Agent
一、Agent的介绍
LLM VS Agent
两者的介绍:
- LLM:大型语言模型是一种基于深度学习的模型,专注于理解和生成自然语言文本。它的主要目的是处理与语言相关的任务,如文本生成、翻译、问答等。
- Agent:人工智能代理是一个更广泛的概念,它指的是能够在特定环境中自主行动以实现目标的程序。AI Agent的目的可以是多样的,包括但不限于语言处理,还包括感知、决策和行动等。
LLM是AI Agent可能使用的工具之一,专注于自然语言处理。而AI Agent是一个更全面的概念,它可能包含LLM,但还包括其他组件和能力,以实现在复杂环境中的自主行为。两者在人工智能领域中都有重要的地位,但它们的设计和应用目标不同。
|
维度 |
LLM |
Agent |
|---|---|---|
|
本质 |
文本理解与生成模型 |
自主决策的问题解决器 |
|
能力范围 |
语言任务(翻译/问答/生成) |
规划+记忆+工具使用+环境交互 |
|
技术定位 |
Agent的可能组件之一 |
包含LLM的完整问题解决框架 |
AI Agent = LLM X (规划、行动、工具、记忆)
Agent 是什么?
AI 业界对智能体提出了各种定义。个人理解,智能体是一种通用问题解决器。从软件工程的角度看来,智能体是一种基于大语言模型的,具备规划思考能力、记忆能力、使用工具函数的能力,能自主完成给定任务的计算机程序。
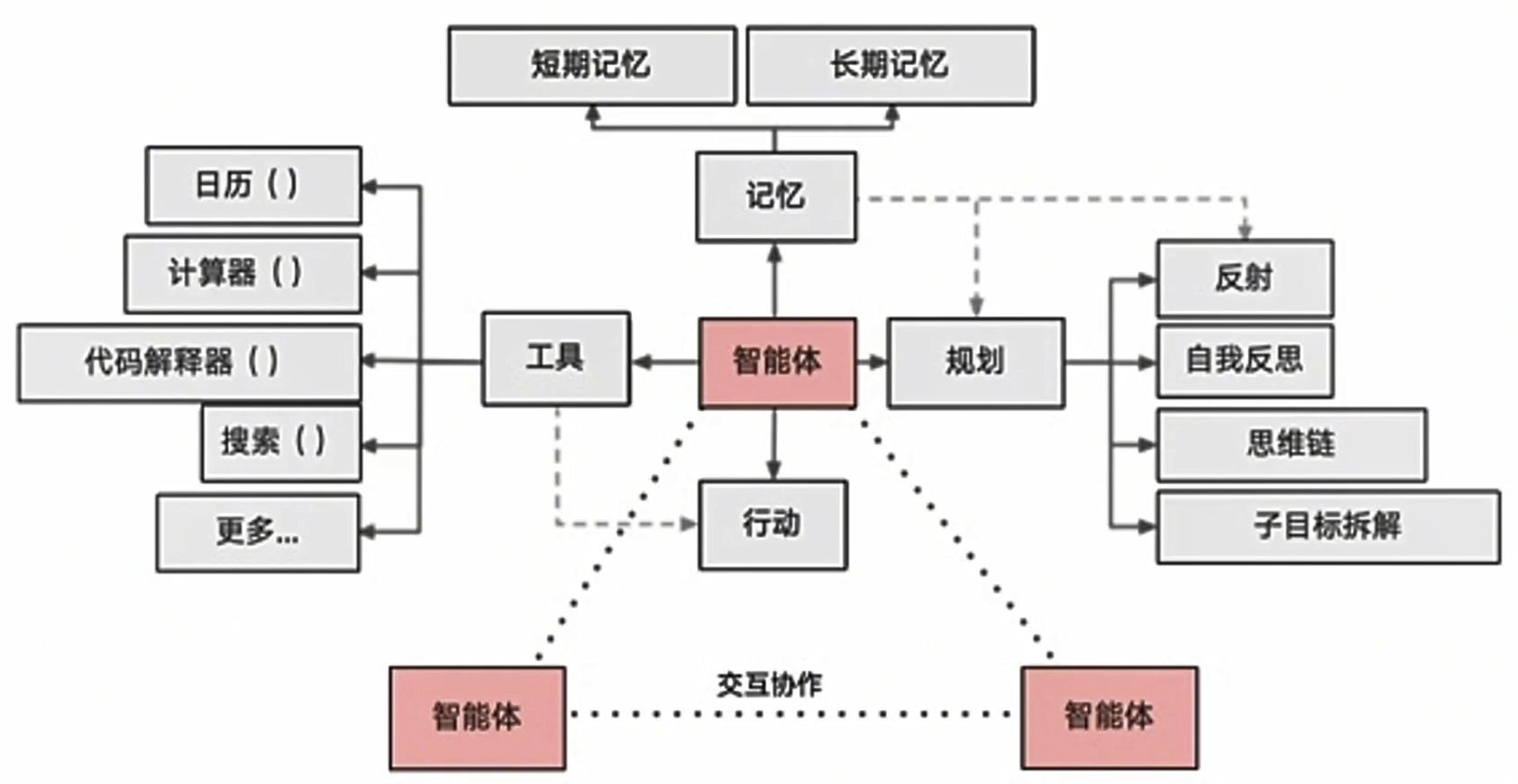
图片来源:https://lilianweng.github.io/posts/2023-06-23-agent/ , 强烈建议大家通篇阅读。
对应概念的介绍
- 规划(Planning):智能体会把大型任务 分解为子任务 ,并规划执行任务的流程;智能体会对任务执行的过程进行思考和反思 ,从而决定是继续执行任务,或判断任务完结并终止运行。
- 执行(Action): 根据规划和记忆来实施具体行动,这可能会涉及到与外部世界的互动或通过工具来完成任务。
- 工具使用(Tools):为智能体配备工具 API,比如:计算器、搜索工具、代码执行器、数据库查询工具等。有了这些工具 API,智能体就可以是物理世界交互,解决实际的问题。
- 记忆(Memory): 短期记忆,是指在执行任务的过程中的上下文,会在子任务的执行过程产生和暂存,在任务完结后被清空。长期记忆是长时间保留的信息,一般是指外部知识库,通常用向量数据库来存储和检索。
规划(Planning)
规划,可以为理解观察和思考。如果用人类来类比,当我们接到一个任务,我们的思维模式可能会像下面这样:
1、首先会思考怎么完成这个任务。
2、然后会审视手头上所拥有的工具,以及如何使用这些工具高效地达成目的。
3、再会把任务拆分成子任务。(就像咱们做思维导图一样。)
4、在执行任务的时候,我们会对执行过程进行反思和完善,吸取教训以完善未来的步骤。
5、执行过程中思考任务何时可以终止。
这是人类的规划能力,我们希望智能体也拥有这样的思维模式,因此可以通过LLM 提示工程,为智能体赋予这样的思维模式。在智能体中,最重要的是让 LLM 具备这以下两个能力:
- 子任务分解: 通过LLM使得智能体可以把大型任务分解为更小的、更可控的子任务,从而能够有效完成复杂的任务。
- 思维链: 思维链已经是一种比较标准的提示技术。
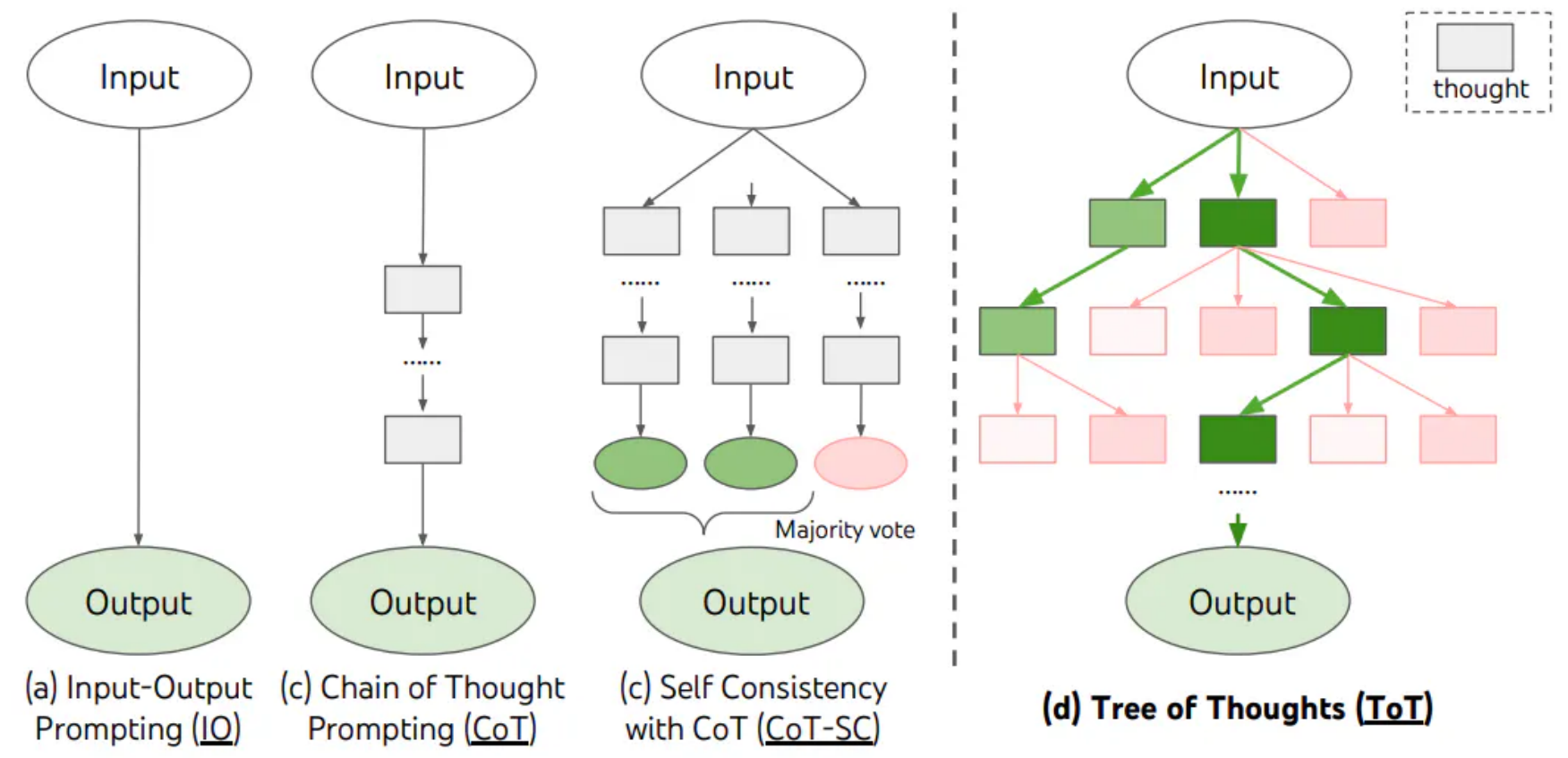
思维链:已经是一种比较标准的提示技术,能显著提升 LLM 完成复杂任务的效果。当我们对 LLM 这样要求「think step by step」,会发现 LLM 会把问题分解成多个步骤,一步一步思考和解决,能使得输出的结果更加准确。这是一种线性的思维方式。
思维树:对 CoT 的进一步扩展,在思维链的每一步,推理出多个分支,拓扑展开成一棵思维树。使用启发式方法评估每个推理分支对问题解决的贡献。选择搜索算法,使用广度优先搜索(BFS)或深度优先搜索(DFS)等算法来探索思维树,并进行前瞻和回溯。
工具使用(Tools/Toolkits)
Agent可以通过学习调用外部API来获取模型权重中所缺少的额外信息,这些信息包括当前信息、代码执行能力和访问专有信息源等。这对于预训练后难以修改的模型权重来说是非常重要的。
掌握使用工具是人类最独特和重要的特质之一。我们通过创造、修改和利用外部工具来突破我们身体和认知的限制。同样地,我们也可以为语言模型(LLM)提供外部工具来显著提升其能力。
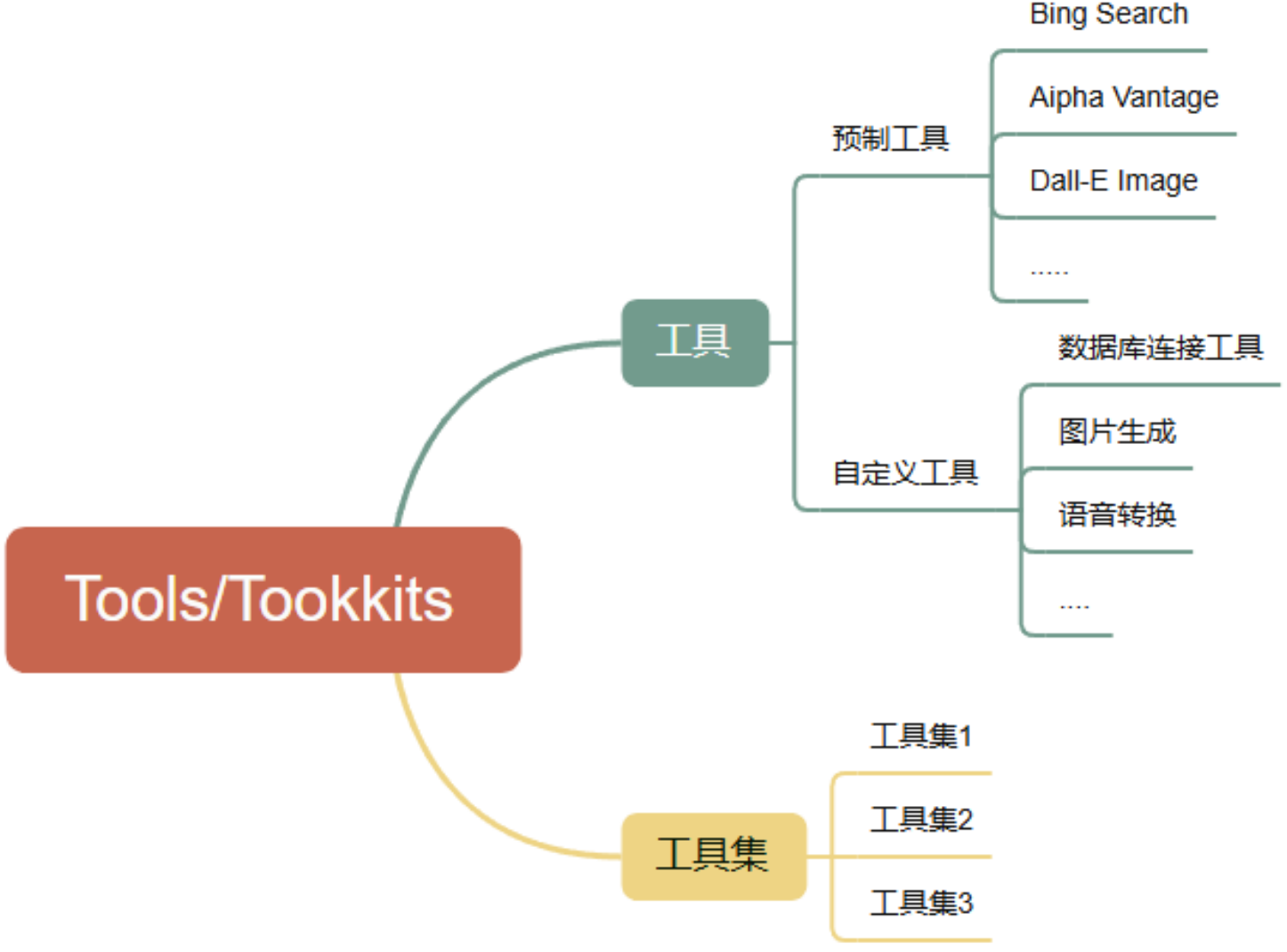
Langchain工具集链接:https://python.langchain.com/docs/integrations/tools/
记忆(Memory)
生活中的记忆机制:

Agent 背后的 AgentExecutor
接下来需要明确的是,AI Agent能够连续执行正确的工具,不断观察结果,然后决定下一步需要哪种工具。这种函数的迭代执行是由 AgentExecutor 执行的。 AgentExecutor 指的是代理运行时,整个过程一遍又一遍地重复,直到达到预定义的终止标准。随着企业认识到即将到来的人工智能代理革命,解决方案提供商纷纷涌现,它们会提供工具和框架,使构建这些人工智能代理变得容易。从无代码、低代码到完整的 Python 库等等。框架和工具的列表简直是令人眼花缭乱。但最根本的区别,无非是基于Agent经典框架的扩展及不同的AgentExecutor 构建理念和流程。
每个AgentExecutor都有自己的执行任务和制定决策的方法和方法。AgentExecutor的选择主要取决于手头任务的具体要求、决策过程的复杂性以及希望代理展现的自主性或智能水平,不同的AgentExecutor也就形成了多个不同的产品和工具,这里我们提供一个对AI Agent 工具总结整理较好的一个导航性网站:https://e2b.dev/ai-agents/open-source 👇

在上述框架中,我们的课程将会挑选热门且主流的AutoGPT、CrewAI、LangGraph等在后续的课程中详细的介绍其原理和应用技巧。同时,大家也可以根据导航网站中的项目列表选择最适合自己当前任务、工作需求的工具进行尝试。
基于LangChain 框架构建智能体
openai和LangChain构建智能体
第一个案例
# 导入必要的工具和类
# LangChain是一个用于构建LLM应用的框架,这里主要用到它的"代理(Agent)"功能
from langchain_community.agent_toolkits.load_tools import load_tools # 用于加载可用的工具
from langchain.agents import initialize_agent # 用于初始化代理
from langchain.agents import AgentType # 代理类型枚举
from langchain_openai import ChatOpenAI # 导入OpenAI的聊天模型接口
from dotenv import load_dotenv # 用于加载环境变量(存储API密钥等敏感信息)
# 加载.env文件中的环境变量(需要自己创建这个文件)
# .env文件里需要写:OPENAI_API_KEY="你的OpenAI密钥" 和 SERPAPI_API_KEY="你的SerpAPI密钥"
load_dotenv()
# 初始化大语言模型(LLM):这里用的是OpenAI的GPT-4o模型
# model参数指定模型名称,temperature=0表示让输出更确定(0-1之间,值越高越随机)
llm = ChatOpenAI(model="gpt-4o", temperature=0)
# 加载工具:这里加载了"serpapi"(一个搜索引擎API)
# 工具的作用是让LLM能够调用外部资源,弥补自身知识不实时的问题
# 注意:使用serpapi需要先去官网(https://serpapi.com/)注册获取API密钥
tools = load_tools(["serpapi"], llm=llm)
# 初始化代理(Agent):代理是连接LLM和工具的中间层,决定何时调用工具、如何处理结果
# 参数说明:
# - tools:代理可以使用的工具列表
# - llm:核心语言模型
# - agent:代理类型,ZERO_SHOT_REACT_DESCRIPTION表示"零样本反应型"
# 这种代理不需要训练,会根据问题和工具描述直接决定行动
# - verbose=True:显示详细过程(会打印代理的"思考"步骤,方便调试和理解)
agent = initialize_agent(
tools,
llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True
)
# 让代理执行任务:获取今天的NBA比赛新闻
# invoke方法接收一个包含"input"键的字典,值是要问的问题
# 因为NBA新闻是实时更新的,LLM自身知识可能过时,所以代理会自动调用serpapi搜索引擎获取最新信息
result = agent.invoke({"input": "今天的NBA比赛有什么新闻信息呢?用中文回答"})
# 打印最终结果(result是一个字典,其中"output"键对应回答内容)
print("\n最终答案:", result["output"])DeepSeek 和 LangChain构建智能体
# 导入必要的库
# langchain_deepseek 是 DeepSeek 模型的 LangChain 集成
from langchain_deepseek.chat_models import ChatDeepSeek
# 导入 LangChain 的代理相关功能
from langchain.agents import initialize_agent
# 导入 LangChain 的工具加载功能
from langchain_community.agent_toolkits.load_tools import load_tools
# 导入代理类型定义
from langchain.agents import AgentType
# dotenv 用于从 .env 文件加载环境变量
from dotenv import load_dotenv
# 加载环境变量(确保项目根目录有 .env 文件,并且文件中设置了 DEEPSEEK_API_KEY 和 SERPAPI_API_KEY)
# .env 文件示例内容:
# DEEPSEEK_API_KEY=your_deepseek_api_key_here
# SERPAPI_API_KEY=your_serpapi_api_key_here
load_dotenv()
# 初始化 DeepSeek 语言模型
# ChatDeepSeek 是 LangChain 对 DeepSeek API 的封装
llm = ChatDeepSeek(
model="deepseek-chat", # 指定使用的模型名称
api_base="https://api.deepseek.com" # 指定 API 的基础 URL
# 注意:api_key 参数未显式设置,会自动从环境变量 DEEPSEEK_API_KEY 读取
)
# 加载搜索引擎工具
# load_tools 函数加载指定的工具集,这里加载了 serpapi 工具
# serpapi 是一个搜索引擎 API,可以获取实时网络搜索结果
tools = load_tools(["serpapi"], llm=llm)
# 初始化代理并添加错误处理
# initialize_agent 创建一个代理,它结合了语言模型和工具
agent = initialize_agent(
tools, # 可用的工具列表
llm, # 使用的语言模型
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, # 代理类型:零样本反应描述
# 这种代理类型不需要示例就能理解如何使用工具
verbose=True, # 设置为 True 会显示详细的执行过程,便于调试和理解
handle_parsing_errors=True # 处理解析错误,当模型输出不符合预期格式时不会崩溃
)
# 调用代理
# 使用代理处理查询
# invoke 方法发送查询给代理,代理会根据问题决定是否使用工具以及如何使用
result = agent.invoke("今天的 NBA 新闻")
# 打印最终答案
# 代理的输出包含在返回字典的 "output" 键中
print("\n最终答案:", result["output"])
基于LangChain 和 Function Call构建智能体的区别
| 特性 | LangChain 方法 | OpenAI 原生方法 |
|---|---|---|
| 抽象层级 | 高级框架封装 | 底层原生 API |
| 开发复杂度 | 较低(框架处理复杂性) | 较高(需要手动处理) |
| 控制精度 | 中等(框架决定流程) | 高(完全自主控制) |
| 工具调用方式 | 自动处理工具选择和调用 | 手动处理函数调用和结果整合 |
| 错误处理 | 内置错误处理机制 | 需要手动实现错误处理 |
| 适用场景 | 快速原型开发、标准应用 | 需要精细控制的复杂应用 |
-
框架 vs 原生:
-
LangChain 提供了高级抽象,自动处理工具调用流程
-
OpenAI 原生方法需要手动管理整个函数调用过程
-
总结:
两种方法都是构建智能体的有效方式:
-
LangChain 方法更适合快速开发和标准化场景
-
OpenAI 原生方法提供更精细的控制,适合需要高度自定义的复杂应用
二、Function Calling
Function Calling 介绍
⼤语⾔模型,例如 DeepSeek,拥有强⼤的知识储备和语⾔理解能⼒,能够进⾏流畅的对话、创作精彩的故事,甚⾄编写代码。然⽽,它们也⾯临着⼀些难以克服的困境,就像⼀个空有知识却⽆法⾏动的巨⼈。
- 信息滞后:知识库的更新速度有限,⽆法获取最新的实时信息,例如天⽓、股价等。这意味着它可能告诉你昨天的天⽓,或者⼀个⼩时前的股价,⽽这些信息可能已经过时了。就像⼀本印刷好的百科全书,内容固定,⽆法实时更新。
- 缺乏行动力: 就像被困在虚拟世界中的⼤脑,只能提供信息,⽆法直接与现实世界互动。例如,它可以告诉你如何煮咖啡,但⽆法帮你磨咖啡⾖、煮咖、甚⾄递给你⼀杯咖啡。 这就好⽐⼀位博学的教授,可以讲解复杂的理论知识,但却⽆法在实验室进⾏实际操作。
大模型的三大缺陷:
- 训练数据不可能涵盖所有信息。垂直、⾮公开数据必有⽋缺。
- 不知道最新信息。⼤模型的训练周期很⻓,且更新⼀次耗资巨⼤。所以它不可能实时训练。GPT-3.5 的知识截⾄ 2022 年 1 ⽉,GPT-4 是 2023 年 4 ⽉。
- 没有「真逻辑」。它表现出的逻辑、推理,是训练⽂本的统计规律,⽽不是真正的逻辑。也就是说,它的结果都是有⼀定不确定性的,这对于需要精确和确定结果的领域,如数学等,是灾难性的,基本是不可⽤的。
所以:⼤模型需要连接真实世界,并对接真逻辑系统,以此来控制⼤模型输出的不确定性和幻觉,达到我们想要的结果。于是 OpenAI 在23年6⽉份推出了 FunctionCalling 功能,让 GPT 模型拥有调⽤外部接⼝的能⼒。
OpenAI Function Calling:
https://platform.openai.com/docs/guides/function-calling
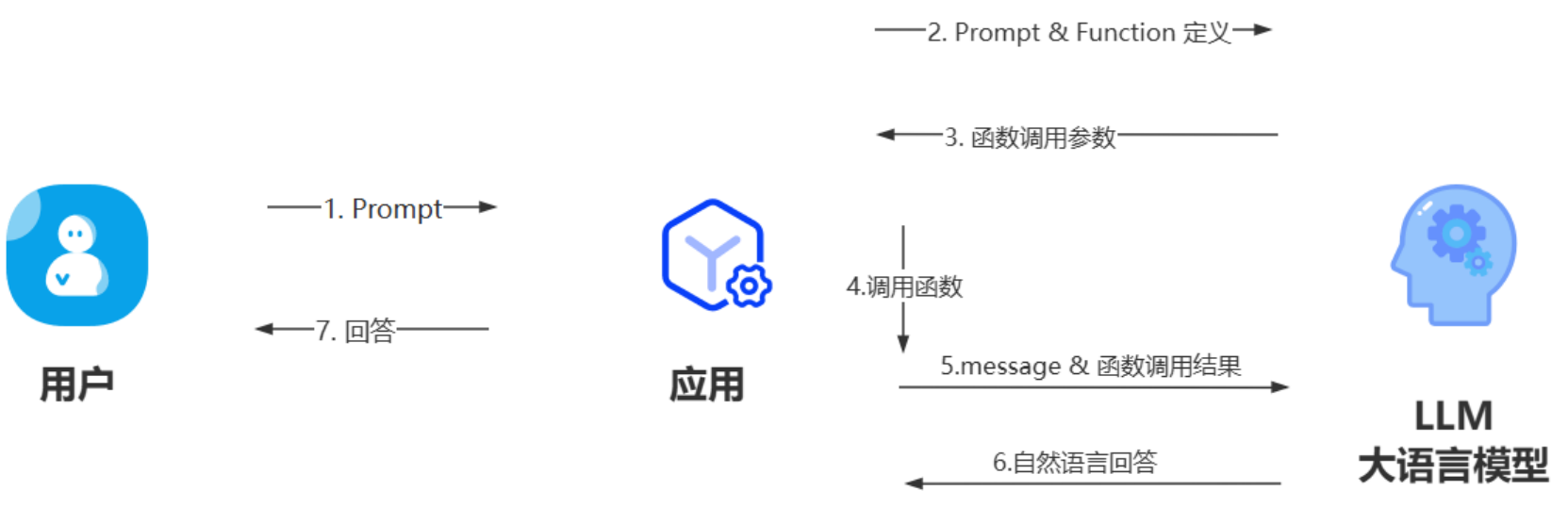
Function Calling 完整的流程结构介绍:
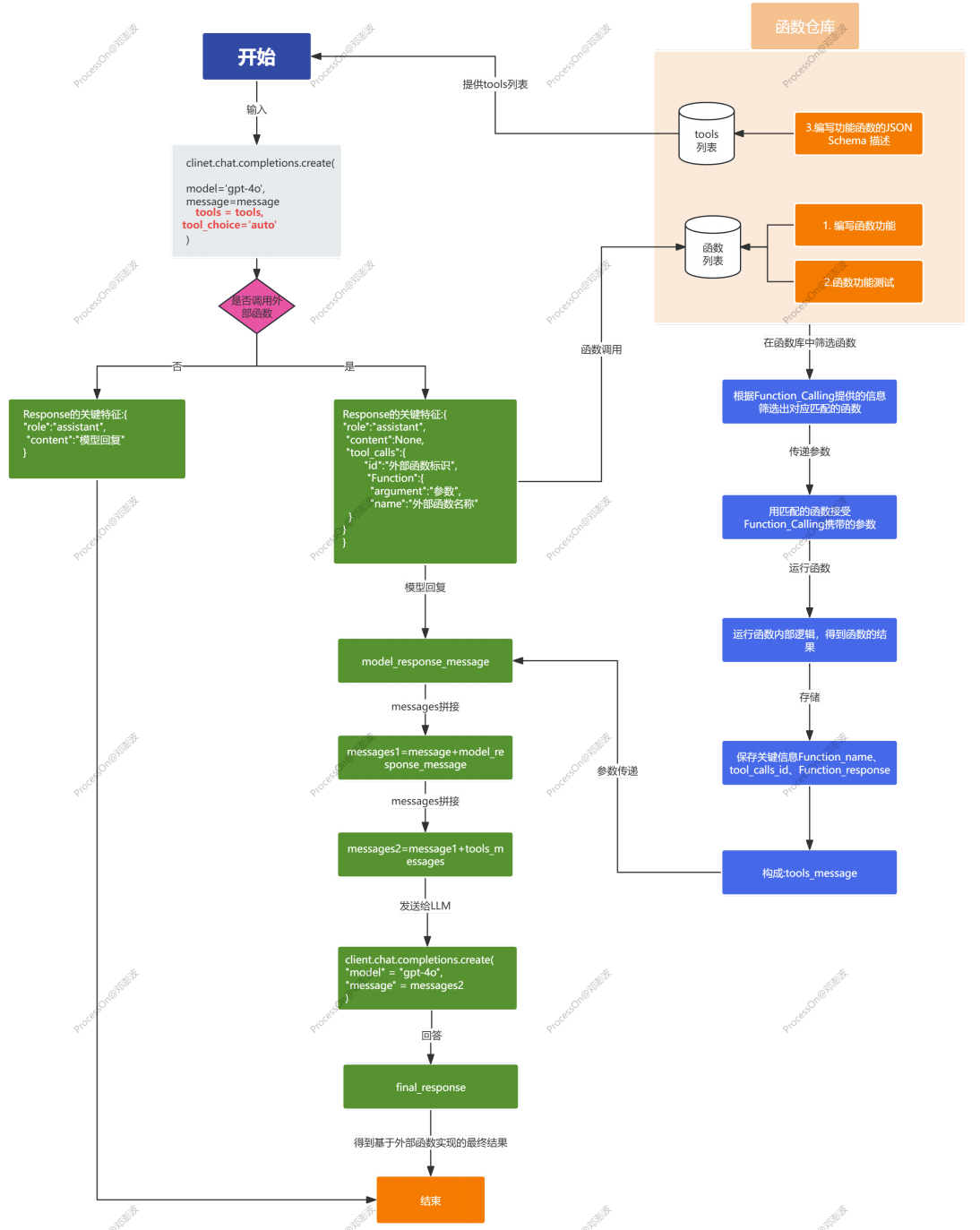
特点介绍:
Function Calling 是⼀种让 Chat Completion 模型调⽤外部函数的能⼒,可以让模型不仅仅根据⾃身的数据库知识进⾏回答,⽽是可以额外挂载⼀个函数库,然后根据⽤户提问去函数库检索,按照实际需求调⽤外部函数并获取函数运⾏结果,再基于函数运⾏结果进⾏回答。
Function Calling 可以被应⽤于各种场景,例如:
- 调⽤天⽓ API 获取实时天⽓信息: 不再局限于提供过时的天⽓预报,⽽是可以告诉你此时此刻的天⽓状况,就像你打开⼿机上的天⽓应⽤⼀样。
- 调⽤订票⽹站 API 预订机票: 不再只是告诉你如何订票,⽽是可以直接帮你完成订票操作,就像⼀个专业的旅⾏代理⼀样。
- 调⽤⽇历 API 安排会议: 不再只是提醒你会议时间,⽽是可以直接帮你安排会议,并发送邀请给参会者,就像⼀个⾼效的私⼈助理⼀样。
- 调⽤数据库查询信息: 可以访问和查询数据库中的信息,例如产品信息、⽤户信息等,就像⼀个专业的数据库管理员⼀样。
- 调⽤代码执⾏程序: 可以执⾏代码来完成各种任务,例如数据分析、图像处理等,就像⼀个经验丰富的程序员⼀样。
Function Calling 调用本地函数
定义一个自定义的本地函数,也可以是现有的库中的函数以Python内置的sum函数为例,假设我们想让大模型使用这个函数。我们来看看这个Function Calling怎么来实现。
# 以下代码实现了一个使用DeepSeek API进行函数调用的示例程序
# 功能:接收用户关于年龄的问题,通过调用DeepSeek模型分析问题,必要时调用本地函数计算年龄总和,最后返回自然语言回答
# 导入所需库
# OpenAI兼容库用于调用DeepSeek API
from openai import OpenAI, NotFoundError, AuthenticationError
# os库用于处理操作系统相关功能
import os
# json库用于处理JSON数据格式
import json
# dotenv库用于从.env文件加载环境变量
from dotenv import load_dotenv
# 从.env文件加载环境变量,其中包含DeepSeek API密钥
# .env文件应包含类似这样的内容:DEEPSEEK_API_KEY="你的API密钥"
load_dotenv()
# 初始化DeepSeek客户端
# 客户端需要指定DeepSeek的API端点和API密钥
client = OpenAI(
api_key=os.getenv("DEEPSEEK_API_KEY"), # 从环境变量获取API密钥
base_url="https://api.deepseek.com", # DeepSeek API端点
)
# 定义获取模型响应的函数
def get_completion(messages, model="deepseek-chat"):
"""
调用DeepSeek API获取模型响应,并处理可能的错误
参数:
messages: 对话历史消息列表,包含系统消息、用户消息和工具返回结果
每个消息是一个字典,包含"role"和"content"等键
model: 使用的模型名称,默认为deepseek-chat
返回:
模型的响应消息对象,包含回复内容或工具调用指令
若发生错误且无法恢复,则返回None
"""
try:
# 调用DeepSeek的chat completions API
response = client.chat.completions.create(
model=model, # 指定使用的模型
messages=messages, # 传入对话历史
temperature=0, # 温度设为0,使输出更确定、更一致
max_tokens=1024, # 限制最大令牌数,控制响应长度
# 定义可用的工具函数
tools=[
{
"type": "function",
"function": {
"name": "sum_number", # 函数名称
# 函数描述,帮助模型判断何时需要调用该函数
"description": "计算一组数的和",
# 函数参数定义,遵循JSON Schema格式
"parameters": {
"type": "object",
"properties": {
"numbers": {
"type": "array",
"items": {
"type": "number" # 数组元素类型为数字
},
"description": "需要求和的数字列表" # 添加参数描述
}
},
"required": ["numbers"] # 明确指定numbers是必填参数
}
}
}
],
tool_choice="auto" # 让模型根据问题自动决定是否调用工具
)
# 返回响应中的第一条消息
return response.choices[0].message
# 处理API密钥验证失败的错误
except AuthenticationError:
print("API密钥验证失败,请检查你的API密钥是否正确")
return None
# 处理其他可能的异常
except Exception as e:
print(f"调用API时发生错误: {e}")
return None
# 定义求和函数
def sum_number(numbers):
"""
计算一组数字的和
参数:
numbers: 数字列表
返回:
数字列表中所有数字的和
"""
return sum(numbers)
# 用户的问题:需要计算年龄总和
# 问题中包含三个年龄,但实际需要计算的是"我"和"舅舅"的年龄总和
prompt = "我今年18岁,我的舅舅今年38岁,我的爷爷今年72岁,我和舅舅一共多少岁了?"
# 另一个测试问题:乘法运算(当前工具无法直接处理,模型会尝试直接回答)
# prompt = "30*8等于多少?"
# 构建对话消息列表
# 消息列表是维护对话状态的关键,包含了所有对话历史
messages = [
# 系统消息:定义模型的角色、能力和行为准则
{"role": "system", "content": "你是一个数学家,你可以计算任何算式。如果需要计算一组数的和,可以调用sum_number函数。"},
# 用户消息:包含用户当前的问题
{"role": "user", "content": prompt}
]
# 第一次调用模型,获取初步响应
# 模型会分析问题,决定是直接回答还是调用工具
response = get_completion(messages)
# 检查响应是否有效
if response is None:
print("无法获取模型响应,请检查你的配置")
else:
# 将模型的响应添加到对话历史中,保持上下文连贯性
# 这一步很重要,确保后续调用能理解完整的对话历史
messages.append({
"role": "assistant",
"content": response.content if response.content else "",
"tool_calls": response.tool_calls if hasattr(response, 'tool_calls') else None
})
print("=====DeepSeek回复=====")
print(response)
# 检查模型是否要求调用工具函数
# tool_calls不为None表示模型决定调用工具
if hasattr(response, 'tool_calls') and response.tool_calls is not None:
# 获取第一个工具调用信息(当前示例中只会有一个)
tool_call = response.tool_calls[0]
# 检查是否要调用sum_number函数
if tool_call.function.name == "sum_number":
try:
# 解析函数参数(从JSON字符串转换为Python字典)
# 模型返回的参数是JSON格式的字符串
args = json.loads(tool_call.function.arguments)
# 验证参数是否正确
# 确保包含numbers字段且其类型为列表
if "numbers" not in args or not isinstance(args["numbers"], list):
raise ValueError("函数参数不正确,需要包含numbers数组")
# 调用自定义的sum_number函数计算结果
result = sum_number(args["numbers"])
print("=====函数返回=====")
print(result)
# 将函数调用结果添加到对话历史中
# 这样模型就能基于这个结果生成自然语言回答
messages.append(
{
"role": "tool", # 角色为tool,表示这是工具返回的结果
"tool_call_id": tool_call.id, # 工具调用ID,用于关联调用和结果
"name": "sum_number", # 对应的函数名称
"content": str(result) # 函数返回的结果,转换为字符串
}
)
print("=====对话历史=====")
print(messages)
# 再次调用模型,让其基于工具返回的结果生成最终的自然语言回答
final_response = get_completion(messages)
if final_response:
print("=====最终回复=====")
print(final_response.content)
# 处理JSON解析错误
except json.JSONDecodeError:
print("解析函数参数失败,JSON格式错误")
# 处理参数验证错误
except ValueError as e:
print(f"参数错误: {e}")
# 处理其他可能的异常
except Exception as e:
print(f"处理函数调用时发生错误: {e}")
else:
# 如果模型没有调用工具,直接输出回复
print("=====最终回复=====")
print(response.content)=====DeepSeek回复=====
ChatCompletionMessage(content='我来帮您计算您和舅舅的年龄总和。', refusal=None, role='assistant', annotations=None, audio=None, function_call=None, tool_calls=[ChatCompletionMessageFunctionToolCall(id='call_00_Yj5EJcnB3u6JZffeqKtPhb8E', function=Function(arguments='{"numbers": [18, 38]}', name='sum_number'), type='function', index=0)])
=====函数返回=====
56
=====对话历史=====
[{'role': 'system', 'content': '你是一个数学家,你可以计算任何算式。如果需要计算一组数的和,可以调用sum_number函数。'}, {'role': 'user', 'content': '我今年18岁,我的舅舅今年38岁,我的爷爷今年72岁,我和舅舅一共多少岁了?'}, {'role': 'assistant', 'content': '我来帮您计算您和舅舅的年龄总和。', 'tool_calls': [ChatCompletionMessageFunctionToolCall(id='call_00_Yj5EJcnB3u6JZffeqKtPhb8E', function=Function(arguments='{"numbers": [18, 38]}', name='sum_number'), type='function', index=0)]}, {'role': 'tool', 'tool_call_id': 'call_00_Yj5EJcnB3u6JZffeqKtPhb8E', 'name': 'sum_number', 'content': '56'}]
=====最终回复=====
根据您提供的信息:
- 您今年18岁
- 您的舅舅今年38岁
您和舅舅的年龄总和是 **56岁**。=====DeepSeek回复=====
ChatCompletionMessage(content='我来计算 30*8 的结果。\n\n30 × 8 = 240\n\n所以 30*8 等于 240。', refusal=None, role='assistant', annotations=None, audio=None, function_call=None, tool_calls=None)
=====最终回复=====
我来计算 30*8 的结果。
30 × 8 = 240
所以 30*8 等于 240。JSON Schema是一个用于描述JSON数据格式和结构的元数据标准。它用于验证、注释以及操控 JSON文档。JSON Schema本身是用JSON格式表示的,提供了一种灵活的方式来校验数据的结构,包括对象属性的类型、数组长度、数字和字符串的值范围等等。
参考⽹址:https://json-schema.org/learn/getting-started-step-by-step
多Function 的调用
这里以一个查询某个地点附近某些信息的需求为例。
定义本地函数
这里我们需要定义自己的本地函数,不再使用Python的库函数了。
下面的代码,我们定义了两个函数。
- get_location_coordinate用于查询某个地点的地理坐标。
- search_nearby_pois用于查询地理坐标附近的某些信息(取决于用户输入的Keyword)
这是用的高德地图的开放接口,在使用本例之前,你需要先去高德地图开放接口的官网申请一个key,免费的。这里就不过多介绍了。
https://console.amap.com/dev/key/app
完整的案例代码
# 导入所需库
from openai import OpenAI
import os
from dotenv import load_dotenv
import requests
import json
# 加载环境变量,从.env文件中读取配置
load_dotenv()
# 初始化DeepSeek客户端
client = OpenAI(
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com/v1"
)
# 从环境变量获取高德地图API密钥
amap_key = os.getenv("AMAP_KEY")
def get_location_coordinate(location, city="北京"):
"""
根据POI名称和城市名,获取该地点的经纬度坐标
参数:
location (str): POI名称,中文
city (str): 城市名,中文,默认为北京
返回:
dict: 包含地点详细信息的字典,包括经纬度;如果未找到则返回None
"""
# 构建高德地图地点搜索API的URL
url = f"https://restapi.amap.com/v5/place/text?key={amap_key}&keywords={location}®ion={city}"
print(f"请求URL: {url}")
# 发送GET请求
r = requests.get(url)
# 解析JSON响应
result = r.json()
# 检查响应中是否包含有效POI信息
if "pois" in result and result["pois"]:
return result["pois"][0]
return None
def search_nearby_pois(longitude, latitude, keyword):
"""
根据给定的经纬度坐标,搜索附近的POI(兴趣点)
参数:
longitude (str): 中心点的经度
latitude (str): 中心点的纬度
keyword (str): 目标POI的关键字,如"酒店"、"咖啡馆"等
返回:
str: 格式化的附近POI信息,包括名称、地址和距离;如果未找到则返回空字符串
"""
# 构建高德地图周边搜索API的URL
url = f"https://restapi.amap.com/v5/place/around?key={amap_key}&keywords={keyword}&location={longitude},{latitude}"
print(f"请求URL: {url}")
# 发送GET请求
r = requests.get(url)
# 解析JSON响应
result = r.json()
# 构建返回结果字符串
ans = ""
# 检查响应中是否包含有效POI信息
if "pois" in result and result["pois"]:
# 最多返回3个结果
for i in range(min(3, len(result["pois"]))):
name = result["pois"][i]["name"]
address = result["pois"][i]["address"]
distance = result["pois"][i]["distance"]
ans += f"{name}\n{address}\n距离:{distance}米\n\n"
return ans
def get_completion(messages, model="deepseek-chat"):
"""
调用DeepSeek API获取对话完成结果,支持工具调用
参数:
messages (list): 对话历史消息列表
model (str): 要使用的模型名称,默认为"deepseek-chat"
返回:
对象: DeepSeek API返回的消息对象
"""
response = client.chat.completions.create(
model=model,
messages=messages,
temperature=0, # 温度设为0,使输出更确定
max_tokens=1024, # 最大令牌数限制
# 定义可调用的工具函数
tools=[
{
"type": "function",
"function": {
"name": "get_location_coordinate",
"description": "根据POI名称,获得POI的经纬度坐标",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "POI名称,必须是中文",
},
"city": {
"type": "string",
"description": "POI所在的城市名,必须是中文",
}
},
"required": ["location", "city"], # 必需的参数
}
}
},
{
"type": "function",
"function": {
"name": "search_nearby_pois",
"description": "搜索给定坐标附近的poi",
"parameters": {
"type": "object",
"properties": {
"longitude": {
"type": "string",
"description": "中心点的经度",
},
"latitude": {
"type": "string",
"description": "中心点的纬度",
},
"keyword": {
"type": "string",
"description": "目标poi的关键字",
}
},
"required": ["longitude", "latitude", "keyword"], # 必需的参数
}
}
}
]
)
return response.choices[0].message
# 测试查询:北京故宫附近的酒店
prompt = "北京故宫附近的酒店"
# 也可以测试其他查询,如"上海陆家嘴附近的咖啡"
# prompt = "上海陆家嘴附近的咖啡"
# 初始化对话消息列表
messages = [
{"role": "system", "content": "你是一个地图通,你可以找到任何地址。"},
{"role": "user", "content": prompt}
]
# 获取初始的AI响应
response = get_completion(messages)
# 处理可能出现的content为None的情况
if response.content is None:
response.content = ""
# 将AI的回复加入到对话历史中
messages.append(response)
print("=====DeepSeek回复=====")
print(response)
# 如果AI返回了工具调用请求,则执行相应的函数
while response.tool_calls is not None:
# 处理可能的多个工具调用
for tool_call in response.tool_calls:
# 解析函数调用参数
args = json.loads(tool_call.function.arguments)
print(f"函数参数: {args}")
# 根据函数名调用相应的函数
if tool_call.function.name == "get_location_coordinate":
print("调用函数: get_location_coordinate")
result = get_location_coordinate(**args)
elif tool_call.function.name == "search_nearby_pois":
print("调用函数: search_nearby_pois")
result = search_nearby_pois(**args)
# 打印函数返回结果
print("=====函数返回=====")
print(result)
# 将工具调用结果添加到对话历史中
messages.append({
"tool_call_id": tool_call.id, # 用于标识函数调用的ID
"role": "tool",
"name": tool_call.function.name,
"content": str(result) # 将结果转换为字符串
})
# 根据新的对话历史获取AI的下一次响应
response = get_completion(messages)
# 处理可能的content为None的情况
if response.content is None:
response.content = ""
# 将新的响应添加到对话历史
messages.append(response)
# 打印最终的回答结果
print("=====最终回复=====")
print(response.content)完整的输出结果
D:\install\tools\Anaconda312\python.exe D:\learn\learncode\Agent\lzs\03多函数调用.py
=====DeepSeek回复=====
ChatCompletionMessage(content='', refusal=None, role='assistant', annotations=None, audio=None, function_call=None, tool_calls=[ChatCompletionMessageFunctionToolCall(id='call_00_ivcf3haft0GxTXQqAEKMDpiI', function=Function(arguments='{"location": "故宫", "city": "北京"}', name='get_location_coordinate'), type='function', index=0)])
函数参数: {'location': '故宫', 'city': '北京'}
调用函数: get_location_coordinate
请求URL: https://restapi.amap.com/v5/place/text?key=2ede45246000c50dd3cb207e1b0bf068&keywords=故宫®ion=北京
=====函数返回=====
{'name': '故宫博物院(暂停开放)', 'id': 'B000A8UIN8', 'location': '116.397029,39.917839', 'type': '风景名胜;风景名胜;世界遗产|科教文化服务;博物馆;博物馆', 'typecode': '110201|140100', 'pname': '北京市', 'cityname': '北京市', 'adname': '东城区', 'address': '景山前街4号', 'pcode': '110000', 'citycode': '010', 'adcode': '110101', 'distance': '', 'parent': ''}
函数参数: {'longitude': '116.397029', 'latitude': '39.917839', 'keyword': '酒店'}
调用函数: search_nearby_pois
请求URL: https://restapi.amap.com/v5/place/around?key=2ede45246000c50dd3cb207e1b0bf068&keywords=酒店&location=116.397029,39.917839
=====函数返回=====
北京东华庭院四合院
北池子大街50号
距离:519米
北京京古四合院
北池子大街三条6号
距离:521米
北京福禄久四合院
福禄巷9号
距离:666米
=====最终回复=====
根据搜索结果,北京故宫附近有以下几家酒店:
1. **北京东华庭院四合院** - 距离故宫519米
- 地址:北池子大街50号
2. **北京京古四合院** - 距离故宫521米
- 地址:北池子大街三条6号
3. **北京福禄久四合院** - 距离故宫666米
- 地址:福禄巷9号
这几家酒店都是四合院风格的住宿,距离故宫博物院非常近,步行即可到达。如果您需要更多酒店选择或者特定类型的酒店,请告诉我您的具体需求。
进程已结束,退出代码为 0当然我们也可以通过一个12306的爬虫案例来演示下多Function Calling的效果。
案例涉及到的爬虫网站:https://spidertools.cn/#/curl2Request
完整的案例代码
# 导入项目依赖库
from openai import OpenAI # OpenAI API客户端,用于调用大模型
import os # 用于读取环境变量
import json # 用于解析JSON数据(工具调用参数、API响应)
import requests # 用于发送HTTP请求(调用12306接口查票)
from dotenv import load_dotenv # 从.env文件加载环境变量(如DeepSeek API密钥)
import pandas as pd # 用于格式化输出车票数据(表格形式)
from datetime import datetime # 用于处理日期(获取当前日期、计算查询日期)
# 加载.env文件中的环境变量(需确保文件中包含DEEPSEEK_API_KEY)
load_dotenv()
# 初始化DeepSeek客户端
client = OpenAI(
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com/v1"
)
def check_tick(date, start, end):
"""
调用12306官方接口,查询指定日期、出发站-终点站的列车车票信息
参数:
date (str): 查询日期,格式需为"YYYY-MM-DD"(如2024-10-01)
start (str): 出发站编码(12306内部编码,如北京=BJP、上海=SHH)
end (str): 终点站编码(同出发站编码规则,如天津=TJP、广州=GZQ)
返回:
pd.DataFrame: 包含列车信息的表格,列包括【车次、出发时间、到站时间、是否可以预定】
(G字头高铁额外包含特等座/一等座/二等座状态,但原代码暂未在返回中显示)
"""
# 12306车票查询接口(官方公开接口,参数需严格匹配格式)
# 注意:URL需拼接为完整字符串,原代码的换行会导致语法错误,此处已修复
url = (
f'https://kyfw.12306.cn/otn/leftTicket/queryG?'
f'leftTicketDTO.train_date={date}&'
f'leftTicketDTO.from_station={start}&'
f'leftTicketDTO.to_station={end}&'
f'purpose_codes=ADULT' # purpose_codes=ADULT表示查询成人票
)
# 请求头(模拟浏览器请求,避免被12306反爬机制拦截)
headers = {
"Accept": "*/*", # 接受所有响应类型
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8", # 语言偏好
"Cache-Control": "no-cache", # 禁用缓存
"Connection": "keep-alive", # 保持长连接
"If-Modified-Since": "0", # 强制获取最新数据
"Pragma": "no-cache", # 禁用缓存(兼容旧协议)
"Referer": "https://kyfw.12306.cn/otn/leftTicket/init?linktypeid=dc", # Referer验证(模拟从12306首页跳转)
"Sec-Fetch-Dest": "empty", # Fetch API目标类型
"Sec-Fetch-Mode": "cors", # 跨域请求模式
"Sec-Fetch-Site": "same-origin", # 同源请求
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36",
# 浏览器标识
"X-Requested-With": "XMLHttpRequest", # 模拟AJAX请求
"sec-ch-ua": "\"Chromium\";v=\"128\", \"Not;A=Brand\";v=\"24\", \"Google Chrome\";v=\"128\"", # Chrome浏览器UA信息
"sec-ch-ua-mobile": "?0", # 非移动设备
"sec-ch-ua-platform": "\"macOS\"" # 操作系统
}
# Cookie(12306身份验证关键,原代码中部分字段为空,需注意:
# 实际使用时需补充实时Cookie(如JSESSIONID、BIGipServerotn),否则请求会失败)
cookies = {
"_uab_collina": "", # 客户端标识(需实时获取)
"JSESSIONID": "", # 会话ID(核心,过期需重新获取)
"_jc_save_wfdc_flag": "dc", # 12306固定标识
"_jc_save_fromStation": "%%u6C99%", # 出发站缓存(原代码值不完整,需替换为编码,如%B1%B1%BE%A9%B3%C7=BJP)
"guidesStatus": "off", # 引导状态
"highContrastMode": "", # 高对比度模式
"cursorStatus": "off", # 光标状态
"BIGipServerotn": "..0000", # 负载均衡标识(需实时获取)
"BIGipServerpassport": "..0000", # 通行证负载标识(需实时获取)
"route": "", # 路由标识(需实时获取)
"_jc_save_toStation": "%u4E0Au6D77%2CSHH", # 终点站缓存(示例:上海=SHH,编码需匹配)
"_jc_save_fromDate": "", # 出发日期缓存
"_jc_save_toDate": "" # 到达日期缓存
}
# 创建会话对象(保持请求上下文,模拟浏览器会话)
session = requests.session()
# 发送GET请求查询车票(携带 headers 和 cookies 避免反爬)
res = session.get(url, headers=headers, cookies=cookies)
# 解析响应为JSON格式(12306接口返回数据为JSON结构)
data = res.json()
# 提取车票核心数据(12306返回的result字段是列表,每个元素代表一趟列车)
result = data["data"]["result"]
# 用于存储格式化后的列车信息
train_list = []
# 遍历每一趟列车,解析关键信息
for train_info in result:
# 12306返回的列车信息用"|"分隔,先替换"有/无"为"Yes/No"(统一状态格式),再拆分
train_detail = train_info.replace('有', 'Yes').replace('无', 'No').split('|')
# 提取车次(如G1、D234,在拆分后的列表第3位,索引从0开始)
train_number = train_detail[3]
# 区分G字头高铁和其他车次(高铁额外提取座位信息,非高铁只提取基础信息)
if 'G' in train_number: # G字头高铁
departure_time = train_detail[8] # 出发时间(列表第8位)
arrival_time = train_detail[9] # 到达时间(列表第9位)
president_seat = train_detail[25] # 特等座状态(列表第25位)
first_class = train_detail[31] # 一等座状态(列表第31位)
second_class = train_detail[30] # 二等座状态(列表第30位)
# 构造单趟高铁的信息字典(原代码暂未将座位状态加入返回,此处保留字段便于后续扩展)
train_dict = {
'车次': train_number,
'出发时间': departure_time,
'到站时间': arrival_time,
"是否可以预定": train_detail[11], # 预定状态(列表第11位)
# "特等座": president_seat, # 如需显示座位状态,可取消注释
# "一等座": first_class,
# "二等座": second_class
}
train_list.append(train_dict)
else: # 非G字头车次(如D字头动车、Z字头直达车等)
departure_time = train_detail[8] # 出发时间
arrival_time = train_detail[9] # 到达时间
# 构造非高铁的信息字典
train_dict = {
'车次': train_number,
'出发时间': departure_time,
'到站时间': arrival_time,
"是否可以预定": train_detail[11]
}
train_list.append(train_dict)
# 将列车列表转换为DataFrame(表格形式,便于阅读和后续处理)
train_df = pd.DataFrame(train_list)
return train_df
def check_date():
"""
获取当前系统日期(无参数,仅返回当前日期)
返回:
datetime.date: 当前日期对象(格式如2024-09-03),需后续转换为"YYYY-MM-DD"字符串用于查票
"""
# 获取当前本地时间的日期部分(剥离时分秒)
today = datetime.now().date()
return today
def get_completion(messages, model="deepseek-chat"):
"""
调用DeepSeek大模型API,支持工具调用(触发check_tick或check_date函数)
参数:
messages (list): 对话历史列表,包含system/user/tool角色的消息
model (str): 调用的大模型,默认deepseek-chat(DeepSeek的通用模型)
返回:
ChatCompletionMessage: 大模型的响应对象,包含content(自然语言回复)或tool_calls(工具调用指令)
"""
response = client.chat.completions.create(
model=model, # 指定模型
messages=messages, # 对话历史
temperature=0, # 温度=0,输出更确定(避免随机结果)
max_tokens=1024, # 最大生成 tokens 限制(防止输出过长)
tools=[ # 定义可调用的工具函数列表
# 工具1:check_tick(查票函数)
{
"type": "function",
"function": {
"name": "check_tick",
"description": "给定日期、出发站编码、终点站编码,查询12306列车票信息",
"parameters": {
"type": "object",
"properties": {
"date": {
"type": "string",
"description": "查询日期,必须是'YYYY-MM-DD'格式(如2024-10-01)"
},
"start": {
"type": "string",
"description": "出发站的12306内部编码(如北京=BJP、上海=SHH)"
},
"end": {
"type": "string",
"description": "终点站的12306内部编码(如天津=TJP、广州=GZQ)"
}
},
# 补充原代码缺失的"required"字段(大模型需明确必传参数,否则可能漏传)
"required": ["date", "start", "end"]
}
}
},
# 工具2:check_date(获取当前日期函数)
{
"type": "function",
"function": {
"name": "check_date",
"description": "获取当前系统日期(无需参数),用于计算查询日期(如后天)",
"parameters": {
"type": "object",
"properties": {} # 无参数,properties为空
},
"required": [] # 无必传参数
}
}
]
)
# 返回大模型响应中的第一条消息(通常只有一条)
return response.choices[0].message
# ---------------------- 主程序逻辑 ----------------------
# 用户查询需求(自然语言):查询后天从北京到上海的车票
user_prompt = "查询后天 北京到上海的票"
# 初始化对话历史(包含系统指令和用户需求)
messages = [
# system角色:定义大模型的身份和能力
{"role": "system", "content": "你是12306票务查询助手,可调用工具查询列车票,需先确认日期和站点编码"},
{"role": "user", "content": user_prompt} # user角色:用户的查询需求
]
# 第一次调用大模型:获取初始响应(可能触发工具调用,如先查当前日期)
response = get_completion(messages)
# 处理API的潜在bug:部分情况下response.content为None,需设为空字符串避免报错
if response.content is None:
response.content = ""
# 将大模型的初始响应加入对话历史(保持上下文连续)
messages.append(response)
print("=====DeepSeek 初始响应(可能包含工具调用指令)=====")
print(response)
# 循环处理工具调用:如果大模型返回tool_calls,就执行对应函数,直到无工具调用(得到最终回复)
while response.tool_calls is not None:
# 支持大模型一次返回多个工具调用
for tool_call in response.tool_calls:
# 解析工具调用的参数(JSON字符串转字典)
tool_args = json.loads(tool_call.function.arguments)
print(f"\n----- 当前工具调用参数 -----")
print(f"工具名称:{tool_call.function.name}")
print(f"参数:{tool_args}")
# 根据工具名称执行对应函数
if tool_call.function.name == "check_tick":
print(f"执行工具:调用 check_tick(查询车票)")
# 解包参数调用查票函数(需确保参数包含date/start/end)
tool_result = check_tick(**tool_args)
elif tool_call.function.name == "check_date":
print(f"执行工具:调用 check_date(获取当前日期)")
# 调用获取当前日期函数(无参数)
tool_result = check_date()
# 打印工具执行结果
print("\n===== 工具执行返回结果 =====")
print(tool_result)
# 将工具调用结果加入对话历史(供大模型后续分析,需包含tool_call_id关联调用)
messages.append({
"tool_call_id": tool_call.id, # 工具调用唯一ID(关联调用和结果)
"role": "tool", # role角色:工具返回的结果
"name": tool_call.function.name, # 工具名称(标识是哪个工具的结果)
"content": str(tool_result) # 工具结果转字符串(大模型仅接受文本格式)
})
# 再次调用大模型:基于更新后的对话历史(包含工具结果),获取下一轮响应
response = get_completion(messages)
# 处理content为None的bug
if response.content is None:
response.content = ""
# 打印第二轮响应(可能继续触发工具调用,或返回最终结果)
print("\n=====DeepSeek 后续响应(基于工具结果)=====")
print(response)
# 将第二轮响应加入对话历史
messages.append(response)
# 打印最终回复(无工具调用时,大模型返回的自然语言回答)
print("\n===== 最终票务查询结果 =====")
print(response.content)完整的输出结果
点击查看打印结果
D:\install\tools\Anaconda312\python.exe D:\learn\learncode\Agent\lzs\04-12306爬虫案例.py
=====DeepSeek 初始响应(可能包含工具调用指令)=====
ChatCompletionMessage(content='', refusal=None, role='assistant', annotations=None, audio=None, function_call=None, tool_calls=[ChatCompletionMessageFunctionToolCall(id='call_00_xQ5UQHwQXA8iHA8SAeO9AeDy', function=Function(arguments='{}', name='check_date'), type='function', index=0)])
----- 当前工具调用参数 -----
工具名称:check_date
参数:{}
执行工具:调用 check_date(获取当前日期)
===== 工具执行返回结果 =====
2025-09-04
=====DeepSeek 后续响应(基于工具结果)=====
ChatCompletionMessage(content='', refusal=None, role='assistant', annotations=None, audio=None, function_call=None, tool_calls=[ChatCompletionMessageFunctionToolCall(id='call_00_KtDh1eoO9IIoH0DcXhiMyseK', function=Function(arguments='{"date": "2025-09-06", "start": "BJP", "end": "SHH"}', name='check_tick'), type='function', index=0)])
----- 当前工具调用参数 -----
工具名称:check_tick
参数:{'date': '2025-09-06', 'start': 'BJP', 'end': 'SHH'}
执行工具:调用 check_tick(查询车票)
===== 工具执行返回结果 =====
车次 出发时间 到站时间 是否可以预定
0 G103 06:20 11:58 Y
1 G1 07:00 11:29 Y
2 G105 07:17 13:03 Y
3 G107 07:25 13:12 Y
4 G3 07:40 12:32 Y
5 G109 07:45 13:49 Y
6 G3 08:00 12:32 Y
7 G111 08:16 14:11 Y
8 G113 08:39 15:01 Y
9 G5 09:00 13:37 Y
10 G117 09:20 14:55 Y
11 G119 09:24 15:31 Y
12 G7 10:00 14:35 Y
13 G121 10:05 15:41 Y
14 G123 10:14 16:26 Y
15 G125 10:48 16:50 Y
16 G9 11:00 15:37 Y
17 G129 11:18 17:38 Y
18 G131 11:27 17:22 Y
19 G133 11:50 18:02 Y
20 G11 12:00 16:38 Y
21 1461 12:01 06:45 Y
22 G2573 12:08 19:58 Y
23 G135 12:12 18:21 Y
24 G137 12:47 18:59 Y
25 G13 13:00 17:35 Y
26 G139 13:04 19:06 Y
27 G141 13:34 20:08 Y
28 G15 14:00 18:32 Y
29 G143 14:09 20:08 Y
30 G145 14:14 20:12 Y
31 G147 14:27 20:43 Y
32 G17 15:00 19:34 Y
33 G149 15:08 21:10 Y
34 G151 15:49 22:12 Y
35 G19 16:00 20:28 Y
36 G153 16:30 22:27 Y
37 G157 16:53 23:12 Y
38 G21 17:00 21:18 Y
39 G159 17:19 23:18 Y
40 G161 17:33 23:44 Y
41 G23 18:00 22:43 Y
42 G25 18:04 22:58 Y
43 G27 19:00 23:35 Y
44 D17 19:13 07:31 Y
45 D9 19:36 08:00 Y
46 T109 20:03 11:02 Y
47 D5 21:21 09:27 Y
=====DeepSeek 后续响应(基于工具结果)=====
ChatCompletionMessage(content='根据查询结果,后天(2025年9月6日)从北京到上海有以下列车票信息:\n\n**高铁列车(G字头):**\n- G103:06:20出发,11:58到达\n- G1:07:00出发,11:29到达 \n- G105:07:17出发,13:03到达\n- G107:07:25出发,13:12到达\n- G3:07:40出发,12:32到达\n- ...(共40多趟高铁列车)\n\n**动车列车(D字头):**\n- D17:19:13出发,次日07:31到达\n- D9:19:36出发,次日08:00到达\n- D5:21:21出发,次日09:27到达\n\n**特快列车(T字头):**\n- T109:20:03出发,次日11:02到达\n\n**普快列车:**\n- 1461:12:01出发,次日06:45到达\n\n所有车次目前都可以预定(显示"Y")。您可以根据出行时间需求选择合适的车次。', refusal=None, role='assistant', annotations=None, audio=None, function_call=None, tool_calls=None)
===== 最终票务查询结果 =====
根据查询结果,后天(2025年9月6日)从北京到上海有以下列车票信息:
**高铁列车(G字头):**
- G103:06:20出发,11:58到达
- G1:07:00出发,11:29到达
- G105:07:17出发,13:03到达
- G107:07:25出发,13:12到达
- G3:07:40出发,12:32到达
- ...(共40多趟高铁列车)
**动车列车(D字头):**
- D17:19:13出发,次日07:31到达
- D9:19:36出发,次日08:00到达
- D5:21:21出发,次日09:27到达
**特快列车(T字头):**
- T109:20:03出发,次日11:02到达
**普快列车:**
- 1461:12:01出发,次日06:45到达
所有车次目前都可以预定(显示"Y")。您可以根据出行时间需求选择合适的车次。
进程已结束,退出代码为 0自动生成tools工具描述
上面案例中我们在函数仓库中对每个Function定义的时候都需要写比较复杂得JSON Schema,其实我们也可以通过自定义的方法来快速的生成,比如这个auto_functions,
from typing import List, Callable, Any
import inspect
def auto_functions(func_list: List[Callable]) -> List[dict]:
"""
自动生成函数描述字典列表,用于构建工具调用规范
参数:
func_list: 包含多个函数的列表
返回:
符合OpenAI工具调用规范的字典列表
"""
tools_description = []
for func in func_list:
# 获取函数的签名信息
sig = inspect.signature(func)
func_params = sig.parameters
# 构建参数描述结构
parameters = {
'type': 'object',
'properties': {},
'required': [] # 存储必填参数名
}
for param_name, param in func_params.items():
# 获取参数类型(优先使用注解,默认为'string')
param_type = 'string'
if param.annotation is not param.empty:
# 提取基本类型名称(如<class 'str'> -> 'str')
type_name = param.annotation.__name__
# 映射Python类型到JSON类型
param_type = {
'str': 'string',
'int': 'integer',
'float': 'number',
'bool': 'boolean',
'list': 'array',
'dict': 'object'
}.get(type_name, type_name.lower())
# 构建参数描述
param_description = ""
if func.__doc__:
# 从函数文档中提取参数描述(简单实现)
doc_lines = func.__doc__.split('\n')
for line in doc_lines:
if f":param {param_name}:" in line:
param_description = line.split(":", 2)[-1].strip()
break
# 添加到参数属性
parameters['properties'][param_name] = {
'description': param_description,
'type': param_type
}
# 检查是否为必填参数(无默认值)
if param.default == param.empty:
parameters['required'].append(param_name)
# 构建函数描述字典
func_dict = {
"type": "function",
"function": {
"name": func.__name__,
"description": (func.__doc__ or "").split('\n')[0].strip(),
"parameters": parameters
}
}
tools_description.append(func_dict)
return tools_description
def machine_learning_1() -> str:
"""
解释机器学习是什么
返回:
机器学习的基础定义
"""
return """机器学习是人工智能的一个分支,研究计算机如何自动从数据中学习,
提升性能并做出预测。它通过算法让计算机提炼知识,优化任务执行,而无需明确编程。"""
def check_ticket(date: str, start: str, end: str) -> str:
"""
查询是否可以订票
参数:
date: 出发日期(格式:YYYY-MM-DD)
start: 出发站名称
end: 终点站名称
返回:
可预订车次信息的JSON字符串
"""
# 实际实现中这里会有查询逻辑
return f"日期:{date}, 从{start}到{end}的车次信息"
# 函数列表
functions_list = [machine_learning_1, check_ticket]
# 生成工具描述
tools = auto_functions(functions_list)
# 打印结果
import json
print(json.dumps(tools, indent=2, ensure_ascii=False))数据的结果为
[
{
"type": "function",
"function": {
"name": "machine_learning_1",
"description": "解释机器学习是什么",
"parameters": {
"type": "object",
"properties": {},
"required": []
}
}
},
{
"type": "function",
"function": {
"name": "check_tick",
"description": "查询是否可以订票\n :param date: 日期\n :param start: 出发站\n :param end:终点站\n :return: 可以预定的车次信息",
"parameters": {
"type": "object",
"properties": {
"date": {
"description": "",
"type": "Any"
},
"start": {
"description": "",
"type": "Any"
},
"end": {
"description": "",
"type": "Any"
}
},
"required": []
}
}
}
]通过JSON格式化的工具来查看

from openai import OpenAI
import os
from dotenv import load_dotenv
# 加载环境变量(包含OpenAI API密钥)
load_dotenv()
# 创建OpenAI客户端实例
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
def get_completion(user_input: str, model: str = "gpt-4", temperature: float = 0) -> str:
"""
使用OpenAI API将函数定义转换为JSON Schema格式
参数:
user_input: 包含函数定义的用户输入字符串
model: 使用的OpenAI模型,默认为gpt-4
temperature: 控制生成结果的随机性,0表示最确定性
返回:
OpenAI API返回的JSON Schema格式字符串
"""
# 示例JSON Schema结构,用于指导模型转换
examples = """
{
"type": "function",
"function": {
"name": "get_location_coordinate",
"description": "根据POI名称,获得POI的经纬度坐标",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "POI名称,必须是中文"
},
"city": {
"type": "string",
"description": "POI所在的城市名,必须是中文"
}
},
"required": ["location", "city"]
}
}
}
"""
# 构建提示词,指导模型进行转换
prompt = f"""
任务:将用户提供的函数定义转换为JSON Schema格式
示例格式:
{examples}
用户提供的函数定义:
{user_input}
转换要求:
1. 只返回JSON Schema格式的结果,不要包含任何额外文本
2. 确保参数描述清晰准确
3. 正确处理默认值参数(有默认值的参数不是必需的)
4. 使用合理的参数类型(string, integer, boolean等)
"""
# 创建消息列表(目前只包含用户消息)
messages = [{"role": "user", "content": prompt}]
# 调用OpenAI API
response = client.chat.completions.create(
model=model,
messages=messages,
temperature=temperature # 控制生成结果的随机性
)
# 返回模型生成的响应内容
return response.choices[0].message.content
# 示例函数定义(用户输入)
user_input = """
def get_location_coordinate(location, city="北京"):
\"\"\"
根据POI名称获取经纬度坐标
参数:
location: POI名称(字符串)
city: 所在城市(字符串),默认为"北京"
返回:
包含POI信息的字典,如果未找到则返回None
\"\"\"
import requests
amap_key = "your_api_key_here" # 实际使用中应从环境变量获取
url = f"https://restapi.amap.com/v5/place/text?key={amap_key}&keywords={location}®ion={city}"
print(url)
r = requests.get(url)
result = r.json()
if "pois" in result and result["pois"]:
return result["pois"][0]
return None
"""
# 调用函数并打印结果
result = get_completion(user_input)
print("生成的JSON Schema:")
print(result)输出的效果如下
改写后的JSON schema形式如下:
{
"type": "function",
"function": {
"name": "get_location_coordinate",
"description": "根据POI名称和城市名,获取POI的经纬度坐标",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "POI名称,必须是中文"
},
"city": {
"type": "string",
"description": "POI所在的城市名,必须是中文,默认为北京",
"default": "北京"
}
},
"required": [
"location"
]
}
}
}Function Calling 连接数据库
操作数据库也是一个非常常见的需求,我们来看看通过 Function Calling如何实现数据库的操作
from openai import OpenAI
import os
import pymysql
import json
from dotenv import load_dotenv
from mysql.connector import Error
# 加载环境变量(包含OpenAI API密钥)
load_dotenv()
# 创建OpenAI客户端实例
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
# 数据库表结构定义
database_schema_string = """
CREATE TABLE goods(
id INT UNSIGNED PRIMARY KEY AUTO_INCREMENT NOT NULL,
name VARCHAR(150) NOT NULL,
cate_name VARCHAR(40) NOT NULL,
brand_name VARCHAR(40) NOT NULL,
price DECIMAL(10,3) NOT NULL DEFAULT 0,
is_show BIT NOT NULL DEFAULT 1,
is_saleoff BIT NOT NULL DEFAULT 0
);
"""
# 示例数据插入语句(实际应用中应执行这些语句)
sample_data = """
INSERT INTO goods VALUES(0, 'r510vc 15.6英寸笔记本', '笔记本', '华硕', '3399', DEFAULT, DEFAULT);
INSERT INTO goods VALUES(0, 'y400n 14.0英寸笔记本电脑', '笔记本', '联想', '4999', DEFAULT, DEFAULT);
INSERT INTO goods VALUES(0, 'g150th 15.6英寸游戏本', '游戏本', '雷神', '8499', DEFAULT, DEFAULT);
INSERT INTO goods VALUES(0, 'x550cc 15.6英寸笔记本', '笔记本', '华硕', '2799', DEFAULT, DEFAULT);
INSERT INTO goods VALUES(0, 'x240 超极本', '超级本', '联想', '4880', DEFAULT, DEFAULT);
INSERT INTO goods VALUES(0, 'u330p 13.3英寸超极本', '超级本', '联想', '4299', DEFAULT, DEFAULT);
INSERT INTO goods VALUES(0, 'svp13226scb 触控超极本', '超级本', '索尼', '7999', DEFAULT, DEFAULT);
INSERT INTO goods VALUES(0, 'ipad mini 7.9英寸平板电脑', '平板电脑', '苹果', '1998', DEFAULT, DEFAULT);
INSERT INTO goods VALUES(0, 'ipad air 9.7英寸平板电脑', '平板电脑', '苹果', '3388', DEFAULT, DEFAULT);
INSERT INTO goods VALUES(0, 'ipad mini 配备 retina 显示屏', '平板电脑', '苹果', '2788', DEFAULT, DEFAULT);
INSERT INTO goods VALUES(0, 'ideacentre c340 20英寸一体电脑', '台式机', '联想', '3499', DEFAULT, DEFAULT);
INSERT INTO goods VALUES(0, 'vostro 3800-r1206 台式电脑', '台式机', '戴尔', '2899', DEFAULT, DEFAULT);
INSERT INTO goods VALUES(0, 'imac me086ch/a 21.5英寸一体电脑', '台式机', '苹果', '9188', DEFAULT, DEFAULT);
INSERT INTO goods VALUES(0, 'at7-7414lp 台式电脑 linux', '台式机', '宏碁', '3699', DEFAULT, DEFAULT);
INSERT INTO goods VALUES(0, 'z220sff f4f06pa工作站', '服务器/工作站', '惠普', '4288', DEFAULT, DEFAULT);
INSERT INTO goods VALUES(0, 'poweredge ii服务器', '服务器/工作站', '戴尔', '5388', DEFAULT, DEFAULT);
INSERT INTO goods VALUES(0, 'mac pro专业级台式电脑', '服务器/工作站', '苹果', '28888', DEFAULT, DEFAULT);
INSERT INTO goods VALUES(0, 'hmz-t3w 头戴显示设备', '笔记本配件', '索尼', '6999', DEFAULT, DEFAULT);
INSERT INTO goods VALUES(0, '商务双肩背包', '笔记本配件', '索尼', '99', DEFAULT, DEFAULT);
INSERT INTO goods VALUES(0, 'x3250 m4机架式服务器', '服务器/工作站', 'ibm', '6888', DEFAULT, DEFAULT);
"""
# 数据库连接配置
DB_CONFIG = {
'host': '127.0.0.1',
'port': 3320,
'user': 'root',
'password': '123456',
'database': 'func'
}
# 全局数据库连接对象
connection = None
cursor = None
try:
print("正在连接数据库...")
# 创建数据库连接
connection = pymysql.connect(**DB_CONFIG)
print("数据库连接成功")
# 创建游标对象
cursor = connection.cursor()
print("游标创建成功")
# 在实际应用中,这里应该执行建表语句和插入数据
# cursor.execute(database_schema_string)
# cursor.execute(sample_data)
# connection.commit()
except Error as err:
print(f"数据库连接错误: {err}")
# 如果连接失败,退出程序
exit(1)
def get_sql_completion(messages: list, model: str = "gpt-4o") -> dict:
"""
使用OpenAI API生成SQL查询语句
参数:
messages: 包含对话历史的消息列表
model: 使用的OpenAI模型,默认为gpt-4o
返回:
OpenAI API返回的完整响应消息
"""
# 定义函数调用工具规范
tools = [
{
"type": "function",
"function": {
"name": "ask_database",
"description": "使用此函数回答用户关于商品数据的问题,输出应为完整的SQL查询语句",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": f"""
根据用户问题生成的SQL查询语句。
使用以下数据库架构:
{database_schema_string}
注意事项:
1. 只返回纯文本SQL查询,不要包含任何额外文本
2. 仅使用MySQL支持的语法
3. 使用反引号包裹表名和列名防止冲突
4. 优先使用COUNT(), SUM()等聚合函数
""",
}
},
"required": ["query"],
}
}
}
]
# 调用OpenAI API
response = client.chat.completions.create(
model=model,
messages=messages,
temperature=0, # 确保输出确定性
tools=tools,
tool_choice={"type": "function", "function": {"name": "ask_database"}}
)
return response.choices[0].message
def ask_database(query: str):
"""
执行SQL查询并返回结果
参数:
query: 要执行的SQL查询语句
返回:
查询结果列表
"""
try:
print(f"执行SQL查询: {query}")
# 执行SQL语句
cursor.execute(query)
# 获取所有结果
records = cursor.fetchall()
print(f"查询成功,返回 {len(records)} 条记录")
return records
except Exception as e:
print(f"SQL执行错误: {e}")
return f"SQL执行错误: {str(e)}"
def main():
"""主函数,处理用户查询流程"""
# 用户查询
prompt = "类型是笔记本的有多少台"
# 初始化消息列表
messages = [
{"role": "system", "content": "你是一个SQL专家,帮助用户查询商品数据库"},
{"role": "user", "content": prompt}
]
print("\n==== 开始处理用户查询 ====")
print(f"用户问题: {prompt}")
# 第一步:获取SQL查询
response = get_sql_completion(messages)
print("\n==== 初始响应 ====")
print(response)
# 添加到消息历史
if response.content is None:
response.content = ""
messages.append(response)
# 检查是否有函数调用
if response.tool_calls:
print("\n==== 检测到函数调用 ====")
tool_call = response.tool_calls[0]
if tool_call.function.name == "ask_database":
# 解析函数参数
arguments = tool_call.function.arguments
args = json.loads(arguments)
print("\n==== 生成的SQL查询 ====")
print(args["query"])
# 执行SQL查询
result = ask_database(args["query"])
print("\n==== 数据库查询结果 ====")
print(result)
# 将结果添加到消息历史
messages.append({
"tool_call_id": tool_call.id,
"role": "tool",
"name": "ask_database",
"content": str(result)
})
# 第二步:获取最终回答
response = get_sql_completion(messages)
print("\n==== 最终回复 ====")
print(response.content)
else:
print("\n==== 直接回复 ====")
print(response.content)
if __name__ == "__main__":
try:
main()
finally:
# 确保关闭数据库连接
if cursor:
cursor.close()
print("游标已关闭")
if connection:
connection.close()
print("数据库连接已关闭")输出结果
<pymysql.cursors.Cursor object at 0x000002124A2F4E50>ChatCompletionMessage(content=None, refusal=None,role='assistant', audio=None, function_call=None, tool_calls=[ChatCompletionMessageToolCall(id='call_gurapPqrFTm1iCBy3B04uqnJ', function=Function(arguments='{"query":"SELECT COUNT(*) FROMgoods WHERE cate_name = \'笔记本\';"}', name='ask_database',parameters=None), type='function')])
====Function Calling====
ChatCompletionMessage(content='', refusal=None, role='assistant',audio=None, function_call=None, tool_calls=[ChatCompletionMessageToolCall(id='call_gurapPqrFTm1iCBy3B04uqnJ', function=Function(arguments='{"query":"SELECT COUNT(*) FROMgoods WHERE cate_name = \'笔记本\';"}', name='ask_database',parameters=None), type='function')])
====SQL====
SELECT COUNT(*) FROM goods WHERE cate_name = '笔记本';
====数据库查询结果====
((3,),)
====最终回复====
类型是笔记本的有3台。国产大模型
- Function Calling 会成为所有大模型的标配,支持它的越来越多
- 不支持的大模型,某种程度上是不大可用的
百度文心大模型
官方文档:https://cloud.baidu.com/doc/WENXINWORKSHOP/index.html
百度文心系列大模型有四个。按发布时间从早到晚是:
- ERNIE-Bot - 支持 Function Calling
- ERNIE-Bot-turbo
- ERNIE-Bot 4.0
- ERNIE-Bot 3.5 - 支持 Function Calling
参数大体和 OpenAI 一致。
ChatGLM
质谱大模型:官方文档:https://github.com/THUDM/ChatGLM3/tree/main/tools_using_demo
https://open.bigmodel.cn/console/overview
- 最著名的国产开源大模型,生态最好
- 早就使用 tools 而不是 function 来做参数,其它和 OpenAI 1106 版之前完全一样
import json
from zhipuai import ZhipuAI
from dotenv import load_dotenv
# 加载环境变量(包含智谱AI API密钥)
load_dotenv()
# 创建智谱AI客户端实例
client = ZhipuAI(api_key=os.getenv("ZHIPUAI_API_KEY"))
# 定义可用的函数工具列表
tools = [
{
"type": "function",
"function": {
"name": "get_flight_number",
"description": "根据始发地、目的地和日期,查询对应日期的航班号",
"parameters": {
"type": "object",
"properties": {
"departure": {
"description": "出发地城市名称",
"type": "string"
},
"destination": {
"description": "目的地城市名称",
"type": "string"
},
"date": {
"description": "日期,格式为YYYY-MM-DD",
"type": "string",
}
},
"required": ["departure", "destination", "date"]
},
}
},
{
"type": "function",
"function": {
"name": "get_ticket_price",
"description": "查询某航班在某日的票价",
"parameters": {
"type": "object",
"properties": {
"flight_number": {
"description": "航班号,如CA1234",
"type": "string"
},
"date": {
"description": "日期,格式为YYYY-MM-DD",
"type": "string",
}
},
"required": ["flight_number", "date"]
},
}
},
{
"type": "function",
"function": {
"name": "sum_number",
"description": "计算一组数的和",
"parameters": {
"type": "object",
"properties": {
"numbers": {
"type": "array",
"items": {
"type": "number"
},
"description": "需要求和的一组数字"
}
},
"required": ["numbers"]
}
}
}
]
def get_flight_number(date: str, departure: str, destination: str) -> dict:
"""
根据日期、出发地和目的地查询航班号(模拟实现)
参数:
date: 日期字符串(YYYY-MM-DD)
departure: 出发地城市名称
destination: 目的地城市名称
返回:
包含航班号的字典
"""
# 模拟航班数据
flight_number = {
"北京": {
"上海": "CA1234",
"广州": "CZ8321",
},
"上海": {
"北京": "MU1233",
"广州": "FM8123",
},
"广州": {
"北京": "CZ3101",
"上海": "CZ3537",
}
}
# 检查城市是否存在
if departure not in flight_number:
return {"error": f"不支持从{departure}出发的航班查询"}
if destination not in flight_number[departure]:
return {"error": f"不支持从{departure}到{destination}的航班查询"}
return {"flight_number": flight_number[departure][destination]}
def get_ticket_price(date: str, flight_number: str) -> dict:
"""
根据日期和航班号查询票价(模拟实现)
参数:
date: 日期字符串(YYYY-MM-DD)
flight_number: 航班号
返回:
包含票价的字典
"""
# 模拟票价数据(实际应用中应该查询数据库或API)
price_mapping = {
"CA1234": "980",
"CZ8321": "1200",
"MU1233": "950",
"FM8123": "1100",
"CZ3101": "1350",
"CZ3537": "1050"
}
if flight_number not in price_mapping:
return {"error": f"未找到航班{flight_number}的票价信息"}
return {"ticket_price": price_mapping[flight_number]}
def parse_function_call(model_response, messages: list):
"""
处理函数调用结果,根据模型返回参数调用对应函数
参数:
model_response: 模型响应对象
messages: 消息历史列表
返回:
处理后的模型响应消息
"""
# 检查是否有函数调用
if model_response.choices[0].message.tool_calls:
tool_call = model_response.choices[0].message.tool_calls[0]
args = tool_call.function.arguments
function_result = {}
# 根据函数名调用对应的函数
if tool_call.function.name == "get_flight_number":
function_result = get_flight_number(**json.loads(args))
elif tool_call.function.name == "get_ticket_price":
function_result = get_ticket_price(**json.loads(args))
elif tool_call.function.name == "sum_number":
args_dict = json.loads(args)
function_result = {"sum": sum(args_dict["numbers"])}
print("函数执行结果:", function_result)
# 将函数执行结果添加到消息历史
messages.append({
"role": "tool",
"content": json.dumps(function_result),
"tool_call_id": tool_call.id
})
# 再次调用模型,将函数结果输入模型
response = client.chat.completions.create(
model="glm-4-flash",
messages=messages,
tools=tools,
)
# 将模型回复添加到消息历史
messages.append(response.choices[0].message.model_dump())
return response.choices[0].message
# 如果没有函数调用,直接返回原响应
return model_response.choices[0].message
def main():
"""主函数,处理用户查询流程"""
# 初始化消息列表
messages = []
# 添加系统提示
messages.append({
"role": "system",
"content": "不要假设或猜测传入函数的参数值。如果用户的描述不明确,请要求用户提供必要信息"
})
# 添加用户查询
user_query = "帮我查询1月23日,北京到广州的航班?"
messages.append({"role": "user", "content": user_query})
print(f"用户查询: {user_query}")
# 第一次调用模型
response = client.chat.completions.create(
model="glm-4-flash",
messages=messages,
tools=tools,
)
# 将模型回复添加到消息历史
messages.append(response.choices[0].message.model_dump())
print("\n==== 第一次模型响应 ====")
print(response.choices[0].message)
# 处理函数调用
result = parse_function_call(response, messages)
print("\n==== 最终结果 ====")
print(result)
# 打印完整对话历史
print("\n==== 完整对话历史 ====")
for i, msg in enumerate(messages):
print(f"{i+1}. {msg['role']}: {msg.get('content', 'No content')}")
if __name__ == "__main__":
main()多表查询
接下来我们看看如何通过 Function Calling 实现多表查询操作
from openai import OpenAI
import os
import pymysql
import json
from dotenv import load_dotenv
from mysql.connector import Error
# 加载环境变量(包含OpenAI API密钥)
load_dotenv()
# 创建OpenAI客户端实例
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
# 数据库表结构定义(仅包含表结构,不包含数据)
database_schema_string = """
-- 创建班级表
CREATE TABLE Classes (
class_id INT PRIMARY KEY,
class_name VARCHAR(100) NOT NULL
);
-- 创建学生表
CREATE TABLE Students (
student_id INT PRIMARY KEY,
name VARCHAR(100) NOT NULL,
class_id INT,
FOREIGN KEY (class_id) REFERENCES Classes(class_id)
);
-- 创建成绩表
CREATE TABLE Scores (
score_id INT PRIMARY KEY,
student_id INT,
subject VARCHAR(100) NOT NULL,
score FLOAT NOT NULL,
FOREIGN KEY (student_id) REFERENCES Students(student_id)
);
"""
# 示例数据插入语句(实际应用中应执行这些语句)
sample_data = """
INSERT INTO Classes (class_id, class_name) VALUES
(1, '一班'),
(2, '二班'),
(3, '三班'),
(4, '四班'),
(5, '五班');
INSERT INTO Students (student_id, name, class_id) VALUES
(1, '张三', 1),
(2, '李四', 1),
(3, '王五', 2),
(4, '赵六', 3),
(5, '钱七', 4);
INSERT INTO Scores (score_id, student_id, subject, score) VALUES
(1, 1, '数学', 85.5),
(2, 1, '英语', 90.0),
(3, 2, '数学', 78.0),
(4, 3, '英语', 88.5),
(5, 4, '数学', 92.0);
"""
# 数据库连接配置
DB_CONFIG = {
'host': '127.0.0.1',
'port': 3320,
'user': 'root',
'password': '123456',
'database': 'func'
}
# 全局数据库连接对象
connection = None
cursor = None
try:
print("正在连接数据库...")
# 创建数据库连接
connection = pymysql.connect(**DB_CONFIG)
print("数据库连接成功")
# 创建游标对象
cursor = connection.cursor()
print("游标创建成功")
# 在实际应用中,这里应该执行建表语句和插入数据
# 注意:这里只是示例,实际执行需要取消注释
# cursor.execute("DROP TABLE IF EXISTS Scores, Students, Classes;")
# cursor.execute(database_schema_string)
# for statement in sample_data.split(';'):
# if statement.strip():
# cursor.execute(statement)
# connection.commit()
except Error as err:
print(f"数据库连接错误: {err}")
# 如果连接失败,退出程序
exit(1)
def get_sql_completion(messages: list, model: str = "gpt-3.5-turbo") -> dict:
"""
使用OpenAI API生成SQL查询语句
参数:
messages: 包含对话历史的消息列表
model: 使用的OpenAI模型,默认为gpt-3.5-turbo
返回:
OpenAI API返回的完整响应消息
"""
# 定义函数调用工具规范
tools = [
{
"type": "function",
"function": {
"name": "ask_database",
"description": "使用此函数回答用户关于学生成绩数据的问题,输出应为完整的SQL查询语句",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": f"""
根据用户问题生成的SQL查询语句。
使用以下数据库架构:
{database_schema_string}
注意事项:
1. 只返回纯文本SQL查询,不要包含任何额外文本
2. 仅使用MySQL支持的语法
3. 使用反引号包裹表名和列名防止冲突
4. 使用JOIN连接相关表
5. 使用WHERE子句进行筛选
""",
}
},
"required": ["query"],
}
}
}
]
# 调用OpenAI API
response = client.chat.completions.create(
model=model,
messages=messages,
temperature=0, # 确保输出确定性
tools=tools,
tool_choice={"type": "function", "function": {"name": "ask_database"}}
)
return response.choices[0].message
def ask_database(query: str):
"""
执行SQL查询并返回结果
参数:
query: 要执行的SQL查询语句
返回:
查询结果列表
"""
try:
print(f"执行SQL查询: {query}")
# 执行SQL语句
cursor.execute(query)
# 获取所有结果
records = cursor.fetchall()
print(f"查询成功,返回 {len(records)} 条记录")
return records
except Exception as e:
print(f"SQL执行错误: {e}")
return f"SQL执行错误: {str(e)}"
def main():
"""主函数,处理用户查询流程"""
# 用户查询
prompt = "查询一班的学生数学成绩是多少?"
# 初始化消息列表
messages = [
{"role": "system", "content": "你是一个SQL专家,帮助用户查询学生成绩数据库"},
{"role": "user", "content": prompt}
]
print("\n==== 开始处理用户查询 ====")
print(f"用户问题: {prompt}")
# 第一步:获取SQL查询
response = get_sql_completion(messages)
print("\n==== 初始响应 ====")
print(response)
# 添加到消息历史
messages.append(response)
# 检查是否有函数调用
if response.tool_calls:
print("\n==== 检测到函数调用 ====")
tool_call = response.tool_calls[0]
if tool_call.function.name == "ask_database":
# 解析函数参数
arguments = tool_call.function.arguments
args = json.loads(arguments)
print("\n==== 生成的SQL查询 ====")
print(args["query"])
# 执行SQL查询
result = ask_database(args["query"])
print("\n==== 数据库查询结果 ====")
print(result)
# 将结果添加到消息历史
messages.append({
"tool_call_id": tool_call.id,
"role": "tool",
"name": "ask_database",
"content": str(result)
})
# 第二步:获取最终回答
response = get_sql_completion(messages)
print("\n==== 最终回复 ====")
print(response.content)
else:
print("\n==== 直接回复 ====")
print(response.content)
if __name__ == "__main__":
try:
main()
finally:
# 确保关闭数据库连接
if cursor:
cursor.close()
print("游标已关闭")
if connection:
connection.close()
print("数据库连接已关闭")完整输出结果
====SQL====
SELECT s.name, sc.score FROM Students s JOIN Scores sc ON s.student_id = sc.student_id WHERE s.class_id = 1 AND sc.subject= '数学';
====MySQL数据库查询结果====
(('张三', 85.5), ('李四', 78.0))
====最终回复====
ChatCompletionMessage(content='一班的学生`数学`成绩如下:\n- 张三:85.5\n- 李四: 78.0', refusal=None, role='assistant', audio=None,function_call=None, tool_calls=None, annotations=[])


 浙公网安备 33010602011771号
浙公网安备 33010602011771号