0.自然语言处理(NLP)学习路径与避坑
常见误区:
- 不要从零实现Transformer(先理解架构)
- 避免死磕数学公式(先掌握API调用)
NLP核心技术(4-6周)
| 技术模块 | 推荐资源 |
|---|---|
| 词嵌入 | Word2Vec论文精读 |
| RNN/LSTM | Colah's LSTM详解 |
| Transformer | The Illustrated Transformer |
| BERT/预训练模型 | Hugging Face课程(免费实践平台) |
学习路线图
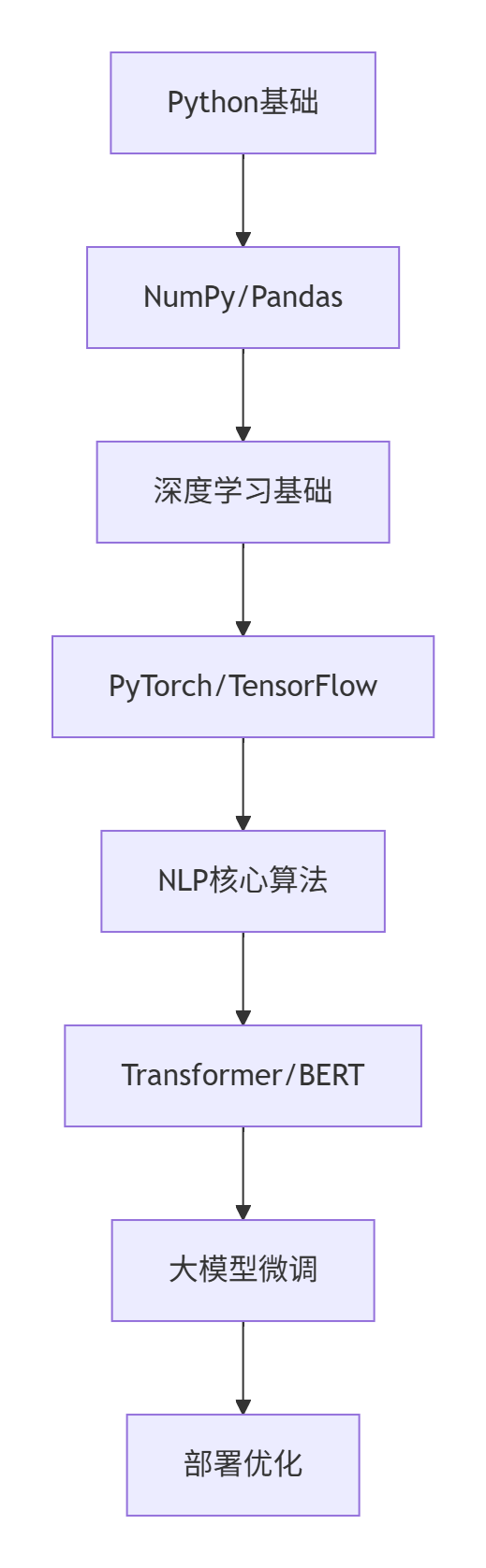
建议学习节奏:
每周10小时 → 3个月可达到:
✅ 文本分类/情感分析
✅ 命名实体识别
✅ 使用LangChain构建问答系统
附加福利:
最新NLP学习包(含中文预训练模型+实战代码)
2021教程的价值与局限性分析
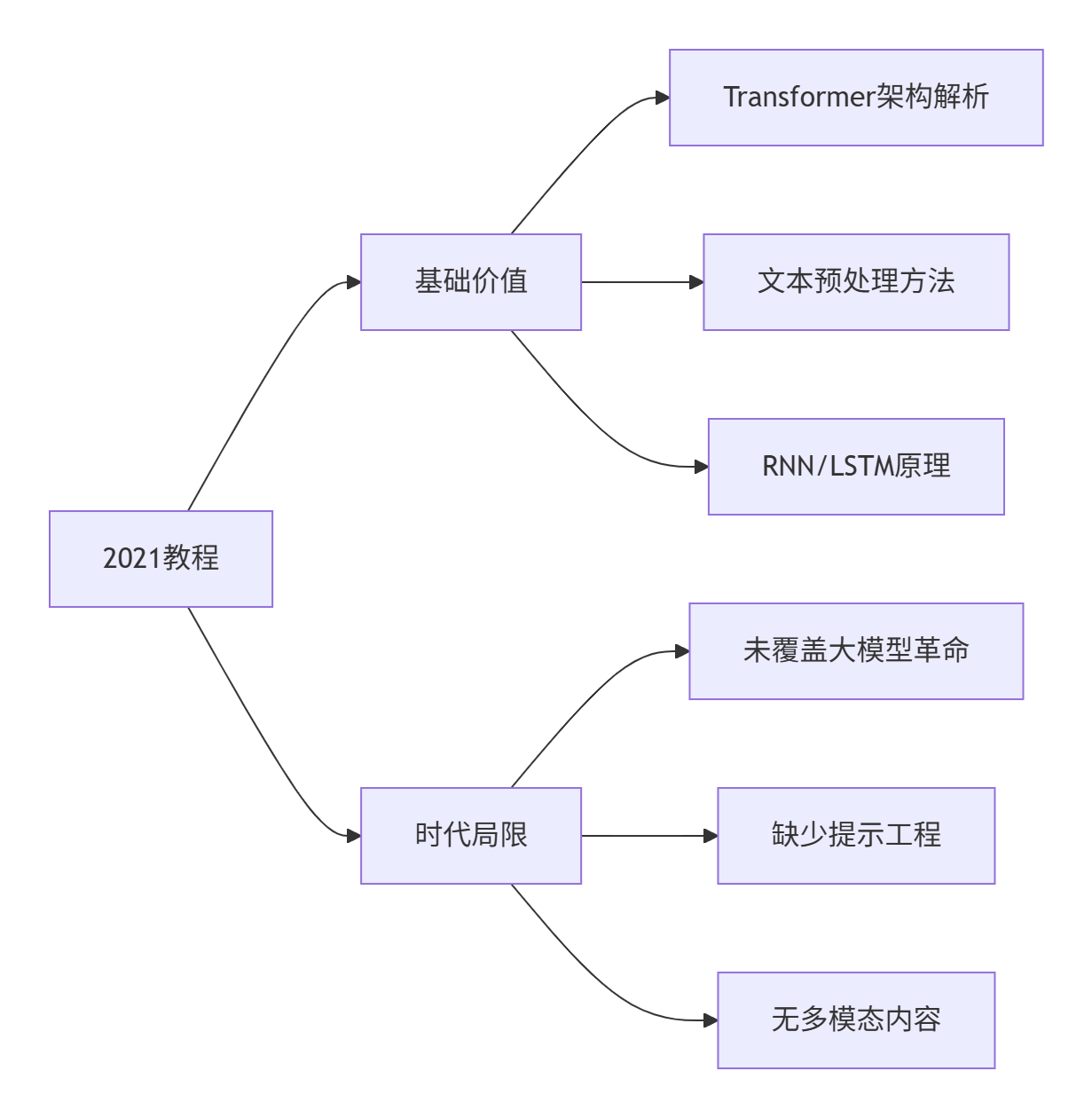
基础价值(仍要学习):
- 文本预处理:分词/标准化技术仍是核心
- HMM/CRF:序列建模的数学基础
- RNN/LSTM:理解梯度消失问题的经典方案
- Transformer:当前所有大模型的基础架构
重大缺失(需重点补充):
- GPT/LLM革命:ChatGPT(2022)、DeepSeek(2023)等技术突破
- 提示工程:zero-shot/few-shot新范式
- 大模型微调技术:LoRA/QLoRA等高效方法
- AI代理系统:AutoGPT、LangChain等新框架
- 多模态模型:文本与图像/语音的融合(CLIP、Whisper)
必须补充的2021-2024关键内容
大型语言模型(LLM)技术栈
| 技术模块 | 核心内容 | 学习资源 |
|---|---|---|
| 架构演进 | GPT-3 → GPT-4 → Mixtral → DeepSeek | LLM发展报告 |
| 提示工程 | CoT思维链、指令微调 | OpenAI Cookbook |
| 高效微调 | LoRA/QLoRA参数优化 | Hugging Face PEFT |
| 部署优化 | vLLM推理加速、GGML量化 | DeepSeek部署指南 |
重大技术变革清单
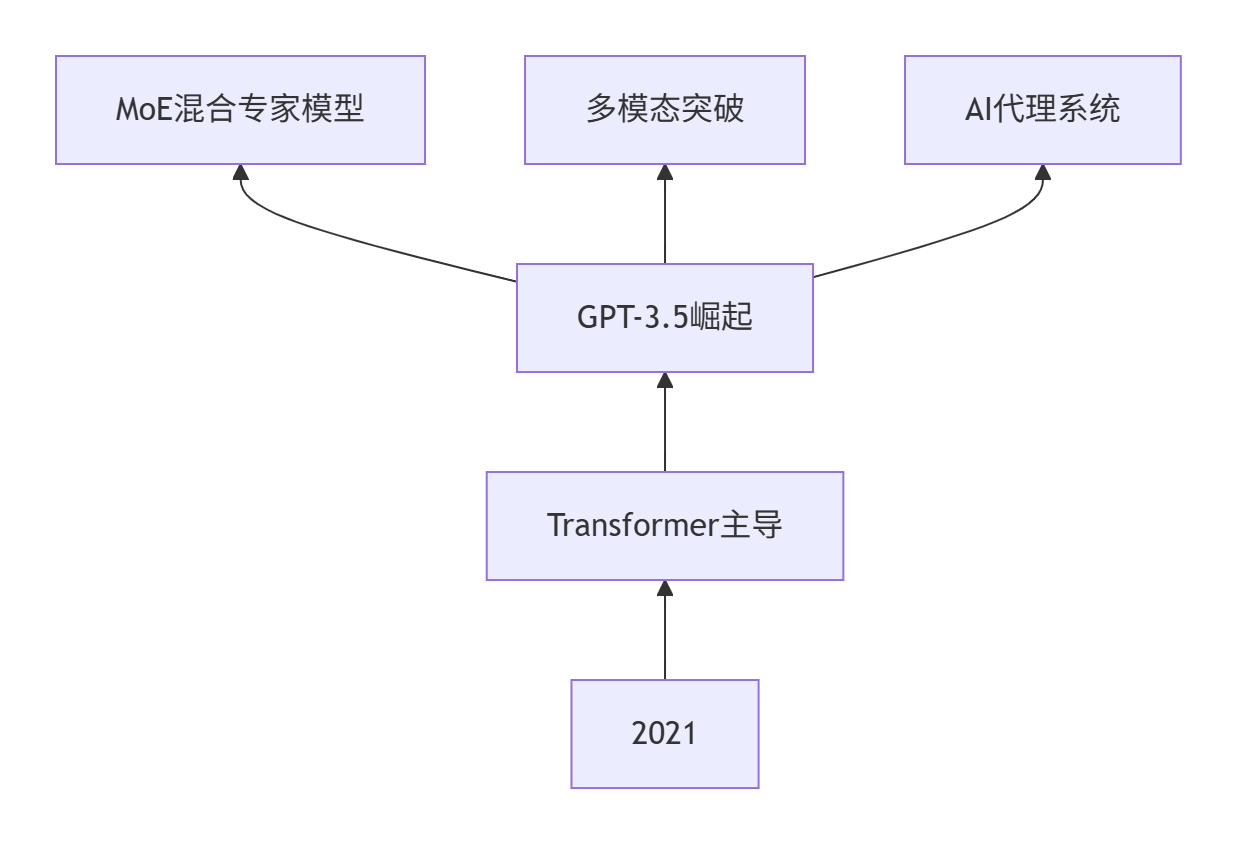
推荐学习路线(2024升级版)
阶段1:基础强化(1-2周)
精读原教程:
- 重点:Transformer实现细节
- 延伸:实现简化版BERT
阶段2:LLM革命(3-4周)
大模型核心:
- Hugging Face NLP课程 - 2024新版
- DeepSeek技术白皮书
新旧知识衔接策略
Transformer升级路径:
基础Transformer → 位置编码改进 → 稀疏注意力 → MoE架构RNN到LLM的演进:

项目迁移示范:
-
- 2021版:基于LSTM的情感分析
- 2024版:使用DeepSeek完成zero-shot情感分析
技术变革影响评估
仅学2021教程会缺失的能力:
- ❌ 大模型提示工程技巧
- ❌ 百亿参数模型微调能力
- ❌ AI代理系统开发经验
- ❌ 多模态融合应用能力
但仍能获得的基础优势:
- ✅ 深入理解注意力机制
- ✅ 掌握文本处理核心方法
- ✅ 具备模型改造的基础能力
关键结论:基础教程仍有50%的价值,但必须配合2023-2024新内容学习才能达到行业要求
学习资源推荐(免费&最新)
-
中文优先资源:
- DeepSeek学习社区
- 李宏毅2024大模型课程
- 清华大学ChatGPT原理拆解
-
实战平台:
建议学习配比:pie
title 学习时间分配
“2021教程” : 30
“大模型技术” : 50
“AI代理开发” : 20
通过这样的学习路径,您不仅能补齐技术缺口,还能在6-8周内达到可开发行业应用的LLM工程师水平。
避坑指南
- 硬件要求:
- 入门:Google Colab免费GPU
- 进阶:RTX 3060(12GB显存)可跑BERT-base
🛡️ NLP 学习避坑指南:硬件配置终极建议(2024 版)
简短回答:
对大多数学习者,前期完全不需要购买显卡!
下面我从投入产出比、学习路径和技术趋势角度详细分析:
一、学习阶段 vs 硬件需求对比表
| 学习阶段 | 推荐方案 | 成本 | 可运行任务 | 是否需要买显卡? |
|---|---|---|---|---|
| 基础理论 | CPU + Colab 备用 | ¥0 | 文本预处理、小模型推理 | ❌ 完全不需要 |
| 模型微调入门 | Colab (免费 GPU) | ¥0 | BERT-base、小型 LSTM | ❌ 不需要 |
| 进阶实战 | 云平台 (¥0.5~2/小时) | ~¥200/月 | 微调 GPT-2、LLaMA-7B | ⚠️ 可暂缓 |
| 研究开发 | RTX 3060 12G | ¥2000 | 微调 13B 模型、多模态训练 | ✅ 建议购买 |
| 生产部署 | RTX 4090 / A100 租赁 | ¥1.5万+ | 百亿参数模型全量微调 | 💡 按需租赁 |
二、为什么前期不需要买显卡?(省下 ¥2000+ 的科学决策)
1. 免费资源完全够用
-
Google Colab:
- 免费 Tesla T4 GPU(15GB 显存)
- 可运行:BERT-large、GPT-2、Flan-T5
- 实操案例:
# 在Colab微调BERT
!pip install transformers
from transformers import BertTokenizer, BertForSequenceClassification
model = BertForSequenceClassification.from_pretrained('bert-base-uncased')
# 直接在免费GPU上训练
model.train() -
Kaggle:
- 每周 30 小时 P100 GPU
- 支持多卡并行训练
-
Hugging Face:免费部署 10GB 模型
2. 技术迭代太快

当前趋势:算法优化 > 硬件堆砌
- QLoRA 技术让 7B 模型可在 12GB 显存运行
- DeepSeek-Coder 1B 模型性能接近 GPT-3
3. 学习焦点错位风险
pie
title 显卡购买后的时间分配
“调试环境” : 45
“解决驱动问题” : 30
“实际学习” : 25
三、什么时候该买显卡?(决策树)
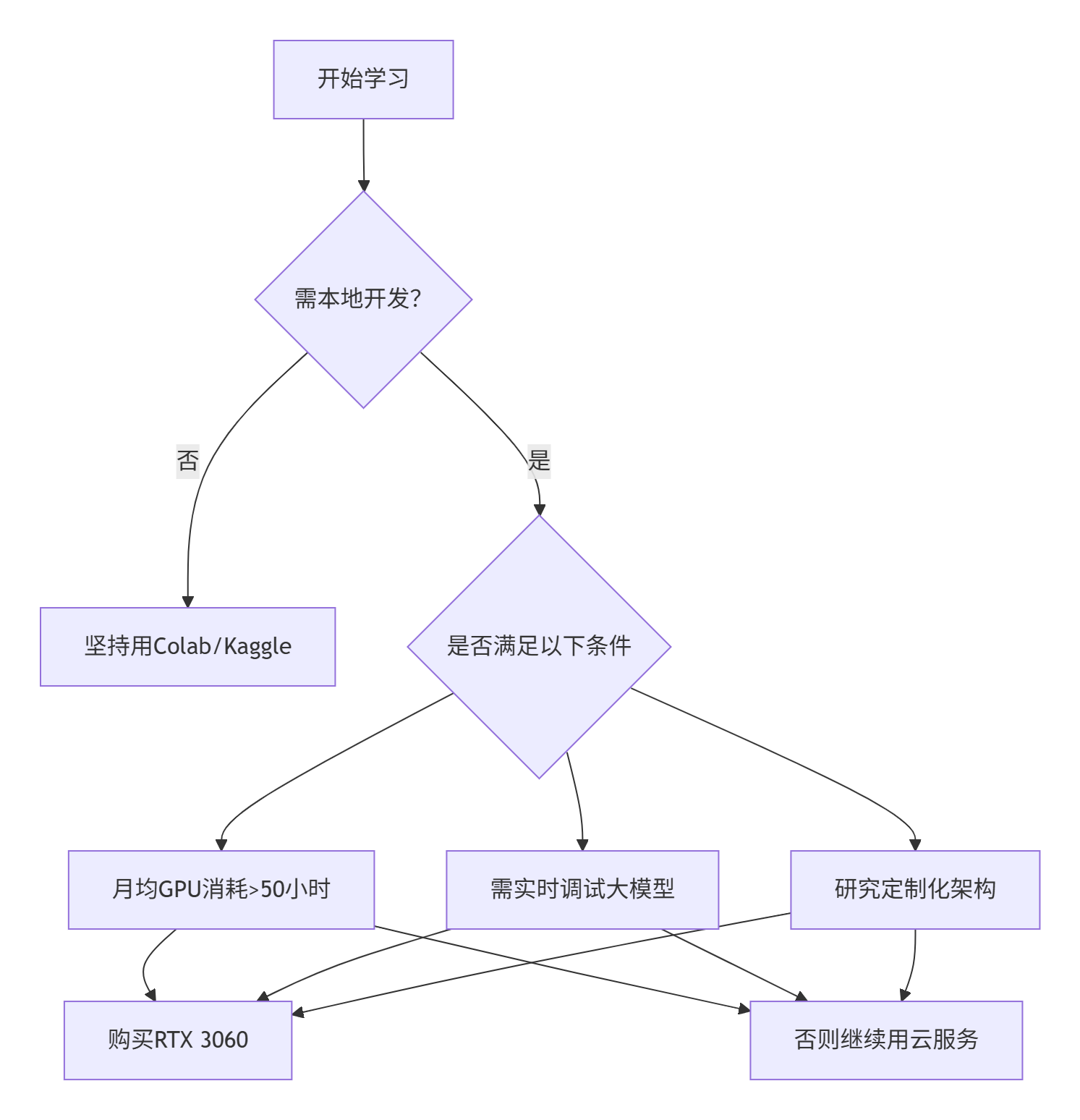
购买建议(2024性价比方案)
| 需求 | 推荐配置 | 价格 | 适用场景 |
|---|---|---|---|
| 基础学习 | 二手 RTX 3060 12G | ¥1600 | 微调7B模型 |
| 多模态开发 | 全新 RTX 4060 Ti 16G | ¥3200 | LLaVA多模态训练 |
| 科研级实验 | RTX 4090 + 租云 | ¥13000 + ¥30/小时 | 本地开发+云端训练 |
四、完全免费的替代方案(实测有效)
1. 组合使用教程
# 方案:Colab开发 + Hugging Face部署
# 开发阶段
from google.colab import drive
drive.mount('/content/drive') # 挂载Google Drive存模型
# 训练微调好的模型
model.save_pretrained('/content/drive/llama-ft')
# 部署阶段
from huggingface_hub import upload_file
upload_file('/content/drive/llama-ft', repo_id="your-username/llama-ft")2. 云平台成本控制
| 平台 | 成本 | 适用阶段 |
|---|---|---|
| Vast.ai | $0.1/小时 (RTX 3090) | 周末突击训练 |
| Lambda Labs | $0.3/小时 (A10) | 论文复现 |
| 阿里云PAI | ¥1.2/小时 (V100) | 国内稳定环境 |
3. 学生福利(重点!)
- GitHub Student Pack:
- Azure $100 额度
- Datadog $100 云服务
- 教育邮箱申请:
- Google Cloud $300 赠金
- AWS Educate $150 额度
五、决策流程图
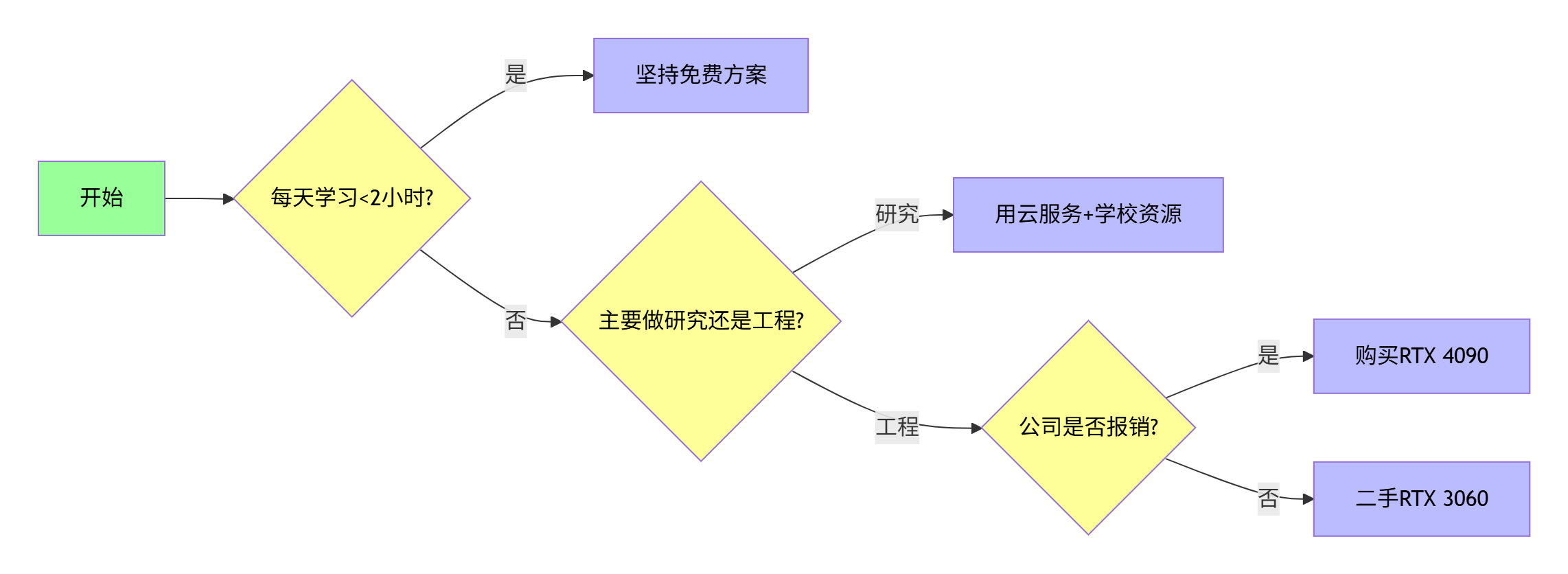
最终建议:
- 前3个月:100% 使用 Colab + Kaggle
- 第4-6个月:按需使用 Vast.ai 云服务(约 ¥200)
- 稳定投入研究后:购买 RTX 4060 Ti 16G(¥3200)
💡 真理时刻:当你用免费资源完成第一个项目后,你会清晰知道自己是否真的需要显卡!在此之前,省下的钱买课程/数据更明智。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号