模型参数更改-适配超长文本处理-新闻分类
新闻分类数据集介绍
新闻分类是一种经典的自然语言处理任务。通常需要对新闻文本进行分类,将其归入不同的类别。
加载 Hugging Face 的新闻分类数据集
我们可以使用 Hugging Face 的 datasets 库来加载新闻分类数据集,如 THucNews。这是一个中文新闻分类数据集,适合用于文本分类任务。(该数据集在huggingface上已经找不到,只能用本地的)
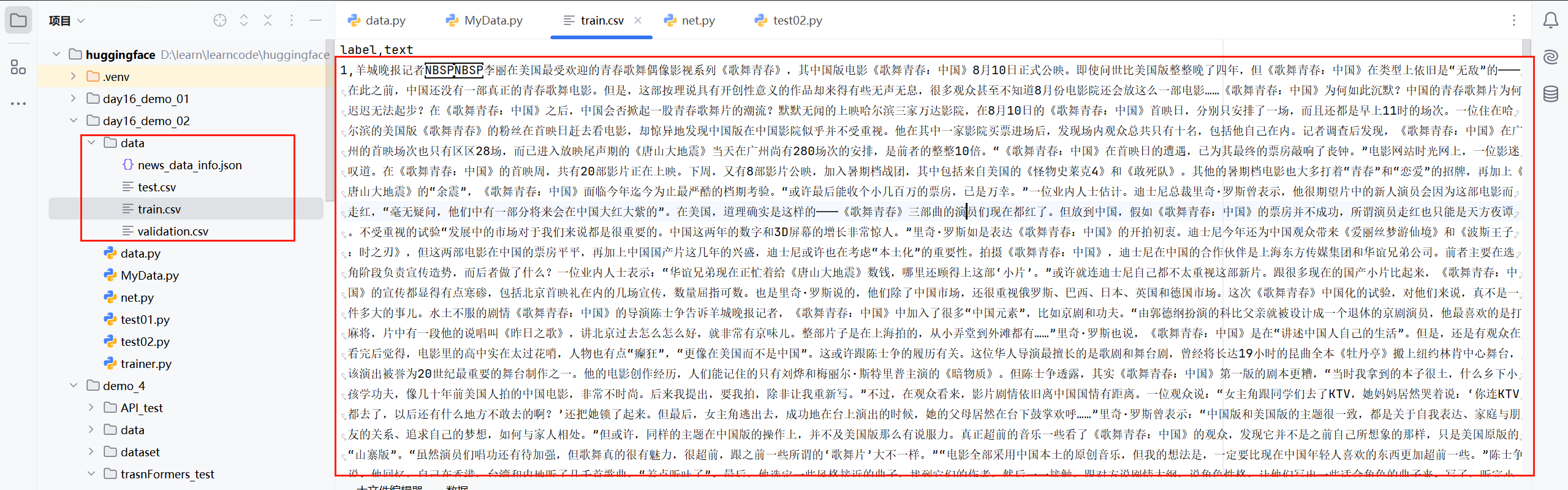
类似于这么长的文本,如果直接使用bert-base-chinese这种小模型处理是不行的,因为:1.bert-base-chinese可以处理的最长文本长度是512;2.如果我们为了适配bert-base-chinese的最大长度将文本强制截断,那肯定会对分类效果产生影响。因此我们只有两种方案:1.修改bert-base-chinese能够处理的最大文本长度;2.使用更大的文本处理模型;
修改bert-base-chinese能够处理的最大文本长度
数据集加载
同原来加载方式一样,定义MyData.py类:
from torch.utils.data import Dataset
from datasets import load_dataset
class MyDataset(Dataset):
def __init__(self,split):
#从磁盘加载csv数据
self.dataset = load_dataset(path="csv",data_files=f"data/{split}.csv",split="train")
def __len__(self):
return len(self.dataset)
def __getitem__(self, item):
text = self.dataset[item]["text"]
label = self.dataset[item]["label"]
return text,label
if __name__ == '__main__':
dataset = MyDataset("test")
print(len(dataset))
for i in range(10):
print(dataset[i])
print(len(dataset[i][0]))
修改bert-base-chinese配置
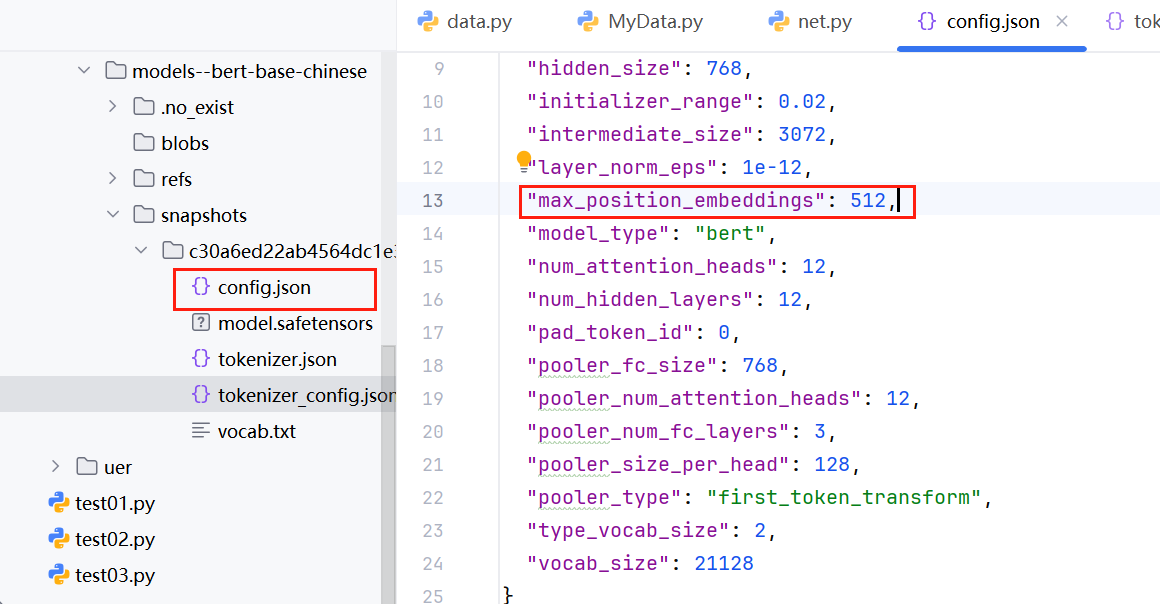
注意:限制bert-base-chinese模型能够处理的最大文本长度的配置是位置编码长度参数,整个模型有多处配置,我们可以使用以下代码直接统一修改:
from transformers import BertModel,BertConfig
# configuration = BertConfig.from_pretrained("bert-base-chinese")
configuration = BertConfig.from_pretrained(r"D:\learn\learncode\huggingface\demo_4\trasnFormers_test\model\bert-base-chinese\models--bert-base-chinese\snapshots\c30a6ed22ab4564dc1e3b2ecbf6e766b0611a33f")
configuration.max_position_embeddings = 1500
print(configuration)
#初始化模型
pretrained = BertModel(configuration).to(DEVICE)
print(pretrained.embeddings.position_embeddings)
print(pretrained)查看打印结果
BertConfig {
"architectures": [
"BertForMaskedLM"
],
"attention_probs_dropout_prob": 0.1,
"classifier_dropout": null,
"directionality": "bidi",
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-12,
"max_position_embeddings": 1500,
"model_type": "bert",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pad_token_id": 0,
"pooler_fc_size": 768,
"pooler_num_attention_heads": 12,
"pooler_num_fc_layers": 3,
"pooler_size_per_head": 128,
"pooler_type": "first_token_transform",
"position_embedding_type": "absolute",
"transformers_version": "4.55.4",
"type_vocab_size": 2,
"use_cache": true,
"vocab_size": 21128
}
Embedding(1500, 768)
BertModel(
(embeddings): BertEmbeddings(
(word_embeddings): Embedding(21128, 768, padding_idx=0)
(position_embeddings): Embedding(1500, 768)
(token_type_embeddings): Embedding(2, 768)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(encoder): BertEncoder(
(layer): ModuleList(
(0-11): 12 x BertLayer(
(attention): BertAttention(
(self): BertSdpaSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
(intermediate_act_fn): GELUActivation()
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
)
(pooler): BertPooler(
(dense): Linear(in_features=768, out_features=768, bias=True)
(activation): Tanh()
)
)注意,我们上面修改了模型的嵌入层,因此,模型的嵌入层也需要重新进行训练,并且我们只训练嵌入层,冻结BERT 的 encoder 部分(不参与训练),完整的模型代码如下:
# 从transformers库导入BERT模型和配置类
from transformers import BertModel, BertConfig
import torch
# 确定使用的设备:如果有GPU则使用cuda,否则使用CPU
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 从本地预训练模型路径加载BERT的配置
# 这里使用的是bert-base-chinese模型的配置
configuration = BertConfig.from_pretrained(
r"D:\learn\learncode\huggingface\demo_4\trasnFormers_test\model\bert-base-chinese\models--bert-base-chinese\snapshots\c30a6ed22ab4564dc1e3b2ecbf6e766b0611a33f"
)
# 修改配置中的最大位置嵌入长度为1500
# 这会影响模型能处理的最大序列长度
configuration.max_position_embeddings = 1500
# 打印修改后的配置信息,确认修改是否生效
print(configuration)
# 根据修改后的配置初始化BERT模型,并将模型移动到指定设备(GPU/CPU)
# 注意:这里是从头初始化模型,而不是加载预训练权重
pretrained = BertModel(configuration).to(DEVICE)
# 打印位置嵌入层信息,查看其维度是否已变为1500
print(pretrained.embeddings.position_embeddings)
# 打印整个模型结构
print(pretrained)
# 定义下游任务模型(基于BERT的分类模型)
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
# 定义一个全连接层,将BERT输出的特征(768维)映射到10个类别
self.fc = torch.nn.Linear(768, 10)
def forward(self, input_ids, attention_mask, token_type_ids):
# 将attention_mask转换为float类型,与嵌入输出的 dtype 匹配
attention_mask = attention_mask.to(torch.float)
# 获取输入序列的嵌入表示,这里让嵌入层参与训练
embedding_output = pretrained.embeddings(
input_ids=input_ids,
token_type_ids=token_type_ids # 虽然代码中没显式传入,但BERT嵌入层通常会使用
)
# 调整attention_mask的形状以适应encoder的要求
# 从 [N, sequence_length] 变为 [N, 1, 1, sequence_length]
attention_mask = attention_mask.unsqueeze(1).unsqueeze(2)
# 确保attention_mask的数据类型与嵌入输出一致
attention_mask = attention_mask.to(embedding_output.dtype)
# 使用torch.no_grad()上下文管理器冻结encoder和pooler部分
# 这意味着在反向传播时不会更新这些层的参数,同时也能节省显存
with torch.no_grad():
# 将嵌入输出和attention_mask传入encoder,获取编码结果
encoder_output = pretrained.encoder(
embedding_output,
attention_mask=attention_mask
)
# 分类任务通常只使用[CLS]标记对应的输出(即序列的第一个位置)
# 将其传入全连接层得到最终的分类结果
out = self.fc(encoder_output.last_hidden_state[:, 0])
return out模型训练
trainer.py
import torch
from torch.optim import AdamW
from MyData import MyDataset
from torch.utils.data import DataLoader
from net import Model
from transformers import BertTokenizer
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
EPOCH = 30000
token = BertTokenizer.from_pretrained("bert-base-chinese")
def collate_fn(data):
sentes = [i[0] for i in data]
label = [i[1] for i in data]
# print(sentes)
#编码
data = token.batch_encode_plus(batch_text_or_text_pairs=sentes,
truncation=True,
padding="max_length",
max_length=1500,
return_tensors="pt",
return_length=True)
input_ids = data["input_ids"]
attention_mask = data["attention_mask"]
token_type_ids = data["token_type_ids"]
labels = torch.LongTensor(label)
# print(input_ids,attention_mask,token_type_ids)
return input_ids,attention_mask,token_type_ids,labels
#创建数据集
train_dataset = MyDataset("train")
val_dataset = MyDataset("validation")
#创建dataloader
train_laoder = DataLoader(dataset=train_dataset,
batch_size=20,
shuffle=True,
drop_last=True,
collate_fn=collate_fn)
if __name__ == '__main__':
#开始训练
print(DEVICE)
model = Model().to(DEVICE)
optimizer = AdamW(model.parameters(),lr=5e-4)
loss_func = torch.nn.CrossEntropyLoss()
model.train()
for epoch in range(EPOCH):
sum_val_acc = 0
sum_val_loss = 0
#训练
for i,(input_ids,attention_mask,token_type_ids,labels) in enumerate(train_laoder):
# print(input_ids)
input_ids, attention_mask, token_type_ids, labels = input_ids.to(DEVICE), attention_mask.to(
DEVICE), token_type_ids.to(DEVICE), labels.to(DEVICE)
out = model(input_ids,attention_mask,token_type_ids)
loss = loss_func(out,labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if i%5==0:
out = out.argmax(dim=1)
acc = (out==labels).sum().item()/len(labels)
print(epoch,i,loss.item(),acc)
torch.save(model.state_dict(), f"params/{epoch}bert-weibo.pth")
print(epoch, "参数保存成功!")注意,需要注意的是,这段代码中使用的是随机初始化的 BERT 模型,如果要获得好的性能,通常应该加载预训练权重并进行微调。也就是说,上面的方法效果并不会太好,因为我们还是改变了BERT模型的“输入”部分,这部分的重新训练效果,并不能得到较好的保证。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号