服务器场景下ChatGLM3-6B部署与多种启动方式
在服务器环境下部署大模型时,常常会遇到各种限制,比如无法直接连接外网下载安装模型文件或者因服务器资源限制导致部署复杂化。因此,掌握在这种受限环境中有效下载和部署大模型的技巧显得尤为重要。本节将介绍一种在远程服务器环境中合理下载大模型文件的方法,以及几种不同的启动方式。通过这些内容,供大家掌握一个可行的部署流程,并深入了解ChatGLM3-6b模型的性能特点,以便未来更好的应用和优化这一模型。
本节内容主要涉及以下三个部分:
-
ChatGLM3-6B模型的性能优势与应用场景
-
基于服务器环境的部署方法
-
运行ChatGLM3-6b的多种启动方式
1. ChatGLM3-6B模型的性能优势与应用场景
选择实践ChatGLM3-6B的理由
ChatGLM3 是智谱AI和清华大学 KEG 实验室在2023年10月27日联合发布的对话预训练模型。其中,ChatGLM3-6B 是 ChatGLM3 系列中的开源模型,免费下载。现在在GitHub上已经拥有了13k的星星。

作为一个2023年上线的开源模型,我们学习实践ChatGLM3-6b模型的意义如下:
-
资源效率:小体量的模型通常需要的计算资源较少,适合在资源受限的环境中使用,例如个人电脑或小型服务器,适合开发者的入门。ChatGLM-6B 使用与 ChatGPT 类似的技术,但是模型参数量只有GPT3的1/30,它针对中文 QA 和对话进行了优化。该模型针对大约 1T 个中文和英文语料库进行训练,并辅以监督微调、反馈引导和人类反馈的强化学习的训练,在性能上足够完善。
-
易于实践和上手:GLM3模型,特别是6B版本,因其较小的模型尺寸,能够在消费级显卡上进行实践,使得更多研究者和开发者有机会接触和使用大模型技术,降低了技术门槛 。并且适用于对于特定任务的优化,能够提供与大型模型相媲美或更适合的特定需求的性能,且训练成本较低。
-
优秀的性能:在10B参数规模以下的模型中,GLM3是一款表现出色中英文对话模型,从响应速度到准确率都有不错的表现,擅长语文、数学、推理、代码、知识等功能。GLM3模型支持微调,这使得模型能够针对特定任务进一步优化,提升性能,满足不同应用场景的需求 。同时有着完整的功能支持,包括多轮对话、原生工具调用、代码执行和Agent任务场景。
-
开源生态贡献:智谱AI将GLM3模型的多个版本进行了开源,包括对话模型、长文本模型以及多模态模型等,ChatGLM3 建立在开源基础之上,使以上所说的功能变得易于使用,使我们能够更深入地了解所涉及的原理。我们还可以根据自己的需求进一步定制和开发,充分的激发大模型的功能。
ChatGLM3-6B模型的基本性能
性能层面,ChatGLM3-6B在10B范围内性能优秀,推理能力接近GPT-3.5;功能层面,ChatGLM3-6B重磅更新多模态功能、代码解释器功能、联网功能以及Agent优化功能四项核心功能,是小而精的大模型。

测评榜单介绍:
-
MMLU (Massive Multitask Language Understanding)
-
简介:MMLU 是一个大规模多任务语言理解基准测试,设计用于评估模型在广泛领域的理解和推理能力。它涵盖了57个不同的学科,包括历史、法律、数学、物理、医学等,评估模型在这些学科中的表现。
-
测评重心:MMLU 主要关注模型的自然语言理解能力,特别是多任务学习的能力。它测试模型在不同领域的知识深度和跨领域的推理能力。
-
GSM8K
-
简介:GSM8K 是一个专门用于评估模型数学推理能力的基准测试,包含了8000多个关于小学数学的高质量问题。每个问题都要求模型能够进行多步骤的逻辑推理,以得出正确答案。
-
测评重心:GSM8K 主要关注模型的数学推理能力,尤其是模型在解决复杂数学问题时的步骤推理和逻辑推断的能力。
-
C-Eval
-
简介:C-Eval 是一个中文综合评估基准测试,专门用于评估中文语言模型的能力。C-Eval 涵盖了多个领域,包括基础知识、专业知识和跨学科应用,旨在评估模型在中文语境下的理解和表达能力。
-
测评重心:C-Eval 主要关注模型的中文能力,包括对中文问题的理解、推理和回答能力,以及在不同知识领域中的表现
开源模型列表:
| 模型 | 介绍 | 上下文token数 | 代码链接 | 模型权重下载链接 |
|---|---|---|---|---|
| ChatGLM3-6B | 第三代 ChatGLM 对话**模型。**ChatGLM3-6B 采用了全新设计的 Prompt 格式,除正常的多轮对话外。同时原生支持工具调用(Function Call)、代码执行(Code Interpreter)和 Agent 任务等复杂场景。 | 8K | Huggingface | 魔搭社区 | 始智社区 | Swanhub | 启智社区 ) | [ChatGLM3](https://github.com/THUDM/ChatGLM3 |
| ChatGLM3-6B-base | 第三代ChatGLM**基座模型。**ChatGLM3-6B-Base 采用了更多样的训练数据、更充分的训练步数和更合理的训练策略。在语义、数学、推理、代码、知识等不同角度的数据集上测评显示,ChatGLM3-6B-Base 具有在 10B 以下的基础模型中最强的性能。 | 8K | Huggingface | 魔搭社区 | 始智社区 | Swanhub | 启智社区 | |
| ChatGLM3-6B-32k | 第三代ChatGLM长上下文对话模型。在ChatGLM3-6B的基础上进一步强化了对于长文本的理解能力,能够更好的处理最多32K长度的上下文。 | 32K | Huggingface | 魔搭社区 | 始智社区 | Swanhub | 启智社区 |
同时ChatGLM-6B模型还支持以下高级用法:工具调用、代码解释器、流式回复、微调、处理不同对话角色、调整响应长度。是非常好的入门级大模型为开发者提供友好、充足的练手空间。
安装问题解答
在安装过程中如果遇到任何问题,可以尝试登录以下网址进行QA,基于ChatGLM_turbo +知识库《ChatGLM3技术文档》构建的机器人,可以较好的专业领域的问题,通过它可以在安装部署环境快速解决或提供思路,以下是网站链接:https://open.bigmodel.cn/shareapp/v1/?share_code=0egooPndEt8OGj-39HjEl

2. 服务器环境的安装部署办法
对于部署ChatGLM3-6B来说,从官方说明上看,其规定了Transformers 库版本应该 4.30.2 以及以上的版本 ,torch 库版本应为 2.0 及以上的版本,gradio 库版本应该为 3.x 的版本,以获得最佳的推理性能。所以为了保证 torch 的版本正确,建议大家严格按照官方文档的说明安装相应版本的依赖包。
-
Step 1. 创建conda虚拟环境
Conda创建虚拟环境的意义在于提供了一个隔离的、独立的环境,用于Python项目和其依赖包的管理。每个虚拟环境都有自己的Python运行时和一组库。这意味着我们可以在不同的环境中安装不同版本的库而互不影响。例如,可以在一个环境中使用Python 3.8,而在另一个环境中使用Python 3.11。对于大模型来说,建议Python版本3.10以上。创建的方式也比较简单,使用以下命令创建一个新的虚拟环境:
# myenv 是你想要给环境的名称,python=3.11 指定了要安装的Python版本。你可以根据需要选择不同的名称和/或Python版本。
conda create -n chatglm3_test python=3.11创建虚拟环境以后需要激活才能进入使用,使用以下命令激活刚刚创建的环境
conda activate chatglm3_test 如果成功激活进入虚拟环境,在命令行最前方的括号内会显示对应的虚拟环境名称。

-
Step 2. 查看当前驱动最高支持的CUDA版本
CUDA(Compute Unified Device Architecture,统一计算设备架构)是一种操作GPU的软件架构,它是一种通用并行计算架构,使GPU能够解决复杂的计算问题。
我们需要根据CUDA版本选择Pytorch框架,先看下当前的CUDA版本,通过以下命令实现功能:
nvidia-sml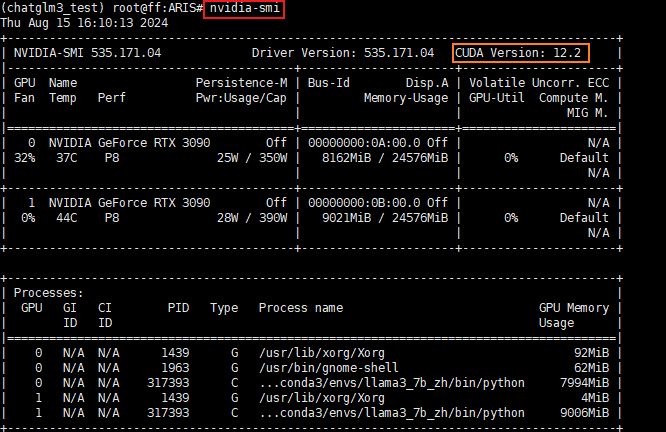
可以看到本台机器的CUDA版本是12.2,接下来的库和依赖安装也要选择与其兼容的Pytorch版本。
-
Step 3. 在虚拟环境中安装Pytorch
进入Pytorch官网:https://pytorch.org/get-started/previous-versions/
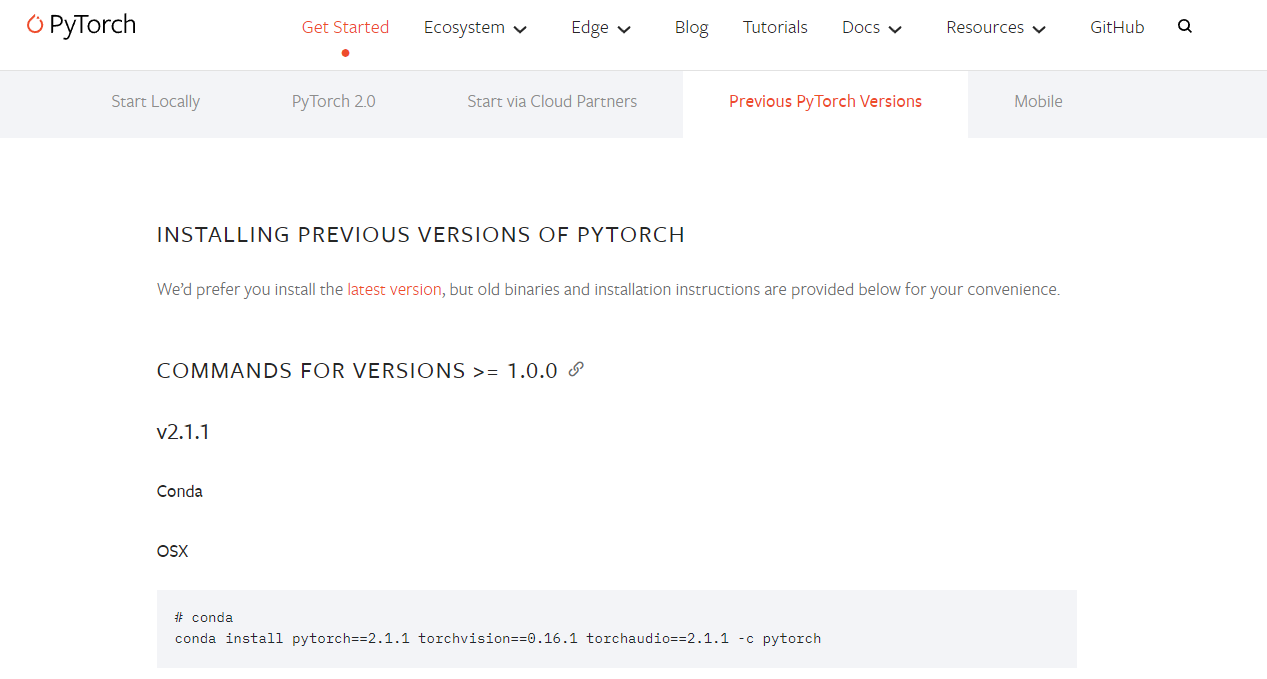
当前的电脑CUDA的最高版本要求是12.2,所以需要找到 >=12.2版本的Pytorch。
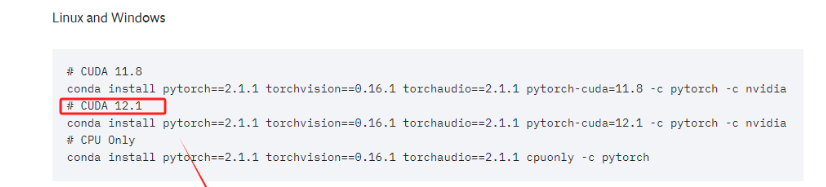
直接复制对应的命令,进入终端执行即可。这实际上安装的是为 CUDA 12.1 优化的 PyTorch 版本。这个 PyTorch 版本预编译并打包了与 CUDA 12.1 版本相对应的二进制文件和库。
conda install pytorch==2.3.1 torchvision==0.18.1 torchaudio==2.3.1 pytorch-cuda=12.1 -c pytorch -c nvidia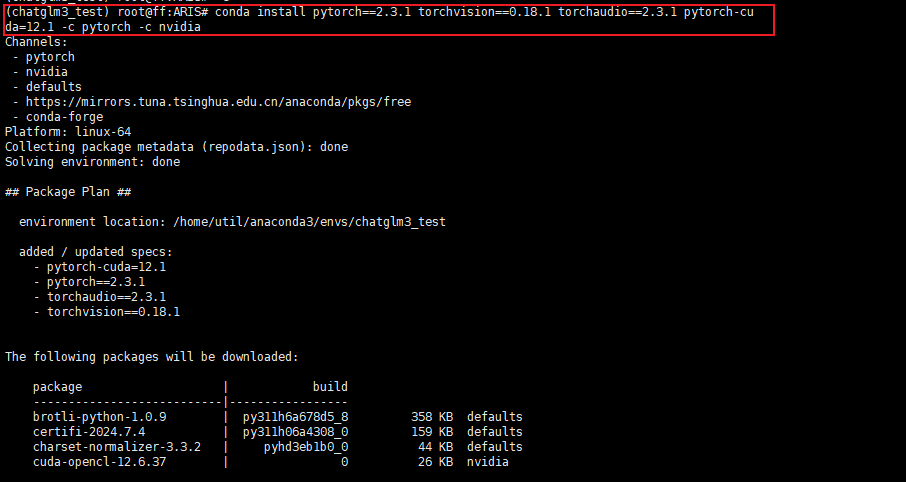
安装完毕后,如果想要检查是否成功安装了GPU版本的PyTorch,可以通过几个简单的步骤在 Python 环境中进行验证:
import torchprint(torch.cuda.is_available())
如果输出是 True,则表示GPU版本的PyTorch已经安装成功并且可以使用CUDA,如果输出是 False,则表明没有安装GPU版本的PyTorch,或者CUDA环境没有正确配置,此时根据教程,重新检查自己的执行过程。
完成验证之后使用ctril+D退出python环境,继续命令行操作。
-
Step 4. 下载ChatGLM3的项目文件
ChatGLM3的代码库和相关文档存储在 GitHub 这个在线平台上。GitHub 是一个广泛使用的代码托管平台,它提供了版本控制和协作功能。
要下载ChatGLM3-6B的项目文件,需要进入ChatGLM3的Github:https://github.com/THUDM/ChatGLM3

在 GitHub 上将项目下载到本地通常有两种主要方式:克隆 (Clone) 和 下载 ZIP 压缩包。鉴于服务器平台一般不能直接连接外网,本节内容介绍一种通过在外部终端下载然后上转至服务器的部署办法。在 GitHub 仓库页面上,通常会有一个“Download ZIP”按钮,我们可以点击这个按钮下载仓库的当前状态的压缩包.

下载后,只需解压缩该文件即可访问项目文件。压缩包中存放的是ChatGLM3运行的一些项目文件。

通过这种方式下载的项目文件,需要xftp这样的工具在上传到服务器使用。
-
Step 5. 下载ChatGLM3的模型权重
刚刚我们下载到的只是ChatGLM3-6B的一些运行文件和项目代码,并不包含ChatGLM3-6B这个模型。这里我们需要进入到 Hugging Face 下载。Hugging Face 是一个丰富的模型库,开发者可以上传和共享他们训练好的机器学习模型。这些模型通常是经过大量数据训练的,并且很大,因此需要特殊的存储和托管服务。
不同于GitHub,GitHub 仅仅是一个代码托管和版本控制平台,托管的是项目的源代码、文档和其他相关文件。同时对于托管文件的大小有限制,不适合存储大型文件,如训练好的机器学习模型。相反,Hugging Face 专门为此类大型文件设计,提供了更适合大型模型的存储和传输解决方案。
注:需要挂梯子才能进入Hugging Face。

按照图示位置打开Files,找到对应权重文件,点击便可进行下载。

下载好的完整的文件信息如下,在正式启动模型前,建议校验下载好的文件完整性以免出现不必要的纰漏。

-
Step 6. 基于Xftp的文件传输办法
Xshell 是一款功能强大的终端模拟软件,主要用于连接和管理远程服务器。它支持多种协议,包括 SSH、Telnet、SFTP、RLOGIN 和 Serial,广泛应用于服务器管理、网络配置和软件开发领域。Xshell的链接地址: https://www.xshell.com/zh/xshell/
Xftp 是一款功能强大的文件传输软件,主要用于 Windows 系统上通过 SFTP(SSH File Transfer Protocol)和 FTP(File Transfer Protocol)协议进行文件传输,并支持直接编辑和自动传输远程文件。Xftp链接地址: https://www.xshell.com/zh/xftp/
Xftp的部署方式也很简单,安装时只需要关注以下几个关键点的选择即可。

注意下载文件所在的目的地文件夹地址。

程序文件夹中选择默认就好,如果点击了现有文件夹准备修改只需返回上一步再返回便进入默认选项。

首次安装需要注册才可以使用,输入名称和邮箱地址后会在对应邮箱中收到注册链接,点击链接完成授权从而开始正式使用系统。

全部安装流程完成后所示界面如下

接下来需要进入Xshell,链接好本机服务器后点击上边栏的绿色图标开始远程连接并启动Xftp,对接成功后开始传输文件。

传输过程只需找到对应的文件夹位置,复制或拖拽便可实现远程传递过程。以下是项目文件的传递过程:

启动文件的传递也是一样的,但是建议将启动文件包含项目权重文件。

文件全部传输完毕后建议进行一边校验以免遗漏,在终端环境中也可以进行查看,不过在Xftp更方便进行项目资源编辑管理。
3. 运行ChatGLM3-6B的多种启动方式介绍
ChatGLM3-6B提供了一些简单应用Demo,存放在供开发者尝试运行。这里我们由简到难依次对其进行介绍。

在basic_demo中集合了多种的调用方式,通过cd basic_demo的方式可以进入对应的文件,ll或ls命令可以查看当前所在文件夹的全部文件。
3.1基于命令行的交互式对话
基于命令行的交互模式简洁高效、占用资源少,并且适合远程访问的方式来进行调用,这种方式可以为非技术用户提供一个脱离代码环境的对话方式,如果只是测试大模型的对话性能采用这种方式进行对话即可。对于这种启动方式,官方提供的脚本名称是:cli_demo.py。

在启动前,我们需要进行一处简单的修改,通过 sudo vim cli_demo.py进入对应文件的编辑模式,因为我们已经把ChatGLM3-6B这个模型下载到了本地,所以需要修改一下模型的加载路径。

修改完成后,直接输入python cli_demo.py即可启动,如果启动成功,就会开启交互式对话,如果输入stop 可以退出该运行环境。

可以看到这个模式下对话可以简单流畅运行
3.2基于Gradio的Web端对话应用
基于网页端的对话是目前非常通用的大语言交互方式,ChatGLM3官方项目组提供了两种Web端对话demo,两个示例应用功能一致,只是采用了不同的Web框架进行开发。首先是基于 Gradio 的Web端对话应用demo。Gradio是一个Python库,用于快速创建用于演示机器学习模型的Web界面。开发者可以用几行代码为模型创建输入和输出接口,用户可以通过这些接口与模型进行交互。用户可以轻松地测试和使用机器学习模型,比如通过上传图片来测试图像识别模型,或者输入文本来测试自然语言处理模型。因此可见Gradio非常适合于快速原型设计和模型展示。
对于这种启动方式,官方提供的脚本名称是:web_demo_gradio.py。同样我们需要使用vim 编辑器方法进入修改模型的加载路径,修改完成后直接使用python启动即可。

如果启动正常,会自动弹出Web页面,可以直接在Web页面上进行交互。

3.3基于Streamlit的Web端对话应用
ChatGLM3官方提供的第二个Web对话应用demo,是一个基于Streamlit的Web应用。Streamlit是另一个用于创建数据科学和机器学习Web应用的Python库。它强调简单性和快速的开发流程,让开发者能够通过编写普通的Python脚本来创建互动式Web应用。Streamlit自动管理UI布局和状态,这样开发者就可以专注于数据和模型的逻辑。Streamlit应用通常用于数据分析、可视化、构建探索性数据分析工具等场景。
对于这种启动方式,官方提供的脚本名称是:web_demo_streamlit.py。同样,先使用 vim 编辑器修改模型的加载路径。

启动命令略有不同,不再使用 python,而是需要使用 streamkit run的方式来启动。
streamkit run web_demo_streamlit.py
3.4基于指定虚拟环境的Jupiter Lab中运行
我们在部署Chatglm3-6B模型之前,创建了一个chatglme3_test虚拟环境来支撑该模型的运行。除了在终端中使用命令行启动,同样可以在Jupyter Lab环境中启动这个模型。具体的执行过程如下:
首先,在终端中找到需要加载的虚拟环境,使用如下命令可以查看当前系统中一共存在哪些虚拟环境,这里可以看到我们之前创建的chatglm3_test虚拟环境,需要使用如下命令进入该虚拟环境:
conda env list #显示已经建好的虚拟环境列表
conda activate `env_name` #进入对应的虚拟环境,这里的`env_name`就是需要进入的虚拟环境名称在该环境中安装ipykernel软件包。这个软件包将允许Jupyter Notebook使用特定环境的Python版本。运行以下命令:
conda install ipykernel
将该环境添加到Jupyter Notebook中。运行以下命令:
# 这里的env_name 替换成需要使用的虚拟环境名称python -m ipykernel install --user --name=yenv_name --display-name="Python(env_name)"完成以上步骤后,在终端输入jupyter lab或Jupyter Notebook启动.

打开后就可以看到,当前环境下我们已经可以使用新的虚拟环境创建Notebook。

基本调用流程也比较简单,官方也给出了一个实例:

只需要从transformers中加载AutoTokenizer 和 AutoModel,指定好模型的路径即可。tokenizer这个词大家应该不会很陌生,可以简单理解我们在之前使用gpt系列模型的时候,使用tiktoken库帮我们把输入的自然语言,也就是prompt按照一种特定的编码方式来切分成token,从而生成API调用的成本。但在Transform中tokenizer要干的事会更多一些,它会把输入到大语言模型的文本,包在tokenizer中去做一些前置的预处理,会将自然语言文本转换为模型能够理解的格式,然后拆分为 tokens(如单词、字符或子词单位)等操作。
而对于模型的加载来说,官方的代码中指向的路径是THUDM/chatglm3-6b,表示可以直接在云端加载模型,所以如果我们没有下载chatglm3-6b模型的话,直接运行此代码也是可以的,只不过第一次加载会很慢,耐心等待即可,同时需要确保当前的网络是联通的(必要的情况下需要开梯子)。
因为我们已经将ChatGLM3-6B的模型权重下载到本地了,所以此处可以直接指向我们下载的Chatglm3-6b模型的存储路径来进行推理测试。

对于其他参数来说,model 有一个eval模式,就是评估的方法,模型基本就是两个阶段的事,一个是训练,一个是推理,计算的量更大,它需要把输入的值做一个推理,如果是一个有监督的模型,那必然存在一个标签值,也叫真实值,这个值会跟模型推理的值做一个比较,这个过程是正向传播。差异如果很大,就说明这个模型的能力还远远不够,既然效果不好,就要调整参数来不断地修正,通过不断地求导,链式法则等方式进行反向传播。当模型训练好了,模型的参数就不会变了,形成一个静态的文件,可以下载下来,当我们使用的时候,就不需要这个反向传播的过程,只需要做正向的推理就好了,此处设置 model.eval()就是说明这个过程。而trust_remote_code=True 表示信任远程代码(如果有), device='cuda' 表示将模型加载到CUDA设备上以便使用GPU加速,这两个就很好理解了。
3.5基于OpenAI风格的API调用方法
ChatGLM3-6B模型提供了OpenAI风格的API调用方法。正如此前所说,在OpenAI几乎定义了整个前沿AI应用开发标准的当下,提供一个OpenAI风格的API调用方法,毫无疑问可以让ChatGLM3模型无缝接入OpenAI开发生态。所谓的OpenAI风格的API调用,指的是借助OpenAI库中的ChatCompletion函数进行ChatGLM3模型调用。而现在,我们只需要在model参数上输入chatglm3-6b,即可调用ChatGLM3模型。调用API风格的统一,无疑也将大幅提高开发效率。

而要执行OpenAI风格的API调用,则首先需要安装openai库,并提前运行openai_api.py脚本。具体执行流程如下:
首先需要注意:OpenAI目前已将openai库更新至1.x,但目前Chatglm3-6B仍需要使用旧版本0.28。所以需要确保当前环境的openai版本。

启动之前,需要安装tiktoken包,用于将文本分割成 tokens。

同时,需要降级typing_extensions依赖包,否则会报错。
pip install typing_extensions==4.8.0
如果想要使用API持续调用Chatglm3-6b模型,需要启动一个脚本,该脚本位于open_api_demo中。通过cd openai_api_demo进入对应文件夹。

使用命令openai_api_request.py启动,第一次启动加载会比较慢。启动成功之后在Jupyter lab上执行如下代码,进行API调用测试。

建议大家尝试采用OpenAI风格的调用方式,是因为目前许多模型(包括GLM-4)都已经采用或兼容这一格式。熟悉这种通用的方法将有助于大家更快地入门,并为构建高级代理系统打下坚实的基础。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号