02.文本张量表示方法2
一、什么是文本张量表示
1.1 直观理解
想象你要教计算机读懂这句话:
"我爱自然语言处理"
计算机只认识数字,所以我们需要:
- 把每个词变成数字向量(词向量)
- 把整句话变成数字矩阵(文本张量)
1.2 举个栗子 🌰
文本 = ["我", "爱", "自然语言处理"]
# 假设每个词对应一个3维向量
我 -> [0.2, 0.5, 0.1]
爱 -> [0.7, 0.3, 0.4]
自然语言处理 -> [0.9, 0.2, 0.8]
# 最终文本张量(3个词×3维向量)
[[0.2, 0.5, 0.1],
[0.7, 0.3, 0.4],
[0.9, 0.2, 0.8]]二、为什么要用张量表示
- 统一格式:所有文本都能转为固定维度的数字
- 保留语义:相似的词有相似的向量(比如"猫"和"狗"的向量比"猫"和"电脑"更接近)
- 适配模型:神经网络可以直接处理这些数字
三、4种常见的文本张量表示方法
3.1 One-Hot编码(最基础)
- 原理:每个词用一个很长的0/1向量表示。又称独热编码,将每个词表示成具有 n 个元素的向量,这个词向量中只有一个元素是 1,其他元素都是 0,不同词汇元素为 1 的位置不同,其中 n 的大小是整个语料中不同词汇的总数。
- 示例:
- 优势:操作简单,容易理解
- 劣势:维度高、无法表达词之间的关系,完全割裂了词与词之间的联系,而且在大语料集下,每个向量的长度过大,占据大量内存
说明:正因为one-hot编码明显的劣势,这种编码方式被应用的地方越来越少,取而代之的是稠密向量的表示方法:word embedding。
3.2 词频统计(TF)
- 原理:统计每个词在句子中出现的次数
- 示例:
3.3 TF-IDF
- 原理:考虑词在全文中的重要性(常见词如"的"权重降低)
- 公式:
TF-IDF = 词频(TF) × 逆文档频率(IDF)
TF-IDF是什么?
1.1 生活比喻 🍎
想象你在分析100篇美食文章:
- TF(词频):"蛋糕"在某篇文章中出现5次 → 说明这篇文章可能重点讲蛋糕
- IDF(逆文档频率):但"的"字在90篇文章都出现过 → 说明"的"不重要
- TF-IDF = TF × IDF → 同时考虑局部重要性和全局重要性
1.2 数学公式

- :总文档数
- :包含词的文档数
完整代码示例
2.1 使用scikit-learn计算TF-IDF
from sklearn.feature_extraction.text import TfidfVectorizer
# 示例文档集
documents = [
"我爱自然语言处理",
"自然语言处理很有趣",
"我爱深度学习"
]
# 初始化TF-IDF向量器
tfidf = TfidfVectorizer(token_pattern=r"(?u)\b\w+\b") # 适配中文
# 计算TF-IDF矩阵
tfidf_matrix = tfidf.fit_transform(documents)
# 打印结果
print("词汇表:", tfidf.get_feature_names_out())
print("TF-IDF矩阵:\n", tfidf_matrix.toarray().round(3))输出解析
- 第一行解读("我爱自然语言处理"):
- "我爱"权重最高(0.707)→ 只在该文档出现
- "自然/语言/处理"权重相同(0.354)→ 同时在第二篇出现
3.4 词嵌入(Embedding)⭐(重点!)
- 原理:通过神经网络学习到的低维度稠密向量
- 特点:
- 向量维度通常50-300维
- 语义相似的词向量距离近
- 可进行数学运算(如:国王 - 男 + 女 ≈ 女王)
生活比喻 🍎
把词嵌入想象成"词的世界地图":
-
-
- 每个词是一个城市
- 向量坐标是经纬度
- 语义相近的词距离近(如"苹果"和"香蕉"都在"水果区")
-
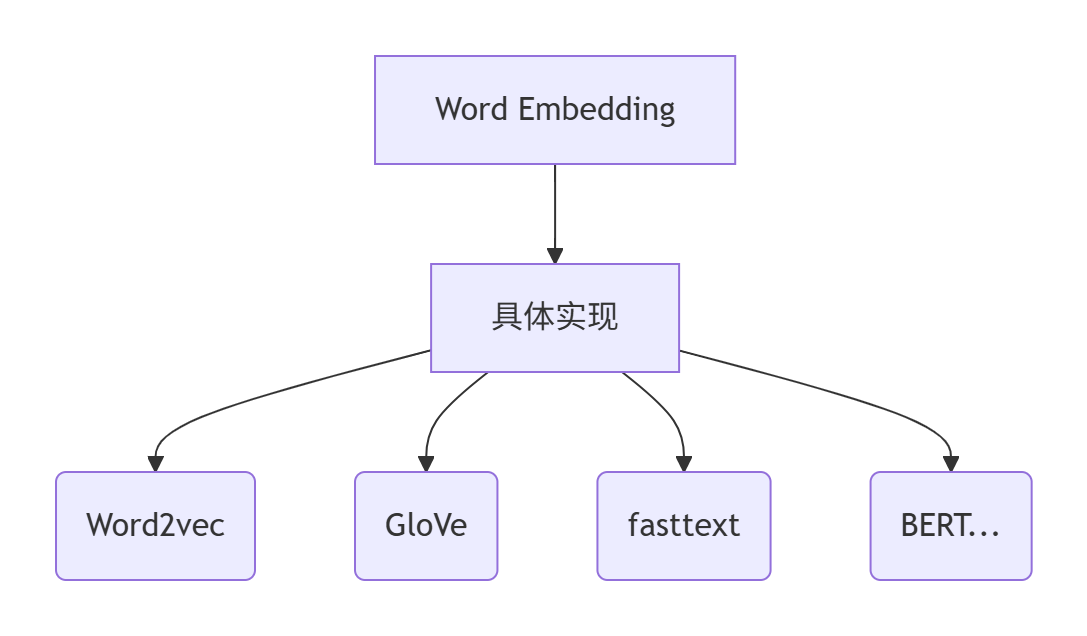
Embedding核心概念对比
| 概念 | 定义 | 特点 |
|---|---|---|
| Word Embedding | 将单词映射到低维稠密向量的技术(统称) | 是技术范畴的统称,包含Word2vec/GloVe/fasttext等具体实现 |
| Word2vec | 2013年Google提出的词嵌入模型(CBOW/Skip-gram两种架构) | 基于局部上下文窗口预测,轻量高效 |
| fasttext | Facebook提出的模型(可视为Word2vec扩展) | 引入子词(subword)信息,能处理未登录词 |
| GloVe | 2014年斯坦福提出的全局词向量模型 | 结合全局统计信息(共现矩阵)和局部窗口 |
如何选择?
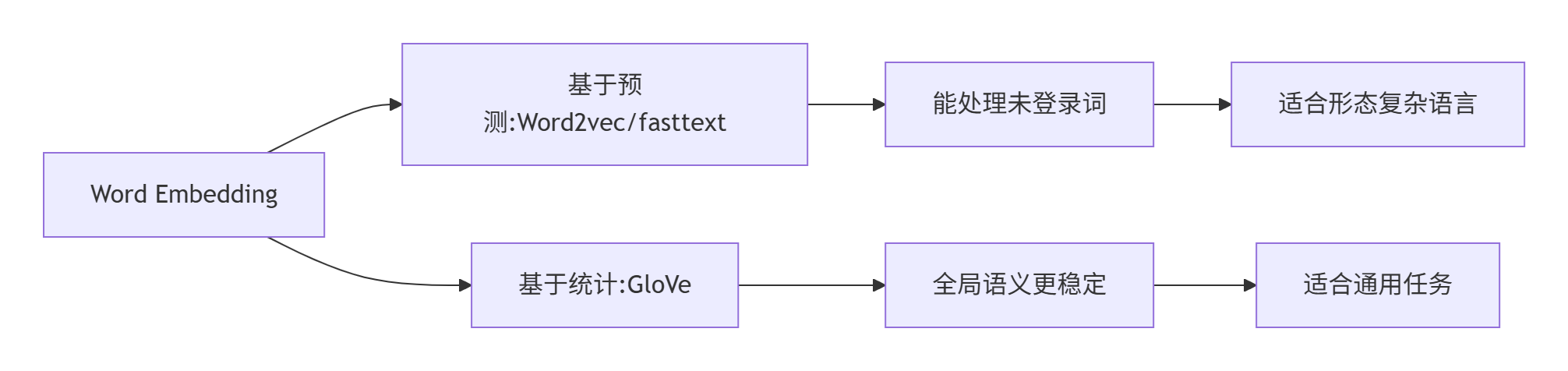
| 场景 | 推荐模型 | 理由 |
|---|---|---|
| 通用英语语义任务 | GloVe | 全局统计信息更稳定 |
| 形态复杂语言(如中文) | fasttext | 子词信息能更好处理复合词 |
| 超大规模数据 | fasttext | 训练速度优势明显 |
| 需要最新技术 | BERT/Transformer | 上下文感知的嵌入 |
性能对比数据
| 模型 | 英语词义相似度任务(Spearman) | 训练速度(10亿词) |
|---|---|---|
| Word2vec | 0.72 | 2小时 |
| GloVe | 0.75 | 6小时 |
| fasttext | 0.73 | 1.5小时 |
| BERT | 0.85 | 3天(需GPU) |
四、如何训练Embedding?
随机初始化 → 训练时自动调整
特点:
-
- 向量值是随机生成的(无实际语义)
- 需要后续训练(如参与神经网络的梯度下降)
- 适合从头开始训练的小规模任务
PyTorch实现:
场景:判断句子情感(正面/负面)
import torch.nn as nn
class TextClassifier(nn.Module):
def __init__(self, vocab_size, embed_dim):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embed_dim) # 随机初始化
self.fc = nn.Linear(embed_dim, 2) # 二分类
def forward(self, text):
embedded = self.embedding(text).mean(dim=1) # 平均词向量
return self.fc(embedded)
# 训练过程
model = TextClassifier(vocab_size=1000, embed_dim=100)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters())
for epoch in range(10):
for text, label in dataloader:
optimizer.zero_grad()
output = model(text)
loss = criterion(output, label)
loss.backward() # 反向传播会计算这个嵌入矩阵中每个元素的梯度;
optimizer.step()#会根据这些梯度更新嵌入矩阵的值(更新embedding层的参数)!使得嵌入向量能更好地适应下游分类任务。关键点:
- 初始的Embedding是随机的
- 通过loss.backward(),optimizer.step()自动调整Embedding矩阵
- 最终得到的词向量会编码任务相关语义
使用预训练词向量(如GloVe、Word2Vec)
预训练 vs 随机初始化的对比
| 特性 | 随机初始化Embedding | 预训练Embedding(例GloVe) |
|---|---|---|
| 向量质量 | 无意义随机值 | 已编码语义关系(如"king - man ≈ queen - woman") |
| 是否需要训练 | 必须经过训练才有意义 | 可冻结(直接使用)或微调 |
| 适用场景 | 小数据集/特殊领域/从零开始训练模型 | 通用领域/中等以上数据量/迁移学习/快速原型开发 |
| 典型准确率 | 较低(需足够数据) | 较高(迁移学习优势) |
| 代码示例 | nn.Embedding(1000, 100) |
GloVe(name='6B', dim=100) |
何时使用哪种方法?
1. 优先使用GloVe的情况
2. 必须用nn.Embedding的情况
# 场景:专业领域词汇(如医疗术语)
embedding = nn.Embedding(num_embeddings=5000, embedding_dim=200) # 自定义词汇量
# 需要后续训练才能获得有意义向量点击查看完整医疗示例
import torch
import torch.nn as nn
from torch.utils.data import DataLoader, Dataset
# ---------------------- 1. 第一步:构建医疗领域专属词表 ----------------------
# 假设从医疗病历数据中统计出5000个核心术语(如“肺炎”“CT影像”“抗生素”等)
medical_vocab = {"肺腺癌": 0, "PD-1抑制剂": 1, "经皮冠状动脉介入术": 2, ..., "(共5000个词)": 4999}
vocab_size = len(medical_vocab) # num_embeddings=5000
embed_dim = 200 # 根据任务复杂度调整
# ---------------------- 2. 第二步:定义模型(用nn.Embedding) ----------------------
class MedicalTextClassifier(nn.Module):
def __init__(self):
super().__init__()
# 初始化医疗领域专属嵌入层(随机初始化,后续训练优化)
self.embedding = nn.Embedding(
num_embeddings=vocab_size, # 领域词表大小
embedding_dim=embed_dim # 嵌入向量维度
)
self.fc = nn.Linear(embed_dim, 3) # 示例:医疗文本三分类(如“良性/恶性/正常”)
def forward(self, text):
# text: 输入的医疗文本(已转为词表索引,形状[batch_size, seq_len])
embedded = self.embedding(text).mean(dim=1) # 平均词向量(聚合句子语义)
return self.fc(embedded)
# ---------------------- 3. 第三步:用医疗数据训练(关键!让嵌入向量“有意义”) ----------------------
# 假设已准备好医疗文本数据集(每条数据包含“文本索引序列+标签”)
class MedicalDataset(Dataset):
def __init__(self, data):
self.data = data # data格式:[(text_indices1, label1), (text_indices2, label2), ...]
def __getitem__(self, idx):
return torch.tensor(self.data[idx][0]), torch.tensor(self.data[idx][1])
def __len__(self):
return len(self.data)
# 加载医疗数据(示例:假设有1000条病历数据)
medical_data = [([0,1,5,...], 1), ([3,7,2,...], 2), ...] # 文本已转成词表索引
dataloader = DataLoader(MedicalDataset(medical_data), batch_size=32, shuffle=True)
# 初始化模型、损失函数、优化器
model = MedicalTextClassifier()
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters()) # 优化器会更新nn.Embedding的参数
# 训练过程(核心:通过反向传播优化嵌入向量)
for epoch in range(20):
model.train()
for text, label in dataloader:
optimizer.zero_grad()
output = model(text)
loss = criterion(output, label)
loss.backward() # 计算nn.Embedding的梯度
optimizer.step() # 更新nn.Embedding的参数(让向量学习医疗语义)简单来说:当通用预训练嵌入 “不好用 / 用不了” 时,nn.Embedding就是特殊领域的最优解 —— 它能从零开始,为领域词汇 “量身定制” 有意义的语义向量。
五、TensorBoard可视化查看词向量
import torch.nn as nn
from torch.utils.tensorboard import SummaryWriter
import fileinput
# 1. 使用nn.Embedding创建词向量
embedding_layer = nn.Embedding(num_embeddings=100, embedding_dim=50)
embedded_vectors = embedding_layer.weight # 关键:提取权重矩阵
# 2. 准备词汇表
meta = list(map(lambda x: x.strip(), fileinput.FileInput(r"D:\learn\000人工智能数据大全\nlp\NLP基础课所有数据和代码\vocab100.csv")))
# 3. 写入TensorBoard
writer = SummaryWriter()
writer.add_embedding(embedded_vectors, metadata=meta)
writer.close()TensorBoard查看步骤
运行代码后生成日志文件
在终端运行:
- 浏览器访问
http://localhost:6006 - 点击顶部导航栏的 Projector 标签页

可视化效果说明
| 功能 | 作用 |
|---|---|
| PCA降维 | 3D展示词向量的主要分布方向 |
| t-SNE | 保留局部相似性的非线性降维 |
| 邻居搜索 | 查找语义相近的词(如"苹果"靠近"水果") |
from torch.utils.tensorboard import SummaryWriter
# 加载预训练词向量(示例使用GloVe)
from torchtext.vocab import GloVe
glove = GloVe(name='6B', dim=50)
# # 获取前100个词及其向量
meta = list(glove.stoi.keys())[:100] # 词汇列表
print(meta)#['the', ',', '.', 'of', 'to', 'and', 'in', 'a', '"', "'s", 'for', '-', 'that', 'on', 'is', 'was', 'said', 'with', 'he', 'as', 'it', 'by', 'at', '(', ')', 'from', 'his', "''", '``', 'an', 'be', 'has', 'are', 'have', 'but', 'were', 'not', 'this', 'who', 'they', 'had', 'i', 'which', 'will', 'their', ':', 'or', 'its', 'one', 'after', 'new', 'been', 'also', 'we', 'would', 'two', 'more', "'", 'first', 'about', 'up', 'when', 'year', 'there', 'all', '--', 'out', 'she', 'other', 'people', "n't", 'her', 'percent', 'than', 'over', 'into', 'last', 'some', 'government', 'time', '$', 'you', 'years', 'if', 'no', 'world', 'can', 'three', 'do', ';', 'president', 'only', 'state', 'million', 'could', 'us', 'most', '_', 'against', 'u.s.']
indices = [glove.stoi[word] for word in meta] # 词索引
print(indices)#[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99]
embedded_vectors = glove.vectors[indices] # 词向量矩阵
print(embedded_vectors)
print(embedded_vectors.shape)
'''
tensor([[ 0.4180, 0.2497, -0.4124, ..., -0.1841, -0.1151, -0.7858],
[ 0.0134, 0.2368, -0.1690, ..., -0.5666, 0.0447, 0.3039],
[ 0.1516, 0.3018, -0.1676, ..., -0.3565, 0.0164, 0.1022],
...,
[ 0.1499, 0.7318, 0.4202, ..., -0.1501, -0.4110, 0.3928],
[-0.6126, -0.8110, -0.1843, ..., 0.0140, 0.1737, -0.6768],
[-0.2805, -0.0832, 1.0143, ..., 0.8242, -0.7768, 0.6647]])
torch.Size([100, 50])
'''
# 写入TensorBoard
writer = SummaryWriter()
writer.add_embedding(embedded_vectors, metadata=meta)
writer.close()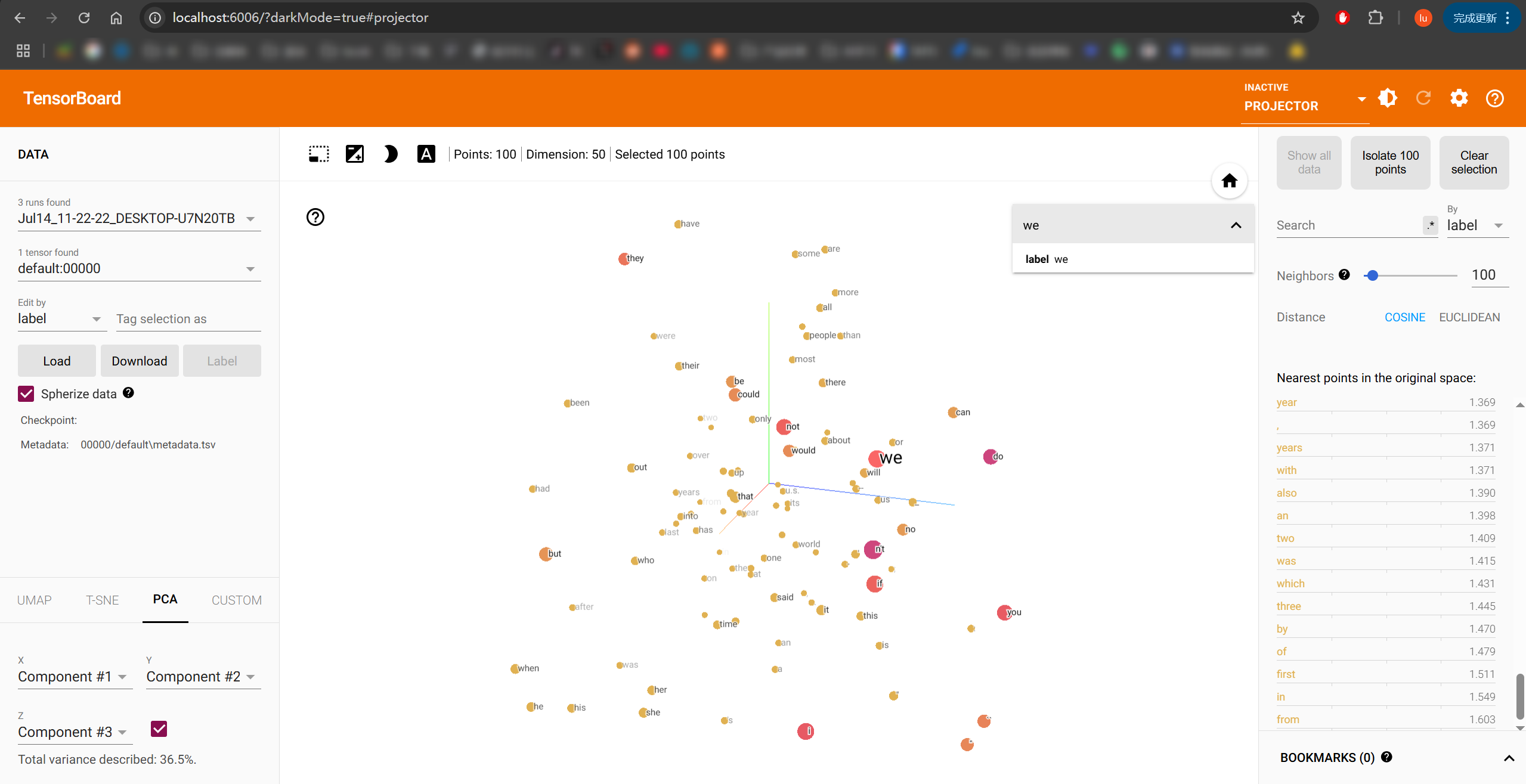
可视化前检查词向量质量
print("语义相似度测试:",torch.cosine_similarity(glove['king'], glove['queen'], dim=0))
# 随机向量的相似度通常接近0
print("语义相似度测试:",torch.cosine_similarity(glove['king'], glove['bug'], dim=0))语义相似度测试: tensor(0.7839)
语义相似度测试: tensor(0.1878)构造有明确分类的数据进行可视化:
import torch
from torch.utils.tensorboard import SummaryWriter
from torchtext.vocab import GloVe
import random
# 1. 加载GloVe词向量
glove = GloVe(name='6B', dim=50)
# 2. 定义分类词汇(确保每个类别至少有33个词)
categories = {
"动物": ["cat", "dog", "lion", "tiger", "elephant", "bear",
"wolf", "fox", "horse", "cow", "pig", "sheep",
"monkey", "panda", "zebra", "giraffe", "deer",
"rabbit", "squirrel", "kangaroo", "dolphin", "whale",
"shark", "octopus", "eagle", "hawk", "owl", "parrot",
"penguin", "frog", "snake", "turtle", "dinosaur"],
"科技": ["computer", "software", "hardware", "internet", "network",
"algorithm", "data", "database", "robot", "ai",
"machine", "learning", "neural", "network", "programming",
"code", "python", "java", "javascript", "html", "css",
"server", "cloud", "blockchain", "crypto", "vr", "ar",
"smartphone", "tablet", "laptop", "processor", "gpu", "cpu"],
"体育": ["football", "soccer", "basketball", "tennis", "baseball",
"volleyball", "golf", "hockey", "cricket", "rugby",
"swimming", "running", "marathon", "cycling", "boxing",
"wrestling", "skiing", "snowboarding", "surfing", "skating",
"badminton", "tabletennis", "athletics", "gymnastics", "diving",
"fencing", "archery", "weightlifting", "judo", "karate", "taekwondo", "ball", "pingpang"]
}
# 3. 检查词汇量
for category, words in categories.items():
if len(words) < 33:
raise ValueError(f"类别 '{category}' 只有 {len(words)} 个词,需要至少33个")
# 4. 合并词汇(每类取33个)
meta = []
embedded_vectors = []
for category, words in categories.items():
selected = random.sample(words, 33)
for word in selected:
try:
meta.append([category, word]) # 改为二维列表
embedded_vectors.append(glove[word])
except KeyError:
meta.append([category, word])
embedded_vectors.append(torch.randn(50))
embedded_vectors = torch.stack(embedded_vectors[:99]) # 确保总数是99(33x3)
# 5. 写入TensorBoard(关键修改)
writer = SummaryWriter()
writer.add_embedding(
embedded_vectors,
metadata=meta, # 现在是二维列表
metadata_header=['category', 'word'] # 对应两列
)
writer.close()
print("运行以下命令查看可视化:")
print("tensorboard --logdir=runs")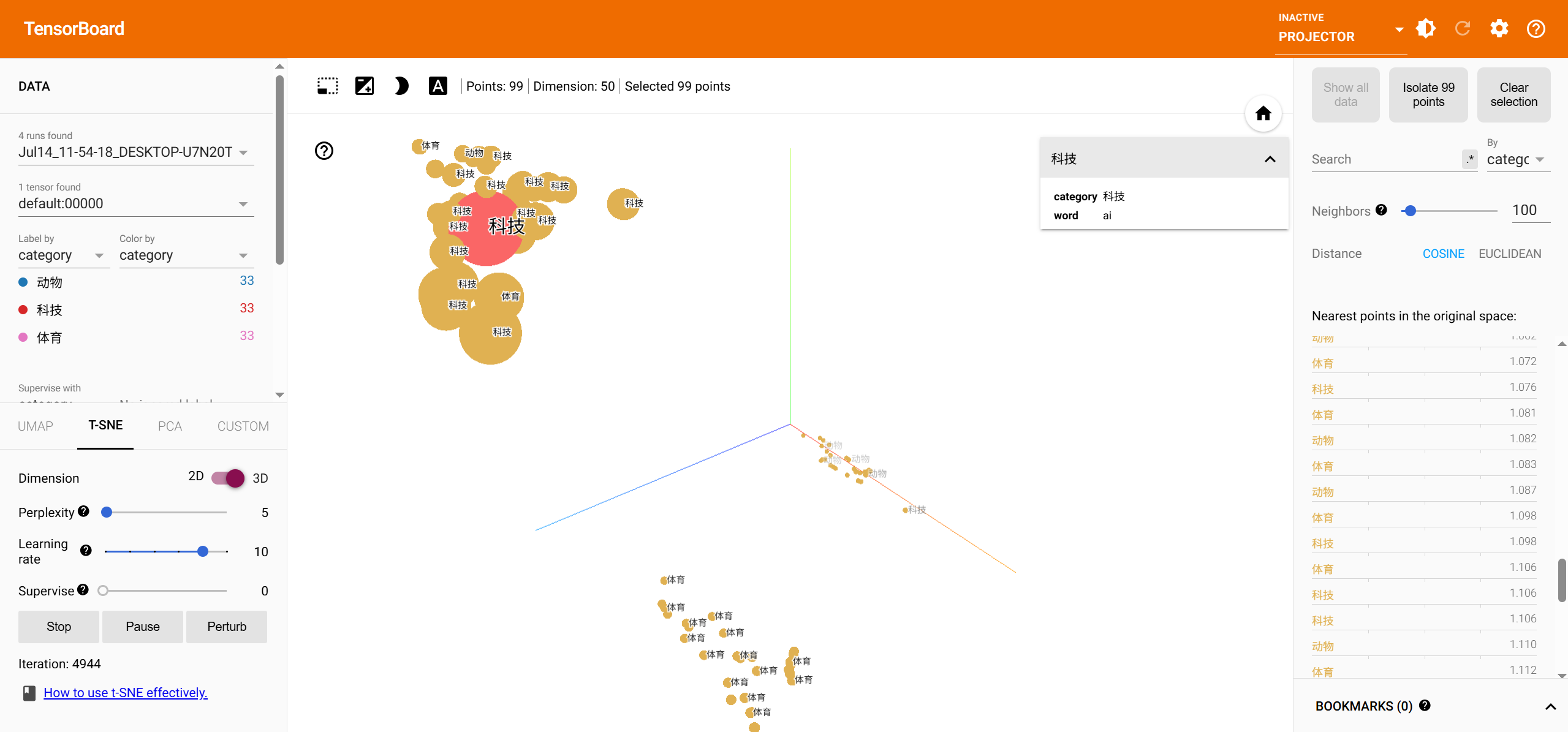
可视化操作指南
- 启动TensorBoard:
- 在浏览器中打开
http://localhost:6006 - 在Projector界面:
- STEP 1:选择
TSNE或PCA降维方法 - STEP 2:在右侧面板点击"Color by"选择
category_word - STEP 3:使用搜索框过滤类别(如输入
科技_显示所有科技词汇)
- STEP 1:选择
预期可视化效果
| 降维方法 | 效果描述 |
|---|---|
| PCA | 三类呈直线方向分离(可能重叠) |
| t-SNE | 三类形成明显聚类(推荐使用) |
| UMAP | 更清晰的聚类边界(需手动安装) |
可视化效果差异
| 可视化特征 | GloVe版 | nn.Embedding版 |
|---|---|---|
| 词向量聚类 | 语义相似的词会自然聚在一起 | 随机分布无规律 |
| 降维结构 | 能反映语义关系(动物/科技等分组) | 无意义散点 |
| 实用价值 | 可直接分析词向量语义 | 需训练后才能分析 |
六、关键总结表
| 方法 | 特点 | 适用场景 |
|---|---|---|
| One-Hot | 简单但高维稀疏 | 小型分类任务 |
| TF-IDF | 考虑词的重要性 | 传统文本分类 |
| Embedding | 低维稠密,保留语义 ⭐ | 深度学习所有NLP任务 |
| 预训练词向量 | 直接使用现成知识(如GloVe) | 数据量小的任务 |
七、新手常见问题
-
Q:Embedding和One-Hot有什么区别?
- One-Hot是稀疏的高维向量(维度=词汇表大小)
- Embedding是稠密的低维向量(可学习语义)
-
Q:为什么我的Embedding输出全是小数?
- 这是正常的!模型会通过训练不断调整这些数值
-
Q:维度选多少合适?
- 小数据集:50-100维
- 大数据集:200-300维
理解了这些,你就掌握了现代NLP的基石技术!接下来可以尝试用Embedding搭建文本分类模型啦~


 浙公网安备 33010602011771号
浙公网安备 33010602011771号