- 了解文本特征处理的作用。
- 掌握实现常见的文本特征处理的具体方法。
文本特征处理包括为语料添加具有普适性的文本特征,如:n-gram 特征,以及对加入特征之后的文本语料进行必要的处理,如:长度规范。
特征处理工作能够有效的将重要的文本特征加入模型训练中,增强模型评估指标。
给定一段文本序列,其中 n 个词或字的相邻共现特征即 n-gram 特征,常用的 n-gram 特征是 bi-gram 和 tri-gram 特征,分别对应 n 为 2 和 3。
示例:
- 分词列表:["是谁","敲动","我心"]
- 数值映射列表:[1,34,21]
- 添加bi-gram特征后:[1,34,21,1000,1001]
- 1000代表"是谁"和"敲动"共同出现且相邻(此时数值映射列表就变成了包含 2-gram 特征的特征列表:[1, 34, 21, 1000],这里的 "是谁" 和 "敲动" 共同出现且相邻就是 bi-gram 特征中的一个。)
- 加 bi-gram 特征后,新列表
[1, 34, 21, 1000, 1001]中:
- 前三个元素
1, 34, 21仍然是 1-gram 特征;
- 新增的
1000, 1001是 2-gram 特征(对应两个相邻词对)。
- 1001代表"敲动"和"我心"共同出现且相邻(那么,最后原始的数值映射列表 [1, 34, 21] 添加了 bi-gram 特征之后就变成了 [1, 34, 21, 1000, 1001]。)
# 一般n-gram中的n取2或者3,这里取2为例
ngram_range = 2
def create_ngram_set(input_list):
"""
description: 从数值列表中提取所有的n-gram特征
:param input_list: 输入的数值列表,可以看作是词汇映射后的列表,里面每个数字的取值范围为[1,25000]
:return: n-gram特征组成的集合
eg:
"""
return set(zip(*[input_list[i:] for i in range(ngram_range)]))
# 调用
input_list = [1, 3, 2, 1, 5, 3]
res = create_ngram_set(input_list)
print(res)
输出结果:
{(1, 3), (3, 2), (2, 1), (1, 5), (5, 3)}
代码详解:
- 对于输入列表
input_list = [1, 3, 2, 1, 5, 3]和ngram_range = 2,[input_list[i:] for i in range(2)]会生成两个子列表:
input_list[0:] → [1, 3, 2, 1, 5, 3](原列表)input_list[1:] → [3, 2, 1, 5, 3](原列表右移 1 位)
这一步的作用是为后续生成相邻元素对做准备。
-
zip(*[子列表1, 子列表2]) 相当于将多个子列表的对应位置元素 “压缩” 成元组。
-
对于上述两个子列表:
zip([1, 3, 2, 1, 5, 3], [3, 2, 1, 5, 3])
会生成元组:(1, 3), (3, 2), (2, 1), (1, 5), (5, 3)。
注意:zip会以最短列表长度为准,因此最后一个元素3被忽略。
- 将上述元组转为集合
{(1, 3), (3, 2), (2, 1), (1, 5), (5, 3)},自动去重(本例中无重复)。
- 对于输入
[1, 3, 2, 1, 5, 3],函数返回:
{(1, 3), (3, 2), (2, 1), (1, 5), (5, 3)}
- 每个元组代表一个bi-gram(2-gram)特征,即相邻两个元素的组合。
- 当
ngram_range = 3时:
- 子列表会变为
[input_list[0:], input_list[1:], input_list[2:]](3 个子列表,右移 0、1、2 位)。
zip会将这 3 个子列表的对应位置元素压缩成三元组,生成所有连续的 3 元素组合(tri-gram)。
一般模型的输入需要等尺寸大小的矩阵,因此在进入模型前需要对每条文本数值映射后的长度进行规范,此时将根据句子长度分布分析出覆盖绝大多数文本的合理长度,对超长文本进行截断,对不足文本进行补齐(一般使用数字 0),这个过程就是文本长度规范。
from tensorflow.keras.preprocessing import sequence
# cutlen根据数据分析中句子长度分布,覆盖90%左右语料的最短长度。
# 这里假定cutlen为10
cutlen = 10
def padding(x_train):
"""
description: 对输入文本张量进行长度规范
:param x_train: 文本的张量表示,形如:[[1, 32, 32, 61], [2, 54, 21, 7, 19]]
:return: 进行截断补齐后的文本张量表示
"""
# 使用sequence.pad_sequences即可完成
return sequence.pad_sequences(x_train, cutlen)
# 假定x_train里面有两条文本,一条长度大于10,一条小于10
x_train = [[1, 23, 5, 32, 55, 63, 2, 21, 78, 32, 23, 1], [2, 32, 1, 23, 1]]
res = padding(x_train)
print(res)
# 假定x_train里面有两条文本,一条长度大于10,一条小于10
x_train = [[1, 23, 5, 32, 55, 63, 2, 21, 78, 32, 23, 1], [2, 32, 1, 23, 1]]
res = padding(x_train)
print(res)
输出效果:
[[ 5 23 5 32 55 63 2 21 78 32]
[ 0 0 0 0 0 2 32 1 23 1]]
- 学习了文本特征处理的作用:
文本特征处理包括为语料添加具有普适性的文本特征,如:n-gram 特征,以及对加入特征之后的文本语料进行必要的处理,如:长度规范。这些特征处理工作能够有效的将重要的文本特征加入模型训练中,增强模型评估指标。
- 学习了常见的文本特征处理方法:
- 学习了什么是 n-gram 特征:
给定一段文本序列,其中 n 个词或字的相邻共现特征即 n-gram 特征,常用的 n-gram 特征是 bi-gram 和 tri-gram 特征,分别对应 n 为 2 和 3。
- 学习了提取 n-gram 特征的函数:create_ngram_set
- 学习了文本长度规范及其作用:
一般模型的输入需要等尺寸大小的矩阵,因此在进入模型前需要对每条文本数值映射后的长度进行规范,此时将根据句子长度分布分析出覆盖绝大多数文本的合理长度,对超长文本进行截断,对不足文本进行补齐(一般使用数字 0),这个过程就是文本长度规范。
- 学习了文本长度规范的实现函数:padding
- 了解文本数据增强的作用。
- 掌握实现常见的文本数据增强的具体方法。
回译数据增强目前是文本数据增强方面效果较好的增强方法,一般基于 google 翻译接口,将文本数据翻译成另外一种语言(一般选择小语种),之后再翻译回原语言,即可认为得到与原语料同标签的新语料,新语料加入到原数据集中即可认为是对原数据集数据增强。
操作简便,获得新语料质量高。
在短文本回译过程中,新语料与原语料可能存在很高的重复率,并不能有效增大样本的特征空间。
进行连续的多语言翻译,如:中文 -> 韩文 -> 日语 -> 英文 -> 中文,根据经验,最多只采用 3 次连续翻译,更多的翻译次数将产生效率低下,语义失真等问题。
谷歌翻译
做个了解就行,不推荐使用
googletrans 使用的是 Google 翻译的非官方 API,可能会被 Google 限制访问。
从 2023 年起,googletrans 库的 translate 方法变成了异步函数,必须用await关键字调用,直接同步调用会返回协程对象而不是翻译结果。
谷歌翻译在国内可能存在访问限制,需要梯子。否则会报错:httpx.ConnectError
代码示例:
# 假设取两条已经存在的正样本和两条负样本
# 将基于这四条样本产生新的同标签的四条样本
p_sample1 = "酒店设施非常不错"
p_sample2 = "这家价格很便宜"
n_sample1 = "拖鞋都发霉了,太差了"
n_sample2 = "电视不好用,没有看到足球"
# 导入google翻译接口工具
from googletrans import Translator
# 实例化翻译对象
translator = Translator()
# 进行第一次批量翻译,翻译目标是韩语
translations = translator.translate([p_sample1, p_sample2, n_sample1, n_sample2], dest='ko')
# 获得翻译后的结果
ko_res = list(map(lambda x: x.text, translations))
# 打印结果
print("中间翻译结果:")
print(ko_res)
# 最后再翻译回中文,完成回译全部流程
translations = translator.translate(ko_res, dest='zh-cn')
cn_res = list(map(lambda x: x.text, translations))
print("回译得到的增强数据:")
print(cn_res)
输出效果:
中间翻译结果:
['호텔 시설은 매우 좋습니다', '이 가격은 매우 저렴합니다', '슬리퍼가 모두 곰팡이가 나서 너무 나쁩니다', 'TV가 작동하지 않아 축구를 보지 못했습니다']
回译得到的增强数据:
['酒店设施非常好', '这个价格非常便宜', '拖鞋都发霉了,太糟糕了', '电视坏了,没看足球']
由于 googletrans 调用的是谷歌翻译的免费 API,可能会有频率限制或 IP 封禁风险。如果需要稳定使用,建议考虑:
- 使用谷歌云翻译的官方付费 API
- 改用其他翻译服务如百度翻译、DeepL 等
- 添加适当的延时逻辑避免频繁调用
translate 是一个轻量型翻译库,默认调用的是 Google 翻译,但:
- 可能因网络问题无法连接到翻译服务器,直接返回原文;
- 对中文的支持不完善,尤其是在未指定源语言时容易识别错误。
# 假设取两条已经存在的正样本和两条负样本
# 将基于这四条样本产生新的同标签的四条样本
p_sample1 = "酒店设施非常不错"
p_sample2 = "这家价格很便宜"
n_sample1 = "拖鞋都发霉了,太差了"
n_sample2 = "电视不好用,没有看到足球"
from translate import Translator
translator_zh_ko = Translator(from_lang="zh-CN", to_lang="ko")
# 进行第一次批量翻译,翻译目标是韩语
# 获得翻译后的结果
ko_res = list(map(lambda x: translator_zh_ko.translate(x), [p_sample1, p_sample2, n_sample1, n_sample2]))
# 打印结果
print("中间翻译结果:")
print(ko_res)
# 最后再翻译回中文,完成回译全部流程
translator_ko_zh = Translator(from_lang="ko", to_lang="zh-CN")
cn_res = list(map(lambda x: translator_ko_zh.translate(x), ko_res))
print("回译得到的增强数据:")
print(cn_res)
中间翻译结果:
['매우 좋은 호텔 시설', '이 숙소는 매우 저렴합니다.', '슬리퍼에 곰팡이가 생겼어요. 아쉽네요.', 'TV가 잘 작동하지 않았고 축구를 보지 못했습니다.']
回译得到的增强数据:
['酒店设施非常好', '这个地方非常实惠。', '我的拖鞋发霉了,真可惜。', '电视不太好,我没有看足球比赛。']
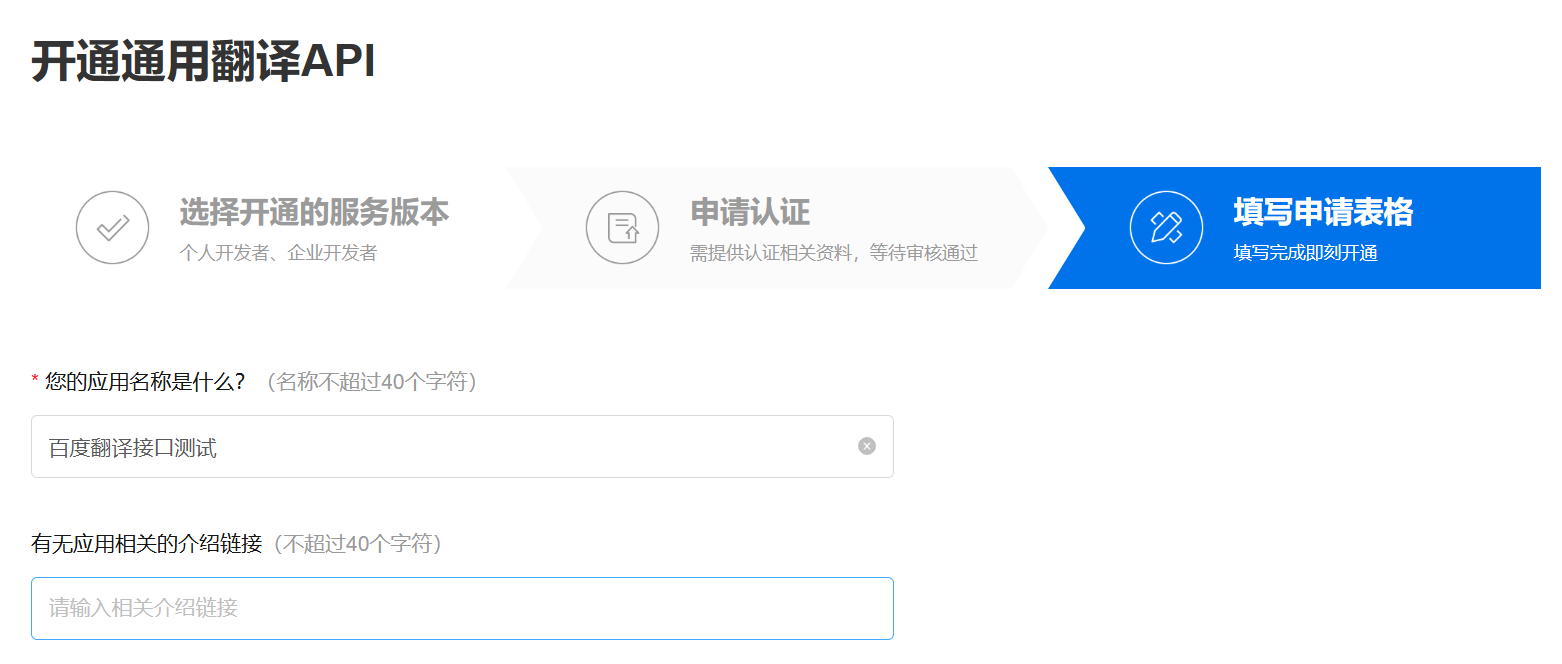
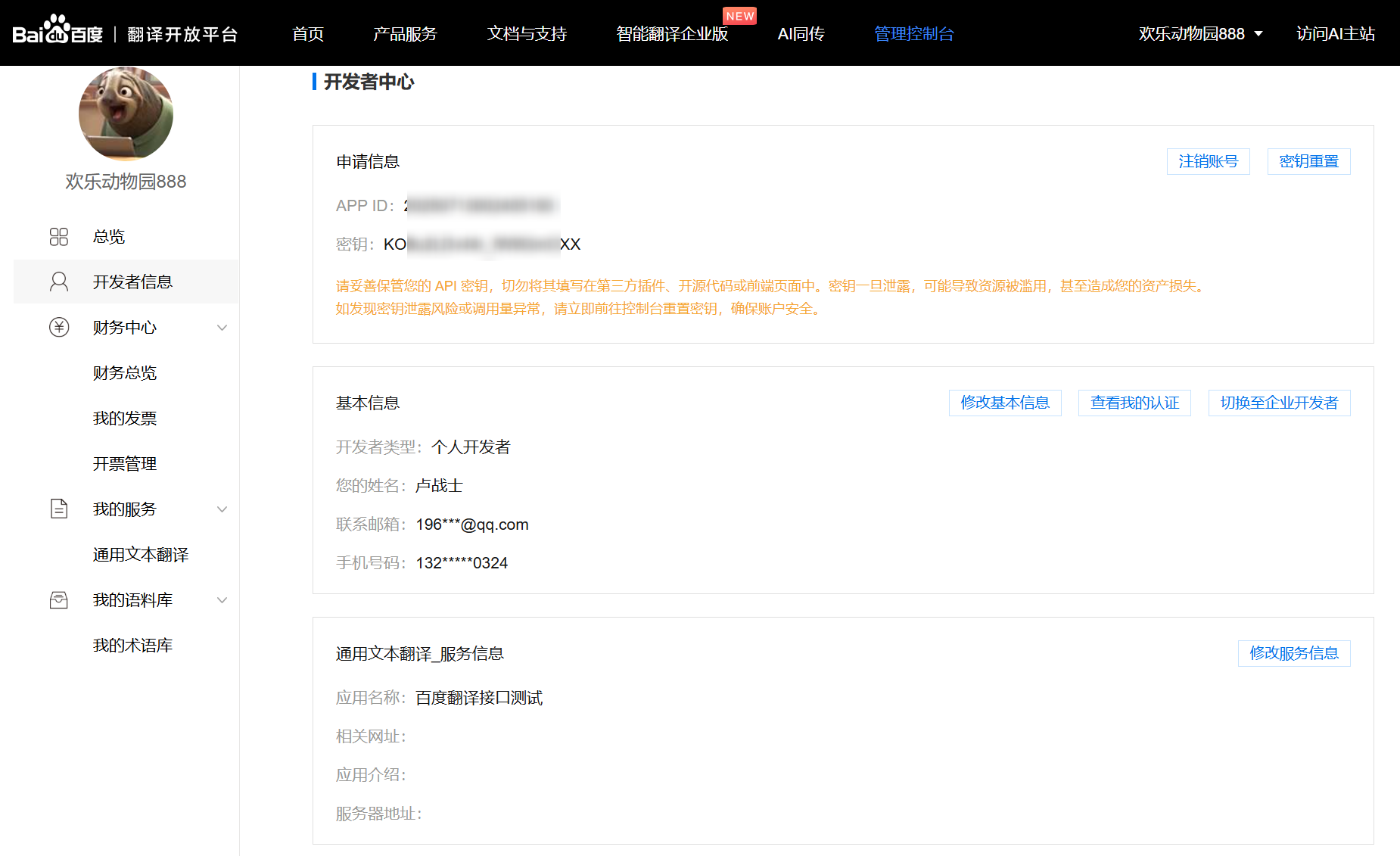
- 访问 百度翻译开放平台,注册账号并创建应用,获取
APP ID 和 密钥(免费版有调用次数限制,足够测试使用)。
详细步骤参照:百度翻译开发者账号申请
import requests
import random
import json
from hashlib import md5
def translate(from_lang, to_lang, text):
# Generate salt and sign
def make_md5(s, encoding='utf-8'):
return md5(s.encode(encoding)).hexdigest()
salt = random.randint(32768, 65536)
sign = make_md5(appid + text + str(salt) + appkey)
# Build request
headers = {'Content-Type': 'application/x-www-form-urlencoded'}
payload = {'appid': appid, 'q': text, 'from': from_lang, 'to': to_lang, 'salt': salt, 'sign': sign}
# Send request
r = requests.post(url, params=payload, headers=headers)
result = r.json()
# Show response
# print(json.dumps(result, indent=4, ensure_ascii=False))
return result
if __name__ == '__main__':
appid = '20250713002405193'
appkey = 'KO8u2LDv44r_fW9GmOXX'
endpoint = 'http://api.fanyi.baidu.com'
path = '/api/trans/vip/translate'
url = endpoint + path
p_sample1 = "酒店设施非常不错"
p_sample2 = "这家价格很便宜"
n_sample1 = "拖鞋都发霉了,太差了"
n_sample2 = "电视不好用,没有看到足球"
# 进行第一次批量翻译,翻译目标是韩语
# 获得翻译后的结果
ko_res = list(map(lambda x: translate('zh', 'kor', x), [p_sample1, p_sample2, n_sample1, n_sample2]))
# 打印结果
print("中间翻译结果:")
print(ko_res)
# 最后再翻译回中文,完成回译全部流程
# 提取韩语翻译结果
ko_texts = [item['trans_result'][0]['dst'] for item in ko_res]
# 回译成中文
cn_res = list(map(lambda x: translate('kor', 'zh', x), ko_texts))
print("回译得到的增强数据:")
print(cn_res)
中间翻译结果:
[{'from': 'zh', 'to': 'kor', 'trans_result': [{'src': '酒店设施非常不错', 'dst': '호텔 시설이 아주 좋아요.'}]}, {'from': 'zh', 'to': 'kor', 'trans_result': [{'src': '这家价格很便宜', 'dst': '이 집은 가격이 매우 싸다'}]}, {'from': 'zh', 'to': 'kor', 'trans_result': [{'src': '拖鞋都发霉了,太差了', 'dst': '슬리퍼 에 곰팡이 가 슬어 너무 나쁘다'}]}, {'from': 'zh', 'to': 'kor', 'trans_result': [{'src': '电视不好用,没有看到足球', 'dst': '텔레비전이 좋지 않아 축구공을 보지 못했다'}]}]
回译得到的增强数据:
[{'from': 'kor', 'to': 'zh', 'trans_result': [{'src': '호텔 시설이 아주 좋아요.', 'dst': '酒店设施很好。'}]}, {'from': 'kor', 'to': 'zh', 'trans_result': [{'src': '이 집은 가격이 매우 싸다', 'dst': '这房子价格很便宜'}]}, {'from': 'kor', 'to': 'zh', 'trans_result': [{'src': '슬리퍼 에 곰팡이 가 슬어 너무 나쁘다', 'dst': '拖鞋发霉了,太坏了'}]}, {'from': 'kor', 'to': 'zh', 'trans_result': [{'src': '텔레비전이 좋지 않아 축구공을 보지 못했다', 'dst': '电视不好,没看到足球'}]}]
- 学习了常见的文本数据增强方法:
回译数据增强法
- 学习了什么是回译数据增强法:
回译数据增强目前是文本数据增强方面效果较好的增强方法,一般基于 google 翻译接口,将文本数据翻译成另外一种语言(一般选择小语种),之后再翻译回原语言,即可认为得到与原语料同标签的新语料,新语料加入到原数据集中即可认为是对原数据集数据增强。
- 学习了回译数据增强优势:
操作简便,获得新语料质量高。
- 学习了回译数据增强存在的问题:
在短文本回译过程中,新语料与原语料可能存在很高的重复率,并不能有效增大样本的特征空间。
- 学习了高重复率解决办法:
进行连续的多语言翻译,如:中文 -> 韩文 -> 日语 -> 英文 -> 中文,根据经验,最多只采用 3 次连续翻译,更多的翻译次数将产生效率低下,语义失真等问题。
- 学习了回译数据增强实现。
附录
百度翻译开发者账号申请
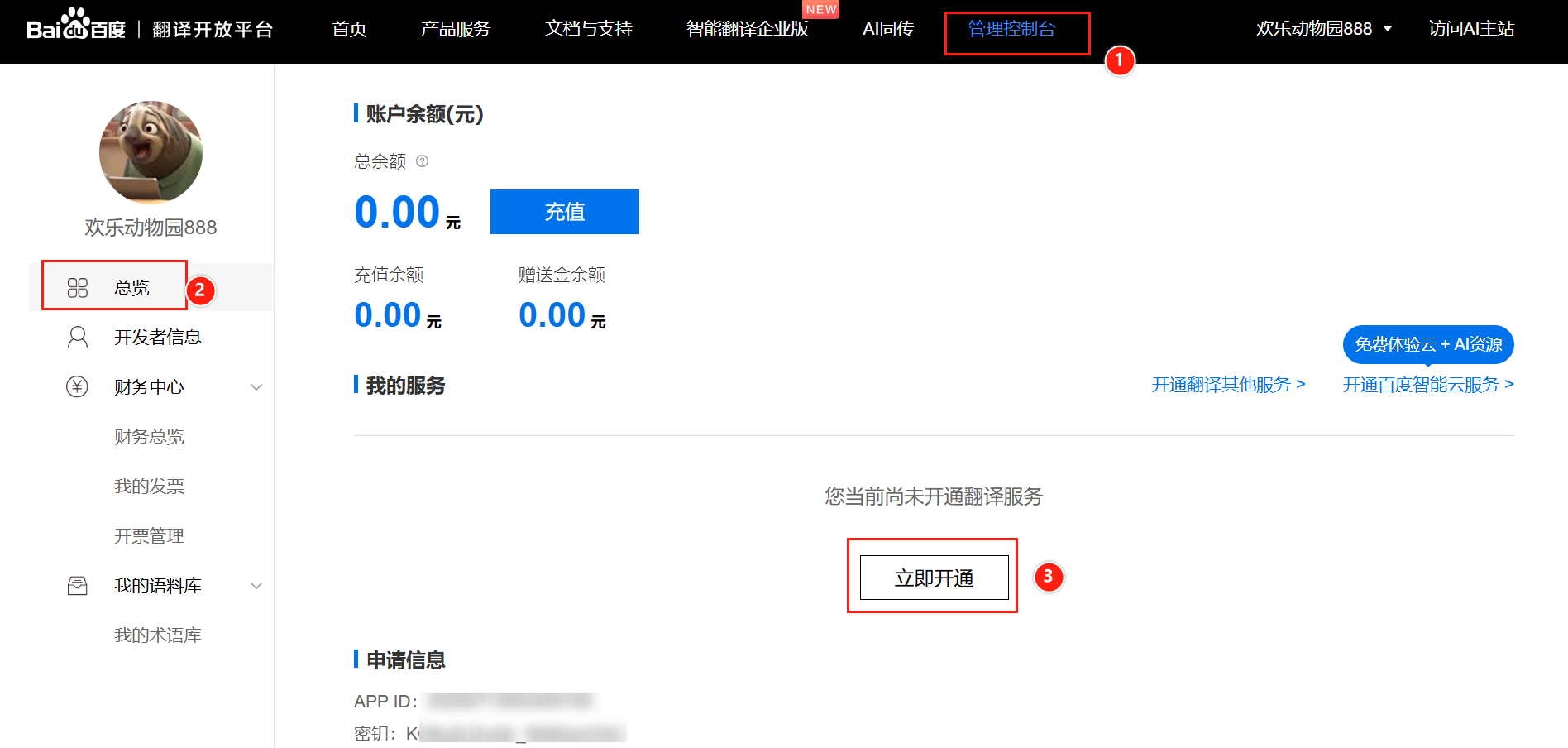
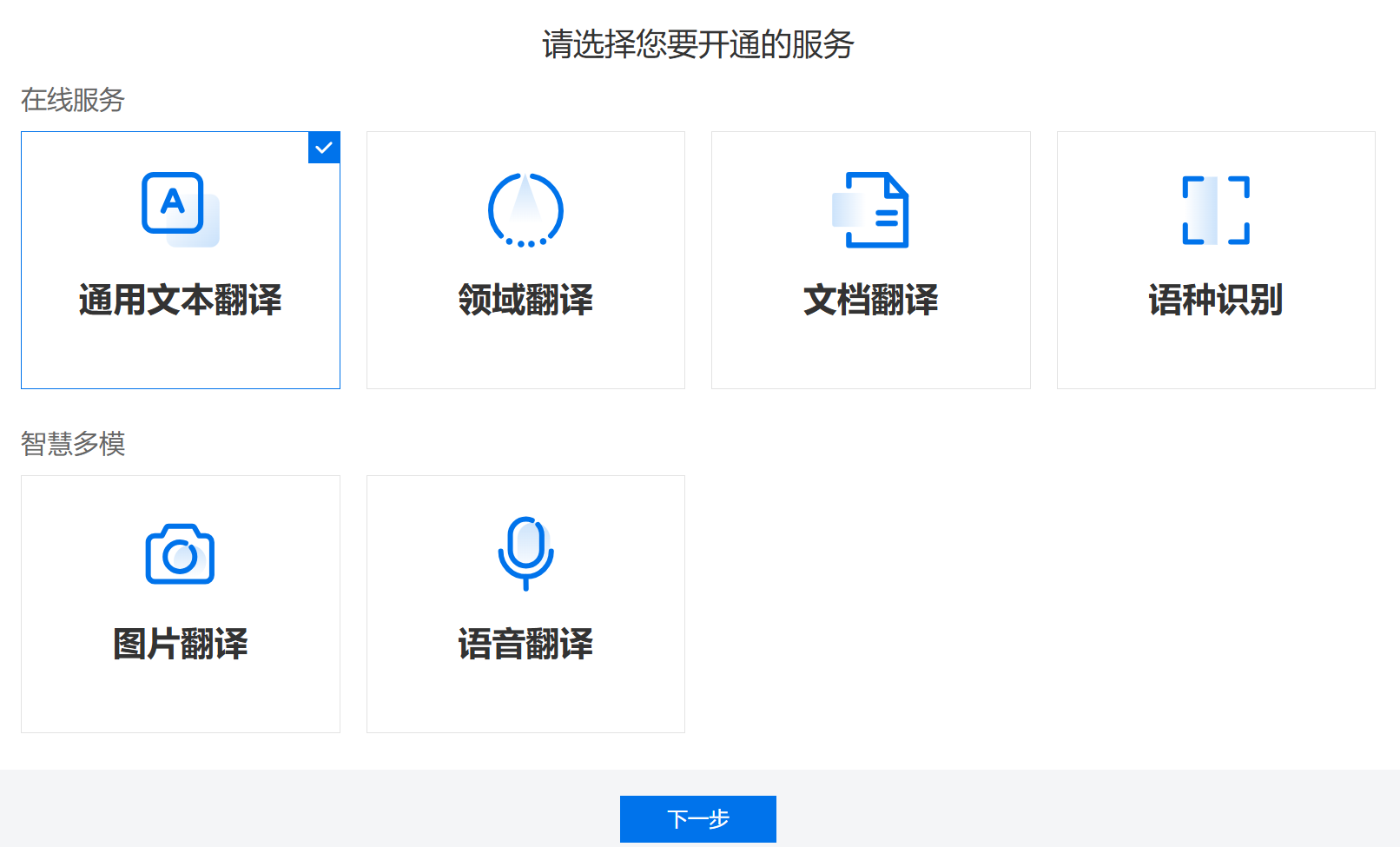
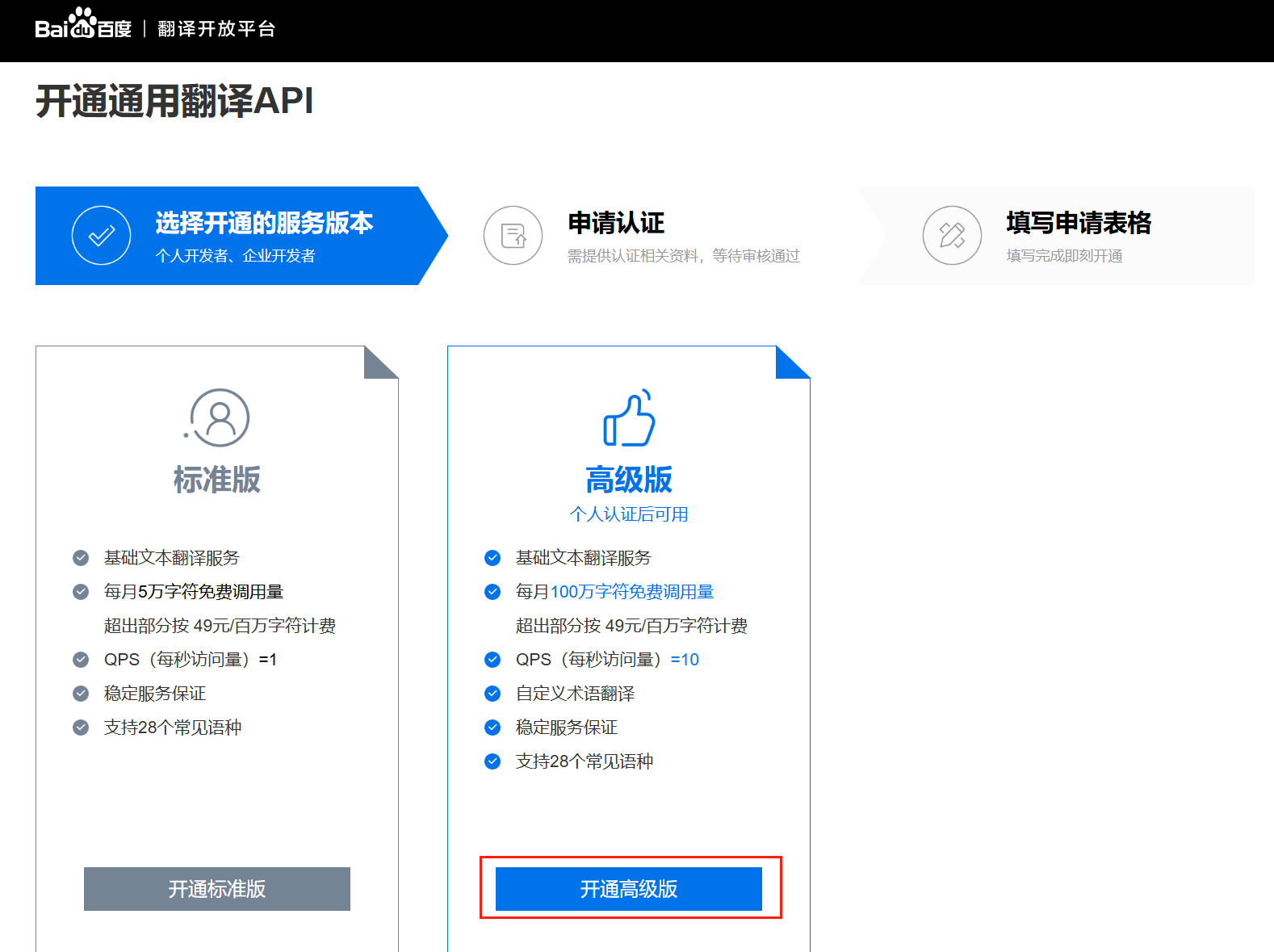
认证成功之后:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号