核方法、核优化、核函数
核函数(Kernel Function)是机器学习和统计学中的核心概念,主要用于将低维数据隐式映射到高维空间,从而解决线性不可分问题。
它在支持向量机(SVM)、核主成分分析(Kernel PCA)等算法中广泛应用。
注意!在升维的时候,构造出来的新维度可能毫无意义,或者意义根本不明确,单纯就是为了增加维度,让机器自己去判断能否在新增的维度上将数据划分开来。
例如:我们只知道两个维度数据,x1:年龄、x2:工资。那么升维时构造出来的新维度可能是x1*x2,或者x12或者x23等等,但是我们不需要知道年龄和工资的乘积到底是什么意思?或是什么意义?
理解这一点对于理解本文至关重要。
问题的引入
- 问题背景:许多数据在低维空间中线性不可分(如异或问题),但在高维空间中可能线性可分。
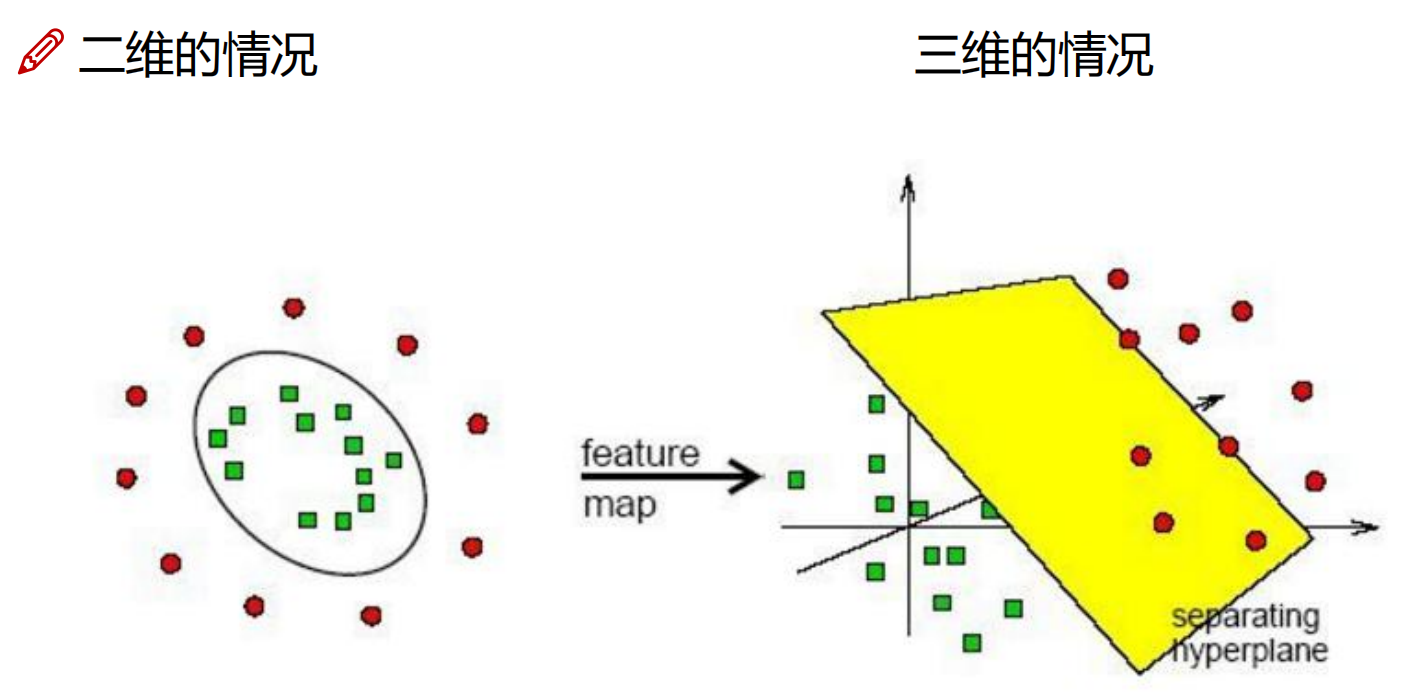
对于线性可分或者线性近似可分的数据集, 线性支持向量机可以很好的划分,如图左。但是,对于图右的数据集呢?很显然, 这个数据集是没有办法用直线分开的。

我们的想法是在低维空间中不能线性分割的点集,通过转化为高维空间中的点集时,很有可能变为线性可分的。
插个题外话:看过《三体》的小伙伴们都知道,故事中的主人公进入到四维空间,发现“视野变得十分的开阔”, 进入四维的人,可以直接将三维中的人的内脏取出来,三体中女巫不是靠魔法取出大脑的,而是进入了四维空间, 将活人的大脑取出来了。在三维里面,内脏不还隔着肚皮嘛!但是进入到四维之后,可以做很多三维中看似不可能的事情。所以, 让我们到高维度空间去玩玩吧!
一个简单的例子如下, 我们引入了一个映射, 将二维空间映射到三维空间,这样, 看似难以分开的数据集,到高维度里面,只需要简单的一个平面。如下图所示。

核方法
定义: 在低维空间中不能线性分割的点集,通过转化为高维空间中的点集时,从而变为线性可分的,这就是核方法。

现在有二维的空间![]() ,我们知道,二维中任意的曲线可以表示成:
,我们知道,二维中任意的曲线可以表示成:
构造一个映射![]() , 得到五维的空间
, 得到五维的空间 ![]() ,我们只取三个维度,
,我们只取三个维度,![]() 将二维的数据映射到三维中去,得到下图:
将二维的数据映射到三维中去,得到下图:

这里有一个视频,很好的演示了一个例子核方法例子。
通过上面的描述, 好像我们通过一个映射, 将数据集映射到新的空间就能解决所有问题了,但是,这个时候会出现维度灾难,刚刚我们只用到了二维的空间,就需要映射到五维的空间, 经过计算,三维就需要映射到十九维了!这个数字真的是指数爆炸,怎么解决这个问题呢, 我们就要用到核技巧啦。
核技巧
问题场景:假设您的数据在二维平面上呈现环形分布(如下图),无论如何画直线都无法分开红蓝点,说明数据在二维空间中线性不可分。
解决思路:将数据映射到更高维空间(如三维),可能找到一个平面(超平面)将数据分开。但直接计算高维空间的内积(即相似度)会非常复杂,核函数的作用就是避免显式计算高维映射,直接在低维空间计算出等价的内积。
通过例子彻底理解核函数


例子:

核函数的通用定义



上面提到的“维度缩放加常数维度”正是通过调整映射函数(如增加系数 和常数项 )来实现这种等价性。
上面的计算,本质上是为了说明:

核函数
核函数的作用与原理
数学定义
- 设原始数据空间为 ,映射函数为
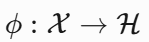 ( 为高维特征空间)。
( 为高维特征空间)。 - 核函数满足:
![]()
怎么判断 呢?换句话来说,怎么判断我们选的这个核函数有效呢?
呢?换句话来说,怎么判断我们选的这个核函数有效呢?
核函数的判定:

Mercer定理
- 条件:核函数对应的Gram矩阵(所有样本对的核值矩阵)必须半正定。
- 意义:确保核函数有效对应某个高维空间的内积。
具体的证明过程比较复杂, 可以参考《统计学习方法》和核函数判断证明
下面介绍SVM中常用的核函数:
常见核函数类型
常⻅核函数

1.多项核中,d=1时,退化为线性核;
- 这两种核的作⽤也是⾸先在属性空间中找到⼀些点,把这些点当做base,核函数的作⽤就是找与该点距离和⻆度满⾜某种关系的样本点。
- 当样本点与该点的夹⻆近乎垂直时,两个样本的欧式⻓度必须⾮常⻓才能保证满⾜线性核函数⼤于0;⽽当样本点与base点的⽅向相同时,⻓度就不必很⻓;⽽当⽅向相反时,核函数值就是负的,被判为反类。即,它在空间上划分出⼀个梭形(例如y=1/x的图像),按照梭形来进⾏正反类划分。
2.⾼斯核亦称为RBF核。
- 理解
- ⾼斯核函数就是在属性空间中找到⼀些点,这些点可以是也可以不是样本点,把这些点当做base,以这些base为圆⼼向外扩展,扩展半径即为带宽,即可划分数据。
- 换句话说,在属性空间中找到⼀些超圆,⽤这些超圆来判定正反类。
3.Sigmoid核:
- 同样地是定义⼀些base,
- 核函数就是将线性核函数经过⼀个tanh函数进⾏处理,把值域限制在了-1到1上。
总之,都是在定义距离,⼤于该距离,判为正,⼩于该距离,判为负。⾄于选择哪⼀种核函数,要根据具体的样本分布情况来确定。
⼀般有如下指导规则:
- 1) 如果Feature的数量很⼤,甚⾄和样本数量差不多时,往往线性可分,这时选⽤LR或者线性核Linear;
- 2) 如果Feature的数量很⼩,样本数量正常,不算多也不算少,这时选⽤RBF核;
- 3) 如果Feature的数量很⼩,⽽样本的数量很⼤,这时⼿动添加⼀些Feature,使得线性可分,然后选⽤LR或者线性核Linear;
- 4) 多项式核⼀般很少使⽤,效率不⾼,结果也不优于RBF;
- 5) Linear核参数少,速度快;RBF核参数多,分类结果⾮常依赖于参数,需要交叉验证或⽹格搜索最佳参数,⽐较耗时;
- 6)应⽤最⼴的应该就是RBF核,⽆论是⼩样本还是⼤样本,⾼维还是低维等情况,RBF核函数均适⽤。
1. 线性核(Linear Kernel)(重点)
线性核,主要用于线性可分的情况,我们可以看到特征空间到输入空间的维度是一样的,其参数少速度快,对于线性可分数据,其分类效果很理想,因此我们通常首先尝试用线性核函数来做分类,看看效果如何,如果不行再换别的。
- 公式:
Linear核函数对数据不做任何变换。
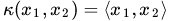
- 特点:直接计算原始空间内积,适用于线性可分数据。
优点:
- 方案首选,奥卡姆剃刀定律
- 简单,可以求解较快一个QP问题
- 可解释性强:可以轻易知道哪些feature是重要的
- 不需要设置任何参数,直接就可以用了。
何时来使用呢?
- 特征已经比较丰富了,样本数据量巨大,需要进行实时得出结果的问题。
- 限制:只能解决线性可分问题
2. 多项式核(Polynomial Kernel)
多项式核函数可以实现将低维的输入空间映射到高纬的特征空间,但是多项式核函数的参数多(),当多项式的阶数比较高的时候,核矩阵的元素值将趋于无穷大或者无穷小,计算复杂度会大到无法计算。
- 公式:
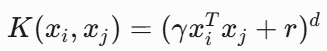
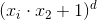
![]() (其他表示方式,了解)
(其他表示方式,了解)
需要给定3个参数:
-
- 缩放因子(对内积进行放缩)
- 偏置项
- :多项式次数(一般情况下2次的更常见
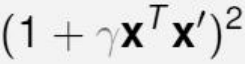 )
)
在实际应用时,需要不断调优三个参数,直到达到理想效果(一般让常数项r=1,多项式次数=2,然后调整缩放比例)
- 特点:适合分类边界为多项式的情况。
- 基本原理:依靠升维使得原本线性不可分的数据线性可分;
- 升维的意义:使得原本线性不可分的数据线性可分;
- 优点:
- 可解决非线性问题
- 可通过主观设置幂数来实现总结的预判
- 缺点:
- 对于大数量级的幂数,不太适用
- 比较多的参数要选择
通常只用在已经大概知道一个比较小的幂数的情况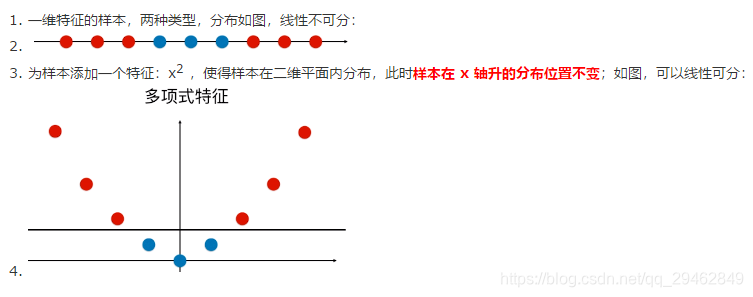
3. 高斯核(RBF Kernel,径向基函数核)(重点)
回顾高斯分布:
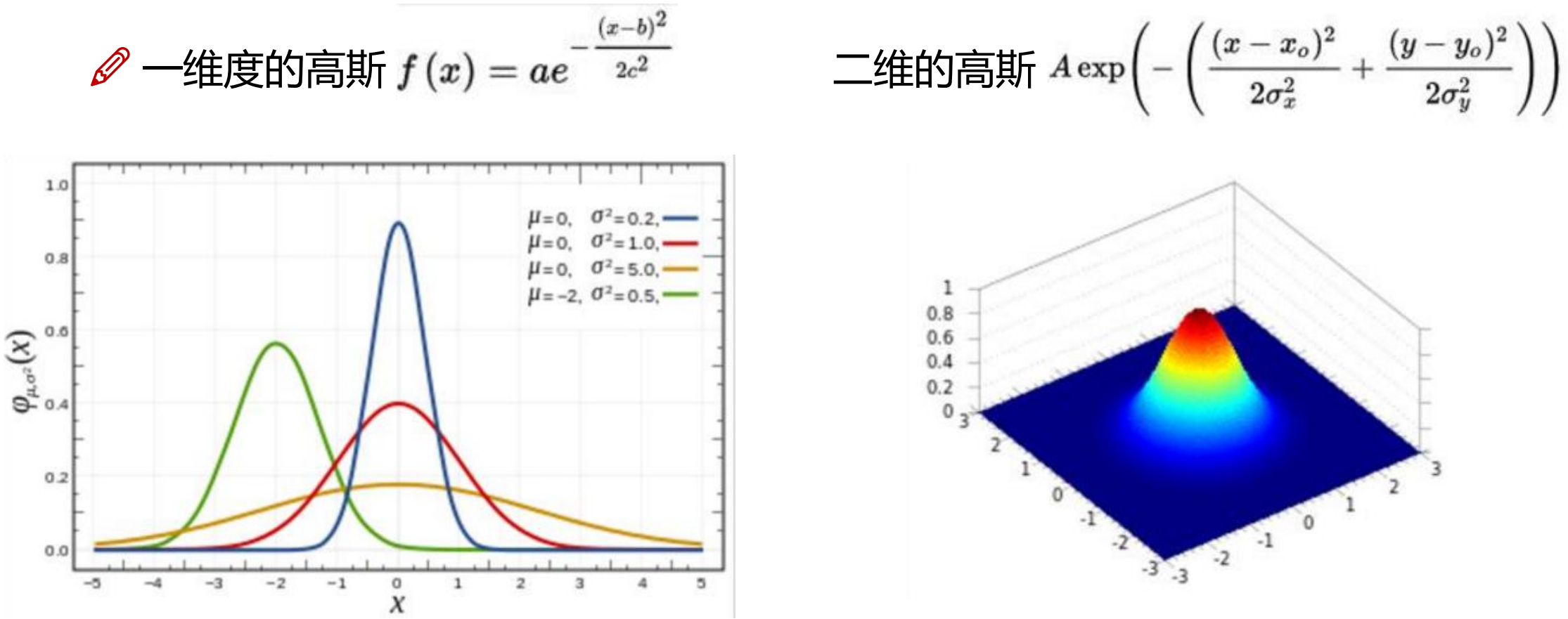
- 公式:
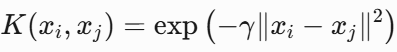
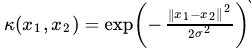
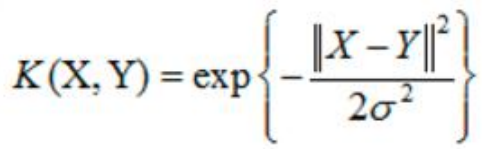
- :控制高斯函数的宽度( 越大,模型越复杂)。
公式理解:
表示什么呢?看起来像是两个样本点之间的距离的度量。
如果X和Y很相似,|X-Y|≈0,e0=1,那结果也就是1了,如果很不相似,|X-Y|≈∞,e-∞=0,那就是0了。
这么做有什么好处呢?能给我做出多少维特征呢?
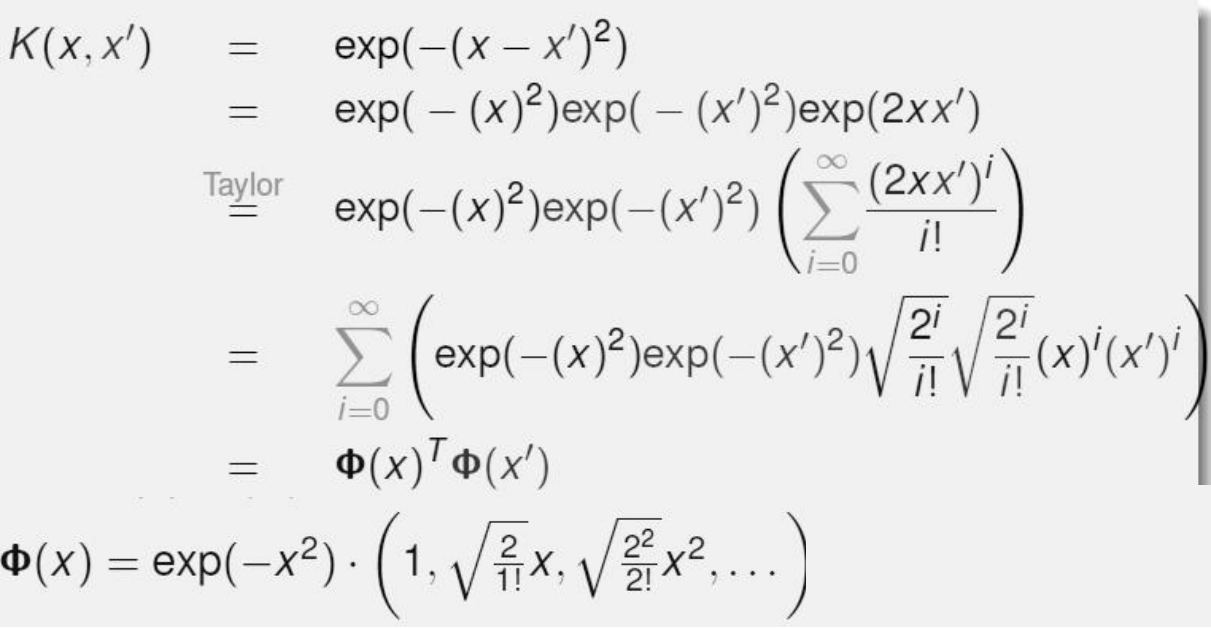
备注:
参数:
对参数是极其敏感的,效果差异也是很大的!
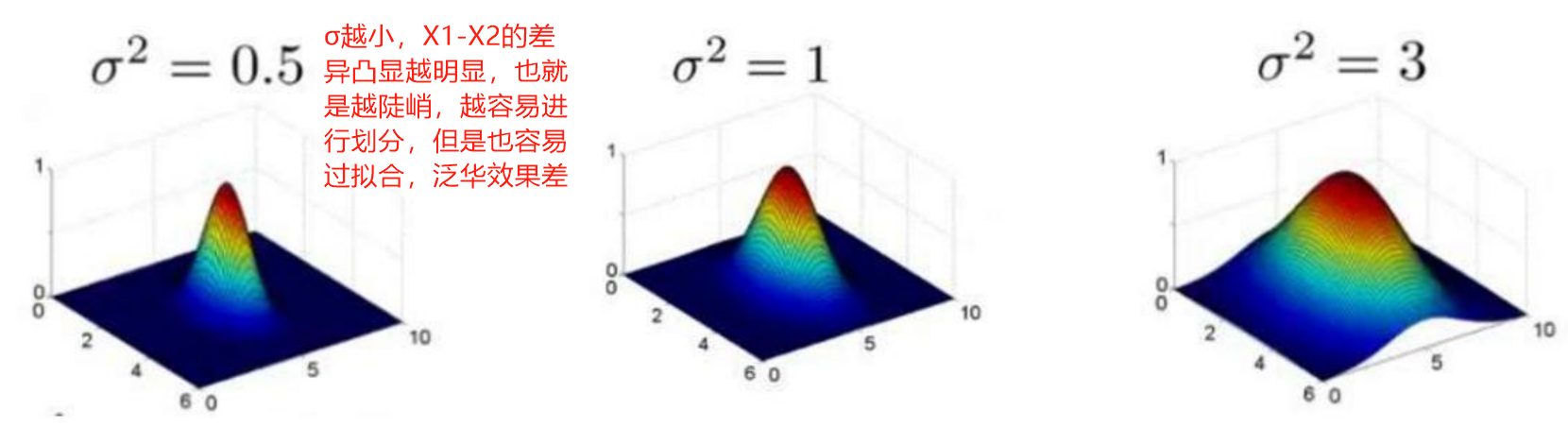
如果σ选得很小,则可以将任意的数据映射为线性可分——当然,这并不一定是好事,因为随之而来的可能是非常严重的过拟合问题。
决策边界会怎么样呢?(σ越小,切分的越厉害,越容易过拟合)
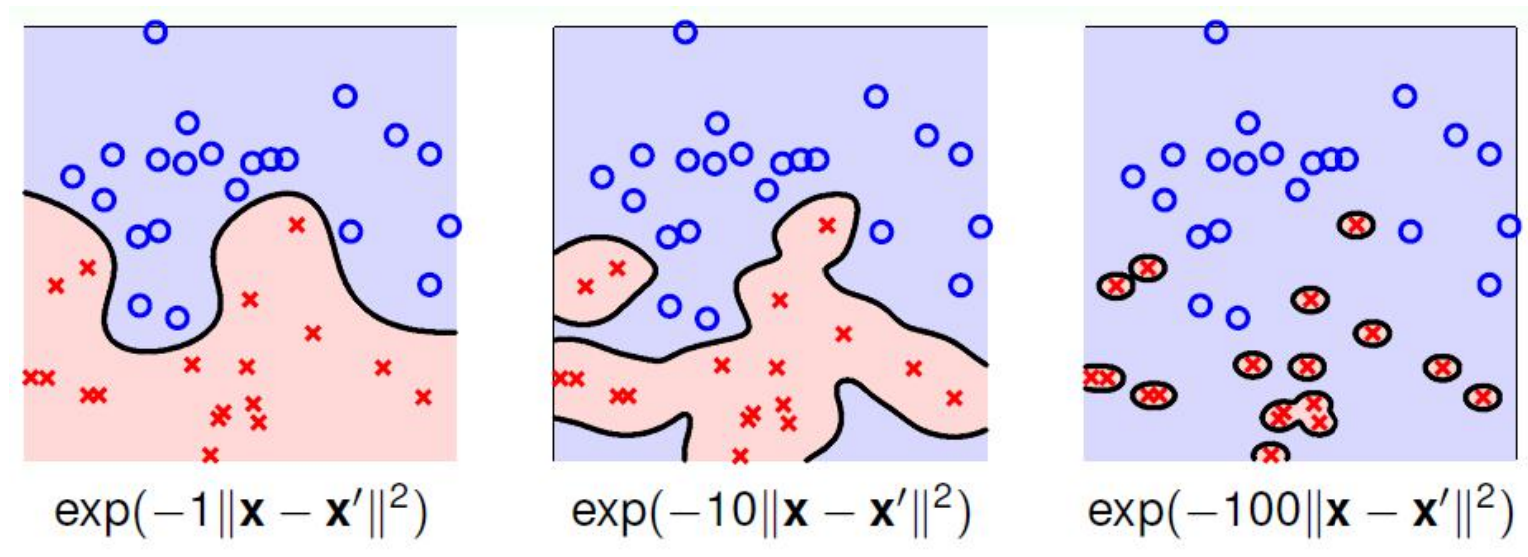
如果σ选得很大,高次特征上的权重实际上衰减得非常快,所以实际上(数值上近似一下)相当于一个低维的子空间;
不过,总的来说,通过调控参数,高斯核实际上具有相当高的灵活性,也是使用最广泛的核函数之一。
总结:
- 特点:
- 映射到无限维空间,理论上可以拟合任何复杂边界。
- 对参数敏感,需谨慎调整 防止过拟合。
- 优点:
- 可以映射到无限维
- 决策边界更为多样
- 只有一个参数,相比多项式核容易选择
- 缺点:
- 可解释性差(无限多维的转换,无法算w)
- 计算速度比较慢(解一个对偶问题)
- 容易过拟合(参数选不好时容易overfitting)
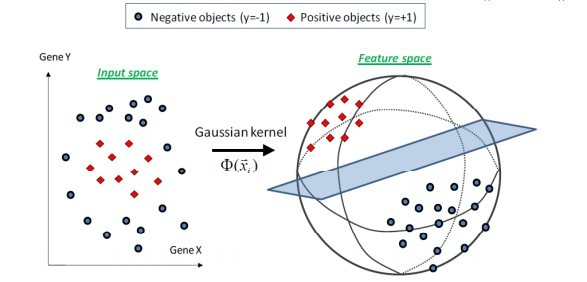
下图所示的例子便是把低维线性不可分的数据通过高斯核函数映射到了高维空间:
4. Sigmoid核(了解)
- 公式:
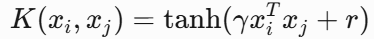
![]()
- 特点:模仿神经网络激活函数,但实际应用较少。
采用sigmoid核函数,支持向量机实现的就是只包含一个隐层,激活函数为 Sigmoid 函数的神经网络。应用SVM方法,隐含层节点数目(它确定神经网络的结构)、隐含层节点对输入节点的权值都是在设计(训练)的过程中自动确定的。而且支持向量机的理论基础决定了它最终求得的是全局最优值而不是局部最小值,也保证了它对于未知样本的良好泛化能力而不会出现过学习现象。
如图, 输入层->隐藏层之间的权重是每个支撑向量,隐藏层的计算结果是支撑向量和输入向量的内积,隐藏层->输出层之间的权重是支撑向量对应的
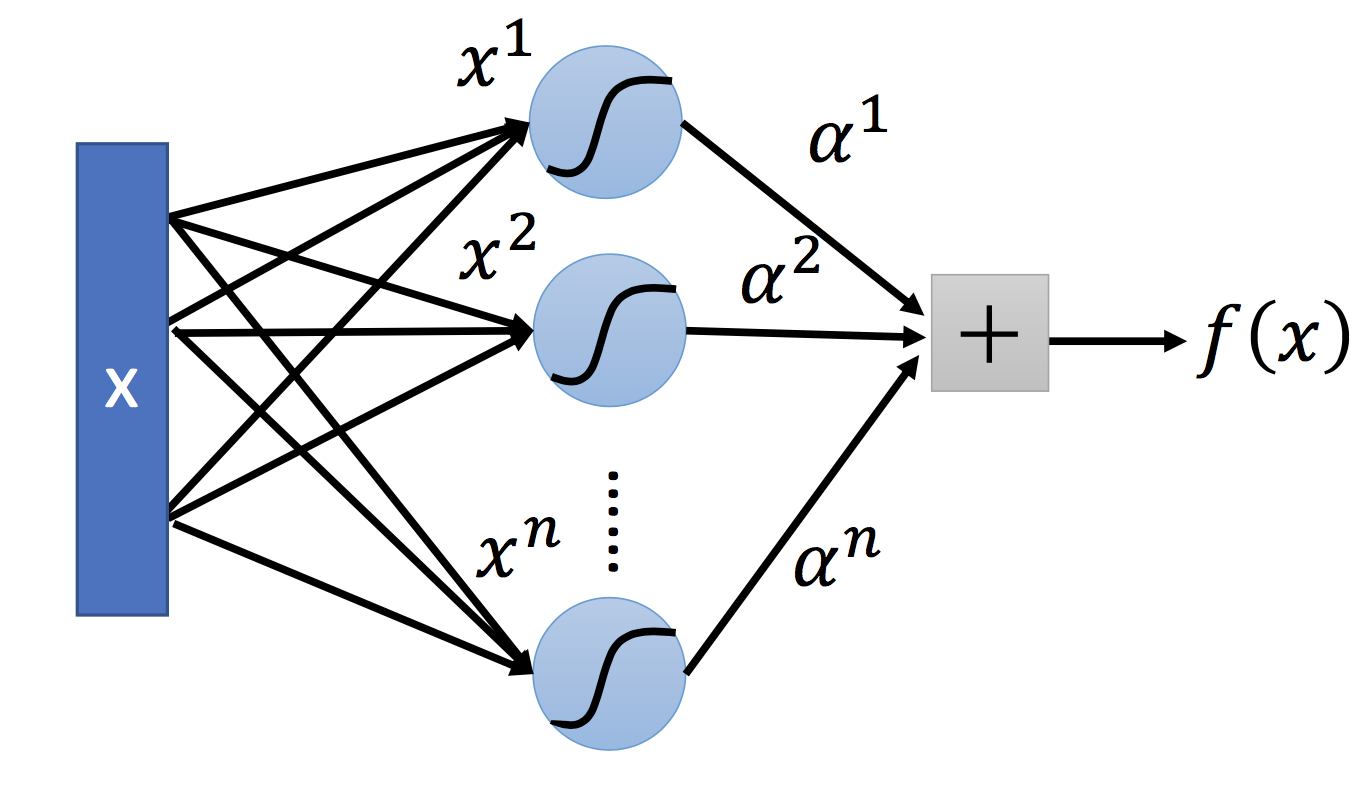
5. 自定义核
- 允许用户定义满足Mercer条件的核函数,需保证Gram矩阵半正定。
三、核函数的选择与调参
因此,在选用核函数的时候,如果我们对我们的数据有一定的先验知识,就利用先验来选择符合数据分布的核函数;如果不知道的话,通常使用交叉验证的方法,来试用不同的核函数,误差最下的即为效果最好的核函数,或者也可以将多个核函数结合起来,形成混合核函数。在吴恩达的课上,也曾经给出过一系列的选择核函数的方法:
- 如果特征的数量大到和样本数量差不多,则选用LR或者线性核的SVM;
- 如果特征的数量小,样本的数量正常,则选用SVM+高斯核函数;
- 如果特征的数量小,而样本的数量很大,则需要手工添加一些特征从而变成第一种情况。
在实战中更多的是:
- 特征维数高选择线性核
- 样本数量可观、特征少选择高斯核(非线性核)
- 样本数量非常多选择线性核(避免造成庞大的计算量)
1. 选择依据
- 数据特性:
- 线性可分 → 线性核(高效且不易过拟合)。
- 非线性可分 → 高斯核或多项式核。
- 计算效率:
- 高斯核计算复杂度较高,适合小规模数据。
- 线性核适合大规模数据。
2. 参数调优
- 高斯核:
- :过大导致过拟合(决策边界复杂),过小导致欠拟合(决策边界平滑)。
- 调整方法:网格搜索(Grid Search)或贝叶斯优化。
- 多项式核:
- :次数过高易过拟合,通常取2~5。
3. 验证方法
- 交叉验证(Cross-Validation)评估不同核函数和参数的泛化性能。
四、核函数的应用场景
1. 支持向量机(SVM)
- 通过核函数处理非线性分类/回归问题。
- 示例代码(使用scikit-learn):
2. 核主成分分析(Kernel PCA)
- 将非线性数据映射到高维空间后进行降维。
3. 高斯过程(Gaussian Process)
- 核函数定义数据点间的协方差关系,用于回归和分类。
五、注意事项
-
过拟合风险:
- 高斯核和多项式核易过拟合,需结合正则化参数(如SVM中的
C)调整。
- 高斯核和多项式核易过拟合,需结合正则化参数(如SVM中的
-
数据标准化:
- 核函数对数据尺度敏感,使用前需标准化(如归一化到[0,1])。
-
计算复杂度:
- 高斯核的复杂度为 ,不适合超大规模数据(可改用近似方法如Nyström)。
六、总结
- 核函数本质:隐式高维映射工具,避免“维度灾难”。
- 选择优先级:优先尝试高斯核(RBF)→ 线性核 → 多项式核。
- 核心优势:将复杂非线性问题转化为高维线性问题,同时保持计算效率。
通过合理选择核函数和参数,可以显著提升模型在非线性任务中的表现。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号