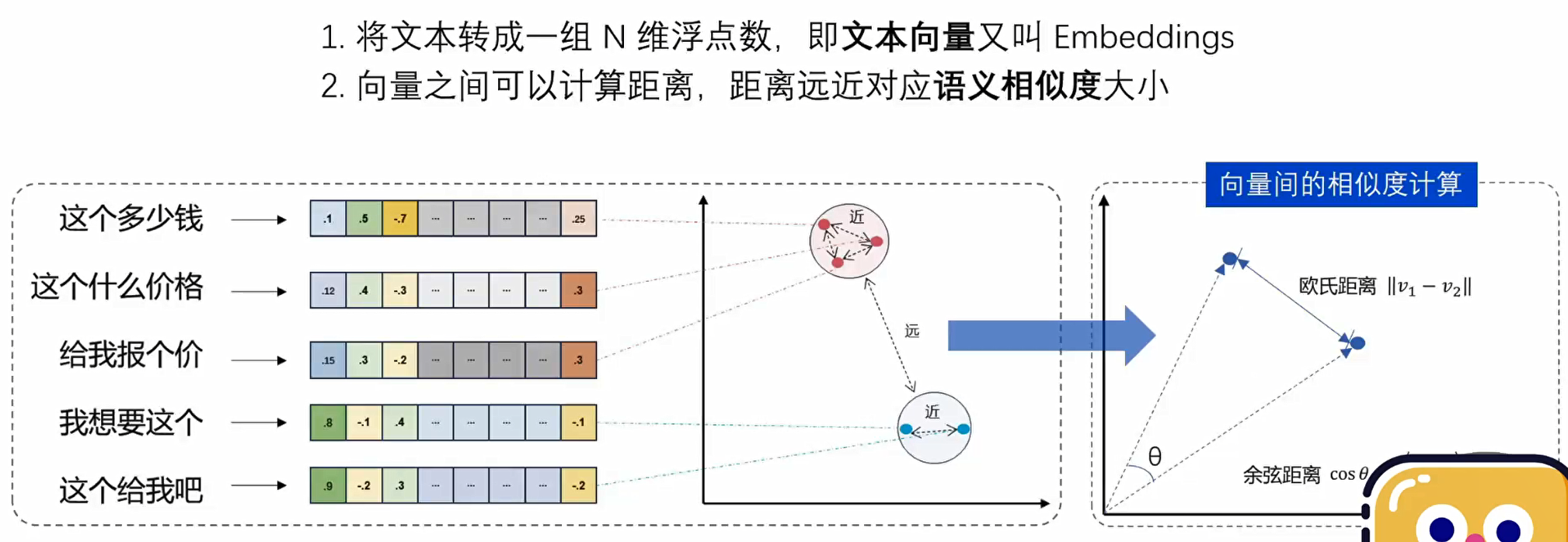
RAG概述
RAG是什么
面试中常问的问题:目前大模型存在什么样的的缺点和解决办法,然后会聊到偏见,幻觉,过时这三个缺点,这时你就必须了解RAG检索增强生成。
检索增强生成是一种使用外部知识源来提高生成式人工智能或大型语言模型准确性和可靠性的技术。具体来说,当需要生成一个回答时,RAG会首先利用一个知识库来获取可能的答案选项,然后由生成的模型来决定最终的输出。这种方法可以理解为在大模型生成答案之前,先让它浏览并吸收知识库中提供的信息,从而提升它生成的质量和可信度。
为什么要使用RAG技术?RAG和模型微调的区别
大模型的幻觉问题微调技术和RAG技术:
- 微调:在已有的预训练模型基础上,再结合特定任务的数据集进一步对其进行训练,使得模型在这一领域中表现更好(考前复习);
- RAG:在生成回答之前,通过信息检索从外部知识库中查找与问题相关的知识,增强生成过程中的信息来源,从而提升生成的质量和准确性(考试带小抄)
- 共同点:都是为了赋予模型某个领域的特定知识,解决大模型的幻觉问题。
RAG(Retrieval-Augmented Generation)的原理:
- 检索(Retrieval):当用户提出问题时,系统会从外部的知识库中检索出与用户输入相关的内容。
- 增强(Augmentation):系统将检索到的信息与用户的输入结合,扩展模型的上下文。然后再传给生成模型(也就是Deepseek);
- 生成(Generation)生成模型基于增强后的输入生成最终的回答。由于这一回答参考了外部知识库中的内容,因此更加准确可读。
标准RAG计算流程
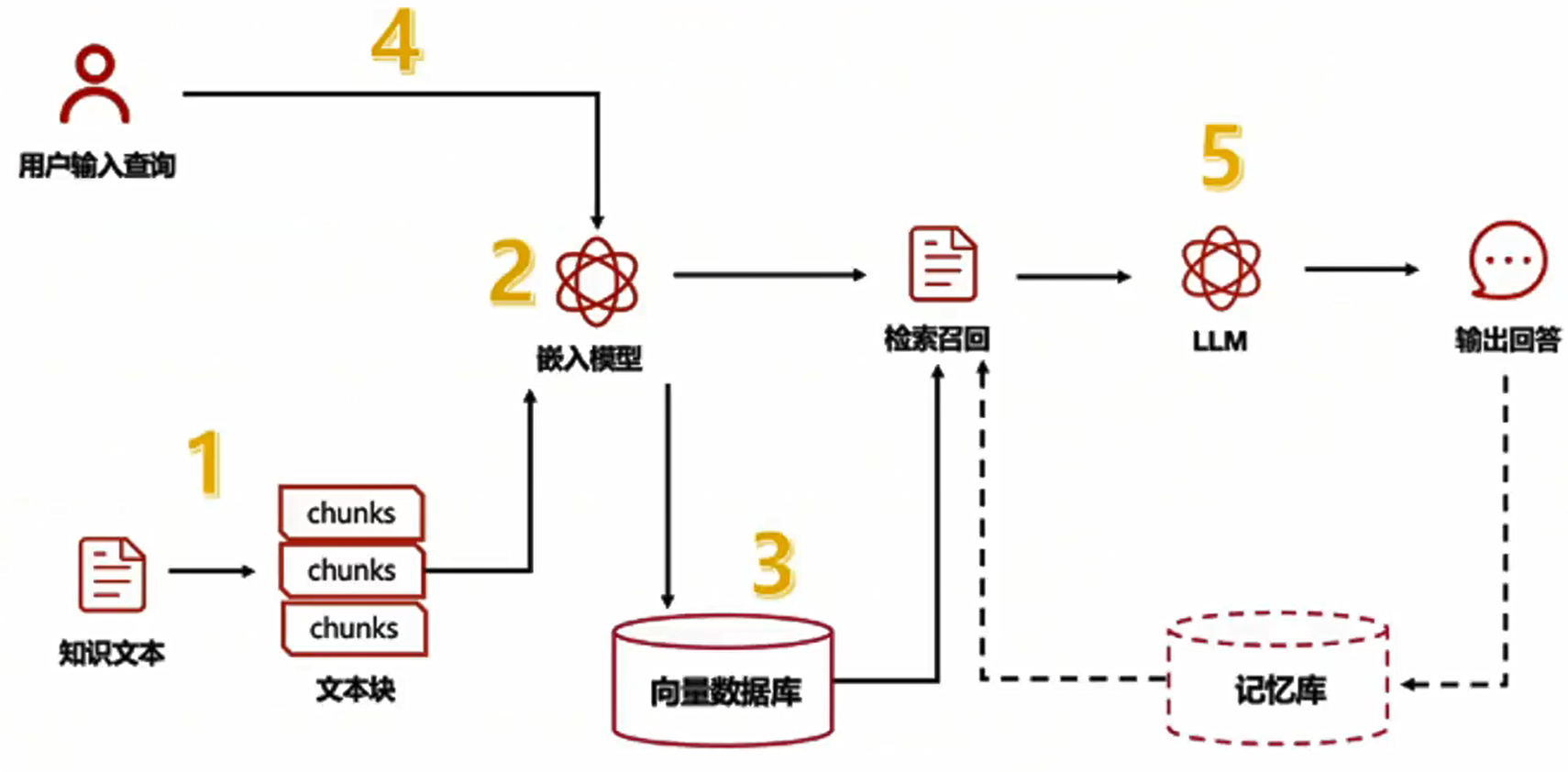
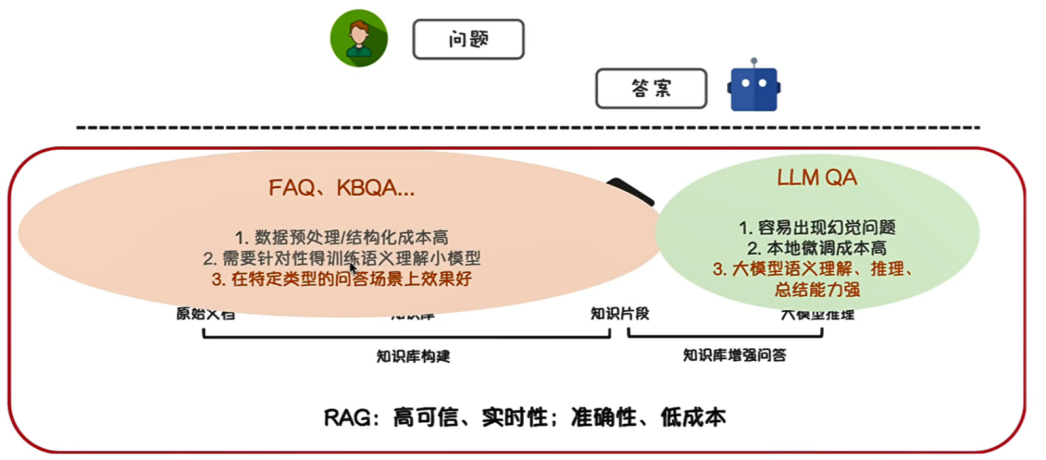
那么有了知识库,没有大模型,可不可以做问答,当然可以,我们常见的FAQ(Frequently Asked Questions,经常问到的问题)和KBQA(Knowledge Base Question Answering,知识图谱问答)是一种基于结构化知识库(即知识图谱)的智能问答方法。给定自然语言问题,该类方法基于知识图对问题进行理解,并根据问题理解的结果从知识图谱中查找或推理出问题对应的答案。但是这种方法往往更适合垂直领域,擅长回答特定类型问题。
那么没有知识库,只有大模型可以吗?不可以,大模型在没有知识库加持的情况下,对一下专业问题经常会胡乱回答(幻觉)。
因此RAG形式,就是把知识库和大模型两者的优势互补,是很不错的架构。

向量存储具体步骤

第一步:文档加载
加载不同的文件格式的数据,langchain内置了很多第三方文件解析库,可以辅助我们完成文件加载。
第二步:文档分块(切割)
由于一篇文档往往分成很多段落,我们需要将文档根据不同的段落进行分块。
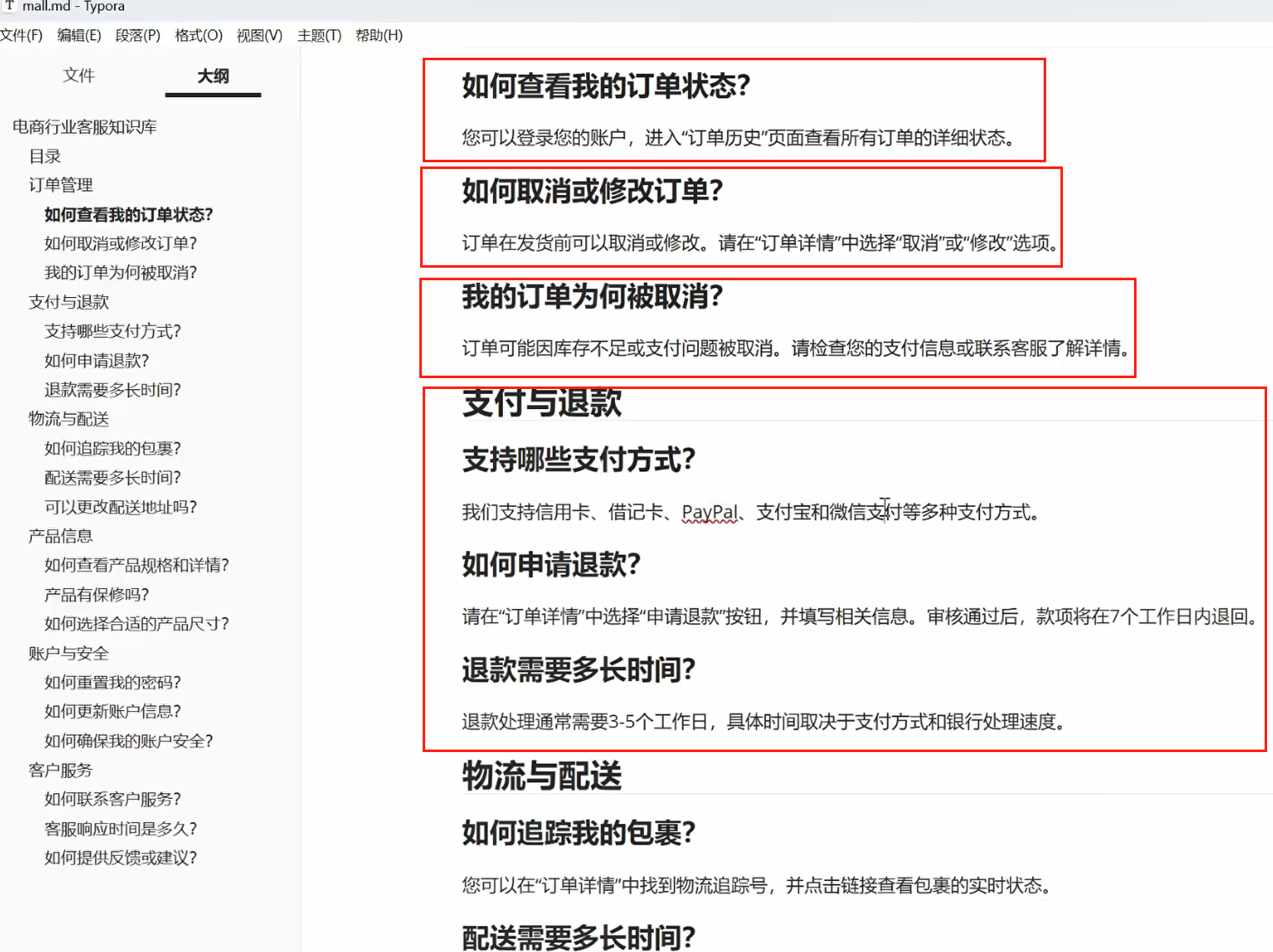
注意,文档切割的时候不一定会百分百精确,例如在分页的部分,段落会断掉。
第三步:向量化
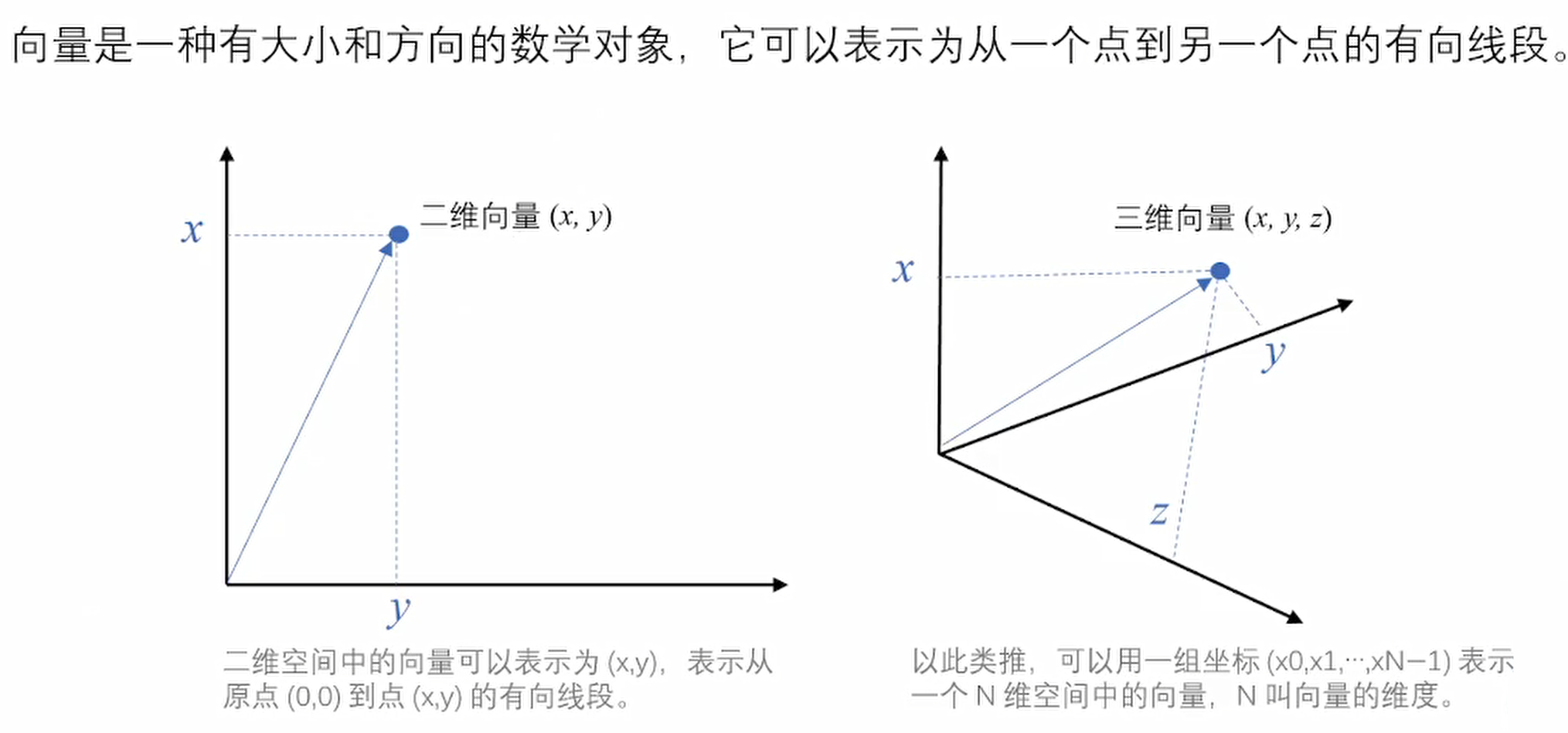
第四步:向量存储
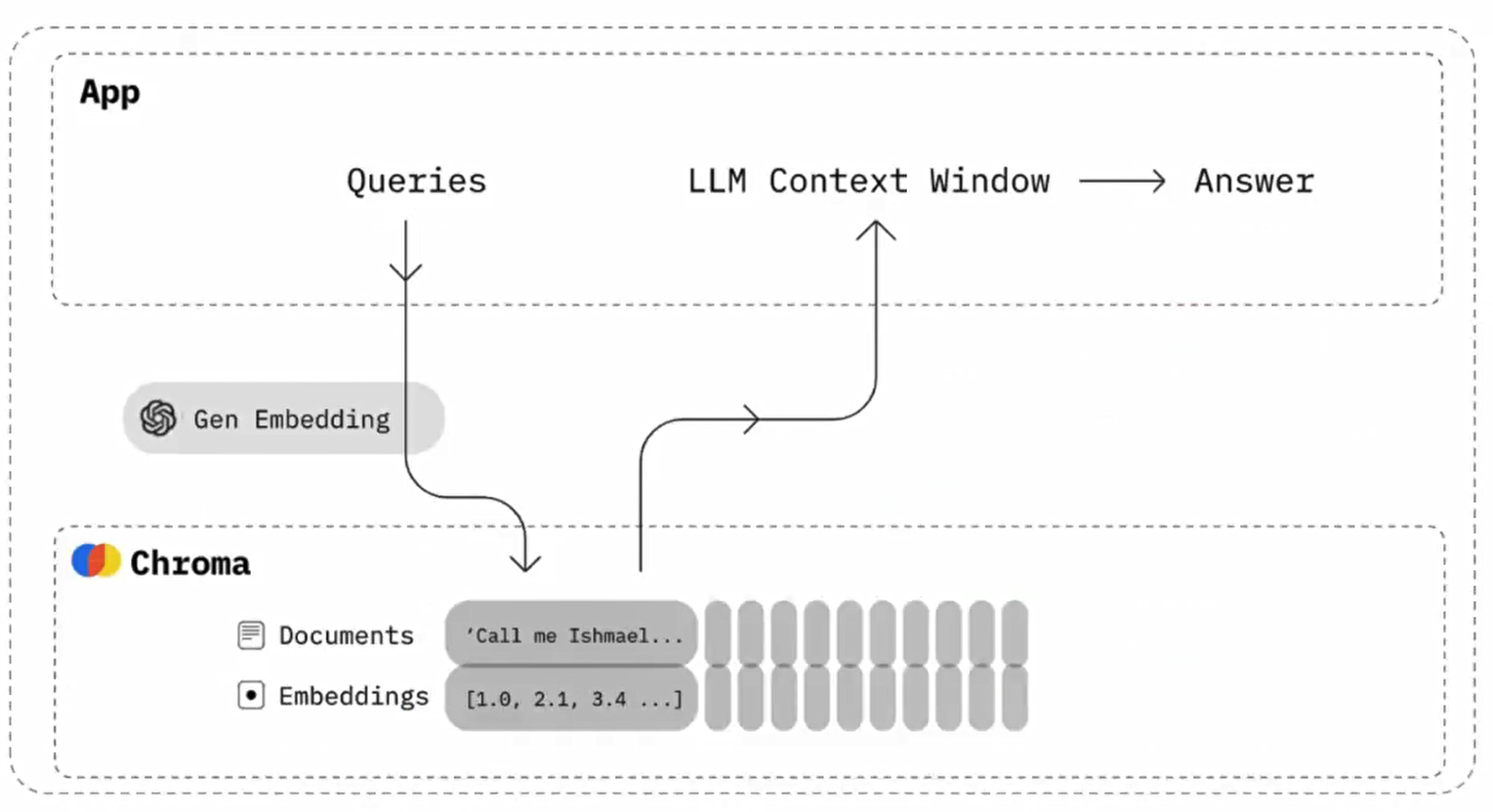
- FAISS: Meta 开源的向量检索引擎
- Chroma: 开源向量数据库,同时有云服务
- Pinecone: 商用向量数据库,只有云服务Milvus: 开源向量数据库,同时有云服务
- Weaviate:开源向量数据库,同时有云服务
- Odrant: 开源向量数据库,同时有云服务
- PGVector: Postgres 的开源向量检索引擎
- RediSearch: Redis 的开源向量检索引擎
- ElasticSearch:也支持向量检索
问:向量化模型需要微调吗?
负责业务的话需要微调。例如医疗。
用户查询检索
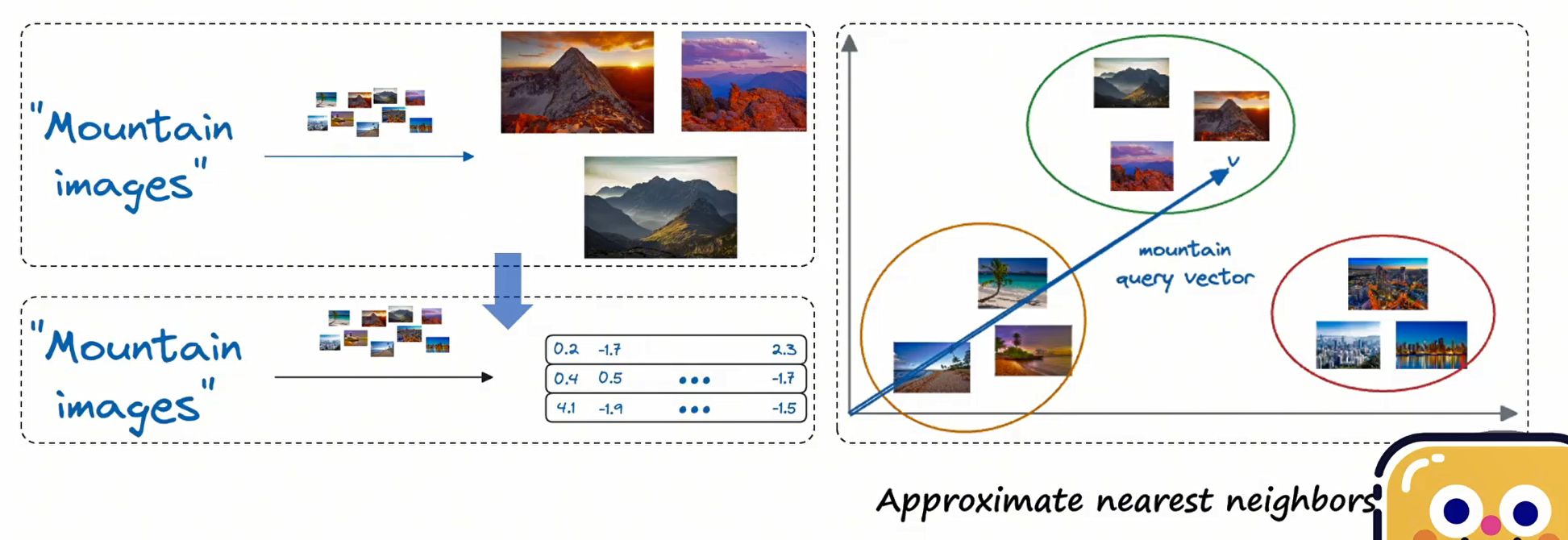
生成问答
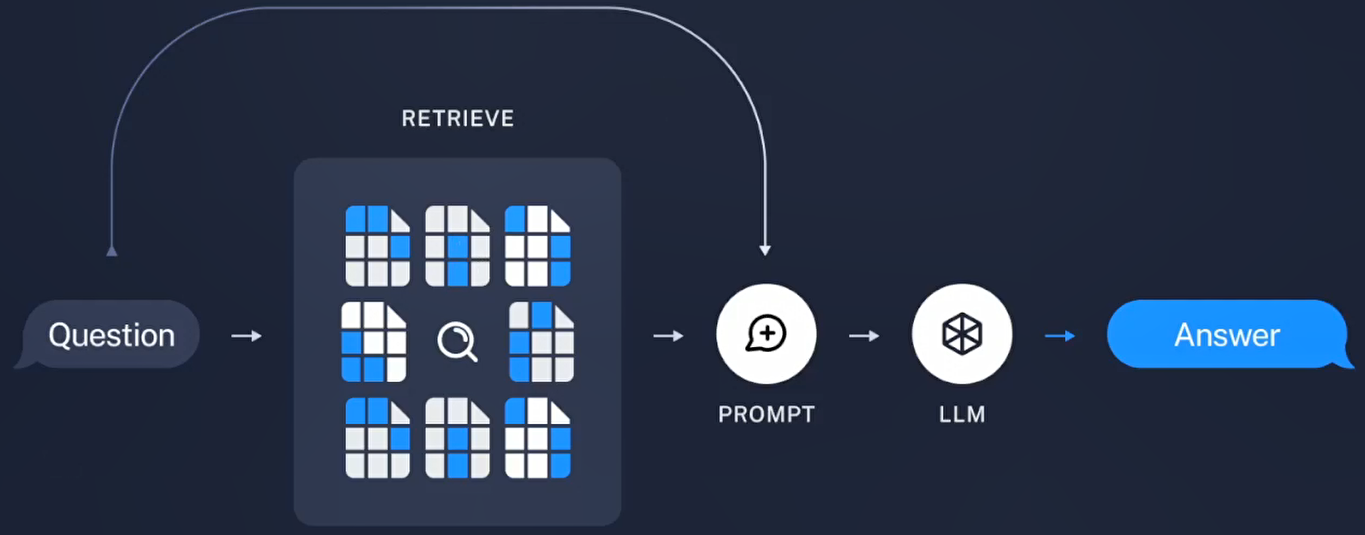
检索出来的“知识”并不能直接使用,还需要大模型进行归纳总结。

进阶
文档切片高级处理
- 简单文本处理
LangChain RecursivecharacterTextSplitter
["\n\n","\n"," ",""]- 复杂文本处理
- 基于NLP篇章分析(discourseparsing)工具
- 提取段落之间的主要关系,把所有包含主从关系的段落合并成一段
- 基于BERT中NSP(nextsentence prediction)训练任务
- 设置相似度阈值t,从前往后依次判断相邻两个段落的相似度分数是否大于t,如果大于则合并,否则断开。
- 基于NLP篇章分析(discourseparsing)工具
RAG可视化构建平台
RAGFlow
Dify


 浙公网安备 33010602011771号
浙公网安备 33010602011771号