爬虫-异步-超时重试、异常处理-高效代码-真的快十倍!!!
阅读本文之前,需要掌握爬虫和Python异步编程的相关知识,拓展阅读:爬虫案例-对比单线程、多线程、多进程、异步编程的效率
import asyncio import aiohttp from aiohttp import ClientSession, ClientTimeout import time from urllib.parse import urlparse # 异步请求函数(支持超时、重试和异常处理) async def fetch_url(session: ClientSession, url: str, semaphore: asyncio.Semaphore, retries=3): try: async with semaphore: # 控制并发量 for attempt in range(retries): try: async with session.get(url, timeout=ClientTimeout(total=10)) as response: if response.status == 200: html = await response.text() print(f"成功获取 {url}") return html else: print(f"请求失败: {url}, 状态码 {response.status}") except (aiohttp.ClientError, asyncio.TimeoutError) as e: if attempt < retries - 1: print(f"第 {attempt + 1} 次重试 {url}: {str(e)}") await asyncio.sleep(1) else: print(f"请求失败(最终): {url}, 错误: {str(e)}") return None except Exception as e: print(f"未知错误: {url}, {str(e)}") return None # 解析 HTML(模拟数据处理) # 解析和存储操作也异步执行,最大化利用 I/O 等待时间 async def parse_html(html: str): # 使用 BeautifulSoup 或其他库解析 await asyncio.sleep(0.001) # 模拟轻量处理 return {"data": "parsed_result"} # 主异步函数 async def main(urls: list, max_concurrency=100): start_time = time.time() timeout = ClientTimeout(total=10) semaphore = asyncio.Semaphore(max_concurrency) # 限制并发量,防止瞬时高并发导致服务器拒绝或本地端口耗尽 async with ClientSession(timeout=timeout) as session:#提升鲁棒性,避免单个请求阻塞整体任务 tasks = [fetch_url(session, url, semaphore) for url in urls] results = await asyncio.gather(*tasks) # 批量提交任务,使用 asyncio.gather 高效管理大量任务 # 异步处理结果(如解析、存储)#解析和存储操作也异步执行,最大化利用 I/O 等待时间 parsed_tasks = [parse_html(html) for html in results if html] parsed_results = await asyncio.gather(*parsed_tasks) # 性能统计 # 统计总耗时、请求成功率等指标。 total_time = time.time() - start_time success_count = sum(1 for res in results if res is not None) print(f"\n总耗时: {total_time:.2f} 秒") print(f"总请求数: {len(urls)}, 成功数: {success_count}") print(f"QPS: {len(urls) / total_time:.2f} (次/秒)") if __name__ == "__main__": # 测试 URL 列表(示例) urls = [ "https://www.example.com", "https://www.google.com", "https://www.github.com" ] * 100 # 重复 100 次模拟高并发 # 运行事件循环 asyncio.run(main(urls, max_concurrency=200))
进阶优化技巧
-
连接池复用
aiohttp.ClientSession默认复用 TCP 连接,减少握手开销。 -
DNS 缓存(Windows已测试,感觉没啥用,速度更慢了)
使用aiohttp.resolver.AsyncResolver缓存 DNS 查询结果。
适用场景
-
-
高频访问相同域名:如爬虫集中抓取某网站的子页面。
-
减少 DNS 查询延迟:提升 API 轮询或实时通信性能。
-
import asyncio from datetime import datetime, timedelta import aiohttp from aiohttp import ClientSession from aiohttp.resolver import AsyncResolver # 解决 Windows 下 aiodns 事件循环兼容性问题 if __name__ == "__main__": asyncio.set_event_loop_policy(asyncio.WindowsSelectorEventLoopPolicy()) class CachedAsyncResolver(AsyncResolver): def __init__(self, ttl=300, *args, **kwargs): super().__init__(*args, **kwargs) self._cache = {} # 缓存字典:{域名: (过期时间, [IP地址])} self._ttl = ttl # 缓存有效期(秒) # 在初始化时启动清理缓存: # ...其他初始化... asyncio.create_task(self.cleanup_cache()) # 线程安全改进: # 若需高并发安全,使用 asyncio.Lock 保护缓存操作: self._lock = asyncio.Lock() # 添加异步锁 async def resolve(self, hostname, port=0, family=0): async with self._lock: # 加锁保证原子操作 now = datetime.now() # 检查缓存是否存在且未过期 if hostname in self._cache: expire_time, ips = self._cache[hostname] if now < expire_time: print(f"使用缓存 DNS 结果: {hostname} -> {ips}") return ips # 直接返回缓存的 IP 列表 # 缓存未命中,执行实际 DNS 查询 ips = await super().resolve(hostname, port, family) # 更新缓存(设置过期时间) self._cache[hostname] = ( now + timedelta(seconds=self._ttl), ips ) print(f"新增 DNS 缓存: {hostname} -> {ips} (有效期至 {self._cache[hostname][0]})") return ips # 缓存清理机制: # 可添加后台任务定期清理过期缓存: async def cleanup_cache(self): while True: await asyncio.sleep(60) # 每分钟清理一次 now = datetime.now() expired_hosts = [ host for host, (expire, _) in self._cache.items() if now >= expire ] for host in expired_hosts: del self._cache[host] print(f"清理过期缓存: {expired_hosts}") async def main(): # 创建自定义解析器(缓存 5 分钟) resolver = CachedAsyncResolver(ttl=300) # 使用自定义解析器 # 通过 TCPConnector(resolver=resolver) 将解析器绑定到 ClientSession。 # 首次请求会触发 DNS 查询并缓存结果,后续请求直接使用缓存。 async with ClientSession( connector=aiohttp.TCPConnector(resolver=resolver) ) as session: # 第一次访问(触发 DNS 查询并缓存) async with session.get("https://www.baidu.com") as resp: print("第一次请求状态码:", resp.status) # 第二次访问(命中缓存) async with session.get("https://www.baidu.com") as resp: print("第二次请求状态码:", resp.status) if __name__ == "__main__": asyncio.run(main())
测试代码
import asyncio from datetime import datetime, timedelta import re import aiohttp import requests from aiohttp import AsyncResolver, ClientSession from bs4 import BeautifulSoup # import winloop # winloop.install() # 解决 Windows 下 aiodns 事件循环兼容性问题 if __name__ == "__main__": asyncio.set_event_loop_policy(asyncio.WindowsSelectorEventLoopPolicy()) class CachedAsyncResolver(AsyncResolver): def __init__(self, ttl=300, *args, **kwargs): super().__init__(*args, **kwargs) self._cache = {} # 缓存字典:{域名: (过期时间, [IP地址])} self._ttl = ttl # 缓存有效期(秒) # 在初始化时启动清理缓存: # ...其他初始化... asyncio.create_task(self.cleanup_cache()) # 线程安全改进: # 若需高并发安全,使用 asyncio.Lock 保护缓存操作: self._lock = asyncio.Lock() # 添加异步锁 async def resolve(self, hostname, port=0, family=0): async with self._lock: # 加锁保证原子操作 now = datetime.now() # 检查缓存是否存在且未过期 if hostname in self._cache: expire_time, ips = self._cache[hostname] if now < expire_time: print(f"使用缓存 DNS 结果: {hostname} -> {ips}") return ips # 直接返回缓存的 IP 列表 # 缓存未命中,执行实际 DNS 查询 ips = await super().resolve(hostname, port, family) # 更新缓存(设置过期时间) self._cache[hostname] = ( now + timedelta(seconds=self._ttl), ips ) print(f"新增 DNS 缓存: {hostname} -> {ips} (有效期至 {self._cache[hostname][0]})") return ips # 缓存清理机制: # 可添加后台任务定期清理过期缓存: async def cleanup_cache(self): while True: await asyncio.sleep(60) # 每分钟清理一次 now = datetime.now() expired_hosts = [ host for host, (expire, _) in self._cache.items() if now >= expire ] for host in expired_hosts: del self._cache[host] print(f"清理过期缓存: {expired_hosts}") # 单个耗时任务 async def process_href(href, rootUrl, session): topicUrl = rootUrl + href # 创建自定义解析器(缓存 5 分钟) resolver = CachedAsyncResolver(ttl=300) # 使用自定义解析器 # 通过 TCPConnector(resolver=resolver) 将解析器绑定到 ClientSession。 # 首次请求会触发 DNS 查询并缓存结果,后续请求直接使用缓存。 async with ClientSession( connector=aiohttp.TCPConnector(resolver=resolver) ) as session: # 第一次访问(触发 DNS 查询并缓存) async with session.get(topicUrl, headers=header) as res: soup = BeautifulSoup(await res.text(), "lxml") return await analysishtml(soup, href) async def analysishtml(soup, href): # 一、获取题目所有说明文本 allP = soup.find("div", id="content").find_all("p") # 创建字典,暂存每一页的各个板块信息 dic = {} # 使用list暂存所有说明 noteList = [] for p in allP: if not p.find("a"): # 排除“返回上一页” noteList.append(p.get_text()) dic["noteList"] = noteList # 二、获取实例代码 try: code = soup.find("div", id="content").find("div", class_="example") if code: dic["code"] = code.get_text() else: pre = soup.find("div", id="content").find("pre") dic["code"] = pre.get_text() except Exception as e: pre = soup.find("div", id="content").find("pre") print(pre) print(f"第{hreflist.index(href) + 1}题获取示例代码出错了:{e}") # 三、获取执行结果 try: result = soup.find("div", id="content").find("pre") if result: dic["result"] = result.get_text() else: imgSrc = soup.find("div", id="content").find("img", attrs={"src": re.compile(r"^//")}).attrs["src"] dic["result"] = f"执行结果为非文本数据:数据链接为:https:{imgSrc}" except Exception as e: print(f"第{hreflist.index(href) + 1}题获取执行结果出错了:{e}") dic["result"] = "无执行结果!" return dic # 写入文件 async def wirteInFile(pageList): with open("../Test/python100例题.txt", "w+", encoding="utf-8") as f: # with open("../Test/python100例题.doc","w+",encoding="utf-8") as f: for dic in pageList: noteList = dic["noteList"] code = dic["code"] result = dic["result"] try: if len(noteList) == 4: f.write(f"{pageList.index(dic) + 1}" + noteList[0] + "\n") f.write(noteList[1] + "\n") f.write(noteList[2] + "\n") f.write(code + "\n") f.write(noteList[3] + "\n") f.write(result + "\n") f.write("*" * 50 + "\n") else: f.write(f"{pageList.index(dic) + 1}" + noteList[0] + "\n") f.write(noteList[1] + "\n") f.write(code + "\n") f.write(noteList[2] + "\n") f.write(result + "\n") f.write("*" * 50 + "\n") except Exception as e: print(f"{pageList.index(dic) + 1}出错了:{e}") print("写入完成!!!") if __name__ == '__main__': url = "https://www.runoob.com/python/python-100-examples.html" rootUrl = "https://www.runoob.com" header = { "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.0.0.0 Safari/537.36" } response = requests.get(url, headers=header) response.encoding = response.apparent_encoding # 将网页内容转为bs4对象 soup = BeautifulSoup(response.text, "lxml") # 查找题目链接 uls = soup.find("div", id="content").find_all("ul") # 定义内容目录链接列表 hreflist = [] for ul in uls: lis = ul.find_all("li") for li in lis: hreflist.append(li.find("a").get("href")) async def main(): time1 = datetime.now() print("*" * 20, time1.strftime('%Y-%m-%d %H:%M:%S'), "*" * 20) async with aiohttp.ClientSession(headers=header) as session: worklist = [process_href(href, rootUrl, session) for href in hreflist] pageList = await asyncio.gather(*worklist) await wirteInFile(pageList) time2 = datetime.now() print("结束时间", "*" * 20, time2.strftime('%Y-%m-%d %H:%M:%S'), "*" * 20) print(time2 - time1) asyncio.run(main())
-
动态调整并发
根据服务器响应时间动态调整信号量值。 -
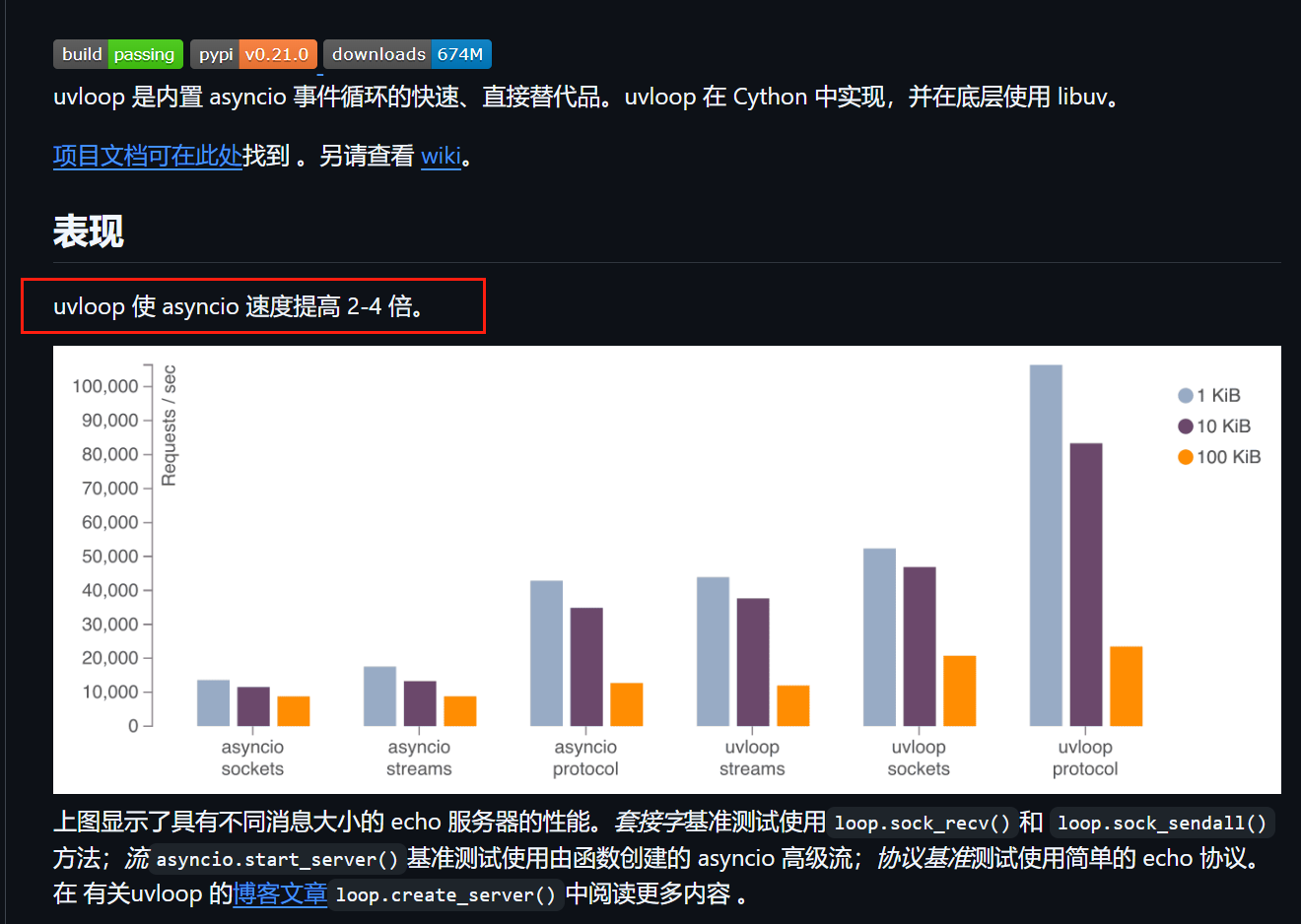
结合 UVLoop
替换默认事件循环为uvloop,提升性能 20-30%:import uvloop uvloop.install()
-
uvloop是一个基于libuv的高性能异步事件循环库,其底层依赖的 C 扩展模块在 Windows 平台上存在兼容性问题。
官方明确声明不支持 Windows(GitHub 仓库说明),主要支持 Linux 和 macOS。
缓存已下载页面(Windows已验证可用,时间稳定在:0:00:02.103662)
模板代码
# 2. 缓存已下载页面 # 若需多次运行爬虫,可缓存已下载的 HTML 内容,避免重复请求: import os import hashlib import requests def get_page(url): cache_dir = "cache" os.makedirs(cache_dir, exist_ok=True) url_hash = hashlib.md5(url.encode()).hexdigest() cache_path = os.path.join(cache_dir, url_hash) if os.path.exists(cache_path): with open(cache_path, "r",encoding="utf-8") as f: return f.read() else: response = requests.get(url) html = response.text with open(cache_path, "r",encoding="utf-8") as f: f.write(html) return html
测试样例
import asyncio import datetime import hashlib import os import re import aiohttp import requests from bs4 import BeautifulSoup # import winloop # winloop.install() # 单个耗时任务 async def process_href(href, rootUrl, session): topicUrl = rootUrl + href # 检查是否存在缓存文件夹 cache_dir = "../cache" os.makedirs(cache_dir, exist_ok=True) url_hash = hashlib.md5(topicUrl.encode()).hexdigest() cache_path = os.path.join(cache_dir, url_hash) if os.path.exists(cache_path): with open(cache_path, "r",encoding="utf-8") as f: soup = BeautifulSoup(f, "lxml") return await analysishtml(soup, href) else: async with session.get(topicUrl, headers=header) as res: soup = BeautifulSoup(await res.text(), "lxml") html = str(await res.text()) with open(cache_path, "w",encoding="utf-8") as f: f.write(html) return await analysishtml(soup, href) async def analysishtml(soup, href): # 一、获取题目所有说明文本 allP = soup.find("div", id="content").find_all("p") # 创建字典,暂存每一页的各个板块信息 dic = {} # 使用list暂存所有说明 noteList = [] for p in allP: if not p.find("a"): # 排除“返回上一页” noteList.append(p.get_text()) dic["noteList"] = noteList # 二、获取实例代码 try: code = soup.find("div", id="content").find("div", class_="example") if code: dic["code"] = code.get_text() else: pre = soup.find("div", id="content").find("pre") dic["code"] = pre.get_text() except Exception as e: pre = soup.find("div", id="content").find("pre") print(pre) print(f"第{hreflist.index(href) + 1}题获取示例代码出错了:{e}") # 三、获取执行结果 try: result = soup.find("div", id="content").find("pre") if result: dic["result"] = result.get_text() else: imgSrc = soup.find("div", id="content").find("img", attrs={"src": re.compile(r"^//")}).attrs["src"] dic["result"] = f"执行结果为非文本数据:数据链接为:https:{imgSrc}" except Exception as e: print(f"第{hreflist.index(href) + 1}题获取执行结果出错了:{e}") dic["result"] = "无执行结果!" return dic # 写入文件 async def wirteInFile(pageList): with open("../Test/python100例题.txt", "w+", encoding="utf-8") as f: # with open("../Test/python100例题.doc","w+",encoding="utf-8") as f: for dic in pageList: noteList = dic["noteList"] code = dic["code"] result = dic["result"] try: if len(noteList) == 4: f.write(f"{pageList.index(dic) + 1}" + noteList[0] + "\n") f.write(noteList[1] + "\n") f.write(noteList[2] + "\n") f.write(code + "\n") f.write(noteList[3] + "\n") f.write(result + "\n") f.write("*" * 50 + "\n") else: f.write(f"{pageList.index(dic) + 1}" + noteList[0] + "\n") f.write(noteList[1] + "\n") f.write(code + "\n") f.write(noteList[2] + "\n") f.write(result + "\n") f.write("*" * 50 + "\n") except Exception as e: print(f"{pageList.index(dic) + 1}出错了:{e}") print("写入完成!!!") if __name__ == '__main__': url = "https://www.runoob.com/python/python-100-examples.html" rootUrl = "https://www.runoob.com" header = { "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.0.0.0 Safari/537.36" } response = requests.get(url, headers=header) response.encoding = response.apparent_encoding # 将网页内容转为bs4对象 soup = BeautifulSoup(response.text, "lxml") # 查找题目链接 uls = soup.find("div", id="content").find_all("ul") # 定义内容目录链接列表 hreflist = [] for ul in uls: lis = ul.find_all("li") for li in lis: hreflist.append(li.find("a").get("href")) async def main(): time1 = datetime.datetime.now() print("*" * 20, time1.strftime('%Y-%m-%d %H:%M:%S'), "*" * 20) async with aiohttp.ClientSession(headers=header) as session: worklist = [process_href(href, rootUrl, session) for href in hreflist] pageList = await asyncio.gather(*worklist) await wirteInFile(pageList) time2 = datetime.datetime.now() print("结束时间", "*" * 20, time2.strftime('%Y-%m-%d %H:%M:%S'), "*" * 20) print(time2 - time1) asyncio.run(main())


 浙公网安备 33010602011771号
浙公网安备 33010602011771号