常用数据处理方法(数据清洗,数据加工,数据格式转换...)
重复值处理
# 检测重复数据 np.any(data.duplicated())
#统计重复值的数量
data.duplicated().sum()
#删除重复数据 data.drop_duplicates()
缺失值处理
-
缺失值的表现形式:
-
NaN(数值缺失)、None(对象类型缺失)、NaT(时间类型缺失)均会被标记为True。 -
空字符串
''、Python的None(在非对象类型列中)可能不会被视为缺失值,需注意数据类型。
-
对数据重复检测完成之后,便可以检测数据中是否存在缺失值,我们可以直接使用 dropna()方法检测并删除缺失的数据,具体方法如下。
缺失值检测
|
|
它们的作用是标记缺失值( |
|
|
|
isnull的否定式,它们是 |
代码风格建议:统一使用 |
pandas中的isnull和notnull两个函数可以用于在Series或DataFrame中检测缺失值,这两个函数的返回是一个布尔类型的Series或DataFrame
# 检测是否存在空值
np.any(pd.isnull(data))
print("缺失值检测结果:", X["Age"].isnull().any()) # 更直观的缺失值检测
print("缺失值数量:", X["Age"].isnull().sum()) # 查看具体缺失数量缺失值数量统计
pd.isnull(data).sum()
如果检测发现缺失值可以对缺失值进行处理:
缺失值删除
dropna() 是 Pandas 中处理缺失值(如 NaN、NaT、None)的核心方法,用于删除包含缺失值的行或列。以下是参数说明和用法总结:
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
axis |
{0, 'index', 1, 'columns'} |
0 | 删除行(axis=0)或列(axis=1)。 |
how |
{'any', 'all'} |
'any' | any:行/列中任一缺失则删除;all:全部缺失才删除。 |
thresh |
int |
None | 保留至少有 thresh 个非缺失值的行/列(与 how 互斥)。 |
subset |
列名列表 |
None | 仅在指定列中检查缺失值(对行操作时有效)。 |
inplace |
bool |
False | 是否直接修改原 DataFrame(建议设为 False,避免副作用)。 |
ignore_index |
bool |
False | 重置索引为 0,1,…,n-1(删除行后索引可能不连续时使用)。 |
常用场景示例
基础数据
import pandas as pd import numpy as np df = pd.DataFrame({ "name": ['Alfred', 'Batman', 'Catwoman'], "toy": [np.nan, 'Batmobile', 'Bullwhip'], "born": [pd.NaT, pd.Timestamp("1940-04-25"), pd.NaT] }) df

#1. 删除至少有一个缺失值的行 df.dropna(axis=0, how='any') # 或简写为: df.dropna() #2. 删除全部为缺失值的列 df.dropna(axis=1, how='all') #3. 保留至少有2个非缺失值的行 df.dropna(thresh=2) #4. 仅在指定列检查缺失值 df.dropna(subset=['name', 'toy'])
进阶用法
重置索引
df.dropna(ignore_index=True)
注意事项
-
inplace=True慎用:直接修改原数据,可能引发后续代码错误(推荐赋值到新变量)。 - 性能优化:对大型数据集,优先使用
subset缩小检查范围。 - 替代方案:若需保留部分数据,可用
fillna()填充缺失值
缺失值填充
fillna 是 Pandas 中用于填充缺失值(NaN/NaT)的核心方法,支持灵活填充策略。以下是参数说明、使用场景及代码示例:
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
value |
标量、字典、Series、DataFrame | None |
填充值。可为统一值或按列/索引指定不同值(如 {'A': 0, 'B': 1})。 |
method |
{'ffill', 'bfill'} |
None |
已弃用。改用 df.ffill(使用前一行对应值填充) 或 df.bfill(使用后一行对应值填充) 方法。 |
axis |
{0, 'index', 1, 'columns'} |
0 |
填充方向:0 按列填充(默认),1 按行填充。 |
inplace |
bool |
False |
是否直接修改原数据(建议设为 False,避免副作用)。 |
limit |
int |
None |
最大连续填充数(如 limit=1 仅填充每组连续缺失的首个 NaN)。 |
常用场景示例
示例数据
import pandas as pd import numpy as np df = pd.DataFrame({ "A": [np.nan, 3, np.nan, np.nan], "B": [2.0, 4.0, np.nan, 3.0], "C": [np.nan, np.nan, np.nan, np.nan], "D": [0.0, 1.0, np.nan, 4.0], "F": [0.0, 1.0, np.nan, 4.0] }) df
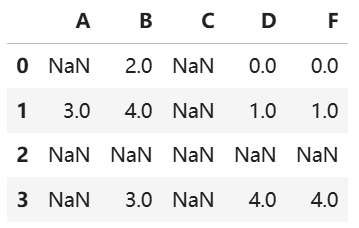
#统一填充所有 NaN df_filled = df.fillna(0) #按列指定不同填充值 values = {"A": 0, "B": 1, "C": 2, "D": 3} df_filled = df.fillna(value=values) df_filled #前向填充(用上方有效值填充) # 替代已弃用的 method='ffill' df_ffill = df.ffill(axis=0) #前后填充(用下方有效值填充) # 替代已弃用的 method='bfill' df_bfill = df.bfill(axis=0) #限制填充次数(limit=1) # 每列最多填充1个连续 NaN df_limited = df.fillna(0, limit=1) #使用另一个 DataFrame 填充 # 用 df2 的同位置值填充(只填充能覆盖到的,且列对应的上的数据) df2 = pd.DataFrame(np.zeros((3, 4)), columns=["A", "B", "C", "E"]) df.fillna(df2)
缺失值填充:插值法
对于复杂填充(如时间序列),可结合 interpolate:
# 线性插值 df_interpolated = df.interpolate(method='linear', axis=0)
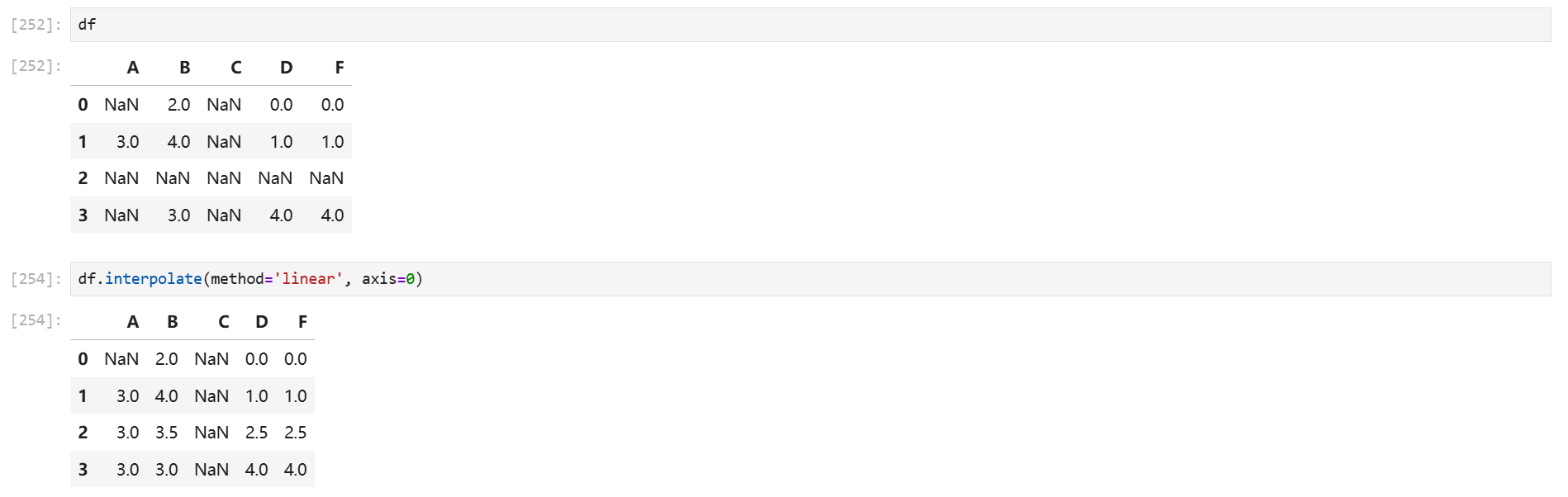
interpolate 是 Pandas 中用于通过插值技术填充缺失值的方法,适用于数值型或时间序列数据,能够根据已有数据推断合理的填充值。
核心参数
| 参数 | 类型/选项 | 默认值 | 说明 |
|---|---|---|---|
method |
'linear', 'time', 'index', 'pad', 'nearest', 'polynomial' 等 |
'linear' |
插值方法(见下方方法详解)。 |
axis |
0(行)或 1(列) |
0 |
沿指定轴插值。 |
limit |
int |
None |
允许填充的最大连续 NaN 数量。 |
limit_direction |
'forward', 'backward', 'both' |
None |
填充方向(前向、后向、双向)。 |
limit_area |
'inside', 'outside' |
None |
限制填充区域:'inside' 仅填充被有效值包围的 NaN,'outside' 仅填充首尾外侧的 NaN。 |
inplace |
bool |
False |
是否直接修改原数据(建议保持 False,返回新对象)。 |
常用插值方法 (method)
| 方法 | 适用场景 | 示例 |
|---|---|---|
'linear' |
默认,等间距线性插值(忽略索引实际值)。 | 填充序列 [1, NaN, 3] → [1, 2, 3]。 |
'time' |
时间序列数据,根据时间间隔插值。(只能在有DatetimeIndex类型索引的情形使用) | 按时间戳间隔均匀填充缺失值。 |
'pad' / 'ffill' |
用前一个有效值填充(等同于 df.ffill())。 |
[1, NaN, 3] → [1, 1, 3]。 |
'nearest' |
用最近的有效值填充。 | [1, NaN, 3, NaN] → [1, 1, 3, 3]。 |
'polynomial' |
多项式插值,需指定 order(如 order=2 二次多项式)。 |
[1, NaN, 3] → 按二次曲线估算中间值。 |
'spline' |
样条插值,需指定 order(依赖 SciPy)。 |
平滑插值,适合波动较大的数据。 |
使用示例
示例数据
import pandas as pd import numpy as np s = pd.Series([0, np.nan, np.nan, 3]) df = pd.DataFrame({ 'A': [1, np.nan, 3, np.nan], 'B': [np.nan, 5, np.nan, 7] })
线性插值填充
s.interpolate() 0 0.0 1 1.0 2 2.0 3 3.0 dtype: float64
时间序列插值
s_time = pd.Series([1, np.nan, 3],index=pd.date_range('2023-01-01', periods=3, freq='D')) s_time.interpolate(method='time') # 按时间均匀填充
多项式插值(二次)
限制填充方向和数量
# 仅向前填充,最多填充1个连续NaN df.interpolate(method='linear', limit_direction='forward', limit=1)
区域限制:仅填充内部缺失值:
s = pd.Series([np.nan, 2, np.nan, 4, np.nan]) s.interpolate(limit_area='inside') # 填充中间的NaN → [NaN, 2, 3, 4, NaN]
注意事项
- 依赖 SciPy:
'polynomial','spline'等方法需安装 SciPy 库。 - 时间序列:使用
method='time'时,索引必须是时间类型(如DatetimeIndex)。 - 性能优化:对大数据集优先使用
'linear'或'ffill',高阶插值(如多项式)计算成本较高。 - 与
fillna对比:fillna:简单填充固定值或前后值。interpolate:通过数学方法估算更合理的值,适合连续数据(如传感器数据、时间序列)。
缺失值为特殊标记的处理方法
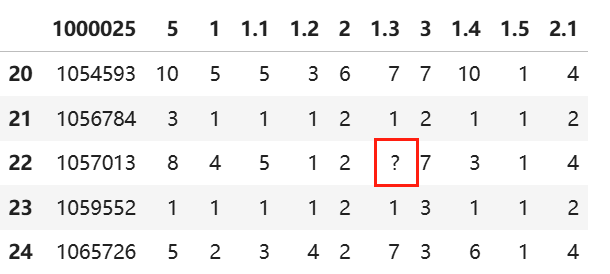
数据来源:
wis = pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.data")
#确认一下是否真的存在“?” for i in range(wis.shape[0]): for j in range(wis.shape[1]): if wis.iloc[i,j]=='?': print(f'第{i}行,第{j}列存在问号,列名为{wis.columns[j]}')
- df.replace(to_replace=, value=)
- to_replace:替换前的值
- value:替换后的值
# 把一些其它值标记的缺失值,替换成np.nan wis = wis.replace(to_replace='?', value=np.nan)
# 删除 wis = wis.dropna()
字段截取
data=pd.read_csv(r'D:\learn\000人工智能数据大全\黑马数据\科学计算数据\链家北京租房数据.csv') data.head()
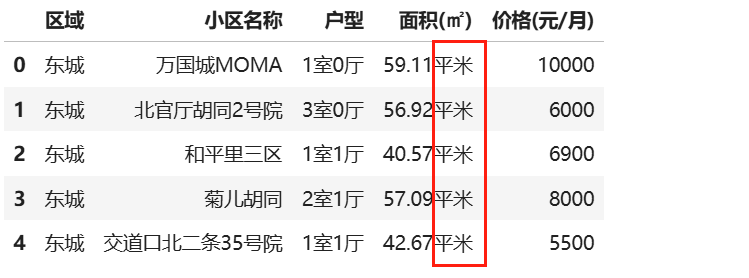
如何把字段‘面积(㎡)’的单位‘平米’全部去掉?
思路:
- 如果我们能够确认所有的数字后面都是‘平米’两个字,那么可以直接使用字符串截取。
- 如果我们不确定数字后面所跟的是不是统一的字符,那么就要使用正则表达式匹配。
1.进行统一长度截取
#使用列表推导式,逐个值截取处理 data.loc[:,'面积(㎡)']=[i[0:-2] for i in data.loc[:,'面积(㎡)']] # 转换成浮点类型 data['面积(㎡)'].astype(float)
#高效代码: # 一步完成截取 + 类型转换(时间复杂度 O(1) 的向量化操作):调用 .str 访问器的向量化操作 data['面积(㎡)'] = data['面积(㎡)'].str.slice(0, -2).astype(float) # 或更简洁的写法(替换法) data['面积(㎡)'] = data['面积(㎡)'].str.replace('平米', '', regex=False).astype(float)
| 方法 | 时间复杂度 | 优势 |
|---|---|---|
| 列表推导式 | O(n) | 灵活性高,但速度慢 |
| 向量化操作 | O(1) | 底层用 C 扩展实现,避免 Python 循环 |
| 正则表达式 | O(n) | 灵活但略慢(若非必要应避免,此处用 regex=False 禁用正则加速) |
性能对比(百万级数据测试)


import pandas as pd import time # 生成 100 万条测试数据 data = pd.DataFrame({ '面积(㎡)': ['100.5平米'] * 1_000_000 }) # 原始方案 t1 = time.time() data['面积(㎡)'] = [i[:-2] for i in data['面积(㎡)']] data['面积(㎡)'] = data['面积(㎡)'].astype(float) print(f"列表推导式耗时: {time.time() - t1:.2f}s") # 向量化方案 t2 = time.time() data['面积(㎡)'] = data['面积(㎡)'].str.replace('平米', '', regex=False).astype(float) print(f"向量化操作耗时: {time.time() - t2:.2f}s")
扩展建议
异常值处理:若字段可能缺失 平米 后缀,可增加校验:
mask = data['面积(㎡)'].str.endswith('平米') data.loc[mask, '面积(㎡)'] = data.loc[mask, '面积(㎡)'].str.slice(0, -2).astype(float)
正则优化:若后缀长度不固定(如 平方米),可用正则表达式:
data['面积(㎡)'] = data['面积(㎡)'].str.replace(r'[^\d.]+', '', regex=True).astype(float)
'''
正则表达式语法解析
-
[^\d.]+:\d: 匹配任意数字(等价于[0-9])。.: 在字符组[...]内,无需转义,直接匹配字面小数点。^: 取反,表示匹配非数字和小数点的字符。
'''
Pandas 的 .str 访问器以及与之搭配的方法
.str 访问器的作用
- 核心功能:将 Pandas Series 中的每个元素视为字符串,并支持批量字符串操作。
- 使用场景:当需要处理 DataFrame 或 Series 中的字符串列时,避免使用 Python 循环(低效),改用向量化操作。
- 常见方法:
- 切片:
.str.slice(start, end) - 替换:
.str.replace(old, new) - 分割:
.str.split(sep) - 匹配:
.str.contains(pattern)、.str.match(pattern) - 其他:
.str.lower()、.str.upper()、.str.len()等。
- 切片:
Python 原生字符串操作 vs. Pandas 字符串操作
| 类型 | Python 原生字符串方法 | Pandas 的 .str 访问器 |
|---|---|---|
| 作用对象 | 单个字符串(如 "hello") |
Pandas Series 或 DataFrame 中的字符串列(如 data['列名']) |
| 操作方式 | 直接调用字符串方法(如 "abc".upper()) |
通过 .str 调用向量化字符串方法(如 data['列名'].str.upper()) |
| 底层实现 | Python 内置方法 | Pandas 扩展的向量化操作,底层通过 C 扩展优化性能 |
| 适用场景 | 单个字符串处理 | 批量处理数据表中的字符串列 |
为何需要 .str 访问器?
- 数据类型问题:Pandas Series 可能包含混合类型(如数字和字符串),直接调用字符串方法会报错。
- 向量化性能:
.str方法底层使用优化的 C 代码,比 Python 循环快数十倍(尤其在处理大规模数据时)。 - 代码简洁性:避免显式循环,代码更易读。
常用 .str 方法示例
| 方法 | 用途 | 示例 |
|---|---|---|
.str.replace() |
替换字符串中的子串 | data['列名'].str.replace('旧', '新') |
.str.contains() |
检查字符串是否包含某模式 | data[data['列名'].str.contains('error')] |
.str.split() |
按分隔符分割字符串 | data['列名'].str.split(',') |
.str.extract() |
提取正则表达式匹配的子串 | data['列名'].str.extract(r'(\d+)') |
.str.startswith() |
检查字符串是否以某前缀开头 | data[data['列名'].str.startswith('A')] |
总结
-
.str和.slice()是 Pandas 特有的,专为高效处理 Series/DataFrame 中的字符串列设计。 - 优势:
- 向量化操作:避免 Python 循环,性能更高。
- 语法统一:与其他 Pandas 方法(如
.astype())无缝衔接。 - 功能丰富:支持正则表达式、复杂字符串处理。
- 适用场景:数据清洗、特征工程、文本分析等需要批量处理字符串的任务。
.str.slice()
- 功能:对 Series 中的每个字符串进行 切片操作,类似 Python 的字符串切片
[start:end],但以向量化方式批量处理。 - 参数:
start:起始位置(包含)。end:结束位置(不包含)。step:步长(可选)。
- 示例:
import pandas as pd # 示例数据 s = pd.Series(["apple", "banana", "cherry"]) # 切片操作:取每个字符串的前3个字符 sliced = s.str.slice(0, 3) print(sliced) # 输出: # 0 app # 1 ban # 2 che
正则表达式筛选查找指定格式字符串
data=pd.read_csv(r'D:\learn\000人工智能数据大全\黑马数据\科学计算数据\链家北京租房数据.csv')
data.head()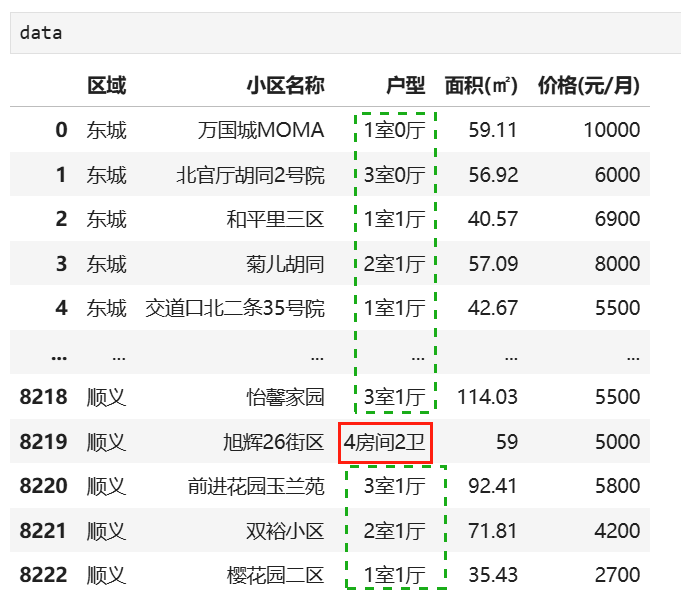
# 写出符合a室b厅格式的正则表达式
pattern = r'^\d+室\d+厅$' # ^ 表示开头,$ 表示结尾
huxing=data['户型']
# 使用 str.match 判断是否匹配,并通过 ~ 取反:找出 【户型】不符合a室b厅这种格式的数据
invalid_data =data[~huxing.str.match(pattern,na=False)]
invalid_data
# ~ 是 逻辑取反操作符,用于对布尔型 Series 进行取反(例如将 True 转为 False,False 转为 True)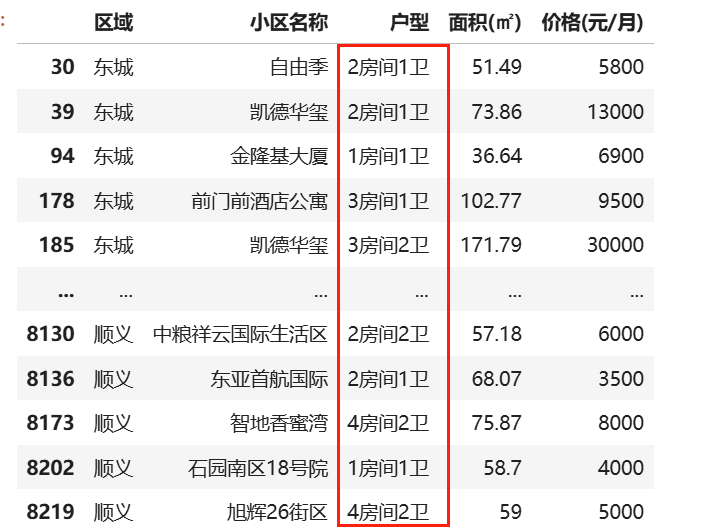
invalid_data.to_csv(r'户型格式异常数据.csv')时间数据
常用函数
pd.to_datetime()
pd.to_datetime() 是 Pandas 中用于将输入转换为日期时间格式的核心函数。以下是一个分层次的讲解:
核心功能
将 标量、数组、Series、DataFrame/dict 转换为 Pandas 的日期时间对象(如 Timestamp, DatetimeIndex 或 datetime64 类型)。
主要参数解析
1. arg
- 输入类型:支持多种格式:
- 字符串、数值(时间戳)、
datetime对象 - 列表、NumPy 数组、Pandas Series
- DataFrame(需包含
year,month,day列)
- 字符串、数值(时间戳)、
- 示例:
pd.to_datetime("2023-10-01") # 字符串 → Timestamp
pd.to_datetime(1696118400, unit='s') # 时间戳 → Timestamp
pd.to_datetime(df[['year', 'month', 'day']]) # DataFrame → DatetimeIndex2. errors(错误处理)
'raise'(默认):解析失败时报错。'coerce':无效输入转为NaT(Not a Time)。'ignore':保留无效输入原样。- 示例:
pd.to_datetime("invalid_date", errors='coerce') # 输出 NaT3. dayfirst 和 yearfirst
- 日期解析顺序:
dayfirst=True:优先解析为日/月/年(如"10/11/12"→ 2012-11-10)。yearfirst=True:优先解析为年/月/日(如"10/11/12"→ 2010-11-12)。
- 注意:非严格模式,解析器可能自动推断。
4. utc(时区处理)
utc=True:强制结果带 UTC 时区。- 示例:
pd.to_datetime("2023-10-01 12:00+08:00", utc=True) # 转为 UTC 时间5. format(格式控制)
- 指定日期字符串的格式(类似
strftime)。 - 示例:
pd.to_datetime("01-10-2023", format="%d-%m-%Y") # 明确格式 → 2023-10-016. unit 和 origin
-
unit:定义数值的时间单位(如's','ms','ns')。 -
origin:定义数值的参考起始时间(默认'unix',即 1970-01-01)。 - 示例:
pd.to_datetime(1, unit='D', origin='2023-01-01') # 2023-01-027. 其他参数
exact:是否严格匹配format格式。infer_datetime_format(已弃用):自动推断格式。cache:缓存重复日期字符串提升速度。
返回值类型
- 标量输入 →
Timestamp - 列表/数组输入 →
DatetimeIndex - Series 输入 →
Series(datetime64类型) - DataFrame 输入 →
DatetimeIndex
常见用例
1. 解析字符串列表
dates = ["2023-01-01", "2023-02-01"]
pd.to_datetime(dates) # DatetimeIndex2. 处理混合时区
pd.to_datetime(["2023-01-01 12:00+08:00", "2023-01-01 12:00"], utc=True)3. 时间戳转换
pd.to_datetime(1696118400, unit='s') # 2023-10-01 00:00:004. 处理 DataFrame
df = pd.DataFrame({'year': [2023], 'month': [10], 'day': [1]})
pd.to_datetime(df) # 2023-10-01注意事项
- 时间戳范围限制:Pandas 支持的时间范围为
1677-09-21 00:12:44至2262-04-11 23:47:16,超出范围会返回 Pythondatetime对象。 - 混合时区警告:若未指定
utc=True,混合时区的输入会触发警告并返回object类型。 - 性能优化:对重复日期使用
cache=True可加速解析。
pd.DatetimeIndex()
pd.DatetimeIndex 是 Pandas 中专门用于处理日期时间数据的索引类型,提供了丰富的日期时间操作功能。
基本概念
- 作用:存储 datetime64 类型的时间序列数据,支持高效的时间相关操作。
- 特性:
- 不可变的类数组结构
- 内部用 int64 存储纳秒级时间戳,通过
Timestamp对象对外展示 - 支持时区(tz-aware)操作
- 版本 2.0.0 起,日期属性(如
.day,.month)的 dtype 改为int32
关键参数
-
data
一维日期数据,支持多种格式:- 字符串列表:
["2020-01-01", "2020-01-02"] datetime对象np.datetime64数组pd.Timestamp对象
- 字符串列表:
-
freq
频率字符串或对象,如'D'(天)、'H'(小时)。若设为'infer',自动推断频率。 -
tz
时区设置,如'Asia/Shanghai'。可通过tz_convert转换时区。 -
ambiguous
处理模糊时间(如夏令时切换):'raise':抛出错误(默认)'infer':尝试推断'NaT':设为缺失值- 布尔数组:手动标记是否为夏令时
-
dayfirst/yearfirst
解析日期时优先按日或年,如dayfirst=True将 "01-02-2020" 解析为 1日2月。
三、核心属性
| 属性 | 描述 | 示例 |
|---|---|---|
| .year/.month/.day | 年、月、日 | 2023, 12, 31 |
| .hour/.minute/.second | 时、分、秒 | 23, 59, 59 |
| .dayofweek | 星期几(周一=0, 周日=6) | |
| .is_leap_year | 是否为闰年 | True/False |
| .is_month_start | 是否月初 | |
| .tz | 时区信息 | tzfile('Asia/Shanghai') |
| .freq | 频率对象 | <Day> |
四、常用方法
1.时区处理
-
tz_localize:设置时区
idx = idx.tz_localize('UTC') # 本地化时区- tz_convert:转换时区
idx = idx.tz_convert('Asia/Shanghai')2. 时间舍入
- floor/ceil/round:按指定频率对齐时间
idx.floor('H') # 向下取整到小时
idx.ceil('D') # 向上取整到天
idx.round('T') # 四舍五入到分钟3. 格式转换
-
strftime:自定义格式输出
idx.strftime('%Y-%m-%d %H:%M:%S')- to_period:转为周期索引
idx.to_period('M') # 转为月度周期4. 集合操作
-
indexer_at_time:筛选特定时间点
idx.indexer_at_time('10:00') # 返回10点的位置- indexer_between_time:筛选时间范围
idx.indexer_between_time('09:00', '18:00')六、注意事项
- 弃用参数:
normalize和closed在 2.1.0 后弃用,建议改用pd.date_range的对应参数。 - 性能优化:直接操作
DatetimeIndex比循环处理更高效。 - 时区处理:始终明确时区,避免隐式转换。
时间戳处理
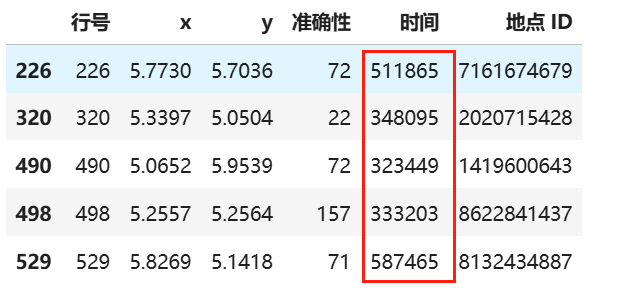
# 3,数据特征构造
# 原数据time特征是时间戳,我们可以将其拆解成年月日时分秒,以及星期几,从而更细力度的估算出某人何时会出现在何地
time=pd.to_datetime(part_data['time'],unit='s')# unit='s':以秒为单位,1970-01-06 22:11:05,从拆分后的数据我们可以看出,时间数据是被脱敏过的,1970年根本没有facebook
# 上一步输出的结果是Series,还需要DatetimeIndex进一步处理,才能城区
time=pd.DatetimeIndex(time)
part_data['day']=time.day
part_data['hour']=time.hour
part_data['weekday']=time.weekday 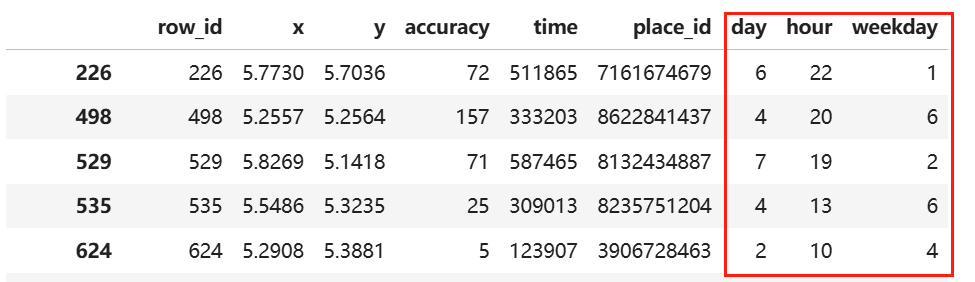


 浙公网安备 33010602011771号
浙公网安备 33010602011771号