8-seaborn高级绘图工具
概述
互补性
- Seaborn 依赖 Matplotlib 实现绘图,两者可混合使用:用 Seaborn 快速生成图表,再用 Matplotlib 调整细节。
- 复杂场景下,两者结合能兼顾效率和灵活性。
| 维度 | Matplotlib | Seaborn |
|---|---|---|
| 定位 | 底层绘图工具,灵活但代码量大 | 高级统计可视化,简洁高效 |
| 适用场景 | 定制化图表、非统计图表、学术出版 | 数据探索、统计分析、快速原型 |
| 默认样式 | 朴素 | 美观(内置主题和调色板) |
| 学习成本 | 较高(需掌握 Figure/Axes 体系) | 较低(面向 DataFrame 和统计语义) |
| 核心优势 | 完全控制图形细节 | 一键生成复杂统计图表 |
实际工作场景使用建议:
- 数据分析阶段:优先用 Seaborn 快速探索数据分布和关系。适用于探索性数据分析(EDA)阶段的多维度数据分布比较。
- 报告/演示输出:用 Seaborn 生成基础图表,再用 Matplotlib 微调样式。
- 复杂定制需求:直接使用 Matplotlib 或混合调用。
安装
# 安装pip install seaborn# 导入import seaborn as sns
全局配置图表样式sns.set()
sns.set() 是 seaborn 中用于全局配置图表样式的核心函数,它会设置默认的主题、调色板、字体等参数,让你的图表看起来更专业。
sns.set() 的作用
-
设置默认主题
通过sns.set(),seaborn会自动应用一套预定义的视觉主题(如背景颜色、网格线、字体大小等),替代matplotlib的默认简陋样式。 -
统一图表风格
全局生效,后续所有绘图(包括matplotlib和seaborn生成的图表)都会继承这些配置,无需重复调整参数。 -
提升可读性
默认主题优化了颜色对比度、坐标轴标签等细节,使数据更清晰易懂。
常用参数
sns.set( context="notebook", # 上下文环境:'paper', 'talk', 'poster'(调整字体大小等) style="darkgrid", # 主题样式:'darkgrid', 'whitegrid', 'dark', 'white' palette="deep", # 调色板:'muted', 'pastel', 'bright', 'colorblind' 等 font="sans-serif", # 字体类型 font_scale=1, # 字体大小缩放比例 rc=None # 直接传递 matplotlib 的 rc 参数(高级设置) )
示例对比
1. 未调用 sns.set()(使用原生 matplotlib 样式)
import matplotlib.pyplot as plt plt.plot([1, 2, 3], [4, 5, 6]) plt.show()
- 效果:白底、无网格线、字体较小,图表较为朴素。
2. 调用 sns.set() 后
import seaborn as sns sns.set() # 应用默认主题 plt.plot([1, 2, 3], [4, 5, 6]) plt.show()
- 效果:灰色背景 + 白色网格线(
darkgrid主题)、字体更大、颜色更柔和。
常见问题
1. 如何自定义样式?
通过参数调整主题和调色板:
sns.set( style="whitegrid", # 白色背景 + 灰色网格线 palette="husl", # 鲜艳的调色板 font_scale=1.5, # 字体放大1.5倍 rc={"lines.linewidth": 2} # 线条宽度设为2 )
2. 如何重置为默认设置?
sns.reset_orig() # 恢复为 matplotlib 原始样式
是否必须调用 sns.set()?
- 不必须,但强烈建议使用。它能显著提升图表美观度,节省手动调整样式的时间。
总结
-
sns.set() 是seaborn的样式初始化函数,一键提升图表颜值。 - 通过参数可灵活定制主题、颜色、字体等细节。
- 适用于数据分析报告、论文配图等需要专业可视化效果的场景。
绘制单变量分布
distplot()已过时
注意:distplot函数函数已经被弃用,下面的代码仅用作了解
seaborn.distplot(a, bins=None, hist=True, kde=True, rug=False, fit=None, color=None)
- (1) a:表示要观察的数据,可以是 Series、一维数组或列表。
- (2) bins:用于控制条形的数量。
- (3) hist:接收布尔类型,表示是否绘制(标注)直方图。
- (4) kde:接收布尔类型,表示是否绘制高斯核密度估计曲线。
- (5) rug:接收布尔类型,表示是否在支持的轴方向上绘制rugplot(地毯图)。
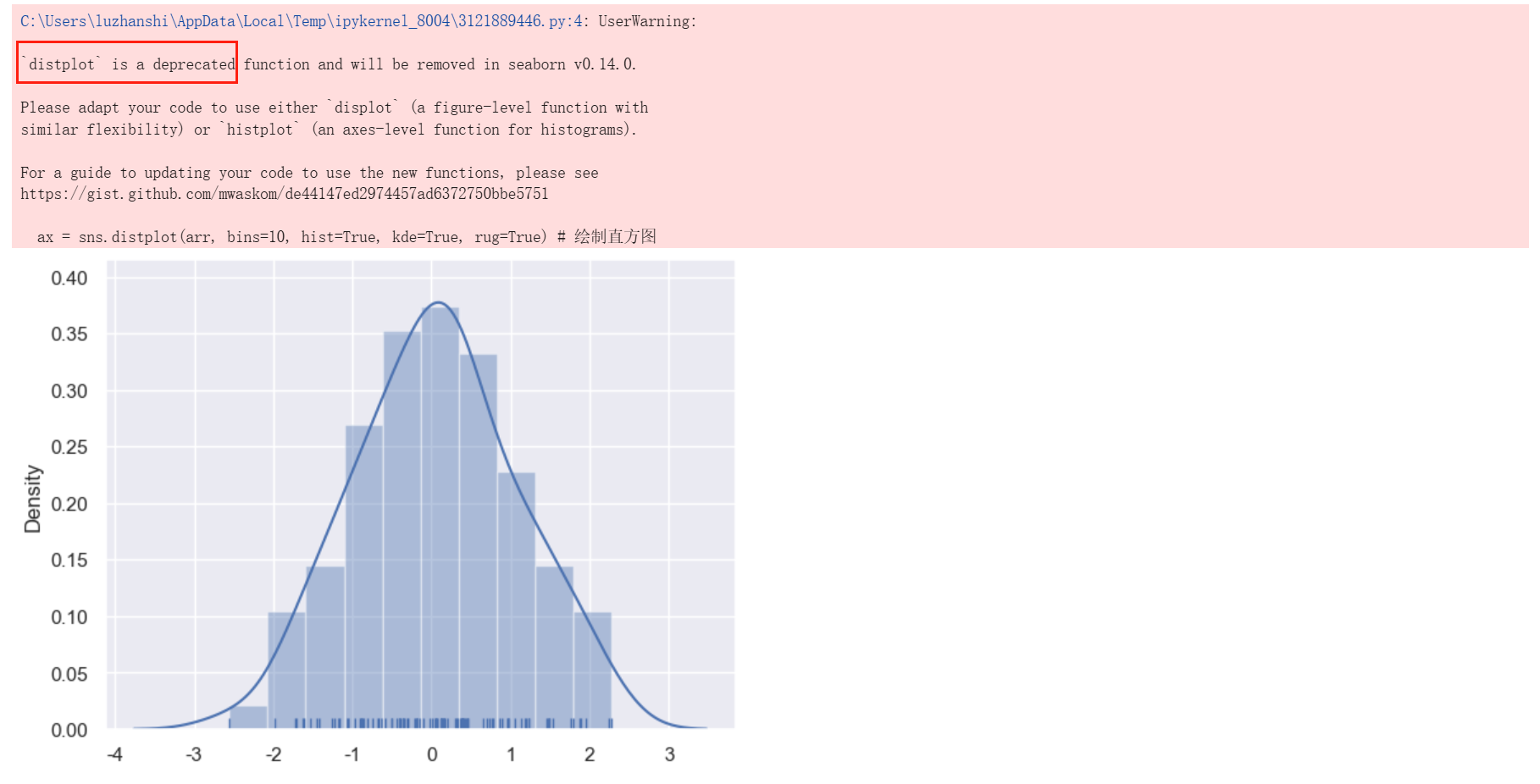
import numpy as np
sns.set()
np.random.seed(0) # 确定随机数生成器的种子,如果不使用每次生成图形不一样
arr = np.random.randn(100) # 生成随机数组
ax = sns.distplot(arr, bins=10, hist=True, kde=True, rug=True) # 绘制直方图
distplot 的功能拆分
distplot 被弃用后,其功能拆分为以下更细粒度的函数:
distplot 的功能 |
替代函数组合 |
|---|---|
| 直方图 (Histogram) | histplot(核心)或 displot(kind="hist") |
| 核密度估计 (KDE) | kdeplot(核心)或 displot(kind="kde") |
| 地毯图 (Rug Plot) | rugplot(需手动叠加) |
| 多图叠加 | 手动组合(如 histplot + kdeplot + rugplot) |
histplot()直方图
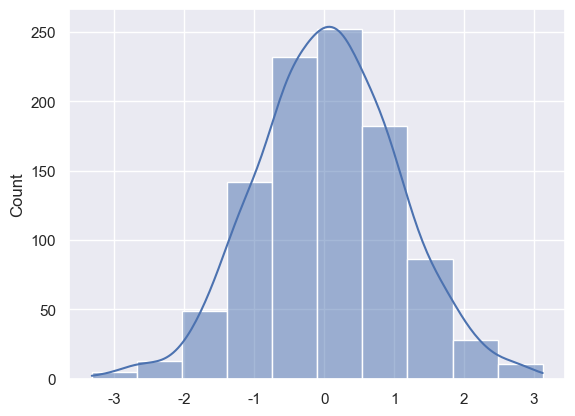
若只需直方图 + KDE,直接使用 histplot
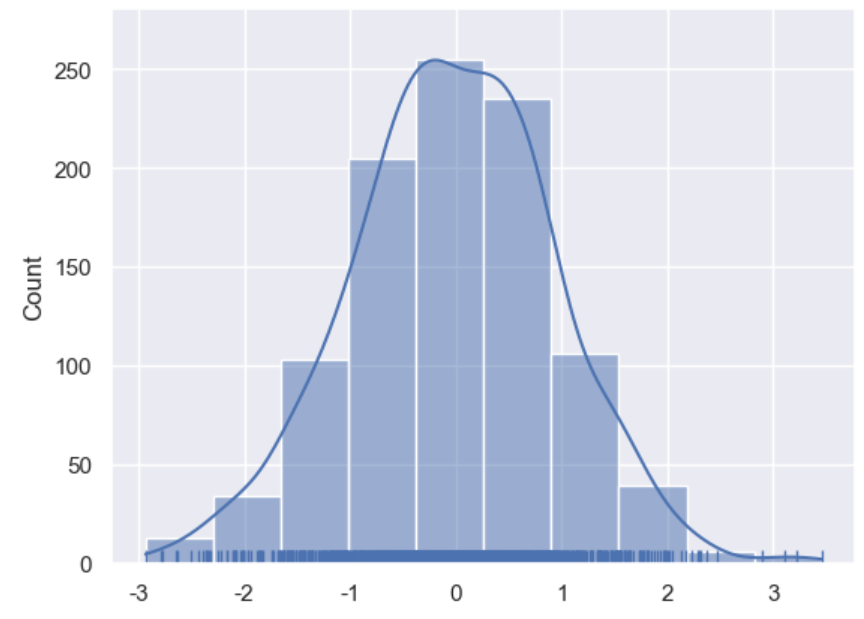
arr=np.random.randn(1000) ax=sns.histplot(arr, bins=10, kde=True) # 绘制直方图 plt.show()
rugplot()地毯图
手动叠加地毯图
arr=np.random.randn(1000) ax=sns.histplot(arr, bins=10, kde=True) # 绘制直方图+核密度曲线 sns.rugplot(arr,ax=ax)#绘制地毯图 plt.show()
displot()分面绘图
| | 类型 | 说明 |
|---|---|---|
data |
DataFrame, ndarray, dict | 输入数据。支持长格式(变量为列)或宽格式(自动转换)。 |
x, y |
向量或 data 中的键 |
指定 x/y 轴的变量名(双变量分析时需同时指定)。 |
hue |
向量或 data 中的键 |
语义变量,将该列数据分组,按不同颜色绘制分布。 |
row, col |
向量或 data 中的键 |
按行或列分面绘制子图(基于变量不同取值)。将该列或行分组,每组绘制一个子图。 |
kind |
'hist', 'kde', 'ecdf' |
绘图类型,默认为 'hist'。
|
rug |
bool | 是否添加 rugplot(显示数据点位置),默认为 False。 |
log_scale |
bool, number 或元组 | 设置坐标轴为对数刻度(如 log_scale=True 或 log_scale=(True, False))。 |
height, aspect |
标量 | 子图高度(英寸)和宽高比(总宽度 = height * aspect)。 |
col_wrap |
int | 分面列的最大数量,超出的列换行显示(不可与 row 同时使用)。 |
-
palette:调色板名称、列表或字典,控制hue分组的颜色映射。 -
hue_order:指定hue分组的顺序。 -
hue_norm:归一化范围(如(0, 100))或Normalize对象,用于数值型hue变量。 -
weights:观测值的权重向量,用于计算加权分布。 -
facet_kws:传递给FacetGrid的参数字典,用于自定义分面子图布局。
返回值
-
FacetGrid对象:管理多个子图,可通过其方法批量设置坐标轴属性,例如:
g = sns.displot(...) g.set_axis_labels("X轴", "Y轴") g.set_titles("分面条件: {col_name}")
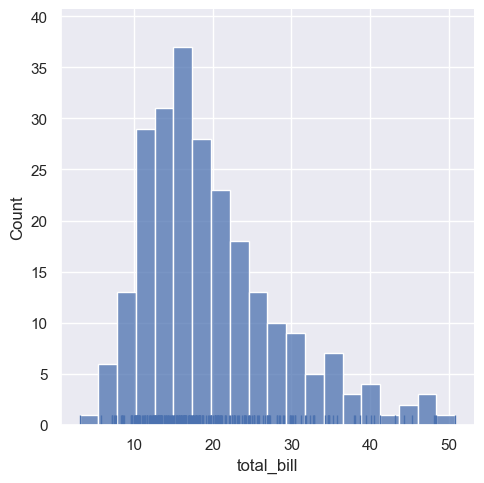
单变量直方图
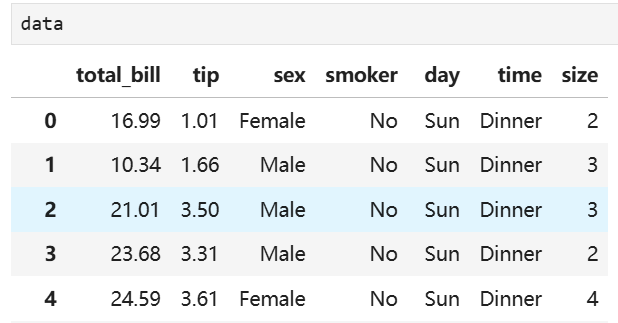
# sns.load_dataset:加载seaborn内置数据集 tips = sns.load_dataset("tips")#tips:一个统计男性女性每天用餐(午餐lunch和晚餐dinner)消费金额及其所付小费的情况的数据集
tips
total_bill tip sex smoker day time size
0 16.99 1.01 Female No Sun Dinner 2
1 10.34 1.66 Male No Sun Dinner 3
2 21.01 3.50 Male No Sun Dinner 3
3 23.68 3.31 Male No Sun Dinner 2
4 24.59 3.61 Female No Sun Dinner 4
... ... ... ... ... ... ... ...
239 29.03 5.92 Male No Sat Dinner 3
240 27.18 2.00 Female Yes Sat Dinner 2
241 22.67 2.00 Male Yes Sat Dinner 2
242 17.82 1.75 Male No Sat Dinner 2
243 18.78 3.00 Female No Thur Dinner 2
244 rows × 7 columns绘图:
sns.displot(data=tips, x="total_bill", kind="hist", bins=20, rug=True) plt.show()
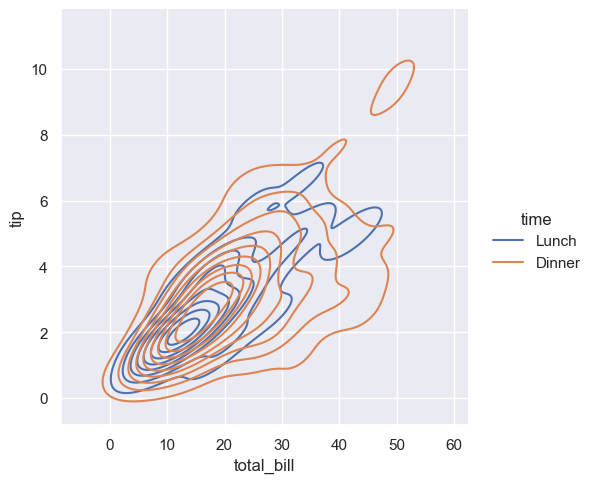
双变量核密度估计图
sns.displot(data=tips, x="total_bill", y="tip", kind="kde", hue="time") plt.show()
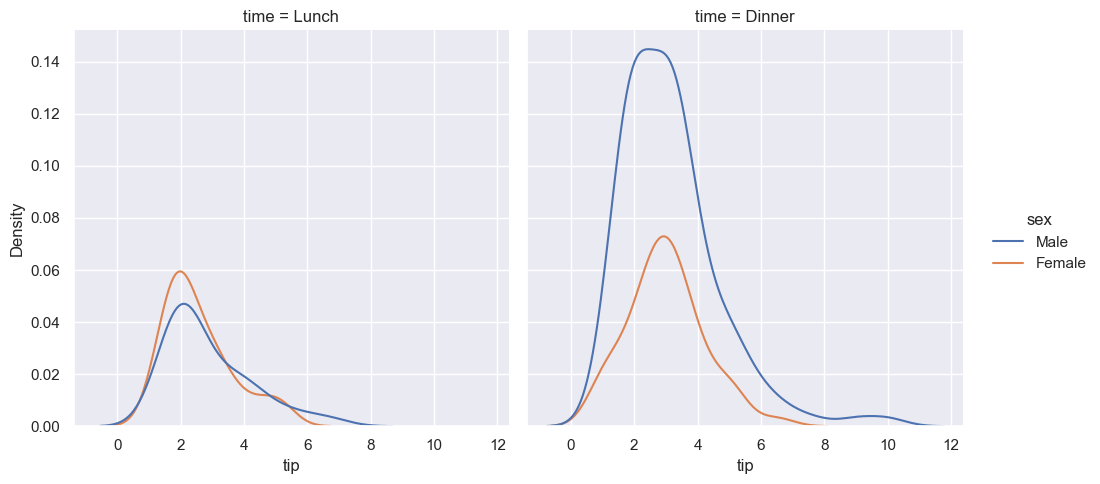
分面核密度估计图
sns.displot(data=tips, x="tip", col="time", kind="kde", hue="sex") plt.show()
注意事项
- 数据格式:
data为 DataFrame 时,x、y、hue等参数直接使用列名。 -
ecdf限制:ecdf仅支持单变量分析,双变量使用时会报错。 - 子图调整:通过
height和aspect调整子图尺寸,例如height=3, aspect=2生成宽高为 3x6 英寸的子图。
底层函数
displot是对以下 axes-level 函数的封装:histplot:直方图(可堆叠、归一化)。kdeplot:核密度估计(支持带宽调整)。ecdfplot:经验累积分布函数(显示数据累计比例)。
- 更多参数(如
bins、kde的bw_adjust)需参考对应底层函数的文档。
绘制双变量分布
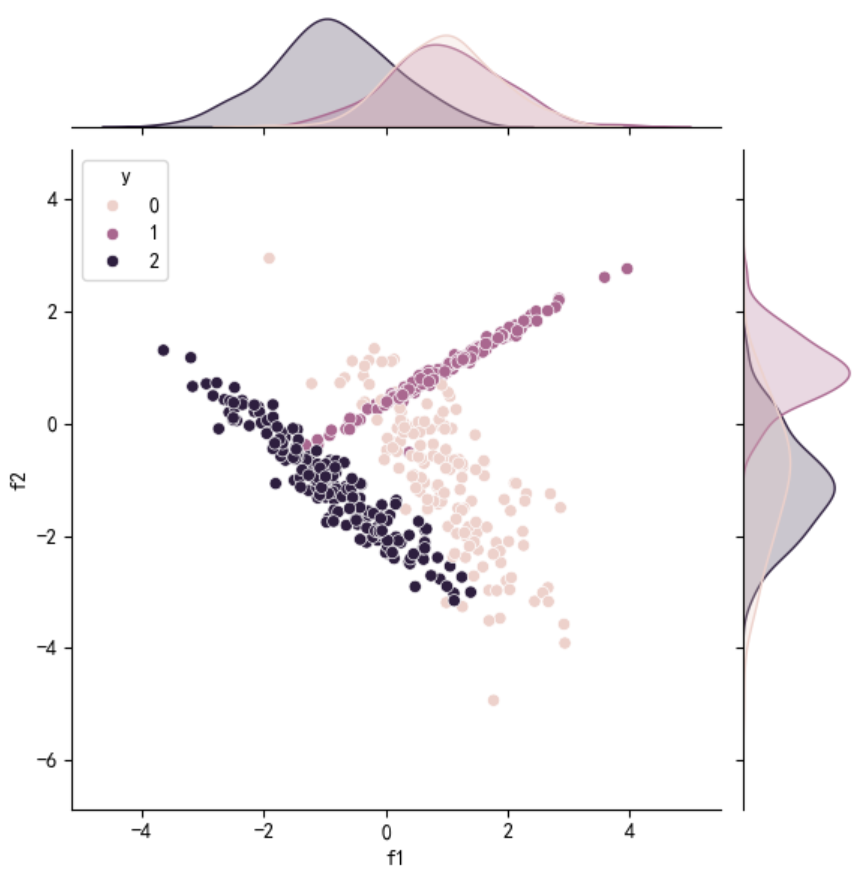
jointplot()
jointplot 是 Seaborn 中用于绘制双变量关系及边缘分布的可视化工具,封装了 JointGrid 类的核心功能,适用于快速探索两个变量之间的关系。
主要功能
- 绘制 双变量关系图(如散点图、回归图、六边形图等)及 单变量边缘分布图(直方图、密度图等)。
- 支持通过
hue参数引入第三个分类变量进行颜色编码。 - 提供多种预设绘图类型(
kind),简化复杂图形的生成。
seaborn.jointplot(x, y, data=None,kind='scatter', stat_func=None(新版本已移除), color=None,ratio=5, space=0.2, dropna=True)
参数说明
数据参数
| 参数 | 描述 |
|---|---|
data |
输入数据,支持 DataFrame、ndarray、字典或列表等格式。 |
x, y |
数据中的变量名或键,分别对应 x 轴和 y 轴的变量。 |
hue |
分类变量名,用于按颜色分组数据点(需配合 palette 使用)。 |
绘图类型与布局
| 参数 | 描述 |
|---|---|
kind |
绘图类型,可选:"scatter"(默认)、"kde"、"hist"、"hex"、"reg"(回归图)、"resid"(残差图)。 |
height |
图形整体高度(正方形,默认 6 英寸)。 |
ratio |
主图高度与边缘图高度的比例(默认 5:1)。该参数的值越大,则中心图的占比会越大。 |
space |
主图与边缘图之间的间距(默认 0.2)。 |
数据处理与轴限制
| 参数 | 描述 |
|---|---|
dropna |
是否删除 x 和 y 中的缺失值(默认 False)。 |
xlim/ylim |
手动设置 x/y 轴的范围(例如 (0, 10))。 |
颜色与样式控制
| 参数 | 描述 |
|---|---|
color |
单一颜色,当不使用 hue 时指定所有元素的颜色。 |
palette |
调色板名称、列表或字典,用于 hue 变量的颜色映射。 |
hue_order |
指定 hue 变量的类别顺序。 |
hue_norm |
标准化 hue 变量的数值范围(如 (0, 100))或使用 Normalize 对象。 |
图形细节
| 参数 | 描述 |
|---|---|
marginal_ticks |
是否在边缘图的坐标轴上显示刻度(默认 False)。 |
joint_kws |
传递给主图函数的额外参数(如 s=50 设置散点大小)。joint_kws={'s':500} |
marginal_kws |
传递给边缘图函数的额外参数(如 bins=20 调整直方图分箱数)。marginal_kws={'bins':50} |
**kwargs |
其他参数,优先级高于 joint_kws。 |
返回值
-
JointGrid对象:包含主图(ax_joint)、边缘直方图(ax_marg_x,ax_marg_y)等子图对象,支持进一步自定义样式或添加图层。
核心特性
-
多类型支持:
-
scatter:散点图(默认)。 -
kde:核密度估计图。 -
hist:直方图。 -
hex:六边形分箱图(展示数据密度)。 -
reg:散点图 + 回归线 + 置信区间。 -
resid:残差图(回归分析后使用)。
-
-
分类着色:
- 通过
hue参数引入第三个变量,结合palette调色板实现数据分组可视化。
- 通过
-
高度可定制:
- 通过
joint_kws和marginal_kws传递参数到底层绘图函数(如sns.scatterplot或sns.histplot)。
- 通过
散点图kind='scatter'(默认值,可省略)
# 创建DataFrame对象 dataframe_obj = pd.DataFrame({"x": np.random.randn(500),"y": np.random.randn(500)}) # 绘制散布图 sns.jointplot(x="x", y="y", data=dataframe_obj) plt.show()
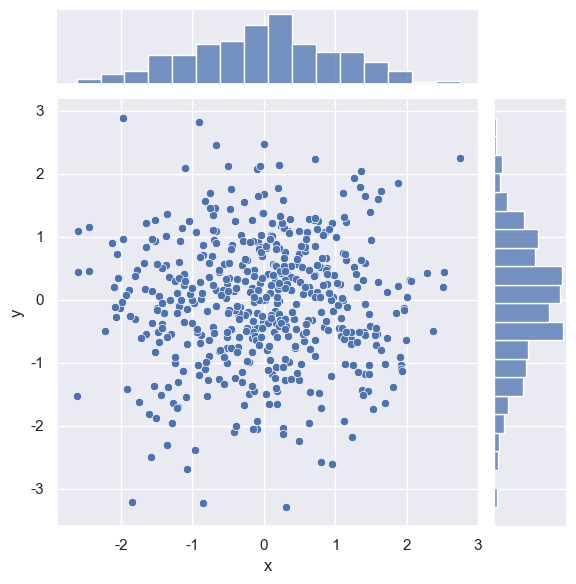
二维直方图kind='hist'
- 图形特征
使用 矩形分箱(矩形方块) 显示数据密度,颜色深浅表示每个矩形区域内数据点的数量。 - 适用场景
数据量中等或较大时,直观显示分布密度和边界。
示例代码:
import seaborn as sns dataframe = pd.DataFrame({"x": np.random.randn(1000), "y": np.random.randn(1000)}) sns.jointplot(x="x", y="y", data=dataframe, kind="hist", bins=30)
plt.show()
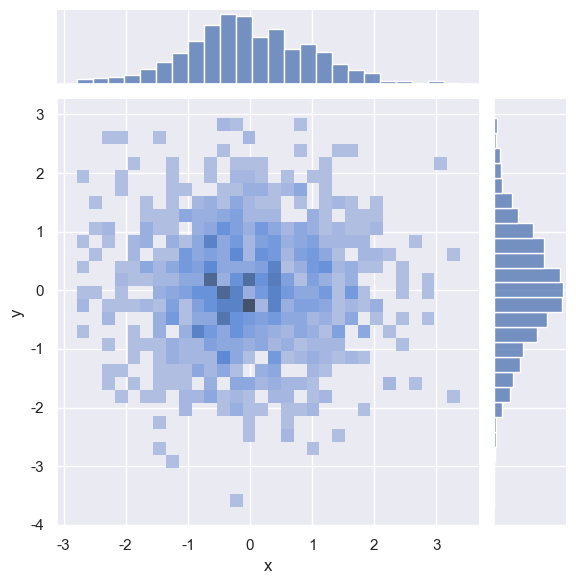
优化:
sns.jointplot( x="x", y="y", data=dataframe, kind="hist", bins=40, # 增加分箱数量以提升细节 cmap="viridis", # 修改颜色映射 marginal_kws={"bins": 80} # 调整边缘直方图分箱 ) plt.show()
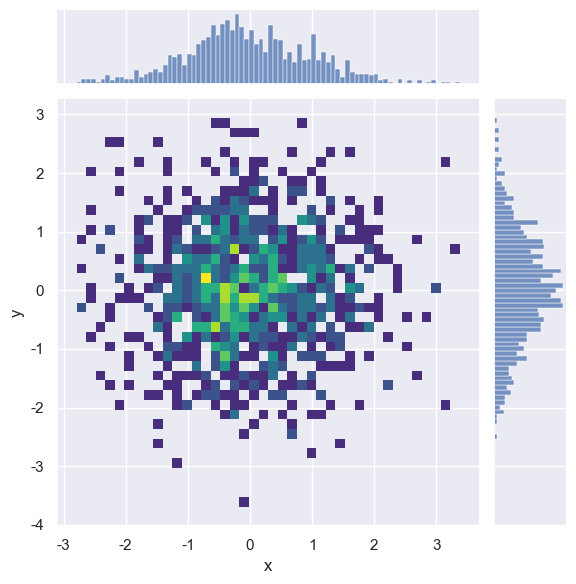
六边形分箱图kind='hex'
- 图形特征
使用 六边形分箱 显示数据密度,颜色深浅表示每个六边形区域内数据点的数量。 - 适用场景
数据量较大时,六边形分箱能更高效地减少视觉碎片化,适合高密度区域的可视化。
# 创建DataFrame对象
dataframe_obj = pd.DataFrame({"x": np.random.randn(500),"y": np.random.randn(500)})
# 绘制二维直方图
sns.jointplot(x="x", y="y", data=dataframe_obj,kind='hex',gridsize=20
) plt.show()
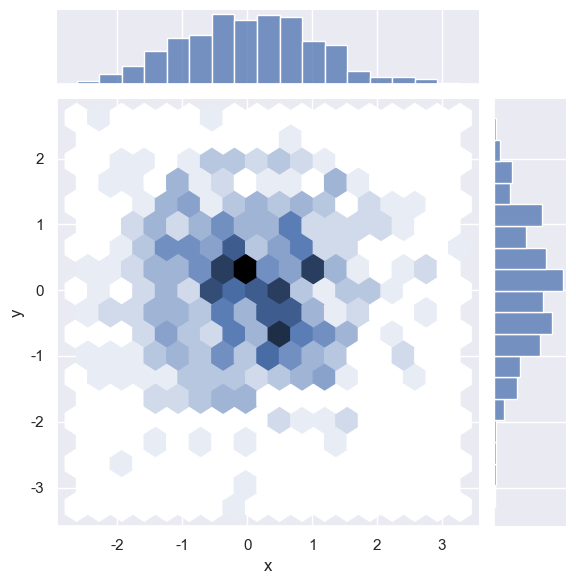
优化:
sns.jointplot( x="x", y="y", data=dataframe, kind="hex", gridsize=25, # 减小六边形尺寸以增加分辨率 cmap="rocket", # 修改颜色映射 marginal_kws={"color": "skyblue"} # 调整边缘图颜色 ) plt.show()
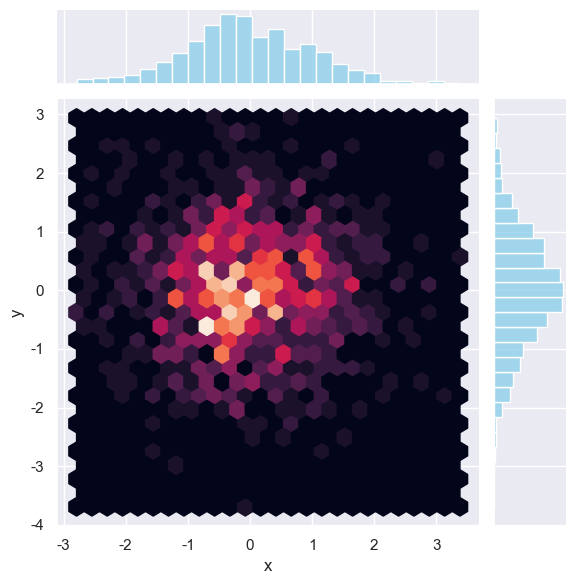
| 维度 | kind='hist' |
kind='hex' |
|---|---|---|
| 分箱形状 | 矩形 | 六边形 |
| 数据量适应性 | 中小规模数据(如 1k~10k 点) | 大规模数据(如 10k+ 点) |
| 视觉效果 | 边界清晰,适合精确分析局部密度 | 过渡平滑,适合观察整体分布趋势 |
| 参数控制 | bins(分箱数量) |
gridsize(六边形网格大小) |
| 颜色映射 | 颜色块边缘明显 | 颜色渐变更自然 |
-
选择
kind='hist'的场景:- 需要精确分析数据分布的局部细节。
- 数据量适中,希望直观展示分箱数量和密度。
-
选择
kind='hex'的场景:- 数据量极大时避免矩形分箱的视觉噪音。
- 需要更美观、平滑的密度过渡效果。
核密度估计图形kind="kde"
核密度估计等高线图,适合连续分布的平滑可视化。
dataframe=pd.DataFrame({"x":np.random.randn(1000),"y":np.random.randn(1000)})
sns.jointplot(x="x", y="y", data=dataframe, kind="kde")
plt.show()
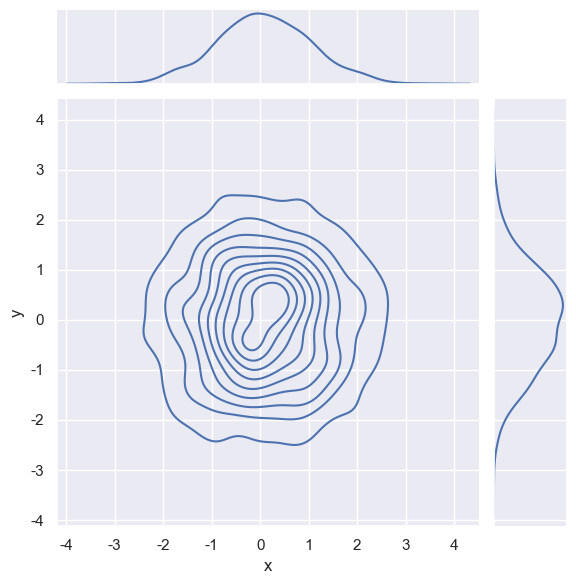
散点图 + 回归线+置信区间kind='reg'
散点图 + 回归线+置信区间,展示变量间的线性关系。
import seaborn as sns tips = sns.load_dataset("tips") # 添加回归线和核密度边缘图 sns.jointplot(data=tips, x="total_bill", y="tip", kind="reg", palette="Set2") plt.show()
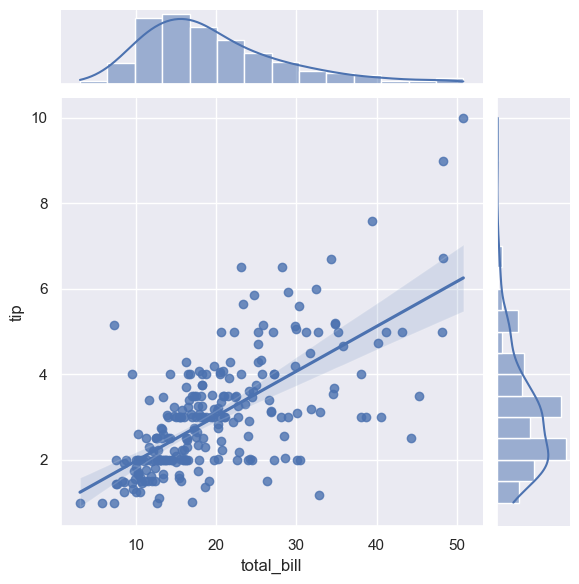
注意事项
- 数据预处理:使用
dropna=True可自动过滤缺失值,避免绘图错误。 - 轴限制设置:
xlim和ylim应在绘图前指定,确保主图与边缘图范围一致。 - 颜色映射冲突:若同时指定
color和hue,hue会覆盖color。
相关函数
-
JointGrid:更灵活的双变量绘图类,支持自定义图层(如添加分布图、注释等)。
通过 jointplot,用户能够快速生成复杂的双变量分析图,适用于数据探索阶段的模式识别和关系验证。
常见问题
-
颜色映射失效:
-
hue仅在部分kind类型(如scatter、kde)中生效,hex或hist类型不支持。
-
-
大数据量性能优化:
-
使用
kind="hex"或kind="kde"替代散点图,避免渲染过多数据点。
-
-
边际图类型调整:
-
通过
marginal_kws={"kind": "kde"}将边际直方图改为密度曲线(需kind="scatter")。
-
高级技巧
多图层叠加:
通过返回的 JointGrid 对象添加额外元素:
g = sns.jointplot(...) g.plot_joint(sns.kdeplot, alpha=0.5) # 在主图上叠加KDE g.ax_joint.set_xlabel("Custom X Label")
保存高清图像:
使用 Matplotlib 接口保存:
g.savefig("jointplot.png", dpi=300, bbox_inches="tight")
seaborn.lmplot()
seaborn.lmplot 是一个用于绘制数据分布和回归模型的强大函数,支持分面分析。
核心功能
- 回归分析:绘制散点图并拟合回归线(线性、多项式、逻辑回归等)。
- 分面展示:通过
hue、col、row参数,按类别变量分开展示不同子图。
基础语法
import seaborn as sns
sns.lmplot(
data=df,
x='x_column',
y='y_column',
hue='group',
col='facet_column',
row='facet_row',
order=2, # 多项式回归阶数
ci=95, # 置信区间
scatter=True,
fit_reg=True
)常用参数详解
| 参数 | 说明 |
|---|---|
data |
数据框(DataFrame),需为「整洁数据」格式。 |
x, y |
指定x轴和y轴的列名(字符串)。 |
hue |
按类别变量分组,用不同颜色区分(如性别、地区等)。 |
col, row |
按类别变量分列或分行显示子图(如日期、时段等)。 |
col_wrap |
分面显示时,每行最多展示的子图数量(如 col_wrap=3 表示每行3个子图)。 |
height |
每个子图的高度(默认5英寸)。 |
aspect |
子图宽高比(默认1,宽度=高度×aspect)。 |
markers |
散点样式(如 markers=['o', 's'] 为不同组别设置圆圈和方块)。 |
order |
多项式回归的阶数(如 order=2 拟合二次曲线)。 |
lowess |
是否使用局部加权回归(非线性拟合,lowess=True)。 |
logistic |
是否使用逻辑回归(二分类问题,logistic=True)。 |
ci |
置信区间大小(如 ci=95 表示95%置信区间,设为 None 关闭)。 |
scatter |
是否显示散点图(默认 True)。 |
fit_reg |
是否显示回归线(默认 True)。 |
典型场景示例
1. 基础回归图
tips=sns.load_dataset('tips')
sns.lmplot(x='total_bill', y='tip', data=tips)
plt.xlabel('total_bill')
plt.ylabel('tip')
plt.title('消费金额和所付小费金额关系图')
plt.show()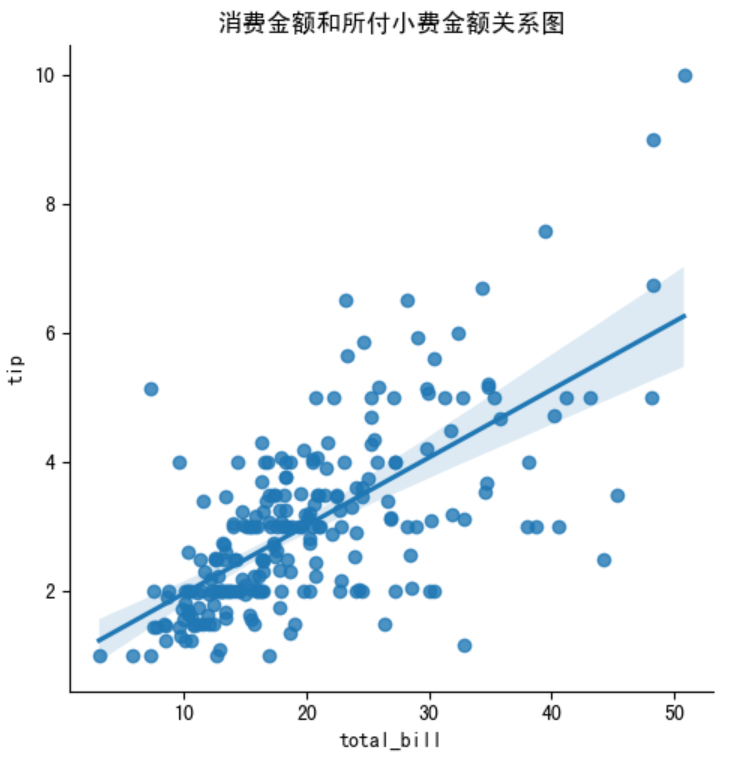
2. 按性别分组(颜色区分)
tips=sns.load_dataset('tips')
sns.lmplot(x='total_bill', y='tip', hue='sex', data=tips)
plt.xlabel('total_bill')
plt.ylabel('tip')
plt.title('消费金额和所付小费金额关系图')
plt.show()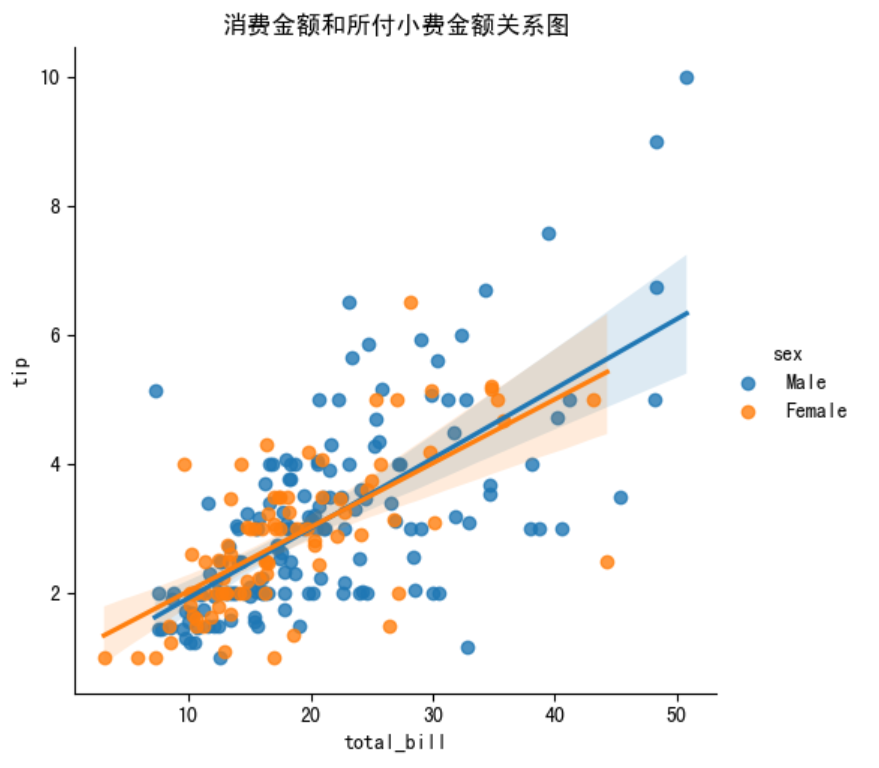
3.分面显示不同日期
tips=sns.load_dataset('tips')
sns.lmplot(x='total_bill', y='tip', hue='sex', col='day',data=tips,col_wrap=3)
plt.xlabel('total_bill')
plt.ylabel('tip')
plt.show() 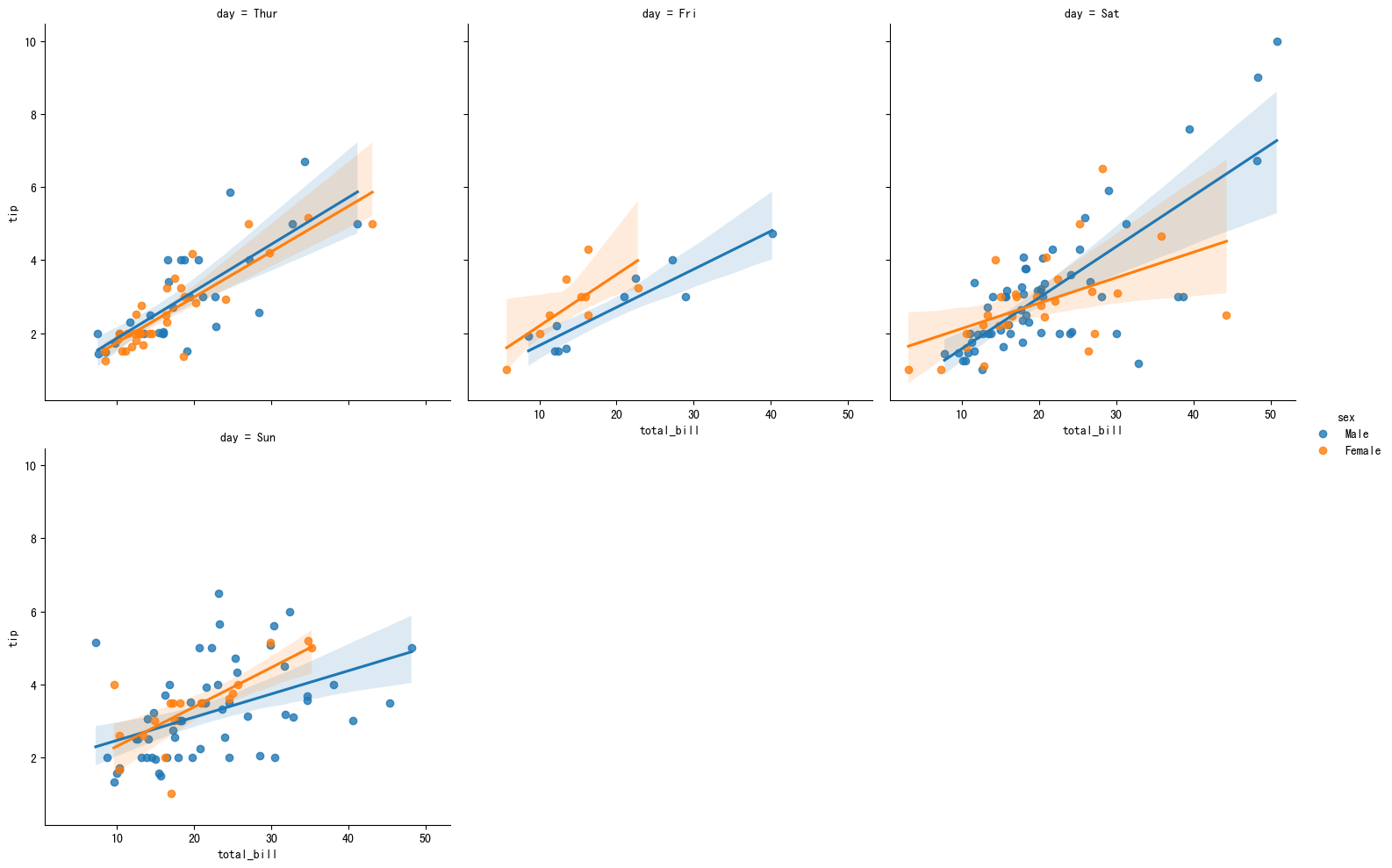
4.二次多项式拟合
tips=sns.load_dataset('tips')
sns.lmplot(x='total_bill', y='tip', data=tips, order=5)
plt.xlabel('total_bill')
plt.ylabel('tip')
plt.show() 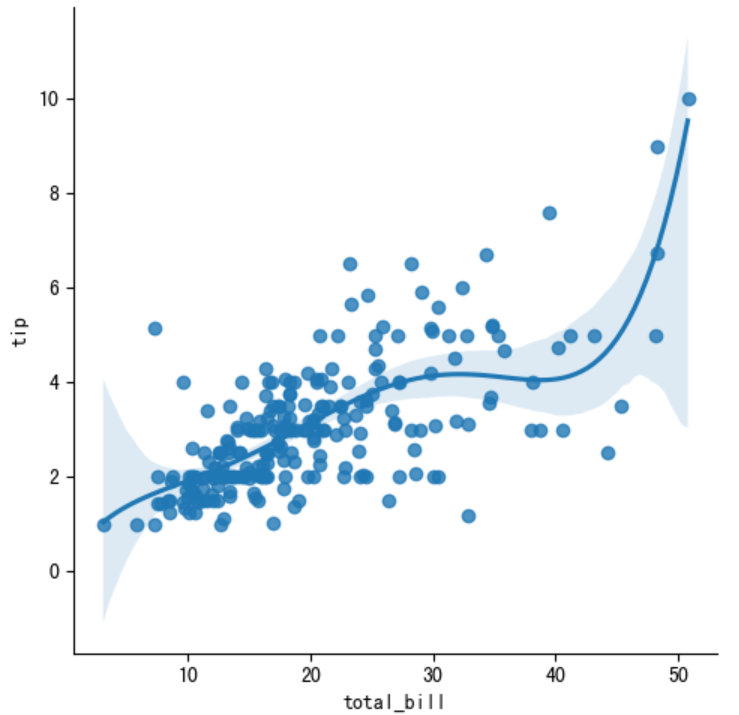
5.逻辑回归(二分类问题)
下面绘制的是泰坦尼克号数据里的年龄和是否幸存的数据分布图,并且拟合出了一条分布曲线表示幸存概率随着年龄的变化而变化的情况。
titanic=sns.load_dataset('titanic')
plt.figure(figsize=(20,8))
sns.lmplot(x='age', y='survived', data=titanic, logistic=True,height=8,aspect=2.5)
plt.xlabel('age')
plt.ylabel('survived')
plt.show() 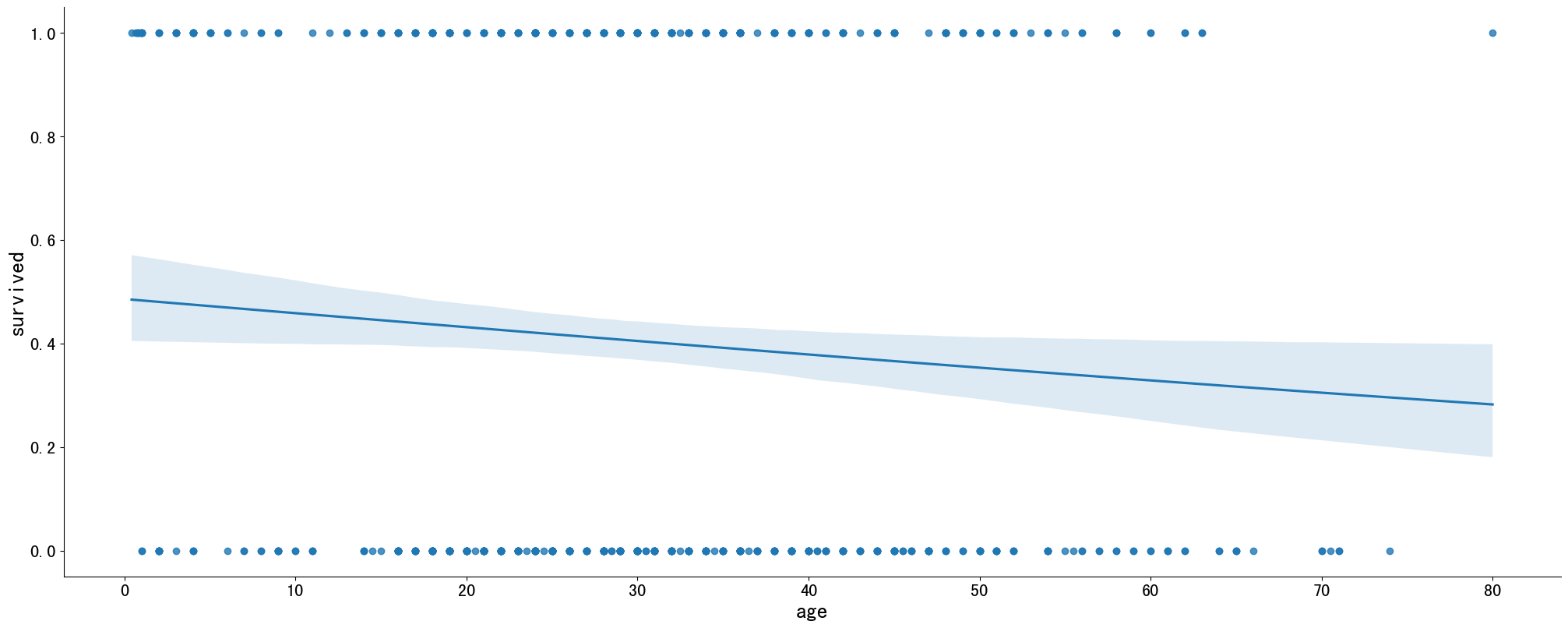
高级技巧
自定义样式:通过 scatter_kws 和 line_kws 调整散点和线条样式:
sns.lmplot(
x='total_bill', y='tip', data=tips,
scatter_kws={'s': 10, 'color': 'gray'}, # 散点大小和颜色
line_kws={'lw': 2, 'color': 'red'} # 回归线粗细和颜色
)处理分类变量:若x为离散值,使用 x_estimator=np.mean 显示每个类别的均值及其置信区间:
sns.lmplot(x='size', y='tip', data=tips, x_estimator=np.mean)性能优化:大数据集时可设置 scatter=False 或 n_boot=100 减少计算时间。
成对的双变量分布
pairplot()
- 输出形式:网格状图表,行和列对应不同变量,支持非方形网格(指定
x_vars和y_vars)。 - 高级封装:基于
PairGrid类,适合快速绘图;若需高度定制化,推荐直接使用PairGrid。
简单案例
# 加载seaborn中的数据集 dataset = sns.load_dataset("iris") dataset.head()
| sepal_length | sepal_width | petal_length | petal_width | species | |
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | setosa |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | virginica |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | virginica |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | setosa |
# 绘制多个成对的双变量分布 sns.pairplot(dataset)
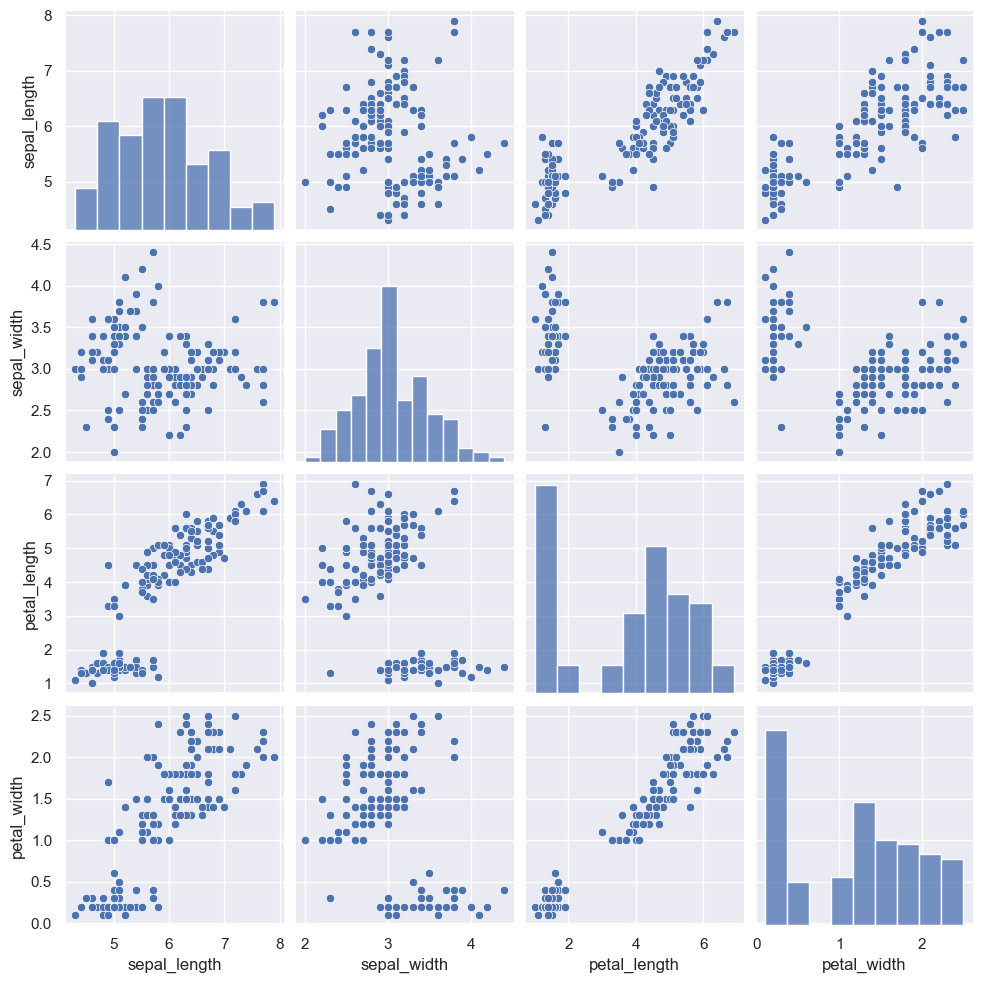
核心参数
| 参数 | 说明 |
|---|---|
data |
必需,Pandas DataFrame 格式,列名为变量名,行代表观测值。 |
hue |
按指定列(分类变量)分组,用不同颜色区分。 |
palette |
调色板名称、列表或字典,定义 hue 分组的颜色映射。 |
vars |
指定要分析的变量列表(默认使用所有数值型列)。 |
x_vars / y_vars |
分别指定行和列的变量,生成非对称网格。 |
kind |
非对角线图类型:'scatter'(默认)、'kde'、'hist'、'reg'。 |
diag_kind |
对角线图类型:'auto'(自动选择)、'hist'、'kde' 或 None。 |
height |
每个子图的高度(英寸),默认 2.5。 |
aspect |
子图宽度 = 高度 × aspect,默认 1(方形)。 |
corner |
若为 True,仅显示下三角网格(避免重复绘图)。 |
dropna |
是否删除含缺失值的数据,默认 False。 |
species 列分组着色,使用 'Set2' 调色板:sns.pairplot(data,hue='species',palette='Set2') plt.show()
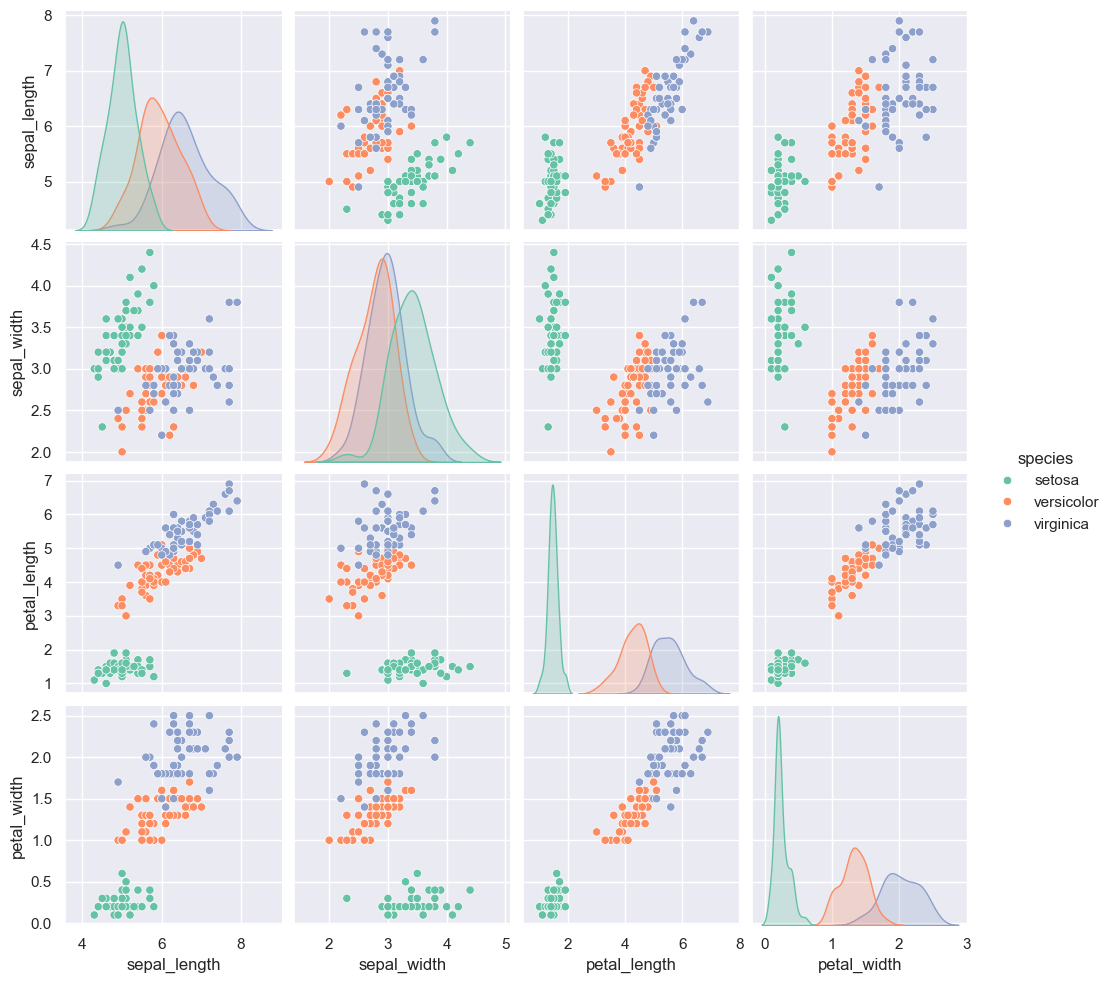
sns.pairplot(data,hue='species',vars=['sepal_length', 'sepal_width'],kind='reg',diag_kind='kde',height=5,aspect=2) plt.show()
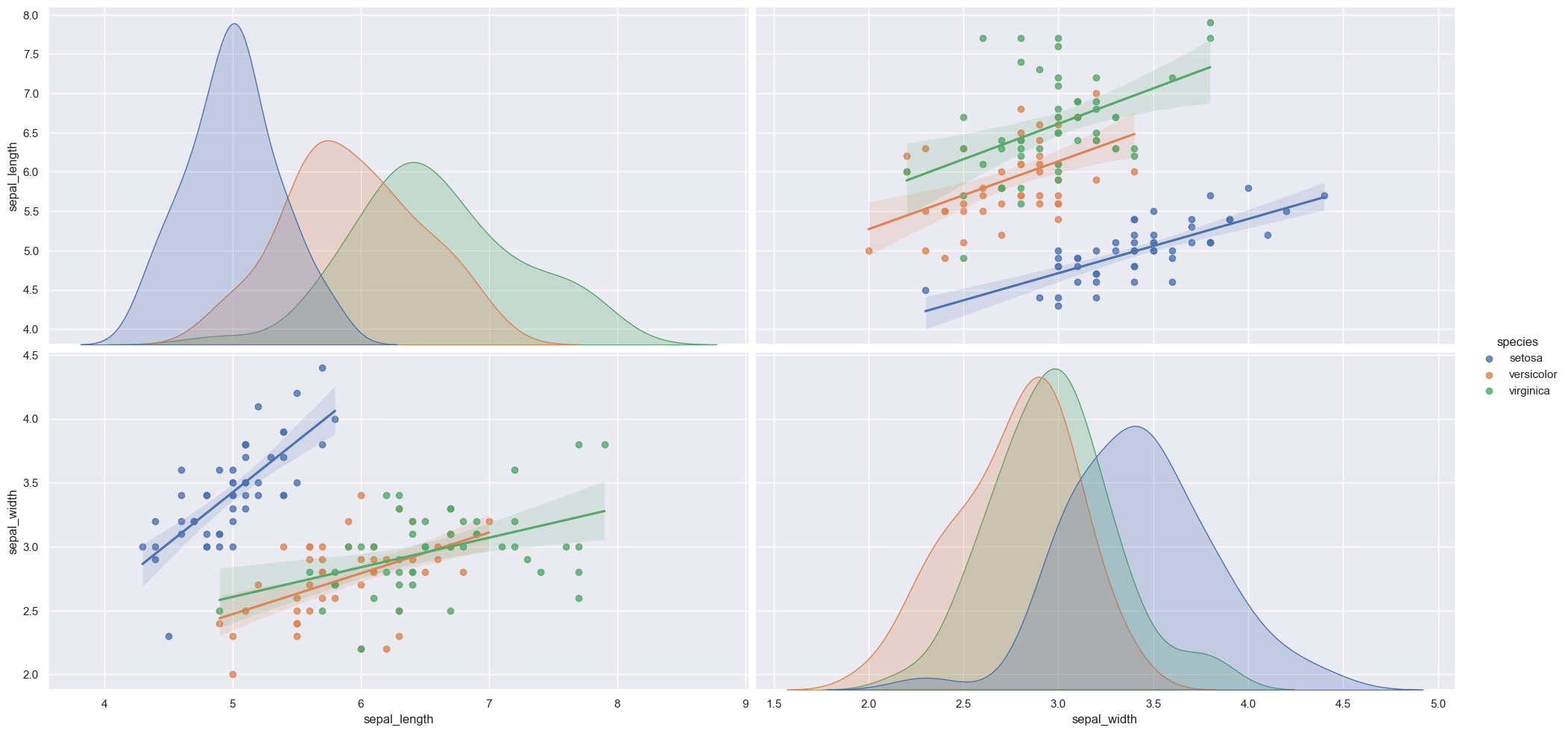
非对称网格:
- 行变量为
['age', 'income'],列变量为['score', 'rating']。
sns.pairplot(df, x_vars=['age', 'income'], y_vars=['score', 'rating'])
注意事项
- 数据类型:仅分析数值型列,忽略非数值列(如分类文本)。
- 缺失值:若
dropna=True,删除含缺失值的行;否则绘图时忽略缺失值。 - 性能:变量过多时图表网格会急剧增大,建议先筛选关键变量。
- 扩展性:通过
plot_kws、diag_kws传递字典参数,定制子图样式:
sns.pairplot(data,vars=['sepal_length', 'sepal_width'],plot_kws={'alpha':0.5}, diag_kws={'edgecolor':'black'}) plt.show()
输出对象
返回 PairGrid 对象,可通过 .map() 或 .map_upper() 等方法进一步添加图层:
g = sns.pairplot(df) g.map_upper(sns.kdeplot) # 在上三角区域添加核密度图
分类数据绘图
- 分类数据散点图: stripplot()与 swarmplot()。
- 分类数据的分布图: boxplot() 与 violinplot()。
- 分类数据的统计估算图:barplot() 与 pointplot()。
分类数据散点图
stripplot()
seaborn.stripplot(x=None, y=None, hue=None, data=None, order=None, hue_order=None, jitter=False)
(1) x,y,hue:用于绘制长格式数据的输入。
(2) data:用于绘制的数据集。如果x和y不存在,则它将作为宽格式,否则将作为长格式。
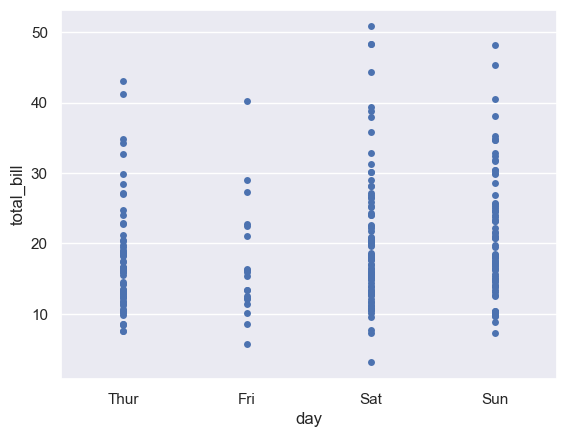
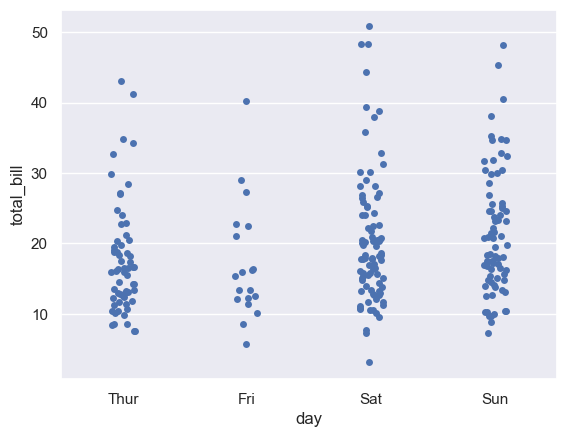
(3) jitter:表示抖动的程度(仅沿类別轴)。当很多数据点重叠时,可以指定抖动的数量或者设为True。注意,jitter默认就是true。
# 获取tips数据 tips = sns.load_dataset("tips") sns.stripplot(x="day", y="total_bill", data=tips,jitter=False)#关闭抖动
sns.stripplot(x="day", y="total_bill", data=tips, jitter=True)#打开抖动
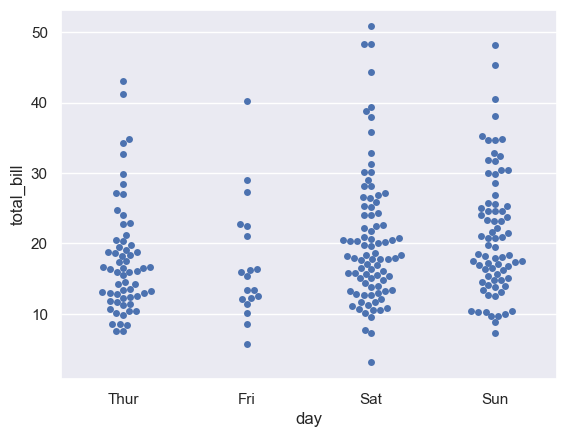
swarmplot()
sns.swarmplot(x="day", y="total_bill", data=tips) plt.show()
分类数据的分布图(类别内分布)
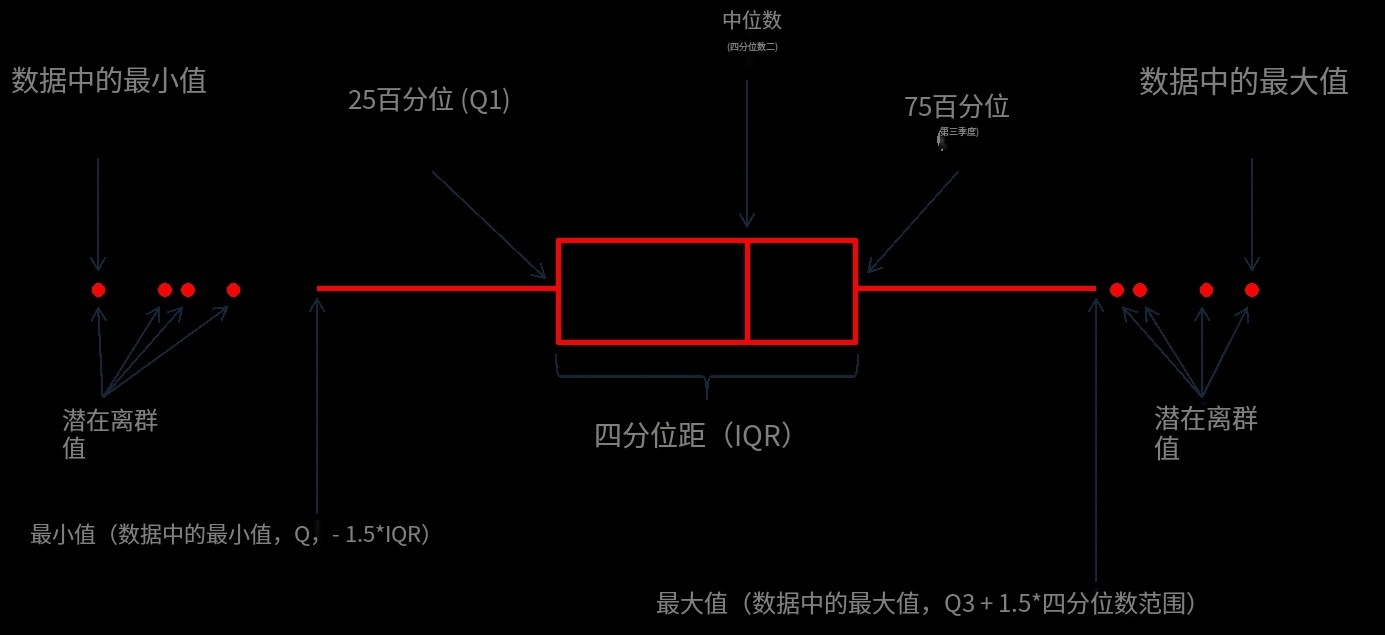
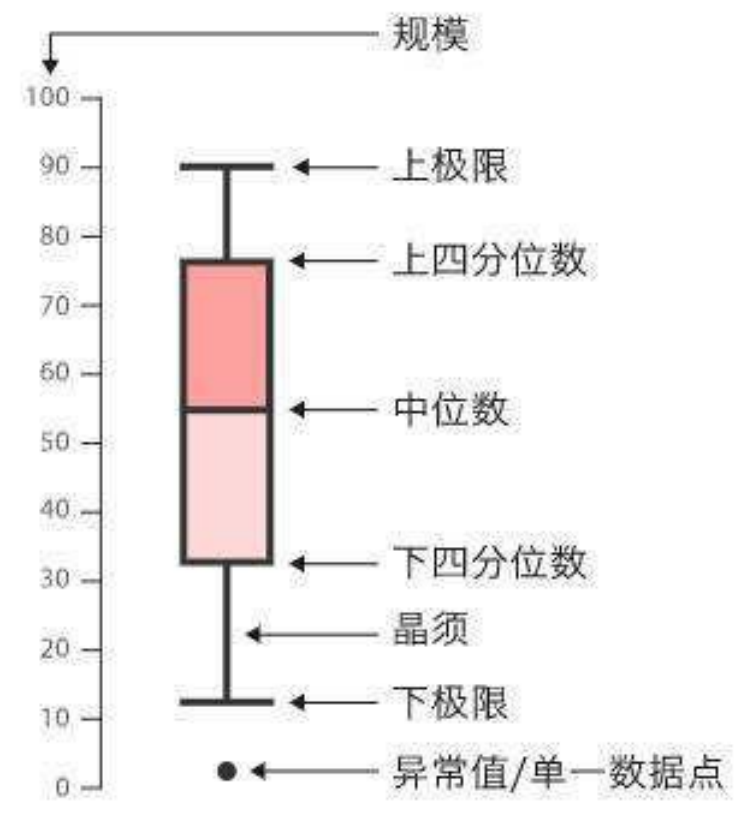
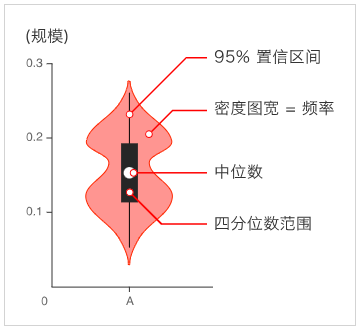
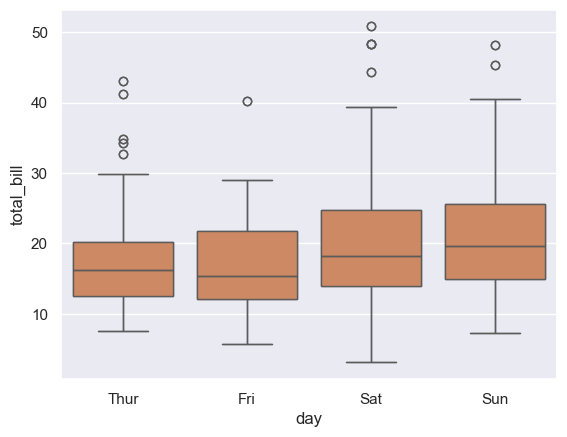
箱形图boxplot()
seaborn.boxplot(x=None, y=None, hue=None, data=None, orient=None, color=None, saturation=0.75, width=0.8)
tips=sns.load_dataset('tips') sns.boxplot(x='day',y='total_bill',data=tips) plt.show()
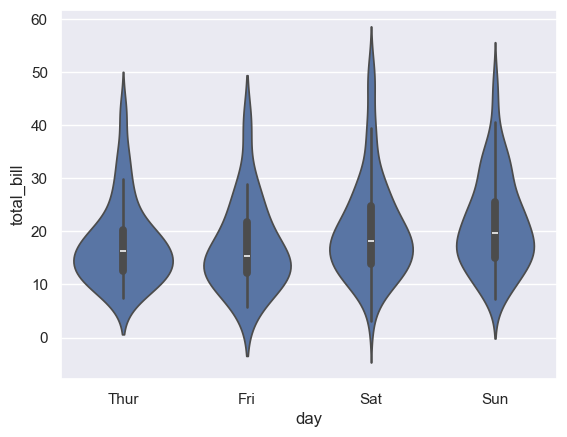
提琴图violinplot()
seaborn.violinplot(x=None, y=None, hue=None, data=None)
tips=sns.load_dataset('tips') sns.violinplot(x='day',y='total_bill',data=tips) plt.show()
分类数据的统计估算图
- barplot()函数:绘制条形图。
- pointplot()函数:绘制点图。
条形图barplot()
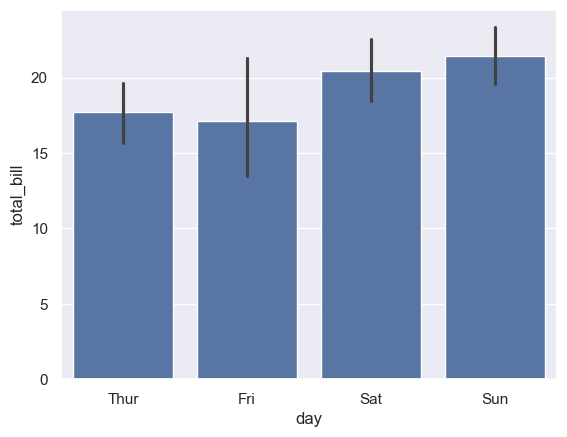
tips=sns.load_dataset('tips') sns.barplot(x='day',y='total_bill',data=tips) plt.show()
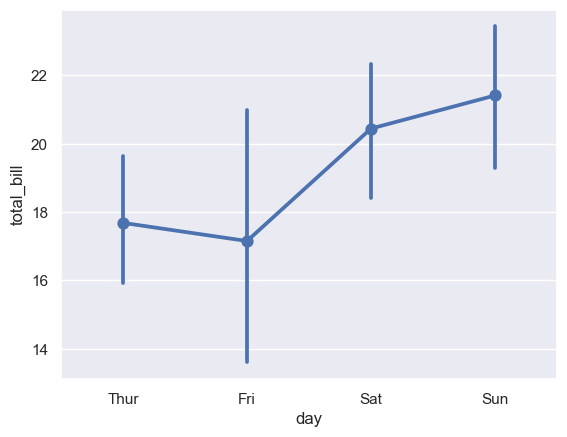
点图 pointplot()
tips=sns.load_dataset('tips') sns.pointplot(x='day',y='total_bill',data=tips) plt.show()
分类数据统计图
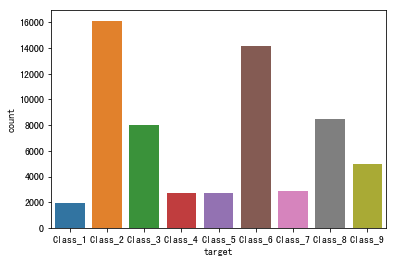
Seaborn.countplot()
countplot()应用场景:
快速分析样本数据分布是否均匀:
import pandas as pd
# 获取数据
data=pd.read_csv(r"D:\learn\000人工智能数据大全\经典数据集\奥托集团产品分类挑战赛\train.csv")
data.head()
#查看数据分布是否均匀
import seaborn as sns
import matplotlib.pyplot as plt
sns.countplot(data,x='target',hue='target')
plt.show()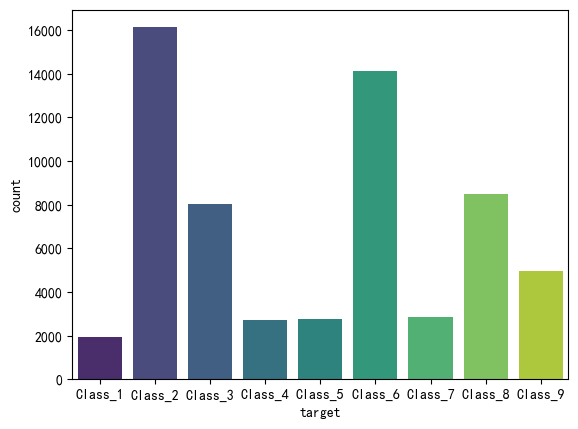
从上图很容易看出,各类数据分布明显不均匀,需要进行数据处理。
功能概述
countplot 是一种分类数据统计图,用条形图(bar plot)展示每个类别的观测值数量。本质上是分类变量的直方图:
- 替代简单直方图(适用于分类变量)
- 支持嵌套变量(使用
hue参数分组) - 统计类型灵活(计数、百分比、概率等)
核心参数详解
| 参数 | 说明 | 示例 |
|---|---|---|
| 数据输入 | ||
data |
数据集(DataFrame/数组等) | data=titanic_df |
x/y |
指定横轴/纵轴变量(二选一) | x="class", y="age" |
hue |
次级分组变量(嵌套分类) | hue="sex" |
| 排序控制 | ||
order |
主分类顺序 | order=["A","B","C"] |
hue_order |
分组顺序 | hue_order=["Male","Female"] |
| 图表样式 | ||
orient |
方向(自动推断) | orient="h"(水平) |
color |
统一颜色 | color="skyblue" |
palette |
分组配色 | palette="viridis" |
saturation |
颜色饱和度 | saturation=0.9 |
width |
条形宽度 | width=0.6 |
dodge |
分组条形防重叠 | dodge=True |
| 统计计算 | ||
stat |
统计量类型<br>'count'(默认)<br>'percent'(百分比)<br>'proportion'(比例) |
stat="percent" |
log_scale |
对数坐标轴 | log_scale=True |
| 高级特性 | ||
native_scale |
保留原生刻度(数值/日期) | native_scale=True |
formatter |
分类标签格式化函数 | formatter=lambda x: x.upper() |
legend |
图例控制 | legend="brief" |
ax |
目标坐标轴 | ax=plt.gca() |
常用场景示例
1. 基础垂直条形图(计数)
data=sns.load_dataset("tips")
sns.countplot(data,x=data['day'])
plt.show()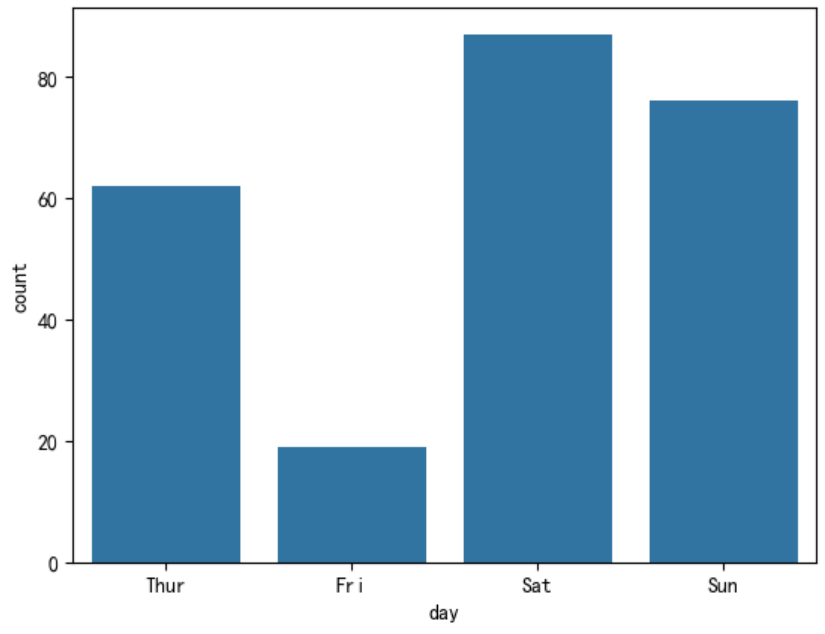
sns.countplot(data,y=data['day'])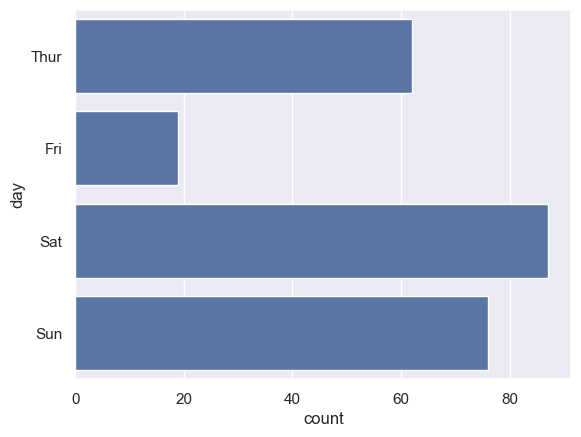
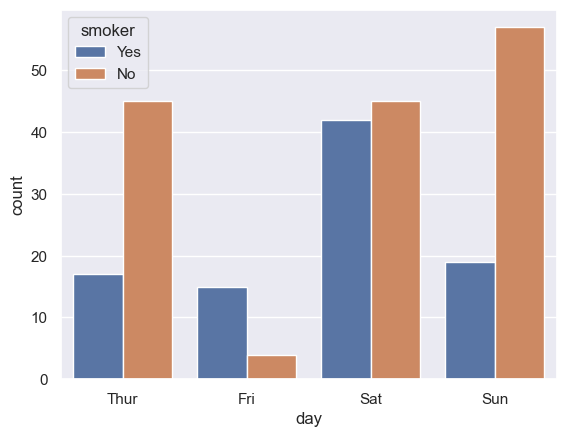
sns.set() data=sns.load_dataset("tips") sns.countplot(data,x='day',hue='smoker',dodge=True ) # 分离条形 plt.show()
order = ["Lunch", "Dinner"]
hue_order = ["Male", "Female"]
palette = {"Male": "#2ca02c", "Female": "#d62728"}
sns.countplot(
data=tips_df,
x="time",
hue="sex",
order=order,
hue_order=hue_order,
palette=palette
)sns.countplot(
data=population_df,
x="country",
log_scale=True # Y轴对数刻度
)重要注意事项
-
数据类型:
- 默认将非数值变量视为分类数据
- 数值型变量需设置
native_scale=True保持原刻度
-
与
histplot区别:histplot:适合数值分布 + 堆叠/直方图模式countplot:专用分类计数 + 简洁API
-
扩展应用:
结合catplot分面绘图:
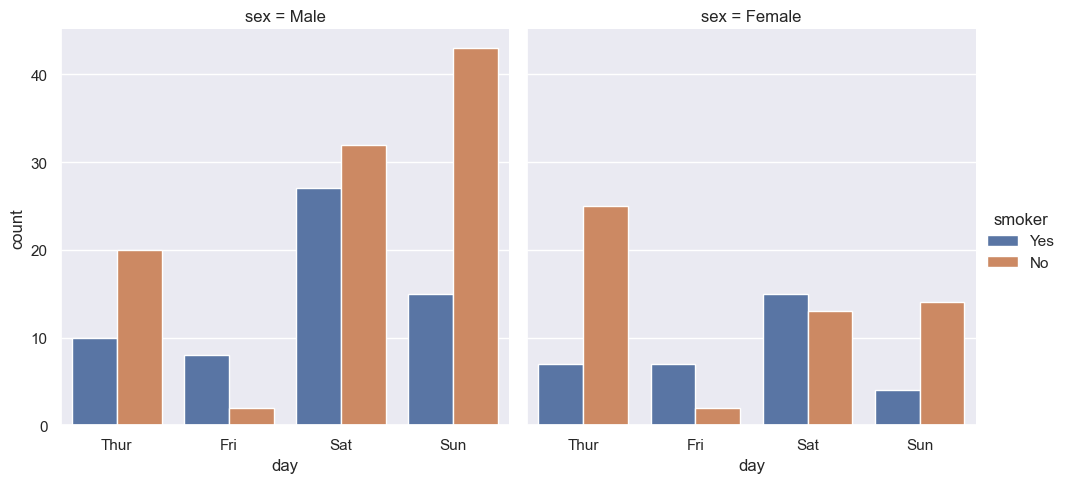
sns.catplot(
data=data,
x="day",
hue="smoker",
col="sex",
kind="count"
)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号