中医临床诊疗智能助手 - RAG 项目实战
💡 这节课会带给你
- 如何用你的垂域数据补充 LLM 的能力
- 如何构建你的垂域(向量)知识库
- 搭建一套完整 RAG 系统需要哪些模块
- 搭建 RAG 系统时更多的有用技巧
- 如何提升 RAG 检索的效果及优化实践
学习目标:
- RAG 技术概述
- RAG WorkFlow 及 RAG 工程化
- 基于 LlamaIndex 快速构建 RAG 项目
- 使用 LlamaIndex 存储和读取 Embedding 向量
- 追踪哪些文档片段被用于检索增强生成
- 深度剖析 RAG 检索底层实现细节
- 自定义 RAG Prompt Template
- RAG 项目企业级生产部署最佳实践
一、 RAG 技术概述
1.1 大模型目前固有的局限性
大语言模型(LLM)是概率生成系统
- 知识时效性:模型知识截止于训练数据时间点(联网搜索)
- 推理局限性:本质是概率预测而非逻辑运算,复杂数学推理易出错(DeepSeek-R1的架构有所不同)
- 专业领域盲区:缺乏垂直领域知识
- 幻觉现象:可能生成看似合理但实际错误的内容
1.2 什么是 RAG?
RAG(Retrieval Augmented Generation)顾名思义,通过检索的方法来增强生成模型的能力。
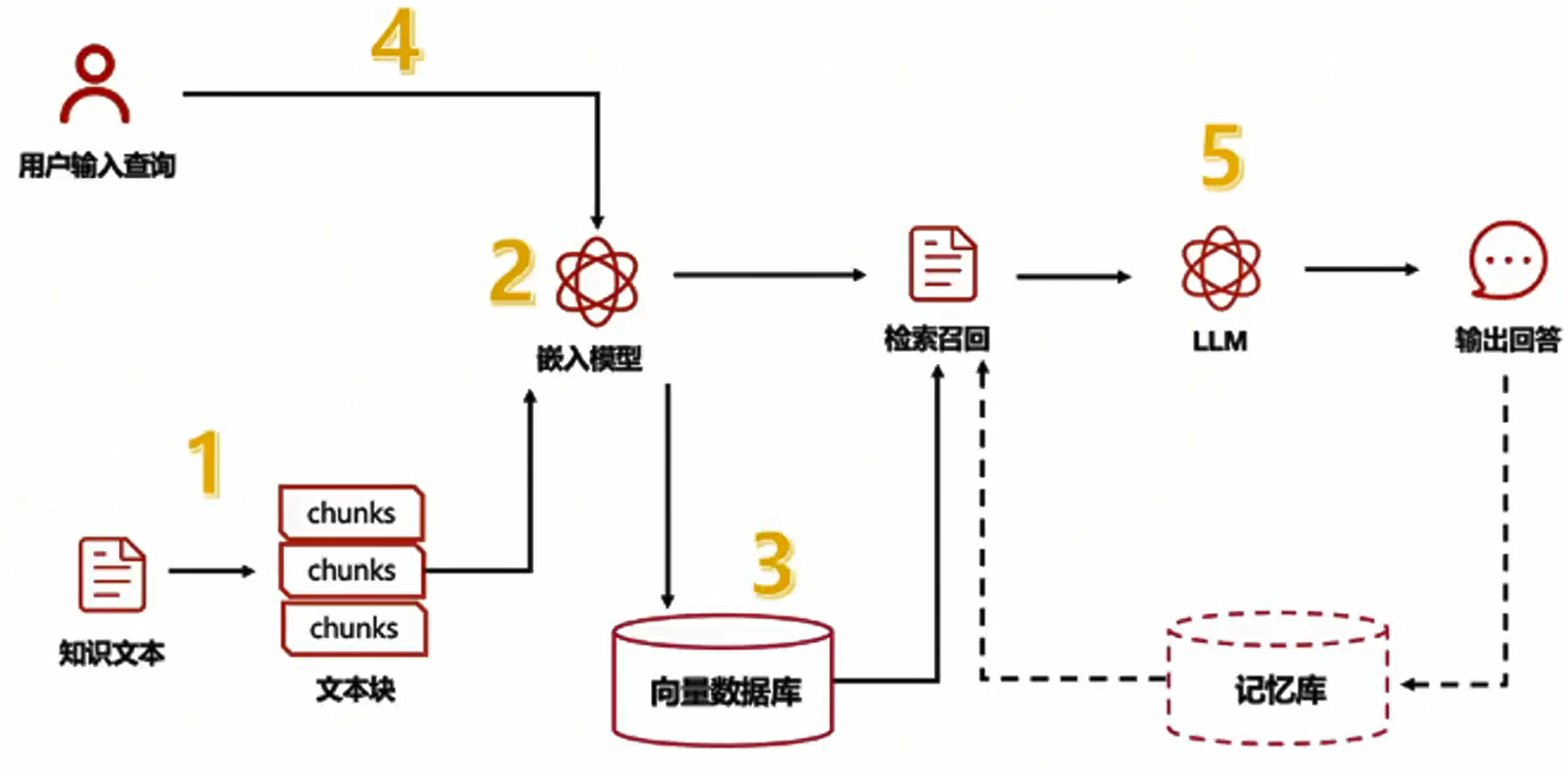
二、RAG 工程化
2.1 RAG系统的基本搭建流程
搭建过程:
- 文档加载,并按一定条件切割成片段
- 将切割的文本片段灌入检索引擎
- 封装检索接口
- 构建调用流程:Query -> 检索 -> Prompt -> LLM -> 回复
2.2 构建索引
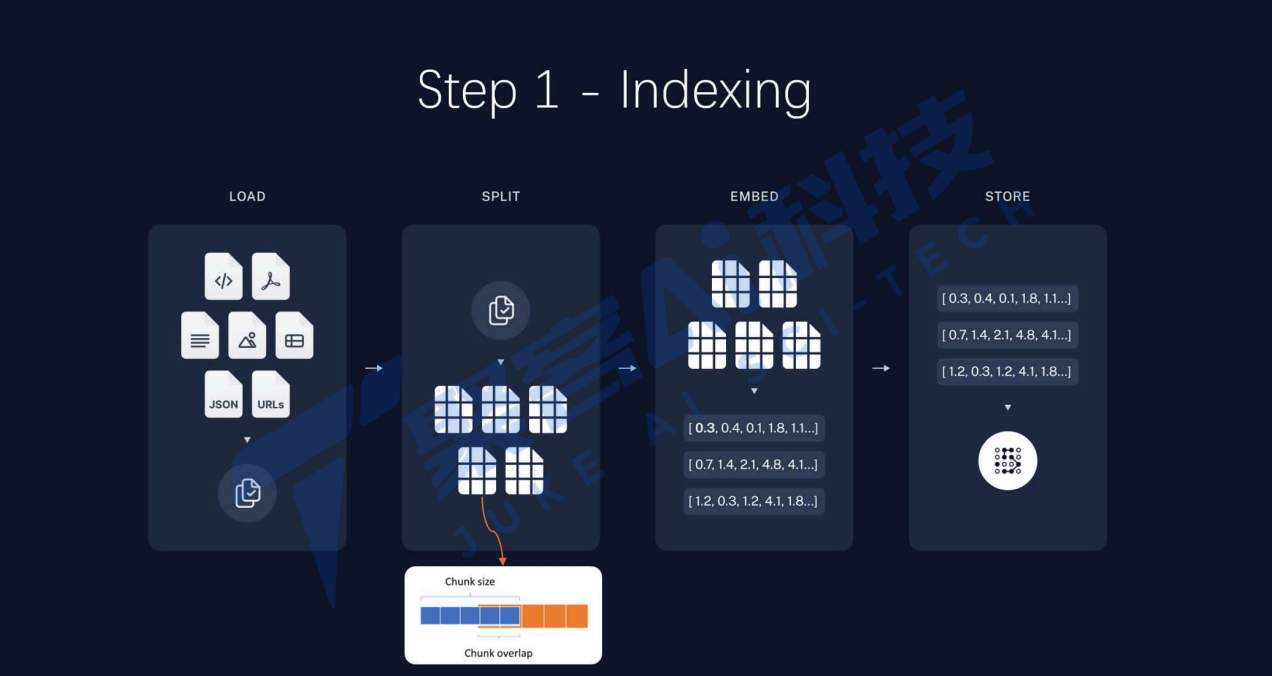
2.3 检索和生成

三、项目环境配置
3.1 使用 conda 创建项目环境
# 创建环境
conda create -n tcm-ai-rag python=3.10
# 激活环境
conda activate tcm-ai-rag3.2 安装项目所需依赖库
# 安装 LlamaIndex 相关包
# !pip install llama-index
# !pip install llama-index-embeddings-huggingface
# !pip install llama-index-llms-huggingface
# 安装 CUDA 版本 Pytorch
# !pip install torch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 --index-url https://download.pytorch.org/whl/cu118四、模型下载
# 安装 modelscope
# !pip install modelscope4.1 下载 Embedding 模型权重
使用BAAI开源的中文bge模型作为embedding模型,使用modlescope提供的SDK将模型权重下载到本地服务器:
模型下载需要等待一段时间
# 使用 modelscope 提供的 sdk 进行模型下载
from modelscope import snapshot_download
# model_id 模型的id
# cache_dir 缓存到本地的路径
model1_dir = snapshot_download(model_id="BAAI/bge-base-zh-v1.5", cache_dir="D:\learn\learncode\Agent\model")4.2 下载 LLM 大模型权重
使用阿里开源的通义千问大模型,使用modelscope提供的SDK将模型权重下载到服务器:
模型很大(14G),需要等待好久哦
model2_dir = snapshot_download(model_id="Qwen/Qwen2.5-7B-Instruct", cache_dir="D:\learn\learncode\Agent\model") 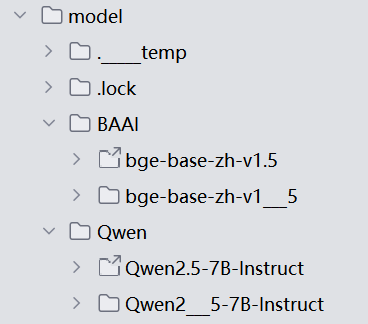
五、构建中医临床诊疗术语证候问答
5.1 语料准备
本应用使用的文档是由国家卫生健康委员和国家中医药管理局发布的中医临床诊疗术语:
《中医临床诊疗术语第1部分:疾病》(修订版).docx
《中医临床诊疗术语第2部分:证候》(修订版).docx
《中医临床诊疗术语第3部分:治法》(修订版).docx
部分内容展示:


5.2 基于 LlamaIndex 来快速构建知识库
5.2.1 导入所需的包
# 5.2.1 导入所需的包
# logging: 用于输出程序运行时的日志信息(方便调试和查看程序状态)
# sys: 用于访问系统相关的功能(这里主要配合日志输出)
# torch: PyTorch深度学习框架(大模型和嵌入模型运行依赖它)
# llama_index相关模块: 一个专门用于构建大模型应用的框架,简化文档处理、索引构建和查询流程
# - PromptTemplate: 用于定义提示词模板(告诉模型如何回答问题)
# - Settings: 全局配置对象(统一设置大模型、嵌入模型等)
# - SimpleDirectoryReader: 读取本地文件夹中的文档
# - VectorStoreIndex: 向量存储索引(核心组件,用于管理文档向量和查询)
# - 其他如load_index_from_storage等: 用于后续加载已保存的索引(当前代码未用到)
import logging
import sys
import torch
from llama_index.core import PromptTemplate, Settings, SimpleDirectoryReader, VectorStoreIndex, load_index_from_storage, StorageContext, QueryBundle
from llama_index.core.schema import MetadataMode
from llama_index.embeddings.huggingface import HuggingFaceEmbedding # 用于加载本地嵌入模型
from llama_index.llms.huggingface import HuggingFaceLLM # 用于加载本地大语言模型
from llama_index.core.node_parser import SentenceSplitter # 用于将文档切分成小块
# 5.2.2 定义日志配置
# 配置日志输出到控制台(sys.stdout),日志级别为INFO(显示重要信息,不显示冗余调试信息)
logging.basicConfig(stream=sys.stdout, level=logging.INFO)
# 给日志器再添加一个控制台输出处理器(确保日志能正常显示,避免被其他设置覆盖)
logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))
# 5.2.3 定义 System Prompt(系统提示词)
# 系统提示词用于告诉大模型"它应该扮演什么角色",相当于给模型设定行为准则
SYSTEM_PROMPT = """You are a helpful AI assistant.""" # 这里定义为"一个有用的AI助手"
# 定义查询包装模板(适配模型的输入格式)
# 很多大模型(如Qwen、Llama)有固定的输入格式要求,需要用特定标签包裹内容
# 这里的[INST]、<<SYS>>、<</SYS>>、[/INST]都是模型要求的格式标签
# {query_str}是占位符,会被实际的用户问题替换
query_wrapper_prompt = PromptTemplate(
"[INST]<<SYS>>\n" + SYSTEM_PROMPT + "<</SYS>>\n\n{query_str}[/INST] "
)
# 5.2.4 使用 llama_index 调用本地大模型
# 注意:实际生产环境中,不会每次运行都加载模型,而是先部署好模型(比如用vLLM框架),再通过API调用
# 这里用HuggingFaceLLM类直接加载本地模型,适合学习和测试
llm = HuggingFaceLLM(
context_window=4096, # 模型能处理的最大上下文长度(包括输入和输出),单位是token(约等于汉字数)
max_new_tokens=2048, # 模型最多能生成的新内容长度(回答的最大长度)
generate_kwargs={ # 生成答案时的参数
"temperature": 0.0, # 控制输出随机性(0表示确定性输出,1表示高度随机)
"do_sample": False # 是否随机采样(False表示按最可能的词生成,更稳定)
},
query_wrapper_prompt=query_wrapper_prompt, # 应用前面定义的查询模板
tokenizer_name=r'D:\learn\learncode\Agent\model\Qwen\Qwen2___5-7B-Instruct', # 本地模型的分词器路径(需替换为你的实际路径)
model_name=r'D:\learn\learncode\Agent\model\Qwen\Qwen2___5-7B-Instruct', # 本地模型的权重路径(需替换为你的实际路径)
device_map="auto", # 自动选择运行设备(有GPU用GPU,没GPU用CPU)
model_kwargs={"torch_dtype": torch.float16}, # 模型加载时的参数,float16表示用半精度计算(节省显存)
)
# 将配置好的大模型设置为全局默认模型(后续所有需要大模型的地方都会用这个)
Settings.llm = llm
# 5.2.5 使用 llama_index 调用本地嵌入模型(Embedding模型)
# 嵌入模型的作用:将文本(如文档片段、用户问题)转换成数字向量(方便计算机计算相似度)
Settings.embed_model = HuggingFaceEmbedding(
model_name=r"D:\learn\learncode\Agent\model\BAAI\bge-base-zh-v1___5" # 本地嵌入模型的路径(需替换为你的实际路径)
)
# 5.2.6 读取文档
# 用SimpleDirectoryReader读取指定文件夹中的文档
# 参数说明:
# - r"D:\...\documents": 文档存放的文件夹路径(r表示路径中的反斜杠不需要转义)
# - required_exts=[".txt"]: 只读取txt格式的文件(忽略其他格式如word、pdf等),这里使用txt是因为我只使用了一部分专业数据(从word里面复制到txt),仅仅作为学习演示,否则我的电脑跑不起来
documents = SimpleDirectoryReader(r"D:\learn\learncode\Agent\documents", required_exts=[".txt"]).load_data()
# 5.2.7 文档处理与索引构建(核心步骤)
# 这一步会自动完成三件事:
# 1. 知识切片:用SentenceSplitter将长文档切分成小块(chunk_size=256表示每块约256个token)
# 为什么切分?因为大模型的上下文长度有限,切分成小块才能被模型处理
# 2. 向量转换:调用前面设置的嵌入模型,将每个文档小块转换成向量
# 3. 向量存储:将向量存入内存(方便后续快速查询相似内容),注意下面一步是暂时存到内存
index = VectorStoreIndex.from_documents(
documents, # 要处理的文档
transformations=[SentenceSplitter(chunk_size=256)] # 切分文档的工具和参数
)
'''
SentenceSplitter 参数详细设置:
预设会以 1024 个 token 为界切割片段, 每个片段的开头重叠上一个片段的 200 个 token 的内容。
chunk_size=1024, # 切片 token 数限制
chunk_overlap=200, # 切片开头与前一片段尾端的重复 token 数
paragraph_separator='\n\n\n', # 段落的分界
secondary_chunking_regex='[^,.;。?!]+[,.;。?!]?' # 单一句子的样式
separator=' ', # 最小切割的分界字元
'''
# 5.2.8 构建查询引擎
# 查询引擎是用户和模型交互的接口,负责:
# - 接收用户问题 → 转换成向量
# - 在索引中搜索与问题最相似的文档片段(similarity_top_k=5表示取最相似的5个)
# - 将这些片段和问题一起传给大模型,让模型基于片段生成答案
query_engine = index.as_query_engine(similarity_top_k=5)
# 5.2.9 生成答案
# 向查询引擎发送问题,得到模型的回答
# 这里的问题是"不耐疲劳,口燥、咽干可能是哪些证候?"(假设文档是中医相关内容)
response = query_engine.query("不耐疲劳,口燥、咽干可能是哪些证候?")
# 打印答案
print(response)
从提供的信息来看,不耐疲劳、口燥、咽干等症状可能与以下几种证候相关:
1. **燥干清窍证**(syndrome/pattern of dryness harassing the upper orifices):这种证候因气候或环境干燥,津液耗损,清窍失濡所致,临床表现为口鼻、咽喉干燥,两眼干涩,舌质瘦小、舌苔干而少津,脉细等。
2. **燥邪犯肺证**(syndrome/pattern of pathogenic dryness invading the lung):这种证候因外感燥邪,或感受风热,化燥伤阴,肺失清肃所致,临床表现为干咳、少痰或无痰,痰黏不易咳出,唇鼻咽喉干燥,声音嘶哑,口渴,咳甚则胸痛,或痰中血丝,舌尖红,舌苔薄黄、少津,脉细或数等。
这些证候都可能表现出口燥、咽干的症状,同时伴有其他相应症状。如果出现不耐疲劳的情况,可能需要进一步考虑是否涉及气血不足或其他因素。建议在专业中医师的指导下进行辨证施治。[/INST]六、使用LlamaIndex存储和读取embedding向量
6.1 上面面临的问题
- 使用llama-index-llms-huggingface构建本地大模型时,会花费相当一部分时间
- 在对文档进行切分,将切分后的片段转化为embedding向量,构建向量索引时,会花费大量的时间
6.2 向量存储
# 6.2 向量存储(持久化索引) 将embedding向量和向量索引存储到文件中
# 上面的步骤中,索引是存在内存中的,程序结束后会消失
# 这一步将索引(包括向量和文档信息)保存到本地文件夹,下次用的时候直接加载,不用重新处理文档
# 参数persist_dir是保存路径(需替换为你的实际路径)
index.storage_context.persist(persist_dir=r'D:\learn\learncode\Agent\doc_emb')
# 提示:llama_index可以很方便地集成主流向量数据库(如Chroma、Milvus等),适合大规模数据存储 
找到刚才定义的persist_dir所在的路径,可以发现该路径下有以下几个文件:
- default_vector_store.json:用于存储embedding向量
- docstore.json:用于存储文档切分出来的片段
- graph_store.json:用于存储知识图数据
- image__vector_store.json:用于存储图像数据
- index_store.json:用于存储向量索引
在上述代码中,我们只用到了纯文本文档,所以生成出来的graph_store.json和image__vector_store.json中没有数据。
6.3 从向量数据库检索
将embedding向量和向量索引存储到文件中后,我们就不需要重复地执行对文档进行切分,将切分后的片段转化为embedding向量,构建向量索引的操作了。
以下代码演示了如何使用LlamaIndex读取结构化文件中的embedding向量和向量索引数据:
# 从存储文件中读取embedding向量和向量索引
storage_context = StorageContext.from_defaults(persist_dir=r"D:\learn\learncode\Agent\doc_emb")
# 根据存储的embedding向量和向量索引重新构建检索索引
index = load_index_from_storage(storage_context)
# 构建查询引擎
query_engine = index.as_query_engine(similarity_top_k=5)
# 查询获得答案
response = query_engine.query("不耐疲劳,口燥、咽干可能是哪些证候?")
print(response)从提供的信息来看,不耐疲劳、口燥、咽干等症状可能与以下几种证候相关:
1. **燥干清窍证**(syndrome/pattern of dryness harassing the upper orifices):这种证候因气候或环境干燥,津液耗损,清窍失濡所致,临床表现为口鼻、咽喉干燥,两眼干涩,舌质瘦小、舌苔干而少津,脉细等。
2. **燥邪犯肺证**(syndrome/pattern of pathogenic dryness invading the lung):这种证候因外感燥邪,或感受风热,化燥伤阴,肺失清肃所致,临床表现为干咳、少痰或无痰,痰黏不易咳出,唇鼻咽喉干燥,声音嘶哑,口渴,咳甚则胸痛,或痰中血丝,舌尖红,舌苔薄黄、少津,脉细或数等。
这些证候都可能表现出口燥、咽干的症状,同时伴有其他相应症状。如果出现不耐疲劳的情况,可能需要进一步考虑是否涉及气血不足或其他因素。建议在专业中医师的指导下进行辨证施治。[/INST]七、追踪哪些文档片段被检索
# 追踪哪些文档片段被检索
# 从存储文件中读取embedding向量和向量索引
storage_context = StorageContext.from_defaults(persist_dir=r"D:\learn\learncode\Agent\doc_emb")
# 根据存储的embedding向量和向量索引重新构建检索索引
index = load_index_from_storage(storage_context)
# 构建查询引擎
query_engine = index.as_query_engine(similarity_top_k=5)
# 获取我们抽取出的相似度 top 5 的片段
contexts = query_engine.retrieve(QueryBundle("不耐疲劳,口燥、咽干可能是哪些证候?"))
print('-' * 10 + 'ref' + '-' * 10)
for i, context in enumerate(contexts):
print('*' * 10 + f'chunk {i} start' + '*' * 10)
content = context.node.get_content(metadata_mode=MetadataMode.LLM)
print(content)
print('*' * 10 + f'chunk {i} end' + '*' * 10)
print('-' * 10 + 'ref' + '-' * 10)
# 查询获得答案
response = query_engine.query("不耐疲劳,口燥、咽干可能是哪些证候?")
print(response)点击查看输出内容
----------ref----------
**********chunk 0 start**********
file_path: D:\learn\learncode\Agent\documents\demo.txt
临床以鼻咽干涩或痛,口唇燥干,舌质红,舌苔白或燥,脉浮或微数,伴见发热、无汗,头痛或肢节酸痛等为特征的证候。
3.6.3.2
燥干清窍证 syndrome/pattern of dryness harassing the upper orifices
因气候或环境干燥,津液耗损,清窍失濡所致。临床以口鼻、咽喉干燥,两眼干涩,少泪、少涕、少津、甚则衄血,舌质瘦小、舌苔干而少津,脉细等为特征的证候。
**********chunk 0 end**********
**********chunk 1 start**********
file_path: D:\learn\learncode\Agent\documents\demo.txt
临床以口鼻、咽喉干燥,两眼干涩,少泪、少涕、少津、甚则衄血,舌质瘦小、舌苔干而少津,脉细等为特征的证候。
3.6.3.3
燥邪犯肺证 syndrome/pattern of pathogenic dryness invading the lung
燥邪伤肺证
因外感燥邪,或感受风热,化燥伤阴,肺失清肃所致。临床以干咳、少痰或无痰,痰黏不易咳出,唇鼻咽喉干燥,声音嘶哑,口渴,咳甚则胸痛,或痰中血丝,舌尖红,舌苔薄黄、少津,脉细或数,初起或伴见发热、恶寒,头痛等为特征的证候。
**********chunk 1 end**********
**********chunk 2 start**********
file_path: D:\learn\learncode\Agent\documents\demo.txt
临床以口鼻皮肤干燥,频频饮水难解口渴,咽干、唾少,或口腔溃疡频发,目涩少泪或无泪,阴道涩滞,形体消瘦,大便燥结,舌质偏红,舌苔干而少津,脉细涩等为特征的证候。
3.8.6.2
燥毒痹阻证 syndrome/pattern of impediment and obstruction of dry toxin
因燥毒伤阴,痹阻经脉、骨节所致。
**********chunk 2 end**********
**********chunk 3 start**********
file_path: D:\learn\learncode\Agent\documents\demo.txt
3.6.3.2
燥干清窍证 syndrome/pattern of dryness harassing the upper orifices
因气候或环境干燥,津液耗损,清窍失濡所致。临床以口鼻、咽喉干燥,两眼干涩,少泪、少涕、少津、甚则衄血,舌质瘦小、舌苔干而少津,脉细等为特征的证候。
3.6.3.3
燥邪犯肺证 syndrome/pattern of pathogenic dryness invading the lung
燥邪伤肺证
因外感燥邪,或感受风热,化燥伤阴,肺失清肃所致。
**********chunk 3 end**********
**********chunk 4 start**********
file_path: D:\learn\learncode\Agent\documents\demo.txt
临床以口鼻皮肤干燥,频频饮水难解口渴,咽干、唾少,或口腔溃疡频发,目涩少泪或无泪,阴道涩滞,形体消瘦,大便燥结,舌质偏红,舌苔干而少津,脉细涩等为特征的证候。
3.8.6.2
燥毒痹阻证 syndrome/pattern of impediment and obstruction of dry toxin
因燥毒伤阴,痹阻经脉、骨节所致。临床以口鼻皮肤干燥,或有红斑、紫癜,游走性关节痛,阵发性肢端青紫、麻木,口舌灼痛,目干涩痛,舌质鲜红,或有裂纹,舌苔剥脱或无,脉细涩,可伴见长期低热,倦怠乏力,面色苍白,大便硬结等为特征的证候。
**********chunk 4 end**********
----------ref----------
The following generation flags are not valid and may be ignored: ['temperature', 'top_p', 'top_k']. Set `TRANSFORMERS_VERBOSITY=info` for more details.
从提供的信息来看,不耐疲劳、口燥、咽干等症状可能与以下几种证候相关:
1. **燥干清窍证**(syndrome/pattern of dryness harassing the upper orifices):这种证候因气候或环境干燥,津液耗损,清窍失濡所致,临床表现为口鼻、咽喉干燥,两眼干涩,舌质瘦小、舌苔干而少津,脉细等。
2. **燥邪犯肺证**(syndrome/pattern of pathogenic dryness invading the lung):这种证候因外感燥邪,或感受风热,化燥伤阴,肺失清肃所致,临床表现为干咳、少痰或无痰,痰黏不易咳出,唇鼻咽喉干燥,声音嘶哑,口渴,咳甚则胸痛,或痰中血丝,舌尖红,舌苔薄黄、少津,脉细或数等。
这些证候都可能表现出口燥、咽干的症状,同时伴有其他相应症状。如果出现不耐疲劳的情况,可能需要进一步考虑是否涉及气血不足或其他因素。建议在专业中医师的指导下进行辨证施治。[/INST]八、RAG 检索底层实现细节
知道了如何追踪哪些文档片段被用于检索增强生成,但我们仍不知道RAG过程中到底发生了什么,为什么大模型能够根据检索出的文档片段进行回复?
# 八、RAG 检索底层实现细节
# 这段代码会展示RAG(检索增强生成)的底层工作过程:
# 大模型为什么能结合文档回答问题?检索到的文档是如何被用到回答中的?
# 通过追踪程序运行过程,能清楚看到"检索→拼接文档→生成回答"的完整流程
# 导入需要的工具包
import logging # 用于输出程序运行日志(相当于"程序的日记本",记录每一步做了什么)
import sys # 用于系统级操作(这里主要配合日志输出到屏幕)
import torch # 深度学习框架(大模型运行需要它来计算)
# 导入LlamaIndex相关工具(LlamaIndex是专门做RAG的框架,简化文档处理和问答流程)
from llama_index.core import (
PromptTemplate, # 定义提示词模板(告诉大模型怎么回答)
Settings, # 全局配置(统一管理模型、回调等设置)
StorageContext, # 存储上下文(管理索引的读取和保存)
load_index_from_storage # 从本地文件加载已保存的索引
)
# 导入回调管理器(用于追踪程序运行中的关键事件,比如"什么时候调用了大模型")
from llama_index.core.callbacks import LlamaDebugHandler, CallbackManager
# 导入本地嵌入模型工具(用于将文字转换成数字向量)
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
# 导入本地大模型工具(用于加载我们下载到电脑上的大模型)
from llama_index.llms.huggingface import HuggingFaceLLM
# 1. 配置日志输出
# 日志就像"程序的操作记录",会把关键步骤打印到屏幕上,方便我们观察程序在做什么
# level=logging.INFO表示只打印重要信息,不显示太多细节
logging.basicConfig(stream=sys.stdout, level=logging.INFO)
# 确保日志能正常显示在屏幕上(防止被其他设置遮挡)
logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))
# 2. 定义大模型的"行为准则"(System Prompt)
# 这就像给大模型"设定身份",告诉它应该怎么说话、扮演什么角色
SYSTEM_PROMPT = """You are a helpful AI assistant.""" # 这里设定为"一个有用的AI助手"
# 定义查询模板(适配模型的输入格式)
# 很多大模型(比如Qwen、Llama)有固定的"说话格式",必须用特定符号包裹内容
# 比如这里的[INST]和[/INST]是Qwen模型要求的格式,<<SYS>>里放系统提示,{query_str}会替换成用户的问题
query_wrapper_prompt = PromptTemplate(
"[INST]<<SYS>>\n" + SYSTEM_PROMPT + "<</SYS>>\n\n{query_str}[/INST] "
)
# 3. 加载本地大模型(用来生成回答的"大脑")
# HuggingFaceLLM是加载本地模型的工具,需要告诉它模型存在电脑的哪个位置
llm = HuggingFaceLLM(
context_window=4096, # 模型能"记住"的最大文字长度(包括问题和回答),单位是token(1token≈1个汉字)
max_new_tokens=2048, # 模型最多能生成的回答长度(防止回答太长)
generate_kwargs={ # 生成回答的参数
"temperature": 0.0, # 回答的随机性(0表示固定答案,1表示更灵活)
"do_sample": False # 是否随机选词(False表示选最可能的词,答案更稳定)
},
query_wrapper_prompt=query_wrapper_prompt, # 应用上面定义的格式模板
# 下面两个路径需要替换成你自己电脑上模型的位置(之前用modelscope下载的路径)
tokenizer_name=r'D:\learn\learncode\Agent\model\Qwen\Qwen2___5-7B-Instruct', # 模型的"分词器"路径(把文字拆成模型能理解的小块)
model_name=r'D:\learn\learncode\Agent\model\Qwen\Qwen2___5-7B-Instruct', # 模型的"权重文件"路径(模型的"知识"存在这里)
device_map="auto", # 自动选择运行设备(有GPU用GPU,没GPU用CPU,GPU速度更快)
model_kwargs={"torch_dtype": torch.float16}, # 用半精度计算(节省电脑内存/显存)
)
# 将这个模型设置为全局默认(整个程序都会用这个模型来生成回答)
Settings.llm = llm
# 4. 配置事件追踪器(核心!用来观察RAG底层过程)
# LlamaDebugHandler就像"录像机",会记录程序运行中的关键事件(比如什么时候检索了文档,什么时候调用了大模型)
llama_debug = LlamaDebugHandler(print_trace_on_end=True) # print_trace_on_end=True表示程序结束后打印完整记录
# 回调管理器:管理这个"录像机",让它能正常工作
callback_manager = CallbackManager([llama_debug])
# 将回调管理器设置为全局默认(让整个程序都被"录像")
Settings.callback_manager = callback_manager
# 5. 加载本地嵌入模型(把文字转换成数字的工具)
# 嵌入模型的作用:把文字(比如"苹果是水果")变成一串数字(向量),方便电脑计算文字之间的相似度
# 比如"苹果"和"香蕉"的向量很接近,"苹果"和"汽车"的向量差别大
Settings.embed_model = HuggingFaceEmbedding(
model_name=r"D:\learn\learncode\Agent\model\BAAI\bge-base-zh-v1___5" # 替换成你自己的嵌入模型路径
)
# 6. 从本地加载已保存的文档索引(跳过重复处理文档)
# 之前我们已经把文档切成小块、转换成向量并保存到了"doc_emb"文件夹(这一步叫"持久化")
# 现在直接加载这个索引,不用重新处理文档,节省时间
storage_context = StorageContext.from_defaults(persist_dir=r"D:\learn\learncode\Agent\doc_emb") # 索引的保存路径
index = load_index_from_storage(storage_context) # 加载索引(索引里包含文档向量和原文片段)
# 7. 构建查询引擎(RAG的"总控制器")
# 查询引擎的作用:接收用户问题→找相关文档→让大模型结合文档回答
# similarity_top_k=5表示:从索引中找和问题最相似的5个文档片段
query_engine = index.as_query_engine(similarity_top_k=5)
# 8. 用查询引擎回答问题
# 问一个问题:"不耐疲劳,口燥、咽干可能是哪些证候?"(假设我们的文档是中医相关内容)
response = query_engine.query("不耐疲劳,口燥、咽干可能是哪些证候?")
# 打印模型的回答
print(response)
# 9. 查看RAG的底层细节:大模型到底收到了什么输入?
# event_pairs是之前"录像机"记录的事件,这里获取大模型的输入和输出记录
event_pairs = llama_debug.get_llm_inputs_outputs()
# 打印大模型实际收到的完整提示(包含检索到的文档片段+用户问题)
# 从这里能看到:RAG会把找到的相关文档片段拼接到问题前,告诉大模型"根据这些内容回答"
print(event_pairs[0][1].payload["formatted_prompt"])九、自定义 Prompt
LlamaIndex中提供的prompt template都是英文的,该如何使用中文的prompt template呢?
# 这段代码主要演示:如何在LlamaIndex中使用中文的提示词模板(prompt template)
# LlamaIndex默认的模板是英文的,对于中文场景可能不够友好,我们可以自定义中文模板并替换默认设置
# 导入需要的工具包
import logging # 用于输出程序运行日志(记录程序的每一步操作)
import sys # 配合日志输出到屏幕
import torch # 深度学习框架(大模型运行依赖)
# 导入LlamaIndex核心工具
from llama_index.core import (
PromptTemplate, # 用于创建提示词模板(核心:定义给模型的"指令格式")
Settings, # 全局配置(管理模型、模板等设置)
StorageContext, # 管理索引的存储和加载
load_index_from_storage # 从本地加载已保存的文档索引
)
# 导入事件追踪工具(用于观察模板是否生效)
from llama_index.core.callbacks import LlamaDebugHandler, CallbackManager
# 导入本地嵌入模型工具(将文字转向量)
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
# 导入本地大模型工具(加载中文大模型)
from llama_index.llms.huggingface import HuggingFaceLLM
# 1. 配置日志(方便观察程序运行过程)
logging.basicConfig(stream=sys.stdout, level=logging.INFO) # 日志输出到屏幕,只显示重要信息
logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout)) # 确保日志正常显示
# 2. 定义中文的系统提示词(System Prompt)
# 系统提示词:给模型设定"身份"和"行为准则",用中文更符合中文模型的习惯
SYSTEM_PROMPT = """你是一个医疗人工智能助手。""" # 这里设定模型为"医疗助手",明确其角色
# 定义查询包装模板(适配模型的输入格式)
# 很多中文大模型(如Qwen)有固定格式要求,用[INST]等标签包裹内容
# {query_str}是占位符,会被实际的用户问题替换
query_wrapper_prompt = PromptTemplate(
"[INST]<<SYS>>\n" + SYSTEM_PROMPT + "<</SYS>>\n\n{query_str}[/INST] "
)
# 3. 定义中文的问答提示词模板(QA Prompt)
# 这个模板的作用:告诉模型"如何结合上下文回答问题",用中文描述更清晰
qa_prompt_tmpl_str = (
"上下文信息如下。\n" # 告诉模型:下面是参考的文档内容
"---------------------\n" # 分隔符,让模型更容易区分不同部分
"{context_str}\n" # 占位符:会被实际检索到的文档片段替换
"---------------------\n"
"请根据上下文信息而不是先验知识来回答以下的查询。" # 核心要求:必须基于提供的文档回答
"作为一个医疗人工智能助手,你的回答要尽可能严谨。\n" # 针对医疗场景的额外要求
"Query: {query_str}\n" # 占位符:会被用户的问题替换
"Answer: " # 提示模型从这里开始输出答案
)
# 用PromptTemplate包装上面的字符串,转换成LlamaIndex能识别的模板对象
qa_prompt_tmpl = PromptTemplate(qa_prompt_tmpl_str)
# 4. 定义中文的优化提示词模板(Refine Prompt)
# 这个模板的作用:当有新的上下文时,指导模型如何优化已有答案(比如文档片段较多时分步优化)
refine_prompt_tmpl_str = (
"原始查询如下:{query_str}\n" # 占位符:用户的原始问题
"我们提供了现有答案:{existing_answer}\n" # 占位符:之前生成的答案
"我们有机会通过下面的更多上下文来完善现有答案(仅在需要时)。\n" # 说明新上下文的作用
"------------\n" # 分隔符
"{context_msg}\n" # 占位符:新的文档片段
"------------\n"
"考虑到新的上下文,优化原始答案以更好地回答查询。 如果上下文没有用,请返回原始答案。\n" # 优化规则
"Refined Answer:" # 提示模型从这里开始输出优化后的答案
)
# 转换成LlamaIndex能识别的模板对象
refine_prompt_tmpl = PromptTemplate(refine_prompt_tmpl_str)
# 5. 加载本地中文大模型(用于生成回答)
llm = HuggingFaceLLM(
context_window=4096, # 模型能处理的最大文字长度(输入+输出)
max_new_tokens=2048, # 模型最多生成的文字长度
generate_kwargs={ # 生成参数
"temperature": 0.0, # 0表示回答固定,不随机(适合需要严谨性的场景,如医疗)
"do_sample": False # 不随机选词,保证答案稳定
},
query_wrapper_prompt=query_wrapper_prompt, # 应用上面定义的格式模板
# 下面替换成你的模型实际路径(之前用modelscope下载的Qwen等中文模型)
tokenizer_name=r'D:\learn\learncode\Agent\model\Qwen\Qwen2___5-7B-Instruct', # 分词器路径(把中文拆成模型能理解的单位)
model_name=r'D:\learn\learncode\Agent\model\Qwen\Qwen2___5-7B-Instruct', # 模型权重路径(模型的"知识")
device_map="auto", # 自动选择运行设备(有GPU用GPU,速度更快)
model_kwargs={"torch_dtype": torch.float16}, # 用半精度计算(节省内存)
)
# 将模型设置为全局默认(整个程序都用这个模型)
Settings.llm = llm
# 6. 配置事件追踪(用于验证中文模板是否生效)
# LlamaDebugHandler:像"录像机"一样记录程序运行中的关键事件(比如模型收到的提示词)
llama_debug = LlamaDebugHandler(print_trace_on_end=True) # 程序结束后打印完整记录
callback_manager = CallbackManager([llama_debug]) # 管理这个"录像机"
Settings.callback_manager = callback_manager # 全局启用追踪
# 7. 加载本地嵌入模型(将中文转成向量)
# 嵌入模型:把中文文字(如"口干舌燥")转成数字向量,方便计算相似度
Settings.embed_model = HuggingFaceEmbedding(
model_name=r"D:\learn\learncode\Agent\model\BAAI\bge-base-zh-v1___5" # 替换成你的中文嵌入模型路径
)
# 8. 加载已保存的文档索引(之前处理好的文档向量)
# 从本地文件夹加载索引(避免重复处理文档,节省时间)
storage_context = StorageContext.from_defaults(persist_dir=r"D:\learn\learncode\Agent\doc_emb") # 索引保存路径
index = load_index_from_storage(storage_context) # 加载索引
# 9. 构建查询引擎(RAG的核心控制器)
query_engine = index.as_query_engine(similarity_top_k=5) # 检索最相似的5个文档片段
# 10. 查看查询引擎中默认的提示词模板类型(了解有哪些模板可以替换)
prompts_dict = query_engine.get_prompts() # 获取所有模板
print(list(prompts_dict.keys())) # 打印模板名称(比如"response_synthesizer:text_qa_template"就是问答模板)
# 11. 用中文模板替换默认的英文模板(关键步骤!)
# update_prompts方法:更新查询引擎中的模板
# 键:要替换的模板名称(从上面的print结果中获取)
# 值:我们定义的中文模板对象
query_engine.update_prompts(
{
"response_synthesizer:text_qa_template": qa_prompt_tmpl, # 替换问答模板
"response_synthesizer:refine_template": refine_prompt_tmpl # 替换优化模板
}
)
# 12. 用中文模板查询并获取答案
response = query_engine.query("不耐疲劳,口燥、咽干可能是哪些证候?") # 中文问题
print(response) # 打印模型用中文生成的回答
# 13. 验证中文模板是否生效(查看模型实际收到的提示词)
# 从事件记录中获取模型的输入
event_pairs = llama_debug.get_llm_inputs_outputs()
# 打印模型收到的完整提示词(可以看到里面的中文模板内容,确认替换成功)
print(event_pairs[0][1].payload["formatted_prompt"])
点击查看打印结果
**********
Trace: index_construction
**********
['response_synthesizer:text_qa_template', 'response_synthesizer:refine_template']
The following generation flags are not valid and may be ignored: ['temperature', 'top_p', 'top_k']. Set `TRANSFORMERS_VERBOSITY=info` for more details.
**********
Trace: query
|_CBEventType.QUERY -> 563.072705 seconds
|_CBEventType.RETRIEVE -> 0.483261 seconds
|_CBEventType.EMBEDDING -> 0.242792 seconds
|_CBEventType.SYNTHESIZE -> 562.587436 seconds
|_CBEventType.TEMPLATING -> 0.0 seconds
|_CBEventType.LLM -> 562.516639 seconds
**********
从提供的信息来看,不耐疲劳、口燥、咽干等症状可能与中医中的“燥干清窍证”和“燥邪犯肺证”相关。
1. **燥干清窍证**:因气候或环境干燥,津液耗损,清窍失濡所致。临床表现包括口鼻、咽喉干燥,两眼干涩,少泪、少涕、少津,甚则衄血,舌质瘦小、舌苔干而少津,脉细等。这些症状与您提到的不耐疲劳、口燥、咽干相符。
2. **燥邪犯肺证**:因外感燥邪,或感受风热,化燥伤阴,肺失清肃所致。临床表现为干咳、少痰或无痰,痰黏不易咳出,唇鼻咽喉干燥,声音嘶哑,口渴,咳甚则胸痛,或痰中带血,舌尖红,舌苔薄黄、少津,脉细或数。虽然这些症状更侧重于咳嗽和痰的情况,但口燥、咽干也是其临床表现之一。
综上所述,不耐疲劳、口燥、咽干等症状可能提示患者存在燥干清窍证或燥邪犯肺证,建议进一步结合其他症状进行综合判断,并在专业医生指导下进行治疗。[/INST]
[INST]<<SYS>>
你是一个医疗人工智能助手。<</SYS>>
上下文信息如下。
---------------------
file_path: D:\learn\learncode\Agent\documents\demo.txt
临床以鼻咽干涩或痛,口唇燥干,舌质红,舌苔白或燥,脉浮或微数,伴见发热、无汗,头痛或肢节酸痛等为特征的证候。
3.6.3.2
燥干清窍证 syndrome/pattern of dryness harassing the upper orifices
因气候或环境干燥,津液耗损,清窍失濡所致。临床以口鼻、咽喉干燥,两眼干涩,少泪、少涕、少津、甚则衄血,舌质瘦小、舌苔干而少津,脉细等为特征的证候。
file_path: D:\learn\learncode\Agent\documents\demo.txt
临床以口鼻、咽喉干燥,两眼干涩,少泪、少涕、少津、甚则衄血,舌质瘦小、舌苔干而少津,脉细等为特征的证候。
3.6.3.3
燥邪犯肺证 syndrome/pattern of pathogenic dryness invading the lung
燥邪伤肺证
因外感燥邪,或感受风热,化燥伤阴,肺失清肃所致。临床以干咳、少痰或无痰,痰黏不易咳出,唇鼻咽喉干燥,声音嘶哑,口渴,咳甚则胸痛,或痰中血丝,舌尖红,舌苔薄黄、少津,脉细或数,初起或伴见发热、恶寒,头痛等为特征的证候。
file_path: D:\learn\learncode\Agent\documents\demo.txt
临床以口鼻皮肤干燥,频频饮水难解口渴,咽干、唾少,或口腔溃疡频发,目涩少泪或无泪,阴道涩滞,形体消瘦,大便燥结,舌质偏红,舌苔干而少津,脉细涩等为特征的证候。
3.8.6.2
燥毒痹阻证 syndrome/pattern of impediment and obstruction of dry toxin
因燥毒伤阴,痹阻经脉、骨节所致。
file_path: D:\learn\learncode\Agent\documents\demo.txt
3.6.3.2
燥干清窍证 syndrome/pattern of dryness harassing the upper orifices
因气候或环境干燥,津液耗损,清窍失濡所致。临床以口鼻、咽喉干燥,两眼干涩,少泪、少涕、少津、甚则衄血,舌质瘦小、舌苔干而少津,脉细等为特征的证候。
3.6.3.3
燥邪犯肺证 syndrome/pattern of pathogenic dryness invading the lung
燥邪伤肺证
因外感燥邪,或感受风热,化燥伤阴,肺失清肃所致。
file_path: D:\learn\learncode\Agent\documents\demo.txt
临床以口鼻皮肤干燥,频频饮水难解口渴,咽干、唾少,或口腔溃疡频发,目涩少泪或无泪,阴道涩滞,形体消瘦,大便燥结,舌质偏红,舌苔干而少津,脉细涩等为特征的证候。
3.8.6.2
燥毒痹阻证 syndrome/pattern of impediment and obstruction of dry toxin
因燥毒伤阴,痹阻经脉、骨节所致。临床以口鼻皮肤干燥,或有红斑、紫癜,游走性关节痛,阵发性肢端青紫、麻木,口舌灼痛,目干涩痛,舌质鲜红,或有裂纹,舌苔剥脱或无,脉细涩,可伴见长期低热,倦怠乏力,面色苍白,大便硬结等为特征的证候。
---------------------
请根据上下文信息而不是先验知识来回答以下的查询。作为一个医疗人工智能助手,你的回答要尽可能严谨。
Query: 不耐疲劳,口燥、咽干可能是哪些证候?
Answer: [/INST]


 浙公网安备 33010602011771号
浙公网安备 33010602011771号