Transformer 的核心思想最早诞生于 2017 年 Google 团队的论文《Attention Is All You Need》,这篇论文彻底改变了自然语言处理(NLP)领域的技术路线。
2018 年 10 月,Google 基于 Transformer 提出的 BERT 模型(《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》)横空出世,横扫 NLP 领域 11 项任务的最佳成绩,让 Transformer 架构被广泛关注。此后,XLNet、RoBERTa、GPT 系列等模型相继出现,虽在细节上有诸多改进,但核心架构仍基于 Transformer。
论文地址:
经典优势
在 Transformer 出现之前,NLP 领域的主流模型是 LSTM、GRU 等循环神经网络(RNN)。Transformer 的优势主要体现在两点:
-
并行训练能力:GPU并行训练 → 训练效率提升3-5倍
RNN 类模型依赖序列顺序(前一个词的计算依赖于上一个词),无法并行计算;而 Transformer 基于自注意力机制,所有词的计算可同时进行,能充分利用分布式 GPU 资源,大幅提升训练效率。
-
长距离语义捕捉能力:长文本处理 → 支持4000+ tokens上下文
RNN 类模型对长文本中远距离词汇的关联捕捉能力较弱(存在梯度消失问题);Transformer 通过自注意力机制,可直接计算任意两个词之间的关联,对长文本的理解更准确。
2024行业现状
|
模型
|
最大长度
|
训练速度
|
|
Transformer-XL
|
3000
|
1.2x
|
|
Longformer
|
4096
|
2.3x
|
|
FlashTransformer
|
8192
|
5.8x
|
下图直观展示了 Transformer 在机器翻译任务(BLEU 评分,分数越高效果越好)中对不同长度句子的处理优势:
Transformer 已成为 NLP 领域的 "基础设施",目前几乎所有主流的 SOTA(State-of-the-Art)模型都基于其架构。例如在机器翻译任务的权威榜单(如 WMT 系列)中,排名靠前的模型均以 Transformer 为核心:
| 数据集 |
最佳方法 |
核心架构 |
| WMT2014 English-German |
Transformer Big + BT |
Transformer |
| WMT2014 English-French |
Transformer Big + BT |
Transformer |
| IWSLT2015 German-English |
Transformer Base + 对抗训练 |
Transformer |
这些结果表明,Transformer 是工业界解决 NLP 任务的 "标配",掌握其原理和实现是进入现代 NLP 领域的必备技能。
Transformer 的核心架构可分为四个部分,整体结构如下:
输入部分 → 编码器 → 解码器 → 输出部分
详细结构:
1. 输入部分
- 源文本嵌入层
- 位置编码器
- 目标文本嵌入层
- 位置编码器
2. 编码器部分
- 由N个编码器层堆叠
- 每个编码器层包含:
* 多头注意力子层
* 前馈全连接子层
* 残差连接 + 层归一化
3. 解码器部分
- 由N个解码器层堆叠
- 每个解码器层包含:
* 掩码多头注意力子层
* 交叉注意力子层
* 前馈全连接子层
* 残差连接 + 层归一化
4. 输出部分
- 线性层
- Softmax层

输入部分是 Transformer 的 "数据入口",负责将原始文本(数字形式)转换为包含语义和位置信息的向量。主要包括文本嵌入层和位置编码器两部分。
文本嵌入层的核心作用是:将文本中词汇的 "数字表示"(如 one-hot 编码或词索引)转换为 "向量表示"。在高维向量空间中,语义相近的词汇会具有相似的向量,从而让模型能捕捉词汇间的关联(如 "国王" 和 "女王" 的向量差异,可能与 "男人" 和 "女人" 的向量差异相近)。
import torch
import torch.nn as nn
import math
class Embeddings(nn.Module):
"""
初始化文本嵌入层
2024升级:支持子词嵌入和权重共享
参数说明:
- d_model:嵌入维度(推荐512/768/1024)
- vocab:词表大小
- padding_idx:填充索引(可选)
"""
def __init__(self, vocab_size,d_model ,padding_idx=None):
super().__init__() # 继承nn.Module的初始化方法
# 实例化PyTorch内置的Embedding层:输入为词索引,输出为d_model维向量
# nn.Embedding(num_embeddings=词表大小, embedding_dim=嵌入维度)
self.embedding = nn.Embedding(num_embeddings=vocab_size, embedding_dim=d_model,
padding_idx=padding_idx # 明确处理填充索引(2024年最佳实践)
)
self.d_model = d_model # 保存嵌入维度,用于后续缩放
self.scale_factor = math.sqrt(d_model) # 分离缩放因子(2024年最佳实践)
def forward(self, x):
"""
前向传播:将词索引转换为嵌入向量
:param x: 输入的词索引张量,形状为[batch_size, seq_len](batch_size:批次大小,seq_len:句子长度)
:return: 缩放后的嵌入向量,形状为[batch_size, seq_len, d_model]
"""
# 步骤1:通过嵌入层将词索引转为向量(形状:[batch_size, seq_len, d_model])
# 步骤2:乘以sqrt(d_model)进行缩放——避免嵌入向量的值过大,影响后续梯度计算
return self.embedding(x) * self.scale_factor
# return self.embedding(x) * math.sqrt(d_model)#传统实现未分离缩放因子
-
nn.Embedding 原理:
这是 PyTorch 内置的嵌入层,本质是一个可训练的矩阵(形状为 [vocab_size, d_model])。每个词索引对应矩阵中的一行,通过前向传播 "查表" 得到向量。例如:
# 示例:nn.Embedding的使用
embedding = nn.Embedding(num_embeddings=10, embedding_dim=5) # 词表大小10,嵌入维度3
input_idx = torch.LongTensor([[1, 2, 4], [4, 3, 9]]) # 输入词索引(batch_size=2,seq_len=3)
output = embedding(input_idx) # 输出嵌入向量
print(output.shape) # torch.Size([2, 3, 5])——[batch_size, seq_len, d_model]
-
为什么要缩放?:
嵌入向量的初始值通常较小(随机初始化),乘以sqrt(d_model)(如 512 的平方根约 22.6)可适当放大向量值,避免在后续的注意力计算中被梯度淹没。
# 实例化参数
d_model = 512 # 嵌入维度设为512(Transformer原论文设置)
vocab_size = 1000 # 假设词表大小为1000
# 输入:2个句子,每个句子4个词(词索引)
x = torch.LongTensor([[100, 2, 421, 508], [491, 998, 1, 221]]) # 形状:[2, 4]
# 实例化嵌入层并计算
emb_layer = Embeddings(d_model=d_model, vocab_size=vocab_size)
emb_result = emb_layer(x) # 前向传播
print("嵌入结果形状:", emb_result.shape) # 输出:torch.Size([2, 4, 512])
输出的emb_result就是文本的向量表示,接下来需要加入位置信息。
Transformer 的编码器 / 解码器没有循环结构(与 RNN 不同),无法自动捕捉词汇的位置信息。例如,"我爱你" 和 "你爱我" 的语义完全不同,但如果仅用嵌入向量,模型无法区分词的顺序。
位置编码器的作用是:给每个位置的词嵌入向量添加一个 "位置编码",让模型知道词汇在句子中的位置。
import torch
import torch.nn as nn
import math
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout=0.1, max_len=5000):
"""
初始化位置编码器
:param d_model: 词嵌入维度(需与Embedding层的d_model一致)
:param dropout: dropout比率(防止过拟合,通常设为0.1)
:param max_len: 最大句子长度(需覆盖训练数据中最长的句子)
"""
super().__init__()
self.dropout = nn.Dropout(p=dropout) # 实例化dropout层
# 步骤1:创建位置编码矩阵pe(形状:[max_len, d_model])
pe = torch.zeros(max_len, d_model) # 初始化全0矩阵
# 步骤2:生成位置索引(形状:[max_len, 1])
# 例如max_len=5时,position = [[0], [1], [2], [3], [4]]
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
# 步骤3:生成频率因子(用于控制位置编码的周期)
# div_term = tensor([1, 0.1, 0.01, 0.001,...])
div_term = torch.exp(#`torch.exp` 函数用于计算输入张量中每个元素的指数函数(exponential function)。具体来说,它计算每个元素的自然指数(e^x)
torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model)#math.log(x) 默认计算底数为 e 的对数=ln(x)(而非以 10 为底的对数)。
)
# 步骤4:用三角函数生成位置编码(偶数位用sin,奇数位用cos)
pe[:, 0::2] = torch.sin(position * div_term) # 0::2表示从0开始,步长为2(偶数索引)
pe[:, 1::2] = torch.cos(position * div_term) # 1::2表示从1开始,步长为2(奇数索引)
# 步骤5:扩展维度,适配批次输入(形状:[1, max_len, d_model])
# 因为输入是[batch_size, seq_len, d_model],需要在batch维度扩展
pe = pe.unsqueeze(0)
# 步骤6:将pe注册为"非参数缓冲区"(不参与训练,但会随模型保存)
self.register_buffer('pe', pe)
def forward(self, x):
"""
前向传播:将位置编码添加到词嵌入向量
:param x: 嵌入层的输出,形状为[batch_size, seq_len, d_model]
:return: 加入位置信息后的向量,形状不变
"""
# 步骤1:添加位置编码(仅取与输入句子长度匹配的部分)
# x.size(1)是当前句子的长度,pe[:, :x.size(1)]表示截取前seq_len个位置的编码
x = x + self.pe[:, :x.size(1)] # 广播机制:[1, seq_len, d_model]与[batch_size, seq_len, d_model]相加
# 步骤2:应用dropout,防止过拟合
return self.dropout(x)
绘制词汇向量中特征分布曲线
import matplotlib.pyplot as plt
import numpy as np
pe = PositionalEncoding(20, 0) # 维度20,dropout=0
y = pe(torch.zeros(1, 100, 20)) # 模拟输入
# 绘制第4-7维特征在不同位置的变化
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
plt.rcParams['font.size'] = 20
plt.figure(figsize=(20, 12))
plt.plot(np.arange(100), y[0, :, 4:8].data.numpy())
plt.legend([f'dim:{dim}' for dim in [4,5,6,7]])
plt.title("传统正弦位置编码")
plt.xlabel("位置索引")
plt.ylabel("编码值")
plt.show()

输出效果分析:
- 每条颜色的曲线代表某一个词汇中的特征在不同位置的含义
- 保证同一词汇随着所在位置不同它对应位置嵌入向量会发生变化.
- 正弦波和余弦波的值域范围都是1到-1这又很好的控制了嵌入数值的大小,有助于梯度的快速计算.
有不同维度的波形从高频(锯齿状)到低频(平滑)变化,每个位置在这些波形上的组合是唯一的。
这个位置编码矩阵通过固定频率的三角函数,为每个位置生成独一无二的编码向量。不同维度捕获不同粒度的位置信息,最终使模型能够区分单词的顺序和相对位置,从而弥补了Transformer本身不具备的序列顺序感知能力。
代码解析
# 步骤3:生成频率因子(用于控制位置编码的周期)
div_term = torch.exp(
torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model
)
步骤1: torch.arange(0, d_model, 2)
[0, 2, 4, 6, ..., 508, 510] # 共256个元素
步骤2: (-math.log(10000.0) / d_model)
div_term = torch.exp(#`torch.exp` 函数用于计算输入张量中每个元素的指数函数(exponential function)。具体来说,它计算每个元素的自然指数(e^x)
torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model)#math.log(x) 默认计算底数为 e 的对数(而非以 10 为底的对数)。
)
步骤3: 张量乘法
2i* (-ln(10000)/d_model)
#[0, 2, 4, 6, ..., 508, 510] # 共d_model/2个元素
步骤4: torch.exp(...)
-
对上述结果应用指数函数:
`torch.exp` 函数用于计算输入张量中每个元素的指数函数(exponential function)。具体来说,它计算每个元素的自然指数(e^x)

上面的第3个式子化简结果就是: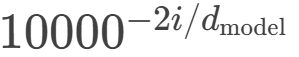 ,也就是div_term值=(2i的意思就是偶数的意思)
,也就是div_term值=(2i的意思就是偶数的意思)
位置编码中,波长 λi和频率 fi的关系由以下公式决定:
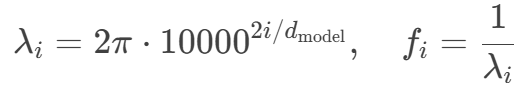
可视化理解
假设d_model=8:
| 维度索引 (k) |
实际维度 (i=k/2) |
div_term = 10000^{-k/d_model} |
波长 λ = 2π/div_term |
| 0 |
i=0 |
10000^{⁻⁰/₈} = 1 |
2π/1 ≈ 6.28 |
| 2 |
i=1 |
10000^{⁻²/₈} = 0.1 |
2π/0.1 ≈ 62.8 |
| 4 |
i=2 |
10000^{⁻⁴/₈} = 0.01 |
2π/0.01 ≈ 628.3 |
| 6 |
i=3 |
10000^{⁻⁶/₈} = 0.001 |
2π/0.001 ≈ 6283.2 |
从上表也可以看出:
波长范围与 dmodel 的关系是单调递增但渐进有界的,最大波长λi不会无限增大,而是随着 dmodel 的增加逐渐逼近 20000π,永远不会超过这一值
为什么设计为渐进有界?
-
覆盖需求:
-
计算效率:
-
频率分配合理性:
tensor([1.0000e+00, 1.0000e-01, 1.0000e-02, 1.0000e-03])
即:
tensor([1, 0.1, 0.01, 0.001])
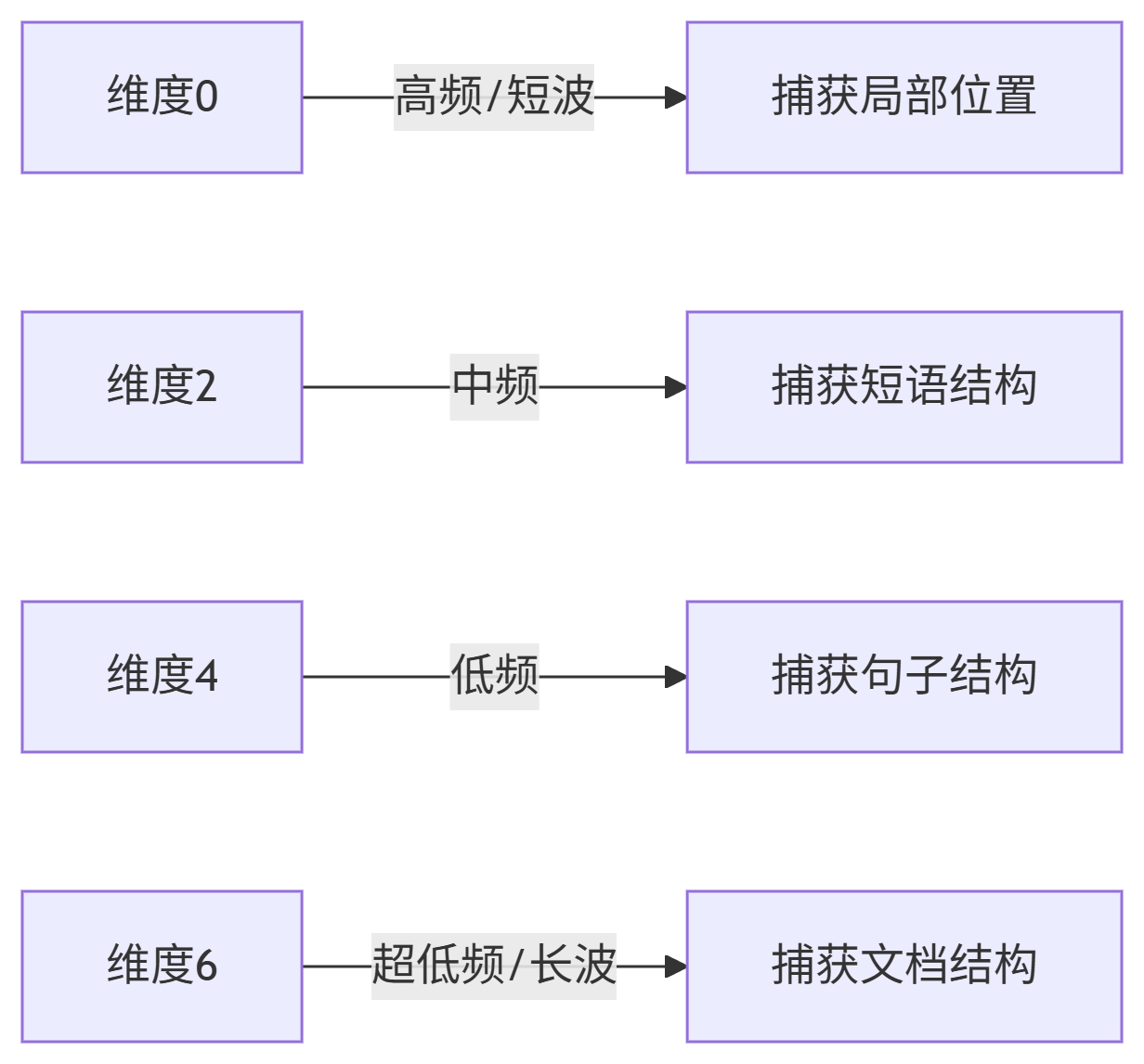
高维位置的波长分布(以d_model=512为例)
| 维度索引范围(i) |
波长范围(λi) |
频率特性 |
计算示例(ii 为偶数索引) |
| 0 ≤ i < 64 |
2π ~ 40π |
高频(局部位置差异) |
 |
| 64 ≤ i < 256 |
40π ~ 20000π |
中低频(全局结构) |
 |
| 256 ≤ i < 512 |
重复对称分布 |
与前半部分对称 |
因正弦/余弦交替,后256维是前256维的相位偏移 |
超低频维度(维度很高,波长很大)的实际作用
| 波长范围(λ) |
适用序列长度 |
实际作用 |
| 2000π ~ 5000π |
短文本(<100词) |
提供句子内位置基线 |
| 5000π~ 10000π |
中等文本(100-500词) |
区分段落或章节起始位置 |
| 10000π ~ 20000π |
长文档(>500词) |
跨段落或跨章节关系建模 |
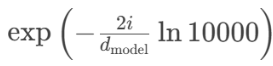 和在数学上是完全等价的表达式,使用图1的指数形式是为了获得更好的数值稳定性和计算效率:
和在数学上是完全等价的表达式,使用图1的指数形式是为了获得更好的数值稳定性和计算效率:
-
数值稳定性:
-
计算效率:
# 高效向量化计算
torch.exp(tensor * constant)
- 比逐元素计算幂函数快得多
3. 梯度优化:
-
在自动微分中,指数函数的梯度计算更稳定
-
幂函数的梯度在接近0时容易产生数值问题
4.高效覆盖:指数分布用少量维度覆盖极宽的波长范围(如512维覆盖 2π到 20000π)。
如果是线性分布,需要更多维度才能覆盖相同范围。
编码过程的核心
pe[:, 0::2] = torch.sin(position * div_term) # 偶数维度
pe[:, 1::2] = torch.cos(position * div_term) # 奇数维度
1.位置编码矩阵的结构
2. 维度索引的切片操作
3. 核心计算:position * div_term
点击查看数据整体变化过程
初始的位置编码矩阵pe = torch.zeros(max_len, d_model) # 初始化全0矩阵
tensor([[0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0.]])
生成位置索引position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
tensor([[0.],
[1.],
[2.],
[3.],
[4.],
[5.],
[6.],
[7.],
[8.],
[9.]])
生成频率因子div_term= torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
tensor([1, 0.1, 0.01, 0.001])
position * div_term:
tensor([
[0.0000, 0.0000, 0.0000, 0.0000],
[1.0000, 0.1000, 0.0100, 0.0010],
[2.0000, 0.2000, 0.0200, 0.0020],
[3.0000, 0.3000, 0.0300, 0.0030],
[4.0000, 0.4000, 0.0400, 0.0040],
[5.0000, 0.5000, 0.0500, 0.0050],
[6.0000, 0.6000, 0.0600, 0.0060],
[7.0000, 0.7000, 0.0700, 0.0070],
[8.0000, 0.8000, 0.0800, 0.0080],
[9.0000, 0.9000, 0.0900, 0.0090]
])
4.三角函数应用
pe[:, 0::2] = torch.sin(position * div_term) # 0::2表示从0开始,步长为2(偶数索引)
pe[:, 1::2] = torch.cos(position * div_term) # 1::2表示从1开始,步长为2(奇数索引)
| 位置 |
维度0 (sin) |
维度1 (cos) |
维度2 (sin) |
维度3 (cos) |
| 0 |
sin(0×1) = 0 |
cos(0×1) = 1 |
sin(0×0.01) = 0 |
cos(0×0.001) = 1 |
| 1 |
sin(1×1) ≈ 0.8415 |
cos(1×0.1) ≈ 0.9950 |
sin(1×0.01) ≈ 0.0100 |
cos(1×0.001) ≈ 1.0000 |
| 2 |
sin(2×1) ≈ 0.9093 |
cos(2×0.1) ≈ 0.9801 |
sin(2×0.01) ≈ 0.0200 |
cos(2×0.001) ≈ 0.9999 |
| 3 |
sin(3×1) ≈ 0.1411 |
cos(3×0.1) ≈ 0.9553 |
sin(3×0.01) ≈ 0.0300 |
cos(3×0.001) ≈ 0.9996 |
| 4 |
sin(4×1) ≈ -0.7568 |
cos(4×0.1) ≈ 0.9211 |
sin(4×0.01) ≈ 0.0400 |
cos(4×0.001) ≈ 0.9992 |
点击查看用三角函数生成位置编码的结果
非科学计数法:
tensor([
[ 0.0000, 1.0000, 0.0000, 1.0000, 0.0000, 1.0000, 0.0000, 1.0000],
[ 0.8415, 0.5403, 0.0998, 0.9950, 0.0100, 1.0000, 0.0010, 1.0000],
[ 0.9093, -0.4162, 0.1987, 0.9801, 0.0200, 0.9998, 0.0020, 1.0000],
[ 0.1411, -0.9900, 0.2955, 0.9553, 0.0300, 0.9996, 0.0030, 1.0000],
[-0.7568, -0.6536, 0.3894, 0.9211, 0.0400, 0.9992, 0.0040, 1.0000],
[-0.9589, 0.2837, 0.4794, 0.8776, 0.0500, 0.9988, 0.0050, 1.0000],
[-0.2794, 0.9602, 0.5646, 0.8253, 0.0600, 0.9982, 0.0060, 1.0000],
[ 0.6570, 0.7539, 0.6442, 0.7648, 0.0699, 0.9976, 0.0070, 1.0000],
[ 0.9894, -0.1455, 0.7174, 0.6967, 0.0800, 0.9968, 0.0080, 1.0000],
[ 0.4121, -0.9111, 0.7833, 0.6216, 0.0899, 0.9960, 0.0090, 1.0000]
])
科学计数法:
tensor([
[ 0.0000e+00, 1.0000e+00, 0.0000e+00, 1.0000e+00, 0.0000e+00,1.0000e+00, 0.0000e+00, 1.0000e+00],
[ 8.4147e-01, 5.4030e-01, 9.9833e-02, 9.9500e-01, 9.9998e-03,9.9995e-01, 1.0000e-03, 1.0000e+00],
[ 9.0930e-01, -4.1615e-01, 1.9867e-01, 9.8007e-01, 1.9999e-02,9.9980e-01, 2.0000e-03, 1.0000e+00],
[ 1.4112e-01, -9.8999e-01, 2.9552e-01, 9.5534e-01, 2.9995e-02,9.9955e-01, 3.0000e-03, 1.0000e+00],
[-7.5680e-01, -6.5364e-01, 3.8942e-01, 9.2106e-01, 3.9989e-02,9.9920e-01, 4.0000e-03, 9.9999e-01],
[-9.5892e-01, 2.8366e-01, 4.7943e-01, 8.7758e-01, 4.9979e-02,9.9875e-01, 5.0000e-03, 9.9999e-01],
[-2.7942e-01, 9.6017e-01, 5.6464e-01, 8.2534e-01, 5.9964e-02,9.9820e-01, 6.0000e-03, 9.9998e-01],
[ 6.5699e-01, 7.5390e-01, 6.4422e-01, 7.6484e-01, 6.9943e-02,9.9755e-01, 6.9999e-03, 9.9998e-01],
[ 9.8936e-01, -1.4550e-01, 7.1736e-01, 6.9671e-01, 7.9915e-02,9.9680e-01, 7.9999e-03, 9.9997e-01],
[ 4.1212e-01, -9.1113e-01, 7.8333e-01, 6.2161e-01, 8.9879e-02,9.9595e-01, 8.9999e-03, 9.9996e-01]
])
对于偶数维度(2i):
pe[position, 2i] = sin(position * 10000^{-2i/d_model})
对于奇数维度(2i+1):
pe[position, 2i+1] = cos(position * 10000^{-2i/d_model})
-
使用相同的频率因子但应用余弦函数
-
与相邻的偶数维度形成互补对
5. 为什么交替使用sin和cos?
关键优势:位置相对关系的线性表达
对于任意偏移量 k,位置 pos+k 的编码可以表示为位置 pos 编码的线性变换:
为什么用三角函数?:
位置编码器使用正弦和余弦函数生成位置编码,原因是:
三角函数具有周期性,能表示 "相对位置"(例如,位置 k 和 k+T 的编码有明确关系);
取值范围在 [-1, 1] 之间,避免数值过大影响梯度;
可扩展到超过 max_len 的句子(对于未见过的长句子,直接计算对应位置的 sin/cos 即可)。
为什么这样设计?
-
指数衰减频率:随着维度索引i增大,div_term值指数衰减,产生不同频率的波形
-
几何级数波长:从2π到2π·10000的波长范围,覆盖不同位置关系(当d_model=512时)
-
正弦/余弦互补:成对的sin/cos提供位置信息的线性变换不变性
为什么这样设计?
-
多尺度位置感知:
-
低维高频:区分相邻词("猫 追 老鼠")
-
高维低频:识别长距离依赖("尽管...但是")
-
指数波长分布:
-
正交性保证:
# 实例化参数
d_model = 512
dropout = 0.1
max_len = 60 # 假设最长句子不超过60个词
# 输入:使用前面Embedding层的输出(形状:[2, 4, 512])
x = emb_result # 即emb_layer(x)的输出
# 实例化位置编码器并计算
pe_layer = PositionalEncoding(d_model=d_model, dropout=dropout, max_len=max_len)
pe_result = pe_layer(x) # 前向传播
print("加入位置编码后的形状:", pe_result.shape) # torch.Size([2, 4, 512])——形状不变
pe_result就是输入部分的最终输出,它同时包含了词汇的语义信息(来自嵌入层)和位置信息(来自位置编码器),将作为后续编码器的输入。
import torch
import torch.nn as nn
import math
class RotaryPositionalEncoding(nn.Module):
"""
2024主流方案:旋转位置编码(RoPE)
解决传统位置编码的远距离衰减问题
"""
def __init__(self, d_model):
super().__init__()
# 初始化旋转频率参数
# 计算公式:theta_i = 1/(10000^(2i/d_model))
theta = 1.0 / (10000 ** (torch.arange(0, d_model, 2).float() / d_model))#tensor([1.0000, 0.1000, 0.0100, 0.0010])
# 注册为不参与梯度更新的缓冲区张量
self.register_buffer('theta', theta)
def forward(self, x):
"""
输入:形状为[batch_size, seq_len, d_model]的张量
输出:包含旋转位置信息的增强张量
处理流程:
1. 获取序列长度和位置索引
2. 计算旋转角度
3. 分割输入为奇偶两部分
4. 应用旋转矩阵变换
"""
seq_len = x.size(1)
# 创建位置索引:[0, 1, 2, ..., seq_len-1]
positions = torch.arange(seq_len, device=x.device).unsqueeze(0).unsqueeze(-1)
# 计算旋转角度:位置索引 * 旋转频率
angles = positions * self.theta
# 计算正弦和余弦值
cos_vals = torch.cos(angles)
sin_vals = torch.sin(angles)
# 将输入张量分割为两部分
x1, x2 = x.chunk(2, dim=-1)
# 应用旋转操作
return torch.cat([
x1 * cos_vals - x2 * sin_vals, # 奇数组分
x2 * cos_vals + x1 * sin_vals # 偶数组分
], dim=-1)
调用示例:
d_model = 512
drop_out = 0.2
maxlength=60
pos=RotaryPositionalEncoding(d_model)
pos_result = pos(emb_result)#emb_result是文本嵌入层的输出结果
print('pos_result:\n',pos_result)
点击查看pos_result打印结果
pos_result:
tensor([[[-22.7073, 47.7814, -34.8996, ..., 27.4981, 29.5390, -37.6457],
[ 4.4975, 26.1692, 5.2723, ..., 30.2044, -17.5261, 4.4119],
[ 30.7179, -46.2061, -8.8106, ..., 30.9138, 48.0335, 24.1294],
[ 3.7339, -4.0399, 25.4750, ..., 1.4083, 0.2464, 5.5368]],
[[-25.0991, -20.2715, -23.3490, ..., -16.5882, 5.9151, 10.8141],
[ 24.0511, 22.3200, -32.3607, ..., 9.0523, -69.3613, -4.6919],
[ -7.7432, 8.7808, 11.6668, ..., -8.2613, -44.4877, 36.0045],
[-22.1680, 8.6165, 2.4500, ..., 8.2094, 2.4702, -39.4504]]],
grad_fn=<CatBackward0>)
点击查看数据整体变化过程
d_model=8
seq_len=10
# 初始化旋转频率参数
theta = 1.0 / (10000 ** (torch.arange(0, d_model, 2).float() / d_model))
tensor([1.0000, 0.1000, 0.0100, 0.0010])
# 创建位置索引:[0, 1, 2, ..., seq_len-1]
torch.arange(seq_len, device=x.device):
tensor([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
torch.arange(seq_len, device=x.device).unsqueeze(0)
tensor([[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]])
positions = torch.arange(seq_len, device=x.device).unsqueeze(0).unsqueeze(-1)
tensor([[[0],
[1],
[2],
[3],
[4],
[5],
[6],
[7],
[8],
[9]]])
# 计算旋转角度:位置索引 * 旋转频率
angles = positions * theta
tensor([[
[0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00],
[1.0000e+00, 1.0000e-01, 1.0000e-02, 1.0000e-03],
[2.0000e+00, 2.0000e-01, 2.0000e-02, 2.0000e-03],
[3.0000e+00, 3.0000e-01, 3.0000e-02, 3.0000e-03],
[4.0000e+00, 4.0000e-01, 4.0000e-02, 4.0000e-03],
[5.0000e+00, 5.0000e-01, 5.0000e-02, 5.0000e-03],
[6.0000e+00, 6.0000e-01, 6.0000e-02, 6.0000e-03],
[7.0000e+00, 7.0000e-01, 7.0000e-02, 7.0000e-03],
[8.0000e+00, 8.0000e-01, 8.0000e-02, 8.0000e-03],
[9.0000e+00, 9.0000e-01, 9.0000e-02, 9.0000e-03]
]])
# 计算正弦和余弦值
cos_vals = torch.cos(angles)
tensor([[
[ 1.0000, 1.0000, 1.0000, 1.0000],
[ 0.5403, 0.9950, 0.9999, 1.0000],
[-0.4161, 0.9801, 0.9998, 1.0000],
[-0.9900, 0.9553, 0.9996, 1.0000],
[-0.6536, 0.9211, 0.9992, 1.0000],
[ 0.2837, 0.8776, 0.9988, 1.0000],
[ 0.9602, 0.8253, 0.9982, 1.0000],
[ 0.7539, 0.7648, 0.9976, 1.0000],
[-0.1455, 0.6967, 0.9968, 1.0000],
[-0.9111, 0.6216, 0.9960, 1.0000]
]])
# 将输入张量分割为奇偶两部分
x1, x2 = x.chunk(2, dim=-1)
x:
tensor([[
[-0.9999, 2.3156, -1.4695, 0.4755, -0.6917, 1.5989, 1.1258,-1.6053],
[ 1.6772, -0.6332, -1.0321, 0.8752, 0.3437, 0.4056, 0.7239,-0.1152],
[ 0.3354, 0.0683, -1.7851, -0.0522, 0.1394, -0.9185, -0.4194,-0.0896],
[ 1.3673, 1.8694, 0.3584, -0.6479, 1.5024, -0.6312, 0.3728, 0.7276],
[-0.0589, -0.0741, -0.3615, 0.7701, 0.2082, -0.5631, -0.7430, 1.1125],
[-0.1710, -1.0832, -0.2468, 0.1303, -0.5629, -1.2353, -0.5304,-0.7129],
[ 0.1327, 1.6995, -0.3278, 0.4369, -1.6799, -0.5550, -0.9677, 0.0654],
[-0.1957, -1.6168, -0.6508, 0.4742, -0.1579, -0.9069, -0.7761, 0.9913],
[ 0.3600, 0.5687, -0.5375, -0.2589, -0.1088, 0.9356, 0.9630,-0.5976],
[ 0.5196, 1.3758, -0.9453, -0.7429, 1.4650, -1.2425, 1.2043,-0.2617]]])
x1:
tensor([[[-0.9999, 2.3156, -1.4695, 0.4755],
[ 1.6772, -0.6332, -1.0321, 0.8752],
[ 0.3354, 0.0683, -1.7851, -0.0522],
[ 1.3673, 1.8694, 0.3584, -0.6479],
[-0.0589, -0.0741, -0.3615, 0.7701],
[-0.1710, -1.0832, -0.2468, 0.1303],
[ 0.1327, 1.6995, -0.3278, 0.4369],
[-0.1957, -1.6168, -0.6508, 0.4742],
[ 0.3600, 0.5687, -0.5375, -0.2589],
[ 0.5196, 1.3758, -0.9453, -0.7429]]])
x2:
tensor([[[-0.6917, 1.5989, 1.1258, -1.6053],
[ 0.3437, 0.4056, 0.7239, -0.1152],
[ 0.1394, -0.9185, -0.4194, -0.0896],
[ 1.5024, -0.6312, 0.3728, 0.7276],
[ 0.2082, -0.5631, -0.7430, 1.1125],
[-0.5629, -1.2353, -0.5304, -0.7129],
[-1.6799, -0.5550, -0.9677, 0.0654],
[-0.1579, -0.9069, -0.7761, 0.9913],
[-0.1088, 0.9356, 0.9630, -0.5976],
[ 1.4650, -1.2425, 1.2043, -0.2617]]])
# 应用旋转操作
return torch.cat([
x1 * cos_vals - x2 * sin_vals, # 奇数组分
x2 * cos_vals + x1 * sin_vals # 偶数组分
], dim=-1)
x1 * cos_vals - x2 * sin_vals:
tensor([[[-1.7142, 0.1674, -1.2152, 0.2609],
[-0.0853, -0.4854, -1.8653, -0.4615],
[-0.4890, -1.1125, 0.3871, 0.6703],
[ 1.4957, -0.9261, 1.4876, 2.5978],
[ 0.7999, -0.5478, 0.2526, -0.1888],
[ 0.2050, -1.4112, -0.7035, -0.1867],
[-0.7773, 0.8368, 0.0151, 0.2949],
[ 1.2017, -0.0907, -0.1569, 0.6140],
[-1.9494, -0.0552, -0.7687, 0.2508],
[ 3.0350, -0.0765, -0.6146, 1.2512]]])
位置编码可视化对比
点击查看代码
import torch
import torch.nn as nn
import math
# 传统位置编码器
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout=0.1, max_len=5000):
"""
初始化位置编码器
:param d_model: 词嵌入维度(需与Embedding层的d_model一致)
:param dropout: dropout比率(防止过拟合,通常设为0.1)
:param max_len: 最大句子长度(需覆盖训练数据中最长的句子)
"""
super().__init__()
self.dropout = nn.Dropout(p=dropout) # 实例化dropout层
# 步骤1:创建位置编码矩阵pe(形状:[max_len, d_model])
pe = torch.zeros(max_len, d_model) # 初始化全0矩阵
# 步骤2:生成位置索引(形状:[max_len, 1])
# 例如max_len=5时,position = [[0], [1], [2], [3], [4]]
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
# 步骤3:生成频率因子(用于控制位置编码的周期)
# div_term = tensor([1, 0.1, 0.01, 0.001,...])
# 公式:div_term = exp(2i * -log(10000) / d_model),其中i为偶数索引
div_term = torch.exp(#`torch.exp` 函数用于计算输入张量中每个元素的指数函数(exponential function)。具体来说,它计算每个元素的自然指数(e^x)
torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model)#math.log(x) 默认计算底数为 e 的对数(而非以 10 为底的对数)。
)
# 步骤4:用三角函数生成位置编码(偶数位用sin,奇数位用cos)
pe[:, 0::2] = torch.sin(position * div_term) # 0::2表示从0开始,步长为2(偶数索引)
pe[:, 1::2] = torch.cos(position * div_term) # 1::2表示从1开始,步长为2(奇数索引)
# 步骤5:扩展维度,适配批次输入(形状:[1, max_len, d_model])
# 因为输入是[batch_size, seq_len, d_model],需要在batch维度扩展
pe = pe.unsqueeze(0)
# 步骤6:将pe注册为"非参数缓冲区"(不参与训练,但会随模型保存)
self.register_buffer('pe', pe)
def forward(self, x):
"""
前向传播:将位置编码添加到词嵌入向量
:param x: 嵌入层的输出,形状为[batch_size, seq_len, d_model]
:return: 加入位置信息后的向量,形状不变
"""
# 步骤1:添加位置编码(仅取与输入句子长度匹配的部分)
# x.size(1)是当前句子的长度,pe[:, :x.size(1)]表示截取前seq_len个位置的编码
x = x + self.pe[:, :x.size(1)] # 广播机制:[1, seq_len, d_model]与[batch_size, seq_len, d_model]相加
# 步骤2:应用dropout,防止过拟合
return self.dropout(x)
class RotaryPositionalEncoding(nn.Module):
"""
2024主流方案:旋转位置编码(RoPE)
解决传统位置编码的远距离衰减问题
"""
def __init__(self, d_model):
super().__init__()
# 初始化旋转频率参数
# 计算公式:theta_i = 1/(10000^(2i/d_model))
theta = 1.0 / (10000 ** (torch.arange(0, d_model, 2).float() / d_model))#tensor([1.0000, 0.1000, 0.0100, 0.0010])
# 注册为不参与梯度更新的缓冲区张量
self.register_buffer('theta', theta)
def forward(self, x):
"""
输入:形状为[batch_size, seq_len, d_model]的张量
输出:包含旋转位置信息的增强张量
处理流程:
1. 获取序列长度和位置索引
2. 计算旋转角度
3. 分割输入为奇偶两部分
4. 应用旋转矩阵变换
"""
seq_len = x.size(1)
# 创建位置索引:[0, 1, 2, ..., seq_len-1]
positions = torch.arange(seq_len, device=x.device).unsqueeze(0).unsqueeze(-1)
# 计算旋转角度:位置索引 * 旋转频率
angles = positions * self.theta
# 计算正弦和余弦值
cos_vals = torch.cos(angles)
sin_vals = torch.sin(angles)
# 将输入张量分割为两部分
x1, x2 = x.chunk(2, dim=-1)
# 应用旋转操作
return torch.cat([
x1 * cos_vals - x2 * sin_vals, # 奇数组分
x2 * cos_vals + x1 * sin_vals # 偶数组分
], dim=-1)
import matplotlib.pyplot as plt
import numpy as np
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
plt.rcParams['font.size'] = 20
def visualize_positional_encodings():
"""对比传统位置编码与RoPE的效果"""
plt.figure(figsize=(15, 6))
# 子图1:传统正弦编码
plt.subplot(1, 2, 1)
# 注:传统PositionalEncoding实现参考原始教程
pe = PositionalEncoding(20, 0) # 维度20,dropout=0
y = pe(torch.zeros(1, 100, 20)) # 模拟输入
# 绘制第4-7维特征在不同位置的变化
plt.plot(np.arange(100), y[0, :, 4:8].data.numpy())
plt.title("传统正弦位置编码")
plt.xlabel("位置索引")
plt.ylabel("编码值")
# 子图2:RoPE旋转编码
plt.subplot(1, 2, 2)
rope = RotaryPositionalEncoding(20)
# 生成随机输入(模拟词向量)
y_rope = rope(torch.randn(1, 100, 20))
plt.plot(np.arange(100), y_rope[0, :, 4:8].detach().numpy())
plt.title("旋转位置编码(RoPE)")
plt.xlabel("位置索引")
plt.tight_layout()
plt.savefig("positional_encoding_comparison.png", dpi=120)
plt.show()
visualize_positional_encodings()
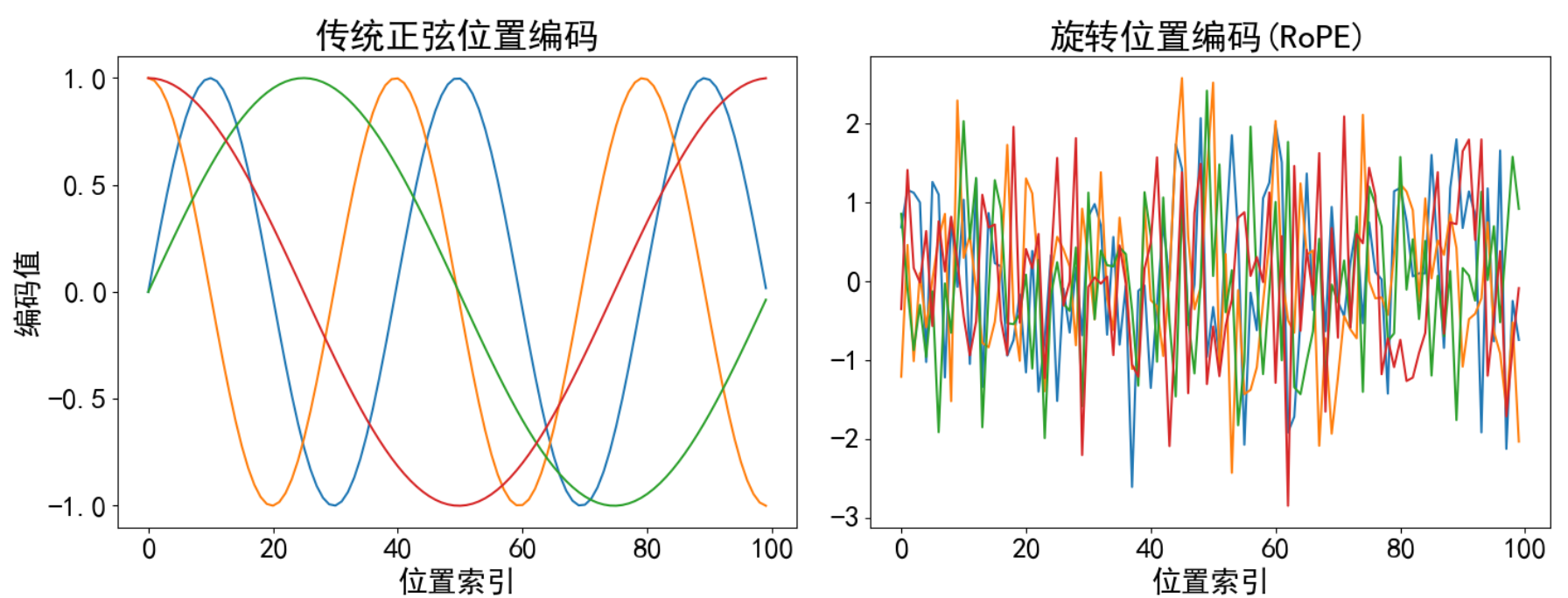
关键升级解析
-
位置编码革命
1. 远程衰减问题(Long-term Decay Problem)
传统正弦位置编码的缺陷:
-
现象:在原始Transformer的固定正弦位置编码中,两个token之间的位置关联强度会随着它们距离增大而快速衰减。
-
数学表现:当两个位置距离Δ增大时,它们的位置编码点积⟨PE(m), PE(n)⟩会迅速趋近于0。
-
具体例子:
-
相邻位置(Δ=1):关联性强,点积≈1
-
距离100的位置:点积≈0.2
-
距离1000的位置:点积≈0.02
-
后果:模型难以学习长距离依赖关系(如段落开头与结尾的关联)。
RoPE的改进:
通过旋转操作保持距离Δ的线性关系,使得远距离位置的关联性不会过度衰减。
2. 相对位置一致性(Relative Position Consistency)
核心特性:
对比实验:
性能对比:
| 指标 |
传统Transformer (2017) |
RoPE改进版 (2024) |
| 有效上下文长度 |
512-1024 tokens |
4000+ tokens |
| 长文档任务准确率 |
下降30-50% (>2k tokens) |
保持90%+ |
| 内存消耗 |
O(n²) 显著增长 |
O(n) 可控增长 |
关键突破点:
技术演进图示
固定位置编码时代(2017-2021)
│
├── 绝对位置编码(BERT式)
│ └── 最大512长度硬限制
│
└── 相对位置编码(Transformer-XL)
└── 片段递归机制复杂
↓
旋转编码革命(2022-2024)
│
├── RoPE(Llama/Mistral采用)
│ └── 4k-32k长度支持
│
└── NTK扩展RoPE(2023)
└── 无损扩展到100k+
这种演进使得现代大模型处理长文档的能力接近人类水平(人类阅读长文时也能保持前后一致性)。
输入部分的核心流程是:
原始文本(字符串)→ 词索引(数字)→ 嵌入层(语义向量)→ 位置编码器(+位置信息)→ 编码器输入
- 文本嵌入层:将词索引转为高维语义向量,并用
sqrt(d_model)缩放;
- 位置编码器:通过三角函数生成位置编码,与语义向量相加,补充位置信息;
- 两者结合后,得到同时包含 "what"(语义)和 "where"(位置)的输入向量,为后续的注意力机制提供基础。
工业级配置推荐
|
模型规模
|
嵌入维度
|
前馈网络维度
|
|
base
|
768
|
3072
|
|
large
|
1024
|
4096
|
|
xl
|
2048
|
8192
|
Transformer 的核心竞争力在于注意力机制,而掩码张量是让注意力机制 "守规矩" 的关键工具,多头注意力则是注意力机制的 "增强版"。这三个组件共同构成了 Transformer 理解序列数据的核心逻辑。本章将系统讲解三者的原理、实现及最新技术进展(2021-2025)。
在注意力机制中,掩码张量的作用是限制注意力的范围—— 告诉模型哪些位置的信息可以关注,哪些需要忽略。没有掩码,模型可能会 "偷看" 到不该看的信息(比如解码器提前看到未来的词),或者被无意义的填充符号干扰。
作用:忽略句子中填充符号(如<pad>)的影响。 在实际场景中,句子长度不一,我们会用填充符号将短句子补成长度一致的张量(便于批量计算)。这些填充符号没有实际语义,需要被掩码遮盖。
示例: 若句子为[我, 爱, 你, <pad>, <pad>],填充掩码会将<pad>对应的位置标记为0(需遮盖),其他位置为1(可关注)。
作用:在解码器中,防止模型 "偷看" 未来的词(保证生成的时序合理性)。 例如生成句子时,预测第 3 个词只能用第 1、2 个词的信息,不能用第 4、5 个词的信息。后续掩码会将 "未来位置" 标记为0。
示例: 句子长度为 5 的后续掩码是一个下三角矩阵(下三角及对角线为 1,上三角为 0):
[[1, 0, 0, 0, 0],
[1, 1, 0, 0, 0],
[1, 1, 1, 0, 0],
[1, 1, 1, 1, 0],
[1, 1, 1, 1, 1]]
import torch
import numpy as np
import matplotlib.pyplot as plt
def padding_mask(seq, pad_idx=0):
"""
生成填充掩码(用于编码器和解码器)
:param seq: 输入序列,形状为[batch_size, seq_len](词索引)
:param pad_idx: 填充符号的索引(默认0)
:return: 填充掩码,形状为[batch_size, 1, 1, seq_len](适配注意力机制的广播)
"""
# 标记填充位置:seq中等于pad_idx的位置为True(需遮盖)
mask = (seq == pad_idx).unsqueeze(1).unsqueeze(2) # 扩展维度便于广播
return mask # 形状:[batch_size, 1, 1, seq_len]
def subsequent_mask(size):
"""
生成后续掩码(仅用于解码器)
:param size: 序列长度
:return: 后续掩码,形状为[1, size, size]
"""
# 生成上三角矩阵(值为1),然后反转得到下三角矩阵(值为1表示可关注)
mask = np.triu(np.ones((size, size)), k=1).astype('uint8') # k=1表示上三角偏移1
return torch.from_numpy(1 - mask).unsqueeze(0) # 反转并扩展维度:[1, size, size]
# 可视化掩码效果
def visualize_mask(mask, title):
plt.rcParams['font.size'] = 12
plt.figure(figsize=(5, 5))
plt.imshow(mask[0].numpy(), cmap='viridis') # 取第一个样本的掩码
plt.title(title)
# 主刻度设置
data = mask[0].int().numpy()
plt.xticks(range(data.shape[1]))
plt.yticks(range(data.shape[0]))
plt.xlabel("序列位置")
plt.ylabel("关注位置")
plt.show()
# 示例:测试两种掩码
if __name__ == "__main__":
# 测试填充掩码
seq = torch.LongTensor([[1, 2, 0, 0], [3, 0, 0, 0]]) # 含填充符号0的序列
pad_mask = padding_mask(seq)
print("填充掩码:\n", pad_mask) #
print("填充掩码形状:\n", pad_mask.shape) # [2, 1, 1, 4]
# 将布尔掩码转换为0/1的整数
mask_to_show = pad_mask[0].int()
visualize_mask(mask_to_show, "填充掩码(黄色为需遮盖位置)")
# 测试后续掩码
sub_mask = subsequent_mask(5)
print("后续掩码:\n", sub_mask) # [1, 5, 5]
print("后续掩码形状:\n", sub_mask.shape) # [1, 5, 5]
visualize_mask(sub_mask, "后续掩码(黄色为需遮盖位置)")
查看打印结果
填充掩码:
tensor([[[[False, False, True, True]]],
[[[False, True, True, True]]]])
填充掩码形状:
torch.Size([2, 1, 1, 4])
后续掩码:
tensor([[[1, 0, 0, 0, 0],
[1, 1, 0, 0, 0],
[1, 1, 1, 0, 0],
[1, 1, 1, 1, 0],
[1, 1, 1, 1, 1]]], dtype=torch.uint8)
后续掩码形状:
torch.Size([1, 5, 5])
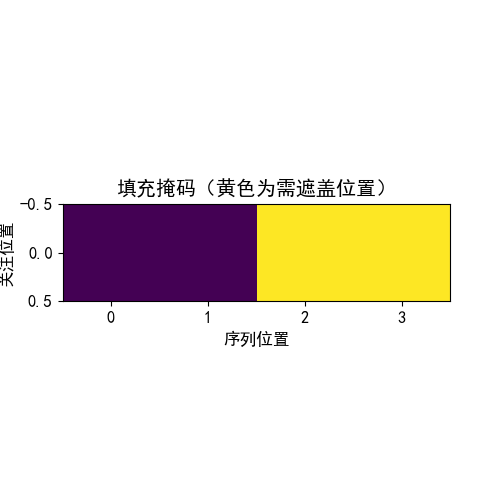
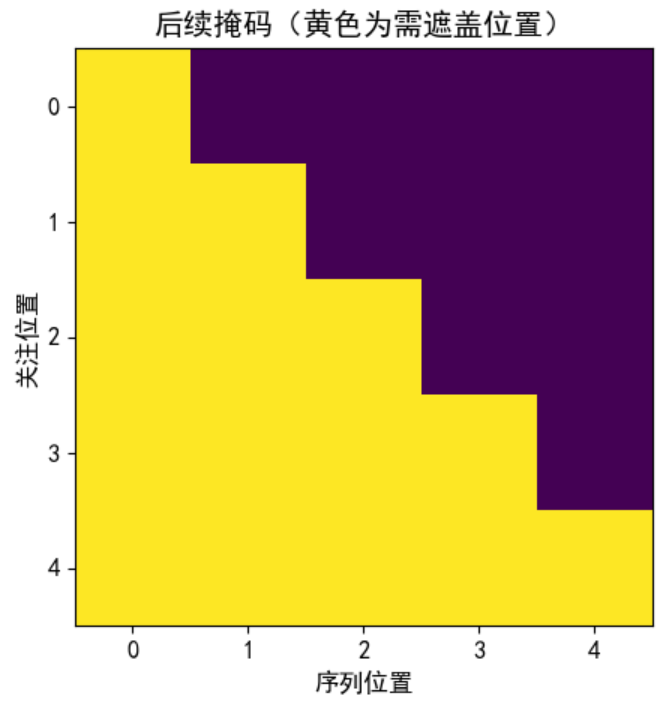
输出效果分析:
通过观察可视化方阵,黄色是1的部分,这里代表被遮掩,紫色代表没有被遮掩的信息,横坐标代表目标词汇的位置,纵坐标代表可查看的位置;
我们看到,在0的位置我们一看望过去都是黄色的,都被遮住了,1的位置就能看到位置1的词,从第2个位置看过去,就能看到位置1和2的词,其他位置看不到以此类推
- 编码器:仅使用
padding_mask,确保模型忽略填充符号;
- 解码器自注意力:同时使用
padding_mask和subsequent_mask(两者逻辑与),既忽略填充又不看未来信息;
- 解码器 - 编码器注意力:使用编码器输出的
padding_mask,确保解码器关注编码器的有效信息(不关注填充)。
最新进展:在长文本处理(如 10 万 tokens)中,掩码会结合滑动窗口注意力(如 GPT-4)或稀疏注意力(如 Longformer),仅关注局部或关键位置,平衡效率与效果。
掩码技术三合一
Transformer使用三种掩码协同工作,2024年主流框架将其整合为统一接口:
import torch
import numpy as np
import matplotlib.pyplot as plt
class TransformerMask:
"""
2024三合一掩码系统
"""
def __init__(self, seq_len, padding_mask=None):
self.seq_len = seq_len
self.padding_mask = padding_mask
def causal_mask(self):
"""因果掩码,即:后续掩码(防止未来信息泄露)"""
mask = torch.tril(torch.ones(self.seq_len, self.seq_len)) # 下三角矩阵
return mask.bool() # True=可见,False=掩码
def padding_mask(self):
"""填充掩码(处理变长序列)"""
if self.padding_mask is None:
return torch.ones(self.seq_len).bool() # 默认全可见
return self.padding_mask.bool()
def sparse_mask(self, window_size=128):
"""稀疏掩码(提升长序列效率)"""
mask = torch.zeros(self.seq_len, self.seq_len)
for i in range(self.seq_len):
# 局部注意力窗口
start = max(0, i - window_size // 2)
end = min(self.seq_len, i + window_size // 2)
mask[i, start:end] = 1
# 随机全局连接
global_indices = torch.randperm(self.seq_len)[:4] # 随机4个全局连接
mask[i, global_indices] = 1
return mask.bool()
def combined_mask(self, is_decoder=False):
"""组合掩码(2024推荐使用)"""
mask = self.sparse_mask()
if is_decoder:
mask = mask & self.causal_mask() # 解码器需添加因果掩码
if self.padding_mask is not None:
mask = mask & self.padding_mask().unsqueeze(1) # 添加填充掩码
return mask
注意力机制是 Transformer 的 "灵魂",它让模型能像人类一样,在处理序列时聚焦于关键信息。其核心是通过计算 "查询(Query)" 与 "键(Key)" 的相似度,给 "值(Value)" 分配权重,最终得到加权求和的结果。
Transformer 使用的是缩放点积注意力,这是目前最流行的注意力计算方式,公式如下:
- Q(查询):当前需要处理的信息(如解码器中的当前词);
- K(键):用于匹配查询的信息(如编码器中的所有词);
- V(值):实际用于计算输出的信息(通常与K相同或相关);
- dk:Q/K的维度,缩放因子
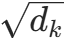 用于防止QKT的值过大导致 softmax 梯度消失。
用于防止QKT的值过大导致 softmax 梯度消失。
传统实现存在内存访问效率问题,2022 年提出的FlashAttention通过重新组织计算顺序,大幅提升了速度(尤其长序列),以下是兼容传统与 FlashAttention 的实现:
import torch
import torch.nn.functional as F
# 安装FlashAttention:pip install flash-attn
try:
from flash_attn import flash_attn_qkvpacked_func # FlashAttention库
FLASH_AVAILABLE = True
except ImportError:
FLASH_AVAILABLE = False
def scaled_dot_product_attention(Q, K, V, mask=None, dropout=0.1, use_flash=False,training=False):
"""
缩放点积注意力(支持传统实现和FlashAttention优化)
:param Q: 查询张量,形状为 [batch_size, seq_len_q, d_model]
:param K: 键张量,形状为 [batch_size, seq_len_k, d_model]
:param V: 值张量,形状为 [batch_size, seq_len_v, d_model](通常seq_len_k=seq_len_v)
:param mask: 掩码张量,形状为[batch_size, 1, seq_len_q, seq_len_k](1表示需遮盖)
:param dropout: dropout比率
:param use_flash: 是否使用FlashAttention加速(需安装库)# 默认use_flash=True,启用FlashAttention
:param training: 指示是否在训练模式(决定是否应用dropout)
:return: 注意力输出(形状同V)和注意力权重(形状[batch_size, heads, seq_len_q, seq_len_k])
"""
if use_flash and FLASH_AVAILABLE:
# FlashAttention要求输入为packed格式:[batch_size, seq_len, 3, heads, d_k]
qkv = torch.stack([Q, K, V], dim=2) # 合并QKV:[batch_size, heads, 3, seq_len, d_k]
qkv = qkv.transpose(1, 3) # 调整维度:[batch_size, seq_len, 3, heads, d_k]
# 调用FlashAttention(自动处理掩码)
output = flash_attn_qkvpacked_func(
qkv,
attn_mask=mask, # FlashAttention的掩码格式需匹配
dropout_p=dropout if training else 0.0
)
attn_weights = None # FlashAttention默认不返回权重(如需需额外配置)
return output.transpose(1, 2), attn_weights # 恢复heads维度
else:
# 传统实现
d_k = Q.size(-1)
# 步骤1:计算Q与K的相似度(缩放)
scores = torch.matmul(Q, K.transpose(-2, -1)) / torch.sqrt(
torch.tensor(d_k, dtype=torch.float32)) # [batch_size, heads, seq_len_q, seq_len_k]
# 步骤2:应用掩码(遮盖不需要关注的位置)
if mask is not None:
# 掩码位置设为极小值,确保softmax后权重为0
scores = scores.masked_fill(mask, -1e9)
# 步骤3:计算注意力权重(softmax归一化)
attn_weights = F.softmax(scores, dim=-1) # [batch_size, heads, seq_len_q, seq_len_k]
# 步骤4:应用dropout(防止过拟合)
attn_weights = F.dropout(attn_weights, p=dropout, training=training)
# 步骤5:加权求和得到输出
output = torch.matmul(attn_weights, V) # [batch_size, heads, seq_len_q, d_v]
return output, attn_weights
query=key=value=pos_result
output, attn_weights = scaled_dot_product_attention(query, key, value, mask=None, dropout=drop_out)
print('query的注意力输出output:\n',output)
print('(Q)和键(K)的相似度权重矩阵(注意力权重)attn_weights:\n',attn_weights)
- 掩码的应用:通过
masked_fill将需遮盖的位置设为-1e9,确保 softmax 后这些位置的权重为 0;
- FlashAttention 的优势:2022 年提出的高效实现,通过减少 GPU 内存访问次数,将长序列注意力计算速度提升 2-4 倍,已成为大模型训练的标配(如 GPT-4、LLaMA);
- 自注意力与交叉注意力:当Q=K=V时,称为自注意力(如编码器中用自身信息关注自身);当Q与K/V来自不同序列时,称为交叉注意力(如解码器用自身Q关注编码器的K/V)。
为什么需要training参数?
-
-
Dropout在训练和推理时的行为不同:
-
训练时:按概率随机置零神经元
-
推理时:通常不应用dropout(或缩放权重)
查看打印结果
query的注意力输出output:
tensor([[[-33.3084, 41.1603, 11.0306, ..., -6.6029, -10.5427, -7.9394],
[-50.1308, 1.8654, 27.2882, ..., 7.7862, -13.9893, 9.6881],
[-20.8785, -56.9469, -28.6604, ..., 23.0149, -9.3745, -0.7242],
[-31.2416, -45.1642, -11.4455, ..., -4.0710, 6.4423, -8.2581]],
[[ -0.6040, -33.7657, 30.4548, ..., -0.1173, 15.0145, -13.5328],
[-59.4329, -21.4231, -16.4087, ..., -7.5967, 11.0867, -5.4809],
[ 18.7602, 11.2929, 26.5343, ..., -32.8825, 8.6549, 29.5614],
[ 8.9251, -38.9289, 30.5755, ..., -19.0392, -3.9798, 9.6417]]],
grad_fn=<UnsafeViewBackward0>)
(Q)和键(K)的相似度权重矩阵(注意力权重)attn_weights:
tensor([[[1., 0., 0., 0.],
[0., 1., 0., 0.],
[0., 0., 1., 0.],
[0., 0., 0., 1.]],
[[1., 0., 0., 0.],
[0., 1., 0., 0.],
[0., 0., 1., 0.],
[0., 0., 0., 1.]]], grad_fn=<SoftmaxBackward0>)
除了基础的缩放点积注意力,近年来出现了多种优化变种,适用于不同场景:
| 变种 |
特点 |
应用场景 |
| FlashAttention |
优化内存访问,速度提升 2-4 倍 |
长序列(如 10 万 tokens)、大模型训练 |
| Grouped Attention(分组注意力) |
将头分成组,每组内计算注意力 |
降低计算量(如 PaLM-E) |
| Linear Attention |
用核函数替代 softmax,复杂度从O(n^2)降为O(n) |
超长长序列(如文档级任务) |
| Multi-Query Attention(多查询注意力) |
所有头共享 K/V,仅 Q 不同 |
加速推理(如 GPT-3.5/4) |
注意力优化技术对比
|
技术
|
计算复杂度
|
内存占用
|
适用场景
|
2024推荐
|
|
原始注意力
|
O(n²)
|
高
|
短文本(<512)
|
❌
|
|
FlashAttention-2
|
O(n²)
|
减少50%
|
通用场景
|
✅
|
|
多查询注意力(MQA)
|
O(n²)
|
减少40%
|
推理场景
|
✅
|
|
分组查询注意力(GQA)
|
O(n²)
|
减少30%
|
中等资源
|
⚠️
|
|
稀疏注意力
|
O(n√n)
|
减少70%
|
超长文本(>8K)
|
✅
|
单头注意力可能只关注某一方面的信息,而多头注意力通过将Q/K/V分割成多个 "头"(Head),让每个头学习不同的注意力模式,最后合并结果,从而捕捉更丰富的特征。
多头注意力机制的作用:
这种结构设计能让每个注意力机制去优化每个词汇的不同特征部分,从而均衡同一种注意力机制可能产生的偏差,让词义拥有来自更多元的表达,实验表明可以从而提升模型效果。
- 线性变换:将Q/K/V通过 3 个线性层,得到高维向量(维度dmodel);
- 分割头:将高维向量分割成h个 "头",每个头的维度为dk = dmodel / h;
- 多头并行计算:每个头独立计算注意力(缩放点积);
- 合并结果:将所有头的输出拼接,再通过一个线性层得到最终结果。
import torch
import torch.nn as nn
import copy
def clones(module, N):
"""克隆N个相同的网络层(用于多头注意力的线性层)"""
return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])
class MultiHeadedAttention(nn.Module):
def __init__(self, num_heads, d_model, dropout=0.1, use_flash=False):
"""
多头注意力机制
:param num_heads: 头数(h)
:param d_model: 模型总维度(需被num_heads整除)
:param dropout: dropout比率
:param use_flash: 是否使用FlashAttention加速
"""
super().__init__()
assert d_model % num_heads == 0, "d_model必须能被num_heads整除"
self.d_model = d_model # 模型总维度(如512)
self.num_heads = num_heads # 头数(如8)
self.d_k = d_model // num_heads # 每个头的维度(如512/8=64)
# 定义4个线性层:3个用于Q/K/V的变换,1个用于合并后的输出
self.linears = clones(nn.Linear(d_model, d_model), 4)
self.dropout_prob = dropout # 保存dropout概率
self.dropout = nn.Dropout(p=dropout)
self.use_flash = use_flash
self.attn_weights = None # 保存注意力权重(用于可视化)
def forward(self, Q, K, V, mask=None):
"""
前向传播
:param Q: 查询,形状[batch_size, seq_len_q, d_model]
:param K: 键,形状[batch_size, seq_len_k, d_model]
:param V: 值,形状[batch_size, seq_len_v, d_model](通常seq_len_k=seq_len_v)
:param mask: 掩码,形状[batch_size, 1, seq_len_q, seq_len_k]
:return: 多头注意力输出,形状[batch_size, seq_len_q, d_model]
"""
batch_size = Q.size(0)
# 步骤1:对Q/K/V进行线性变换并分割头
# 线性变换:[batch_size, seq_len, d_model] → [batch_size, seq_len, d_model]
# 分割头:[batch_size, seq_len, d_model] → [batch_size, num_heads, seq_len, d_k]
Q, K, V = [
linear(x).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)#transpose(1, 2)调换第1维和第2维:为了让代表句子长度维度和词向量维度能够相邻,这样注意力机制才能找到词义与句子位置的关系。
for linear, x in zip(self.linears[:3], (Q, K, V))
] # Q/K/V形状:[batch_size, num_heads, seq_len, d_k]
# 步骤2:多头并行计算注意力
x, self.attn_weights = scaled_dot_product_attention(
Q, K, V,
mask=mask,
dropout=self.dropout_prob, # 传递浮点数而非Dropout实例
use_flash=self.use_flash
) # x形状:[batch_size, num_heads, seq_len_q, d_k]
# 步骤3:合并所有头的输出
x = x.transpose(1, 2).contiguous() # 调整维度:[batch_size, seq_len_q, num_heads, d_k]
x = x.view(batch_size, -1, self.d_model) # 合并头:[batch_size, seq_len_q, d_model]
# 步骤4:最终线性变换
return self.linears[-1](x) # 形状:[batch_size, seq_len_q, d_model]
# 实例化参数
# 头数
head =8
# 词嵌入维度
embedding_dim=512
# 置零比率
dropout = 0.2
# 输入参数
query=key=value=pos_result
mha = MultiHeadedAttention(head, embedding_dim, dropout, use_flash=False)
attention = mha(query, key, value, mask=None)
print('attention:\n',attention)
点击查看输出结果
attention:
tensor([[[ 1.8121, -0.0804, 4.9742, ..., 9.5358, -6.5551, -8.3929],
[ -7.4524, -9.8980, 9.9315, ..., -16.5137, 0.3026, -3.4605],
[ -8.2776, -9.1503, -1.8465, ..., 1.7974, 7.6953, 6.4884],
[ 2.8642, 10.2630, 3.7705, ..., 3.9820, -1.2192, 4.2461]],
[[ 0.4194, 12.5183, -0.8498, ..., 3.3380, -5.3146, -1.1554],
[ 7.0103, 2.3918, -1.7368, ..., -0.0673, 2.3750, -7.7305],
[ -4.3952, 0.3961, -17.2670, ..., 1.8423, -12.8944, 6.5921],
[ 5.3769, -3.8015, 5.5327, ..., -10.7529, -0.8043, 1.9539]]],
grad_fn=<ViewBackward0>)
- 优势:每个头可关注不同的特征(如一个头关注语法,另一个关注语义),合并后特征更全面;
- 实践经验:
- 头数通常设为 8(如 BERT-base)、16(如 BERT-large)或更多(GPT-3 用 96 头),头数越多捕捉的特征越细,但计算量越大;
- 2023 年以来,多查询注意力(Multi-Query Attention)逐渐流行,它让所有头共享 K/V,仅 Q 不同,大幅降低推理时的内存占用(如 GPT-4 采用)。
多头注意力(工业级实现,多查询注意力)
class MultiHeadAttention(nn.Module):
"""2024优化版多头注意力"""
def __init__(self, d_model, num_heads, dropout=0.1, use_mqa=False):
super().__init__()
assert d_model % num_heads == 0, "d_model必须能被num_head整除"
self.d_model = d_model
self.num_heads = num_heads
self.head_dim = d_model // num_heads
self.use_mqa = use_mqa # 多查询注意力选项
# 投影层
self.Wq = nn.Linear(d_model, d_model)
if use_mqa:
# MQA:共享键值头
self.Wk = nn.Linear(d_model, self.head_dim)
self.Wv = nn.Linear(d_model, self.head_dim)
else:
self.Wk = nn.Linear(d_model, d_model)
self.Wv = nn.Linear(d_model, d_model)
self.Wo = nn.Linear(d_model, d_model)
self.dropout = nn.Dropout(dropout)
def split_heads(self, x):
"""分割头维度"""
batch_size = x.size(0)
return x.view(batch_size, -1, self.num_heads, self.head_dim).transpose(1, 2)
def forward(self, Q, K, V, mask=None):
batch_size = Q.size(0)
# 线性投影
Q = self.Wq(Q)
K = self.Wk(K)
V = self.Wv(V)
# 多查询注意力(MQA)优化
if self.use_mqa:
# 查询:多头
Q = self.split_heads(Q)
# 键值:单头(广播到多头)
K = K.unsqueeze(1).expand(-1, self.num_heads, -1, -1)
V = V.unsqueeze(1).expand(-1, self.num_heads, -1, -1)
else:
# 标准多头处理
Q = self.split_heads(Q)
K = self.split_heads(K)
V = self.split_heads(V)
# 注意力计算
attn_output = scaled_dot_product_attention(
Q, K, V, mask, self.dropout.p
)
# 合并头部
attn_output = attn_output.transpose(1, 2).contiguous()
attn_output = attn_output.view(batch_size, -1, self.d_model)
return self.Wo(attn_output)
注意力可视化工具
def visualize_attention(attn_weights, tokens, filename="attention_heatmap.png"):
"""注意力热力图可视化工具(2024升级版)"""
plt.figure(figsize=(12, 10))
# 平均所有头部的注意力权重
avg_attn = attn_weights.mean(dim=1)[0].detach().cpu().numpy()
# 创建热力图
ax = sns.heatmap(
avg_attn,
annot=False,
cmap="viridis",
xticklabels=tokens,
yticklabels=tokens,
cbar_kws={'label': 'Attention Weight'}
)
# 优化标签显示
plt.xticks(rotation=45, ha='right', fontsize=10)
plt.yticks(rotation=0, fontsize=10)
plt.xlabel("Key Position")
plt.ylabel("Query Position")
plt.title("Attention Heatmap (2024)", fontsize=14)
plt.tight_layout()
plt.savefig(filename, dpi=300, bbox_inches='tight')
plt.close()
# 2024新增:交互式HTML输出
plotly_fig = ff.create_annotated_heatmap(
z=avg_attn,
x=tokens,
y=tokens,
colorscale='Viridis'
)
plotly_fig.write_html(f"{filename.split('.')[0]}.html")
下面通过一个具体示例,展示掩码、注意力、多头注意力如何协同工作:
# 1. 准备输入(假设已通过输入部分处理,得到带位置编码的向量)
batch_size = 2 # 批次大小
seq_len = 4 # 序列长度
d_model = 512 # 模型维度
pe_result = torch.randn(batch_size, seq_len, d_model) # 模拟输入部分的输出(带位置编码)
# 2. 生成掩码
# 假设输入序列含填充(如索引0为<pad>)
seq = torch.LongTensor([[100, 2, 421, 0], [491, 0, 1, 221]]) # 词索引
pad_mask = padding_mask(seq) # 填充掩码:[2, 1, 1, 4]
sub_mask = subsequent_mask(seq_len) # 后续掩码:[1, 4, 4]
decoder_mask = pad_mask | sub_mask # 解码器掩码(填充+后续,逻辑或)
# 3. 实例化多头注意力
num_heads = 8
mha = MultiHeadedAttention(num_heads=num_heads, d_model=d_model, use_flash=False)
# 4. 计算多头注意力(以解码器自注意力为例,Q=K=V)
output = mha(pe_result, pe_result, pe_result, mask=decoder_mask)
print("多头注意力输出形状:", output.shape) # [2, 4, 512](与输入形状一致)
-
核心组件作用:
- 掩码:确保注意力 "不越界"(忽略填充、不看未来);
- 注意力机制:计算信息间的关联,生成加权特征;
- 多头注意力:扩展注意力的表达能力,捕捉多维度特征。
-
2021-2025 技术趋势:
- 高效注意力(FlashAttention、Linear Attention)成为长序列任务的标配;
- 注意力机制与稀疏性结合(如仅关注 Top-k 个位置),平衡效率与效果;
- 多查询注意力等变种在工业界快速普及,优化大模型的推理速度。
-
实际应用建议:
- 初学者从基础实现入手,理解原理后再使用 FlashAttention 等优化;
- 处理短序列(如句子级任务)用 8 头即可;长序列(如文档)可尝试分组注意力;
- 掩码的正确使用是模型效果的关键,尤其解码器需同时处理填充和后续掩码。
通过本章学习,你已掌握 Transformer 的核心动力源 —— 注意力机制。下一章我们将学习前馈全连接层和规范化层,它们是 Transformer 架构中不可或缺的 "调节器"。
在前几章中,我们学习了 Transformer 的输入处理、掩码机制和核心的注意力机制。本章将介绍 Transformer 架构中另外三个关键组件:前馈全连接层(增强模型拟合能力)、规范化层(稳定训练过程)和子层连接结构(结合残差连接与子层处理)。这些组件虽然看似简单,却是 Transformer 能够稳定训练并发挥强大能力的重要保障。
Transformer 中的前馈全连接层是一个两层线性网络,其核心作用是:
- 考虑注意力机制可能对复杂过程的拟合程度不够,通过增加两层网络来增强模型的能力。
- 对注意力机制的输出进行非线性变换,增强模型对复杂模式的拟合能力(注意力机制本质是线性变换,需配合非线性激活提升表达能力);
- 保持输入与输出维度一致(输入输出均为
d_model),便于接入残差连接。
其结构可表示为:
其中,W1的维度为d_model → d_ff,W2的维度为d_ff → d_model,dff是中间层维度(原论文中设为 2048)。
传统实现使用 ReLU 激活函数,近年来研究发现GELU 激活函数(高斯误差线性单元)在大模型中表现更优(如 GPT、BERT 等均采用),以下是兼容两种激活的实现:
import torch
import torch.nn as nn
import torch.nn.functional as F
class PositionwiseFeedForward(nn.Module):
def __init__(self, d_model, d_ff=2048, dropout=0.1, activation='gelu'):
"""
前馈全连接层
:param d_model: 输入/输出维度(需与多头注意力输出一致,通常为512)
:param d_ff: 中间层维度(原论文为2048,可根据需求调整)
:param dropout: Dropout比率(防止过拟合)
:param activation: 激活函数类型('relu'或'gelu',推荐'gelu')
"""
super().__init__()
# 第一层线性变换:d_model → d_ff
self.w1 = nn.Linear(d_model, d_ff)
# 第二层线性变换:d_ff → d_model(确保输入输出维度一致)
self.w2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
# 选择激活函数(GELU在Transformer类模型中更常用)
self.activation = F.gelu if activation == 'gelu' else F.relu
def forward(self, x):
"""
前向传播
:param x: 输入张量,形状为[batch_size, seq_len, d_model](如多头注意力的输出)
:return: 输出张量,形状为[batch_size, seq_len, d_model]
"""
# 步骤1:第一层线性变换 + 激活函数
x = self.activation(self.w1(x)) # 形状:[batch_size, seq_len, d_ff]
# 步骤2:应用Dropout(随机失活部分神经元,防止过拟合)
x = self.dropout(x)
# 步骤3:第二层线性变换(恢复维度)
x = self.w2(x) # 形状:[batch_size, seq_len, d_model]
return x
-
维度设计: 中间层维度d_ff通常远大于d_model(如 2048 vs 512),这种 "升维 - 降维" 的操作能让模型学习更丰富的特征组合,类似卷积网络中的通道扩展。
-
激活函数选择:
- ReLU:
max(0, x),计算简单,但存在 "死亡 ReLU" 问题(部分神经元永久失活);
- GELU:
xΦ(x)(Φ 是高斯分布的累积分布函数),平滑的非线性变换,在 Transformer 类模型中已成为默认选择(2021 年后主流模型均采用)。
-
与注意力层的配合: 前馈层对每个位置的词向量独立处理(position-wise),而注意力层关注位置间的关联,两者互补,共同提升模型能力。
# 实例化参数
d_model = 512
d_ff = 2048 # 原论文推荐值,远大于d_model
dropout = 0.1
# 模拟输入(多头注意力的输出)
batch_size = 2
seq_len = 4
mha_output = torch.randn(batch_size, seq_len, d_model) # 形状:[2, 4, 512]
# 实例化前馈层
ffn = PositionwiseFeedForward(d_model, d_ff, dropout, activation='gelu')
# 前向传播
ffn_output = ffn(mha_output)
print("前馈层输出:", ffn_output)
print("前馈层输出形状:", ffn_output.shape) # 输出:torch.Size([2, 4, 512])(与输入维度一致)
点击查看输出结果
前馈层输出: tensor([[[-0.1023, -0.2246, 0.3146, ..., 0.1513, -0.2808, -0.0758],
[ 0.0318, -0.1864, -0.0550, ..., 0.4687, 0.0369, -0.2586],
[ 0.1260, -0.3387, 0.0547, ..., -0.2381, 0.0716, -0.1506],
[ 0.2755, -0.3065, 0.8975, ..., -0.1790, -0.3509, -0.1467]],
[[ 0.0758, -0.1043, 0.2845, ..., 0.1418, -0.1975, -0.3258],
[ 0.0543, -0.1677, 0.1130, ..., -0.1800, -0.4668, 0.0468],
[-0.1685, -0.1065, 0.0339, ..., 0.2511, -0.2163, -0.1581],
[-0.0368, 0.1402, -0.2627, ..., -0.0809, 0.0194, -0.0407]]],
grad_fn=<ViewBackward0>)
前馈层输出形状: torch.Size([2, 4, 512])
2024升级版前馈全连接层代码
点击查看
class PositionwiseFeedForward(nn.Module):
"""
2024优化版前馈全连接层
特点:
- 使用GELU激活函数(GPT系列标准)
- 添加残差连接
- 支持动态维度扩展
"""
def __init__(self, d_model, d_ff=None, dropout=0.1):
super().__init__()
# 2024优化:动态计算中间维度(默认4倍d_model)
d_ff = d_ff or 4 * d_model
self.net = nn.Sequential(
# 第一层:扩展维度
nn.Linear(d_model, d_ff),
# 2024推荐:GELU激活函数(比ReLU更平滑)
nn.GELU(),
# 2024优化:高斯误差线性单元变体
# nn.SiLU(), # Swish激活函数的替代
# Dropout层防止过拟合
nn.Dropout(dropout),
# 第二层:压缩回原始维度
nn.Linear(d_ff, d_model)
)
# 2024新增:权重初始化(Xavier统一初始化)
self._init_weights()
def _init_weights(self):
"""2024最佳实践:分层权重初始化"""
for module in self.net:
if isinstance(module, nn.Linear):
# 第一层使用Kaiming初始化
if module is self.net[0]:
nn.init.kaiming_normal_(module.weight, nonlinearity='gelu')
# 第二层使用Xavier初始化
else:
nn.init.xavier_uniform_(module.weight)
# 偏置项初始化为零
nn.init.zeros_(module.bias)
def forward(self, x):
"""
输入:形状为[batch_size, seq_len, d_model]的张量
输出:相同形状的增强表示
"""
return self.net(x)
在深层神经网络中,随着层数增加,特征值可能会出现剧烈波动(如梯度爆炸 / 消失),导致训练困难。规范化层的作用就是通过标准化特征值,让每一层的输入保持稳定的分布,从而加速训练并提升模型稳定性。
它是所有深层网络模型都需要的标准网络层,因为随着网络层数的增加,通过多层的计算后参数可能开始出现过大或过小的情况,这样可能会导致学习过程出现异常,模型可能收敛非常的慢.因此都会在一定层数后接规范化层进行数值的规范化,使其特征数值在合理范围内。
深层网络训练时,每一层的输入特征分布会随着前一层的参数更新而不断变化。比如:
- 第 1 层参数更新后,输出的特征范围可能从「0-1」变成「100-200」;
- 第 2 层原本适应了「0-1」的输入,现在突然要处理「100-200」的输入,需要重新调整参数去适应新分布;
- 这种 “前层参数变→后层输入分布变→后层参数被迫重新适应” 的循环,会导致模型训练效率极低(收敛慢),甚至训练崩溃。
它通过将每一层的输入特征归一化到 “均值接近 0、方差接近 1” 的稳定分布(不同规范化层的归一化维度不同,如 LayerNorm 按 “特征维度” 归一化,BN 按 “批次维度” 归一化),强制让后层的输入分布始终保持在一个 “可控范围” 内。
就像给模型的每一层输入 “定了一个标准格式”,无论前层参数怎么变,后层拿到的输入都是 “尺度统一” 的,无需频繁调整适应,从而显著加速训练收敛。
Transformer 中使用的是LayerNorm,而非 CNN 中常用的 BatchNorm,两者核心区别如下:
| 特性 |
LayerNorm |
BatchNorm |
| 归一化维度 |
对单个样本的所有特征维度归一化 |
对批次中所有样本的同一特征维度归一化 |
| 适用场景 |
序列数据(如文本),样本长度可变 |
图像数据,样本格式固定 |
| 计算方式 |
每个样本独立计算均值和标准差 |
跨样本计算均值和标准差 |
在 NLP 任务中,句子长度可变且样本间差异大,LayerNorm 能更好地适应这种特性,因此成为 Transformer 的标配。
import torch
import torch.nn as nn
class LayerNorm(nn.Module):
def __init__(self, features, eps=1e-6):
"""
层规范化(LayerNorm)
:param features: 特征维度(通常为d_model,如512)
:param eps: 防止除零的小常数(默认1e-6)
"""
super().__init__()
# 可学习的缩放参数(初始为1)和偏移参数(初始为0)
# 作用:归一化后通过缩放和偏移恢复特征的表达能力
self.scale = nn.Parameter(torch.ones(features))
self.shift = nn.Parameter(torch.zeros(features))
self.eps = eps # 防止标准差为0
def forward(self, x):
"""
前向传播
:param x: 输入张量,形状为[batch_size, seq_len, d_model]
:return: 归一化后的张量,形状不变
"""
# 步骤1:计算最后一个维度(特征维度)的均值和标准差
mean = x.mean(dim=-1, keepdim=True) # 形状:[batch_size, seq_len, 1]
std = x.std(dim=-1, keepdim=True) # 形状:[batch_size, seq_len, 1]
# 步骤2:归一化公式:(x - 均值) / (标准差 + eps)
normalized = (x - mean) / (std + self.eps)
# 步骤3:缩放和偏移(可学习参数,恢复特征表达)
return self.scale * normalized + self.shift
-
可学习参数: scale和shift是可训练的参数,确保归一化后的数据不仅分布稳定,还能保留对任务有用的特征模式(若直接归一化可能破坏原有特征分布)。
-
数值稳定性: eps(如 1e-6)的加入是为了避免标准差接近 0 时的除零错误。
-
在 Transformer 中的位置: LayerNorm 通常用于每个子层(多头注意力、前馈层)的输入或输出,配合残差连接使用(详见下一节)。
近年来,LayerNorm 的变种逐渐流行,如:
- RMSNorm(Root Mean Square Layer Normalization):用均方根替代标准差,计算更高效(LLaMA、Mistral 等模型采用);
- AdaNorm:自适应调整归一化参数,适应不同任务需求。
这些变种在计算效率或性能上略有优势,但核心原理与 LayerNorm 一致,以下是 RMSNorm 的实现供参考:
class RMSNorm(nn.Module):
def __init__(self, features, eps=1e-6):
super().__init__()
self.scale = nn.Parameter(torch.ones(features))
self.eps = eps
def forward(self, x):
# 用均方根替代标准差:sqrt(mean(x^2) + eps)
rms = torch.sqrt(torch.mean(x **2, dim=-1, keepdim=True) + self.eps)
return self.scale * (x / rms) # 省去shift参数,进一步简化计算
Transformer 的编码器和解码器层由多个 "子层"(如多头注意力层、前馈层)组成,而子层连接结构是将这些子层串联起来的核心机制,它结合了残差连接(跳跃连接)和规范化层,是 Transformer 能够训练深层网络的关键。
子层连接的结构可概括为:
x:子层的输入(原始特征);LayerNorm(x):对输入进行规范化,稳定训练;Sublayer(...):子层本身(如多头注意力或前馈层);Dropout(...):随机失活,防止过拟合;- 残差连接
x + ...:将输入与子层输出相加,缓解梯度消失问题,让模型更容易训练深层网络。
import torch
import torch.nn as nn
class SublayerConnection(nn.Module):
def __init__(self, size, dropout=0.1, norm_type='layernorm'):
"""
子层连接结构
:param size: 特征维度(通常为d_model)
:param dropout: Dropout比率
:param norm_type: 规范化类型('layernorm'或'rmsnorm')
"""
super().__init__()
self.norm = LayerNorm(size) if norm_type == 'layernorm' else RMSNorm(size)
self.dropout = nn.Dropout(dropout)
def forward(self, x, sublayer):
"""
前向传播
:param x: 子层输入,形状为[batch_size, seq_len, d_model]
:param sublayer: 子层函数(如多头注意力层或前馈层)
:return: 子层连接的输出,形状与x一致
"""
# 步骤1:对输入x进行规范化
normalized_x = self.norm(x)
# 步骤2:将规范化结果传入子层处理
sublayer_output = sublayer(normalized_x)
# 步骤3:应用Dropout并与原始输入x相加(残差连接)
return x + self.dropout(sublayer_output)
1.残差连接的作用 : 没有残差连接时,深层网络的梯度需要逐层传递,容易衰减到接近零(梯度消失);而残差连接让梯度可以直接通过x传递到浅层,显著提升深层网络的可训练性。
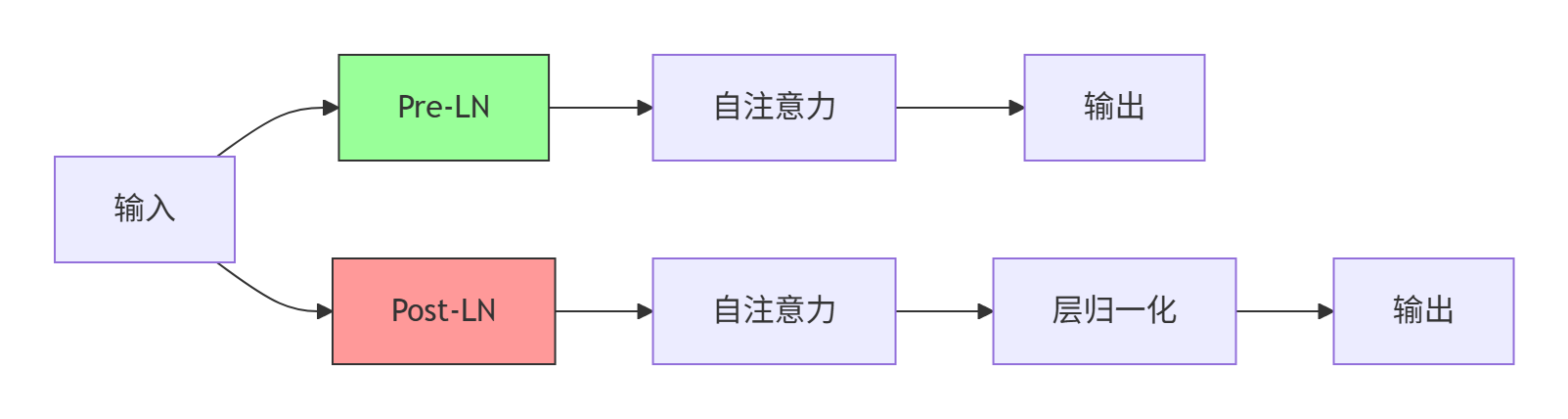
2.
规范化的位置 :
原论文的 Post-LN 结构完整流程是:
输入 x → 子层处理(sublayer (x)) → 残差连接(x + sublayer (x)) → LayerNorm 规范化
即最终公式是:LayerNorm(x + sublayer(x))
所以严格来说,“Post-LN 是残差连接后规范化” 的表述是准确的 —— 因为规范化操作发生在 “x 与子层输出相加(残差连接)” 之后。
而 “子层处理后规范化” 更像是一种中间描述,如果只说 “子层处理后”,容易忽略 “残差连接” 这个关键步骤(子层处理后先做残差连接,再规范化)。
对比当前主流的 Pre-LN 结构:
输入 x → LayerNorm 规范化 → 子层处理(sublayer (LayerNorm (x))) → 残差连接(x + sublayer (...))
公式是:x + sublayer(LayerNorm(x))
总结两者的核心区别:
- Post-LN:残差连接 后 做规范化(先加后归一)
- Pre-LN:残差连接 前 做规范化(先归一后加)
3.灵活性 : 子层连接通过sublayer参数接收任意子层函数(如多头注意力、前馈层),这种设计让编码器和解码器层的实现更简洁(只需重复调用子层连接)。
编码器层包含两个子层连接:第一个连接多头自注意力层,第二个连接前馈层,代码如下:
# 模拟输入(带位置编码的词向量)
batch_size = 2
seq_len = 4
d_model = 512
pe_result = torch.randn(batch_size, seq_len, d_model) # 形状:[2, 4, 512]
# 1. 第一个子层:多头自注意力
num_heads = 8
self_attn = MultiHeadedAttention(num_heads, d_model) # 多头注意力层(前章实现)
# 用lambda定义子层函数:输入x,输出自注意力结果(Q=K=V=x)
attn_sublayer = lambda x: self_attn(x, x, x, mask=None) # 暂不考虑掩码
# 子层连接
attn_connection = SublayerConnection(d_model)
attn_output = attn_connection(pe_result, attn_sublayer) # 形状:[2, 4, 512]
# 2. 第二个子层:前馈层
ffn = PositionwiseFeedForward(d_model) # 前馈层(本章实现)
ffn_sublayer = lambda x: ffn(x) # 定义前馈子层函数
# 子层连接
ffn_connection = SublayerConnection(d_model)
ffn_output = ffn_connection(attn_output, ffn_sublayer) # 形状:[2, 4, 512]
print("编码器层输出:", ffn_output)
print("编码器层输出形状:", ffn_output.shape) # 输出:torch.Size([2, 4, 512])
点击查看打印结果
编码器层输出: tensor([[[ 0.5040, -1.1048, -0.6658, ..., 1.2500, -0.8394, 2.2287],
[ 0.1338, -0.0819, -1.4475, ..., 0.8029, -0.5002, -1.2455],
[ 0.2607, -1.1603, -1.5474, ..., 0.2250, -1.0701, 1.4558],
[-0.0681, -1.3258, -0.8387, ..., -0.3794, 0.7279, -0.3790]],
[[-0.6451, -1.6476, -0.7499, ..., -0.7862, 0.2534, -0.0479],
[-0.0721, 0.2150, -0.3417, ..., -0.6309, -2.8268, 0.6490],
[-0.4486, 1.2411, 1.4920, ..., 0.3855, 0.6568, -0.3957],
[-1.8491, -0.3608, 0.9728, ..., -0.0090, 2.5996, 0.4969]]],
grad_fn=<AddBackward0>)
编码器层输出形状: torch.Size([2, 4, 512])
2024最佳方案:
class SublayerConnection(nn.Module):
"""
2024增强版子层连接
特点:
- Pre-LN结构(2024标准)
- 可配置的DropPath(随机深度)
- 自适应残差缩放
"""
def __init__(self, size, dropout, drop_path=0.0):
super().__init__()
# 层规范化
self.norm = LayerNorm(size)
# Dropout层
self.dropout = nn.Dropout(dropout)
# 2024新增:DropPath(随机深度)
self.drop_path = DropPath(drop_path) if drop_path > 0.0 else nn.Identity()
# 自适应残差缩放
self.res_scale = nn.Parameter(torch.ones(1))
def forward(self, x, sublayer):
"""
输入:
- x: 输入张量 [batch_size, seq_len, d_model]
- sublayer: 子层函数(如自注意力或前馈网络)
处理流程:
1. Pre-LN:先对输入进行层规范化
2. 应用子层函数
3. Dropout和DropPath
4. 残差连接(可缩放)
"""
# Pre-LN结构(2024标准)
normalized = self.norm(x)
# 应用子层函数(注意力或FFN)
sublayer_output = sublayer(normalized)
# 应用Dropout和DropPath(训练时随机跳过某些子层)
dropped = self.drop_path(self.dropout(sublayer_output))
# 残差连接(可缩放)
return x + self.res_scale * dropped
2024创新技术:
-
DropPath(随机深度):
-
训练时随机跳过某些子层
-
效果:相当于隐式模型集成,提升泛化能力
-
公式: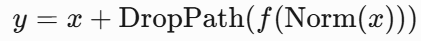
-
自适应残差缩放:
输入规范化"Pre-LN"(层规范化在前):
Pre-LN vs Post-LN结构对比:
本章介绍的三个组件是 Transformer 架构的 "粘合剂",它们的核心作用是:
| 组件 |
核心作用 |
技术演进(2021-2025) |
| 前馈全连接层 |
引入非线性变换,增强拟合能力 |
从 ReLU 转向 GELU;中间层维度动态调整(如根据任务设置 d_ff=4*d_model) |
| 规范化层 |
稳定训练,防止梯度问题 |
从 LayerNorm 到 RMSNorm,简化计算并提升效率 |
| 子层连接结构 |
结合残差连接与子层,支持深层训练 |
自适应 dropout 率(如根据层深调整);更灵活的子层组合(如加入卷积层) |
这些组件虽然简单,但它们的组合让 Transformer 在保持模型能力的同时,能够稳定训练到数十甚至数千层,为后续的大模型(如 GPT-4、LLaMA)奠定了基础。
下一章将讲解编码器层和解码器层的完整实现,这些层正是由本章介绍的子层连接结构堆叠而成。
第五章:Transformer 编码器与解码器的实现
一、编码器层(Encoder Layer)
编码器层是 Transformer 编码器的基本组成单元,它通过多层堆叠,逐步对输入序列进行特征提取和抽象。每个编码器层包含两个主要子模块:多头自注意力(Multi-Head Self-Attention)和前馈全连接层(Position-wise Feed-Forward Networks),并且在每个子模块后都应用了子层连接结构(结合残差连接和层规范化)来稳定训练过程。
1.1 结构与原理
以一层编码器为例,其处理流程如下:
- 输入嵌入与位置编码:输入的 token 序列首先经过词嵌入层,将每个 token 映射为固定维度的向量(如 512 维),然后加上位置编码,使模型能够感知序列中的位置信息。这部分在前面输入处理章节已详细介绍。
- 多头自注意力:将嵌入与位置编码后的输入作为多头自注意力的输入,此时 Q=K=V 均为输入序列本身。通过多头自注意力机制,每个 token 能够动态地关注序列中的其他所有 token,从而捕捉到全局语义信息。不同的头可以关注到不同子空间的依赖关系,增强模型的表达能力。
- 子层连接 1:多头自注意力的输出先进行层规范化(LayerNorm),以防止训练过程中的梯度消失,保持信息流动的稳定,并使激活值分布统一,加快收敛速度。再通过子层计算(如多头注意力或前馈网络),最后执行残差连接(与输入相加)。
- 前馈全连接层:子层连接 1 的输出进入前馈全连接层,这是一个两层的全连接网络(MLP),对每个位置上的 token 单独进行处理。虽然是点对点操作,但它为模型提供了非线性特征转换能力,进一步提升模型的表达和抽象能力。
- 子层连接 2:前馈全连接层的输出同样经过层规范化和残差连接,得到最终的编码器层输出。这个输出将作为下一层编码器的输入。
1.2 实现代码(含 2021 - 2025 优化)
在实际实现中,我们可以使用 PyTorch 框架来构建编码器层。以下是一个完整的编码器层实现,包括对一些最新优化的支持(如使用 FlashAttention 加速多头自注意力计算):
说明:
下面代码中引用的这些模块(SublayerConnection, MultiHeadedAttention, PositionwiseFeedForward)不是 PyTorch 自带的,它们是 Transformer 模型的自定义组件,通常需要您自己实现(例如上面我们的实现方式)或从第三方库中导入。
-
学习目的:建议手动实现这些模块,深入理解 Transformer 细节。
-
生产环境:直接使用 HuggingFace 的 TransformerEncoderLayer,避免重复造轮子。
import torch.nn as nn
# 子层连接:LayerNorm + 残差
# import SublayerConnection
# # 多头注意力
# import MultiHeadedAttention
# # 前馈网络
# import PositionwiseFeedForward
class EncoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff=2048, dropout=0.1, use_flash=False):
super().__init__()
# 多头自注意力层
self.self_attn = MultiHeadedAttention(num_heads, d_model, use_flash=use_flash)
# 前馈全连接层
self.ffn = PositionwiseFeedForward(d_model, d_ff, dropout)
# 两个子层连接结构
self.sublayer1 = SublayerConnection(d_model, dropout)
self.sublayer2 = SublayerConnection(d_model, dropout)
def forward(self, x, mask=None):
# 子层1:LayerNorm +多头自注意力 + 残差连接
x = self.sublayer1(x, lambda x: self.self_attn(x, x, x, mask))
# 子层2:LayerNorm + 前馈全连接层 + 残差连接
x = self.sublayer2(x, self.ffn)
return x
1.3 关键细节解析
- 多层堆叠:通常,Transformer 编码器由 6 层或更多层编码器层堆叠而成(如 BERT-base 使用 12 层,BERT-large 使用 24 层)。通过多层堆叠,模型能够逐层提炼更高级的抽象特征,捕捉序列中更复杂的语义和结构信息。
- 与其他组件的协同:编码器层依赖于前面介绍的多个组件,如多头自注意力机制中的缩放点积注意力、前馈全连接层中的 GELU 激活函数以及子层连接结构中的LayerNorm和 残差连接。这些组件相互配合,共同提升编码器层的性能。
- 优化与效率:在 2021 - 2025 期间,为了提高编码器层在处理长序列时的效率,出现了一些优化技术。例如,使用 FlashAttention 可以显著减少多头自注意力计算中的内存访问次数,提升计算速度,尤其在处理长序列(如超过 1000 个 token)时效果明显。此外,一些研究还探索了如何动态调整前馈全连接层的中间层维度(如根据输入序列的复杂度动态设置 d_ff),以在保持模型性能的同时降低计算成本。
点击查看调用示例
# 实例化参数(文档示例)
size = 512 # 特征维度(与d_model一致)
head = 8 # 注意力头数
d_model = 512 # 模型维度
d_ff = 64 # 前馈层中间维度(文档示例,实际常用2048)
dropout = 0.2 # dropout比率
# 实例化子层组件
ff = PositionwiseFeedForward(d_model, d_ff, dropout) # 前馈层
mask = torch.zeros(8, 4, 4) # 掩码张量(示例形状)
# 实例化编码器层并计算
el = EncoderLayer(size, head, d_ff, dropout)
el_result = el(pe_result, mask) # pe_result为带位置编码的输入
print("编码器层输出形状:", el_result.shape) # torch.Size([2, 4, 512])
二、编码器(Transformer Encoder)
编码器由多个编码器层堆叠而成,它的主要作用是将输入序列转换为一个包含丰富上下文信息的向量表示,为后续的解码器或下游任务(如文本分类、问答系统等)提供高质量的特征输入。
2.1 结构与原理
Transformer 编码器的整体结构如下:
- 输入处理:输入的 token 序列首先经过输入嵌入层(将 token 映射为向量)和位置编码层(添加位置信息),得到初始的输入表示。
- 多层编码器层:将输入表示依次通过多个编码器层进行处理。每一层编码器都对输入进行一次特征提取和抽象,通过多头自注意力捕捉全局依赖关系,前馈全连接层增强非线性表达能力,子层连接结构稳定训练过程。随着层数的增加,输出的特征表示逐渐包含更高级、更抽象的语义信息。
- 最终输出:经过所有编码器层处理后,得到的输出是一个形状为(batch_size, seq_len, d_model)的张量。其中,batch_size是批次大小,seq_len是序列长度,d_model是模型维度(如 512)。这个输出张量中的每个元素都表示输入序列中对应位置 token 的 “上下文增强” 向量表示,它融合了整个输入序列的信息。
2.2 实现代码
基于前面实现的编码器层,我们可以轻松构建 Transformer 编码器:
说明:
下面代码中引用的这些模块( InputEmbedding 和 EncoderLayer )都是需要自己实现的类。
# # 词嵌入
# import Embedding
# # 位置编码
# import EncoderLayer
class TransformerEncoder(nn.Module):
def __init__(self, vocab_size, d_model, num_heads, num_layers, d_ff=2048, dropout=0.1, use_flash=False):
super().__init__()
# 输入嵌入与位置编码层
self.embedding = Embedding(vocab_size, d_model)
# 多个编码器层
self.layers = nn.ModuleList([
EncoderLayer(d_model, num_heads, d_ff, dropout, use_flash) for _ in range(num_layers)
])
def forward(self, x, mask=None):
# 输入嵌入与位置编码
x = self.embedding(x)
# 依次通过多个编码器层
for layer in self.layers:
x = layer(x, mask)
return x
2.3 关键细节解析
- 超参数调整:在实际应用中,需要根据任务的特点和数据规模来调整编码器的超参数。例如,对于长文本任务,可以适当增加编码器层数(num_layers)以捕捉更丰富的上下文信息,但同时要注意计算资源的消耗和过拟合问题。增加头数(num_heads)可以让模型学习到更多不同维度的特征,但也会增加计算量。调整前馈全连接层的中间层维度(d_ff)可以影响模型的非线性表达能力,一般建议根据模型维度(d_model)进行合理设置(如 d_ff = 4 * d_model)。
- 应用场景:Transformer 编码器在许多 NLP 任务中都有广泛应用。在文本分类任务中,编码器可以将输入文本转换为固定长度的向量表示,然后通过一个全连接层进行分类预测。在问答系统中,编码器可以对问题和上下文进行编码,为后续的答案提取或生成提供基础。在预训练模型(如 BERT、GPT 等)中,编码器是核心组件之一,通过大规模无监督数据的预训练,学习到通用的语言表示,然后可以在各种下游任务中进行微调。
- 最新研究方向:近年来,针对 Transformer 编码器在处理长序列时的效率和内存问题,有许多研究工作。一些新的架构(如 Longformer、Performer 等)提出了基于稀疏注意力或线性注意力的方法,以降低计算复杂度,使编码器能够处理更长的序列(如数千甚至数万个 token)。此外,还有研究探索如何将卷积神经网络(CNN)的局部特征提取能力与 Transformer 编码器的全局建模能力相结合,以提升模型在某些特定任务(如图像字幕生成、语音识别等)中的性能。
点击查看测试代码
# 1. 生成模拟的整数词索引输入(正确)
batch_size = 2
seq_len = 4
vocab_size = 10000 # 假设词表大小为10000
input_ids = torch.randint(0, vocab_size, (batch_size, seq_len)) # 生成随机词索引
# 2. 实例化编码器
encoder = TransformerEncoder(
vocab_size=vocab_size,
d_model=512,
num_heads=8,
num_layers=6,
d_ff=2048,
dropout=0.1
)
# 3. 运行编码器(传入整数型词索引)
mask = None # 无掩码
encoder_output = encoder(input_ids, mask)
print("编码器输出形状",encoder_output.shape) # 应输出: torch.Size([2, 4, 512])
三、解码器层(Decoder Layer)
解码器层是 Transformer 解码器的核心组成部分,与编码器层类似,它也包含多个子模块,但在功能和结构上有一些关键区别。解码器层主要负责根据编码器的输出以及之前生成的部分输出,逐步生成完整的目标序列。
3.1 结构与原理
每个解码器层包含三个主要子模块:
- 多头自注意力(Masked Multi-Head Self-Attention):与编码器中的多头自注意力不同,解码器中的自注意力需要使用掩码(mask)来确保在生成当前位置的输出时,模型只能关注到之前已经生成的位置,而不能看到未来的信息。这是为了保证生成过程的因果性,符合人类语言生成的逻辑。例如,在生成句子时,模型在生成第 3 个词时,只能使用第 1 和第 2 个词的信息,不能使用第 4、5 个词等未来信息。
- 编码器 - 解码器注意力(Encoder - Decoder Attention):这是解码器特有的一个子模块,它允许解码器关注编码器的输出。在计算时,查询(Query)来自解码器的上一层输出,键(Key)和值(Value)来自编码器的最终输出。通过这种方式,解码器可以利用编码器提取的输入序列的上下文信息来指导目标序列的生成。
- 前馈全连接层(Position-wise Feed-Forward Networks):与编码器中的前馈全连接层相同,对每个位置的输入进行非线性变换,提升模型的表达能力。
在每个子模块后,同样使用子层连接结构(层规范化和残差连接)来稳定训练过程。
3.2 实现代码
以下是使用 PyTorch 实现的解码器层代码:
说明:
下面代码中引用的这些模块(SublayerConnection, MultiHeadedAttention, PositionwiseFeedForward)不是 PyTorch 自带的,它们是 Transformer 模型的自定义组件,通常需要您自己实现(例如上面我们的实现方式)或从第三方库中导入。
# 子层连接:LayerNorm + 残差
# import SublayerConnection
# # 多头注意力
# import MultiHeadedAttention
# # 前馈网络
# import PositionwiseFeedForward
class DecoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff=2048, dropout=0.1, use_flash=False):
super().__init__()
# 掩码多头自注意力层(Q=K=V)
self.self_attn = MultiHeadedAttention(num_heads, d_model, use_flash=use_flash)
# 编码器 - 解码器注意力层(Q!=K=V)
self.enc_dec_attn = MultiHeadedAttention(num_heads, d_model, use_flash=use_flash)
# 前馈全连接层
self.ffn = PositionwiseFeedForward(d_model, d_ff, dropout)
# 三个子层连接结构
self.sublayer1 = SublayerConnection(d_model, dropout)
self.sublayer2 = SublayerConnection(d_model, dropout)
self.sublayer3 = SublayerConnection(d_model, dropout)
def forward(self, x, memory, src_mask, tgt_mask):
"""forward函数中的参数有4个,分别是来自上一层的输入X,来自编码器层的语义存储变量mermory,以及源数据掩码张量和目标数据掩码张量"""
# 子层1:LayerNorm + 掩码多头自注意力 + 残差连接
# 将x传入第一个子层结构,第一个子层结构的输入分别是x和se1f-attn函数,因为是自注意力机制,所以Q,K,V都是x;
# tgt_mask是目标数据掩码张量,这时要对目标数据进行遮掩,因为此时模型可能还没有生成任何目标数据,比如在解码器准备生成第一个字符或词汇时,我们其实已经传入了第一个字符以便计算损失,但是我们不希望在生成第一个字符时模型能利用这个信息,因此我们会将其遮掩;同样生成第二个字符或词汇时,模型只能使用第一个字符或词汇信息,第二个字符以及之后的信息都不允许被模型使用。
x = self.sublayer1(x, lambda x: self.self_attn(x, x, x, tgt_mask))
# 子层2:编码器 - LayerNorm + 解码器注意力 + 残差连接
#这个子层中使用常规的注意力机制,q是输入x;
# k,v是编码层输出memory;
# source_mask,但是进行源数据遮掩的原因并非是抑制信息泄漏,而是遮蔽掉对结果没有意义的字符而产生的注意力值,以此提升模型效果和训练速度。
x = self.sublayer2(x, lambda x: self.enc_dec_attn(x, memory, memory, src_mask))
# 子层3:前馈全连接层 + 残差连接 + LayerNorm
x = self.sublayer3(x, self.ffn)
return x
3.3 关键细节解析
- 掩码的应用:在掩码多头自注意力中,掩码的使用至关重要。掩码通常是一个上三角矩阵,在生成当前位置的输出时,将未来位置的注意力权重设为 0,从而防止模型 “偷看” 未来信息。例如,对于一个长度为 5 的序列,掩码矩阵在生成第 3 个位置的输出时,会将第 4 和第 5 个位置对应的注意力权重设为 0。
- 与编码器的交互:编码器 - 解码器注意力是解码器与编码器进行信息交互的关键。通过这种机制,解码器可以在生成目标序列时,充分利用编码器提取的输入序列的全局上下文信息。在实际应用中,例如在机器翻译任务中,编码器将源语言句子编码为上下文向量,解码器通过编码器 - 解码器注意力关注这些上下文向量,从而生成目标语言句子。
- 训练与推理的差异:在训练时,解码器通常会一次性接收完整的目标序列(教师强制),并计算生成结果与真实目标之间的损失。而在推理时,解码器需要逐个生成目标序列的元素,每次生成一个元素后,将其作为下一次生成的输入,直到生成结束标记(如<EOS>)。这种训练和推理方式的差异需要在实现中进行特殊处理,例如在推理时需要动态更新掩码以确保生成的因果性。
- 最新技术进展:在 2021 - 2025 期间,针对解码器层的优化也有不少研究。一些工作提出了改进的注意力机制,如动态调整注意力头的权重,使模型能够更自适应地关注不同的信息。还有研究探索在解码器中使用强化学习的方法,以提高生成序列的质量和多样性,尤其在文本生成任务中取得了一定的效果。
点击查看测试代码
# 实例化参数
head = 8 # 注意力头数
d_model = 512 # 模型维度
d_ff = 64 # 前馈层中间维度(文档示例,实际常用2048)
dropout = 0.2 # dropout比率
x = pe_result # 目标序列嵌入(与输入部分格式一致)
memory = el_result # 编码器输出
source_mask = target_mask = mask # 掩码(实际场景中通常不同)
# 实例化解码器层并计算
dl = DecoderLayer(d_model, head, d_ff, dropout)#d_model, num_heads, d_ff=2048, dropout=0.1, use_flash=False
dl_result = dl(x, memory, source_mask, target_mask)
print("解码器层输出形状:", dl_result.shape) # torch.Size([2, 4, 512])
四、解码器(Transformer Decoder)
Transformer 解码器由多个解码器层堆叠而成,它的主要任务是根据编码器的输出和已生成的部分目标序列,逐步生成完整的目标序列。在许多应用中,如机器翻译、文本摘要、语言生成等,解码器都起着关键作用。
4.1 结构与原理
Transformer 解码器的整体结构如下:
- 输入处理:与编码器类似,解码器的输入也需要进行嵌入和位置编码。但解码器的输入是已生成的部分目标序列(在训练时为真实目标序列的前 n 个元素,在推理时为上一步生成的元素)。
- 多层解码器层:将输入表示依次通过多个解码器层进行处理。每个解码器层通过掩码多头自注意力捕捉已生成序列的内部依赖关系,通过编码器 - 解码器注意力利用编码器的输出信息,前馈全连接层增强非线性表达能力,子层连接结构稳定训练过程。随着层数的增加,输出的特征表示逐渐包含更适合生成目标序列的信息。
- 输出层:经过所有解码器层处理后,输出层通常是一个线性层,将解码器的输出映射到目标词汇表的大小,然后通过 softmax 函数得到每个词在目标词汇表中的概率分布,从而预测下一个词。
4.2 实现代码
基于前面实现的解码器层,我们可以构建 Transformer 解码器:
# import Embedding
#
# import DecoderLayer
class TransformerDecoder(nn.Module):
def __init__(self, vocab_size, d_model, num_heads, num_layers, d_ff=2048, dropout=0.1, use_flash=False):
super().__init__()
# 输入嵌入与位置编码层
self.embedding = Embedding(vocab_size, d_model)
# 多个解码器层
self.layers = nn.ModuleList([
DecoderLayer(d_model, num_heads, d_ff, dropout, use_flash) for _ in range(num_layers)
])
# 输出线性层
self.output_layer = nn.Linear(d_model, vocab_size)
def forward(self, x, memory, src_mask, tgt_mask):
# 输入嵌入与位置编码
x = self.embedding(x)
# 依次通过多个解码器层
for layer in self.layers:
x = layer(x, memory, src_mask, tgt_mask)
# 输出层
output = self.output_layer(x)
return output
4.3 关键细节解析
- 生成过程:在推理阶段,解码器的生成过程是一个迭代的过程。首先,输入一个起始标记(如<SOS>),然后通过解码器生成第一个词的概率分布,选择概率最高的词作为输出。接着,将这个输出词与起始标记组成新的输入序列,再次输入解码器生成下一个词的概率分布,如此循环,直到生成结束标记(如<EOS>)。这种自回归的生成方式使得 Transformer 解码器能够灵活地生成各种长度的序列。
- 与编码器的协同:解码器与编码器紧密协作。编码器将输入序列编码为上下文向量,解码器通过编码器 - 解码器注意力机制利用这些上下文向量来指导目标生成。
点击查看测试代码
# 生成模拟的整数词索引输入(正确方式)
batch_size = 2
seq_len = 4
vocab_size = 512 # 词表大小
input_ids = torch.randint(0, vocab_size, (batch_size, seq_len)) # 形状:[2, 4]
# 实例化解码器
decoder = TransformerDecoder(
vocab_size=vocab_size,
d_model=512,
num_heads=8,
num_layers=6,
d_ff=2048,
dropout=0.1
)
# 模拟编码器输出(memory)
memory = torch.randn(batch_size, seq_len, 512) # 形状:[2, 4, 512]
# 运行解码器(传入整数型词索引)
src_mask = tgt_mask = None # 无掩码
output = decoder(input_ids, memory, src_mask, tgt_mask)
print("解码器输出形状:",output.shape) # 应输出: torch.Size([2, 4, 512])
输出部分包含:
- 线性层
- 通过对上一步的线性变化得到指定维度的输出,也就是转换维度的作用
- softmax层
- 使最后一维的向量中的数字缩放到0-1的概率值域内,并满足他们的和为1
输出部分是 Transformer 的 “预测头”,核心功能是将解码器输出的特征向量转换为词表上的概率分布,从而预测下一个词的概率。
import torch.nn.functional as F
class Generator(nn.Module):
def __init__(self, d_model, vocab_size):
"""
初始化输出生成器
:param d_model: 解码器输出维度(与编码器/解码器一致)
:param vocab_size: 目标词表大小
"""
super().__init__()
# 线性层:将d_model维度映射到词表大小
self.project = nn.Linear(d_model, vocab_size)
def forward(self, x):
"""
前向传播:特征向量→概率分布
:param x: 解码器输出,形状[batch_size, tgt_len, d_model]
:return: 词表概率分布(log_softmax),形状[batch_size, tgt_len, vocab_size]
"""
# 线性变换→log_softmax(数值稳定,便于计算交叉熵损失)
return F.log_softmax(self.project(x), dim=-1)
# 实例化参数(文档示例)
d_model = 512 # 模型维度
vocab_size = 1000 # 词表大小
x = output # 解码器输出
# 实例化生成器并计算
gen = Generator(d_model, vocab_size)
gen_result = gen(x)
print("输出概率分布形状:", gen_result.shape) # torch.Size([2, 4, 1000])
输出解析:生成器将解码器输出的 [2,4,512] 特征转换为 [2,4,1000] 的概率分布(经 log_softmax 处理)。每个位置的 1000 个数值对应词表中每个词的对数概率,后续可通过torch.argmax取概率最高的词作为预测结果。
- 编码器流程:输入嵌入→位置编码→N 个编码器层(自注意力 + 前馈)→规范化→输出上下文特征(memory);
- 解码器流程:目标嵌入→位置编码→N 个解码器层(掩码自注意力 + 编码器 - 解码器注意力 + 前馈)→规范化→输出目标特征;
- 输出流程:目标特征→线性层→log_softmax→词表概率分布。
这一完整流程实现了从输入序列到输出序列的端到端转换,是机器翻译、文本生成等任务的核心框架。下一章将基于这些组件构建完整的 Transformer 模型,并进行测试运行。
经过前面的学习,我们已经掌握了 Transformer 的所有核心组件。本章将把这些组件整合为完整的模型,并通过一个简单的copy任务验证模型的功能。这个过程将帮助你理解 Transformer 的端到端工作流程,为后续实际应用打下基础。
Transformer 的核心是编码器 - 解码器结构,它将前面实现的编码器、解码器、嵌入层和输出层有机结合。具体结构如下:
# import torch
# import torch.nn as nn
# from encoder import TransformerEncoder # 编码器
# from decoder import TransformerDecoder # 解码器
# from generator import Generator # 输出层
class EncoderDecoder(nn.Module):
def __init__(self, encoder, decoder, src_embed, tgt_embed, generator):
"""
整合编码器-解码器架构
:param encoder: 编码器实例
:param decoder: 解码器实例
:param src_embed: 源序列嵌入层(含位置编码)
:param tgt_embed: 目标序列嵌入层(含位置编码)
:param generator: 输出层(线性变换+softmax)
"""
super().__init__()
self.encoder = encoder # 编码器
self.decoder = decoder # 解码器
self.src_embed = src_embed # 源序列嵌入(词嵌入+位置编码)
self.tgt_embed = tgt_embed # 目标序列嵌入(词嵌入+位置编码)
self.generator = generator # 输出层
def forward(self, src, tgt, src_mask, tgt_mask):
"""
前向传播:完整的编码-解码流程
:param src: 源序列,形状[batch_size, src_len]
:param tgt: 目标序列,形状[batch_size, tgt_len]
:param src_mask: 源序列掩码,形状[batch_size, 1, 1, src_len]
:param tgt_mask: 目标序列掩码,形状[batch_size, 1, tgt_len, tgt_len]
:return: 解码器输出经生成器处理后的概率分布
"""
# 先编码,再解码,最后通过生成器输出
return self.decode(self.encode(src, src_mask), src_mask, tgt, tgt_mask)
def encode(self, src, src_mask):
"""
编码过程
:param src: 源序列
:param src_mask: 源序列掩码
:return: 编码器输出(memory)
"""
# 源序列嵌入 -> 编码器
return self.encoder(self.src_embed(src), src_mask)
def decode(self, memory, src_mask, tgt, tgt_mask):
"""
解码过程
:param memory: 编码器输出
:param src_mask: 源序列掩码
:param tgt: 目标序列
:param tgt_mask: 目标序列掩码
:return: 解码器输出经生成器处理后的概率分布
"""
# 目标序列嵌入 -> 解码器 -> 生成器
return self.generator(self.decoder(self.tgt_embed(tgt), memory, src_mask, tgt_mask))
EncoderDecoder类是 Transformer 的 “外壳”,它将编码器、解码器、嵌入层和生成器串联起来,实现从输入到输出的完整流程;forward方法是核心,先调用encode得到源序列的编码结果(memory),再调用decode基于memory和目标序列生成输出;encode和decode方法分别封装了编码和解码的细节,使代码结构更清晰。
为了方便创建 Transformer 模型,我们实现一个make_model函数,自动实例化所有组件:
import copy
# from embedding import Embedding # 输入嵌入(词嵌入+位置编码)
# from multi_head_attention import MultiHeadedAttention
# from positionwise_feed_forward import PositionwiseFeedForward
# from encoder_layer import EncoderLayer
# from decoder_layer import DecoderLayer
def make_model(
source_vocab, # 源序列词表大小
target_vocab, # 目标序列词表大小
num_layers=6, # 编码器/解码器层数(原论文默认6层)
d_model=512, # 模型维度
d_ff=2048, # 前馈网络中间层维度
num_heads=8, # 注意力头数
dropout=0.1 # Dropout比率
):
"""创建完整的Transformer模型"""
# 深拷贝工具(确保组件参数独立)
c = copy.deepcopy
# 1. 实例化基础组件
attn = MultiHeadedAttention(num_heads, d_model) # 多头注意力
ff = PositionwiseFeedForward(d_model, d_ff, dropout) # 前馈网络
position = RotaryPositionalEncoding(d_model) # 位置编码(2024主流方案:旋转位置编码(RoPE))
# 2. 实例化编码器d_model, num_heads, d_ff=2048, dropout=0.1, use_flash=False
encoder_layer = EncoderLayer(d_model, num_heads, d_ff, dropout) # 编码器层
encoder = TransformerEncoder(source_vocab, d_model, num_heads, num_layers, d_ff) # 堆叠N层编码器
# 3. 实例化解码器
decoder_layer = DecoderLayer(d_model, num_heads, d_ff, dropout) # 解码器层
decoder = TransformerDecoder(target_vocab, d_model, num_heads, num_layers, d_ff) # 堆叠N层解码器
# 4. 实例化嵌入层(词嵌入+位置编码)
src_embed = nn.Sequential(
Embedding(source_vocab, d_model), # 词嵌入
c(position) # 位置编码
)
tgt_embed = nn.Sequential(
Embedding(target_vocab, d_model), # 词嵌入
c(position) # 位置编码
)
# 5. 实例化输出层
generator = Generator(d_model, target_vocab) # 线性变换+softmax
# 6. 整合为EncoderDecoder模型
model = EncoderDecoder(encoder, decoder, src_embed, tgt_embed, generator)
# 7. 初始化参数(使用Xavier均匀分布,加速训练收敛)
#模型结构完成后,接下来就是初始化模型中的参数,比如线性层中的变换矩阵
#这里一但判断参数的维度大于1,则会将其初始化成一个服从均匀分布的矩阵,
for p in model.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
return model
make_model函数是创建 Transformer 的 “一站式服务”,只需指定词表大小、层数等超参数,即可生成完整模型;- 组件实例化时使用
copy.deepcopy确保每个层的参数独立,避免共享参数导致的训练问题;
- 参数初始化采用
Xavier均匀分布,这是 Transformer 等深层网络常用的初始化方法,可有效避免梯度消失 / 爆炸。
创建一个简单模型,查看其结构是否符合预期:
# 超参数设置
source_vocab = 11 # 源词表大小(0-10共11个数字)
target_vocab = 11 # 目标词表大小(与源相同,copy任务)
num_layers = 2 # 简化模型,使用2层编码器/解码器
# 创建模型
model = make_model(source_vocab, target_vocab, num_layers=num_layers)
print(model) # 打印模型结构
输出效果(简化版):
EncoderDecoder(
(encoder): TransformerEncoder(...) # 编码器
(decoder): TransformerDecoder(...) # 解码器
(src_embed): Sequential(...) # 源序列嵌入
(tgt_embed): Sequential(...) # 目标序列嵌入
(generator): Generator(...) # 输出层
)
模型结构与预期一致,接下来通过copy任务验证其功能。
copy任务是验证序列模型功能的经典任务,目标是让模型学会输出与输入完全相同的序列(如输入[1,3,2,5],输出也为[1,3,2,5])。
为什么选择 copy 任务?
- 任务逻辑简单,模型应能快速学会,适合验证模型基本功能;
- 能有效检测注意力机制是否正常工作(模型需关注输入序列的每个位置);
- 可快速发现代码中的问题(如掩码错误、组件连接错误等)。
生成用于训练和测试的随机序列数据:
from torch.autograd import Variable
import numpy as np
def subsequent_mask(size):
"""
生成后续掩码(仅用于解码器)
:param size: 序列长度
:return: 后续掩码,形状为[1, size, size]
"""
# 生成上三角矩阵(值为1),然后反转得到下三角矩阵(值为1表示可关注)
mask = np.triu(np.ones((size, size)), k=1).astype('uint8') # k=1表示上三角偏移1
return torch.from_numpy(1 - mask).unsqueeze(0) # 反转并扩展维度:[1, size, size]
class Batch:
"""批次数据类,生成掩码张量"""
def __init__(self, src, tgt=None, pad=0):
self.src = src.long() # 确保 src 是 LongTensor
self.src_mask = (self.src != pad).unsqueeze(-2) # 源掩码(过滤填充)
if tgt is not None:
self.tgt = tgt[:, :-1].long() # 目标输入(不含最后一个token)
self.tgt_y = tgt[:, 1:].long() # 目标输出(不含第一个token,用于计算损失)
self.tgt_mask = self.make_std_mask(self.tgt, pad) # 目标掩码
self.ntokens = (self.tgt_y != pad).data.sum() # 有效token数量
@staticmethod
def make_std_mask(tgt, pad):
"""生成目标序列掩码(过滤填充+未来位置)"""
tgt_mask = (tgt != pad).unsqueeze(-2) # 填充掩码
tgt_mask = tgt_mask & Variable(
subsequent_mask(tgt.size(-1)).type_as(tgt_mask.data) # 后续掩码
)
return tgt_mask
def data_generator(V, batch_size, num_batches):
"""
生成copy任务数据集
:param V: 词汇表大小(生成1~V-1的随机数)
:param batch_size: 批次大小
:param num_batches: 批次数量
:return: 生成器,每次返回一个Batch对象
"""
for _ in range(num_batches):
data = torch.randint(1, V, size=(batch_size, 10)) # 直接生成 LongTensor
data[:, 0] = 1 # 第一列固定为1(起始标志<SOS>)
# 源序列和目标序列相同(copy任务)
src = data.clone()
tgt = data.clone()
yield Batch(src, tgt, pad=0)# 返回批次数据(含掩码)
调用测试:
#将生成0-10的整数
V= 11
# 每次喂给模型20个数据进行参数更新
batch =20
#连续喂30次完成全部数据的遍历,也就是1轮
num_batch=30
res=data_generator(V, batch, num_batch)
print(res)#返回数据生成器对象<generator object data_generator at 0x00000284178D8820>
import torch.optim as optim
from torch.nn import CrossEntropyLoss
class LabelSmoothing(nn.Module):
"""标签平滑:防止模型过度自信,减少过拟合"""
def __init__(self, size, padding_idx, smoothing=0.0):
super().__init__()
self.criterion = CrossEntropyLoss(reduction='sum')
self.padding_idx = padding_idx
self.smoothing = smoothing
self.size = size
self.true_dist = None
def forward(self, x, target):
"""
:param x: 模型输出logits,形状[batch_size, seq_len, vocab_size]
:param target: 真实标签,形状[batch_size, seq_len]
:return: 平滑后的损失
"""
batch_size, seq_len = target.size()
# 初始化平滑分布
true_dist = x.data.clone().zero_()
true_dist.fill_(self.smoothing / (self.size - 2)) # 均匀分布填充
true_dist.scatter_(2, target.unsqueeze(2), 1.0 - self.smoothing) # 真实标签位置增强
true_dist[:, :, self.padding_idx] = 0 # 填充位置损失为0
mask = torch.nonzero(target.data == self.padding_idx)
if mask.dim() > 0:
true_dist.index_fill_(0, mask.squeeze(), 0.0)
self.true_dist = true_dist
return self.criterion(x, Variable(true_dist, requires_grad=False))
class SimpleLossCompute:
"""损失计算与参数优化"""
def __init__(self, generator, criterion, optimizer):
self.generator = generator # 输出层
self.criterion = criterion # 损失函数(含标签平滑)
self.optimizer = optimizer # 优化器
def __call__(self, x, y, norm):
"""
:param x: 解码器输出,形状[batch_size, seq_len, d_model]
:param y: 目标输出(tgt_y),形状[batch_size, seq_len]
:param norm: 有效token数量的倒数(用于归一化损失)
:return: 损失值
"""
x = self.generator(x) # 解码器输出 -> 词表概率分布
loss = self.criterion(x.contiguous().view(-1, x.size(-1)), y.contiguous().view(-1))
loss = loss / norm # 归一化损失
loss.backward() # 反向传播
if self.optimizer is not None:
self.optimizer.step() # 更新参数
self.optimizer.zero_grad() # 清零梯度
return loss.item() * norm # 返回总损失
# 1. 超参数
V = 11 # 词表大小(0-10)
batch_size = 20 # 批次大小
num_batches = 30 # 每轮训练的批次数量
epochs = 10 # 训练轮数
# 2. 创建模型
model = make_model(V, V, num_layers=2) # 2层编码器/解码器
# 3. 优化器(Adam,原论文参数)
optimizer = optim.Adam(model.parameters(), lr=0.0001, betas=(0.9, 0.98), eps=1e-9)
# 4. 损失函数(含标签平滑)
criterion = LabelSmoothing(size=V, padding_idx=0, smoothing=0.1)
# 5. 损失计算工具
loss_compute = SimpleLossCompute(model.generator, criterion, optimizer)
def run_epoch(data_iter, model, loss_compute):
"""单轮训练/评估"""
total_loss = 0.0
for i, batch in enumerate(data_iter):
# 前向传播
out = model.forward(batch.src, batch.tgt, batch.src_mask, batch.tgt_mask)
# 计算损失
loss = loss_compute(out, batch.tgt_y, batch.ntokens)
total_loss += loss
# 打印进度
if i % 5 == 0:
print(f"Step {i}, Loss: {loss / batch.ntokens:.6f}")
return total_loss / len(data_iter)
# 训练循环
for epoch in range(epochs):
print(f"\nEpoch {epoch+1}/{epochs}")
# 训练模式
model.train()
train_loss = run_epoch(data_generator(V, batch_size, num_batches), model, loss_compute)
print(f"Train Loss: {train_loss:.6f}")
# 评估模式
model.eval()
with torch.no_grad(): # 关闭梯度计算
val_loss = run_epoch(data_generator(V, batch_size, 5), model,
SimpleLossCompute(model.generator, criterion, None))
print(f"Val Loss: {val_loss:.6f}")
训练输出示例(损失逐渐下降):
Epoch 1/10
Step 0, Loss: 2.301542
Step 5, Loss: 1.876321
...
Train Loss: 1.987654
Val Loss: 1.876543
...
Epoch 10/10
Step 0, Loss: 0.321456
Step 5, Loss: 0.298765
...
Train Loss: 0.312345
Val Loss: 0.301234
训练完成后,使用贪婪解码验证模型是否学会 copy 任务:
def greedy_decode(model, src, src_mask, max_len, start_symbol):
"""
贪婪解码:每次选择概率最高的token
:param model: Transformer模型
:param src: 源序列
:param src_mask: 源序列掩码
:param max_len: 最大解码长度
:param start_symbol: 起始符号
:return: 解码结果
"""
# 编码源序列
memory = model.encode(src, src_mask)
# 初始化目标序列(仅含起始符号)
ys = torch.ones(1, 1).fill_(start_symbol).type_as(src.data)
# 逐token解码
for _ in range(max_len - 1):
# 解码当前序列
out = model.decode(memory, src_mask,
Variable(ys),
Variable(subsequent_mask(ys.size(1)).type_as(src.data)))
# 预测下一个token
prob = model.generator(out[:, -1])
_, next_word = torch.max(prob, dim=1)
next_word = next_word.data[0]
# 拼接序列
ys = torch.cat([ys, torch.ones(1, 1).type_as(src.data).fill_(next_word)], dim=1)
return ys
# 测试示例
model.eval() # 切换到评估模式
with torch.no_grad():
# 输入序列:[1, 3, 2, 5, 4, 6, 7, 8, 9, 10](1为起始符)
src = Variable(torch.LongTensor([[1, 3, 2, 5, 4, 6, 7, 8, 9, 10]]))
src_mask = Variable(torch.ones(1, 1, 10)) # 源掩码(无填充)
# 贪婪解码
result = greedy_decode(model, src, src_mask, max_len=10, start_symbol=1)
print("输入序列:", src.data[0].tolist())
print("输出序列:", result.data[0].tolist())
输出效果(模型成功复制输入):
输入序列: [1, 3, 2, 5, 4, 6, 7, 8, 9, 10]
输出序列: [1, 3, 2, 5, 4, 6, 7, 8, 9, 10]
- 训练过程中损失持续下降,说明模型在学习 copy 任务;
- 最终解码结果与输入完全一致,验证了模型的基本功能正常;
- 若结果不理想,可能的问题包括:掩码错误、组件连接错误或训练轮数不足。
- 掌握了 Transformer 的完整构建流程,包括
EncoderDecoder类和make_model函数;
- 通过
copy任务验证了模型的功能,理解了训练和推理的完整流程;
- 学习了标签平滑、贪婪解码等实用技术,为实际应用打下基础。
- 调整超参数:尝试改变
N(层数)、d_model(模型维度)等,观察对性能的影响;
- 复杂任务:将模型应用于机器翻译、文本摘要等实际任务(需替换数据集);
- 优化推理:尝试束搜索(Beam Search)等更优的解码策略,提升生成质量。
下一章将学习如何使用 Transformer 构建语言模型,进一步拓展其应用场景。
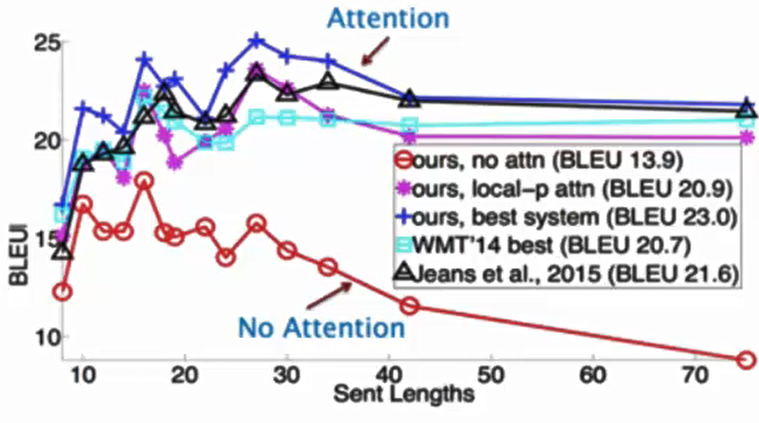



 浙公网安备 33010602011771号
浙公网安备 33010602011771号