爬虫-lxml选择器(xPath语法,原本用来解析XML的)
xPath(XML Path language)是一门路径语言,在XML中查找信息的语言,可用来在XML文档中对元素和属性进行遍历。
基本使用
import requests from lxml import etree header = { "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.0.0.0 Safari/537.36"} url = "https://www.baidu.com" response = requests.get(url, headers=header) html = etree.HTML(response.text) # 会对标签自动补全,容错率更高,即使html写的不规范,也能解析 print(html) # parse_html = etree.parse(response.text)#严格遵守W3C规范,用来解析HTML极其容易报错,不推荐 # print(parse_html) # fromstring_html = etree.fromstring(response.text)#严格遵守W3C规范,用来解析HTML极其容易报错,不推荐 # print(fromstring_html) # 将HTML序列化 tostringhtml = etree.tostring(html, pretty_print=True, method="html", encoding="utf-8").decode("utf-8") # print(tostringhtml) # 节点名称:选取此节点的所有子节点 xpath = html.xpath("div") # 以列表形式返回 print(xpath) # 以列表形式返回 # /从根节点选取(一步一步往下选:/html/body/div) xpath = html.xpath("/html/body/div") # 以列表形式返回 print(xpath) for each in xpath: decode = etree.tostring(each, pretty_print=True, method="html", encoding="utf-8").decode("utf-8") # print(decode) # //从文档任何地方匹配,把匹配到的标签全部返回 xpath = html.xpath("//a") # 以列表形式返回文档中的所有a标签 print(xpath) for each in xpath: decode = etree.tostring(each, pretty_print=True, method="html", encoding="utf-8").decode("utf-8") print(decode) # .选取当前节点 xpath = html.xpath("//a/.") # 以列表形式返回文档中的所有a标签 print(xpath) # ..选取当前节点的父节点 xpath = html.xpath("//a/..") # 以列表形式返回文档中的所有a标签 print(xpath) # @选择属性 html_xpath = html.xpath("//a[@href='https://wenku.baidu.com/?fr=bdpcindex']") print(html_xpath)
谓语
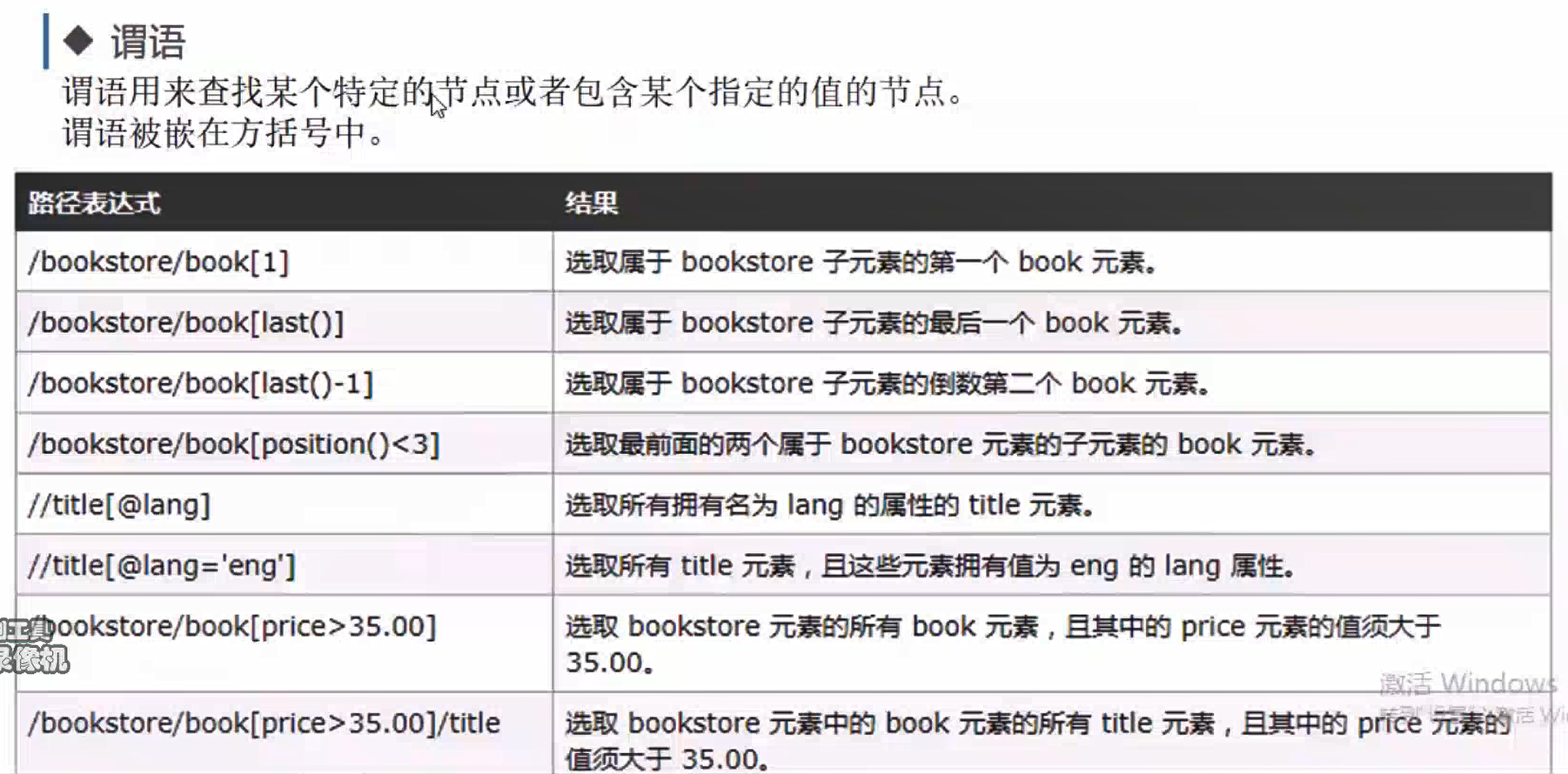
# 谓语 xpath = html.xpath("//div[@id='bottom_layer']//p[1]/a[1]")#选取所有匹配项中的第一个 xpath = html.xpath("//div[@id='bottom_layer']//p[last()]")#选取所有匹配项中的最后一个 xpath = html.xpath("//div[@id='bottom_layer']//p[last()-5]/a")#选取所有匹配项中的倒数第6个 xpath = html.xpath("//div[@id='bottom_layer']//p[position()<3]/a")#选取所有匹配项中的前两个 xpath = html.xpath("//div[@id='bottom_layer']//p[position()<3]/a[@target='_blank']")#选取target属性值是_blank的a标签#<a class="text-color" href="http://ir.baidu.com" target="_blank">About Baidu</a> xpath = html.xpath("//div[@id='bottom_layer']//p[a='关于百度']")#查找p标签,要求里面包含a标签,且a标签值为“关于百度” for each in xpath: print(etree.tostring(each, pretty_print=True, method="html", encoding="utf-8").decode("utf-8"))
选取未知节点
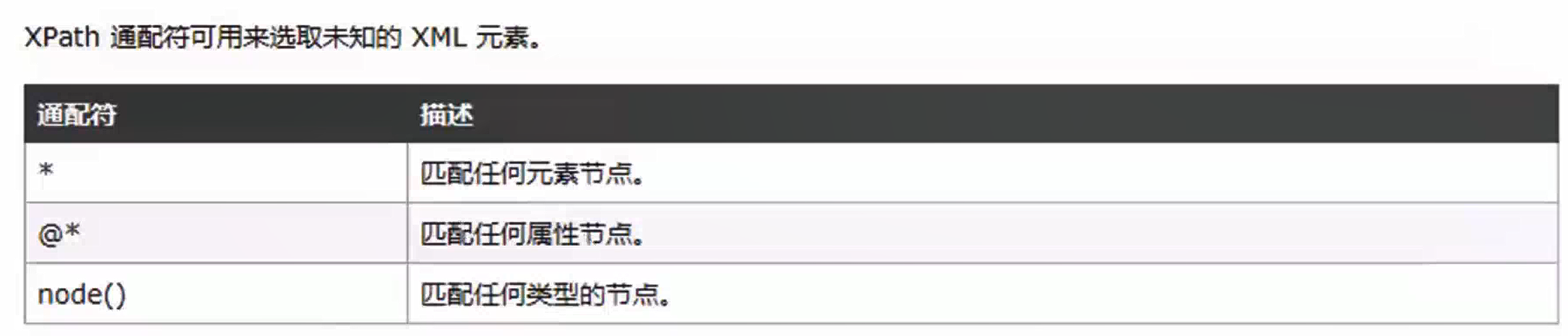
xpath = html.xpath("//div[@id='bottom_layer']//p[a=*]")#*匹配任何元素节点 xpath = html.xpath("//div[@id='bottom_layer']//p/a[@class='text-color']") xpath = html.xpath("//div[@id='bottom_layer']//p/*[@class='text-color']")#*匹配任何元素节点 xpath = html.xpath("//div[@id='bottom_layer']//p[@*='lh']")#@*匹配任何属性节点:<p class="lh"><span class="text-color">©2025 Baidu </span></p> xpath = html.xpath("//div[@id='bottom_layer']//p[@*='lh']/node()")#node()匹配任何类型节点
Xpath运算符
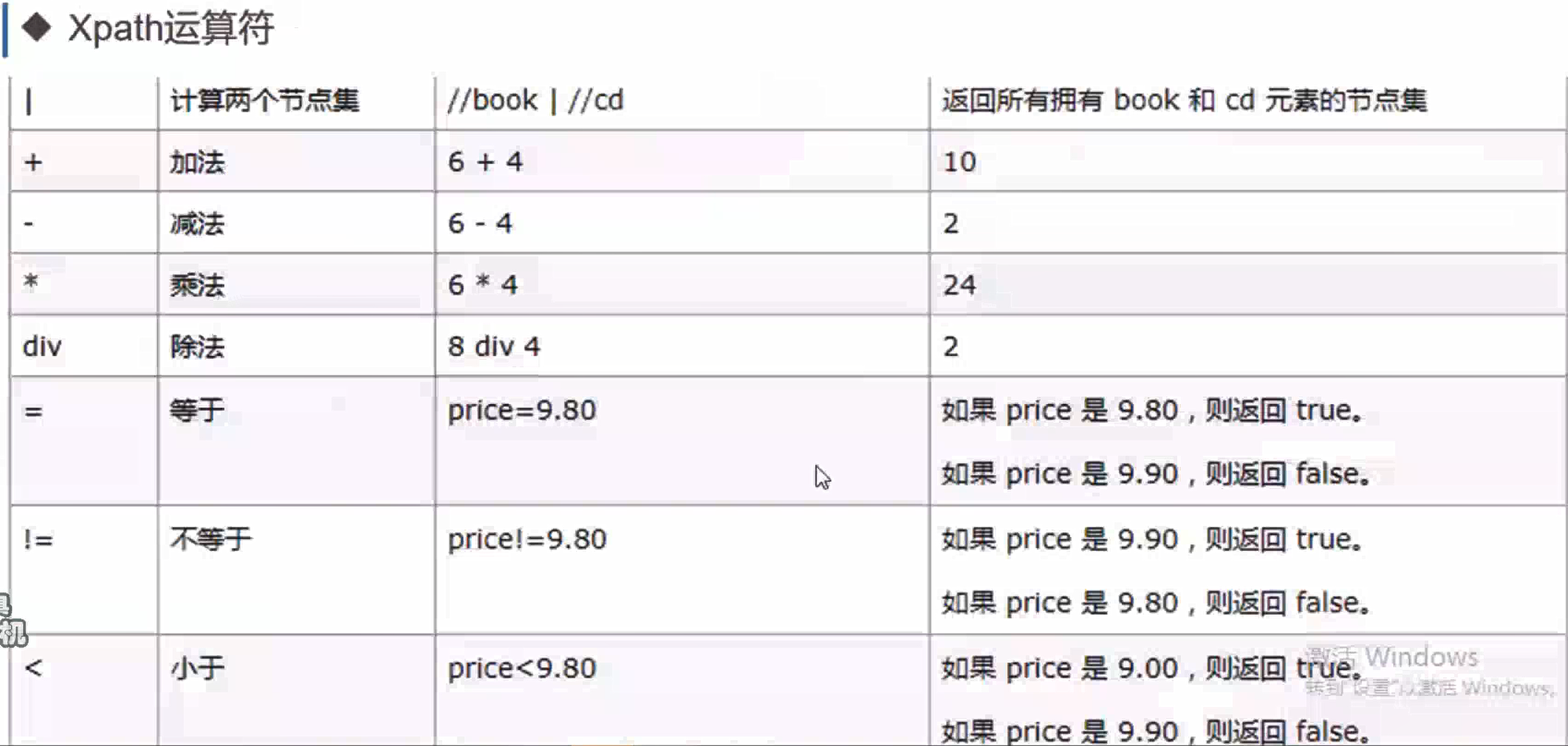
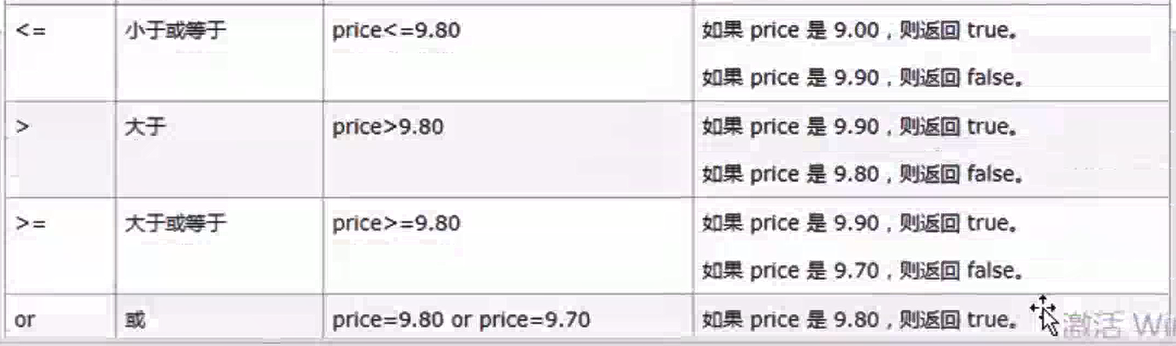
# **************************************************运算符************************************************** # xpath = html.xpath("//div[@id='bottom_layer']//p[@*='lh']/(a | span)")#使用 | 合并路径时,每个分支必须是完整的 XPath 表达式。这种就会报错 xpath = html.xpath("//div[@id='bottom_layer']//p[@*='lh']/a | //div[@id='bottom_layer']//p[@*='lh']/span")#正确 xpath = html.xpath("//div[@id='bottom_layer' or @class='s-bottom-space']") for each in xpath: print(etree.tostring(each, pretty_print=True, method="html", encoding="utf-8").decode("utf-8")) xpath = html.xpath("//div[@id='bottom_layer']//p[@*='lh']/a or span")#返回True print(xpath)#True print("*"*50) # 获取文本 xpath = html.xpath("//div[@id='bottom_layer' or @class='s-bottom-space']//p/span/text()") print(xpath) xpath = html.xpath("string(//div[@id='bottom_layer' or @class='s-bottom-space']//p/span)")#['互联网新闻信息服务许可证11220180008', '网络文化经营许可证: 京网文〔2023〕1034-029号', '互联网宗教信息服务许可证编号:京(2022)0000043', '药品医疗器械网络信息服务备案(京)网药械信息备字(2021)第00159号', '医疗器械网络交易服务第三方平台备案凭证(京)网械平台备字(2020)第00002号', '药品网络交易服务第三方平台备案凭证(京)网药平台备字〔2023〕第000002号', '©2025\xa0Baidu\xa0'] print(xpath)#互联网新闻信息服务许可证11220180008 # 获取属性 xpath = html.xpath("string(//div[@id='bottom_layer']//p/a/@href)") print(xpath)#//home.baidu.com不知道为什么,只取了第一个a标签的href;XPath 中的 string() 函数会将匹配到的 第一个节点 转换为字符串,因此即使路径匹配多个元素,它也只返回第一个结果。这是你只获取到第一个 href 的根本原因。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号