开源大模型排行
对于不具备大模型研发能力的公司而言,了解技术边界并高效进行技术选型显得尤为重要。一个有效的评测系统可以避免重复开发和不必要的技术争论,促进更为顺畅的沟通。此外,对于研发人员和学术界人士来说,各类模型的效果对比能够反映出不同技术路线的有效性,从而提供参考,减少资源浪费,推动整个大模型生态的高效发展。
虽然开源模型本质上下载和使用都是免费的,但是这还有一些隐形成本,比如由模型参数大小带来的硬件推理成本,以及不同基座模型能力不同导致后期微调/应用时所需的成本也不同,选择一个合适任务环境的模型有时候比选择一个分数榜高的模型有时更为重要,本章节摘录了第三方的测评结果,力求为大家带来一个相对公平的测试结果。
CLiB中文大模型能力评测榜单:https://github.com/jeinlee1991/chinese-llm-benchmark?tab=readme-ov-file
MMLU - 一种针对大模型的语言理解能力的测评,是目前最著名的大模型语义理解测评之一,任务涵盖的知识很广泛,语言是英文,用以评测大模型基本的知识覆盖范围和理解能力。
C Eval - C-Eval 是一个全面的中文基础模型评估套件。它包含了13948个多项选择题,涵盖了52个不同的学科和四个难度级别。用以评测大模型中文理解能力。
AGI Eval - 微软发布的大模型基础能力评测基准,主要评测大模型在人类认知和解决问题的一般能力,涵盖全球20种面向普通人类考生的官方、公共和高标准录取和资格考试,包含中英文数据。
GSM8K - OpenAI发布的大模型数学推理能力评测基准,涵盖了8500个中学水平的高质量数学题数据集。数据集比之前的数学文字题数据集规模更大,语言更具多样性,题目也更具挑战性。


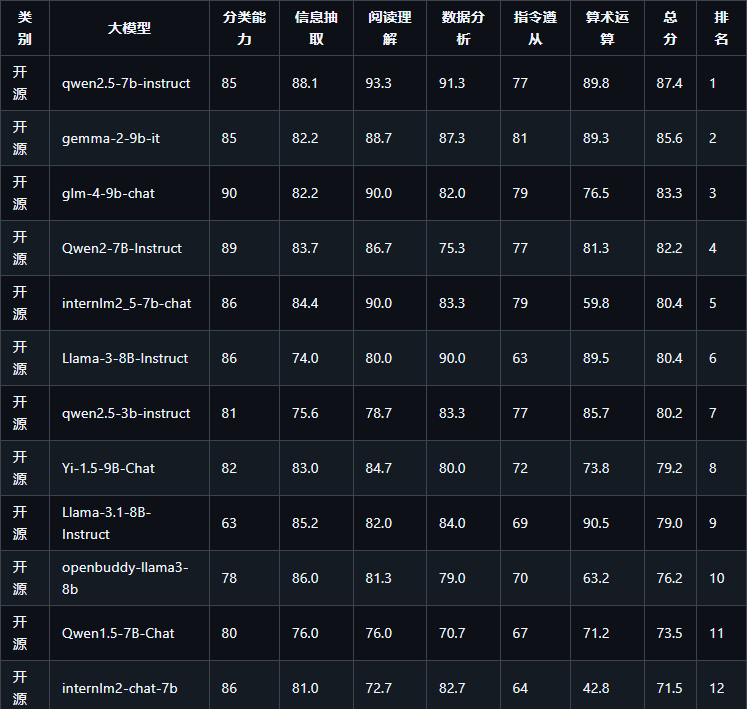
10B以下开源模型榜单
优点
-
计算资源需求低:相较于大型模型,10B以下的模型在计算资源和存储需求上更为轻量,适合在资源有限的设备上运行,例如移动设备和边缘计算设备。
-
更快的推理速度:较小的模型在推理时的响应速度较快,适合实时应用场景,如聊天机器人、语音助手和即时翻译等。
-
训练成本较低:训练10B以下的模型所需的时间和计算资源相对较少,使得开发和实验的成本更低,更适合中小型企业和科研机构。
-
适应性强:小模型可以更容易地进行微调和迁移学习,使得它们能够快速适应新的任务或领域。
-
更易于部署:由于其较小的体积和低资源需求,10B以下的模型可以更方便地部署到云端、移动端和嵌入式设备上。
适合的应用场景
-
聊天机器人和虚拟助手:适合用于自然语言处理的基本任务,如文本生成、问答和情感分析。
-
文本分类和情感分析:在情感分析、主题分类和评论过滤等任务中表现良好。
-
语言翻译:可以用于简单的翻译任务,尤其是针对特定领域(如旅游、餐饮等)的翻译。
-
信息提取和摘要:适合从较短文本中提取关键信息或生成摘要。
-
教育和辅助学习:用于个性化学习助手或教育工具,帮助学生进行知识巩固。
-
实验和快速原型:在研究和开发初期阶段,可以使用小模型进行实验和原型设计,快速验证想法。
-
文本生成和创作:适用于创作短篇文章、社交媒体内容或自动回复等场景。
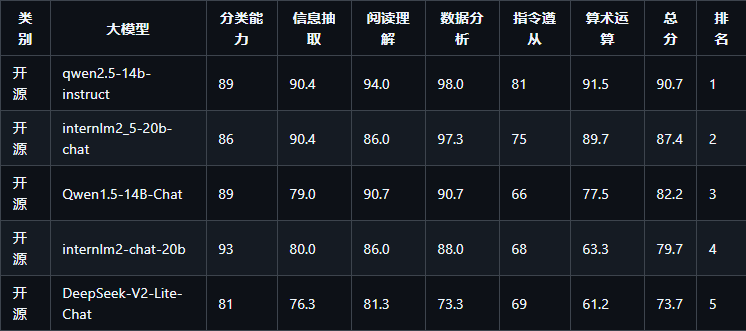
10~20B 开源模型榜单
优点
-
良好的性能平衡:相较于较小的模型,这一参数范围的模型通常在语言理解和生成能力上有显著提升,能够处理更复杂的任务。
-
更丰富的上下文理解:这些模型可以处理更长的上下文信息,适合需要上下文理解和连贯性的任务,如长篇文章的生成或对话系统。
-
多任务学习能力:在一个模型中训练多种任务,能够实现更好的泛化能力,适合需要同时完成多项任务的应用。
-
高效的微调能力:由于模型参数相对较多,能够更好地适应不同领域和任务的微调,尤其是在数据量适中的情况下。
-
对抗性训练:可以更有效地进行对抗性训练,提高模型的鲁棒性,使其在面对噪声或对抗样本时表现更佳。
适合的应用场景
-
对话系统:适合用于更复杂的聊天机器人和虚拟助手,能够提供更自然、更智能的对话体验。
-
文本生成:用于长篇文章、故事创作和其他需要深入内容生成的场景,能够保持一致的风格和主题。
-
翻译和转述:在多语言处理和内容转述中表现出色,能够捕捉细微的语言差异。
-
信息检索和推荐系统:适合用于构建智能搜索引擎和推荐系统,能够理解用户查询的复杂性。
-
数据增强和合成:用于生成训练数据,帮助模型更好地适应小样本学习或少样本学习场景。
-
情感分析和社会网络分析:适用于分析社交媒体内容和用户情感,能够从复杂文本中提取深层次的情感信息。
-
医疗和法律领域的文本处理:在特定领域中提供高质量的文本处理和信息提取,帮助专业人士更高效地处理大量信息。
-
研究和开发:作为实验模型,用于探索新算法、新架构或新应用的研究。
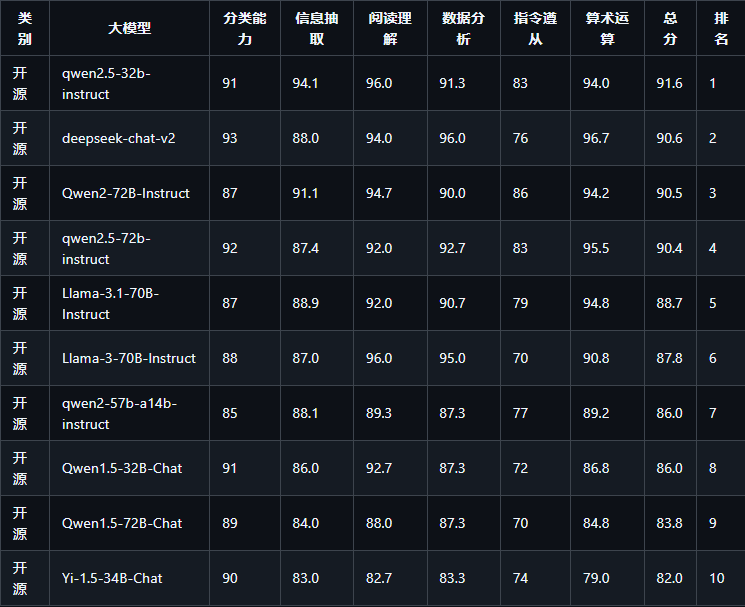
30B 以上大模型排行榜
优点
-
卓越的语言理解和生成能力:这些大型模型通常在自然语言处理任务中展现出卓越的性能,能够生成更自然、更连贯的文本。
-
丰富的知识基础:由于训练数据量大,模型通常具备广泛的知识背景,能够处理多领域的问题并生成相关的内容。
-
增强的上下文处理能力:较大的参数量使得模型能够处理更长的上下文,适合复杂的对话和文本生成任务。
-
更强的推理和逻辑能力:在需要深度推理和逻辑分析的任务中,大模型展现出更强的能力,能够执行复杂的推理链。
-
高效的迁移学习能力:能够在不同的任务和领域之间迁移知识,适合快速适应新的应用场景。
-
鲁棒性和适应性:在面对不确定性和噪声时,表现出更高的鲁棒性,适合处理复杂和动态环境中的任务。
适合的应用场景
-
复杂对话系统:可用于构建高度智能的对话代理,能够进行长时间和多轮的自然对话。
-
高质量文本生成:适合长篇内容的生成,如小说、剧本、研究论文等,确保语义连贯和风格一致。
-
多模态应用:在结合图像、音频等多种数据源时表现出色,如视觉问答和图像描述生成。
-
知识问答系统:能够从广泛的知识库中提取信息,支持复杂的问答任务。
-
个性化推荐系统:在分析用户偏好和行为数据时,生成更精准的个性化内容和推荐。
-
高级文本分析:适用于法律、医疗等行业中的复杂文本分析与信息提取,帮助专业人士处理复杂文档。
-
科学研究和创新:为学术研究提供强大的支持,帮助科学家进行数据分析、文献综述和理论建模。
-
跨语言处理:支持多语言的理解和生成,适合国际化应用和全球市场的需求。
-
大规模自动化任务:在企业环境中,自动化处理复杂的业务流程,如客户支持、内容审核等。
信息抽取排行榜
示例文本:“招商银行5亿元,建设银行增长约3.5亿元,农业银行约2亿元。”
提取出的组织机构名称:
招商银行建设银行农业银行

分类能力排行榜
将以下10个单词分类为动物或植物。树木、狮子、玫瑰、草地、松鼠、猴子、蘑菇、兔子、山羊、香蕉
动物:狮子、松鼠、猴子、兔子、山羊。
植物:树木、玫瑰、草地、蘑菇、香蕉。

阅读理解能力排行榜
阅读理解能力是一种符合能力,考查针对给定信息的理解能力。 依据给定信息的种类,可以细分为:文章问答、表格问答、对话问答……
评测样本举例:
牙医:好的,让我们看看你的牙齿。从你的描述和我们的检查结果来看,你可能有一些牙齦疾病,导致牙齿的神经受到刺激,引起了敏感。此外,这些黑色斑点可能是蛀牙。病人:哦,真的吗?那我该怎么办?牙医:别担心,我们可以为你制定一个治疗计划。我们需要首先治疗牙龈疾病,然后清除蛀牙并填充牙洞。在此过程中,我们将确保您感到舒适,并使用先进的技术和材料来实现最佳效果。病人:好的,谢谢您,医生。那么我什么时候可以开始治疗?牙医:让我们为您安排一个约会。您的治疗将在两天后开始。在此期间,请继续刷牙,使用牙线,并避免吃过于甜腻和酸性的食物和饮料。病人:好的,我会的。再次感谢您,医生。牙医:不用谢,我们会尽最大的努力帮助您恢复健康的牙齿。基于以上对话回答:病人在检查中发现的牙齿问题有哪些?

数据分析排行榜
专门考查大模型对表格的理解分析能力,常用于数据分析。评测样本举例:
李四, 27, 男, 中国, 178, 72, 本科
Anna, 34, 女, 瑞典, 170, 60, 硕士
Carlos, 39, 男, 阿根廷, 177, 78, 博士
Yuki, 22, 女, 日本, 158, 48, 高中
John, 31, 男, 加拿大, 180, 74, 硕士
Sofia, 30, 女, 俄罗斯, 165, 62, 本科
David, 45, 男, 英国, 183, 85, 博士
问题:身高最矮的是哪国人?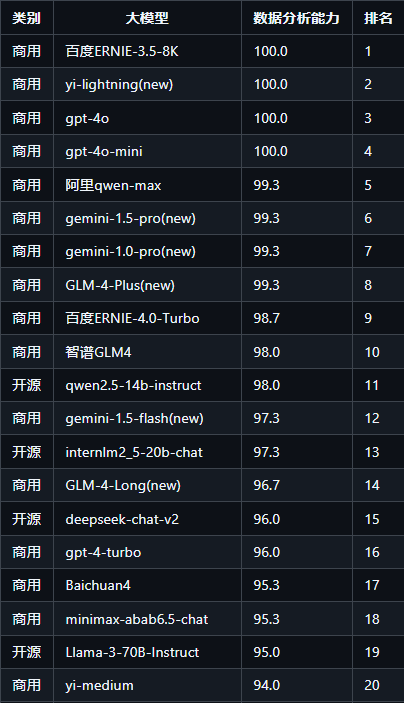
中文指令遵循能力
顾名思义,旨在监测大模型的中文指令理解和执行能力,例子:
写一篇至少150字的博客,介绍睡在吊床上的好处。

数学能力
考查大模型的数学基础能力可以设计以下测试题目,涵盖1000以内的整数加减法和不超过2位有效数字的浮点数加减乘除。
整数加减法题目:
378 + 124 = ?
850 - 432 = ?
512 + 249 = ?
640 - 215 = ?
789 + 156 + 34 = ?
浮点数加减乘除题目:
0.56 + 0.75 = ?
0.45 - 0.2 = ?
1.2 * 0.3 = ?
0.99 / 0.3 = ?
0.85 + 0.4 / 0.25 = ?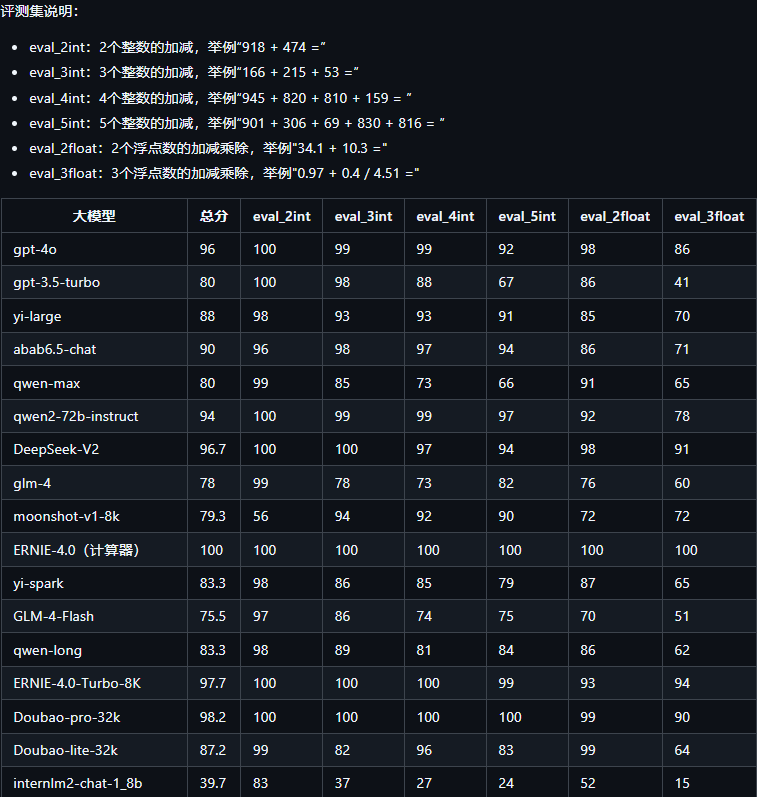
编程能力
本着以下两个测试指标进行了全模型的排行:
HumanEval是OpenAI于2021年推出的一个用于评估代码生成模型性能的数据集,包含164个手工编写的编程问题。每个问题提供了函数签名、文档字符串及多个单元测试,涵盖语言理解、推理、算法和简单数学等方面,难度与简单的软件面试问题相当。该数据集的特点在于,生成的代码不仅需语法正确,还需通过所有相关的单元测试,确保功能正确性。评估结果通过Pass@k指标表示,k表示一次性生成不同答案的数量中至少有1个正确答案的比例,例如Pass@1和Pass@10。
MBPP(Mostly Basic Programming Problems)是谷歌于2021年推出的一个数据集,包含974个设计用于初级程序员的短小Python函数问题。该数据集提供每个问题的文本描述和功能正确性测试用例,评估方式与HumanEval类似,通过Pass@k指标衡量模型生成的答案准确性。

该榜单来自dataleaner:https://www.datalearner.com/ai-models/leaderboard/datalearner-llm-leaderboard
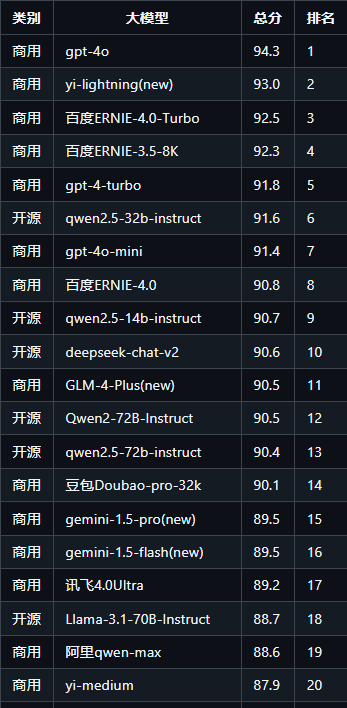
综合能力排行
其他模型榜单推荐
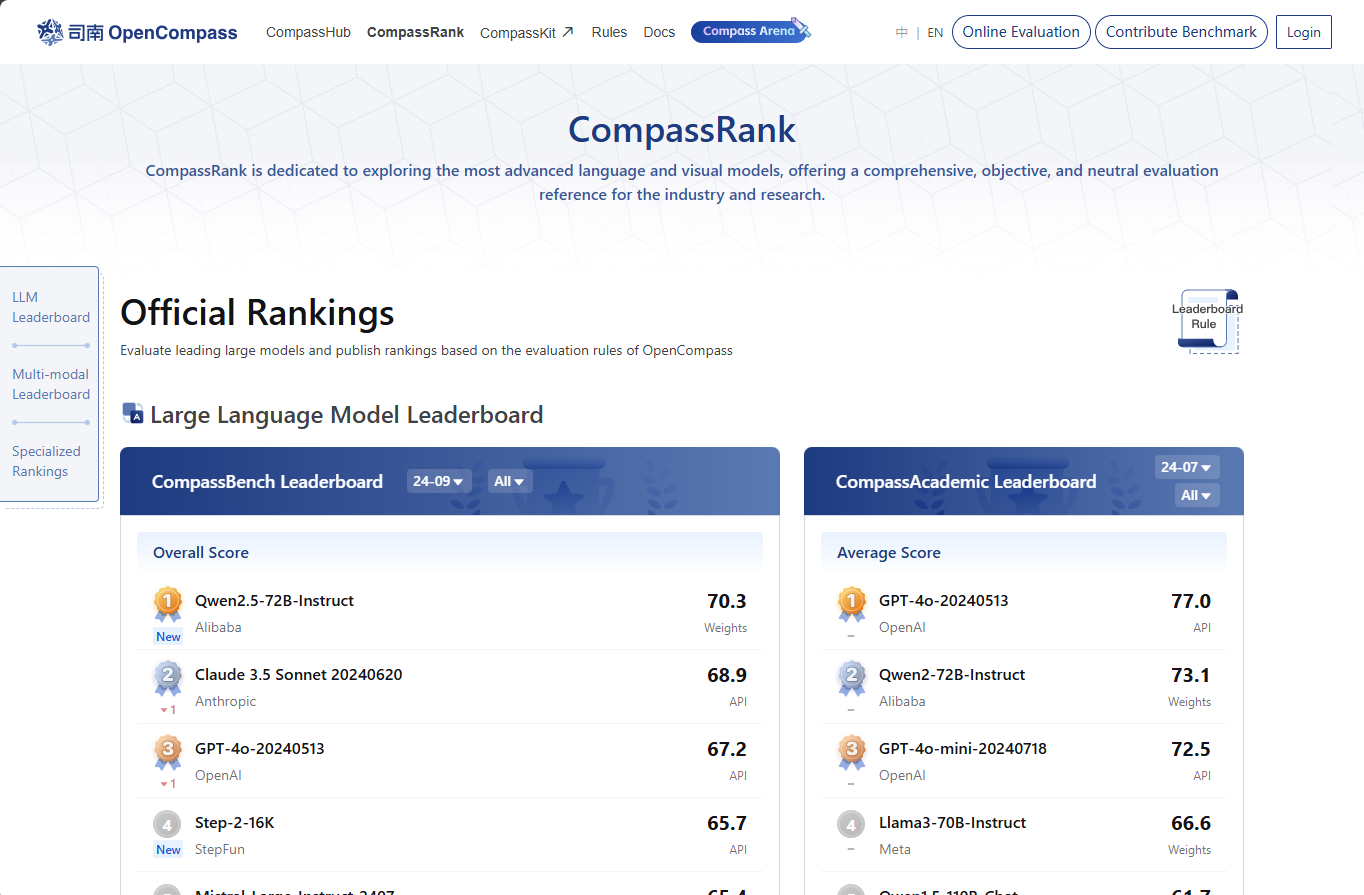
司南Opencompass
该平台同时支持模型竞技场进行模型能力对比测试。
官网地址:https://rank.opencompass.org.cn/home
数据学习
该网站同时提供有关AI的新闻咨询,适合学术研究学习。
官网地址:https://www.datalearner.com/ai-models/leaderboard/datalearner-llm-leaderboard



 浙公网安备 33010602011771号
浙公网安备 33010602011771号