
"difficulty": "moderate"
},
{
"question_id": 33,
"db_id": "california_schools",
"question": "If there are any, what are the websites address of the schools with a free meal count of 1,900-2,000 to students aged 5-17? Include the name of the school.",
"evidence": "",
"SQL": "SELECT T2.Website, T1.`School Name` FROM frpm AS T1 INNER JOIN schools AS T2 ON T1.CDSCode = T2.CDSCode WHERE T1.`Free Meal Count (Ages 5-17)` BETWEEN 1900 AND 2000 AND T2.Website IS NOT NULL",
"difficulty": "moderate"
}这种数据集我们可以直接转换成alpaca 格式使用,直接对应的就是 question对应 instruction、 input对应的evidence、SQL对应的就是output
data = {
"question_id": 34,
"db_id": "california_schools",
"question": "What is the free rate for students between the ages of 5 and 17 at the school run by Kacey Gibson?",
"evidence": "Eligible free rates for students aged 5-17 = `Free Meal Count (Ages 5-17)` / `Enrollment (Ages 5-17)`",
"SQL": "SELECT CAST(T2.`Free Meal Count (Ages 5-17)` AS REAL) / T2.`Enrollment (Ages 5-17)` FROM schools AS T1 INNER JOIN frpm AS T2 ON T1.CDSCode = T2.CDSCode WHERE T1.AdmFName1 = 'Kacey' AND T1.AdmLName1 = 'Gibson'",
"difficulty": "moderate"
}
# 转换为 Alpaca 格式
alpaca_format = [
{
"instruction": data["question"],
"input": data["evidence"],
"output": data["SQL"]
}
]
import json
# json.dumps():json.dumps()是json模块中的一个函数,用于将Python对象转换为JSON格式的字符串。这个函数的参数sharegpt_format是要被转换的Python对象,通常是一个字典或列表。
# indent=4:这个参数指定了输出的JSON字符串的缩进级别。在这里,indent=4表示每个层级的缩进使用4个空格。这使得生成的JSON字符串更加易读,便于查看。
print(json.dumps(alpaca_format, indent=4))[
{
"instruction": "What is the free rate for students between the ages of 5 and 17 at the school run by Kacey Gibson?",
"input": "",
"output": "SELECT CAST(T2.`Free Meal Count (Ages 5-17)` AS REAL) / T2.`Enrollment (Ages 5-17)` FROM schools AS T1 INNER JOIN frpm AS T2 ON T1.CDSCode = T2.CDSCode WHERE T1.AdmFName1 = 'Kacey' AND T1.AdmLName1 = 'Gibson'"
}
]- sharegpt格式
data = {
"question_id": 34,
"db_id": "california_schools",
"question": "What is the free rate for students between the ages of 5 and 17 at the school run by Kacey Gibson?",
"evidence": "Eligible free rates for students aged 5-17 = `Free Meal Count (Ages 5-17)` / `Enrollment (Ages 5-17)`",
"SQL": "SELECT CAST(T2.`Free Meal Count (Ages 5-17)` AS REAL) / T2.`Enrollment (Ages 5-17)` FROM schools AS T1 INNER JOIN frpm AS T2 ON T1.CDSCode = T2.CDSCode WHERE T1.AdmFName1 = 'Kacey' AND T1.AdmLName1 = 'Gibson'",
"difficulty": "moderate"
}
# 转换为 ShareGPT 格式
sharegpt_format = [
{
"id": str(data["question_id"]),
"conversations": [
{"from": "human", "value": data["question"]},
{"from": "gpt", "value": data["SQL"]}
]
}
]
import json
print(json.dumps(sharegpt_format, indent=4))[
{
"id": "34",
"conversations": [
{
"from": "human",
"value": "What is the free rate for students between the ages of 5 and 17 at the school run by Kacey Gibson?"
},
{
"from": "gpt",
"value": "SELECT CAST(T2.`Free Meal Count (Ages 5-17)` AS REAL) / T2.`Enrollment (Ages 5-17)` FROM schools AS T1 INNER JOIN frpm AS T2 ON T1.CDSCode = T2.CDSCode WHERE T1.AdmFName1 = 'Kacey' AND T1.AdmLName1 = 'Gibson'"
}
]
}
]在 LLama_Factory/data/dataset_info.json 文件中提供您的数据集定义,并采用以下格式:
对于 alpaca 格式的数据集,其 dataset_info.json 文件中的列应为:
"dataset_name": {
"file_name": "dataset_name.json"(自己命名的文件名称及相对路径即可),
"columns": {
"prompt": "instruction",
"query": "input",
"response": "output",
"system": "system"(选填),
"history": "history"(选填)
}
}
对于 sharegpt 格式的数据集,dataset_info.json 文件中的列应该包括:
"dataset_name": {
"file_name": "dataset_name.json"(自己命名的文件名称及相对路径即可),
"formatting": "sharegpt",
"columns": {
"messages": "conversations",
"system": "system"(选填),
"tools": "tools"(选填)
},
"tags": {
"role_tag": "from",
"content_tag": "value",
"user_tag": "user",
"assistant_tag": "assistant"
}
}会支持多模态数据集:
[
{
"conversations": [
{
"from": "human",
"value": "<image>人类指令"
},
{
"from": "gpt",
"value": "模型回答"
}
],
"images": [
"图像路径(必填)"
]
}
][
{
"conversations": [
{
"from": "human",
"value": "<video>人类指令"
},
{
"from": "gpt",
"value": "模型回答"
}
],
"videos": [
"视频路径(必填)"
]
}
]对于上述格式的数据,dataset_info.json 中的数据集描述应为:
"数据集名称": {
"file_name": "data.json",
"formatting": "sharegpt",
"columns": {
"messages": "conversations",
"videos": "videos"
}
}
为什么文件中已有的数据注册方式和上边提示的不一样?
不同版本适配方式不一样,大家了解就好!
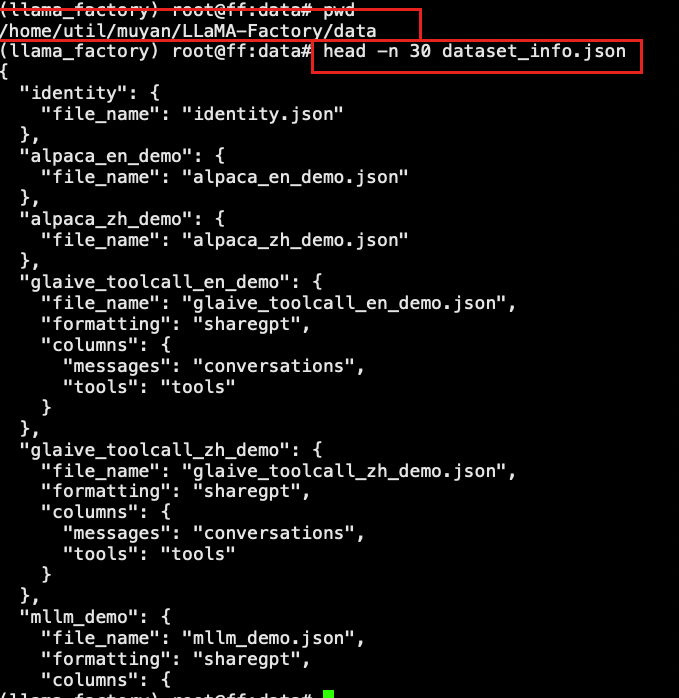
进入到LLaMA-Factory/src/llamafactory/data路径下
查看parser.py 文件
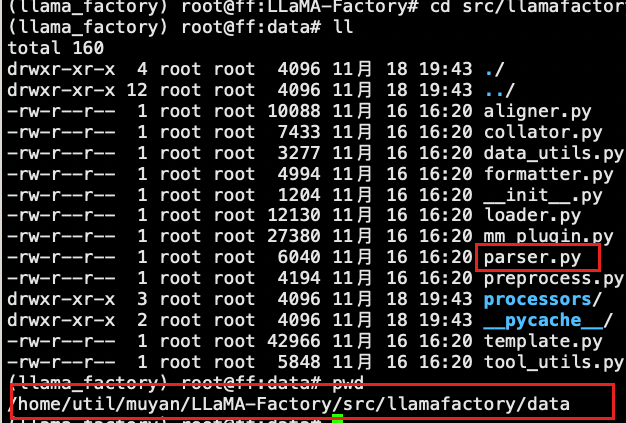
这里在当前版本中已经做了字段映射,不需要在配置映射关系,但是配置也没有关系。
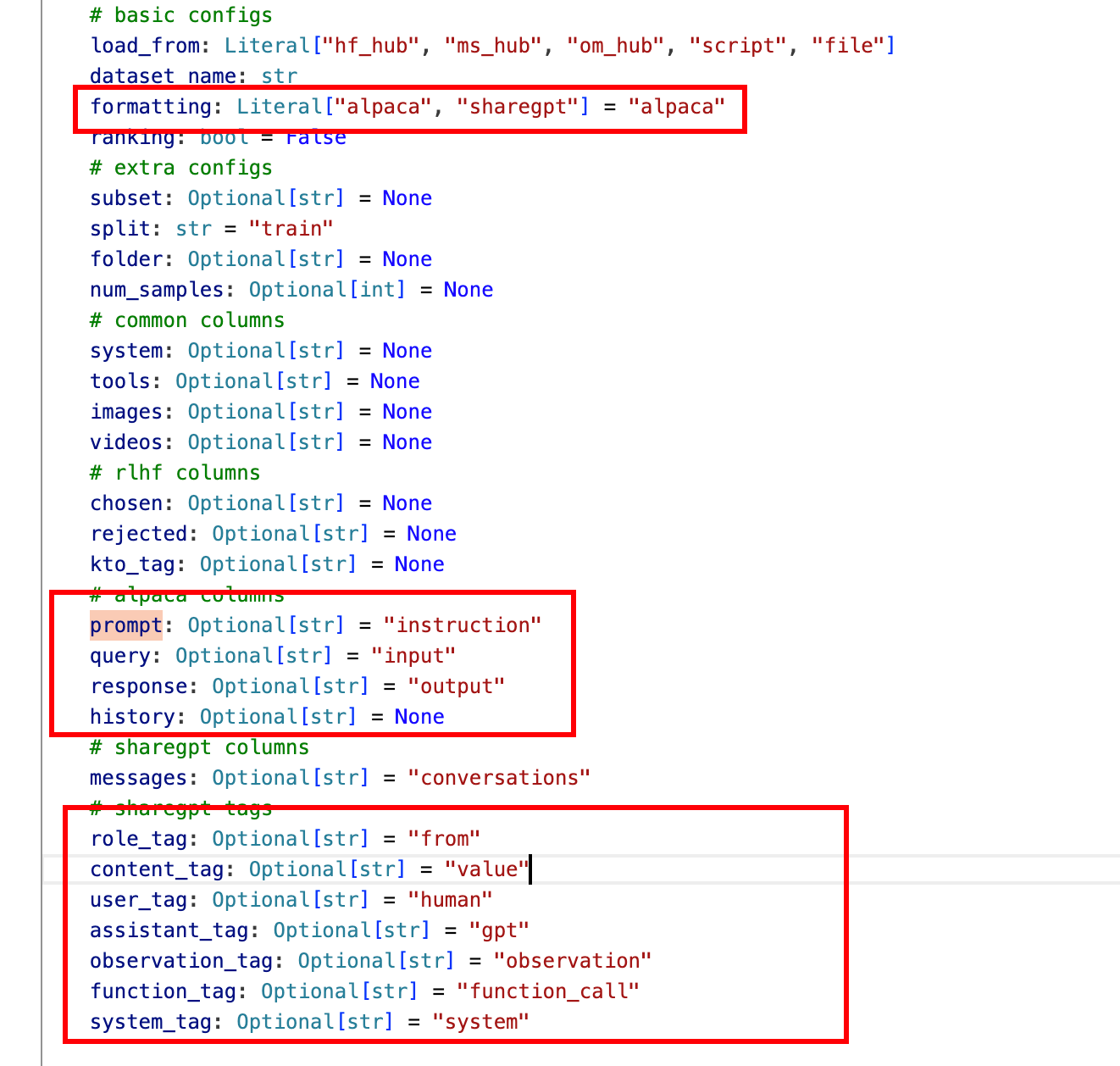
2.2 数据处理实战
多轮对话数据

# 查看数据结构cosql_train.json: head -n 800 cosql_train.json
data = [
{
"final": {
"utterance": "Find the name of the department which has the highest average salary of professors.",
"query": "SELECT dept_name FROM instructor GROUP BY dept_name ORDER BY avg(salary) DESC LIMIT 1"
},
"database_id": "college_2",
"interaction": [
{
"utterance": "Find out the average salary of professors?",
"utterance_toks": [
"Find",
"out",
"the",
"average",
"salary",
"of",
"professors",
"?"
],
"query": "SELECT avg ( salary ) FROM instructor",
"query_toks_no_value": [
"select",
"avg",
"(",
"salary",
")",
"from",
"instructor"
],
"sql": {
"from": {
"table_units": [
[
"table_unit",
3
]
],
"conds": []
},
"select": [
False,
[
[
5,
[
0,
[
0,
14,
False
],
None
]
]
]
],
"where": [],
"groupBy": [],
"having": [],
"orderBy": [],
"limit": None,
"intersect": None,
"union": None,
"except": None
}
},
{
"utterance": "Find the average salary of the professors of each department?",
"query": "SELECT avg ( salary ) , dept_name FROM instructor GROUP BY dept_name"
},
{
"utterance": "Which department has the highest average salary of professors?",
"query": "SELECT dept_name FROM instructor GROUP BY dept_name ORDER BY avg ( salary ) DESC LIMIT 1"
},
{
"utterance": "Which department has the lowest average salary of professors?",
"query": "SELECT dept_name FROM instructor GROUP BY dept_name ORDER BY avg ( salary ) LIMIT 1"
},
{
"utterance": "In which department Mr. Mird work for?",
"query": "SELECT dept_name FROM instructor where name = 'Mird'"
},
{
"utterance": "How much is the salary Mr. Mird earns currently?",
"query": "SELECT salary FROM instructor where name = 'Mird'"
}
]
}
]
# 初始化一个空列表来存储转换后的对话
sharegpt_format = []
# 遍历每个条目(在这个例子中只有一个条目)
for entry in data:
# 初始化一个空列表来存储当前条目的对话
conversation = []
# 将 final 中的对话添加到对话中
if "final" in entry:
conversation.append({
"from": "human",
"value": entry["final"]["utterance"]
})
conversation.append({
"from": "gpt",
"value": entry["final"]["query"]
})
# 遍历每个交互
for interaction in entry["interaction"]:
# 将用户的指令添加到对话中
conversation.append({
"from": "human",
"value": interaction["utterance"]
})
# 将模型的响应添加到对话中
conversation.append({
"from": "gpt",
"value": interaction["query"]
})
# 将当前对话添加到最终的格式中
sharegpt_format.append({
"conversations": conversation
})
import json
# 将转换后的格式转换为JSON字符串并打印
print(json.dumps(sharegpt_format, indent=4))[
{
"conversations": [
{
"from": "human",
"value": "Find the name of the department which has the highest average salary of professors."
},
{
"from": "gpt",
"value": "SELECT dept_name FROM instructor GROUP BY dept_name ORDER BY avg(salary) DESC LIMIT 1"
},
{
"from": "human",
"value": "Find out the average salary of professors?"
},
{
"from": "gpt",
"value": "SELECT avg ( salary ) FROM instructor"
},
{
"from": "human",
"value": "Find the average salary of the professors of each department?"
},
{
"from": "gpt",
"value": "SELECT avg ( salary ) , dept_name FROM instructor GROUP BY dept_name"
},
{
"from": "human",
"value": "Which department has the highest average salary of professors?"
},
{
"from": "gpt",
"value": "SELECT dept_name FROM instructor GROUP BY dept_name ORDER BY avg ( salary ) DESC LIMIT 1"
},
{
"from": "human",
"value": "Which department has the lowest average salary of professors?"
},
{
"from": "gpt",
"value": "SELECT dept_name FROM instructor GROUP BY dept_name ORDER BY avg ( salary ) LIMIT 1"
},
{
"from": "human",
"value": "In which department Mr. Mird work for?"
},
{
"from": "gpt",
"value": "SELECT dept_name FROM instructor where name = 'Mird'"
},
{
"from": "human",
"value": "How much is the salary Mr. Mird earns currently?"
},
{
"from": "gpt",
"value": "SELECT salary FROM instructor where name = 'Mird'"
}
]
}
]将上边代码更改后,处理整个文件
# 创建文件 concert_sharegpt.py
import json
import argparse
def convert_to_sharegpt_format(input_file, output_file):
# 读取输入 JSON 文件
with open(input_file, 'r') as file:
data = json.load(file)
# 初始化一个空列表来存储转换后的对话
sharegpt_format = []
# 遍历每个条目(在这个例子中可能有多个条目)
for entry in data:
# 初始化一个空列表来存储当前条目的对话
conversation = []
# 将 final 中的对话添加到对话中
if "final" in entry:
conversation.append({
"from": "human",
"value": entry["final"]["utterance"]
})
conversation.append({
"from": "gpt",
"value": entry["final"]["query"]
})
# 遍历每个交互
for interaction in entry["interaction"]:
# 将用户的指令添加到对话中
conversation.append({
"from": "human",
"value": interaction["utterance"]
})
# 将模型的响应添加到对话中
conversation.append({
"from": "gpt",
"value": interaction["query"]
})
# 将当前对话添加到最终的格式中
sharegpt_format.append({
"conversations": conversation
})
# 将转换后的数据写入输出 JSON 文件
with open(output_file, 'w') as output_file_handle:
json.dump(sharegpt_format, output_file_handle, indent=4)
if __name__ == "__main__":
# 创建 ArgumentParser 对象
parser = argparse.ArgumentParser(description="Convert CoSQL train data to ShareGPT format.")
# 添加输入文件路径参数
parser.add_argument("input_file", type=str, help="Path to the input JSON file (e.g., cosql_train.json)")
# 添加输出文件路径参数
parser.add_argument("output_file", type=str, help="Path to the output JSON file (e.g., sharegpt_cosql_train.json)")
# 解析命令行参数
args = parser.parse_args()
# 调用转换函数
convert_to_sharegpt_format(args.input_file, args.output_file)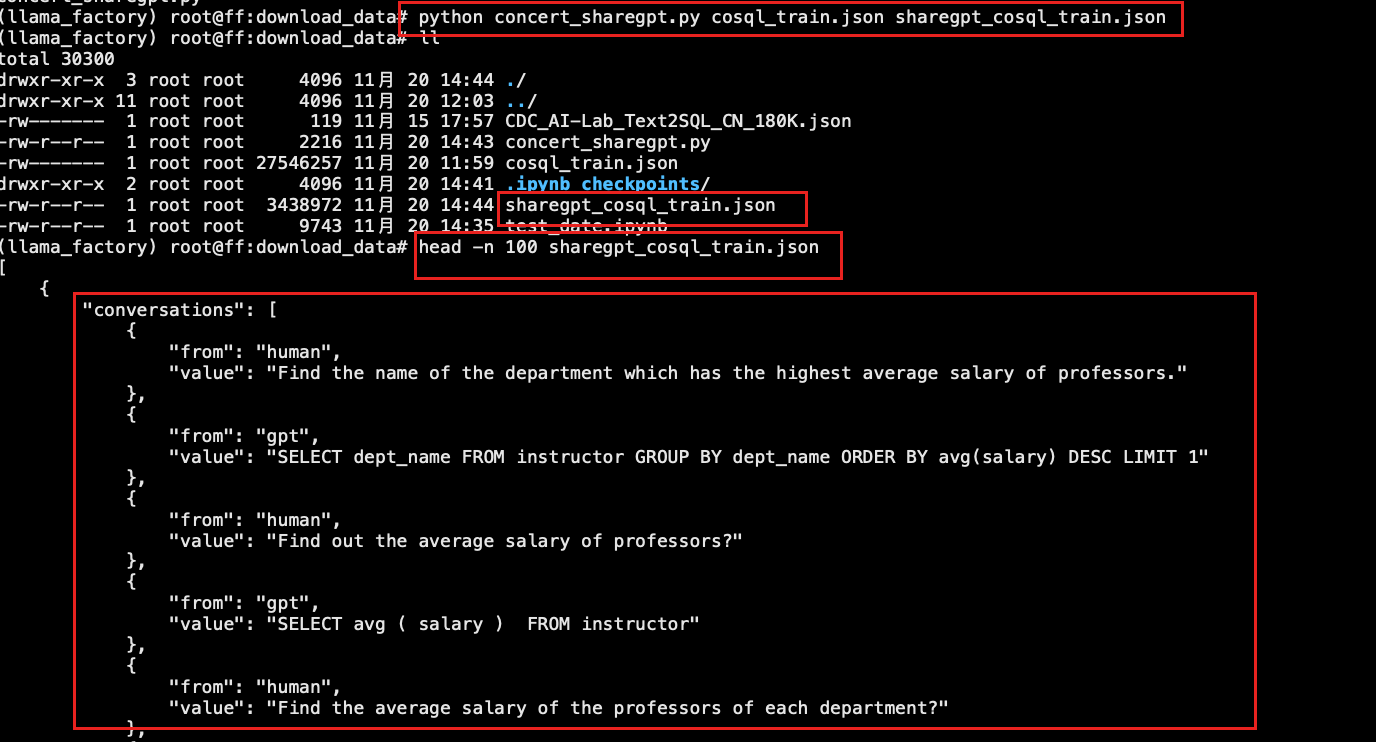
# 创建文件 convert_alpaca.py 转换alpaca格式代码 单轮对话数据
# 使用bird数据https://bird-bench.github.io/
import json
import argparse
def convert_to_alpaca_format(input_file, output_file):
# 读取输入 JSON 文件
with open(input_file, 'r') as file:
data = json.load(file)
# 初始化一个空列表来存储转换后的对话
alpaca_format = []
# 遍历每个条目(在这个例子中可能有多个条目)
for entry in data:
# 将当前条目转换为 Alpaca 格式
alpaca_entry = {
"instruction": entry["question"],
"input": entry["evidence"],
"output": entry["SQL"]
}
# 将转换后的条目添加到最终的格式中
alpaca_format.append(alpaca_entry)
# 将转换后的数据写入输出 JSON 文件
with open(output_file, 'w') as output_file_handle:
json.dump(alpaca_format, output_file_handle, indent=4)
if __name__ == "__main__":
# 创建 ArgumentParser 对象
parser = argparse.ArgumentParser(description="Convert CoSQL train data to Alpaca format.")
# 添加输入文件路径参数
parser.add_argument("input_file", type=str, help="Path to the input JSON file (e.g., cosql_train.json)")
# 添加输出文件路径参数
parser.add_argument("output_file", type=str, help="Path to the output JSON file (e.g., alpaca_cosql_train.json)")
# 解析命令行参数
args = parser.parse_args()
# 调用转换函数
convert_to_alpaca_format(args.input_file, args.output_file)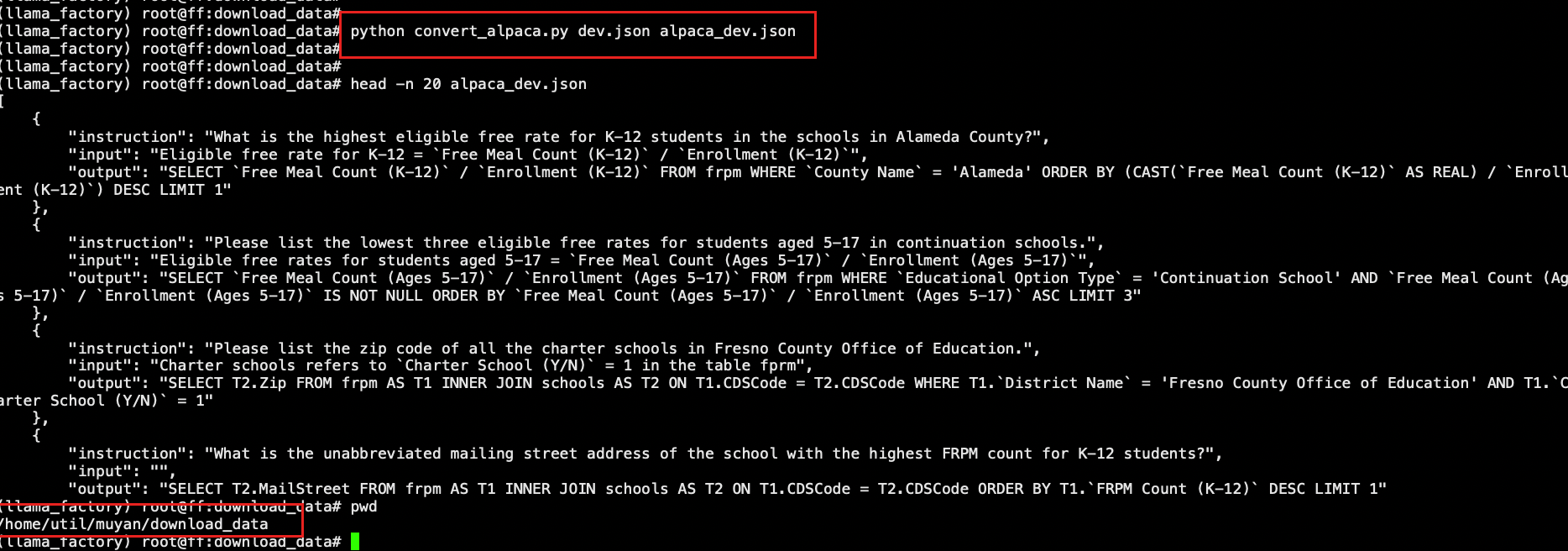
2.3 数据注册
注意路径
mv download_data/alpaca_dev.json LLaMA-Factory/data/
mv download_data/sharegpt_cosql_train.json LLaMA-Factory/data/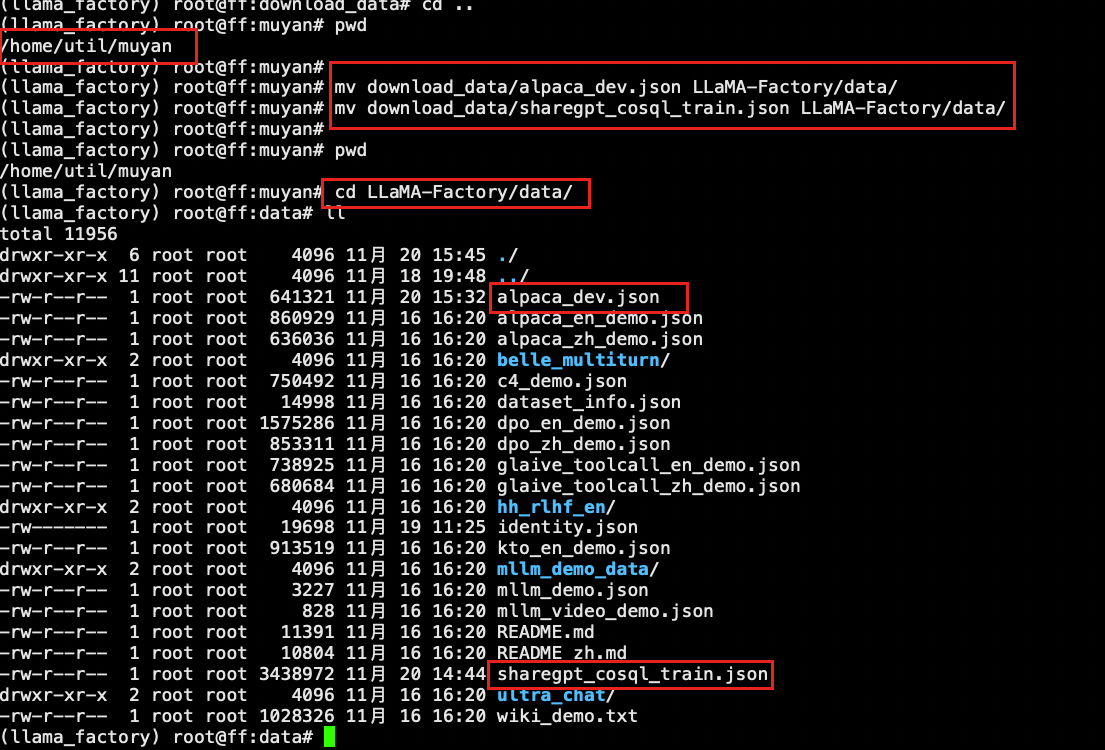
- 注册数据文件
路径:/home/util/muyan/LLaMA-Factory/data
vim dataset_info.json
"alpaca_dev": {
"file_name": "alpaca_dev.json"
},
"sharegpt_cosql_train": {
"file_name": "sharegpt_cosql_train.json",
"formatting": "sharegpt",
"columns": {
"messages": "conversations"
}
},
- 去界面查看数据集
注意需要启动llama_factory
可以使用上节课命令
export USE_MODELSCOPE_HUB=1
export CUDA_VISIBLE_DEVICES=0,1
nohup llamafactory-cli webui >20241119.log 2>&1 &
访问界面 http://192.168.110.133:7860/ Train标签
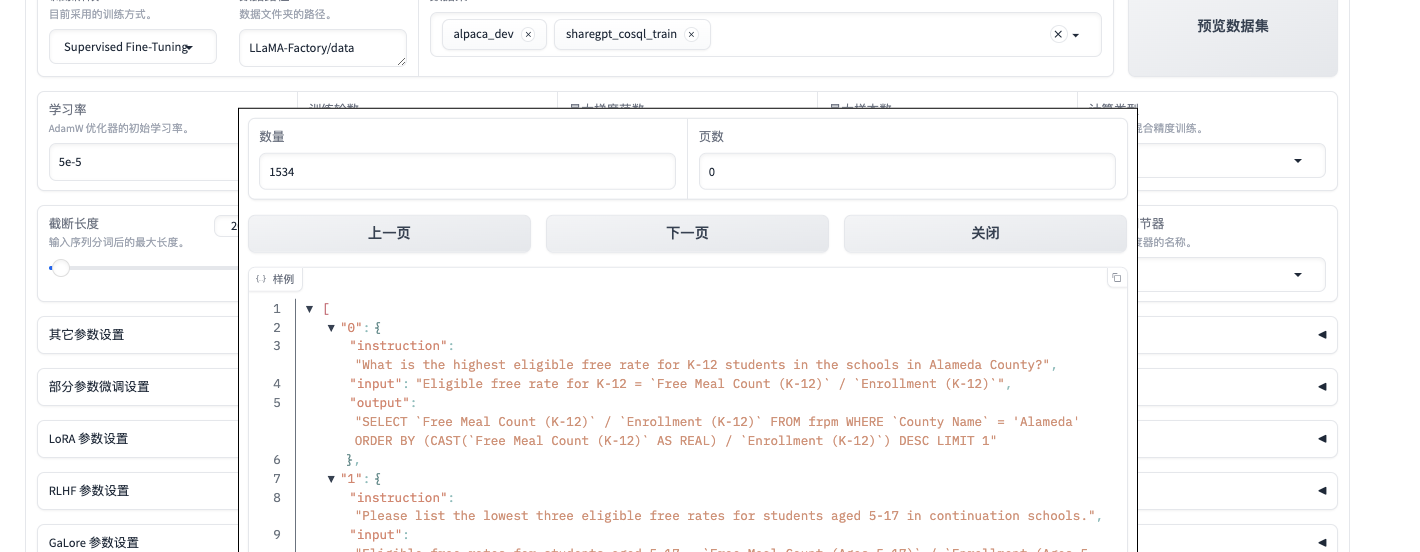
点击数据预览进行查看注意:只能查看第一个数据集的内容
3. 实战数据微调
3.1 LORA参数详解与实战
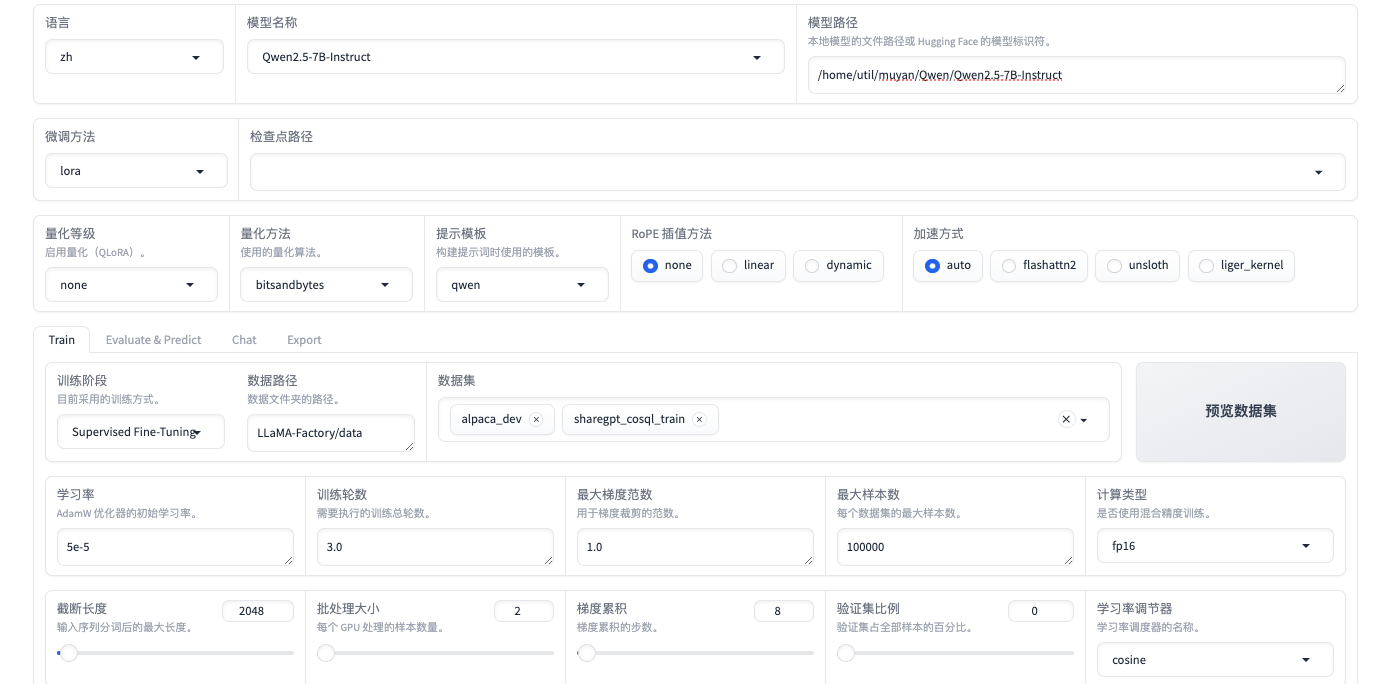

1. 基本配置
--stage sft:指定训练阶段,这里是监督微调(Supervised Fine-Tuning, SFT)。
--do_train True:指定是否进行训练,True表示进行训练。 false 为不训练
--model_name_or_path /home/util/muyan/Qwen/Qwen2.5-7B-Instruct:指定预训练模型的路径。
--output_dir saves/Qwen2.5-7B-Instruct/lora/train_2024-11-20-16-00-00:指定输出目录,保存训练结果和日志。
2. 数据处理
--preprocessing_num_workers 16:指定预处理数据时使用的线程数。提高数据预处理速度,但可能增加CPU和内存资源的消耗,通常是总核数-1或者-2
--dataset_dir LLaMA-Factory/data:指定数据集目录。
--dataset alpaca_dev,sharegpt_cosql_train:指定使用的数据集,可以是多个数据集,用逗号分隔。
--cutoff_len 2048:指定输入序列的最大长度。 调小模型只能处理较短的上下文信息,可能会丢失一些重要的上下文,影响模型的性能,但是性能会节约
--max_samples 100000:指定最多使用的样本数量。
增大:更多的样本可以提供更多的训练信号,有助于模型学习到更丰富的特征和模式,可能提高模型的泛化能力。
减小:较少的样本可能导致模型过拟合,无法充分学习到数据的多样性,影响模型的泛化能力。
3. 训练配置
--num_train_epochs 3.0:指定训练的总轮数。
模型会在整个数据集上进行更多的轮次训练,有机会学习到更多细节,提高模型性能,但也可能增加过拟合的风险。
--per_device_train_batch_size 2:指定每个设备上的训练批次大小。
更大的批次大小可以提供更稳定的梯度估计,有助于模型收敛,但可能会导致模型过拟合。
--gradient_accumulation_steps 8:指定梯度累积步骤数,用于模拟更大的批次大小。
提高模型稳定性,但增加内存使用和训练时间。
--learning_rate 5e-05:指定学习率。等价于 0.00005 相当与小数点往前移动了5位数 如果是3e-5 对应的是0.00003,e-6小数点往前移动六位
权重更新的步长可能会太大,导致模型在损失函数的最小值附近震荡,甚至发散,无法收敛到最优解。或者是过拟合状态
反之容易欠拟合很难发挥模型最好性能
--lr_scheduler_type cosine:指定学习率调度器类型,这里是余弦退火。帮助模型在接近最优解时进行更细致的调整,提高收敛性和最终的模型性能
Constant:适合于需要稳定学习率的任务,尤其是在模型已经经过预训练并且只需微调的情况下。
Cosine Annealing:训练周期较长的情况下,可以有效避免在训练后期的震荡。
--warmup_steps 0:指定学习率预热步数。
--max_grad_norm 1.0:指定梯度裁剪的最大范数。
调大会加速收敛,但可能会造成梯度爆炸,小会慢,但是相对收敛速度较慢
--logging_steps 5:指定每多少步记录一次日志。
主要记录日志信息,调大会节约空间,小了会详细但是相对花费时间多一些
--save_steps 100:指定每多少步保存一次模型检查点。
会做中间节点的保存,调大频率会低,会节约空间,调小保存步骤更加详细。
--packing False:指定是否使用打包技术。
True:打包技术可以提高训练效率,尤其是在处理短序列数据时,但可能会增加数据预处理的复杂性。
False:不使用打包技术,训练过程更简单,但可能会因为填充带来的计算浪费而降低效率
--report_to none:指定报告训练进度的方式,none表示不报告。
类似TensorBoard 这样的外部系统
4. 优化器和混合精度
--fp16 True:指定是否使用混合精度训练。
如果显示fp32 则不会有当前命令生成
--optim adamw_torch:指定优化器类型,这里是AdamW。 在其他参数设置一栏中进行设置{"optim": "adamw_torch"}
如 Adam、SGD 会影响模型的收敛速度和最终性能。
--ddp_timeout 180000000:指定分布式训练的超时时间。
更大的超时时间可以给进程更多的时间来同步,避免因网络延迟或计算差异导致的训练中断,小了可能因为某些网络动荡而造成中断。
5. LoRA 配置
--finetuning_type lora:指定微调类型,这里是LoRA(Low-Rank Adaptation)。
选择其他类型会对应变化 例如:freeze
--lora_rank 8:指定LoRA的秩。
LoRA 的秩决定了添加的低秩矩阵的大小。秩越小,添加的参数量越少,计算开销也越小。这个需要因微调场景效果来变更
--lora_alpha 16:指定LoRA的比例因子。
LoRA 的比例因子(alpha)用于缩放低秩矩阵的贡献。较大的 alpha 值可以使低秩矩阵的贡献更大,从而增强微调的效果。让rank的作用更大,可能会导致过拟合。
--lora_dropout 0:指定LoRA的dropout概率。
调大:增加模型的泛化能力,减少过拟合,调小:减少模型的正则化,可能提高模型的表达能力
--lora_target all:指定LoRA的目标层,all表示所有层。部分参数微调设置
可以指定特定层调整
q_proj:查询投影层
v_proj:值投影层
k_proj:键投影层
fc:全连接层
6. 其他配置
--template qwen:指定使用的模板。
--flash_attn auto:指定是否使用Flash Attention,auto表示自动选择。
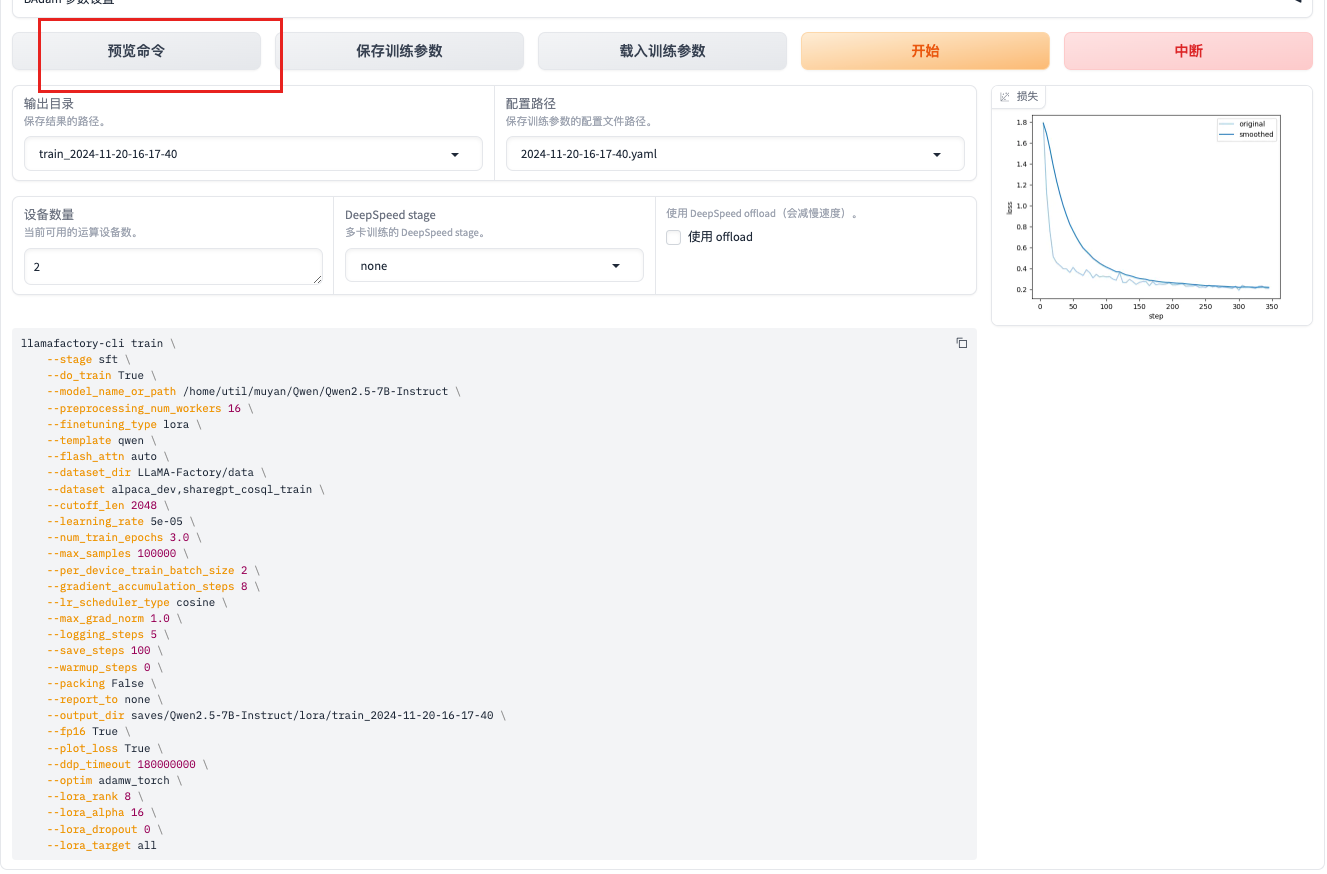
--plot_loss True:指定是否绘制损失曲线。如果点击保存命令,会将当前命令进行保存,也是启动命令的相对路径中的conf文件夹中
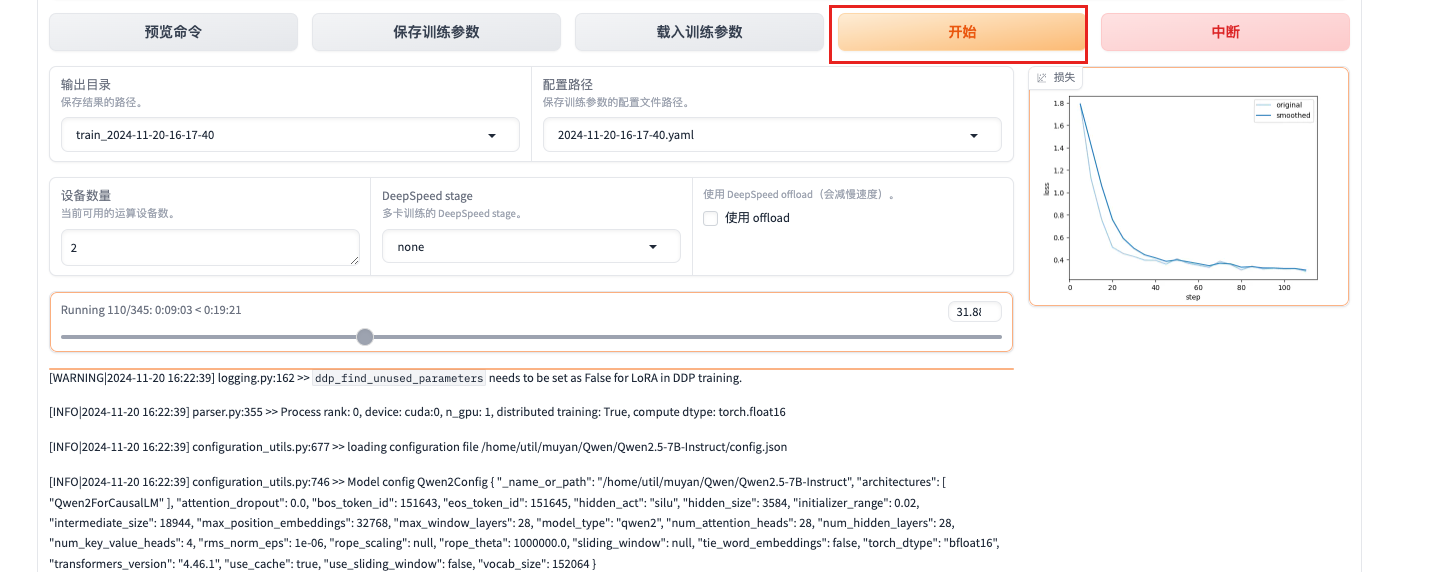
损失曲线的含义
1. 横轴(X轴)
表示训练的迭代次数(或训练步数)或训练的epoch数量。
作用:了解模型在训练过程中经历了多少次更新。每个点对应于训练过程中的一个特定时间点。
2. 纵轴(Y轴)
纵轴表示损失值(loss),通常是模型在训练集或验证集上的损失函数值。
作用:反映模型的预测与真实标签之间的差距。较低的损失值通常意味着模型的预测效果较好。
损失曲线的关系
损失值与训练进度:随着训练的进行,损失值通常会逐渐降低,表明模型在学习数据中的模式。如果损失值在训练过程中持续下降,说明模型正在有效地学习。
过拟合与欠拟合:
欠拟合:如果损失值在训练初期就很高且没有明显下降,可能表明模型未能有效学习数据特征。
过拟合:如果训练损失持续下降,而验证损失在某个点后开始上升,说明模型可能在训练集上过拟合,无法很好地泛化到验证集。
3.2 微调模型验证
执行完成花费30分钟
Please list the lowest three eligible free rates for students aged 5-17 in continuation schools.
请列出继续教育学校针对5至17岁学生的最低三个免费费率。
不加载lora微调块回复译文
为了向您提供针对 5-17 岁学生的继续教育学校的最低三个免费费率,我需要有关您所指国家或地区的更多具体信息,因为费率和资格标准可能因地点而异。继续教育学校,也称为替代教育计划,通常是为无法在传统学校环境中取得成功的学生设计的。
您可以采取以下一些常规步骤来查找所需的信息:
访问教育部门的官方网站:大多数国家/地区都有教育部门的官方网站,提供有关学费、资格标准和学生免费费率的详细信息。
联系当地教育当局:联系当地教育委员会或学区以获取有关免费费率和资格的具体信息。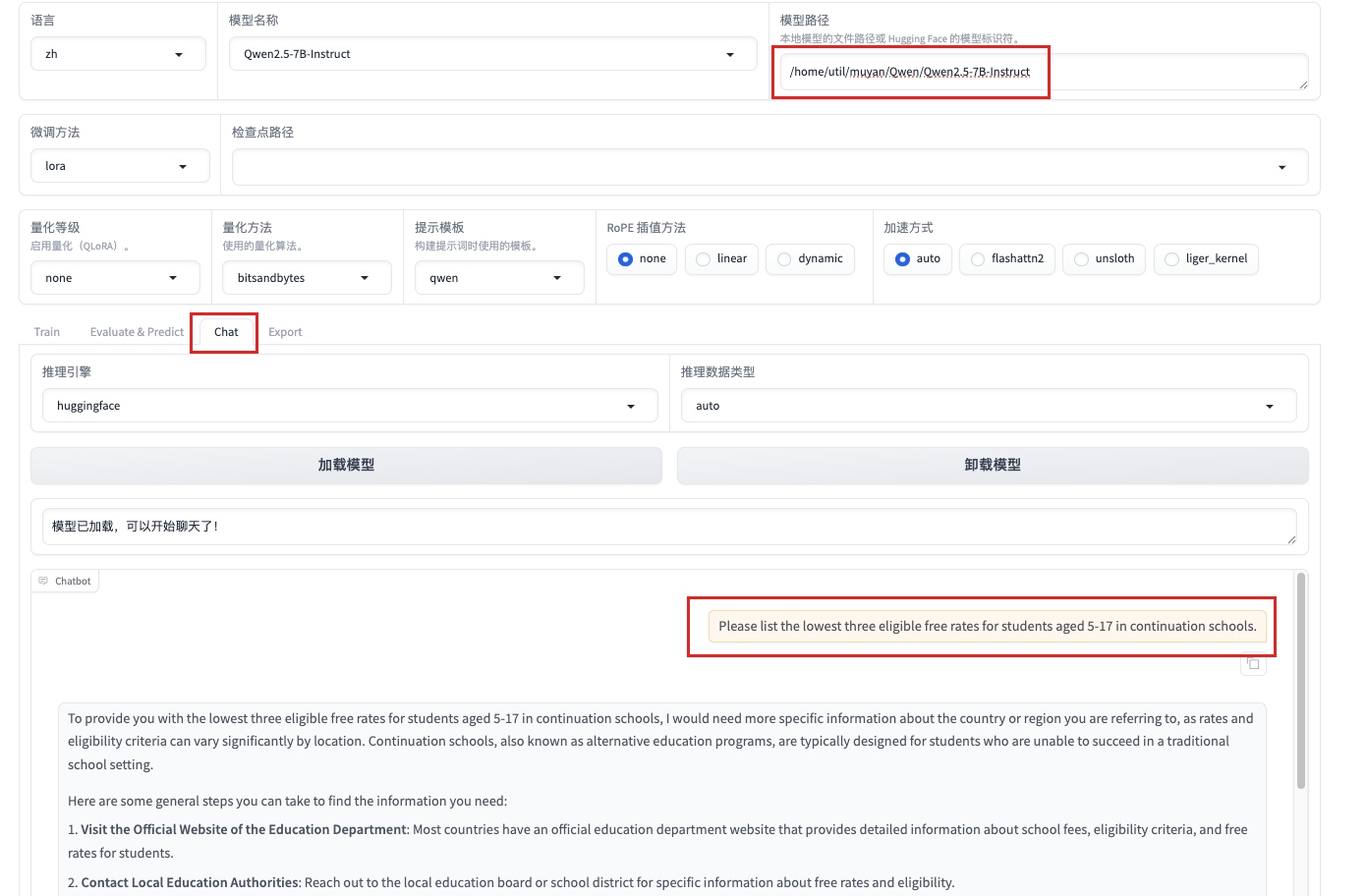
Please list the lowest three eligible free rates for students aged 5-17 in continuation schools.
请列出继续教育学校针对5至17岁学生的最低三个免费费率。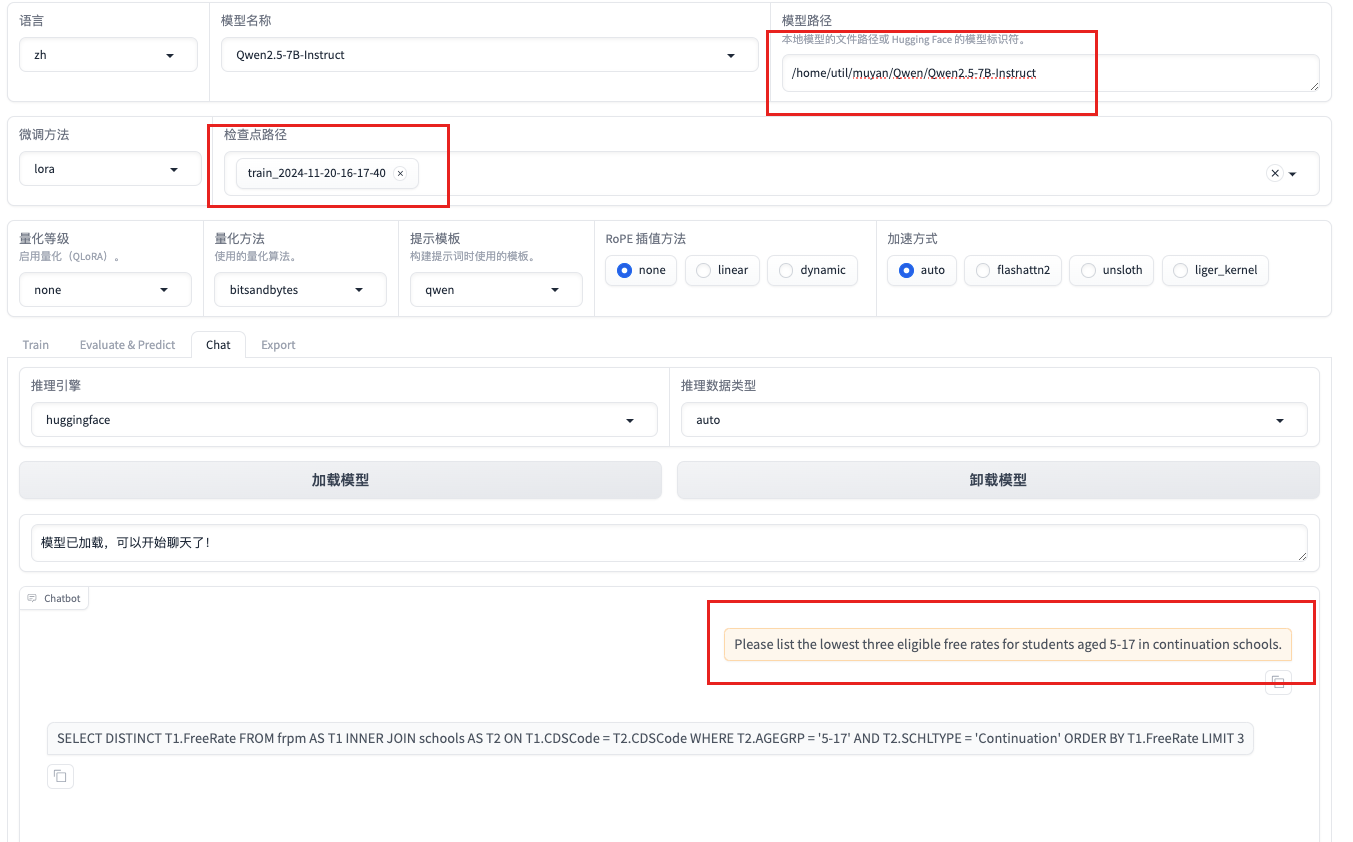
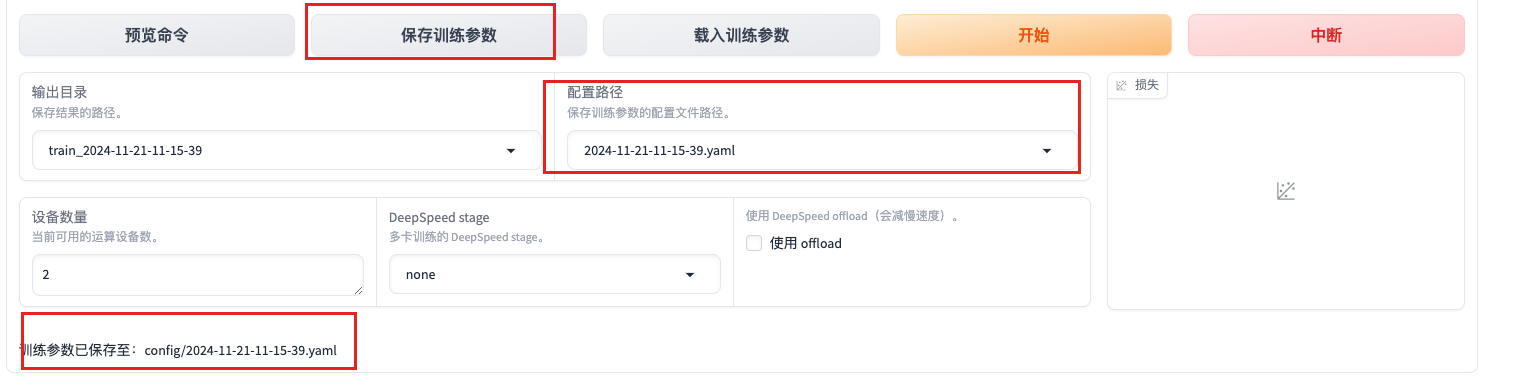
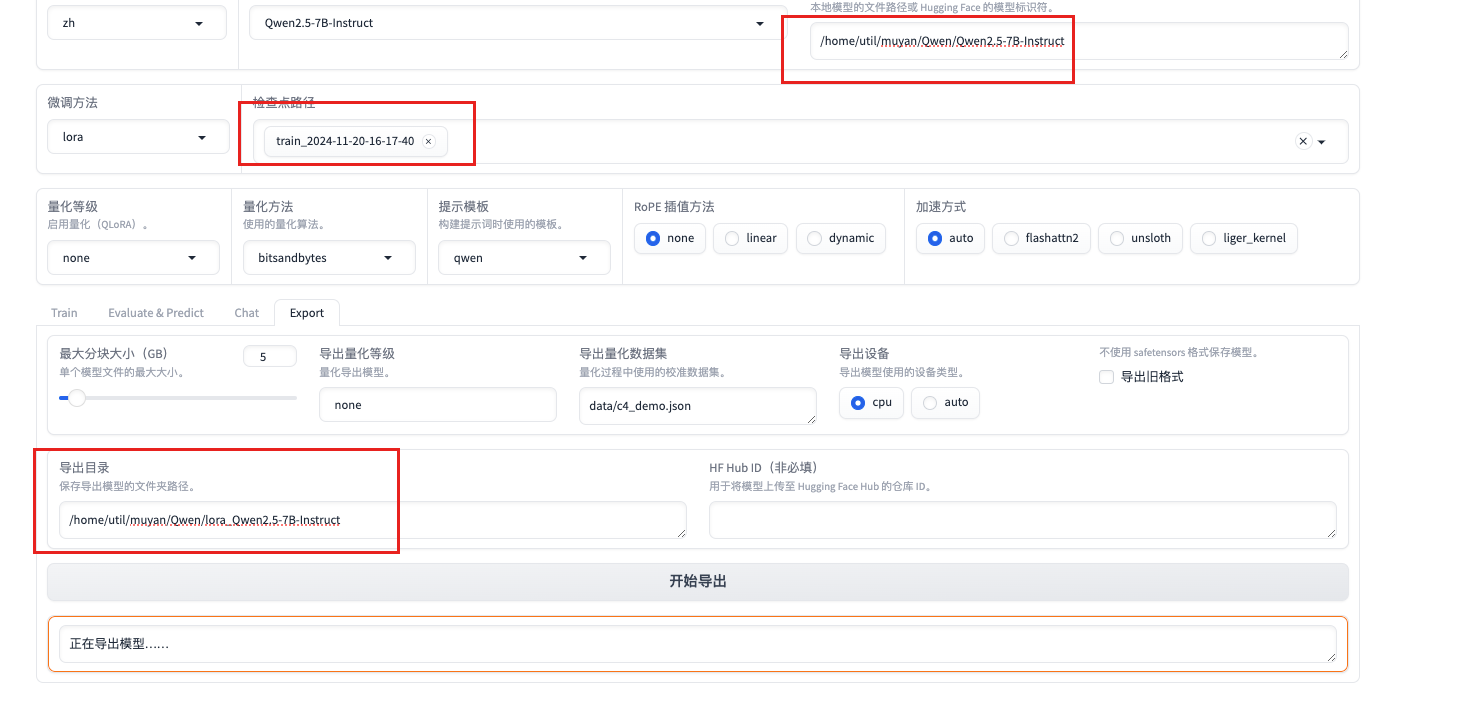
- 导出模型 再次验证
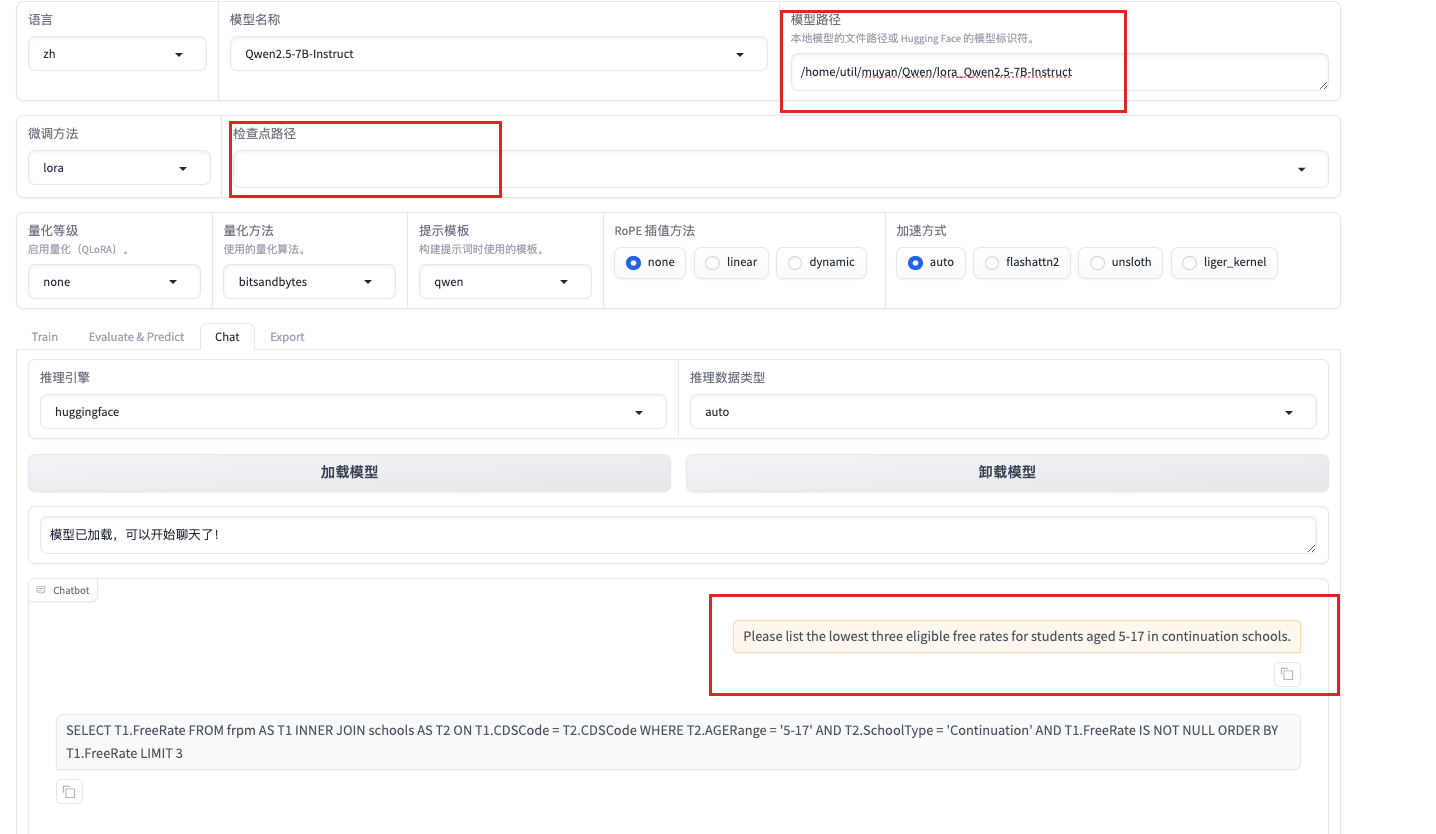
- 模型效果校验:
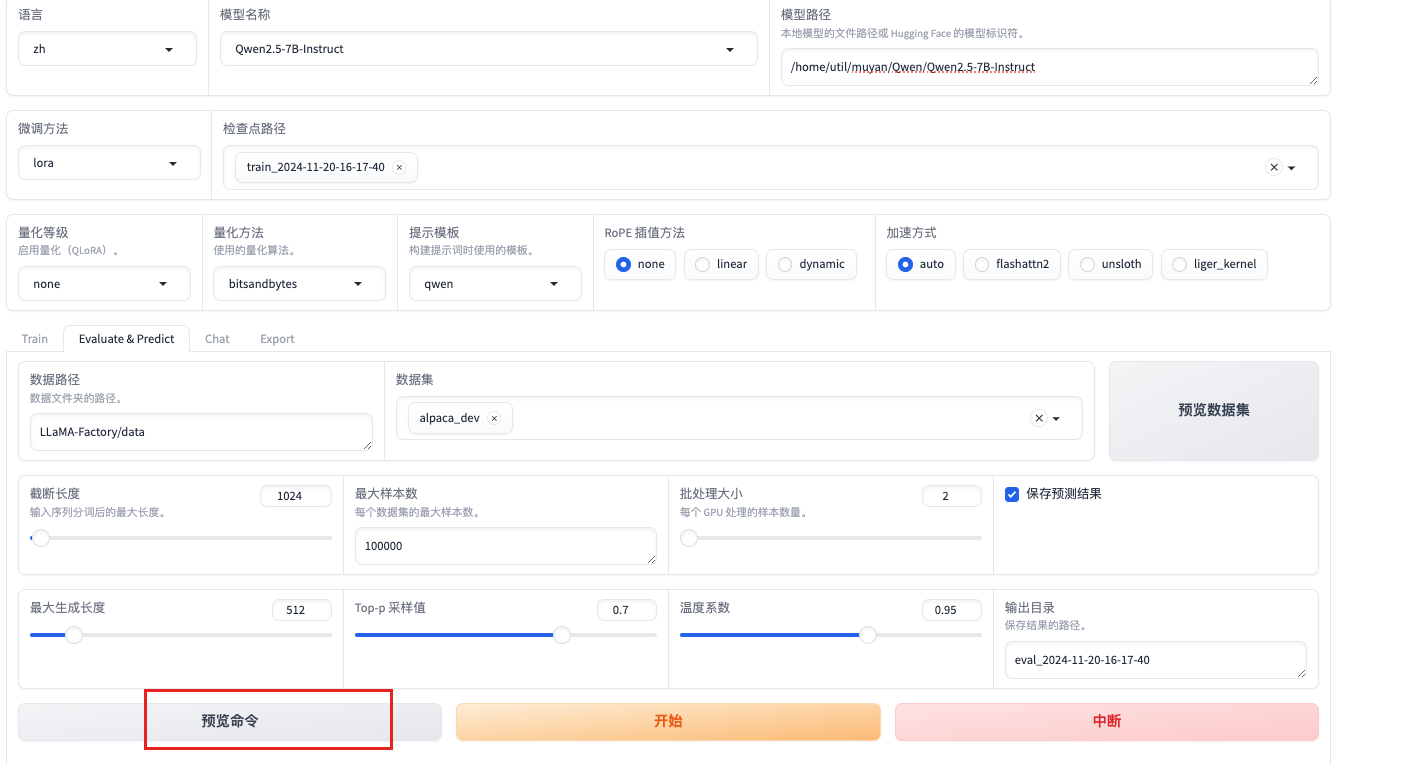
llamafactory-cli train \
--stage sft \
--model_name_or_path /home/util/muyan/Qwen/Qwen2.5-7B-Instruct \
--preprocessing_num_workers 16 \
--finetuning_type lora \
--quantization_method bitsandbytes \
--template qwen \
--flash_attn auto \
--dataset_dir LLaMA-Factory/data \
--eval_dataset alpaca_dev \
--cutoff_len 1024 \
--max_samples 100000 \
--per_device_eval_batch_size 2 \
--predict_with_generate True \
指定是否在评估时生成文本。
--max_new_tokens 512 \
--top_p 0.7 \
--temperature 0.95 \
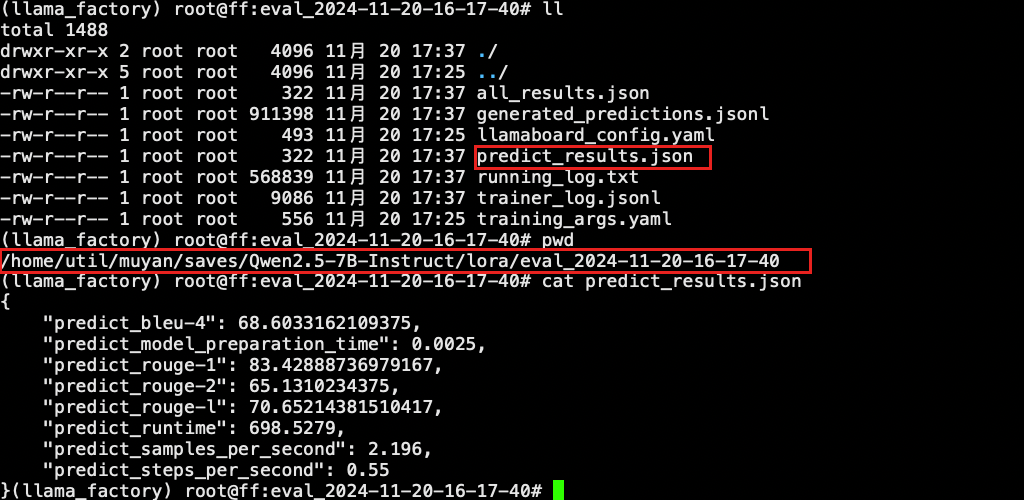
--output_dir saves/Qwen2.5-7B-Instruct/lora/eval_2024-11-21-11-15-39 \
--do_predict True \
指定是否执行预测
--adapter_name_or_path saves/Qwen2.5-7B-Instruct/lora/train_2024-11-21-00-11-43
指定适配器的名称或路径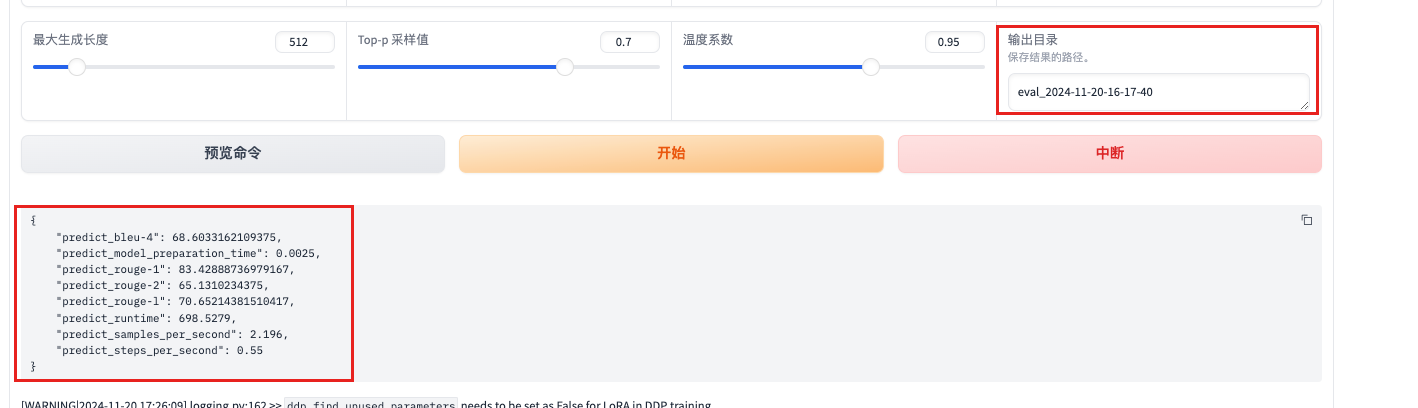
"predict_bleu-4": 68.6033162109375 衡量生成文本与参考文本的相似度
"predict_model_preparation_time": 0.0025 模型准备阶段时间,加载模型和数据预处理的时间。
"predict_rouge-1": 83.42888736979167 成文本与参考文本在单个词(1-gram)层面的重叠度。
"predict_rouge-2": 65.1310234375
"predict_rouge-l": 70.65214381510417 最长公共子序列层面的重叠度较高
"predict_runtime": 698.5279 评估运行时间
"predict_samples_per_second": 2.196 每秒处理的样本数
"predict_steps_per_second": 0.55 每秒处理的步数,每个 batch 上的前向传播和后向传播的次数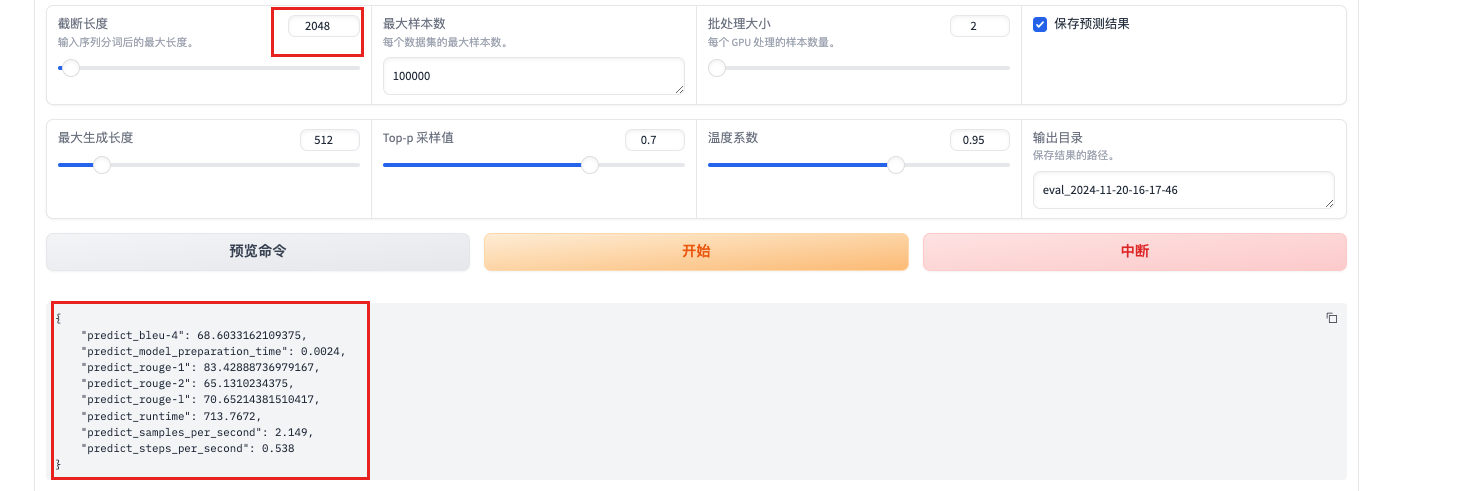
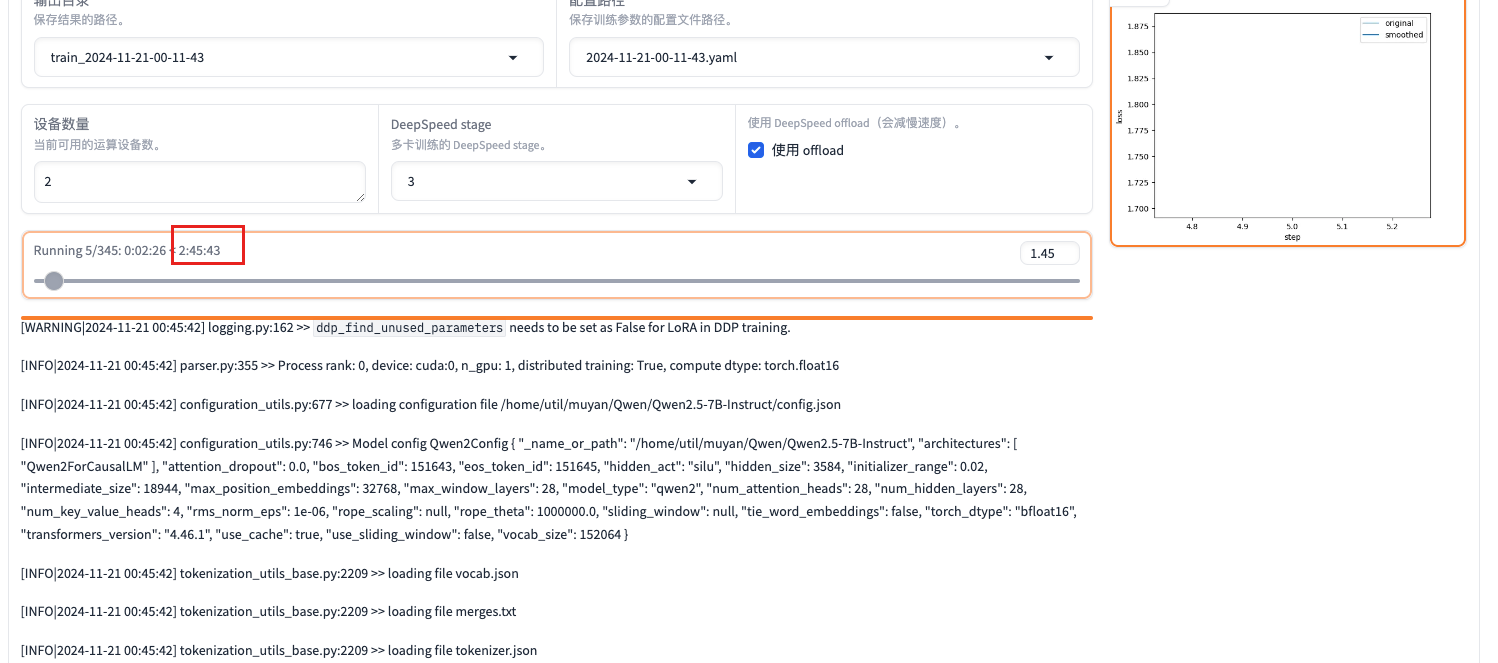
3.3 使用deepspeed 微调模型
ZeRO Stage 1 对优化器状态进行分片(sharding),每个进程只保留其所需的优化器状态的一部分。
ZeRO Stage 2 对优化器状态和梯度进行分片,进一步减少内存占用。
ZeRO Stage 3 对优化器状态、梯度和模型参数进行分片。
DeepSpeed Offload 将部分计算和数据存储任务从 GPU 卸载到 CPU 或 NVMe 存储。 释放 GPU 内存,使得可以训练更大的模型。
省资源但是花费时间较多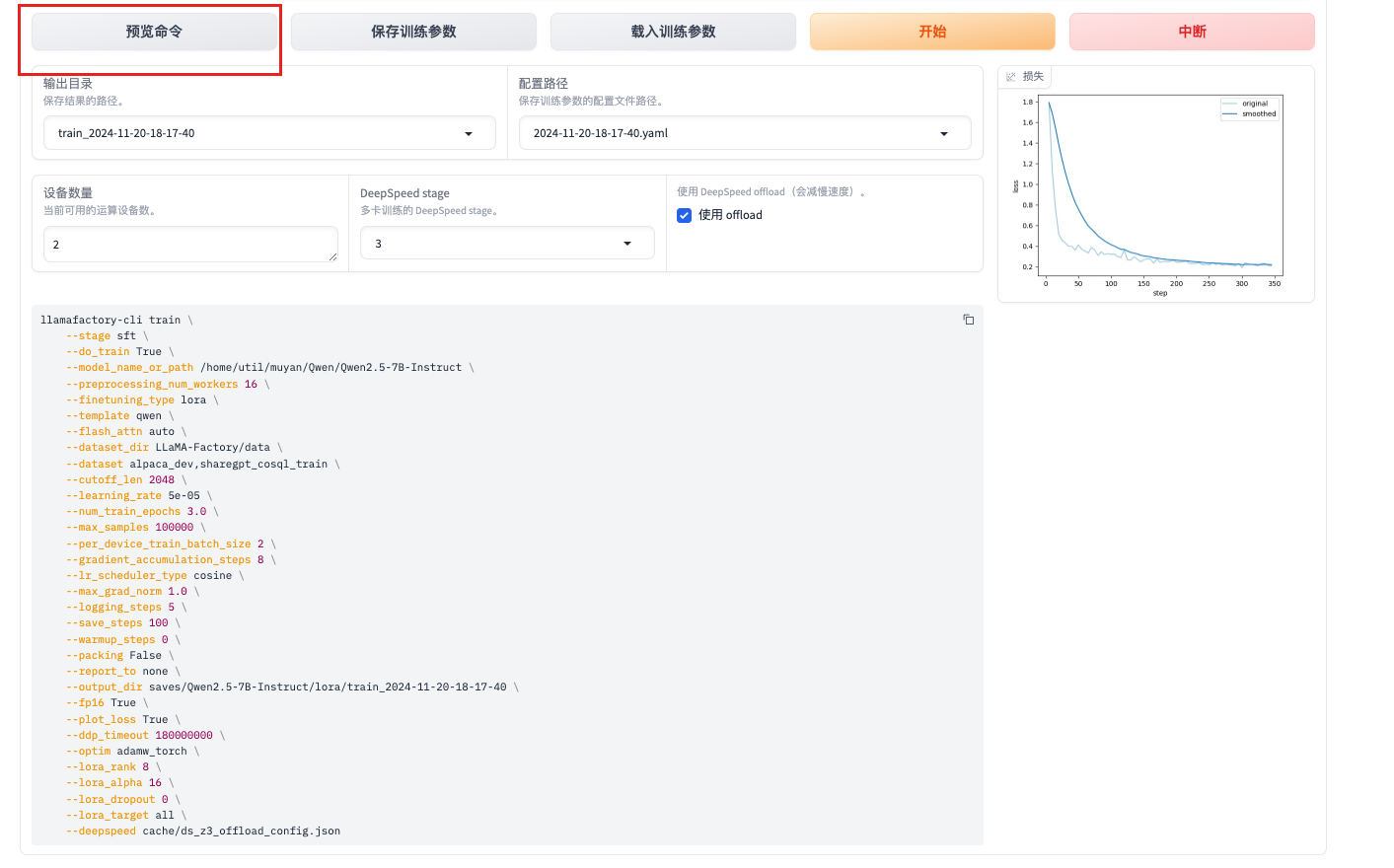
生成命令只增加了deepspeed cache/ds_z3_offload_config.json
llamafactory-cli train \
--stage sft \
--do_train True \
--model_name_or_path /home/util/muyan/Qwen/Qwen2.5-7B-Instruct \
--preprocessing_num_workers 16 \
--finetuning_type lora \
--template qwen \
--flash_attn auto \
--dataset_dir LLaMA-Factory/data \
--dataset alpaca_dev,sharegpt_cosql_train \
--cutoff_len 2048 \
--learning_rate 5e-05 \
--num_train_epochs 3.0 \
--max_samples 100000 \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 8 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 5 \
--save_steps 100 \
--warmup_steps 0 \
--packing False \
--report_to none \
--output_dir saves/Qwen2.5-7B-Instruct/lora/train_2024-11-20-18-17-40 \
--fp16 True \
--plot_loss True \
--ddp_timeout 180000000 \
--optim adamw_torch \
--lora_rank 8 \
--lora_alpha 16 \
--lora_dropout 0 \
--lora_target all \
--deepspeed cache/ds_z3_offload_config.json节约训练资源

对应时间会加长
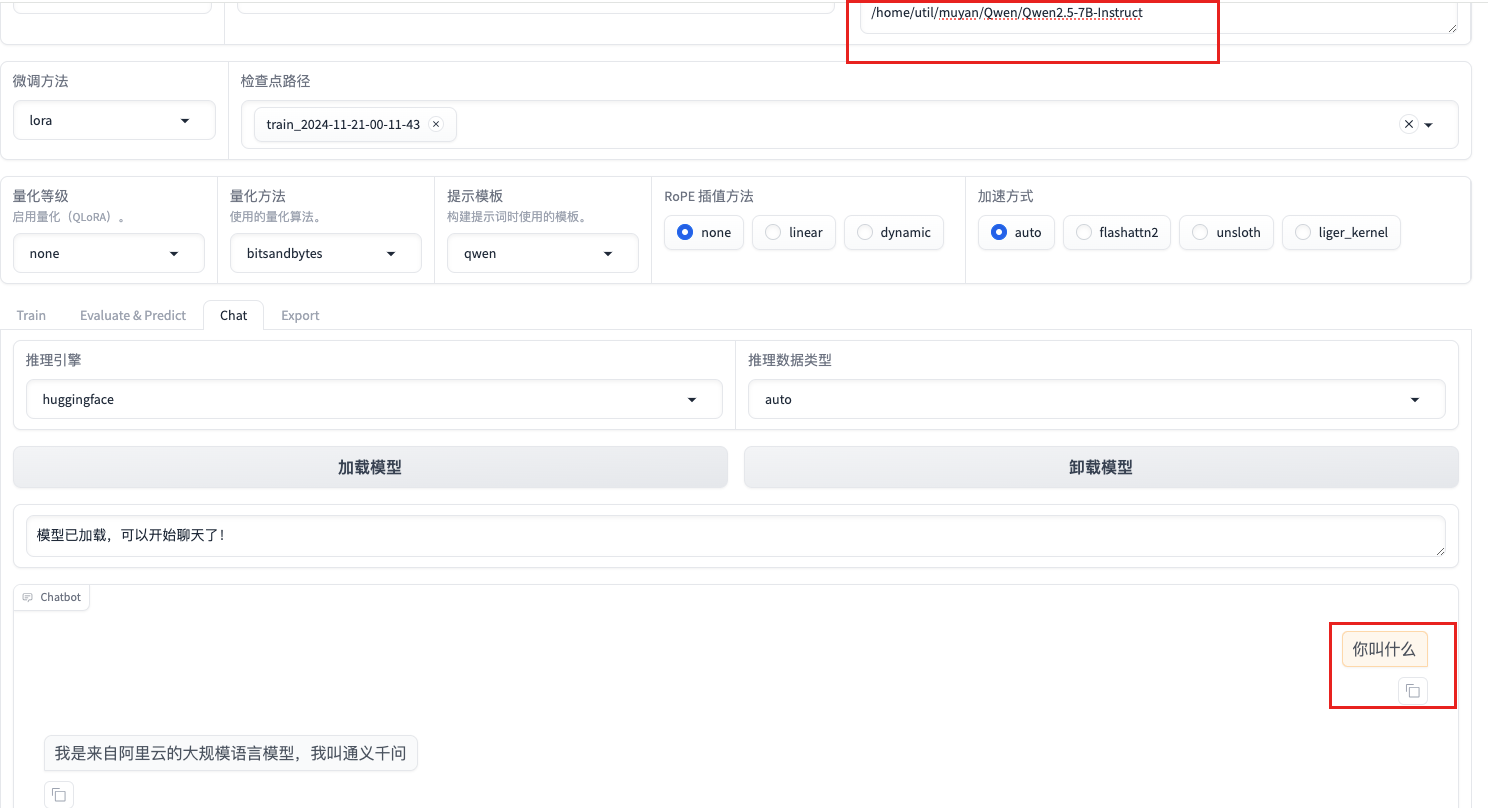
测试使用deepspeed微调后原生能力
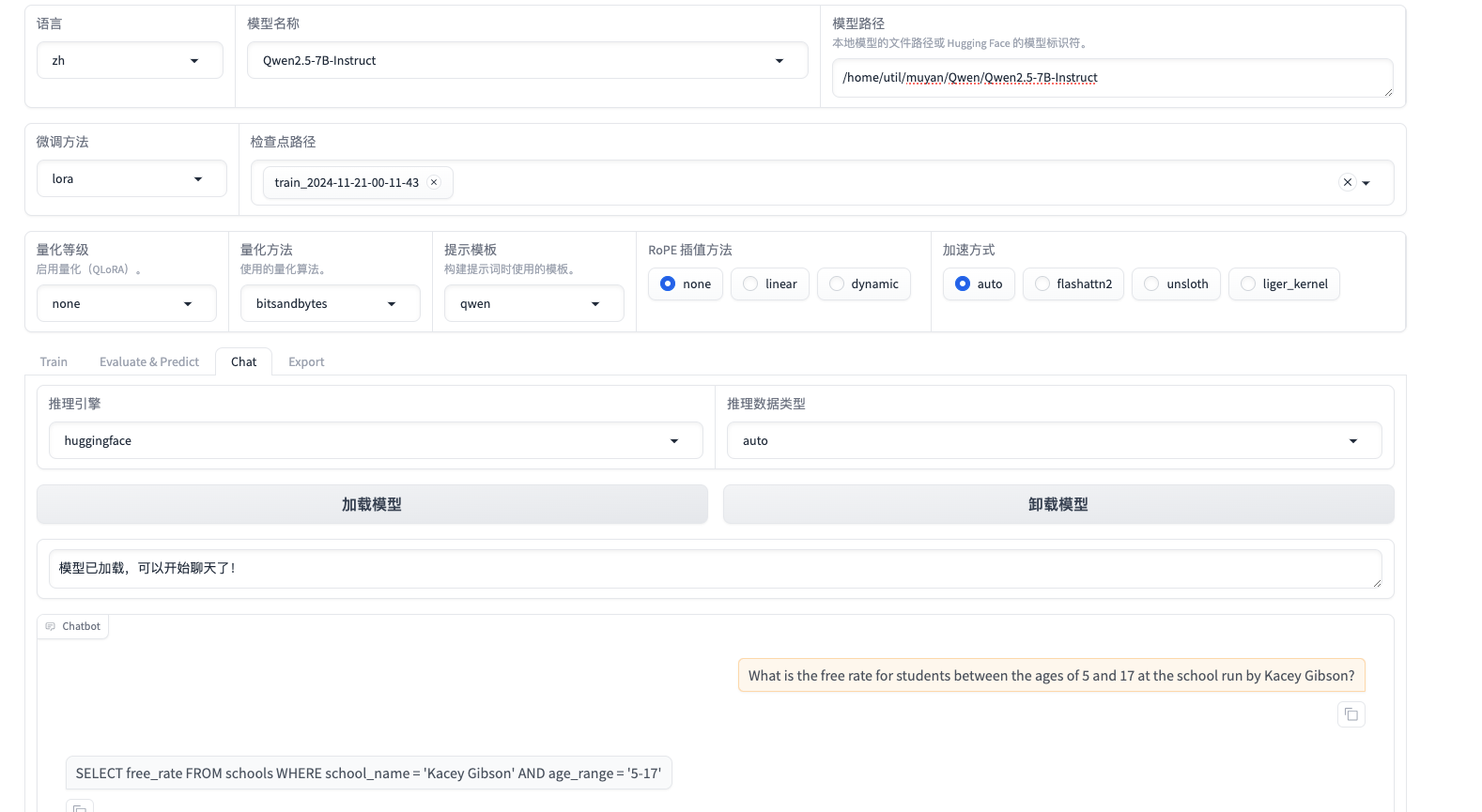
对应sql生成能力
- 注意事项:
官网推荐deepspeed==0.14.0
但是实际匹配应用会对应版本pip install deepspeed==0.14.5
切记切记不要用最新的deepspeed 版本,最新的是0.15 会将其余包更改版本进行强制替换。引起其他错误。- 当前deepspeed==0.14.0 的异常

- 当前deepspeed==0.14.4 的异常

- 模型命令保存
4. 总结


 浙公网安备 33010602011771号
浙公网安备 33010602011771号