《绝地求生》玩家排名预测
1 项目背景
---- 你能预测《绝地求生》玩家战斗结束后的排名吗?
绝地求⽣(Player unknown's Battlegrounds),俗称吃鸡,是⼀款战术竞技型射击类沙盒游戏。
这款游戏是⼀款⼤逃杀类型的游戏,每⼀局游戏将有最多100名玩家参与,他们将被投放在绝地岛(battlegrounds)上,在游戏的开始时所有⼈都⼀⽆所有。玩家需要在岛上收集各种资源,在不断缩⼩的安全区域内对抗其他玩家,让⾃⼰⽣存到最后。
本作拥有很⾼的⾃由度,玩家可以体验⻜机跳伞、开越野⻋、丛林射击、抢夺战利品等玩法,⼩⼼四周埋伏的敌⼈,尽可能成为最后1个存活的⼈。

该游戏中,玩家需要在游戏地图上收集各种资源,并在不断缩⼩的安全区域内对抗其他玩家,让⾃⼰⽣存到最后。
2 数据集介绍
本项目中,将为您提供⼤量匿名的《绝地求⽣》游戏统计数据。
其格式为每⾏包含⼀个玩家的游戏后统计数据,列为数据的特征值。
数据来⾃所有类型的⽐赛:单排,双排,四排;不保证每场⽐赛有100名⼈员,每组最多4名成员。
⽂件说明:
- train_V2.csv - 训练集
- test_V2.csv - 测试集
数据集局部图如下图所示:

数据集中字段解释:
- Id [⽤户id]
- Player’s Id
- groupId [所处⼩队id]
- ID to identify a group within a match. If the same group of players plays in different matches, they will have adifferent groupId each time.
- matchId [该场⽐赛id]
- ID to identify match. There are no matches that are in both the training and testing set.
- assists [助攻数]
- Number of enemy players this player damaged that were killed by teammates.
- boosts [使⽤能量,道具数量]
- Number of boost items used.
- damageDealt [总伤害]
- Total damage dealt. Note: Self inflicted damage is subtracted.
- DBNOs [击倒敌⼈数量]
- Number of enemy players knocked.
- headshotKills [爆头数]
- Number of enemy players killed with headshots.
- heals [使⽤治疗药品数量]
- Number of healing items used.
- killPlace [本⼚⽐赛杀敌排⾏]
- Ranking in match of number of enemy players killed.
- killPoints [Elo杀敌排名]
- Kills-based external ranking of player. (Think of this as an Elo ranking where only kills matter.) If there is avalue other than -1 in rankPoints, then any 0 in killPoints should be treated as a “None”.
- kills [杀敌数]
- Number of enemy players killed.
- killStreaks [连续杀敌数]
- Max number of enemy players killed in a short amount of time.
- longestKill [最远杀敌距离]
- Longest distance between player and player killed at time of death. This may be misleading, as downing aplayer and driving away may lead to a large longestKill stat.
- matchDuration [⽐赛时⻓]
- Duration of match in seconds.
- matchType [⽐赛类型(⼩组⼈数)]
- String identifying the game mode that the data comes from. The standard modes are “solo”, “duo”, “squad”,“solo-fpp”, “duo-fpp”, and “squad-fpp”; other modes are from events or custom matches.
- maxPlace [本局最差名次]
- Worst placement we have data for in the match. This may not match with numGroups, as sometimes the data skips over placements.
- numGroups [⼩组数量]
- Number of groups we have data for in the match.
- rankPoints [Elo排名]
- Elo-like ranking of player. This ranking is inconsistent and is being deprecated in the API’s next version, so use with caution. Value of -1 takes place of “None”.
- revives [救活队员的次数]
- Number of times this player revived teammates.
- rideDistance [驾⻋距离]
- Total distance traveled in vehicles measured in meters.
- roadKills [驾⻋杀敌数]
- Number of kills while in a vehicle.
- swimDistance [游泳距离]
- Total distance traveled by swimming measured in meters.
- teamKills [杀死队友的次数]
- Number of times this player killed a teammate.
- vehicleDestroys [毁坏机动⻋的数量]
- Number of vehicles destroyed.
- walkDistance [步⾏距离]
- Total distance traveled on foot measured in meters.
- weaponsAcquired [收集武器的数量]
- Number of weapons picked up.
- winPoints [胜率Elo排名]
- Win-based external ranking of player. (Think of this as an Elo ranking where only winning matters.) If there is a value other than -1 in rankPoints, then any 0 in winPoints should be treated as a “None”.
- winPlacePerc [百分⽐排名]
- The target of prediction. This is a percentile winning placement, where 1 corresponds to 1st place, and 0 corresponds to last place in the match. It is calculated off of maxPlace, not numGroups, so it is possible to have missing chunks in a match.
3 项目评估方式
你必须创建⼀个模型,根据他们的最终统计数据预测玩家的获胜概率排名,从1(第⼀名)到0(最后⼀名)。
最后结果通过平均绝对误差(MAE)进⾏评估,即通过预测的winPlacePerc和真实的winPlacePerc之间的平均绝对误差。
关于MAE:
计算公式:
$$ MAE(X,h) = \frac{1}{m} \sum_{i=1}^{m} {|h(x^{(i)}) - y^{(i)}|}$$
- Mean Absolute Error,平均绝对误差。
- 是绝对误差的平均值
- 能更好地反映预测值误差的实际情况
- API:
-
sklearn.metrics.mean_absolute_error
4.代码实现
获取数据、数据信息查看
导入数据,且查看数据的基本信息

data.tail()
data.describe()
8 rows × 25 columns
data.info()查看详细信息
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 4446966 entries, 0 to 4446965
Data columns (total 29 columns):
Id object
groupId object
matchId object
assists int64
boosts int64
damageDealt float64
DBNOs int64
headshotKills int64
heals int64
killPlace int64
killPoints int64
kills int64
killStreaks int64
longestKill float64
matchDuration int64
matchType object
maxPlace int64
numGroups int64
rankPoints int64
revives int64
rideDistance float64
roadKills int64
swimDistance float64
teamKills int64
vehicleDestroys int64
walkDistance float64
weaponsAcquired int64
winPoints int64
winPlacePerc float64
dtypes: float64(6), int64(19), object(4)
memory usage: 983.9+ MB可以看到数据一共有4446966条
# 查看一共多少场比赛
np.unique(data['matchId']).shape#(47965,)
# 查看一共多少个开黑团队
np.unique(data['groupId']).shape#(2026745,)数据基本处理
缺失值处理
# 如果你想要逐列检查,需要使用Pandas原生的.any()方法(不是NumPy的)。它会沿列方向(axis=0)聚合结果,逐列返回布尔值。
data.isna().any()查看结果
Id False
groupId False
matchId False
assists False
boosts False
damageDealt False
DBNOs False
headshotKills False
heals False
killPlace False
killPoints False
kills False
killStreaks False
longestKill False
matchDuration False
matchType False
maxPlace False
numGroups False
rankPoints False
revives False
rideDistance False
roadKills False
swimDistance False
teamKills False
vehicleDestroys False
walkDistance False
weaponsAcquired False
winPoints False
winPlacePerc True
dtype: bool我们发现“winplaceperc”的值存在NaN
# 查询出存在nan值的数据
data[data['winPlacePerc'].isna()]
1 rows × 29 columns
# 因为只有一个玩家是这样,直接进行删除处理。
data=data.drop(2744604)
data.shape#(4446965, 29)补充说明
方法 返回类型 功能说明 np.any(data.isnull())单个布尔值 检查整个数据集是否有空值(无法定位列) data.isnull().any()Pandas Series 逐列检查是否存在空值(最佳方案) data.isnull().sum()Pandas Series 计算每列的空值数量(进一步量化问题) data.columns[data.isnull().any()]列表 直接获取存在空值的列名列表(推荐!)
规范化处理
删除对局人数较少的数据
查看每场比赛参加的人数:
处理完缺失值之后,我们看一下每场参加的人数会有多少呢,是每次都会匹配100个人,才开始游戏吗?
方法1:
根据每局游戏的ID进行分组然后统计每个id对应的数据条数:
data.groupby('matchId')['matchId'].count().sort_values()查看统计结果
matchId
e5a77433bc436f 2
8aa5066c4b6a79 5
9f2b49358564ea 6
39d2800dad8ae6 6
bc10cc08f1f56a 7
...
51b68a308313f9 100
1f6851edf8ad9e 100
3bd0db1836530f 100
3be2b807005541 100
5ee9860774ef58 100
Name: matchId, Length: 47964, dtype: int64从统计数据我们发现,居然还有每局游戏只有两个人参加的数据,这些数据并不适合我们做数据分析。为了判断出大部分游戏对局都是多少人,我们把上面的数据可视化:
pd_data=pd.DataFrame(data.groupby('matchId')['matchId'].count().values,columns=['pop_nums'])
pd_data| pop_nums | |
|---|---|
| 0 | 95 |
| 1 | 98 |
| 2 | 95 |
| 3 | 100 |
| 4 | 93 |
47964 rows × 1 columns
plt.figure(figsize=(20,8))
sns.countplot(pd_data,x='pop_nums',hue='pop_nums')
plt.ylabel('游戏局数')
plt.show()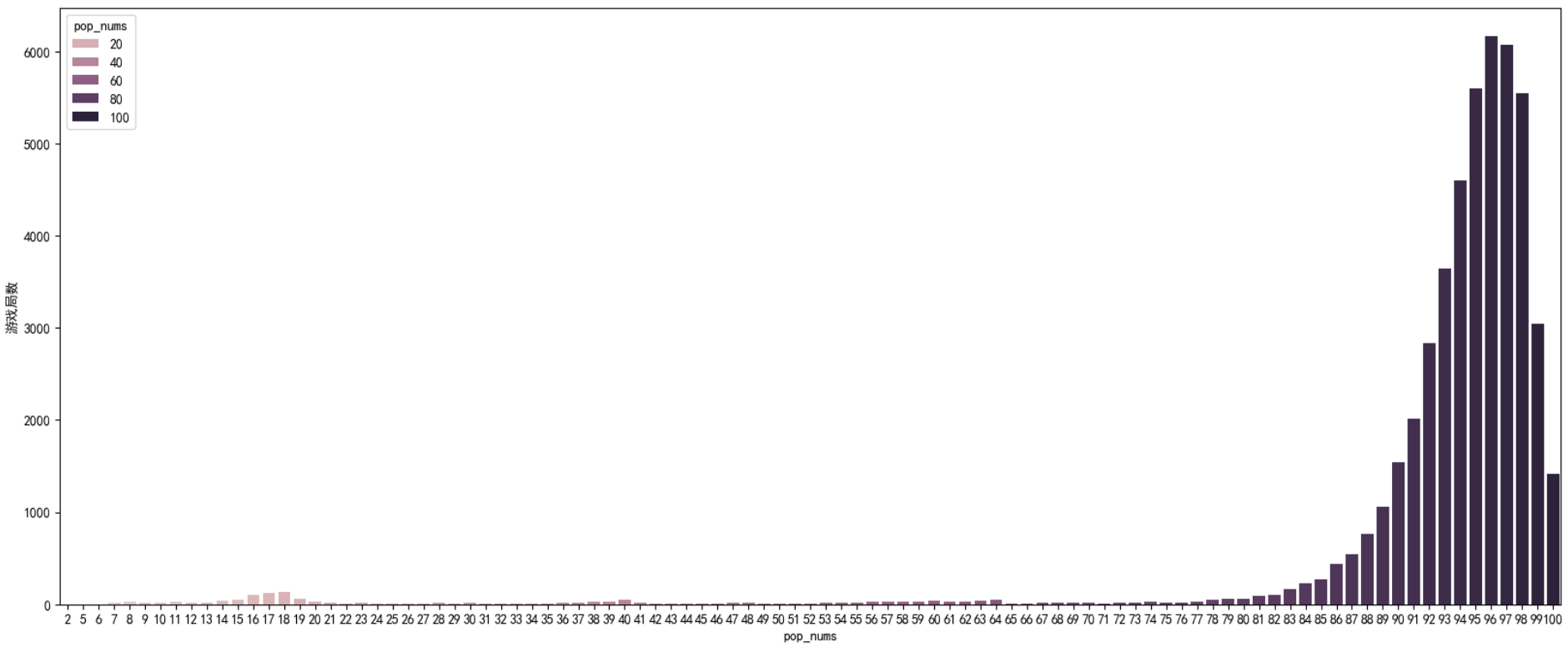
通过观察我们发现,每次游戏人数≥75的数据居多,并且,我们认为正常的游戏参与人数就应该在75~100之间,太少的人数没有研究意义,所以每场游戏参与人数小于75的数据都可以删除
# 生成所有对局的matchId列表备用
all_matchId=np.unique(data['matchId'])
len(all_matchId)#47964
# 生成所有对局人数少于75人的游戏id集合
drop_data_index=all_matchId[data.groupby('matchId')['matchId'].count()<75]
# 生成所有数据的boolen类型的索引(要保留的是True,要删除的是False)
bool_drop_index=~data['matchId'].isin(drop_data_index)
bool_drop_index查看打印结果
0 True
1 True
2 True
3 True
4 True
...
4446961 True
4446962 True
4446963 True
4446964 True
4446965 True
Name: matchId, Length: 4446965, dtype: booldata=data[bool_drop_index]
data.shape#(4389644, 29)方法2:
#直接将每局参加的游戏人数,整合到每一条数据当中去
data['playersJoined']=data.groupby('matchId')['matchId'].transform('count')
# 通过每场参加人数进行,按值升序排列
data['playersJoined'].sort_values(ascending=True)查看统计结果
1206365 2
2109739 2
3956552 5
3620228 5
696000 5
...
1347821 100
1147206 100
3745624 100
209187 100
2746500 100
Name: playersJoined, Length: 4446965, dtype: int64通过结果发现,最少的一局,竟然只有两个人,wtf!!!!
补充说明:
groupby后使用count()与transform('count')的区别1.
data.groupby('matchId')['matchId'].count()
- 作用:生成每个分组的聚合计数结果
- 结果形式:
- 返回一个
Series- 索引 = 唯一分组键 (
matchId)- 值 = 该分组内记录的数量
- 特征:
- 数据缩减:输出数据量 = 唯一分组数量 (
len(output) == groupby.nunique())- 适用于汇总统计
# 输出示例: matchId 10001 4 # 此matchId有4条记录 10002 2 # 此matchId有2条记录 10003 3 # 此matchId有3条记录 Name: matchId, dtype: int642.
data.groupby('matchId')['matchId'].transform('count')
- 作用:为每个原始数据点添加所属分组的计数
- 结果形式:
- 返回一个与原始数据长度相同的
Series- 保持原始索引顺序
- 每个值 = 当前记录所在分组的记录总数
- 特征:
- 数据保持:输出数据量 = 原始数据行数 (
len(output) == len(data))- 适用于创建分组相关特征列
# 输出示例(原始数据索引保持不变): 0 4 # 第1行属于matchId=10001(该组有4条) 1 4 # 第2行同样属于matchId=10001 2 2 # 第3行属于matchId=10002(该组有2条) 3 3 # 第4行属于matchId=10003 4 3 # 第5行属于matchId=10003 5 3 # 第6行属于matchId=10003 Name: matchId, dtype: int64
方法 最佳使用场景 count()检查每个分组的记录数
(如:统计每场比赛的玩家数量)transform('count')在原始数据中新增分组计数特征
(如:为每行添加“当前比赛的玩家总数”列)
# 通过绘制图像,查看每局开始人数
# 通过seaborn下的countplot方法,可以直接绘制统计过数量之后的直方图
plt.figure(figsize=(20,8))
sns.countplot(data,x='playersJoined',hue='playersJoined')
plt.title('每局比赛参加总人数')
plt.grid()
plt.show()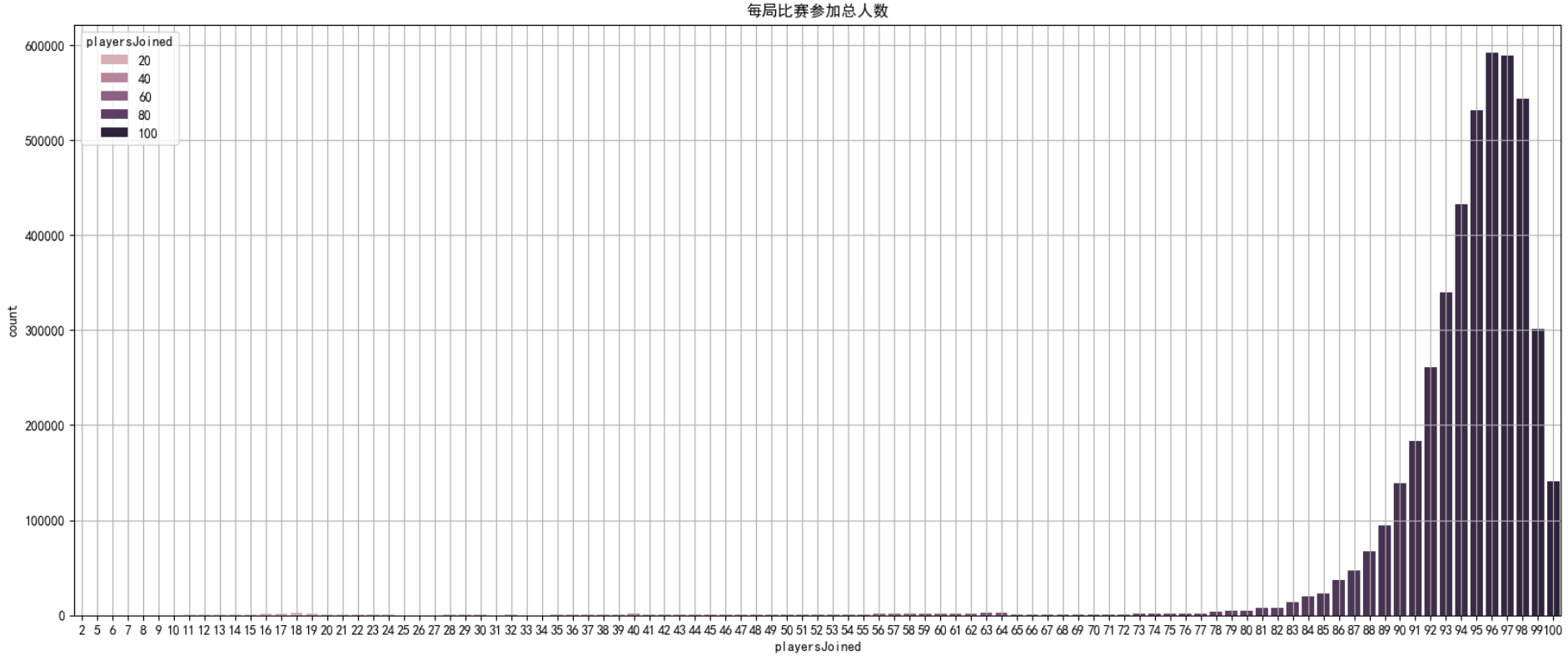
# 只保留对局人数≥75的数据
data=data[data['playersJoined']>=75]
data.shape#(4389644, 30)和方法1的处理结果完全一样规范化输出部分数据
现在我们统计了“每局玩家数量”,那么我们就可以通过“每局玩家数量”来进一步考证其它特征,同时对其规范化设置
试想:一局只有70个玩家的杀敌数,和一局有100个玩家的杀敌数,应该是不可以同时比较的
下面的几个特征值,可以考虑根据每局玩家数量的多少,进行‘标准化’
-
1.kills(杀敌数)
-
2.damageDealt(总伤害)
-
3.maxPlace(本局最差名次)
-
4.matchDuration(比赛时长)
# 对部分特征值进行规范化:【注意!下面的‘规范化’(标准化)计算公式,仅仅是我们的个人直觉,并不是固定的公式,在实际工作过程中要灵活对待】
data['killsNorm'] = data['kills']*((100-data['playersJoined'])/100 + 1)
data['damageDealtNorm'] = data['damageDealt']*((100-data['playersJoined'])/100 + 1)
data['maxPlaceNorm'] = data['maxPlace']*((100-data['playersJoined'])/100 + 1)
data['matchDurationNorm'] = data['matchDuration']*((100-data['playersJoined'])/100 + 1)# 比较经过规范化的特征值和原始特征值的值
to_show = ['Id', 'kills','killsNorm','damageDealt', 'damageDealtNorm', 'maxPlace', 'maxPlaceNorm', 'matchDuration', 'matchDurationNorm']
data[to_show][0:11]| Id | kills | killsNorm | damageDealt | damageDealtNorm | maxPlace | maxPlaceNorm | matchDuration | matchDurationNorm | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 7f96b2f878858a | 0 | 0.00 | 0.000 | 0.00000 | 28 | 29.12 | 1306 | 1358.24 |
| 1 | eef90569b9d03c | 0 | 0.00 | 91.470 | 99.70230 | 26 | 28.34 | 1777 | 1936.93 |
| 2 | 1eaf90ac73de72 | 0 | 0.00 | 68.000 | 69.36000 | 50 | 51.00 | 1318 | 1344.36 |
| 3 | 4616d365dd2853 | 0 | 0.00 | 32.900 | 35.86100 | 31 | 33.79 | 1436 | 1565.24 |
| 4 | 315c96c26c9aac | 1 | 1.03 | 100.000 | 103.00000 | 97 | 99.91 | 1424 | 1466.72 |
| 5 | ff79c12f326506 | 1 | 1.05 | 100.000 | 105.00000 | 28 | 29.40 | 1395 | 1464.75 |
部分变量合成
此处我们把特征:heals(使用治疗药品数量)和boosts(能量、道具使用数量)合并成一个新的变量,命名:”heals_and_boosts“, 这是一个探索性过程,最后结果不一定有用,如果没有实际用处,最后再把它删除。
# 创建新变量“heals_and_boosts”
data['heals_and_boosts'] = data['heals'] + data['boosts']
data[["heals", "boosts", "heals_and_boosts"]].tail()| heals | boosts | heals_and_boosts | |
|---|---|---|---|
| 4446961 | 0 | 0 | 0 |
| 4446962 | 0 | 1 | 1 |
| 4446963 | 0 | 0 | 0 |
| 4446964 | 2 | 4 | 6 |
| 4446965 | 1 | 2 | 3 |
异常值处理
异常值处理:删除有击杀,但是完全没有移动的玩家
一些行中的数据统计出来的结果非常反常规,那么这些玩家肯定有问题,为了训练模型的准确性,我们会把这些异常数据剔除。
通过以下操作,识别出玩家在游戏中有击杀数,但是全局没有移动;
这类型玩家肯定是存在异常情况(挂**),我们把这些数据删除。
# 创建新变量,统计玩家移动距离
data['totalDistance'] = data['rideDistance'] + data['walkDistance'] + data['swimDistance']
# 创建新变量,统计玩家是否在游戏中,有击杀,但是没有移动,如果是返回True, 否则返回false
data['killsWithoutMoving'] = ((data['kills'] > 0) & (data['totalDistance'] == 0))
# 检查是否存在有击杀但是没有移动的数据
data[data['killsWithoutMoving'] == True].shape#(278, 37)
# 删除这些数据
data.drop(data[data['killsWithoutMoving'] == True].index, inplace=True)异常值处理:删除驾车杀敌数异常的数据
# 查看载具杀敌数超过十个的玩家
data[data['roadKills'] > 10]
3 rows × 37 columns
# 删除这些数据
data.drop(data[data['roadKills'] > 10].index, inplace=True)异常值处理:删除玩家在一局中杀敌数超过30人的数据
# 首先绘制玩家杀敌数的条形图
plt.figure(figsize=(10,4))
sns.countplot(data,x="kills",hue='kills')
plt.show()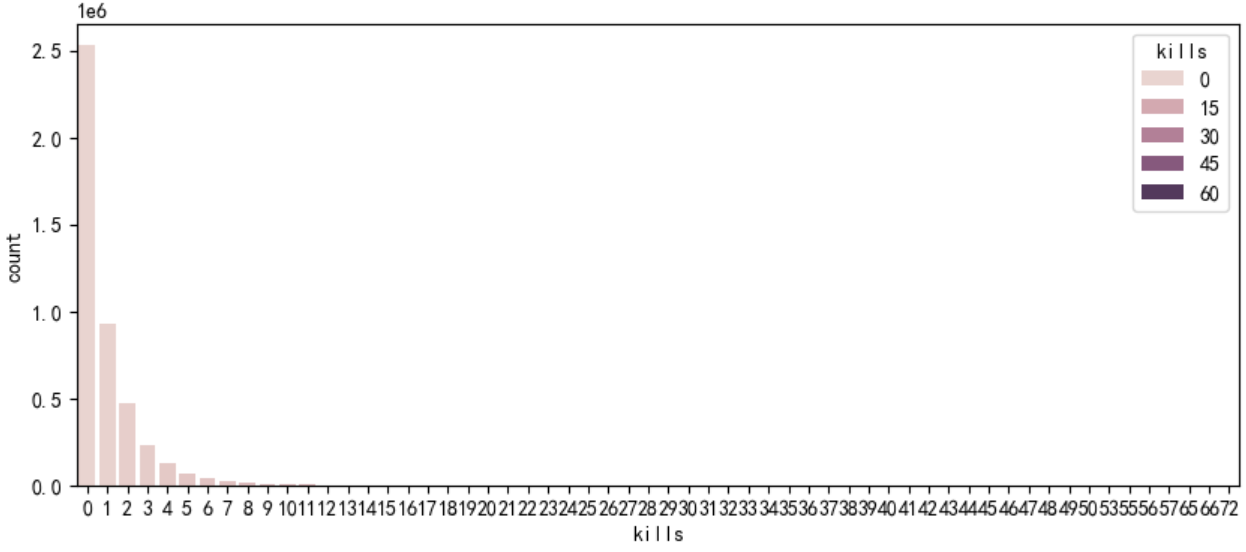 分析发现,单人单局击杀人数,在0~15以内的数据居多,并且,常规理解,单局如果击杀超过30人,那这个玩家大概率有问题,此类数据也删除
分析发现,单人单局击杀人数,在0~15以内的数据居多,并且,常规理解,单局如果击杀超过30人,那这个玩家大概率有问题,此类数据也删除
# 异常数据删除
data.drop(data[data['kills'] > 30].index, inplace=True)异常值处理:删除爆头率异常数据
如果一个玩家的击杀爆头率过高,也说明其有问题
# 创建变量爆头率
data['headshot_rate'] = data['headshotKills'] / data['kills']
# 由于很多data['kills']数据值是0,所以data['headshotKills'] / data['kills']的结果会出现很多NAN(数学上除以零是未定义操作(返回NaN))所以进行空值填充:
data['headshot_rate'] = data['headshot_rate'].fillna(0)# 绘制爆头率图像
plt.figure(figsize=(20,8))
sns.histplot(data['headshot_rate'] , bins=10, kde=False)
plt.show()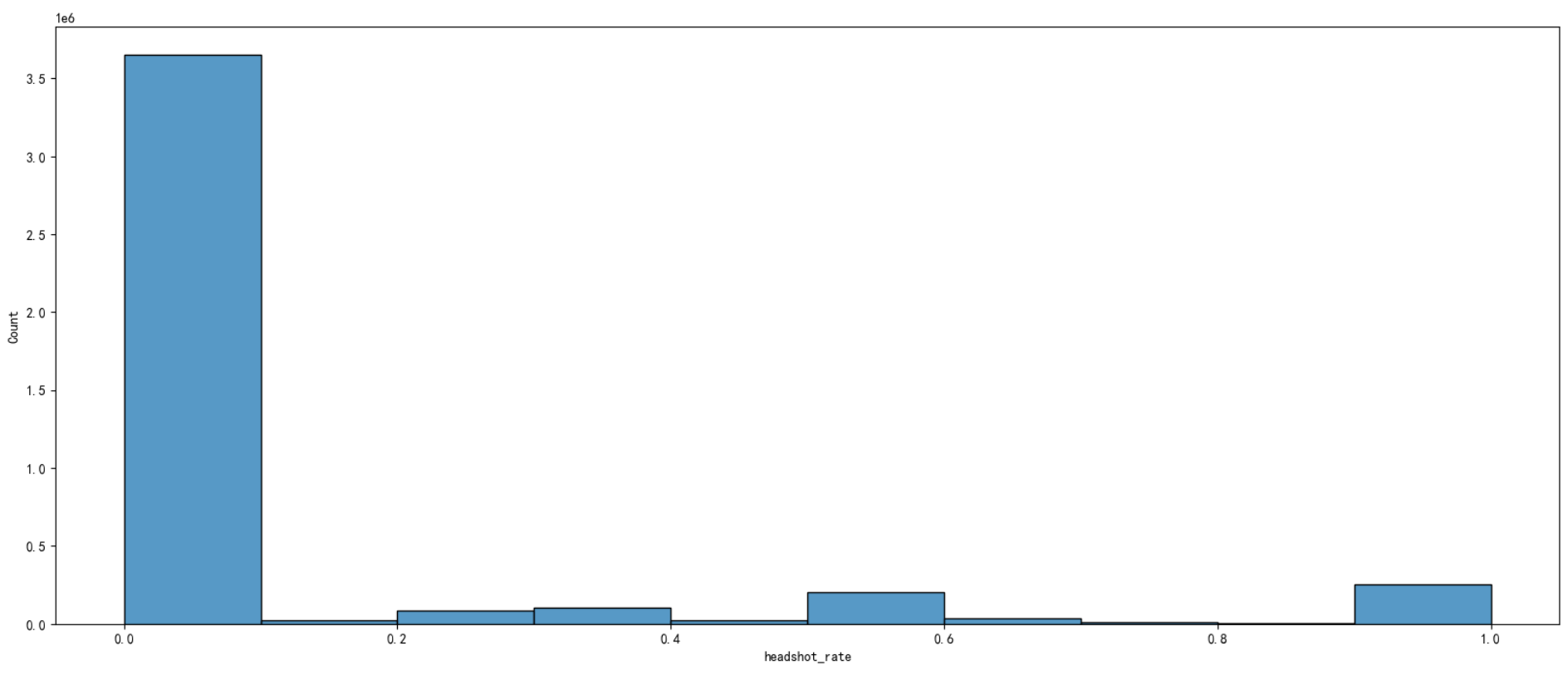 观察发现,存在部分爆头率=1的游戏数据,根据我们的经验判断,如果“枪枪暴击”(爆头率=1,击杀数又很高),那一定有问题,这部分数据删除。
观察发现,存在部分爆头率=1的游戏数据,根据我们的经验判断,如果“枪枪暴击”(爆头率=1,击杀数又很高),那一定有问题,这部分数据删除。
#删除爆头率=1且击杀人数大于9的数据
train.drop(train[(train['headshot_rate'] == 1) & (train['kills'] > 9)].index, inplace=True)异常值处理:删除最远杀敌距离异常数据
# 绘制图像
plt.figure(figsize=(12,4))
sns.histplot(data['longestKill'], bins=10, kde=False)
plt.show()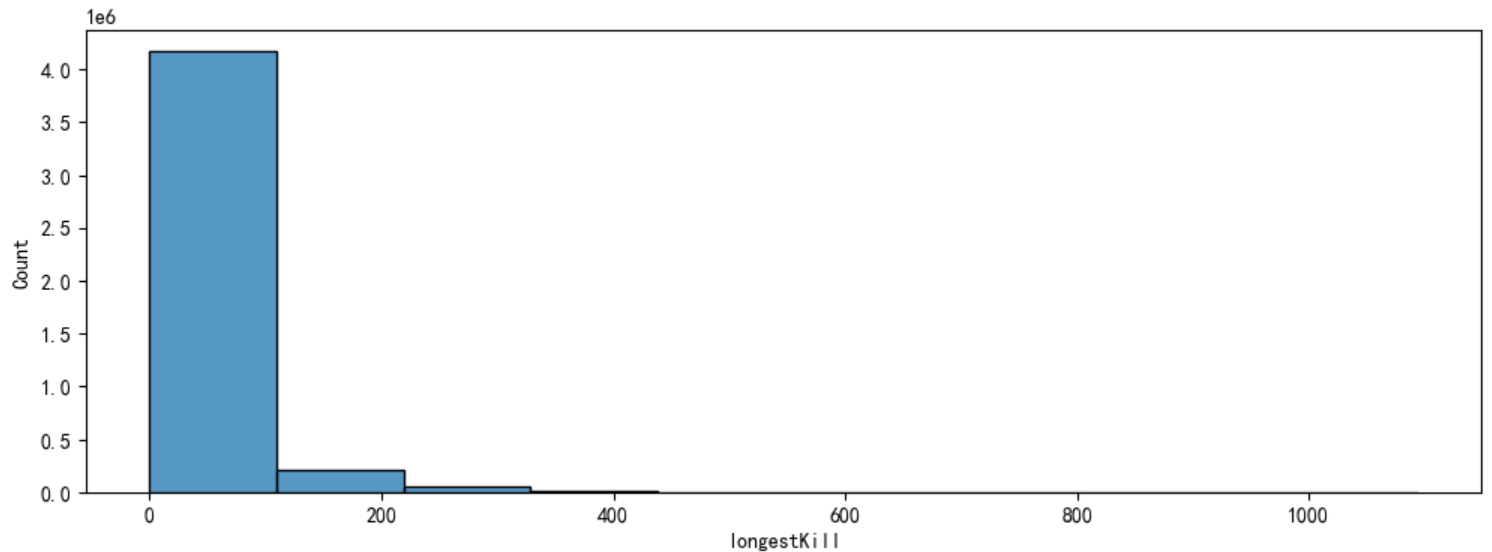
# 找出最远杀敌距离大于等于1km的玩家
data[data['longestKill'] >= 1000].shape#(20, 38)
data.drop(data[data['longestKill'] >= 1000].index, inplace=True)异常值处理:删除关于运动距离的异常值
# 距离整体描述
data[['walkDistance', 'rideDistance', 'swimDistance', 'totalDistance']].describe()查看打印结果
walkDistance rideDistance swimDistance totalDistance
count 4.445311e+06 4.445311e+06 4.445311e+06 4.445311e+06
mean 1.154628e+03 6.063272e+02 4.510977e+00 1.765466e+03
std 1.183514e+03 1.498567e+03 3.050773e+01 2.183257e+03
min 0.000000e+00 0.000000e+00 0.000000e+00 0.000000e+00
25% 1.554000e+02 0.000000e+00 0.000000e+00 1.584000e+02
50% 6.864000e+02 0.000000e+00 0.000000e+00 7.893000e+02
75% 1.977000e+03 2.606500e-01 0.000000e+00 2.729000e+03
max 2.578000e+04 4.071000e+04 3.823000e+03 4.127010e+04##### a)行走距离处理
data.drop(data[data['walkDistance'] >= 10000].index, inplace=True)
##### b)载具行驶距离处理
data.drop(data[data['rideDistance'] >= 20000].index, inplace=True)
##### c)游泳距离处理
data.drop(data[data['swimDistance'] >= 2000].index, inplace=True)其他异常值处理(汇总):
#武器收集异常值处理
data.drop(data[data['weaponsAcquired'] >= 80].index, inplace=True)
#删除使用治疗药品数量异常值
data.drop(data[data['heals'] >= 40].index, inplace=True)
data.shape#(4388818, 38)类别型数据处理
比赛类型one-hot处理
# 查看所有比赛类型,共有16种方式
data['matchType'].unique()array(['squad-fpp', 'duo', 'solo-fpp', 'squad', 'duo-fpp', 'solo','crashfpp', 'flaretpp', 'normal-duo-fpp', 'normal-squad-fpp','flarefpp', 'crashtpp', 'normal-squad'], dtype=object)# 对matchType进行one_hot编码
data = pd.get_dummies(data, columns=['matchType'],dtype=int)
data.shape#(4388818, 50)# 通过正则匹配查看具体内容
matchType_encoding = data.filter(regex='matchType')
matchType_encoding.head()
groupId,matchId分组
关于groupId,matchId这类型数据,也是类别型数据。但是它们的数据量特别多,如果你使用one-hot编码,无异于自杀。
在这儿我们把它们变成用数字统计的类别型数据依旧不影响我们正常使用。
深入了解请参照:《将分组ID转换为分类编码》
# 转换groupId
data['groupId'] = data['groupId'].astype('category') # 转换为分类类型
data["groupId_cat"] = data["groupId"].cat.codes # 生成数值编码列
# 转换matchId
data['matchId'] = data['matchId'].astype('category')
data['matchId_cat'] = data['matchId'].cat.codes
# 查看转换前后对比
data[['groupId','groupId_cat','matchId', 'matchId_cat']].head()| groupId | groupId_cat | matchId | matchId_cat | |
|---|---|---|---|---|
| 0 | 4d4b580de459be | 606787 | a10357fd1a4a91 | 29100 |
| 1 | 684d5656442f9e | 818345 | aeb375fc57110c | 31671 |
| 2 | 6a4a42c3245a74 | 833854 | 110163d8bb94ae | 3039 |
| 3 | a930a9c79cd721 | 1325082 | f1f1f4ef412d7e | 43759 |
| 4 | de04010b3458dd | 1737721 | 6dc8ff871e21e6 | 19857 |
# 删除之前列
data.drop(['groupId', 'matchId'], axis=1, inplace=True)数据截取
取部分数据进行使用(1000000)
# 取前100万条数据,进行训练
sample = 1000000
df_sample = data.sample(sample)
df_sample.shape确定特征值和目标值
# 确定特征值和目标值
df = df_sample.drop(["winPlacePerc", "Id"], axis=1) #all columns except target
y = df_sample['winPlacePerc'] # Only target variable
df.head()分割训练集和测试集
from sklearn.model_selection import train_test_split
X_train, X_valid, y_train, y_valid = train_test_split(df, y, test_size=0.2)机器学习(模型训练)和评估
# 导入需要训练和评估api
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_absolute_error使用随机森林对模型进行训练
初步使用随机森林进行模型训练
# 模型训练
m1 = RandomForestRegressor(n_estimators=40,
min_samples_leaf=3,
max_features='sqrt',
n_jobs=-1)
# n_jobs=-1 表示训练的时候,并行数和cpu的核数一样,如果传入具体的值,表示用几个核去跑
m1.fit(X_train, y_train)y_pre = m1.predict(X_valid)
m1.score(X_valid, y_valid)#0.923133163429638mean_absolute_error(y_true=y_valid, y_pred=y_pre)#0.061137330399194244经过第一次计算,得出准确率为:0.92, mae=0.061
再次使用随机森林,进行模型训练
减少特征值,提高模型训练效率
# 查看特征值在当前模型中的重要程度
m1.feature_importances_array([1.70994982e-03, 8.57201722e-02, 1.71476563e-02, 2.63285365e-03,9.02603306e-04, 4.81997107e-02, 1.71340609e-01, 1.96386369e-03,1.81473733e-02, 7.55792958e-03, 1.12858509e-02, 9.97257841e-03,5.20548487e-03, 5.95332856e-03, 3.43553397e-03, 2.22559531e-03,2.61489160e-02, 3.41877800e-05, 1.87234334e-03, 1.17119730e-04,2.34354083e-05, 2.27681743e-01, 5.75196300e-02, 2.26903639e-03,4.67689314e-03, 7.17538187e-03, 8.37875293e-03, 6.37966414e-03,1.07765079e-02, 5.05920085e-02, 1.86650530e-01, 0.00000000e+00,4.59080299e-03, 3.51273963e-05, 5.79526626e-08, 2.16062885e-04,4.97798055e-04, 1.26486683e-07, 2.47920146e-06, 9.64647197e-08,7.56916941e-09, 6.73510814e-06, 1.41331332e-04, 1.05644017e-03,1.07668733e-03, 8.46344542e-04, 3.91903295e-03, 3.91362603e-03])imp_df = pd.DataFrame({"cols":df.columns, "imp":m1.feature_importances_})
imp_df.head()| cols | imp | |
|---|---|---|
| 0 | assists | 0.001710 |
| 1 | boosts | 0.085720 |
| 2 | damageDealt | 0.017148 |
| 3 | DBNOs | 0.002633 |
| 4 | headshotKills | 0.000903 |
imp_df = imp_df.sort_values("imp", ascending=False)
imp_df.head()| cols | imp | |
|---|---|---|
| 21 | walkDistance | 0.227682 |
| 30 | totalDistance | 0.186651 |
| 6 | killPlace | 0.171341 |
| 1 | boosts | 0.085720 |
| 22 | weaponsAcquired | 0.057520 |
# 绘制特征重要性程度图,仅展示排名前二十的特征
imp_df[:20].plot('cols', 'imp', figsize=(20,8), kind = 'barh')
plt.show()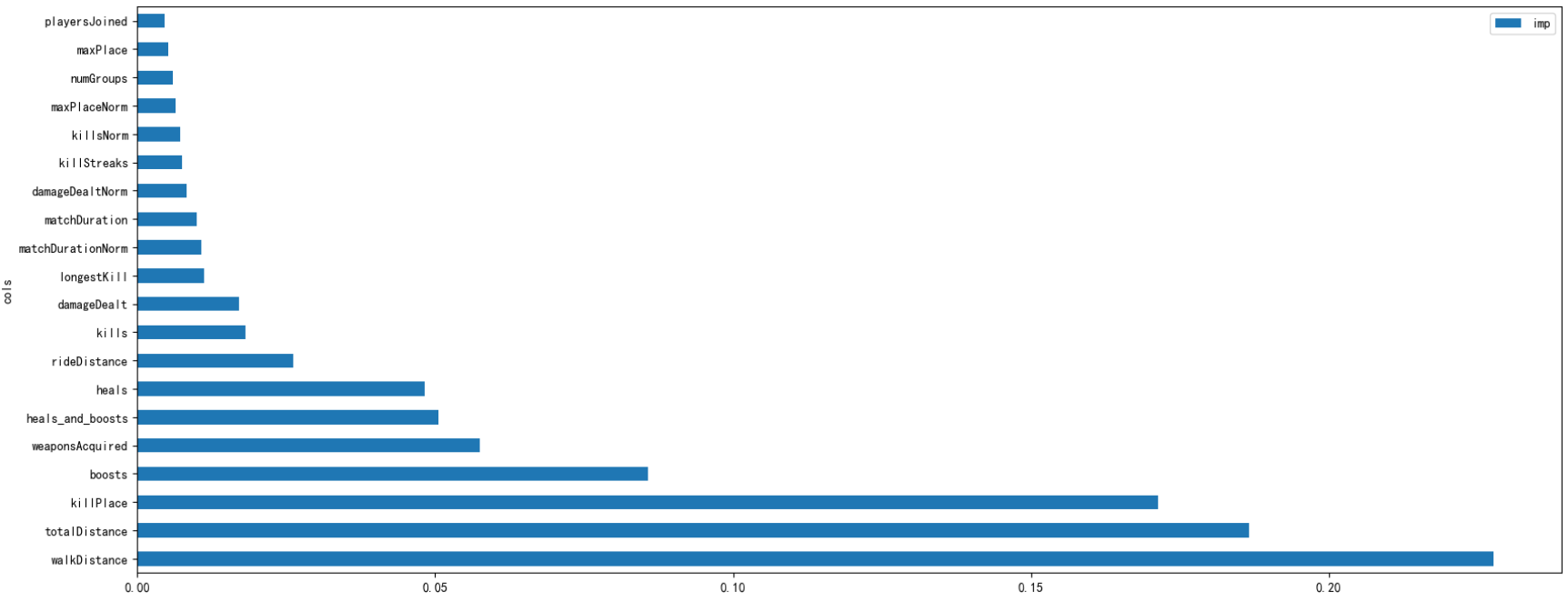
# 保留比较重要的特征
to_keep = imp_df[imp_df.imp>0.005].cols
# 由这些比较重要的特征值,生成新的df
df_keep = df[to_keep]
X_train, X_valid, y_train, y_valid = train_test_split(df_keep, y, test_size=0.2)
# 模型训练
m2 = RandomForestRegressor(n_estimators=40, min_samples_leaf=3, max_features='sqrt',n_jobs=-1)
m2.fit(X_train, y_train)# 模型评分
y_pre = m2.predict(X_valid)
m2.score(X_valid, y_valid)#0.9292946790993083
# mae评估
mean_absolute_error(y_true=y_valid, y_pred=y_pre)#0.05859451927410338
# 如果使用该种方法,最后得到的结果,反而更差,停止优化!使用lightGBM对模型进行训练
模型初次尝试
import lightgbm as lgb
# 创建模型,训练模型
gbm = lgb.LGBMRegressor(objective='regression',
num_leaves=31,
learning_rate=0.05,
n_estimators=20)
gbm.fit(X_train, y_train, eval_set=[(X_valid, y_valid)], eval_metric='l1', callbacks=[lgb.early_stopping(stopping_rounds=5)])
# ps:最后几个参数必须一起使用.# 测试集预测
y_pred = gbm.predict(X_valid, num_iteration=gbm.best_iteration_)
mean_absolute_error(y_valid, y_pred)#0.12236065111366412,我们反向均方误差值更大了,效果还没有随机森林好,那是因为我们还没有进行调参模型二次调优(交叉验证网格搜索)
from sklearn.model_selection import GridSearchCV
# 网格搜索,参数优化
estimator = lgb.LGBMRegressor(num_leaves=31)
param_grid = {
'learning_rate': [0.01, 0.1, 1],
'n_estimators': [20, 40, 60, 100, 200, 300]
}
gbm = GridSearchCV(estimator, param_grid, cv=5, n_jobs=-1) # 此处原来有个警告,通过此添加,解决掉!!!
gbm.fit(X_train, y_train)运行报错:
MemoryError: Unable to allocate 1.22 MiB for an array with shape (160000,) and data type int64问题根本原因分析
并行处理导致的内存溢出
n_jobs=-1表示使用所有CPU核心并行计算- 每个核心都在同时处理不同的参数组合+交叉验证
- 总内存消耗 = 核心数 × (模型大小 × 参数组合数 × CV折数)
- 对于大数据集,这会导致指数级内存增长
参数组合过多
learning_rate: 3种取值n_estimators: 6种取值- 总参数组合 = 3 × 6 = 18种
- 5折交叉验证 → 18×5=90个模型同时训练(在并行模式下)
LightGBM的特性
- 每个树模型需要存储分裂点、特征直方图等
num_leaves=31会产生约2^(31)个潜在节点- 当
n_estimators设置为较大值(如300)时特别吃内存数据集大小
- 您使用百万行数据(
1000000样本)- 如果特征数量也多(X_train列数多),内存需求剧增
🛠 解决方案
方案1:减少资源需求
from sklearn.model_selection import GridSearchCV
# 网格搜索,参数优化
estimator = lgb.LGBMRegressor(num_leaves=31)
param_grid = {
'learning_rate': [0.01, 0.1, 1],
'n_estimators': [20, 40, 60, 100, 200, 300]
}
gbm_2 = GridSearchCV(estimator, param_grid,
cv=3, # 减少交叉验证折数
n_jobs=4, # 限制并行数量(不要用-1)
verbose=1 # 监控进度
)
gbm_2.fit(X_train, y_train)# 测试集预测
y_pred = gbm_2.predict(X_valid)
mean_absolute_error(y_valid, y_pred)#0.055662442315718645print('交叉验证\网格搜索调试后,最好的参数模型是:', gbm_2.best_params_)交叉验证\网格搜索调试后,最好的参数模型是: { 'n_estimators': 300,'learning_rate': 0.1}最佳方案:使用内存效率更高的随机搜索
from sklearn.model_selection import RandomizedSearchCV
estimator = lgb.LGBMRegressor(num_leaves=31)
param_grid = {
'learning_rate': [0.01, 0.1, 1],
'n_estimators': [20, 40, 60, 100, 200, 300]
}
# 改用随机搜索,只抽样部分参数组合
gbm_3 = RandomizedSearchCV(
estimator,
param_distributions=param_grid,
n_iter=8, # 只随机尝试8种组合
cv=3, # 减少交叉验证折数
n_jobs=4, # 限制并行进程数
random_state=42
)
gbm_3.fit(X_train, y_train)# 测试集预测
y_pred = gbm_3.predict(X_valid)
mean_absolute_error(y_valid, y_pred)#0.05952216992217456,虽然速度提升了,但是误差确变大了print('交叉验证\网格搜索调试后,最好的参数模型是:', gbm_3.best_params_)交叉验证\网格搜索调试后,最好的参数模型是: {'n_estimators': 60, 'learning_rate': 0.1}📈 内存优化策略对比
策略 内存减少 训练时间影响 效果保持 随机搜索 高 (70-80%) 显著缩短 基本不变 减少并行 高 (60-70%) 增加 保持 减少CV折数 中等 (40-50%) 缩短 略降 缩小数据集 高 缩短 可能下降 调整模型参数 可变 可变 可能下降
✅ 其他推荐实践
第一步:改用随机搜索
第二步:添加内存监控
from memory_profiler import memory_usage mem_usage = memory_usage(gbm.fit(X_train, y_train)) print(f'最大内存使用: {max(mem_usage)} MB')
lgb_params = {'num_leaves': 31}
lgb.cv(lgb_params, train_data, num_boost_round=100,
nfold=5, stratified=False, shuffle=True)模型三次调优[思路]
# n_estimators
scores = []
n_estimators = [500, 1000,1500]
for nes in n_estimators:
lgbm = lgb.LGBMRegressor(boosting_type='gbdt',
num_leaves=31,
max_depth=5,
learning_rate=0.1,
n_estimators=nes,
min_child_samples=20,
n_jobs=-1)
lgbm.fit(X_train, y_train, eval_set=[(X_valid, y_valid)], eval_metric='l1',callbacks=[lgb.early_stopping(stopping_rounds=5)])
y_pre = lgbm.predict(X_valid)
mae = mean_absolute_error(y_valid, y_pre)
scores.append(mae)
print("test data mae eval : {}".format(mae))plt.plot(n_estimators,scores,'o-')
plt.ylabel("mae")
plt.xlabel("n_estimator")
print("best n_estimator {}".format(n_estimators[np.argmin(scores)]))#best n_estimator 1000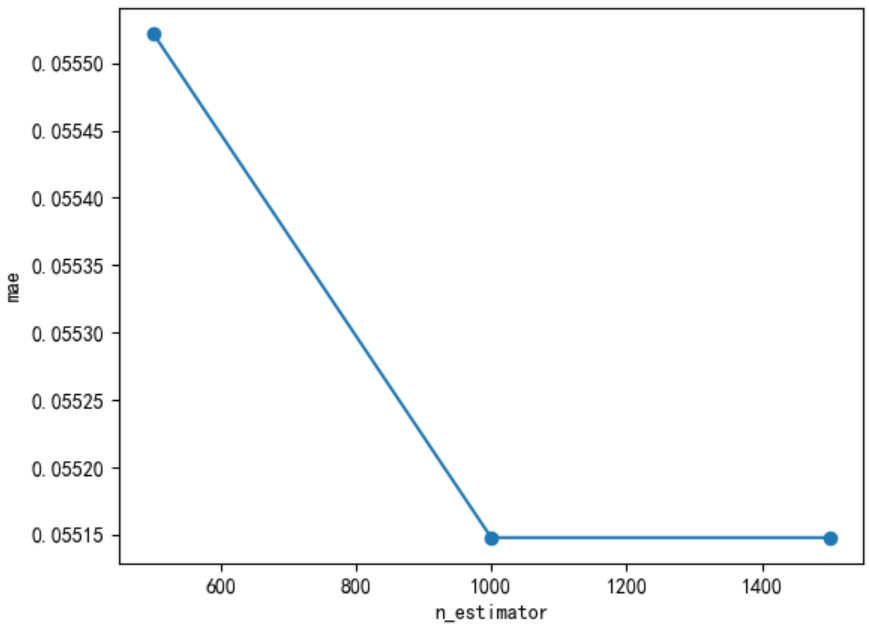
# max_depths
scores = []
max_depths = [1, 5, 7, 9]
for nes in max_depths:
lgbm = lgb.LGBMRegressor(boosting_type='gbdt',
num_leaves=31,
max_depth=nes,
learning_rate=0.1,
n_estimators=1000,
min_child_samples=20,
n_jobs=-1)
lgbm.fit(X_train, y_train, eval_set=[(X_valid, y_valid)], eval_metric='l1',callbacks=[lgb.early_stopping(stopping_rounds=5)])
y_pre = lgbm.predict(X_valid)
mae = mean_absolute_error(y_valid, y_pre)
scores.append(mae)
print("test data mae eval : {}".format(mae))plt.plot(max_depths,scores,'o-')
plt.ylabel("mae")
plt.xlabel("max_depths")
print("best max_depths {}".format(max_depths[np.argmin(scores)]))#best max_depths 9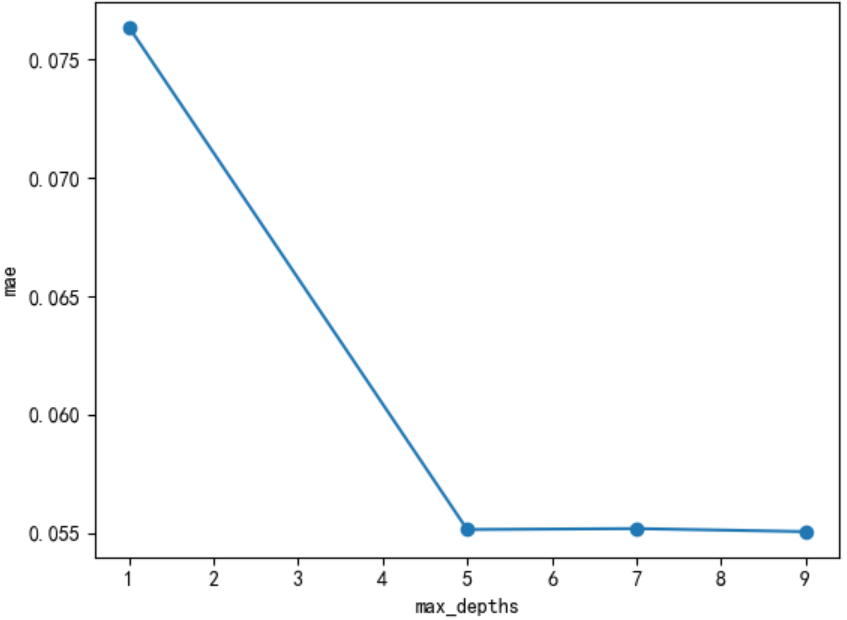


 浙公网安备 33010602011771号
浙公网安备 33010602011771号