云服务器部署大模型-在AutoDL中快速部署ChatGLM3-6B模型
本节内容介绍的是在AutoDL平台上租赁算⼒资源,并完成ChatGLM3-6B的部署调⽤的流程。根据官⽅介绍,ChatGLM3-6B ⽬前⽀持GPU运⾏(需要英伟达显卡)、CPU运⾏以及Apple M系列芯⽚运⾏。其中GPU运⾏需要⾄少6GB以上显存(4Bit精度运⾏模式下),⽽CPU运⾏则需要⾄少32G的内存。⽽由于Apple M系列芯⽚需要最少13G内存运⾏。在正式安装之前,需要先确保拥有⾜够的算⼒资源,以下推荐的是⼀种轻量化的部署⽅式,⾮常适合⼊⻔级的测试开发:AutoDL租赁服务器进⾏快速部署.
物理机 or 云服务
- 完全⼩⽩,对⼤模型技术没有了解,建议⽤新⼈账号⽩嫖各⼤云服务平台的免费算⼒,再考虑购买或者租赁。
- 如果经常做微调实验,或实验室学⽣系统学习,有⾃⼰的物理机将更加⽅便,按照学习实践部分内容采购即可。
- 为⽤⼾提供相关的推理服务,⾸选云服务,有更⼤参数量,更好性能的模型选择,随⽤随停,按量计费。
- “独⻆兽”公司AI应⽤/⼤模型AI技术创新公司……,需要⼤规模⼤批量的微调训练或者对内/对外提供⼤量推理服务,按需配备⾼性能GPU服务器。
物理机部分⼤家可以按照前序了解的⾃⾏购买,但是这⾥再次强调,购买需谨慎,尤其在⼆⼿平台购买⼆⼿显卡需要更仔细专业的判断。⽬前国内市场也会有A、H系列显卡流通,可能是存货、⼆⼿、……渠道,但是这类⾼性能显卡要更专业细致的判断,谨防被骗。
云服务⼚商
算⼒平台
主要适⽤于学习和训练,不适⽤于企业级部署提供服务。
- ModelScope:阿⾥出品,中国的“HuggingFace”,模型开源社区,绑定阿⾥云有(24GB显存+36⼩时)GPU环境。https://www.modelscope.cn/home
- Colab:⾕歌出品,升级服务仅需 9 美⾦。https://colab.research.google.com/
- Kaggle:免费,每周 30 ⼩时 T4,P100 可⽤。https://www.kaggle.com/
- AutoDL:价格亲⺠,⽀持 Jupyter Notebook 及 ssh,国内可⽤。https://www.autodl.com/home
算⼒准备
在正式安装之前,需要先确保拥有⾜够的算⼒资源,以下推荐的是⼀种轻量化的部署⽅式,⾮常适合⼊⻔级的测试开发:⾸先可以从以下链接中进⼊AutoDL的官⽅⽹址,在右上⻆的选项⾥可以注册/登录.

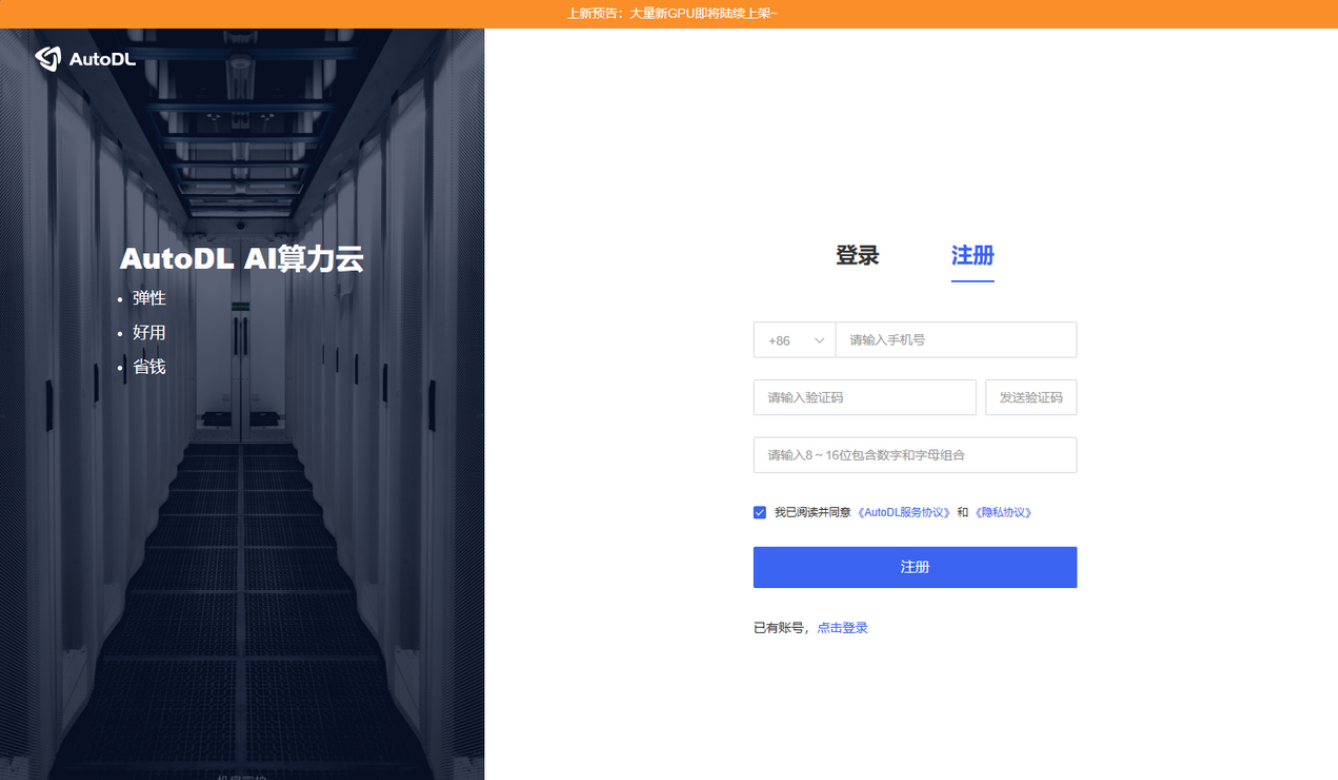
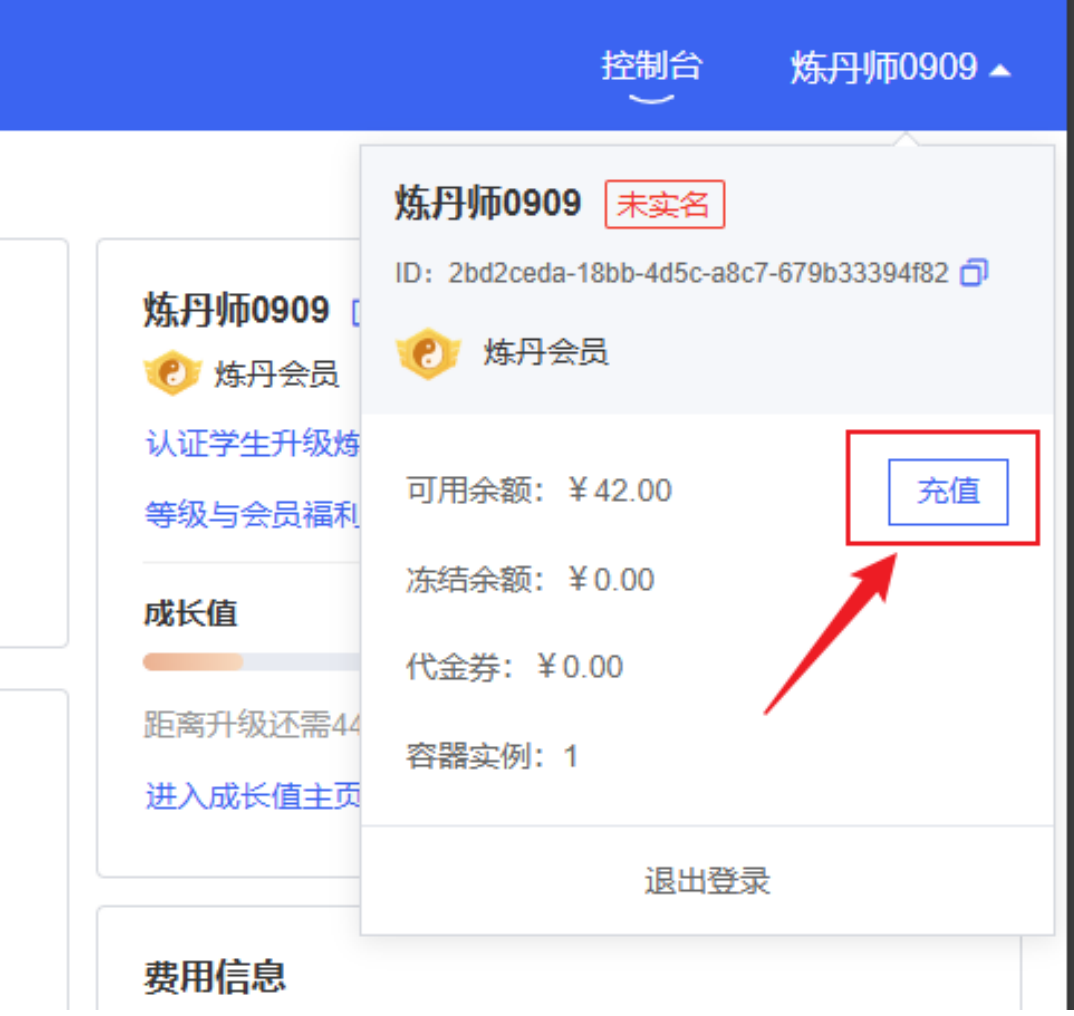
进⼊界⾯之后点击右上⻆的⽤⼾信息可以查看余额和进⾏充值,其⾦额可以⾃定义。注意:只有账⼾ 有余额才能在后续算⼒市场租赁主机。
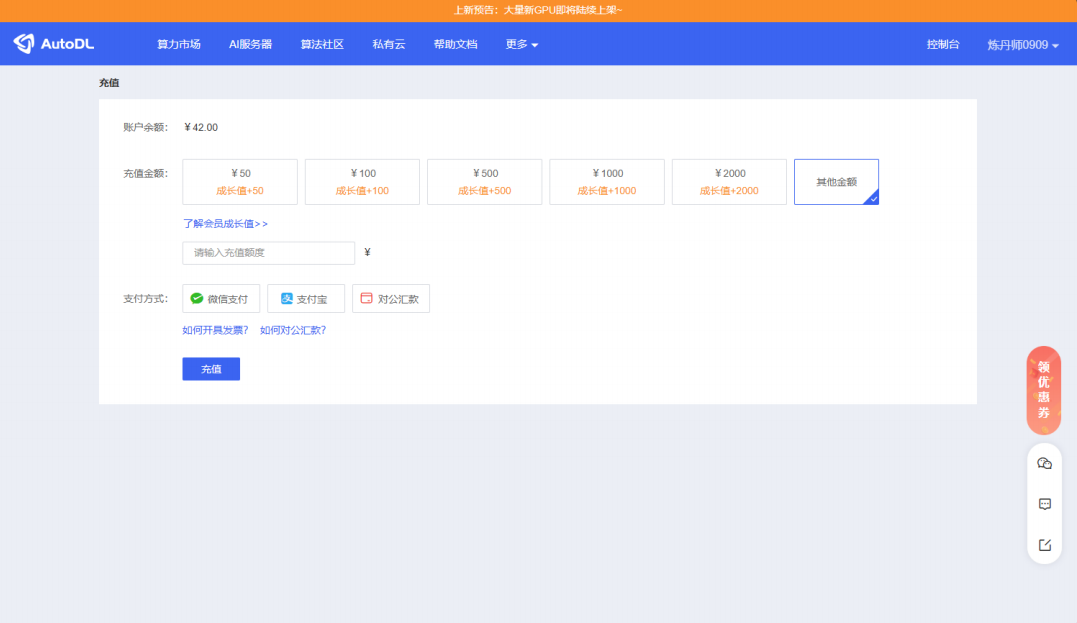
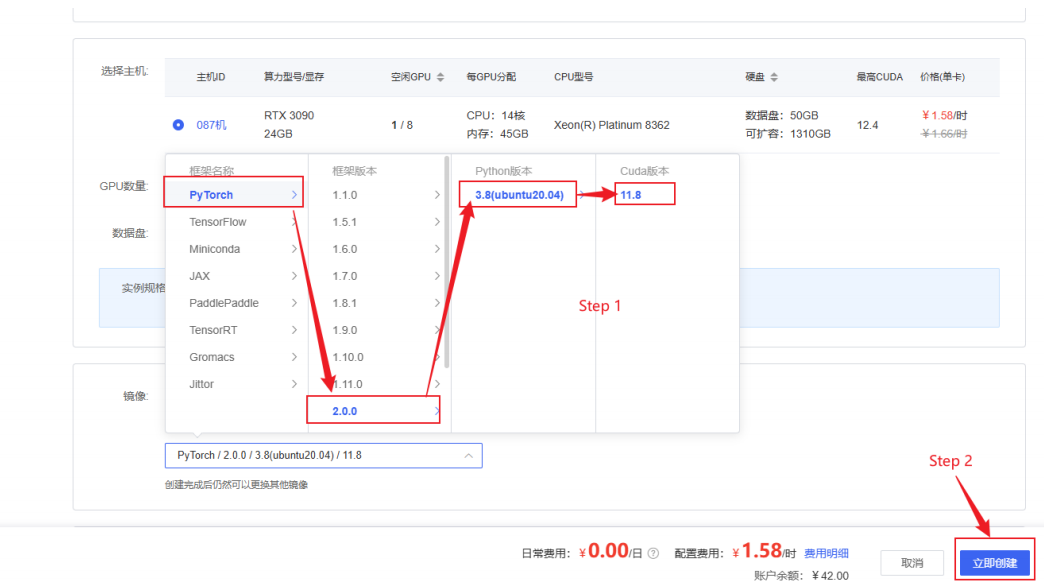
确认⽤⼾余额充裕后点击左上⻆的算⼒市场,租赁合适的主机,推荐的配置为:计费⽅式选择按量计 费、地区任选、GPU型号选择RTX3090/24GB、GPU数量选择为1。
选择RTX3090/24GB卡的理由是ChatGLM3-6B的GPU运⾏需要⾄少6GB以上显存(4Bit精度运⾏模式下),⽽CPU运⾏则需要⾄少32G的内存。其中CPU运⾏模式下内存占⽤过⼤且运⾏效率较低,GPU模式部署才能有效的进⾏⼤模型的学习实践。基于性能和性价⽐进⾏考量,我们建议选择以上参数进⾏部署。
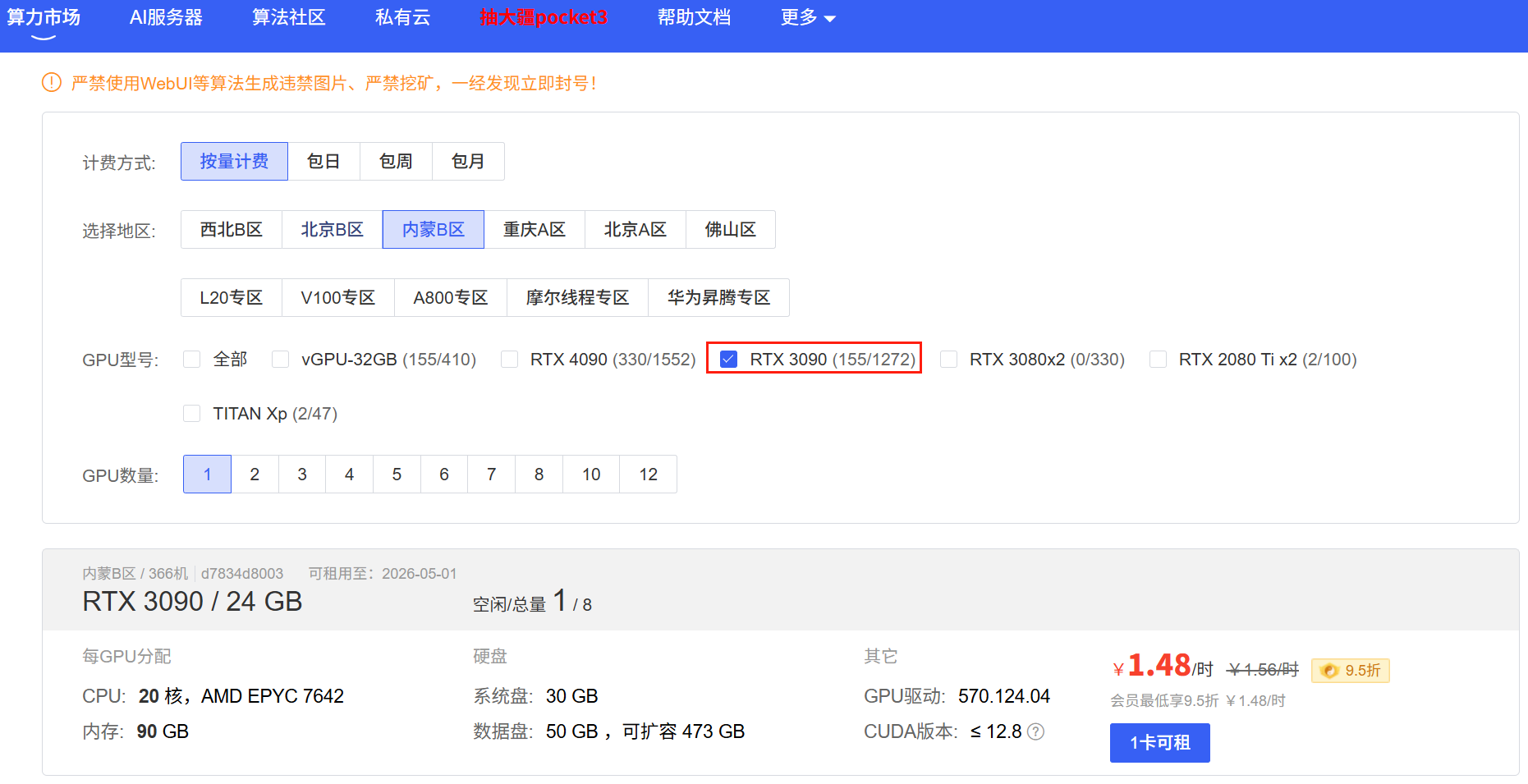
选择好合适的主机后需要在下⽅的镜像栏中选择适合的框架⸺框架名称:PyTorch,框架版本:2.0.0,Python版本:3.8(Ubuntu20.04),Cuda版本11.8.选择好之后点击右下⻆的⽴即创建便可完成配置。
其中 PyTorch 是⼀个流⾏的深度学习框架,⽀持⼤规模模型的训练和推理。Python 3.8 是⼀个稳定且常⽤的版本,兼容⼤多数机器学习库和⼯具。选择 Ubuntu 20.04 作为操作系统版本是因为其⻓期⽀持和⼴泛使⽤,特别适合在⽣产环境中部署。Cuda 是 NVIDIA 提供的并⾏计算平台和编程模型,⽀持GPU 加速。选择 Cuda 11.8 版本是因为它与 PyTorch 2.0.0 兼容。
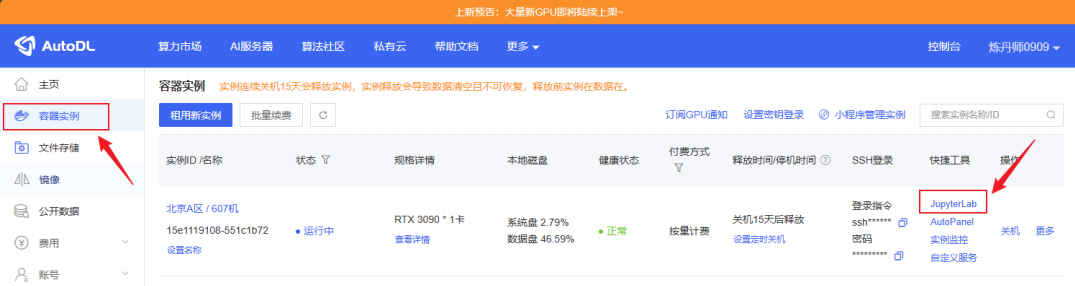
创建完成后,点击左边栏的容器实例便可随时找到配置好的实例,在快捷⼯具栏中点击Jupyter lab开始模型的安装部署。
换源和安装依赖包
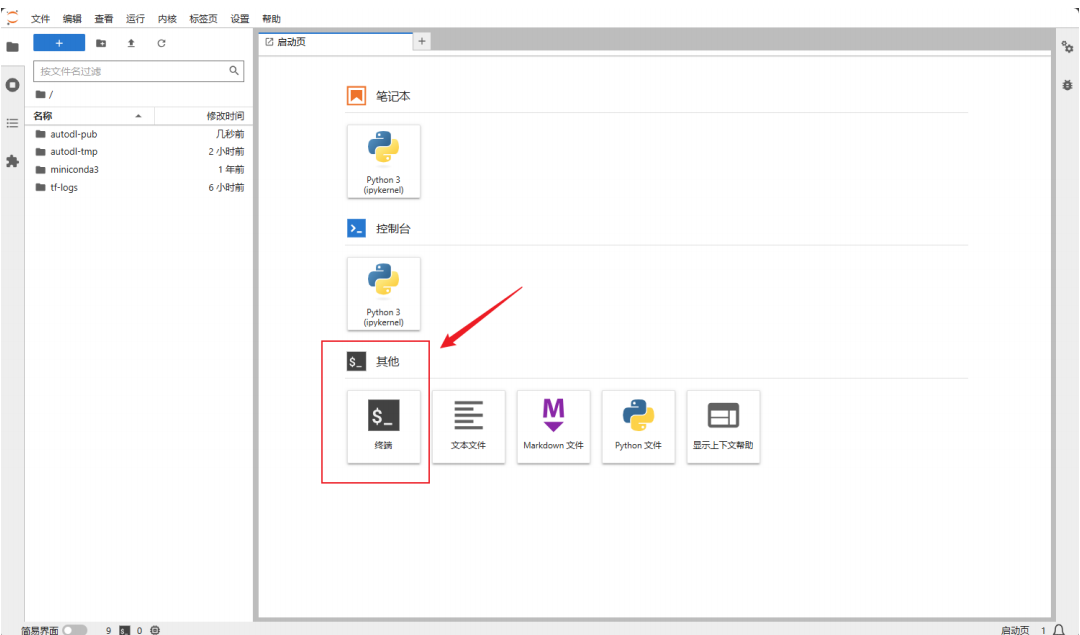
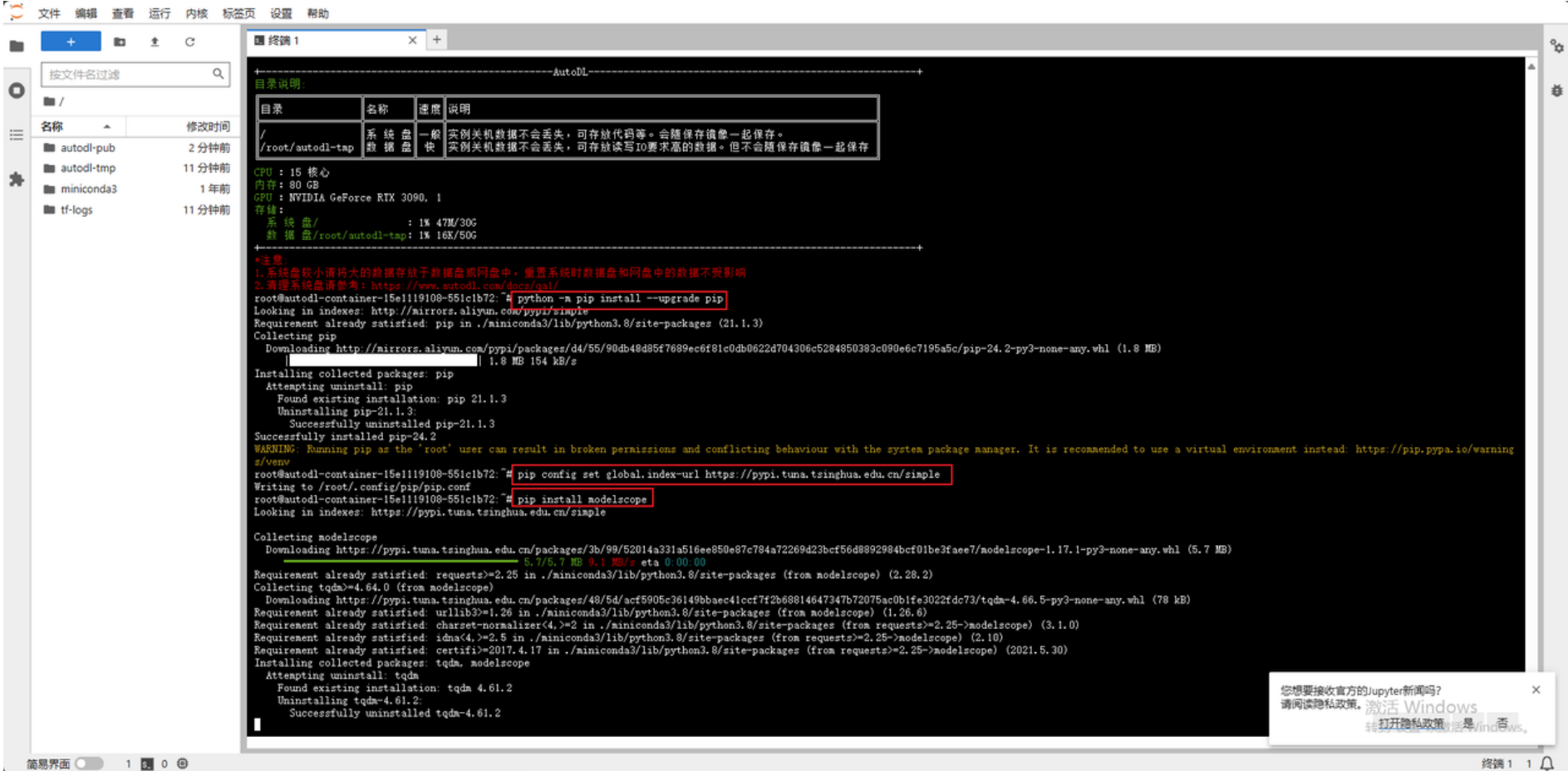
进⼊Jupyter lab打开终端开始环境配置,⾸先要进⾏的是 pip 换源和安装依赖包。点击启动终端,在其中逐⾏输⼊以下代码以实现功能。
在终端通过命令升级 pip,确保使⽤的是最新版本的 pip,这样可以避免在安装库时出现兼容性问题。
更换 pip 的默认源为清华⼤学的镜像源,以加速 Python 库的下载和安装。
以下是安装的库的介绍:
modelscope: ⽤于模型推理和部署的库,⽀持多种机器学习和深度学习模型。
transformers: 包含了⼤量预训练的 Transformer 模型,包括 BERT、GPT 等等。
sentencepiece: ⼀个⽤于处理⽂本的库,特别是对⼦词单元进⾏分词操作,常⽤于⾃然语⾔处理任务。
# 升级pip
python -m pip install --upgrade pip
# 更换 pypi 源加速库的安装
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
pip install modelscope
pip install transformers
pip install sentencepiece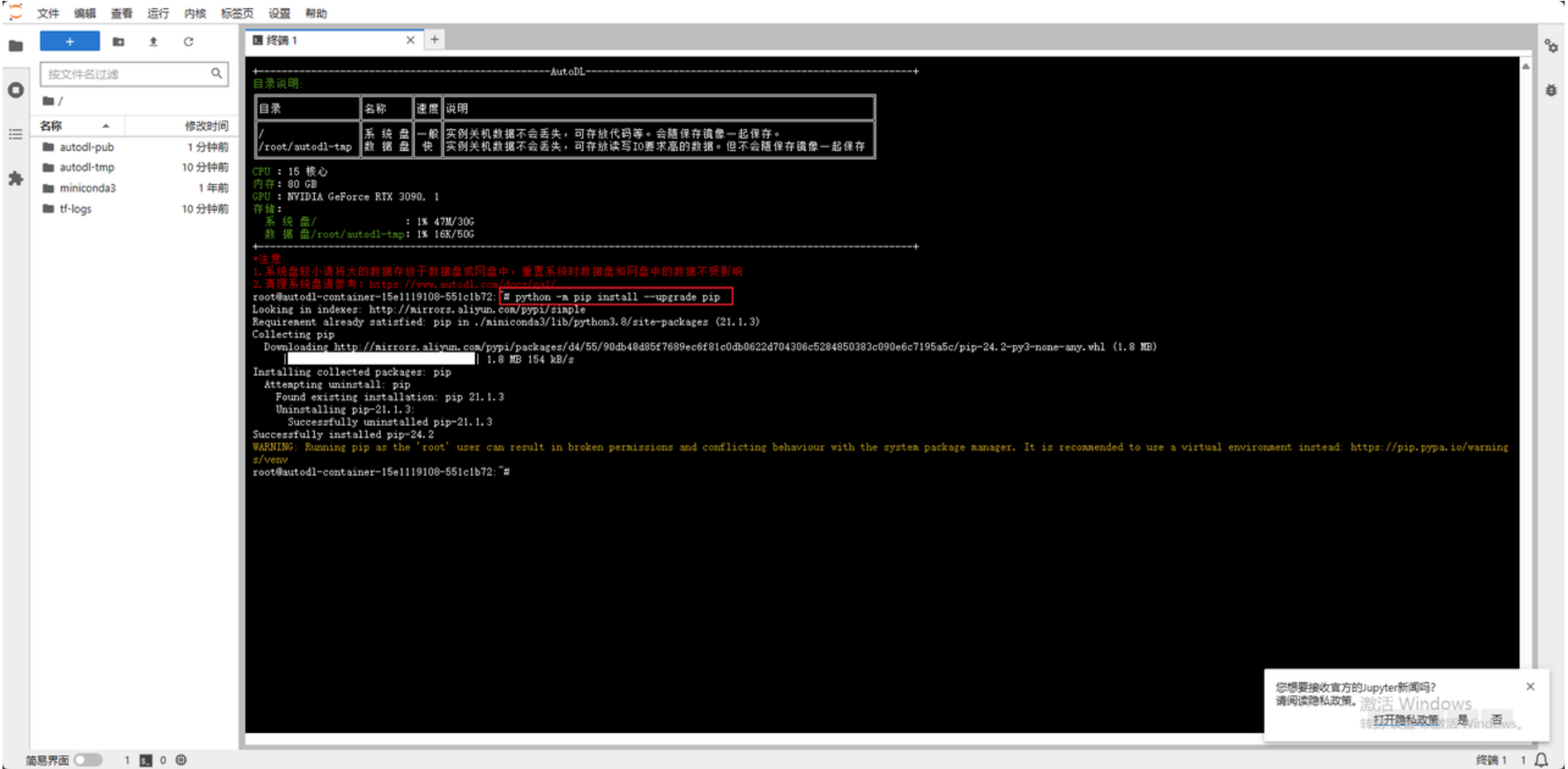

模型下载
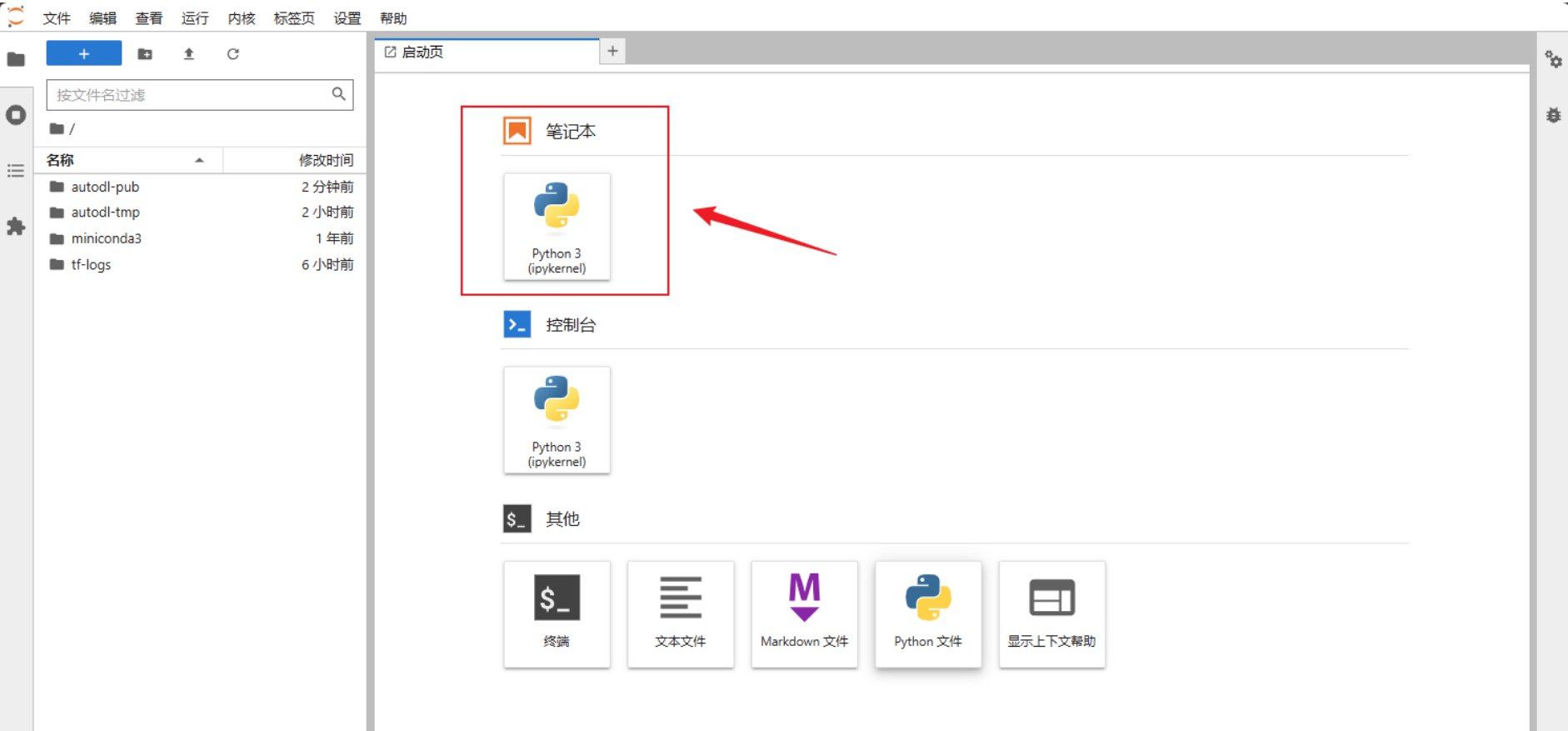
在启动⻚打开新的Jupiter notebook进⾏模型的下载。
这⾥选择的是使⽤ modelscope 中的snapshot_download函数下载模型,这个函数中的第⼀个参数为模型名称,第⼆个参数 cache_dir 为模型的下载路径。
打开Jupyter Lab⽂件执⾏以下代码进⾏下载,ChatGLM3-6B模型⼤⼩为 14 GB,下载模型⼤概需要20~25 分钟。
import torch
from modelscope import snapshot_download, AutoModel, AutoTokenizer
import os
model_dir = snapshot_download('ZhipuAI/chatglm3-6b', cache_dir='/root/autodl-tmp', revision='master')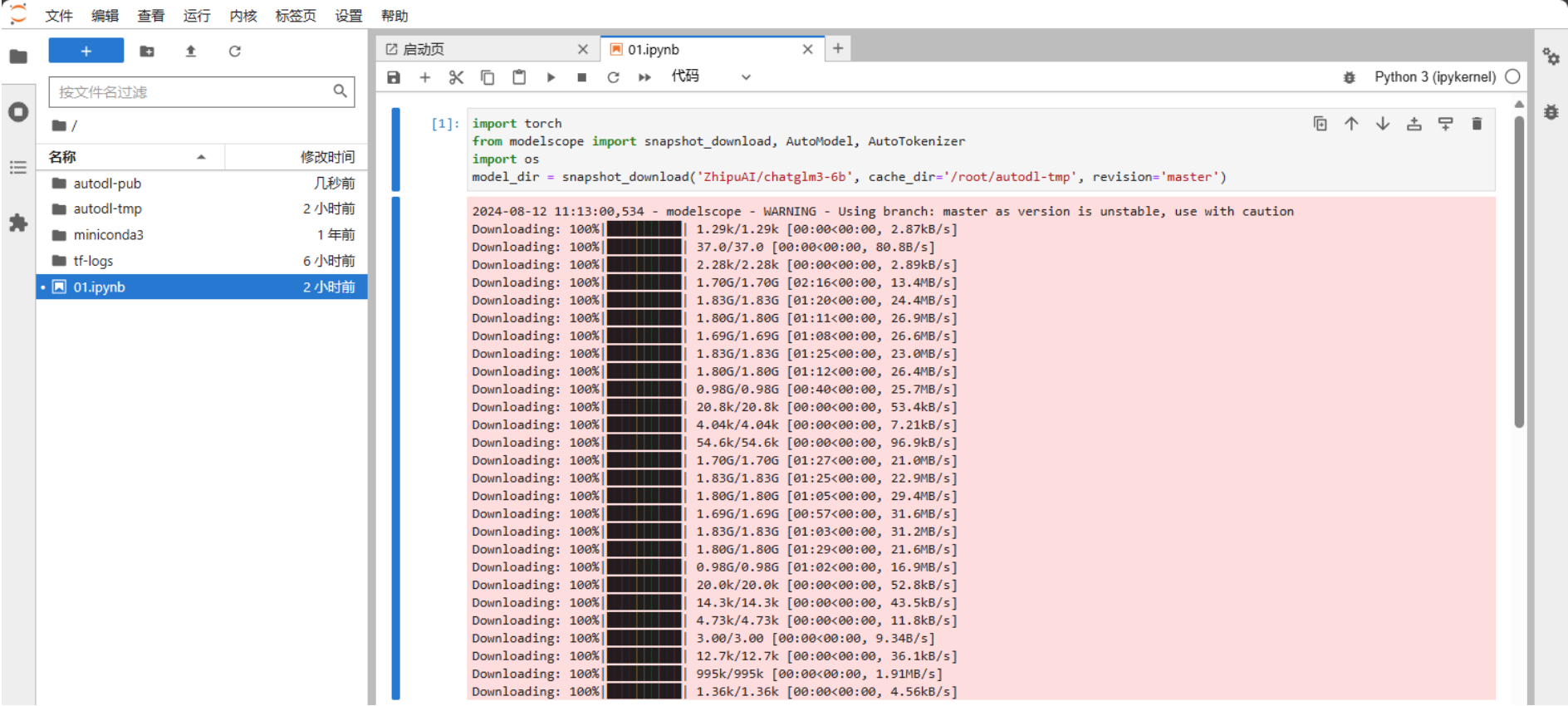
启动模型的代码
在/root/autodl-tmp路径下新建trans.py⽂件并在其中输⼊以下内容
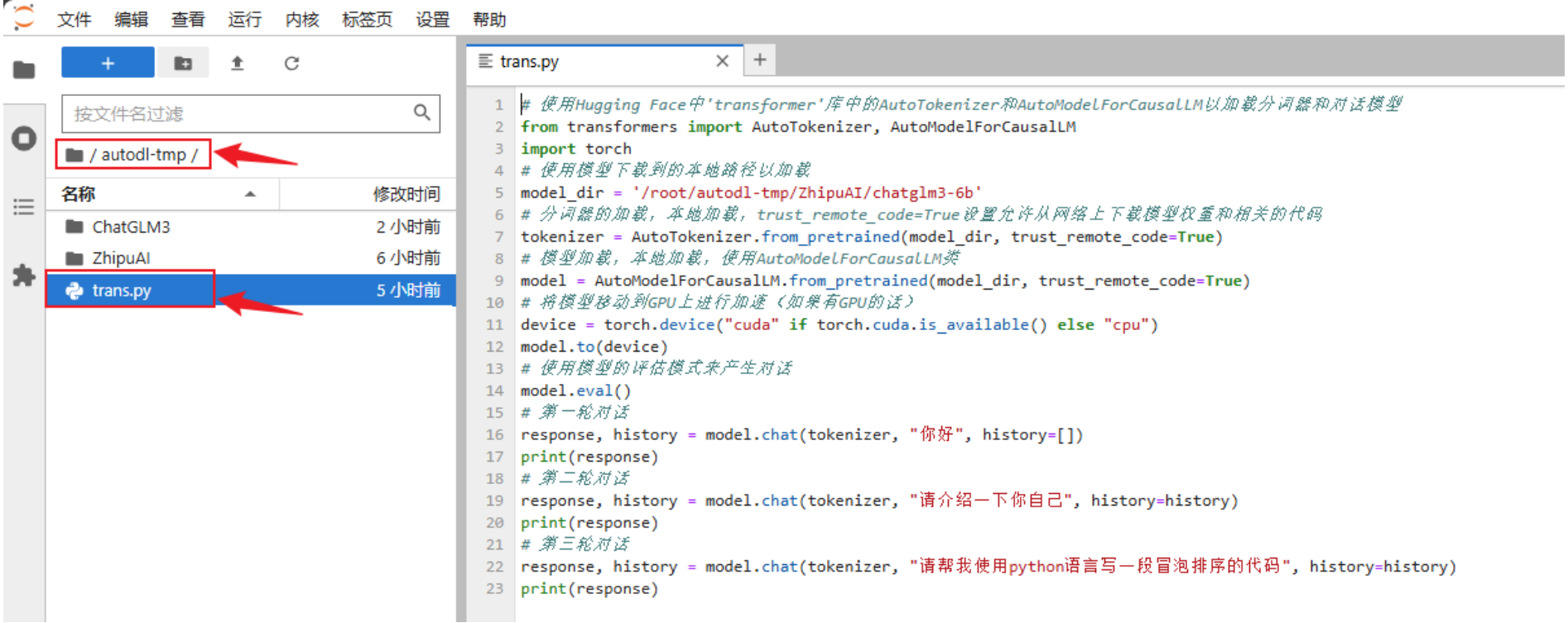
from transformers import AutoTokenizer, AutoModelForCausalLM # 使⽤Hugging Face中'transformer'库中的AutoTokenizer和AutoModelForCausalLM以加载分词器和对话模型
import torch
model_dir = '/root/autodl-tmp/ZhipuAI/chatglm3-6b' # 使⽤模型下载到的本地路径以加载
tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)
# 分词器的加载,本地加载,trust_remote_code=True设置允许从⽹络上下载模型权重和相关的代码
model = AutoModelForCausalLM.from_pretrained(model_dir,
trust_remote_code=True) # 模型加载,本地加载,使⽤AutoModelForCausalLM类
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 将模型移动到GPU上进⾏加速(如果有GPU的话)
model.to(device)
model.eval() # 使⽤模型的评估模式来产⽣对话
# 第⼀轮对话
response, history = model.chat(tokenizer, "你好", history=[])
print(response)
# 第⼆轮对话
response, history = model.chat(tokenizer, "请介绍⼀下你⾃⼰", history=history)
print(response)
# 第三轮对话
response, history = model.chat(tokenizer, "请帮我使⽤python语⾔写⼀段冒泡排序的代码", history=history)
print(response)部署运⾏
需要注意的是,如果transfomers的版本不匹配会导致报错,因此我们需要先降其版本。回到启动⻚打开终端分别输⼊以下指令将版本确定⾄4.37.2:
pip uninstall transformers #卸载当前版本
pip install --upgrade transformers==4.37.2 #安装指定版本
随后在终端输⼊以下指令,可以发现在平台上部署成功。可以看到,终端返回了前⾯trans.py⽂件提出的三个问题。
cd /root/autodl-tmp #将路径导向指定位置
Python trans.py #执⾏对应⽂件


 浙公网安备 33010602011771号
浙公网安备 33010602011771号