PEFT主流高效微调方法介绍&实战
前言
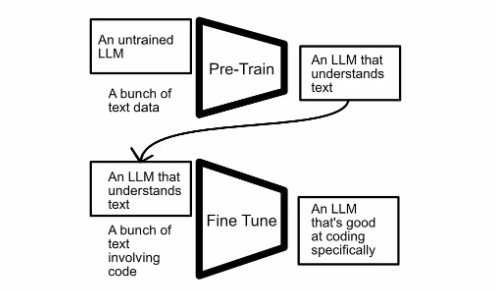
微调是一种在特定于特定任务的新数据集上进一步训练(或微调)预训练模型的方法。该技术涉及根据新数据调整模型所有层的权重。它允许模型专门满足细微的任务,并且通常会为专业应用程序带来更高的性能。
目录
目录
一 主流微调方法
1 Full Fine-Tuning
2 Prefix-Tuning
3 Prompt Tuning
4 P-Tuning v1
5 P-Tuning v2
6 LoRA & QLoRA
二 DeepSpeed原理浅析
1 ZeRO-Offload
2 ZeRO-Infinity
3 ZeRO-1、2、3
三 基于ChatGLM3-6b进行P-Tuning v2微调实战
1 微调环境准备
2 微调数据下载与预处理
3 执行P-Tuning v2微调
4 使用微调后的模型
5 微调效果评测
微调是什么
微调大型语言模型 (LLM) 涉及在特定数据集上调整预训练模型,以提高特定任务的性能。此过程在一般预训练结束后开始。用户为模型提供更集中的数据集,其中可能包括特定于行业的术语或以任务为中心的交互,目的是帮助模型为特定使用案例生成更相关的响应。
微调允许模型调整其预先存在的权重和偏差,以更好地适应特定问题。这提高了输出的准确性和相关性,使 LLM 在实际、专业的应用中比受过广泛训练的同类产品更有效。虽然微调可能是高度计算密集型的,但参数高效微调 (PEFT) 等新技术使其效率更高,甚至可以在消费级显卡上运行。微调既可以在开源 LLM(如 Meta LLaMA 和 Mistral 模型)上执行,也可以在某些商业 LLM 上执行,前提是模型的开发人员提供了此功能。例如,OpenAI 允许对 GPT-3.5 和 GPT-4 进行线上微调。
-
微调方法分类
在微调的方法上分类可分为全参数微调(Full Fine-Tuning)和部分参数微调(Partial Fine-Tuning),其中全参数微调指的是对整个模型进行微调,该预训练模型的所有层和参数都会被更新和优化。全参数微调的方法适用于任务和预训练模型之间存在较大差异的情况,或者任务需要模型具有高度灵活性和自适应能力的情况,但是这种方法会消耗大量的计算资源和时间,对成本有较高的要求。部分微调指的是在微调过程中只更新模型的顶层或少数几层,其余的层和权重固定不变。这样可以节省大量的计算资源,但是效果会随着数据量的大小、与原模型的相似程度以及微调方法而定。
PEFT (Parameter-Efficient Fine-Tuning)是部分微调的一种具体实现方式,它通过引入不同的技术,进一步提高了微调效率,通常在大语言模型(如 GPT、BERT 等)的微调中广泛应用。PEFT 的目标是在保持模型性能的前提下,极大减少需要微调的参数量,避免了对整个模型进行大规模训练,从而降低资源消耗。同时,也能实现与全量参数微调相当的性能。参数高效微调方法甚至在某些情况下比全量微调效果更好,可以更好地泛化到域外场景。
-
使用高效微调方法的原因
-
大模型参数量过大,训练成本高。
-
通过自有数据提升大模型在特定领域的能力。
-
在特定服务中使用大模型的能力。
-
保护企业数据安全。
一、主流微调方法
1. Prefix-Tuning
Prefix-Tuning指的是在微调模型的过程中固定语言模型的参数,仅优化一个小的连续的特定任务向量(称为prefix)。prefix-tuning在充分数据下获得了与微调相当的性能,在小数据集上优于微调。以下是 Prefix-Tuning论文地址:
https://arxiv.org/abs/2101.00190
在Prefix Tuning方法提出之前,相关工作主要集中在手动设计离散模板或自动化搜索离散模板。手动设计的模板对模型的最终性能极其敏感,哪怕仅仅增加、删除一个词或调整词的位置,都会对结果产生显著影响。而自动化搜索离散模板的过程通常成本较高,且搜索出的离散token组合可能并非最优解。此外,传统的微调范式要求针对每个下游任务对预训练模型进行独立微调,并保存相应的微调后模型权重,这不仅增加了存储空间的占用,也导致微调过程耗时较长。
传统的微调范式Fine-turning会利用预训练模型去对不同的下游任务进行微调,对每个任务都要保存一份微调后的模型权重。比如下图展示的三个不同任务的Transformer模型,分别用来做翻译、摘要和将格式转化(table-to-text)。每个任务都有自己的微调模型,这意味着模型的所有权重都在微调过程中针对特定任务进行了更新。这种方法通常需要大量的数据和计算资源,因为整个模型都在学习任务特定的知识。
基于上述两个因素,Prefix-tuning 就提出了一种不同的微调策略,对基于Transformers结构的模型,它会将特定的前缀添加到输入序列的开始部分,相当于任务特定的提示,可以是一组固定的词或是可训练的嵌入向量。这样做的效果相较于传统的离散token微调范式所消耗的成本更小,优化效果更好。
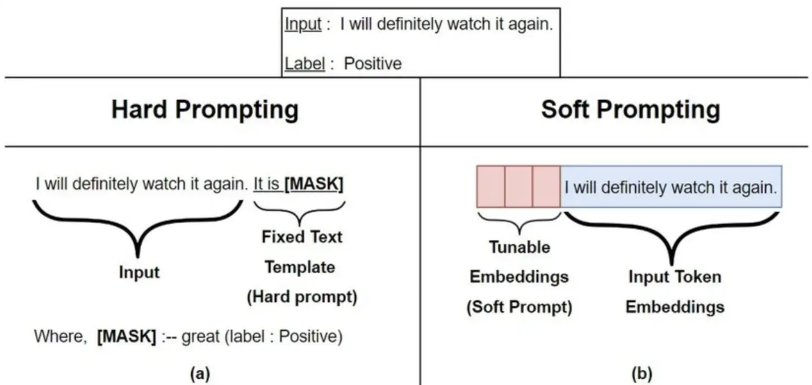
该方法其实和构造Prompt类似,只是Prompt是人为构造的“显式”的提示,并且无法更新参数,而Prefix则是可以学习的“隐式”的提示。但是这个Prefix 并不是一些明确的单词,比如对于文本摘要任务来说,我们添加 this is summarization(明确指出这是一个摘要的任务),相反,这个prefix加的是一些隐式的Token。这里就需要了解两个概念:
-
Hard Prompt:也称离散Prompt,是一个实际的文本字符串(自然语言,人工可读),通常由中文或英文词汇组成;
-
Soft Prompt:也称连续Prompt,通常是在向量空间优化出来的提示,通过梯度搜索之类的方式进行优化;
在Hoft Promot中,提示语的变化对模型最终的性能特别敏感,加一个词、少一个词或者变动位置都会造成比较大的变化。成本比较高,并且效果不太好。显然:Prefix Tuning属于Soft prompt。也就是我们学习调整的就是这部分的参数,从而达到微调的目的。与调整约3.6%LM参数的工作相比,Prefix Tuning的方法进一步减少了30倍的任务特定参数,仅调整了0.1%,同时保持表到文本任务的可比性能。
在Soft Prompt中,LM 的模型权重被冻结,并且有单独的可学习张量与模型权重连接,并针对特定的下游任务进行训练。我们希望以最佳方式学习能够给我们带来最佳结果的提示。所有方法都适用于足够小的标记数据集。
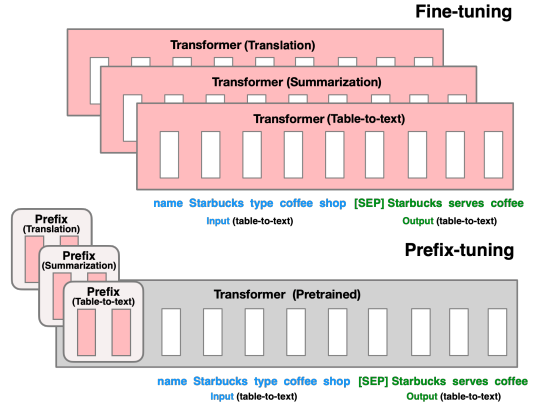
Prefix Tuning针对不同的模型结构有设计不同的模式,以自回归的模型为例,不再使用token去作为前缀,而是直接使用参数作为前缀(粉红色部分),并只优化这部分,冻结主体部分的参数。同时,为了防止直接更新Prefix的参数导致训练不稳定的情况,他们在Prefix层前面加了MLP结构(相当于将Prefix分解为更小维度的Input与MLP的组合后输出的结果),训练完成后,只保留Prefix的参数。
简单的说,Prefix Tuning训练一个上游前缀,它引导一个未修改的LM,因此,单个LM可以同时支持许多任务。在个性化的上下文中,任务对应于用户。Prefix Tuning将为每个用户设置一个单独的前缀,只训练该用户的数据,从而避免数据交叉污染。此外,基于前缀的体系结构使Prefix Tuning能够在单个批处理中处理来自多个用户/任务的示例,这是其他轻量级微调方法不可能实现的。

Encoder端增加前缀是为了引导输入部分的编码,Decoder 端增加前缀是为了引导后续token的生成。
Prefix-tuning 的优势在于它不需要调整模型的全部权重,而是通过在输入中添加前缀来调整模型的行为,这样可以节省大量的计算资源,同时使得一个单一的模型能够适应多种不同的任务。
2. Prompt Tuning
Prompt Tuning 方法可以看做是Prefix Tuning的简化版本,它给每个任务都定义了自己的Prompt,将真实的Tokens转化为可微的virtual token,并加入人工设计的锚字符(与任务高度相关的Token),拼接到数据上作为输出,但只在输入层加入Prompt tokens。它使用手动设计的提示,在few shot设置中适应不同的任务。以下是Prompt Tuning论文地址:
https://arxiv.org/pdf/2104.08691.pdf
Prompt Tuning通过在输入中添加特定的提示(prompt)来引导模型生成所需的输出。这些提示是可学习的,并在微调过程中进行优化,以提高模型在特定任务上的表现。
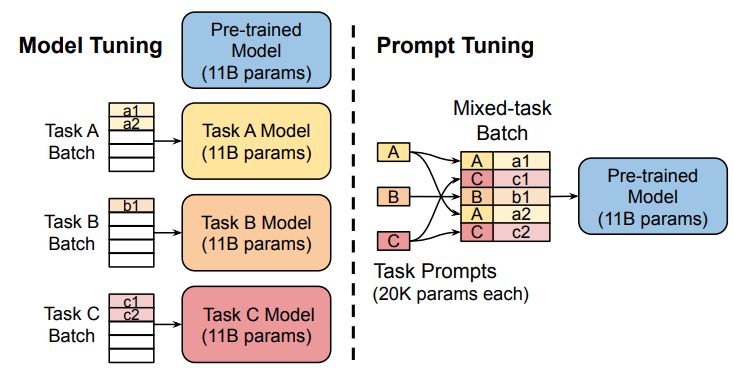
如图所示,传统的微调方法需要为每个下游任务创建整个预训练模型的任务特定副本,并且推理必须在不同的批次中进行。Prompt Tuning只需要为每个任务存储一个较小的任务特定提示,同时可以使用原始的预训练模型进行混合任务推理。Prompt Tuning可以通过反向传播更新参数来学习prompts,而不是人工设计prompts;同时冻结模型原始权重,只训练prompts参数,训练完以后,用同一个模型可以做多任务推理。
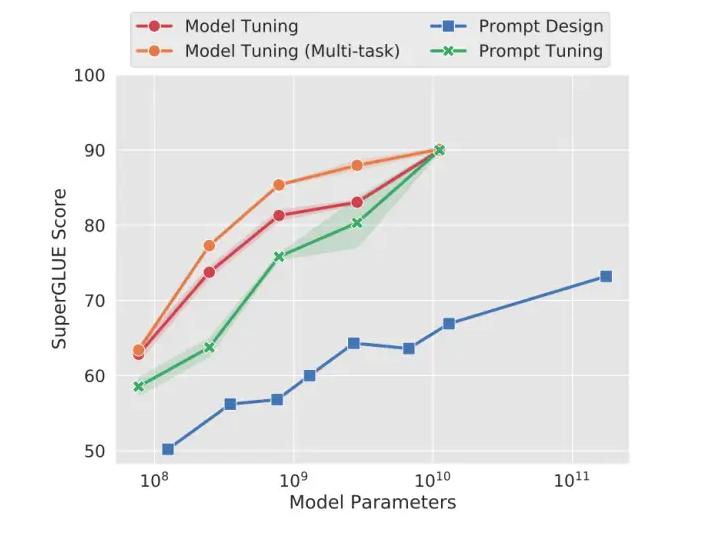
实验表明,随着大模型的参数量的增加,Prompt Tuning的方法会逼近全参数微调的结果。此外,Prompt token 的长度在20左右时的表现已经不错(超过20之后,提升Prompt token长度,对模型的性能提升不明显了),同样的,这个gap也会随着模型参数规模的提升而减小(即对于超大规模模型而言,即使 Prompt token 长度很短,对性能也不会有太大的影响)。
虽然Prompt Tuning和Prefix Tuning都涉及在输入数据中加入可学习的向量,但两者的策略和目的不一样:
-
Prompt Tuning:可学习向量(通常称为prompt tokens)旨在模仿自然语言提示的形式,它们被设计为引导模型针对特定任务生成特定类型的输出。这些向量通常被看作是任务指导信息的一部分,倾向于用更少量的向量模仿传统的自然语言提示。
-
Prefix Tuning:可学习前缀Prefix更多地用于提供输入数据的直接上下文信息,这些前缀作为模型内部表示的一部分,可以影响整个模型的行为。
下面的训练例子说明了两者的区别:
```
Prompt Tuning示例:
输入序列: "Prompt 1, Prompt2 | 这部电影令人振奋。"
问题: 评价这部电影的情感倾向。
答案: 模型需要预测情感倾向(例如“积极”)
提示: 无明确的外部提示,
充当引导模型的内部提示,因为这里的问题是隐含的,即判断文本中表达的情感倾向。```
Prefix Tuning 示例:
输入序列: " Prefix1, Prefix 2 | I want to watch a movie."
问题: 根据前缀生成后续的自然语言文本。
答案: 模型生成的文本,如“that is exciting and fun.”
提示: 前缀本身提供上下文信息,没有单独的外部提示
```3. P-Tuning v1
P-Turning V1的核心是使用可微的virtual token(虚拟标记)替换了原来的discrete tokens(离散标记),且仅加入到输入层,并使用prompt encoder(提示编码器)对virtual token进行编码学习。以下是 P-Tuning v1 论文地址:
P-tuning 将提示视为一组可学习的参数,这些参数通过反向传播进行更新。此方法与上述两种方法不同,更符合提示优化,但提示是向量而不是离散提示。使用提示编码器,可以是 LSTM 或多层感知器。
Prompt Tuning更新使用的参数是静态的、可训练的虚拟标记嵌入。这些嵌入在初始化后保持固定,除非在训练过程中被更新,相对简单,因为它只涉及调整一组固定的嵌入参数。在处理多种任务时表现良好,但在处理特别复杂或需要细粒度控制的任务时受限。所以,P-Turining v1 就在输入的句子中也是加入了隐式的 virtual token,区别就是:前面的方式是直接对它进行一个学习更新,只不过不会更新大模型中的参数,只是更新我们加入的 virtual token这样一个参数,P-Turning v1 是对添加的virtual Token,又使用BiLSTM + MLP(双向长短记忆网络+多层感知机) 对其进行了一个编码。


如上图所示的例子:提示搜索“英国的首都是[ __ ]”的一个例子。鉴于上下文(蓝色区域“英国”)和目标(红色区域“面具”),橙色区域指提示模型完成任务的关键信息。在(a)离散化提示工程方法中,提示生成器只接收离散的奖励;相反,在(b)P-tuning中,连续的提示嵌入和提示编码器可以以一种可微的方式进行优化。
P-tuning将每个离散提示转换为模板。
T {[P0:i],x,[P(i+1):j],y,[P(j+1):k]
这会将任务转换为查找并填写输入文本中的空白以找到具有最佳结果的提示。P_i 是需要学习的连续提示嵌入,h_i 是模型输入。编码器用于将 P_i 映射h_i}。
这种方法与提示调整非常相似,因为它们都将LLM保留为黑匣子,并且不向其中添加任何参数。不同之处在于额外的编码器,并允许我们串联离散且可学习的提示。相较于zero-shot、few-shot这种提示工程方法,P-tuining v1调整模型对较小模型的影响最大。

Prompt Tuning和P-Tuning的共同点:
- Prefix Tuning是将额外的embedding加在开头,看起来更像是模仿Instruction指令;而P-Tuning的位置则不固定。
- Prefix Tuning通过在每个Attention层都加入Prefix Embedding来增加额外的参数,通过MLP来初始化;而P-Tuning只是在输入的时候加入Embedding,并通过LSTM+MLP来初始化。
那么Prompt Tuning和P-Tuning等方法存在两个主要的问题:
-
缺乏模型参数规模和任务通用性:Prompt Tuning论文中表明当模型规模超过100亿个参数时,提示优化可以与全量微调相媲美。但是对于那些较小的模型(小于1B),提示优化和全量微调的表现有很大差异,这大大限制了提示优化的适用性。
-
缺乏任务普遍性:尽管Prompt Tuning和P-tuning在像文本分类、阅读理解等任务中有较好的表现,尤其是在这些任务中通过设计良好的提示可以很好地引导预训练模型,但提示调优对硬序列标记任务(即序列标注需要预测一连串的标签,而非单一的标签)的有效性仍然有限。
-
缺少深度提示优化,在Prompt Tuning和P-tuning中,连续提示只被插入transformer第一层的输入embedding序列中,在接下来的transformer层中,插入连续提示的位置的embedding是由之前的transformer层计算出来的,这可能导致两个可能的优化挑战,即由于序列长度的限制可调参数的数量是有限的;输入embedding对模型预测只有相对间接的影响。
-
P-tuning v1有两个显著缺点:任务不通用和规模不通用。在一些复杂的自然语言理解NLU任务上效果很差,同时预训练模型的参数量不能过小。
由于序列长度的限制,可调参数的数量是有限的,输入embedding对模型预测只有相对间接的影响。这些问题在P-tuning v2得到了改进。
4. P-Tuning v2
P-Tuning v2 构建于 P-Tuning 和 Prefix-Tuning 技术的基础之上,核心优化策略在于引入深度提示编码(Deep Prompt Encoding)和多任务学习(Multi-task Learning)。以下是 P-Tuning v2论文地址:
以下是P-tuning v1 和 v2 框架的对比。在右侧的 P-Tuning v2 中,连续提示(continuous prompt)被添加到序列的前端,并且每一层网络都引入了可训练的提示。而在左侧的 v1 模型中,提示仅插入到输入嵌入层,这会导致可训练参数受限于句子的长度。此外,P-Tuning v2 还进行了以下改进:
- 移除了 Reparameterization 加速机制,提升了训练效率。
- 引入了多任务学习优化策略,先基于多任务数据集对提示进行预训练,再适应特定的下游任务。
- 放弃了词汇映射的 Verbalizer,改用 [CLS] 和字符标签,与传统微调方法一致,利用 CLS 或 token 的输出进行自然语言理解(NLU),增强了通用性,并适用于序列标注任务
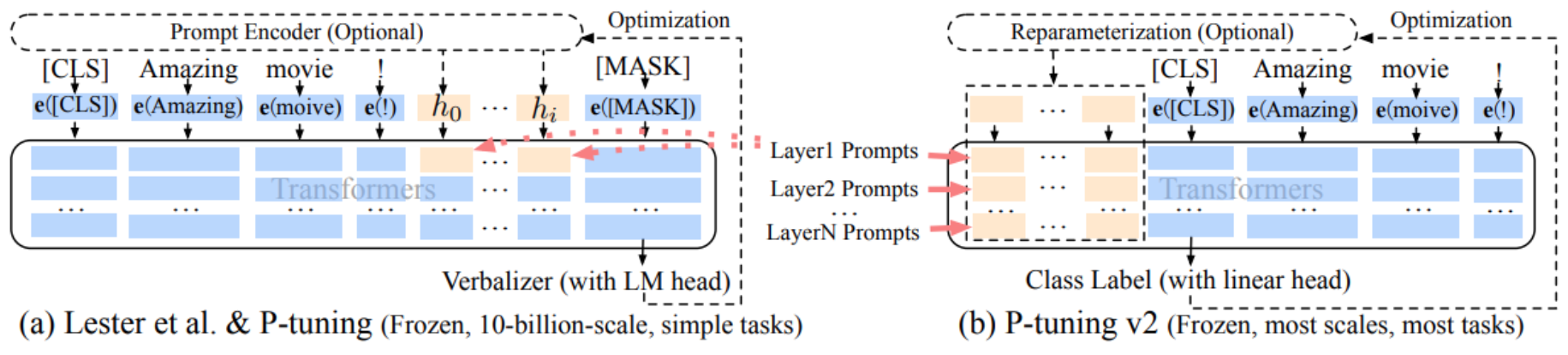
Deep Prompt Encoding:P-Tuning v2在每一层都加入了Prompts tokens作为输入,而不是仅仅加在输入层,这带来两个方面的好处:
- 更多可学习的参数(从P-tuning和Prompt Tuning的0.01%增加到0.1%-3%),同时也足够参数高效。
- 加入到更深层结构中的Prompt能给模型预测带来更直接的影响。
Multi-task learning:基于多任务数据集的Prompt进行预训练,然后再适配到下游任务。对于pseudo token的continous prompt,随机初始化比较难以优化,因此采用multi-task方法同时训 练多个数据集,共享continuous prompts去进行多任务预训练,可以让prompt有比较好的初始化。
Prefix-Tuning v2 引入了动态生成前缀的机制,而不仅仅是使用固定的前缀。这使得前缀可以更好地适应不同的输入和上下文,从而提升模型的灵活性和准确性。P-Tuning v2 通过在不同层之间共享部分前缀参数,减少了模型的总参数量和计算复杂度,从而提高了微调效率,同时减少了过拟合的风险。通过设计多任务前缀,使得一个前缀能够适应多个下游任务。这种方法尤其适合处理跨领域任务,减少了每个任务都需要独立训练前缀的开销。
所以P-Tuning v2是一种在不同规模和任务中都可与微调相媲美的提示方法。P-Tuning v2对从330M到10B的模型显示出一致的改进,并在序列标注等困难的序列任务上以很大的幅度超过了Prompt Tuning和P-Tuning。
在Prefix Tuning和P-Tuning V2每一层的transformer的输入的不是上一层的输出而是随机初始化的embedding。
5. LoRA & QLoRA
除此之外,还有比较主流的LoRA,QLoRA,其中LoRA的原理已经在上节课内容介绍过(《LORA微调原理&实战》),该方法具有节省计算资源、加快训练速度、保持模型的原有权重、可模块化和拓展的优点。QLoRA是在微调过程中同时进行微调和量化,这意味着微调可以在更小的显存要求下进行。以下是LoRA论文地址:
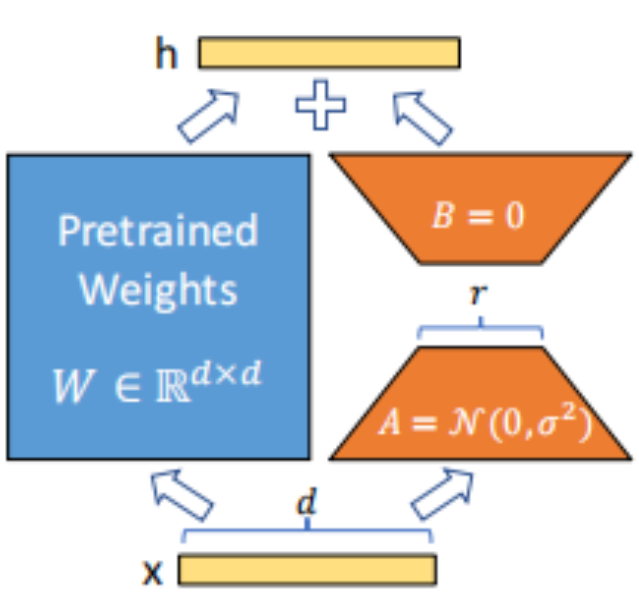
- LoRA(Low-Rank Adaptation) 基本概念 LoRA通过在预训练模型的基础上添加低秩矩阵来适应特定任务,而不是微调整个模型的所有参数。具体来说,LoRA冻结了原模型的权重,只训练新增的低秩矩阵参数,从而显著减少了微调所需的参数量和计算成本
- QLoRA(Quantized LoRA) 基本概念 QLoRA结合了量化技术和LoRA方法,通过对模型参数进行量化处理,进一步减少了存储和计算需求,同时保持了LoRA的低秩适应特性。
优点 存储高效:通过量化减少了参数存储需求。 计算高效:结合LoRA的低秩适应,进一步降低了计算成本。
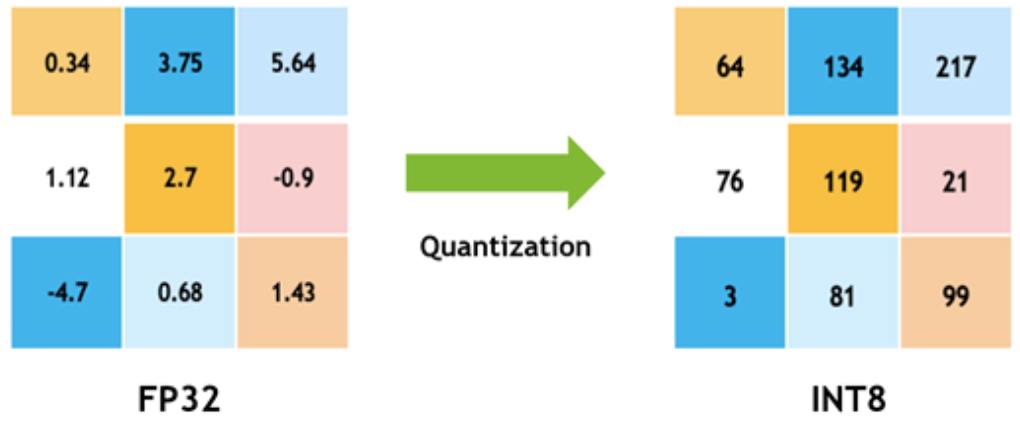
出于节约资源的目的,QLoRA可以在微调中将模型参数转换成低精度的数据类型,比如8位或4位,来大幅减少内存使用并加快计算速度。这个原理其实很简单:它将所有32位的可能值映射到一个更小范围的有限值上(例如,8位可以表示256个不同的值)。这一过程可以想象为将高精度的值围绕若干个固定点进行分组,这些固定点代表了其周围的值。
QLoRA 的核心优势在于将 4-bit 量化技术 与 LoRA 微调方法相结合。通过量化模型的权重到 4-bit 表示,它能够大幅减少模型的存储和计算需求,而不会显著损害模型的性能。并且QLoRA 能够在压缩的同时保持与全精度模型相当的性能。进而够进一步降低显存需求,提升大模型微调的效率,特别是在处理超大规模模型时具有显著的优势。
6. Adapter Tuning
2019年谷歌的研究团队设计了Adapter结构,将其嵌入Transformer的结构里面,在训练时,固定住原来的预训练参数不变,只对新增的 Adapter 结构进行微调。同时为了保证训练的高效性(也就是尽可能少的引入更多参数),以下是Adapter Tuning论文地址:https://arxiv.org/pdf/1902.00751
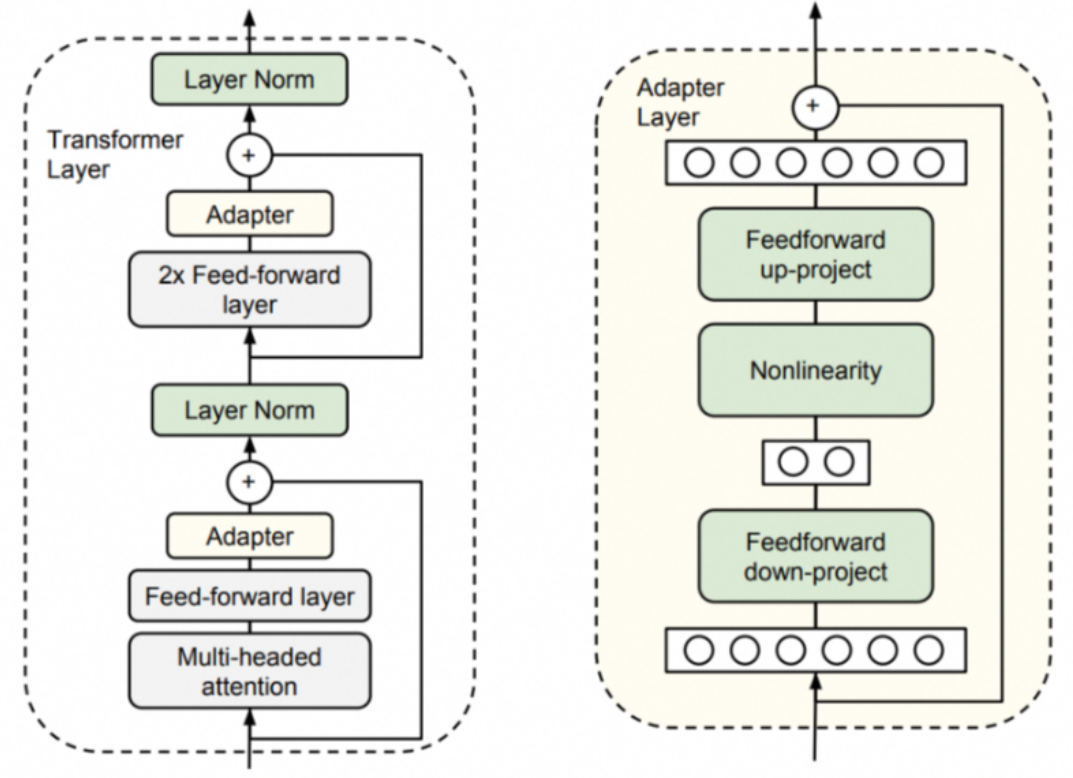
他们将 Adapter 设计为这样的结构:
首先是一个 down-project 层将高维度特征映射到低维特征 然后过一个非线形层之后,再用一个 up-project 结构将低维特征映射回原来的高维特征 同时也设计了 skip-connection 结构,确保了在最差的情况下能够退化为identity(类似残差结构)。
与传统的微调方法不同,Adapter Tuning 仅需要更新适配器中的参数,模型的大部分预训练参数保持不变。这大大减少了需要训练和存储的参数数量。因为适配器模块占用的参数量很小,可以为每个任务保存不同的适配器,而不需要保存完整的微调模型。
Adapter Tuning 特别适合那些需要在大规模预训练模型上进行任务适应的场景,例如跨任务、跨领域的应用,或需要频繁更新和切换任务的环境。
二、DeepSpeed原理浅析
如果大家在尝试训练大型推荐系统或微调像 llama-7B 这样相对较小的LLM的时候 ,可能会遇到令人沮丧的 OOM 错误。 为什么 7B 参数模型(假设 fp32 或每个参数权重 4 字节)不适合具有 7B*4=28GB 内存的 GPU?除了参数之外,每个设备还需要访问梯度(与参数大小相同)和优化器状态,例如,如果使用 ADAM 优化器(参数大小的两倍),则需要梯度的一阶和二阶矩。
在实际训练、微调大模型的时候,由于大模型的参数量很大,其训练效率和所消耗的资源、时间是不可忽视的指标,在实际训练大语言模型的时候一般是要配备多GPU的集群,但实际的机器利用率往往只能达到其最大效率的一半左右。这也就是说,只是一味的堆料并不能有效地带来模型训练效率的提升。同样,即使系统具有更高的吞吐量,也并不能保证所训练出的模型具有更高的精度或更快的收敛速度。
Deepspeed是微软的大规模分布式训练工具。专门用于训练超大模型。其主要解决了训练万亿参数模型的两个基本挑战:显存效率和计算效率。因此,DeepSpeed 可以扩展至在显存中放下最巨大的模型但不会牺牲速度的优势。
DeepSpeed已经在Github上的地址:https://github.com/microsoft/DeepSpeed
在使用方法上DeepSpeed是一个开源深度学习优化库,专门设计来提高大型模型训练的效率和扩展性。这个库采用了一系列先进技术,如模型并行化、梯度累积、动态精度缩放和混合精度训练等,来实现快速训练。除此之外,DeepSpeed还搭载了一套强大的辅助工具集,涵盖分布式训练管理、内存优化以及模型压缩等功能,帮助开发者更有效地处理和优化大规模的深度学习任务。值得一提的是,DeepSpeed是基于PyTorch构建的,因此对于现有的PyTorch项目,开发者可以轻松地实施迁移。此库已在众多大规模深度学习应用中得到验证,涉及领域包括但不限于语言模型、图像分类和目标检测。
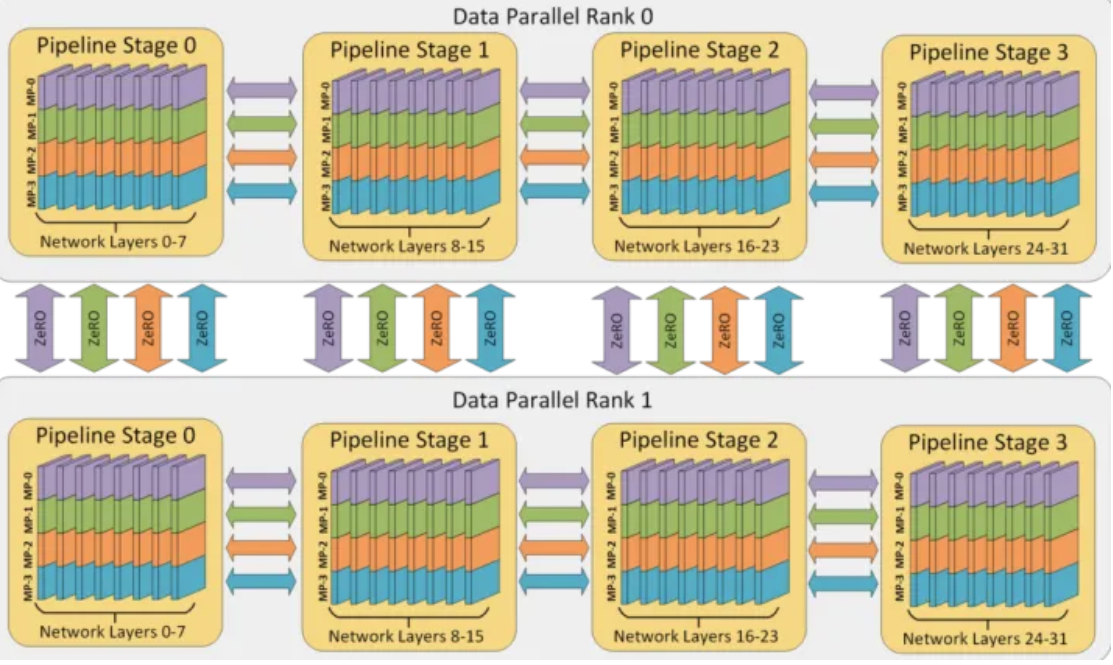
DeepSpeed的参数非常多,最核心的技术就是ZeRO(Zero Redundancy Optimizer ),其中ZeRO-Offload是将一部分计算(参数、梯度、优化器状态)和内存管理任务从 GPU 卸载到 CPU,从而大大降低了 GPU 的内存消耗,允许在较小的 GPU 内存配置下训练大规模模型。其中 ZeRO 可以在当前一代 GPU 集群上训练具有 1000 亿个参数的深度学习模型,吞吐量是当前最佳系统的三到五倍。

ZeRO-Infinity 是 DeepSpeed 的一种扩展技术,专门用于在超大规模模型(如数千亿或万亿参数的模型)上实现高效训练和推理。它构建在 ZeRO (Zero Redundancy Optimizer) 系列优化技术的基础上,通过整合 CPU 内存、NVMe 存储和 GPU 显存,最大限度地扩展训练和推理能力,从而支持更大规模的模型而无需昂贵的硬件升级。
- 显存(GPU Memory):用于前向和反向传播的关键计算,存储当前正在处理的模型参数和激活值。
- CPU 内存(Host Memory):用于存储暂时不需要的梯度、优化器状态和部分模型参数,当 GPU 内存不足时,这些数据可以动态地移到 CPU 内存。
- NVMe 存储:当 CPU 内存也不足时,ZeRO-Infinity 可以进一步将数据交换到 NVMe 存储设备,利用高速固态硬盘来扩展模型的训练能力。
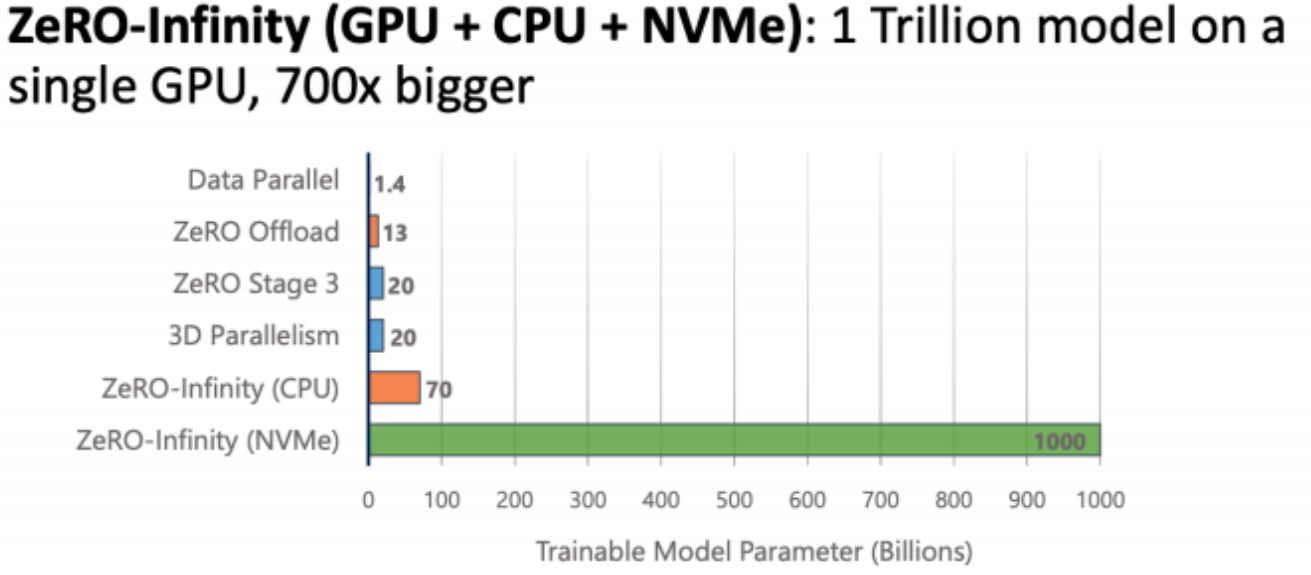
除了实现高效推理以外,DeepSpeed还提高了模型的训练速度。不管大模型还是小模型的训练,训练的效率一定是框架需要重点关注的,需要在保证精确性的前提下,保证它快。

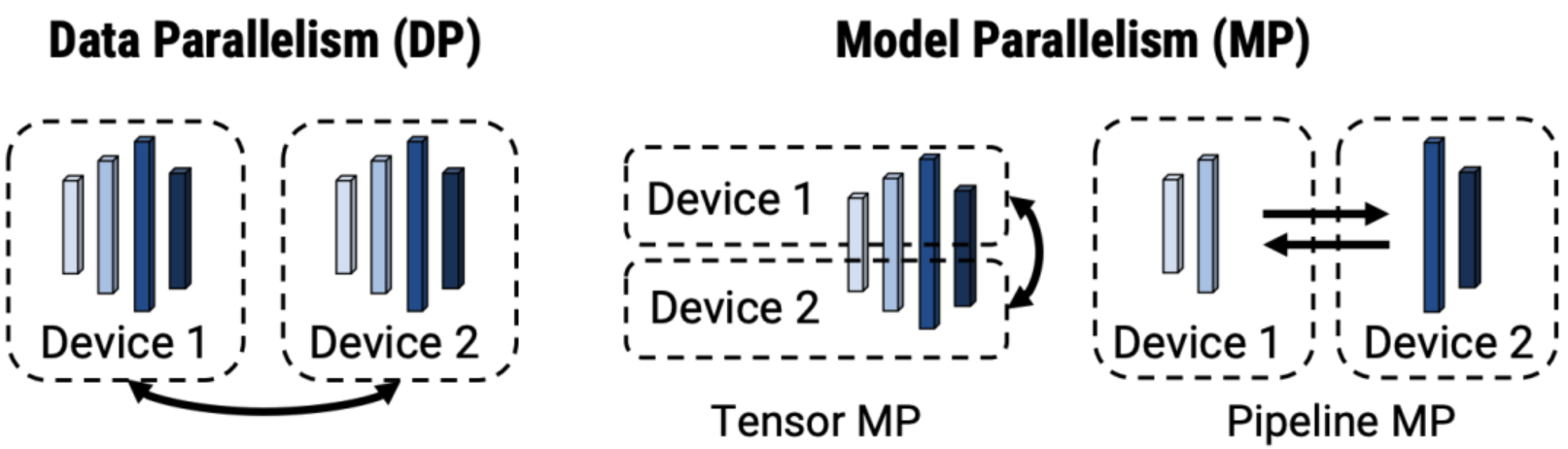
并行模型:
-
数据并行 Data Parallelism(DP):整个模型会复制到所有GPU上,输入数据会被分割成多个batch到不同的GPU上。也因为每个GPU都在处理不同的数据子集,所以在独立执行前向传播后计算的损失(loss)也会有所不同,接着每个GPU根据其计算出的损失执行反向传播,计算梯度。当所以GPU计算完成后,求平均。这个平均梯度代表了整个数据集上的平均梯度。使用这个平均梯度更新模型的参数。从而确保所有GPU上的模型都保持同步。数据并行性无助于减少每个设备的内存占用:具有超过 10 亿个参数的模型即使在具有 32GB 内存的 GPU 上也会出现内存不足的情况。
-
张量并行 Tensor MP:对模型做横向切分,也就是层内的切分,每一层的计算被分割成几个较小的部分,每部分独立在不同的GPU上进行计算。比如最大层是一个MLP层,有非常大的计算,但一张卡放不下,就需要切分成两个小的分别放在两张卡上计算。由于细粒度计算和昂贵的通信,张量并行无法有效地扩展到单个节点之外。模型并行框架经常需要广泛的代码集成,这些代码集成可能是特定于模型架构的。
-
流水线并行 Pipeline MP:把模型的不同层分在不同的GPU上,比如12层的模型,前6层分在一个GPU上,后六层分在一个GPU上。像我们常用的Transformer结果,它会分成一个个Block,所以一般不同的Block会分布不同的层中。
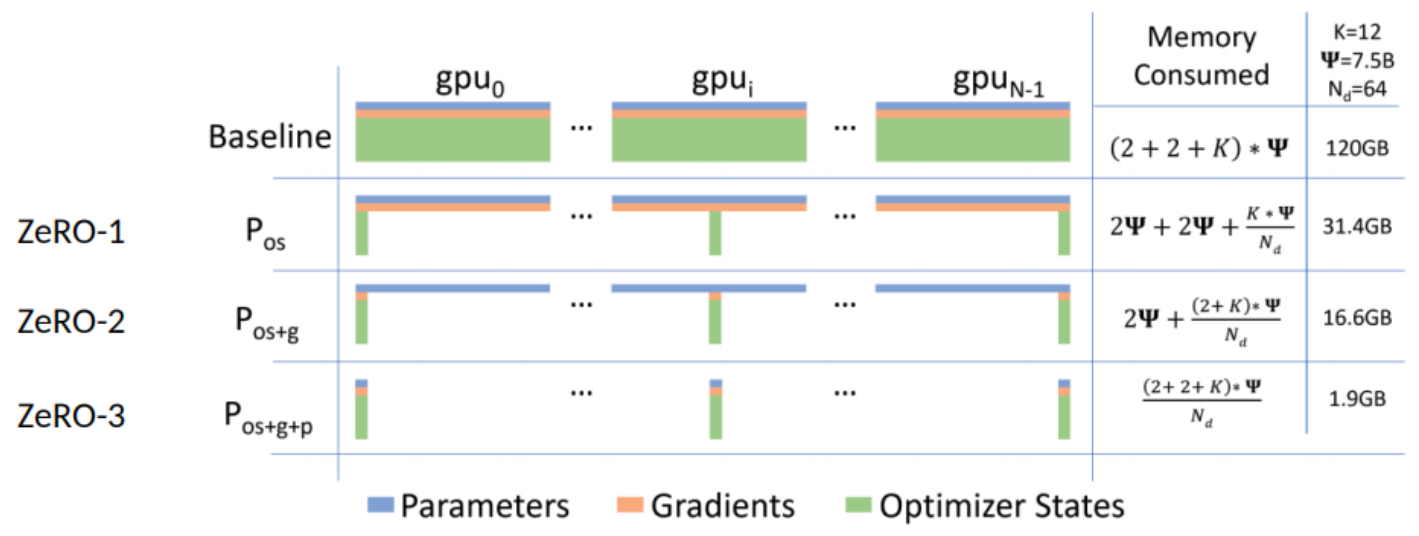
ZeR0实际上分为三个版本:ZeR0-1只会对优化器状态做切分。ZeR0-2会对优化器状态和梯度做切分。ZeR0-3是对优化器状态、梯度和模型参数做切分,并分布在多个设备或节点上,最大化利用计算资源。
- φ:假设有一个模型,这个模型由φ个参数,也就是由φ个浮点数组成的模型,每个参数如果以fp16的形式存放,一个参数是32float,也就是4bit,所以这里就是2φ。
- 梯度,同样是2φ的显存占用。
- 优化器状态就是K倍的φ,优化器的状态根据实现的形式是不一样的,这里选择12进行比较。
在Baseline(数据并行模式)中,这120GB显存是每张卡都要占用的,所以现在最大的H100这种80G的显存都放不下。但是使用ZeRO-1则占用31.4G显存,ZeRO-2占用16.6G显存,ZeRO-3占用1.9G显存.
ZeRO 消除了内存冗余,并使集群的全部聚合内存容量可用。启用所有三个阶段后,ZeRO 可以在 1024 个 NVIDIA GPU 上训练万亿参数模型。具有Adam 16 位精度优化器的万亿参数模型需要大约 16 TB 的内存来保存优化器状态、梯度和参数。 16TB 除以 1024 就是 16GB,这对于 GPU 来说完全在合理范围内。
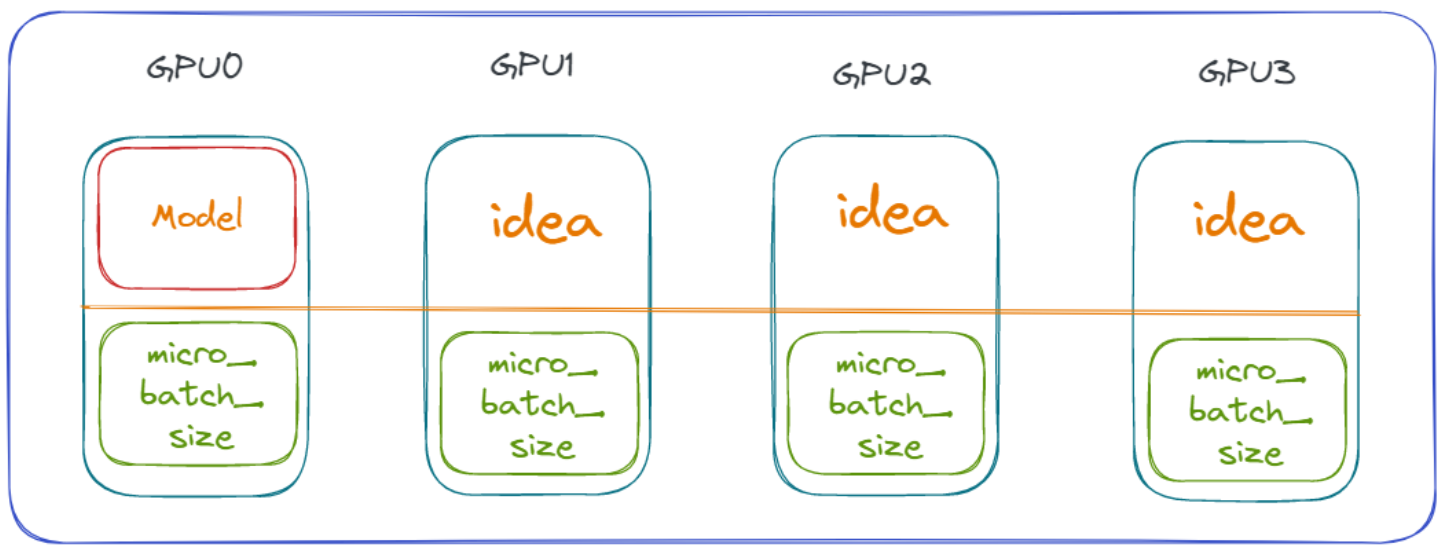
在实际计算过程中,GPU1 ~ GPU3 计算显存空间的使用会根据 GPU0 的可使用显存空间来确定,这就造成了一个问题:在显存使用上,GPU0 = GPU1 = GPU2 = GPU3,对 GPU1~GPU3 来说是一种巨大的浪费。而且,这种浪费随着模型精度、参数的增加愈发明显。
什么是micro_batch_size?
Pipeline会把输入进来的mini_batch 分成设备个 micro_batch。
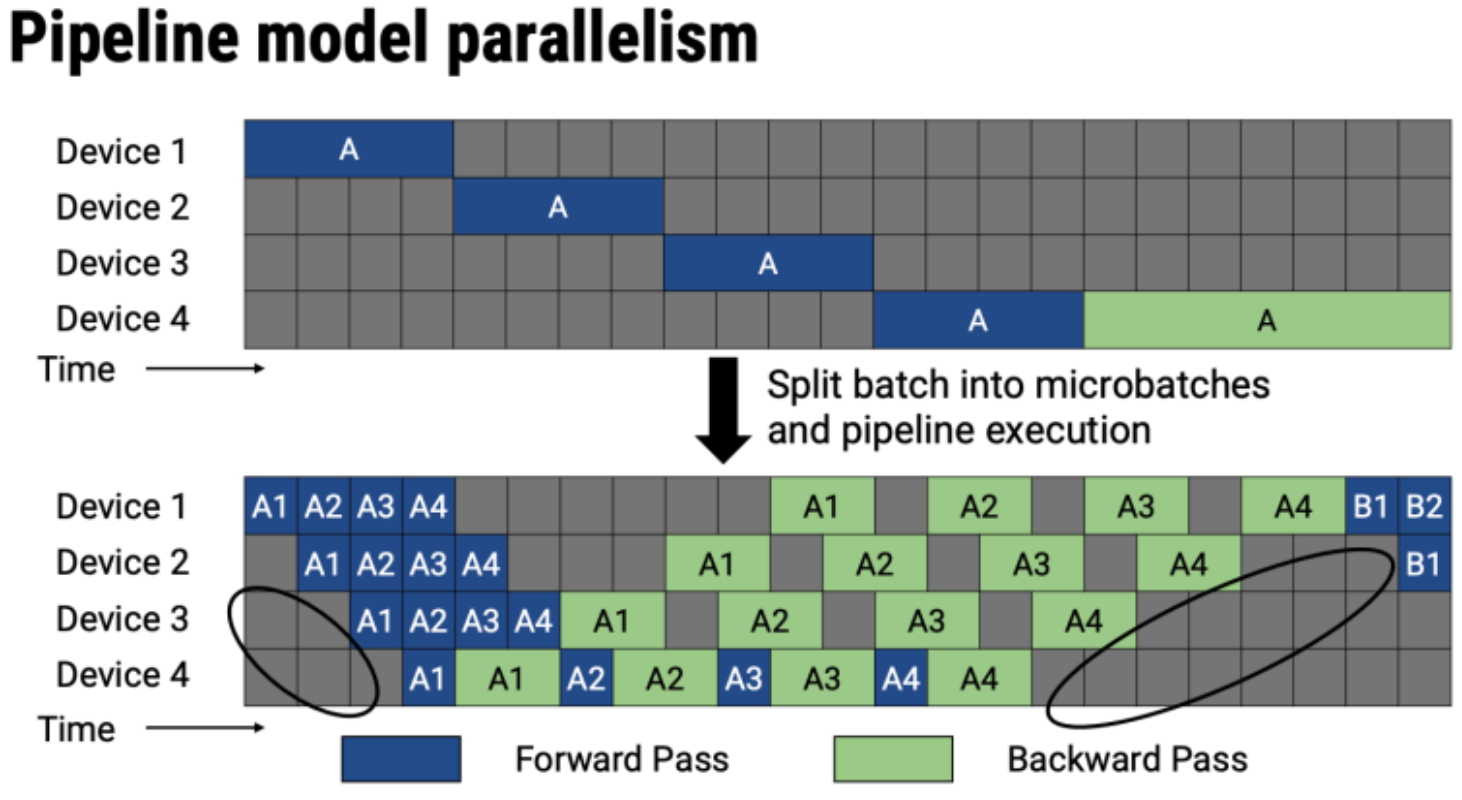
理想的计算加载方式应该是将模型加载在每个GPU上,减少模型对单个GPU的占用依赖,如下图所示:
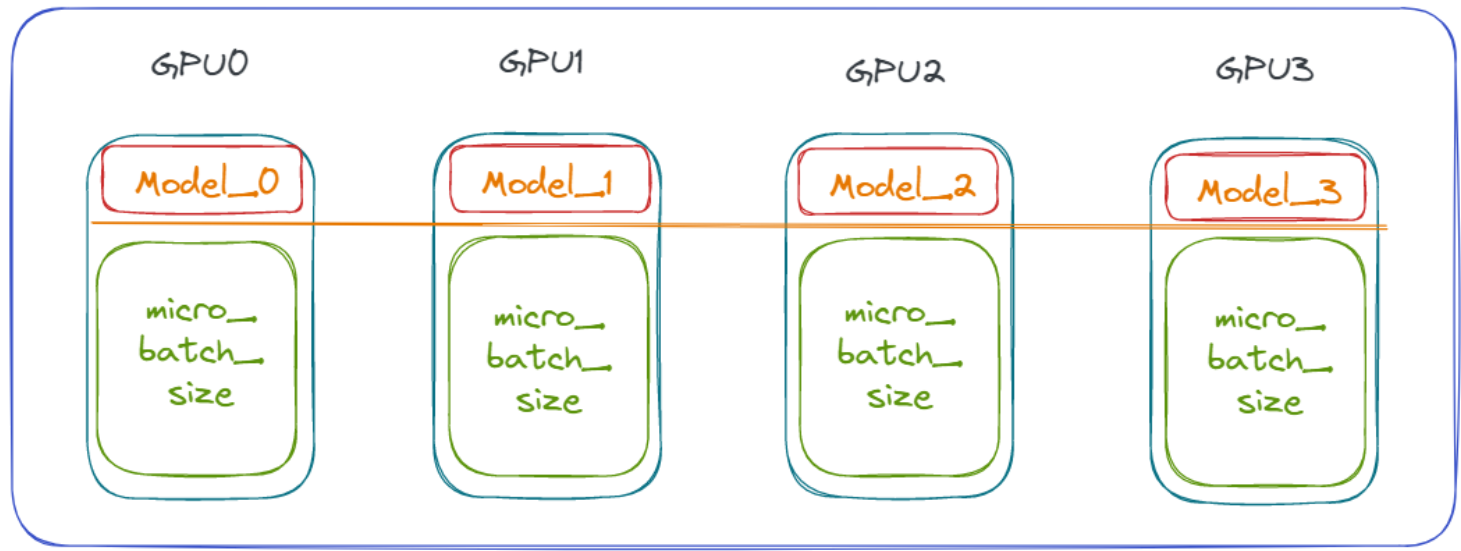
DeepSpeed 就是实现这样的加载,结合Deepspeed框架的优化特性,充分发挥每块GPU的计算和显存潜能,从而提高整体的训练效率和资源利用率。
在理解了DeepSpeed原理后,我们尝试进行模型加载并观察其内存消耗情况。
在微调过程中,参数配置和优化对于模型性能和训练效率至关重要。合理的参数设置不仅可以加速模型的收敛,还可以提高模型的表现。特别是当我们使用高级的训练框架如DeepSpeed时,更需要对每个参数有深入的理解和精细的调整。DeepSpeed训练过程中涉及的主要参数和分类如下:
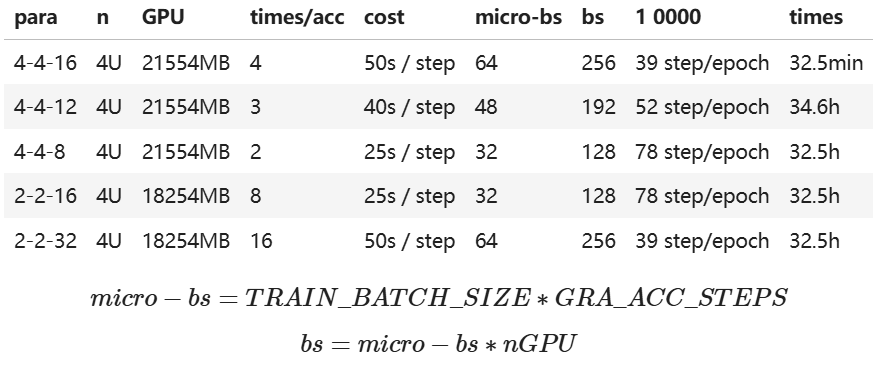
其中,para列中的4-4-16所在位置参数分别表示per_device_train_batch_size、per_device_eval_batch_size、gradient_accumulation_steps。
注:10000条数据在当前para下完成一个epoch需要步数;10000/48/4=52 step/epoch; 10000/32/4=78 step/epoch
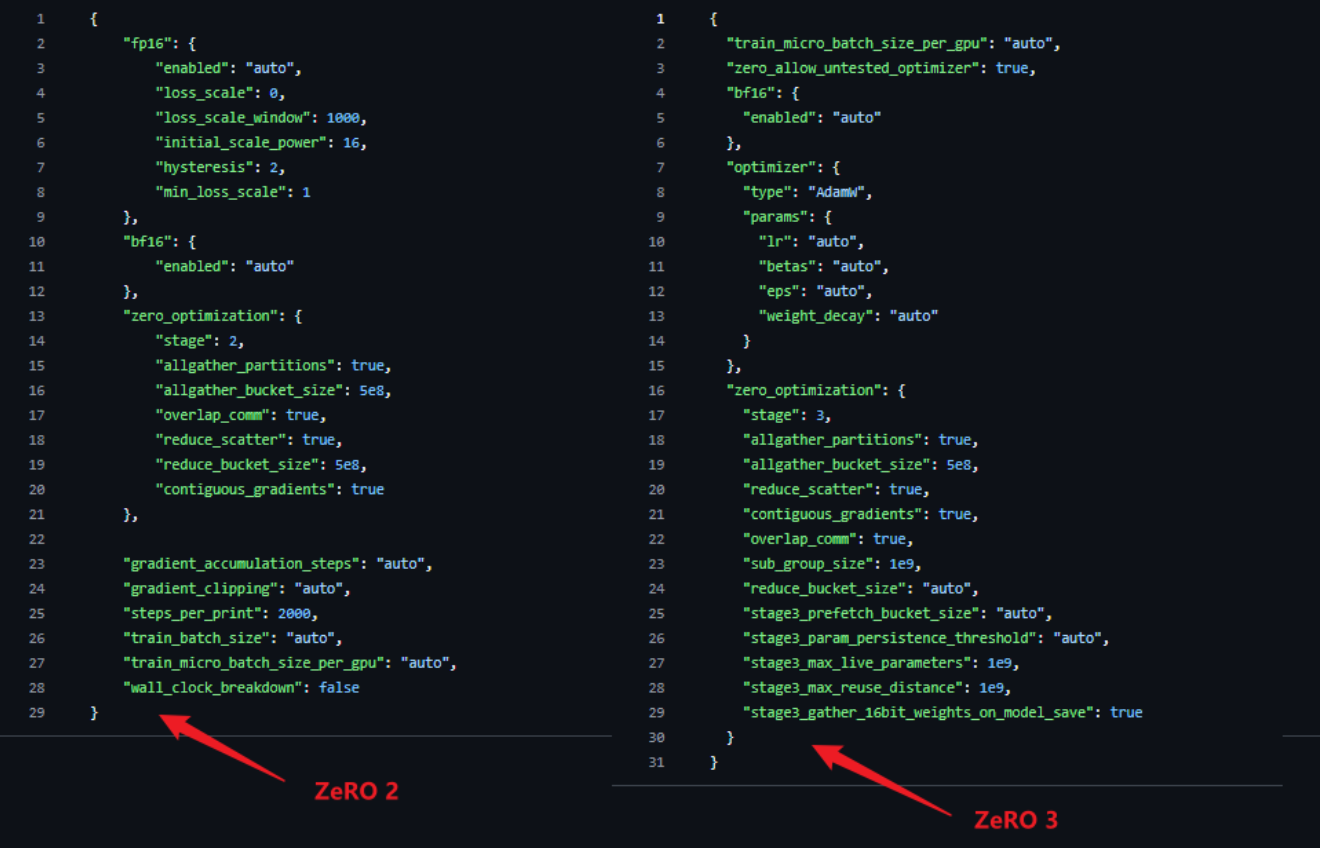
ZeRO的易操作性:只需更改几行代码即可使PyTorch 模型能够使用DeepSpeed 和ZeRO。与当前的模型并行库相比,DeepSpeed 不需要重新设计代码或模型重构。它也不会限制模型维度(例如注意力头的数量、隐藏大小等)、批量大小或任何其他训练参数。对于多达 60 亿个参数的模型,即可以方便地使用数据并行(由 ZeRO 提供支持),而无需模型并行,而相比之下,对于超过 13 亿个参数的模型,标准数据并行会耗尽内存。 ZeRO 的第二阶段和第三阶段将进一步增加仅通过数据并行性即可训练的模型大小。此外,DeepSpeed 支持 ZeRO 支持的数据并行性与模型并行性的灵活组合。
三、基于ChatGLM3-6b进行P-Tuning v2微调实战
3.1 微调环境准备
本次实验环境配置:
- 操作系统:Ubuntu 22.04;
- GPU:3090双卡,总共48G显存;
- CPU:AMD 5900X;
- 存储:64G内存+2T SSD数据盘;
官方硬件需求:显存:24GB及以上(推荐使用30系或A10等sm80架构以上的NVIDIA显卡进行尝试) 内存:16GB RAM: 2.9 /16 GB GPU RAM: 15.5/16.0 GB
本教程P-Tuning V2微调方法是使得原有的ChatGLM3-6b模型具备专业的广告生成能力。项目地址:https://github.com/THUDM/ChatGLM3/tree/main/finetune_demo
首先我们需要完成微调所需的相关依赖的安装,在文件相对路径/chatglm3/finetune_demo下可以找到requirement.txt文件,里面包含了所有的依赖以及对应版本。

在微调环境准备阶段,需要先检查代码的运行地址,确保运行地址处于 finetune_demo 中。 并确保已经安装了 requirements.txt中全部依赖。 使用以下命令安装依赖:
pip install -r requirements.txt
这条命令会读取 requirements.txt 文件,并安装其中列出的所有依赖包。

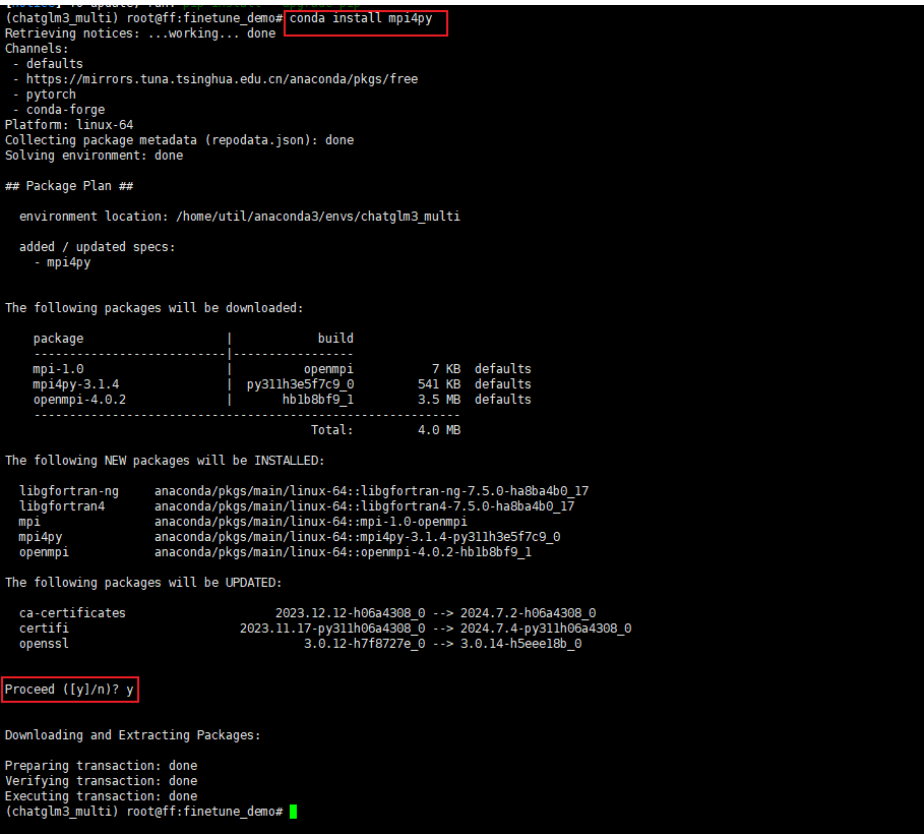
- 其中mpi4py这个依赖,如果在正常状态
pip install方法不能直接拉取,需要conda install的方式下载,会同时拉去前置的openmpi依赖。
3.2 微调数据下载与预处理
官网为广告生成能力项目提供了一个微调示例:AdvertiseGen 数据集,里面包含两个文件分别是训练集和测试集。可以进入Tsinghua Cloud:https://cloud.tsinghua.edu.cn/f/b3f119a008264b1cabd1/?dl=1 下载并上传到finetune_demo/data路径下。
- 模型路径大家要使用绝对路径。因为LoRA仅存储adapter部分参数,而adapter配置 json文件记录了预训练模型的路径,用于读取预训练模型权重。
一种更便捷的方式就是在服务器终端使用wget命令来进行下载。同时下载到的AdvertiseGen数据集是一个.tar.gz的压缩文件,需要解压才可使用:
wget - O AdvertiseGen https://cloud.tsinghua.edu.cn/f/b3f119a008264b1cabd1/?dl=1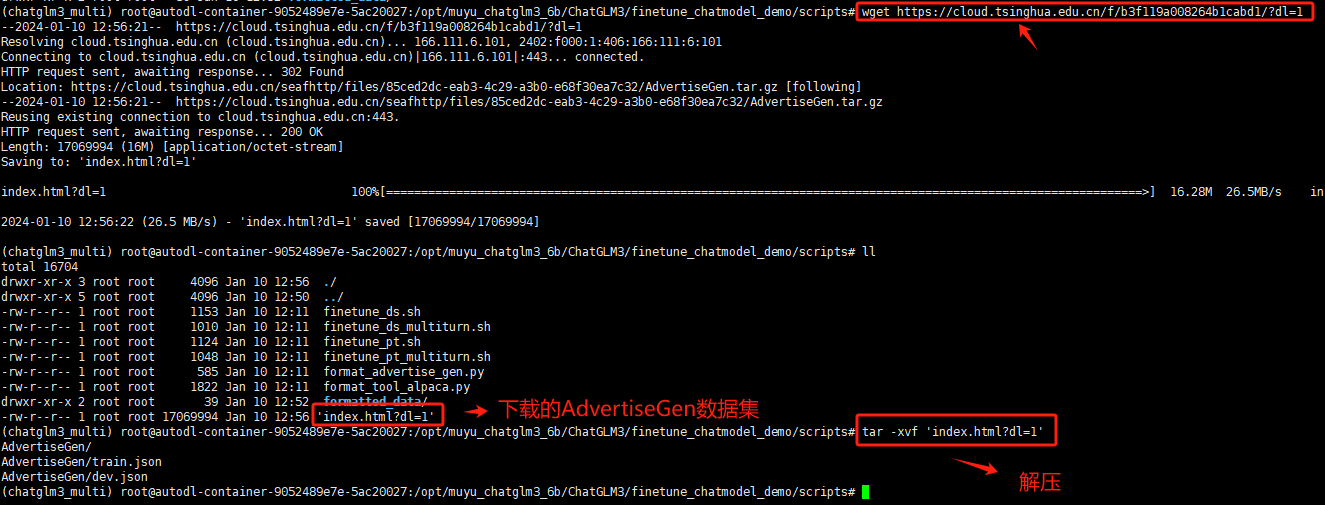
该数据集任务为根据输入(content)生成一段广告词(summary),其数据格式如下:
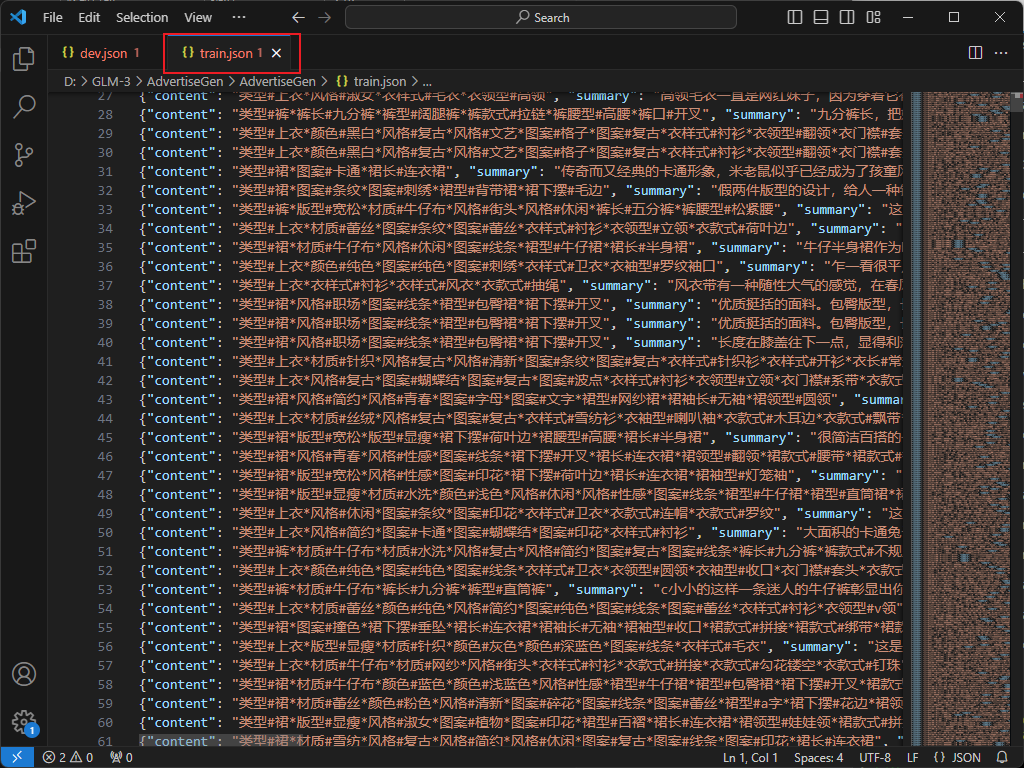
{"content": "类型#上衣*风格#街头*图案#创意*衣样式#卫衣", "summary": "在这件卫衣上,BRAND-white集合了女性化的柔美还有不变的街头风采,<UNK><UNK>的向日葵花朵美丽的出现在胸前和背后,犹如暗<UNK>闪光的星星一般耀眼又充满着<UNK>的生命力,而后品牌标志性的logo<UNK>出现,呈现出将花束固定的效果,有趣极了,穿的不仅是服饰。更是新颖创意的载体。"}我们需要修改成单轮对话的数据微调格式。可以直接在数据集所在的文件夹新建一个python脚本文件用来转化,代码内容如下:
import json
import time
def process_and_save_json(input_filepath, output_filepath):
# 记录开始时间
start_time = time.time()
with open(input_filepath, 'r', encoding='utf-8') as file:
for line in file:
data = json.loads(line.strip())
user_data = {
"role": "user",
"content": data["content"]
}
assistant_data = {
"role": "assistant",
"content": data["summary"]
}
outfile = open(output_filepath, 'a', encoding='utf-8')
json.dump({"conversations": [user_data, assistant_data]}, outfile, ensure_ascii=False)
outfile.write('\n')
# 记录结束时间
end_time = time.time()
elapsed_time = end_time - start_time
print("耗时:", elapsed_time, "秒")
input_filepath = 'train.json' # 传入处理前的json
output_filepath = 'train2.json' # 处理后的保存位置
process_and_save_json(input_filepath, output_filepath)执行后,数据格式如下:
{"conversations": [{"role": "user", "content": "类型#裙*裙长#半身裙"}, {"role": "assistant", "content": "这款百搭时尚的仙女半身裙,整体设计非常的飘逸随性,穿上之后每个女孩子都能瞬间变成小仙女啦。料子非常的轻盈,透气性也很好,穿到夏天也很舒适。"}]}
-
转化结束后新文件名称是
xx2.json文件,注意文件名称的修改或调用地址的确定。
3.3 执行P-Tuning v2微调
在正式微调之前可以,先通过配置文件了解以下对应的参数。P-Tuning v2的配置文件在相对路径chatglm3/finetune_demo/configs中,适当调节参数可以达到更合适的微调效果以及适配对应具体的显卡能力:
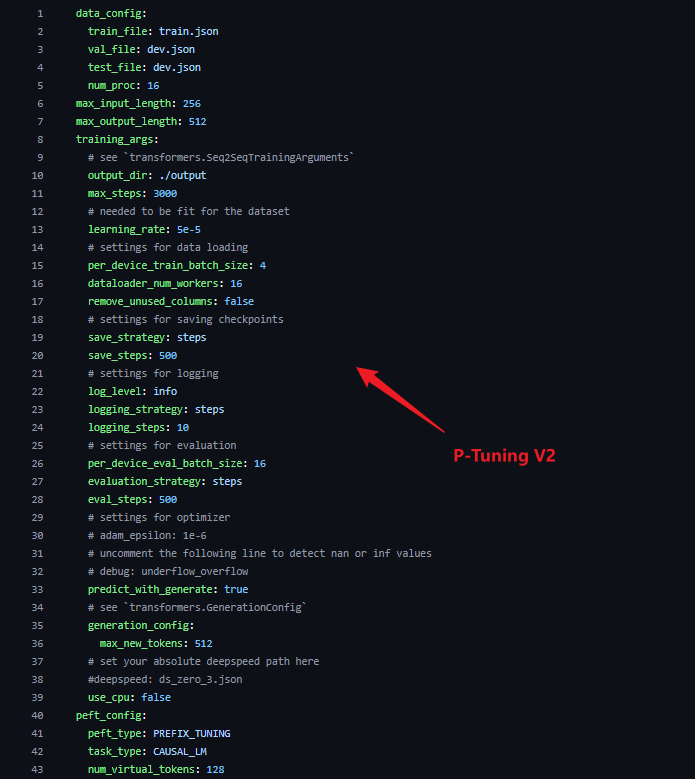
具体的参数含义如下:
data_config部分
-
train_file: 训练数据集的文件路径。
-
val_file: 验证数据集的文件路径。
-
test_file: 测试数据集的文件路径。
-
num_proc: 在加载数据时使用的进程数量。
-
max_input_length: 输入序列的最大长度。
-
max_output_length: 输出序列的最大长度。: 输出序列的最大长度。: 输出序列
training_args 部分
-
output_dir: 用于保存模型和其他输出的目录。
-
max_steps: 训练的最大步数。
-
max_steps: 训练的最大步数。
-
per_device_train_batch_size: 每个设备(如 GPU)的训练批次大小。
-
dataloader_num_workers: 加载数据时使用的工作线程数量。
-
remove_unused_columns: 是否移除数据中未使用的列。
-
save_strategy: 模型保存策略(例如,每隔多少步保存一次)。
-
save_steps: 每隔多少步保存一次模型。
-
log_level: 日志级别(如 info)。
-
logging_strategy: 日志记录策略。
-
logging_steps: 每隔多少步记录一次日志。
-
per_device_eval_batch_size: 每个设备的评估批次大小。
-
evaluation_strategy: 评估策略(例如,每隔多少步进行一次评估)。
-
eval_steps: 每隔多少步进行一次评估。
-
predict_with_generate: 是否使用生成模式进行预测。
generation_config 部分
-
max_new_tokens: 生成的最大新 token 数量。
peft_config 部分
-
peft_type: 使用的参数有效调整类型(如 LORA)。
-
task_type: 任务类型,这里是因果语言模型(CAUSAL_LM)。
-
P-TuningV2 参数:
-
num_virtual_tokens: 虚拟 token 的数量。
-
通过在命令行输入以下代码执行可以在单机多卡/多机多卡环境下运行,这是使用 deepspeed 作为加速方案的。
OMP_NUM_THREADS=1 torchrun --standalone --nnodes=1 --nproc_per_node=8 finetune_hf.py data/AdvertiseGen/ /home/util/ARIS/chatglm3/chatglm3-6b configs/ptuning_v2_.yaml-
OMP_NUM_THREADS=1:这是一个环境变量,控制OpenMP库在多线程运算中的并行线程数。将其设置为1表示每个进程只使用一个线程进行计算,避免过多的线程争用资源,可能会提升分布式计算的效率。
-
torchrun: 是用于启动分布式PyTorch训练的工具。它用于替代之前的
torch.distributed.launch,更现代化和易于使用。它会自动初始化分布式环境并管理多进程训练。 -
standalone:这个表示在单机模式(standalone mode)下运行,即所有训练进程都在一台机器上进行。它不需要额外的集群配置,是常用于小规模分布式训练的简化模式。
-
nnodes=1:指定训练的节点数。在分布式训练中,节点通常指的是一台物理或虚拟机。这里
nnodes=1表示只有一个节点参与训练。 -
nproc_per_node=8:表示在每个节点上启动 8 个进程。由于是单节点,意味着这台机器将运行 8 个并行的训练进程。通常,
nproc_per_node与机器上的 GPU 数量对应,这里应该是有 8 个 GPU,每个进程使用一张 GPU。
通过以下代码可以在单机单卡环境下运行。
python finetune_hf.py data/AdvertiseGen/ /home/util/ARIS/chatglm3/chatglm3-6b configs/ptuning_v2_.yaml从保存点开始训练
如果按照上述方式进行训练,每次微调都会从头开始。如果你想从训练一半的模型开始微调,可以加入第四个参数,这个参数有两种传入方式:
-
yes, 自动从最后一个保存的 Checkpoint开始训练
-
XX, 断点号数字 例如
500则从序号为500 的Checkpoint开始训练。
以下是一个从最后一个保存点继续微调的示例代码的示例:
python finetune_hf.py data/AdvertiseGen/ /home/util/ARIS/chatglm3/chatglm3-6b configs/ptuning_v2_.yaml yescheckpoint中存储的是训练过程中保存的模型状态,包括模型参数、优化器状态、当前epoch等信息。
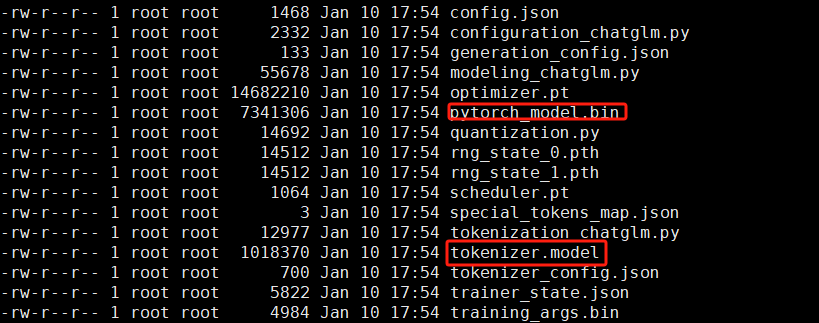
不同的训练参数,会产生不同数量的checkpoint,比如在脚本中,SAVE_INTERVAL 设置为1000,这说明每1000个训练步骤保存一次模型。如果MAX_STEP设置为3000,就应该有3个checkpoints被保存,这个也很好计算。
3.4 使用微调后的模型
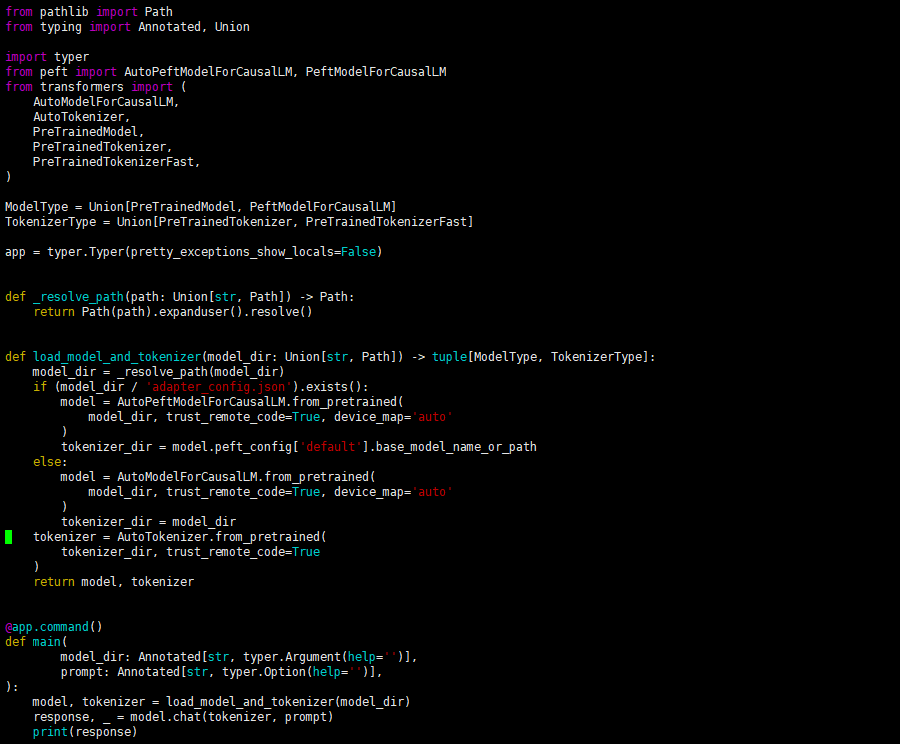
可以在 finetune_demo/inference_hf.py 中使用微调后的模型,仅需要一行代码就能进行模型的推理测试。
python inference_hf.py your_finetune_path --prompt your prompt
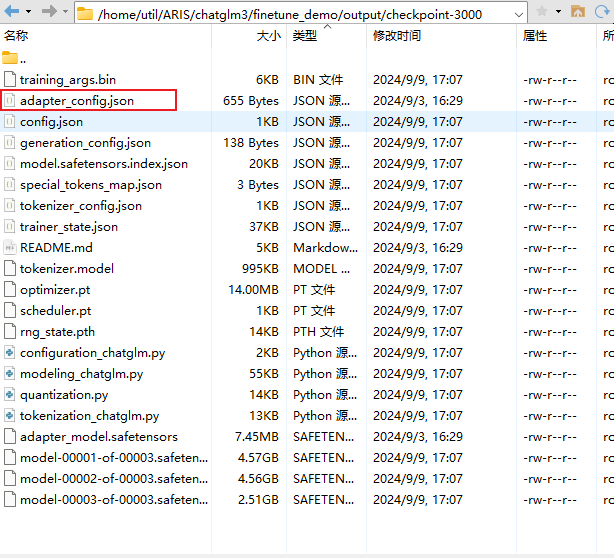
也可以在/chatglm3/finetune_demo文件夹下的finetune_hf.py启动微调后的模型推理,不过需要先修改文件adapter_config.json中调用的地址才能正确运行。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号