不均衡数据问题&欠采样、过采样
类别不平衡数据集基本介绍
其实,在现实环境中,采集的数据(建模样本)往往是⽐例失衡的。⽐如⽹贷数据,逾期⼈数的⽐例是极低的(千分之⼏的⽐例);奢侈品消费⼈群鉴定等。
创造数据不均衡数据集
sklearn.datasets.make_classification() 是 scikit-learn 中用于生成人工分类数据集的核心函数
参数详解表
| 参数 | 默认值 | 说明 | 影响数据特性 |
|---|---|---|---|
n_samples |
100 | 总样本数 | 数据集规模 |
n_features |
20 | 特征总数 | 维度复杂性 |
n_informative |
2 | 有效特征数 | 实际预测能力 |
n_redundant |
2 | 冗余特征数(由有效特征线性组合) | 特征间相关性 |
n_repeated |
0 | 复制特征数:重复特征数(随机复制) | 无信息特征 |
n_classes |
2 | 类别数量 | 分类复杂度 |
weights |
None | 类别比例 | 平衡性调整 |
flip_y |
0.01 | 标签噪声 | 分类难度 |
class_sep |
1.0 | 类别分离度 | 区分难度(>1易分,<1难分) |
n_clusters_per_class |
2 | 每类簇数 | 类别内部结构 |
hypercube |
True | 簇形状 | |
random_state |
None | 随机种子 |
生成3类不均衡数据:
from sklearn.datasets import make_classification
from collections import Counter
import matplotlib.pyplot as plt
#生成不均衡数据
X,y=make_classification(n_samples=5000,n_features=2,n_informative=2,n_redundant=0,n_repeated=0,n_classes=3,weights=[0.01,0.05,0.94],
n_clusters_per_class=1,random_state=42)
#统计各个标签的样本数量
print(Counter(y))#Counter({2: 4668, 1: 266, 0: 66})
#数据可视化
plt.figure(figsize=(20,8))
plt.scatter(X[:,0],X[:,1],c=y)
plt.show() 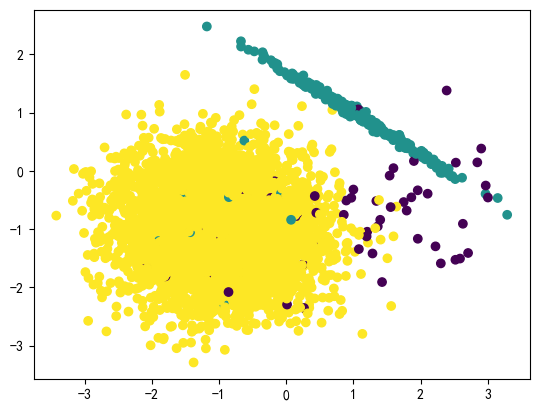
可以看出样本的三个标签中,1,2的样本量极少,样本失衡。接下来,我们就要基于以上数据,进⾏相应的处理。
不均衡数据处理方式

在Python中,有Imblearn包,它就是为处理数据⽐例失衡⽽⽣的。官网: https://imbalanced-learn.org/stable/
下⾯使⽤imblearn进⾏不均衡数据处理。
安装Imblearn包
pip install imbalanced-learn第三⽅包链接:https://pypi.org/project/imbalanced-learn/
关于类别不平衡的问题,主要有两种处理⽅式:
- 过采样
- 增加数量较少那⼀类样本的数量,使得正负样本⽐例均衡。
- ⽋采样
- 减少数量较多那⼀类样本的数量,使得正负样本⽐例均衡。
过采样
什么是过采样⽅法
对训练集⾥的少数类进⾏“过采样”(oversampling),即增加⼀些少数类样本使得正、反例数⽬接近,然后再进⾏学 习。
随机过采样⽅法
随机过采样是在少数类Smin 中随机选择⼀些样本,然后通过复制所选择的样本⽣成样本集E,将它们添加到Smin 中来扩⼤原始数据集,从⽽得到新的少数类集合Snew_min。
新的数据集Snew_min=Smin+E
通过代码实现随机过采样⽅法:
from imblearn.over_sampling import RandomOverSampler # 随机过采样 RandomOverSampler_X,RandomOverSampler_y=RandomOverSampler(random_state=42).fit_resample(X,y) # 查看新数据分布情况 Counter(RandomOverSampler_y)#Counter({2: 4668, 1: 4668, 0: 4668}) plt.figure(dpi=100) plt.scatter(RandomOverSampler_X[:,0],RandomOverSampler_X[:,1],c=RandomOverSampler_y) plt.show()
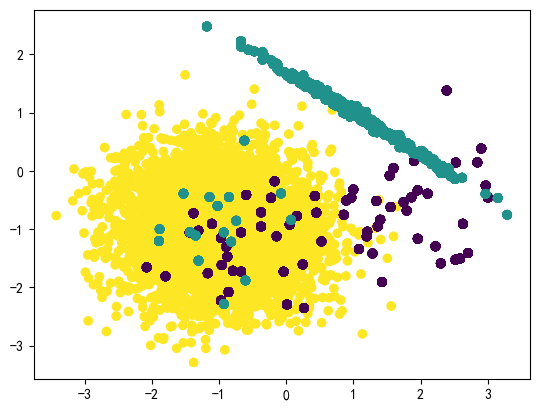
过采样代表性算法-SMOTE
SMOTE算法合成新少数类样本的算法描述如下:
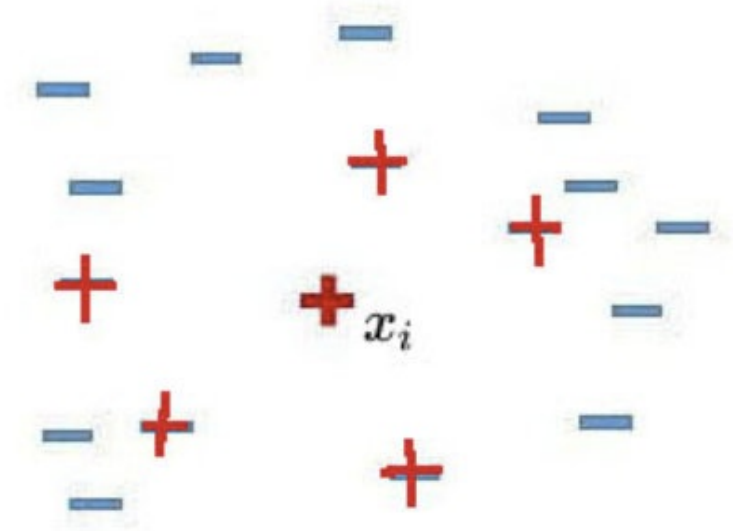
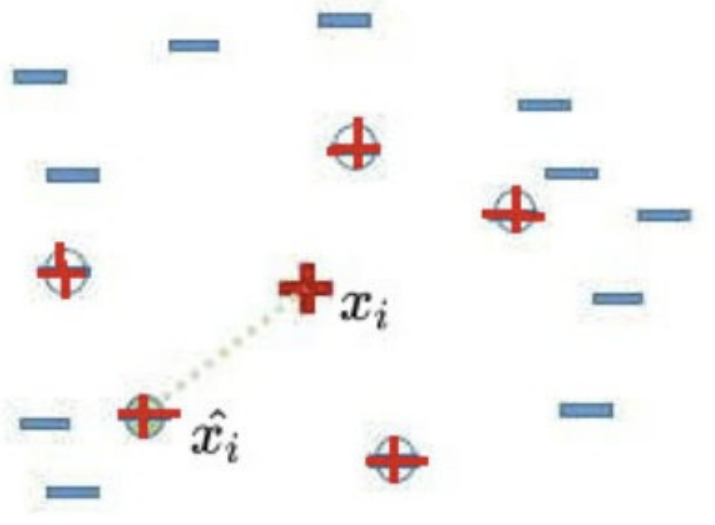
1)对于少数类中的每一个样本Xi,以欧氏距离为标准计算它到少数类样本集Smin 中所有样本的距离,得到其k近邻。
2)根据样本不平衡比例设置一个采样比例以确定采样倍率N,对于每一个少数类样本Xi,从其k近邻中随机选择若干个样本,假设选择的是![]()
3)对于每一个随机选出来的近邻![]() ,分别与Xi按照如下公式构建新的样本。
,分别与Xi按照如下公式构建新的样本。
![]()
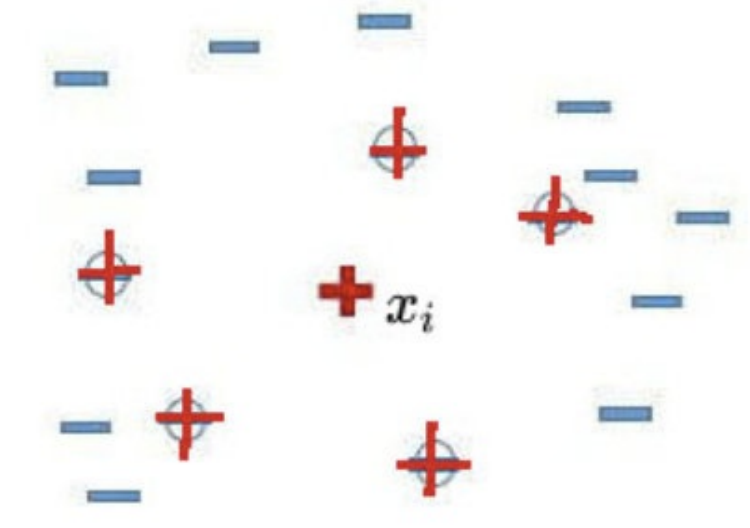

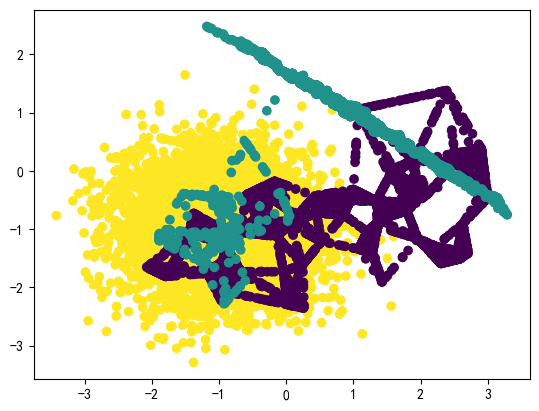
from imblearn.over_sampling import SMOTE # SMOTE过采样 SMOTE_X,SMOTE_y=SMOTE(random_state=42).fit_resample(X,y) # 查看新数据分布情况 Counter(SMOTE_y) # 采样后样本结果 #Counter({2: 4668, 1: 4668, 0: 4668}) plt.figure(dpi=100) plt.scatter(SMOTE_X[:,0],SMOTE_X[:,1],c=SMOTE_y) plt.show()
欠采样
什么是欠采样⽅法
直接对训练集中多数类样本进⾏“⽋采样”(undersampling),即去除⼀些多数类中的样本使得正例、反例数⽬接近,然后再进行学习。
随机欠采样⽅法
随机⽋采样顾名思义即从多数类Smax中随机选择⼀些样样本组成样本集E。然后将样本集E从Smax中移除。
新的数据集:
![]()
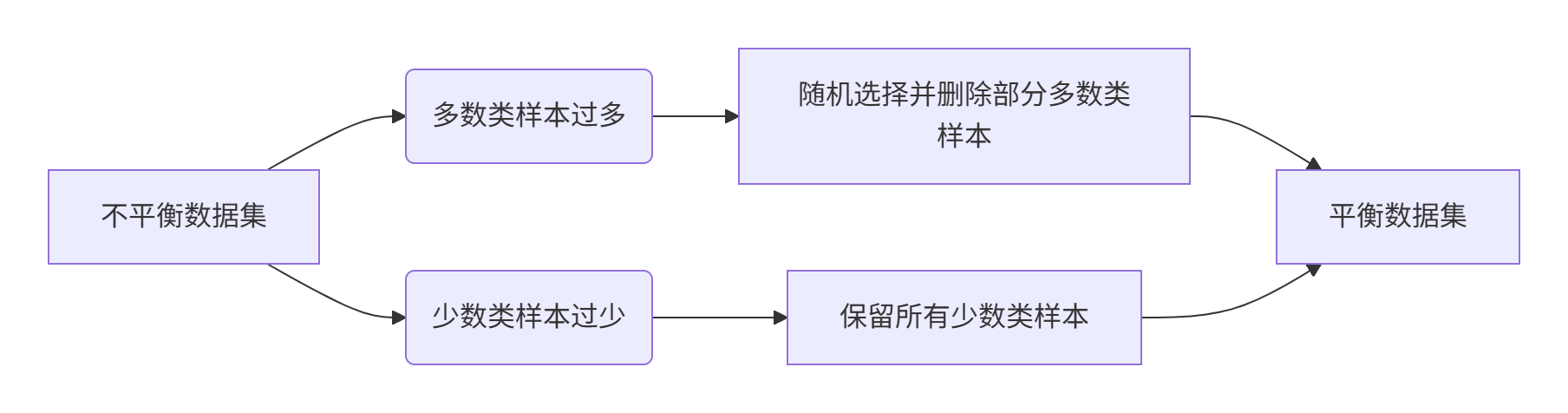
API
imblearn.under_sampling.RandomUnderSampler(),这是imbalanced-learn库(imblearn)中用于处理不平衡数据集的一种下采样方法。
它的工作原理:从多数类中随机删除一些样本,使得多数类和少数类的样本数量达到平衡(通常是1:1,但也可以通过参数调整)。
使用场景
- 当少数类样本数量不足时
- 当计算资源有限(欠采样减少数据量)
- 当多数类样本可被合理精简时
- 常用于二分类问题中类分布失衡的情况
工作流程示例
假设原始数据集:
- 多数类:10,000个样本(类别0)
- 少数类:200个样本(类别1)
应用 RandomUnderSampler 后:
- 保留所有200个少数类样本
- 随机选择200个多数类样本
- 最终平衡数据集:400个样本(200+200)
代码实现
from imblearn.under_sampling import RandomUnderSampler
# 随机欠采样采样
RandomUnderSampler_X,RandomUnderSampler_y=RandomUnderSampler(random_state=42).fit_resample(X,y)
# 查看新数据分布情况
Counter(RandomUnderSampler_y)
# 采样后样本结果
#Counter({0: 66, 1: 66, 2: 66})
plt.figure(dpi=100)
plt.scatter(RandomUnderSampler_X[:,0],RandomUnderSampler_X[:,1],c=RandomUnderSampler_y)
plt.show() 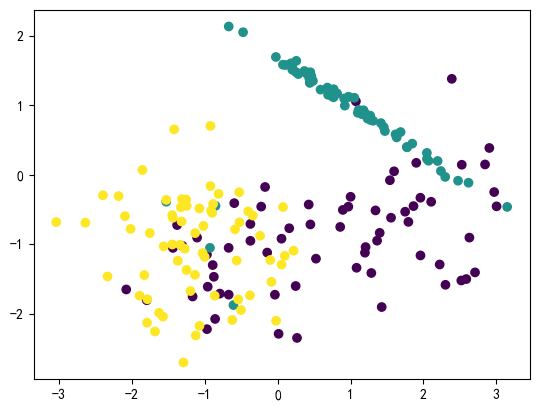
优缺点分析
✅ 优点:
- 高效减少数据规模(提高计算效率)
- 防止模型偏置(避免模型忽略少数类)
- 简单易实现
- 适合大规模数据集
❌ 缺点:
- 信息丢失(可能删除重要样本)
将多数类样本删除有可能会导致分类器丢失有关多数类的重要信息。
- 降低模型泛化能力
- 对稀有事件敏感(可能删除关键样本)
- 可能放大噪声影响
# 在不采样时调整类权重
model = RandomForestClassifier(class_weight='balanced')典型应用场景
- 金融欺诈检测(欺诈交易极少)
- 疾病诊断(罕见病例较少)
- 设备故障预测(故障事件稀少)
- 网络入侵检测(攻击行为少见)
📌 重要提示:欠采样最适合多数类样本高度冗余的情况。对于高价值多数类样本,应考虑使用过采样(SMOTE)或组合方法。
官网
深入学习Imbalanced-learn处理不均衡数据,请参照官网: https://imbalanced-learn.org/stable/


 浙公网安备 33010602011771号
浙公网安备 33010602011771号