算法选择指导
解决机器学习问题最难的部分往往在于找到合适的估算器。不同的估算器适用于不同类型的数据和不同的问题。
关于在计算的过程中,如何选择合适的算法进⾏计算,可以参考scikit learn官⽅给 的指导意⻅:
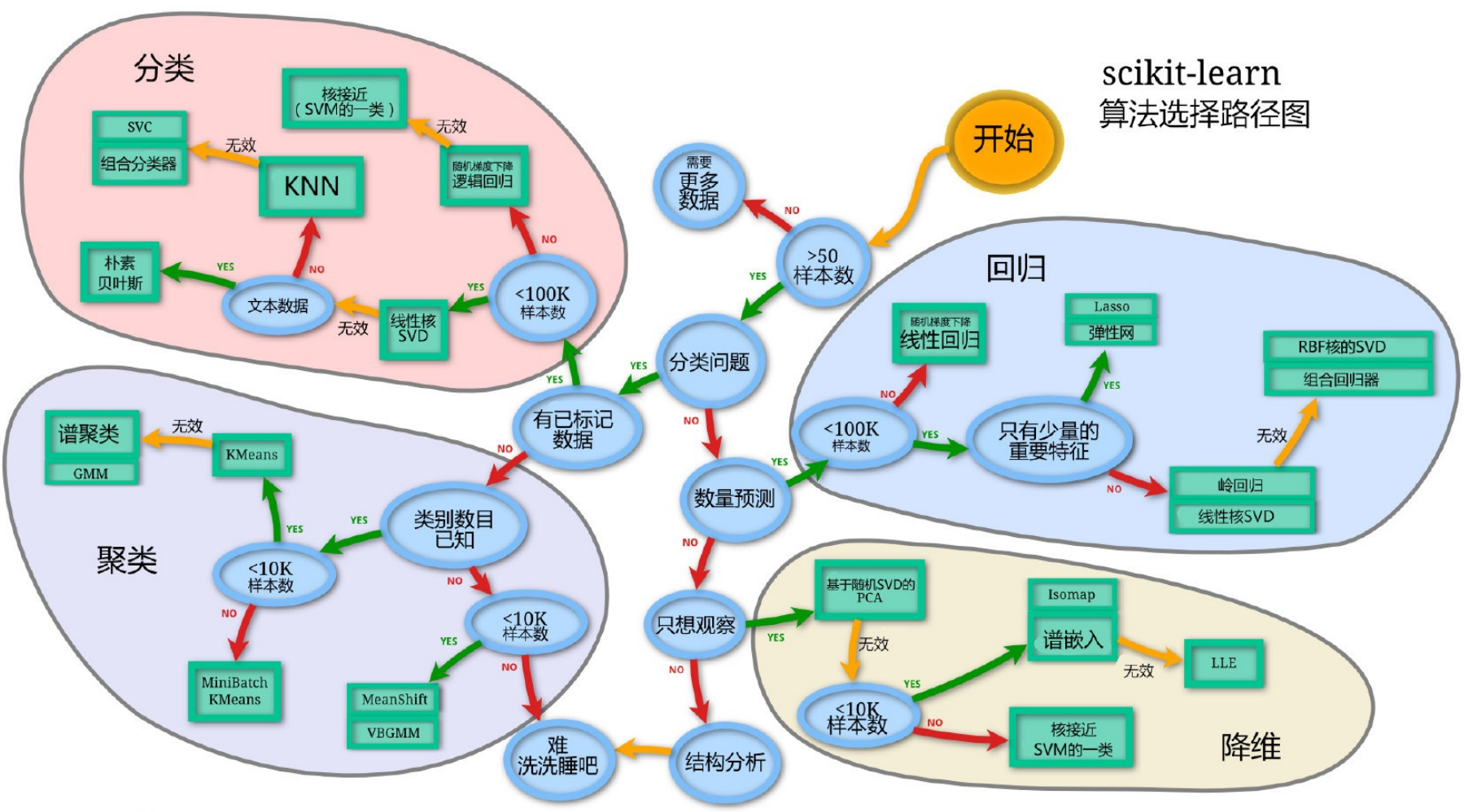
Scikit-Learn 官方算法选择指南
Scikit-Learn 官方提供了非常实用的算法选择指南,帮助用户根据数据类型、问题类型和数据规模快速选择合适的机器学习算法。以下是官方资源的详细说明:
核心官方资源
1. 机器学习算法选择流程图(Cheat Sheet)
官方网址: https://scikit-learn.org/stable/tutorial/machine_learning_map/index.html
这个直观的流程图是选择算法的最实用工具:
- 从识别问题类型开始:分类、回归还是聚类
- 考虑数据规模:小样本还是大数据
- 考虑数据类型:文本、图像或其他类型
- 考虑特殊需求:需要特征重要性或处理类别不平衡

关键选择原则总结
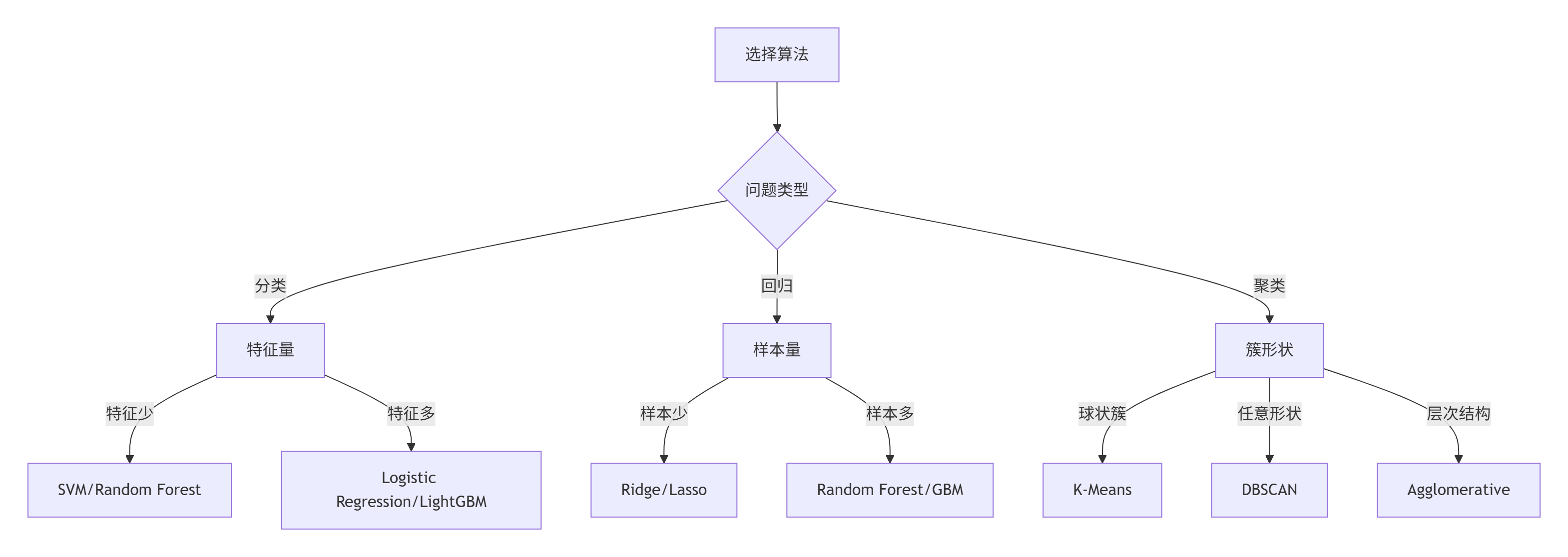
1. 问题类型导向选择
| 问题类型 | 首选举算法 | 备选算法 |
|---|---|---|
| 分类 | 随机森林、梯度提升机 | SVM、KNN、朴素贝叶斯 |
| 回归 | 梯度提升回归、随机森林回归 | Lasso、岭回归、SVR |
| 聚类 | K-Means、DBSCAN | 层次聚类、谱聚类 |
| 降维 | PCA、t-SNE | LDA、NMF |
2. 数据规模敏感选择

3. 特定场景优化选择
| 场景 | 推荐算法 | 原因 |
|---|---|---|
| 高维数据 | 线性SVM、正则化线性模型 | 计算效率高 |
| 类别不平衡 | BalancedRandomForest | 内置平衡处理 |
| 自动特征工程 | 梯度提升树 | 自动特征组合 |
| 可解释性 | 线性模型、决策树 | 透明决策过程 |
| 流数据 | SGDClassifier | 增量学习 |
官方推荐实践
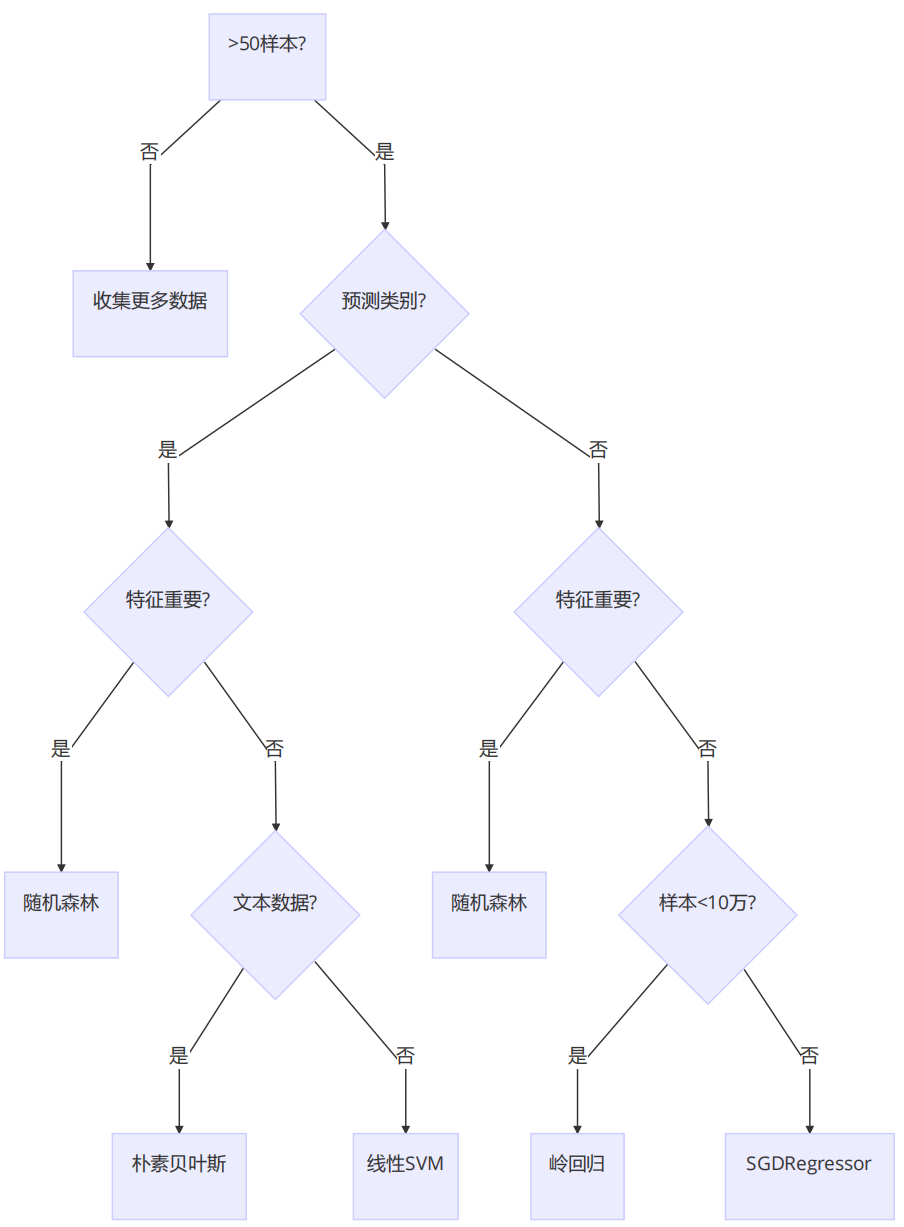
1. 监督学习算法选择流程
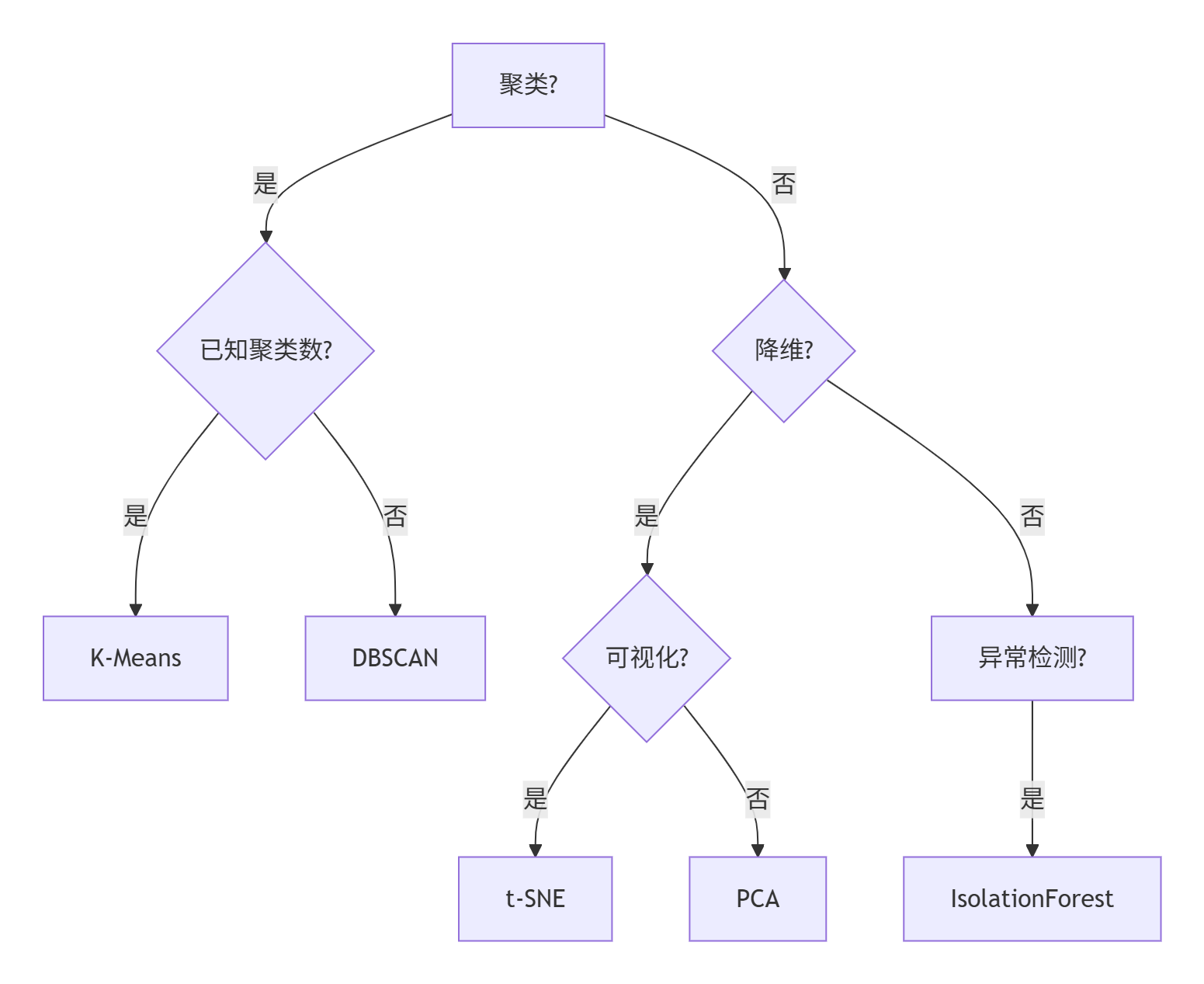
2. 无监督学习选择指南
预处理技巧及算法
预处理流程
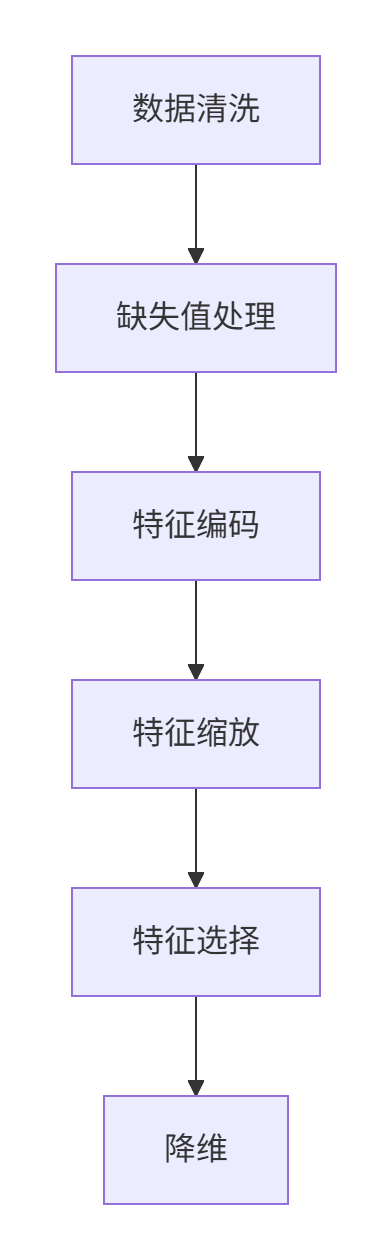
主要预处理技术
-
缺失值处理:
- 数值特征:中位数填补 (
SimpleImputer(strategy='median')) - 类别特征:众数填补 (
SimpleImputer(strategy='most_frequent'))
- 数值特征:中位数填补 (
-
类别特征编码:
- 标准方法:
OneHotEncoder(当类别较少时) - 高基数类别:
TargetEncoder或CatBoostEncoder - 二元特征:
LabelEncoder
- 标准方法:
-
特征缩放:
方法 适用场景 优点 缺点 StandardScaler 大多数算法(除树模型) 数据符合标准正态分布 易受异常值影响 RobustScaler 含异常值的数据 对异常值鲁棒 保留原始分布 MinMaxScaler 神经网络、要求特定范围 将数据缩放到给定范围 对异常值敏感 Normalizer 文本分类、聚类 样本为单位归一化 非特征操作 -
特征选择:
- 过滤法:
SelectKBest+f_classif/mutual_info_classif - 包装法:
RFE(递归特征消除) - 嵌入法:树模型的特征重要性
- 过滤法:
-
降维技术:
方法 适用场景 优点 缺点 PCA 连续特征降维 最大限度保留方差 失去可解释性 TruncatedSVD 稀疏矩阵降维 适合文本数据 计算成本高 t-SNE 数据可视化 保留局部结构 无法扩展新样本
预处理管道示例
总结
算法小抄(Cheat Sheet)
分类算法比较表
| 算法 | 适用场景 | 优点 | 缺点 | 时间复杂度 | 内存占用 |
|---|---|---|---|---|---|
| Logistic Regression | 二分类、线性问题 | 结果可解释、训练速度快 | 只能处理线性问题 | O(features × samples) | 低 |
| SVM (Linear) | 中小数据集、高维特征 | 在高维空间表现好、适合特征数>样本数 | 难解释、对参数敏感 | O(samples² × features) | 中 |
| SVM (RBF Kernel) | 中小数据集、非线性问题 | 强大的非线性分类能力 | 需要仔细调参、对内存要求高 | O(samples³ × features) | 高 |
| k-NN | 小数据集、低维数据 | 简单直观、无需训练 | 预测慢、高维表现差 | O(samples × features) | 高 |
| Decision Tree | 各种规模数据、需要解释性 | 易于理解和解释 | 容易过拟合、不稳定 | O(samples × features) | 低 |
| Random Forest | 各类数据集 | 高准确率、抗过拟合 | 训练速度慢、解释性有限 | O(trees × samples × features) | 中 |
| Gradient Boosting | 各类数据集、高精度需求 | 当前最准确算法之一 | 训练速度慢、需要调参 | O(trees × samples × features) | 中 |
| Naive Bayes | 文本分类、高维数据 | 非常快速、适合稀疏数据 | 特征独立性假设可能不成立 | O(features × classes) | 低 |
回归算法比较表
| 算法 | 适用场景 | 优点 | 缺点 | 关键参数 |
|---|---|---|---|---|
| Linear Regression | 特征与目标线性相关 | 简单快速、可解释 | 需满足线性假设 | - |
| Ridge Regression | 存在共线性特征 | 解决多重共线性 | 不自动特征选择 | alpha |
| Lasso Regression | 特征选择、高维数据 | 自动特征选择 | 可能过度压缩系数 | alpha |
| ElasticNet | 高维共线性数据 | L1+L2正则化 | 有两个参数需调优 | alpha, l1_ratio |
| SVR (Support Vector Reg.) | 非线性问题 | 鲁棒性好 | 难调参、训练慢 | C, epsilon |
| Random Forest Reg. | 复杂非线性关系 | 处理非线性能力强 | 可能过拟合 | n_estimators, max_depth |
| Gradient Boosting Reg. | 高精度需求 | 高精度 | 训练慢、需调参 | n_estimators, learning_rate |
聚类算法比较表
| 算法 | 适用场景 | 优点 | 缺点 | 关键参数 |
|---|---|---|---|---|
| K-Means | 已知聚类数量、凸形簇 | 简单高效 | 需指定k值、对异常值敏感 | n_clusters |
| DBSCAN | 任意形状簇、有噪声数据 | 自动确定簇数、抗噪声 | 密度不均时表现差 | eps, min_samples |
| Agglomerative | 层次结构数据 | 生成层次结构 | 计算成本高 | n_clusters, linkage |
| Spectral Clust. | 非凸形簇、连接图 | 复杂形状处理能力强 | 高计算复杂度 | n_clusters, affinity |
补充学习资源
-
比较算法性能:
https://scikit-learn.org/stable/auto_examples/classification/plot_classifier_comparison.html -
模型评估指南:
https://scikit-learn.org/stable/modules/model_evaluation.html -
算法使用教程目录:
https://scikit-learn.org/stable/tutorial/index.html -
算法参数调优指南:
https://scikit-learn.org/stable/modules/grid_search.html -
实践案例库:
https://scikit-learn.org/stable/auto_examples/index.html
其他技巧
性能优化技巧
大数据集处理:
-
- 使用增量学习:
SGDClassifier,MiniBatchKMeans - 降低精度:
np.float32替代float64 - 特征压缩:
PCA或特征选择
- 使用增量学习:
计算加速
# 设置n_jobs参数并行计算
model = RandomForestClassifier(n_jobs=-1)
# 使用低级优化
from sklearn.config import set_config
set_config(enable_cython_pairwise_dist=True)
# GPU加速(部分算法支持)
from sklearn.svm import SVC
model = SVC(kernel='rbf', device='cuda')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号