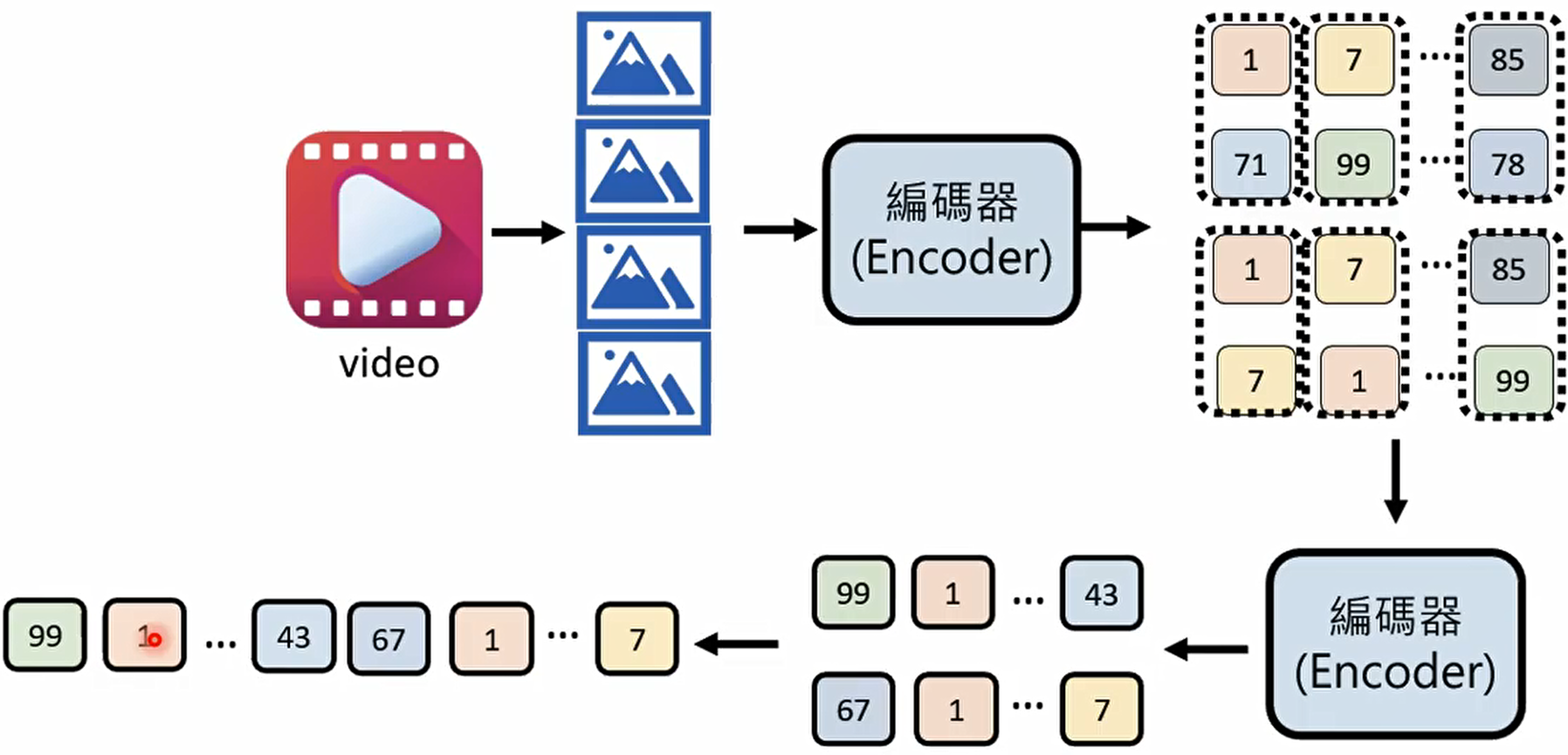
图片由像素构成,而视频则是由一帧帧连续的图片组成。

那么,AI 是如何 “看懂” 这些影像的呢?
图片
如今的 AI 处理图片时,会通过编码器(Encoder)将像素信息转化为一系列特征数据,再由解码器(Decoder)还原出我们能理解的图像;
https://arxiv.org/abs/2111.06377
视频
处理视频时,编码器则会整合多帧画面的信息,捕捉帧与帧之间的关联。这种 “编码 - 解码” 的思路,是 AI 处理复杂视觉信息的基础。
视频处理时,除了可以在宽高上做压缩,还可以在时间维度上压缩:
https://arxiv.org/abs/2103.15691
openai在视频处理时也采取了类似的做法:
https://openai.com/index/video-generation-models-as-world-simulators/
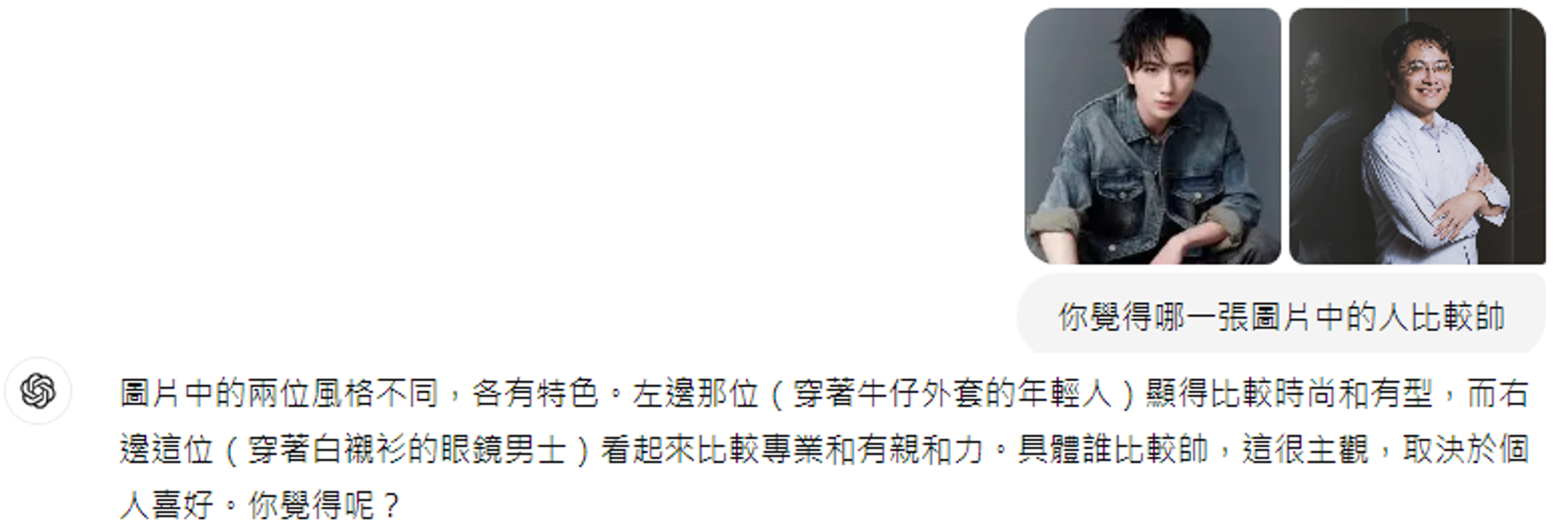
0. 影像生成文本

生成视频
生成式 AI 在影像领域的应用形式非常丰富,主要可以分为以下几类:
这是目前最受关注的生成方式,即通过文字描述(condition)让 AI 生成对应的图片或视频。比如 OpenAI 的 Sora 模型,就能根据文字指令生成逼真的视频片段。
https://openai.com/research/video-generation-models-as-world-simulators
https://openai.com/sora
文字生影像的过程,就像让 AI 根据 “剧本” 拍电影。例如输入 “五只灰色狼崽在偏远的 gravel 路上嬉戏追逐”,AI 就能生成对应的动态画面。
除了文字,AI 还能以现有影像为基础进行创作,比如缺失内容生成、风格转换(将照片变成油画风格)、画质提升(把模糊画面变清晰)等。
此外,还有像 “Talking Head” 这样的技术,能让上传的参考图像动起来,实现类似数字人说话的效果。
Paper: https://arxiv.org/abs/2403.17694

将上传的图片,根据你要讲的话,生成动态头像

如果想更精准地控制生成效果,还可以借助草图、深度图、边缘检测图等特殊输入。比如 ControlNet 模型,就能根据这些结构化信息生成符合预期的图像,让创意落地更可控。
ControlNet: https://arxiv.org/abs/2302.05543
要让 AI 生成高质量的影像,海量的训练数据是基础。LAION-5B 数据集,它包含了 58.5B 的图像 - 文本对,覆盖了丰富的场景和描述,为文字生图模型提供了强大的 “素材库”。
https://laion.ai/blog/laion-5b/
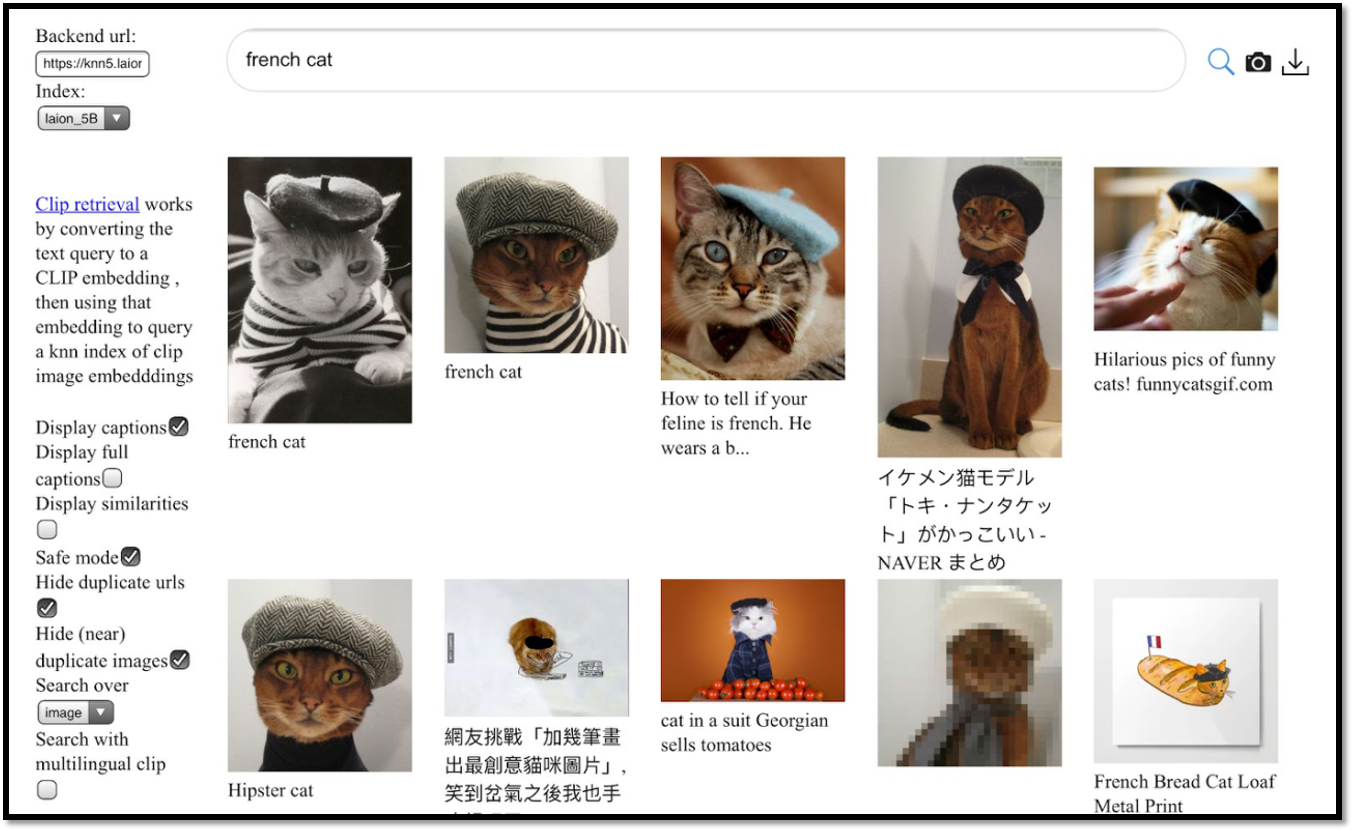
这些数据就像 AI 的 “教科书”,模型通过学习图像与文字的对应关系,才能理解 “雪地裡的猫”“陽光下的貓” 等描述的差异,并生成符合预期的画面。
以文字生图为例,模型的工作过程可以简单理解为:将文字描述转化为特征向量,再通过 Transformer 等结构生成图像的特征,最后解码为像素画面。为了提高效率,模型通常会采用平行生成的方式,同时生成多个候选结果再优化。
生成的影像 “好不好”,需要有评估标准。借助 CLIP 模型进行评分的方法:CLIP 会计算生成图像与文字描述的匹配度,分数越高,说明图像越符合预期。比如生成 “沙滩上的狗”,如果图像中狗确实在沙滩上,CLIP 分数就会较高;如果生成的是 “陽光下的貓”,分数就会很低。
https://arxiv.org/abs/2103.00020
DALL绘图案例:
一张图胜过千言万语
这是李宏毅老师家的钟表,李宏毅老师想让DALL绘制一模一样的图:画一个有现代简约设计风格的的钟。钟面是一个大约圆形的框架框架为黑色金属材质,没有传统的钟面刻度。钟的中央部分是一块浅色接近长方形的木板,上下镂空,木板的右下角印有“patya”字样,没有其余花纹。钟针为黑色,设计简约,只有时针和分针,没有秒针。钟针安装在木板的中央部分。
个人化图像生成
https://arxiv.org/abs/2208.01618
https://arxiv.org/abs/2208.12242
假设我们需要AI绘制我们桌子上的一个摆件,我们使用很少有人用过的符合来描述它,例如"S*":
然后我们简单给模型几张示例图,告诉他这就是“S*”:
然后我们就可以使用模型来绘制各种“S*”及其变体:
课程中详细介绍了四类经典的生成式模型,各有特色:
VAE(变分自编码器)
通过编码器将图像转化为潜在向量,再用解码器还原,擅长捕捉数据的整体分布。
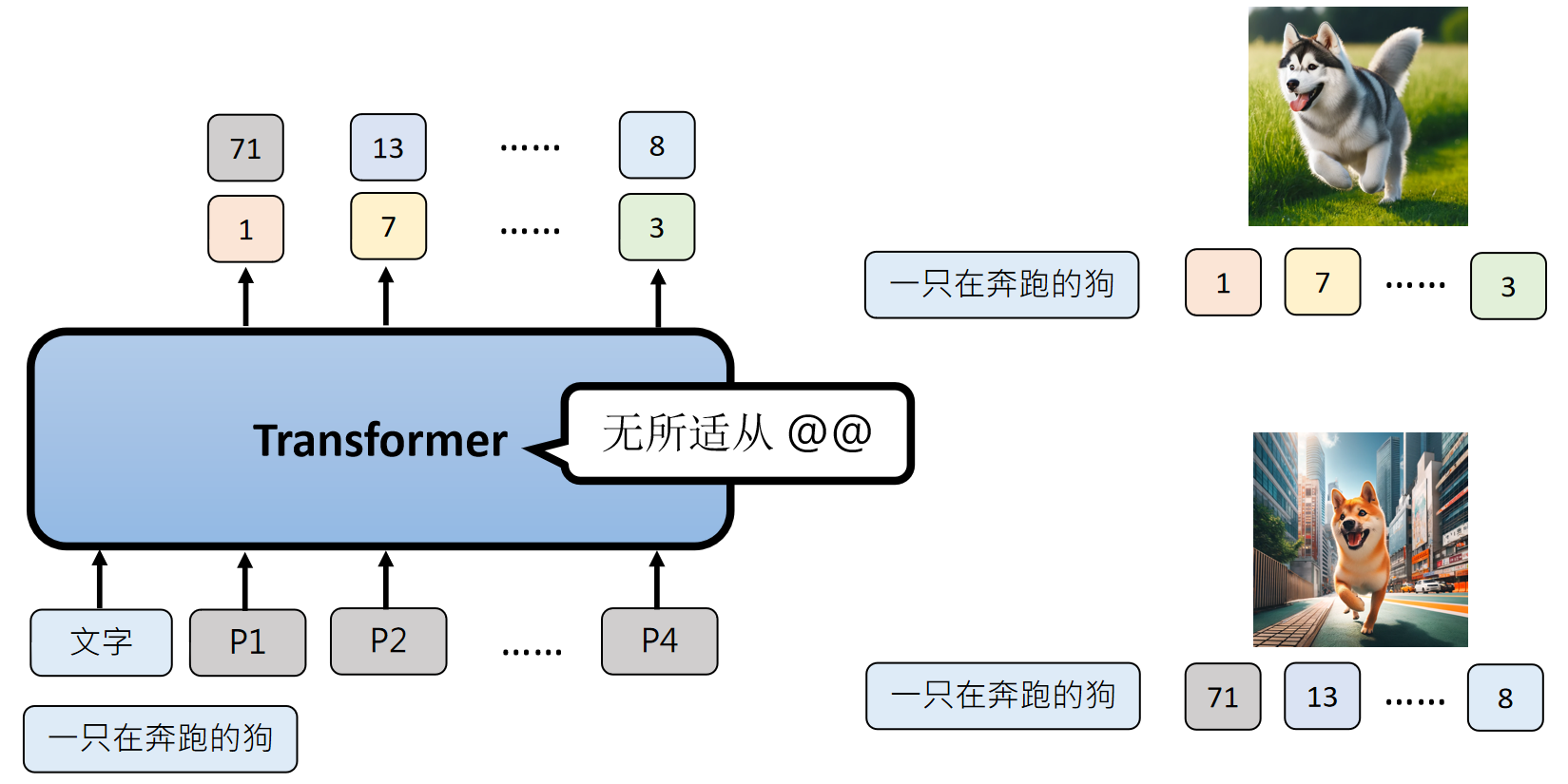
Auto-Encoder ——解决图片很难被文字描述问题
例如,模型学习“一只在奔跑的狗”时,可能会看到在田野奔跑的哈士奇,也可能看到在都市奔跑的柴犬,对模型来说,很难融合这种信息,很难学习。
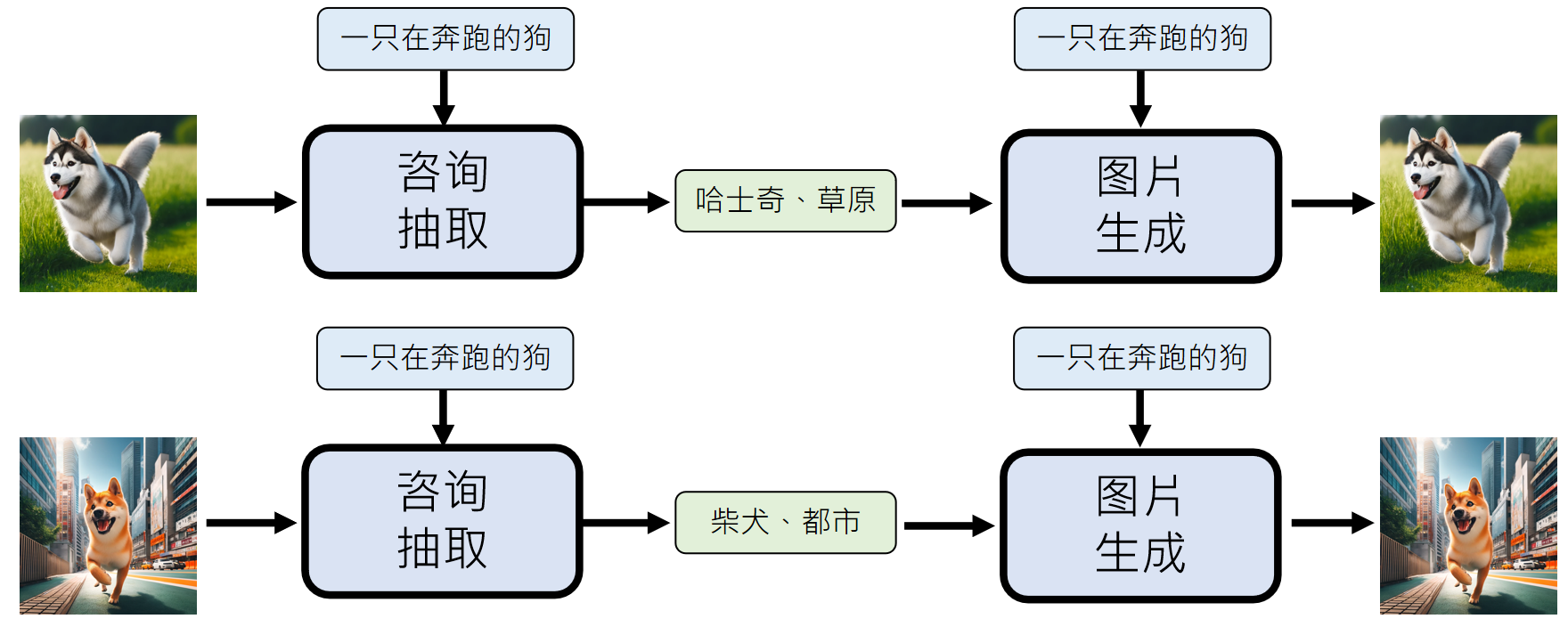
图片信息抽取模型
那么我们如何让描述图片的文字更丰富呢?为我们可以训练一个抽取图片描述的模型,让它来生产关于图片的描述,这样,得到的文字描述和图片数据集用来训练视频生成模型就会好很多。
那怎么训练“咨询抽取”模型呢?
我们可以让“咨询抽取”模型和图片生成模型一起训练,我们不需要知道“咨询抽取”模型抽取了什么信息,我们只要图片生成模型根据抽取到的信息生成和“输入图片”越接近越好(或者一模一样)的图片就行了。
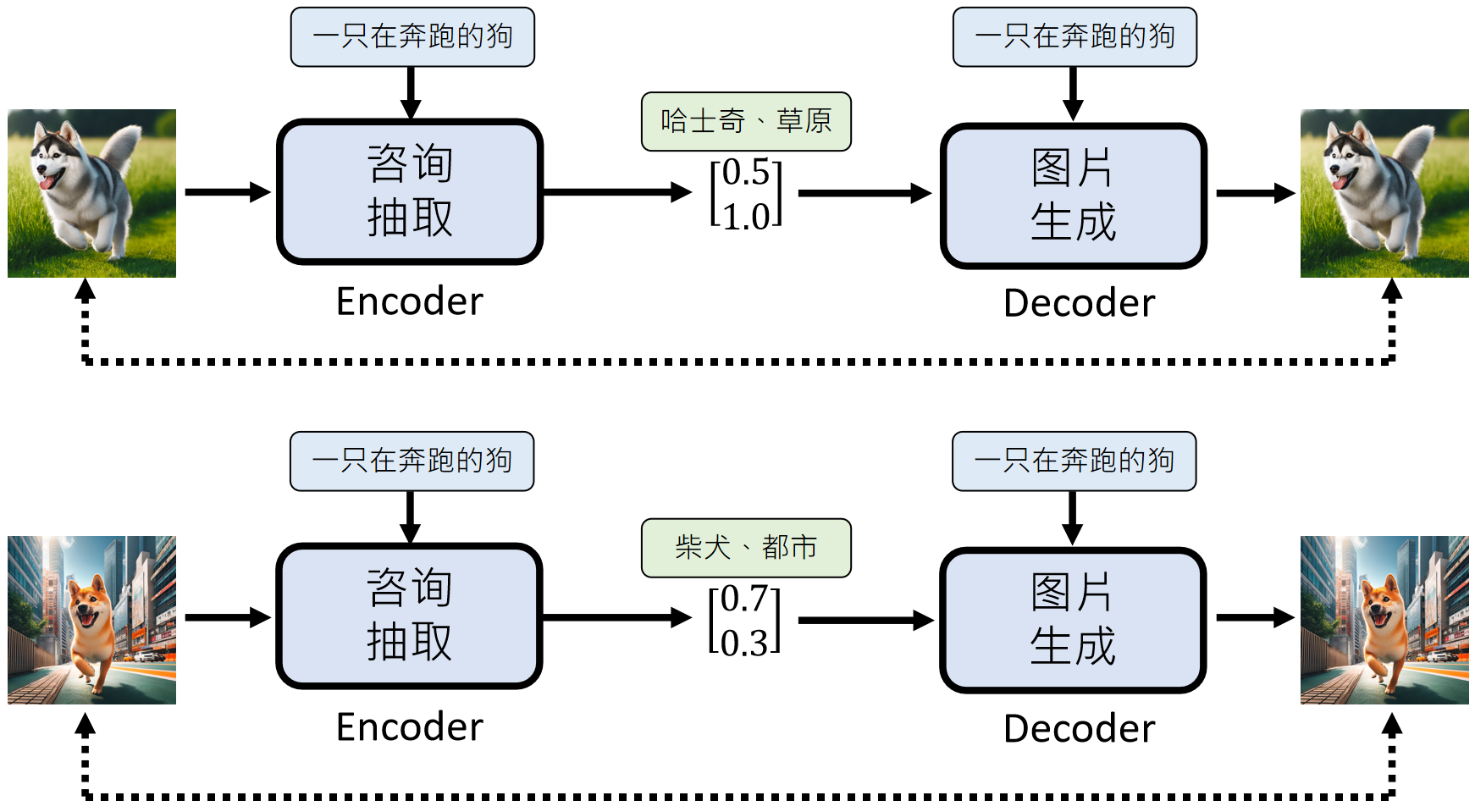
整个完整的框架叫做Auto-Encoder :
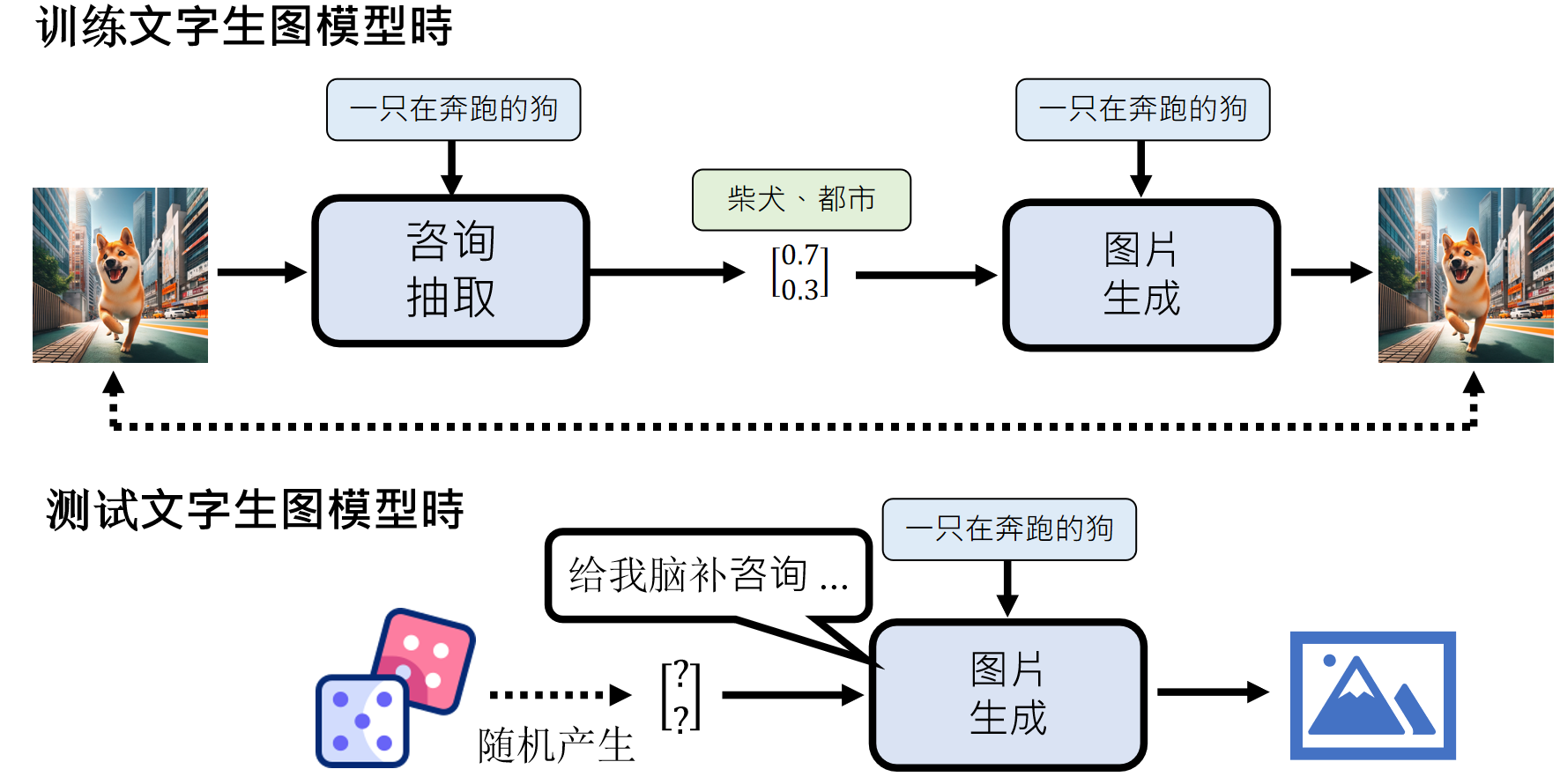
训练时我们有图片可以输入,从而抽取到图片咨询,但是我们在真正使用文字生成图片时,我们的输入只有“一直奔跑的狗”这么一句话。那么额外的描述信息从哪获取呢?我们采取随机生成的方法:
上面的模式对应的模型就是:VAE
Flow-based
基于可逆变换,能精确计算数据的概率分布,生成过程较为高效。
和VAE模型不同的模型是Flow-based ,它省略了Encoder,因为它认为,Encoder做的事情正好是Decoder的相反操作,所以它要求Decoder里的所有函数必须要有对应的反函数,这样就可以逆推出Encoder了:
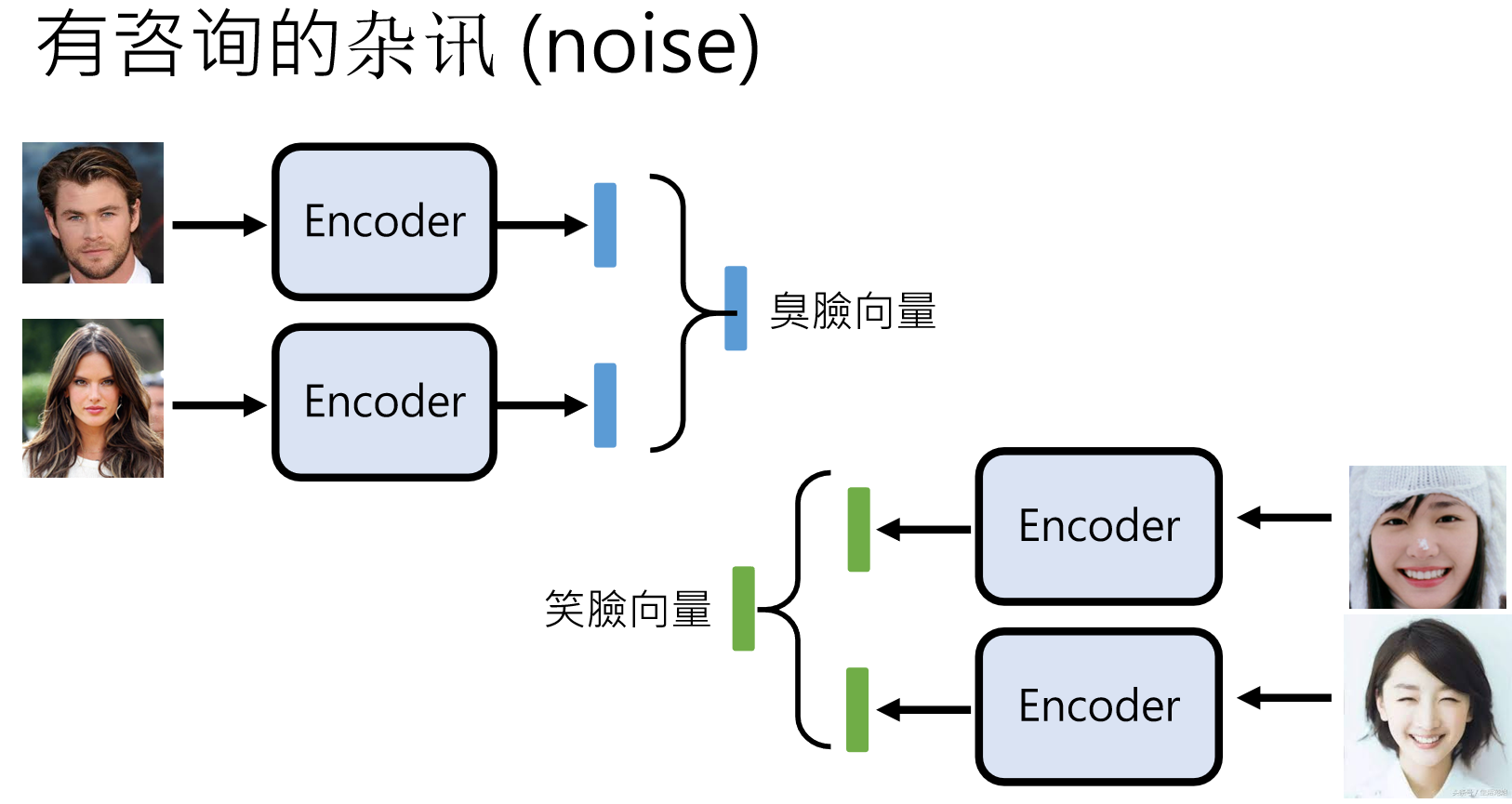
noise的运用
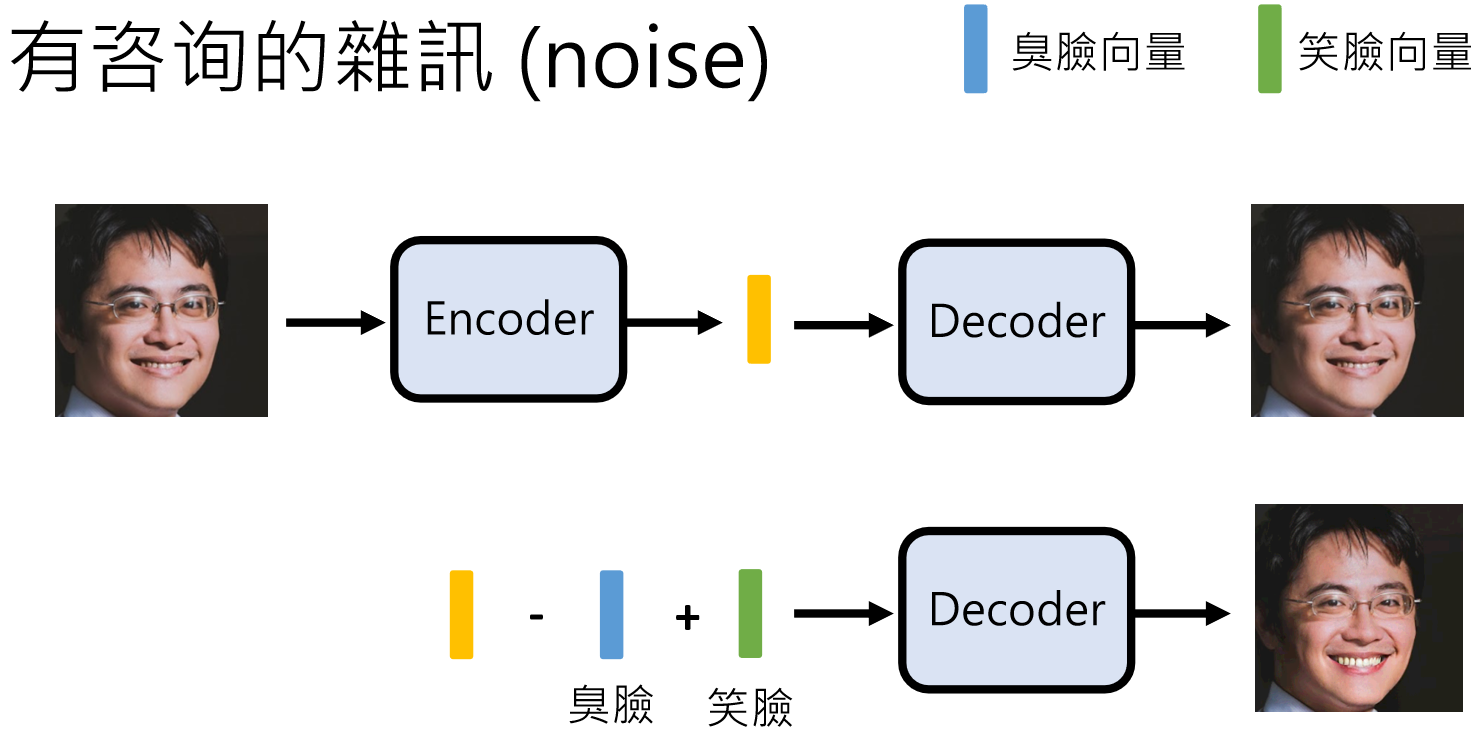
文献里面大部分会把抽取到的图片信息叫做“noise”,但这并不意味着他不重要。我们可以直接使用这些向量对图片做出很多调整,例如下面我们把抽取得到的笑脸向量和臭脸向量加入到运算当中,可以实现让人笑的更开心:
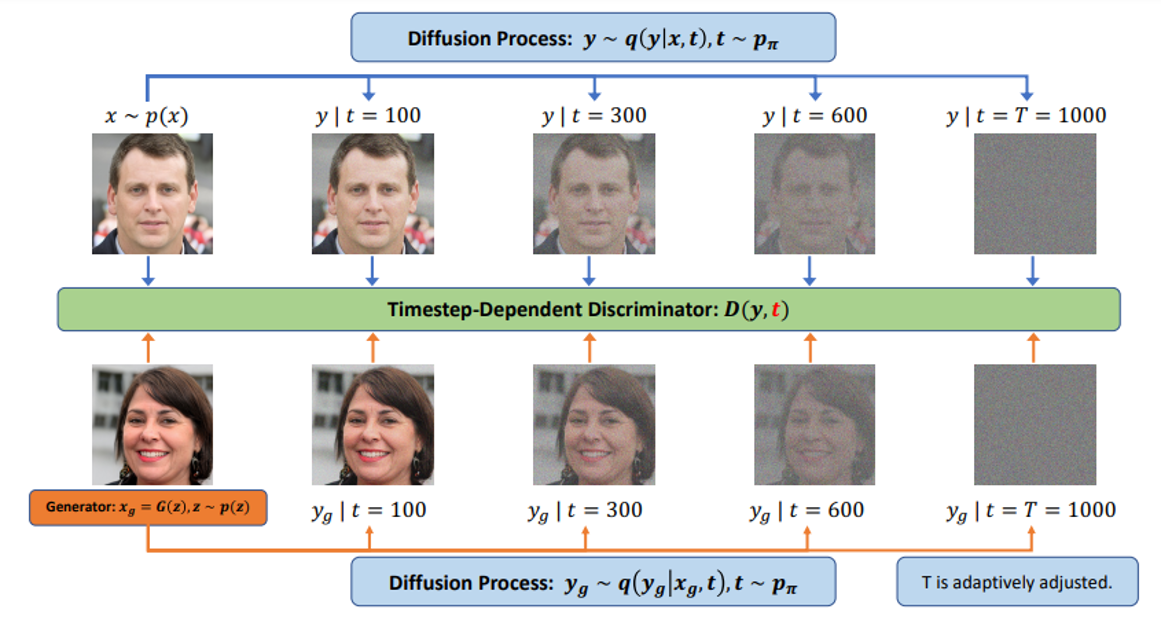
Diffusion
通过逐步 “去噪” 生成图像,生成质量高,OpenAI 的 Sora 就采用了这种方法。

Source of image: https://openai.com/index/video-generation-models-as-world-simulators/
Diffusion里的Decoder每次都是只做一件事:“消除噪音”,往往需要500-1000次重复操作,这也是Diffusion的痛点,目前的主要研究方向也是如何采取更少的去噪步骤,来生成同样清晰的图片。

如何产生有杂讯的训练资料?人工创造:

在Diffusion框架里,添加杂讯的过程叫做:Forward Process ,去除杂讯的过程叫做:Reverse Process :

其实sora里使用的就是Diffusion + Transformer :https://arxiv.org/abs/2212.09748
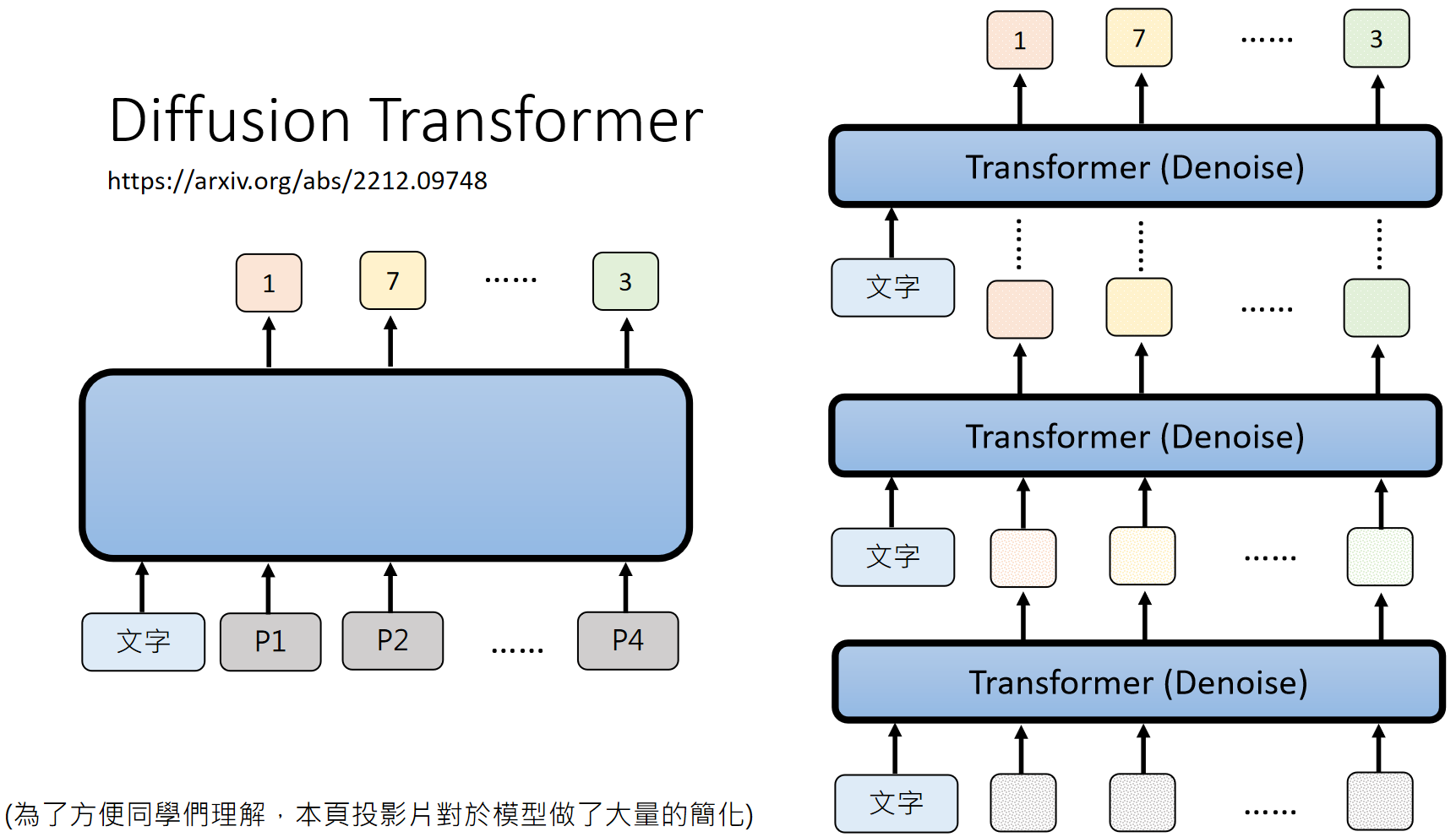
此处是极度简化后的讲法,详细说明请见:https://www.youtube.com/watch?v=azBugJzmz-o&list=PLJV_el3uVTsNi7PgekEUFsyVllAJXRsP-
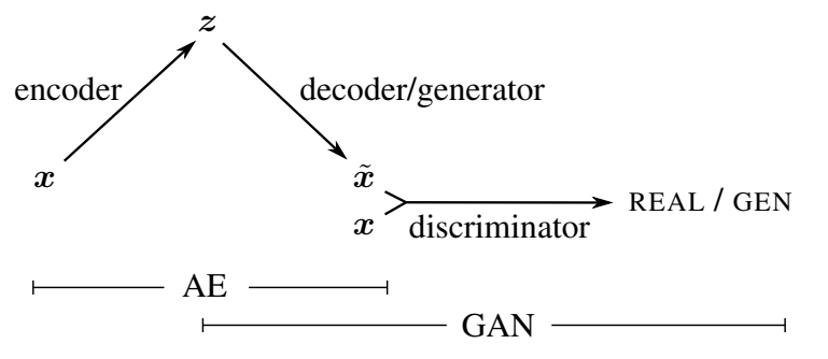
GAN(生成对抗网络)
Generative Adversarial Network (GAN)
由生成器和判别器 “对抗” 训练,生成器(Generator )努力生成逼真图像,判别器(Discriminator )则负责 “打假”,两者互相促进,生成效果生动。
这里的判别器类似前面讲到的CLIP,只不过GAN里叫做Discriminator,他就负责判别一个图片是否符合文字描述:
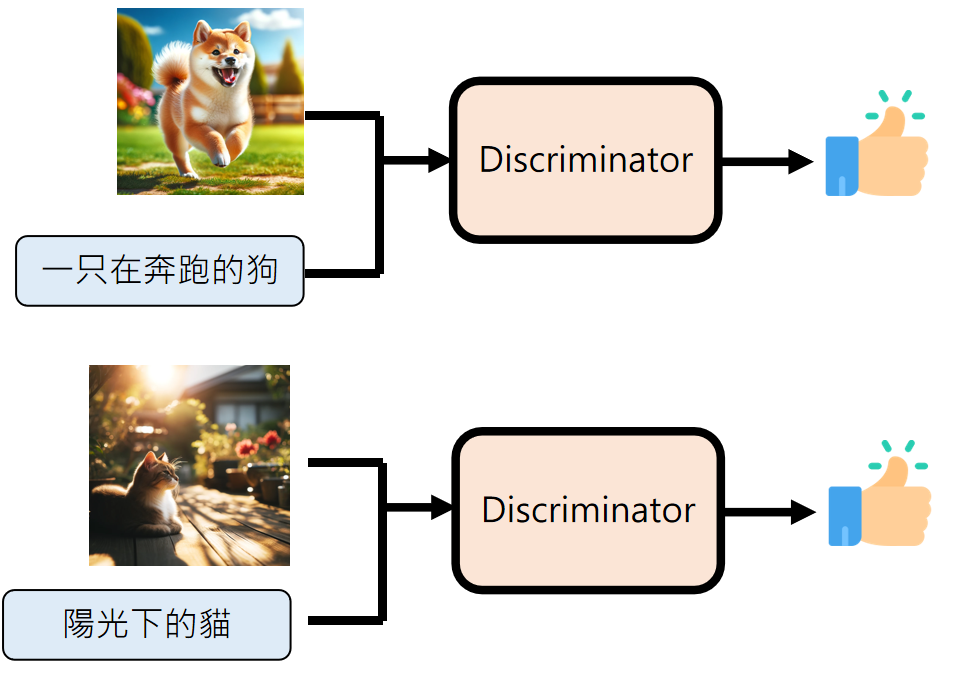
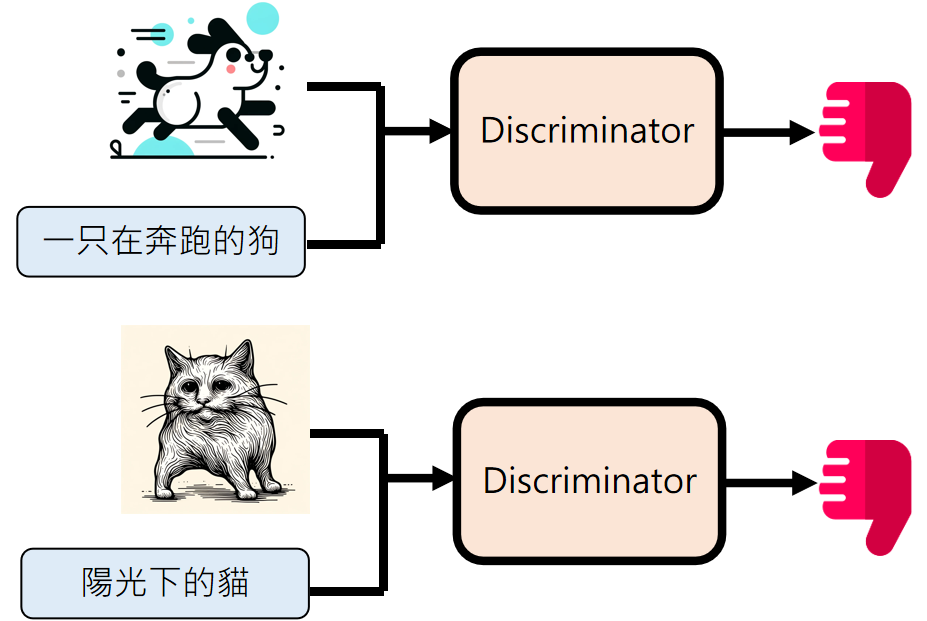
Discriminator 和 Generator 会交替训练 :


GAN的训练类似大型语言模型 RLHF 阶段,不同的是Discriminator 就是Reward Model ,不同之处在于:Discriminator 判断只要 AI 产生的都是坏的。
GAN 是个外挂 ,他可以结合前面讲到的三种框架:
- VAE + GAN :https://arxiv.org/abs/1512.09300
- Flow + GAN :https://arxiv.org/abs/1705.08868
- Diffusion + GAN :https://arxiv.org/abs/2206.02262
进一步深入学习参照:

(2016 機器學習) VAE https://youtu.be/8zomhgKrsmQ
(2018 機器學習及其深層與結構化) GAN https://www.youtube.com/watch?v=DQNNMiAP5lw&list=PLJV_el3uVTsMq6JEFPW35BCiOQTsoqwNw
(2019 機器學習) Flow-based https://youtu.be/uXY18nzdSsM
(2023 機器學習)Diffusion https://www.youtube.com/watch?v=azBugJzmz-o&list=PLJV_el3uVTsNi7PgekEUFsyVllAJXRsP-
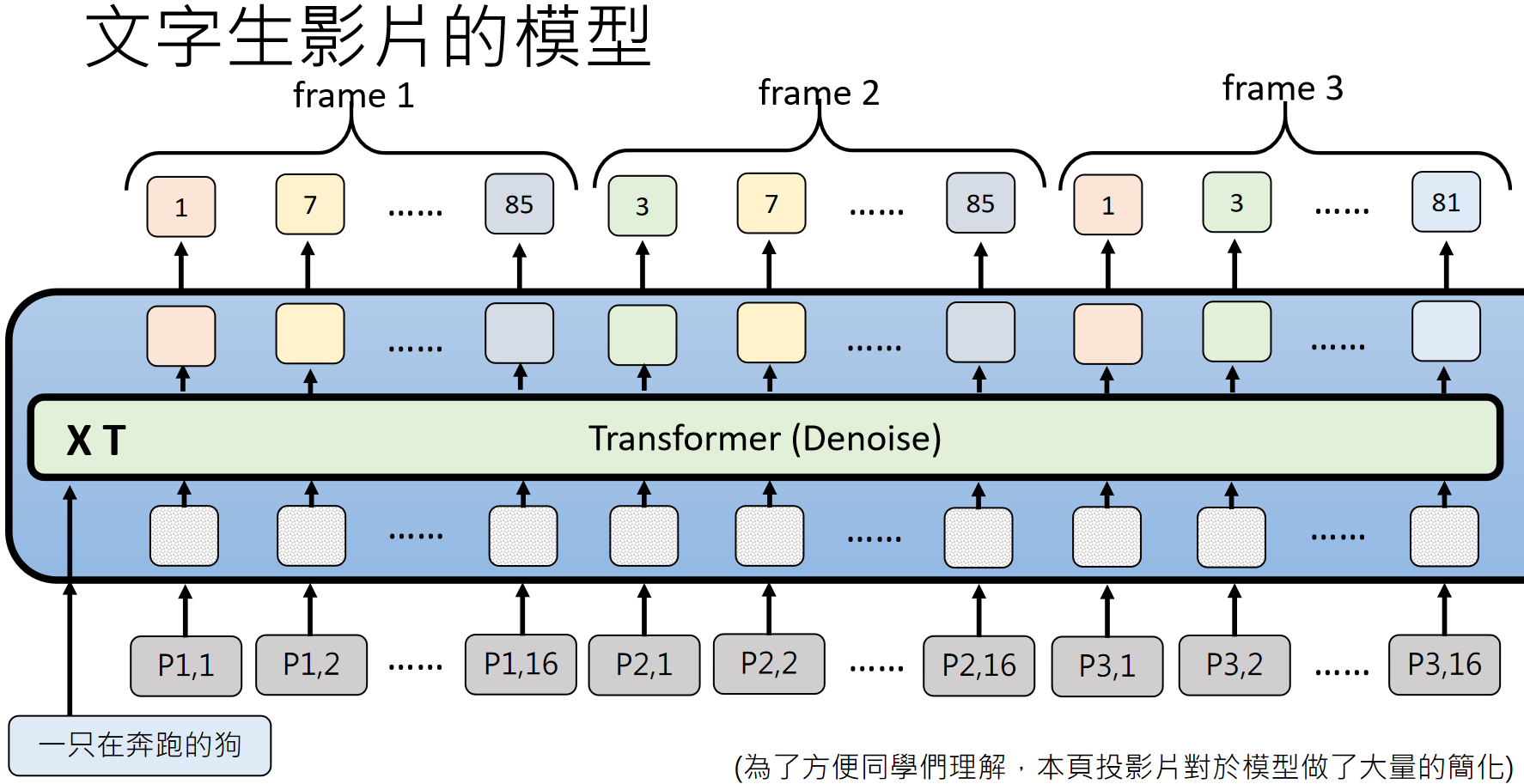
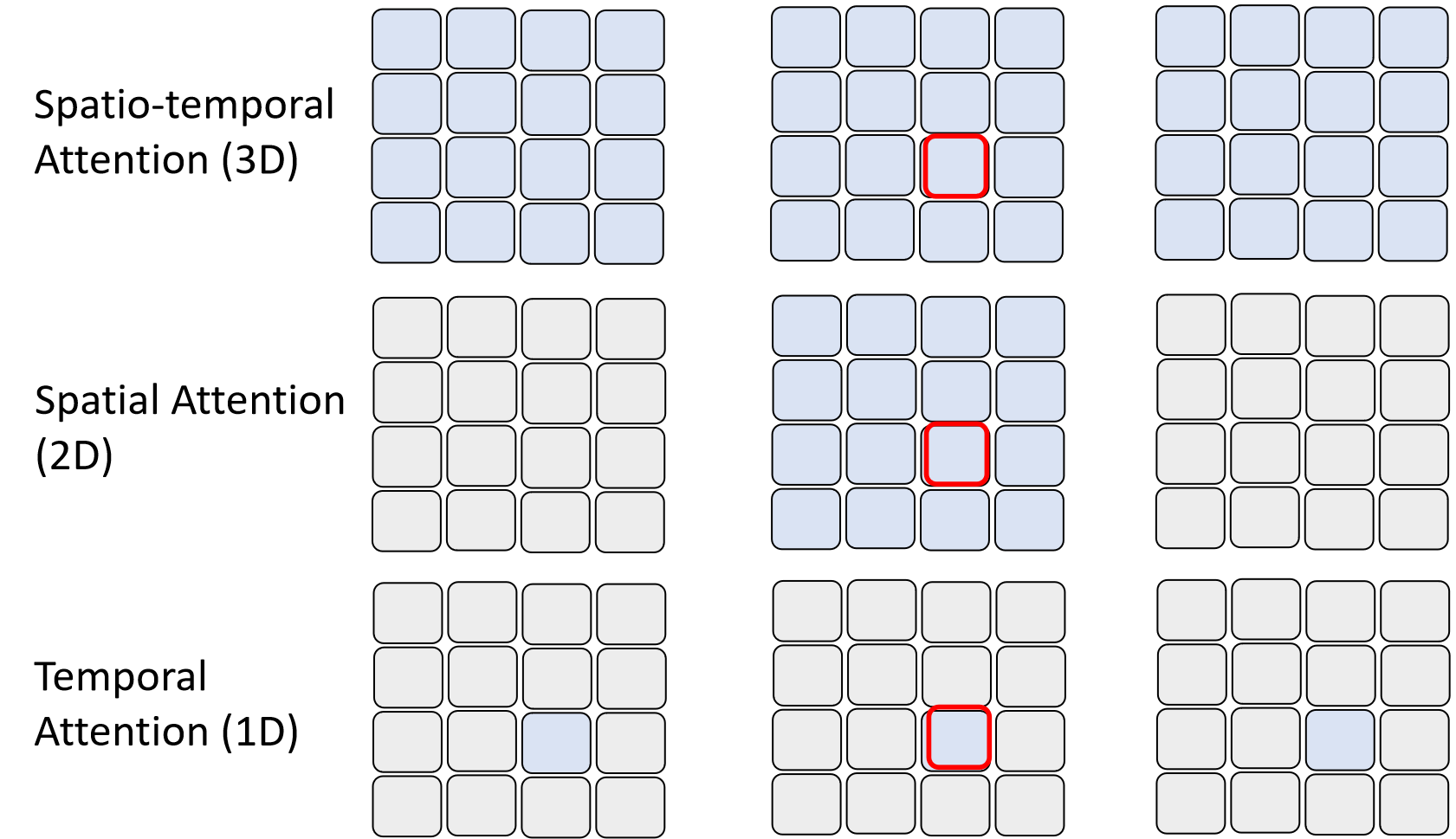
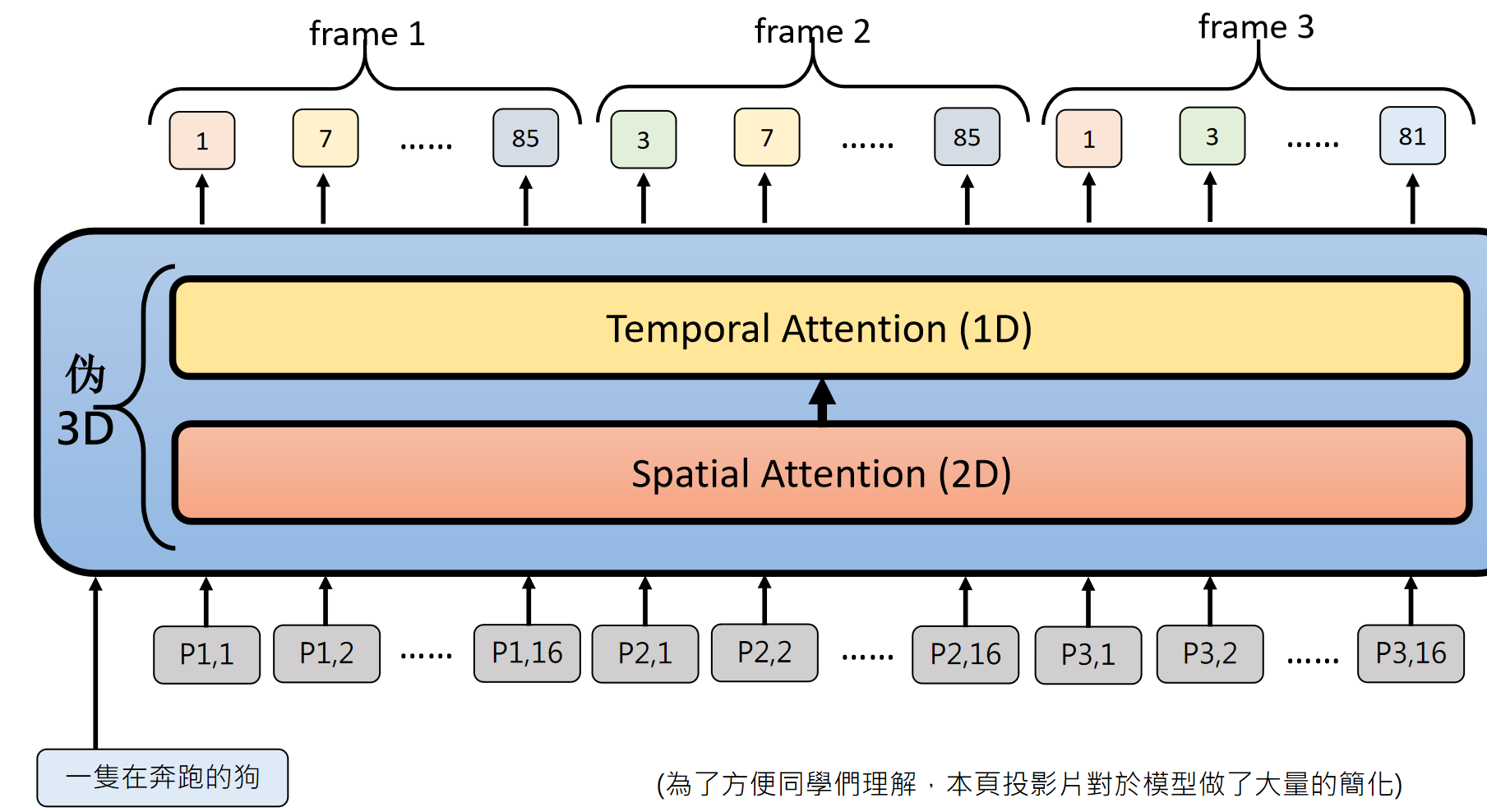
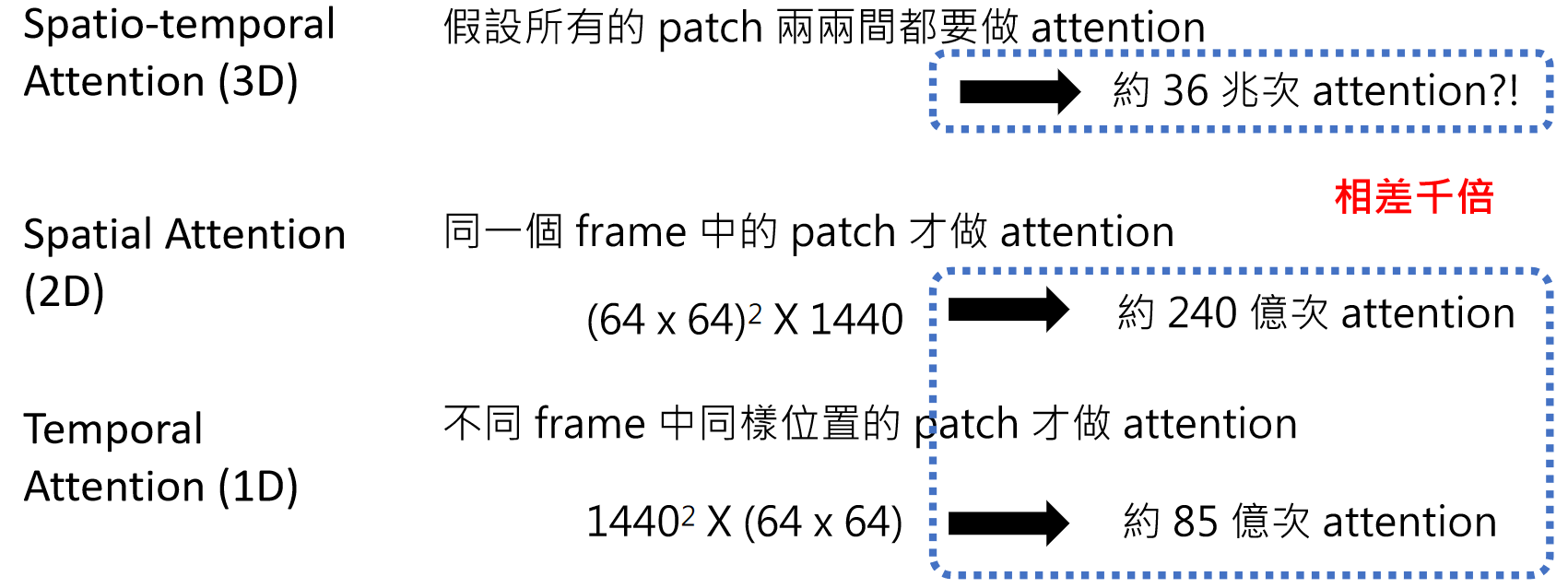
视频包含时间维度,假设每秒 24 帧,每帧有 64x64 个 patch,一分钟的视频就有约 600 万个 patch。如果每个 patch 之间都要计算注意力,会产生约 36 兆次运算,这显然不现实。
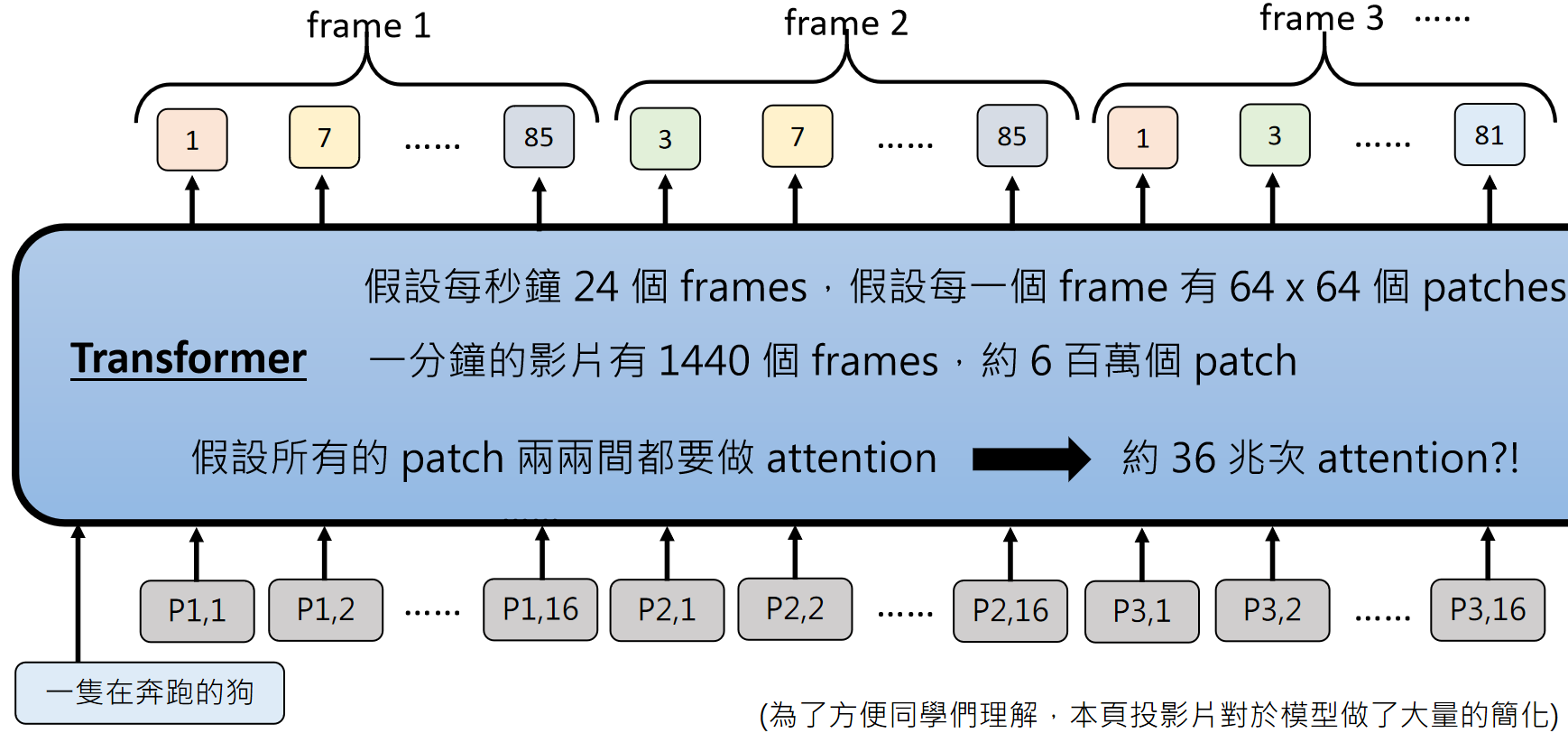
为了解决这个问题,模型会采用时空注意力分离的策略:同一帧内的 patch 计算空间注意力,不同帧同一位置的 patch 计算时间注意力,大幅减少运算量。
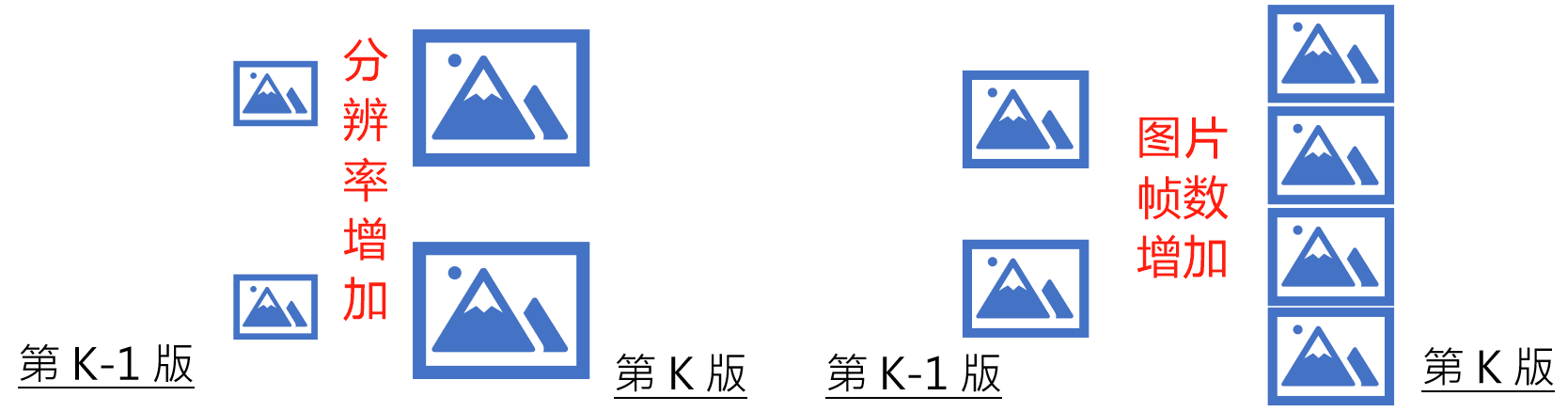
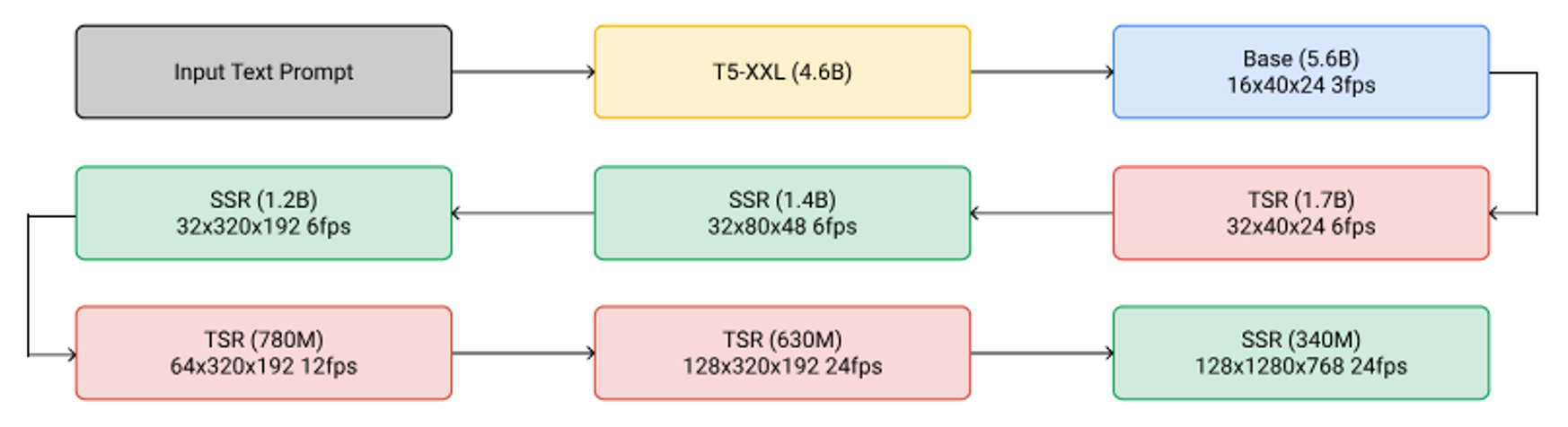
视频生成通常需要多阶段模型协作,从低分辨率、低帧率逐步提升到高分辨率、高帧率。比如 Imagen Video 就有多个版本的模型,分别负责不同分辨率和帧率的生成,最终组合出流畅的高清视频。
例如:Google Imagen Video :https://arxiv.org/abs/2210.02303
像 Genie 这样的项目,探索 “生成式互动环境”—— 不仅能生成影像,还能根据用户的动作指令实时调整画面,比如让虚拟人物移动、改变场景等。这意味着未来的影像生成 AI 可能会成为 “虚拟世界的导演”,让我们能直接参与并操控生成的内容。
例如:直接操控这个人要走去哪里 :

直接做个开放世界游戏?
延伸阅读
语言模型如何将图片作为输入
https://arxiv.org/abs/2405.17247

Diffusion Models 如何产生影片
https://arxiv.org/abs/2405.03150


















 浙公网安备 33010602011771号
浙公网安备 33010602011771号