以ChatGLM3为例实现本地大模型的更新
前言:
随着大模型技术的迅速发展和迭代,模型的功能以及自身架构可能会随着新版本的发布而不断更新。因此,掌握如何及时关注版本变化并进行相应更新,已经成为如今的从业者应具备的重要技能之一。
在更新大模型时,需要重点关注以下几个方面:首先,确保项目文件、依赖的库和模型的权重文件均已更新到最新版本。其次,在完成下载并替换模型文件后,务必检查配置文件,以确保其指向最新的模型文件路径。最后,建议进行全面的运行测试,以验证模型是否正常工作,确保更新的有效性和稳定性。
为了更好地说明这一过程,本文将以ChatGLM3-6b模型为例,详细介绍更新操作的步骤与注意事项。希望通过本教程让大家不仅能够掌握具体的操作方法,更能理解更新过程中的关键思路和原则。
本节主要包含以下内容:
-
使用git工具简洁部署ChatGLM3-6b办法
-
更新项目文件
-
更新依赖
-
更新模型权重文件
1. 通过git在GitHub和hugging face上快速部署ChatGLM3-6b大模型办法
1.1 github和hugging face的简单介绍
GitHub 是一个基于 Git 的代码托管平台,广泛用于软件开发和版本控制。它不仅为开发者提供了一个存储和管理代码的地方,还支持协作开发、代码审查、项目管理等多种功能。GitHub 是开源项目的首选平台,许多知名的开源项目都托管在 GitHub 上。开发者可以轻松地贡献代码、报告问题和参与讨论。GitHub 提供了企业版(GitHub Enterprise),适用于大型企业和团队的内部协作。企业版提供了更强的安全性和管理功能,并且GitHub 对个人开发者和学生也非常友好,提供了免费的公共仓库和丰富的学习资源。以下是它的官网链接:https://github.com/

Hugging Face 是一个丰富的模型库,开发者可以上传和共享他们训练好的机器学习模型。这些模型通常是经过大量数据训练的,并且很大,因此需要特殊的存储和托管服务,类似于GitHub在代码托管和协作中的作用。
Hugging Face不同于GitHub的是,GitHub 仅仅是一个代码托管和版本控制平台,托管的是项目的源代码、文档和其他相关文件。同时对于托管文件的大小有限制,不适合存储大型文件,如训练好的机器学习模型。相反,Hugging Face 专门为此类大型文件设计,提供了更适合大型模型的存储和传输解决方案。此外,Hugging Face 与多家学术机构和科技公司建立了合作关系,共同推进 NLP 和人工智能领域的研究和应用。以下是它的官网链接:https://huggingface.co/

1.2 ChatGLM3-6b快速私有化部署办法
注:此办法需要在能科xue上网的环境下实现
在部署ChatGLM3-6B模型时,建议使用Transformers库的4.30.2至4.40.0版本、torch库的2.0及以上版本,以及gradio的3.x版本,以确保最佳的推理性能。同时,建议大家严格按照官方文档中的说明安装相应版本的依赖包。
一、 创建conda虚拟环境
Conda创建虚拟环境的重要意义在于为Python项目及其依赖包提供了一个隔离的、独立的运行环境。每个虚拟环境都拥有其专属的Python版本和相应的库集合。这种机制使得我们能够在不同环境中安装并使用各种版本的库,而不会相互干扰。例如,我们可以在一个环境中运行Python 3.8,同时在另一个环境中使用Python 3.9。
对于大型模型的开发和部署,建议采用Python 3.10或更高版本。创建虚拟环境的过程相对简单,只需通过以下命令即可快速构建一个全新的虚拟环境。这种方法不仅确保了项目的独立性,还大大提高了开发的灵活性和可维护性。通过虚拟环境,开发者可以更好地管理项目依赖,避免版本冲突,从而提升整体开发效率。
# myenv 是你想要给环境的名称,python=3.11 指定了要安装的Python版本。你可以根据需要选择不同的名称和/或Python版本。conda create -n myenv python=3.11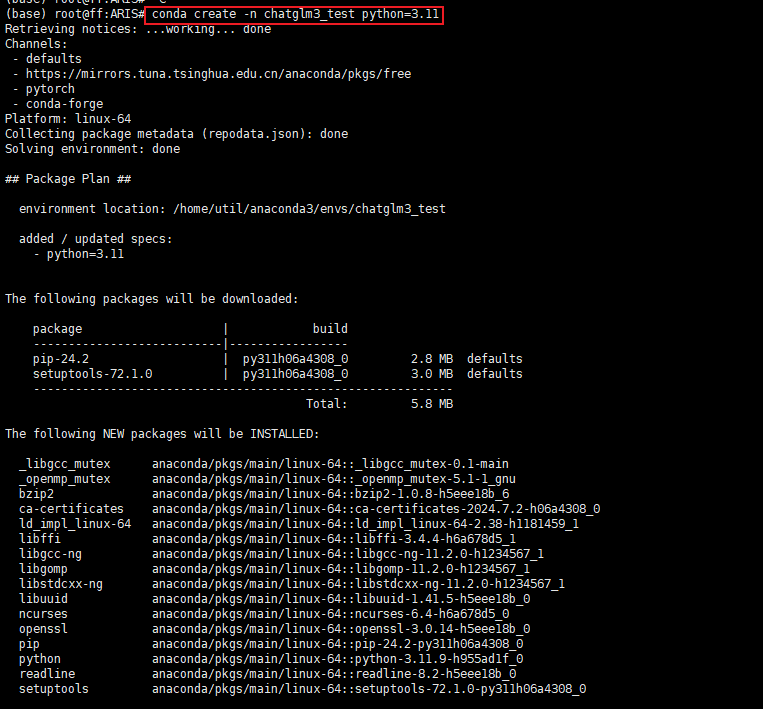
创建虚拟环境后需要激活它才能开始使用,使用以下命令来激活刚创建的虚拟环境:
conda activate chatglm3_test 
如果成功激活,可以看到在命令行的最前方的括号中,就标识了当前的虚拟环境(chatglm3_test),然后,按照官方的要求安装torch。
二、 根据驱动支持的CUDA版本下载Pytorch
CUDA(Compute Unified Device Architecture,统一计算设备架构)是一种操作GPU的软件架构,它是一种通用并行计算架构,使GPU能够解决复杂的计算问题。
我们需要根据CUDA版本选择Pytorch框架,先看下当前的CUDA版本,通过以下命令实现功能:
nvidia-sml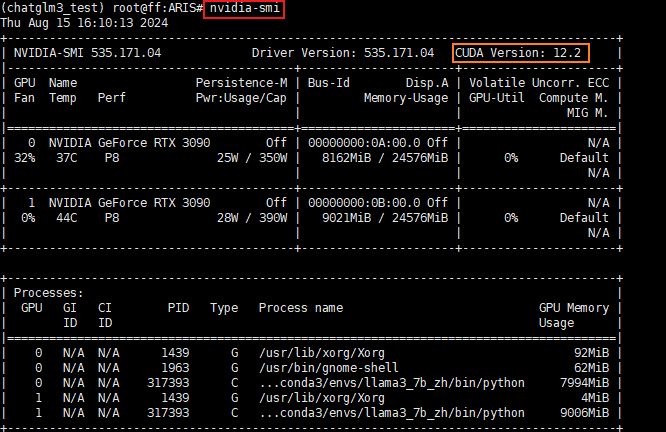
可以看到本台机器的CUDA版本是12.2,接下来的库和依赖安装也要选择与其兼容的Pytorch版本。
PyTorch 是一个开源的深度学习框架,由 Facebook 的人工智能研究团队(FAIR)开发和维护(当然现在可能也更名叫MAIR了)。Pytorch专门针对 GPU 加速的深度神经网络(DNN)编程。以其简洁优雅的语法结构赢得了 Python 开发者的广泛青睐。
进入Pytorch官网:https://pytorch.org/get-started/previous-versions/
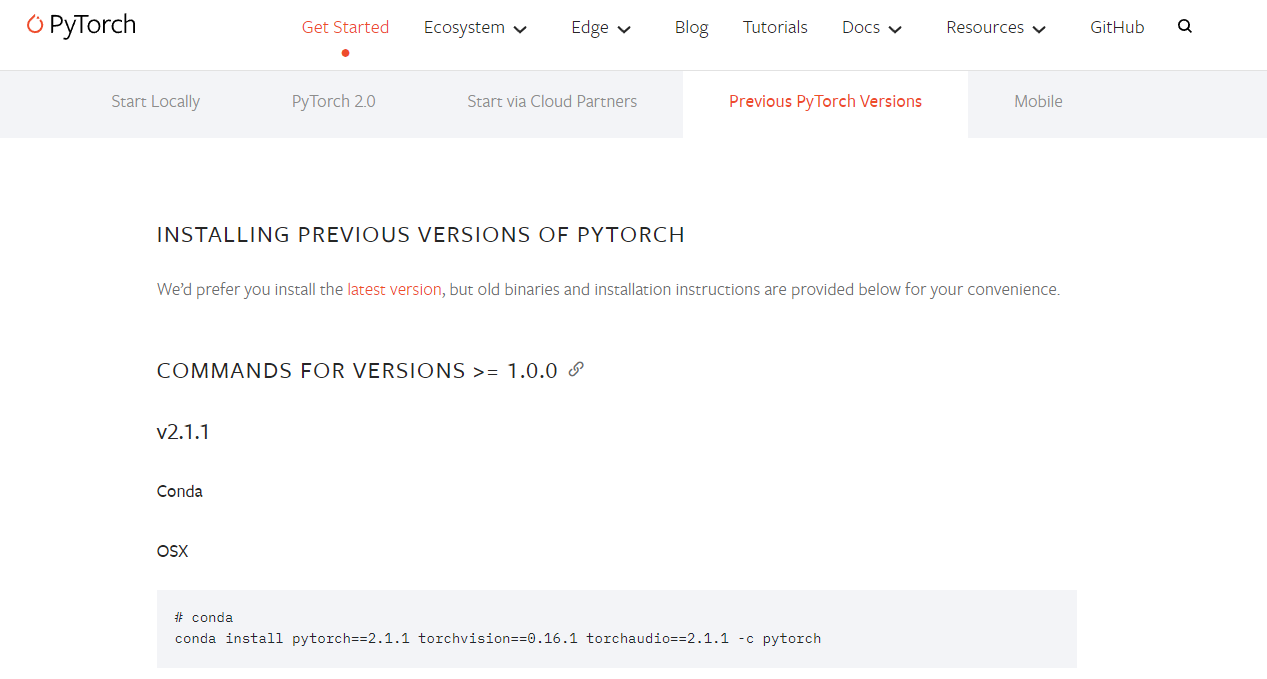
当前这台电脑的CUDA版本是12.2,需要根据此限制,选择当前最新版本的Pytorch即可。
注:这里大家要根据自己的实际情况灵活的选择适合自己的Pytorch版本
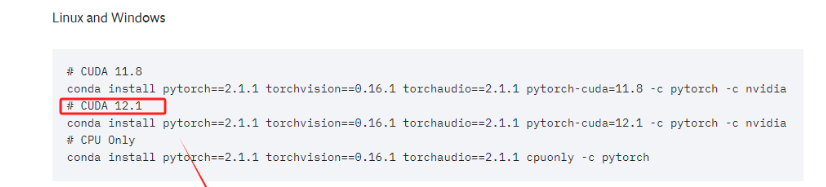
直接复制对应的命令,进入终端执行即可。这实际上安装的是为 CUDA 12.1 优化的 PyTorch 版本。这个 PyTorch 版本预编译并打包了与 CUDA 12.1 版本相对应的二进制文件和库。
conda install pytorch==2.3.1 torchvision==0.18.1 torchaudio==2.3.1 pytorch-cuda=12.1 -c pytorch -c nvidia
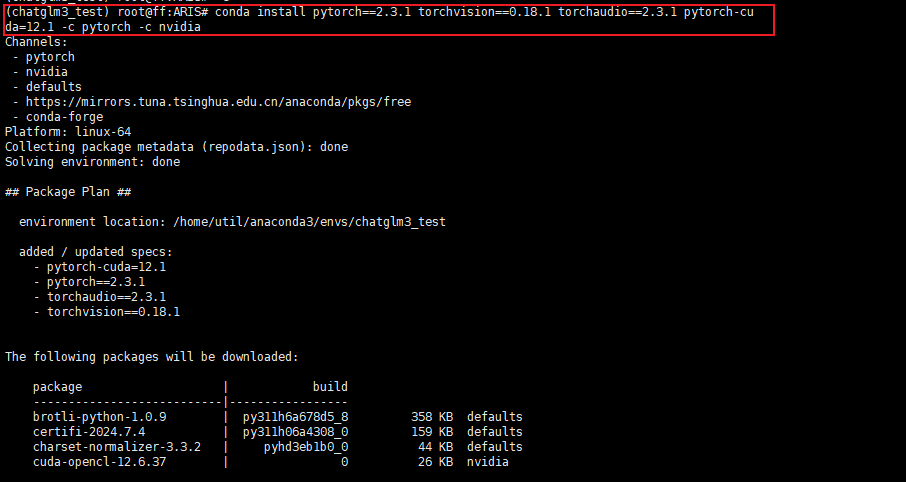
安装完毕后,如果想要检查是否成功安装了GPU版本的PyTorch,可以通过几个简单的步骤在 Python 环境中进行验证:
import torchprint(torch.cuda.is_available())
如果输出是 True,则表示GPU版本的PyTorch已经安装成功并且可以使用CUDA,如果输出是 False,则表明没有安装GPU版本的PyTorch,或者CUDA环境没有正确配置,此时根据教程,重新检查自己的执行过程。
完成验证之后使用ctril+D退出python环境,继续命令行操作。
三、 下载ChatGLM3的项目文件
ChatGLM3的代码库和相关文档存储在 GitHub 这个在线平台上。GitHub 是一个广泛使用的代码托管平台,它提供了版本控制和协作功能。要下载ChatGLM3-6B的项目文件,需要进入ChatGLM3的Github:https://github.com/THUDM/ChatGLM3

在 GitHub 上将项目下载到本地通常有两种主要方式:克隆 (Clone) 和 下载 ZIP 压缩包。
克隆 (Clone)是使用 Git 命令行的方式。我们可以克隆仓库到本地计算机,从而创建仓库的一个完整副本。这样做的好处是我们可以跟踪远程仓库的所有更改,并且可以提交自己的更改。如果要克隆某一个仓库,可以使用如下命令:
git clone <repository-url> # 其中 <repository-url> 是 GitHub 仓库的 URL。推荐使用克隆 (Clone)的方式。对于ChatGLM3这个项目来说,我们首先在GitHub上找到其仓库的URL。

在执行命令之前,先安装git软件包。
sudo apt install git
创建一个用于存放ChatGLM3-6B项目文件的文件夹并进入

执行克隆命令,将Github上的项目文件下载至本地。
git clone https://github.com/THUDM/ChatGLM3.git
如果成功拉取资源,在对应文件夹下会出现以下的文件内容:

四、 升级pip安装包版本
pip 是 Python 的一个包管理器,用于安装和管理 Python 软件包。允许从 Python Package Index(PyPI)和其他索引中安装和管理第三方库和依赖。一般使用 pip 来安装、升级和删除 Python 软件包。除此之外,pip 自动处理 Python 软件包的依赖关系,确保所有必需的库都被安装。在Python环境中,尽管我们是使用conda来管理虚拟环境,但conda是兼容pip环境的,所以使用pip下载必要的包是完全可以的。
在终端命令行升级 pip,确保使用的是最新版本的 pip,如果使用的是旧版本的 pip,可能无法安装一些最新的包,或者可能无法正确解析依赖关系。最新版本的pip这样可以避免在安装库时出现兼容性问题。
python -m pip install --upgrade pip
五、 使用pip安装ChatGLM3的项目依赖
一般项目中都会提供 requirements.txt这样一个文件,该文件包含了项目运行所必需的所有 Python 包及其精确版本号。使用这个文件,可以确保在不同环境中安装相同版本的依赖,从而避免了因版本不一致导致的问题。我们可以借助这个文件,使用pip一次性安装所有必需的依赖,而不必逐个手动安装,大大提高效率。命令如下:
pip install -r requirements.txt
六、 从Hugging Face下载ChatGLM3模型权重文件
刚刚我们下载到的只是ChatGLM3-6B的一些运行文件和项目代码,并不包含ChatGLM3-6B这个模型。接下来我们需要进入到 Hugging Face 下载。
下载路径如下:

注:需要挂梯子才能进入。

然后按照如下位置,找到对应的下载URL。

复制此命令,进入到服务器的命令行准备执行。

七、 安装Git LFS并初始化
Git Large File Storage(Git LFS)是一种用于处理大文件的工具,在 Hugging Face 下载大模型时,通常需要安装 Git LFS,主要的原因是:Git 本身并不擅长处理大型文件,因为在 Git 中,每次我们提交一个文件,它的完整内容都会被保存在 Git 仓库的历史记录中。但对于非常大的文件,这种方式会导致仓库变得庞大而且低效。而 Git LFS, 就不会直接将它们的内容存储在仓库中。相反,它存储了一个轻量级的“指针”文件,它本身非常小,它包含了关于大型文件的信息(如其在服务器上的位置),但不包含文件的实际内容。当我们需要访问或下载这个大型文件时,Git LFS 会根据这个指针去下载真正的文件内容。
实际的大文件存储在一个单独的服务器上,而不是在 Git 仓库的历史记录中。所以如果不安装 Git LFS 而直接从 Hugging Face 或其他支持 LFS 的仓库下载大型文件,通常只会下载到一个包含指向实际文件的指针的小文件,而不是文件本身。
所以,我们需要先安装git-lfs这个工具。命令如下:
sudo apt-get install git-lfs
安装完成后,需要初始化 Git LFS。这一步是必要的,因为它会设置一些必要的钩子。Git 钩子(hooks)是 Git 提供的一种强大的功能,允许在特定的重要动作(如提交、推送、合并等)发生时自动执行自定义脚本。这些钩子是在 Git 仓库的 .git/hooks 目录下的脚本,可以被配置为在特定的 Git 命令执行前后触发。钩子可以用于各种自动化任务,比如:
-
代码检查: 在提交之前自动运行代码质量检查或测试,如果检查失败,可以阻止提交。
-
自动化消息: 在提交或推送后发送通知或更新任务跟踪系统。
-
自动备份: 在推送到远程仓库之前自动备份仓库。
-
代码风格格式化: 自动格式化代码以符合团队的代码风格标准。
而初始化git lfs,会设置一些在上传或下载大文件是必要的操作,如在提交之前检查是否有大文件被 Git 正常跟踪,而不是通过 Git LFS 跟踪,从而防止大文件意外地加入到 Git 仓库中。(pre-commit 钩子)或者在合并后,确保所有需要的 LFS 对象都被正确拉取(post-merge)等。初始化命令如下:
git lfs install
八、 使用Git LFS下载ChatGLM3的模型权重文件
直接复制Hugging Face上提供的命令,在终端运行,等待下载完成即可。
git clone https://huggingface.co/THUDM/chatglm3-6b
全部需要下载的模型文件如下:

九、 启动前进行文件校验
在Hugging Face完成模型权重文件的下载后,在原来的项目文件夹中会出现一个新的文件夹,名为chatglm3-6b。

进入chatglm3-6b模型的文件目录,检查并确认所有必要文件齐全且无遗漏。

至此,我们就已经把ChatGLM3-6B模型部署运行前所需要的文件全部准备完毕。
2. 大模型更新办法
当我们在更新大模型的时候注意要更新它的:项目文件、模型权重、依赖文件即可。
以下是具体的更新办法:
2.1 更新项目文件
这里推荐使用git来做版本控制,这是由于git作为一个分布式版本控制系统,它被设计用于高效地处理从小型到大型的项目,并且在速度、数据完整性和分布式工作流方面表现出色且方便可靠。
当我们采用git方法下载ChatGLM3-6b模型项目文件后,进行git pull origin + 分支名 便可拉取远程仓库的更新。
在这个过程中,Git 会尝试将远程仓库的更改合并到本地仓库。对于本地存在的同名文件,行为取决于文件的状态:
-
本地未修改的文件:如果本地的同名文件自上次提交以来没有被修改,那么
git pull会更新这些文件以匹配远程仓库中的最新版本。这种情况下,本地文件会被远程仓库中的文件更新所覆盖。 -
本地已修改但未提交的文件:如果对本地的同名文件进行了更改但还没有提交,当尝试执行 git pull 时,Git 会警告有未提交的更改,可能会阻止合并操作并显示类似于 "Your local changes to the following files would be overwritten by merge" 的信息。这时,需要先提交本地更改、暂存它们或者放弃这些更改,然后再进行 git pull。
-
合并冲突:如果远程仓库和本地仓库都对同一个文件进行了更改,那么在执行 git pull 时可能会发生合并冲突。Git 不会自动覆盖这些文件,而是会要求手动解决这些冲突。

当然项目文件的更新也可以通过手动的方式实现,方法同样为在官网上下载最新的项目文件然后在本地对应的文件夹进行覆盖。
2.2 更新模型权重文件
ChatGLM3-6B模型的权重主要是从以下两个网站下载:
-
Hugging Face:https://huggingface.co/THUDM/chatglm3-6b/tree/main (需要科xue上网)
-
modelscope:https://modelscope.cn/models/ZhipuAI/chatglm3-6b/files
去查看一下该次更新是否涉及模型权重文件的更新。我这里以 Hugging Face 为例:

如果发现部分项目权重文件已和Github的项目代码同步更新,同样需要更新本地的模型权重文件。针对与单独的或者几个文件,高效的更新方式如下:

然后进入服务器中,使用wget命令下载更新。

注: 如果使用摩搭社区更新模型权重文件,使用Chrome浏览器并不能生成链接,此时可以通过之前介绍的方法,点击指定的文件,进去后直接复制链接,下载到本地或通过XFTP等工具传到远程服务器上。
2.3 更新依赖
检查依赖的更新首先到对应的GitHub官网查看对应的项目文件中的requirements.txt是否有新的依赖包。在本例中访问网站https://github.com/THUDM/ChatGLM3进行检查。



所以,在当前的虚拟环境下,安装好最新的依赖,依次执行如下操作:
-
Step 1. 进入项目的Python虚拟环境

-
Step 2. 安装新的依赖包

至此,环境和文件配置就已更新完成。接下来尝试查看新代码是否能够顺利执行。
2.4 运行测试
在这一环节,我们将使用上一个版本的 ChatGLM3-6b 更新数据进行讲解,旨在帮助大家更好地理解整个流程。希望通过此示范,大家能够熟悉更新步骤并掌握其中的关键细节。
一般比较规范的GitHub项目在每次提交更新前,都会有比较清晰的说明:

可以进入ReadMe查看细节:

保存退出后,使用python api_server.py尝试启动。

从报错信息上看,很明显的是这行代码再向Hugging Face 请求Tokenizer分词器。

解决方法很简单,像模型权重一样,把它下载到本地:
-
Hugging Face 下载地址:https://huggingface.co/BAAI/bge-large-zh-v1.5/tree/main (需要科xue上网)
-
modelscope 下载地址:https://modelscope.cn/search?page=1&search=bge-large-zh-v1.5&type=model

再次修改api_server.py的配置文件,更改Tokenizer 的加载位置:
vim api_server.py
保存退出后,再次使用python api_server.py尝试启动。



 浙公网安备 33010602011771号
浙公网安备 33010602011771号