决策树
决策树思想的来源⾮常朴素,程序设计中的条件分⽀结构就是if-else结构,最早的决策树就是利⽤这类结构分割数据的⼀种分类学习⽅法
决策树:
- 是⼀种树形结构,本质是⼀颗由多个判断节点组成的树
- 其中每个内部节点表示⼀个属性上的判断,
- 每个分⽀代表⼀个判断结果的输出,
- 最后每个叶节点代表⼀种分类结果。
怎么理解这句话?通过⼀个对话例⼦

想⼀想这个⼥⽣为什么把年龄放在最上⾯判断!!!!!!!!!
上⾯案例是⼥⽣通过定性的主观意识,把年龄放到最上⾯,那么如果需要对这⼀过程进⾏量化,该如何处理呢?
此时需要⽤到信息论中的知识:信息熵,信息增益
决策树分类原理
熵
1.1 概念
物理学上,熵 Entropy 是“混乱”程度的量度。

系统越有序,熵值越低;系统越混乱或者分散,熵值越⾼。
1948年⾹农提出了信息熵(information Entropy)的概念。
- 信息理论:
1、从信息的完整性上进⾏的描述:
当系统的有序状态⼀致时,数据越集中的地⽅熵值越⼩,数据越分散的地⽅熵值越⼤。
2、从信息的有序性上进⾏的描述:
当数据量⼀致时,系统越有序,熵值越低;系统越混乱或者分散,熵值越⾼。
"信息熵" 是度量样本集合纯度最常⽤的⼀种指标。
假定当前样本集合 D 中第 k 类样本所占的⽐例为 pk (k = 1, 2,. . . , |y|) ,p = ![]() , D为样本的所有数量,Ck为第k类样本的数量。
, D为样本的所有数量,Ck为第k类样本的数量。
则 D的信息熵定义为((log是以2为底,lg是以10为底):
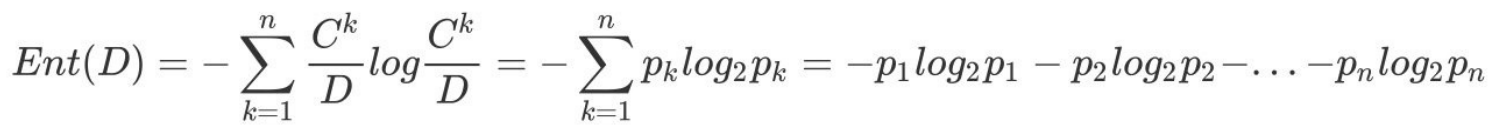
其中:Ent(D) 的值越⼩,则 D 的纯度越⾼.
1.2 案例
假设我们没有看世界杯的⽐赛,但是想知道哪⽀球队会是冠军,我们只能猜测某⽀球队是或不是冠军,然后观众⽤对或不对来回答,我们想要猜测次数尽可能少,你会⽤什么⽅法?
答案:
⼆分法:
假如有 16 ⽀球队,分别编号,先问是否在 1-8 之间,如果是就继续问是否在 1-4 之间,以此类推,直到最后判断出冠军球队是哪⽀。
如果球队数量是 16,我们需要问 4 次来得到最后的答案。那么世界冠军这条消息的信息熵就是 4。
那么信息熵等于4,是如何进⾏计算的呢?
Ent(D) = -(p1 * logp1 + p2 * logp2 + ... + p16 * logp16),
其中 p1, ..., p16 分别是这 16 ⽀球队夺冠的概率。
当每⽀球队夺冠概率相等都是 1/16 的时:Ent(D) = -(1/16 * log1/16)*16 = 4
每个事件概率相同时,熵最⼤,这件事越不确定。
随堂练习:
篮球⽐赛⾥,有4个球队 {A,B,C,D} ,获胜概率分别为{1/2, 1/4, 1/8, 1/8},求Ent(D)
答案:
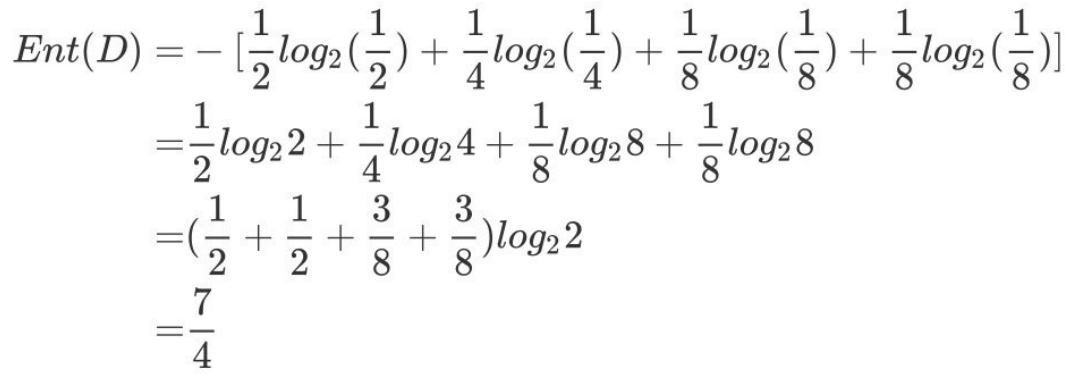
决策树的划分依据(1)----信息增益
2.1 概念
信息增益:以某特征划分数据集前后的熵的差值。熵可以表示样本集合的不确定性,熵越⼤,样本的不确定性就越⼤。
因此可以使⽤划分前后集合熵的差值来衡量使⽤当前特征对于样本集合D划分效果的好坏。
信息增益 = entroy(前) - entroy(后)
定义与公式
假定离散属性a有 V 个可能的取值:
a1,a2...aV
假设离散属性性别有2(男,女)个可能的取值
若使⽤a来对样本集 D 进⾏划分,则会产⽣ V 个分⽀结点。
其中第v个分⽀结点包含了 D 中所有在属性a上取值为av 的样本,记为D v. 我们可根据前⾯给出的信息熵公式计算出D v 的信息熵,再考虑到不同的分⽀结点所包含的样本数不同,给分⽀结点赋予权重![]()
即样本数越多的分⽀结点的影响越⼤,于是可计算出⽤属性a对样本集 D 进⾏划分所获得的"信息增益" (informationgain)
其中:
特征a对训练数据集D的信息增益Gain(D,a)定义为:集合D的信息熵Ent(D)与给定特征a条件下D的信息条件熵Ent(D∣a)之差,即公式为:
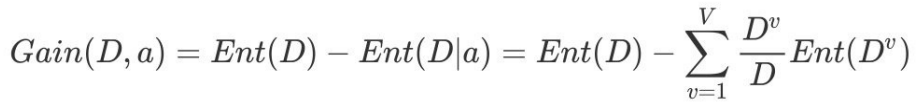
公式的详细解释:
信息熵的计算:
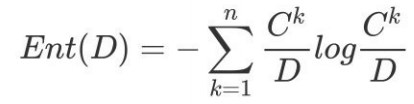
条件熵的计算:

其中:
D v 表示a属性中第v个分⽀节点包含的样本数
C kv 表示a属性中第v个分⽀节点包含的样本数中,第k个类别下包含的样本数
⼀般⽽⾔,信息增益越⼤,则意味着使⽤属性 a 来进⾏划分所获得的"纯度提升"越⼤。因此,我们可⽤信息增益来进⾏决策树的划分属性选择,著名的 ID3 决策树学习算法 [Quinlan, 1986] 就是以信息增益为准则来选择划分属性。
其中,ID3 名字中的 ID 是 Iterative Dichotomiser (迭代⼆分器)的简称
2.2 案例:
如下图,第⼀列为论坛号码,第⼆列为性别,第三列为活跃度,最后⼀列⽤户是否流失。
我们要解决⼀个问题:性别和活跃度两个特征,哪个对⽤户流失影响更⼤?
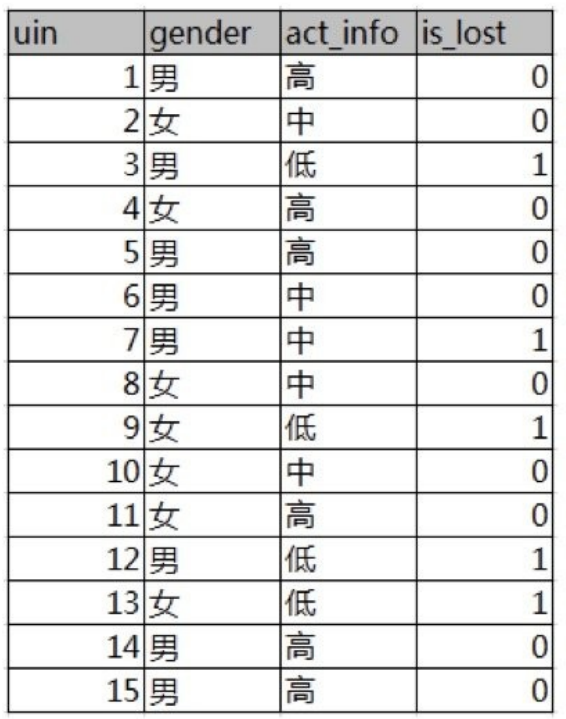
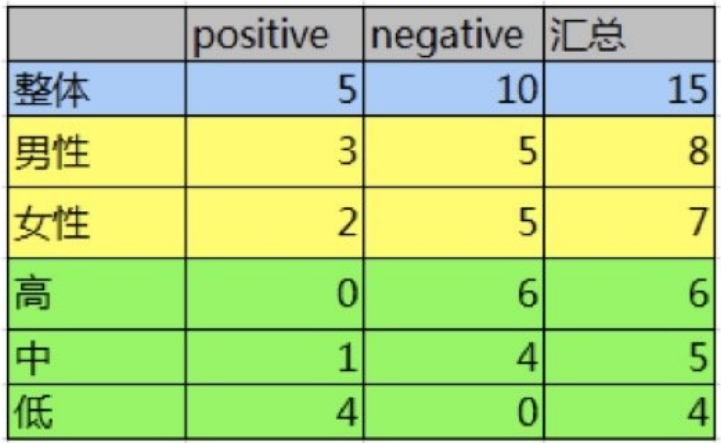
备注:上表positive表示:已流失。negative表示未流失。
通过计算信息增益可以解决这个问题,统计上右表信息
其中Positive为正样本(已流失),Negative为负样本(未流失),下⾯的数值为不同划分下对应的⼈数。
可得到三个熵:
a.计算类别信息熵
整体熵:
![]()
b.计算性别属性的信息熵(a="性别")
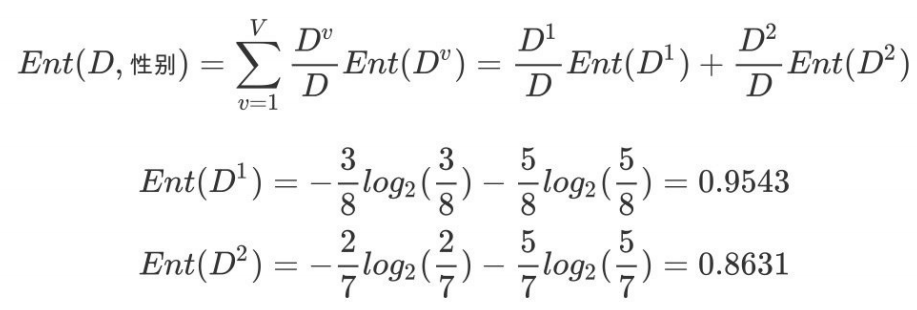
c.计算性别的信息增益(a="性别")
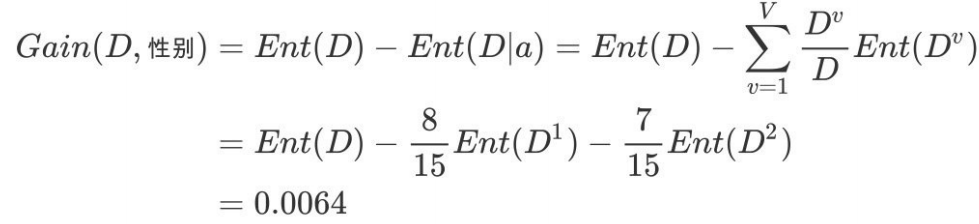
b.计算活跃度属性的信息熵(a="活跃度")
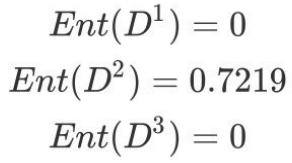
c.计算活跃度的信息增益(a="活跃度")

活跃度的信息增益⽐性别的信息增益⼤,也就是说,活跃度对⽤户流失的影响⽐性别⼤。在做特征选择或者数据分析的时候,我们应该重点考察活跃度这个指标。
决策树的划分依据(2)----信息增益率
3.1 概念
在上⾯的介绍中,我们有意忽略了"编号"这⼀列.若把"编号"也作为⼀个候选划分属性,则根据信息增益公式可计算出它的信息增益为 0.9182,远⼤于其他候选划分属性。
计算每个属性的信息熵过程中,我们发现,该属性(编号)的条件信息熵为0, 也就是其信息增益为0.9182. 但是很明显这么分类,最后出现的结果不具有泛化效果.⽆法对新样本进⾏有效预测.
实际上,信息增益准则对可取值数⽬较多的属性有所偏好(例如性别可取值只有男女两种,年龄(假设1~100岁)就有100种),为减少这种偏好可能带来的不利影响,著名的 C4.5 决策树算法 [Quinlan, 1993J 不直接使⽤信息增益,⽽是使⽤"增益率" (gain ratio) 来选择最优划分属性.
增益率:增益率是⽤前⾯的信息增益Gain(D, a)和属性a对应的"固有值"(intrinsic value) [Quinlan , 1993J的⽐值来共同定义的。
属性 a 的可能取值数⽬越多(即 V 越⼤),则 IV(a) 的值通常会越⼤.
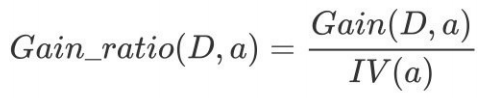
其中:
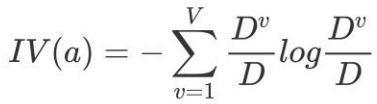
3.2 案例
3.2.1 案例⼀
a.计算类别信息熵
b.计算性别属性的信息熵(性别、活跃度)
c.计算活跃度的信息增益(性别、活跃度)
d.计算属性分裂信息度量
⽤分裂信息度量来考虑某种属性进⾏分裂时分⽀的数量信息和尺⼨信息,我们把这些信息称为属性的内在信息(instrisic information)。信息增益率⽤信息增益/内在信息,会导致属性的重要性随着内在信息的增⼤⽽减⼩(也就是说,如果这个属性本身不确定性就很⼤,那我就越不倾向于选取它),这样算是对单纯⽤信息增益有所补偿。

e.计算信息增益率

活跃度的信息增益率更⾼⼀些,所以在构建决策树的时候,优先选择通过这种⽅式,在选取节点的过程中,我们可以降低取值较多的属性的选取偏好。
3.2.2 案例⼆
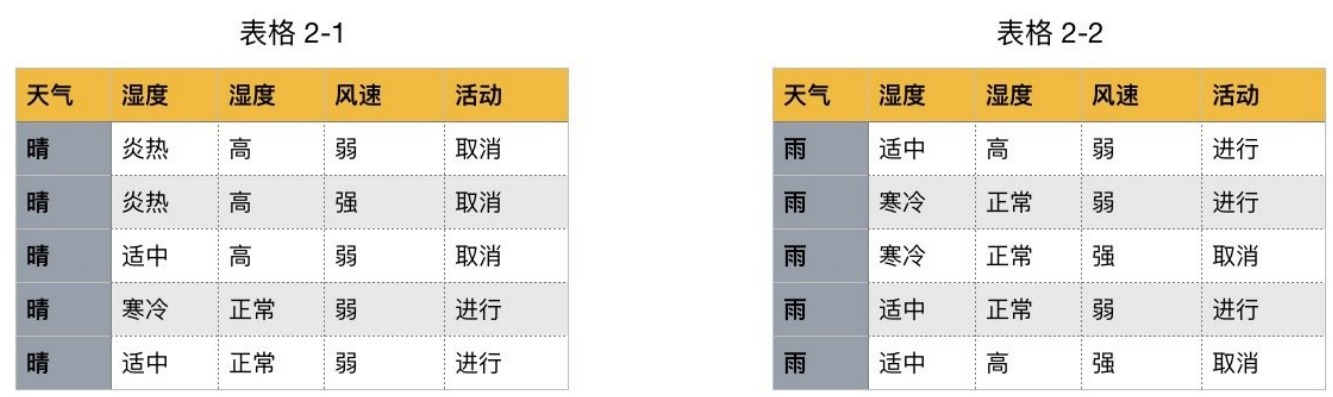
如下图,第⼀列为天⽓,第⼆列为温度,第三列为湿度,第四列为⻛速,最后⼀列该活动是否进⾏。
我们要解决:根据下⾯表格数据,判断在对应天⽓下,活动是否会进⾏?

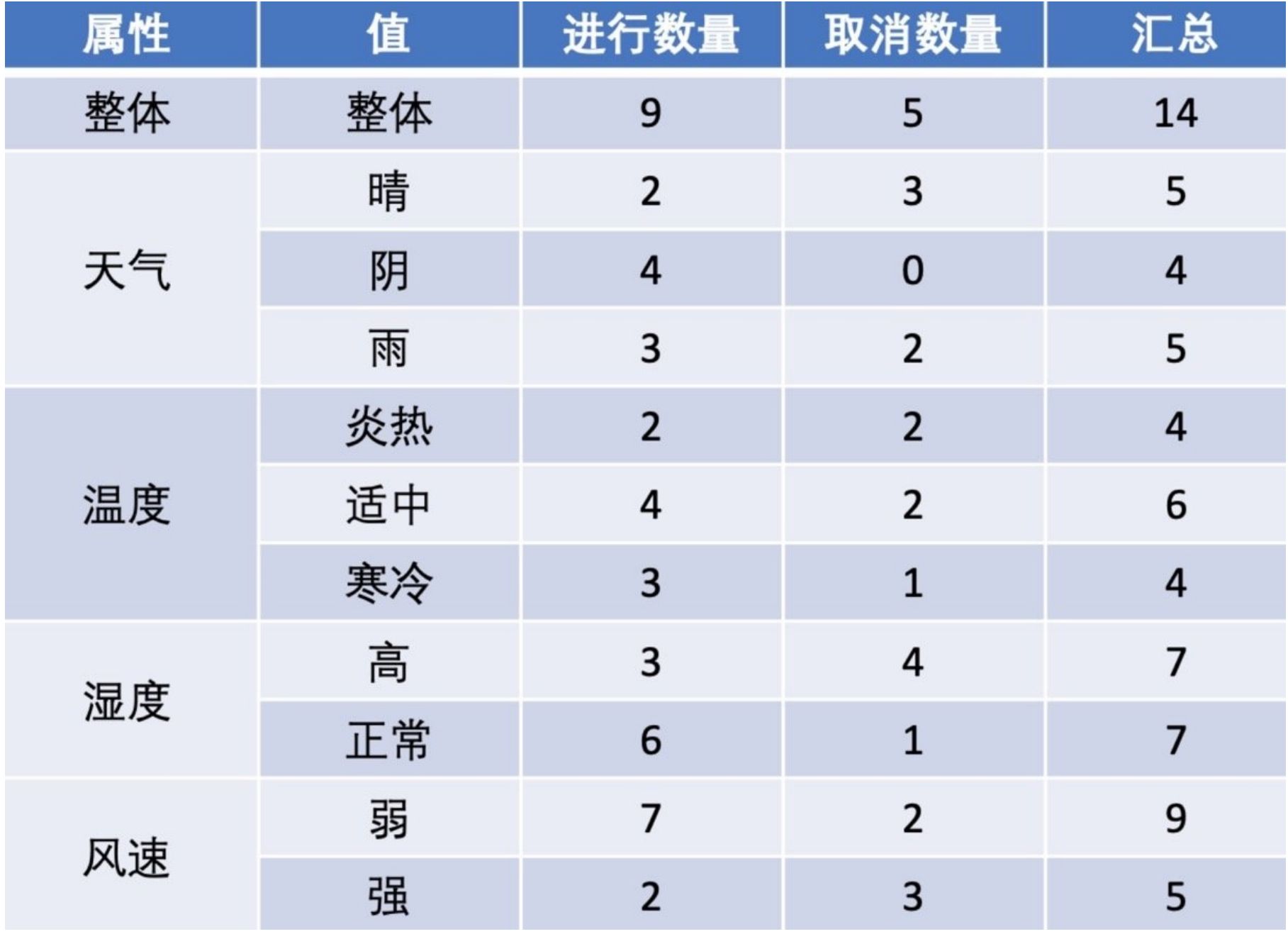
该数据集有四个属性,属性集合A={ 天⽓,温度,湿度,⻛速}, 类别标签有两个,类别集合L={进⾏,取消}。
a.计算类别信息熵
类别信息熵表示的是所有样本中各种类别出现的不确定性之和。根据熵的概念,熵越⼤,不确定性就越⼤,把事情搞清楚所需要的信息量就越多。
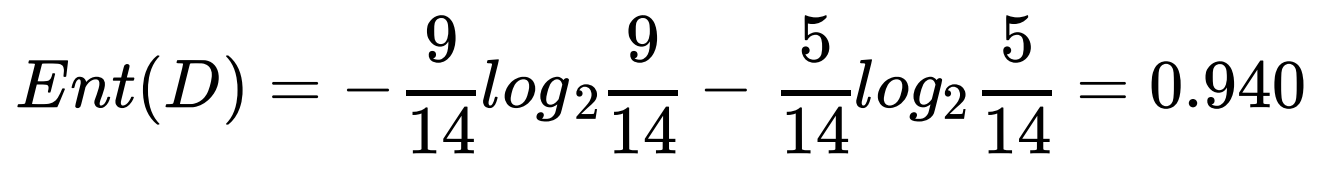
b.计算每个属性的信息熵
每个属性的信息熵相当于⼀种条件熵。他表示的是在某种属性的条件下,各种类别出现的不确定性之和。属性的信息熵越⼤,表示这个属性中拥有的样本类别越不“纯”。

c.计算信息增益
信息增益的 = 熵 - 条件熵,在这⾥就是类别信息熵 - 属性信息熵,它表示的是信息不确定性减少的程度。如果⼀个属性的信息增益越⼤,就表示⽤这个属性进⾏样本划分可以更好的减少划分后样本的不确定性,当然,选择该属性就可以更快更好地完成我们的分类⽬标。
信息增益就是ID3算法的特征选择指标。

假设我们把上⾯表格1的数据前⾯添加⼀列为"编号",取值(1--14). 若把"编号"也作为⼀个候选划分属性,则根据前⾯步骤: 计算每个属性的信息熵过程中,我们发现,该属性的值为0, 也就是其信息增益为0.940. 但是很明显这么分类,最后出现的结果不具有泛化效果.此时根据信息增益就⽆法选择出有效分类特征。所以,C4.5选择使⽤信息增益率对ID3进⾏改进。
d.计算属性分裂信息度量
⽤分裂信息度量来考虑某种属性进⾏分裂时分⽀的数量信息和尺⼨信息,我们把这些信息称为属性的内在信息(instrisicinformation)。信息增益率⽤信息增益/内在信息,会导致属性的重要性随着内在信息的增⼤⽽减⼩(也就是说,如果这个属性本身不确定性就很⼤,那我就越不倾向于选取它),这样算是对单纯⽤信息增益有所补偿。
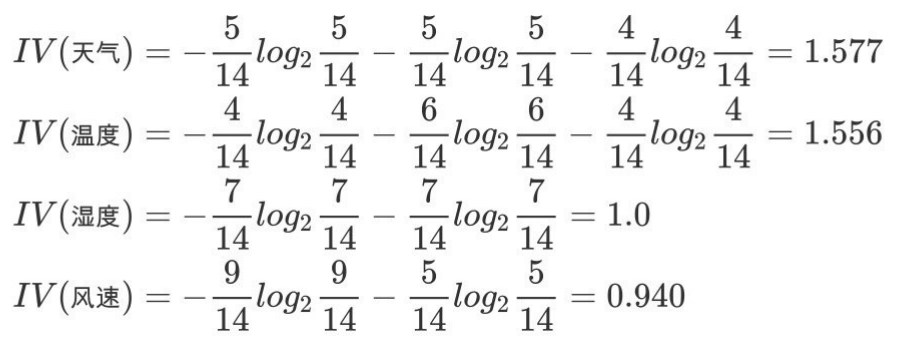
e.计算信息增益率

天⽓的信息增益率最⾼,选择天⽓为分裂属性。发现分裂了之后,天⽓是“阴”的条件下,类别是”纯“的,所以把它定义为叶⼦节点,选择不“纯”的结点继续分裂。
在⼦结点当中重复过程1~5,直到所有的叶⼦结点⾜够"纯"。
现在我们来总结⼀下C4.5的算法流程
while(当前节点"不纯"):
1.计算当前节点的类别熵(以类别取值计算)
2.计算当前阶段的属性熵(按照属性取值下的类别取值计算)
3.计算信息增益
4.计算各个属性的分裂信息度量
5.计算各个属性的信息增益率
end while
当前阶段设置为叶⼦节点3.3 为什么使⽤C4.5要好
1.用信息增益率来选择属性
克服了⽤信息增益来选择属性时偏向选择值多的属性的不⾜。
2.采用了⼀种后剪枝⽅法
避免树的⾼度⽆节制的增⻓,避免过度拟合数据
3.对于缺失值的处理
在某些情况下,可供使⽤的数据可能缺少某些属性的值。假如〈x,c(x)〉是样本集S中的⼀个训练实例,但是其属性A的值A(x)未知。
处理缺失属性值的⼀种策略是赋给它结点n所对应的训练实例中该属性的最常⻅值;
另外⼀种更复杂的策略是为A的每个可能值赋予⼀个概率。
例如,给定⼀个布尔属性A,如果结点n包含6个已知A=1和4个A=0的实例,那么A(x)=1的概率是0.6,⽽A(x)=0的概率是0.4。于是,实例x的60%被分配到A=1的分⽀,40%被分配到另⼀个分⽀。
C4.5就是使⽤这种⽅法处理缺少的属性值。
决策树的划分依据(3) ----基尼值和基尼指数
4.1 概念
CART 决策树 [Breiman et al., 1984] 使⽤"基尼指数" (Gini index)来选择划分属性.
CART 是Classification and Regression Tree的简称,这是⼀种著名的决策树学习算法,分类和回归任务都可⽤
基尼值Gini(D):从数据集D中随机抽取两个样本,其类别标记不⼀致的概率。故,Gini(D)值越⼩,数据集D的纯度越⾼。
数据集 D 的纯度可⽤基尼值来度量:
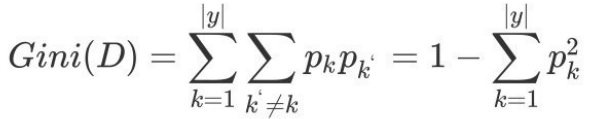
p =
D为样本的所有数量,C k为第k类样本的数量。
基尼指数Gini_index(D):⼀般,选择使D划分后基尼指数最⼩的属性作为最优化分属性。
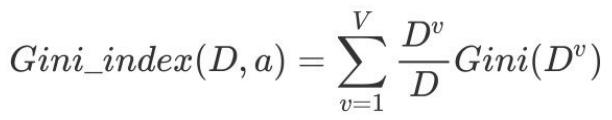
4.2 案例
请根据下图列表,按照基尼指数的划分依据,做出决策树。
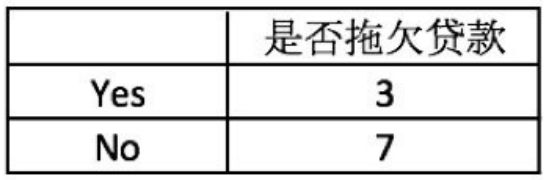
| 序号 | 是否有房 | 婚姻状况 | 年收入 | 是否拖欠贷款 |
|---|---|---|---|---|
| 1 | yes | single | 125k | no |
| 2 | no | married | 100k | no |
| 3 | no | single | 70k | no |
| 4 | yes | married | 120k | no |
| 5 | no | divorced | 95k | yes |
| 6 | no | married | 60k | no |
| 7 | yes | divorced | 220k | no |
| 8 | no | single | 85k | yes |
| 9 | no | married | 75k | no |
| 10 | No | Single | 90k | Yes |
1,对数据集⾮序列标号属性{是否有房,婚姻状况,年收⼊}分别计算它们的Gini指数,取Gini指数最⼩的属性作为决策树的根节点属性。
第⼀次⼤循环
2,根节点的Gini值为:
![]()
3,当根据是否有房来进⾏划分时,Gini指数计算过程为:
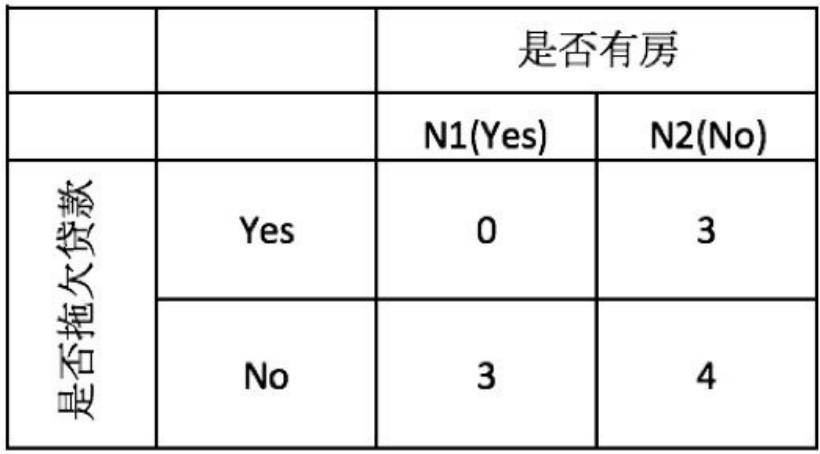

4,若按婚姻状况属性来划分,属性婚姻状况有三个可能的取值{married,single,divorced},分别计算划分后的Gini系数增益。
{married} | {single,divorced}
{single} | {married,divorced}
{divorced} | {single,married}
注意:Gini系数每次只能同时计算“两种情况”,假设有三种情况:高、中、低,那么要分为三次来计算:{高、非高}、{中、非中}、{低、非低}

对⽐计算结果,根据婚姻状况属性来划分根节点时取Gini指数最⼩的分组作为划分结果,即:
{married} | {single,divorced}
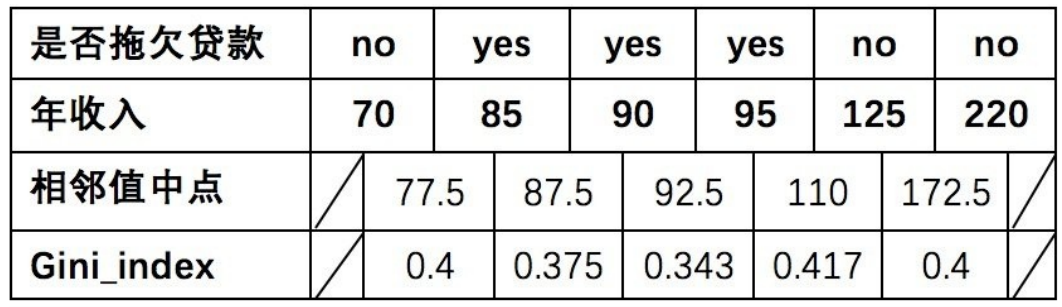
5,同理可得年收⼊Gini:
对于年收⼊属性为数值型属性,⾸先需要对数据按升序排序,然后从⼩到⼤依次⽤相邻值的中间值作为分隔将样本划分为两组。例如当⾯对年收⼊为60和70这两个值时,我们算得其中间值为65。以中间值65作为分割点求出Gini指数。

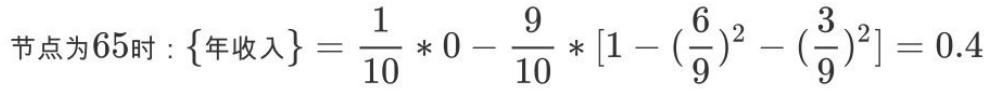
根据计算知道,三个属性划分根节点的指数最⼩的有两个:年收⼊属性和婚姻状况,他们的指数都为0.3。此时,选取⾸先出现的属性【married】作为第⼀次划分。
第⼆次⼤循环
6,接下来,采⽤同样的⽅法,分别计算剩下属性,其中根节点的Gini系数为(此时是否拖⽋贷款的各有3个records)
![]()
7,对于是否有房属性,可得:
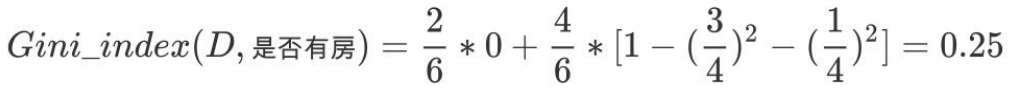
8,对于年收⼊属性则有:
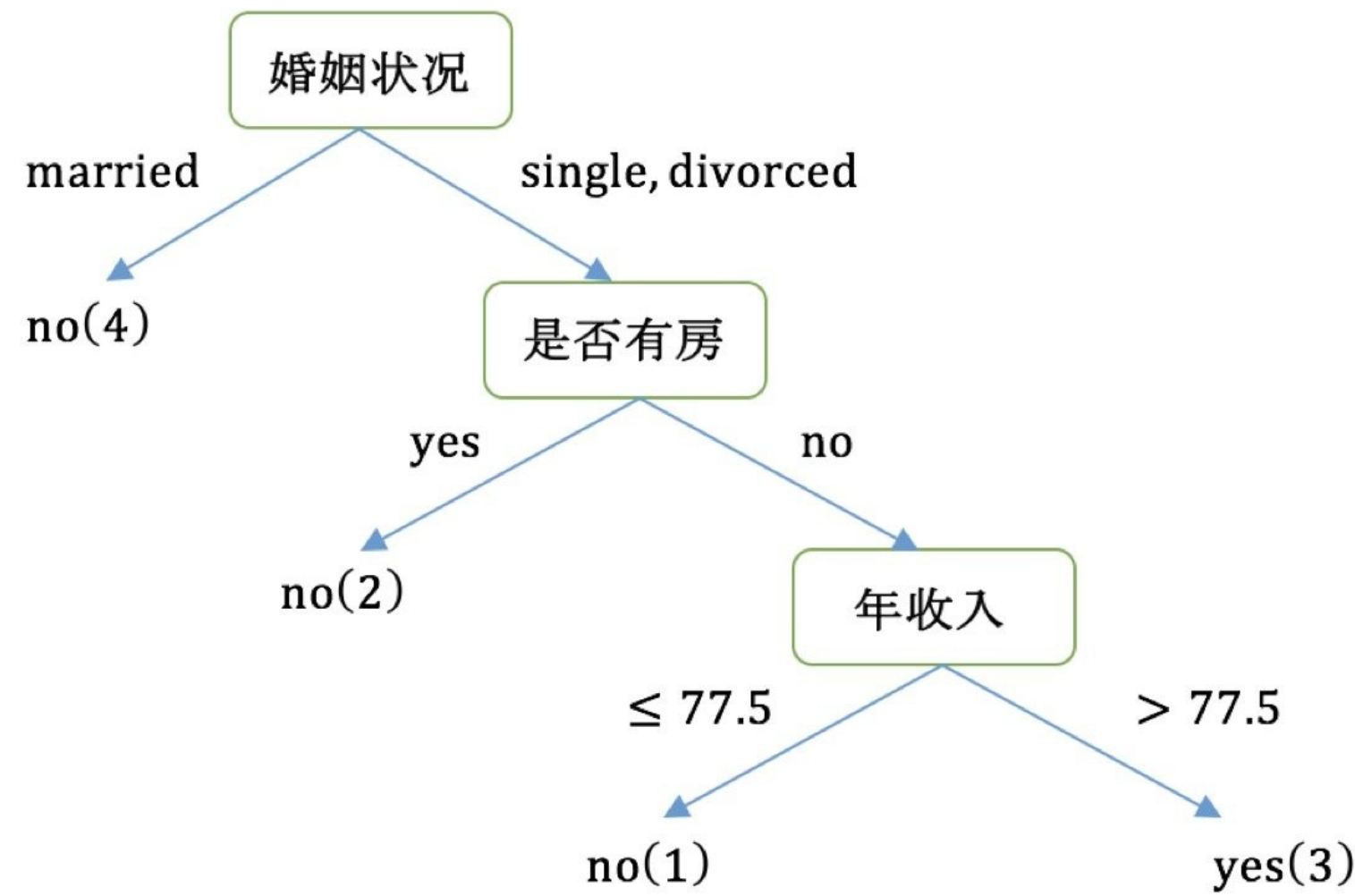
经过如上流程,构建的决策树,如下图:
现在我们来总结⼀下CART的算法流程
while(当前节点"不纯"):
1.遍历每个变量的每⼀种分割⽅式,找到最好的分割点
2.分割成两个节点N1和N2
end while
每个节点⾜够“纯”为⽌总结对比
5.1 常⻅决策树的启发函数⽐较
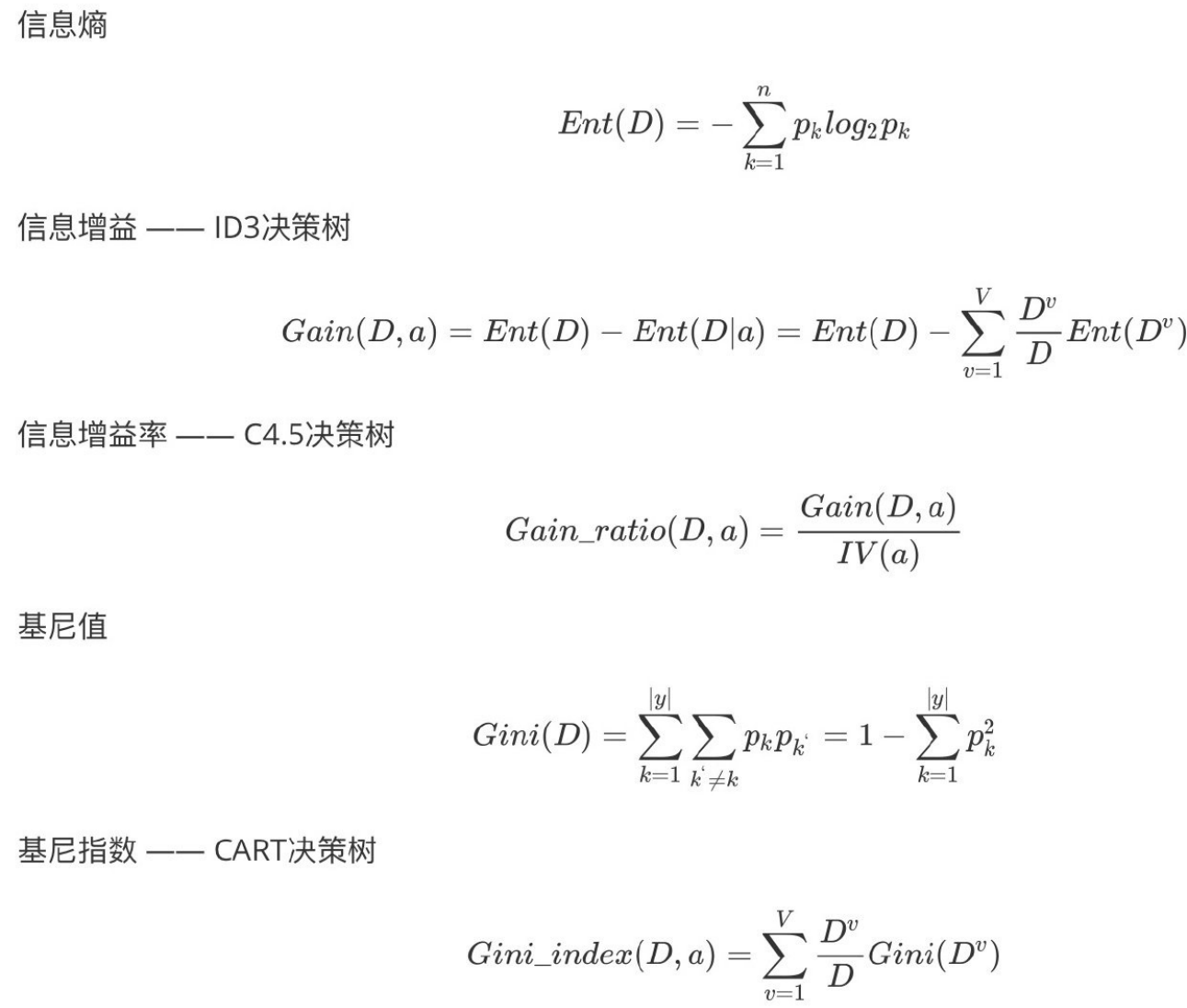
| 名称 | 提出时间 | 分支方式 | 备注 |
|---|---|---|---|
| ID3 | 1975 | 信息增益 | ID3 只能对离散属性的数据集构成决策树 |
| C4.5 | 1993 | 信息增益率 | 优化后解决了 ID3 分支过程中总喜欢偏向选择值较多的属性 |
| CART | 1984 | Gini 系数 | 可以进行分类和回归,可以处理离散属性,也可以处理连续属性 |
5.1.1 ID3 算法
存在的缺点
(1) ID3算法在选择根节点和各内部节点中的分⽀属性时,采⽤信息增益作为评价标准。信息增益的缺点是倾向于选择取值较多的属性,在有些情况下这类属性可能不会提供太多有价值的信息.
(2) ID3算法只能对描述属性为离散型属性的数据集构造决策树。
5.1.2 C4.5算法
做出的改进(为什么使⽤C4.5要好)
(1) ⽤信息增益率来选择属性
(2) 可以处理连续数值型属性
(3)采⽤了⼀种后剪枝⽅法
(4)对于缺失值的处理
C4.5算法的优缺点
-
- 优点:
- 产⽣的分类规则易于理解,准确率较⾼。
- 缺点:
- 在构造树的过程中,需要对数据集进⾏多次的顺序扫描和排序,因⽽导致算法的低效。
- 此外,C4.5只适合于能够驻留于内存的数据集,当训练集⼤得⽆法在内存容纳时程序⽆法运⾏。
- 优点:
5.1.3 CART算法
CART算法相⽐C4.5算法的分类⽅法,采⽤了简化的⼆叉树模型,同时特征选择采⽤了近似的基尼系数来简化计算。
C4.5不⼀定是⼆叉树,但CART⼀定是⼆叉树。
5.1.4 多变量决策树(multi-variate decision tree)
同时,⽆论是ID3, C4.5还是CART,在做特征选择的时候都是选择最优的⼀个特征来做分类决策,但是⼤多数,分类决策不应该是由某⼀个特征决定的,⽽是应该由⼀组特征决定的。这样决策得到的决策树更加准确。这个决策树叫做多变量决策树(multi-variate decision tree)。在选择最优特征的时候,多变量决策树不是选择某⼀个最优特征,⽽是选择最优的⼀个特征线性组合来做决策。这个算法的代表是OC1,这⾥不多介绍。
如果样本发⽣⼀点点的改动,就会导致树结构的剧烈改变。这个可以通过集成学习⾥⾯的随机森林之类的⽅法解决。
5.2 决策树变量的两种类型:
- 数字型(Numeric):变量类型是整数或浮点数,如前⾯例⼦中的“年收⼊”。⽤“>=”,“>”,“<”或“<=”作为分割条件
(排序后,利⽤已有的分割情况,可以优化分割算法的时间复杂度)。
- 名称型(Nominal):类似编程语⾔中的枚举类型,变量只能从有限的选项中选取,⽐如前⾯例⼦中的“婚姻情况”,只能是“单身”,“已婚”或“离婚”,使⽤“=”来分割。
5.3 如何评估分割点的好坏?
如果⼀个分割点可以将当前的所有节点分为两类,使得每⼀类都很“纯”,也就是同⼀类的记录较多,那么就是⼀个好分割点。
⽐如上⾯的例⼦,“拥有房产”,可以将记录分成了两类,“是”的节点全部都可以偿还债务,⾮常“纯”;“否”的节点,可以偿还贷款和⽆法偿还贷款的⼈都有,不是很“纯”,但是两个节点加起来的纯度之和与原始节点的纯度之差最⼤,所以按照这种⽅法分割。
构建决策树采⽤贪⼼算法,只考虑当前纯度差最⼤的情况作为分割点。
cart剪枝
为什么要剪枝

图形描述
- 横轴表示在决策树创建过程中树的结点总数,纵轴表示决策树的预测精度。
- 实线显示的是决策树在训练集上的精度,虚线显示的则是在⼀个独⽴的测试集上测量出来的精度。
- 随着树的增⻓,在训练样集上的精度是单调上升的, 然⽽在独⽴的测试样例上测出的精度先上升后下降。
出现这种情况的原因:
- 原因1:噪声、样本冲突,即错误的样本数据。
- 原因2:特征即属性不能完全作为分类标准。
- 原因3:巧合的规律性,数据量不够⼤。
剪枝 (pruning)是决策树学习算法对付"过拟合"的主要⼿段。
在决策树学习中,为了尽可能正确分类训练样本,结点划分过程将不断重复,有时会造成决策树分⽀过多,这时就可能因训练样本学得"太好"了,以致于把训练集⾃身的⼀些特点当作所有数据都具有的⼀般性质⽽导致过拟合。因此,可通过主动去掉⼀些分⽀来降低过拟合的⻛险。
如何判断决策树泛化性能是否提升呢?
可使⽤前⾯介绍的留出法,即预留⼀部分数据⽤作"验证集"以进⾏性 能评估。例如对下表的⻄⽠数据集,我们将其随机划分为两部分,其中编号为 {1,2,3,6, 7, 10, 14, 15, 16, 17} 的样例组成训练集,编号为 {4, 5,8, 9, 11, 12, 13} 的样例组成验证集。
训练集:
| 编号 | 色泽 | 根蒂 | 敲声 | 纹理 | 脐部 | 触感 | 好瓜 |
|---|---|---|---|---|---|---|---|
| 1 | 青绿 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 是 |
| 2 | 乌黑 | 蜷缩 | 沉闷 | 清晰 | 凹陷 | 硬滑 | 是 |
| 3 | 乌黑 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 是 |
| 6 | 青绿 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 软粘 | 是 |
| 7 | 乌黑 | 稍蜷 | 浊响 | 稍糊 | 稍凹 | 软粘 | 是 |
| 10 | 青绿 | 硬挺 | 清脆 | 清晰 | 平坦 | 软粘 | 否 |
| 14 | 浅白 | 稍蜷 | 沉闷 | 稍糊 | 凹陷 | 硬滑 | 否 |
| 15 | 乌黑 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 软粘 | 否 |
| 16 | 浅白 | 蜷缩 | 浊响 | 模糊 | 平坦 | 硬滑 | 否 |
| 17 | 青绿 | 蜷缩 | 沉闷 | 稍糊 | 稍凹 | 硬滑 | 否 |
验证集:
| 编号 | 色泽 | 根蒂 | 敲声 | 纹理 | 脐部 | 触感 | 好瓜 |
|---|---|---|---|---|---|---|---|
| 4 | 青绿 | 蜷缩 | 沉闷 | 清晰 | 凹陷 | 硬滑 | 是 |
| 5 | 浅白 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 是 |
| 8 | 乌黑 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 硬滑 | 是 |
| 9 | 乌黑 | 稍蜷 | 沉闷 | 稍糊 | 稍凹 | 硬滑 | 否 |
| 11 | 浅白 | 硬挺 | 清脆 | 模糊 | 平坦 | 硬滑 | 否 |
| 12 | 浅白 | 蜷缩 | 浊响 | 模糊 | 平坦 | 软粘 | 否 |
| 13 | 青绿 | 稍蜷 | 浊响 | 稍糊 | 凹陷 | 硬滑 | 否 |
假定咱们采⽤信息增益准则来划分属性选择,则上表中训练集将会⽣成⼀棵下⾯决策树。
为便于讨论,我们对圈中的部分结点做了编号。
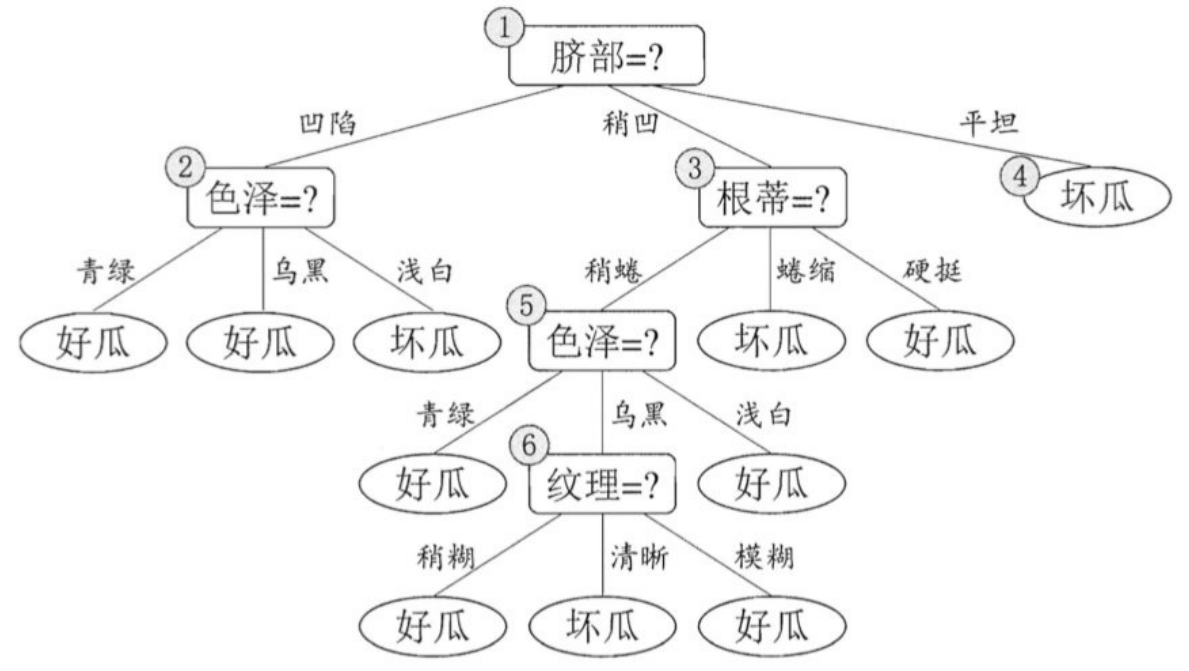
接下来,我们⼀起看⼀下,如何对这⼀棵树进⾏剪枝。
2 常⽤的减枝⽅法
决策树剪枝的基本策略有"预剪枝" (pre-pruning)和"后剪枝"(post- pruning) 。
预剪枝是指在决策树⽣成过程中,对每个结点在划分前先进⾏估计,若当前结点的划分不能带来决策树泛化性能提升,则停⽌划分并将当前结点标记为叶结点;
后剪枝则是先从训练集⽣成⼀棵完整的决策树,然后⾃底向上地对⾮叶结点进⾏考察,若将该结点对应的⼦树替换为叶结点能带来决策树泛化性能提升,则将该⼦树替换为叶结点。
预剪枝
⾸先,基于信息增益准则,我们会选取属性"脐部"来对训练集进⾏划分,并产⽣ 3 个分⽀,如下图所示。然⽽,是否应该进⾏这个划分呢?预剪枝要对划分前后的泛化性能进⾏估计。
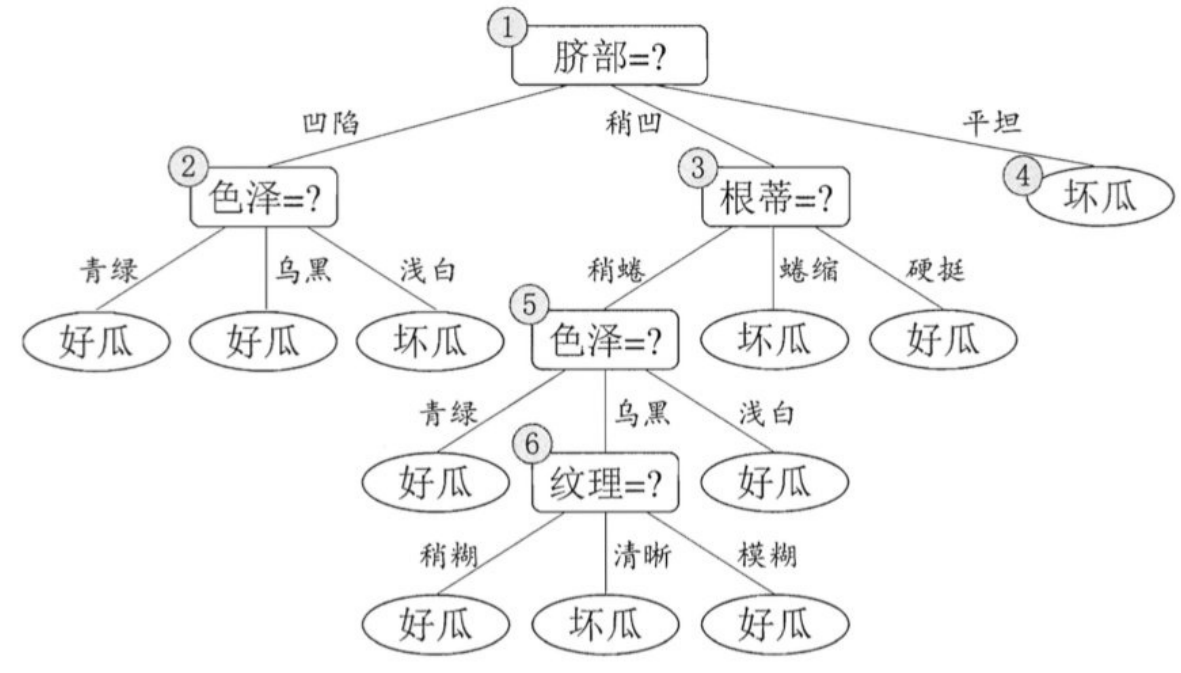
在划分之前,所有样例集中在根结点。
若不进⾏划分,该结点将被标记为叶结点,其类别标记为训练样例数最多的类别,假设我们将这个叶结点标记为"好⽠"。
⽤前⾯表的验证集对这个单结点决策树进⾏评估。则编号为 {4,5,8} 的样例被分类正确。另外 4个样例分类错误,于是验证集精度为3/ 7 ∗ 100% = 42.9%。
在⽤属性"脐部"划分之后,上图中的结点2、3、4分别包含编号为 {1,2,3, 14}、 {6,7, 15, 17}、 {10, 16} 的训练样例,因此这 3 个结点分别被标记为叶结点"好⽠"、 "好⽠"、 "坏⽠"。

此时,验证集中编号为 {4, 5, 8,11, 12} 的样例被分类正确,验证集精度为5 /7 ∗ 100% = 71.4% > 42.9%.
于是,⽤"脐部"进⾏划分得以确定。
然后,决策树算法应该对结点2进⾏划分,基于信息增益准则将挑选出划分属性"⾊泽"。然⽽,在使⽤"⾊泽"划分后,编号为 {5} 的验证集样本分类结果会由正确转为错误,使得验证集精度下降为 57.1%。于是,预剪枝策略将禁 ⽌结点2被划分。
对结点3,最优划分属性为"根蒂",划分后验证集精度仍为 71.4%. 这个 划分不能提升验证集精度,于是,预剪枝策略禁⽌结点3被划分。
对结点4,其所含训练样例⼰属于同⼀类,不再进⾏划分.
于是,基于预剪枝策略从上表数据所⽣成的决策树如上图所示,其验证集精度为 71.4%. 这是⼀棵仅有⼀层划分的决策树,亦称"决策树桩" (decision stump).
后剪枝:
后剪枝先从训练集⽣成⼀棵完整决策树,继续使⽤上⾯的案例,从前⾯计算,我们知前⾯构造的决策树的验证集精度为42.9%。
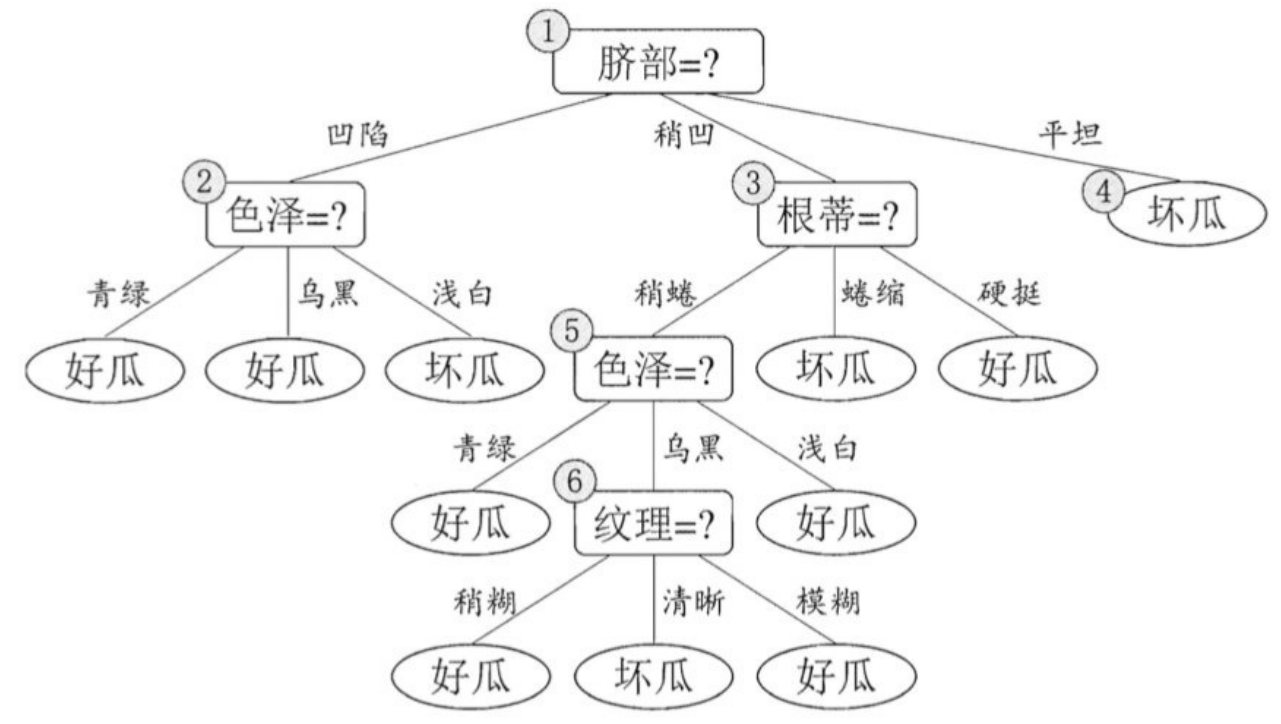
后剪枝⾸先考察结点6,若将其领衔的分⽀剪除则相当于把6替换为叶结点。替换后的叶结点包含编号为 {7, 15} 的训练样本,(好瓜坏瓜1:1就默认是好瓜)于是该叶结点的类别标记为"好⽠",此时决策树的验证集精度提⾼⾄ 57.1%。于是,后剪枝策略决定剪枝,如下图所示。
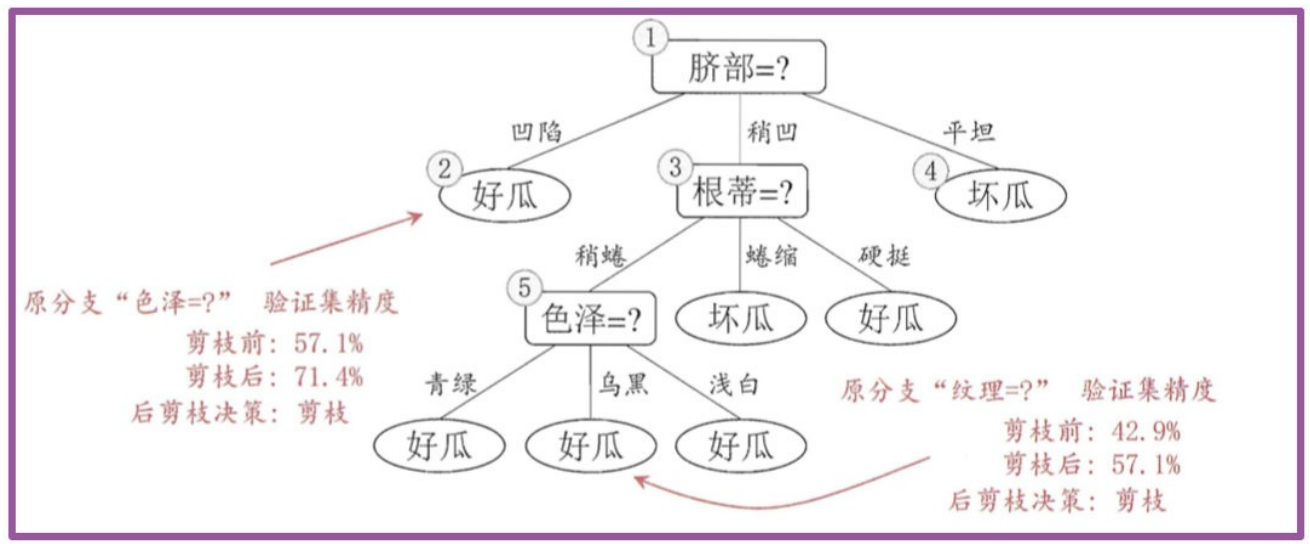
然后考察结点5,若将其领衔的⼦树替换为叶结点,则替换后的叶结点包含编号为 {6,7,15}的训练样例,叶结点类别标记为"好⽠';此时决策树验证集精度仍为 57.1%. 于是,可以不进⾏剪枝.
对结点2,若将其领衔的⼦树替换为叶结点,则替换后的叶结点包含编号 为 {1, 2, 3, 14} 的训练样例,叶结点标记为"好⽠"此时决策树的验证集精度提⾼⾄ 71.4%. 于是,后剪枝策略决定剪枝.
对结点3和1,若将其领衔的⼦树替换为叶结点,则所得决策树的验证集 精度分别为 71.4% 与 42.9%,均未得到提⾼,于是它们被保留。
最终,基于后剪枝策略所⽣成的决策树就如上图所示,其验证集精度为 71.4%。
对⽐两种剪枝⽅法
- 后剪枝决策树通常⽐预剪枝决策树保留了更多的分⽀。
- ⼀般情形下,后剪枝决策树的⽋拟合⻛险很⼩,泛化性能往往优于预剪枝决策树。
- 但后剪枝过程是在⽣成完全决策树之后进⾏的。 并且要⾃底向上地对树中的所有⾮叶结点进⾏逐⼀考察,因此其训练时间开销⽐未剪枝决策树和预剪枝决策树都要⼤得多。
3 ⼩结
- 剪枝原因【了解】
- 噪声、样本冲突,即错误的样本数据
- 特征即属性不能完全作为分类标准
- 巧合的规律性,数据量不够⼤。
- 常⽤剪枝⽅法【知道】
- 预剪枝
- 在构建树的过程中,同时剪枝
- 限制节点最⼩样本数
- 指定数据⾼度
- 指定熵值的最⼩值
- 在构建树的过程中,同时剪枝
- 后剪枝
- 把⼀棵树,构建完成之后,再进⾏从下往上的剪枝
- 预剪枝
分类决策树API
class sklearn.tree.DecisionTreeClassifier(criterion=’gini’, max_depth=None,random_state=None)
- criterion
- 特征选择标准
- "gini"或者"entropy",前者代表基尼系数,后者代表信息增益。⼀默认"gini",即CART算法。
- min_samples_split
- 内部节点再划分所需最⼩样本数
- 这个值限制了⼦树继续划分的条件,如果某节点的样本数少于min_samples_split,则不会继续再尝试选择最优特征来进⾏划分。 默认是2。如果样本量不⼤,不需要管这个值。如果样本量数量级⾮常⼤,则推荐增⼤这个值。我之前的⼀个项⽬例⼦,有⼤概10万样本,建⽴决策树时,我选择了min_samples_split=10。可以作为参考。
- min_samples_leaf
- 叶⼦节点最少样本数
- 这个值限制了叶⼦节点最少的样本数,如果某叶⼦节点数⽬⼩于样本数,则会和兄弟节点⼀起被剪枝。
- 默认是1,可以输⼊最少的样本数的整数,或者最少样本数占样本总数的百分⽐。如果样本量不⼤,不需要管这个值。如果样本量数量级⾮常⼤,则推荐增⼤这个值。之前的10万样本项⽬使min_samples_leaf的值为5,仅供参考。
- max_depth
- 决策树最⼤深度
- 决策树的最⼤深度,默认可以不输⼊,如果不输⼊的话,决策树在建⽴⼦树的时候不会限制⼦树的深度。
- ⼀般来说,数据少或者特征少的时候可以不管这个值。如果模型样本量多,特征也多的情况下,推荐限制这个最⼤深度,具体的取值取决于数据的分布。常⽤的可以取值10-100之间
- random_state
- 随机数种⼦
案例:泰坦尼克号乘客⽣存预测
1 案例背景
泰坦尼克号沉没是历史上最臭名昭着的沉船之⼀。1912年4⽉15⽇,在她的处⼥航中,泰坦尼克号在与冰⼭相撞后沉没,在2224名乘客和机组⼈员中造成1502⼈死亡。这场耸⼈听闻的悲剧震惊了国际社会,并为船舶制定了更好的安全规定。 造成海难失事的原因之⼀是乘客和机组⼈员没有⾜够的救⽣艇。尽管幸存有⼀些运⽓因素,但有些⼈⽐其他⼈更容易⽣存,例如妇⼥,⼉童和上流社会。 在这个案例中,我们要求您完成对哪些⼈可能存活的分析。特别是,我们要求您运⽤机器学习⼯具来预测哪些乘客幸免于悲剧。
案例:https://www.kaggle.com/c/titanic/overview
我们提取到的数据集中的特征包括票的类别,是否存活,乘坐班次,年龄,登陆home.dest,房间,船和性别等。
数据:https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv
经过观察数据得到:

- 1 Pclass是指乘客仓等级(1,2,3),是社会经济阶层的代表。
- 2 其中age数据存在缺失。
2 步骤分析
- 1.获取数据
- 2.数据基本处理
- 2.1 确定特征值,⽬标值
- 2.2 缺失值处理
- 2.3 数据集划分
- 3.特征⼯程(字典特征抽取)
- 4.机器学习(决策树)
- 5.模型评估
3 代码实现
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction import DictVectorizer
from sklearn.tree import DecisionTreeClassifier
# 1.获取数据
data=pd.read_csv("https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv")
# 2.数据基本处理
# 2.1 确定特征值,⽬标值
X=data[["Pclass","Sex","Age"]]
y=data["Survived"]
# 2.2 缺失值处理
print("缺失值检测结果:", X["Age"].isnull().any()) # 更直观的缺失值检测
print("缺失值数量:", X["Age"].isnull().sum()) # 查看具体缺失数量
X.loc[:,"Age"]=X["Age"].fillna(X["Age"].mean())
# 2.3 数据集划分
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.2,random_state=66)
# 3.特征⼯程(字典特征抽取)
transfromer=DictVectorizer(sparse=False)
'''
特征中出现类别符号,需要进⾏one-hot编码处理(DictVectorizer)
x.to_dict(orient="records") 需要将数组特征转换成字典数据
[{'Pclass': 3, 'Sex': 'female', 'Age': 29.69911764705882}, {'Pclass': 3, 'Sex': 'male', 'Age': 21.0}...]
'''
transfrom_X_train=transfromer.fit_transform(X_train.to_dict(orient="records"))
transfrom_X_test=transfromer.transform(X_test.to_dict(orient="records"))
# 4.机器学习(决策树)
estimator=DecisionTreeClassifier(criterion="entropy", max_depth=5)#决策树API当中,如果没有指定max_depth那么会根据信息熵的条件直到最终结束。这⾥我们可以指定树的深度来进⾏限制树的⼤⼩
estimator.fit(transfrom_X_train,y_train)
# 5.模型评估
res=estimator.predict(transfrom_X_test)
score=estimator.score(transfrom_X_test,y_test)
print("预测结果:\n",res)
print("模型得分:\n",score)查看打印结果
预测结果:
[1 0 0 1 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 1 0 0 1 0 0 0 0 0 0 0 0 0 0 1 0 0 0
0 0 1 0 1 0 0 1 1 0 0 0 1 0 0 0 0 0 0 0 1 0 0 1 1 0 1 0 0 0 0 0 0 0 0 0 0
0 1 0 1 0 0 1 0 0 0 0 0 1 1 0 0 0 1 0 0 0 0 0 0 1 1 1 0 1 1 0 0 0 1 0 0 0
0 0 0 0 0 1 1 0 1 1 1 0 0 0 0 0 0 0 0 0 0 0 1 1 1 0 1 1 0 0 1 1 0 0 1 1 0
0 0 0 0 0 1 1 0 0 0 1 0 1 0 1 0 0 1 1 1 0 0 0 0 0 0 0 0 0 0 0]
模型得分:
0.7988826815642458上述代码为什么必须进行特征提取?
"Sex"列是字符串类型("male"、"female")- Scikit-learn 的模型(包括决策树)只能处理数值型数据
- 模型无法直接理解字符串类型的类别特征
Scikit-learn 的所有模型要求输入为:
-
- 二维数值矩阵 (n_samples × n_features)而不是包含混合类型的 Pandas DataFrame
决策树可视化
保存树的结构到dot⽂件
sklearn.tree.export_graphviz() 该函数能够导出DOT格式
- tree.export_graphviz(estimator,out_file='tree.dot’,feature_names=[‘’,’’])
from sklearn.tree import export_graphviz
export_graphviz(estimator,r'D:\data\机器学习\tree.dot',feature_names=['Age', 'Pclass', 'female', 'male'])
#上面的feature_names参数可以通过特征提取器的get_feature_names_out方法获取:
#transfromer.get_feature_names_out()#array(['Age', 'Pclass', 'Sex=female', 'Sex=male'], dtype=object)
#注意,非数值类的属性的所有可能都要列出来:例如有的数据源的仓位等级并不是纯数据:1,2,3,是1rt,2nd,3rd
export_graphviz(estimator, out_file="./data/tree.dot", feature_names=['age', 'pclass=1st', 'pclass=2nd', 'pclass=3rd', '⼥性', '男性'])执行上述代码之后就会在指定目录下生成dot文件:
打开dot文件,内容格式如下:
点击查看dot文件内容
digraph Tree {
node [shape=box, fontname="helvetica"] ;
edge [fontname="helvetica"] ;
0 [label="male <= 0.5\ngini = 0.477\nsamples = 712\nvalue = [433.0, 279.0]"] ;
1 [label="Pclass <= 2.5\ngini = 0.37\nsamples = 257\nvalue = [63, 194]"] ;
0 -> 1 [labeldistance=2.5, labelangle=45, headlabel="True"] ;
2 [label="Age <= 2.5\ngini = 0.116\nsamples = 145\nvalue = [9, 136]"] ;
1 -> 2 ;
3 [label="gini = 0.0\nsamples = 1\nvalue = [1, 0]"] ;
2 -> 3 ;
4 [label="Pclass <= 1.5\ngini = 0.105\nsamples = 144\nvalue = [8, 136]"] ;
2 -> 4 ;
5 [label="Age <= 49.5\ngini = 0.05\nsamples = 78\nvalue = [2, 76]"] ;
4 -> 5 ;
6 [label="gini = 0.03\nsamples = 66\nvalue = [1, 65]"] ;
5 -> 6 ;
7 [label="gini = 0.153\nsamples = 12\nvalue = [1, 11]"] ;
5 -> 7 ;
8 [label="Age <= 56.0\ngini = 0.165\nsamples = 66\nvalue = [6, 60]"] ;
4 -> 8 ;
9 [label="gini = 0.142\nsamples = 65\nvalue = [5, 60]"] ;
8 -> 9 ;
10 [label="gini = 0.0\nsamples = 1\nvalue = [1, 0]"] ;
8 -> 10 ;
11 [label="Age <= 38.5\ngini = 0.499\nsamples = 112\nvalue = [54.0, 58.0]"] ;
1 -> 11 ;
12 [label="Age <= 6.5\ngini = 0.493\nsamples = 102\nvalue = [45, 57]"] ;
11 -> 12 ;
13 [label="Age <= 1.5\ngini = 0.298\nsamples = 11\nvalue = [2, 9]"] ;
12 -> 13 ;
14 [label="gini = 0.0\nsamples = 4\nvalue = [0, 4]"] ;
13 -> 14 ;
15 [label="gini = 0.408\nsamples = 7\nvalue = [2, 5]"] ;
13 -> 15 ;
16 [label="Age <= 12.0\ngini = 0.498\nsamples = 91\nvalue = [43, 48]"] ;
12 -> 16 ;
17 [label="gini = 0.0\nsamples = 6\nvalue = [6, 0]"] ;
16 -> 17 ;
18 [label="gini = 0.492\nsamples = 85\nvalue = [37, 48]"] ;
16 -> 18 ;
19 [label="Age <= 55.5\ngini = 0.18\nsamples = 10\nvalue = [9, 1]"] ;
11 -> 19 ;
20 [label="gini = 0.0\nsamples = 9\nvalue = [9, 0]"] ;
19 -> 20 ;
21 [label="gini = 0.0\nsamples = 1\nvalue = [0, 1]"] ;
19 -> 21 ;
22 [label="Pclass <= 1.5\ngini = 0.304\nsamples = 455\nvalue = [370, 85]"] ;
0 -> 22 [labeldistance=2.5, labelangle=-45, headlabel="False"] ;
23 [label="Age <= 28.5\ngini = 0.472\nsamples = 97\nvalue = [60, 37]"] ;
22 -> 23 ;
24 [label="Age <= 24.5\ngini = 0.488\nsamples = 19\nvalue = [8, 11]"] ;
23 -> 24 ;
25 [label="Age <= 14.5\ngini = 0.469\nsamples = 8\nvalue = [5, 3]"] ;
24 -> 25 ;
26 [label="gini = 0.0\nsamples = 2\nvalue = [0, 2]"] ;
25 -> 26 ;
27 [label="gini = 0.278\nsamples = 6\nvalue = [5, 1]"] ;
25 -> 27 ;
28 [label="Age <= 27.5\ngini = 0.397\nsamples = 11\nvalue = [3, 8]"] ;
24 -> 28 ;
29 [label="gini = 0.245\nsamples = 7\nvalue = [1, 6]"] ;
28 -> 29 ;
30 [label="gini = 0.5\nsamples = 4\nvalue = [2, 2]"] ;
28 -> 30 ;
31 [label="Age <= 60.5\ngini = 0.444\nsamples = 78\nvalue = [52, 26]"] ;
23 -> 31 ;
32 [label="Age <= 30.5\ngini = 0.465\nsamples = 68\nvalue = [43, 25]"] ;
31 -> 32 ;
33 [label="gini = 0.305\nsamples = 16\nvalue = [13, 3]"] ;
32 -> 33 ;
34 [label="gini = 0.488\nsamples = 52\nvalue = [30.0, 22.0]"] ;
32 -> 34 ;
35 [label="Age <= 75.5\ngini = 0.18\nsamples = 10\nvalue = [9, 1]"] ;
31 -> 35 ;
36 [label="gini = 0.0\nsamples = 9\nvalue = [9, 0]"] ;
35 -> 36 ;
37 [label="gini = 0.0\nsamples = 1\nvalue = [0, 1]"] ;
35 -> 37 ;
38 [label="Age <= 9.5\ngini = 0.232\nsamples = 358\nvalue = [310, 48]"] ;
22 -> 38 ;
39 [label="Pclass <= 2.5\ngini = 0.5\nsamples = 18\nvalue = [9, 9]"] ;
38 -> 39 ;
40 [label="gini = 0.0\nsamples = 6\nvalue = [0, 6]"] ;
39 -> 40 ;
41 [label="Age <= 2.5\ngini = 0.375\nsamples = 12\nvalue = [9, 3]"] ;
39 -> 41 ;
42 [label="gini = 0.0\nsamples = 4\nvalue = [4, 0]"] ;
41 -> 42 ;
43 [label="gini = 0.469\nsamples = 8\nvalue = [5, 3]"] ;
41 -> 43 ;
44 [label="Age <= 32.25\ngini = 0.203\nsamples = 340\nvalue = [301, 39]"] ;
38 -> 44 ;
45 [label="Age <= 30.75\ngini = 0.232\nsamples = 254\nvalue = [220, 34]"] ;
44 -> 45 ;
46 [label="gini = 0.203\nsamples = 236\nvalue = [209, 27]"] ;
45 -> 46 ;
47 [label="gini = 0.475\nsamples = 18\nvalue = [11, 7]"] ;
45 -> 47 ;
48 [label="Age <= 61.5\ngini = 0.11\nsamples = 86\nvalue = [81, 5]"] ;
44 -> 48 ;
49 [label="gini = 0.094\nsamples = 81\nvalue = [77, 4]"] ;
48 -> 49 ;
50 [label="gini = 0.32\nsamples = 5\nvalue = [4, 1]"] ;
48 -> 50 ;
}那么这个结构不能看清结构,所以可以在⼀个⽹站上显示
树结构可视化
将dot文件内容全选复制粘贴到Graphviz的网页版:http://webgraphviz.com/:
点击Generate Graph按钮即可生成树状图:
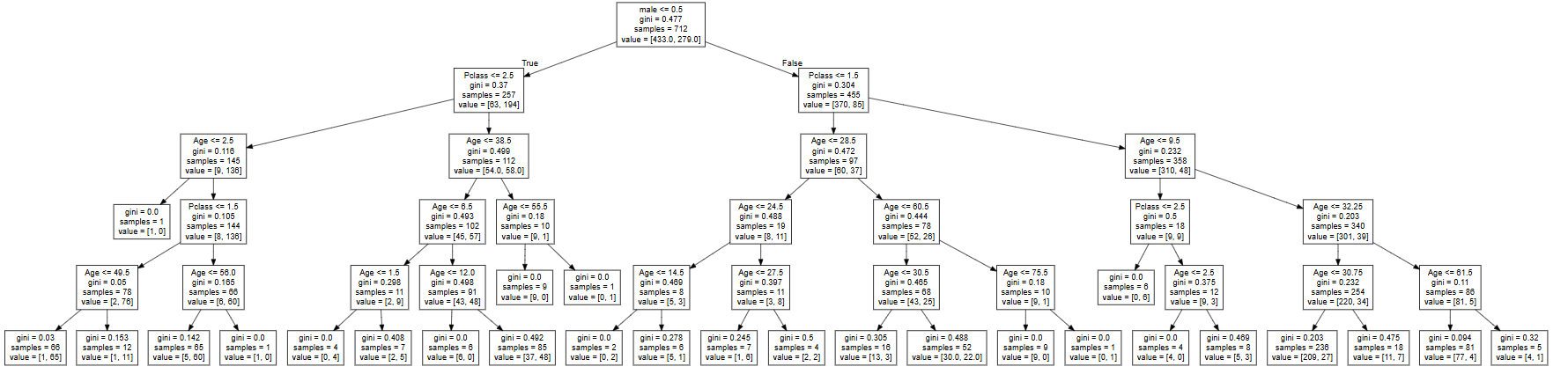
如果生成树图失败或者一直显示loading...,可能需要翻qiang解决。
什么是Graphviz?
Graphviz是一个开源的图形可视化软件。图形可视化是一种将结构信息表示为抽象图形和网络图的方法。
回归决策树
前⾯已经讲到,关于数据类型,我们主要可以把其分为两类,连续型数据和离散型数据。在⾯对不同数据时,决策树也可以分为两⼤类型:
- 分类决策树和回归决策树。
- 前者主要⽤于处理离散型数据,后者主要⽤于处理连续型数据。
1.原理概述
不管是回归决策树还是分类决策树,都会存在两个核⼼问题:
- 如何选择划分点?
- 如何决定叶节点的输出值?
⼀个回归树对应着输⼊空间(即特征空间)的⼀个划分以及在划分单元上的输出值。分类树中,我们采⽤信息论中的⽅法,通过计算选择最佳划分点。
⽽在回归树中,采⽤的是启发式的⽅法。假如我们有n个特征,每个特征有si (i ∈ (1, n))个取值,那我们遍历所有特征, 尝试该特征所有取值,对空间进⾏划分,直到取到特征 j 的取值 s,使得损失函数最⼩,这样就得到了⼀个划分点。描述该过程的公式如下:
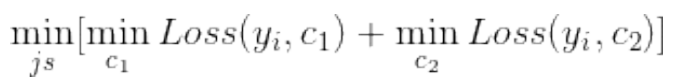
假设将输⼊空间划分为M个单元:R1, R2, ..., Rm 那么每个区域的输出值就是:cm = avg(yi∣xi ∈ Rm)也就是该区域内所有点y值的平均数。
举例:
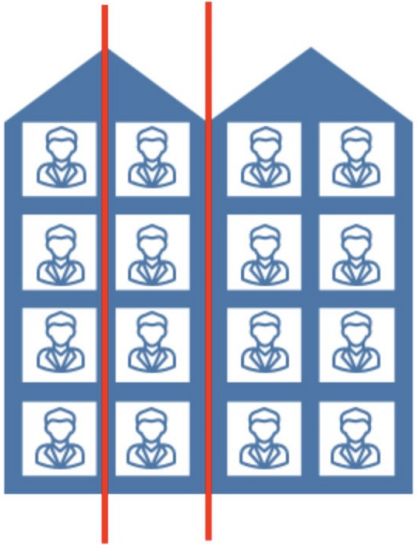
如下图,假如我们想要对楼内居⺠的年龄进⾏回归,将楼划分为3个区域R1, R2 , R3(红线),那么:
R1的输出就是第⼀列四个居⺠年龄的平均值,
R2的输出就是第⼆列四个居⺠年龄的平均值,
R3的输出就是第三、四列⼋个居⺠年龄的平均值。
2.算法描述
- 输⼊:训练数据集D:
- 输出:回归树f(x).
- 在训练数据集所在的输⼊空间中,递归的将每个区域划分为两个⼦区域并决定每个⼦区域上的输出值,构建⼆叉决策树:
- (1)选择最优切分特征 j 与切分点 s,求解
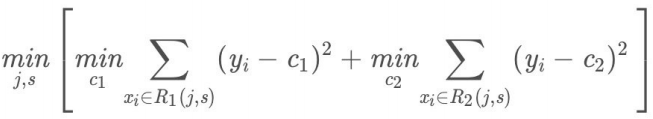
遍历特征 j ,对固定的切分特征 j 扫描切分点 s,选择使得上式达到最⼩值的一对( j , s ).
-
- (2)⽤选定的一对(j, s)划分区域并决定相应的输出值:
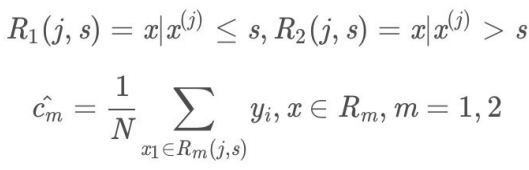
-
- (3)继续对两个⼦区域调⽤步骤(1)和(2),直⾄满⾜停⽌条件。
- (4)将输⼊空间划分为M个区域R1 , R 1, ..., R m, ⽣成决策树:
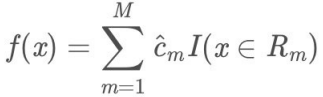
3.简单实例
为了易于理解,接下来通过⼀个简单实例加深对回归决策树的理解。
训练数据⻅下表,⽬标是得到⼀棵最⼩⼆乘回归树。
| x | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| y | 5.56 | 5.7 | 5.91 | 6.4 | 6.8 | 7.05 | 8.9 | 8.7 | 9 | 9.05 |
3.1 实例计算过程
(1)选择最优的切分特征j与最优切分点s:
- 确定第⼀个问题:选择最优切分特征:
- 在本数据集中,只有⼀个特征,因此最优切分特征⾃然是x。
- 确定第⼆个问题:我们考虑9个切分点 [1.5, 2.5, 3.5, 4.5, 5.5, 6.5, 7.5, 8.5, 9.5] 。
- 损失函数定义为平⽅损失函数Loss(y, f(x)) = (f(x) − y) 2,将上述9个切分点依此代⼊下⾯的公式,其中
c m= avg(yi∣xi ∈ R m)
a、计算⼦区域输出值:
例如,取 s=1.5。此时R1 = 1, R2 = 2, 3, 4, 5, 6, 7, 8, 9, 10,这两个区域的输出值分别为:
- c1 = 5.56
- c2 = (5.7 + 5.91 + 6.4 + 6.8 + 7.05 + 8.9 + 8.7 + 9 + 9.05)/9 = 7.50。
同理,得到其他各切分点的⼦区域输出值,如下表:
| s | 1.5 | 2.5 | 3.5 | 4.5 | 5.5 | 6.5 | 7.5 | 8.5 | 9.5 |
|---|---|---|---|---|---|---|---|---|---|
| c1 | 5.56 | 5.63 | 5.72 | 5.89 | 6.07 | 6.24 | 6.62 | 6.88 | 7.11 |
| c2 | 7.5 | 7.73 | 7.99 | 8.25 | 8.54 | 8.91 | 8.92 | 9.03 | 9.05 |
b、计算损失函数值,找到最优切分点:
把c1, c2的值代⼊到同平⽅损失函数Loss(y, f(x)) = (f(x) − y) 2,当s=1.5时,
![]()
同理,计算得到其他各切分点的损失函数值,可获得下表:
| s | 1.5 | 2.5 | 3.5 | 4.5 | 5.5 | 6.5 | 7.5 | 8.5 | 9.5 |
|---|---|---|---|---|---|---|---|---|---|
| m(s) | 15.72 | 12.07 | 8.36 | 5.78 | 3.91 | 1.93 | 8.01 | 11.73 | 15.74 |
显然取 s=6.5时,m(s)最⼩。因此,第⼀个划分变量【j=x,s=6.5】
(2)⽤选定的(j,s)划分区域,并决定输出值;
- 两个区域分别是:R1 = {1, 2, 3, 4, 5, 6}, R2 = {7, 8, 9, 10}
- 输出值c = avg(yi∣xi ∈ Rm), c1 = 6.24, c2 = 8.91
(3)调⽤步骤 (1)、(2),继续划分:
对R1继续进⾏划分:
| x | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| y | 5.56 | 5.7 | 5.91 | 6.4 | 6.8 | 7.05 |
取切分点[1.5,2.5,3.5,4.5,5.5],则各区域的输出值c如下表:
| s | 1.5 | 2.5 | 3.5 | 4.5 | 5.5 |
|---|---|---|---|---|---|
| c1 | 5.56 | 5.63 | 5.72 | 5.89 | 6.07 |
| c2 | 6.37 | 6.54 | 6.75 | 6.93 | 7.05 |
计算损失函数值m(s):
| s | 1.5 | 2.5 | 3.5 | 4.5 | 5.5 |
|---|---|---|---|---|---|
| m(s) | 1.3087 | 0.754 | 0.2771 | 0.4368 | 1.0644 |
s=3.5时,m(s)最⼩。
(4)⽣成回归树
假设在⽣成3个区域之后停⽌划分,那么最终⽣成的回归树形式如下:

回归决策树和线性回归对⽐
代码示例
import numpy as np
from sklearn.tree import DecisionTreeRegressor
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
# 生成训练数据
x=np.arange(1,11,1).reshape(-1,1)
y = np.array([5.56, 5.70, 5.91, 6.40, 6.80, 7.05, 8.90, 8.70, 9.00, 9.05])
# 模型创建与训练
m1=DecisionTreeRegressor(max_depth=1)#最大树深度1
m2=DecisionTreeRegressor(max_depth=3)#最大树深度2
m3=LinearRegression()
m1.fit(x,y)
m2.fit(x,y)
m3.fit(x,y)
# 准备1000条测试数据(特征值)
x_test=np.arange(0,10,0.01).reshape(-1,1)
# 模型预测
y1=m1.predict(x_test)
y2=m2.predict(x_test)
y3=m3.predict(x_test)
# 预测结果可视化
plt.figure(figsize=(10,6))
plt.scatter(x,y,label='训练数据')
plt.plot(x_test,y1,label='max_depth=1')
plt.plot(x_test,y2,label='max_depth=3')
plt.plot(x_test,y3,label='LinearRegression')
plt.xlabel('特征值')
plt.ylabel('目标值')
plt.legend()
plt.show() 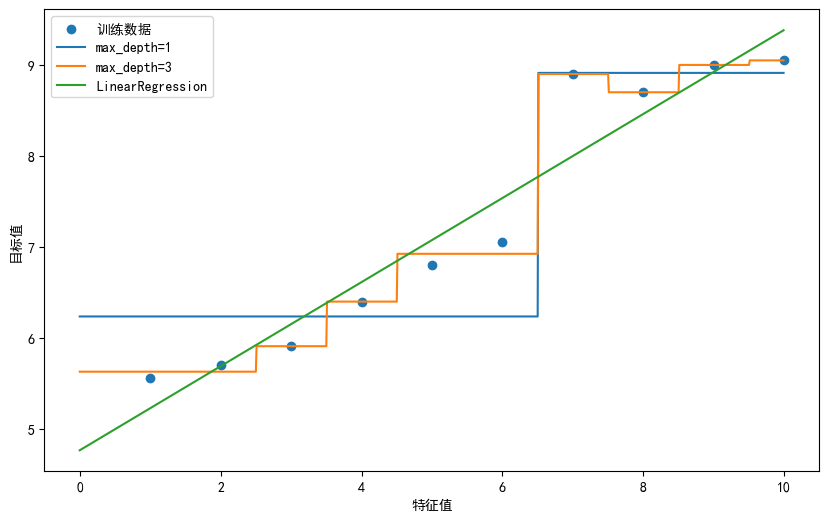
⼩结
回归决策树算法总结【指导】
- 输⼊:训练数据集D:
- 输出:回归树f(x).
- 流程:在训练数据集所在的输⼊空间中,递归的将每个区域划分为两个⼦区域并决定每个⼦区域上的输出值,
- 构建⼆叉决策树:
- (1)选择最优切分特征 j 与切分点 s,求解
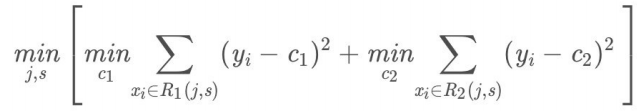
遍历特征j,对固定的切分特征j扫描切分点s,选择使得上式达到最⼩值的对(j, s).
-
- (2)⽤选定的对(j, s)划分区域并决定相应的输出值:
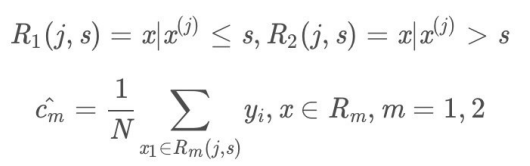
-
- (3)继续对两个⼦区域调⽤步骤(1)和(2),直⾄满⾜停⽌条件。
- (4)将输⼊空间划分为M个区域R1, R2 , ..., RM , ⽣成决策树:
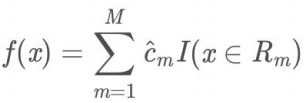

 浙公网安备 33010602011771号
浙公网安备 33010602011771号