06.HMM和CRF
1. 先理解序列标注问题
在自然语言处理(NLP)中,序列标注是指为输入序列中的每个单元(如单词、字符)分配一个标签。例如:
- 输入序列(观测序列):["人生", "该", "如何", "起头"]
- 输出序列(隐含序列):["名词", "代词", "代词", "动词"]
这就是一个典型的词性标注任务。
HMM和CRF都是用来解决这类序列标注问题的概率模型。
2. HMM(隐马尔可夫模型)
核心思想
基于马尔可夫假设的统计模型,用于处理序列数据。核心思想是系统状态不可直接观测(隐含),但可通过观测序列推断。
- 输入:文本序列(如句子分词后的单词列表)。
- 输出:对应的隐含序列(如词性标注序列)。
- 示例:
观测序列:["人生","该","如何","起头"] → 隐含序列:["n","r","r","v"](名词、代词、代词、动词)。
HMM假设:
- 马尔可夫性:当前状态(标签)只依赖于前一个状态(标签)。
- 比如,"动词"后面更可能接"名词",而不是"形容词"。
- 观测独立性:当前观测值(单词)只依赖于当前状态(标签)。
- 比如,标签"名词"更可能生成单词"人生",而不是"跑步"。
HMM训练与预测
- 参数定义:
- 转移概率矩阵(A):隐含状态间的转移概率(如词性"n"后接"v"的概率)。
- 发射概率矩阵(B):隐含状态生成观测值的概率(如词性"n"生成单词"人生"的概率)。
- 初始概率(π):序列起始状态的分布。
- 训练:通过大量标注数据(观测序列+隐含序列)估计参数(A, B, π),最大化联合概率。训练中采用隐含假设:隐含序列中每个单元的可能性只与上一个单元有关。
- 预测:
- 使用维特比算法(动态规划)找到概率最大的隐含序列路径。
- 给定输入序列 (x₁, x₂, ..., xₙ),通过模型计算得到隐含序列的条件概率分布,再使用维特比算法找出概率最大的序列路径,即为输出的隐含序列 (y₁, y₂, ..., yₙ)。
- 使用维特比算法(动态规划)找到概率最大的隐含序列路径。
HMM的优缺点
- 优点:计算快,适合小规模数据。
- 缺点:
- 强假设(当前标签只依赖前一个标签)可能不成立。
- 无法直接建模观测值之间的依赖关系(如"起头"和"如何"的关联)。
3. CRF(条件随机场)
核心思想
判别式概率图模型,直接建模观测序列与隐含序列的条件概率关系,无马尔可夫假设限制。
CRF是判别式模型,直接建模P(标签序列|观测序列),而不是像HMM那样建模联合概率。
- 没有马尔可夫假设:可以建模任意长度的依赖关系(如当前标签可能依赖前后多个标签)。
- 特征函数:通过人工定义的特征(如"当前单词是否以‘吗’结尾")捕捉观测与标签的关系。
- 输入/输出:与HMM相同,但模型结构和训练方式不同。
共同应用:
解决NLP中的序列标注问题,如分词、词性标注、命名实体识别(NER)。
核心任务:
给定观测序列,预测最可能的隐含标签序列。
模型表示
CRF的得分函数:
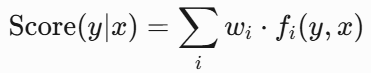
- 是特征函数(如"当前标签是动词且前一个标签是名词")。
- 是权重,通过训练学习。
CRF的优缺点
- 优点:
- 更灵活,可以建模全局特征(如句首句尾的标签规律)。
- 准确率通常高于HMM。
- 缺点:
- 需要人工设计特征函数(但现代CRF常结合神经网络自动学习特征)。
- 计算比HMM慢。
4. HMM vs CRF 对比
| 维度 | HMM | CRF |
|---|---|---|
| 核心假设 | 存在隐含假设(隐含序列单元仅与上一单元相关) | 无隐含假设 |
| 模型类型 | 生成式(建模联合概率) | 判别式(建模条件概率) |
| 依赖假设 | 当前标签只依赖前一个标签 | 可建模任意长度的依赖 |
| 特征能力 | 只能通过发射概率建模单词 | 可自定义复杂特征(如前缀、后缀) |
| 计算效率 | 快(因假设简化计算) | 慢(但现代优化后差距缩小) |
| 准确率 | 低(假设过强,忽略上下文),当隐含序列单元关联超出上一单元时,准确率降低 | 高(灵活建模全局特征),不受隐含假设限制,准确率更高 |
| 适用场景 | 小数据、实时性要求高(对预测性能要求较高的场合) | 大数据、高精度需求(对准确率要求较高的场合) |
5. 发展现状
- 传统优势:
HMM和CRF在2010年代前广泛用于序列任务,F是序列标注的主流模型。尤其在数据量较小、计算资源有限时表现良好。 - 当前趋势:
随着深度学习兴起,RNN、LSTM、Transformer等模型因其自动特征学习和更强的表达能力,逐渐取代传统方法。- BiLSTM-CRF:用LSTM自动学习特征,CRF做标签解码,曾是NER的黄金标准。
- Transformer:BERT等预训练模型+CRF仍是当前最先进方法。
- 遗留价值:
- HMM仍用于简单任务、实时性要求高的场景(如语音识别初步处理)。
- CRF的思想(全局标签依赖)被融入神经网络。
- CRF有时作为神经网络输出层的后处理(如BiLSTM-CRF模型)。
6. 关键总结
- HMM:
- 马尔可夫假设 + 概率图模型。强假设,计算快。
- 依赖局部概率,计算高效但表达能力有限。
- 适合入门学习,但实际应用受限。
- CRF:
- 全局特征建模 + 判别式训练。
- 更灵活,准确率高但计算复杂,需要特征工程。
- 现代NLP中常与神经网络结合。
- 选择建议:
- 如果学习基础概念,从HMM入手。
- 数据量小、需快速部署 → HMM。
- 数据充足、追求精度 → CRF或深度学习模型。
- 如果解决实际问题,直接用BiLSTM-CRF或BERT-CRF。
通过对比可见,HMM和CRF虽逐渐被深度学习替代,但其理论价值(如概率图模型、序列解码方法)仍影响现代NLP模型设计。
7. 举个栗子🌰
假设任务是命名实体识别(NER):
- HMM:
- 会认为"北京"作为地名的概率高,但可能忽略上下文(如"北京天气"中"北京"是地名,而"北京话"中不是)。
- CRF:
- 可以定义特征:"如果当前词是地名且下一个词是‘天气’,则更可能是地名"。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号