08.参数初始化
参数初始化可以有效减缓梯度爆炸和梯度消失现象,可以让我们训练层数更多的神经网络。
对于某一个神经元来说,需要初始化的参数有两类:一类是权重W,还有一类是偏置b,偏置b初始化为0即可。而权重W的初始化比较重要,我们着重来介绍常见的初始化方式。
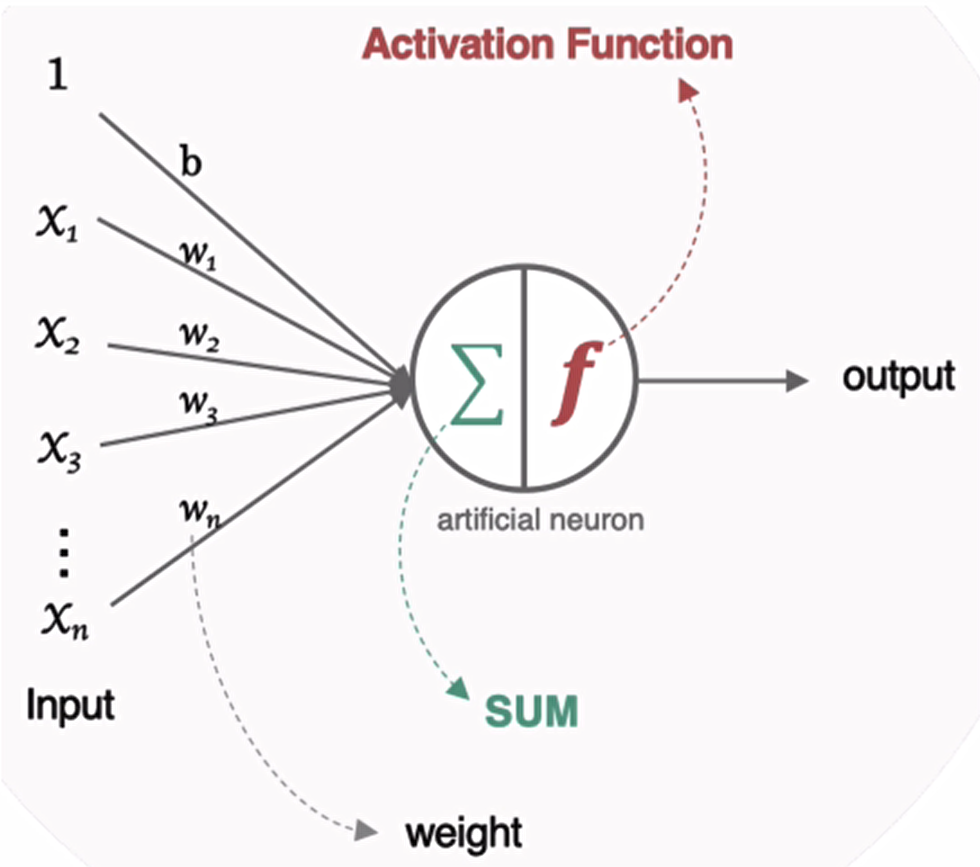
引入
假设一个神经元有三个输入,且b=0:

那么这个映射使用函数就可以表示为:
![]()
在多个神经元的情况下,如果w的初始化值一样,那么就会导致不同神经元的参数值初始化一样,并且变化趋势也一样,神经元的形式就很单一,也就是对称现象:
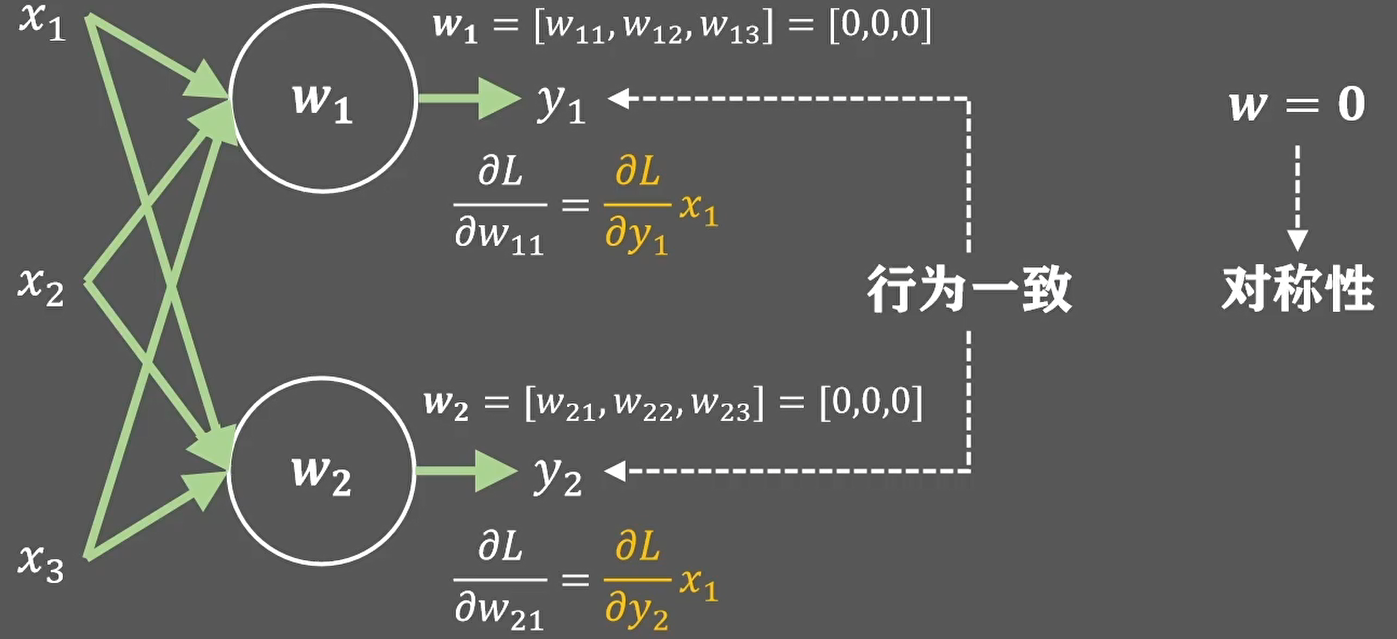
为了避免对称现象的出现,我想需要在参数初始化的时候增加一些随机性,例如在均值为0,方差为1的正态分布里面采样W:
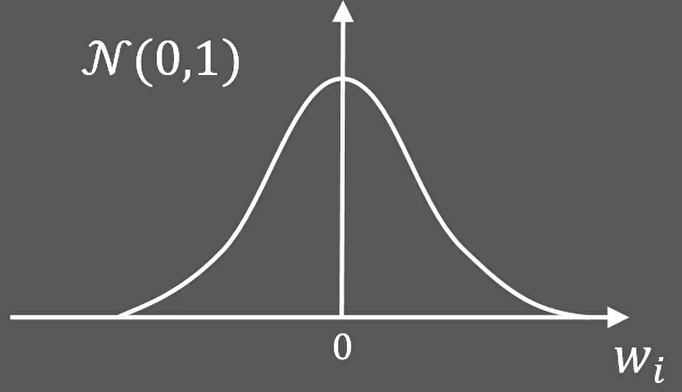
为了方便理解,我们让输入x1,x2,x3都等于1,那么:
![]()
因此,线性输出y的方差也就是这三个随机变量的方差之和等于3:
![]()
那么y的标准差就是√3:
![]()
这也意味着,输入经过神经元之后,输出的离散程度提高了。
如果神经元不止三个输入,而是n个,那么y的标准差,也就是离散程度就会被放大√n倍:

![]()
当我们不使用任何激活函数的时候,放大的y值就会被累积在反向传播的过程里,这样就会造成梯度爆炸。
深入理解其原因参照:为什么不使用激活函数会造成梯度爆炸
而如果我们使用双曲正切函数作为激活函数,那么有可能因为y的值过大或者过小,而得到一个非常小的梯度,这样反而会造成梯度消失问题。

Xavier
所以,为了让神经网络训练过程稳定下来,我们需要将y的方差落在一个可控范围内,例如让它等于1:
![]()
那么要求w分布满足的目标方差就要是1/n:
![]()
如果我们不仅考虑本层输入的维度,还考虑下一层神经元的数量,那么平均值后的方差就等于2除以输入层和输出层神经元的总和:
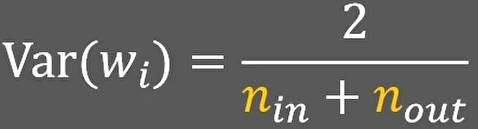
关于上面多层之间的方差累积,不应该是乘积吗?为什么是求和?如果不理解参照文末:多层直接的方差累积,为什么是求和?
现在知道了参数W应该满足的方差,我们就可以使用两种方法来进行参数初始化:
- 正态分布初始化
我们只需要均值为0,反差为目标方差的正态分布中随机采样就可以了:
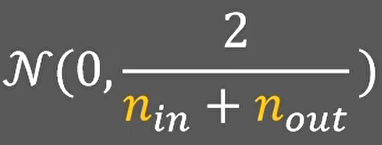
- 均匀分布初始化
为了确定均匀分布的起始点,我们需要知道一些基础知识:当x满足从a到b的均匀分布时,x的方差就等于(b-a)2/12:
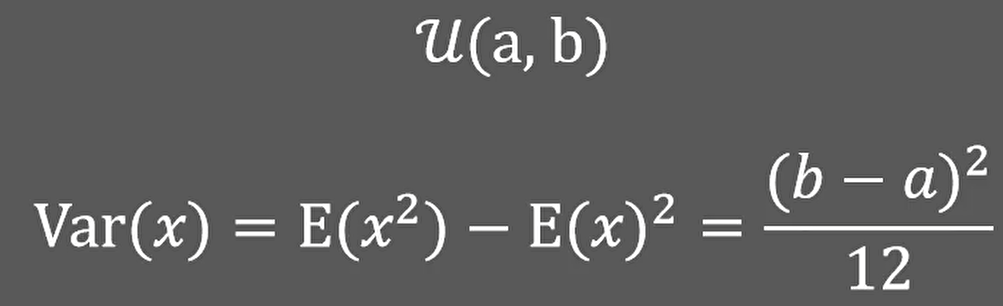
因为需要保证采样的均值为0,所以我们可以写成从-a到a的均匀分布,带人公式后,得到方差为a2/3:
![]()
![]()
已知上述公式,将目标方差带入:
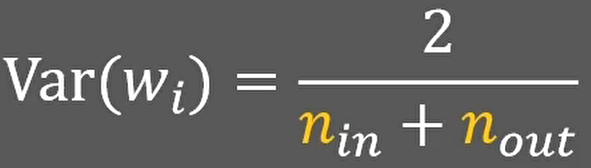
就可以得到初始化参数w使用的均匀分布了:

以上两个初始化分布就是2010年提出的Xavier初始化方法。
he初始化
Xavier参数初始化方法对tanh激活方法非常友好,但是对relu激活方法却非常不如意:
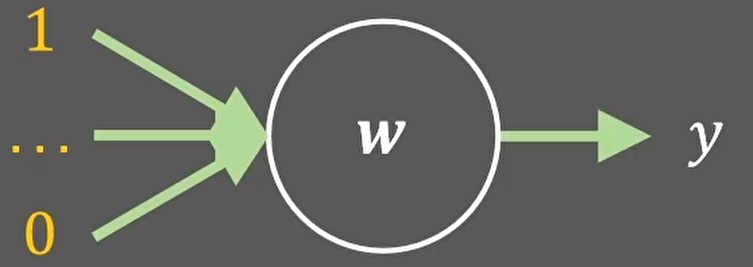
假设我们上层的输入是经过relu处理之后的,那么有一半的输入会变成0:
这样y的方差就会变成:
![]()
因此,要求w分布满足的目标方差也就变成了:
![]()
如果我们使用的leakrelu或者p-relu激活方法,那么w分布满足的目标方差就是:
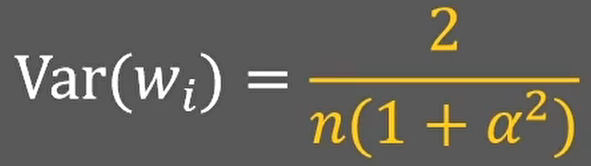
如果α=0,p-relu就退化为relu激活函数,两个方差的式子也就一样了:
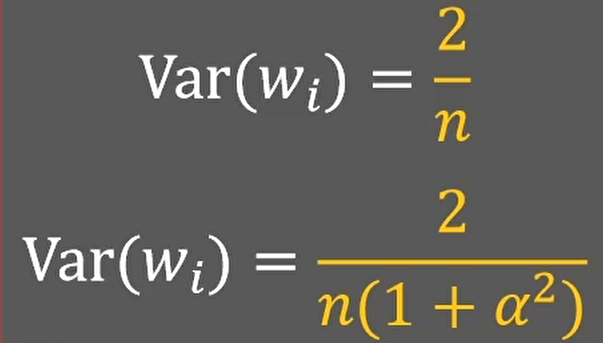
和之前思路一样,我们也可以通过正态分布初始化和均匀分布初始化两种方法来采样w:
- 正态分布初始化

- 均匀分布初始化
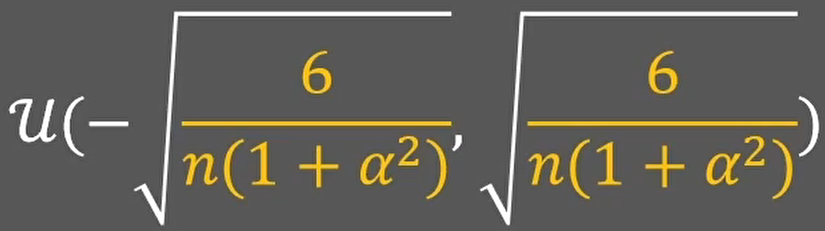
这就是2015年提出的he初始化方法也Kaiming初始化方法。
随机初始化
随机初始化从均值为0,标准差是1的高斯分布中取样,使用一些很小的值对参数W进行初始化。
标准初始化
权重参数初始化从区间均匀随机取值。即在![]() 均匀分布中生成当前神经元的权重,其中d为每个神经元的输入数量。
均匀分布中生成当前神经元的权重,其中d为每个神经元的输入数量。
- :当前层每个神经元的输入连接数(即前一层神经元数量)。
Xavier初始化API
[ˈzeɪvjər],2010年提出
该方法的基本思想是各层的激活值和梯度的方差在传播过程中保持一致,也叫做Glorot初始化。在tf.keras中实现的方法有两种:
- 正态化Xavier初始化:
Glorot 正态分布初始化器,也称为 Xavier 正态分布初始化器。它从以0为中心,标准差为 stddev=sqrt(2 /(fan_in + fan_out))的正态分布中抽取样本,其中 fan_in 是输入神经元的个数, fan_out 是输出的神经元个数。
示例代码:
import tensorflow as tf
# 实例化
initializers=tf.keras.initializers.glorot_normal()
#指定参数维度,并采样得到权重值
values=initializers(shape=(9,1))
# 打印结果
print(values)tf.Tensor(
[[-0.08961562]
[-0.20381981]
[-0.6347338 ]
[ 0.34258437]
[ 0.65838915]
[-0.12559023]
[ 0.36905822]
[-0.02720254]
[ 0.02490802]], shape=(9, 1), dtype=float32)- 标准化Xavier初始化
Glorot 均匀分布初始化器,也称为 Xavier均匀分布初始化器。它从[-limit,limit]中的均匀分布中抽取样本,其中 limit是 sqrt(6/(fan_in + fan_out)),其中 fan_in 是输入神经元的个数, fan_out 是输出的神经元个数。
示例代码:
import tensorflow as tf
# 实例化
initializers=tf.keras.initializers.glorot_uniform()
#指定参数维度,并采样得到权重值
values=initializers(shape=(9,1))
# 打印结果
print(values)tf.Tensor(
[[ 0.5864737 ]
[-0.21126193]
[ 0.21506947]
[-0.07514834]
[ 0.26516378]
[-0.28064796]
[-0.07495058]
[-0.7506803 ]
[-0.09512872]], shape=(9, 1), dtype=float32)He初始化API
2015年提出
he初始化,也称为Kaiming初始化,出自大神何恺明之手,它的基本思想是正向传播时,激活值的方差保持不变;反向传播时,关于状态值的梯度的方差保持不变。在tf.keras中也有两种:
- 正态化的he初始化
He 正态分布初始化是以0为中心,标准差为stddev=sqrt(2/fan_in)的截断正态分布中抽取样本,其中 fan_in 是输入神经元的个数,在tf.keras中的实现方法为:
# 实例化
initializers=tf.keras.initializers.he_normal()
#指定参数维度,并采样得到权重值
values=initializers(shape=(9,1))
# 打印结果
print(values)tf.Tensor(
[[ 0.92333037]
[ 0.46596143]
[ 0.7372162 ]
[-0.4344145 ]
[-0.14783919]
[-0.0793089 ]
[-0.13940148]
[-0.27763277]
[-0.14538212]], shape=(9, 1), dtype=float32)- 标准化的he初始化
He 均匀方差缩放初始化器。它从[-limit,limit]中的均匀分布中抽取样本,其中 limit 是sqrt(6/fan_in),其中 fan_in 输入神经元的个数。实现为:
# 实例化
initializers=tf.keras.initializers.he_uniform()
#指定参数维度,并采样得到权重值
values=initializers(shape=(9,1))
# 打印结果
print(values)tf.Tensor(
[[ 0.26170146]
[ 0.2875104 ]
[-0.7832847 ]
[ 0.21410537]
[ 0.5126947 ]
[-0.38704196]
[-0.2887956 ]
[-0.39889997]
[-0.7302332 ]], shape=(9, 1), dtype=float32)
总结
tanh一般使用Xavier初始化方法
ReLU及其变种一般使用Kaiming初始化方法
补充
为什么不使用激活函数会造成梯度爆炸



多层直接的方差累积,为什么是求和?


 浙公网安备 33010602011771号
浙公网安备 33010602011771号