ChatGLM3-6B简介、Ubuntu环境下安装ChatGLM3-6B
大模型的部署整体而言并不复杂,官方通常会提供标准的部署流程。然而,许多人在实际部署过程中会遇到各种问题,导致部署难以成功。主要原因在于这个过程中涉及到大量依赖库的安装和更新,以及需要根据本地环境的安装情况及时调整代码逻辑。此外,部署还对硬件有一定的要求,因此整体而言,部署和使用仍然存在一定门槛。为此,我们特别整理了一份详细的ChatGLM3-6B模型部署教程,供大家参考和学习。
在本教程主要涉及了以下三个部分:
-
准备工作
-
ChatGLM3-6B基本介绍
-
ChatGLM3-6B本地部署流程
1.启动安装部署前的准备工作
-
操作系统要求
首先看系统要求。目前开源的大模型都支持在Windows、Linux和Mac上部署运行。但在应用开发领域中,Linux 系统通常被优先选择而不是 Windows,主要原因是Linux 系统具有强大的包管理系统(如 apt, yum, pacman),允许开发者轻松安装、更新和管理软件包,这比 Windows 操作系统上的软件安装和管理更加方便快捷。同时Linux系统与多种编程语言和开发工具的兼容性较好,尤其是一些开源工具,仅支持在Linux系统上使用。整体来看,在应用运行方面对硬件的要求较低,且在处理多任务时表现出色,所以被广泛认为是一个非常稳定和可靠的系统,特别是对于服务器和长时间运行的应用。
Linux 操作系统有许多不同的发行版,每种发行版都有其特定的特点和用途,如CentOS、Ubuntu和Debian等。 CentOS 是一种企业级的 Linux 发行版,以稳定性和安全性著称。它是 RHEL(Red Hat Enterprise Linux)的免费替代品,与 RHEL 完全兼容,适用于服务器和企业环境。而Ubuntu,是最受欢迎的 Linux 发行版之一,其优势就是对用户友好和很强的易用性,其图形化界面都适合大部分人的习惯。
所以,在实践大模型时,强烈建议大家使用Ubuntu系统。同时,本教程也是针对Ubuntu 22.04 桌面版系统来进行ChatGLM3-6B模型的部署和运行的。
-
硬件配置要求
其次,关于硬件的需求,ChatGLM3-6B支持GPU运行(需要英伟达显卡)、CPU运行以及Apple M系列芯片运行。其中GPU运行需要至少6GB以上显存(4Bit精度运行模式下),而CPU运行则需要至少32G的内存。由于Apple M系列芯片是统一内存架构,因此需要13G内存即可运行。其中CPU运行模式下内存占用过大且运行效率较低,因此我们也强调过,GPU模式部署才能有效的进行大模型的学习实践。
在本教程中,我们将重点讲解如何配置GPU环境来部署运行ChatGLM3-6B模型。
基于上述两方面的原因,我们在上期内容详细介绍了如何部署一个纯净的Ubuntu 22.04双系统。本期内容就在这样的环境基础上,安装必要的大模型运行依赖环境,并实际部署、运行及使用ChatGLM3-6B模型。
在开始之前,请大家确定当前使用的硬件环境满足ChatGLM3-6B模型本地化运行的官方最低配置需求:

如果配置满足需求,接下来我们就一步一步执行本地化部署ChatGLM3-6B模型。本期内容将首先介绍ChatGLM3-6B模型在Ubuntu 22.04系统下单显卡部署流程,更加贴合实际工业生产的多卡推理部署办法将在未来的课程中展开讲述。
2. ChatGLM3-6B基本介绍
ChatGLM3 是智谱AI和清华大学 KEG 实验室在2023年10月27日联合发布的开源的、支持中英双语的对话语言模型。ChatGLM3-6B 是 ChatGLM3 系列中的开源模型具有62亿个参数,其可以免费下载,以及免费的商业化使用。
该模型在保留了前两代模型对话流畅、部署门槛低等众多优秀特性的基础上,ChatGLM3-6B 引入了如下特性:ChatGLM 3 GitHub
-
更强大的基础模型: ChatGLM3-6B 的基础模型 ChatGLM3-6B-Base 采用了更多样的训练数据、更充分的训练步数和更合理的训练策略。在语义、数学、推理、代码、知识等不同角度的数据集上测评显示,在44个中英文公开数据集测试中处于国内模型的第一位。ChatGLM3-6B-Base 具有在 10B 以下的基础模型中最强的性能。
-
更完整的功能支持: ChatGLM3-6B 采用了全新设计的 Prompt 格式,除正常的多轮对话外。同时原生支持工具调用(Function Call)、代码执行(Code Interpreter)和 Agent 任务等复杂场景。
-
更全面的开源序列: 除了对话模型 ChatGLM3-6B 外,还开源了基础模型 ChatGLM3-6B-Base、长文本对话模型 ChatGLM3-6B-32K。以上所有权重对学术研究完全开放,在填写问卷进行登记后亦允许免费商业使用。

性能层面,ChatGLM3-6B在10B范围内性能表现出色,推理能力接近GPT-3.5;功能层面,ChatGLM3-6B具有多模态功能、代码解释器功能、联网功能以及Agent优化功能四项核心功能,是性能非常不错的小体量开源大模型。不过由于 ChatGLM3-6B 模型规模较小,且模型受概率随机性因素影响,无法保证输出内容的准确。同时模型的输出容易被用户的输入误导。想要获得较理想的效果还需要微调以及提示工程等方法的强化,

AI Agent(人工智能代理)是一个能够自主执行任务或达成目标的系统或程序,能够围绕复杂问题进行任务拆解,规划多步执行步骤;能够实时围绕自动编写的代码进行debug;能够根据人类意见反馈修改答案,实时积累修改对话,并进行阶段性微调等等,具有很强的决策和执行能力。那ChatGLM3-6B模型开放的Function calling能力,是大语言模型推理能力和复杂问题处理能力的核心体现,是本次ChatGLM 3模型最为核心的功能迭代,也是ChatGLM 3模型性能提升的有力证明。

相关的信息获取方途径
-
智谱清言:https://chatglm.cn
-
API开放平台:https://bigmodel.cn/
-
Github仓库:https://github.com/THUDM/ChatGLM-6B
开源模型列表:
| 模型 | 介绍 | 上下文token数 | 代码链接 | 模型权重下载链接 |
|---|---|---|---|---|
| ChatGLM3-6B | 第三代 ChatGLM 对话**模型。**ChatGLM3-6B 采用了全新设计的 Prompt 格式,除正常的多轮对话外。同时原生支持工具调用(Function Call)、代码执行(Code Interpreter)和 Agent 任务等复杂场景。 | 8K | Huggingface | 魔搭社区 | 始智社区 | Swanhub | 启智社区 ) | [ChatGLM3](https://github.com/THUDM/ChatGLM3 |
| ChatGLM3-6B-base | 第三代ChatGLM**基座模型。**ChatGLM3-6B-Base 采用了更多样的训练数据、更充分的训练步数和更合理的训练策略。在语义、数学、推理、代码、知识等不同角度的数据集上测评显示,ChatGLM3-6B-Base 具有在 10B 以下的基础模型中最强的性能。 | 8K | Huggingface | 魔搭社区 | 始智社区 | Swanhub | 启智社区 | |
| ChatGLM3-6B-32k | 第三代ChatGLM长上下文对话模型。在ChatGLM3-6B的基础上进一步强化了对于长文本的理解能力,能够更好的处理最多32K长度的上下文。 | 32K | Huggingface | 魔搭社区 | 始智社区 | Swanhub | 启智社区 |
3. ChatGLM3-6B本地部署流程
对于部署ChatGLM3-6B来说,从官方说明上看,其规定了Transformers 库版本应该 4.30.2 以及以上的版本 ,torch 库版本应为 2.0 及以上的版本,gradio 库版本应该为 3.x 的版本,以获得最佳的推理性能。所以为了保证 torch 的版本正确,建议大家严格按照官方文档的说明安装相应版本的依赖包。
-
Step 1. 创建conda虚拟环境
Conda创建虚拟环境的意义在于提供了一个隔离的、独立的环境,用于Python项目和其依赖包的管理。每个虚拟环境都有自己的Python运行时和一组库。这意味着我们可以在不同的环境中安装不同版本的库而互不影响。例如,可以在一个环境中使用Python 3.8,而在另一个环境中使用Python 3.9。对于大模型来说,建议Python版本3.10以上。创建的方式也比较简单,使用以下命令创建一个新的虚拟环境:
# myenv 是你想要给环境的名称,python=3.8 指定了要安装的Python版本。你可以根据需要选择不同的名称和/或Python版本。conda create -n chatglm3_test python=3.11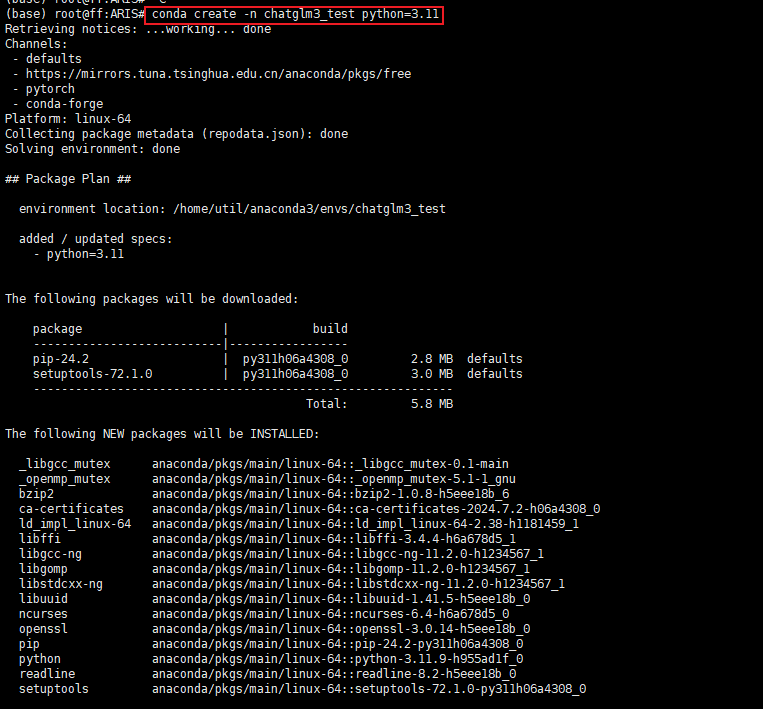
创建虚拟环境后需要激活它才能开始使用,使用以下命令来激活刚创建的虚拟环境:
conda activate chatglm3_test 
如果成功激活,可以看到在命令行的最前方的括号中,就标识了当前的虚拟环境(chatglm3_test),然后,按照官方的要求安装torch。
-
Step 2. 查看当前驱动最高支持的CUDA版本
CUDA(Compute Unified Device Architecture,统一计算设备架构)是一种操作GPU的软件架构,它是一种通用并行计算架构,使GPU能够解决复杂的计算问题。
我们需要根据CUDA版本选择Pytorch框架,先看下当前的CUDA版本,通过以下命令实现功能:
nvidia-sml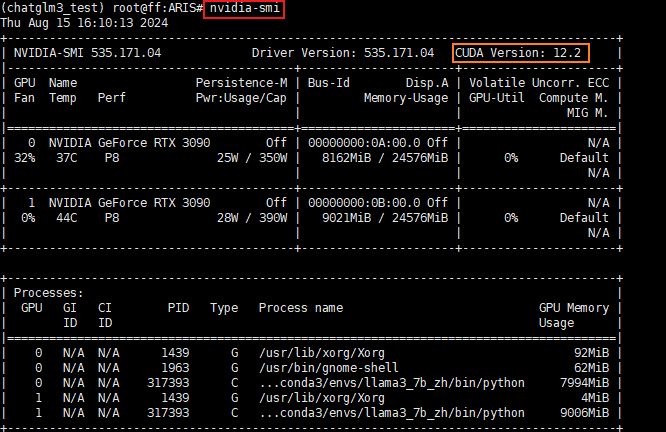
可以看到本台机器的CUDA版本是12.2,接下来的库和依赖安装也要选择与其兼容的Pytorch版本。
-
Step 3. 在虚拟环境中安装Pytorch
PyTorch 是一个开源的深度学习框架,由 Facebook 的人工智能研究团队(FAIR)开发和维护(当然现在可能也更名叫MAIR了)。Pytorch专门针对 GPU 加速的深度神经网络(DNN)编程。Torch 是一个经典的对多维矩阵数据进行操作的张量(tensor )库,在机器学习和其他数学密集型应用有广泛应用。与Tensorflow的静态计算图不同,pytorch的计算图是动态的,可以根据计算需要实时改变计算图。并且Pytorch具有非常简洁的格式为广大Python用户舒适体验。
进入Pytorch官网:https://pytorch.org/get-started/previous-versions/
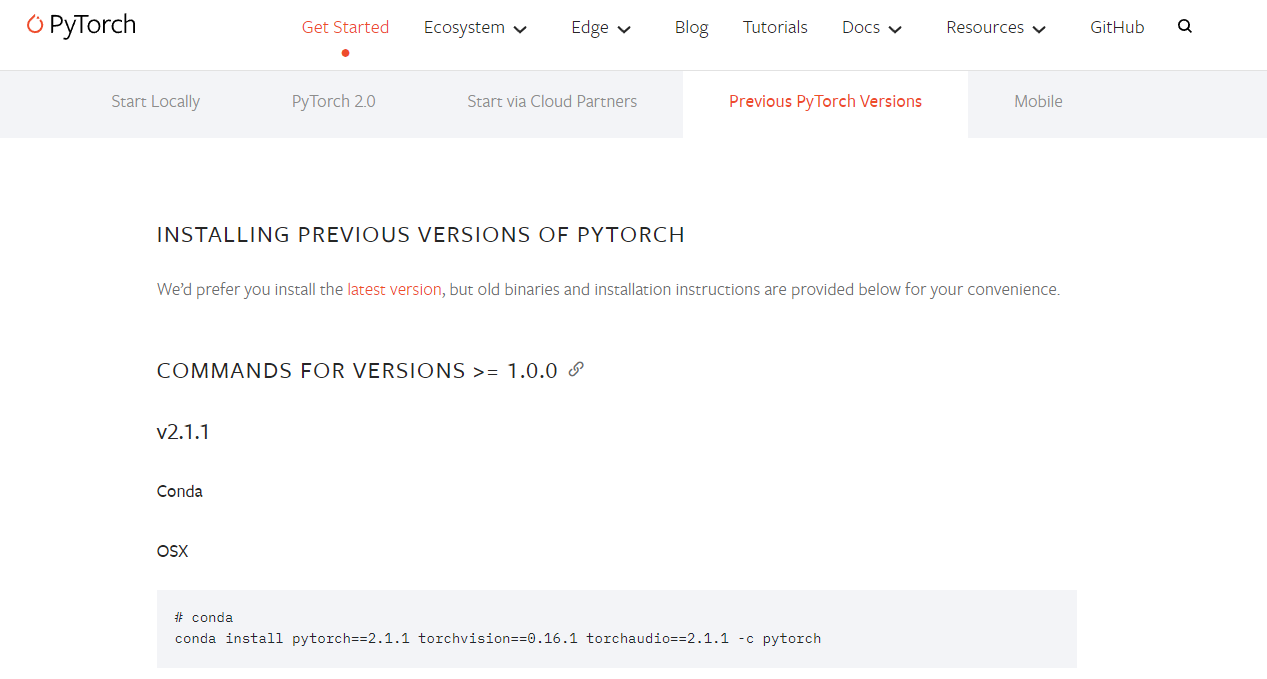
当前的电脑CUDA的最高版本要求是12.2,所以需要找到=<12.2版本的Pytorch(也就是小于等于本机CUDA版本的安装命令,直接安装即可)。
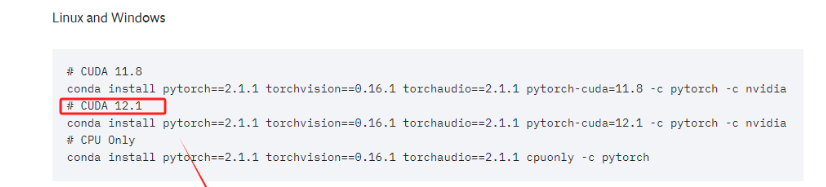
直接复制对应的命令,进入终端执行即可。这实际上安装的是为 CUDA 12.1 优化的 PyTorch 版本。这个 PyTorch 版本预编译并打包了与 CUDA 12.1 版本相对应的二进制文件和库。
conda install pytorch==2.3.1 torchvision==0.18.1 torchaudio==2.3.1 pytorch-cuda=12.1 -c pytorch -c nvidia
-
Step 4. 安装Pytorch验证
安装完毕后,如果想要检查是否成功安装了GPU版本的PyTorch,可以通过几个简单的步骤在 Python 环境中进行验证:
import torch
print(torch.cuda.is_available())
如果输出是 True,则表示GPU版本的PyTorch已经安装成功并且可以使用CUDA,如果输出是 False,则表明没有安装GPU版本的PyTorch,或者CUDA环境没有正确配置,此时根据教程,重新检查自己的执行过程。
完成验证之后使用ctril+D退出python环境,继续命令行操作。
-
Step 5. 下载git及建立项目文件夹
在执行命令之前,先安装git软件包。
sudo apt install git
然后创建一个存放ChatGLM3-6B项目文件的文件夹。
mkdir chatglm3
ls
cd chatglm3ls
-
Step 6. 获取ChatGLM3-6B项目资源
这里提供一种无需FQ可以下载模型办法,到魔搭社区官网中快速下载,以下是model scope的ChatGLM3-6B的网址:https://www.modelscope.cn/models/ZhipuAI/chatglm3-6b
登录进入官网后点击模型库选项开始搜索所需要的模型名称。

在模型搜索栏输入关键词GLM3-6B即可找到对应系列模型,点击标题名为chatglm3-6b的选项,进入模型详情页。

在详情页有模型的基本介绍、对应官网的链接、以及它的下载资源和简单的下载流程说明。

-
Step 7. 升级pip版本
pip 是 Python 的一个包管理器,用于安装和管理 Python 软件包。允许从 Python Package Index(PyPI)和其他索引中安装和管理第三方库和依赖。一般使用 pip 来安装、升级和删除 Python 软件包。除此之外,pip 自动处理 Python 软件包的依赖关系,确保所有必需的库都被安装。在Python环境中,尽管我们是使用conda来管理虚拟环境,但conda是兼容pip环境的,所以使用pip下载必要的包是完全可以的。
在终端命令行升级 pip,确保使用的是最新版本的 pip,如果使用的是旧版本的 pip,可能无法安装一些最新的包,或者可能无法正确解析依赖关系。最新版本的pip这样可以避免在安装库时出现兼容性问题。
python -m pip install --upgrade pip
-
Step 8. 使用pip安装相关的软件依赖
首先,我们需要安装一系列的 Python 包,这些包是使用 Hugging Face Transformers 库所必需的。可以使用以下命令来安装这些依赖项:
pip install protobuf 'transformers>=4.30.2' cpm_kernels 'torch>=2.0' gradio mdtex2html sentencepiece accelerate
随后进行modelscope的库下载,当程序运行完成并在底部发现Succefully installed modelscope字样时说明下载成功。

-
Step 9. 在Python环境下载模型
输入python进入环境,输入以下代码使用snapshot_download函数进行模型的下载:
from modelscope import snapshot_download
model_dir = snapshot_download("ZhipuAI/chatglm3-6b", revision = "v1.0.0")
transformers版本过高或过低都会导致运行大模型时出现错误,因此我们需要指定transformers的版本使得版本兼容,通过以下指令可以查看transformers的版本:
pip show transformers通过以下指令来卸载当前的版本以及安装指定的transformers版本
pip uninstall transfomers
pip install --upgrade transformers==4.37.2
-
Step 10. 在Python环境下载模型
在python环境中继续输入以下代码调用 ChatGLM3-6B 模型来生成对话:
from modelscope import AutoTokenizer, AutoModel, snapshot_download
model_dir = snapshot_download("ZhipuAI/chatglm3-6b", revision = "v1.0.0")
tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)
model = AutoModel.from_pretrained(model_dir, trust_remote_code=True).half().cuda()
model = model.eval()
response, history = model.chat(tokenizer, "你好", history=[])
print(response)
response, history = model.chat(tokenizer, "晚上睡不着应该怎么办", history=history)
print(response)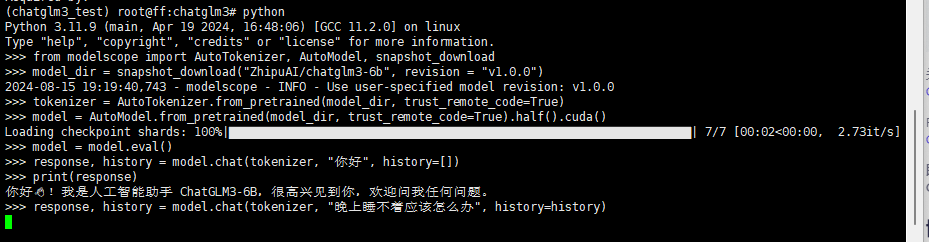
大模型推理完毕后可以看到返回的结果,说明安装部署成功。

以上就是Ubuntu系统下通过python环境在终端安装部署ChatGLM3-6B模型的全部流程,欢迎大家进行学习交流!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号