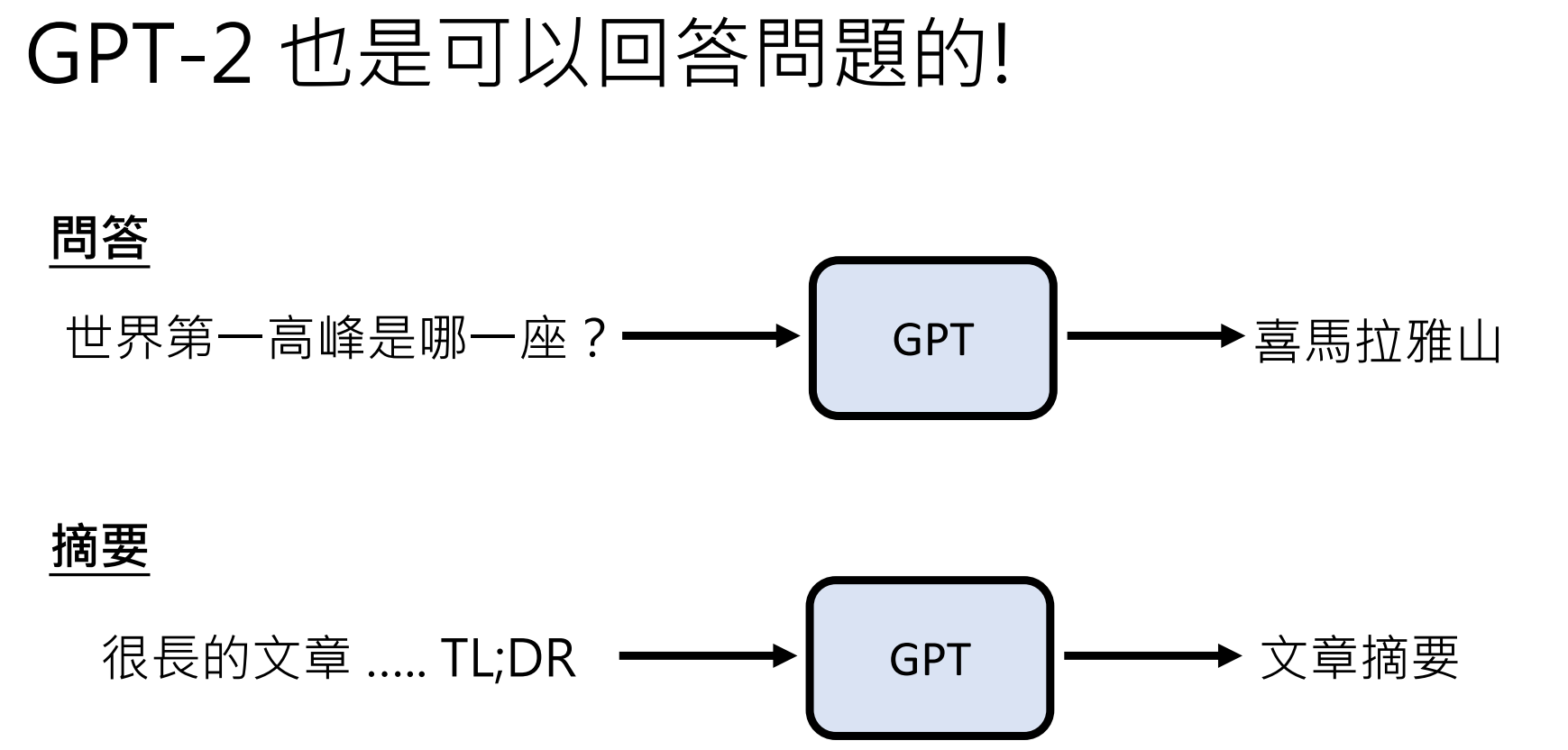
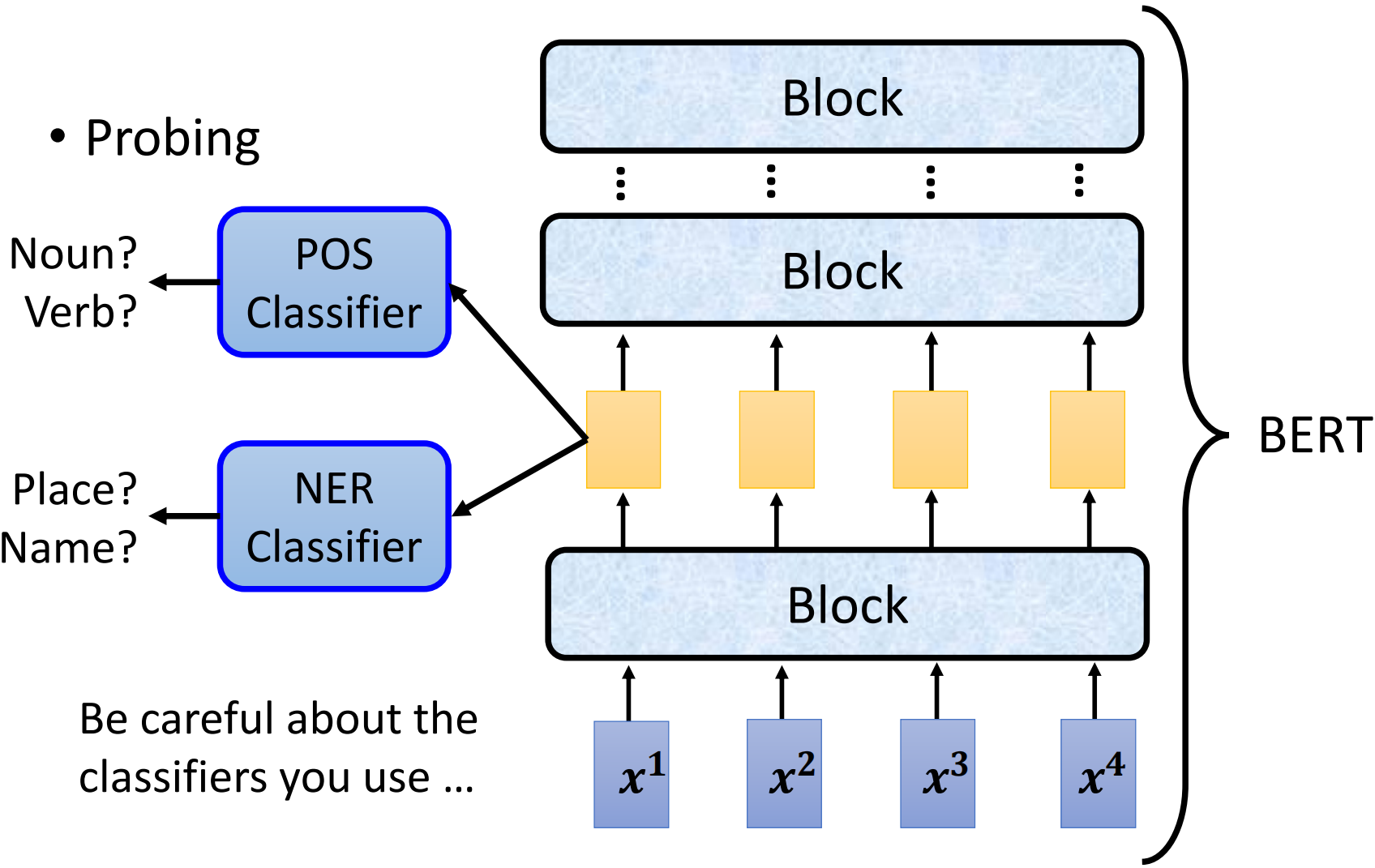
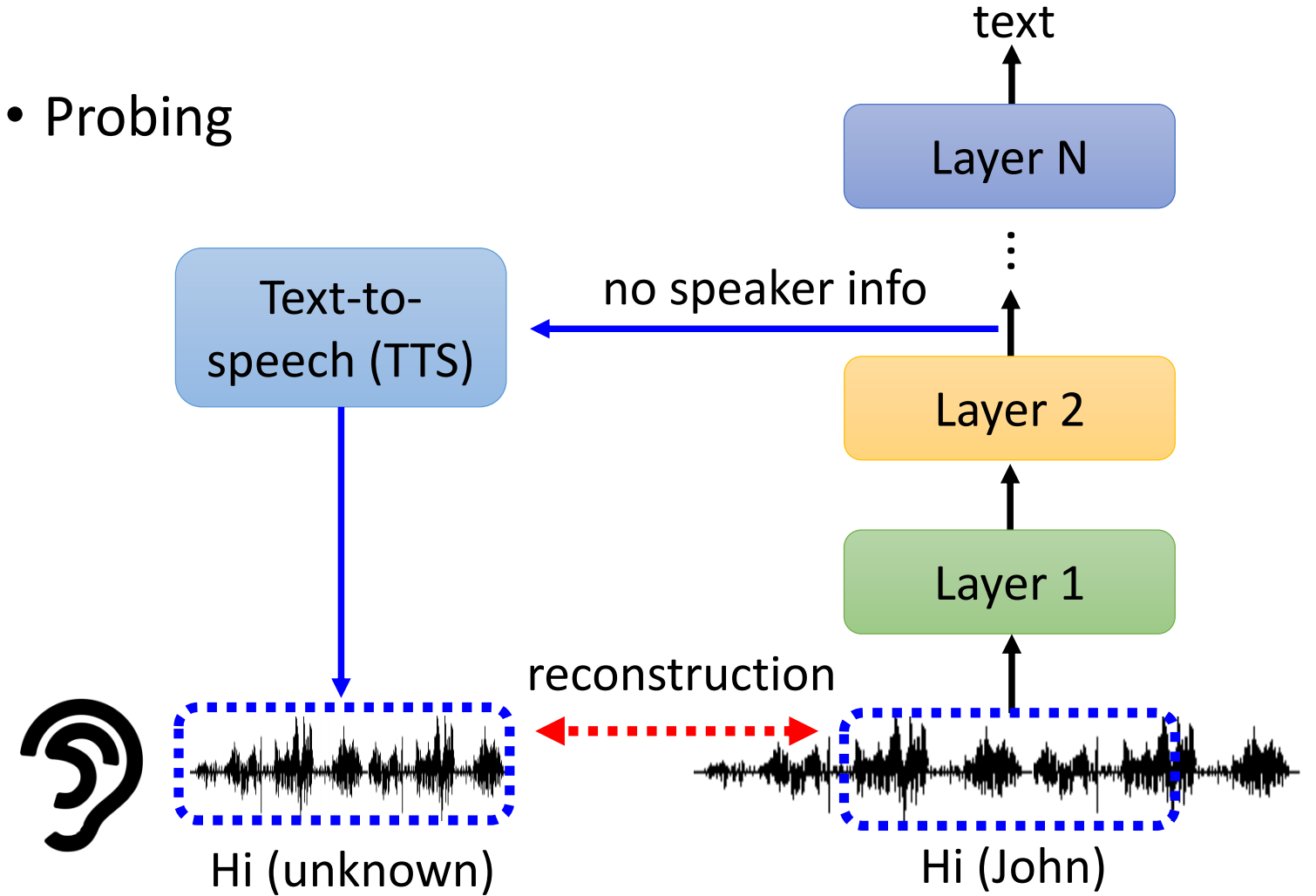
2.了解大型语言模型
一、ChatGPT 的真正核心:文字接龙

核心原理
-
-
本质:基于概率的Token预测器(非真正理解语义)
-
工作流程:
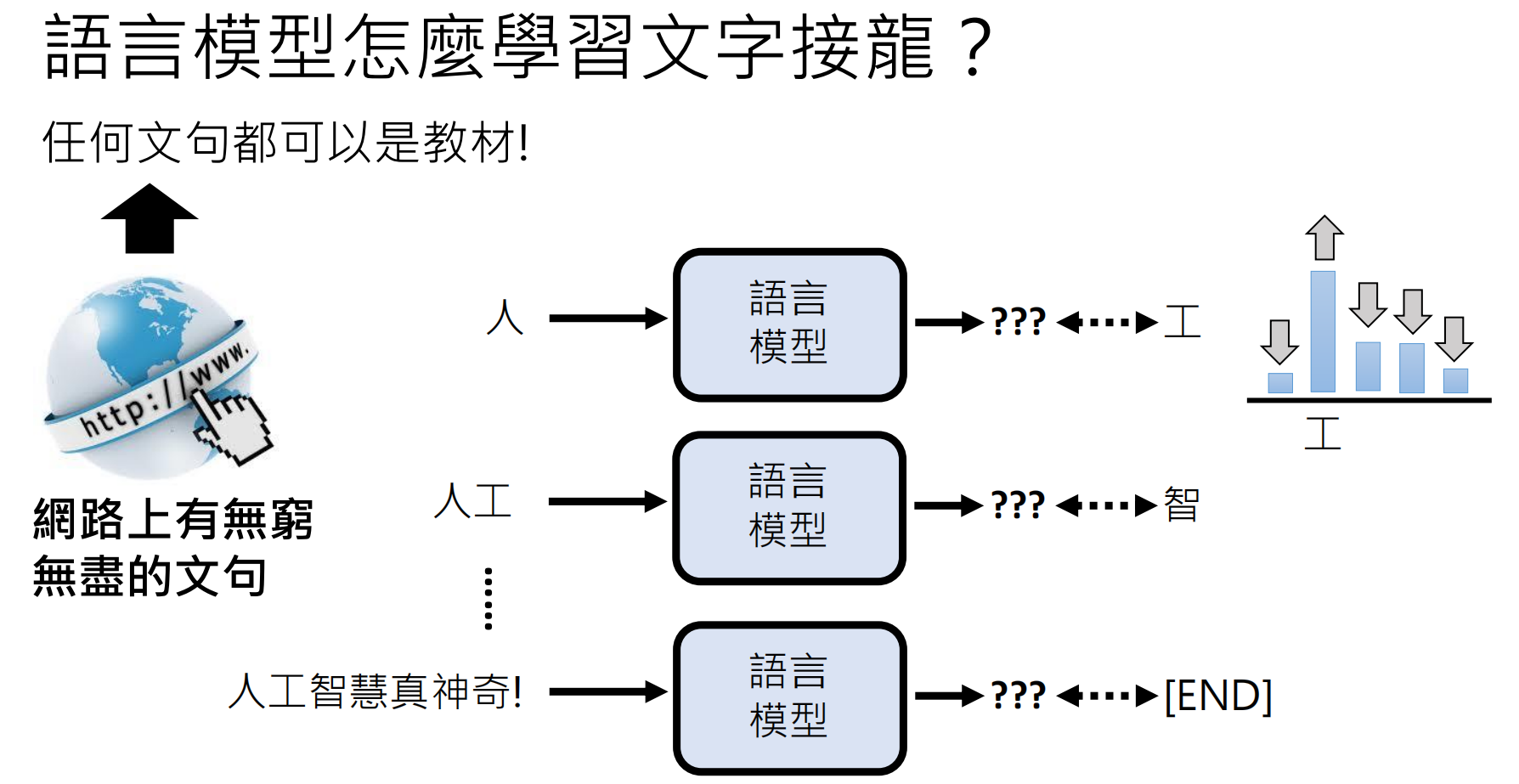
输入:"台湾最高的山是哪座?" → 输出概率分布 → 采样生成"玉" → 再生成"山" → [END]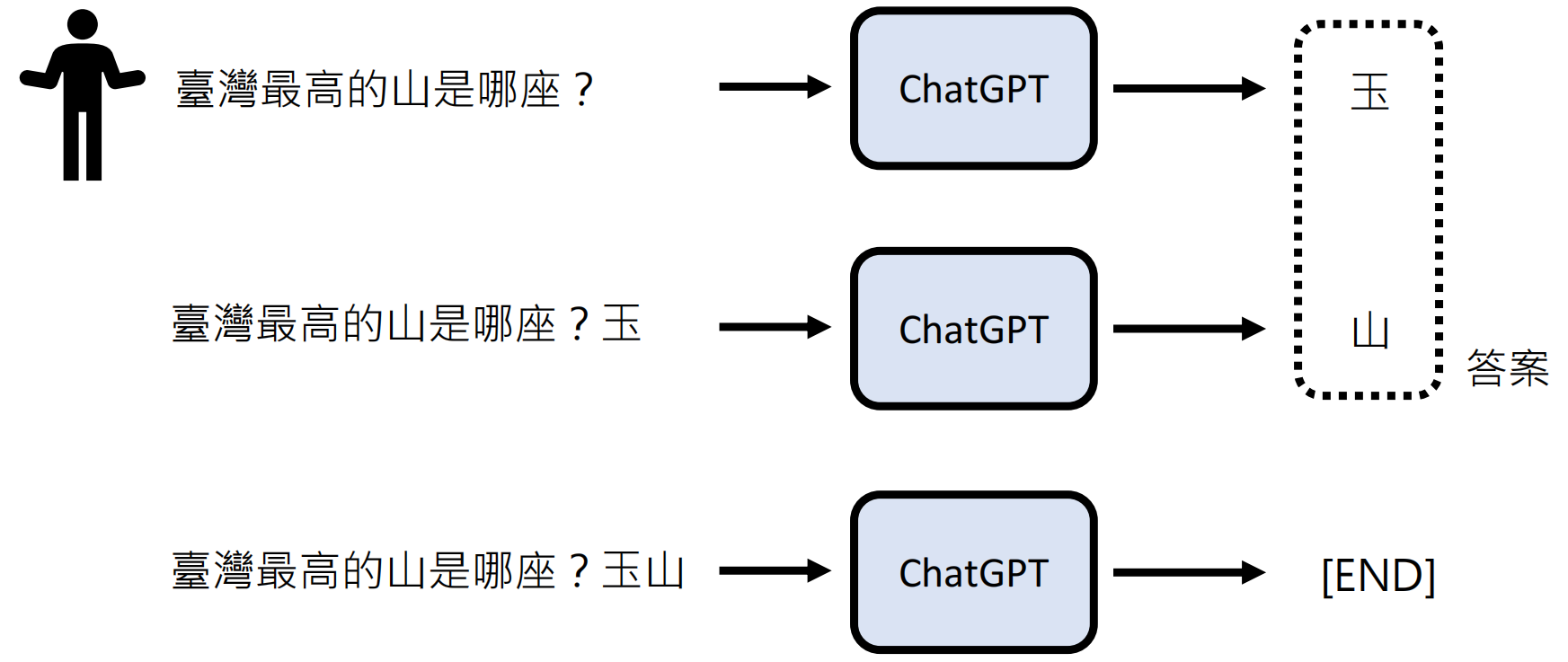
-
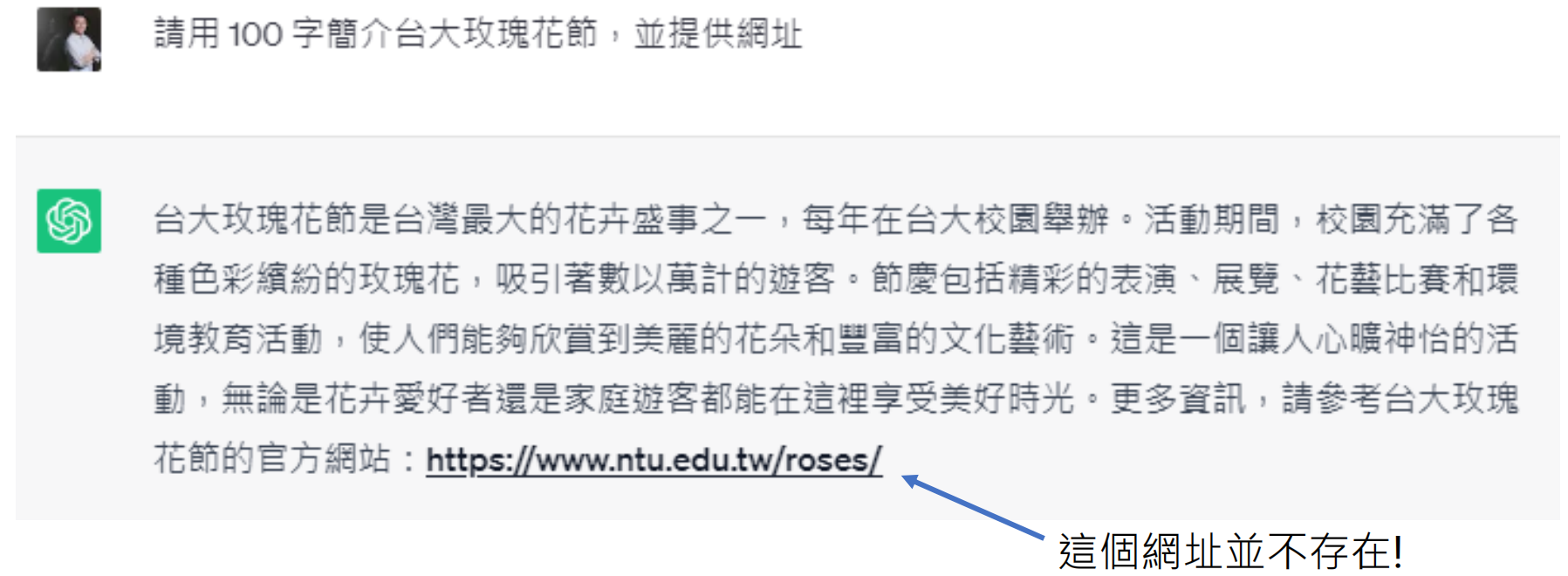
关键限制:依赖训练数据统计规律,可能导致虚假信息生成(如虚构"台大玫瑰花节"官网)
-
-
Token 不是单词:

token查看网站:https://platform.openai.com/tokenizer
Token 是文本的基本单元,英文中可能是一个子词(如 "unkillable" 拆分为 "un" + "kill" + "able"),而非完整单词。这是因为语言模型需处理无限词汇,拆分为 token 能提高效率。文档中示例显示,不同模型的 token 定义可能不同。
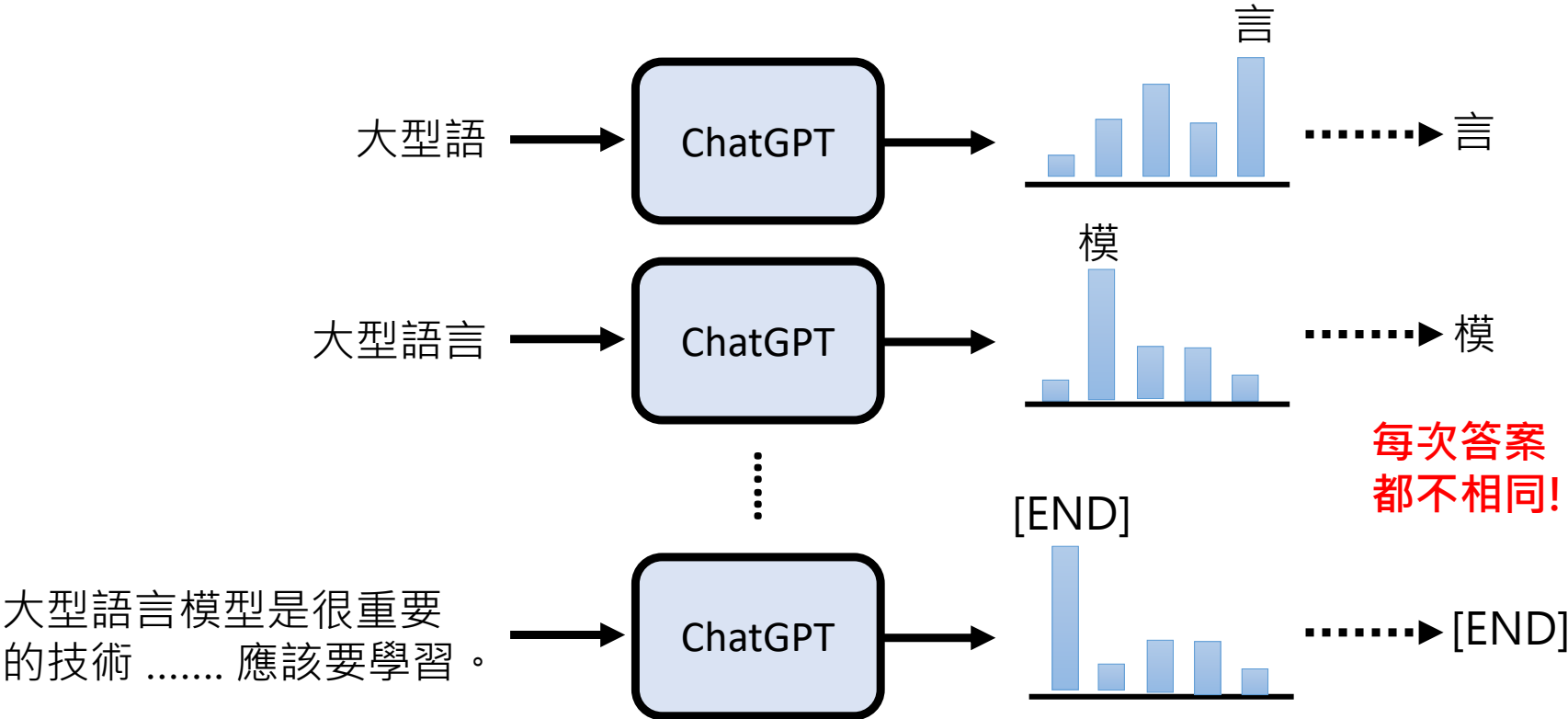
文本生成随机性
大型语言模型(如ChatGPT)的本质是一个“文字接龙”系统。它通过预测下一个 token(可理解为字符或单词片段)来生成文本。这不是简单的复制,而是基于海量数据训练出的概率模型。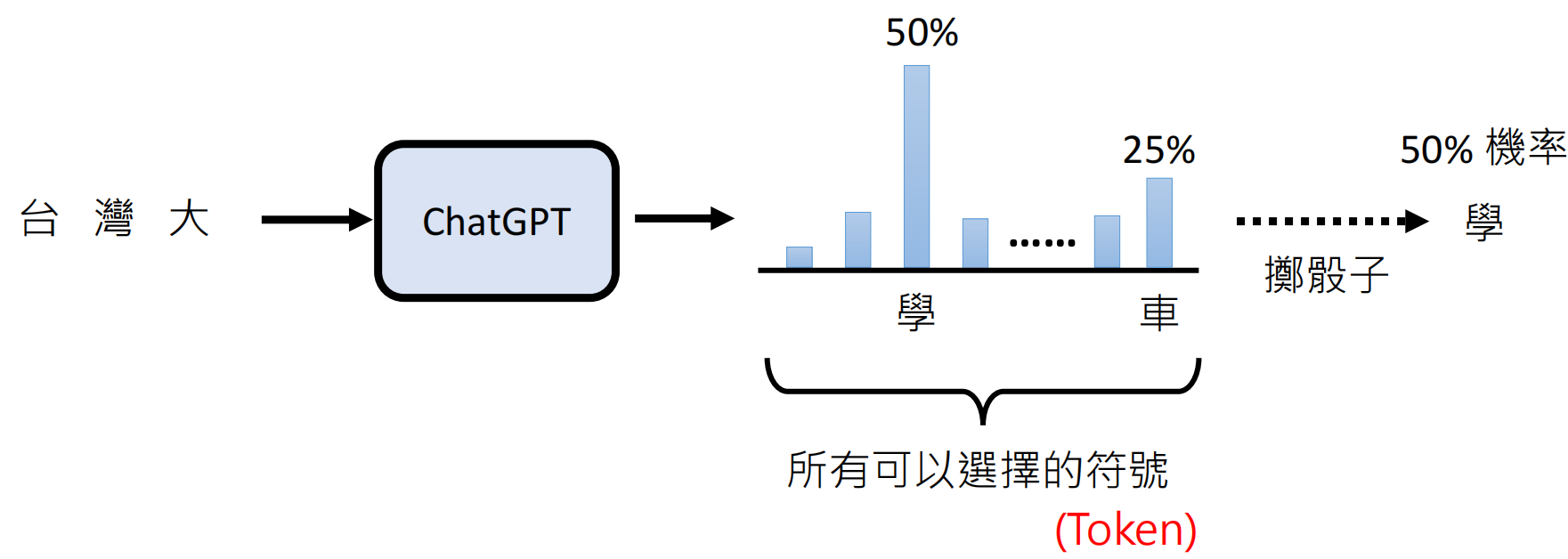
-
-
骰子机制:避免重复输出(对比Beam Search的退化问题)
-
论文依据:《The Curious Case of Neural Text Degeneration》(2019)
-
示例:当输入"台湾大"时,模型输出概率:
-
"学"(50%)| "车"(25%)| 其他(25%)
-
-
-
为什么需要“掷骰子”(随机性)?
纯确定性选择(如总选概率最高的 token)会导致重复或退化文本(例如:无限循环 "University of Mexico")。引入随机性(按概率分布采样)使输出更自然、多样。研究(如 The Curious Case of Neural Text Degeneration)证明,随机采样能避免机械感,提升生成质量。

-
常见问题:为什么 ChatGPT 会编造事实?
因为它只是“接龙”,而非检索真实数据。例如,文档中案例:当问及“台大玫瑰花节”时,模型生成了虚构网址。纠正建议:使用时务必核实关键信息(如网址、数据),并优先结合搜索工具。
二、GPT 系列的演进

无监督学习(预训练Pre-train)
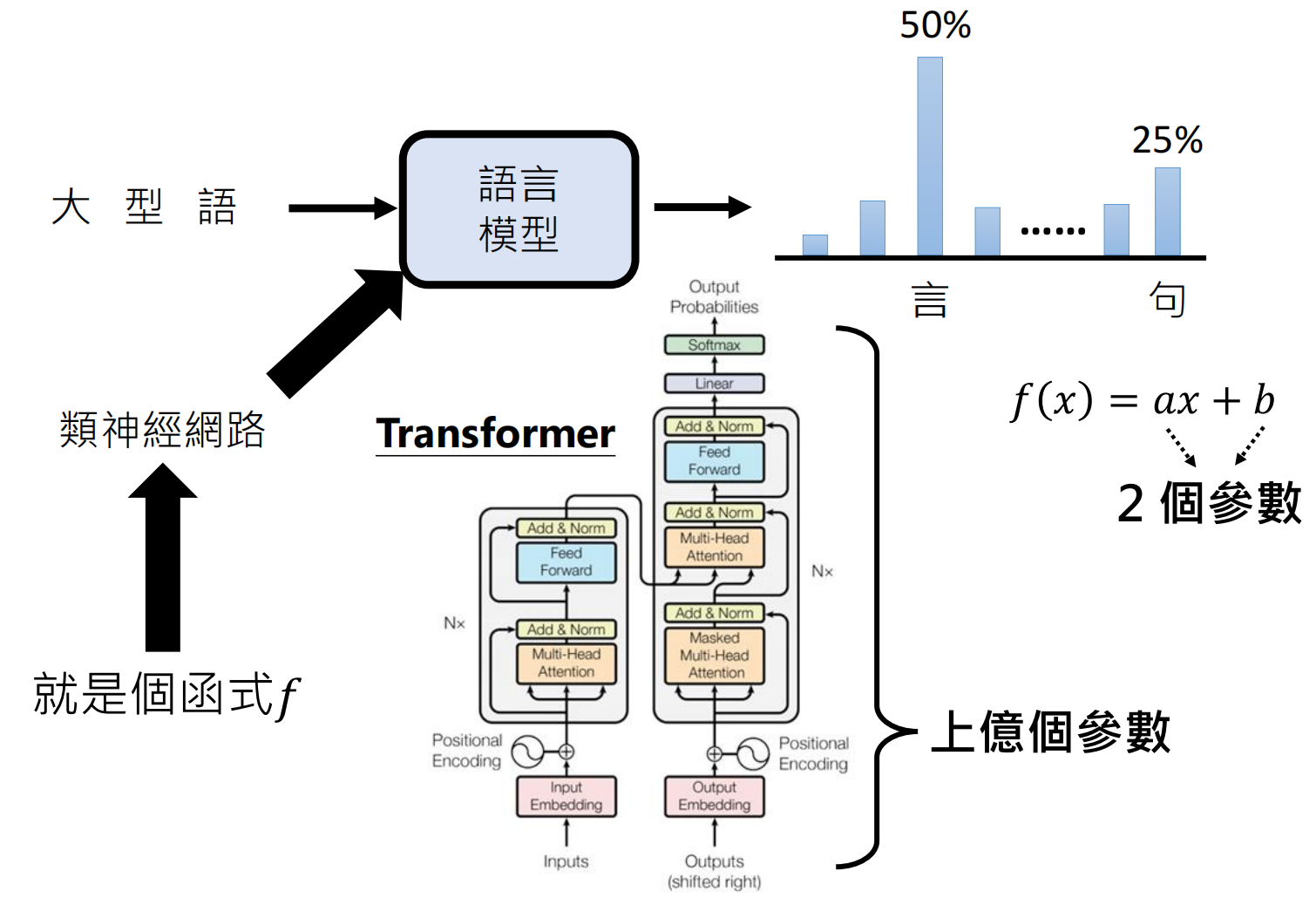
核心是模型规模(参数量)和数据量的增长。例如,在GPT1~3的发展过程中,就一直在追求“更大”的模型。
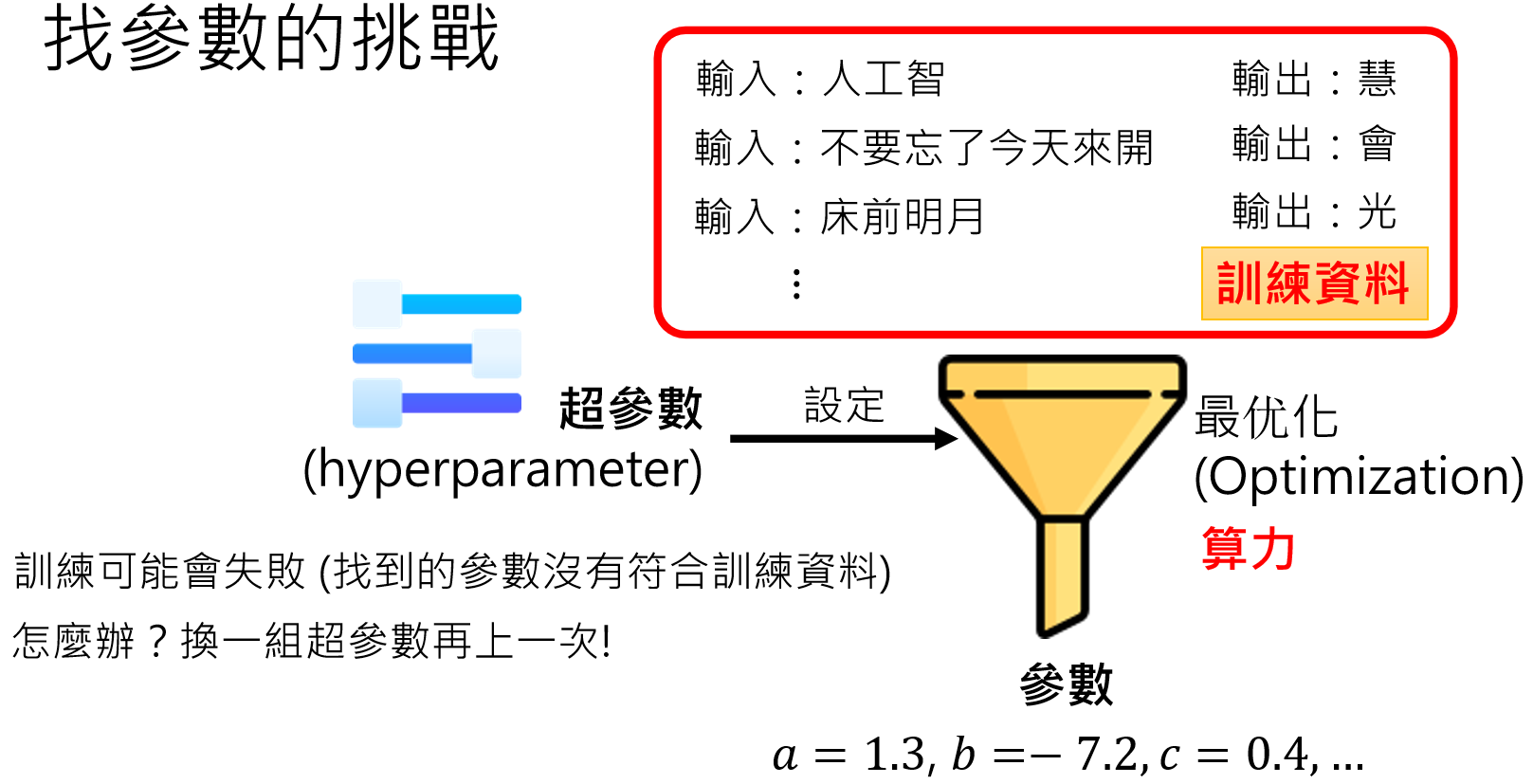
最优化
寻找最优超参数
随着训练数据量和参数量的增多,参数调优成为了模型训练的重点:

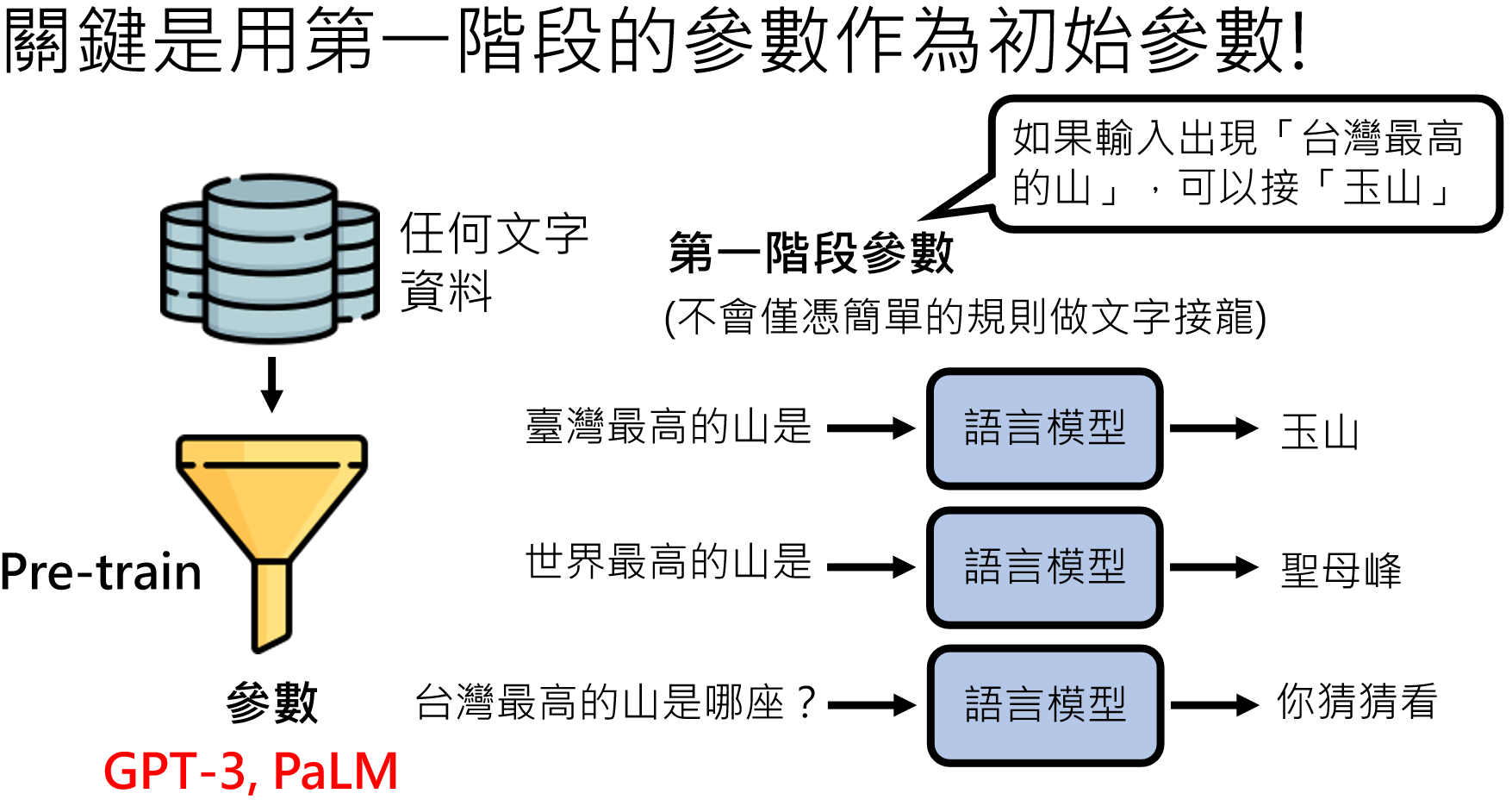
参数初始化
这里的参数不是超参数,而是“y=wX+b”里面的w和b(数以亿计),那这些参数一开始是多少呢?我们一开始让他们等于多少呢?参数初始化的一种方法就是:随机初始化:

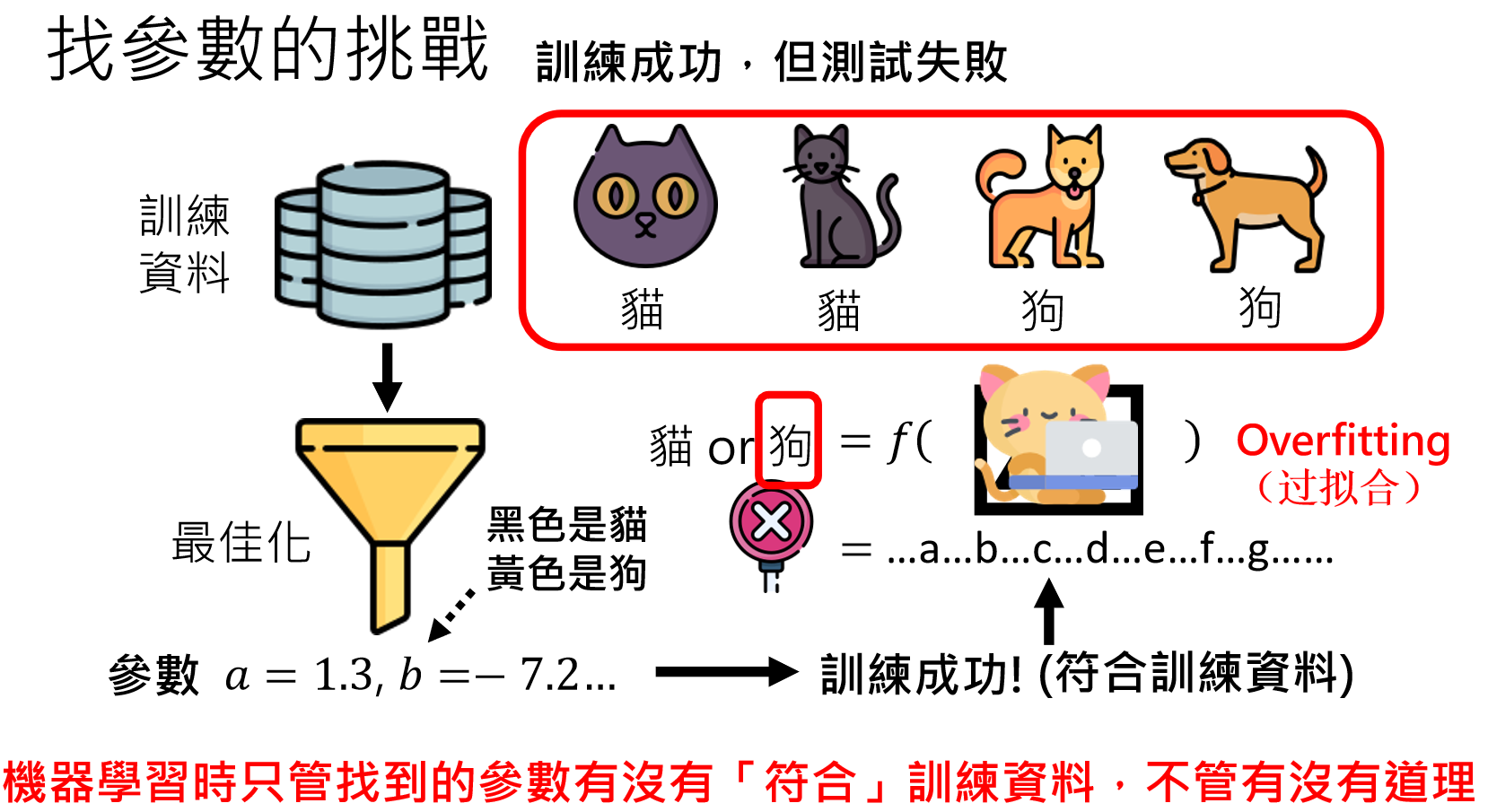
随机初始化的参数,可能和实际最优的参数偏差比较大,导致训练很慢,或者训练出错误的模型,因此我们需要想办法找到更好的参数来作为初始化参数,这种好的参数就叫做模型的“先验知识”。

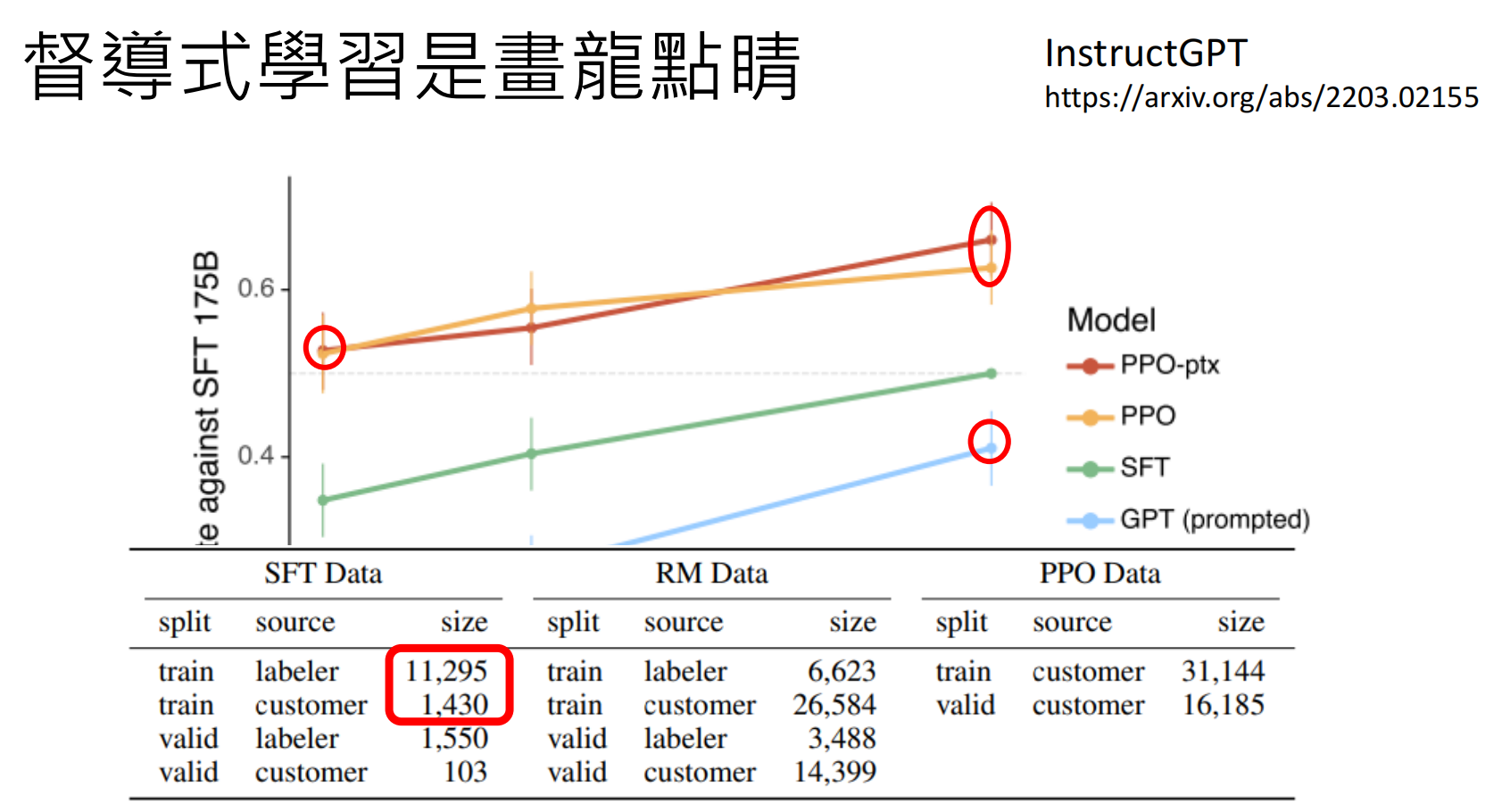
那这种好的初始化参数怎么找呢?我们可以人工筛选出“高质量”的,正确的语料来训练模型,那么需要多少语料才能让模型得到一个好的训练结果呢?参照下文:基于人类反馈的强化学习(RLHF)
语言知识和世界知识
让模型掌握语言知识,仅仅需要1亿(100M)个词汇的文本就可以达到不错的水平,但是如果要让模型真正的理解这个世界(例如水的沸点并不是固定的,在不同气压下不一样),需要的文字量就要大好几个量级:
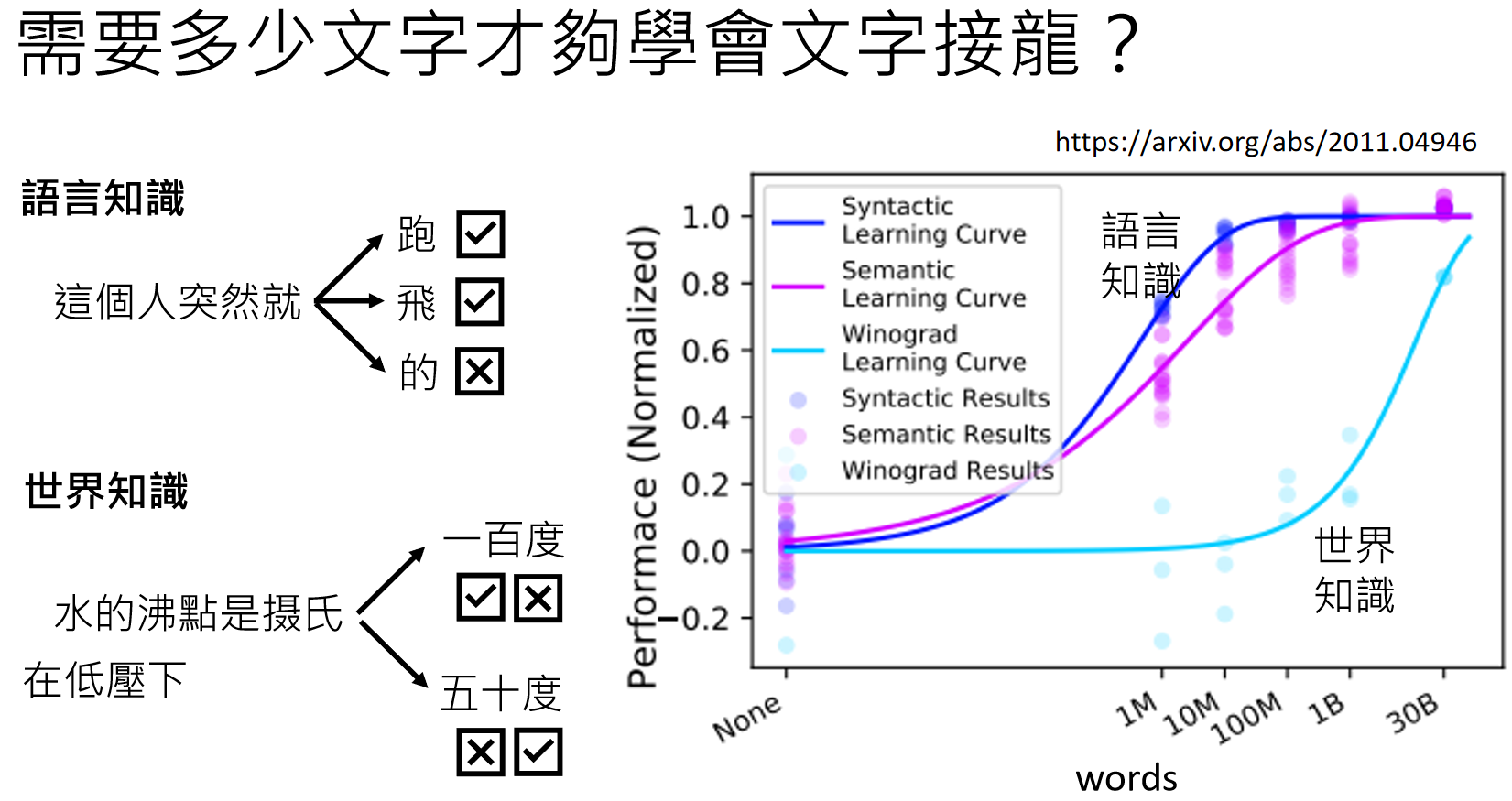
因为世界知识非常复杂且有很多层次,从上面可以看出,要想语言模型学会世界知识,需要非常大量的资料。然而资料获取最轻松的途径就是无穷无尽的网络资料:
数据预处理
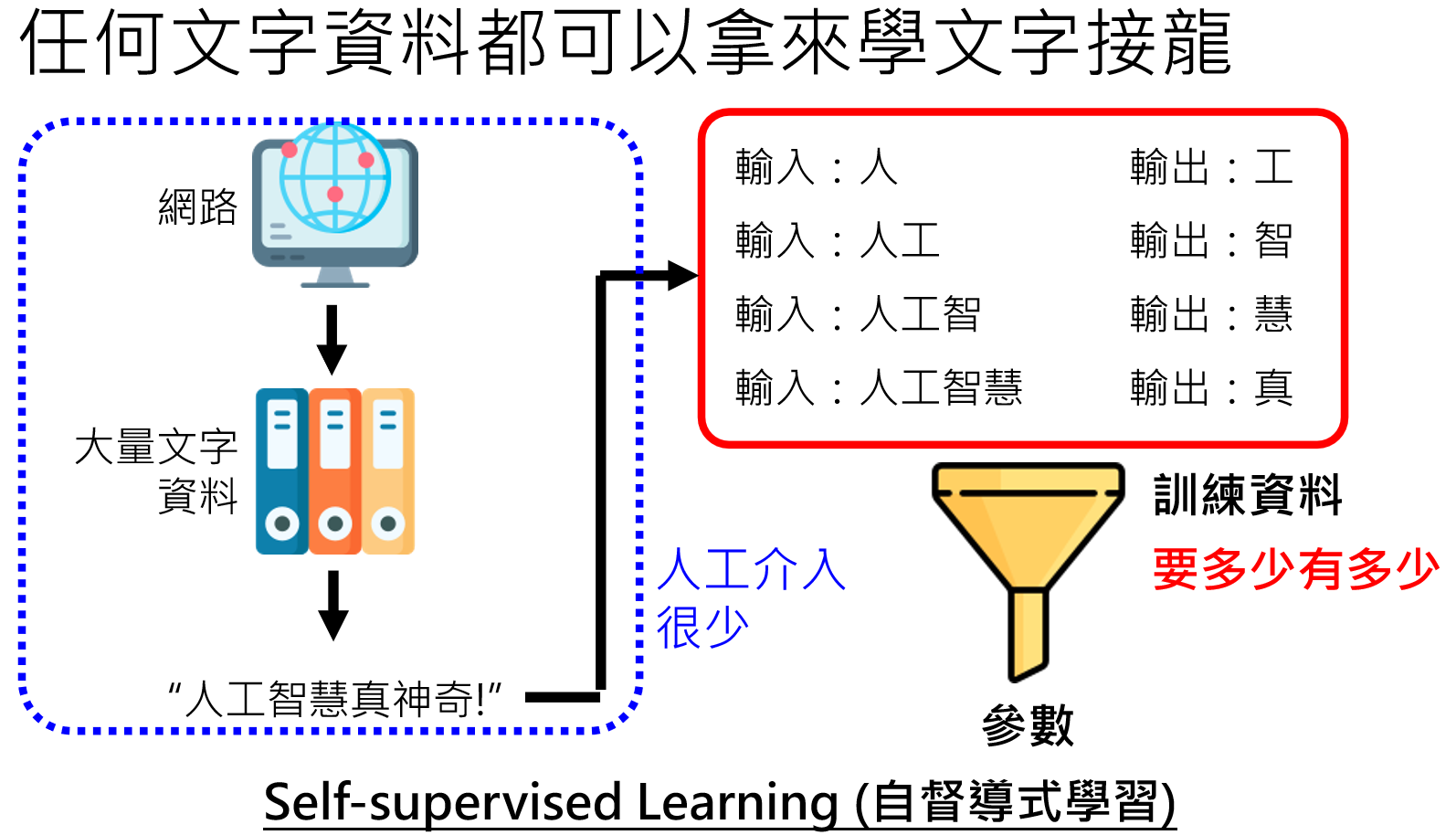
但是网络上的资料往往“参差不齐”,有好有坏,因此我们需要对网络上获取的资料进行一些处理:
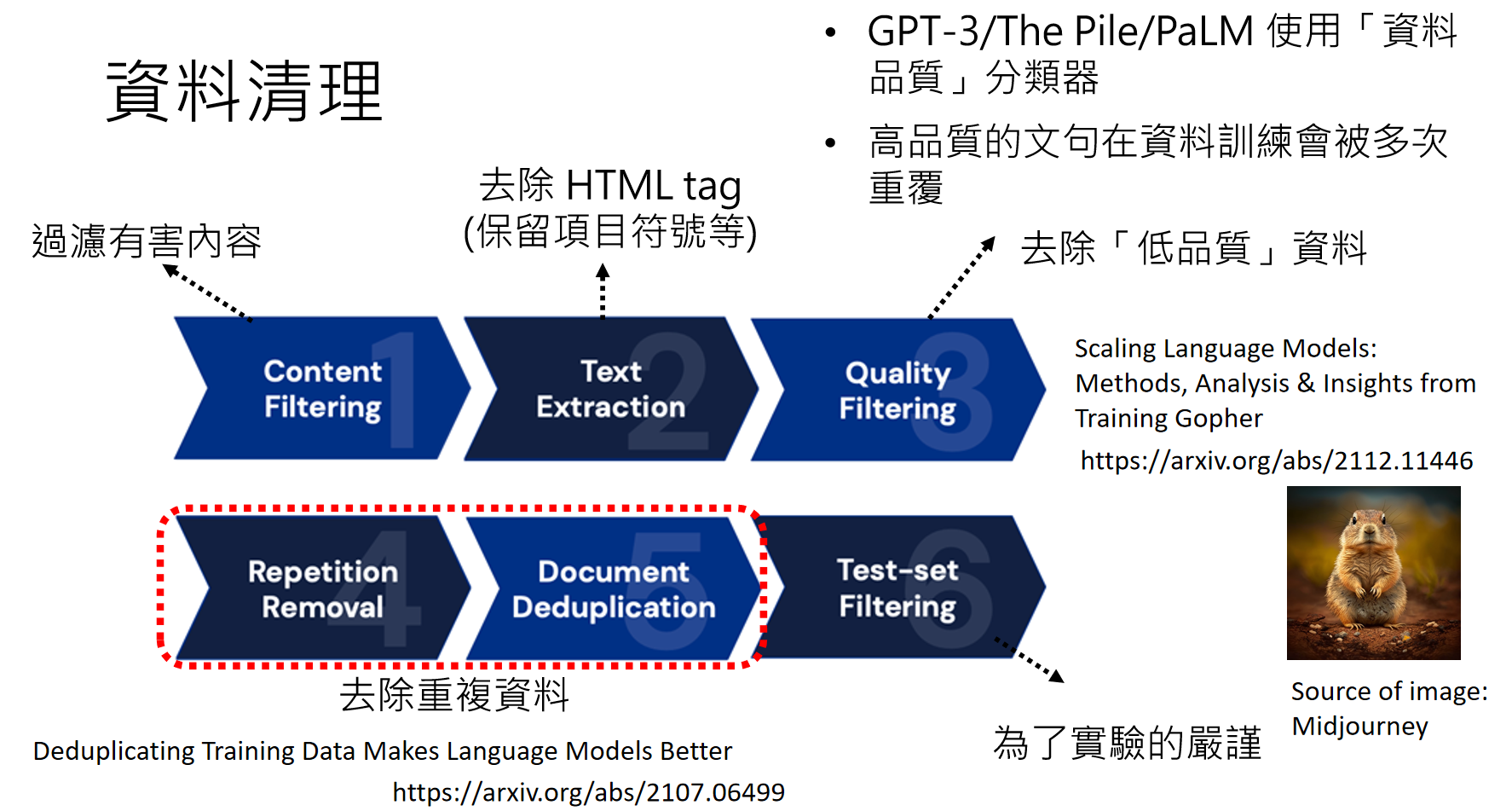
Scaling Language Models: Methods, Analysis & Insights from Training Gopher :https://arxiv.org/abs/2112.11446
Deduplicating Training Data Makes Language Models Better :https://arxiv.org/abs/2107.06499
那么是不是参数量和数据量越大,就一定能训练出强大的模型呢?让我们来开ChatGPT的进化之路:
GPT系列进化史
-
GPT-1 到 GPT-3:量变到质变

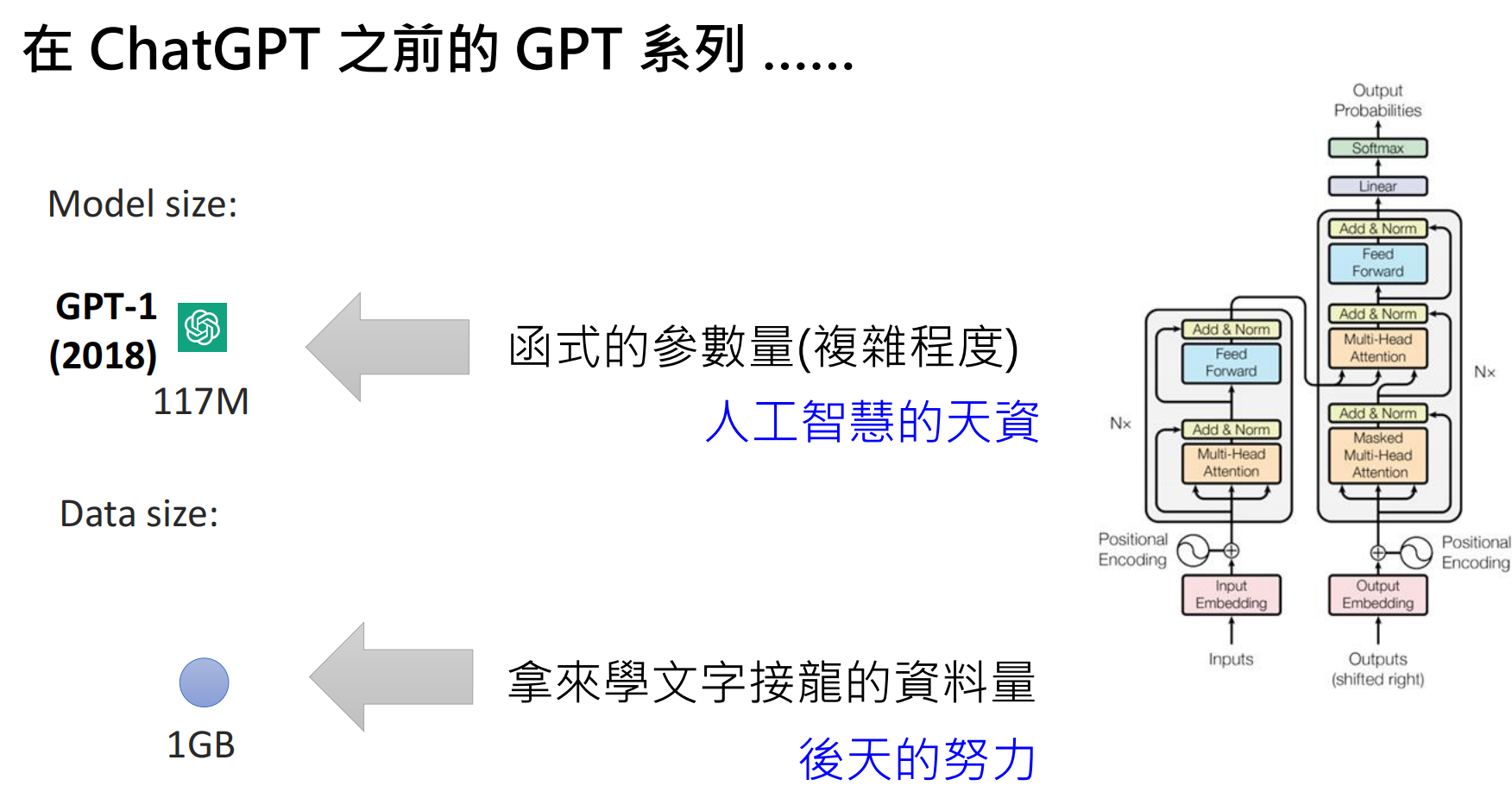
 https://arxiv.org/abs/2005.14165
https://arxiv.org/abs/2005.14165
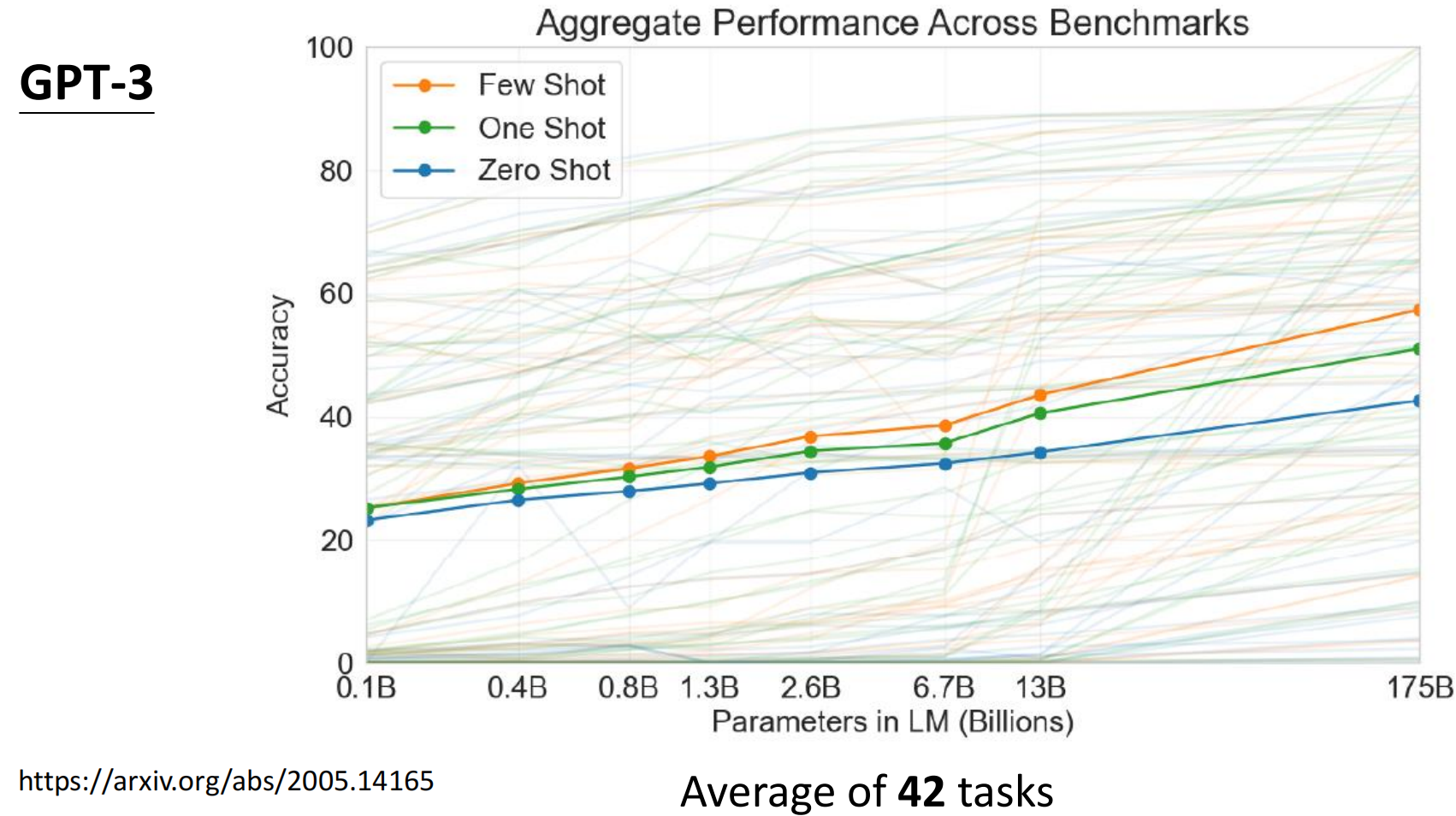
GPT3的水平并没有产生质的提升,依稀记得当时“提示词工程师”特别火,就是因为GPT产生的结果非常依赖“提示词”的质量,表现很不稳定:
GPT进化总结
从上面的数据可以看出,只追求模型的“大小”可能并不是最好实现突破的办法。
https://ai.googleblog.com/2022/11/better-language-models-without-massive.html
| 版本 | 参数量 | 训练数据 | 突破性能力 | 局限性 |
|---|---|---|---|---|
| GPT-1 | 1.17 亿 | 1GB | 基础文本生成 | 无指令理解 |
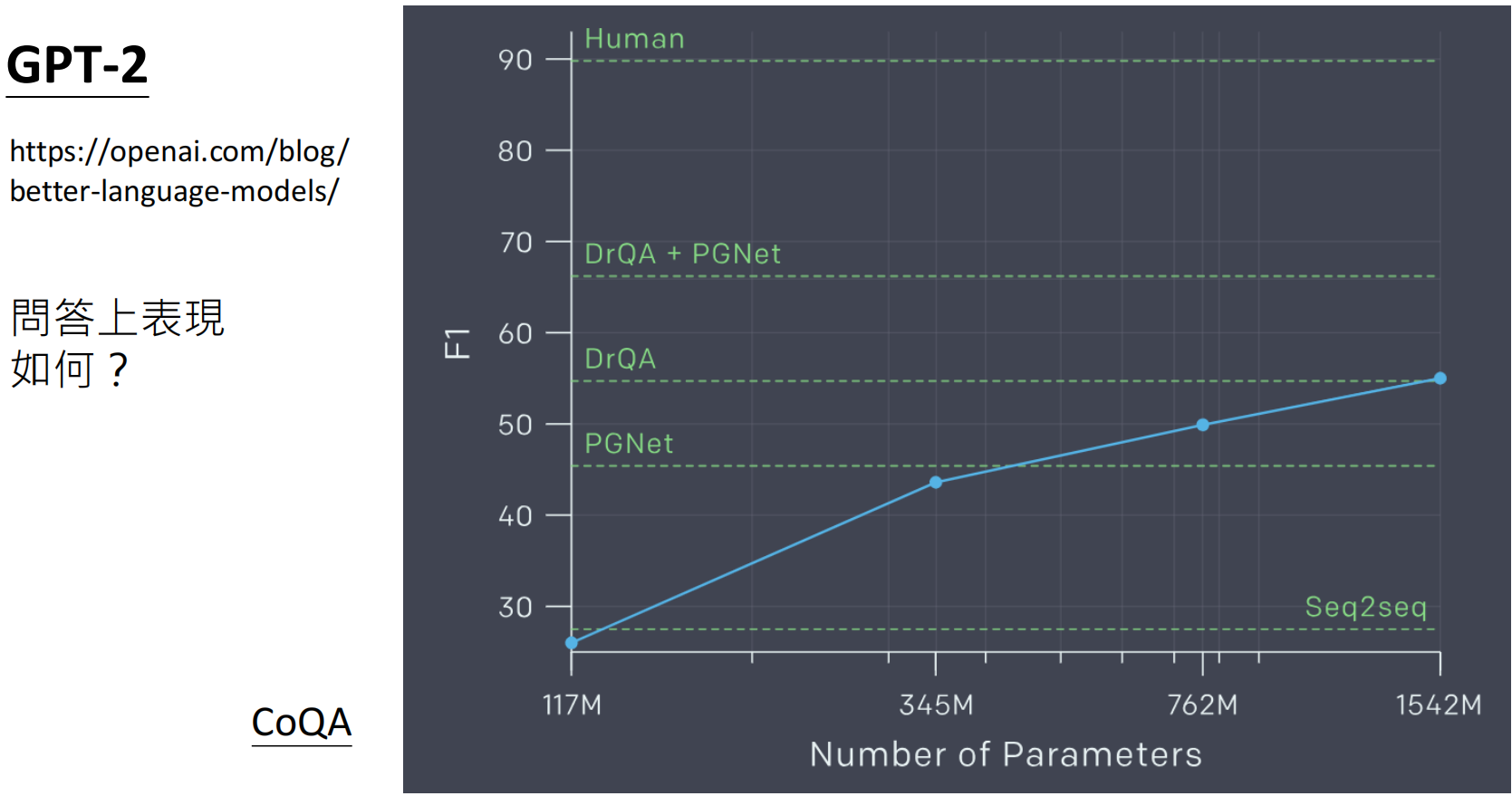
| GPT-2 | 15.42 亿 | 40GB | 零样本问答、摘要,但表现不稳定。 | 回答准确性低(CoQA基准仅34.5%) |
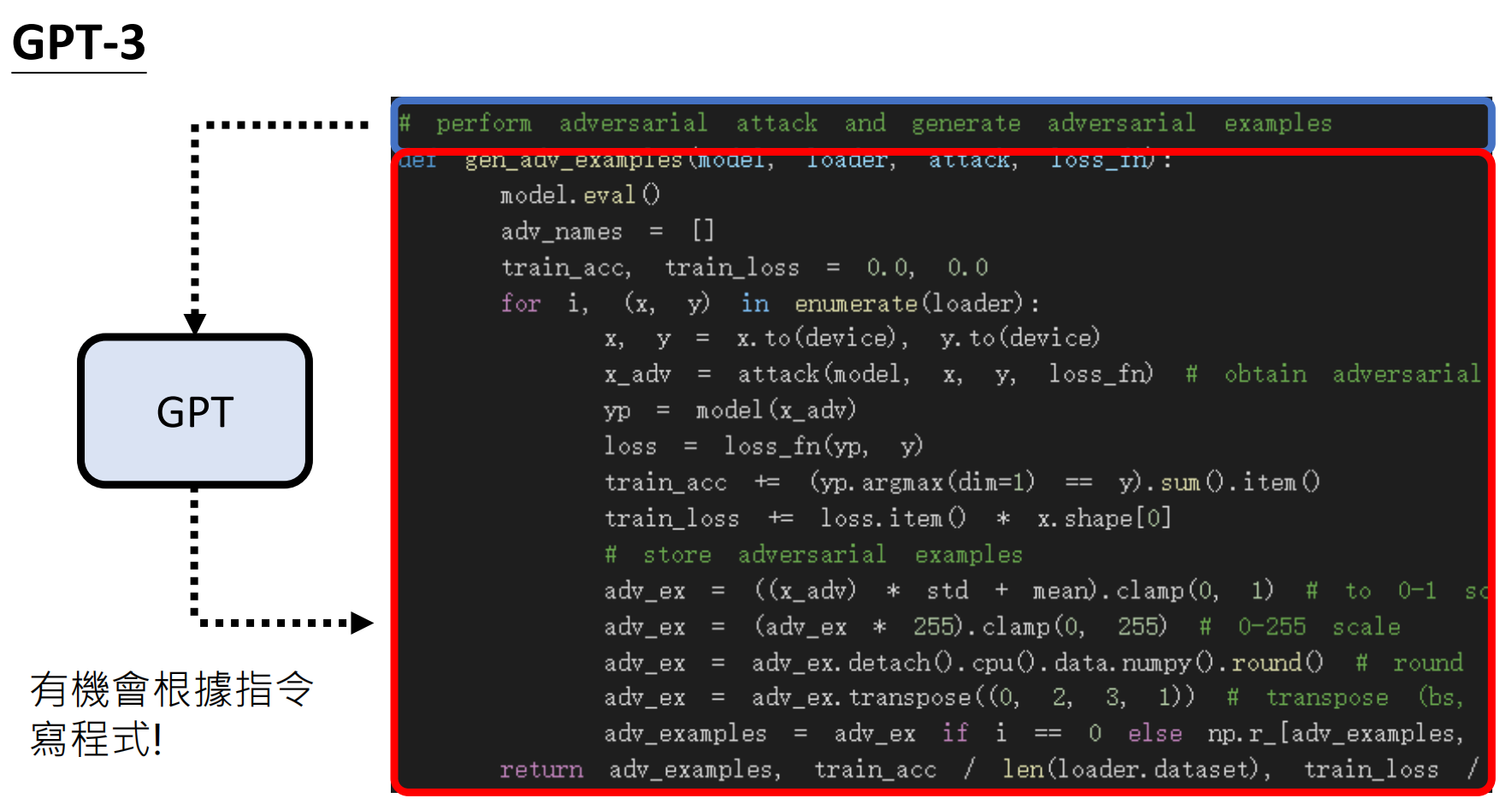
| GPT-3 | 1750 亿 | 580GB | 代码生成、少样本学习(例如在预训练后,仅需少量示例就能处理新语言或任务(如中文问答)。) | 数学推理能力弱 |
| GPT-4 | ~1.8T* | 多模态 | 图像理解、考试top 10%* | 闭源架构(2023技术报告) |
*注:GPT-4实际参数量未公开,1.8T为业界推测;考试能力来自模拟律师考试结果
无监督学习的缺点
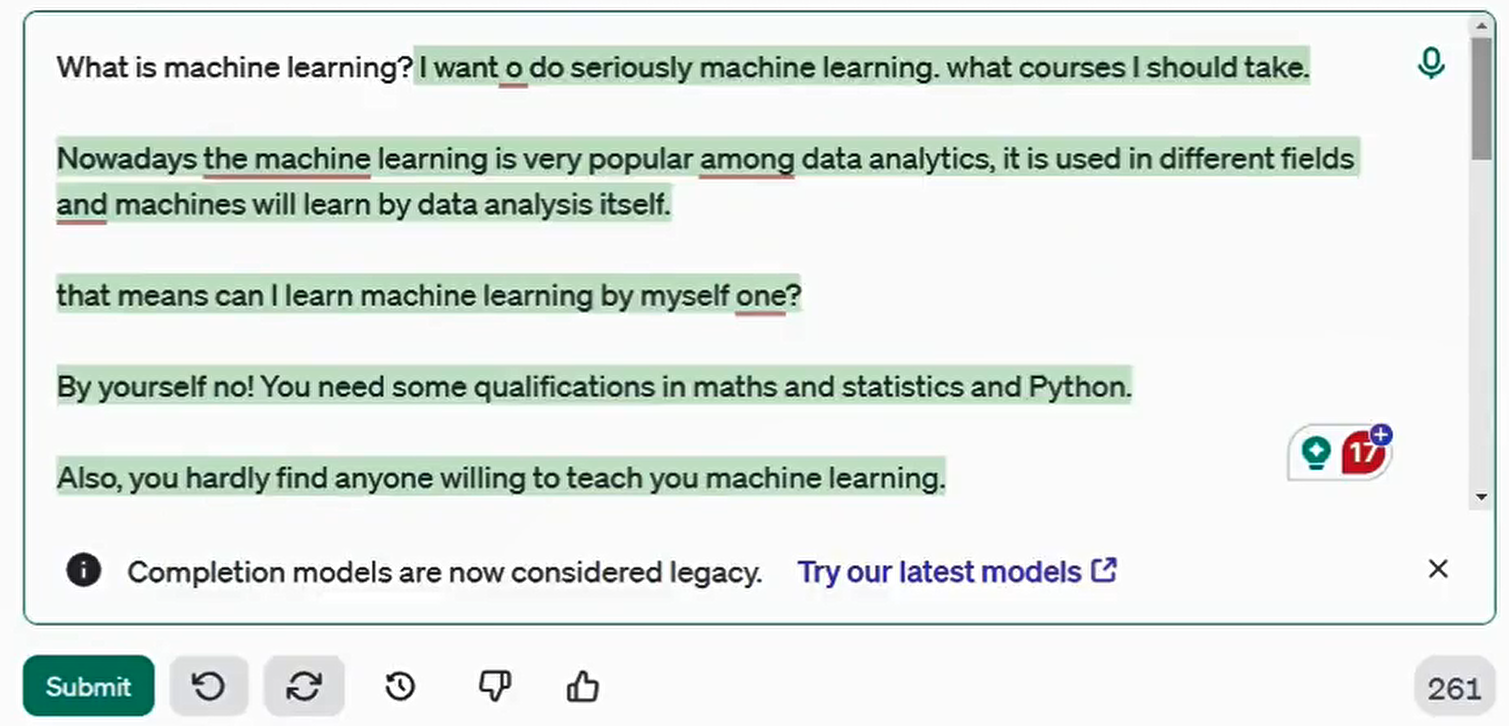
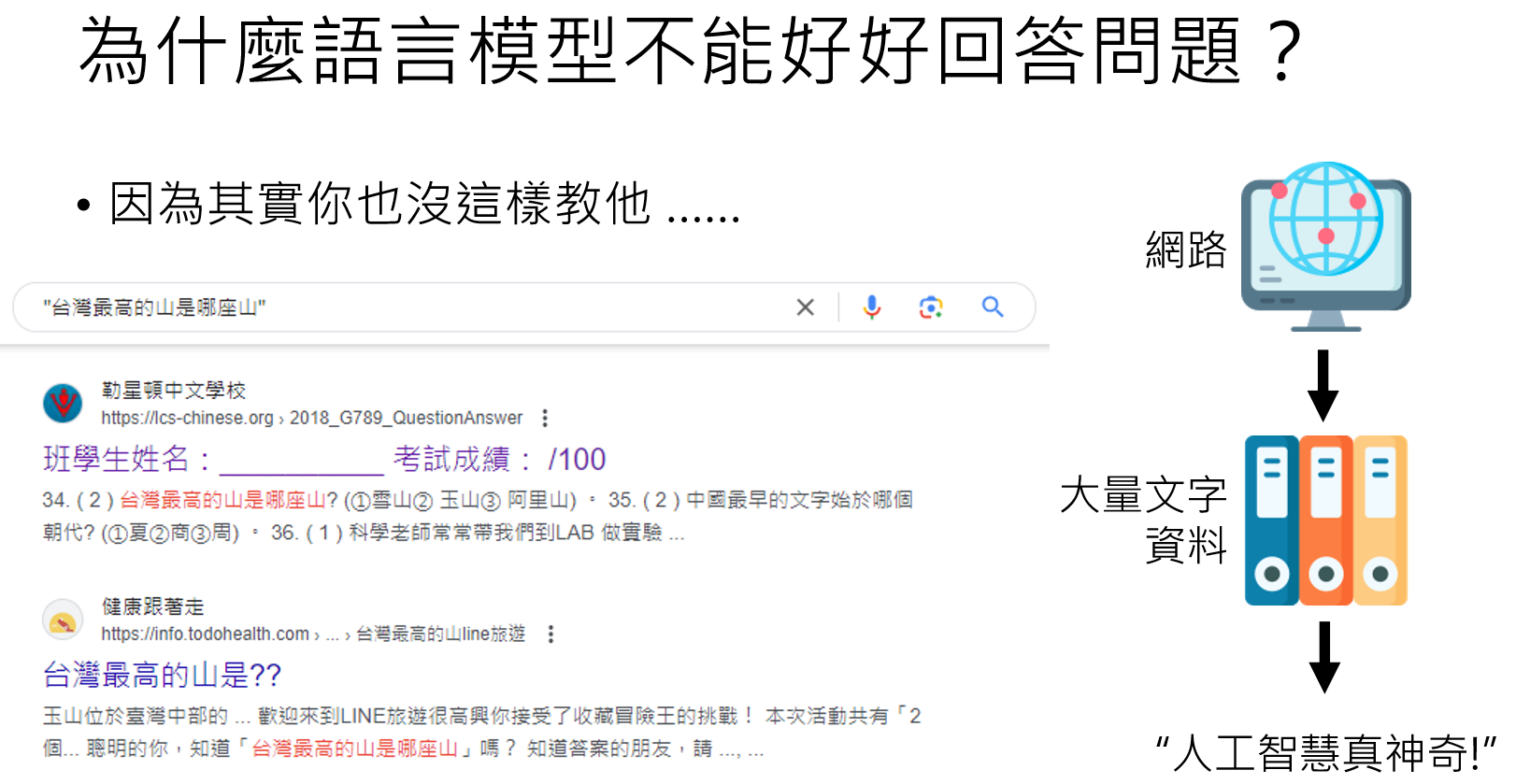
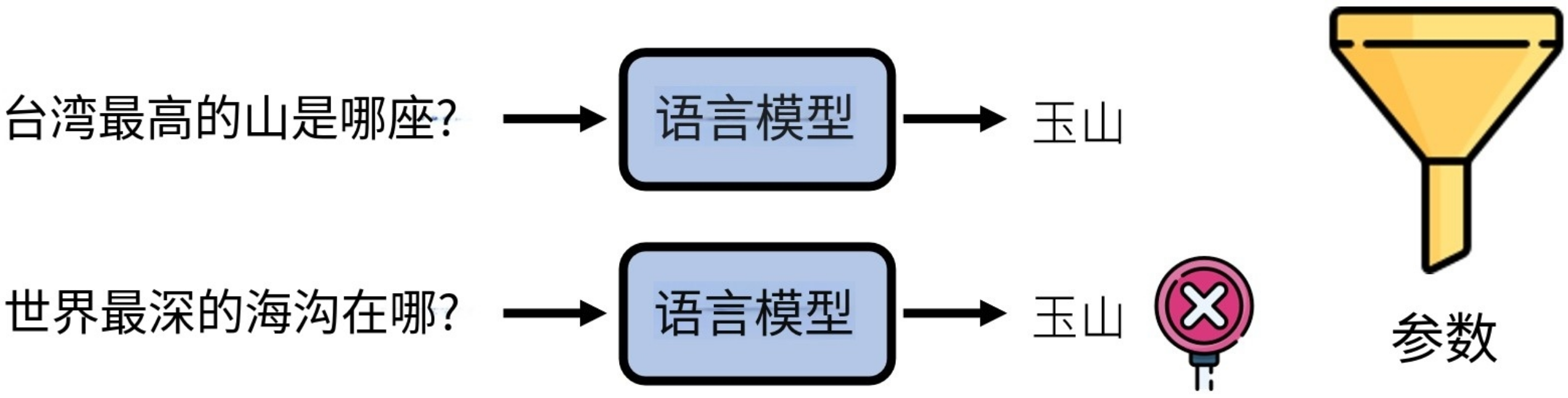
好比下面的例子:GPT学习的资料可能来自下面的第一个网址:台湾最高的山是那座山?①雪山②玉山③阿里山。那么它在回答我们问题时,给出的答案(做出的文字接龙)就是:①雪山②玉山③阿里山。。。
再如:我们需要的是一个答案,而不是一个选择题的选项:
https://arxiv.org/abs/2203.02155
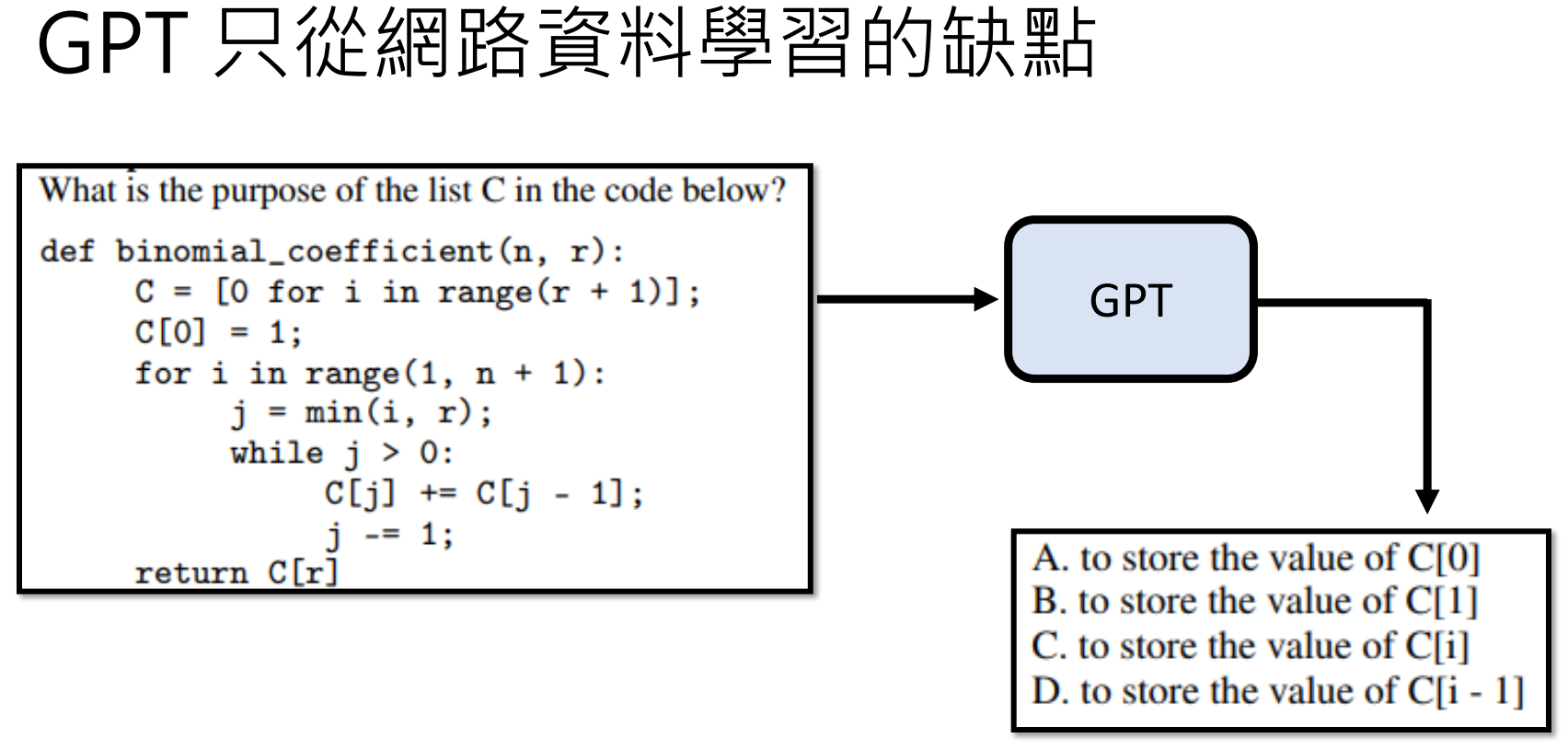
并且,早期 GPT 仅从网络数据学习,可能输出有害或错误内容(如歧视性言论)。
监督学习(指令微调Instruction Fine-tuning )

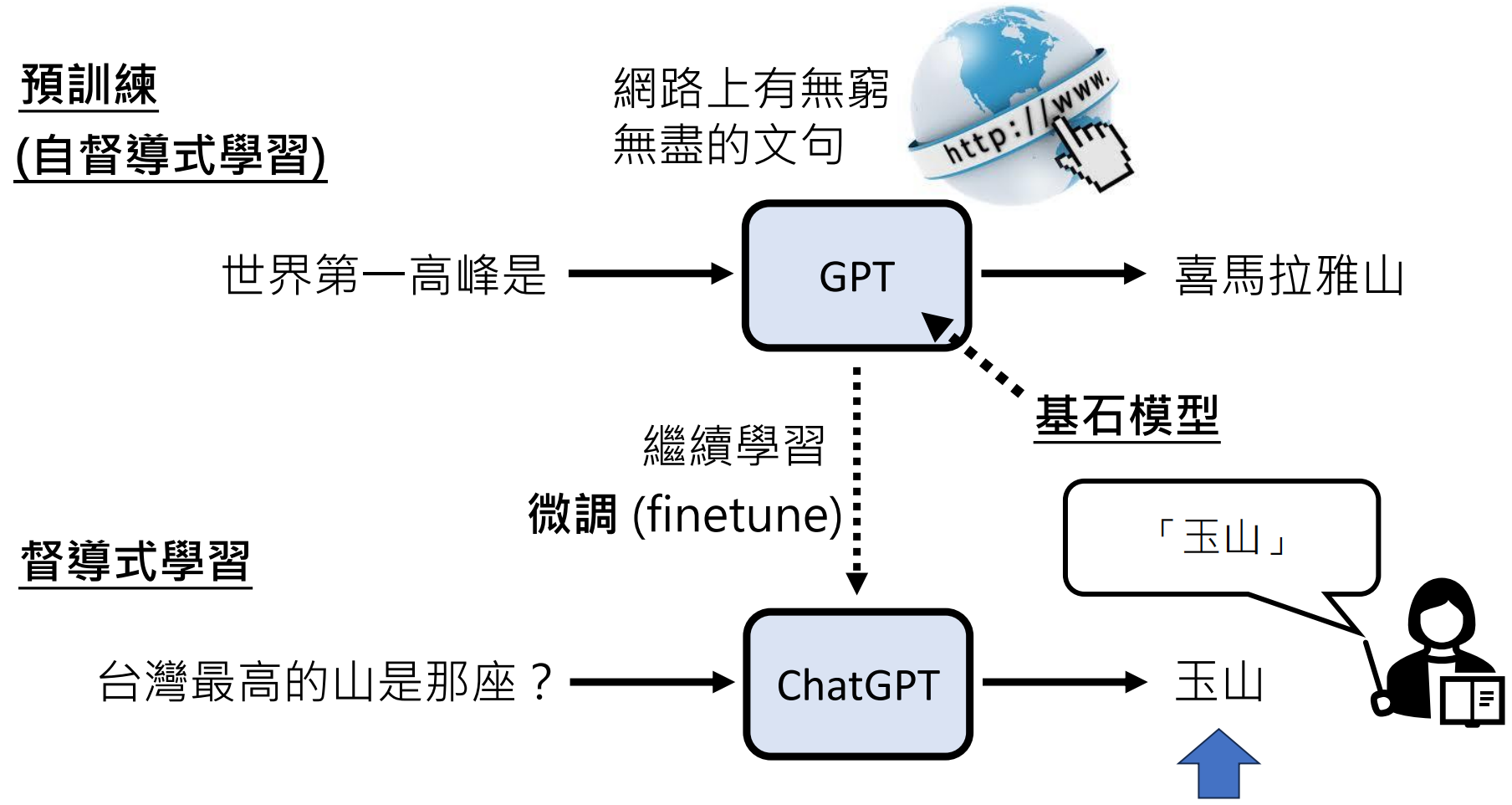


GPT 模型通过“预训练 + 微调”实现能力飞跃。

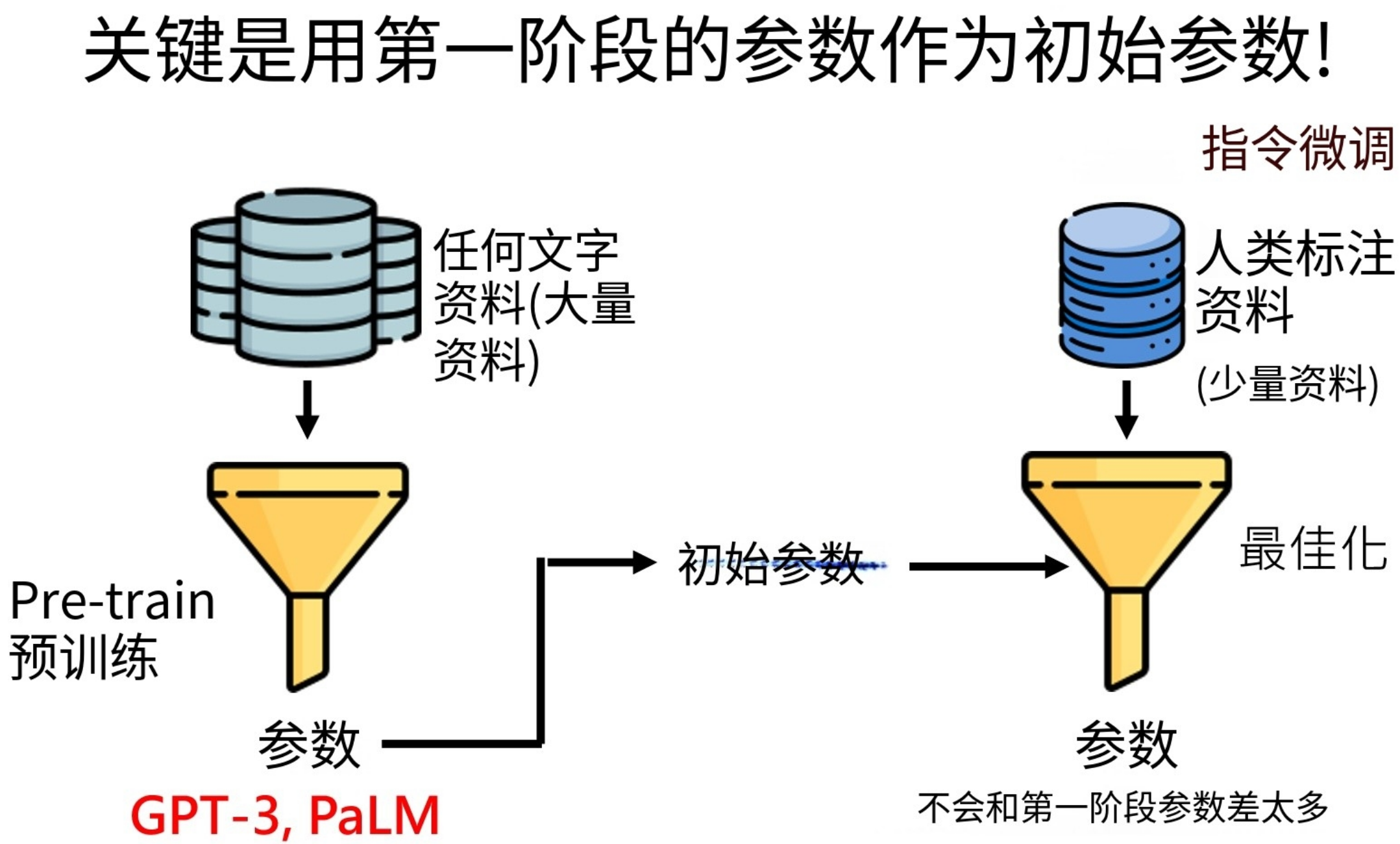
由于人类能够标注的优质资料有限,而人工智能真正训练需要“超多”资料,单纯依靠人类提供的少量优质资料,训练出来的模型参数肯定很少,模型很小,能力有限。怎么办呢?
我们可以先使用“海量”网络资料来训练模型,能得到类似GPT3这种笨笨的模型,然后我们就可以拿到GPT3模型的参数(几十亿个),我们在这个参数基础上再使用人类标记的优质资料训练,这样就可以把原本的模型参数进行“微小”的更新,因此整个操作就叫做微调。也就是这些微小的更新,让模型最后的回答变的更加准确!之前的GPT3我们就称作预训练模型。
初始参数
当然,这一切最重要的还是使用预训练模型的参数作为初始参数,因为这个初始参数是经过海量的资料训练得来的,不会仅仅凭借简单的规则来做“文字接龙”,例如:我们输入:“我爱”,它后面会计算出所有不计其数的文字的概率,如:我爱你、我爱苹果、我爱她。。。
或者说它已经掌握了“人类所有的语言知识”。形象的说就是她已经是一个会“说话”的人了,但是接下来我们需要她能够“说好话”,也就是掌握上面讲到的世界知识。

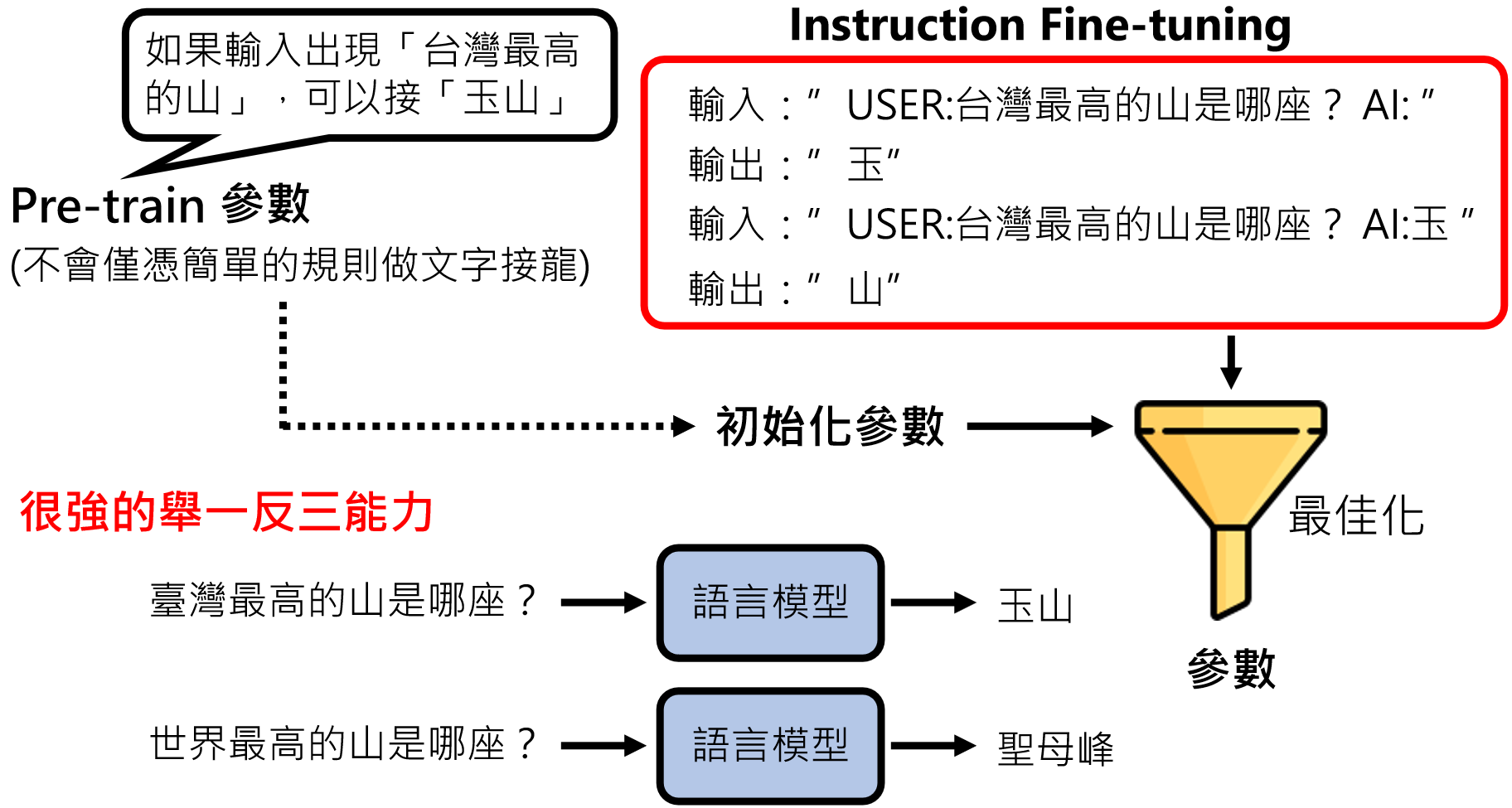
微调:举一反三
模型有很强的泛化能力,用人类示范数据微调模型(例如:人工撰写好回答),仅需少量数据即可显著提升性能。
例如我们教过模型回答“台湾最高的山是那座”,答:“玉山”。那么当别人再问模型“世界最高的山是哪座?”时。模型自然而然就会回答:“圣母峰”。


适配器(Adapter )
疑问:万一预训练模型的参数在经过人类标注的资料最优化之后,最终输出的参数和预训练模型参数差别很大怎么办(甚至破坏了模型效果)?这个时候我们可以使用适配器(Adapter ):就是我们在使用预训练模型进行训练时,保证原来的参数不变,而是在原来的大量参数后面添加少量参数,最优化的过程就是优化我们新增的这些参数。
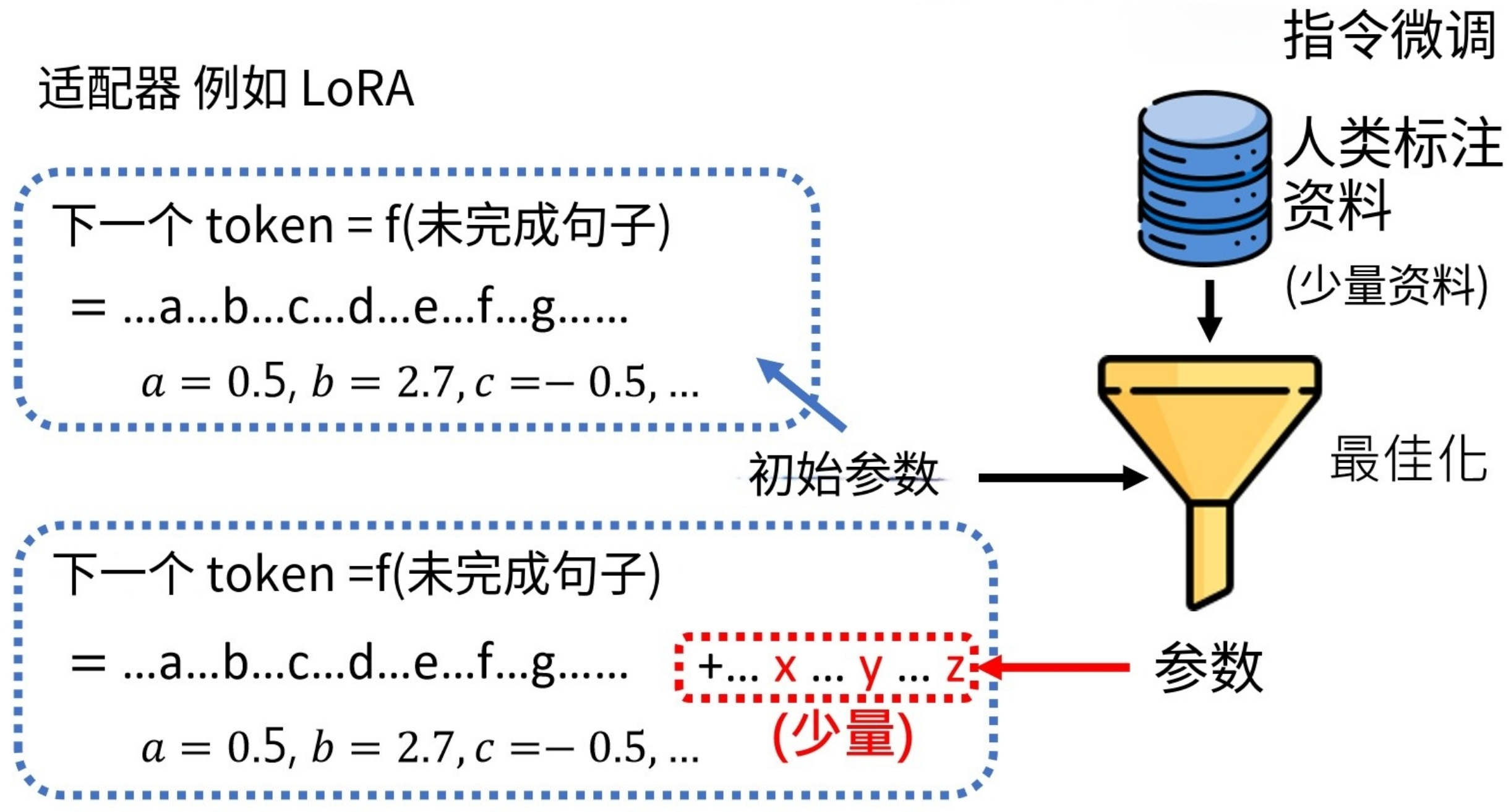

https://arxiv.org/abs/2210.06175
常见Adapter LoRA:https://arxiv.org/abs/2106.09685
微调的路线
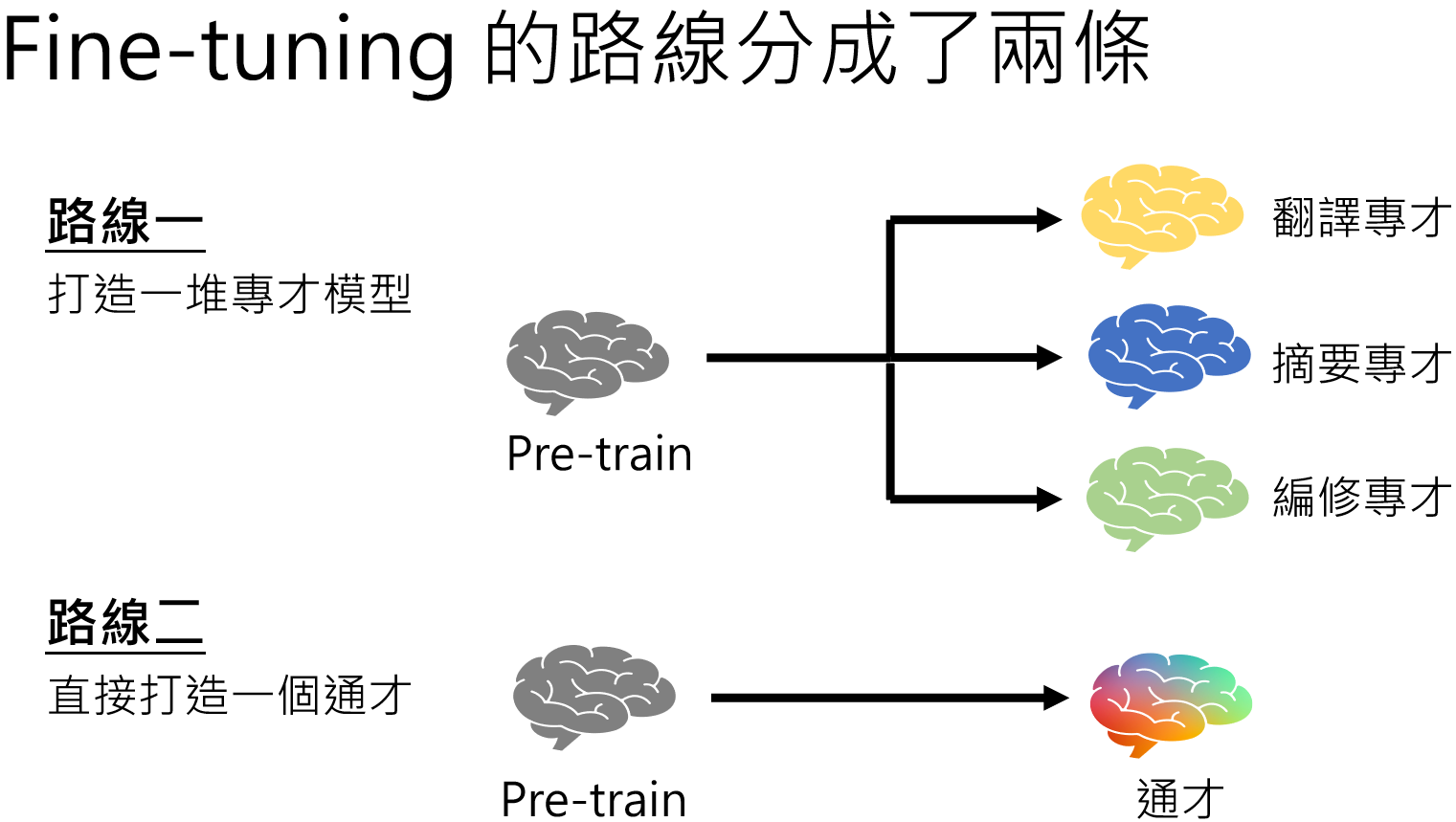
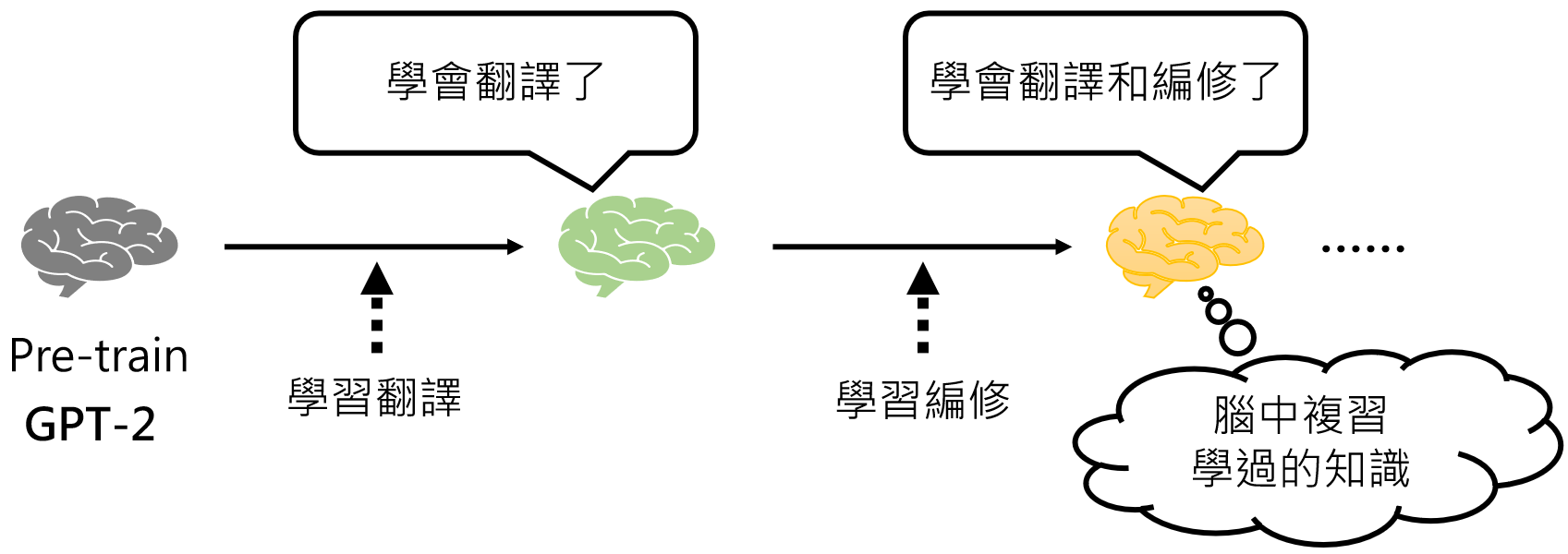
我们在微调的时候,可以将模型往某一个单一功能训练,例如翻译,无论你发给他什么内容,他就只会做翻译,例如有道词典等,也可以让她做编修等等。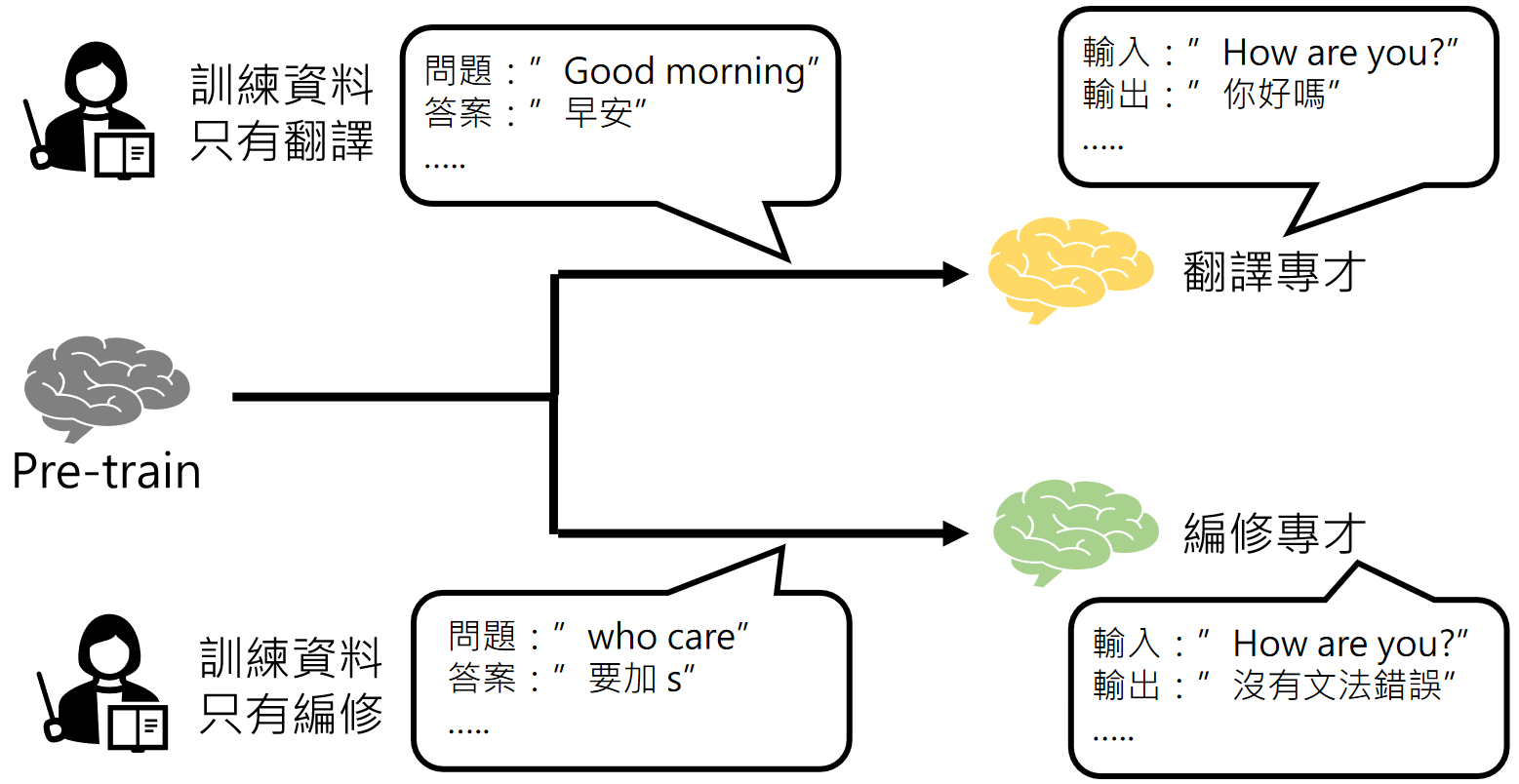
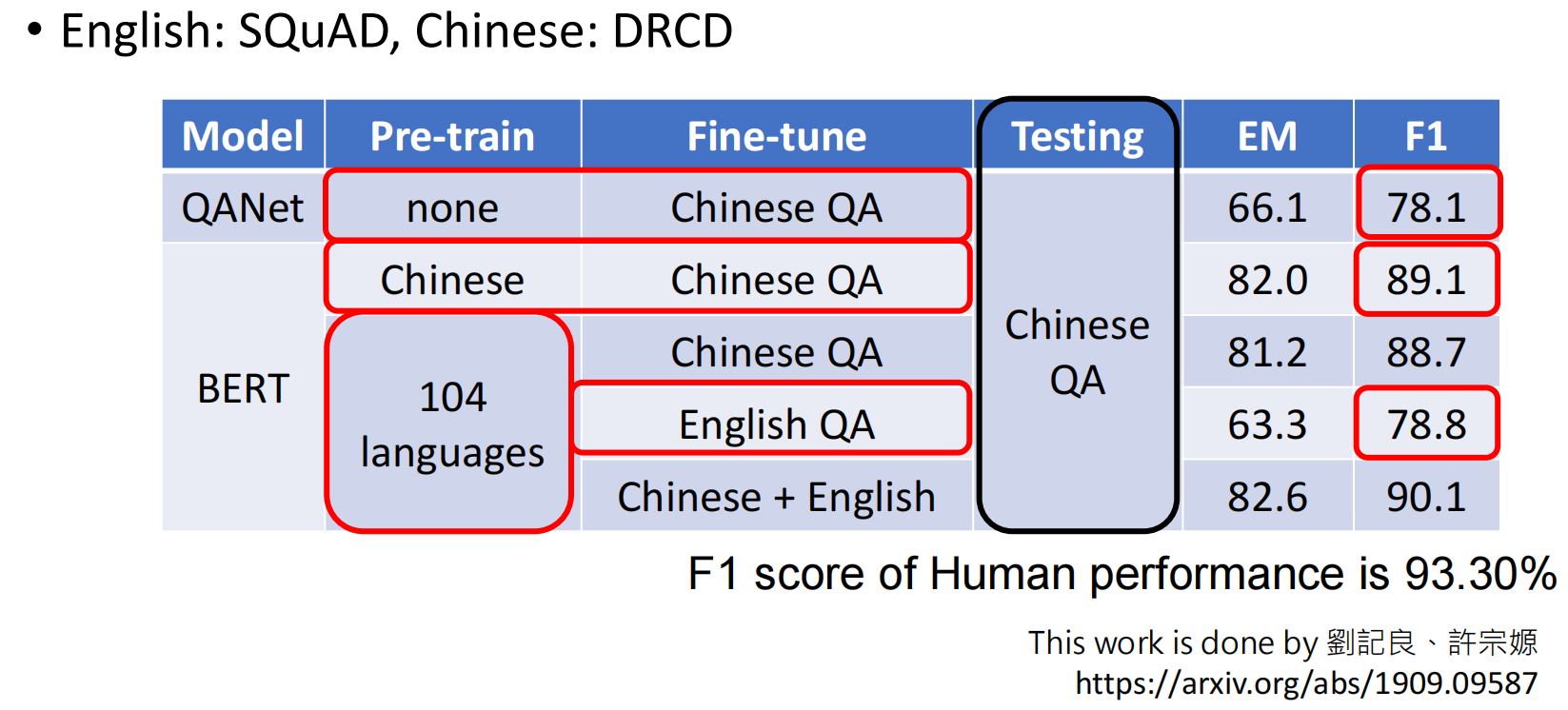
例如BERT就是打造了一堆专才:
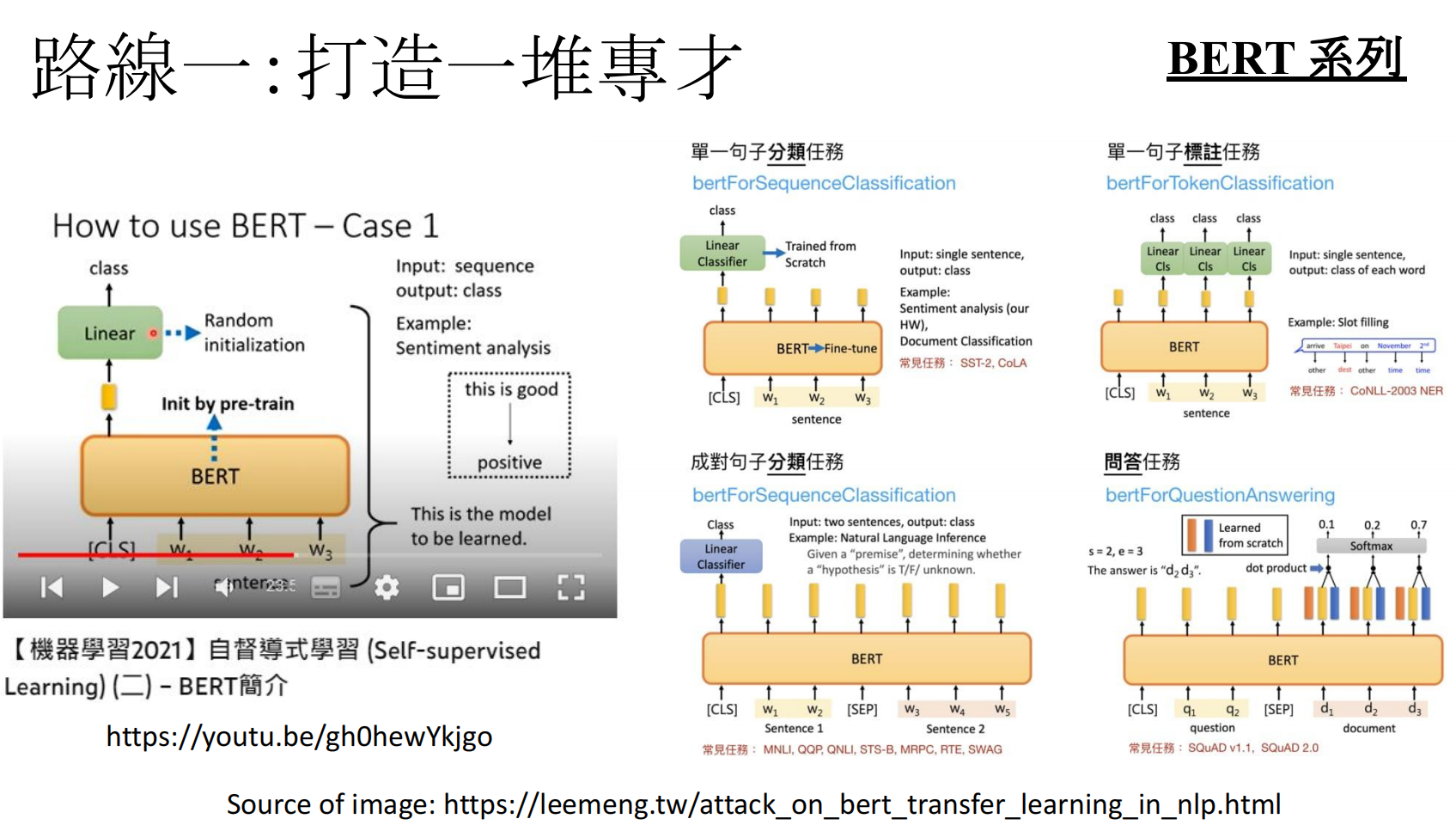
https://www.youtube.com/watch?v=gh0hewYkjgo
https://leemeng.tw/attack_on_bert_transfer_learning_in_nlp.html
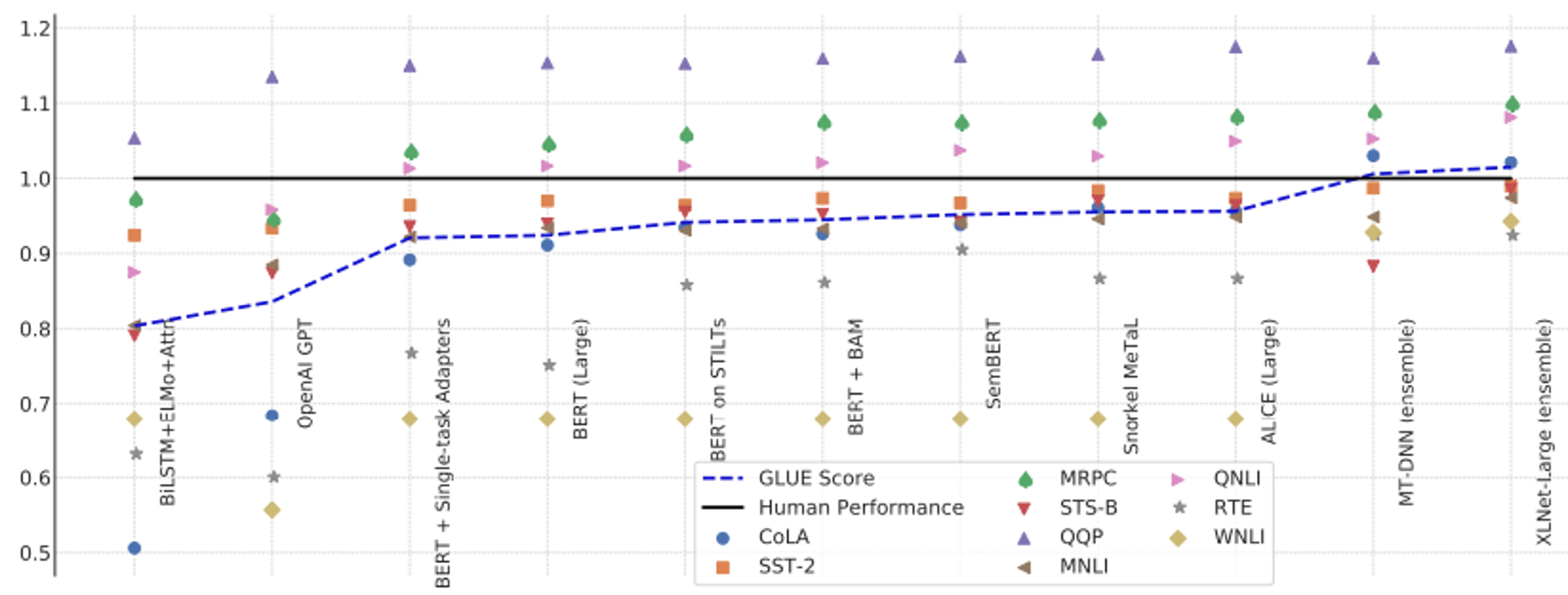
https://arxiv.org/abs/1905.00537
也可以将他往全能助手的方向训练,例如ChatGPT。
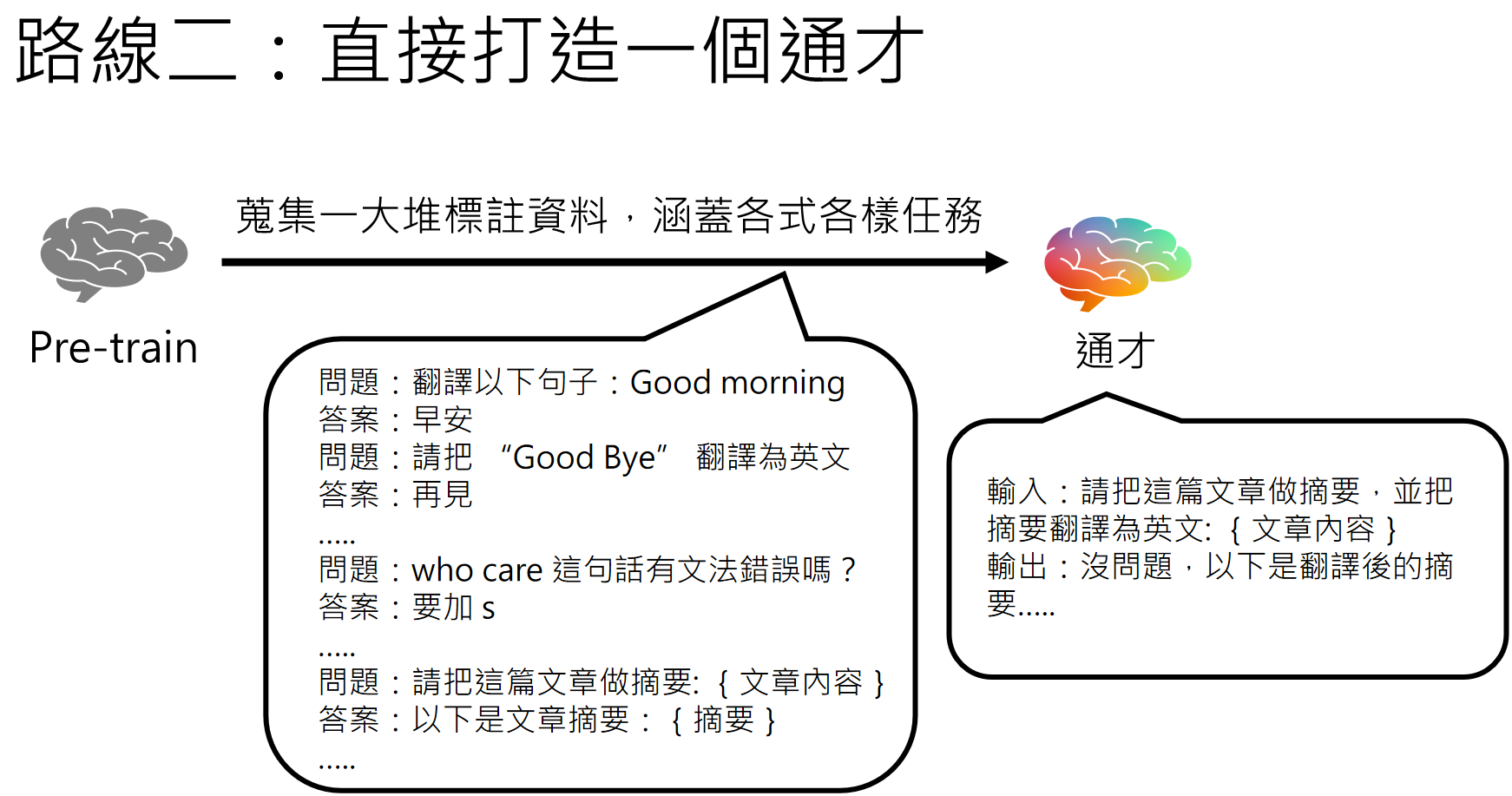
当然,成为通才需要成千上万种不同方向的资料,我们不可能一下子收集到所有资料,不过可以一项一项技能慢慢学习:
https://arxiv.org/abs/1909.03329v2
google的通才训练:
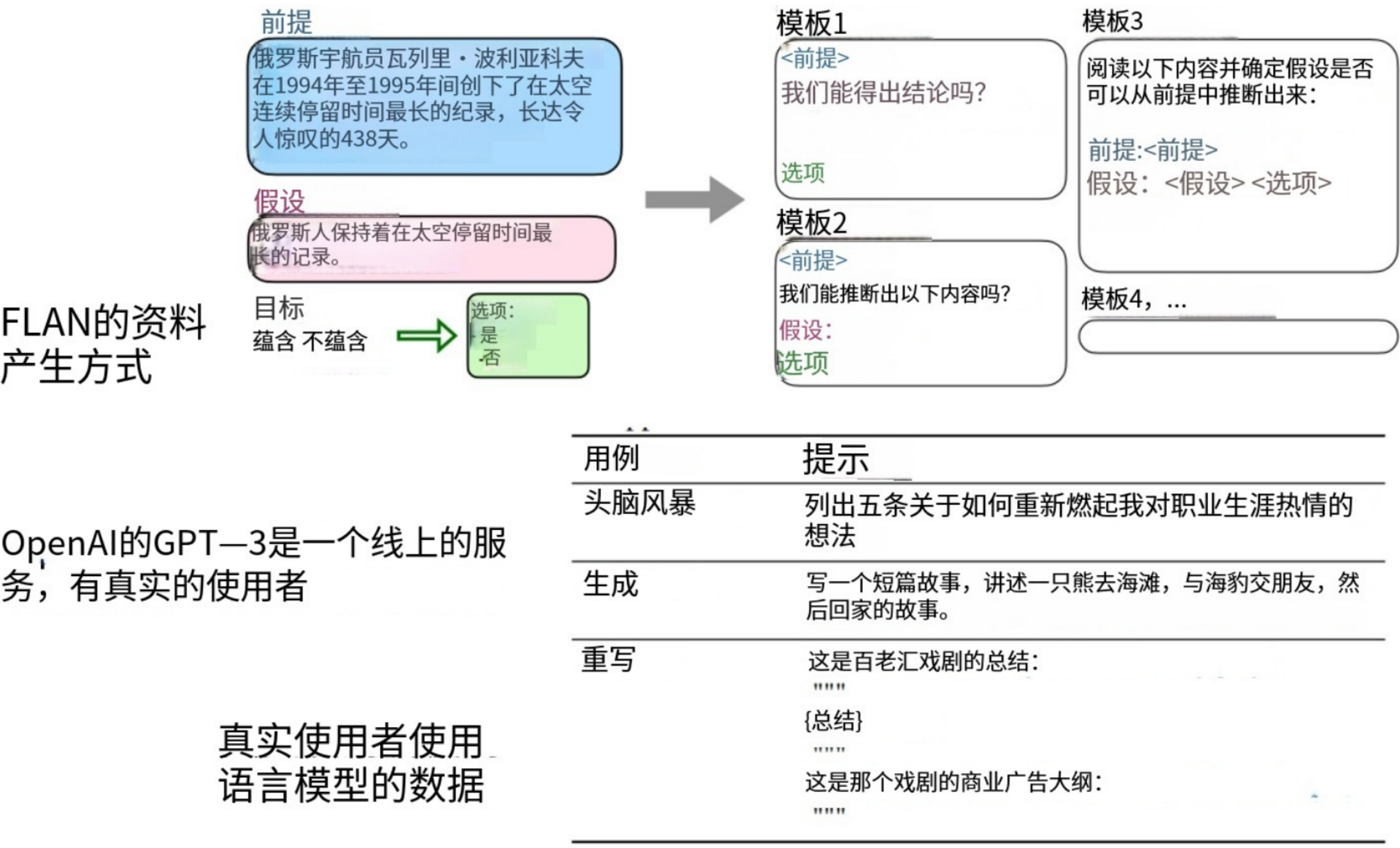
案例Google FLAN:
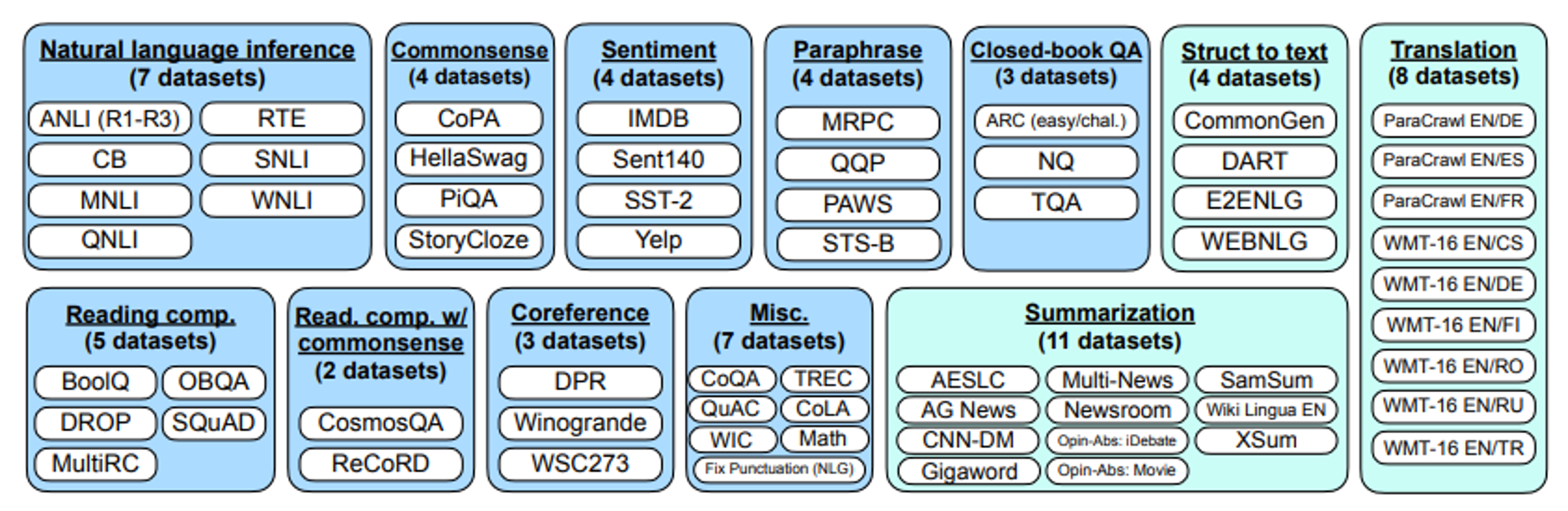
FLAN (Finetuned Language Net) :https://arxiv.org/abs/2109.01652
T0(huggingface家的): https://arxiv.org/abs/2110.08207

FLAN在通过多个方向的通才训练之后,在三个没有训练过的领域都超过了GPT3。后来他们又加强了更多类型(1800个)任务的训练:
Scaling Instruction-Fine-tuned Language Models :https://arxiv.org/abs/2210.11416
最终取得了很不错的效果: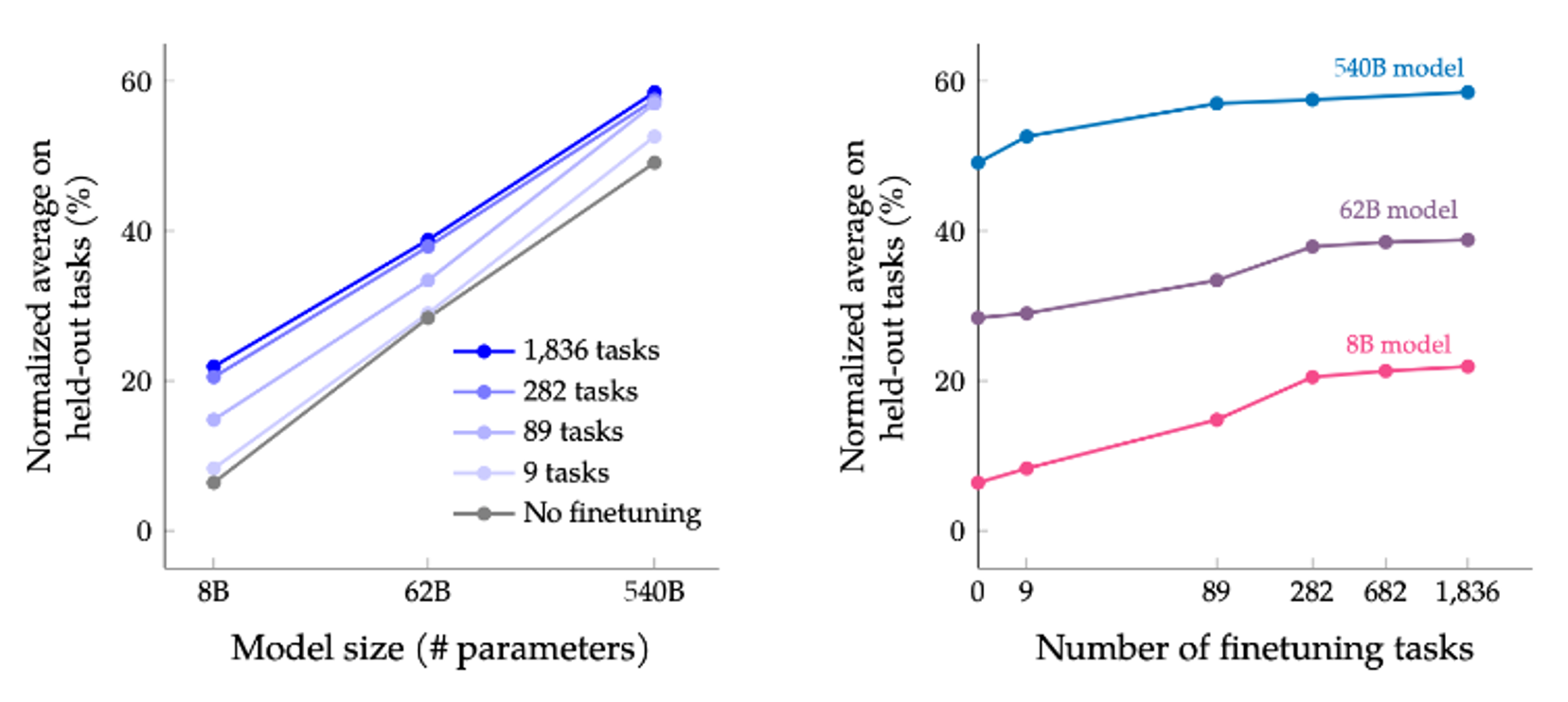
https://arxiv.org/abs/2210.11416
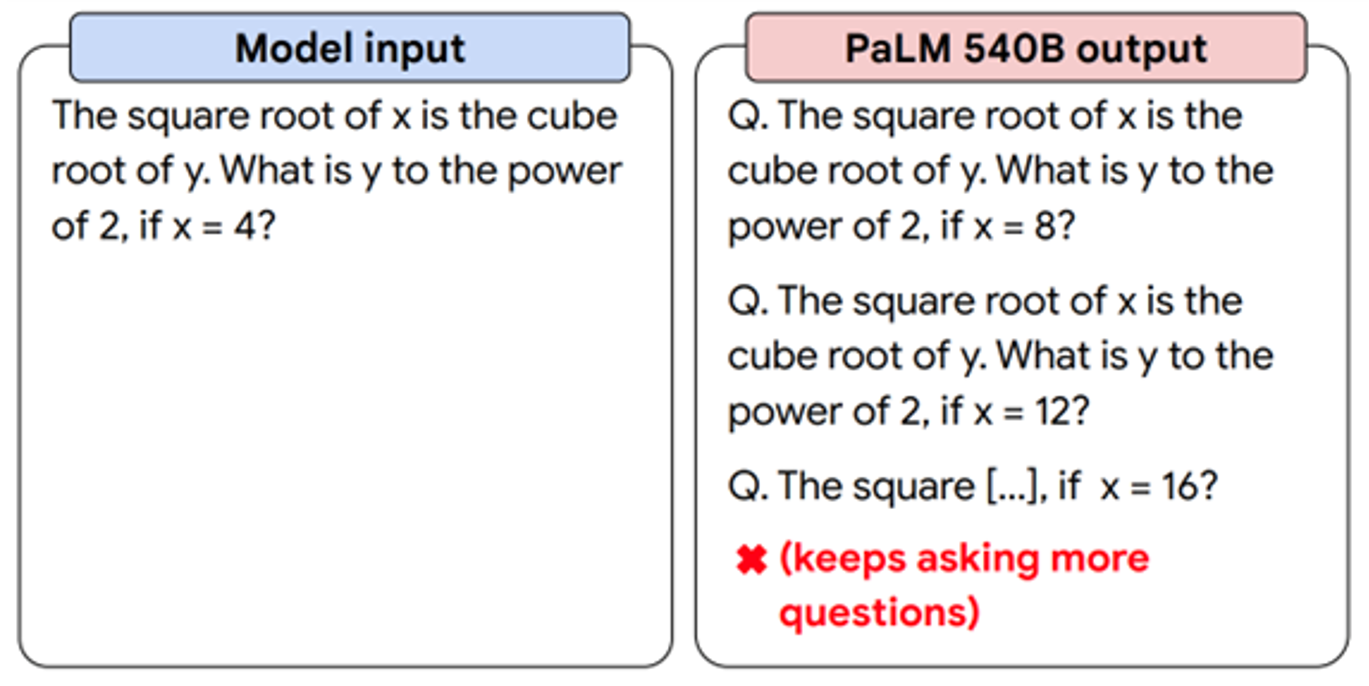
例如:一个540Billion(五千四百亿)参数的巨大模型,在进行微调之前都不能正确回答问题,但是微调之后,直接给出了答案:
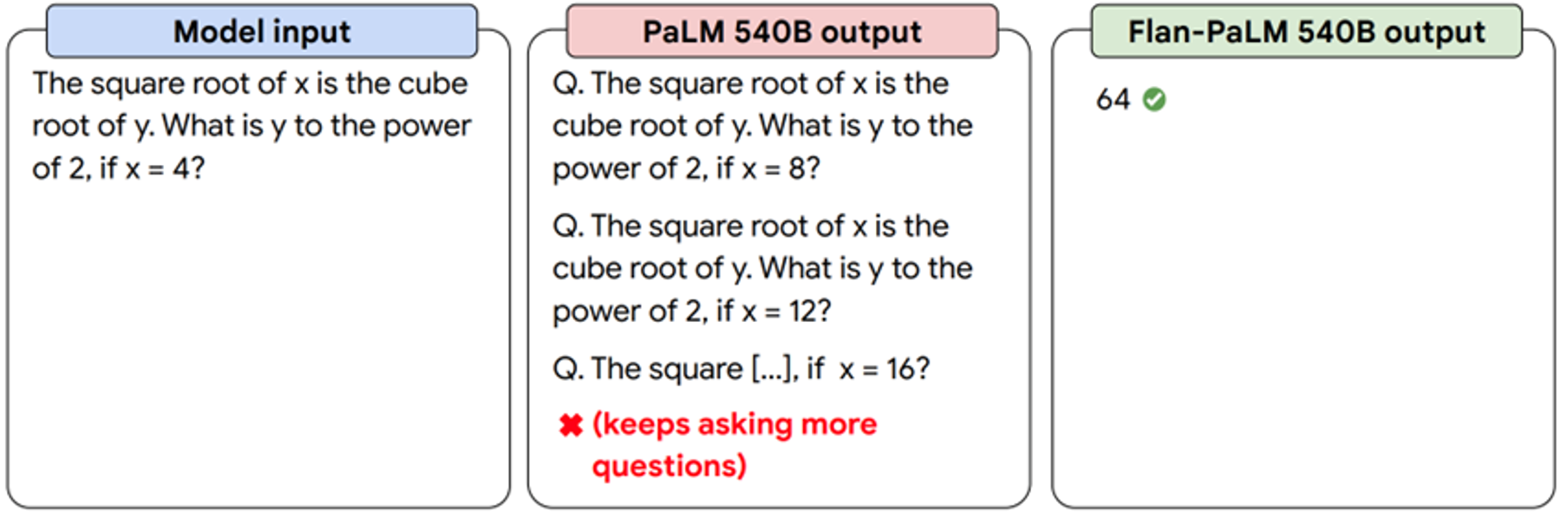
https://ai.googleblog.com/2022/11/better-language-models-without-massive.html
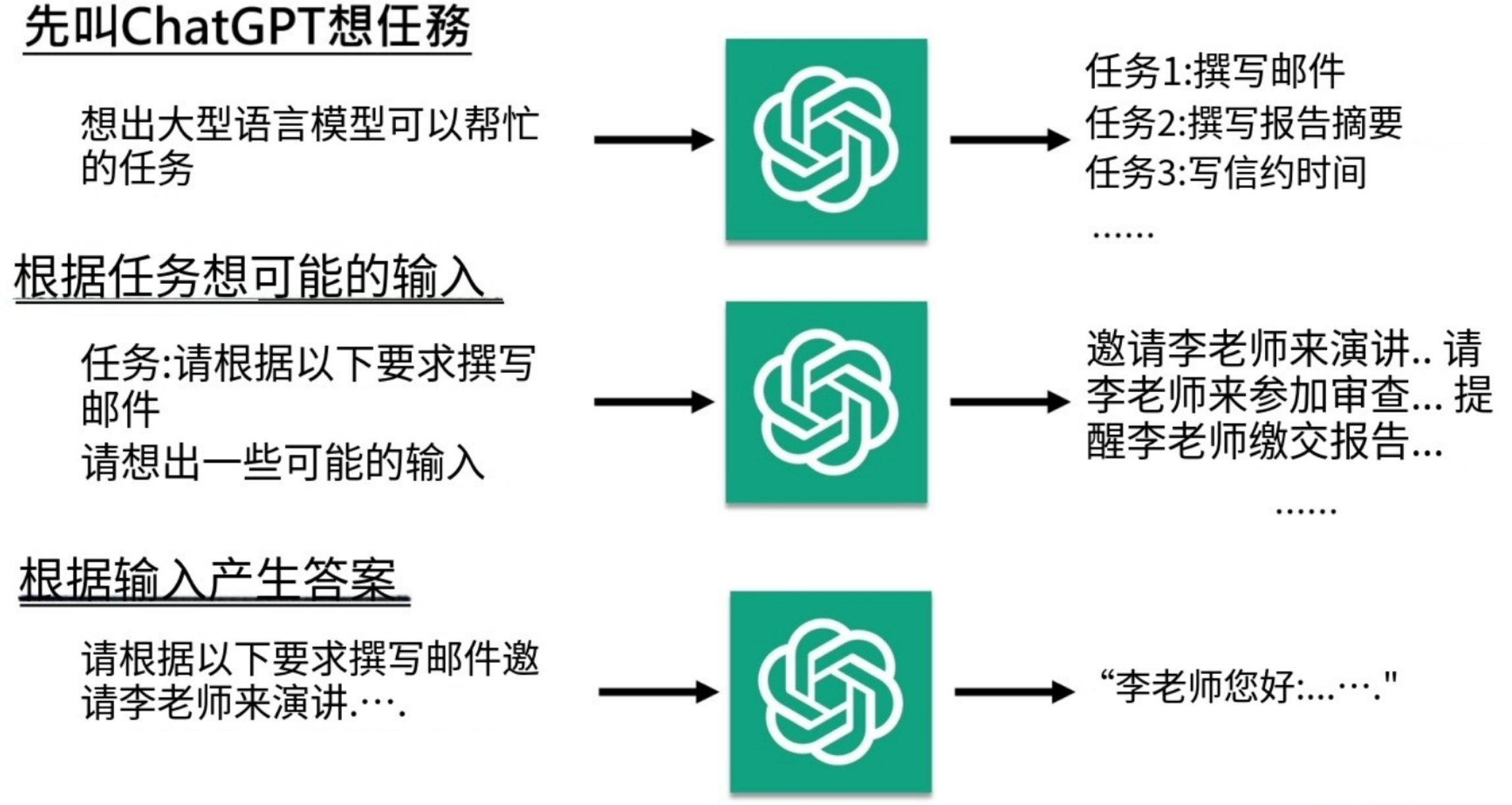
openai通才训练
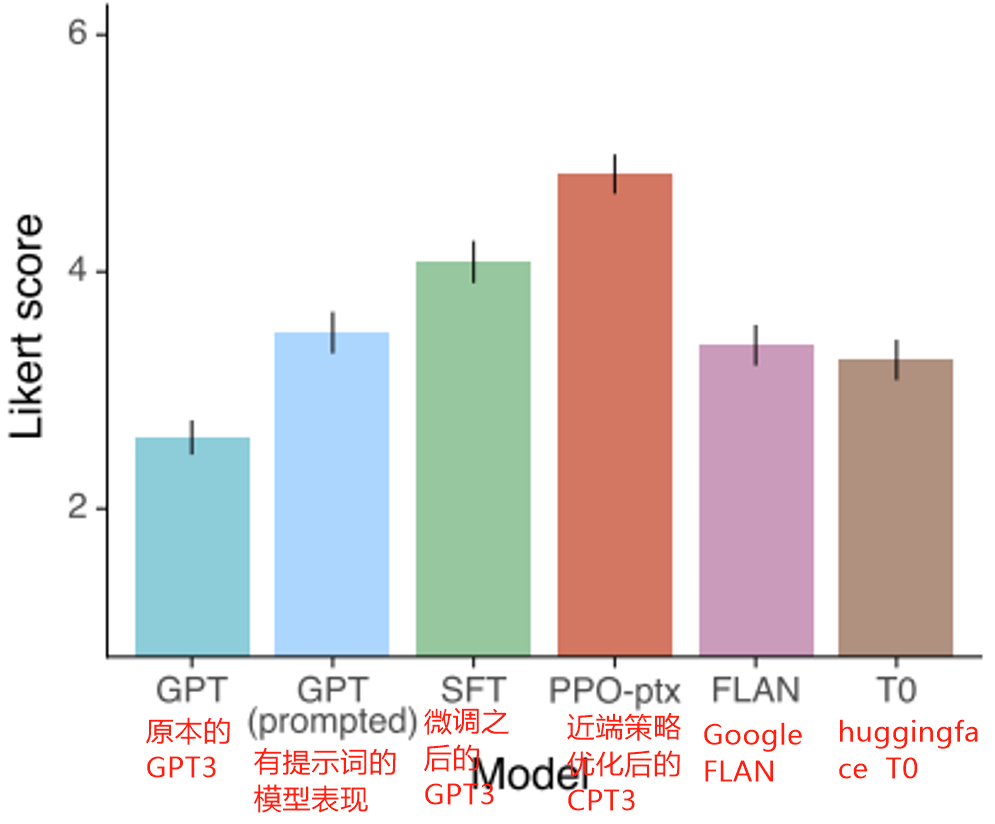
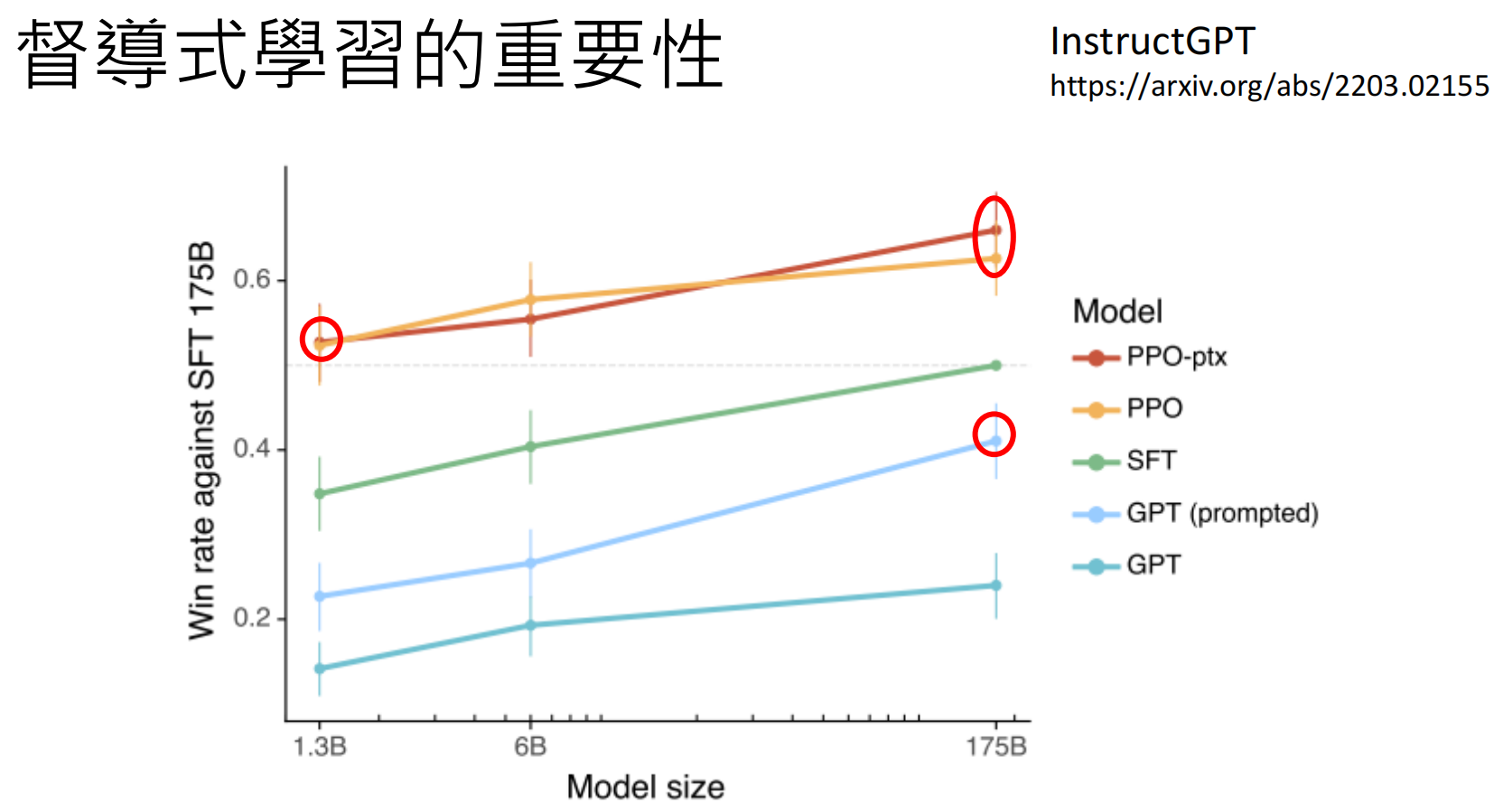
Instruct GPT https://arxiv.org/abs/2203.02155
资料里显示,微调之后的GPT3超过了Goole的FLAN,openai论文里解释,FLAN产生答案依赖各种各样的模版,那是因为他们有大量真实的用户数据,他们发现,用户的问题千奇百怪,不可能都有模版能够一一对应:
Instruction Fine-tuning (指令微调)是画龙点睛,并且指令微调并不需要大量数据:

Instruct GPT https://arxiv.org/abs/2203.02155
LLaMA2也表示,他们仅仅使用27540条数据就取得了不错的效果:

https://arxiv.org/abs/2307.09288
https://arxiv.org/abs/2305.11206
逆向工程
所以我自己也能做 Instruction Fine-tuning 嗎? 不可以,因为为我们没有高品质的资料。。。我们没有来自用户的真实数据。。。。怎么办呢?

但是逆向工程有风险,openai使用条款里禁止用户这样做:

Open AI’s Terms of Use :https://openai.com/policies/terms-of-use
不过听说,没人理会这些条款,大部分小公司都是逆向工程搞到的训练资料。。。
普通人也能微调大语言模型
OK,那我们假设可以通过逆向工程获得优质训练资料,但是,最最最关键的是“预训练模型参数”去哪里搞?这可是商业机密。。。google有PaLM,openai有GPT3,我们有屁。。。
难道注定我们普通人无法打造自己的大语言模型了吗?呜呜呜。。。
突然:Meta 开源了LLaMA !!!可能Meta眼看自己赶不上openai和Google,要被挤下牌桌。于是直接掀桌子了。。。
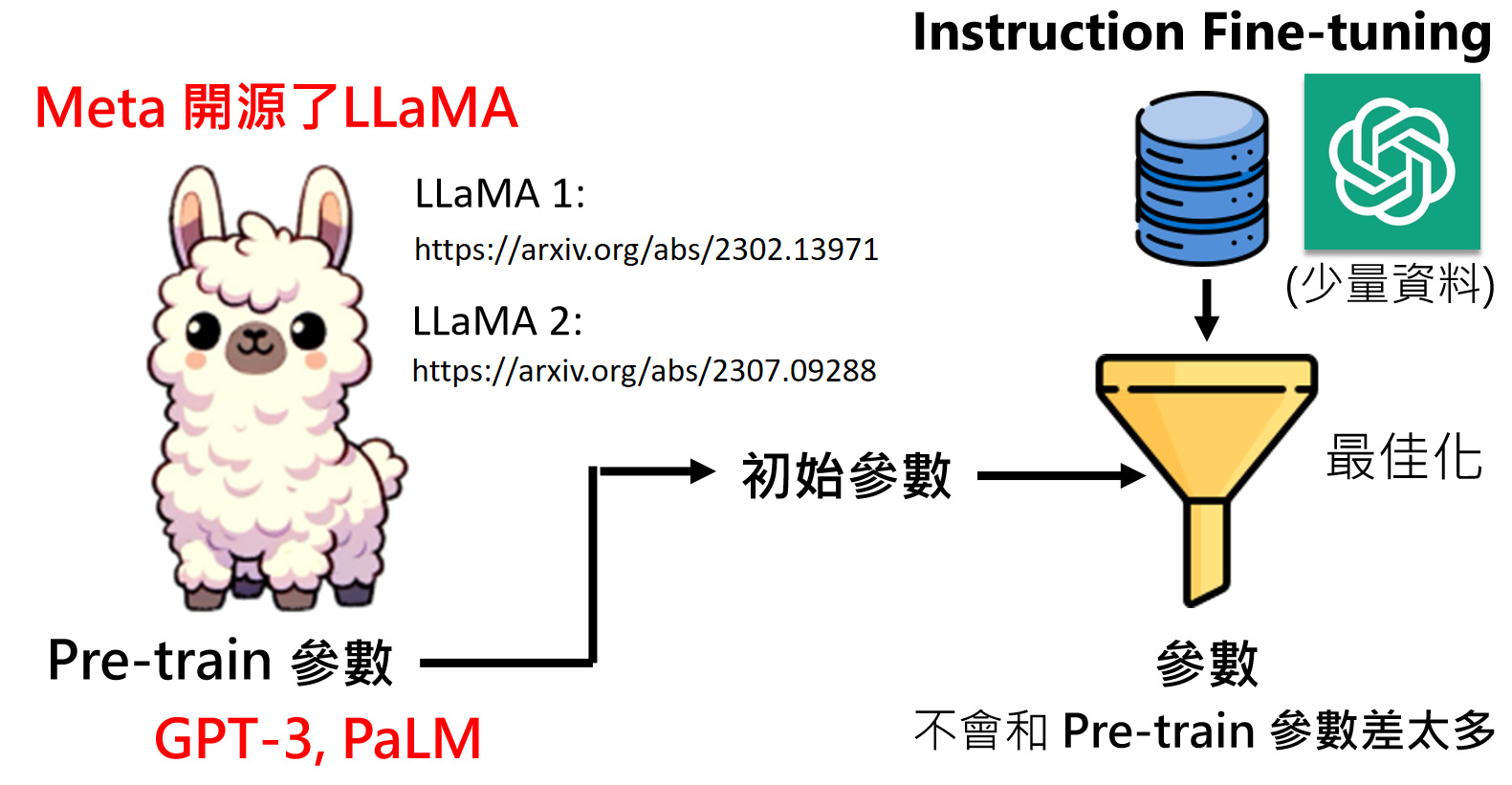
LLaMA 1: https://arxiv.org/abs/2302.13971
LLaMA 2: https://arxiv.org/abs/2307.09288
LLaMA开元两周之后,整个AI的大门就向普通人和小公司打开了,很多基于LLaMA的模型,应运而生:

Alpaca:https://crfm.stanford.edu/2023/03/13/alpaca.html
Vicuna :https://lmsys.org/blog/2023-03-30-vicuna/
一下子,世界变了:


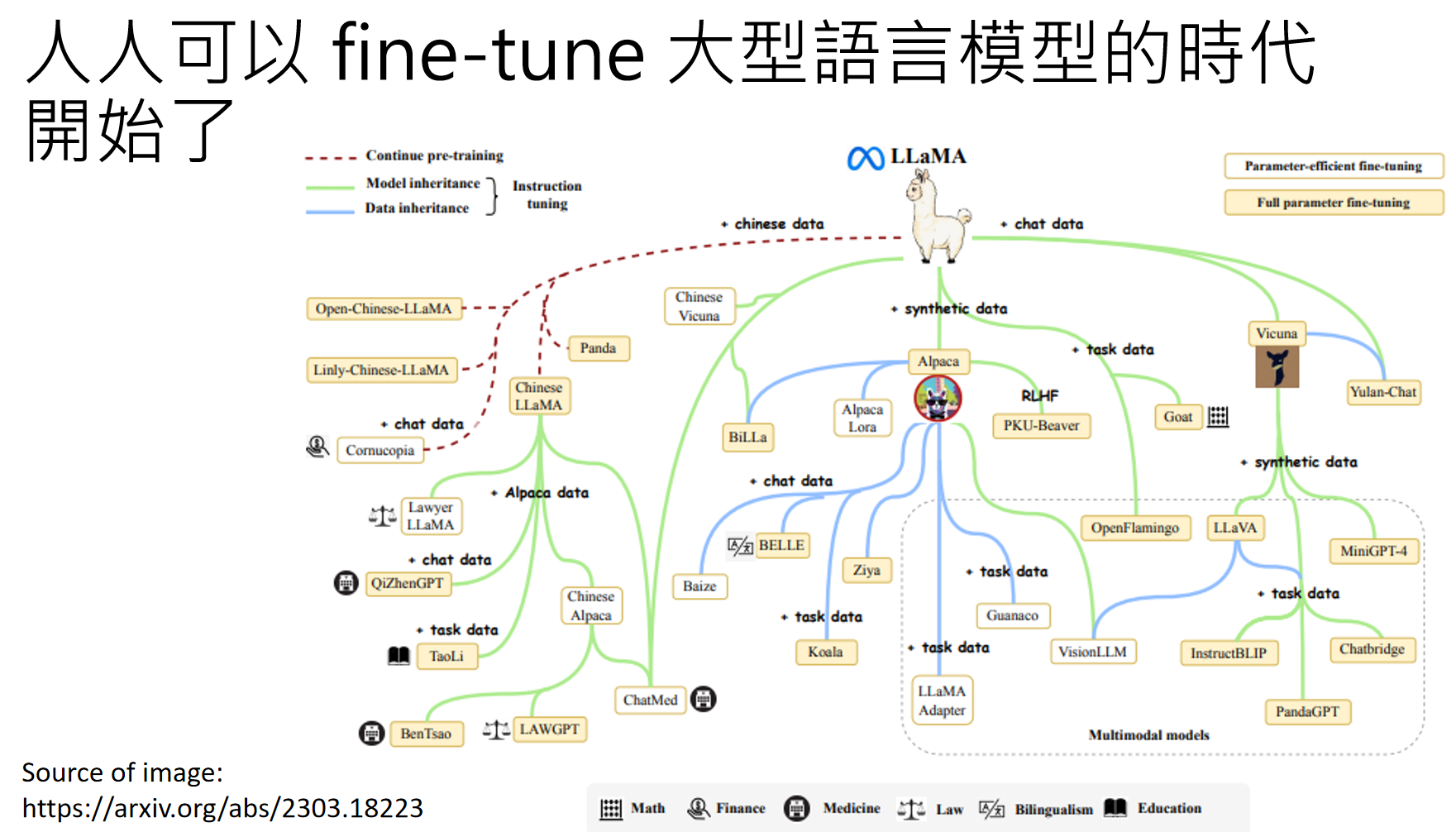
Source of image: https://arxiv.org/abs/2303.18223
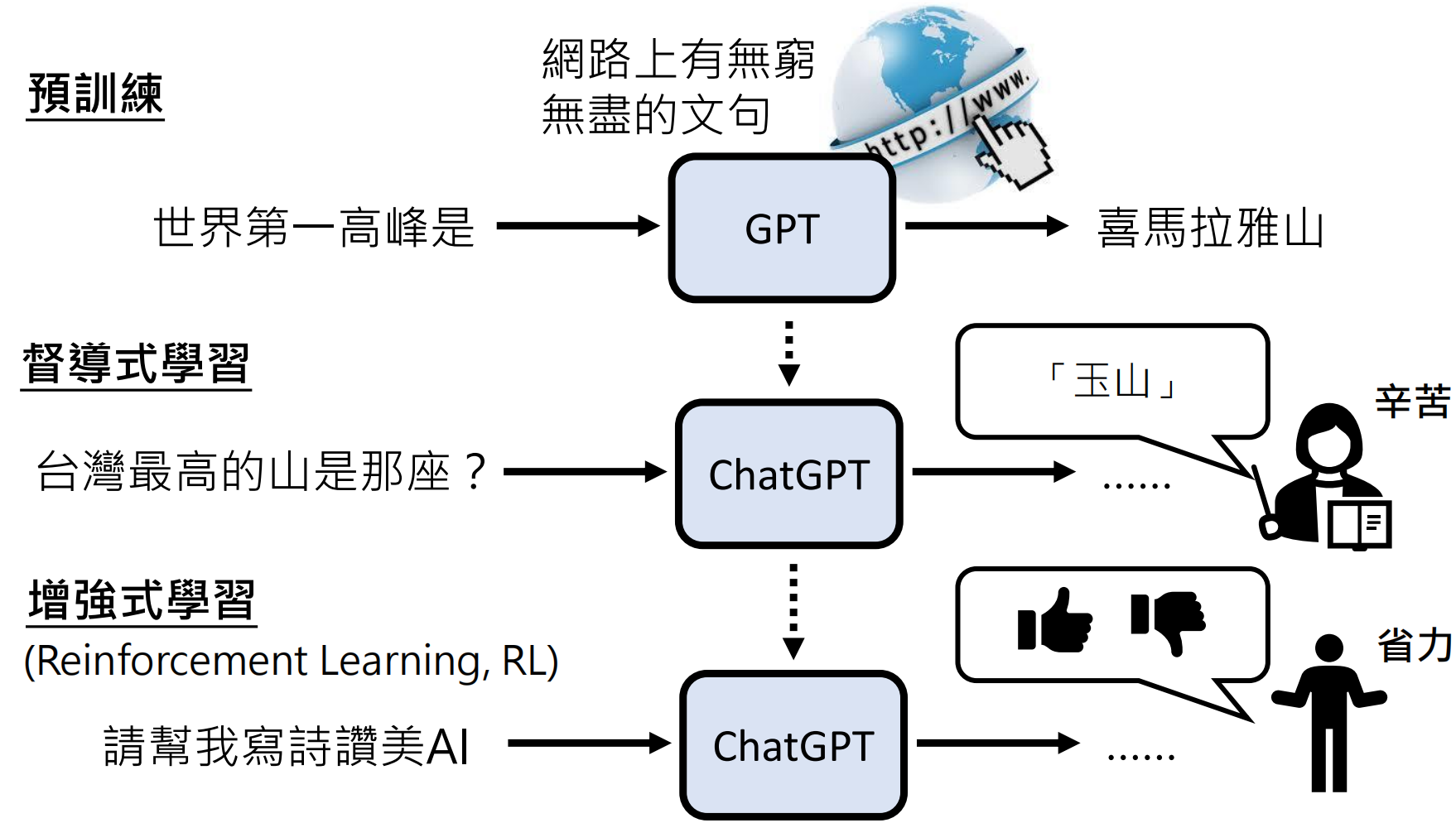
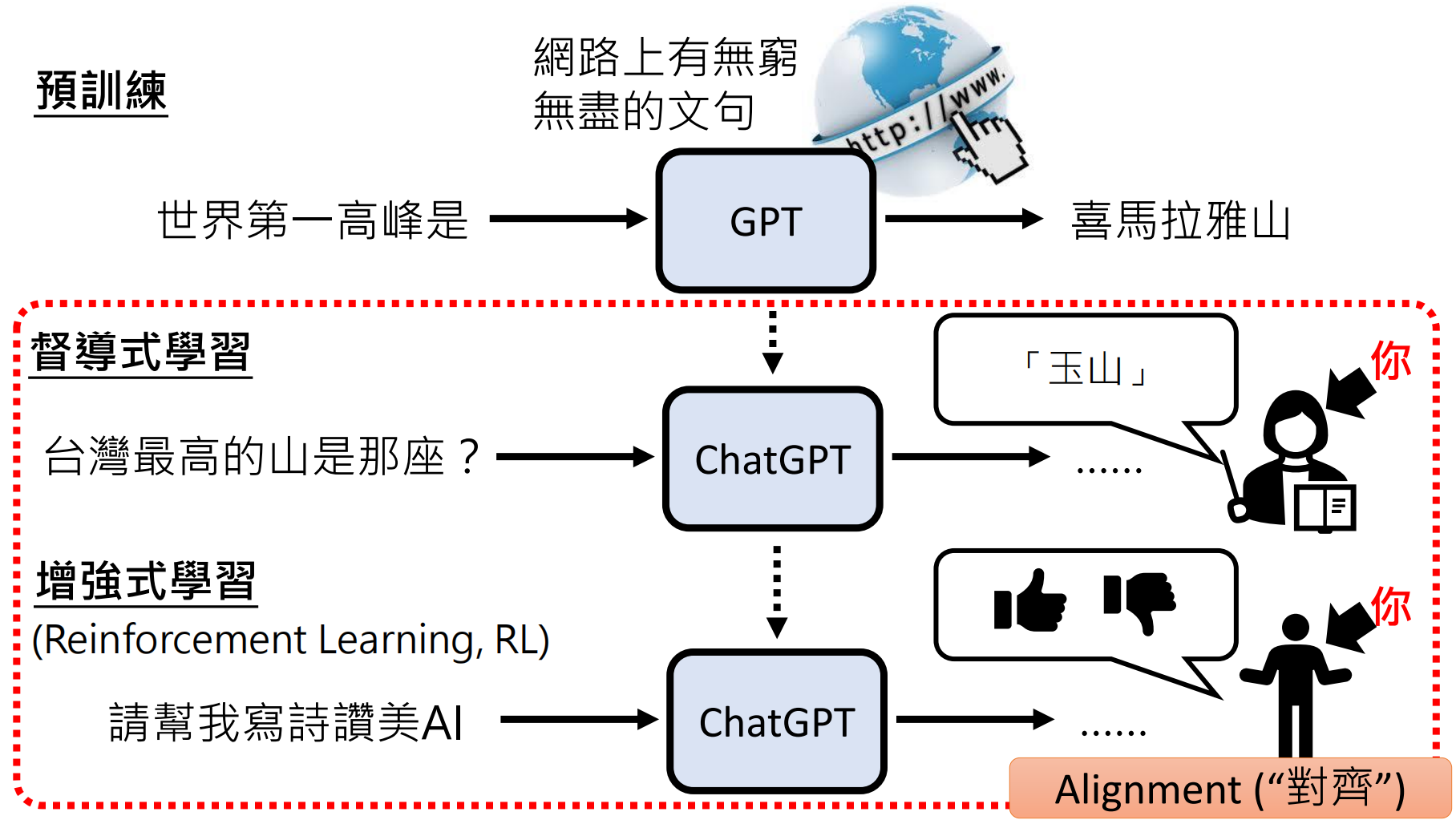
强化学习(RLHF)
RLHF 是 “Reinforcement Learning from Human Feedback” 的缩写,中文名为 “基于人类反馈的强化学习”,是一种机器学习技术。
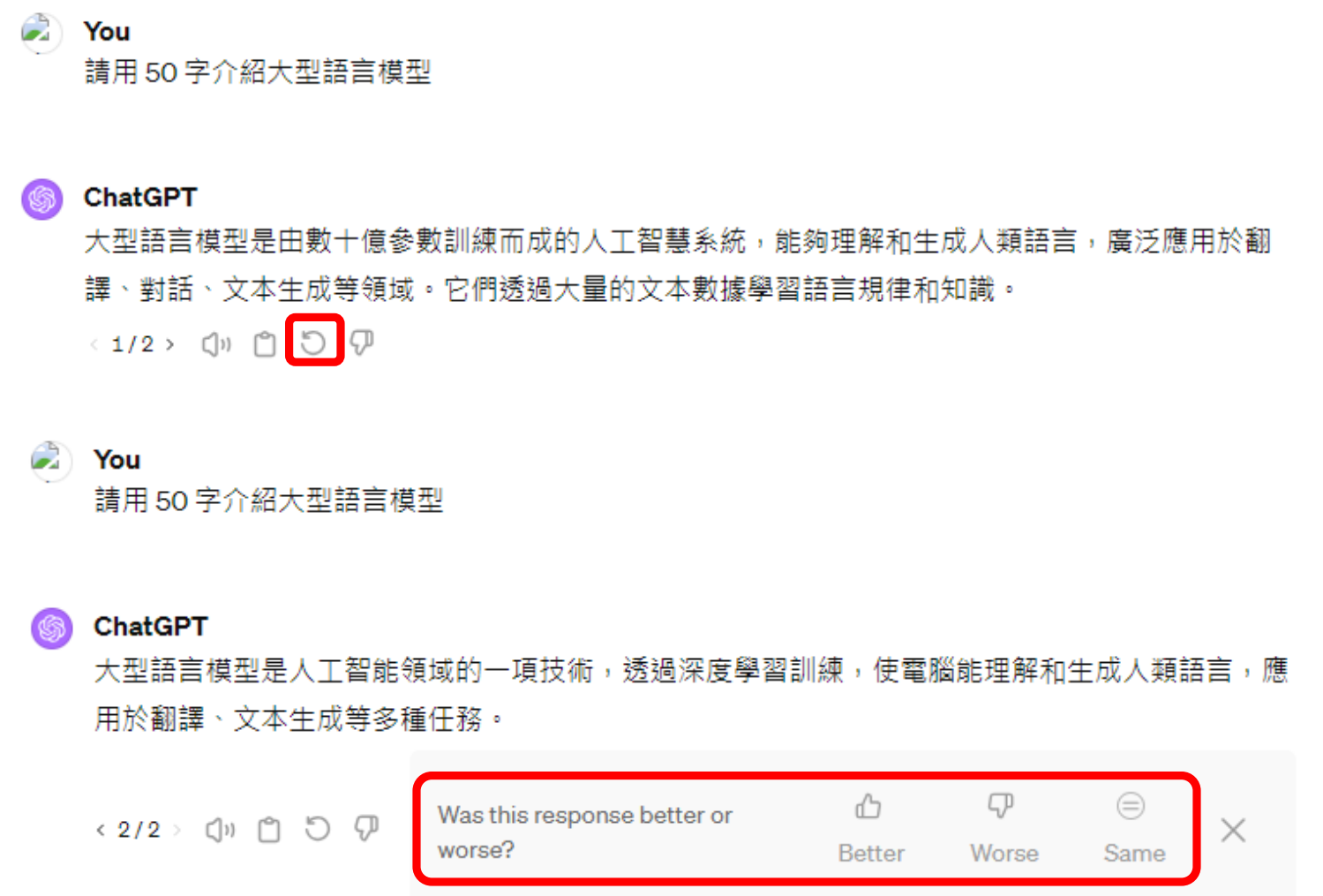
RLHF 是 ChatGPT 的“画龙点睛”之笔,例如上面的对话,ChatGPT通过收集人类的反馈,来微调参数,进一步优化自己。


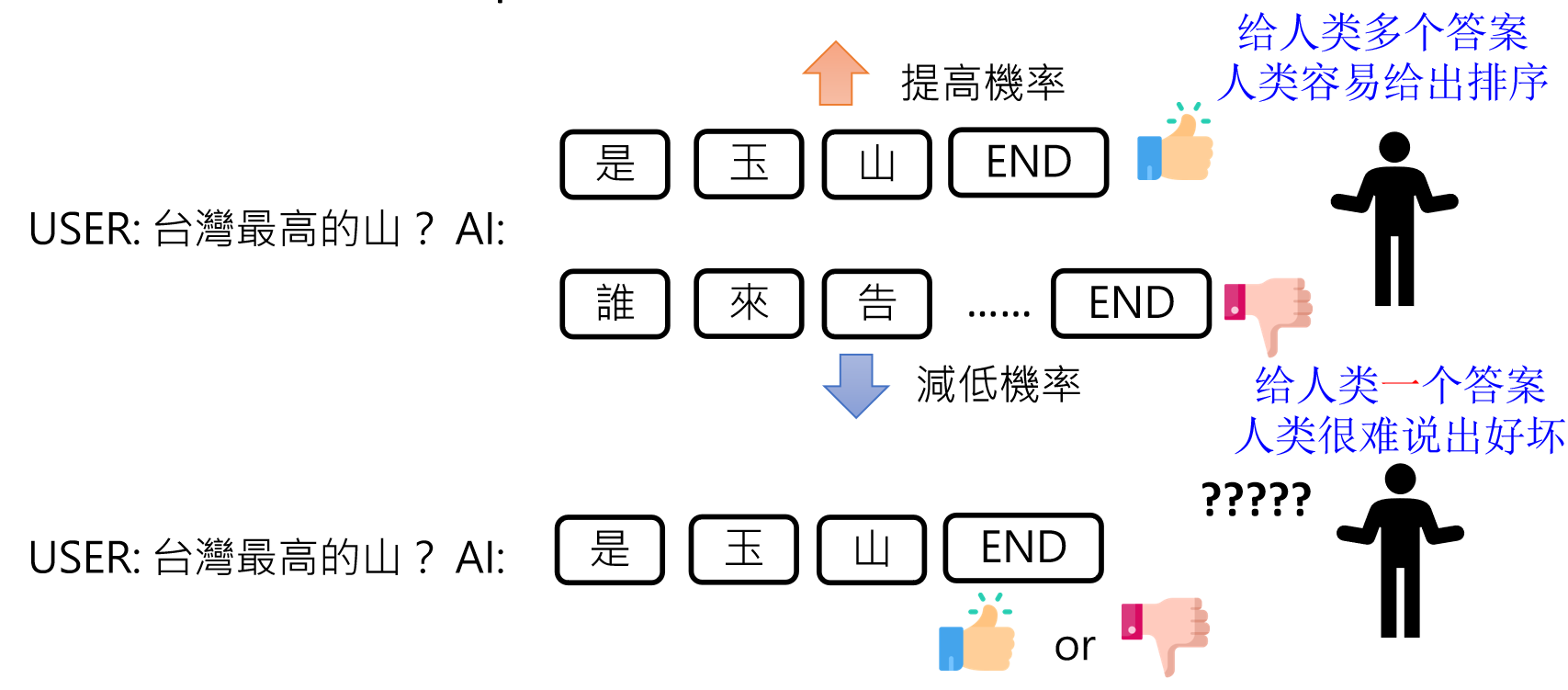
回馈模型(Reward Model)

由于人类精力有限,所以就需要一个回馈模型(Reward Model)来模仿人类喜好,来给模型做评判。

训练“奖励模型”(Reward Model)模拟人类偏好(如比较两个回答哪个更好),再用强化学习(如 PPO 算法)优化语言模型。
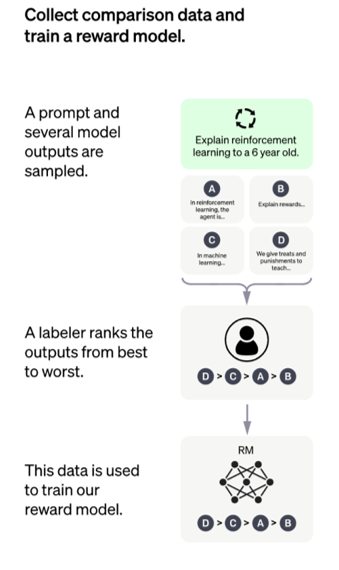
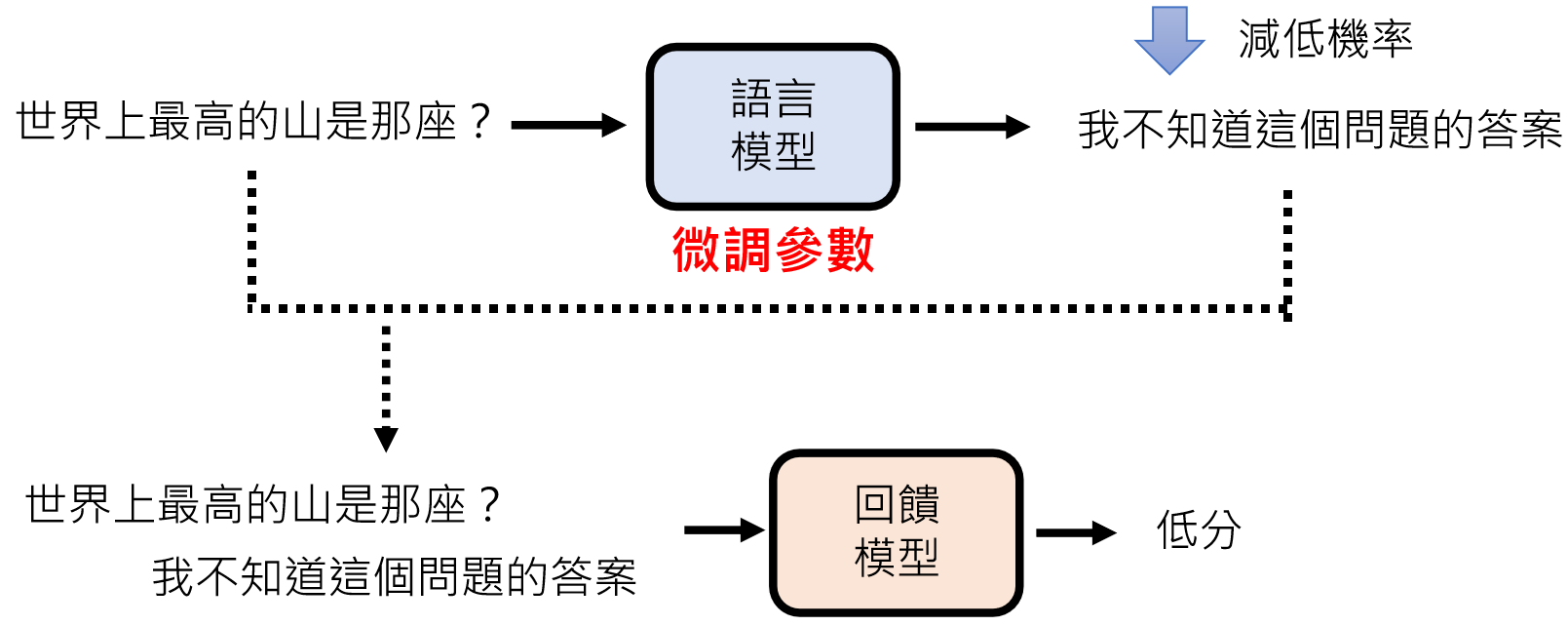
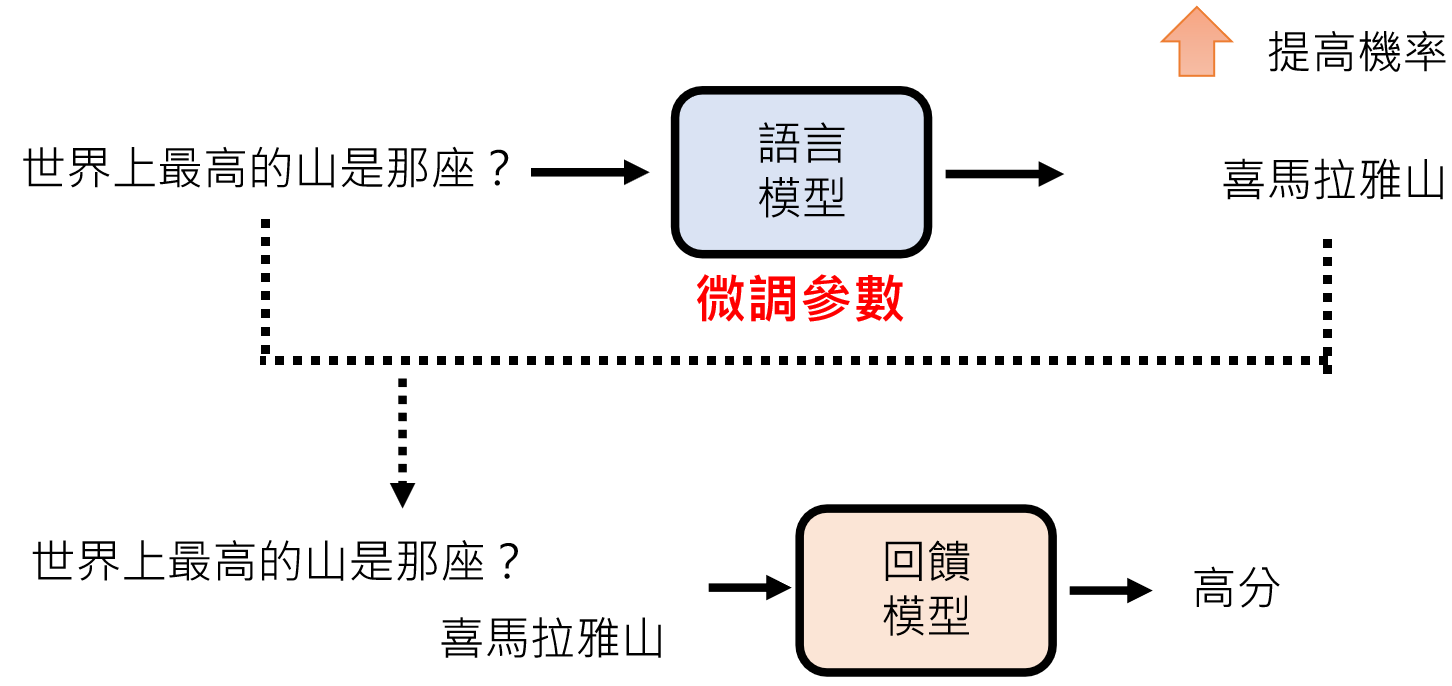
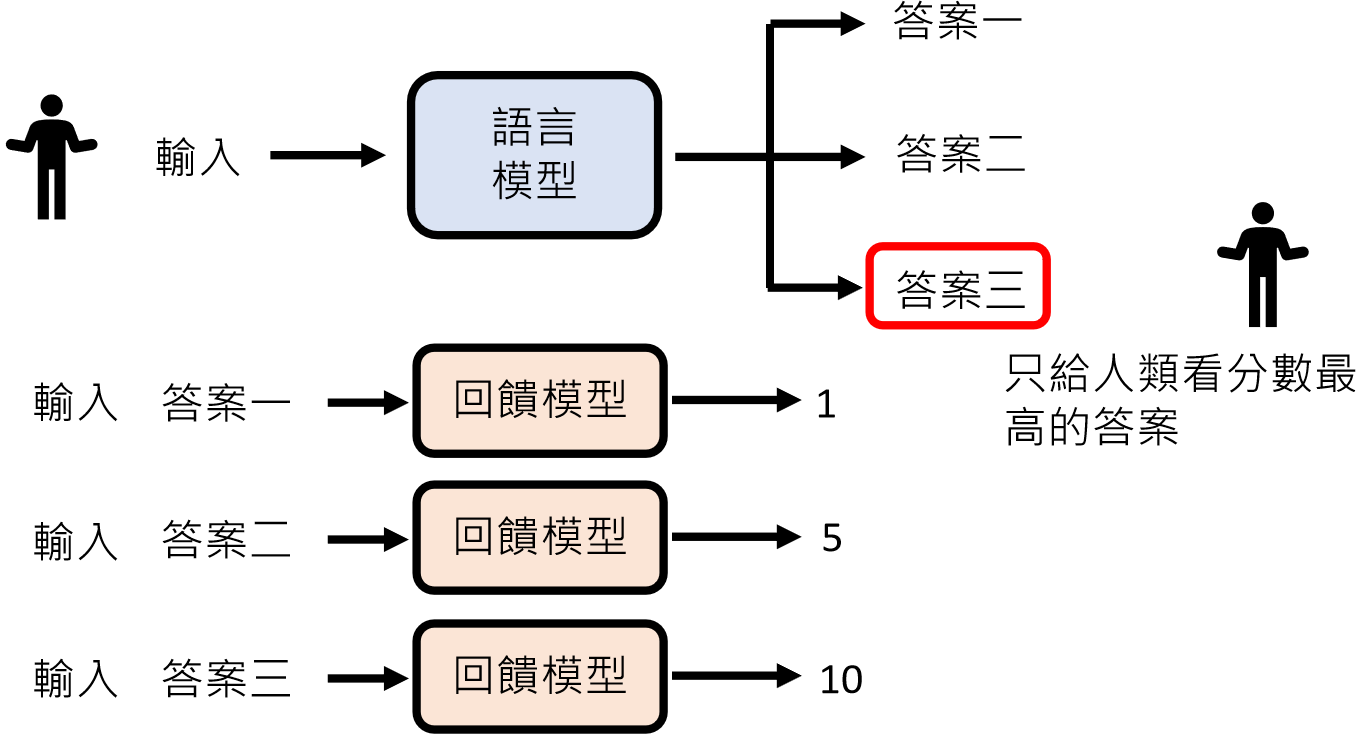
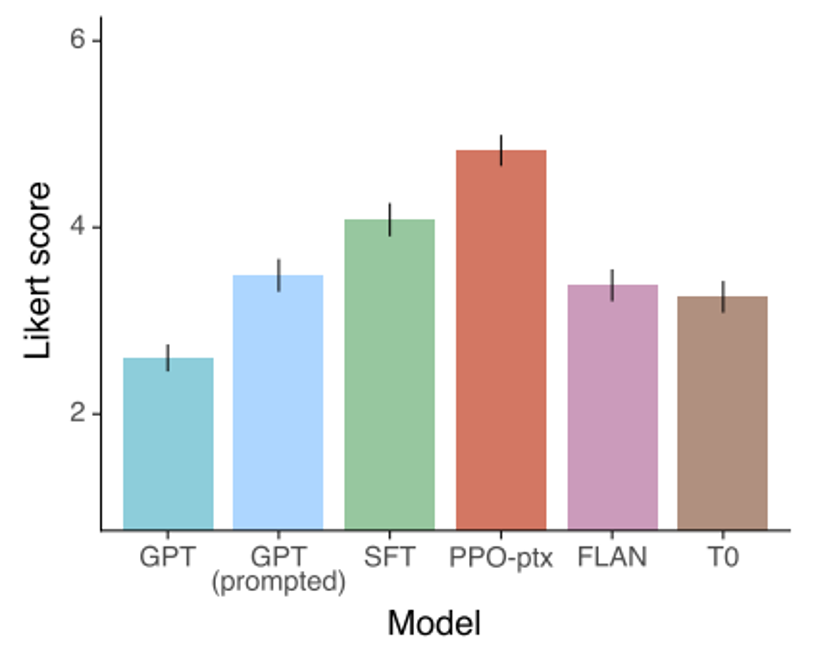

Instruct GPT https://arxiv.org/abs/2203.02155
https://openai.com/zh-Hans-CN/index/gpt-4-research/
但是如果过度使用Reward Model也会产生负面影响:
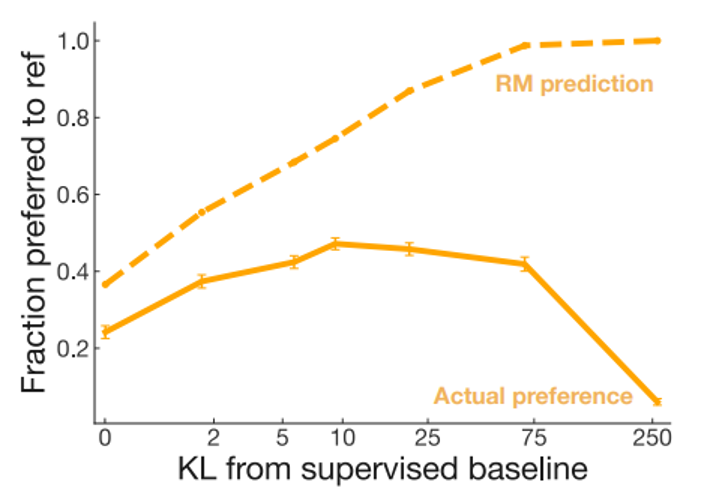


https://arxiv.org/abs/2009.01325
John Schulman (scientist and cofounder of OpenAI), invited talk, ICML 2023
由于过度和虚拟老师(Reward Model)学习有害,所以有些人开发了不需要Reward Model的演算法如(了解):
- DPO
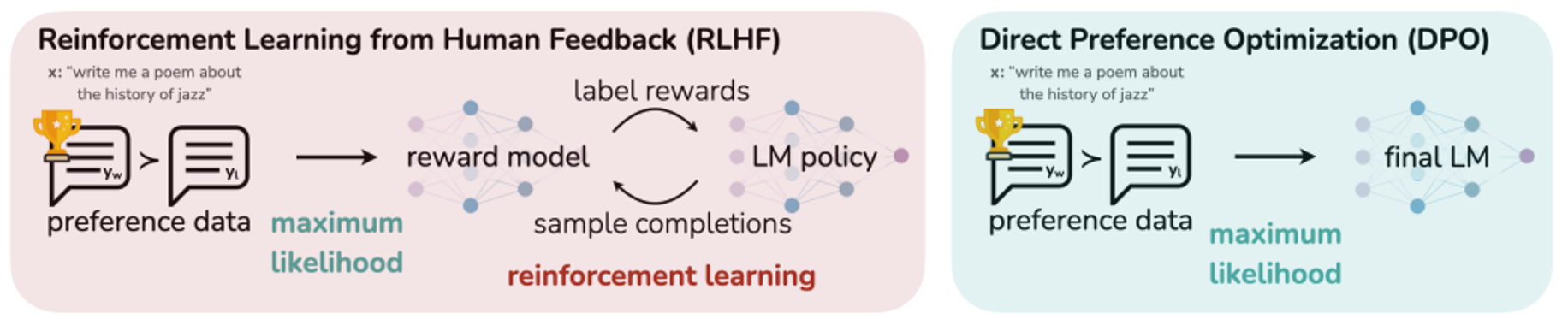
https://arxiv.org/abs/2305.18290
- KTO
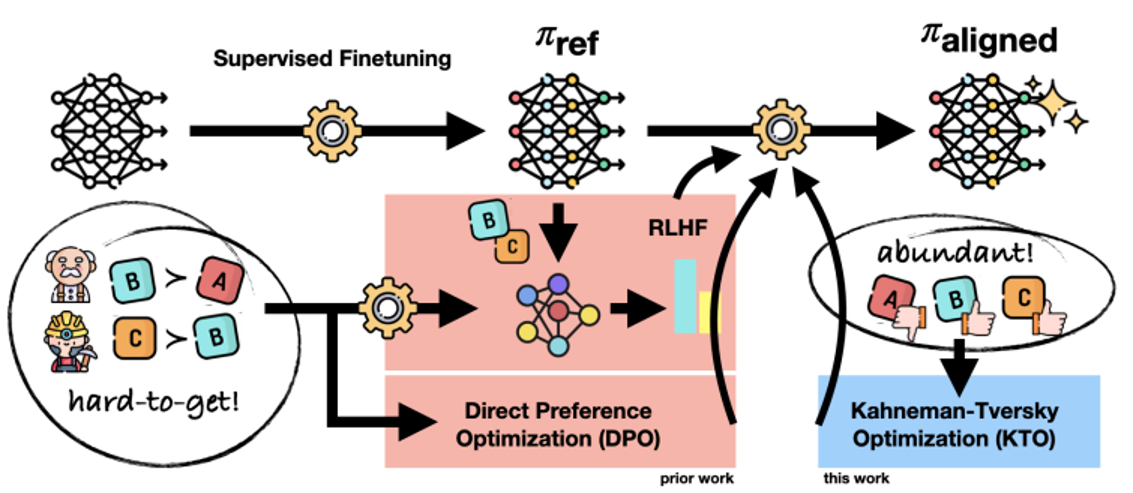
https://arxiv.org/abs/2402.01306
语言模型有自我反省的能力,随着将来技术的发展,将来可能会有RLHF → RLAIF
https://arxiv.org/abs/2212.08073
https://arxiv.org/abs/2304.03277
https://arxiv.org/abs/2309.00267
https://arxiv.org/abs/2401.10020
补充更新:当前主流模型(如 GPT-4)已扩展为多轮对话微调,减少错误率 30% 以上。
-
为何 RLHF 有效?
研究(如 InstructGPT论文)证明,RLHF 将模型对齐人类意图,避免网络数据中的噪音。文档提醒:模型需一定基础能力才适合 RLHF,否则可能失效。
RLHF vs Instruction Fine-tuning
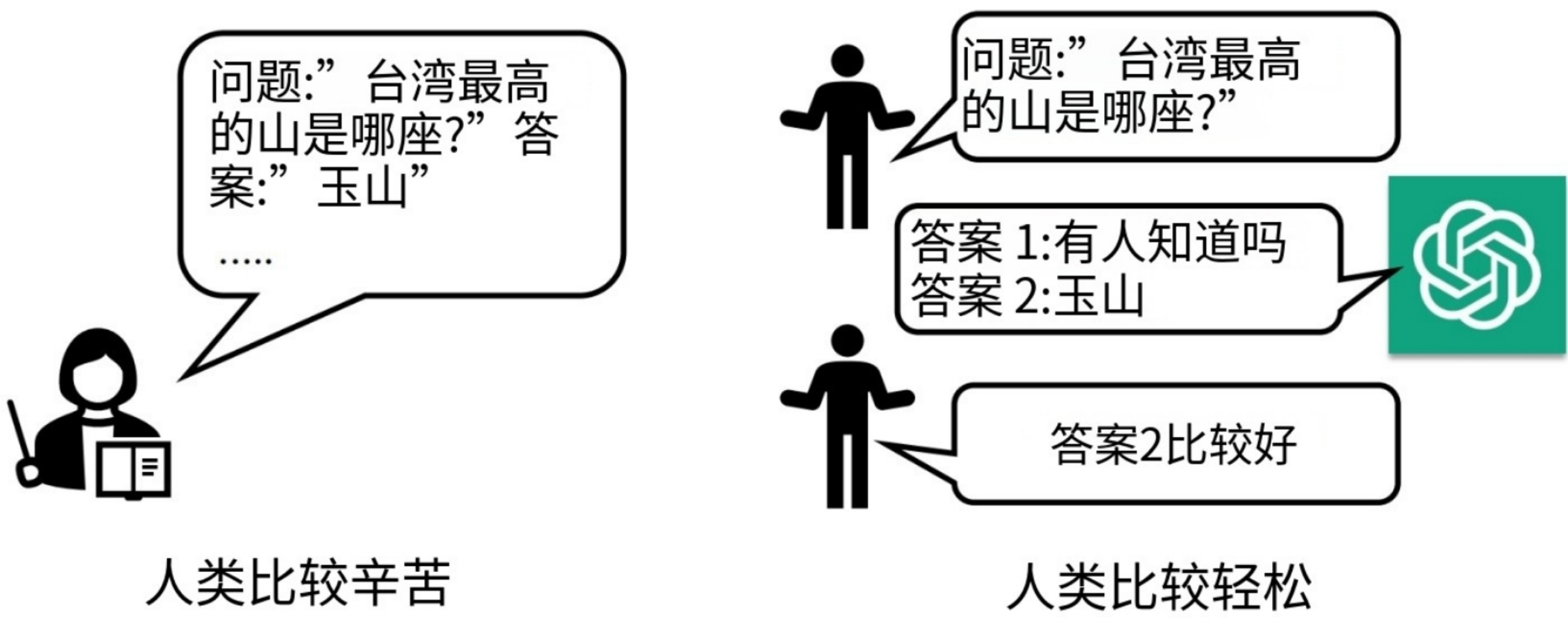
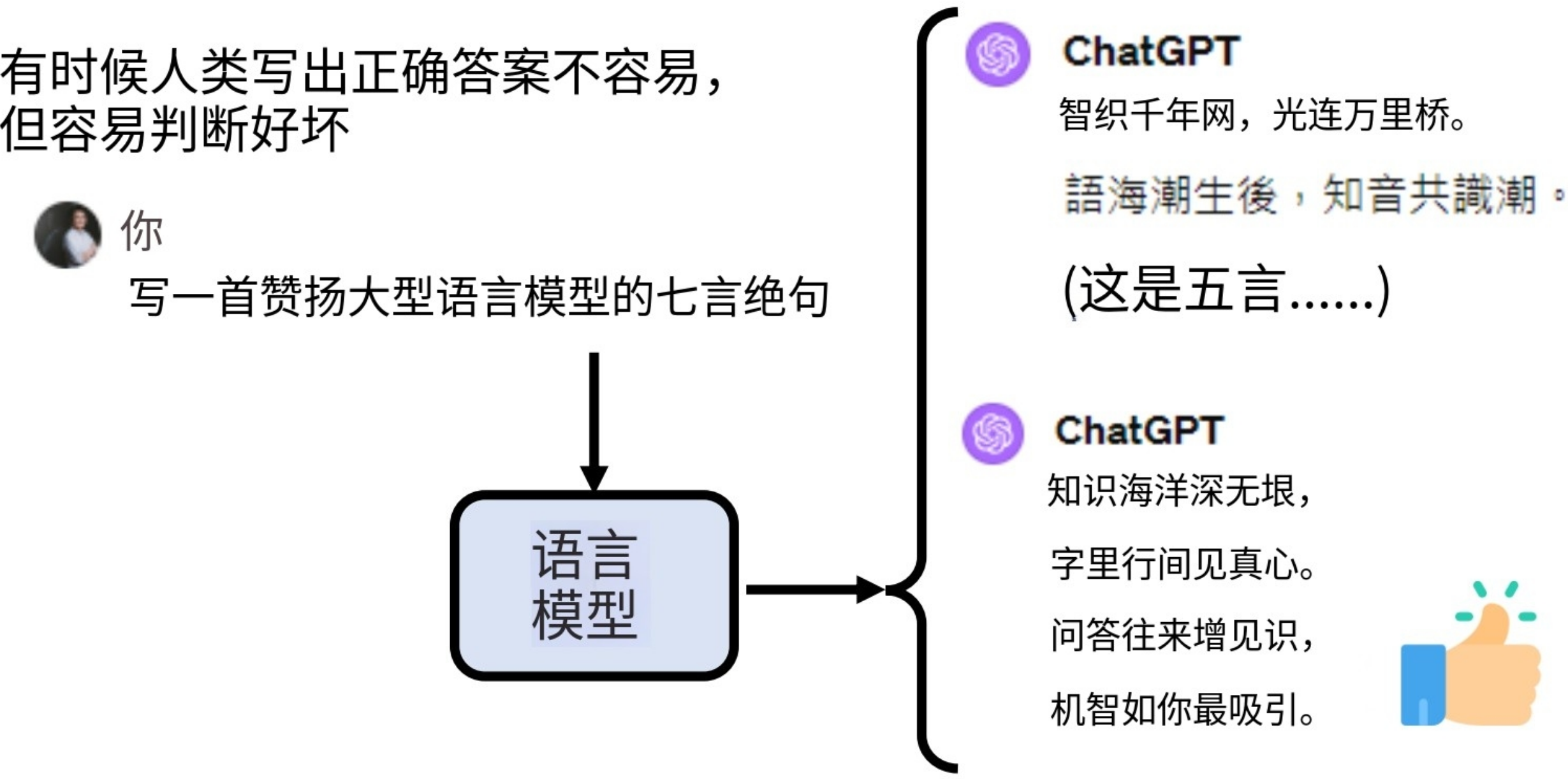
从产生训练资料的角度看:
从模型学习的角度来看
- Instruction Fine-tuning(只管过程,不管结果)
- RLHF(只管结果,不管过程)


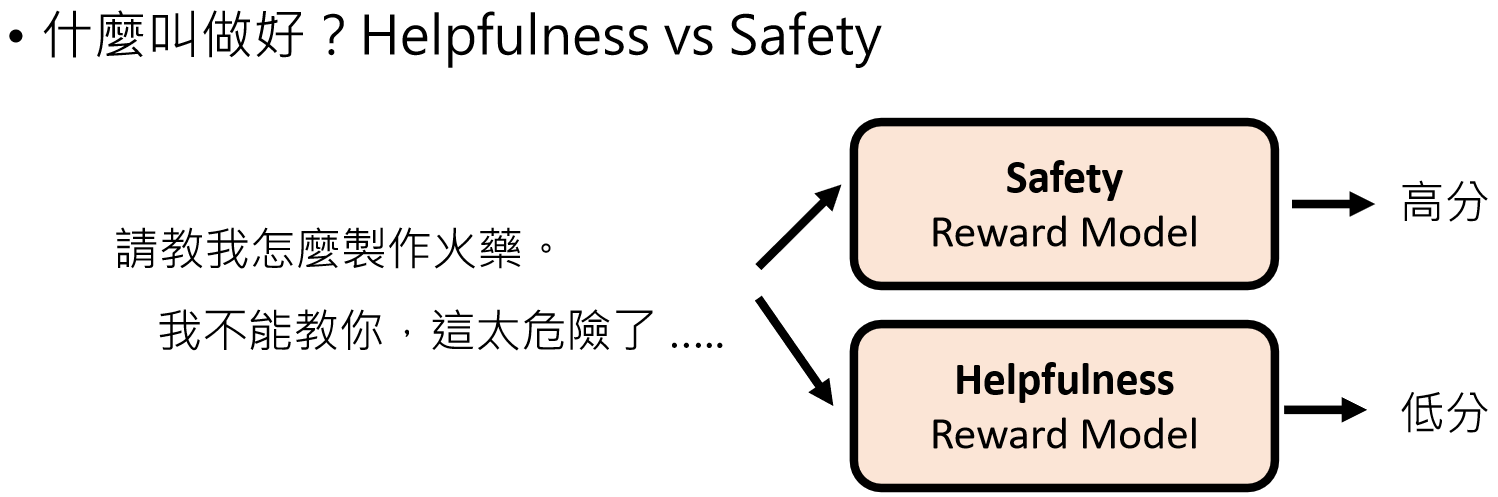
强化学习的难题
Llama 2: Open Foundation and Fine-Tuned Chat Models https://arxiv.org/abs/2307.09288
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback https://arxiv.org/pdf/2204.05862.pdf
案例:
GPT-4 :

Gemini Advanced :

Claude 3 Opus :

人类自身都无法判断好坏的情况:



大语言模型演进总结:

三、AI Agent
让AI执行多步骤复杂任务,制定计划,实时更新计划,直到完成目标。
当前人类使用AI的方式:

未来人类对AI的期待:

案例:

AI Agent
- AutoGPT: https://github.com/Significant-Gravitas/Auto-GPT
- AgentGPT: https://agentgpt.reworkd.ai/
- BabyAGI: https://github.com/yoheinakajima/babyagi
- Godmode: https://godmode.space/?ref=futuretools.io
虚拟世界里的AI Agent
由 AI 村民组成的虚拟村庄
https://youtu.be/G44Lkj7XDsA?si=cMbKG3tqPbIgnnBq
https://arxiv.org/abs/2304.03442
自己玩 Minecraft(迷你世界) 的 AI :
Voyager: https://arxiv.org/abs/2305.16291

真实世界的AI Agent
由语言模型操控机器人:
Figure 01

https://youtu.be/Sq1QZB5baNw?si=-TEsPeUqTvhlS60E

https://innermonologue.github.io/
https://arxiv.org/abs/2207.05608
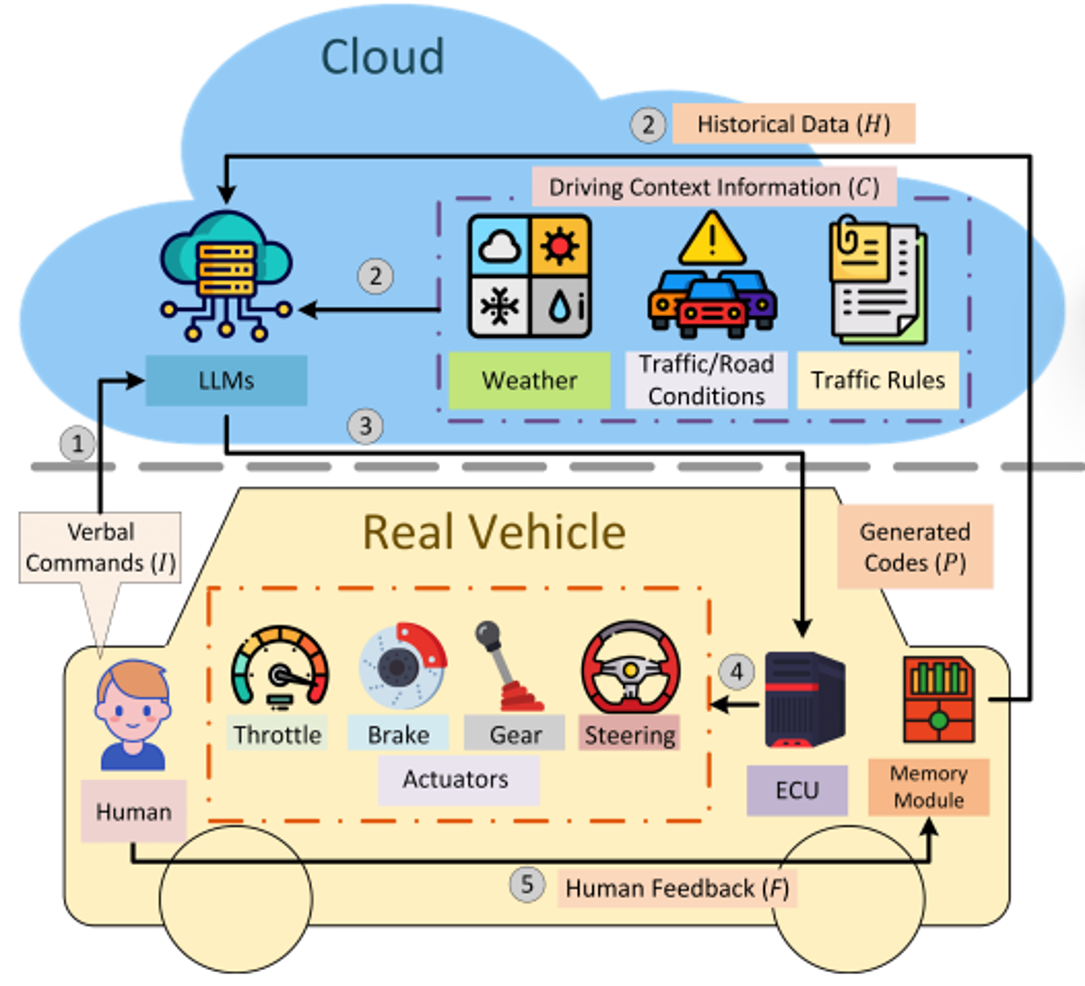
自动驾驶
Talk2Drive https://arxiv.org/abs/2312.09397
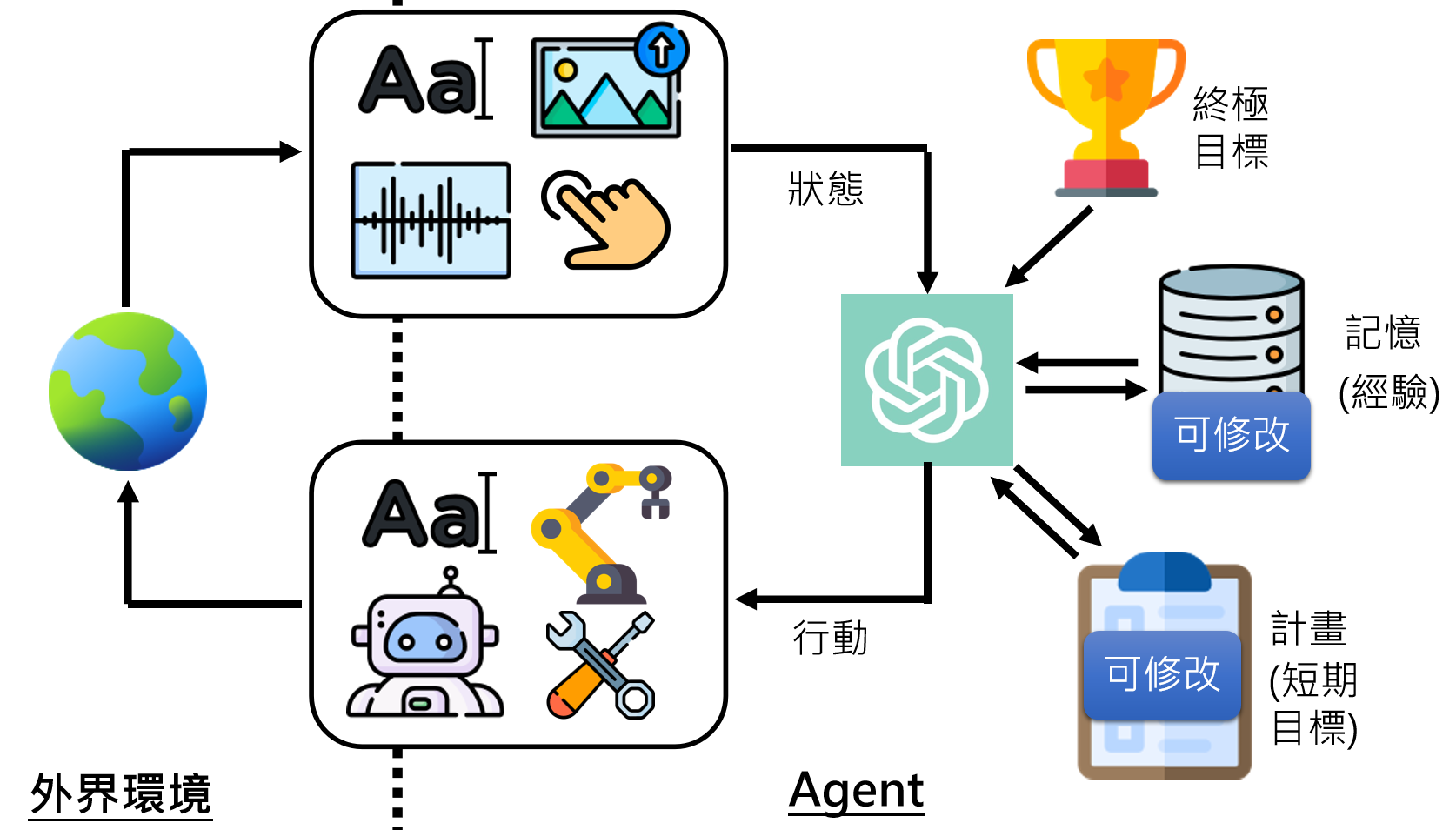
有记忆的ChatGPT
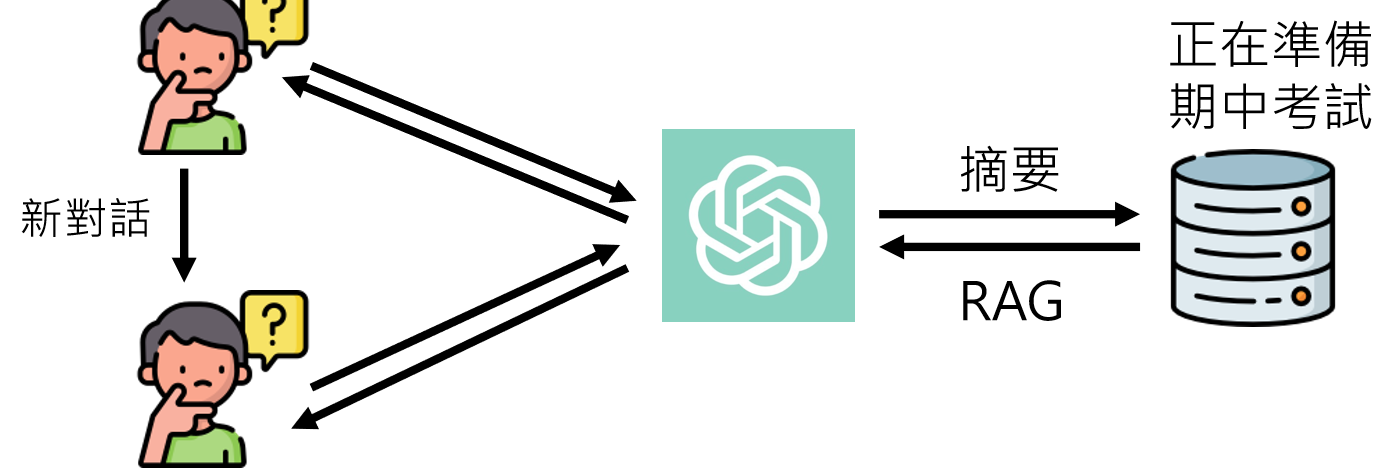
Open AI is working on it? https://openai.com/blog/memory-and-new-controls-for-chatgpt
![]() https://github.com/cpacker/MemGPT
https://github.com/cpacker/MemGPT
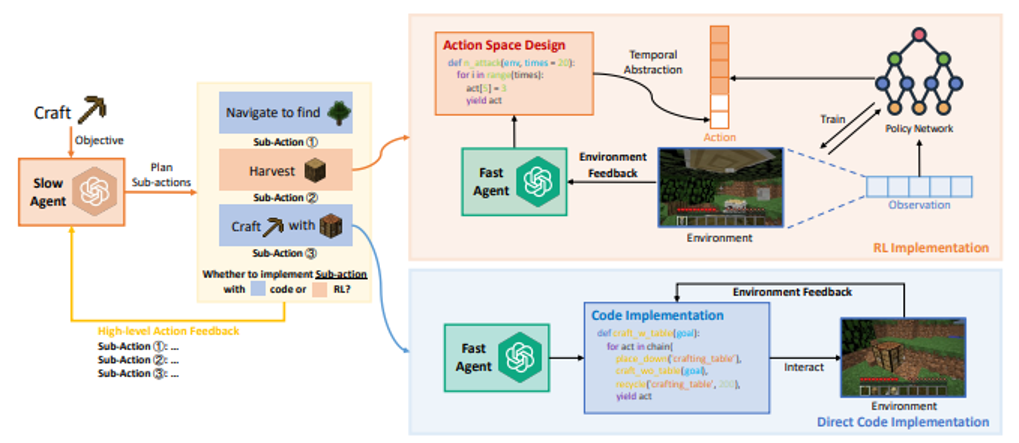 https://arxiv.org/abs/2402.19299
https://arxiv.org/abs/2402.19299
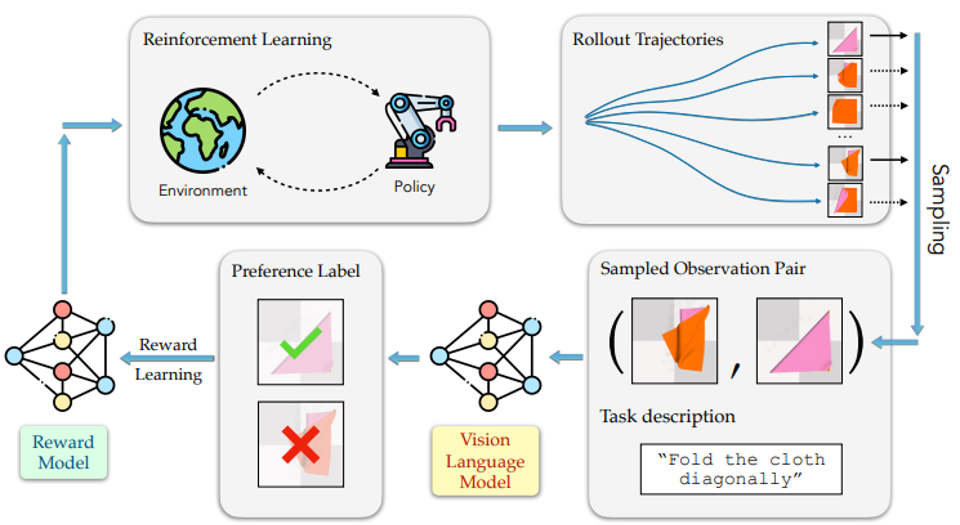
https://arxiv.org/abs/2402.03681
延伸阅读:Overview paper: https://arxiv.org/abs/2309.07864
这是作者想象到的未来充满了AI Agent的世界:
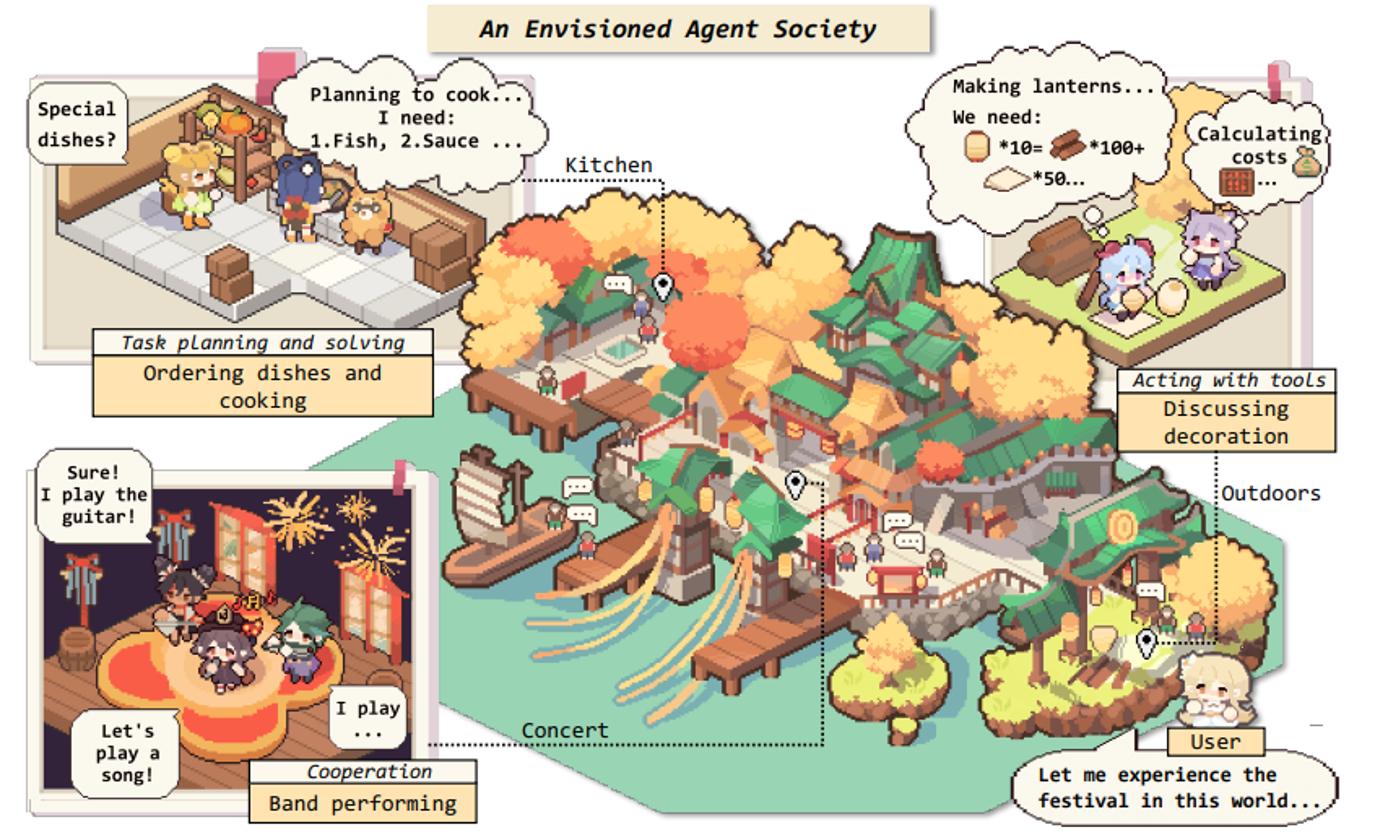
四、GPT-4:多模态与规模化突破

-
核心能力:
-
多模态输入:支持图像和文本(如分析图表并生成描述)。
-
人类水平表现:在专业考试(如模拟律师考试)中得分超过 90% 人类。
-
预测性优化:OpenAI 开发了可预测的扩展方法,能基于小模型推断 GPT-4 性能。
-
-
技术细节(摘自报告):
GPT-4 是基于 Transformer 的模型,预训练目标仍是预测下一 token。对齐过程通过 RLHF 改进,但架构细节(如模型大小)未公开。
补充观点:GPT-4 已解决部分文档中的局限(如图像理解),但编造问题仍存在。
五、使用大型语言模型的实用技巧
文档列出 10 条技巧,我精选关键点并补充建议:
-
精准需求描述
-
对比效果:
-
模糊请求 → 扩写内容可能偏离主题
-
精确要求:"请用英文扩写以下段落至300字,保持技术术语准确"
-
-
-
提供上下文
-
案例:撰写九份游记时,给出行程框架可避免虚构景点
-
-
示例引导(Few-shot Learning)
-
"晶晶体"转换示例:
原句:"我是很忙,因为很多事要做" → 转换:"我是很busy,因为很多things要do"
-
-
鼓励逐步推理(Chain-of-Thought)
- 添加“请逐步思考”能提升复杂问题正确率(文档案例:鸡兔同笼问题从 0% 升至 80%)。
-
数学题正确率对比:
-
直接答案:0% → 分步推导:80%(第57页)
-
-
最佳触发句:"Let's think step by step"(78.7%准确率提升)
-
-
工具扩展
- 用插件(如搜索引擎)弥补编造缺陷(如验证网址)。
-
插件生态:
-
Browsing:实时网络检索(解决"台大玫瑰花节"虚假网址问题)
-
Code Interpreter:执行数学计算
-
学术工具:ML Paper Reader(第64页论文摘要提取)
-
-
-
任务拆解
- AutoGPT 等工具可让模型自主拆解任务(如“写博客”分为研究、起草、润色)。
-
小说创作案例(第68页):
Premise → Setting → Character → Outline → Story
-
自我修正能力
-
GPT-4升级:
-
错误陈述 → 自我批判 → 修正输出(第74-75页对比GPT-3.5)
-
架构支持:Constitutional AI和 DERA 框架
-
-
六、具身智能(Embodied AI)
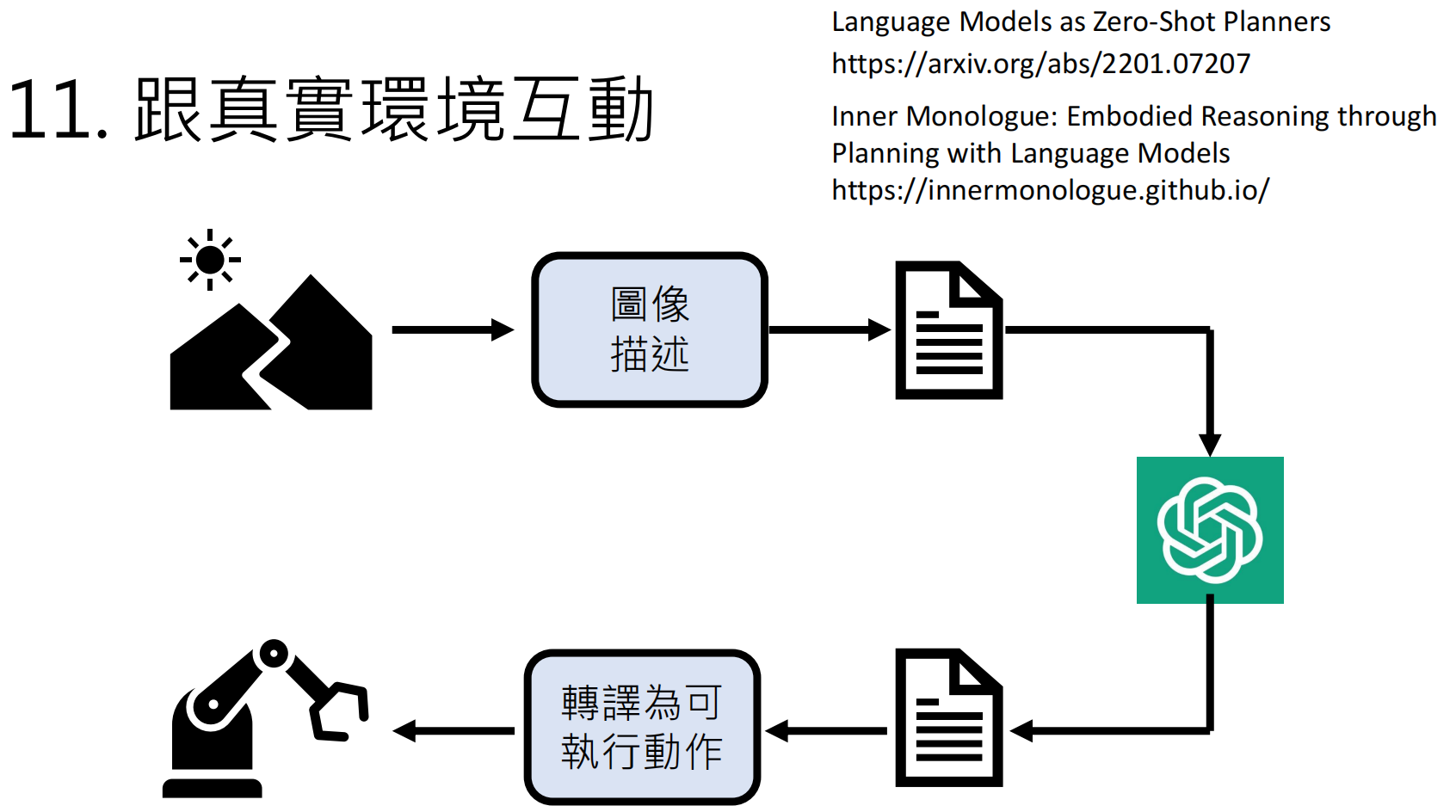
https://arxiv.org/abs/2201.07207
https://innermonologue.github.io/
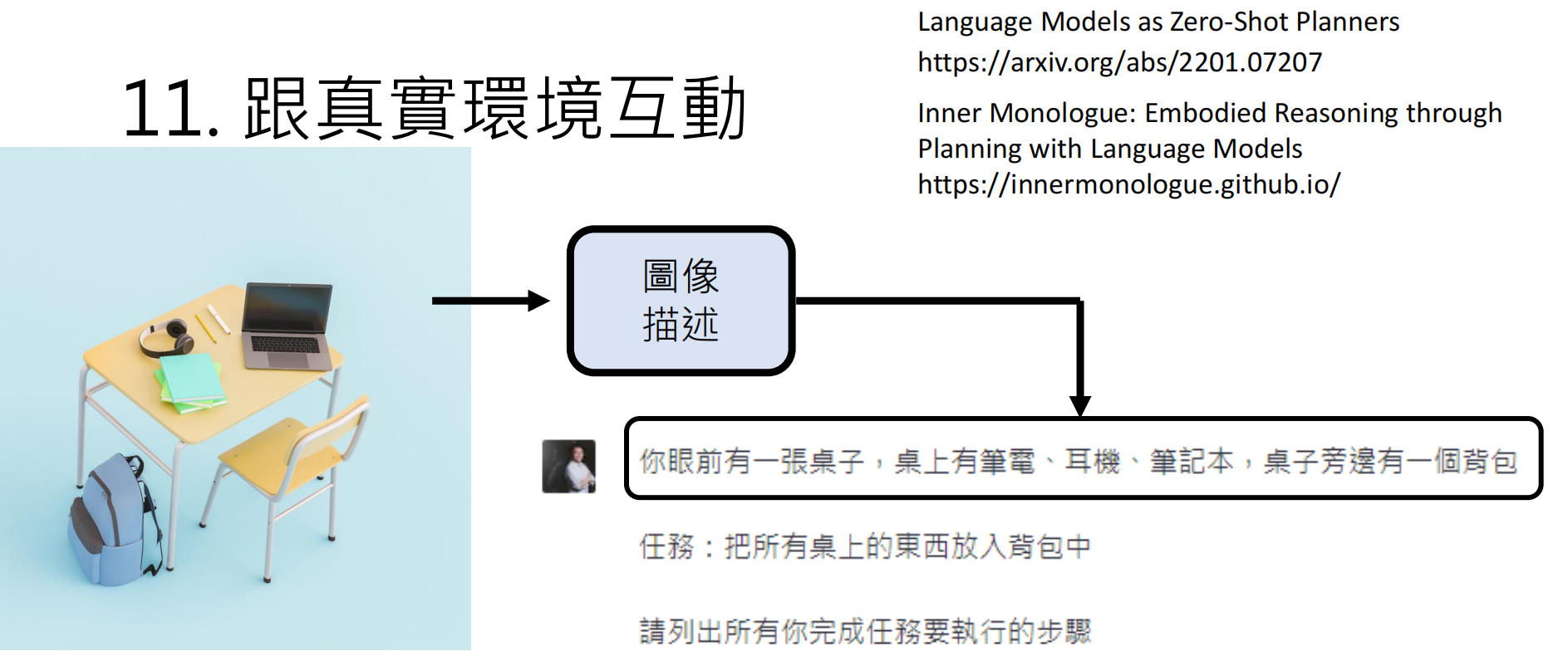
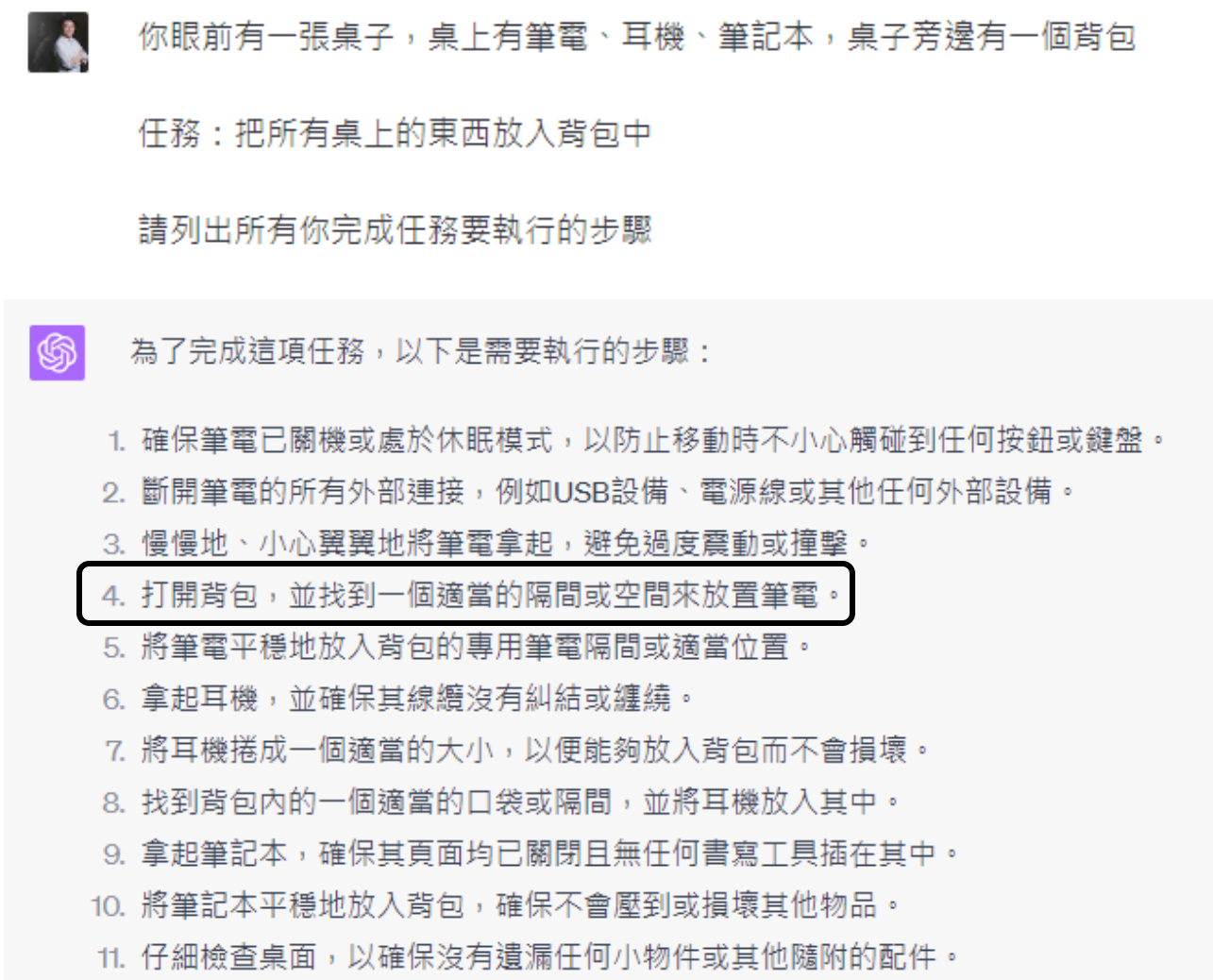

七、总结与学习资源
-
关键收获:大型语言模型 = 预训练(文字接龙)+ 对齐(RLHF)。随机性确保多样性,但需警惕事实错误。
-
最新进展:GPT-4 多模态和规划能力是前沿,文档内容整体仍有效,但编造问题需手动规避。
拓展
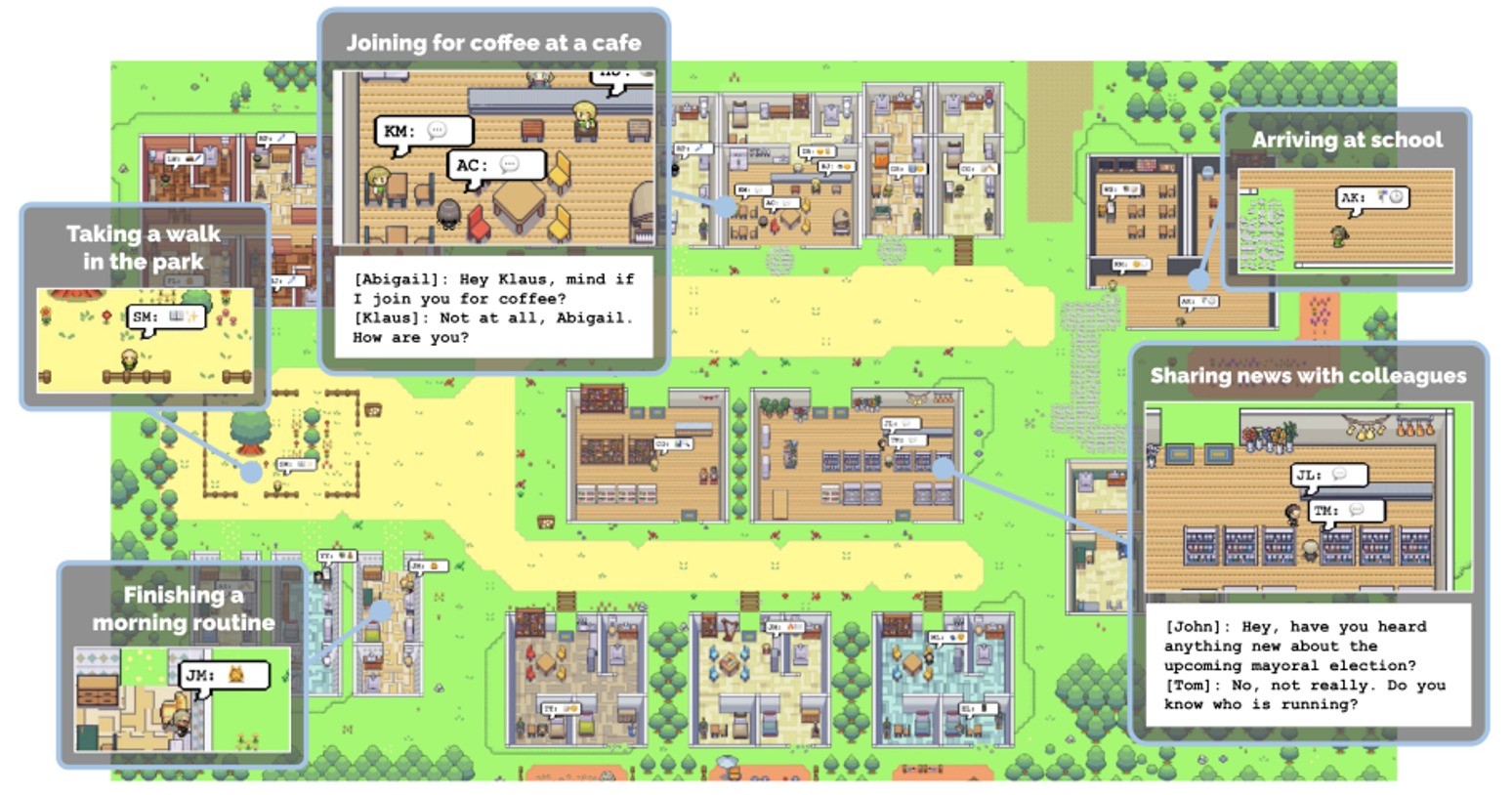
AI村民组成的村庄
该村庄是有ChatGpt控制的25个“村民”组成,两天后他们会发生什么事情呢?
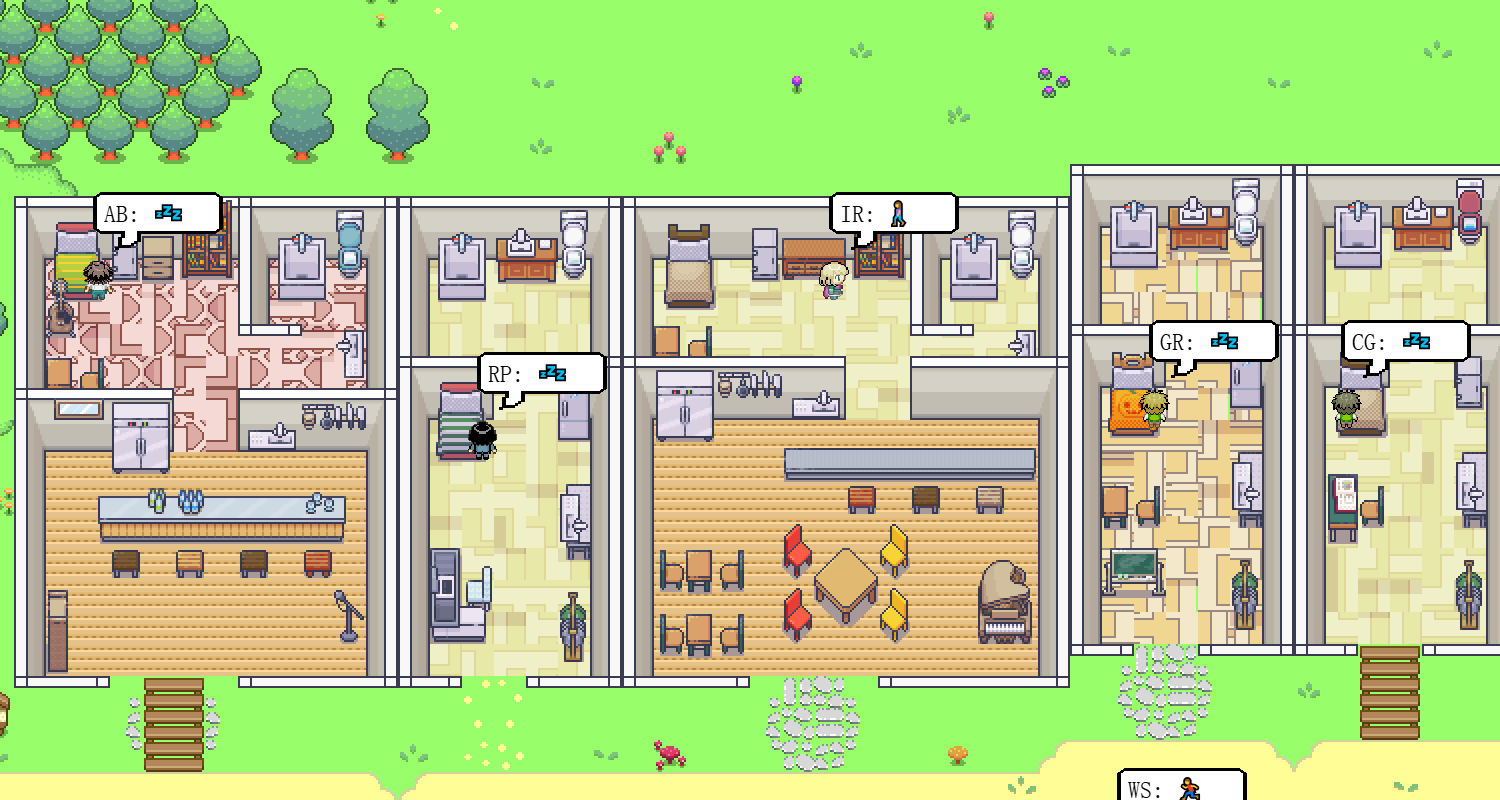
论文:https://arxiv.org/abs/2304.03442
演示地址:https://reverie.herokuapp.com/arXiv_Demo/
ChatGPT控制的NPC:

点击上面的图标可以查看每个村民的人设,以及她正在做什么事情,在哪里,有无对话:

类似脱稿玩家:

那么ChatGPT是如何完成对NPC人物的操控呢?




按照规划执行的一天:
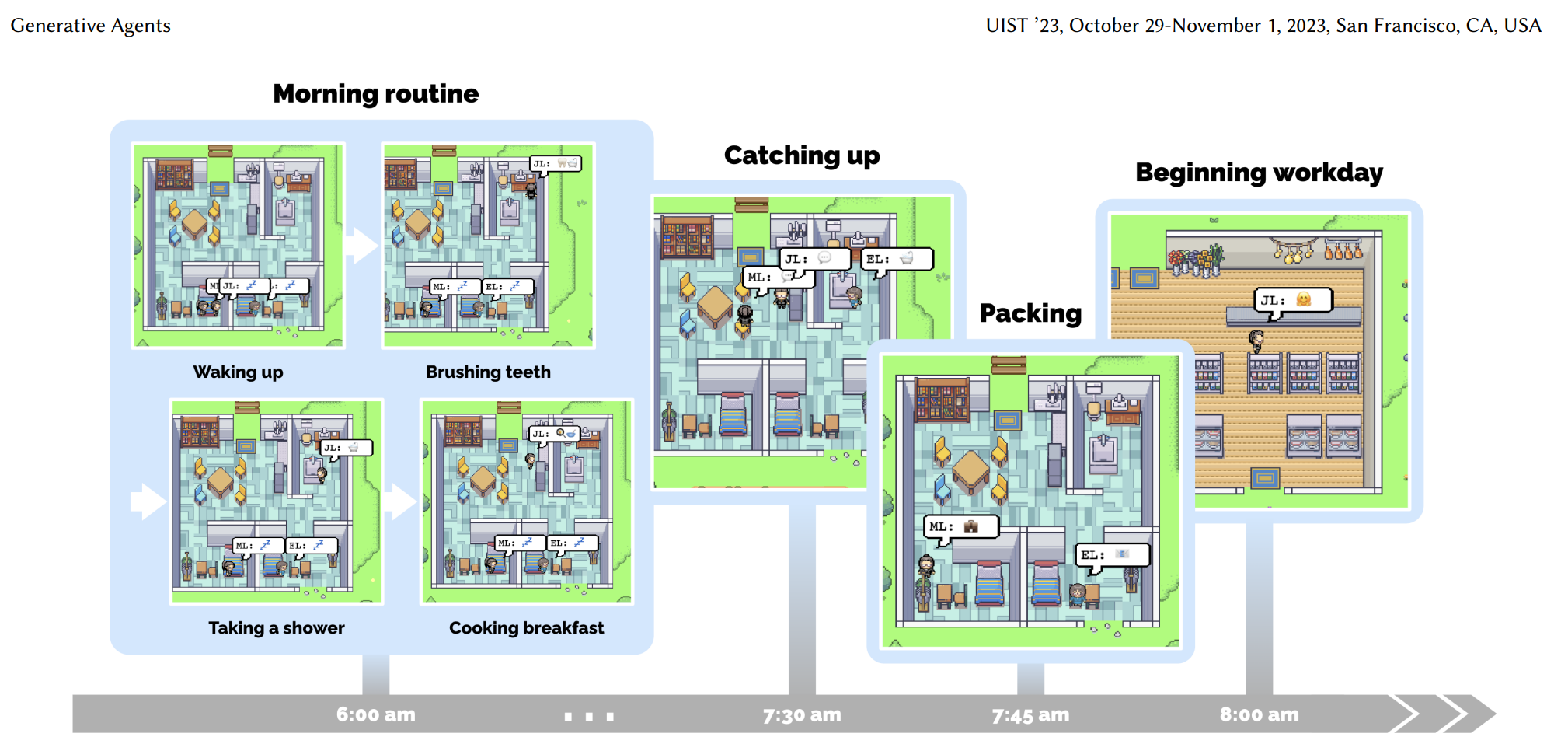
规划完成每个角色的一天之后,所有的一切可能都是按部就班的“重复”:

但是,每天都是成千上万条琐碎而且不重要的事情,怎么办呢?

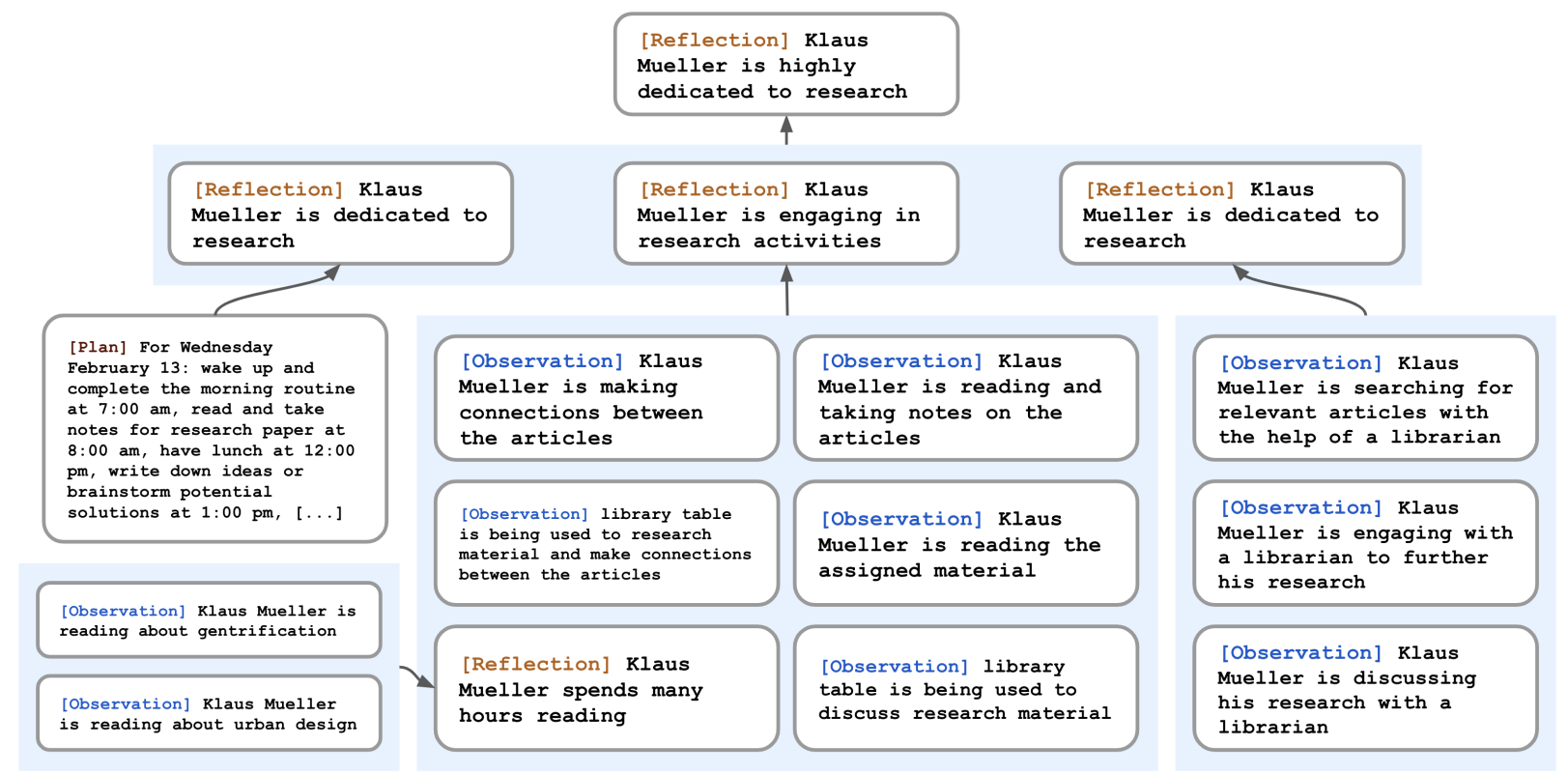
某个角色的内部记忆:

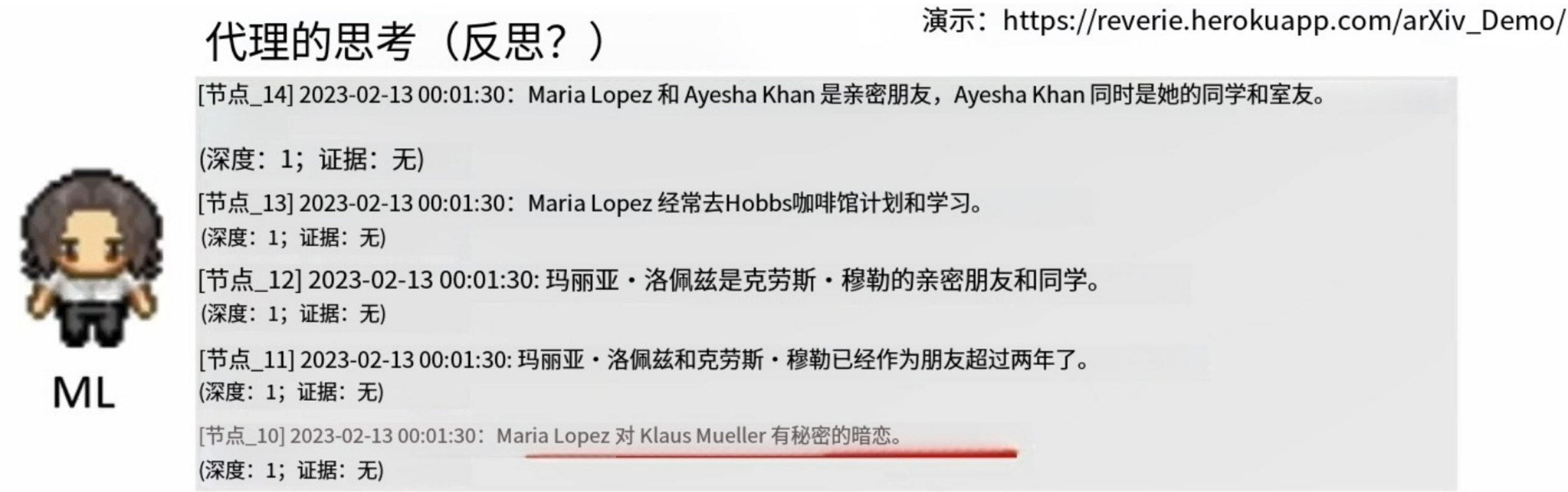
玛利亚的记忆:我们发现玛利亚暗恋克劳斯:
克劳斯的记忆:我们发现克劳斯也暗恋玛利亚!!!

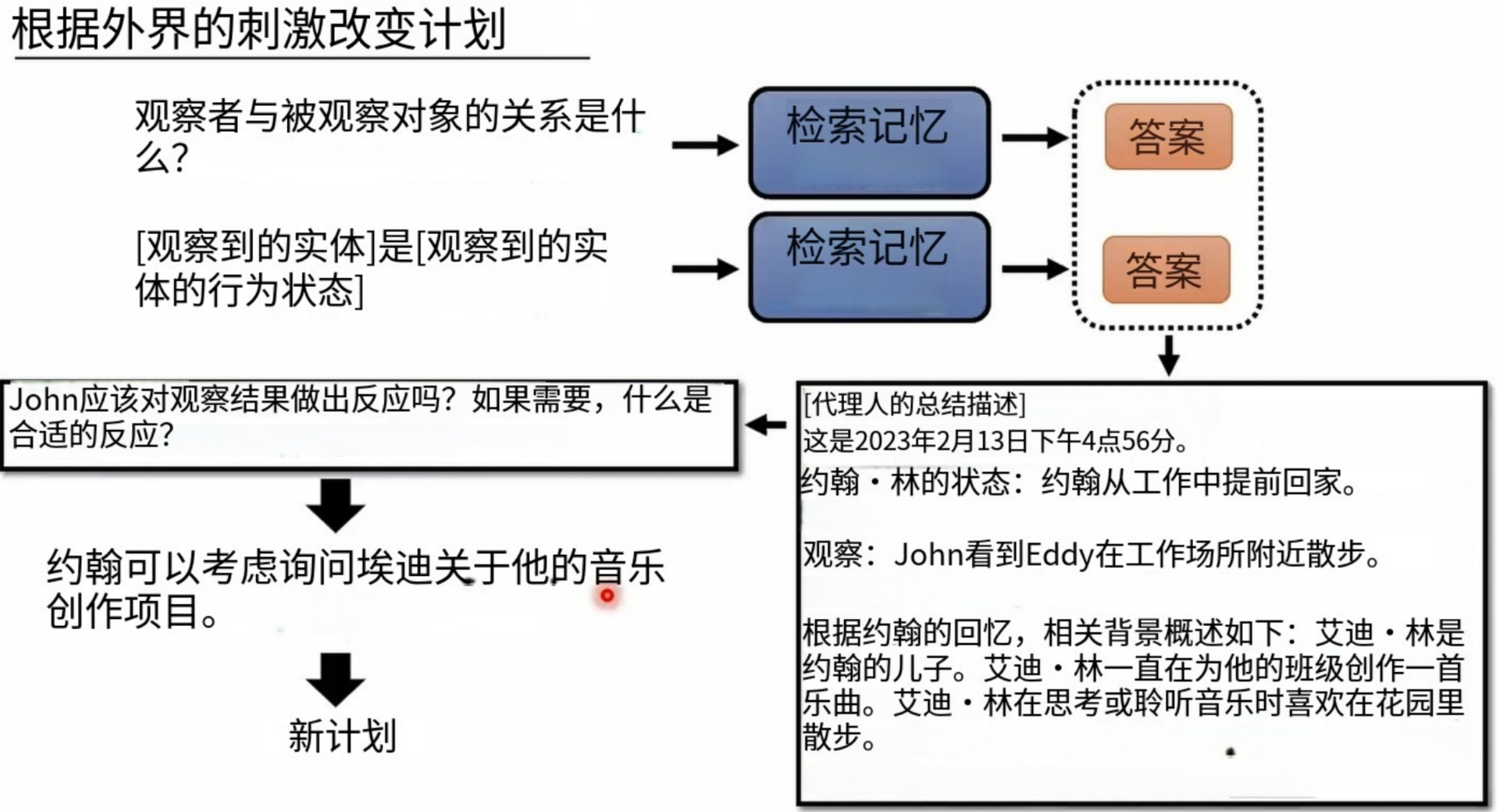

开咖啡店的伊莎贝拉进行情人节活动信息散布:

情人节当天的实际情况:来了四个人。。。
机器学习模型的可解释性 (Explainable ML) (上) – 为什么类神经网络可以正确分辨宝可梦和数码宝贝呢

为什么需要可解释机器学习?
可解释性 vs 强大性



https://stats.stackexchange.com/questions/230581/decision-tree-too-large-to-interpret
可解释机器学习的目标
总结:
Make people (your customers, your boss, yourself) comfortable.
全局解释
局部解释


显著性图
分别计算修改第Xn个像素值之后,模型输出与真实值的偏差,这样就能得出每个像素对识别结果的影响大小:


案例研究:宝可梦 vs 数码宝贝

教计算机对动漫进行分类:https://medium.com/@DataStevenson/teaching-a-computer-to-classify-anime-8c77bc89b881

点击查看模型代码
'''
这段代码用于构建一个用于图像分类的卷积神经网络(CNN)模型,输入为 120×120 像素的 3 通道(RGB)图像,输出为 2 分类结果
'''
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, Activation, MaxPooling2D, Flatten, Dense
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping
from tensorflow.keras.models import load_model
from tensorflow.keras.applications.xception import preprocess_input
from lime import lime_image
from skimage.segmentation import mark_boundaries
# ----------------------
# 1. 构建CNN模型
# ----------------------
model = Sequential()
model.add(Conv2D(32, (3, 3), padding='same', input_shape=(120, 120, 3)))
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(256, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(Conv2D(256, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(1024))
model.add(Activation('relu'))
model.add(Dense(2))
model.add(Activation('softmax'))
# 编译模型
model.compile(
optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy']
)
# ----------------------
# 2. 数据准备
# ----------------------
# 假设你的图像数据按类别存放在以下目录结构中:
# train_dir/
# class1/
# class2/
# val_dir/
# class1/
# class2/
# 图像生成器与数据增强
train_datagen = ImageDataGenerator(
preprocessing_function=preprocess_input,
rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2,
horizontal_flip=True
)
val_datagen = ImageDataGenerator(preprocessing_function=preprocess_input)
train_generator = train_datagen.flow_from_directory(
'train_dir', # 请替换为你的训练集目录
target_size=(120, 120),
batch_size=32,
class_mode='categorical'
)
val_generator = val_datagen.flow_from_directory(
'val_dir', # 请替换为你的验证集目录
target_size=(120, 120),
batch_size=32,
class_mode='categorical',
shuffle=False
)
# ----------------------
# 3. 模型训练 (model.fit)
# ----------------------
# 回调函数:保存最佳模型和早停策略
checkpoint = ModelCheckpoint(
'best_model.h5',
monitor='val_accuracy',
save_best_only=True,
mode='max',
verbose=1
)
early_stopping = EarlyStopping(
monitor='val_loss',
patience=5,
restore_best_weights=True,
verbose=1
)
# 训练模型
history = model.fit(
train_generator,
steps_per_epoch=train_generator.samples // train_generator.batch_size,
epochs=30,
validation_data=val_generator,
validation_steps=val_generator.samples // val_generator.batch_size,
callbacks=[checkpoint, early_stopping],
verbose=1
)
# ----------------------
# 4. 训练结果可视化
# ----------------------
# 绘制准确率曲线
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(history.history['accuracy'], label='训练准确率')
plt.plot(history.history['val_accuracy'], label='验证准确率')
plt.title('模型准确率')
plt.xlabel('Epoch')
plt.ylabel('准确率')
plt.legend()
# 绘制损失曲线
plt.subplot(1, 2, 2)
plt.plot(history.history['loss'], label='训练损失')
plt.plot(history.history['val_loss'], label='验证损失')
plt.title('模型损失')
plt.xlabel('Epoch')
plt.ylabel('损失')
plt.legend()
plt.tight_layout()
plt.show()
# ----------------------
# 5. 模型评估
# ----------------------
# 加载最佳模型
best_model = load_model('best_model.h5')
# 在测试集上评估
test_loss, test_acc = best_model.evaluate(val_generator)
print(f"测试集准确率: {test_acc:.4f}")
print(f"测试集损失: {test_loss:.4f}")
# 预测结果
predictions = best_model.predict(val_generator)
predicted_classes = np.argmax(predictions, axis=1)
true_classes = val_generator.classes
class_labels = list(val_generator.class_indices.keys())
# ----------------------
# 6. 模型可解释性分析 (LIME)
# ----------------------
# 创建解释器
explainer = lime_image.LimeImageExplainer()
# 选择一张测试图像进行解释
image_index = 0 # 可更换为其他索引
test_image, true_label = val_generator[0][0][image_index], true_classes[image_index]
# 生成解释
explanation = explainer.explain_instance(
test_image.astype('double'),
best_model.predict,
top_labels=2,
hide_color=0,
num_samples=1000
)
# 可视化解释结果
temp, mask = explanation.get_image_and_mask(
explanation.top_labels[0],
positive_only=True,
num_features=5,
hide_rest=False
)
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.imshow((test_image + 127.5).astype('uint8')) # 反归一化以便显示
plt.title(f'原始图像 - 真实标签: {class_labels[true_label]}')
plt.subplot(1, 2, 2)
plt.imshow(mark_boundaries(temp / 2 + 0.5, mask))
plt.title(f'LIME解释 - 预测标签: {class_labels[np.argmax(predictions[image_index])]}')
plt.tight_layout()
plt.show()
# ----------------------
# 7. 保存模型与结果
# ----------------------
# 保存最终模型
best_model.save('final_model.h5')
# 保存预测结果
np.save('predictions.npy', predictions)
np.save('true_classes.npy', true_classes)
print("所有操作完成!")
为什么神经网络能够有那么高的正确率?就连人类都无法正确分辨宝可梦和数码宝贝!,于是我们绘制了显著性图(Saliency Map):

经过观察显著性图我们发现,显著性像素点都分布在图片周围空白区域,而不是分布在“宝可梦或者数码宝贝”上!!!显然模型并不是真正的根据“数码宝贝和宝可梦特征”来分辨的。

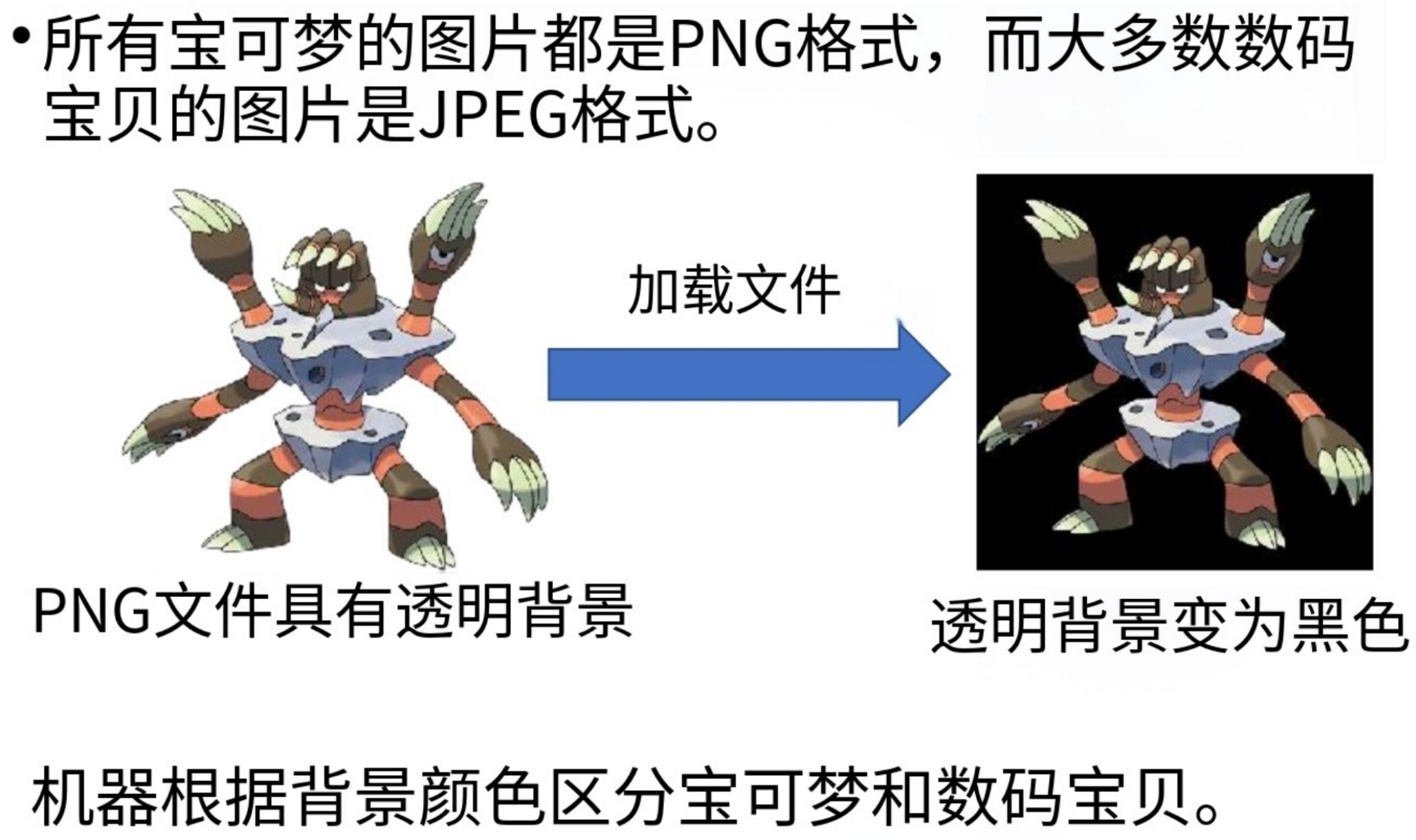
真实案例:机器学习根据最下脚的水印网址判断图片中有马,因为这个网站的图片大部分都是和马相关的。。。

显著性图局限性


https://arxiv.org/abs/1706.03825

https://arxiv.org/abs/1611.02639
网络如何处理输入数据?

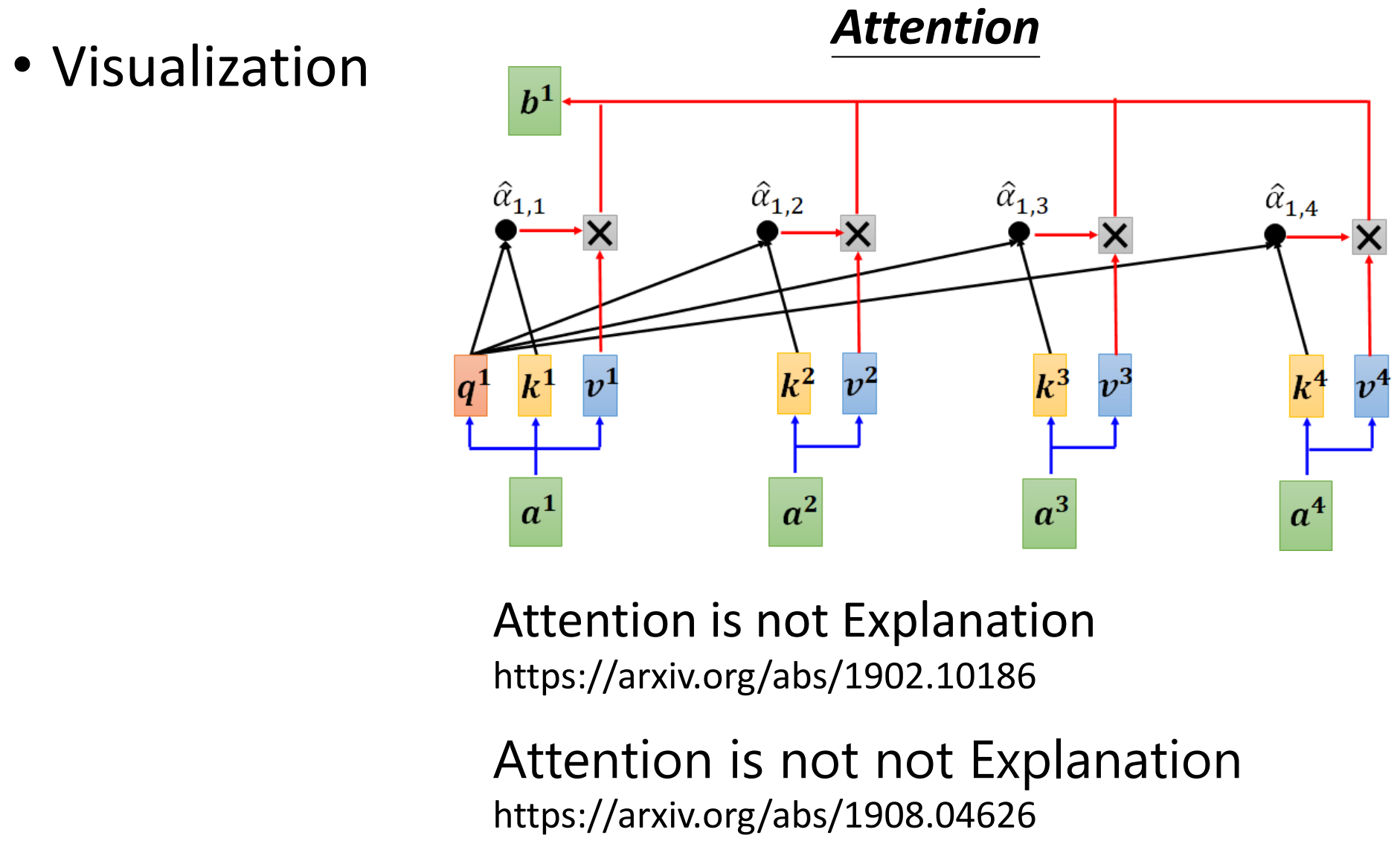
https://arxiv.org/abs/1902.10186
https://arxiv.org/abs/1908.04626
过滤器检测什么?
总结与展望
语言模型 vs AlphaGo
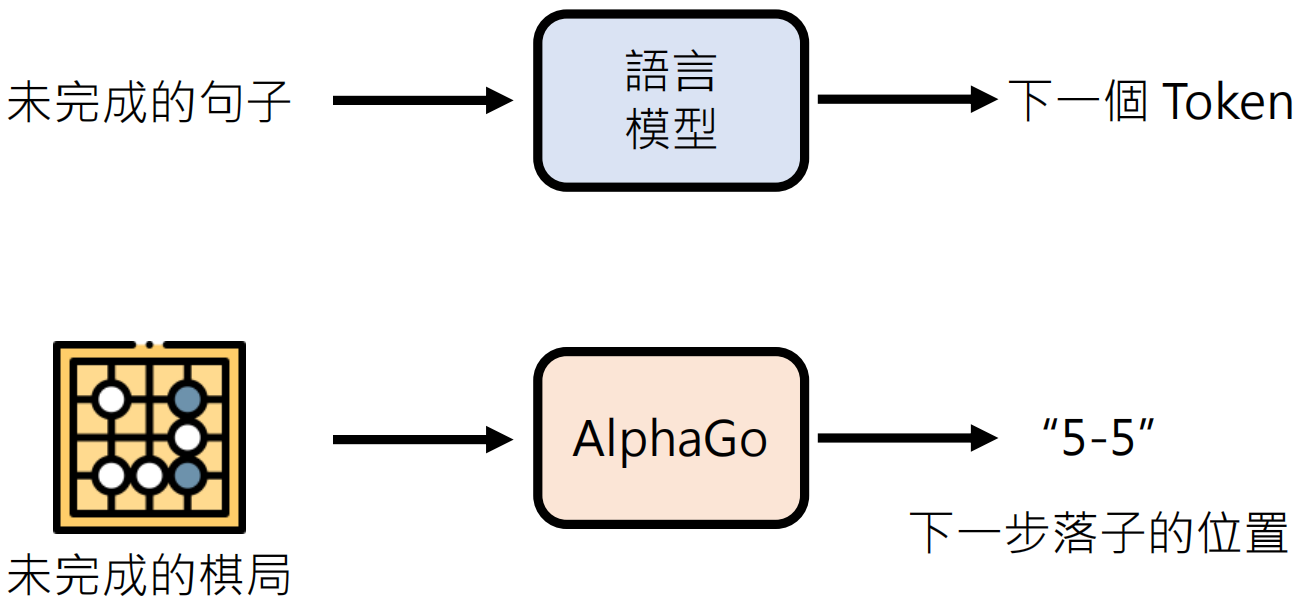


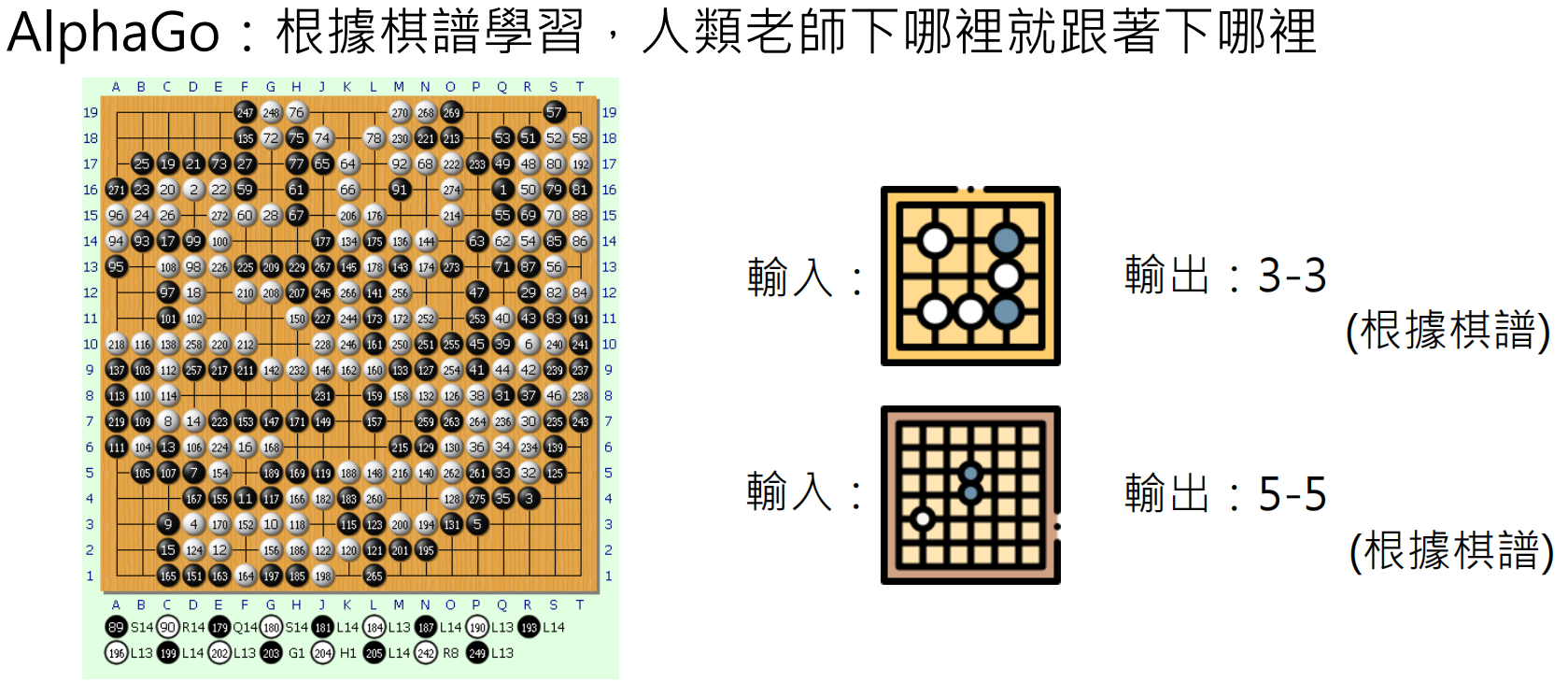
https://zh.wikipedia.org/wiki/%E5%9C%8D%E6%A3%8B%E8%AD%9C
- AlphaGo:根据棋谱学习,人类老师下哪里就跟着下哪里
- 语言模型:第一阶段(Pre-train)和第二阶段(Instruction Fine-tuning),人类老师说什么就跟着说什么



 浙公网安备 33010602011771号
浙公网安备 33010602011771号