单机多卡启动大模型办法
前言:
无论是在单机单卡(一台机器上只有一块GPU)还是单机多卡(一台机器上有多块GPU)的硬件配置上启动ChatGLM3-6B模型,其前置环境配置和项目文件是相同的。如果大家对配置过程还不熟悉,建议回看前两节课程内容学习进行初始配置、文件部署和运行;如果跟着上一节课件实践过单机单卡的操作流程,我们建议针对本期内容的单机多卡也设置创建一个新的虚拟环境。这样做可以有效避免版本冲突和依赖问题,确保多卡环境具备专门优化的、独立于单卡环境的配置,简化项目的维护和调试过程。
在实际的生产开发中,一个独立项目对应一个单独的隔离环境是一个比较标准的做法,也建议大家以后在做项目开发的时候遵循。具体的部署流程如下:
-
更新Conda
-
升级Conda到最新版本并检验
-
使用Conda更新软件包
-
创建独立的虚拟环境并进入
-
安装Pytorch并检验
-
下载大模型的项目文件
-
安装大模型运行所需的环境依赖
-
下载大模型的权重文件
本课件为单机多卡情况提供的部署指南,执行多卡环境下ChatGLM3-6B模型的启动步骤。
创建独立虚拟环境以部署运行多卡 ChatGLM3
首先我们创建一个新的虚拟环境用来进行多卡的部署启动,以避免与现有环境中的包产生冲突,通过以下命令创建新的环境(此处设置名称为chatglm3_multi),部署的完整流程如有不熟悉可以翻看上节内容:
conda create --name chatglm3_multi python=3.11
使用 conda activate + 指定虚拟环境名称 的方式,进入该虚拟环境。如果命令行最前面的括号中显示该虚拟环境,说明进入成功。

除此之外,大家一定要注意:如果使用远程连接,关闭了当前终端,或者是重启了电脑等情况后,再次启动ChatGLM3-6B模型服务时,需要先进入这个虚拟环境。进入指定的虚拟环境方法如下:通过 conda env list指令可以显示全部创建的虚拟环境,conda activate +虚拟环境名称就可以激活对应的虚拟环境了。

单机多卡启动ChatGLM3-6b模型
单机多卡(多个 GPU)环境相较于单机单卡(一个 GPU),可以提供更高的计算能力,但同时也会存在更复杂的资源管理和更复杂的程序代码。比如我们需要考虑如何使所有的 GPU 的负载均衡,如果某个 GPU 负载过重,而其他 GPU 空闲,这会导致资源浪费和性能瓶颈,除此之外,还要考虑每个 GPU 的内存不会被过度使用及模型训练过程中GPU 之间的同步和通信。
尽管如此,单机多卡或者多机多卡往往才是工业界实际使用的方式,单机单卡的瓶颈非常有限,所以这方面的内容还是非常有必要掌握的。而如果初次接触,我们需要做的就是:学会有效的使用简单的GPU监控工具来帮助配置一些重要的超参数,例如批大小(batch size),像出现 GPU 内存溢出(即显存不足)等情况,去考虑减小批大小等等。
1. 如何查看机器的GPU数量
方式一:lspci 命令。这是最常用的方法之一,这个命令会显示与图形相关的设备信息,列出所有 PCI 设备,包括 GPU,其执行命令如下:
lspci | grep VGA
方式二:如果系统中安装的是 NVIDIA GPU 和驱动程序,最熟知且最直观的nvidia-smi 命令。

2. GPU性能参数详解
参数很多,如何理解各个数值的意义及需要关注哪些信息呢?我们首先来看上半部分的输出:

在这部分我们需要主要关注的信息有
持续模式(Persistence-M):开启状态时会使得GPU保持高性能状态,即使没有活跃的工作负载, 这种模式可以减少GPU从低功耗状态切换到高性能状态所需的延迟。 通常用于需要快速GPU响应的场景,如服务器环境或某些专业应用。 但是,启用此模式会增加功耗,因为GPU始终保持在较高的能耗状态。这里显示的是off的状态。这对于大多数普通用户和工作站来说是理想的设置,因为它可以在需要时提供性能,同时在空闲时节省能源。
性能状态(P-state):P8是最低功耗状态之一,通常在GPU空闲或负载很低时使用。P-States范围通常从P0到P12,P0表示最大性能,P12表示状态最小性能。在较高数位的状态下,GPU核心频率和内存频率会大幅降低,以节省能源。 这种状态通常在显卡没有执行任何重要任务时启用,比如桌面显示或轻量级应用程序运行时。如果需要使用GPU的全部性能,例如进行游戏或深度学习任务,GPU会自动切换到更高的性能状态(如P0或P2)
显存利用情况(Memory-Usage):运行任何程序都要消耗显存资源,当显存用尽的时候就会停止运行进程(俗称显存爆了),这时候就需要关闭一些程序的运行或重启程序,否则无法继续进行模型的训练或推理。
再来看下半部分的输出:

在这张图中,"G" 代表 "General"(通用)。这是指进程的类型。,除此以外,通常还会有其他类型指标。虽然图中只显示了 "G" 类型,但基于常见的系统监控工具和实践,以下介绍一些其他可能的类型指标:
-
C - Compute:表示计算密集型进程,通常与 GPU 计算任务相关。
-
M - Memory:指内存密集型进程,可能会大量使用 GPU 内存。
-
E - Encode:表示编码进程,通常与视频编码任务相关。
-
D - Decode:表示解码进程,通常与视频解码任务相关。
-
N - Network:可能表示网络相关的 GPU 加速进程。
-
I - I/O:表示输入/输出密集型进程。
-
K - Kernel:可能表示 GPU 内核或驱动相关的进程。
-
S - System:系统级进程。
-
U - User:用户级进程。
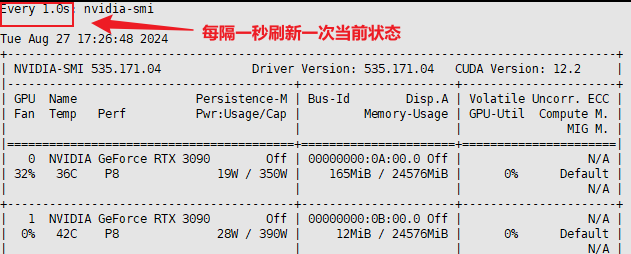
除了直接运行 nvidia-smi 命令之外,还可以加一些参数,来查看一些本机 GPU 使用的实时情况,这种方式也是在执行训练过程中最简单直观且比较常用的一种监测方式,执行命令如下:
watch -n 1 nvidia-smi
-n 参数可以自己灵活调整,后面添加的数字就是以秒为单位执行一次刷新。
3. 多卡启动办法实现
在 Linux 系统中想要在多GPU环境下启动一个应用服务,并且指定使用某些特定的GPU,主要有两种方式:
-
CUDA_VISIBLE_DEVICES环境变量
使用CUDA_VISIBLE_DEVICES环境变量是最常用的方法之一。这个环境变量可以控制哪些GPU对CUDA程序可见。例如,如果系统有4个GPU(编号为0, 1, 2, 3),而你只想使用编号为1和2的GPU,那么可以在命令行中这样设置:
CUDA_VISIBLE_DEVICES=1,2 python your_script.py这会让your_script.py只看到并使用编号为1和2的GPU。
-
修改程序代码
这种方式需要直接在代码中设置CUDA设备。例如,在PyTorch中,可以使用torch.cuda.set_device()函数来指定使用哪个GPU,除此之外,某些框架或工具(如vLLM或Ollma)提供也可能提供相关的参数或环境变量来控制GPU的使用,但都需要修改相关的启动代码。
选择哪种方法取决于具体需求和使用的框架或工具。通常,CUDA_VISIBLE_DEVICES是最简单和最直接的方式,而且它不需要修改代码,这使得它在不同环境和不同应用程序之间非常灵活。如果有控制多个服务并且每个服务需要使用不同GPU的需求,那么需要根据具体情况结合使用。
接下来我们依次尝试上述两种方式来启动ChatGLM3-6B模型服务。
-
根据GPU数量自动进行分布式启动
这里我们以命令行的交互方式来进行多卡启动测试。官方提供的脚本名称是:cli_demo.py。
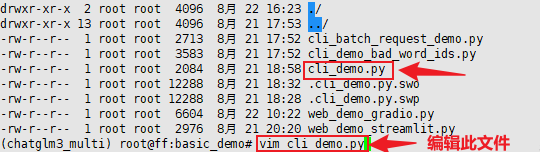
在启动前,仅需要进行一处简单的修改,因为我们已经把ChatGLM3-6B这个模型下载到了本地,所以需要修改一下模型的加载路径。

如果仅修改模型权重就执行启动,该过程会自动检测可用的 GPU 并将模型的不同部分映射到这些 GPU 上。状态如下:
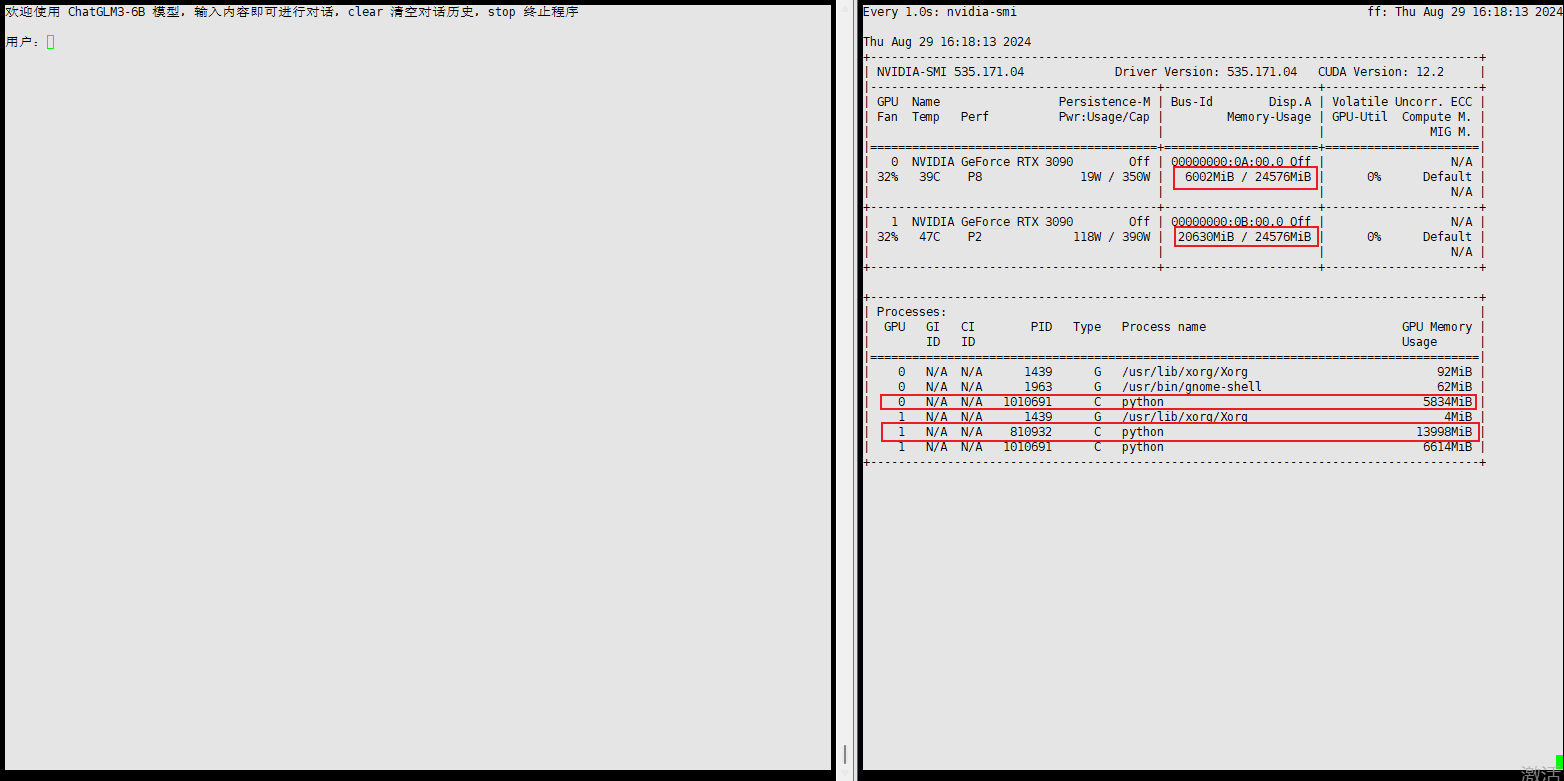
这里输入Stop 退出启动程序,GPU资源就会立即被释放。

默认启动会自动使用多块GPU的资源的原因,在于cli_demo.py这个.py文件中的这行代码:

参数device_map="auto", 这个参数指示 transformers 库自动检测可用的 GPU 并将模型的不同部分映射到这些 GPU 上。如果机器上有多个 GPU,模型会尝试在这些 GPU 上进行分布式处理。其通过分析各个 GPU 的当前负载和能力来完成。负载均衡的目标是最大化所有GPU的利用率,避免任何一个GPU过载。

可以通过如下代码,查看当前环境下的GPU情况:
import torch
# 检查 CUDA 是否可用
cuda_available = torch.cuda.is_available()
print(f"CUDA available: {cuda_available}")
# 列出所有可用的 GPU
if cuda_available:
num_gpus = torch.cuda.device_count()
print(f"Number of GPUs available: {num_gpus}")
for i in range(num_gpus):
print(f"GPU {i}: {torch.cuda.get_device_name(i)}")
# 获取当前默认 GPU
print(f"Current CUDA device: {torch.cuda.current_device()}")
else:
print("No GPUs available."可以把上述代码写在一个.py文件中,执行该文件后会输出当前机器上的GPU资源情况,方便我们对当前的资源情况有一个比较清晰的认知。

-
在代码程序中指定某几块GPU加载服务
如果想要指定使用某一块GPU,那么需要这样修改代码cli_demo.py中的代码:
import torch
# 设置 GPU 设备
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
#model = AutoModel.from_pretrained(MODEL_PATH, trust_remote_code=True, device_map="auto").eval()
model = AutoModel.from_pretrained(MODEL_PATH, trust_remote_code=True).eval()
# 将模型移到指定的 GPU
model = model.to(device)
修改后看下启动情况:

更多数人的情况是:比如当前机器中有4块GPU,我们只想使用前两块GPU做此次任务的加载,该如何选择呢?这很常见,其问题主要在于:如果某块GPU已经处于满载运行当中,这时我们再使用四块默认同时运行的话大概率会提示out of memory报错,或者提示显卡不平衡imblance的warning警告。
如果是想在代码中指定多块卡运行该服务,需要在代码中添加这两行代码:
import osos.environ["CUDA_VISIBLE_DEVICES"] = ','.join(map(str, [0,1]))
然后保存修改后,执行启动过程就可以了。

-
直接使用CUDA_VISIBLE_DEVICES环境变量启动
第二种方法就是设置 CUDA 设备环境变量。这个方法非常简单,且不涉及更改Python代码。只需要在运行 Python 脚本之前,在命令行中设置 CUDA_VISIBLE_DEVICES 环境变量。这个环境变量告诉 PyTorch 使用哪个 GPU。例如,如果想使用第二块 GPU(GPU 编号从 0 开始),就可以这样启动程序:
CUDA_VISIBLE_DEVICES=1 python cli_demo.py 
如果想使用两块 GPU启动,那么可以使用逗号,来进行分割。
CUDA_VISIBLE_DEVICES=0,1 python cli_demo.py 
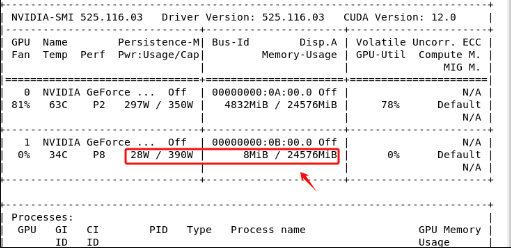
同样的,显卡的功率消耗也会随着推理进行运算而增长。输入stop指令后功耗复原。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号