09.RNN经典案例-人名分类器
任务识别:
本案例的任务是根据输入的人名,预测其可能来自的国家,涉及 18 个国家。这是一个典型的分类问题,在实际应用中,例如在国际化公司的用户注册流程中,可根据用户填写的名字自动分配国家、地区信息,限制手机号码位数等,以提高效率和用户友好度。
原数据下载地址:https://download.pytorch.org/tutorial/data.zip
数据概览:
Chinese.txt部分数据预览:
Ang
Au-Yong
Bai
Ban
Bao
Bei
Bian
Bui
Cai
Cao
Cen
Chai
Chaim
Chan
Chang
Chao
Che
Chen
Cheng
Cheung
Chew
Chieu
Chin
Chong1. 数据预处理与模型构建
1.1 导入必备工具包
1.2 数据预处理
1.3 数据转换为张量
1.4 构建RNN模型
2. 构建训练函数
2.1 辅助函数
2.2 训练函数
def train(model, criterion, optimizer, category_tensor, name_str_tensor):
"""
训练模型的一个样本
参数:
model: 模型(RNN/LSTM/GRU)
criterion: 损失函数
optimizer: 优化器
category_tensor: 类别张量
name_str_tensor: 人名张量
返回:
输出和损失
"""
# 初始化隐藏状态
if isinstance(model, LSTM):
hidden, cell = model.initHiddenAndCell()
else:
hidden = model.initHidden()
# 将模型梯度归零
model.zero_grad()
# 遍历人名的每个字符
for i in range(name_str_tensor.size()[0]):
if isinstance(model, LSTM):
output, hidden, cell = model(name_str_tensor[i], hidden, cell)
else:
output, hidden = model(name_str_tensor[i], hidden)
# 计算损失
loss = criterion(output.squeeze(0), category_tensor)
# 反向传播
loss.backward()
# 更新参数
optimizer.step()
return output, loss.item()
def timeSince(since):
"""
计算从某个时间点到现在的时间差
参数:
since: 起始时间
返回:
格式化的时间字符串
"""
now = time.time()
s = now - since
m = int(s / 60)
s -= m * 60
return f"{m}m {int(s)}s"
def trainModel(model, model_name, n_iters=100000, print_every=5000, plot_every=1000, learning_rate=0.005):
"""
训练模型
参数:
model: 要训练的模型
model_name: 模型名称
n_iters: 训练迭代次数
print_every: 每隔多少次打印一次信息
plot_every: 每隔多少次记录一次损失用于绘图
learning_rate: 学习率
返回:
训练过程中的损失列表
"""
start = time.time()
current_loss = 0
all_losses = []
# 定义损失函数和优化器
criterion = nn.NLLLoss()
optimizer = optim.SGD(model.parameters(), lr=learning_rate)
for iter in range(1, n_iters + 1):
# 获取随机训练样本
category, name_str, category_tensor, name_str_tensor = randomTrainingExample()
# 训练模型
output, loss = train(model, criterion, optimizer, category_tensor, name_str_tensor)
current_loss += loss
# 打印训练信息
if iter % print_every == 0:
guess, guess_i = categoryFromOutput(output)
correct = '✓' if guess == category else f'✗ ({category})'
print(f"{iter} {iter / n_iters * 100:.1f}% {timeSince(start)} {loss:.4f} {name_str} / {guess} {correct}")
# 记录损失用于绘图
if iter % plot_every == 0:
all_losses.append(current_loss / plot_every)
current_loss = 0
# 绘制损失曲线
plt.figure()
plt.plot(all_losses)
plt.title(f'{model_name} Training Loss')
plt.xlabel('Iterations (x1000)')
plt.ylabel('Loss')
plt.show()
return all_losses
# 训练RNN模型
print("Training RNN...")
rnn_losses = trainModel(rnn, "RNN")
# 训练LSTM模型
print("\nTraining LSTM...")
lstm_losses = trainModel(lstm, "LSTM")
# 训练GRU模型
print("\nTraining GRU...")
gru_losses = trainModel(gru, "GRU")
# 比较三种模型的训练损失
plt.figure(figsize=(10, 6))
plt.plot(rnn_losses, label='RNN')
plt.plot(lstm_losses, label='LSTM')
plt.plot(gru_losses, label='GRU')
plt.title('Comparison of Training Losses')
plt.xlabel('Iterations (x1000)')
plt.ylabel('Loss')
plt.legend()
plt.show()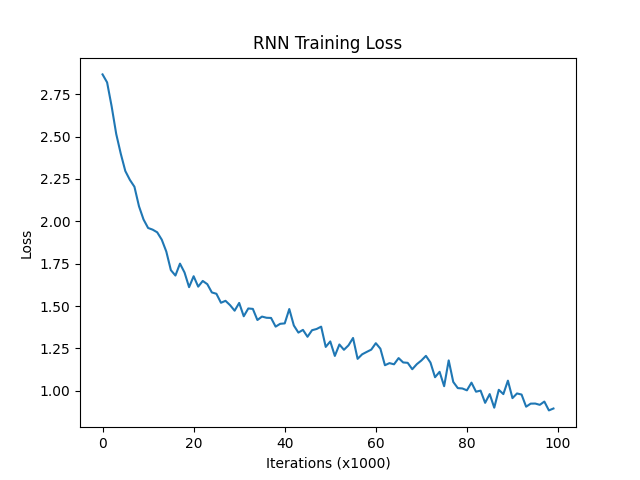
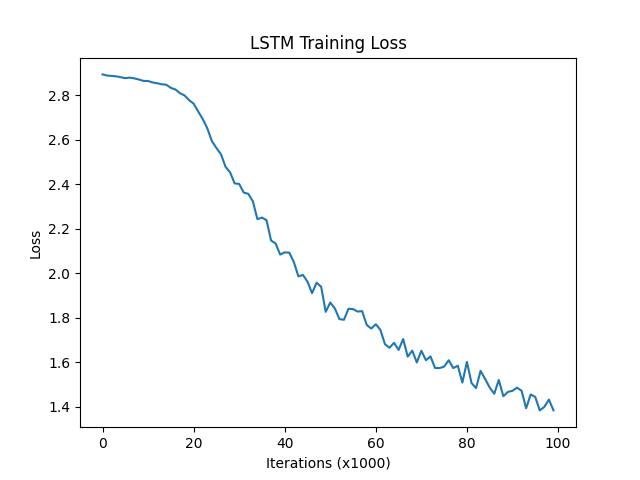
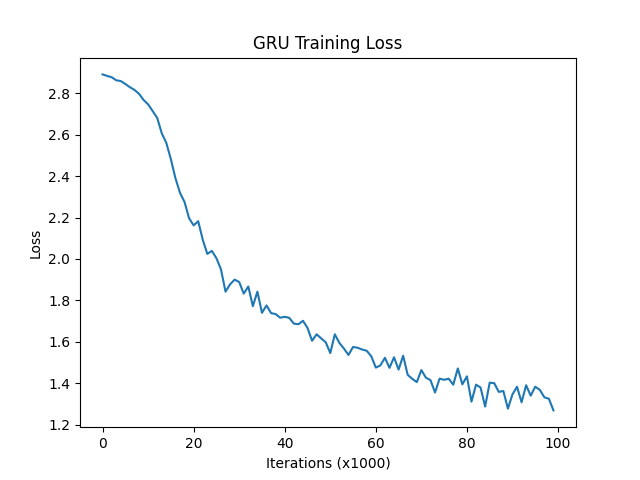
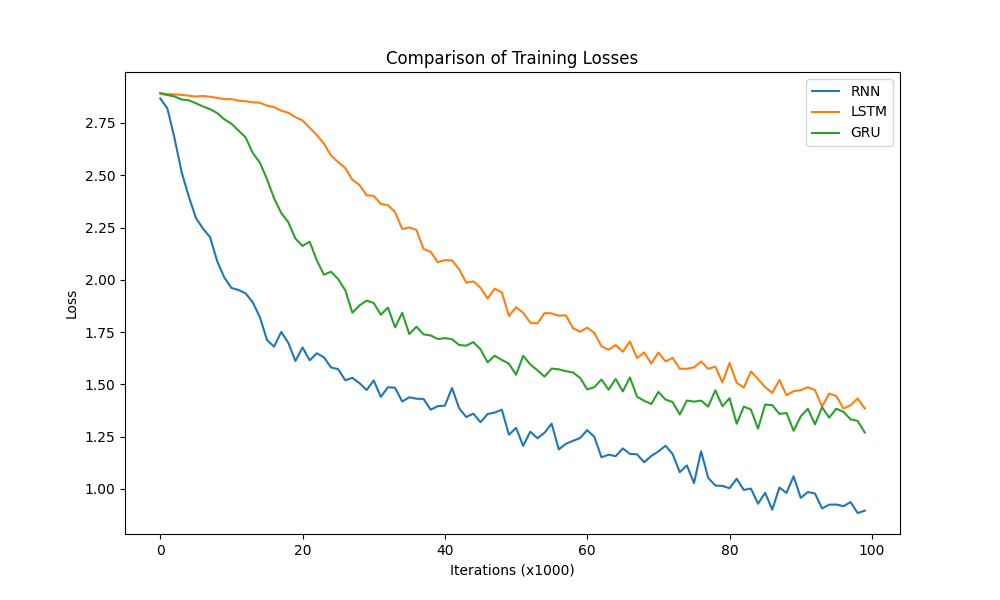
损失对比曲线分析:
模型训练的损失降低快慢代表模型收敛程度,由图可知,传统RNN的模型收敛情况最好,然后是GRU,最后是LSTM,这是因为: 我们当前处理的文本数据是人名,他们的长度有限且长距离字母间基本无特定关联,因此无法发挥改进模型LSTM和GRU的长距离捕捉语义关联的优势。所以在以后的模型选用时,要通过对任务的分析以及实验对比,选择最适合的模型。
点击查看完整训练日志
Training RNN...
5000 5.0% 0m 14s 2.6088 Severins / Greek ✗ (Dutch)
10000 10.0% 0m 28s 0.9120 Phung / Vietnamese ✓
15000 15.0% 0m 42s 0.2584 Matsoukis / Greek ✓
20000 20.0% 0m 57s 2.1118 Sugase / Arabic ✗ (Japanese)
25000 25.0% 1m 11s 0.4751 Henderson / Scottish ✓
30000 30.0% 1m 26s 0.2416 Jong / Korean ✓
35000 35.0% 1m 40s 2.0303 Letsos / Scottish ✗ (Greek)
40000 40.0% 1m 54s 0.7113 Opova / Czech ✓
45000 45.0% 2m 9s 3.3019 Haynes / Arabic ✗ (English)
50000 50.0% 2m 23s 3.0582 Colon / Irish ✗ (Spanish)
55000 55.0% 2m 37s 0.0201 Zouvelekis / Greek ✓
60000 60.0% 2m 52s 2.0891 Bell / Irish ✗ (Scottish)
65000 65.0% 3m 6s 0.8991 Kober / Czech ✓
70000 70.0% 3m 21s 1.0251 Eoin / Irish ✓
75000 75.0% 3m 35s 3.2046 Macdonald / English ✗ (Scottish)
80000 80.0% 3m 49s 0.1424 Karahalios / Greek ✓
85000 85.0% 4m 4s 3.1600 Peers / Portuguese ✗ (English)
90000 90.0% 4m 18s 1.7004 Felix / Spanish ✓
95000 95.0% 4m 33s 0.0310 Dubanowski / Polish ✓
100000 100.0% 4m 47s 0.3119 Piatek / Polish ✓
Training LSTM...
5000 5.0% 0m 24s 2.8998 Auttenberg / Greek ✗ (Polish)
10000 10.0% 0m 48s 2.9027 Bonfils / Japanese ✗ (French)
15000 15.0% 1m 12s 2.8958 Salcedo / Japanese ✗ (Spanish)
20000 20.0% 1m 36s 2.8935 Raske / Czech ✗ (Dutch)
25000 25.0% 2m 0s 2.7027 Machado / Scottish ✗ (Portuguese)
30000 30.0% 2m 24s 2.8205 Santos / Arabic ✗ (Spanish)
35000 35.0% 2m 48s 1.3920 Poplawski / Polish ✓
40000 40.0% 3m 11s 2.2951 Geiger / French ✗ (German)
45000 45.0% 3m 36s 2.8979 Asker / German ✗ (Arabic)
50000 50.0% 3m 59s 2.2894 Kennedy / Dutch ✗ (Scottish)
55000 55.0% 4m 23s 0.4661 Sorrentino / Italian ✓
60000 60.0% 4m 47s 0.3506 Sorrentino / Italian ✓
65000 65.0% 5m 10s 1.1480 Rahal / Arabic ✓
70000 70.0% 5m 34s 1.0543 Shimizu / Japanese ✓
75000 75.0% 5m 57s 0.3870 Tommii / Japanese ✓
80000 80.0% 6m 20s 1.3761 Sanda / Japanese ✓
85000 85.0% 6m 44s 2.3956 Bartosz / Spanish ✗ (Polish)
90000 90.0% 7m 7s 1.5289 Tso / Korean ✗ (Chinese)
95000 95.0% 7m 31s 3.3459 Forbes / Portuguese ✗ (English)
100000 100.0% 7m 54s 1.2309 Rome / French ✓
Training GRU...
5000 5.0% 0m 20s 2.8352 Amatore / Russian ✗ (Italian)
10000 10.0% 0m 41s 2.7114 Can / Irish ✗ (Dutch)
15000 15.0% 1m 1s 2.8145 Machado / Spanish ✗ (Portuguese)
20000 20.0% 1m 22s 2.1758 Freitas / Greek ✗ (Portuguese)
25000 25.0% 1m 42s 0.3820 Sotiris / Greek ✓
30000 30.0% 2m 3s 1.1031 Cui / Chinese ✓
35000 35.0% 2m 24s 1.0792 You / Vietnamese ✗ (Korean)
40000 40.0% 2m 44s 1.1914 Xun / Korean ✗ (Chinese)
45000 45.0% 3m 5s 0.7041 Seok / Korean ✓
50000 50.0% 3m 27s 1.5210 Cunningham / Scottish ✓
55000 55.0% 3m 52s 2.0188 Readman / Scottish ✗ (English)
60000 60.0% 4m 15s 0.9751 Mcdonald / Scottish ✓
65000 65.0% 4m 36s 0.1497 Renov / Russian ✓
70000 70.0% 4m 58s 0.7613 Hama / Japanese ✓
75000 75.0% 5m 20s 0.5726 Kogara / Japanese ✓
80000 80.0% 5m 45s 2.4267 Andres / Portuguese ✗ (German)
85000 85.0% 6m 7s 1.6796 Kerridge / English ✓
90000 90.0% 6m 29s 2.1302 Schoorel / Spanish ✗ (Dutch)
95000 95.0% 6m 51s 0.5340 Sinclair / Scottish ✓
100000 100.0% 7m 13s 0.2052 Okuda / Japanese ✓训练耗时对比图分析:
模型训练的耗时长短代表模型的计算复杂度,由图可知,也正如我们之前的理论分析,传统RNN复杂度最低,耗时几乎只是后两者的一半,然后是GRU,最后是复杂度最高的LSTM。
结论:
模型选用一般应通过实验对比,并非越复杂或越先进的模型表现越好,而是需要结合自己的特定任务,从对数据的分析和实验结果中获得最佳答案
3. 构建预测函数
4. 构建评估函数和混淆矩阵
评估函数
混淆矩阵
# 构建混淆矩阵
def plotConfusionMatrix(model, n_examples=1000):
"""
绘制混淆矩阵
参数:
model: 要评估的模型
n_examples: 要评估的样本数量
"""
# 初始化混淆矩阵
confusion = torch.zeros(n_categories, n_categories)
for _ in range(n_examples):
category, name_str, category_tensor, name_str_tensor = randomTrainingExample()
output = evaluate(model, name_str_tensor)
guess, guess_i = categoryFromOutput(output)
category_i = all_categories.index(category)
confusion[category_i][guess_i] += 1
'''
category_i:真实类别的索引(来自randomTrainingExample随机选取的真实标签)
guess_i:模型预测的类别索引(来自categoryFromOutput)
只有当两者相等时才会在对角线上累加
假设评估1000个样本后:
Predicted
Eng Jap Chi
Actual Eng 900 50 50
Jap 30 920 50
Chi 20 30 950
'''
# 归一化混淆矩阵
# 将每行的值转换为概率,使所有的值范围变为0-1,对角线上的概率值表示分类准确率。
for i in range(n_categories):
confusion[i] = confusion[i] / confusion[i].sum()
# 设置图形
fig = plt.figure(figsize=(10, 10))
ax = fig.add_subplot(111)
cax = ax.matshow(confusion.numpy())
fig.colorbar(cax)
# 设置坐标轴
ax.set_xticks(range(n_categories))
ax.set_yticks(range(n_categories))
ax.set_xticklabels(all_categories, rotation=90)
ax.set_yticklabels(all_categories)
# 设置标签
ax.set_xlabel('Predicted')
ax.set_ylabel('Actual')
if isinstance(model, LSTM):
plt.title('LSTM Confusion Matrix')
elif isinstance(model, GRU):
plt.title('GRU Confusion Matrix')
else:
plt.title('RNN Confusion Matrix')
plt.show()
# 绘制RNN的混淆矩阵
print("RNN Confusion Matrix:")
plotConfusionMatrix(rnn)
# 绘制LSTM的混淆矩阵
print("LSTM Confusion Matrix:")
plotConfusionMatrix(lstm)
# 绘制GRU的混淆矩阵
print("GRU Confusion Matrix:")
plotConfusionMatrix(gru)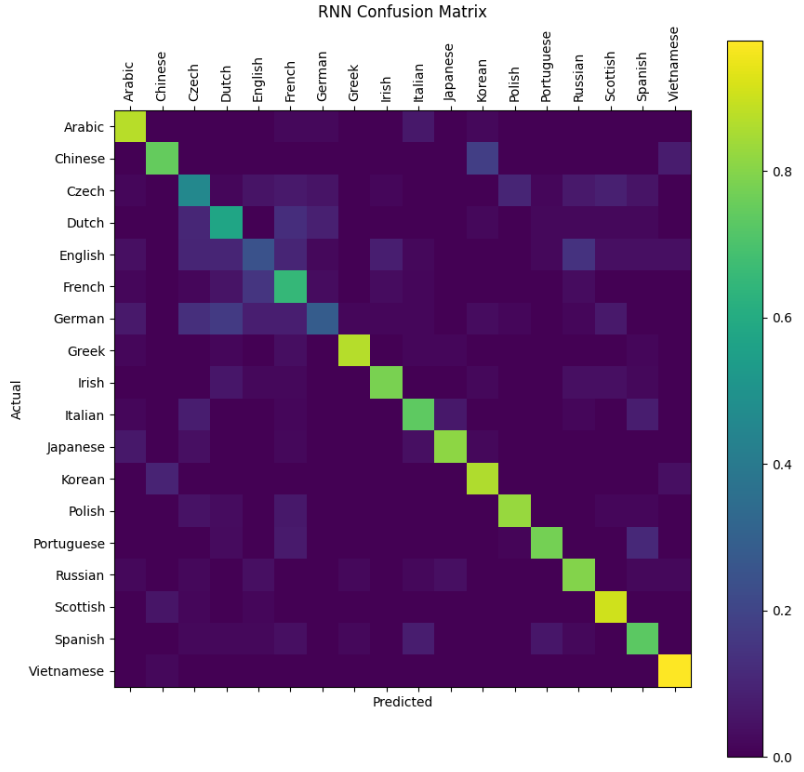
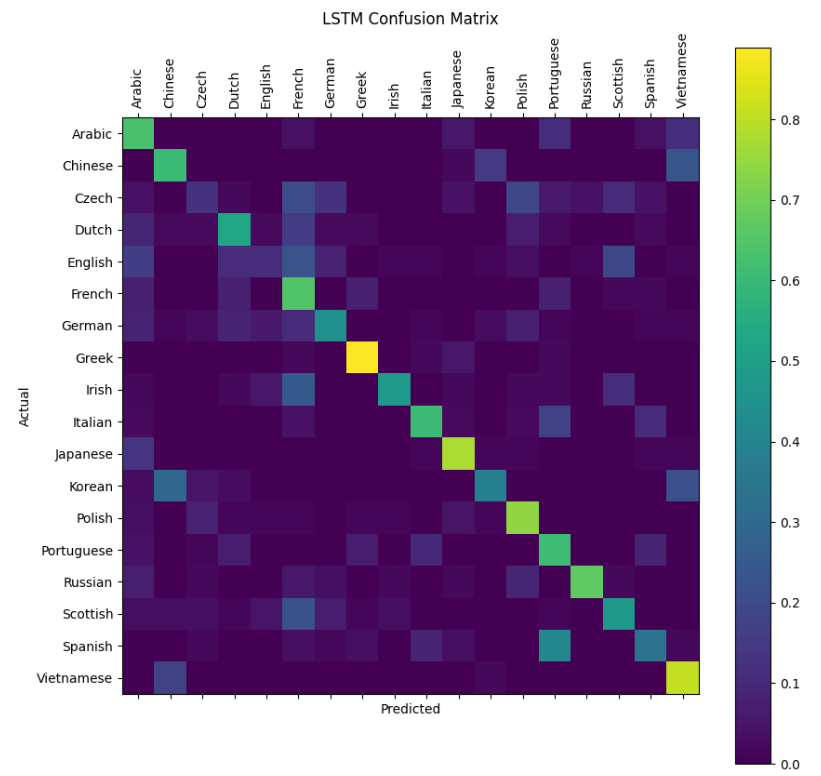
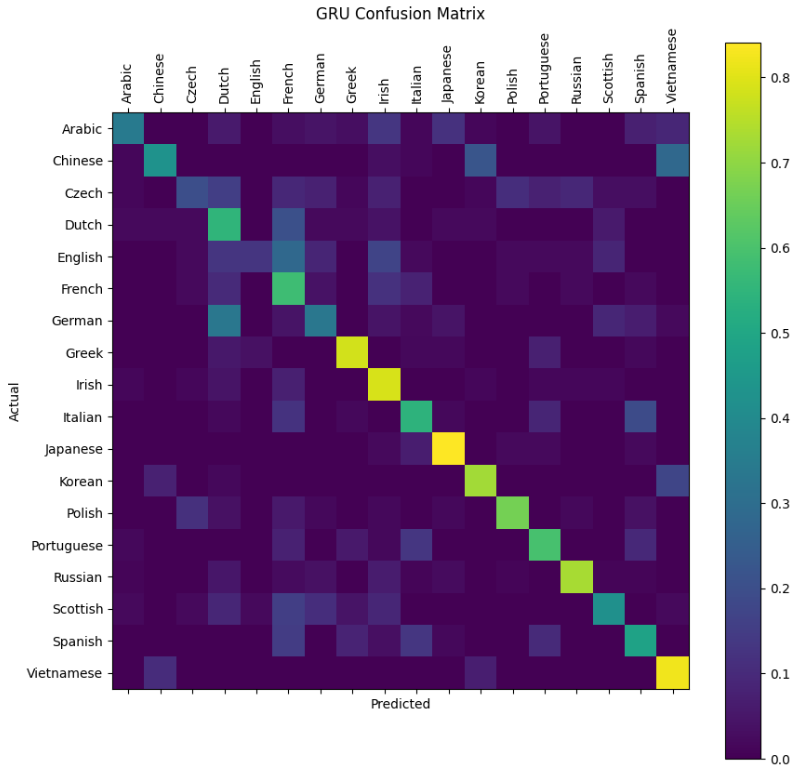
- 对角线元素 表示真实类别为
i时的正确分类概率(召回率/recall) - 非对角线元素 表示将类别
i误分类为j的概率
总结:
- 混淆矩阵对角线是正确分类
- 非对角线是各类别间的混淆情况
- 好的模型会使对角线值明显大于其他位置
这个设计正是为了直观展示模型在哪些类别上容易混淆(比如西班牙语和葡萄牙语名字可能容易互相误判)。
5. 保存和加载模型
总结
本教程完整实现了基于RNN、LSTM和GRU的人名分类器,包括:
- 数据预处理:读取数据、字符规范化、转换为张量
- 模型构建:实现了三种循环神经网络模型
- 训练过程:实现了训练函数和训练循环
- 评估和预测:实现了模型评估、预测和混淆矩阵可视化
- 模型保存和加载
通过比较可以发现,LSTM和GRU模型通常比传统RNN表现更好,训练损失下降更快,最终准确率更高。在实际应用中,可以根据需求选择适合的模型。
这个案例展示了如何使用PyTorch构建循环神经网络来解决实际的分类问题,可以扩展到其他类似的序列分类任务中。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号